Context vectors that capture “side information” can make experiments more informative.Read More
Creating a sophisticated conversational experience using Amazon Lex in Australian English
Amazon Lex is a service for building conversational interfaces into any application using voice and text. To build truly engaging conversational experiences, you need high quality speech recognition and natural language understanding that understands the intent of the customer accurately.
We are excited to announce that Amazon Lex now supports Australian English. With Australian English, you can deliver a robust and localized conversational experience that accurately understands the Australian dialect. You can also respond to users with natural sounding Amazon Polly Australian voices to provide a fully localized conversational experience.
This post shows how you can build a bot with Australian English support and use the pre-defined built-ins to deliver a superior experience to your users.
Building an Amazon Lex bot
This post uses the following conversation to model a bot:
User: I’d like to schedule an appointment for a dishwasher repair.
Agent: Sure, what city are you in?
User: Ballarat.
Agent: Got it. And what’s the serial number?
User: 1234.
Agent: Ok. For that model, I have technicians available next week. When would you prefer to have them visit?
User: Can I get someone on 4/9?
Agent: Sure. You are all set for September 4th.
User: Thanks!
The first step is to build an Amazon Lex bot with intents to manage appointments. The ScheduleAppointment, ModifyAppointment, and CancelAppointment intents provide this capability. You can download a sample bot definition to follow along with this post.
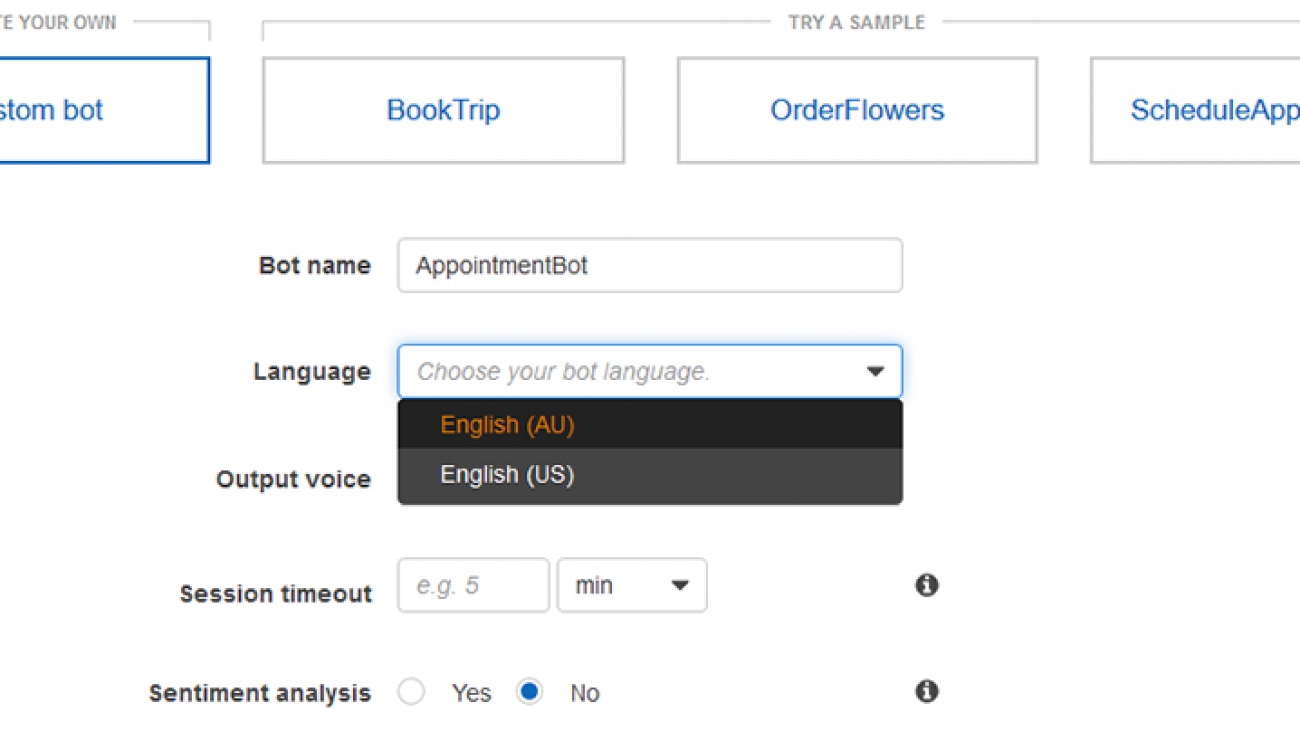
Creating a bot in Australian English
For this post, you will create an Amazon Lex bot called AppointmentBot. Alternatively, you can also import the sample bot directly and skip the bot creation process.
- Open the AWS console, and make sure you have selected the Asia Pacific (Sydney)/ap-southeast-2 region.
- Go to the Amazon Lex console. On the Bots tab, choose Create.
- Select Custom Bot.
- Enter the Bot name and select English (AU) as Language.
- Select the Output voice. The list of voices are specific to the language selected for the bot.
- Specify Sentiment analysis, Session timeout, and COPPA settings.
- Choose Create.
- Once the bot is created, create
ScheduleAppointment,ModifyAppointment, andCancelAppointmentintents for your bot by adding sample utterances and slot values. - Select Build.
At this point, you should have a working Lex bot.
 for Language")
Setting up an Amazon Connect flow
In this section, we deploy the bot in an Amazon Connect Interactive Voice Response (IVR).
Creating your Amazon Connect instance
In this first step, you create your Amazon Connect instance:
- On the AWS Management Console, choose Amazon Connect.
- If this is your first Amazon Connect instance, choose Get started; otherwise, choose Add an instance.
- For Identity management, choose Store users within Amazon Connect.
- Enter a URL prefix such as
test-instance-############, where “############” is your current AWS account number. - Choose Next step.
- For Create an administrator, enter a name, password, and email address.
- Choose Next step.
- For Telephony Options, leave both call options selected by default.
- Choose Next step.
- For Data storage, choose Next step.
- Review the settings and choose Create instance.
- After your instance is created, choose Get started.
Associating your bot with your Amazon Connect instance
Now that you have an Amazon Connect instance, you can claim a phone number, create a contact flow, and integrate with the AppointmentBot Lex bot you created in the prior step. First, associate your bot with your Amazon Connect instance:
- On the Amazon Connect console, open your instance by choosing the Instance Alias
- Choose Contact flows.
- From the drop-down list, choose
AppointmentBot. If you don’t see the bot in the list, make sure you have selected the same Region you used when you created your Lex bot. - Choose + Add Lex Bot.
Configuring Amazon Connect to work with your bot
Now you can use your bot with Amazon Connect.
- On the Amazon Connect dashboard, for Step 1, Choose Begin.
- For your phone number, choose Australia for the country, Direct Dial or Toll Free, and choose a phone number.
- Choose Next.
- If you want to test your new phone number, try it on the next screen or choose Skip for now.
For this post, you can skip hours of operation, creating queues, and creating prompts. For more information on these features, see the Amazon Connect Administrator Guide.
- For Step 5, Create contact flows, choose View contact flows.
- Choose Create contact flow.
- Change the name of the contact flow to
Manage repairs. - From the Set drop-down menu, drag a Set voice card to the contact flow canvas. Open the card and change the Language to “English (Australian)”, choose an available Voice, and choose Save.
- Drag a connector from the Entry point card to your new Set voice card.
- From the Interact drop-down menu, drag a Play prompt card to the contact flow canvas.
- In the Play prompt details, choose Text-to-speech or chat text.
- In the text box, enter
Hi. How can I help? You can schedule or change a repair appointment. - Choose Save.
- Drag a connector from the Set voice card to your new Play prompt card.
- Drag a Get customer input card to the contact flow canvas.
- In the Get customer input details, choose Text-to-speech or chat text.
- In the text box, enter
What would you like to do? - Choose Amazon Lex, and choose the
AppointmentBotbot in the drop-down list. - Add each
AppointmentBotintent to the contact flow:ScheduleAppointment,ModifyAppointment,CancelAppointment, andDisconnect. - Choose Save.
- Drag a connector from the Play prompt card to the Get customer input
- Drag a Play prompt card to the contact flow.
- Choose Text-to-speech or chat text.
- In the text box, enter
Is there anything else I can help you with? - Choose Save.
- Drag connectors for each entry (except for Disconnect) in the Get customer input card to the new Play prompt card.
- Drag a connector from the new Play prompt card back to the Get customer input card.
- From the Terminate/Transfer drop-down menu, and drag a Disconnect/Hang up card to the contact flow.
- Drag a connector from the Disconnect entry in the Get customer input card to the Disconnect/Hang up card.
Your contact flow should look something like the following image.

- Choose Save to save your contact flow.
- Choose Publish to make your new contact flow available to your callers.
- Choose the Dashboard icon from the side menu.
- Choose Dashboard.
- Choose View phone numbers.
- Choose your phone number to edit it, and change the contact flow or IVR to the
Manage Repairscontact flow you just created. Choose Save.
Your Amazon Connect instance is now configured to work with your Amazon Lex bot. Try calling the phone number to see how it works.
Conclusion
Conversational experiences are vastly improved when you understand your user’s accent and respond in a style familiar to them. With Australian English support on Amazon Lex, you can now build bots that are better at understanding the Australian English accent. You can also use pre-defined slots to capture local information such as names and cities. Australian English allows you deliver a robust and localized conversational experience to your users in the Australia region. Australian English is available at the same price, and in the same Regions, as US English. You can try Australian English via the console, the AWS Command Line Interface (AWS CLI), and the AWS SDKs. Start building your Aussie bot today!
About the Authors
 Brian Yost is a Senior Consultant with the AWS Professional Services Conversational AI team. In his spare time, he enjoys mountain biking, home brewing, and tinkering with technology.
Brian Yost is a Senior Consultant with the AWS Professional Services Conversational AI team. In his spare time, he enjoys mountain biking, home brewing, and tinkering with technology.
 Anubhav Mishra is a Product Manager with AWS. He spends his time understanding customers and designing product experiences to address their business challenges.
Anubhav Mishra is a Product Manager with AWS. He spends his time understanding customers and designing product experiences to address their business challenges.
Translating PDF documents using Amazon Translate and Amazon Textract
In 1993, the Portable Document Format or the PDF was born and released to the world. Since then, companies across various industries have been creating, scanning, and storing large volumes of documents in this digital format. These documents and the content within them are vital to supporting your business. Yet in many cases, the content is text-heavy and often written in a different language. This limits the flow of information and can directly influence your organization’s business productivity and global expansion strategy. To address this, you need an automated solution to extract the contents within these PDFs and translate them quickly and cost-efficiently.
In this post, we show you how to create an automated and serverless content-processing pipeline for analyzing text in PDF documents using Amazon Textract and translating them with Amazon Translate.
Amazon Textract automatically extracts text and data from scanned documents. Amazon Textract goes beyond simple OCR to also identify the contents of fields in forms and information stored in tables. This allows Amazon Textract to read virtually any type of document and accurately extract text and data without needing any manual effort or custom code.
Once the text and data are extracted, you can use Amazon Translate is a neural machine translation service that delivers fast, high-quality, and affordable language translation. Neural machine translation is a form of language translation automation that uses deep learning models to deliver more accurate and natural-sounding translation than traditional statistical and rule-based translation algorithms. The translation service is trained on a wide variety of content across different use cases and domains to perform well on many kinds of content. Its asynchronous batch processing capability enables you to translate a large collection of text or HTML documents with a single API call.
Solution overview
To be scalable and cost-effective, this solution uses serverless technologies and managed services. In addition to Amazon Textract and Amazon Translate, the solution uses the following services:
- Amazon Simple Storage Service (Amazon S3) – Stores your documents and allows for central management with fine-tuned access controls.
- Amazon Simple Notification Service (Amazon SNS) – Enables you to decouple microservices, distributed systems, and serverless applications with a highly available, durable, secure, fully managed pub/sub messaging service.
- AWS Lambda – Runs code in response to triggers such as changes in data, changes in application state, or user actions. Because services like Amazon S3 and Amazon SNS can directly trigger a Lambda function, you can build a variety of real-time serverless data-processing systems.
- AWS Step Functions – Coordinates multiple AWS services into serverless workflows.
Solution architecture
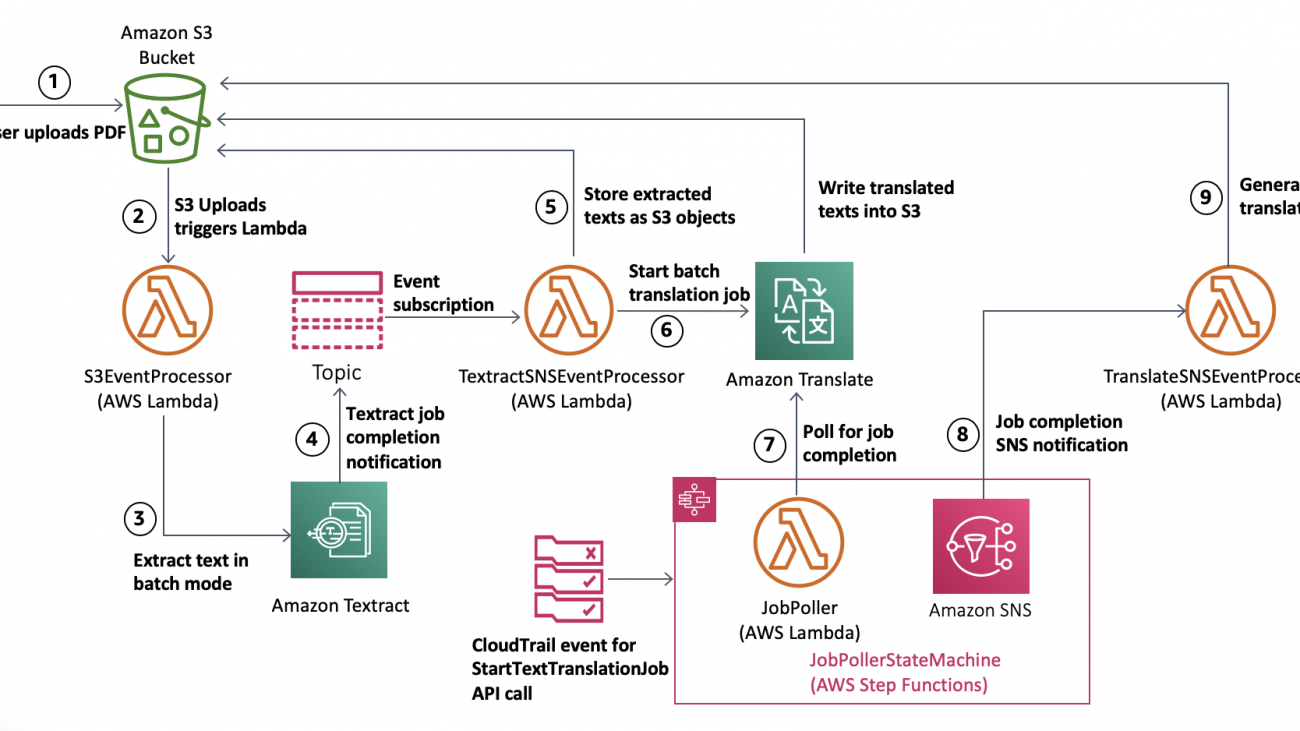
The architecture workflow contains the following steps:
- Users upload a PDF for analysis to Amazon S3.
- The Amazon S3 upload triggers a Lambda function.
- The function invokes Amazon Textract to extract text from the PDF in batch mode.
- Amazon Textract sends an SNS notification when the job is complete.
- A Lambda function reads the Amazon Textract response and stores the extracted text in Amazon S3.
- The Lambda function from the previous step invokes Amazon Translate in batch mode to translate the extracted texts into the target language.
- The Step Functions-based job poller polls for the translation job to complete.
- Step Functions sends an SNS notification when the translation is complete.
- A Lambda function reads the translated texts in Amazon S3 and generates a translated document in Amazon S3.
The following diagram illustrates this architecture.

For processing documents at scale, you can expand this solution to include Amazon Simple Queue Service (Amazon SQS) to queue the jobs and handle any potential failure related to throttling and default service concurrency limits. For more information about the limits in Amazon Translate and Amazon Textract, see Guidelines and Limits and Limits in Amazon Textract, respectively.
Deploying the solution with AWS CloudFormation
The first step is to use an AWS CloudFormation template to provision the necessary resources needed for the solution, including the AWS Identity and Access Management (IAM) roles, IAM policies, and SNS topics.
- Launch the AWS CloudFormation template by choosing the following (this creates the stack the
us-east-1Region):

- For Stack name, enter a unique stack name for this account; for example,
document-translate. - For TargetLanguageCode, enter the language code that you want your translated documents in; for example,
esfor Spanish.
For more information about supported languages, see Supported Languages and Language Codes.
- In the Capabilities and transforms section, and select the check-boxes to acknowledge that AWS CloudFormation will create IAM resources and transform the AWS Serverless Application Model (AWS SAM) template.
AWS SAM templates simplify the definition of resources needed for serverless applications. When deploying AWS SAM templates in AWS CloudFormation, AWS CloudFormation performs a transform to convert the AWS SAM template into a CloudFormation template. For more information, see Transform.
- Choose Create stack.

The stack creation may take up to 20 minutes, after which the status changes to CREATE_COMPLETE. You can see the name of the newly created S3 bucket on the Outputs tab.

Translating the document
To translate your document, upload a document in English to the input folder of the S3 bucket you created in the previous step.

For this post, we scanned the “Universal Declaration of Human Rights,” created by the United Nations.

This upload event triggers the Lambda function <Stack name>-S3EventProcessor-<Random string>, which invokes the Amazon Textract startDocumentTextDetection API to extract the text from the scanned document.
When Amazon Textract completes the batch job, it sends an SNS notification. The notification triggers the Lambda function <Stack name>-TextractSNSEventProcessor-<Random string>, which processes the Amazon Textract response page by page to extract the LINE block elements to store them in the S3 bucket.
Amazon Textract extracts LINE block elements with a BoundingBox. A sentence in the scanned document results in multiple LINE block elements. To make sure that Amazon Translate has the entire sentence in scope for translation, the solution combines multiple LINE block elements to recreate the sentence boundary in the source document. This done by using the BreakIterator class available for Java. For more information, see Class BreakIterator.
The sentences are then stored in the S3 bucket as individual objects. Finally, the Amazon Translate job startTextTranslationJob is invoked with the input S3 bucket location where the text to be translated is available.
The Amazon Translate job completion SNS notification from the job poller triggers the Lambda function <Stack name>-TranslateJobSNSEventProcessor-<Random string>. The function creates the editable document by combining the translated texts created by the Amazon Translate batch job in the output folder of the S3 bucket with the following naming convention: inputFileName-TargetLanguageCode.docx.

The following screenshot shows the document translated in Spanish.

The solution also supports translating documents for right-to-left (RTL) script languages such as Arabic and Hebrew. The following screenshot shows the translated document in Arabic (language code: ar).

For any pipeline failure, check the Amazon CloudWatch logs for the corresponding Lambda function and look for potential errors that caused the failure.
To do a translation in a different language, you can update the LANG_CODE environment variable for the <Stack name>-TextractSEventProcessor-<Random string> function and trigger the solution pipeline by uploading a new document into the input folder of the S3 bucket.

Conclusion
In this post, we demonstrated how to extract text from PDF documents and translate them into an editable document in a different language using Amazon Translate asynchronous batch processing. For a low-latency, low-throughput solution translating smaller PDF documents, you can perform the translation through the real-time Amazon Translate API.
The ability to process data at scale is becoming important to organizations across all industries. Managed machine learning services like Amazon Textract and Amazon Translate can simplify your document processing and translation needs, helping you focus on addressing core business needs while keeping overall IT costs manageable.
For further reading, we recommend the following:
- Asynchronous Batch Processing
- Detecting and Analyzing Text in Multipage Documents
- Translating documents with Amazon Translate, AWS Lambda, and the new Batch Translate API
- Automatically extract text and structured data from documents with Amazon Textract
- Getting a batch job completion message from Amazon Translate
About the Authors

Siva Rajamani is a Boston-based Enterprise Solutions Architect for AWS. He enjoys working closely with customers and supporting their digital transformation and AWS adoption journey. His core areas of focus are Serverless, Application Integration, and Security. Outside of work, he enjoys outdoors activities and watching documentaries.

Sudhanshu Malhotra is a Boston-based Enterprise Solutions Architect for AWS. He’s a technology enthusiast who enjoys helping customers find innovative solutions to complex business challenges. His core areas of focus are DevOps, Machine Learning, and Security. When he’s not working with customers on their journey to the cloud, he enjoys reading, hiking, and exploring new cuisines.

Office Ready? Jetson-Driven ‘Double Robot’ Supports Remote Working
Apple’s iPad 2 launch in 2011 ignited a touch tablet craze, but when David Cann and Marc DeVidts got their hands on one they saw something different: They rigged it to a remote-controlled golf caddy and posted a video of it in action on YouTube.
Next came phone calls from those interested in buying such a telepresence robot.
Hacks like this were second nature for the friends who met in 2002 while working on the set of the BattleBots TV series, featuring team-built robots battling before live audiences.
That’s how Double Robotics began in 2012. The startup went on to attend YCombinator’s accelerator, and it has sold more than 12,000 units. That cash flow has allowed the small team with just $1.8 million in seed funding to carry on without raising capital, a rarity in hardware.
Much has changed since they began. Double Robotics, based in Burlingame, Calif., today launched its third-generation model, the Double 3, sporting an NVIDIA Jetson TX2 for AI workloads.
“We did a bunch of custom CUDA code to be able to process all of the depth data in real time, so it’s much faster than before, and it’s highly tailored to the Jetson TX2 now,” said Cann.
Remote Worker Presence

The Double device, as it’s known, was designed for remote workers to visit offices in the form of the robot so they could see their co-workers in meetings. Video-over-internet call connections allow people to see and hear their remote colleague on the device’s tablet screen.
The Double has been a popular ticket at tech companies on the East and West Coasts in the five years prior to the pandemic, and interest remains strong but in different use cases, according to the company. It has also proven useful in rural communities across the country, where people travel long distances to get anywhere, the company said.
NVIDIA purchased a telepresence robot from Double Robotics so that non-essential designers sheltering at home could maintain daily contact with work on Selene, the world’s seventh-fastest computer.
Some customers who use it say it breaks down communication barriers for remote workers, with the physical presence of the robot able to interact better than using video conferencing platforms.
Also, COVID-19 has spurred interest for contact-free work using the Double. Pharmaceutical companies have contacted Double Robotics asking how the robot might aid in international development efforts, according to Cann. The biggest use case amid the pandemic is for using the Double robots in place of international business travel, he said. Instead of flying in to visit a company office, the office destination could offer a Double to would-be travelers.
Double 3 Jetson Advances
Now shipping, the Double 3 features wide-angle and zoom cameras and can support night vision. It also uses two stereovision sensors for depth vision, five ultrasonic range finders, two wheel encoders and an inertial measurement unit sensor.
Double Robotics will sell the head of the new Double 3 — which includes the Jetson TX2 — to existing customers seeking to upgrade its brains for access to increasing levels of autonomy.
To enable the autonomous capabilities, Double Robotics relied on the NVIDIA Jetson TX2 to process all of the camera and sensor data in realtime, utilizing the CUDA-enabled GPUs and the accelerated multimedia and image processors.
The company is working on autonomous features for improved self-navigation and safety features for obstacle avoidance as well as other capabilities, such as improved auto docking for recharging and auto pilot all the way into offices.
Right now the Double can do automated assisted driving to help people avoid hitting walls. The company next aims for full office autonomy and ways to help it get through closed doors.
“One of the reasons we chose the NVIDIA Jetson TX2 is that it comes with the Jetpack SDK that makes it easy to get started and there’s a lot that’s already done for you — it’s certainly a huge help to us,” said Cann.
The post Office Ready? Jetson-Driven ‘Double Robot’ Supports Remote Working appeared first on The Official NVIDIA Blog.

Telltale Signs: AI Researchers Trace Cancer Risk Factors Using Tumor DNA
Life choices can change a person’s DNA — literally.
Gene changes that occur in human cells over a person’s lifetime, known as somatic mutations, cause the vast majority of cancers. They can be triggered by environmental or behavioral factors such as exposure to ultraviolet light or radiation, drinking or smoking.
By using NVIDIA GPUs to analyze the signature, or molecular fingerprint, of these mutations, researchers can better understand known causes of cancer, discover new risk factors and investigate why certain cancers are more common in certain areas of the world than others.
The Cancer Grand Challenges’ Mutographs team, an international research group funded by Cancer Research U.K., is using NVIDIA GPU-accelerated machine learning models to study DNA from the tumors of 5,000 patients with five cancer types: pancreas, kidney and colorectal cancer, as well as two kinds of esophageal cancer.
Using powerful NVIDIA DGX systems, researchers from the Wellcome Sanger Institute — a world leader in genomics — and the University of California, San Diego, collaborated with NVIDIA developers to achieve more than 30x acceleration when running their machine learning software SigProfiler.
“Research projects such as the Mutographs Grand Challenge are just that — grand challenges that push the boundary of what’s possible,” said Pete Clapham, leader of the Informatics Support Group at the Wellcome Sanger Institute. “NVIDIA DGX systems provide considerable acceleration that enables the Mutographs team to not only meet the project’s computational demands, but to drive it even further, efficiently delivering previously impossible results.”
Molecular Detective Work
Just as every person has a unique fingerprint, cancer-causing somatic mutations have unique patterns that show up in a cell’s DNA.
“At a crime scene, investigators will lift fingerprints and run those through a database to find a match,” said Ludmil Alexandrov, computational lead on the project and an assistant professor of cellular and molecular medicine at UCSD. “Similarly, we can take a molecular fingerprint from cells collected in a patient’s biopsy and see if it matches a risk factor like smoking or ultraviolet light exposure.”
Some somatic mutations have known sources, like those Alexandrov mentions. But the machine learning model can pull out other mutation patterns that occur repeatedly in patients with a specific cancer, but have no known source.
When that happens, Alexandrov teams up with other scientists to test hypotheses and perform large-scale experiments to discover the cancer-causing culprit.
Discovering a new risk factor can help improve cancer prevention. Researchers in 2018 traced back a skin cancer mutational signature to an immunosuppressant drug, which now lists the condition as one of its possible side effects, and helps doctors better monitor patients being treated with the drug.
Enabling Whirlwind Tours of Global Data
In cases where the source of a mutational signature is known, researchers can analyze trends in the occurrence of specific kinds of somatic mutations (and their corresponding cancers) in different regions of the world as well as over time.
“Certain cancers are very common in one part of the world, and very rare in others. And when people migrate from one country to another, they tend to acquire the cancer risk of the country they move to,” said Alexandrov. “What that tells you is that it’s mostly environmental.”
Researchers on the Mutographs project are studying a somatic mutation linked to esophageal cancer, a condition some studies have correlated with the drinking of scalding beverages like tea or maté.
Esophageal cancer is much more common in Eastern South America, East Africa and Central Asia than in North America or West Africa. Finding the environmental or lifestyle factor that puts people at higher risk can help with prevention and early detection of future cases.
The Mutographs researchers teamed up with NVIDIA to accelerate the most time-consuming parts of the SigProfiler AI framework on NVIDIA GPUs. When running pipeline jobs with double precision on NVIDIA DGX systems, the team observed more than 30x acceleration compared to using CPU hardware. With single precision, Alexandrov says, SigProfiler runs significantly faster, achieving around a 50x speedup.
The DGX system’s optimized software and NVLink interconnect technology also enable the scaling of AI models across all eight NVIDIA V100 Tensor Core GPUs within the system for maximum performance in both model development and deployment.
For research published in Nature this year, Alexandrov’s team analyzed data from more than 20,000 cancer patients, which used to take almost a month.
“With NVIDIA DGX, we can now do that same analysis in less than a day,” he said. “That means we can do much more testing, validation and exploration.”
Subscribe to NVIDIA healthcare news here.
Main image credit: Wellcome Sanger Institute
The post Telltale Signs: AI Researchers Trace Cancer Risk Factors Using Tumor DNA appeared first on The Official NVIDIA Blog.
Five tips for a successful Facebook Fellowship application from the people who review them
Until October 1, PhD students from around the world are invited to apply for the Facebook Fellowship, a program that supports talented PhD students engaged in innovative research in any year of their PhD study.
Each year, our research teams review thousands of high-quality applications from bright and passionate PhD students. For this year’s round of applications, we connected with some of them to discuss what they look for in an application and what advice they would give to prospective applicants. Drawing from their experience reading hundreds of research statements, CVs, and letters of recommendation, they came up with the following five tips.
Tip 1: Communicate impact
“Reading the proposals is really exciting. I love seeing the ways talented scholars are pushing the state of the art,” says Udi Weinsberg, Research Scientist Manager within Core Data Science (CDS). “I especially enjoy proposals that tackle real problems with novel solutions. Great proposals explain the problem and its importance, and focus on the novelty of the proposed solution compared to past work.”
You may also like
The six most common Fellowship questions, answered by Facebook Fellow Moses Namara
CDS Research Scientist Manager Aude Hofleitner agrees: “I love reading the proposals every year. I like to see both the novelty of the research and its applications.”
To help communicate the potential impact of your research, AI Software Engineer Shubho Sengupta recommends narrowing things down. “Forming concrete steps that show results within a two- to three-year time frame is a great place to start,” he says. “Oftentimes, proposals tend to be too broad. Some preliminary results that support the direction you want to pursue give reviewers some confidence about the proposal.”
Tip 2: Focus on framing
Security Engineering Manager Nektarios Leontiadis emphasizes the importance of your research proposal’s structure: “A big lesson I learned from my adviser during my PhD is that the framing [of your research statement] matters. I would offer the following as a guideline:
- What is the problem?
- Why is it important?
- Why is it not solved yet?
- What is the shape of your proposed solution?
- How is your research addressing the problem?
“More specifically for the Fellowship, I am always looking to understand very clearly the potential relevance to Facebook’s business over the short, mid, and long term.”
Tip 3: Do some research
A good way to determine what research Facebook is conducting is to do research online. From publications and open sourcing to conference sponsorships and blog posts, we are very open about the research we invest in at Facebook.
“Take time to understand Facebook’s challenges within your research domain and write down which applications could benefit from your knowledge,” says Edith Beigne, Director of Silicon Research. “Would your research enable a new feature or improve existing feature performances? This will help you select your topic correctly. However, do not hesitate to reach out to us with questions if no topics seem to fit.”
Beigne continues, “It is also important for reviewers to understand how you would benefit from being a Facebook Fellow. How would Facebook influence your academic career?”
Tip 4: Refine and clarify
Reviewers read through lots of applications. In order for an application to stand out, it should keep things simple and clear. Hofleitner recommends avoiding the nitty-gritty details and sticking to high-level descriptions: “[Research statements] shouldn’t go into too much technical detail but provide a clear description of why the research is critical and innovative.”
On refining the information in your Fellowship application, Beigne adds, “The summary of your work should be very clear, and objectives should be included in your abstracts so that we can more easily understand your research interests.”
Tip 5: Check for readability
When writing a research statement, it’s important to check for readability to make sure reviewers can easily understand what you are trying to convey. “The research itself matters way more than grammar,” says Sharon Ayalde, Program Manager of the Facebook Fellowship. “However, if our reviewers can’t fully understand what they’re reading, then they can’t appreciate the research.”
The Facebook Fellowship program is open to PhD students from anywhere in the world. Applicants who are not completely fluent in English may need to take an extra step.
“Depending on how comfortable you are writing in English, I recommend sharing your statement with someone who can specifically check for language,” Ayalde continues. “This will help ensure that your brilliant ideas get communicated effectively.”
—
Applications for the Facebook Fellowship Program close on October 1. To learn more about the program and to apply, visit the Fellowship page.
The post Five tips for a successful Facebook Fellowship application from the people who review them appeared first on Facebook Research.
Learning to Summarize with Human Feedback
We’ve applied reinforcement learning from human feedback to train language models that are better at summarization. Our models generate summaries that are better than summaries from 10x larger models trained only with supervised learning. Even though we train our models on the Reddit TL;DR dataset, the same models transfer to generate good summaries of CNN/DailyMail news articles without any further fine-tuning. Our techniques are not specific to summarization; in the long run, our goal is to make aligning AI systems with human preferences a central component of AI research and deployment in many domains.
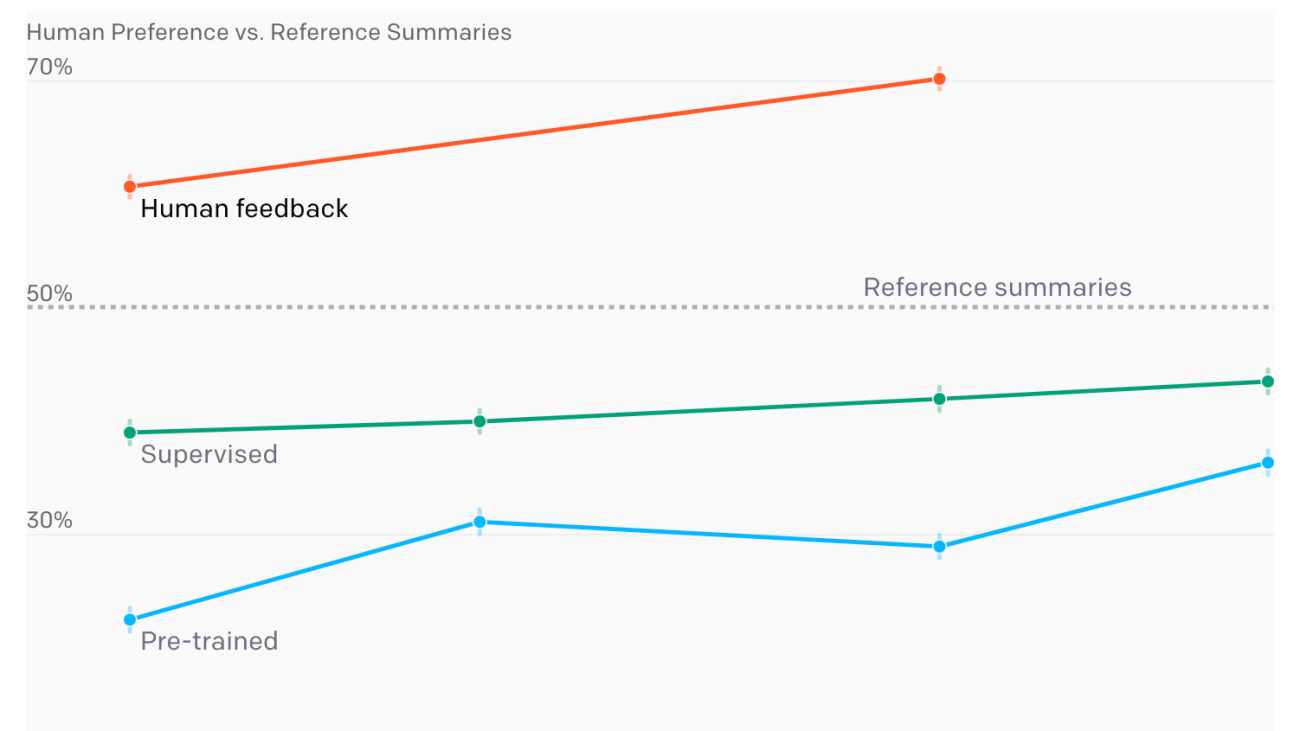
Human feedback models outperform much larger supervised models and reference summaries on TL;DR
Figure 1: The performance of various training procedures for different model sizes. Model performance is measured by how often summaries from that model are preferred to the human-written reference summaries. Our pre-trained models are early versions of GPT-3, our supervised baselines were fine-tuned to predict 117K human-written TL;DRs, and our human feedback models are additionally fine-tuned on a dataset of about 65K summary comparisons.

Large-scale language models are becoming increasingly capable on NLP tasks. These models are usually trained with the objective of next word prediction on a dataset of human-written text. But this objective doesn’t capture exactly what we want; usually, we don’t want our models to imitate humans, we want them to give high-quality answers. This mismatch is clear when a model is trained to imitate low-quality human-written text, but it can also happen in more subtle ways. For example, a model trained to predict what a human would say might make up facts when it is unsure, or generate sentences reflecting harmful social bias, both failure modes that have been well-documented.
As part of our work on safety, we want to develop techniques that align our models’ objectives with the end behavior we really care about. As our models become more powerful, we believe aligning them with our goals will be very important to ensure they are beneficial for humans. In the short term, we wanted to test if human feedback techniques could help our models improve performance on useful tasks.
We focused on English text summarization, as it’s a challenging problem where the notion of what makes a “good summary” is difficult to capture without human input. We apply our method primarily to an existing dataset of posts submitted to the social network Reddit[1] together with human-written “TL;DRs,” which are short summaries written by the original poster.
We first train a reward model via supervised learning to predict which summaries humans will prefer.[2] We then fine-tune a language model with reinforcement learning (RL) to produce summaries that score highly according to that reward model. We find that this significantly improves the quality of the summaries, as evaluated by humans, even on datasets very different from the one used for fine-tuning.
Our approach follows directly from our previous work on learning from human feedback. There has also been other work on using human feedback to train summarization models. We push the technique further by scaling to larger models, collecting more feedback data, closely monitoring researcher-labeler agreement, and providing frequent feedback to labelers. Human feedback has also been used to train models in several other domains, such as dialogue, semantic parsing, translation, story and review generation, evidence extraction, and more traditional RL tasks.
Results
Post from Reddit (r/)
show more
Human-written reference summary
Human feedback 6B model
Supervised 6B model
Pre-trained 6B model
We evaluated several different summarization models—some pre-trained on a broad distribution of text from the internet, some fine-tuned via supervised learning to predict TL;DRs, and some fine-tuned using human feedback.[3] To evaluate each model, we had it summarize posts from the validation set and asked humans to compare their summaries to the human-written TL;DR. The results are shown in Figure 1.
We found that RL fine-tuning with human feedback had a very large effect on quality compared to both supervised fine-tuning and scaling up model size. In particular, our 1.3 billion parameter (1.3B) model trained with human feedback outperforms our 12B model trained only with supervised learning. Summaries from both our 1.3B and 6.7B human feedback models are preferred by our labelers to the original human-written TL;DRs in the dataset.[4]
People make different trade-offs when writing summaries, including between conciseness and coverage of the original text; depending on the purpose of the summary, different summary lengths might be preferred. Our labelers tended to prefer longer summaries, so our models adapted to that preference and converged to the longest allowable length. Controlling for length reduced human preferences for our 6.7B model’s summaries from 70% to 65%, explaining a minority of our gains.[5]
Transfer results
Human feedback models trained on Reddit transfer to generate excellent summaries of CNN/DM news articles without further training
The performance (human-rated summary quality on a 1–7 scale) of various training procedures and model sizes.[6] Note that our human feedback models generate summaries that are significantly shorter than summaries from models trained on CNN/DM.
At a given summary length, our 6.7B human feedback model trained on Reddit performs almost as well as a fine-tuned 11B T5 model, despite not being re-trained on CNN/DM.
Article from CNN/DM ()
show more
Human-written reference summary
Human feedback 6B model (transfer)
Supervised 6B model (transfer)
Pre-trained 6B model
T5 11B model (fine-tuned on CNN/DM)
Supervised 6B model (fine-tuned on CNN/DM)
To test our models’ generalization, we also applied them directly to the popular CNN/DM news dataset. These articles are more than twice as long as Reddit posts and are written in a very different style. Our models have seen news articles during pre-training, but all of our human data and RL fine-tuning was on the Reddit TL;DR dataset.
This time we evaluated our models by asking our labelers to rate them on a scale from 1–7.[7] We discovered that our human feedback models transfer to generate excellent short summaries of news articles without any training. When controlling for summary length, our 6.7B human feedback model generates summaries that are rated higher than the CNN/DM reference summaries written by humans. This suggests that our human feedback models have learned something more general about how to summarize text, and are not specific to Reddit posts.
Approach

A diagram of our method, which is similar to the one used in our previous work.
Our core method consists of four steps: training an initial summarization model, assembling a dataset of human comparisons between summaries, training a reward model to predict the human-preferred summary, and then fine-tuning our summarization models with RL to get a high reward.
We trained several supervised baselines by starting from GPT-style transformer models trained on text from the Internet, and fine-tuning them to predict the human-written TL;DR via supervised learning. We mainly use models with 1.3 and 6.7 billion parameters. As a sanity check, we confirmed that this training procedure led to competitive results[8] on the CNN/DM dataset.
We then collected a dataset of human quality judgments. For each judgment, a human compares two summaries of a given post and picks the one they think is better.[9] We use this data to train a reward model that maps a (post, summary) pair to a reward r. The reward model is trained to predict which summary a human will prefer, using the rewards as logits.
Finally, we optimize the policy against the reward model using RL. We use PPO with 1 million episodes in total, where each episode consists of the policy summarizing a single article and then receiving a reward r. We include a KL penalty that incentivizes the policy to remain close to the supervised initialization.
Collecting data from humans
Any training procedure that uses human feedback is directly influenced by the actual humans labeling the data. In our previous work on fine-tuning language models from human preferences, our labelers often gave high ratings to summaries we thought were average, which was reflected in the quality of our trained models.
In response, in this project we invested heavily in ensuring high data quality. We hired about 80 contractors using third-party vendor sites,[10] and paid them an hourly wage regardless of the number of summaries evaluated.[11] Hiring contractors rather than relying on crowdsourcing websites allowed us to maintain a hands-on relationship with labelers: we created an onboarding process, developed a website with a customizable labeler interface, answered questions in a shared chat room, and had one-on-one video calls with labelers. We also made sure to clearly communicate our definition of summary quality, after spending significant time reading summaries ourselves, and we carefully monitored agreement rates between us and labelers throughout the project.
Optimizing the reward model
Optimizing our reward model eventually leads to sample quality degradation
Starting from the 1.3B supervised baseline (point 0 on the x-axis), we use RL to optimize the policy against the reward model, which results in policies with different “distances” from the baseline (x-axis, measured using the KL divergence from the supervised baseline). Optimizing against the reward model initially improves summaries according to humans, but eventually overfits, giving worse summaries. This graph uses an older version of our reward model, which is why the peak of the reward model is less than 0.5.
Post from Reddit (r/AskReddit)
I’m a 28yo man, and I would like to get into gymnastics for the first time.
Title said just about all of it. I’m 28, very athletic (bike/ surf/ snowboard) and I have always wanted to do gymnastics.
I like to do flips and spins off bridges and on my snowboard, and it seems to me gymnastics would be a great way to do those movements I like, in a controlled environment. The end goal of this is that it would be fun, and make me better at these movements in real life.
But is it too late for me? Should 28 year old guys such as myself be content with just watching those parkour guys on youtube? Or can I learn the ways of the gymnastic jedi? BTW, I live in San Jose CA.
KL = 0
I want to do gymnastics, but I’m 28 yrs old. Is it too late for me to be a gymnaste?!
KL = 9
28yo guy would like to get into gymnastics for the first time. Is it too late for me given I live in San Jose CA?
KL = 260
28yo dude stubbornly postponees start pursuing gymnastics hobby citing logistics reasons despite obvious interest??? negatively effecting long term fitness progress both personally and academically thoght wise? want change this dumbass shitty ass policy pls
Optimizing against our reward model is supposed to make our policy align with human preferences. But the reward model is only a proxy for human preferences, as it only sees a small amount of comparison data from a narrow distribution of summaries. While the reward model performs well on the kinds of summaries it was trained on, we wanted to know how much we could optimize against it until it started giving useless evaluations.
We trained policies at different “optimization strengths” against the reward model, and asked our labelers to evaluate the summaries from these models. We did this by varying the KL coefficient, which trades off the incentive to get a higher reward against the incentive to remain close to the initial supervised policy. We found the best samples had roughly the same predicted reward as the 99th percentile of reference summaries from the dataset. Eventually optimizing the reward model actually makes things worse.
Limitations
If we have a well-defined notion of the desired behavior for a model, our method of training from human feedback allows us to optimize for this behavior. However, this is not a method for determining what the desired model behavior should be. Deciding what makes a good summary is fairly straightforward, but doing this for tasks with more complex objectives, where different humans might disagree on the correct model behavior, will require significant care. In these cases, it is likely not appropriate to use researcher labels as the “gold standard”; rather, individuals from groups that will be impacted by the technology should be included in the process to define “good” behavior, and hired as labelers to reinforce this behavior in the model.
We trained on the Reddit TL;DR dataset because the summarization task is significantly more challenging than on CNN/DM. However, since the dataset consists of user-submitted posts with minimal moderation, they sometimes contain content that is offensive or reflects harmful social biases. This means our models can generate biased or offensive summaries, as they have been trained to summarize such content.
Part of our success involves scaling up our reward model and policy size. This requires a large amount of compute, which is not available to all researchers: notably, fine-tuning our 6.7B model with RL required about 320 GPU-days. However, since smaller models trained with human feedback can exceed the performance of much larger models, our procedure is more cost-effective than simply scaling up for training high-quality models on specific tasks.
Though we outperform the human-written reference summaries on TL;DR, our models have likely not reached human-level performance, as the reference summary baselines for TL;DR and CNN/DM are not the highest possible quality. When evaluating our model’s TL;DR summaries on a 7-point scale along several axes of quality (accuracy, coverage, coherence, and overall), labelers find our models can still generate inaccurate summaries, and give a perfect overall score 45% of the time.[12] For cost reasons, we also do not directly compare to using a similar budget to collect high-quality demonstrations, and training on those using standard supervised fine-tuning.
Future directions
We’re interested in scaling human feedback to tasks where humans can’t easily evaluate the quality of model outputs. For example, we might want our models to answer questions that would take humans a lot of research to verify; getting enough human evaluations to train our models this way would take a long time. One approach to tackle this problem is to give humans tools to help them evaluate more quickly and accurately. If these tools use ML, we can also improve them with human feedback, which could allow humans to accurately evaluate model outputs for increasingly complicated tasks.
In addition to tackling harder problems, we’re also exploring different types of feedback beyond binary comparisons: we can ask humans to provide demonstrations, edit model outputs to make them better, or give explanations as to why one model output is better than another. We’d like to figure out which kinds of feedback are most effective for training models that are aligned with human preferences.
If you are interested in working on these research questions, we’re hiring!
OpenAI
Facebook grants CrowdTangle access to all research award recipients
Facebook believes in supporting independent academic research. This is why we announced in July a new public application for academics to gain access to CrowdTangle, a public insights tool from Facebook that makes it easy to follow, analyze, and report on what’s happening across social media. We also launched a new data access hub where researchers could see all the Facebook data sets that are available to them.
To take this one step further, starting today, we are granting CrowdTangle access to all current and future university-based research award winners. Access will be granted to the principal investigators (PI) and co-PI(s) of all winning proposals. To obtain access, PIs will need to submit an application. They will then be approved for access automatically.
More information on obtaining CrowdTangle access through research awards is available on each individual research award page. Learn more about CrowdTangle’s work with academics and researchers on the CrowdTangle website.
The post Facebook grants CrowdTangle access to all research award recipients appeared first on Facebook Research.
New available survey data shares insights on COVID-19 prevention and a potential vaccine
While preventive measures are currently the only tools people can use to protect themselves from contracting COVID-19, knowledge about the effectiveness of these measures varies around the world. The COVID-19 Preventive Health Survey is designed to help researchers understand people’s knowledge, attitudes, and practices about COVID-19 prevention. By reporting people’s knowledge about measures such as physical distancing and use of masks, the survey can support policymakers and researchers to develop improved messaging and outreach to communities. This data can also help health systems prepare to address communities where future vaccine acceptance appears low.
This survey was launched in July 2020 in 67 countries and territories through a partnership between Facebook, the Massachusetts Institute of Technology (MIT), and Johns Hopkins University Center for Communication Programs (JHU CCP), and advised on by the World Health Organization Global Outbreak Alert and Response Network. The survey asks people to self-report their adherence to preventive measures, such as washing hands and wearing masks, as well as what they know about COVID-19, including symptoms of the disease, risk factors, and how their community is handling the pandemic. The survey also asks respondents about perceived behaviors of others in their communities and assesses whether communities would want a future COVID-19 vaccine.
“This new survey gives us a different view on COVID-19 by measuring beliefs, knowledge, and behaviors that are critical to effective responses,” says Dean Eckles, Associate Professor at MIT.
Privacy-preserving approach
Facebook and partners designed the survey with privacy in mind from the start. This survey leverages the same model as the COVID-19 Symptom Surveys, where Facebook invites a sample of Facebook users to take a survey off of the Facebook platform by our academic partner. In addition to language preference, Facebook shares a single de-identified statistic known as a survey weight, which doesn’t identify a person but helps researchers correct for nonresponse bias. This helps ensure that the sample more accurately reflects the characteristics of the population represented in the data. Facebook does not share who took the survey with partners, and they do not share individual survey responses with Facebook. Facebook has access only to the aggregate survey data that is publicly available.
Data available for research
- Researchers and others can access aggregate, de-identified survey data via MIT’s public API.
- Academic and nonprofit researchers can also request microdata access here and sign a data use agreement.
Analysis
We used publicly available aggregate data from the Preventive Health Survey in the following analysis. These charts include data on adults ages 20 years or older from countries and territories that received a one-time snapshot survey, as well as countries and territories that received wave surveys, fielded three times between July and August 2020.
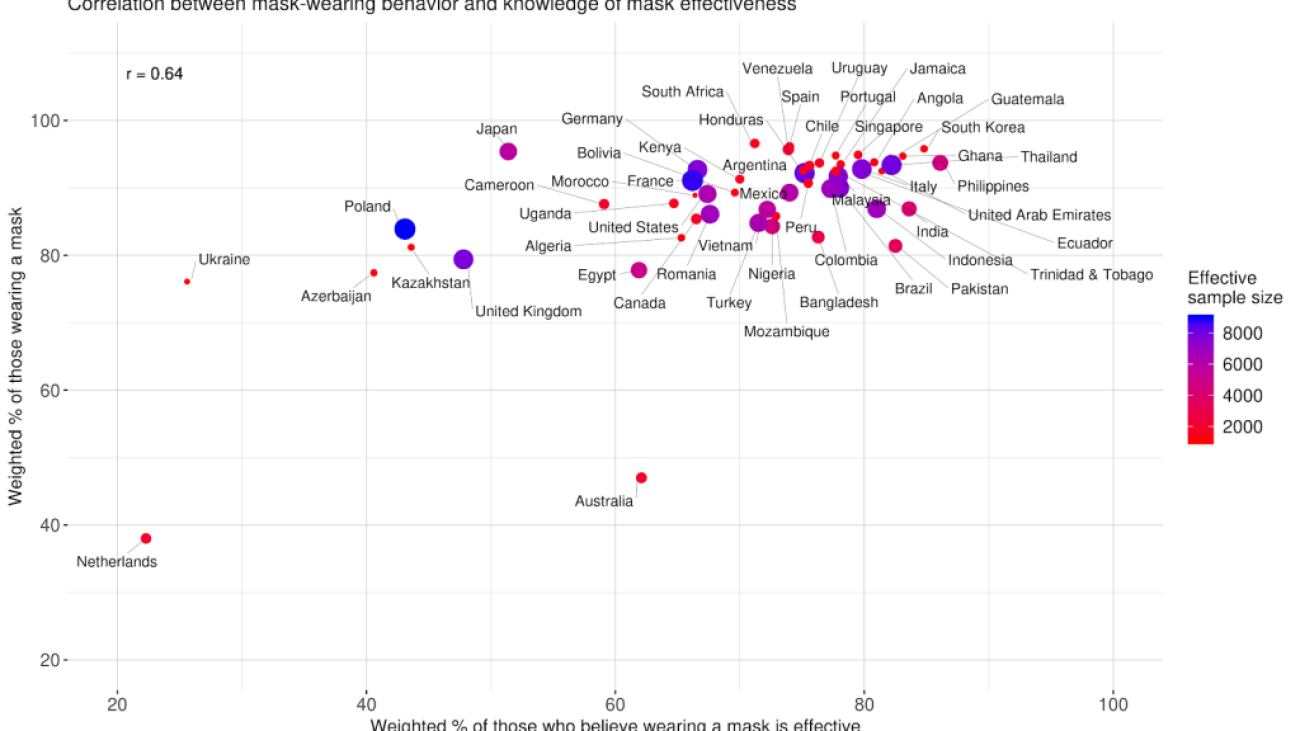
Mask knowledge and mask usage
We first analyze the correlation between knowledge of mask effectiveness and mask usage in countries and territories with at least an 1,000 effective sample size. Mask usage includes respondents who self-reported that they wore a mask at least one time in the last week to prevent contracting COVID-19. Mask knowledge includes those who responded that wearing a mask is very or extremely effective in preventing COVID-19. Though we do not control for mask mandates, we see that the percent of people wearing a mask is moderately correlated with the percent of people who believe wearing a mask is effective (correlation coefficient = 0.64).

Preventive behaviors in the United States
We then examine preventive behaviors in the United States by age group, including whether respondents said they washed their hands, wore a mask, or kept at least 1 meter of distance from others in the last week to avoid contracting COVID-19. We see that the 41-to-50 age group is the least likely to practice preventive behaviors overall: This group consistently has the lowest or second-lowest percentage of people across all three preventive behaviors, even though older populations are at an increased risk of COVID-19 complications. Of the three behaviors, keeping a 1-meter distance is the least adopted behavior, especially among the younger age groups. About 10 percent fewer respondents between 20 and 50 years old report keeping a 1-meter distance from others, compared with washing hands and wearing a mask.

COVID-19 vaccine acceptance
Given the number of efforts underway to develop a COVID-19 vaccine, we analyzed the percentage of respondents who said they would take a COVID-19 vaccine, if one were to become available. The following figure shows the countries and territories with the five highest and five lowest percentages of people who said they would take a COVID-19 vaccine. Future research may elucidate how these sentiments change over time and how they are affected by COVID-19 and flu vaccine developments in the near future.

Partnership opportunities and next steps
The Preventive Health Survey adds to a number of data sets and resources that Facebook’s Data for Good program has made available to support partners with public health responses during COVID-19. The survey can be used to tailor risk communication to specific populations, evaluate the efficacy of policies such as stay-at-home orders and masks, and inform decision-making from both policy and program perspectives.
“Covering dozens of countries with this kind of data collection and analysis will be unparalleled,” says J. Douglas Storey, PhD, JHU CCP’s Director of Communication Science and Research. “There has never been any global source of information like this, and it will capture the more nuanced drivers of behavior and a range of psychosocial factors not currently being collected in a systematic way.”
To generate actionable insights from the survey that can be used quickly in national responses, our partners are developing public dashboards. MIT’s dashboard is available here and JHU CCP’s dashboard is coming soon.
We welcome feedback on the usefulness of the data and how similar survey efforts in the future may be most helpful for researchers aiding public health responses. For any questions related to the Preventive Health Survey, please reach out to PHSurvey@fb.com.
The post New available survey data shares insights on COVID-19 prevention and a potential vaccine appeared first on Facebook Research.
Startup’s AI Platform Allows Contact-Free Hospital Interactions
Hands-free phone calls and touchless soap dispensers have been the norm for years. Next up, contact-free hospitals.
San Francisco-based startup Ouva has created a hospital intelligence platform that monitors patient safety, acts as a patient assistant and provides a sensory experience in waiting areas — without the need for anyone to touch anything.
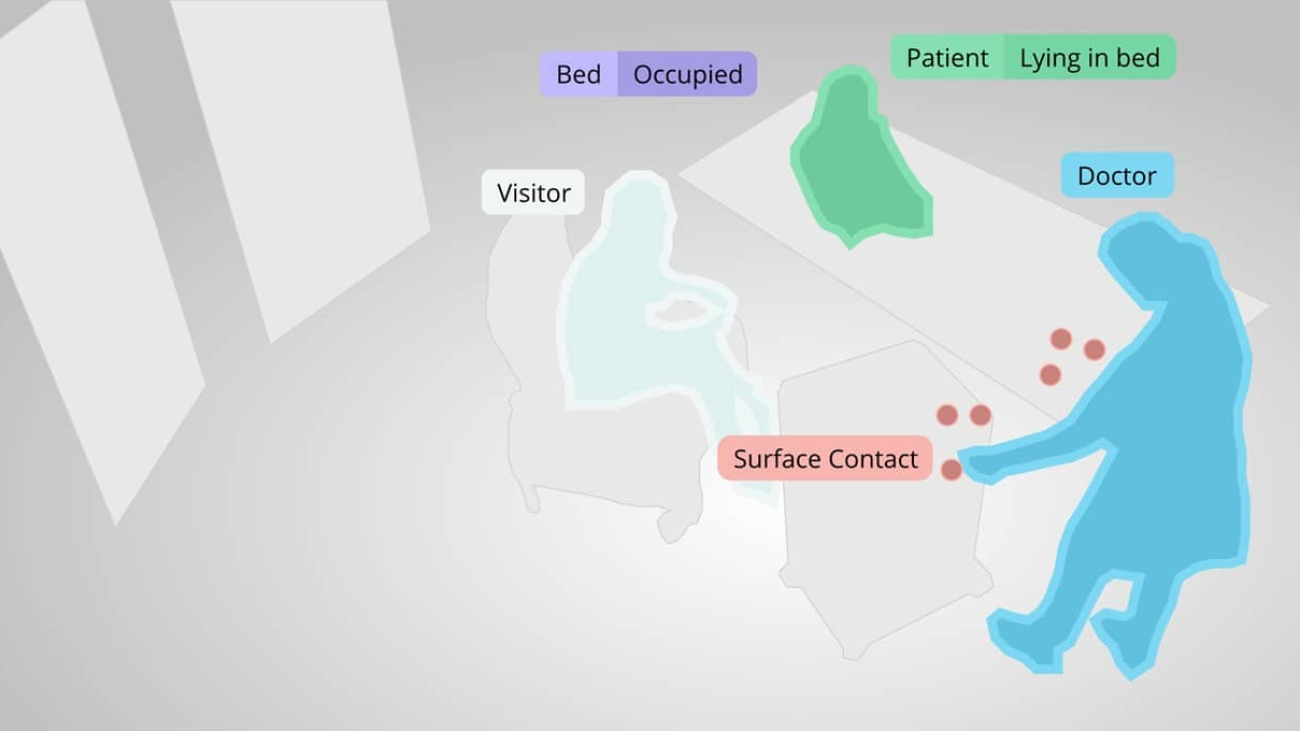
The platform uses the NVIDIA Clara Guardian application framework so its optical sensors can take in, analyze and provide healthcare professionals with useful information, like whether a patient with high fall-risk is out of bed. The platform is optimized on NVIDIA GPUs and its edge deployments use the NVIDIA Jetson TX1 module.
Ouva is a member of NVIDIA Inception, a program that provides AI startups go-to-market support, expertise and technology. Inception partners also have access to NVIDIA’s technical team.
Dogan Demir, founder and CEO of Ouva, said, “The Inception program informs us of hardware capabilities that we didn’t even know about, which really speeds up our work.”
Patient Care Automation
The Ouva platform automates patient monitoring, which is critical during the pandemic.
“To prevent the spread of COVID-19, we need to minimize contact between staff and patients,” said Demir. “With our solution, you don’t need to be in the same room as a patient to make sure that they’re okay.”
More and more hospitals use video monitoring to ensure patient safety, he said, but without intelligent video analytics, this can entail a single nurse trying to keep an eye on up to 100 video feeds at once to catch an issue in a patient’s room.
By detecting changes in patient movement and alerting workers of them in real time, the Ouva platform allows nurses to pay attention to the right patient at the right time.
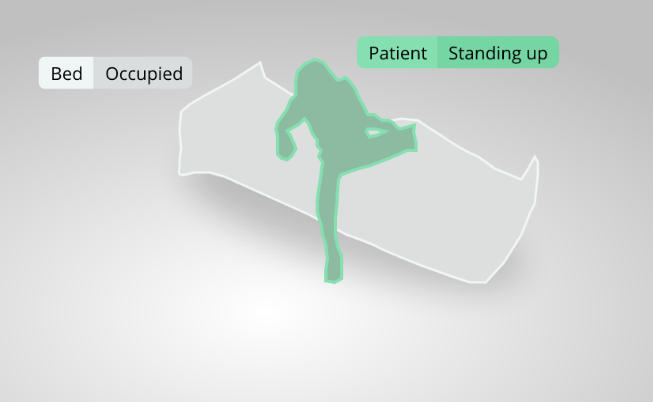
“The platform minimizes the time that nurses may be in the dark about how a patient is doing,” said Demir. “This in turn reduces the need for patients to be transferred to the ICU due to situations that could’ve been prevented, like a fall or brain injury digression due to a seizure.”
According to Ouva’s research, the average hospitalization cost for a fall injury is $35,000, with an additional $43,000 estimated per person with a pressure injury like an ulcer from the hospital bed. This means that by preventing falls and monitoring a patient’s position changes, Ouva could help save $4 million per year for a 100-bed facility.
Ouva’s system also performs personal protective equipment checks and skin temperature screenings, as well as flags contaminated areas for cleaning, which can reduce a nurse’s hours and contact with patients.
Radboud University Medical Center in the Netherlands recently integrated Ouva’s platform for 10 of its neurology wards.
“Similar solutions typically require contact with the patient’s body, which creates an infection and maintenance risk,” said Dr. Harry van Goor from the facility. “The Ouva solution centrally monitors patient safety, room hygiene and bed turnover in real time while preserving patients’ privacy.”
Patient Assistant and Sensory Experience
The platform can also guide patients through a complex hospital facility by providing answers to voice-activated questions about building directions. Medical City Hospital in Dallas was the first to pick up this voice assistant solution for their Heart and Spine facilities at the start of COVID-19.
In waiting areas, patients can participate in Ouva’s touch-free sensory experience by gesturing at 60-foot video screens that wrap around walls, featuring images of gardens, beaches and other interactive locations.
The goal of the sensory experience, made possible by NVIDIA GPUs, is to reduce waiting room anxiety and improve patient health outcomes, according to Demir.
“The amount of pain that a patient feels during treatment can be based on their perception of the care environment,” said Demir. “We work with physical and occupational therapists to design interactive gestures that allow people to move their bodies in ways that both improve their health and their perception of the hospital environment.”
Watch Ouva’s sensory experience in action:
Stay up to date with the latest healthcare news from NVIDIA and check out our COVID-19 research hub.
The post Startup’s AI Platform Allows Contact-Free Hospital Interactions appeared first on The Official NVIDIA Blog.