Posted by Josh Gordon for the TensorFlow team
TensorFlow 2.3 has been released! The focus of this release is on new tools to make it easier for you to load and preprocess data, and to solve input-pipeline bottlenecks, whether you’re working on one machine, or many.
- tf.data adds two mechanisms to solve input pipeline bottlenecks and improve resource utilization. For advanced users, the new service API provides a way to improve training speed when the host attached to a training device can’t keep up with the data consumption needs of your model. It allows you to offload input preprocessing to a CPU cluster of data-processing workers that run alongside your training job, increasing accelerator utilization. A second new feature is the tf.data snapshot API, which allows you to persist the output of your input preprocessing pipeline to disk, so you can reuse it on a different training run. This enables you to trade storage space to free up additional CPU time.
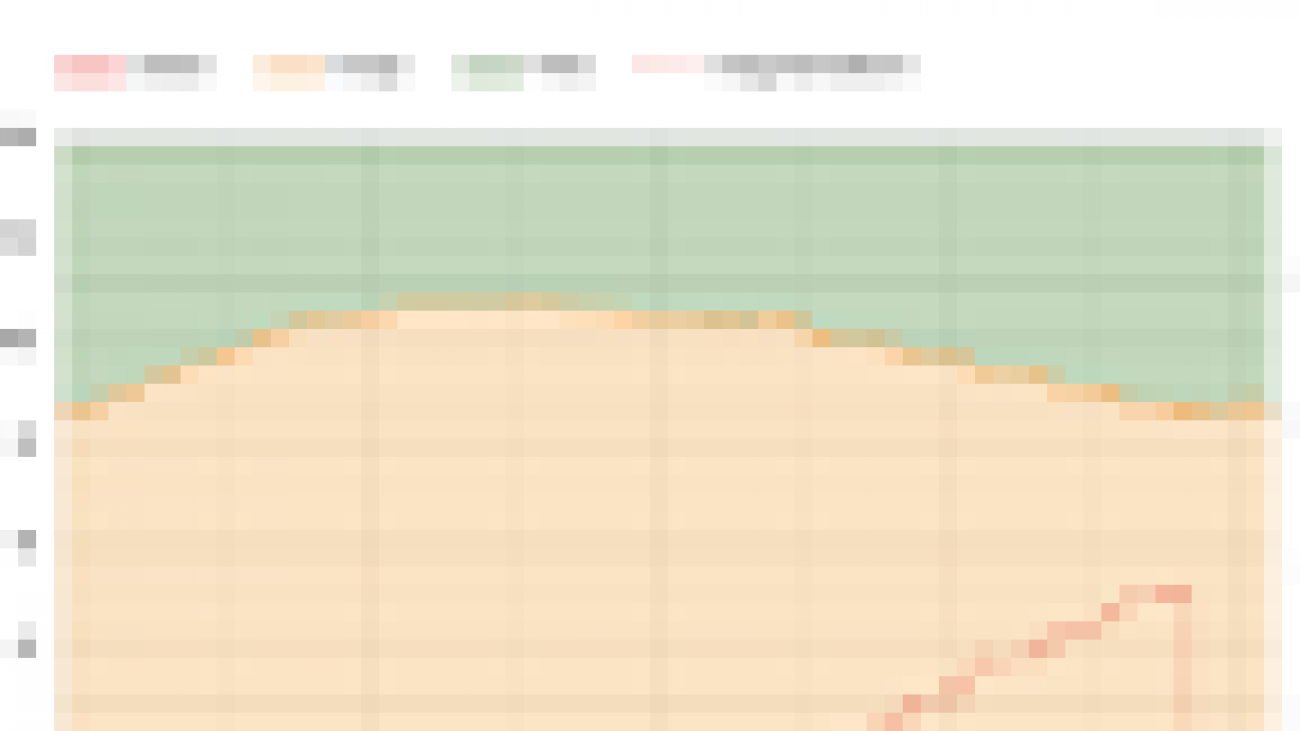
- The TF Profiler adds two new tools as well: a memory profiler to visualize your model’s memory usage over time, and a Python tracer that allows you to trace Python function calls in your model. You can read more about these below (and if you’re new to the TF Profiler, be sure to check out this article).
- TensorFlow 2.3 adds experimental support for the new Keras Preprocessing Layers API. These layers allow you to package your preprocessing logic inside your model for easier deployment – so you can ship a model that takes raw strings, images, or rows from a table as input. There are also new user-friendly utilities that allow you to easily create a tf.data.Dataset from a directory of images or text files on disk, in a few lines of code.
 |
| The new memory profiler |
New features in tf.data
tf.data.service
Modern accelerators (GPUs, TPUs) are incredibly fast. To avoid performance bottlenecks, it’s important to ensure that your data loading and preprocessing pipeline is fast enough to provide data to the accelerator when it’s needed. For example, imagine your GPU can classify 200 examples/second, but your data input pipeline can only load 100 examples/second from disk. In this case, your GPU would be idle (waiting for data) 50% of the time. And, that’s assuming your input-pipeline is already overlapped with GPU computation (if not, your GPU would be waiting for data 66% of the time).
In this scenario, you can double training speed by using the tf.data.experimental.service to generate 200 examples/second, by distributing data loading and preprocessing to a cluster you run alongside your training job. The tf.data service has a dispatcher-worker architecture, with one dispatcher and many workers. You can find documentation on setting up a cluster here, and you can find a complete example here that shows you how to deploy a cluster using Google Kubernetes Engine.
Once you have a tf.data.service running, you can add distributed dataset processing to your existing tf.data pipelines using the distribute transformation:
ds = your_dataset()
ds = dataset.apply(tf.data.experimental.service.distribute(processing_mode="parallel_epochs", service=service_address))Now, when you iterate over the dataset, data processing will happen using the tf.data service, instead of on your local machine.
Distributing your input pipeline is a powerful feature, but if you’re working on a single machine, tf.data has tools to help you improve input pipeline performance as well. Be sure to check out the cache and prefetch transformations – which can greatly speed up your pipeline in a single line of code.
tf.data snapshot
The tf.data.experimental.snapshot API allows you to persist the output of your preprocessing pipeline to disk, so you can materialize the preprocessed data on a different training run. This is useful for trading off storage space on disk to free up more valuable CPU and accelerator time.
For example, suppose you have a dataset that does expensive preprocessing (perhaps you are manipulating images with cropping or rotation). After developing your inputline pipeline to load and preprocess data:
dataset = create_input_pipeline()You can snapshot the results to a directory by applying the snapshot transformation:
dataset = dataset.apply(tf.data.experimental.snapshot("/snapshot_dir"))The snapshot will be created on disk when you iterate over the dataset for the first time. Subsequent iterations will read from snapshot_dir instead of recomputing dataset elements.
Snapshot computes a fingerprint of your dataset so it can detect changes to your input pipeline, and recompute outdated snapshots automatically. For example, if you modify a Dataset.map transformation or add additional images to a source directory, the fingerprint will change, causing the snapshot to be recomputed. Note that snapshot cannot detect changes to an existing file, though. Check out the documentation to learn more.
New features in the TF Profiler
The TF Profiler (introduced in TF 2.2) makes it easier to spot performance bottlenecks. It can help you identify when an application is input-bound, and can provide suggestions for what can be done to fix it. You can learn more about this workflow in the Analyze tf.data performance with the TF Profiler guide.
In TF 2.3, the Profiler has a few new capabilities and several usability improvements.
- The new Memory Profiler enables you to monitor memory usage during training. If a training job runs out of memory, you can pinpoint when the peak memory usage occured and which ops consumed the most memory. If you collect a profile, the Memory Profiler tool appears in the Profiler dashboard with no extra work.
- The new Python Tracer helps trace the Python call stack to provide additional insight on what is being executed in your program. It appears in the Profiler’s Trace Viewer. It can be enabled in programmatic mode using the ProfilerOptions or in sampling mode through the TensorBoard “capture profile” UI (you can find more information about these modes in this guide).
New Keras data loading utilities
In TF 2.3, Keras adds new user-friendly utilities (image_dataset_from_directory and text_dataset_from_directory) to make it easy for you to create a tf.data.Dataset from a directory of images or text files on disk, in just one function call. For example, if your directory structure is:
flowers_photos/
daisy/
dandelion/
roses/
sunflowers/
tulips/You can use image_dataset_from_directory to create a tf.data.Dataset that yields batches of images from the subdirectories and labels:
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
“datasets/cats_and_dogs”,
validation_split=0.2,
subset="training",
seed=0,
image_size=(img_height, img_width),
batch_size=32)If you’re starting a new project, we recommend using image_dataset_from_directory over the legacy ImageDataGenerator. Note this utility doesn’t perform data augmentation (this is meant to be done using the new preprocessing layers, described below). You can find a complete example of loading images with this utility (as well as how to write a similar input-pipeline from scratch with tf.data) here.
Performance tip
After creating a tf.data.Dataset (either from scratch, or using image_dataset_from_directory) remember to configure it for performance to ensure I/O doesn’t become a bottleneck when training a model. You can use a one-liner for this. With this line of code:
train_ds = train_ds.cache().prefetch(buffer_size=tf.data.experimental.AUTOTUNE)You create a dataset that caches images in memory (once they’re loaded off disk during the first training epoch), and overlaps preprocessing work on the CPU with training work on the GPU. If your dataset is too large to fit into memory, you can also use .cache(filename) to automatically create an efficient on-disk cache, which is faster to read than many small files.
You learn more in the Better performance with the tf.data API guide.
New Keras preprocessing layers
In TF 2.3, Keras also adds new experimental preprocessing layers that can simplify deployment by allowing you to include your preprocessing logic as layers inside your model, so they are saved just like other layers when you export your model.
- Using the new TextVectorization layer, for example, you can develop a text classification model that accepts raw strings as input (without having to re-implement any of the logic for tokenization, standardization, vectorization, or padding server-side).
- You can also use resizing, rescaling, and normalization layers to develop an image classification model that accepts any size of image as input, and that automatically normalizes pixel values to the expected range. And, you can use new data augmentation layers (like RandomRotation) to speed up your input-pipeline by running data augmentation on the GPU.
- For structured data, you can use layers like StringLookup to encode categorical features, so you can develop a model that takes a row from a table as input. You can check out this RFC to learn more.
The best way to learn how to use these new layers is to try the new text classification from scratch, image classification from scratch, and structured data classification from scratch examples on keras.io.
Note that all of these layers can either be included inside your model, or can be applied to your tf.data input-pipeline via the map transformation. You can find an example here.
Please keep in mind, these new preprocessing layers are experimental in TF 2.3. We’re happy with the design (and anticipate they will be made non-experimental in 2.4) but realize we might not have gotten everything right on this iteration. Your feedback is very welcome. Please file an issue on GitHub to let us know how we can better support your use case.
Next steps
Check out the release notes for more information. To stay up to date, you can read the TensorFlow blog, follow twitter.com/tensorflow, or subscribe to youtube.com/tensorflow. If you’ve built something you’d like to share, please submit it for our Community Spotlight at goo.gle/TFCS. For feedback, please file an issue on GitHub. Thank you!Read More









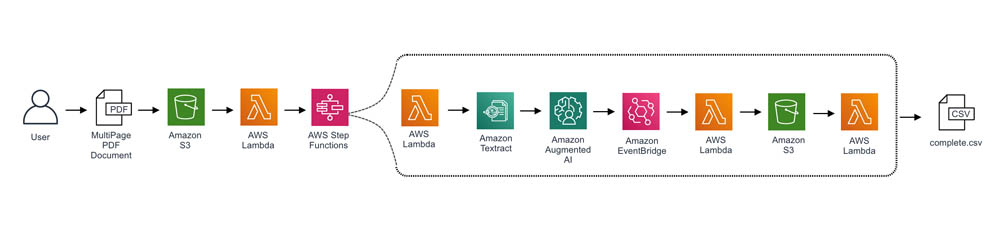











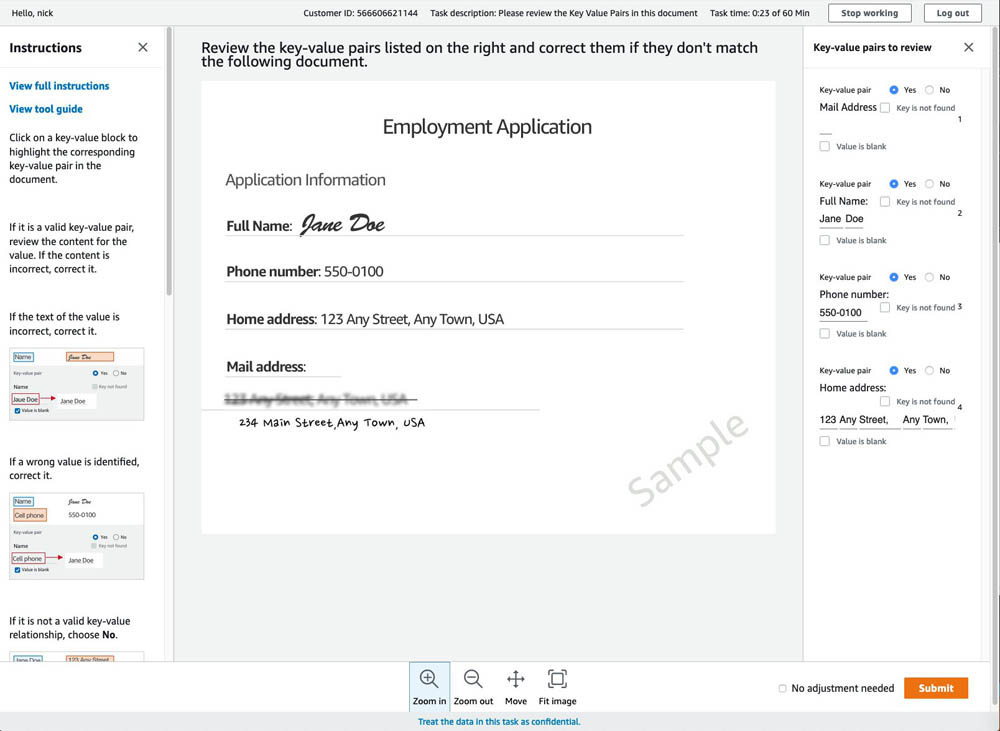
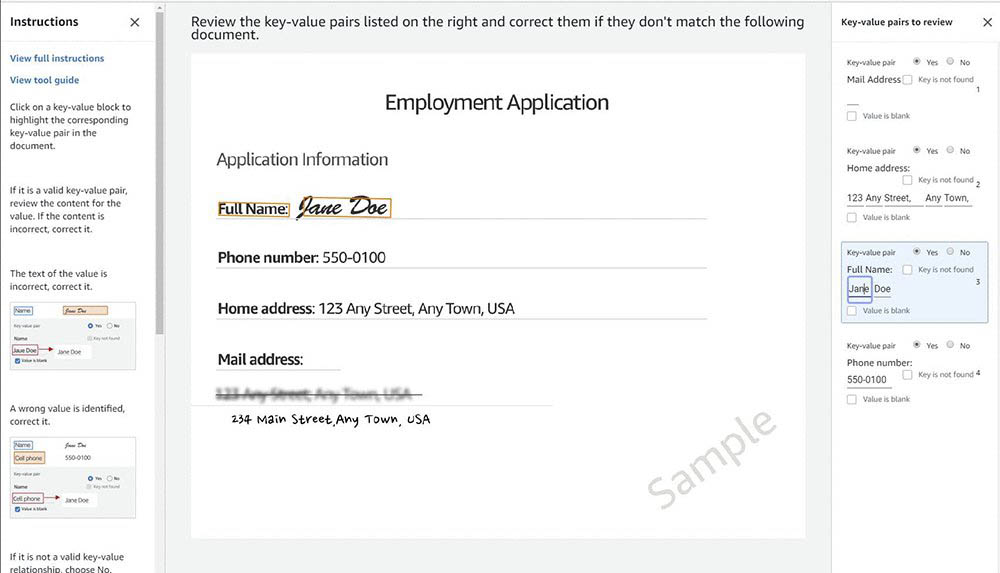
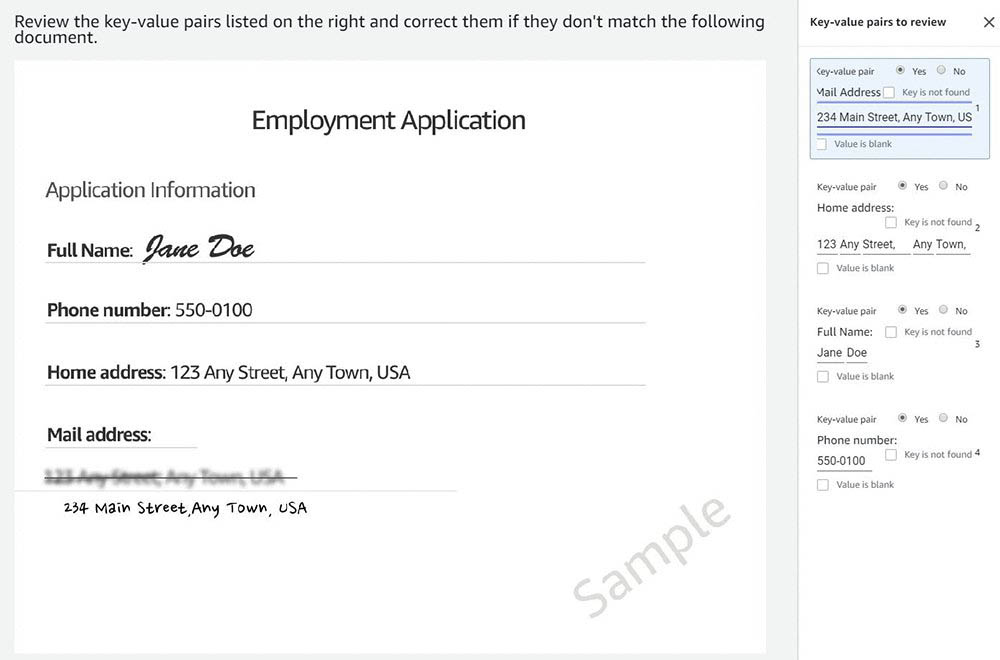
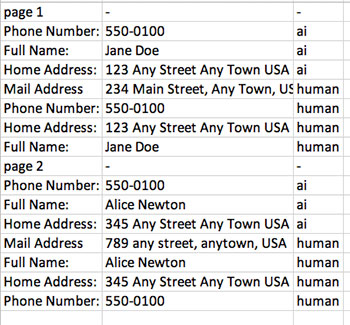
 Nicholas Nelson is an AWS Solutions Architect for Strategic Accounts based out of Seattle, Washington. His interests and experience include Computer Vision, Serverless Technology, and Construction Technology. Outside of work, you can find Nicholas out cycling, paddle boarding, or grilling!
Nicholas Nelson is an AWS Solutions Architect for Strategic Accounts based out of Seattle, Washington. His interests and experience include Computer Vision, Serverless Technology, and Construction Technology. Outside of work, you can find Nicholas out cycling, paddle boarding, or grilling! Kashif Imran is a Principal Solutions Architect at Amazon Web Services. He works with some of the largest AWS customers who are taking advantage of AI/ML to solve complex business problems. He provides technical guidance and design advice to implement computer vision applications at scale. His expertise spans application architecture, serverless, containers, NoSQL and machine learning.
Kashif Imran is a Principal Solutions Architect at Amazon Web Services. He works with some of the largest AWS customers who are taking advantage of AI/ML to solve complex business problems. He provides technical guidance and design advice to implement computer vision applications at scale. His expertise spans application architecture, serverless, containers, NoSQL and machine learning. Anuj Gupta is Senior Product Manager for Amazon Augmented AI. He focuses on delivering products that make it easier for customers to adopt machine learning. In his spare time, he enjoys road trips and watching Formula 1.
Anuj Gupta is Senior Product Manager for Amazon Augmented AI. He focuses on delivering products that make it easier for customers to adopt machine learning. In his spare time, he enjoys road trips and watching Formula 1.











 Mona Mona is an AI/ML Specialist Solutions Architect based out of Arlington, VA. She works with World Wide Public Sector team and helps customers adopt machine learning on a large scale. She is passionate about NLP and ML Explainability areas in AI/ML.
Mona Mona is an AI/ML Specialist Solutions Architect based out of Arlington, VA. She works with World Wide Public Sector team and helps customers adopt machine learning on a large scale. She is passionate about NLP and ML Explainability areas in AI/ML. Prem Ranga is an Enterprise Solutions Architect based out of Houston, Texas. He is part of the Machine Learning Technical Field Community and loves working with customers on their ML and AI journey. Prem is passionate about robotics, is an Autonomous Vehicles researcher, and also built the Alexa-controlled Beer Pours in Houston and other locations.
Prem Ranga is an Enterprise Solutions Architect based out of Houston, Texas. He is part of the Machine Learning Technical Field Community and loves working with customers on their ML and AI journey. Prem is passionate about robotics, is an Autonomous Vehicles researcher, and also built the Alexa-controlled Beer Pours in Houston and other locations.