No matter the reason, sharing images or videos of child sexual abuse (CSAM) online has a devastating impact on the child depicted in that content. Every time that content is shared, it revictimizes that child. Preventing and eradicating online child sexual exploitation and abuse requires a cross-industry approach, and Facebook is committed to doing our part to protect children on and off our apps. To that end, we have taken a careful, research-informed approach to understand the basis for sharing child sexual abuse and exploitation material on our platform, to ultimately develop effective and targeted solutions for our apps and help others committed to protecting children.
Over the past year, we’ve consulted with the world’s leading experts in child exploitation, including the National Center for Missing and Exploited Children (NCMEC) and Professor Ethel Quayle, to improve our understanding of why people may share child exploitation material on our platform. Research, such as Ken Lanning’s work in 2010, and our own child safety investigative team’s experiences suggested that people who share these images are not a homogeneous group; they share this imagery for different reasons. Understanding the possible or apparent intent of a sharer is important to developing effective interventions. For example, to be effective, the intervention we make to stop those who share this imagery based on a sexual interest in children will be different from the action we take to stop someone who shares this content in a poor attempt to be funny.
You may also like
We set out to answer the following questions: Did we see possible evidence of different intentions among people who shared CSAM on our platforms, and if so, what behaviors were usually associated with them? Do some users likely share CSAM to intentionally exploit children (for example, out of sexual interest or for commercial benefit)? Were there other users who shared CSAM without necessarily intending to harm children (for example, a person sharing it out of outrage or shock, or two teens sexting)?
Why did we want to understand differences in sharers?
Protecting children and addressing the sharing of child sexual abuse material cannot be solely rooted in a “detect, report, and remove” model. Prevention must also be at the core of the work we do to protect children, alongside our continual reporting and removal responsibilities. By attempting to understand the differences in CSAM sharers, we hope to:
- Provide additional context to NCMEC and law enforcement to improve our reports to NCMEC of cases of child sexual abuse and exploitation found on our apps. Our CyberTips allow for more effective triaging of cases, helping them quickly identify children who are presently being abused.
- Develop more effective and targeted interventions to prevent the sharing of these images.
- Tailor our responses to people who share this imagery based on their likely intent to reduce the sharing and resharing of these images — from the most severe product actions (for example, removing from the platform) to prevention education messaging (for example, our recently announced proactive warnings)
- Develop a deeper understanding of why people share CSAM to support a prevention-first approach to child exploitation in the future supported by a more effective “detect and response” model; and share our learnings with all those dedicated to safeguarding children to inform their important work
Research review
We reviewed 10 pieces of research from the world’s leading experts of child exploitation focused on the intentions, behaviors, or typologies of CSAM offenders. The papers included Ken Lanning’s work in 2010, “Child Molesters: A Behavioural Analysis”; Ethel Quayle’s 2016 review of typologies of internet offenders; Tony Krone’s foundational 2004 paper, “A Typology of Child Pornography Offending”; and Elliott and Beech’s 2009 work, “Understanding Online Child Pornography Use: Applying Sexual Offense Theory to Internet Offenders.”
The research noted a number of key themes around the types of involvement people can have with child sexual abuse material, such as the intersections between online and offline offending, spectrums of offending involvements (from browsing to producing imagery), populations involved in this behavior have diverse characteristics and that there are distinct behaviors from different categories of offenders.
From research to a draft taxonomy of intent
Much of the foundational research on why people engage with CSAM involved access to and evaluations of individuals’ psychological make up. However, Facebook’s application of this research to our platforms involves relying on behavioral signals from a fixed point in time and from a snapshot of users’ life on our platforms. We do not label users in any specific clinical or medical way, but try to understand likely intentions and potential trajectories of behavior in order to provide the most effective online response to prevent this abuse from occurring in the first place. A diverse range of people can and do offend against children.
Our taxonomy, built in consultation with the National Center for Missing and Exploited Children and Professor Ethel Quayle, was most heavily influenced by Lanning’s 2010 work. His research outlined a number of categories of people who engage with harmful behavior or content involving children. Lanning broke down those who offend against children into two key groups: preferential sex offenders and situational sex offenders.
Lanning categorized the situational offender as someone who “does not usually have compulsive-paraphilic sexual preferences including a preference for children. They may, however, engage in sex with children for varied and sometimes complex reasons.” A preferential sex offender, according to Lanning, has “definite sexual inclinations” toward children, such as pedophilia.
Lanning also wrote about miscellaneous offenders, in which he included a number of different types of personae of sharers. This group captures media reporters (or vigilante groups or individuals), “pranksters” (people who share out of humor or outrage), and other groups. This category for Lanning was a catchall to explain the intention and behavior of those who were still breaking the law but who “are obviously less likely to be prosecuted.”
Development for Facebook users
We used an evidence-informed approach to understand the presentation of child exploitation material offenders on our platform. This means that we used the best information available and combined it with our experiences at Facebook to create an initial taxonomy of intent for those who share child exploitative material on our platforms.
The prevalence of this content on our platform is very low, meaning sends and views of it are very infrequent. But when we do find this type of violating content, regardless of the context or the person’s motivation for sharing it, we remove it and report it to NCMEC.
When we applied these groupings to what we were seeing at Facebook, we developed the following taxonomic groupings:
- “Malicious” users
- Preferential offenders
- Commercial offenders
- Situational offenders
- “Nonmalicious” users
- Unintentional offenders
- Minor nonexploitative users
- Situational “risky” offenders
Within the taxonomy, we have two overarching categories. In the “malicious” group are people we believe intended to harm children with their behavior, and in the “nonmalicious” group are people whose behavior is problematic and potentially harmful, but who we believe based on contextual clues and other behaviours likely did not intend to cause harm to children. For example, they shared the content with an expression of abhorrence.
In the subcategories of “malicious” users, we have leaned on work by Lanning and Elliott and Beech. Preferential and situational offenders being as per Lanning’s definition above, with commercial offenders coming from Elliott and Beech’s work — criminally minded individuals, not necessarily motivated by sexual gratification but by the desire to profit from child-exploitative imagery.
In the subcategories of “nonmalicious” users, we parse Lanning’s “miscellaneous” grouping. Unintentional offenders groups individuals who have shared imagery that depicts the exploitation of children, but who did so out of intentions such as outrage, attempted humor (e.g., . through the creation of a meme), or vigilante motives. This behavior is still illegal; we will still report it to NCMEC, but the user experience for these people might need to be different from that of those with malicious intent.
The category “minor nonexploitative” came from feedback from our partners about the consensual, developmentally appropriate behavior that older teens may engage in. Throughout our consultations, a number of global experts, organizations, and academic researchers highlighted that children are, at times, a distinct grouping in some ways. Children can and do sexually offend against other children, but children also can engage in consensual, developmentally appropriate sexual behavior with one another. In a systematic review of sexting behavior among youth in 2018, it was noted that ‘sexting’ is “becoming a normative component of teen sexual behavior and development” We added the “minor nonexploitative” category to our taxonomy in accord with this research. While the content produced is technically illegal and the behavior risky – as this imagery can be later exploited by others – it was important for us to separate out the nonexploitative sharing of sexual imagery between teens.
The final grouping of nonmalicious offenders came from initial analysis of Facebook data. Our investigators and data scientists observed behavior from users where they were sharing a large amount of adult sexual content and amongst that content was child exploitative imagery, to which the user was potentially unaware that the imagery represented a child (which may depict children in their late teens, whose primary and secondary sexual characters appear developed to that of adulthood). We report these images to NCMEC as they depict the abuse of children that we are aware of, but the users in these situations may not be aware that the image depicts a child. We are still concerned about their behavior and may want to offer interventions to prevent any escalation in behavior.
Application
Using our above taxonomy, a group of child-safety investigators at Facebook analysed over 200 accounts that we reported to NCMEC for uploading CSAM, drawn across taxonomic classes during the period 2019 to mid-2020, to identify on-platform behaviors that they believed were indicative of the different intent classes. While only the individual who uploads CSAM will ever truly know their own intent, these indicators generally surfaced patterns of persistent, conscious engagement with CSAM and other minor-sexualising content if it existed. These indicators include behaviours such as obfuscation of identity, child-sexualising search terms, and creating connections with groups, pages, and accounts whose clear purpose is to sexualise children
We have now been testing these indicators to identify individuals who exhibit or lack malicious intent. Our application of the intent taxonomy is very new and we continue to develop our methodology, but we can share some early results. We evaluated 150 accounts that we reported to NCMEC for uploading CSAM in July and August of 2020 and January 2021, and we estimate that more than 75% of these did not exhibit malicious intent (i.e. did not intend to harm a child), but appeared to share for other reasons, such as outrage or poor humor. While this study represents our best understanding, these findings should not be considered a precise measure of the child safety ecosystem.
Our work is now to develop technology that will apply the intent taxonomy to our data at scale. We believe understanding the intentions of sharers of CSAM will help us to effectively target messaging, interventions, and enforcement to drive down the sharing of CSAM overall.
Definitions and Examples for each taxonomic group
Malicious Users
- Preferential Offenders: People whose motivation is based on an inherent and underlying sexual interest in children (i.e. pedophiles/hebephiles). They are only sexually interested in children.
- Example: User is connected with a number of minors, who is coercing them to produce CSAM, with threats to share the existing CSAM they have obtained.
- Commercial Offenders: People who facilitate child sexual abuse for the purpose of financial gain. These individuals profit from the creation of CSAM and may not have a sexual interest in children
- Example: A parent who is making their child available for child abuse via live stream in exchange for payment.
- Situational Offenders: People who take advantage of situations and opportunities that present to engage with CSAM and minors. They may be morally indiscriminate, they may be interested in many paraphilic topics and CSAM is one part of that.
- Example: User who is reaching out to multiple other users to solicit sexual imagery (adults and children), if a child shares back imagery, they will engage with that imagery and child.
Non-malicious Users
- Unintentional Offenders: This is a broad category of people who may not mean to cause harm to the child depicted in the CSAM share but are sharing out of humor, outrage, or ignorance.
- Example: User shares a CSAM meme of a child’s genitals being bitten by an animal because they think it’s funny.
- Minor Non-Exploitative Users: Children who are engaging in developmentally normative behaviour, that while technically illegal or against policy, is not inherently exploitative, but does contain risk.
- Example: Two 16 year olds sending sexual imagery to each other. They know each other from school and are currently in a relationship.
- Situational “Risky” Offenders: Individuals who habitually consume and share adult sexual content, and who come into contact with and share CSAM as part of this behaviour, potentially without awareness of the age of subjects in the imagery they have received or shared.
- Example: A user received CSAM that depicts a 17 year old, they are unaware that the content is CSAM. They reshare it in a group where people are sharing adult sexual content.
The post Understanding the intentions of Child Sexual Abuse Material (CSAM) sharers appeared first on Facebook Research.




 Dr. Ali Arsanjani is the Tech Sector AI/ML Leader and Principal Architect for AI/ML Specialist Solution Architects with AWS helping customers make optimal use of ML using the AWS platform. He is also an adjunct faculty member at San Jose State University, teaching and advising students in the Data Science Masters Programs.
Dr. Ali Arsanjani is the Tech Sector AI/ML Leader and Principal Architect for AI/ML Specialist Solution Architects with AWS helping customers make optimal use of ML using the AWS platform. He is also an adjunct faculty member at San Jose State University, teaching and advising students in the Data Science Masters Programs.








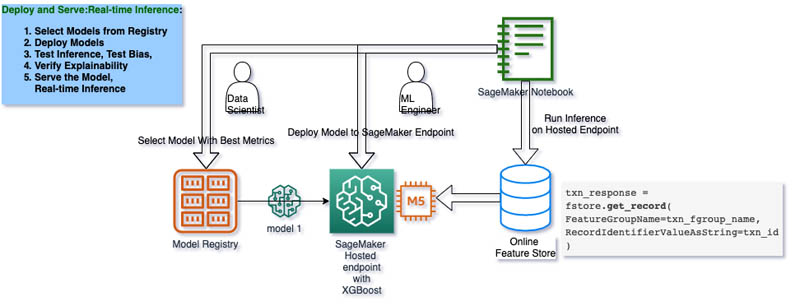
 Deploying the model
Deploying the model





 Srinath Godavarthi is a Senior Solutions Architect at AWS and is based in the Washington, DC, area. In that role, he helps public sector customers achieve their mission objectives with well-architected solutions on AWS. Prior to AWS, he worked with various systems integrators in healthcare, public safety, and telecom verticals. He focuses on innovative solutions using AI and ML technologies.
Srinath Godavarthi is a Senior Solutions Architect at AWS and is based in the Washington, DC, area. In that role, he helps public sector customers achieve their mission objectives with well-architected solutions on AWS. Prior to AWS, he worked with various systems integrators in healthcare, public safety, and telecom verticals. He focuses on innovative solutions using AI and ML technologies.
 Pranusha Manchala is a Solutions Architect at AWS based in Virginia. She works with hundreds of EdTech customers and provides them with architectural guidance for building highly scalable and cost-optimized applications on AWS. She found her interests in machine learning and artificial intelligence and started to dive deep into this technology. Prior to AWS, she did her masters in Computer Science with double majors in Networking and Cloud Computing.
Pranusha Manchala is a Solutions Architect at AWS based in Virginia. She works with hundreds of EdTech customers and provides them with architectural guidance for building highly scalable and cost-optimized applications on AWS. She found her interests in machine learning and artificial intelligence and started to dive deep into this technology. Prior to AWS, she did her masters in Computer Science with double majors in Networking and Cloud Computing.





 Hasan Poonawala is a Machine Learning Specialist Solution Architect at AWS, based in London, UK. Hasan helps customers design and deploy machine learning applications in production on AWS. He is passionate about the use of machine learning to solve business problems across various industries. In his spare time, Hasan loves to explore nature outdoors and spend time with friends and family.
Hasan Poonawala is a Machine Learning Specialist Solution Architect at AWS, based in London, UK. Hasan helps customers design and deploy machine learning applications in production on AWS. He is passionate about the use of machine learning to solve business problems across various industries. In his spare time, Hasan loves to explore nature outdoors and spend time with friends and family. Jiahang Zhong is the Head of Data Science at Zopa. He is responsible for data science and machine learning projects across the business, with focus on credit risk, financial crime, operation optimization and customer engagement.
Jiahang Zhong is the Head of Data Science at Zopa. He is responsible for data science and machine learning projects across the business, with focus on credit risk, financial crime, operation optimization and customer engagement.
 Prem Ranga is an Enterprise Solutions Architect based out of Atlanta, GA. He is part of the Machine Learning Technical Field Community and loves working with customers on their ML and AI journey. Prem is passionate about robotics, is an Autonomous Vehicles researcher, and also built the Alexa-controlled Beer Pours in Houston and other locations.
Prem Ranga is an Enterprise Solutions Architect based out of Atlanta, GA. He is part of the Machine Learning Technical Field Community and loves working with customers on their ML and AI journey. Prem is passionate about robotics, is an Autonomous Vehicles researcher, and also built the Alexa-controlled Beer Pours in Houston and other locations. Nathalie Rauschmayr is an Applied Scientist at AWS, where she helps customers develop deep learning applications.
Nathalie Rauschmayr is an Applied Scientist at AWS, where she helps customers develop deep learning applications. Jana Gnanachandran is an Enterprise Solutions Architect at AWS, focusing on Data Analytics, AI/ML, and Serverless platforms. He helps AWS customers across numerous industries to design and build highly scalable, data-driven, analytical solutions to accelerate their cloud adoption. In his spare time, he enjoys playing tennis, 3D printing, and photography.
Jana Gnanachandran is an Enterprise Solutions Architect at AWS, focusing on Data Analytics, AI/ML, and Serverless platforms. He helps AWS customers across numerous industries to design and build highly scalable, data-driven, analytical solutions to accelerate their cloud adoption. In his spare time, he enjoys playing tennis, 3D printing, and photography.