Bidirectional Encoder Representations from Transformers (BERT) [1] has become one of the most popular models for natural language processing (NLP) applications. BERT can outperform other models in several NLP tasks, including question answering and sentence classification.
Training the BERT model on large datasets is expensive and time consuming, and achieving low latency when performing inference on this model is challenging. Latency and throughput are key factors to deploy a model in production. In this post, we focus on optimizing these factors for BERT inference tasks. We also compare the cost of deploying BERT on different Amazon Elastic Compute Cloud (Amazon EC2) instances.
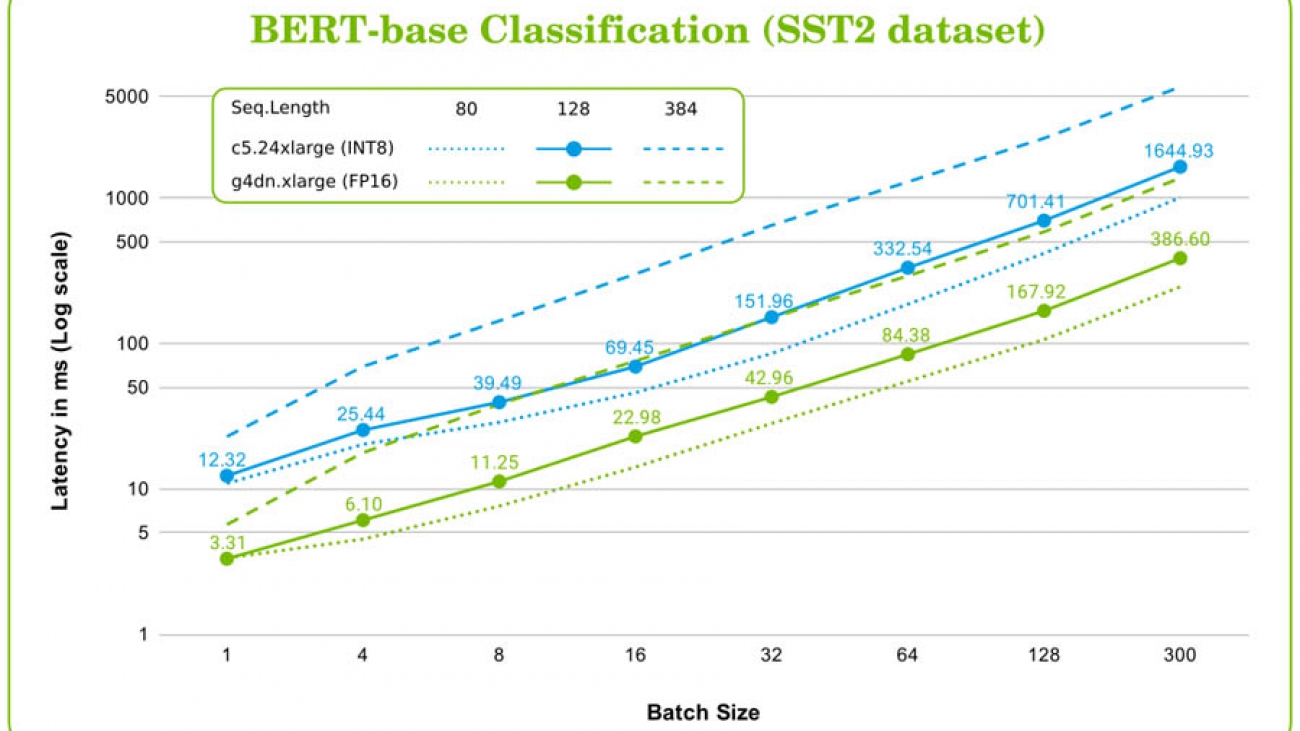
When running inference on the BERT-base model, the g4dn.xlarge GPU instance achieves between 2.6–5 times lower latency (3.8 on average) than a c5.24xlarge CPU instance. The g4dn.xlarge instance also achieves the best cost-effective ratio (cost per requests) compared to c5.xlarge, c5.24xlarge, and m5.xlarge CPU instances. Specifically, the cost of processing 1 million BERT-inference requests with sequence length 128 is $0.20 on g4dn.xlarge, whereas on c5.xlarge (the best of these CPU instances), the cost is $3.31—the GPU instance is 16.5 times more efficient.
We achieved these results after a set of GPU optimizations on MXNet, described in the section Optimizing BERT model performance on MXNET 1.6 and 1.7 of this post.
Amazon EC2 G4 instances
G4 instances are optimized for machine learning application deployments. They’re equipped with NVIDIA T4 GPUs, powered by Tensor Cores, and deliver groundbreaking AI performance: up to 65 TFLOPS in FP16 precision and up to 130 TOPS in INT8 precision.
Amazon EC2 offers a variety of G4 instances with one or multiple GPUs, and with different amounts of vCPU and memory. You can perform BERT inference below 5 milliseconds on a single T4 GPU with 16 GB, such as on a g4dn.xlarge instance (the cost of this instance at the time of writing is $0.526 per hour on demand in the US East (N. Virginia) Region.
For more information about G4 instances, see Amazon EC2 G4 Instances.
GluonNLP and MXNet
GluonNLP is a deep learning framework built on top of MXNet, which was specifically designed for NLP applications. It extends MXNet, providing NLP models, datasets, and examples.
GluonNLP includes an efficient implementation of the BERT model, scripts for training and performing inference, and several datasets (such as GLUE benchmark and SQuAD). For more information, see GluonNLP: NLP made easy.
For this post, we use the GluonNLP BERT implementation to perform inference on NLP tasks. Specifically, we use MXNet version 1.7 and GluonNLP version 0.10.0.
BERT-base inference results
We present results performing two different BERT tasks: question answering and classification (sentimental analysis using the Stanford Sentiment Treebank (SST2) dataset). We achieved the results after a set of GPU optimizations on MXNet.
In the following graphs, we compare latency achieved by a single GPU on a g4dn.xlarge instance with FP16 precision vs. the most efficient CPU instance in terms of latency, c5.24xlarge with INT8 precision, MKL BLAS and 24 OpenMP threads.
The following graph shows BERT-base latency on c5.25xlarge (INT8) and g4dn.xlarge (FP16) instances performing a classification inference task (SST2 dataset). Different sequence length values (80, 128, 384), and different batch sizes (1, 4, 16, 8 ,32, 64, 128, 300) are shown. In the case of sequence length, 128 values are included as labels.

The following graph shows BERT-base latency on c5.24xlarge (INT8) and g4dn.xlarge (FP16) instances performing a question answering inference task (SQuAD dataset). Different sequence length values (80, 128, 384), and different batch sizes (1, 4, 16, 8 ,32, 64, 128, 300) are shown. In the case of sequence length, 128 values are included as labels.

In the following two graphs, we present a cost comparison between several instances based on the throughput (sentences/s) and the cost of each instance on demand (cost per hour) in the US East (N. Virginia) Region.
The following graph shows dollars per 1 million sequence classification requests, for different instances, batch size 128, and several sequence lengths (80, 128 and 384). The price on demand of each instance per hour was based on the US East (N. Virginia) Region: $0.192 for m5.xlarge, $0.17 for c5.xlarge, $4.08 for c5.24xlarge, and $0.526 g4dn.xlarge.

The following graph shows dollars per 1 million question answering requests, for different instances, batch size 128, and several sequence lengths (80, 128 and 384). The price on demand of each instance per hour was based on the US East (N. Virginia) Region: $0.192 for m5.xlarge, $0.17 for c5.xlarge, $4.08 for c5.24xlarge, and $0.526 g4dn.xlarge.

Deploying BERT on G4 instances
You can easily reproduce the results in the preceding section on a g4dn.xlarge instance. You can start from a pretrained model and fine-tune it for a specific task before running inference, or you can download one of the following fine-tuned models:
Then complete the following steps:
- To initialize a G4 instance, on the Amazon EC2 console, choose Deep Learning AMI (Ubuntu 18.04) Version 28.1 (or posterior) and a G4 instance.
- Connect to the instance and set MXNet 1.7 and GluonNLP 0.10.x:
pip install mxnet-cu102==1.7.0
git clone --branch v0.10.x https://github.com/dmlc/gluon-nlp.git
cd gluon-nlp; pip install -e .; cd scripts/bert
python setup.py install
The command python setup.py install generates a custom graph pass (bertpass_lib.so) that optimizes the graph, and therefore performance. It can be passed to the inference script as an argument.
- If you didn’t download any fine-tuned parameters, you can now fine-tune your model to specify a sequence length and use a GPU.
- For a question answering task, run the following script (approximately 180 minutes):
python3 finetune_squad.py --max_seq_length 128 --gpu
-
- For a classification task, run the following script:
python3 finetune_classifier.py --task_name [task_name] --max_len 128 --gpu 0
In the preceding code, task choices include ‘MRPC’, ‘QQP’, ‘QNLI’, ‘RTE’, ‘STS-B’, ‘CoLA’, ‘MNLI’, ‘WNLI’, ‘SST’ (refers to SST2), ‘XNLI’, ‘LCQMC’, and ‘ChnSentiCorp’. Computation time depends on the specific task. For SST, it should take less than 15 minutes.
By default, these scripts run 3 epochs (to achieve the published accuracy in [1]).
They generate an output file, output_dir/net.params, where the fine-tuned parameters are stored and from where they can be loaded at inference step. Scripts also perform a prediction test to check accuracy.
You should get an F1 score of 85 or higher in question answering, and a validation metric higher to 0.92 in SST classification task.
You can now perform inference using validation datasets.
- Force MXNet to use FP32 precision in Softmax and LayerNorm layers for better accuracy when using FP16.
These two layers are susceptible to overflow, so we recommend always using FP32. MXNet takes care of it if you set the following:
export MXNET_SAFE_ACCUMULATION=1
- Activate True FP16 computation for performance purposes.
General matrix multiply operations don’t present accuracy issues in this model. By default, they’re computed using FP32 accumulation (for more information, see the section Optimizing BERT model performance on MXNET 1.6 and 1.7 in this post), but you can activate the FP16 accumulation setting:
export MXNET_FC_TRUE_FP16=1
- Run inference:
python3 deploy.py --model_parameters [path_to_finetuned_params] --task [_task_] --gpu 0 --dtype float16 --custom_pass=bertpass_lib.so
In the preceding code, the task can be one of ‘QA’, ‘embedding’, ‘MRPC’, ‘QQP’, ‘QNLI’, ‘RTE’, ‘STS-B’, ‘CoLA’, ‘MNLI’, ‘WNLI’, ‘SST’, ‘XNLI’, ‘LCQMC’, or ‘ChnSentiCorp’ [1].
This command exports the model (JSON and parameter files) into the output directory (output_dir/[task_name]), and performs inference using the validation dataset corresponding to each task.
It reports the average latency and throughput.
The second time you run it, you can skip the export step by adding the tag --only_infer and specifying the exported model to use by adding --exported_model followed by the prefix name of the JSON or parameter files.
Optimal latency is achieved on G4 instances with FP16 precision. We recommend adding the flag -dtype float16 and activating MXNET_FC_TRUE_FP16 when performing inference. These flags shouldn’t reduce the final accuracy in your results.
By default, all these scripts use BERT-base (12 transformer-encoder layers). If you want to use BERT-large, use the flag --bert_model bert_24_1024_16 when calling the scripts.
Optimizing BERT model performance on MXNet 1.6 and 1.7
Computationally, the BERT model is mainly dominated by general matrix multiply operations (GEMMs). They represent up to 56% of time consumed when performing inference. The following chart shows the percentage of computational time spent on each operation type performing BERT-base inference (sequence length 128 and batch size 128).

MXNet uses the cuBLAS library to efficiently compute these GEMMs on the GPU. These GEMMs belong to the multi-head self-attention part of the model (4 GEMMs per transformer layer), and the feed-forward network (2 GEMMs per transformer layer).
In this section, we discuss optimizing the most computational-consuming operations.
The following table shows the improvement of each optimization. The performance improvements were achieved by the different GPU BERT optimizations implemented on MXNet and GluonNLP, performing a question answering inference task (SQuAD dataset), and using a sequence length of 128. Speedup achieved is shown for different batch sizes.

LayerNorm, Softmax and AddBias
Although LayerNorm was already optimized for GPUs on MXNet 1.5, the implementation of Softmax was optimized in MXNet 1.6. The new implementation improves inference performance on GPUs by optimizing the device memory accesses and using the CUDA registers and shared memory during reduction operations more efficiently. Additionally, you have the option to apply a max_length mask within the C++ Softmax operator, which removes the need to apply the mask at the Python level.
The addition of bias terms following GEMMs was also optimized. Instead of using an mshadow broadcast summation, a custom CUDA kernel is now attached to the FullyConnected layer, which includes efficient device memory accesses.
Multi-head self-attention
The following equation defines the attention mechanism used in the BERT model [2], where Q represents the query, K the key, V the value, and dk the inner dimension of these three matrices:

Three different linear projections (FullyConnected: GEMMs and Bias-Addition) are performed to obtain Q, K, and V from the same input (when the same input is employed, the mechanism is denominated self-attention), but with different weights:
-
- Q = input Wqt
- K = input Wkt
- V = input Wvt
The input size is (BatchSize, SeqLength, EmbeddingDim), and each weight tensor W size is (ProjectionDim, EmbeddingDim).
In multi-head attention, many projections and attention functions are applied to the input as the number of heads, augmenting the dimensions of the weights so that each W size is ((NumHeads x ProjectionDim), EmbeddingDim).
All these projections are independent, so we can compute them in parallel within the same operation, producing an output which size is (BatchSize, SeqLength, 3 x NumHeads x ProjectionDim). That is, GluonNLP uses a single FullyConnected layer to compute Q, K, and V.
To compute the attention function (the preceding equation), we first need to compute the dot product QKT. We need to perform this computation independently for each head, with m=SeqLength number of Q rows, n=SeqLength number of K columns, and k=ProjectionDim size of vectors in the dot product. We can use a batched dot product operation, where the number of batches is (BatchSize x NumHeads), to compute all the dot products within the same operation.
However, to perform such an operation in cuBLAS, we need to have the batches and heads dimensions contiguous (in order to have a regular pattern to express distance between batches), but that isn’t the case by default (SeqLength dimension is between them). To avoid rearranging Q, K, and V, GluonNLP transposes the input so that its shape is (SeqLength, BatchSize, EmbeddingDim), and Q, K, and V are directly projected into a tensor with shape (SeqLength, BatchSize, 3 x NumHeads x ProjectionDim).
Moreover, to avoid splitting the joint QKV output, we can compute the projections in an interleaved fashion, allocating continuously the applied weights Wq, Wk, Wv of each individual head. The following diagram depicts the interleaved projection operation, where P is the projection size, and we end with a joint QKV output with shape (SeqLength, BatchSize, NumHeads x 3 x ProjectionDim).

This strategy allows us to compute QKT from a unique joint input tensor with cuBLASGEMMStridedBatched, setting the number of batches to (BatchSize x NumHeads) and the stride to (3 x ProjectionDim). We also use a strided batched GEMM to compute the dot product of V (same stride as before) with the output of the Softmax function. We implemented MXNet operators that deal with this cuBLAS configuration.
True FP16
Since MXNet 1.7, you can compute completely in FP16 precision GEMMs. By default, when the data type is FP16, MXNet sets cuBLAS to internally use FP32 accumulation. You can now set the environment variable MXNET_FC_TRUE_FP16 to 1 to force MXNet to use FP16 as the cuBLAS internal computation type.
Pointwise fusion and prearrangement of MHA weights and bias using a custom graph pass
Finally, the feed-forward part of the model, which happens after each transformer layer, uses Gaussian Exponential Linear Unit (GELU) as its activation function. This operation follows a feed-forward FullyConnected operation, which includes bias addition. We use the MXNet functionality of custom graph passes to detach the bias addition from the FullyConnected operation and fuse it with GELU through the pointwise fusion mechanism.
In our custom graph pass for BERT, we also prearrange the weights and bias terms for the multi-head self-attention computation so that we avoid any overhead at runtime. As explained earlier, weights need to be interleaved, and bias terms need to be joint into a unique tensor. We do this before exporting the model. This strategy shows benefits in small batch size cases.
Conclusion
In this post, we presented an efficient solution for performing BERT inference tasks on EC2 G4 GPU instances. We showed how a set of MXNet optimizations boost GPU performance, achieving speeds up to twice as fast in both question answering and classification tasks.
We have shown that g4dn.xlarge instances offer lower latency (below 4 milliseconds with batch size 1) than any EC2 CPU instance, and g4dn.xlarge is 3.8 times better than c5.24xlarge on average. Finally, g4dn.xlarge offers the best cost per million requests ratio—16 times better than CPU instances (c5.xlarge) on average.
Acknowledgments
We would like to thank Triston Cao, Murat Guney from NVIDIA, Sandeep Krishnamurthy from Amazon, the Amazon-MXNet team, and the NVIDIA MXNet team for their feedback and support.
Disclaimer
The content and opinions in this post are those of the third-party authors and AWS is not responsible for the content or accuracy of this post.
References
- Devlin, Jacob, et al. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
- Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems. 2017.
About the Authors
Moises Hernandez Fernandez is an AI DevTech Engineer at NVIDIA. He works on accelerating NLP applications on GPUs. Before joining NVIDIA, he was conducting research into the brain connectivity, optimizing the analysis of diffusion MRI using GPUs. Moises received a PhD in Neurosciences from Oxford University.
Haibin Lin is a former Applied Scientist at Amazon Web Services. He works on distributed systems, deep learning, and NLP. He is a PPMC and committer of Apache MXNet, and a major contributor to the GluonNLP toolkit. He has finished his M.S. in Computer Science at Carnegie Mellon University, advised by Andy Pavlo. Prior to that, he has received a B.Eng. in Computer Science from University of Hong Kong and Shanghai Jiao Tong University jointly.
Przemyslaw Tredak is a senior developer technology engineer on the Deep Learning Frameworks team at NVIDIA. He is a committer of Apache MXNet and leads the MXNet team at NVIDIA.
Anish Mohan is a Machine Learning Architect at Nvidia and the technical lead for ML/DL engagements with key Nvidia customers in the greater Seattle region. Before Nvidia, he was at Microsoft’s AI Division, working to develop and deploy AI/ML algorithms and solutions.
Read More




 Once a target protein has been identified, researchers search for candidate compounds that have the right properties to bind with it. To evaluate how effective drug candidates will be, researchers can screen drug candidates virtually, as well as in real-world labs.
Once a target protein has been identified, researchers search for candidate compounds that have the right properties to bind with it. To evaluate how effective drug candidates will be, researchers can screen drug candidates virtually, as well as in real-world labs.

 Gadi Hutt is a Sr. Director, Business Development at AWS. Gadi has over 20 years’ experience in engineering and business disciplines. He started his career as an embedded software engineer, and later on moved to product lead positions. Since 2013, Gadi leads Annapurna Labs technical business development and product management focused on hardware acceleration software and hardware products like the EC2 FPGA F1 instances and AWS Inferentia along side with its Neuron SDK, accelerating machine learning in the cloud.
Gadi Hutt is a Sr. Director, Business Development at AWS. Gadi has over 20 years’ experience in engineering and business disciplines. He started his career as an embedded software engineer, and later on moved to product lead positions. Since 2013, Gadi leads Annapurna Labs technical business development and product management focused on hardware acceleration software and hardware products like the EC2 FPGA F1 instances and AWS Inferentia along side with its Neuron SDK, accelerating machine learning in the cloud.





 Sai Sharanya Nalla is a Data Scientist at AWS Professional Services. She works with customers to develop and implement AI and ML solutions on AWS. In her spare time, she enjoys listening to podcasts and audiobooks, long walks, and engaging in outreach activities.
Sai Sharanya Nalla is a Data Scientist at AWS Professional Services. She works with customers to develop and implement AI and ML solutions on AWS. In her spare time, she enjoys listening to podcasts and audiobooks, long walks, and engaging in outreach activities. Inchara B Diwakar is a Data Scientist at AWS Professional Services. She designs and engineers ML solutions at scale, with experience across healthcare, manufacturing and retail verticals. Outside of work, she enjoys the outdoors, traveling and a good read.
Inchara B Diwakar is a Data Scientist at AWS Professional Services. She designs and engineers ML solutions at scale, with experience across healthcare, manufacturing and retail verticals. Outside of work, she enjoys the outdoors, traveling and a good read.