Politecnico di Milano professor Stefano Ceri is working to integrate genomic datasets into a single accessible system with the support of an Amazon Machine Learning Research Award.Read More
AWS and Hugging Face Collaborate to Simplify and Accelerate Adoption of Natural Language Processing Models
Just like computer vision a few years ago, the decade-old field of natural language processing (NLP) is experiencing a fascinating renaissance. Not a month goes by without a new breakthrough! Indeed, thanks to the scalability and cost-efficiency of cloud-based infrastructure, researchers are finally able to train complex deep learning models on very large text datasets, in order to solve business problems such as question answering, sentence comparison, or text summarization.
In this respect, the Transformer deep learning architecture has proven very successful, and has spawned several state of the art model families:
- Bidirectional Encoder Representations from Transformers (BERT): 340 million parameters [1]
- Text-To-Text Transfer Transformer (T5): over 10 billion parameters [2]
- Generative Pre-Training (GPT): over 175 billion parameters [3]
As amazing as these models are, training and optimizing them remains a challenging endeavor that requires a significant amount of time, resources, and skills, all the more when different languages are involved. Unfortunately, this complexity prevents most organizations from using these models effectively, if at all. Instead, wouldn’t it be great if we could just start from pre-trained versions and put them to work immediately?
This is the exact challenge that Hugging Face is tackling. Founded in 2016, this startup based in New York and Paris makes it easy to add state of the art Transformer models to your applications. Thanks to their popular transformers, tokenizers and datasets libraries, you can download and predict with over 7,000 pre-trained models in 164 languages. What do I mean by ‘popular’? Well, with over 42,000 stars on GitHub and 1 million downloads per month, the transformers library has become the de facto place for developers and data scientists to find NLP models.
At AWS, we’re also working hard on democratizing machine learning in order to put it in the hands of every developer, data scientist and expert practitioner. In particular, tens of thousands of customers now use Amazon SageMaker, our fully managed service for machine learning. Thanks to its managed infrastructure and its advanced machine learning capabilities, customers can build and run their machine learning workloads quicker than ever at any scale. As NLP adoption grows, so does the adoption of Hugging Face models, and customers have asked us for a simpler way to train and optimize them on AWS.
Working with Hugging Face Models on Amazon SageMaker
Today, we’re happy to announce that you can now work with Hugging Face models on Amazon SageMaker. Thanks to the new HuggingFace estimator in the SageMaker SDK, you can easily train, fine-tune, and optimize Hugging Face models built with TensorFlow and PyTorch. This should be extremely useful for customers interested in customizing Hugging Face models to increase accuracy on domain-specific language: financial services, life sciences, media and entertainment, and so on.
Here’s a code snippet fine-tuning the DistilBERT model for a single epoch.
from sagemaker.huggingface import HuggingFace
hf_estimator = HuggingFace(
entry_point='train.py',
pytorch_version = '1.6.0',
transformers_version = '4.4',
instance_type='ml.p3.2xlarge',
instance_count=1,
role=role,
hyperparameters = {
'epochs': 1,
'train_batch_size': 32,
'model_name':'distilbert-base-uncased'
}
)
huggingface_estimator.fit({'train': training_input_path, 'test': test_input_path})
As usual on SageMaker, the train.py script uses Script Mode to retrieve hyperparameters as command line arguments. Then, thanks to the transformers library API, it downloads the appropriate Hugging Face model, configures the training job, and runs it with the Trainer API. Here’s a code snippet showing these steps.
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments
...
model = AutoModelForSequenceClassification.from_pretrained(args.model_name)
training_args = TrainingArguments(
output_dir=args.model_dir,
num_train_epochs=args.epochs,
per_device_train_batch_size=args.train_batch_size,
per_device_eval_batch_size=args.eval_batch_size,
warmup_steps=args.warmup_steps,
evaluation_strategy="epoch",
logging_dir=f"{args.output_data_dir}/logs",
learning_rate=float(args.learning_rate)
)
trainer = Trainer(
model=model,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=train_dataset,
eval_dataset=test_dataset
)
trainer.train()As you can see, this integration makes it easier and quicker to train advanced NLP models, even if you don’t have a lot of machine learning expertise.
Customers are already using Hugging Face models on Amazon SageMaker. For example, Quantum Health is on a mission to make healthcare navigation smarter, simpler, and most cost-effective for everybody. Says Jorge Grisman, NLP Data Scientist at Quantum Health: “we use Hugging Face and Amazon SageMaker a lot for many NLP use cases such as text classification, text summarization, and Q&A with the goal of helping our agents and members. For some use cases, we just use the Hugging Face models directly and for others we fine tune them on SageMaker. We are excited about the integration of Hugging Face Transformers into Amazon SageMaker to make use of the distributed libraries during training to shorten the training time for our larger datasets“.
Kustomer is a customer service CRM platform for managing high support volume effortlessly. Says Victor Peinado, ML Software Engineering Manager at Kustomer: “Kustomer is a customer service CRM platform for managing high support volume effortlessly. In our business, we use machine learning models to help customers contextualize conversations, remove time-consuming tasks, and deflect repetitive questions. We use Hugging Face and Amazon SageMaker extensively, and we are excited about the integration of Hugging Face Transformers into SageMaker since it will simplify the way we fine tune machine learning models for text classification and semantic search“.
Training Hugging Face Models at Scale on Amazon SageMaker
As mentioned earlier, NLP datasets can be huge, which may lead to very long training times. In order to help you speed up your training jobs and make the most of your AWS infrastructure, we’ve worked with Hugging Face to add the SageMaker Data Parallelism Library to the transformers library (details are available in the Trainer API documentation).
Adding a single parameter to your HuggingFace estimator is all it takes to enable data parallelism, letting your Trainer-based code use it automatically.
huggingface_estimator = HuggingFace(. . .
distribution = {'smdistributed':{'dataparallel':{ 'enabled': True }}}
)That’s it. In fact, the Hugging Face team used this capability to speed up their experiment process by over four times!
Getting Started
You can start using Hugging Face models on Amazon SageMaker today, in all AWS Regions where SageMaker is available. Sample notebooks are available on GitHub. In order to enjoy automatic data parallelism, please make sure to use version 4.3.0 of the transformers library (or newer) in your training script.
Please give it a try, and let us know what you think. As always, we’re looking forward to your feedback. You can send it to your usual AWS Support contacts, or in the AWS Forum for SageMaker.
[1] “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding“, Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova.[2] “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer“, Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu.
[3] “Improving Language Understanding by Generative Pre-Training“, Alec Radford Karthik Narasimhan Tim Salimans Ilya Sutskever.
About the Author
 Julien is the Artificial Intelligence & Machine Learning Evangelist for EMEA. He focuses on helping developers and enterprises bring their ideas to life. In his spare time, he reads the works of JRR Tolkien again and again.
Julien is the Artificial Intelligence & Machine Learning Evangelist for EMEA. He focuses on helping developers and enterprises bring their ideas to life. In his spare time, he reads the works of JRR Tolkien again and again.
Announcing AWS Media Intelligence Solutions
Today, we’re pleased to announce the availability of AWS Media Intelligence (AWS MI) solutions, a combination of services that empower you to easily integrate AI into your media content workflows. AWS MI allows you to analyze your media, improve content engagement rates, reduce operational costs, and increase the lifetime value of media content. With AWS MI, you can choose turnkey solutions from participating AWS Partners or use AWS Solutions to enable rapid prototyping. These solutions cover four important use cases: content search and discovery, captioning and localization, compliance and brand safety, and content monetization.
The demand for media content in the form of audio, video and images is growing at an unprecedented rate. Consumers are relying on content not only to entertain, but also to educate and facilitate purchasing decisions. To meet this demand, media content production is exploding. However, the process of producing, distributing, and monetizing this content is often complex, expensive and time consuming. Applying AI and machine learning (ML) capabilities like image and video analysis, audio transcription, machine translation, and text analytics can solve many of these problems. AWS continues to invest with leading technology and consulting partners to meet customer requests for ready-to-use ML capabilities across the most popular use cases.
AWS Media Intelligence use cases
AWS MI solutions are powered by AWS AI services, like Amazon Rekognition for image and video analysis, Amazon Transcribe for audio transcription, Amazon Comprehend for natural language comprehension, and Amazon Translate for language translation.
As a result, AWS MI can process and analyze media assets to automatically generate metadata from images, video, and audio content for downstream workloads at scale. Together, these solutions support AWS MI’s four primary use cases:
Search and discovery
Search and discovery use cases utilize AWS image and speech recognition capabilities to perform automatic metadata tagging on media assets and object identification such as logos and characters to create searchable indexes. Historically, humans would manually review and annotate content to facilitate search. This reduces the amount of human-led annotation, content production costs, and highlight generation efforts. AWS Partners CLIPr, Dalet, EditShare, Empress Media Asset Management, Evertz, GrayMeta, IMT, Keycore, Quantiphi, PromoMii, SDVI, Starchive, Synchronized, and TrackIt all offer off-the-shelf solutions built on top of AWS AI/ML technology to meet highly specific customer needs.
Customers who are using Search and discovery solutions include TF1, a French free-to-air television channel owned by TF1 Group. They work with Synchronized, an AWS MI
Technology Partner who provides turnkey search and discovery solutions for broadcasters and over the top (OTT) platforms. Nicolas Lemaitre, the Digital Director for the TF1 Group says, “Due to the ever-increasing size of the MYTF1 catalog, manual delivery of editorial tasks, such as the creation of thumbnails, is no longer scalable. Synchronized’s Media Intelligence solution and its applied artificial intelligence allow us to automate part of these tasks and enhance our premium content. We can now process bulk video content rapidly and with high quality control reducing cost and time to market.”
Subtitling and localization
Subtitling and localization use cases increase user engagement and reach by using our speech recognition and machine translation services to produce subtitles in the languages that cater to a diverse audience. CaptionHub and EEG are AWS Partners that combine their own expertise with AWS AI/ML capabilities to offer rich subtitling and localization solutions.
As an international financial services provider, Allianz SE offers over 100 million customers worldwide products and solutions in insurance and asset management. They work with CaptionHub, an AWS Technology
Partner who provides an AI-powered platform for enterprise subtitles powered by Amazon Transcribe and Amazon Translate. Steve Flynn, the marketing manager at Allianz says, “Video is a fast growing tool for internal education and external marketing for Allianz, globally. We had a large backlog of videos that we needed to transcribe where speed of production was the imperative factor. With AWS Partner CaptionHub, we have been able to speed up the initial transcription and translation of captions by using speech recognition and machine translation. I am producing the captions in 1/8th of the time I did before. The speech recognition accuracy has been impressive and adds a new dimension of professionalism to our videos. ”
Compliance and brand safety
With fully managed image, video or speech analysis APIs, compliance and brand safety capabilities make it easy to detect inappropriate, unwanted, or offensive content to increase brand safety and comply with content standards or regional regulations. AWS Partners offering Compliance and brand safety solutions include Dalet, EditShare, GrayMeta, Quantiphi and SDVI.
SmugMug is a photo sharing,
photo hosting service, and online video company that operates two large Internet-scale platforms: SmugMug & Flickr. Don MacAskill, the co-founder, CEO, & Chief Geek at Smugmug says, “As a large, global platform, unwanted content is extremely risky to the health of our community and can alienate photographers. We use Amazon Rekognition’s content moderation feature to find and properly flag unwanted content, enabling a safe and welcoming experience for our community. Especially at Flickr’s huge scale, doing this without Amazon Rekognition is nearly impossible. Now, thanks to content moderation with Amazon Rekognition, our platform can automatically discover and highlight amazing photography that more closely matches our members’ expectations, enabling our mission to inspire, connect, and share.”
Content monetization
Lastly, you can boost ROI with our newest content monetization solutions that are contextual and effective. This is an area in which ML drives innovation that aims to deliver the right ads at the right time to the right consumer based on context. Contextual advertising increases advertisers return on investment while minimizing disruption to viewers. With content monetization solutions, you can generate rich metadata from audio and visual assets that allows you to optimize ad insertion placement and automatically identify sponsorship opportunities. Any organization seeking online media advertising optimization can benefit from solutions from AWS Partners Infinitive, Quantiphi, TrackIt, or TripleLift.
TripleLift is an AWS Technology Partner that provides a programmatic advertising platform powered by AWS MI. Tastemade, a leading food and lifestyle brand, has deployed TripleLift ad experiences in over 200 episodes of their programming. Jeff Imberman, Tastemade’s Head of Sales and Brand Partnerships, says “TripleLift’s deep learning-based video analysis provides us with a scalable solution for finding thousands of moments for inserting integrated ad experiences in programming, supplementing a high touch marketing function with artificial intelligence.”

AWS Media Intelligence Partners
Swami Sivasubramanian, the VP of Amazon Machine Learning at AWS says, “The volume of media content that our customers are creating and managing is growing exponentially. Customers can dramatically reduce the time and cost requirements to produce, distribute and monetize media content at scale with AWS Media Intelligence and its underlying AI services. We are excited to announce these solutions backed by a strong group of AWS Technology and Consulting Partners. They are committed to delivering turnkey solutions that enable our customers to easily achieve the benefits of ML transformation while removing the heavy lifting needed to integrate ML capabilities into their existing media content workflows.”
AWS Partners that provide AWS MI solutions include AWS Technology Partners: CaptionHub, CLIPr, Dalet, EditShare, EEG Video, Empress, Evertz, GrayMeta, IMT, PromoMii, SDVI, Starchive, Synchronized, and TripleLift. For customers who require a custom solution or seek additional assistance with AWS MI, AWS Consulting Partners: Infinitive, KeyCore, Quantiphi, and TrackIt can help.
For more than 50 years, Evertz has specialized in connecting content creators and audiences by simplifying complex broadcast and new-media workflows, including delivering captioning and subtitling services via the cloud. Martin Whittaker, Technical Director of MAM and Automation at Evertz, says, “Effective captioning is increasingly used as a tool to drive engagement with audiences who are streaming video content in public spaces or in other regions around the world. Using Amazon Transcribe, Evertz’s Emmy Award-winning Mediator-X cloud playout platform delivers a cost-effective way to generate and receive speech-to-text caption and subtitle files at scale. Mediator’s Render-X transcode engine converts caption files into different formats for use across all terrestrial, direct to consumer (D2C) and OTT TV channels or video on demand (VOD) deliveries, eliminating redundancies in resourcing.”
PromoMii provides video content editing tools powered by AWS AI services such as Amazon Comprehend, Amazon Rekognition, and Amazon Transcribe. Michael Moss, Co-founder and CEO of PromoMii says, “AI creates a paradigm shift in virtually every sector, especially in video editing. With Nova, our video editing platform powered by AWS Media Intelligence, our customers are able to save 70% on video editing time and reduce costs by up to 97%. Now Disney and other customers are able to produce a quantitatively higher amount of quality content. Working closely with AWS MI helps us to develop and deploy our technology at a faster pace to meet market demand. What would have taken us weeks before, now only takes a matter of days or even hours.”
AWS solutions and open source frameworks for Media Intelligence
AWS Solutions for MI provide an accelerator and pattern for partners or customers who want to build internally without starting from the ground up. Media2Cloud is a serverless, open source solution for seamless media ingestion into AWS and to export assets into a Media Asset Management (MAM) system used by many of our MI partners. Media2Cloud has pre-built mechanisms to augment content with ML-generated descriptive metadata powered by AWS AI services for search and discovery.
AWS Content Analysis solution enables customers to perform automated video content analysis using a serverless application model to generate meaningful insights through machine learning (ML) generated metadata. The solution leveraging AWS image and video analysis, speech transcription, machine translation and text analytics.
The custom brand detection solution is specifically built to help content producers prepare a dataset and train models to identify and detect specific brands on videos and images. This combines Amazon Rekognition Custom Labels and Amazon SageMaker Ground Truth.
You can also create an ad insertion solution by combining Amazon Rekognition with AWS Elemental MediaTailor. MediaTailor is a channel assembly and personalized ad insertion solution for video providers to create linear OTT channels using existing video content and monetize those channels, or other live streams and VOD content.
Get started with AWS Media Intelligence
With AWS, you have access to a range of options including AWS Technology and Consulting Partners and open source projects that help you get started with AWS Media Intelligence
- Contact a participating AWS Partner by visiting the AWS MI Partners page for more information, demos, and contact details.
- Attend a Tech Talk webinar and learn more about AWS Media Intelligence on April 26 at 11am PST. “Increase the lifetime value of media content, while reducing costs with AWS Media Intelligence solutions.” Registration will open in early April.
- Want to build it yourself? Get started with our pre-built AWS solutions used by many MI Partners:
- Media2Cloud, an automated video asset ingestion and metadata tagging
- AWS Content Analysis, a video analytics solutions for search, subtitling and translation
- Amazon Rekognition Custom Labels, Amazon Transcribe vocabulary filters, Amazon Transcribe content redaction, and Amazon SageMaker Ground Truth for content compliance
- Ad insertion solution, an ad insertion solution to help monetize your video content
- Learn more about the underlying AI services: Amazon Rekognition, Amazon Transcribe, Amazon Translate, and Amazon Comprehend.
About the Authors
 Vasi Philomin is the GM for Machine Learning & AI at AWS, responsible for Amazon Lex, Polly, Transcribe, Translate and Comprehend.
Vasi Philomin is the GM for Machine Learning & AI at AWS, responsible for Amazon Lex, Polly, Transcribe, Translate and Comprehend.

Esther Lee is a Product Manager for AWS Language AI Services. She is passionate about the intersection of technology and education. Out of the office, Esther enjoys long walks along the beach, dinners with friends and friendly rounds of Mahjong.
Pretrained Transformers as Universal Computation Engines
Transformers have been successfully applied to a wide variety of modalities:
natural language, vision, protein modeling, music, robotics, and more. A common
trend with using large models to train a transformer on a large amount of
training data, and then finetune it on a downstream task. This enables the
models to utilize generalizable high-level embeddings trained on a large
dataset to avoid overfitting to a small task-relevant dataset.
We investigate a new setting where instead of transferring the high-level
embeddings, we instead transfer the intermediate computation modules – instead
of pretraining on a large image dataset and finetuning on a small image
dataset, we might instead pretrain on a large language dataset and finetune on
a small image dataset. Unlike conventional ideas that suggest the attention
mechanism is specific to the training modality, we find that the self-attention
layers can generalize to other modalities without finetuning.
Helping newsrooms experiment together with AI
In our JournalismAI report, journalists around the world told researchers they are eager to collaborate and explore the benefits of AI, especially as it applies to newsgathering, production and distribution.
To facilitate their collaboration, the Google News Initiative and Polis – the journalism think tank at the London School of Economics and Political Science – are launching the JournalismAI Collab Challenges, an opportunity for three groups of five newsrooms from the Americas, Europe, the Middle East and Africa, and Asia Pacific to experiment together.
Each cohort – selected by Polis – will have six months to either cover global news stories using AI-powered storytelling techniques or to develop prototypes of new AI-based products and processes.
Participants will receive support from the JournalismAI team and partner institutions in each region: in the Americas, the challenge will be co-hosted with the Knight Lab at Northwestern University; in Europe, the Middle East and Africa, the challenge will be co-hosted with BBC News Labs and Clwstwr. JournalismAI’s partner in Asia Pacific will be announced later this year.
The Collab Challenges build on a successful pilot run by JournalismAI last year. More than 20 global newsrooms joined forces to solve four common problems using AI, from creating automated news summaries to mitigating newsroom biases, and from powering archives to increasing audience loyalty. JournalismAI online trainings are available on the Google News Initiative Training Center, where they have already been seen by more than 110,000 participants.
Newsrooms interested in participating in this free, year-long program must have made AI a strategic priority, must guarantee the participation of two staff members – one from editorial and one from the technical department – who can participate two to four hours a week, and must embrace collaboration with other publishers.
The outcome of their work – whose ownership will be shared among participants – will be presented at the second edition of the JournalismAI Festival in November.
Applications for the Americas challenge and the Europe, the Middle East and Africa Challenge open today and close at 11:59 PM GMT on April 5. The Challenge will open later this year in Asia Pacific.
To learn more about the process, please visit Polis blog and sign up for the JournalismAI newsletter.
Sweden’s AI Catalyst: 300-Petaflops Supercomputer Fuels Nordic Research
A Swedish physician who helped pioneer chemistry 200 years ago just got another opportunity to innovate.
A supercomputer officially christened in honor of Jöns Jacob Berzelius aims to establish AI as a core technology of the next century.
Berzelius (pronounced behr-zeh-LEE-us) invented chemistry’s shorthand (think H20) and discovered a handful of elements including silicon. A 300-petaflops system now stands on the Linköping University (LiU) campus, less than 70 kilometers from his birthplace in south-central Sweden, like a living silicon tribute to innovations yet to come.
“Many cities in Sweden have a square or street that bears Berzelius’s name, but the average person probably doesn’t know much about him,” said Niclas Andersson, technical director at the National Supercomputer Centre (NSC) at Linköping University, which is home to the system based on the NVIDIA DGX SuperPOD.
The BerzeLiUs system will be twice as fast as Sweden’s current top computer and would rank among the top 10 percent on the latest list of the world’s TOP500 supercomputers.
An Ambitious AI Agenda
Andersson and others hope many people will feel ripples from the ambitious work planned for the BerzeLiUs supercomputer. For starters, it may initially tackle as many as seven two-year projects that aim to make leaps forward in areas like wireless communications, cybersecurity, large-scale IoT and efficient programming.

In addition, Swedish researchers can use the system to collaborate with their longstanding research colleagues at Singapore’s Nanyang Technical University (NTU) on six new efforts. They include finding new ways to enhance data analytics with visualization, developing more secure AI algorithms and orchestrating multiple AI models to work as one to schedule the NTU’s campus bus network.
It’s all part of Sweden’s largest private research initiative focused on AI innovation. Known simply as WASP, the Wallenberg Artificial Intelligence, Autonomous Systems and Software Program is a 15-year effort that’s already recruited a faculty of more than three dozen international researchers and engaged 40 companies.
Backing Science for a Better World
The effort is spearheaded by the Knut and Alice Wallenberg Foundation, Sweden’s largest private financier of research. It contributed most of the 5.5 billion kronor ($650 million) for WASP. In a separate gift, the foundation donated 300 million kronor ($36 million) last October to Linköping University to build and run the BerzeLiUs supercomputer for WASP and other researchers.
WASP hosted a virtual event in December that attracted speakers from Ericsson, IKEA, Volvo and SEB Group, one of Sweden’s largest banks. At the event, the foundation’s vice chair, Marcus Wallenberg — scion of the country’s best-known family of industrialists — noted the collaboration between academia and industry is vital for research that makes a positive impact on society. In addition, Wallenberg spoke with NVIDIA CEO Jensen Huang at the inauguration of the BerzeLiUs system (see video below).
There’s little doubt that, like early advances in chemistry, AI is becoming part of our daily lives.
“AI will be everywhere, it will get into many places we can’t imagine at this point,” said Andersson, whose 25-year career at NSC has been devoted to work in high performance computing.
The New Formula: HPC+AI
“HPC traditionally is mostly about simulation; and now, with the advent of AI, simulation becomes an input to new kinds of data analytics that will drive computing to much wider use — it’s a big trend shift,” he said.
Specifically, the BerzeLiUs system will help researchers scale their work to handle the larger datasets and models that power discoveries with AI.

“Most people have been working with single machines that are not as powerful as DGX systems, so our most important task in the coming years is to help develop algorithms that can scale; and there are very large problems that can use many GPU nodes,” he said.
Inside the New Machine
The BerzeLiUs system consists of 60 NVIDIA DGX A100 systems, linked on a 200 Gbit/second NVIDIA Mellanox InfiniBand HDR network. The same network links the processors to 1.5 petabytes of flash memory on four storage servers from DataDirect Networks.
The single InfiniBand network ensures data gets into the system fast, and AI is all about data. “Buying more storage might be the first upgrade we will need because 60 DGX A100 systems can suck up a lot of data fast,” Andersson said.
To get started quickly, NSC asked NVIDIA and Atos, who managed the build and integration, to configure the system’s software. The stack will include the Atos Codex AI Suite as well as access to NGC, NVIDIA’s hub for GPU-optimized software for AI and HPC.
In the end, all the bits and bytes come down to people who, like Berzelius, create advances that drive society forward.
“We need many new explorers in the universe of AI because it will infiltrate and transform all disciplines of research,” said Andersson.
The post Sweden’s AI Catalyst: 300-Petaflops Supercomputer Fuels Nordic Research appeared first on The Official NVIDIA Blog.
Create forecasting systems faster with automated workflows and notifications in Amazon Forecast
You can now enable notifications for workflow status changes while using Amazon Forecast, allowing you to work seamlessly without the disruption of having to check if a particular workflow has completed. Additionally, you can now automate workflows through the notifications to increase work efficiency. Forecast uses machine learning (ML) to generate more accurate demand forecasts, without requiring any prior ML experience. Forecast brings the same technology used at Amazon.com to developers as a fully managed service, removing the need to manage resources or rebuild your systems.
Previously, you had to proactively check to see if a job was complete at the end of each stage, whether it was importing your data, training the predictor, or generating the forecast. The time needed to import your data or train a predictor can vary depending on the size and contents of your data. The wait time can feel even longer when you have to constantly check the status before being able to proceed to the next task. The work flow disruption can negatively impact the entire day’s work. Additionally, if you were integrating Forecast into software solutions, you had to build notifications yourself, creating additional work.
Now, with a one-time setup of workflow notifications, you can choose to either be notified when a specific step is complete or set up sequential workflow tasks after the preceding workflow is complete, which eliminates administrative overhead. Forecast enables notifications by onboarding to Amazon EventBridge, which lets you activate these notifications either directly through the Forecast console or through APIs. You can customize the notification based on your preference of rules and selected events. You can also use EventBridge notifications to fully automate the forecasting cycle end to end, allowing for an even more streamlined experience using Forecast. Software as a service (SaaS) providers can set up routing rules to determine where to send generated forecasts to build applications that react in real time to the data that is received.
EventBridge allows you to build event-driven Forecast workflows. For example, you can create a rule that when data has been imported into Forecast, the completion of this event triggers the next step of training a predictor through AWS Lambda functions. We explore using Lambda functions to automate the Forecast workflow through events in the next section. Or, after the predictor has been trained, you can set up a new rule to receive an SMS text message notification through Amazon Simple Notification Service (Amazon SNS), reminding you to return to Forecast to evaluate the accuracy metrics of the predictor before proceeding to the next step. For this post, we use Lambda with Amazon Simple Email Service (Amazon SES) to send notification messages. For more information, see How do I send email using Lambda and Amazon SES?
Solution overview
In this section, we provide an example of how you can automate Forecast workflows using EventBridge notifications, from importing data, training a predictor, and generating forecasts.
It starts by creating rules in EventBridge that can be accessed through the API, SDK, CLI, and the Forecast console. You can also see the demonstration in the next section. For this use case, we select the target for all the rules as a Lambda function. For instructions on creating the functions and adding the necessary permissions, see Steps 1 and 2 in Tutorial: Schedule AWS Lambda Functions Using EventBridge.
You create rules for the following:
- Dataset import – Checks whether the status field in the event is ACTIVE and invokes the Forecast Create Predictor
- Predictor – Checks whether the status field in the event is ACTIVE and invokes the Forecast Create Forecast
- Forecast – Checks whether the status field in the event is ACTIVE and invokes the Forecast Create Forecast Export
- Forecast Export – Checks whether the status field in the event is ACTIVE and it invokes Amazon SES to send an email. At this point, the forecast export results are already exported to your Amazon Simple Storage Service (Amazon S3) bucket.
After you set up the rules, you can start with your first workflow of calling the dataset import job API. Forecast starts sending status change events with statuses like CREATE_IN_PROGRESS, ACTIVE, CREATE_FAILED, and CREATE_STOPPED to your account. After the event gets matched to the rule, it invokes the target Lambda function configured on the rule, and moves to the next steps of training a predictor, creating a forecast, and finally exporting the forecasts. After the forecasts are exported, you receive an email notification.
The following diagram illustrates this architecture.

Create rules for Forecast notifications through EventBridge
To create your rules for notifications, complete the following steps:
- On the Forecast console, choose your dataset.
- In the Dataset imports section, choose Configure notifications.
Links to additional information about setting up notifications is available in the help pane.

You’re redirected to the EventBridge console, where you now create your notification.
- In the navigation pane, under Events, choose Rules.
- Choose Create rule.

- For Name, enter a name.
- Under Define pattern, select Event pattern.
- For Event matching patterns, select Pre-defined pattern by service.
- For Event type, choose your event on the drop-down menu.
For this post, we choose Forecast Dataset Import Job State Change because we’re interested in knowing when the dataset import is complete.
When you choose your event, the appropriate event pattern is populated in the Event pattern section.
- Under Select event bus, select AWS default event bus.
- Confirm that Enable the rule on the select event bus is enabled.
- For Target, choose Lambda function.
- For Function, choose the function you created.
- Choose Create.
Make sure that the rule and targets are in the same Region.
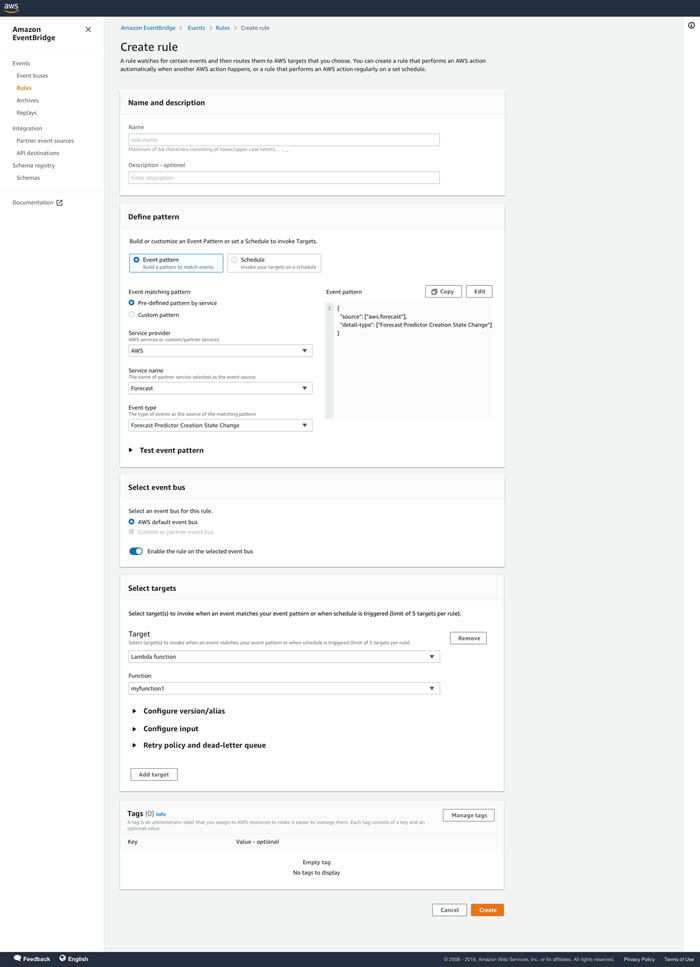
You’re redirected to the Rules page on the EventBridge console, where you can see a confirmation that your rule was created successfully.
Conclusion
You can now enable notifications for workflow status changes while using Forecast. With a one-time setup of workflow notifications, you can choose to either get notified or set up sequential workflow tasks after the preceding workflow has completed, eliminating administrative overhead.
To get started with this capability, see Setting Up Job Status Notifications. You can use this capability in all Regions where Forecast is publicly available. For more information about Region availability, see AWS Regional Services.
About the Authors
 Alex Kim is a Sr. Product Manager for Amazon Forecast. His mission is to deliver AI/ML solutions to all customers who can benefit from it. In his free time, he enjoys all types of sports and discovering new places to eat.
Alex Kim is a Sr. Product Manager for Amazon Forecast. His mission is to deliver AI/ML solutions to all customers who can benefit from it. In his free time, he enjoys all types of sports and discovering new places to eat.
 Ranjith Kumar Bodla is an SDE in the Amazon Forecast team. He works as a backend developer within a distributed environment with a focus on AI/ML and leadership. During his spare time, he enjoys playing table tennis, traveling, and reading.
Ranjith Kumar Bodla is an SDE in the Amazon Forecast team. He works as a backend developer within a distributed environment with a focus on AI/ML and leadership. During his spare time, he enjoys playing table tennis, traveling, and reading.
 Raj Vippagunta is a Senior SDE at AWS AI Services. He leverages his vast experience in large-scale distributed systems and his passion for machine learning to build practical service offerings in the AI space. He has helped build various solutions for AWS and Amazon. In his spare time, he likes reading books and watching travel and cuisine vlogs from across the world.
Raj Vippagunta is a Senior SDE at AWS AI Services. He leverages his vast experience in large-scale distributed systems and his passion for machine learning to build practical service offerings in the AI space. He has helped build various solutions for AWS and Amazon. In his spare time, he likes reading books and watching travel and cuisine vlogs from across the world.
 Shannon Killingsworth is a UX Designer for Amazon Forecast and Amazon Personalize. His current work is creating console experiences that are usable by anyone, and integrating new features into the console experience. In his spare time, he is a fitness and automobile enthusiast.
Shannon Killingsworth is a UX Designer for Amazon Forecast and Amazon Personalize. His current work is creating console experiences that are usable by anyone, and integrating new features into the console experience. In his spare time, he is a fitness and automobile enthusiast.
What drives Nithya Sambasivan’s fight for fairness
When Nithya Sambasivan was finishing her undergraduate degree in engineering, she felt slightly unsatisfied. “I wanted to know, ‘how will the technology I build impact people?’” she says. Luckily, she would soon discover the field of Human Computer Interaction (HCI) and pursue her graduate degrees.
She completed her master’s and PhD in HCI focusing on technology design for low-income communities in India. “I worked with sex workers, slum communities, microentrepreneurs, fruit and vegetables sellers on the streetside…” she says. “I wanted to understand what their values, aspirations and struggles are, and how we can build with them in mind.”
Today, Nithya is the founder of the HCI group at the Google Research India lab and an HCI researcher at PAIR, a multidisciplinary team at Google that explores the human side of AI by doing fundamental research, building tools, creating design frameworks, and working with diverse communities. She recently sat down to answer some of our questions about her journey to researching responsible AI, fairness and championing historically underrepresented technology users.
How would you explain your job to someone who isn’t in tech?
I’m a human-computer interaction (HCI) researcher, which means I study people to better understand how to build technology that works for them. There’s been a lot of focus in the research community on building AI systems and the possibility of positively impacting the lives of billions of people. I focus on human-centered, responsible AI; specifically looking for ways it can empower communities in the Global South, where over 80% of the world’s population lives. Today, my research outlines a road map for fairness research in India, calling for re-contextualizing datasets and models while empowering communities and enabling an entire fairness ecosystem.
What originally inspired your interest in technology?
I grew up in a middle class family, the younger of two daughters from the South of India. My parents have very progressive views about gender roles and independence, especially in a conservative society — this definitely influenced what and how I research; things like gender, caste and poverty. In school, I started off studying engineering, which is a conventional path in India. Then, I went on to focus on HCI and designing with my own and other under-represented communities around the world.

How do Google’s AI Principles inform your research? And how do you approach your research in general?
Context matters. A general theory of algorithmic fairness cannot be based on “Western” populations alone. My general approach is to research an important long-term, foundational problem. For example, our research on algorithmic fairness reframes the conversation on ethical AI away from focusing mainly on Western, meaning largely European or North American, perspectives. Another project revealed that AI developers have historically focused more on the model — or algorithm — instead of the data. Both deeply affect the eventual AI performance, so being so focused on only one aspect creates downstream problems. For example, data sets may fully miss sub-populations, so when they are deployed, they may have much higher error rates or be unusable. Or they could make outcomes worse for certain groups, by misidentifying them as suspects for crimes or erroneously denying them bank loans they should receive.
These insights not only enable AI systems to be better designed for under-represented communities; they also generate new considerations in the field of computing for humane and inclusive data collection, gender and social status representation, and privacy and safety needs of the most vulnerable. They are then incorporated into Google products that millions of people use, such as Safe Folder on Files Go, Google Go’s incognito mode, Neighbourly‘s privacy, Safe Safer by Google Maps and Women in STEM videos.
What are some of the questions you’re seeking to answer with your work?
How do we challenge inherent “West”-centric assumptions for algorithmic fairness, tech norms and make AI work better for people around the world?
For example, there’s an assumption that algorithmic biases can be fixed by adding more data from different groups. But in India, we’ve found that data can’t always represent individuals or events for many different reasons like economics and access to devices. The data could come mostly from middle class Indian men, since they’re more likely to have internet access. This means algorithms will work well for them. Yet, over half the population — primarily women, rural and tribal communities — lack access to the internet and they’re left out. Caste, religion and other factors can also contribute to new biases for AI models.
How should aspiring AI thinkers and future technologists prepare for a career in this field?
It’s really important that Brown and Black people enter this field. We not only bring technical skills but also lived experiences and values that are so critical to the field of computing. Our communities are the most vulnerable to AI interventions, so it’s important we shape and build these systems. To members of this community: Never play small or let someone make you feel small. Involve yourself in the political, social and ecological aspects of the invisible, not on tech innovation alone. We can’t afford not to.
Lab126, University of Maryland collaborate to develop reliability models to build resilient devices
Amazon Lab126 and the Center for Risk and Reliability will study how devices are accidentally damaged — and how to help ensure they survive more of those incidents.Read More
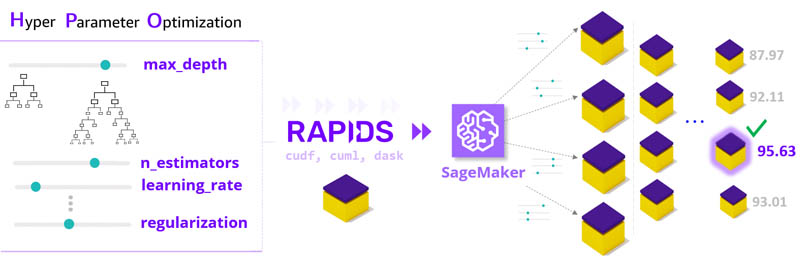
RAPIDS and Amazon SageMaker: Scale up and scale out to tackle ML challenges
In this post, we combine the powers of NVIDIA RAPIDS and Amazon SageMaker to accelerate hyperparameter optimization (HPO). HPO runs many training jobs on your dataset using different settings to find the best-performing model configuration.
HPO helps data scientists reach top performance, and is applied when models go into production, or to periodically refresh deployed models as new data arrives. However, HPO can feel out of reach on non-accelerated platforms as dataset sizes continue to grow.
With RAPIDS and SageMaker working together, workloads like HPO are GPU scaled up (multi-GPU) within a node and cloud scaled out over parallel instances. With this collaboration of technologies, machine learning (ML) jobs like HPO complete in hours instead of days, while also reducing costs.
The Amazon Packaging Experience Team (CPEX) recently found similar speedups using our HPO demo framework on their gradient boosted models for selecting minimal packaging materials based on product features. For more information about their relentless quest to shrink packaging and reduce waste with AI, see Inside Amazon’s quest to use less cardboard.
Getting started
We encourage you to get hands-on and launch a SageMaker notebook so you can replicate this demo or use your own dataset. This RAPIDS with SageMaker HPO example is part of the amazon-sagemaker-examples GitHub repository, which is integrated into the SageMaker UX, making it very simple to launch. We also have a video walkthrough of this material.
The key ingredients for cloud HPO are a dataset, a RAPIDS ML workflow containerized as a SageMaker estimator, and a SageMaker HPO tuner definition. We go through each element in order and provide benchmarking results.
Dataset
Our hope is that you can use your own dataset for this walkthrough, so we’ve tried to make this easy by supporting any tabular dataset as input, such as Parquet or CSV format, stored on Amazon Simple Storage Service (Amazon S3).
For this post, we use the dataset to set up a classification workflow for whether a flight will arrive more than 15 minutes late. This dataset has been collected by the US Bureau of Transportation for over 30 years and includes 14 features (such as distance, source, origin, carrier ID, and scheduled vs. actual departure and arrival).
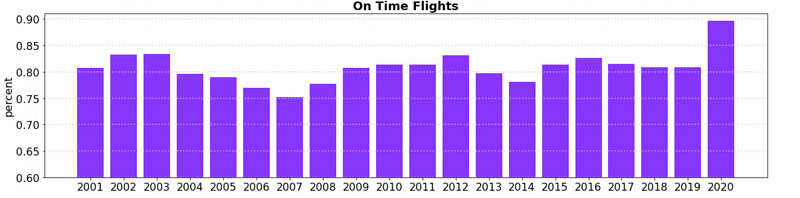
The following graph shows that for the past 20 years, 81% of flights arrived on time—meaning less than 15 minutes late to arrive at their destination. 2020 is at 90% due to less congestion in the sky.
The following graph shows the number of domestic US flights (in millions) for the last 20 years. We can see that although 2020 counts have only been reported through September, the year is going to come in below the running average.

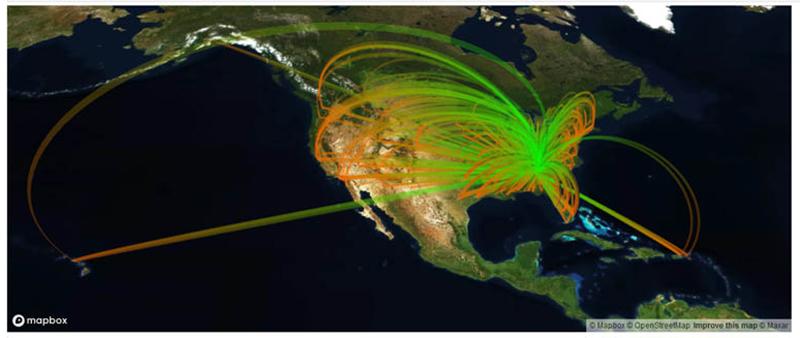
The following image shows 10,000 flights out of Atlanta. The arch height represents delays. Flights out of most airports arrive late when covering a great distance. Atlanta is an outlier, with delays common even for short flights.
SageMaker estimator
Now that we have our dataset, we build a RAPIDS ML workflow and package it using the SageMaker Training API into an interface called an estimator. Our estimator is essentially a container image that holds our code as well as some additional software (sagemaker-training-toolkit), which helps make sure everything is correctly hooking up to the AWS Cloud. SageMaker uses our estimator image as a way to deploy the same logic to all the parallel instances that participate in the HPO search process.
RAPIDS ML workflow
For this post, we built a lightweight RAPIDS ML workflow that doesn’t delve into data augmentation or feature engineering, but rather offers the bare essentials so that everything is simple and the focus remains on HPO. The steps of the workflow include data ingestion, model training, prediction, and scoring.
We offer four variations of the workflow, which unlock increasing amounts of parallelism and allow for experimentation with different libraries and instance types. The curious reader is welcome to dive into the code for each option:
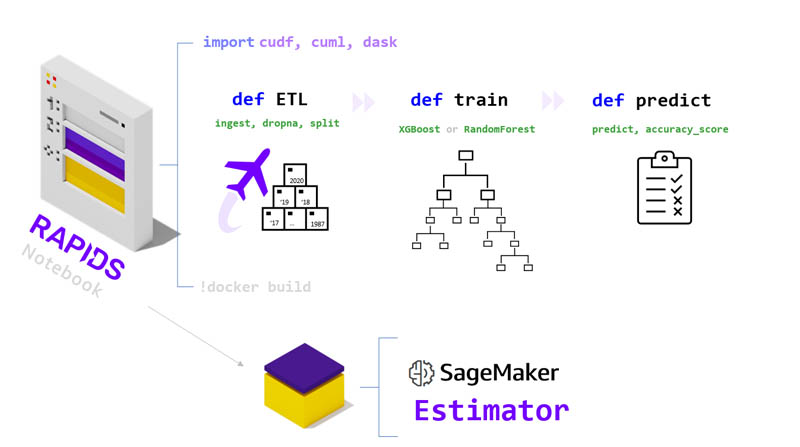
At a high level, all the workflows accomplish the same goal, however in the GPU case, we replace the CPU Pandas and CPU SKLearn libraries with RAPIDS cuDF and cuML, respectively. Because the dataset scales into very large numbers of samples (over 10 years of airline data), we recommend using the multi-CPU and multi-GPU workflows, which add Dask and enable data and computation to be distributed among parallel workers. Our recommendations are captured in the notebook, which offers an on-the-fly instance type recommendation based on the choice of CPU vs. GPU as well as dataset size.
HPO tuning
Now that we have our dataset and estimator prepared, we can turn our attention to defining how we want the hyperparameter optimization process to unfold. Specifically, we should now decide on the following:
- Hyperparameter ranges
- The strategy for searching through the ranges
- How many experiments to run in parallel and the total experiments to run
Hyperparameter ranges
The hyperparameter ranges are at the heart of HPO. Choosing large ranges for parameters allows the search to consider many model configurations and increase its probability of finding a champion model.
In this post, we focus on tuning model size and complexity by varying the maximum depth and the number of trees for XGBoost and Random Forest. To guard against overfitting, we use cross-validation so that each configuration is retested with different splits of the train and test data.
Search strategy
In terms of HPO search strategy, SageMaker offers Bayesian and random search. For more information, see How Hyperparameter Tuning Works. For this post, we use the random search strategy.
HPO sizing
Lastly, in terms of sizing, we set the notebook defaults to a relatively small HPO search of 10 experiments, running two at a time so that everything runs quickly end-to-end. For a more realistic use case, we used the same code but ramped up the number of experiments to 100, which is what we have benchmarked in the next section.
Results and benchmarks
In our benchmarking, we tested 100 XGBoost HPO runs with 10 years of the airline dataset (approximately 60 million flights). On the ml.p3.8xlarge 4x Volta100 GPU instances, we see a 14 times reduction (over 3 days vs. 6 hours) and a 4.5 times cost reduction vs. the ml.m5.24xlarge instances.
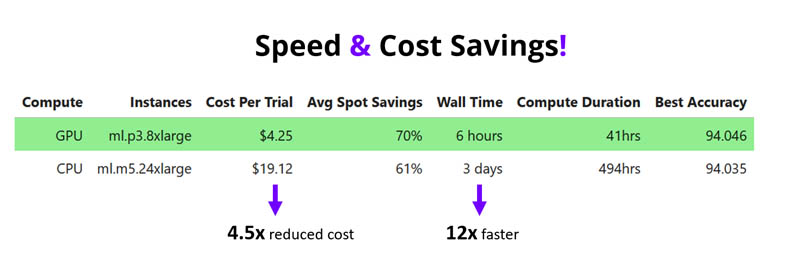
Production grade HPO jobs running on the CPU may time out because they exceed the 24-hour runtime limit we added as a safeguard (in our run, 12 out of 100 CPU jobs were stopped).
As a final benchmarking exercise to showcase what’s happening on each training run, we show an example of a single fold of cross-validation on the entire airline dataset (33 years going back to 1987) for both XGBoost and Random Forest with a middle-of-the-pack model complexity (max_depth is 15, n_estimators is 500).

We can see the computational advantage of the GPU for model training and how this advantage grows along with the parallelism inherent in the algorithm used (Random Forest is embarrassingly parallel, whereas XGBoost builds trees sequentially).

Deploying our best model with the Forest Inference Library
As a final touch, we also offer model serving. This is done in the serve.py code, where a Flask server loads the best model found during HPO and uses the Forest Inference Library (FIL) for GPU-accelerated large batch inference. The FIL works for both XGBoost and Random Forest, and can be 28 times faster relative to CPU-based inference.
Conclusion
We hope that after reading this post, you’re inspired to try combining RAPIDS and SageMaker for HPO. We’re sure you’ll benefit from the tremendous acceleration made possible by GPUs at cloud scale. AWS also recently launched the Ampere100 GPUs in the form of p4d instances, which are the fastest ML nodes in the cloud, and should be coming to SageMaker soon.
At NVIDIA and AWS, we hope to continue working to democratize high performance computing both in terms of ease of use (such as SageMaker notebooks that spawn large compute workloads) and in terms of total cost of ownership. If you run into any issues, let us know via GitHub. You can also get in touch with us via Slack, Google Groups, or Twitter. We look forward to hearing from you!
About the Authors
Wenming Ye is an AI and ML specialist architect at Amazon Web Services, helping researchers and enterprise customers use cloud-based machine learning services to rapidly scale their innovations. Previously, Wenming had a diverse R&D experience at Microsoft Research, SQL engineering team, and successful startups.
Miro Enev, PhD is a Principal Solution Architect at NVIDIA.