Today’s marketer has a wide array of channels to communicate with their customers. However, sending the right message to the right customer on the right channel at the right time remains the preeminent challenge marketers face. In this post, I show you how to combine Braze, a customer engagement platform built on AWS for today’s on-demand, always-connected customers, and Amazon Personalize to meet this challenge and deliver experiences that surprise and delight your customers.
Braze makes it easy to organize your customers into audiences, which update in real-time, based on their behavior and profile traits. Messaging campaigns are created to target audiences through messaging channels such as email, SMS, and push notifications. Multi-step and multi-channel engagement journeys can also be designed using Braze Canvas. Campaigns and Canvases are triggered manually, based on a schedule, or even due to customer actions. However, your ability to personalize messages sent to customers is limited to what is available in their profile. Including product and content recommendations based on the learned interests of each customer as they engage with your web and mobile application is needed to truly personalize each message.
Amazon Personalize is an AWS service that uses machine learning algorithms to create recommender systems based on the behavioral data of your customers. The recommenders are private to your AWS account and based only on the data you provide. Through the Braze Connected Content feature, you are able to connect Braze to the same Amazon Personalize recommenders used to power recommendations in your web and mobile application. Since Amazon Personalize is able to adjust recommendations for each customer based on their behavior in real-time, the messages sent through Braze reflect their current preferences and intent.
Overview of solutions
I present two architectures in this post: one that uses the real-time capabilities of Braze and Amazon Personalize, and another that trades some of the freshness of real-time recommendations for a more cost-effective batch approach. The approach you select should match the goals of your engagement strategy and the scale of your messaging needs. Fortunately, the features and integration options of Braze and Amazon Personalize provide the flexibility to suit your operational requirements.
Real-time integration
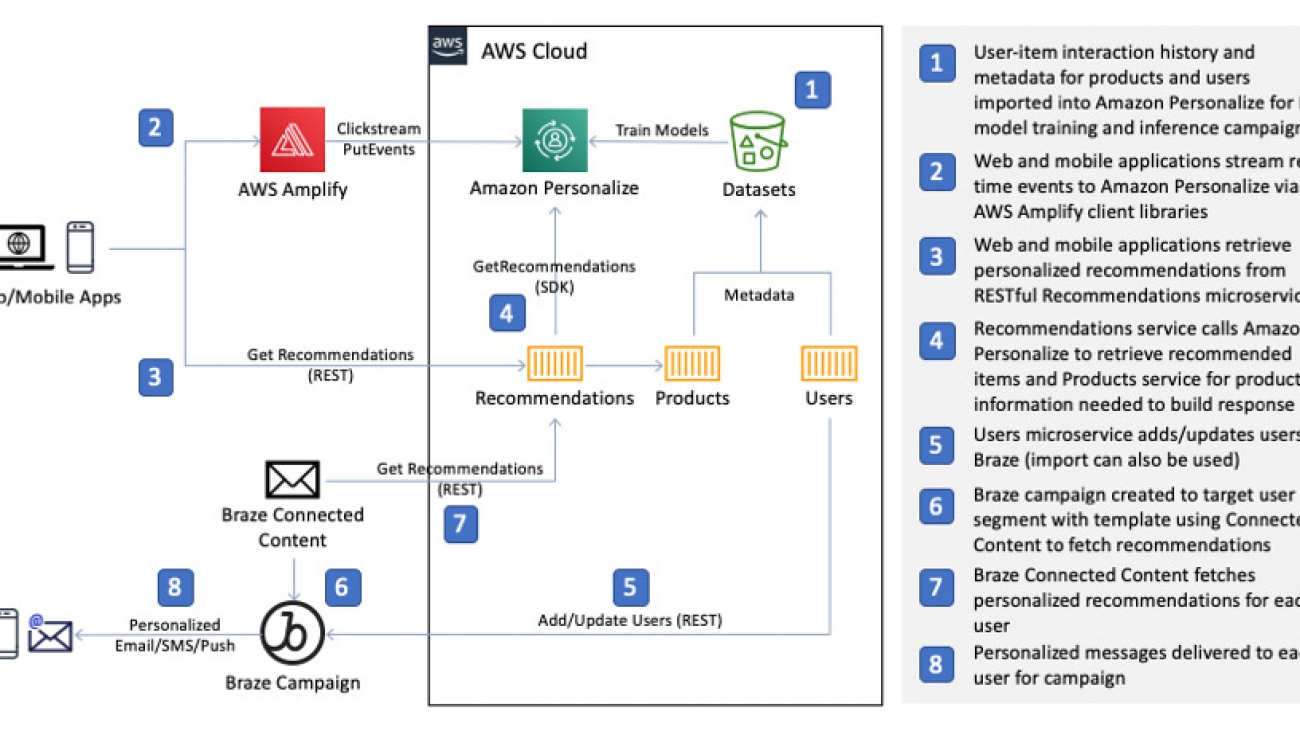
We start with a real-time integration architecture. The following diagram depicts the relevant components of a sample ecommerce application in which you use Amazon Personalize to provide machine learning (ML)-powered recommenders, referred to as solutions. The primary data used to build solutions is user-item interaction history. For an ecommerce application, this includes events such as viewing a product, adding a product to a shopping cart, and purchasing a product. When rich metadata on events, items, and users is available, you can incorporate it to further improve the relevance of recommendations from the recommender. Examples of metadata include device type, location, and season for events; category, genre, and price point for items; and users’ age, gender, and subscription tier. After you create solutions, you can create autoscaling API endpoints called campaigns with just a few clicks to retrieve personalized recommendations.
Later in this post, I show you how to deploy this application in your AWS account. A self-guided workshop is also packaged with the application that you use to walk through sending personalized emails with Braze.
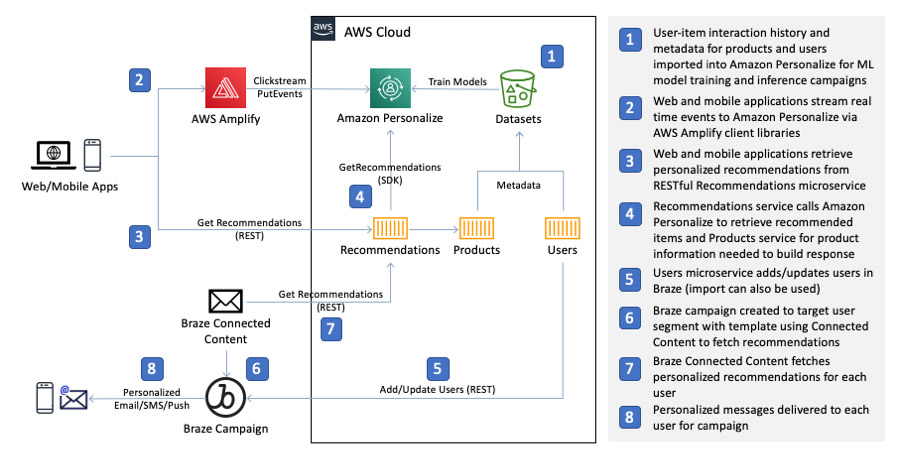
Our example ecommerce application retrieves personalized recommendations from a Recommendations microservice that appends the recommended item IDs from Amazon Personalize with rich product information from a Products microservice. As users engage with the application and indicate interest by viewing a product, adding a product to their shopping cart, or purchasing a product, events representing these actions are streamed to Amazon Personalize via the AWS Amplify JavaScript client library where Amazon Personalize automatically adjusts recommendations in real time based on user activity.
With personalization built into the application, you can connect Amazon Personalize with Braze to deliver personalized recommendations through outbound engagement channels such as email, SMS, and push notifications.
Braze allows you to create message templates that use the Liquid templating language to substitute placeholders in your template with values from a customer’s profile or even from an external resource. In the real-time architecture, we use the Recommendations microservice from the sample application as the external resource and Braze Connected Content as the feature to retrieve personalized recommendations to include in your message templates. The following Connected Content Liquid tag, placed at the top of your message, illustrates how to call the Recommendations service from Braze to retrieve recommendations for a user:
{% connected_content http://<RecommendationsServiceHostName>/recommendations?userID={{${user_id}}}&fullyQualifyImageUrls=1&numResults=4 :save result %}
The tag has the following elements:
- Liquid tags are framed within {
% and %} This allows you to embed tags and expressions inside message templates that may also contain text or HTML.
- The tag type is declared just after the start of the tag. In this case,
connected_content is the tag type. For the full list of supported tags, see Personalization Using Liquid Tags.
- You next define a fully-qualified URL to the HTTP resource that Connected Content calls for each user. You replace
<RecommendationsServiceHostName> with the host name for the Elastic Load Balancer for the Recommendations service in your deployment of the sample application.
- The Recommendations service provides a few resources for different personalization features. The resource for user recommendations is accessed from the
/recommendations path.
- The query string parameters come next. The user is identified by the
userID parameter, and the {{${user_id}}} expression instructs Braze to interpolate the user’s ID for each call to the service.
- The last two query string parameters,
fullyQualifyImageUrls=1 and numResults=4, tell the Recommendations service that we want the product image URLs to be fully qualified so they can be displayed in the user’s email client and, in this case, to only return the top four recommendations, respectively.
- The
:save result expression tells Braze to assign the JSON response from the Recommendations service to a template variable named result. With the response saved, you can then access elements of the response using Liquid tags in the rest of the template.
The following code shows the format of a response from the Recommendations service:
[
{
"product": {
"id": "2",
"url": "http://recs.cloudfront.net/#/product/2",
"sk": "",
"name": "Striped Shirt",
"category": "apparel",
"style": "shirt",
"description": "A classic look for the summer season.",
"price": 9.99,
"image": "http://recs.cloudfront.net/images/apparel/1.jpg",
"featured": "true"
}
},
{
"product": {
"id": "1",
"url": "http://recs.cloudfront.net/#/product/1",
"sk": "",
"name": "Black Leather Backpack",
"category": "accessories",
"style": "bag",
"description": "Our handmade leather backpack will look great at the office or out on the town.",
"price": 109.99,
"image": "http://recs.cloudfront.net/images/accessories/1.jpg",
"featured": "true"
}
},
...
]
For brevity, the preceding code only shows the first two recommended products. Several product attributes are available that you can use in the Braze message template to represent each recommendation. To access a specific element of an array or list as we have here, you can use array subscripting notation in your Liquid tag. For example, the following tag interpolates the product name for the first recommended product in the response. For the preceding sample response, the tag resolves to “Striped Shirt”:
{{result[0].product.name}}
When you combine the information in the personalized recommendation response from the Recommendations service with Liquid tags, the possibilities for building message designs are endless. The following code is a simplified example of how you could display a product recommendation in an HTML email template:
<table>
<tr>
<td>
<a href="{{result[0].product.url}}" target="_blank">
<img src="{{result[0].product.image}}" width="200" alt="{{result[0].product.name}}" />
</a>
</td>
<td>
<h2>{{result[0].product.name}}</h2>
<p>{{result[0].product.description}}</p>
<p>Only <strong>$ {{result[0].product.price}}</strong>!</p>
<a class="button" href="{{result[0].product.url}}">Buy Now</a>
</td>
</tr>
</table>
Batch integration
The batch integration architecture replaces the use of the Braze Connected Content feature with an Amazon Personalize batch recommendations job that is used to push attribute updates to Braze. Batch recommendations involve creating a file in an Amazon Simple Storage Service (Amazon S3) bucket that includes the users who you wish to generate recommendations for. A reference to this file is then used to submit a job to Amazon Personalize to generate recommendations for each user in the file and output the results to another Amazon S3 file of your choosing. You can use the output of the batch recommendations job to associate personalized recommendations with user profiles in Braze as custom attributes. The Liquid tags in the message templates we saw earlier are changed to access the recommendations as custom attributes from the user profile rather than the Connected Content response.
As noted earlier, the trade-off you’re making with the batch approach is sacrificing the freshness of real-time recommendations for a more cost-effective solution. Because batch recommendations don’t require an Amazon Personalize campaign, the additional requests from Connected Content to your campaign for each user are eliminated. For Braze campaigns that target extremely large segments, this can result in a significant reduction in requests. Furthermore, if you don’t need an Amazon Personalize campaign for other purposes or you’re creating an Amazon Personalize solution dedicated to email personalization, you can forego creating a campaign entirely.
The following diagram illustrates one of the many possible approaches to designing a batch architecture. The web application components from the real-time architecture still apply; they are excluded from this diagram for brevity.
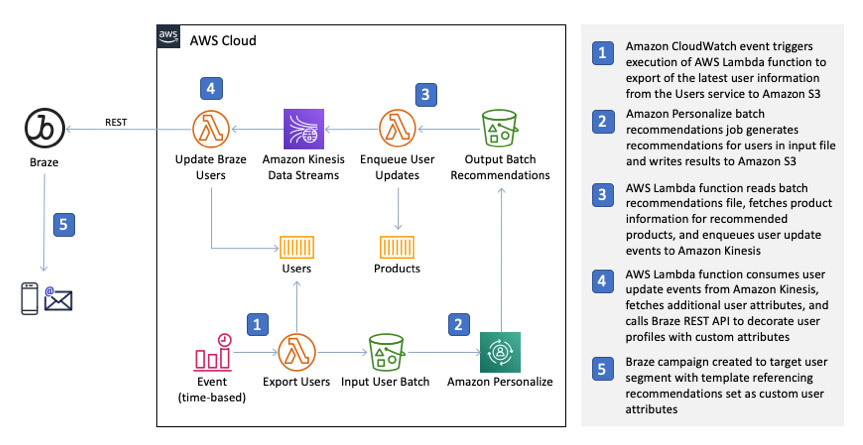
You use Amazon CloudWatch Events to periodically trigger an AWS Lambda function that builds an input file for an Amazon Personalize batch recommendations job. When the batch recommendations job is complete, another Lambda function processes the output file, decorates the recommended items with rich product information, and enqueues user update events in Amazon Kinesis Data Streams. Finally, another Lambda function consumes the stream’s events and uses the Braze User API to update user profiles.
The use of a Kinesis data stream provides a few key benefits, including decoupling the batch job from the transactional Braze user update process and the ability to pause, restart, and replay user update events.
Real-time integration walkthrough
You implement the real-time integration in the Retail Demo Store sample ecommerce application. In this post, we walk you through the process of deploying this project in your AWS account and describe how to launch the self-guided Braze workshop bundled with the application.
You complete the following steps:
- Deploy the Retail Demo Store project to your AWS account using the supplied AWS CloudFormation templates (25–30 minutes).
- Build Amazon Personalize solutions and campaigns that provide personalized recommendations (2 hours).
- Import users into Braze and build a Braze campaign that uses Connected Content to retrieve personalized recommendations from Amazon Personalize (1 hour).
- Clean up resources.
Prerequisites
For this walkthrough, you need the following prerequisites:
- An AWS account
- A user in your AWS account with the necessary privileges to deploy the project
- A Braze account
If you don’t have a Braze account, please contact your Braze representative. We also assume that you have completed at least the Getting Started with Braze LAB course.
Step 1: Deploying the Retail Demo Store to your AWS account
From the following table, choose Launch Stack in the Region of your choice. This list of Regions doesn’t represent all possible Regions where you can deploy the project, just the Regions currently configured for deployment.
| Region |
Launch |
| US East (N. Virginia) |
 |
| US West (Oregon) |
|
| Europe (Ireland) |
|
Accept all the default template parameter values and launch the template. The deployment of the project’s resources takes 25–30 minutes.
Step 2: Building Amazon Personalize campaigns
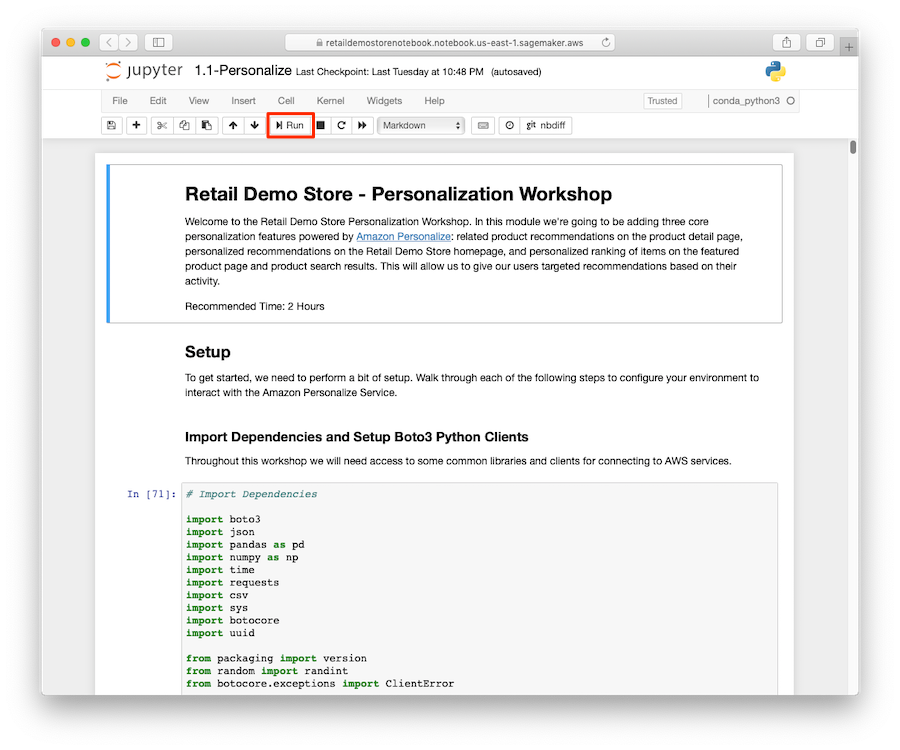
Before you can provide personalized product recommendations, you first need to train the ML models and provision the inference endpoints in Amazon Personalize that you need to retrieve recommendations. The CloudFormation template deployed in Step 1 includes an Amazon SageMaker notebook instance that provides a Jupyter notebook with detailed step-by-step instructions. The notebook takes approximately 2 hours to complete.
- Sign in to the AWS account where you deployed the CloudFormation template in Step 1.
- On the Amazon SageMaker console, choose Notebook instances.
- If you don’t see the
RetailDemoStore notebook instance, make sure you’re in the same Region where you deployed the project.
- To access the notebook instance, choose Open Jupyter or Open JupyterLab.
- When the Jupyter web interface is loaded for the notebook instance, choose the
workshop/1-Personalization/1.1-Personalize.ipynb.
The notebooks are organized in a directory structure, so you may have to choose the workshop folder to see the notebook subdirectories.
- When you have the
1.1-Personalize notebook open, step through the workshop by reading and running each cell.
You can choose Run from the Jupyter toolbar sequentially run the code in the cells.
Step 3: Sending personalized messages from Braze
With the Amazon Personalize solutions and campaigns to produce personalized recommendations in place, you can now import users into your Braze account, build a messaging template that uses Braze Connected Content to retrieve recommendations from Amazon Personalize, and build a Braze campaign to send targeted emails to your users.
Similar to the Personalization workshop in Step 1, the Braze messaging workshop steps you through the process. This notebook takes approximately 1 hour to complete.
- If necessary, repeat the instructions in Step 1 to open a Jupyter or JupyterLab browser window from the Amazon SageMaker notebook instance in your Retail Demo Store deployment.
- When the Jupyter web interface is loaded for the notebook instance, choose the
workshop/4-Messaging/4.2-Braze.ipynb notebook.
As with before, you may have to choose the workshop folder to see the notebook subdirectories.
- When you have the
4.2-Braze notebook open, step through the workshop by reading and running each cell.
Step 4: Cleaning up
To avoid incurring future charges, delete the resources the Retail Demo Store project created by deleting the CloudFormation stack you used during deployment. For more information about the source code for this post and the full Retail Demo Store project, see the GitHub repo.
Conclusion
As marketers compete for the attention of customers through outbound messaging, there is increasing pressure to effectively target the right users, at the right time, on the right channel, and with the right messaging. Braze provides the solution to the first three challenges. You can solve the final challenge with Braze Connected Content and Amazon Personalize, and deliver highly personalized product and content recommendations that reflect each customer’s current interests.
How are you using outbound messaging to reach your customers? Is there an opportunity to increase engagement with your customers with more relevant and personalized content?
About Braze
Braze is an AWS Advanced Technology Partner and holder of the AWS Digital Customer Experience and Retail competencies. Top global brands such as ABC News, Urban Outfitters, Rakuten, and Gap are sending tens of billions of messages per month to over 2 billion monthly active users with Braze.
About the Author
 James Jory is a Solutions Architect in Applied AI with AWS. He has a special interest in personalization and recommender systems and a background in ecommerce, marketing technology, and customer data analytics. In his spare time, he enjoys camping and auto racing simulation.
James Jory is a Solutions Architect in Applied AI with AWS. He has a special interest in personalization and recommender systems and a background in ecommerce, marketing technology, and customer data analytics. In his spare time, he enjoys camping and auto racing simulation.
Read More







 Watson G. Srivathsan is the Sr. Product Manager for Amazon Translate, AWS’s natural language processing service. On weekends you will find him exploring the outdoors in the Pacific Northwest.
Watson G. Srivathsan is the Sr. Product Manager for Amazon Translate, AWS’s natural language processing service. On weekends you will find him exploring the outdoors in the Pacific Northwest.





 Charles Gibson is an Enterprise Transformation Architect in Professional Services at Amazon Web Services. He helps customers migrate and modernize their businesses on the AWS Cloud. Charles enjoys cooking Northern Italian food for friends and family.
Charles Gibson is an Enterprise Transformation Architect in Professional Services at Amazon Web Services. He helps customers migrate and modernize their businesses on the AWS Cloud. Charles enjoys cooking Northern Italian food for friends and family.