Amazon SageMaker notebooks now support R out-of-the-box, without needing you to manually install R kernels on the instances. Also, the notebooks come pre-installed with the reticulate library, which offers an R interface for the Amazon SageMaker Python SDK and enables you to invoke Python modules from within an R script. You can easily run machine learning (ML) models in R using the Amazon SageMaker R kernel to access the data from multiple data sources. The R kernel is available by default in all Regions that Amazon SageMaker is available in.
R is a programming language built for statistical analysis and is very popular in data science communities. In this post, we will show you how to connect to the following data sources from the Amazon SageMaker R kernel using Java Database Connectivity (JDBC):
For more information about using Amazon SageMaker features using R, see R User Guide to Amazon SageMaker.
Solution overview
To build this solution, we first need to create a VPC with public and private subnets. This will allow us to securely communicate with different resources and data sources inside an isolated network. Next, we create the data sources in the custom VPC and the notebook instance with all necessary configuration and access to connect various data sources using R.
To make sure that the data sources are not reachable from the Internet, we create them inside a private subnet of the VPC. For this post, we create the following:
- Amazon EMR cluster inside a private subnet with Hive and Presto installed. For instructions, see Getting Started: Analyzing Big Data with Amazon EMR.
- Athena resources. For instructions, see Getting Started.
- Amazon Redshift cluster inside a private subnet. For instructions, see Create a sample Amazon Redshift cluster.
- Amazon Aurora MySQL-compatible cluster running inside a private subnet. For instructions, see Creating an Amazon Aurora DB Cluster.
Connect to the Amazon EMR cluster inside the private subnet using AWS Systems Manager Session Manager to create Hive tables.
To run the code using the R kernel in Amazon SageMaker, create an Amazon SageMaker notebook. Download the JDBC drivers for the data sources. Create a lifecycle configuration for the notebook containing the setup script for R packages, and attach the lifecycle configuration to the notebook on create and on start to make sure the setup is complete.
Finally, we can use the AWS Management Console to navigate to the notebook to run code using the R kernel and access the data from various sources. The entire solution is also available in the GitHub repository.
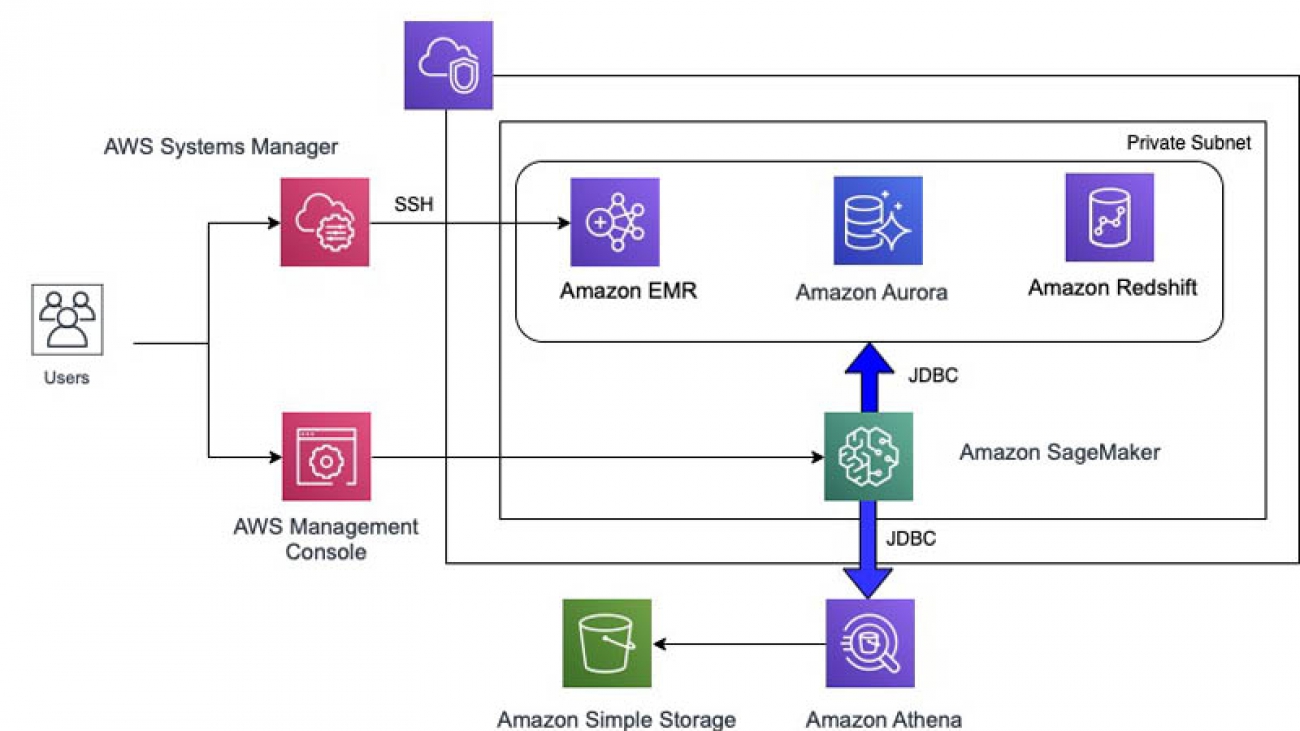
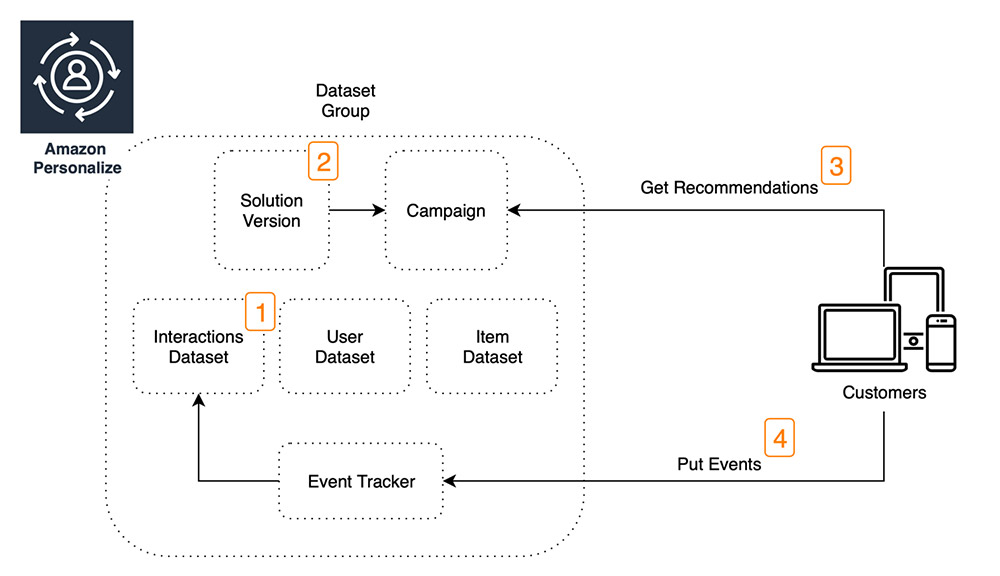
Solution architecture
The following architecture diagram shows how you can use Amazon SageMaker to run code using the R kernel by establishing connectivity to various sources. You can also use the Amazon Redshift query editor or Amazon Athena query editor to create data resources. You need to use the Session Manager in AWS Systems Manager to SSH to the Amazon EMR cluster to create Hive resources.

Launching the AWS CloudFormation template
To automate resource creation, you run an AWS CloudFormation template. The template gives you the option to create an Amazon EMR cluster, Amazon Redshift cluster, or Amazon Aurora MySQL-compatible cluster automatically, as opposed to executing each step manually. It will take a few minutes to create all the resources.
- Choose the following link to launch the CloudFormation stack, which creates the required AWS resources to implement this solution:

- On the Create stack page, choose Next.

- Enter a stack name.
- You can change the default values for the following stack details:
| Stack Details | Default Values |
| Choose Second Octet for Class B VPC Address (10.xxx.0.0/16) | 0 |
| SageMaker Jupyter Notebook Instance Type | ml.t2.medium |
| Create EMR Cluster Automatically? | “Yes” |
| Create Redshift Cluster Automatically? | “Yes” |
| Create Aurora MySQL DB Cluster Automatically? | “Yes” |
- Choose Next.
- On the Configure stack options page, choose Next.
- Select I acknowledge that AWS CloudFormation might create IAM resources.
- Choose Create stack.

You can now see the stack being created, as in the following screenshot.

When stack creation is complete, the status shows as CREATE_COMPLETE.

- On the Outputs tab, record the keys and their corresponding values.

You use the following keys later in this post:
- AuroraClusterDBName – Aurora cluster database name
- AuroraClusterEndpointWithPort – Aurora cluster endpoint address with port number
- AuroraClusterSecret – Aurora cluster credentials secret ARN
- EMRClusterDNSAddress – EMR cluster DNS name
- EMRMasterInstanceId – EMR cluster primary instance ID
- PrivateSubnets – Private subnets
- PublicSubnets – Public subnets
- RedshiftClusterDBName – Amazon Redshift cluster database name
- RedshiftClusterEndpointWithPort – Amazon Redshift cluster endpoint address with port number
- RedshiftClusterSecret – Amazon Redshift cluster credentials secret ARN
- SageMakerNotebookName – Amazon SageMaker notebook instance name
- SageMakerRS3BucketName – Amazon SageMaker S3 data bucket
- VPCandCIDR – VPC ID and CIDR block
Creating your notebook with necessary R packages and JAR files
JDBC is an application programming interface (API) for the programming language Java, which defines how you can access a database. RJDBC is a package in R that allows you to connect to various data sources using the JDBC interface. The notebook instance that the CloudFormation template created ensures that the necessary JAR files for Hive, Presto, Amazon Athena, Amazon Redshift and MySQL are present in order to establish a JDBC connection.
- In the Amazon SageMaker Console, under Notebook, choose Notebook instances.
- Search for the notebook that matches the
SageMakerNotebookNamekey you recorded earlier.

- Select the notebook instance.
- Click on “Open Jupyter” under “Actions” to locate the “jdbc” directory.

The CloudFormation template downloads the JAR files for Hive, Presto, Athena, Amazon Redshift, and Amazon Aurora MySQL-compatible inside the “jdbc” directory.

- Locate the lifecycle configuration attached.
A lifecycle configuration allows you to install packages or sample notebooks on your notebook instance, configure networking and security for it, or otherwise use a shell script for customization. A lifecycle configuration provides shell scripts that run when you create the notebook instance or when you start the notebook.

- Inside the Lifecycle configuration section, choose View script to see the lifecycle configuration script that sets up the R kernel in Amazon SageMaker to make JDBC connections to data sources using R.

It installs the RJDBC package and dependencies in the Anaconda environment of the Amazon SageMaker notebook.
Connecting to Hive and Presto
Amazon EMR is the industry-leading cloud big data platform for processing vast amounts of data using open source tools such as Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi, and Presto.
You can create a test table in Hive by logging in to the EMR master node from the AWS console using the Session Manager capability in Systems Manager. Systems Manager gives you visibility and control of your infrastructure on AWS. Systems Manager also provides a unified user interface so you can view operational data from multiple AWS services and allows you to automate operational tasks across your AWS resources. Session Manager is a fully managed Systems Manager capability that lets you manage your Amazon Elastic Compute Cloud (Amazon EC2) instances, on-premises instances, and virtual machines (VMs) through an interactive, one-click browser-based shell or through the AWS Command Line Interface (AWS CLI).
You use the following values from the AWS CloudFormation Outputs tab in this step:
- EMRClusterDNSAddress – EMR cluster DNS name
- EMRMasterInstanceId – EMR cluster primary instance ID
- SageMakerNotebookName – Amazon SageMaker notebook instance name
- On the Systems Manager Console, under Instances & Nodes, choose Session Manager.

- Choose Start Session.

- Start an SSH session with the EMR primary node by locating the instance ID as specified by the value of the key
EMRMasterInstanceId.

This starts the browser-based shell.
- Run the following SSH commands:
# change user to hadoop whoami sudo su - hadoop - Create a test table in Hive from the EMR master node as you have already logged in using SSH:
# Run on the EMR master node to create a table called students in Hive hive -e "CREATE TABLE students (name VARCHAR(64), age INT, gpa DECIMAL(3, 2));" # Run on the EMR master node to insert data to students created above hive -e "INSERT INTO TABLE students VALUES ('fred flintstone', 35, 1.28), ('barney rubble', 32, 2.32);" # Verify hive -e "SELECT * from students;" exit exit
The following screenshot shows the view in the browser-based shell.

- Close the browser after exiting the shell.
To query the data from Amazon EMR using the Amazon SageMaker R kernel, you open the notebook the CloudFormation template created.
- On the Amazon SageMaker Console, under Notebook, chose Notebook instances.
- Find the notebook as specified by the value of the key
SageMakerNotebookName. - Choose Open Jupyter.

- To demonstrate connectivity from the Amazon SageMaker R kernel, choose Upload and upload the ipynb notebook.

- Alternatively, from the New drop-down menu, choose R to open a new notebook.

- Enter the code as mentioned in “hive_connect.ipynb”, replacing the
emr_dnsvalue with the value from keyEMRClusterDNSAddress:
- Alternatively, from the New drop-down menu, choose R to open a new notebook.
- Run all the cells in the notebook to connect to Hive on Amazon EMR using the Amazon SageMaker R console.

You follow similar steps to connect Presto:
- On the Amazon SageMaker Console, open the notebook you created.
- Choose Open Jupyter.
- Choose Upload to upload the ipynb notebook.
- Alternatively, from the New drop-down menu, choose R to open a new notebook.
- Enter the code as mentioned in “presto_connect.ipynb”, replacing the
emr_dnsvalue with the value from keyEMRClusterDNSAddress:
- Run all the cells in the notebook to connect to PrestoDB on Amazon EMR using the Amazon SageMaker R console.

Connecting to Amazon Athena
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon Simple Storage Service (Amazon S3) using standard SQL. Amazon Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. To connect to Amazon Athena from the Amazon SageMaker R kernel using RJDBC, we use the Amazon Athena JDBC driver, which is already downloaded to the notebook instance via the lifecycle configuration script.
You also need to set the query result location in Amazon S3. For more information, see Working with Query Results, Output Files, and Query History.
- On the Amazon Athena Console, choose Get Started.
- Choose Set up a query result location in Amazon S3.
- For Query result location, enter the Amazon S3 location as specified by the value of the key
SageMakerRS3BucketName. - Optionally, add a prefix, such as
results. - Choose Save.

- Create a database or schema and table in Athena with the example Amazon S3 data.
- Similar to connecting to Hive and Presto, to establish a connection from Athena to Amazon SageMaker using the R kernel, you can upload the ipynb notebook.
- Alternatively, open a new notebook and enter the code in “athena_connect.ipynb”, replacing the
s3_bucketvalue with the value from keySageMakerRS3BucketName:
- Alternatively, open a new notebook and enter the code in “athena_connect.ipynb”, replacing the
- Run all the cells in the notebook to connect to Amazon Athena from the Amazon SageMaker R console.

Connecting to Amazon Redshift
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. It allows you to run complex analytic queries against terabytes to petabytes of structured data, using sophisticated query optimization, columnar storage on high-performance storage, and massively parallel query execution. To connect to Amazon Redshift from the Amazon SageMaker R kernel using RJDBC, we use the Amazon Redshift JDBC driver, which is already downloaded to the notebook instance via the lifecycle configuration script.
You need the following keys and their values from the AWS CloudFormation Outputs tab:
- RedshiftClusterDBName – Amazon Redshift cluster database name
- RedshiftClusterEndpointWithPort – Amazon Redshift cluster endpoint address with port number
- RedshiftClusterSecret – Amazon Redshift cluster credentials secret ARN
The CloudFormation template creates a secret for the Amazon Redshift cluster in AWS Secrets Manager, which is a service that helps you protect secrets needed to access your applications, services, and IT resources. Secrets Manager lets you easily rotate, manage, and retrieve database credentials, API keys, and other secrets throughout their lifecycle.
- On the AWS Secrets Manager Console, choose Secrets.
- Choose the secret denoted by the
RedshiftClusterSecretkey value.

- In the Secret value section, choose Retrieve secret value to get the user name and password for the Amazon Redshift cluster.

- On the Amazon Redshift Console, choose Editor (which is essentially the Amazon Redshift query editor).
- For Database name, enter
redshiftdb. - For Database password, enter your password.
- Choose Connect to database.

- Run the following SQL statements to create a table and insert a couple of records:
CREATE TABLE public.students (name VARCHAR(64), age INT, gpa DECIMAL(3, 2)); INSERT INTO public.students VALUES ('fred flintstone', 35, 1.28), ('barney rubble', 32, 2.32); - On the Amazon SageMaker Console, open your notebook.
- Choose Open Jupyter.
- Upload the ipynb notebook.
- Alternatively, open a new notebook and enter the code as mentioned in “redshift_connect.ipynb”, replacing the values for
RedshiftClusterEndpointWithPort,RedshiftClusterDBName, andRedshiftClusterSecret:
- Alternatively, open a new notebook and enter the code as mentioned in “redshift_connect.ipynb”, replacing the values for
- Run all the cells in the notebook to connect to Amazon Redshift on the Amazon SageMaker R console.

Connecting to Amazon Aurora MySQL-compatible
Amazon Aurora is a MySQL-compatible relational database built for the cloud, which combines the performance and availability of traditional enterprise databases with the simplicity and cost-effectiveness of open-source databases. To connect to Amazon Aurora from the Amazon SageMaker R kernel using RJDBC, we use the MariaDB JDBC driver, which is already downloaded to the notebook instance via the lifecycle configuration script.
You need the following keys and their values from the AWS CloudFormation Outputs tab:
- AuroraClusterDBName – Aurora cluster database name
- AuroraClusterEndpointWithPort – Aurora cluster endpoint address with port number
- AuroraClusterSecret – Aurora cluster credentials secret ARN
The CloudFormation template creates a secret for the Aurora cluster in Secrets Manager.
- On the AWS Secrets Manager Console, locate the secret as denoted by the
AuroraClusterSecretkey value.

- In the Secret value section, choose Retrieve secret value to get the user name and password for the Aurora cluster.

To connect to the cluster, you follow similar steps as with other services.
- On the Amazon SageMaker Console, open your notebook.
- Choose Open Jupyter.
- Upload the ipynb notebook.
- Alternatively, open a new notebook and enter the code as mentioned in “aurora_connect.ipynb”, replacing the values for
AuroraClusterEndpointWithPort,AuroraClusterDBName, andAuroraClusterSecret:
- Alternatively, open a new notebook and enter the code as mentioned in “aurora_connect.ipynb”, replacing the values for
- Run all the cells in the notebook to connect Amazon Aurora on the Amazon SageMaker R console.

Conclusion
In this post, we demonstrated how to connect to various data sources, such as Hive and PrestoDB on Amazon EMR, Amazon Athena, Amazon Redshift, and Amazon Aurora MySQL-compatible cluster, in your environment to analyze, profile, run statistical computions using R from Amazon SageMaker. You can extend this method to other data sources via JDBC.
Author Bio
 Kunal Ghosh is a Solutions Architect at AWS. His passion is building efficient and effective solutions on the cloud, especially involving analytics, AI, data science, and machine learning. Besides family time, he likes reading, swimming, biking, and watching movies, and he is a foodie.
Kunal Ghosh is a Solutions Architect at AWS. His passion is building efficient and effective solutions on the cloud, especially involving analytics, AI, data science, and machine learning. Besides family time, he likes reading, swimming, biking, and watching movies, and he is a foodie.
 Gagan Brahmi is a Specialist Solutions Architect focused on Big Data & Analytics at Amazon Web Services. Gagan has over 15 years of experience in information technology. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS.
Gagan Brahmi is a Specialist Solutions Architect focused on Big Data & Analytics at Amazon Web Services. Gagan has over 15 years of experience in information technology. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS.
















 Woody Borraccino is a Senior AI Solutions Architect at AWS.
Woody Borraccino is a Senior AI Solutions Architect at AWS.










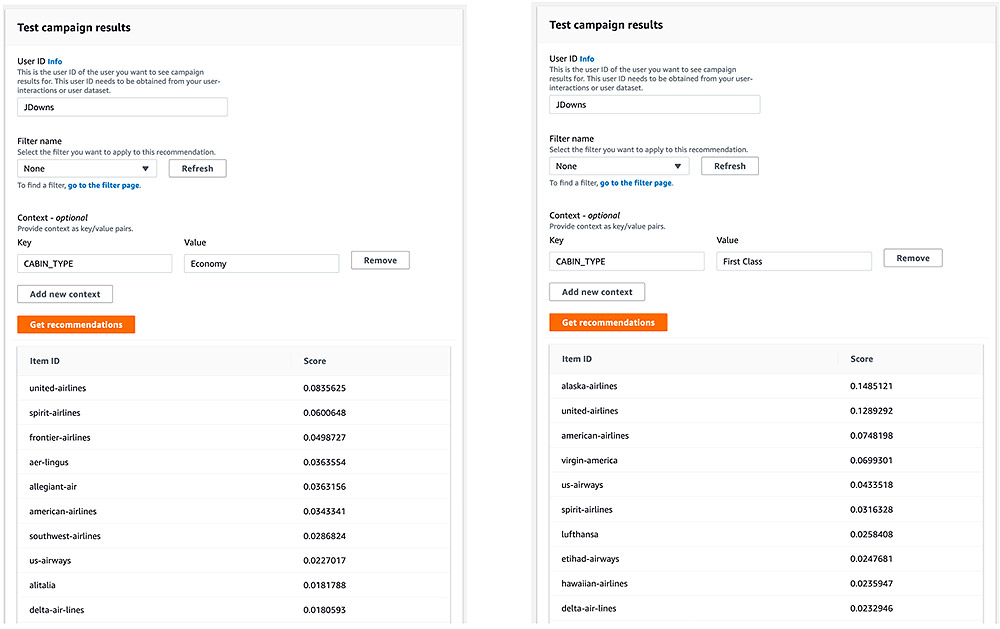

 Luis Lopez Soria is an AI/ML specialist solutions architect working with the AWS machine learning team. He works with AWS customers to help them adopt machine learning on a large scale. He enjoys playing sports, traveling around the world, and exploring new foods and cultures.
Luis Lopez Soria is an AI/ML specialist solutions architect working with the AWS machine learning team. He works with AWS customers to help them adopt machine learning on a large scale. He enjoys playing sports, traveling around the world, and exploring new foods and cultures.






 Namita Das is a Sr. Product Manager for Amazon Forecast. Her current focus is to democratize machine learning by building no-code/low-code ML services. She frequently advises startups and has started dabbling in baking.
Namita Das is a Sr. Product Manager for Amazon Forecast. Her current focus is to democratize machine learning by building no-code/low-code ML services. She frequently advises startups and has started dabbling in baking. Danielle Robinson is an Applied Scientist on the Amazon Forecast team. Her research is in time series forecasting and in particular how we can apply new neural network-based algorithms within Amazon Forecast. Her thesis research was focused on developing new, robust, and physically accurate numerical models for computational fluid dynamics. Her hobbies include cooking, swimming, and hiking.
Danielle Robinson is an Applied Scientist on the Amazon Forecast team. Her research is in time series forecasting and in particular how we can apply new neural network-based algorithms within Amazon Forecast. Her thesis research was focused on developing new, robust, and physically accurate numerical models for computational fluid dynamics. Her hobbies include cooking, swimming, and hiking. Aaron Spieler is a working student in the Amazon Forecast team. He is starting his masters degree at the University of Tuebingen, and studied Data Engineering at Hasso Plattner Institute after obtaining a BS in Computer Science from University of Potsdam. His research interests span time series forecasting (especially using neural network models), machine learning, and computational neuroscience.
Aaron Spieler is a working student in the Amazon Forecast team. He is starting his masters degree at the University of Tuebingen, and studied Data Engineering at Hasso Plattner Institute after obtaining a BS in Computer Science from University of Potsdam. His research interests span time series forecasting (especially using neural network models), machine learning, and computational neuroscience. Gunjan Garg: Gunjan Garg is a Sr. Software Development Engineer in the AWS Vertical AI team. In her current role at Amazon Forecast, she focuses on engineering problems and enjoys building scalable systems that provide the most value to end-users. In her free time, she enjoys playing Sudoku and Minesweeper.
Gunjan Garg: Gunjan Garg is a Sr. Software Development Engineer in the AWS Vertical AI team. In her current role at Amazon Forecast, she focuses on engineering problems and enjoys building scalable systems that provide the most value to end-users. In her free time, she enjoys playing Sudoku and Minesweeper. Chinmay Bapat is a Software Development Engineer in the Amazon Forecast team. His interests lie in the applications of machine learning and building scalable distributed systems. Outside of work, he enjoys playing board games and cooking.
Chinmay Bapat is a Software Development Engineer in the Amazon Forecast team. His interests lie in the applications of machine learning and building scalable distributed systems. Outside of work, he enjoys playing board games and cooking.





 Dave Williams is a Cloud Consultant for AWS Professional Services. He works with public sector customers to securely adopt AI/ML services. In his free time, he enjoys spending time with his family, traveling, and watching college football.
Dave Williams is a Cloud Consultant for AWS Professional Services. He works with public sector customers to securely adopt AI/ML services. In his free time, he enjoys spending time with his family, traveling, and watching college football. Adarsha Subick is a Cloud Consultant for AWS Professional Services based out of Virginia. He works with public sector customers to help solve their AI/ML-focused business problems. In his free time, he enjoys archery and hobby electronics.
Adarsha Subick is a Cloud Consultant for AWS Professional Services based out of Virginia. He works with public sector customers to help solve their AI/ML-focused business problems. In his free time, he enjoys archery and hobby electronics. Saman Zarandioon is a Sr. Software Development Engineer for Amazon Comprehend. He earned a PhD in Computer Science from Rutgers University.
Saman Zarandioon is a Sr. Software Development Engineer for Amazon Comprehend. He earned a PhD in Computer Science from Rutgers University.