
With less than a week to re:Invent 2020, we are feeling the excitement and thrill, and looking forward to seeing you all at the world’s premier cloud learning event. As always, artificial intelligence (AI) and machine learning (ML) continue to be on the list of top topics with our customers and partners. We’re making it bigger and better this year with the first ever machine learning keynote, over 50 technical breakout sessions, live racing with the AWS DeepRacer League, and more. You’ll hear from AWS experts as well as many of our customers including NASCAR, Intuit, McDonalds, Mobileye, NFL, Siemens Energy, and many others, across industries such as sports, finance, retail, autonomous vehicles, manufacturing, and more.
To help you plan your agenda for the extravaganza, here are a few highlights from the artificial intelligence and machine learning track at re:Invent 2020. So fasten your seat belts, register now, and let’s get started.
Machine Learning Keynote
This year, we’re hosting the first ever machine learning keynote, delivered by Swami Sivasubramanian, Vice President, Machine Learning, AWS. Join Swami live and hear how AWS is freeing builders to innovate on machine learning with the latest developments in AI and ML. We are excited to bring you new product launches, demos, customer stories, and more.
Getting started with AI and ML
If you’re new to AI and ML, we have some sessions that’ll help you get started with the basics on how AI and ML can bring value to your business. These sessions cover the foundational elements of AI and ML, and make it fun for you with the popular AWS DeepRacer and AWS DeepComposer devices.
From PoC to Production (Session AIM203)
If you’re planning to implement ML in your organization and wondering where to start, this session is for you. Learn how to achieve success using ML at scale, including best practices to get from concept to production.
Discover insights to deliver customer delight (AIM202)
Sheer volume of customer responses and sentiments should not deter you from delivering excellent customer service. Learn how you can use Amazon Comprehend to extract valuable information and convert it into business insights.
Get rolling with AWS DeepRacer (AIM204)
Developers, start your engines. Get hands-on with AWS DeepRacer and learn about the basics of machine learning and reinforcement learning in a fun and exciting way. Build a model and submit it to the AWS DeepRacer League for a chance to win prizes and glory.
Get started with Generative AI with AWS DeepComposer (AIM207)
Generative AI has been used to solve unique problems across many industries. Learn about the latest concepts in generative AI techniques such as GANs and autoregressive models, while having fun using music with AWS DeepComposer.
Let’s get practical with use cases across industries
The broad applicability of machine learning means it can help customers for a wide range of use cases across many industries. In these sessions, we dive deep into the practical aspects of AI and ML for use cases in industries including finance, healthcare, retail, media and entertainment, and more.
Intelligent document processing for the insurance industry (AIM310)
The insurance industry spends millions of dollars on manual data extraction efforts that are error-prone, expensive, and tedious. Learn how you can use Amazon Textract and Amazon Augmented AI (Amazon A2I) to get your automated document processing workflow into production, and turn tedious processes into streamlined operations.
Deliver a superior personal experience in M&E (AIM211)
Learn how to add ML-powered recommendation engines to increase subscription and consumption with a personalized approach for your media and entertainment requirements. In this session, we talk about how Amazon Personalize can deliver excellent results for all your business requirements.
Learn how NASCAR is making content searchable and accessible with Amazon Transcribe (AIM205)
Media and entertainment content are growing exponentially. In this session, NASCAR will share how they use Amazon Transcribe to enhance user engagement with automated video subtitles. We will also discuss how other customers can use Amazon Transcribe to cost effectively create accurate transcriptions of videos and podcasts, generate metadata for content cataloging and search, and moderate content.
Build computer vision training datasets with the National Football League (NFL) (AIM307)
Tracking players on a sports field is challenging, and training high-quality ML models to predict player movement and injury can be daunting. In this session, learn how the NFL uses Amazon SageMaker Ground Truth to build training datasets to track all 22 players on the field for player safety and tracking game statistics, with a fun and insightful demo.
Use AI to automate clinical workflows (AIM303)
Learn how healthcare organizations can harness the power of AI to automate clinical workflows, digitize medical information, extract and summarize information, and protect patient data. In this session, we demonstrate how the wide range of AI services from AWS, including Amazon Textract, Amazon Comprehend Medical, Amazon Transcribe Medical, and Amazon Kendra, work together to extract, analyze, and summarize data within medical records.
Catch online fraud and act to achieve successful outcomes (AIM208)
Fraud is a problem across industries, and organizations can lose billions of dollars each year. In this session, learn how Amazon Fraud Detector can help you catch online fraud with the rich experience and expertise of over 20 years at Amazon using machine learning. Learn how customers are applying Amazon Fraud Detector to their businesses with a detailed discussion and demo.
Secure and compliant machine learning for regulated industries (AIM309)
As more and more workloads move to the cloud, having a secure environment is mandatory. At AWS, security is top priority for us, and this session dives deep into provisioning a secure ML environment using Amazon SageMaker. We deep dive into customer architectures for regulated industries such as finance with detailed concepts and a technical demo.
AI and DevOps – an unbeatable combination
Find your most expensive lines of code with Amazon CodeGuru (AIM306)
Improving application response times, resolving service issues faster and more accurately, and understanding your code better is top of mind with most developers. In this session, you learn how Amazon CodeGuru can help you with intelligent recommendations to automate code reviews during development, and how you can improve performance of your applications with a more robust code.
Advanced topics for the experienced ML practitioner
We have a number of sessions that dive deep into the technical details of machine learning across our service portfolio as well as deep learning frameworks including TensorFlow, PyTorch, and Apache MXNet. These sessions dive deep into code with demos and enable the advanced developer or the data scientist in you to solve many challenges with deep technical solutions.
Get started with Amazon SageMaker (AIM209)
Amazon SageMaker is a fully managed service enabling all developers and data scientists with every aspect of the ML lifecycle. Join us in this session as we show you how you can get started with SageMaker for a variety of use cases, including predictive maintenance, churn prediction, credit risk, and more, with a simple and intuitive experience.
Use fully managed Jupyter notebooks in Amazon SageMaker Studio (AIM305)
Managing compute instances to view, run, or share notebooks can be tedious. With Amazon SageMaker Studio Notebooks, it’s easy to use notebooks for your ML projects. The underlying compute resources are fully elastic and the notebooks can be shared with others, making collaboration easy and scalable. This session demonstrates how you can use Jupyter notebooks with SageMaker Studio, the first fully integrated development environment for machine learning.
Train ML models at scale with billions of parameters in TensorFlow 2.0 (AIM405)
Training large models with many inputs is often restricted due to limiting factors such as GPU memory. In this session, we dive deep into a technical solution with model parallelism, placing layers of models on multiple GPU devices to utilize the aggregate memory. We demonstrate how you can train models at scale using Amazon SageMaker and TensorFlow 2.0.
Workplace safety and identity verification (AIM407)
Today, there have been new challenges to the workplace introduced by COVID-19 across businesses. Join us in this session to learn how Amazon Rekognition helps enhance workplace safety and help ensure safe identity verification with an automated, scalable solution. See how employees and customers can be safe in both physical and online environments in the changing workplace environment.
Scaling ML environments on Kubernetes (AIM313)
Setting up ML environments on Kubernetes for training and inference is becoming increasingly common. In this session, we demonstrate how you can run training at scale easily using Amazon SageMaker Operators for Kubernetes with secure, high-availability endpoints using autoscaling policies. You can also hear from Intuit on how they built a Kubernetes controller using SageMaker Operators, Apache Spark, and Argo for their high-availability systems.
Maintain highly accurate ML models by detecting model drift (AIM304)
Accuracy of models is often affected due to the difference in data between the one used for training and the one in production to generate predictions. In this session, you learn how Amazon SageMaker Model Monitor automatically detects drift in deployed models, provides detailed alerts to help identify the problem, and helps maintain highly accurate ML models.
Interpretability and Explainability in Machine Learning (AIM408)
As ML becomes increasingly ubiquitous across industries, use cases, and applications, it becomes critical to understand the results of ML models and their predictions. In this session, we discuss the science of interpretability with Amazon SageMaker and look under the hood to understand how ML models work. We also introduce model explainability, an area of increasing interest in the field of machine learning.
AWS DeepRacer – The fastest and most fun way to get rolling with machine learning
Machine learning can be a lot of fun with AWS DeepRacer. Developers of all skill levels from beginners to experts can get hands-on with AWS DeepRacer by learning to train models in a cloud-based 3D racing simulator. Whether you are novice to machine learning or an expert, AWS DeepRacer is for you. Start your engines here and test your skills in the AWS DeepRacer League in an exciting autonomous car racing experience throughout re:Invent to compete for prizes and glory.
Don’t miss out on the action. Register now for free and see you soon on the artificial intelligence and machine learning track at re:Invent 2020.
About the Author
 Shyam Srinivasan is on the AWS Machine Learning marketing team. He cares about making the world a better place through technology and loves being part of this journey. In his spare time, Shyam likes to run long distances, travel around the world, and experience new cultures with family and friends.
Shyam Srinivasan is on the AWS Machine Learning marketing team. He cares about making the world a better place through technology and loves being part of this journey. In his spare time, Shyam likes to run long distances, travel around the world, and experience new cultures with family and friends.
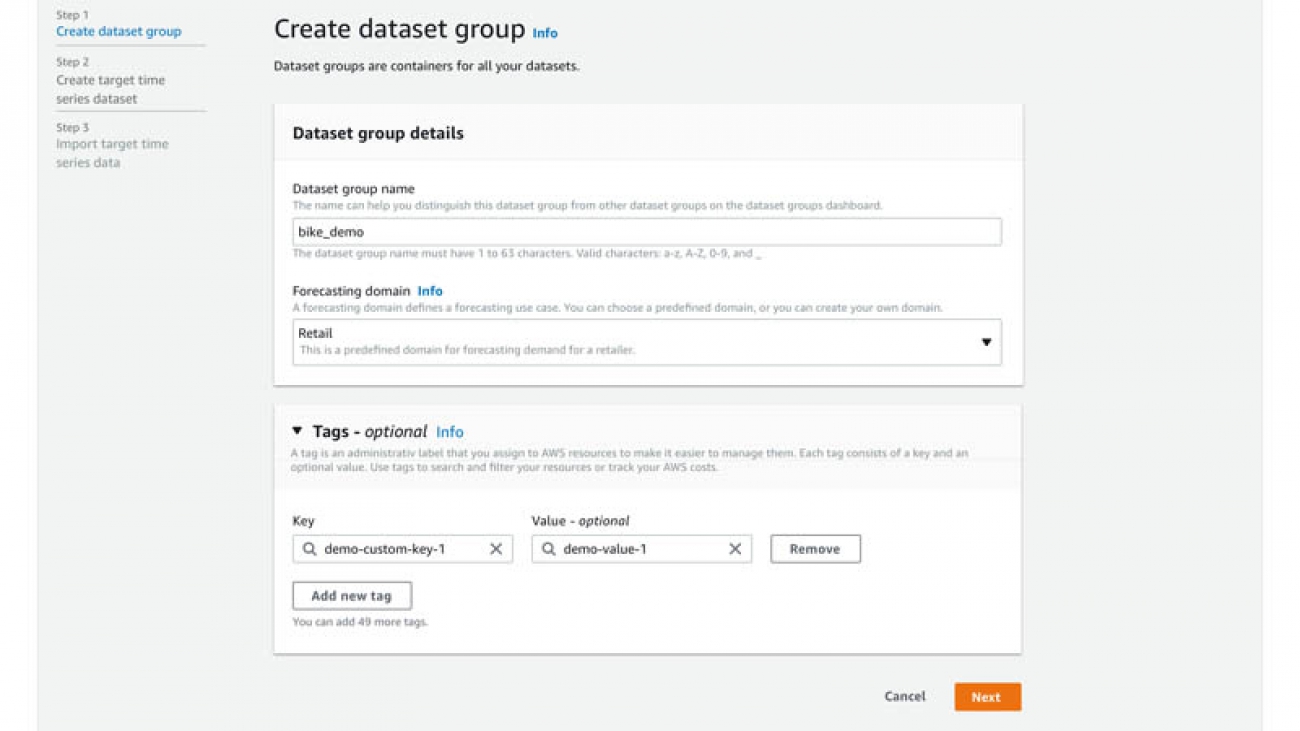
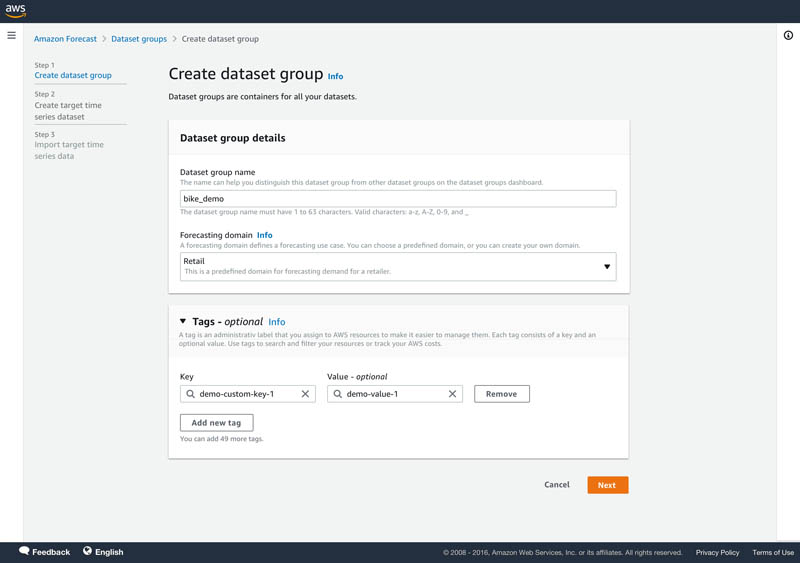

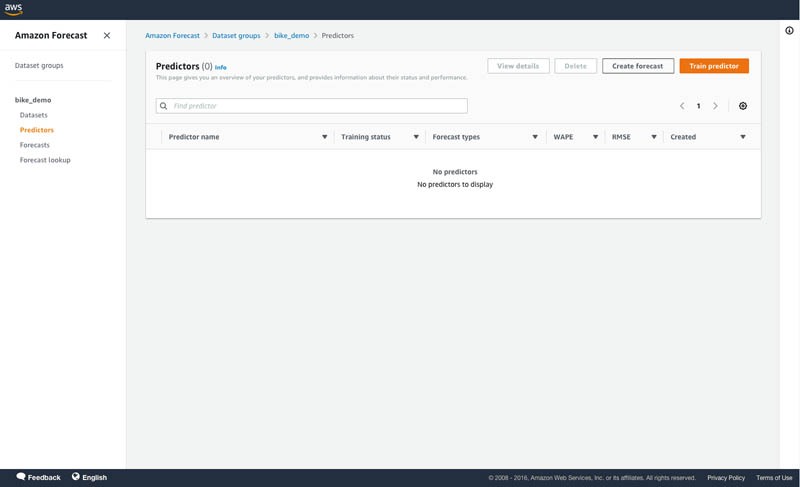

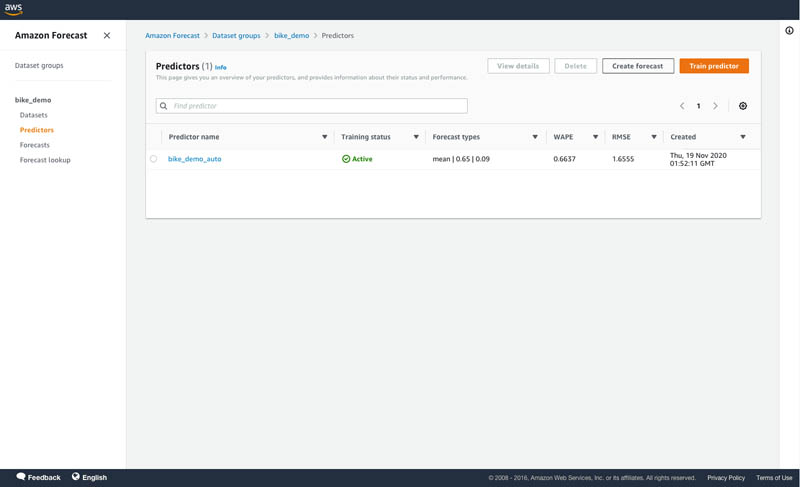



 Namita Das is a Sr. Product Manager for Amazon Forecast. Her current focus is to democratize machine learning by building no-code/low-code ML services. On the side, she frequently advises startups and is raising a puppy named Imli.
Namita Das is a Sr. Product Manager for Amazon Forecast. Her current focus is to democratize machine learning by building no-code/low-code ML services. On the side, she frequently advises startups and is raising a puppy named Imli. Punit Jain is working as SDE on the Amazon Forecast team. His current work includes building large scale distributed systems to solve complex machine learning problems with high availability and low latency as a major focus. In his spare time, he enjoys hiking and cycling.
Punit Jain is working as SDE on the Amazon Forecast team. His current work includes building large scale distributed systems to solve complex machine learning problems with high availability and low latency as a major focus. In his spare time, he enjoys hiking and cycling. Christy Bergman is working as an AI/ML Specialist Solutions Architect at AWS. Her work involves helping AWS customers be successful using AI/ML services to solve real world business problems. Prior to joining AWS, Christy worked as a Data Scientist in banking and software industries. In her spare time, she enjoys hiking and bird watching.
Christy Bergman is working as an AI/ML Specialist Solutions Architect at AWS. Her work involves helping AWS customers be successful using AI/ML services to solve real world business problems. Prior to joining AWS, Christy worked as a Data Scientist in banking and software industries. In her spare time, she enjoys hiking and bird watching.
 Esther Lee is a Product Manager for AWS Language AI Services. She is passionate about the intersection of technology and education. Out of the office, Esther enjoys long walks along the beach, dinners with friends and friendly rounds of Mahjong.
Esther Lee is a Product Manager for AWS Language AI Services. She is passionate about the intersection of technology and education. Out of the office, Esther enjoys long walks along the beach, dinners with friends and friendly rounds of Mahjong.

 Jorge Alfaro Hidalgo is an Enterprise Solutions Architect in AWS Mexico with more than 20 years of experience in IT industry, he is passionate about helping enterprises to AWS cloud journey building innovative solutions to achieve their business objectives.
Jorge Alfaro Hidalgo is an Enterprise Solutions Architect in AWS Mexico with more than 20 years of experience in IT industry, he is passionate about helping enterprises to AWS cloud journey building innovative solutions to achieve their business objectives. Mauricio Zajbert has more than 30 years of experience in the IT industry and a fully recovered infrastructure professional; he’s currently Solutions Architecture Manager for Enterprise accounts in AWS Mexico leading a team that helps customers in their cloud journey. He’s lived through several technology waves and deeply believes none has offered the benefits of the cloud.
Mauricio Zajbert has more than 30 years of experience in the IT industry and a fully recovered infrastructure professional; he’s currently Solutions Architecture Manager for Enterprise accounts in AWS Mexico leading a team that helps customers in their cloud journey. He’s lived through several technology waves and deeply believes none has offered the benefits of the cloud.




 Graham Horwood is a data scientist at Amazon AI. His work focuses on natural language processing technologies for customers in the public and commercial sectors.
Graham Horwood is a data scientist at Amazon AI. His work focuses on natural language processing technologies for customers in the public and commercial sectors. Ben Snively is an AWS Public Sector Specialist Solutions Architect. He works with government, non-profit, and education customers on big data/analytical and AI/ML projects, helping them build solutions using AWS.
Ben Snively is an AWS Public Sector Specialist Solutions Architect. He works with government, non-profit, and education customers on big data/analytical and AI/ML projects, helping them build solutions using AWS. Sameer Karnik is a Sr. Product Manager leading product for Amazon Comprehend, AWS’s natural language processing service.
Sameer Karnik is a Sr. Product Manager leading product for Amazon Comprehend, AWS’s natural language processing service.






 Nick Minaie is an Artificial Intelligence and Machine Learning (AI/ML) Specialist Solution Architect, helping customers on their journey to well-architected machine learning solutions at scale. In his spare time, Nick enjoys family time, abstract painting, and exploring nature.
Nick Minaie is an Artificial Intelligence and Machine Learning (AI/ML) Specialist Solution Architect, helping customers on their journey to well-architected machine learning solutions at scale. In his spare time, Nick enjoys family time, abstract painting, and exploring nature. Sam Liu is a product manager at Amazon Web Services (AWS). His current focus is the infrastructure and tooling of machine learning and artificial intelligence. Beyond that, he has 10 years of experience building machine learning applications in various industries. In his spare time, he enjoys making short videos for technical education or animal protection.
Sam Liu is a product manager at Amazon Web Services (AWS). His current focus is the infrastructure and tooling of machine learning and artificial intelligence. Beyond that, he has 10 years of experience building machine learning applications in various industries. In his spare time, he enjoys making short videos for technical education or animal protection.










 Blake DeLee is a Rochester, NY-based conversational AI consultant with AWS Professional Services. He has spent five years in the field of conversational AI and voice, and has experience bringing innovative solutions to dozens of Fortune 500 businesses. Blake draws on a wide-ranging career in different fields to build exceptional chatbot and voice solutions.
Blake DeLee is a Rochester, NY-based conversational AI consultant with AWS Professional Services. He has spent five years in the field of conversational AI and voice, and has experience bringing innovative solutions to dozens of Fortune 500 businesses. Blake draws on a wide-ranging career in different fields to build exceptional chatbot and voice solutions. As a Product Manager on the Amazon Lex team, Harshal Pimpalkhute spends his time trying to get machines to engage (nicely) with humans.
As a Product Manager on the Amazon Lex team, Harshal Pimpalkhute spends his time trying to get machines to engage (nicely) with humans.