Deep learning is at the forefront of most machine learning (ML) implementations across a broad set of business verticals. Driven by the highly flexible nature of neural networks, the boundary of what is possible has been pushed to a point where neural networks can outperform humans in a variety of tasks, such as object detection tasks in the context of computer vision (CV) problems.
Object detection, which is one type of CV task, has many applications in various fields like medicine, retail, or agriculture. For example, retail businesses want to be able to detect stock keeping units (SKUs) in store shelf images to analyze buyer trends or identify when product restock is necessary. Object detection models allow you to implement these diverse use cases and automate your in-store operations.
In this post, we discuss Detectron2, an object detection and segmentation framework released by Facebook AI Research (FAIR), and its implementation on Amazon SageMaker to solve a dense object detection task for retail. This post includes an associated sample notebook, which you can run to demonstrate all the features discussed in this post. For more information, see the GitHub repository.
Toolsets used in this solution
To implement this solution, we use Detectron2, PyTorch, SageMaker, and the public SKU-110K dataset.
Detectron2
Detectron2 is a ground-up rewrite of Detectron that started with maskrcnn-benchmark. The platform is now implemented in PyTorch. With a new, more modular design, Detectron2 is flexible and extensible, and provides fast training on single or multiple GPU servers. Detectron2 includes high-quality implementations of state-of-the-art object detection algorithms, including DensePose, panoptic feature pyramid networks, and numerous variants of the pioneering Mask R-CNN model family also developed by FAIR. Its extensible design makes it easy to implement cutting-edge research projects without having to fork the entire code base.
PyTorch
PyTorch is an open-source, deep learning framework that makes it easy to develop ML models and deploy them to production. With PyTorch’s TorchScript, developers can seamlessly transition between eager mode, which performs computations immediately for easy development, and graph mode, which creates computational graphs for efficient implementations in production environments. PyTorch also offers distributed training, deep integration into Python, and a rich ecosystem of tools and libraries, which makes it popular with researchers and engineers.
An example of that rich ecosystem of tools is TorchServe, a recently released model-serving framework for PyTorch that helps deploy trained models at scale without having to write custom code. TorchServe is built and maintained by AWS in collaboration with Facebook and is available as part of the PyTorch open-source project. For more information, see the TorchServe GitHub repo and Model Server for PyTorch Documentation.
Amazon SageMaker
SageMaker is a fully managed service that provides every developer and data scientist with the ability to build, train, and deploy ML models quickly. SageMaker removes the heavy lifting from each step of the ML process to make it easier to develop high-quality models.
Dataset
For our use case, we use the SKU-110 dataset introduced by Goldman et al. in the paper “Precise Detection in Densely Packed Scenes” (Proceedings of 2019 conference on Computer Vision and Patter Recognition). This dataset contains 11,762 images of store shelves from around the world. Researchers use this dataset to test object detection algorithms on dense scenes. The term density here refers to the number of objects per image. The average number of items per image is 147.4, which is 19 times more than the COCO dataset. Moreover, the images contain multiple identical objects grouped together that are challenging to separate. The dataset contains bounding box annotation on SKUs. The categories of product aren’t distinguished because the bounding box labels only indicate the presence or absence of an item.
Introduction to Detectron2
Detectron2 is FAIR’s next generation software system that implements state-of-the-art object detection algorithms. It’s a ground-up rewrite of the previous version, Detectron, and it originates from maskrcnn-benchmark. The following screenshot is an example of the high-level structure of the Detectron2 repo, which will make more sense when we explore configuration files and network architectures later in this post.

For more information about the general layout of computer vision and deep learning architectures, see A Survey of the Recent Architectures of Deep Convolutional Neural Networks.
Additionally, if this is your first introduction to Detectron2, see the official documentation to learn more about the feature-rich capabilities of Detectron2. For the remainder of this post, we solely focus on implementation details pertaining to deploying Detectron2-powered object detection on SageMaker rather than discussing the underlying computer vision-specific theory.
Update the SageMaker role
To build custom training and serving containers, you need to attach additional Amazon Elastic Container Registry (Amazon ECR) permissions to your SageMaker AWS Identity and Access Management (IAM) role. You can use an AWS-authored policy (such as AmazonEC2ContainerRegistryPowerUser) or create your own custom policy. For more information, see How Amazon SageMaker Works with IAM.
Update the dataset
Detectron2 includes a set of utilities for data loading and visualization. However, you need to register your custom dataset to use Detectron2’s data utilities. You can do this by using the function register_dataset in the catalog.py file from the GitHub repo. This function iterates on the training, validation, and test sets. At each iteration, it calls the function aws_file_mode, which returns a list of annotations given the path to the folder that contains the images and the path to the augmented manifest file that contains the annotations. Augmented manifest files are the output format of Amazon SageMaker Ground Truth bounding box jobs. You can reuse the code associated with this post on your own data labeled for object detection with Ground Truth.
Let’s prepare the SKU-110K dataset so that training, validation, and test images are in dedicated folders, and the annotations are in augmented manifest file format. First, import the required packages, define the S3 bucket, and set up the SageMaker session:
from pathlib import Path
from urllib import request
import tarfile
from typing import Sequence, Mapping, Optional
from tqdm import tqdm
from datetime import datetime
import tempfile
import json
import pandas as pd
import numpy as np
import boto3
import sagemaker
bucket = "my-bucket" # TODO: replace with your bucker
prefix_data = "detectron2/data"
prefix_model = "detectron2/training_artefacts"
prefix_code = "detectron2/model"
prefix_predictions = "detectron2/predictions"
local_folder = "cache"
sm_session = sagemaker.Session(default_bucket=bucket)
role = sagemaker.get_execution_role()
Then, download the dataset:
sku_dataset = ("SKU110K_fixed", "http://trax-geometry.s3.amazonaws.com/cvpr_challenge/SKU110K_fixed.tar.gz")
if not (Path(local_folder) / sku_dataset[0]).exists():
compressed_file = tarfile.open(fileobj=request.urlopen(sku_dataset[1]), mode="r|gz")
compressed_file.extractall(path=local_folder)
else:
print(f"Using the data in `{local_folder}` folder")
path_images = Path(local_folder) / sku_dataset[0] / "images"
assert path_images.exists(), f"{path_images} not found"
prefix_to_channel = {
"train": "training",
"val": "validation",
"test": "test",
}
for channel_name in prefix_to_channel.values():
if not (path_images.parent / channel_name).exists():
(path_images.parent / channel_name).mkdir()
for path_img in path_images.iterdir():
for prefix in prefix_to_channel:
if path_img.name.startswith(prefix):
path_img.replace(path_images.parent / prefix_to_channel[prefix] / path_img.name)
Next, upload the image files to Amazon Simple Storage Service (Amazon S3) using the utilities from the SageMaker Python SDK:
channel_to_s3_imgs = {}
for channel_name in prefix_to_channel.values():
inputs = sm_session.upload_data(
path=str(path_images.parent / channel_name),
bucket=bucket,
key_prefix=f"{prefix_data}/{channel_name}"
)
print(f"{channel_name} images uploaded to {inputs}")
channel_to_s3_imgs[channel_name] = inputs
SKU-110k annotations are stored in CSV files. The following function converts the annotations to JSON lines (refer to the GitHub repo to see the implementation):
def create_annotation_channel(
channel_id: str, path_to_annotation: Path, bucket_name: str, data_prefix: str,
img_annotation_to_ignore: Optional[Sequence[str]] = None
) -> Sequence[Mapping]:
r"""Change format from original to augmented manifest files
Parameters
----------
channel_id : str
name of the channel, i.e. training, validation or test
path_to_annotation : Path
path to annotation file
bucket_name : str
bucket where the data are uploaded
data_prefix : str
bucket prefix
img_annotation_to_ignore : Optional[Sequence[str]]
annotation from these images are ignore because the corresponding images are corrupted, default to None
Returns
-------
Sequence[Mapping]
List of json lines, each lines contains the annotations for a single. This recreates the
format of augmented manifest files that are generated by Amazon SageMaker GroundTruth
labeling jobs
"""
…
channel_to_annotation_path = {
"training": Path(local_folder) / sku_dataset[0] / "annotations" / "annotations_train.csv",
"validation": Path(local_folder) / sku_dataset[0] / "annotations" / "annotations_val.csv",
"test": Path(local_folder) / sku_dataset[0] / "annotations" / "annotations_test.csv",
}
channel_to_annotation = {}
for channel in channel_to_annotation_path:
annotations = create_annotation_channel(
channel,
channel_to_annotation_path[channel],
bucket,
prefix_data,
CORRUPTED_IMAGES[channel]
)
print(f"Number of {channel} annotations: {len(annotations)}")
channel_to_annotation[channel] = annotations
Finally, upload the manifest files to Amazon S3:
def upload_annotations(p_annotations, p_channel: str):
rsc_bucket = boto3.resource("s3").Bucket(bucket)
json_lines = [json.dumps(elem) for elem in p_annotations]
to_write = "n".join(json_lines)
with tempfile.NamedTemporaryFile(mode="w") as fid:
fid.write(to_write)
rsc_bucket.upload_file(fid.name, f"{prefix_data}/annotations/{p_channel}.manifest")
for channel_id, annotations in channel_to_annotation.items():
upload_annotations(annotations, channel_id)
Visualize the dataset
Detectron2 provides toolsets to inspect datasets. You can visualize the dataset input images and their ground truth bounding boxes. First, you need to add the dataset to the Detectron2 catalog:
import random
from typing import Sequence, Mapping
import cv2
from matplotlib import pyplot as plt
from detectron2.data import DatasetCatalog, MetadataCatalog
from detectron2.utils.visualizer import Visualizer
# custom code
from datasets.catalog import register_dataset, DataSetMeta
ds_name = "sku110k"
metadata = DataSetMeta(name=ds_name, classes=["SKU",])
channel_to_ds = {"test": ("data/test/", "data/test.manifest")}
register_dataset(
metadata=metadata, label_name="sku", channel_to_dataset=channel_to_ds,
)
You can now plot annotations on an image as follows:
dataset_samples: Sequence[Mapping] = DatasetCatalog.get(f"{ds_name}_test")
sample = random.choice(dataset_samples)
fname = sample["file_name"]
print(fname)
img = cv2.imread(fname)
visualizer = Visualizer(
img[:, :, ::-1], metadata=MetadataCatalog.get(f"{ds_name}_test"), scale=1.0
)
out = visualizer.draw_dataset_dict(sample)
plt.imshow(out.get_image())
plt.axis("off")
plt.tight_layout()
plt.show()
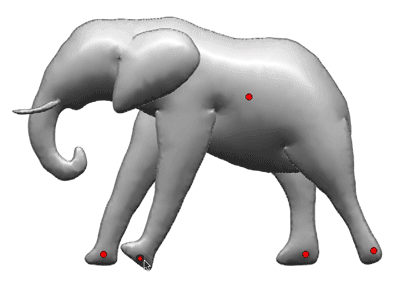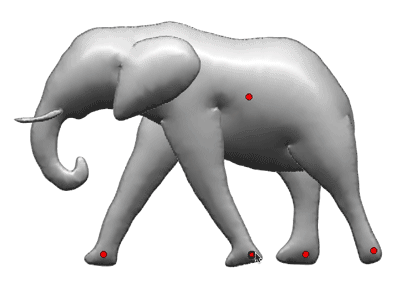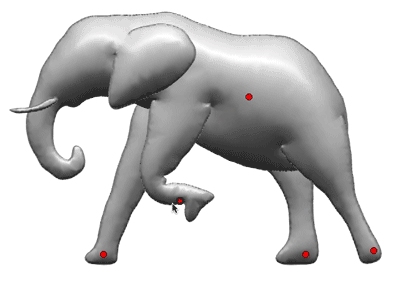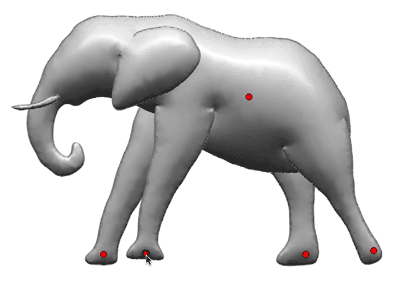
The following picture shows an example of ground truth bounding boxes on a test image.

Distributed training on Detectron2
You can use Docker containers with SageMaker to train Detectron2 models. In this post, we describe how you can run distributed Detectron2 training jobs for a larger number of iterations across multiple nodes and GPU devices on a SageMaker training cluster.
The process includes the following steps:
- Create a training script capable of running and coordinating training tasks in a distributed environment.
- Prepare a custom Docker container with configured training runtime and training scripts.
- Build and push the training container to Amazon ECR.
- Initialize training jobs via the SageMaker Python SDK.
Prepare the training script for the distributed cluster
The sku-100k folder contains the source code that we use to train the custom Detectron2 model. The script training.py is the entry point of the training process. The following sections of the script are worth discussing in detail:
- __main__ guard – The SageMaker Python SDK runs the code inside the main guard when used for training. The
train function is called with the script arguments.
- _parse_args() – This function parses arguments from the command line and from the SageMaker environments. For example, you can choose which model to train among Faster-RCNN and RetinaNet. The SageMaker environment variables define the input channel locations and where the model artifacts are stored. The number of GPUs and the number of hosts define the properties of the training cluster.
- train() – We use the Detectron2 launch utility to start training on multiple nodes.
- _train_impl()– This is the actual training script, which is run on all processes and GPU devices. This function runs the following steps:
- Register the custom dataset to Detectron2’s catalog.
- Create the configuration node for training.
- Fit the training dataset to the chosen object detection architecture.
- Save the training artifacts and run the evaluation on the test set if the current node is the primary.
Prepare the training container
We build a custom container with the specific Detectron2 training runtime environment. As a base image, we use the latest SageMaker PyTorch container and further extend it with Detectron2 requirements. We first need to make sure that we have access to the public Amazon ECR (to pull the base PyTorch image) and our account registry (to push the custom container). The following example code shows how to log in to both registries prior to building and pushing your custom containers:
# loging to Sagemaker ECR with Deep Learning Containers
!aws ecr get-login-password --region us-east-2 | docker login --username AWS --password-stdin 763104351884.dkr.ecr.us-east-2.amazonaws.com
# loging to your private ECR
!aws ecr get-login-password --region us-east-2 | docker login --username AWS --password-stdin <YOUR-ACCOUNT-ID>.dkr.ecr.us-east-2.amazonaws.com
After you successfully authenticate with Amazon ECR, you can build the Docker image for training. This Dockerfile runs the following instructions:
- Define the base container.
- Install the required dependencies for Detectron2.
- Copy the training script and the utilities to the container.
- Build Detectron2 from source.
Build and push the custom training container
We provide a simple bash script to build a local training container and push it to your account registry. If needed, you can specify a different image name, tag, or Dockerfile. The following code is a short snippet of the Dockerfile:
# Build an image of Detectron2 that can do distributing training on Amazon Sagemaker using Sagemaker PyTorch container as base image
# from https://github.com/aws/sagemaker-pytorch-container
ARG REGION=us-east-1
FROM 763104351884.dkr.ecr.${REGION}.amazonaws.com/pytorch-training:1.6.0-gpu-py36-cu101-ubuntu16.04
############# Detectron2 pre-built binaries Pytorch default install ############
RUN pip install --upgrade torch==1.6.0+cu101 torchvision==0.7.0+cu101 -f https://download.pytorch.org/whl/torch_stable.html
############# Detectron2 section ##############
RUN pip install
--no-cache-dir pycocotools~=2.0.0
--no-cache-dir detectron2 -f https://dl.fbaipublicfiles.com/detectron2/wheels/cu101/torch1.6/index.html
ENV FORCE_CUDA="1"
# Build D2 only for Volta architecture - V100 chips (ml.p3 AWS instances)
ENV TORCH_CUDA_ARCH_LIST="Volta"
# Set a fixed model cache directory. Detectron2 requirement
ENV FVCORE_CACHE="/tmp"
############# SageMaker section ##############
COPY container_training/sku-110k /opt/ml/code
WORKDIR /opt/ml/code
ENV SAGEMAKER_SUBMIT_DIRECTORY /opt/ml/code
ENV SAGEMAKER_PROGRAM training.py
WORKDIR /
# Starts PyTorch distributed framework
ENTRYPOINT ["bash", "-m", "start_with_right_hostname.sh"]
Schedule the training job
You’re now ready to schedule your distributed training job. First, you need to do several common imports and configurations, which are described in detail in our companion notebook. Second, it’s important to specify which metrics you want to track during the training, which you can do by creating a JSON file with the appropriate regular expressions for each metric of interest. See the following example code:
metrics = [
{"Name": "training:loss", "Regex": "total_loss: ([0-9\.]+)",},
{"Name": "training:loss_cls", "Regex": "loss_cls: ([0-9\.]+)",},
{"Name": "training:loss_box_reg", "Regex": "loss_box_reg: ([0-9\.]+)",},
{"Name": "training:loss_rpn_cls", "Regex": "loss_rpn_cls: ([0-9\.]+)",},
{"Name": "training:loss_rpn_loc", "Regex": "loss_rpn_loc: ([0-9\.]+)",},
{"Name": "validation:loss", "Regex": "total_val_loss: ([0-9\.]+)",},
{"Name": "validation:loss_cls", "Regex": "val_loss_cls: ([0-9\.]+)",},
{"Name": "validation:loss_box_reg", "Regex": "val_loss_box_reg: ([0-9\.]+)",},
{"Name": "validation:loss_rpn_cls", "Regex": "val_loss_rpn_cls: ([0-9\.]+)",},
{"Name": "validation:loss_rpn_loc", "Regex": "val_loss_rpn_loc: ([0-9\.]+)",},
]
Finally, you create the estimator to start the distributed training job by calling the fit method:
training_instance = "ml.p3.8xlarge"
od_algorithm = "faster_rcnn" # choose one in ("faster_rcnn", "retinanet")
d2_estimator = Estimator(
image_uri=training_image_uri,
role=role,
sagemaker_session=training_session,
instance_count=1,
instance_type=training_instance,
hyperparameters=training_job_hp,
metric_definitions=metrics,
output_path=f"s3://{bucket}/{prefix_model}",
base_job_name=f"detectron2-{od_algorithm.replace('_', '-')}",
)
d2_estimator.fit(
{
"training": training_channel,
"validation": validation_channel,
"test": test_channel,
"annotation": annotation_channel,
},
wait=training_instance == "local",
)
Benchmark the training job performance
This set of steps allows you to scale the training performance as needed without changing a single line of code. You just have to pick your training instance and the size of your cluster. Detectron2 automatically adapts to the training cluster size by using the launch utility. The following table compares the training runtime in seconds of jobs running for 3,000 iterations.
|
Faster-RCNN (seconds) |
RetinaNet (seconds) |
| ml.p3.2xlarge – 1 node |
2,685 |
2,636 |
| ml.p3.8xlarge – 1 node |
774 |
742 |
| ml.p3.16xlarge – 1 node |
439 |
400 |
| ml.p3.16xlarge – 2 nodes |
338 |
311 |
The training time reduces on both Faster-RCNN and RetinaNet with the total number of GPUs. The distribution efficiency is approximately of 85% and 75% when passing from an instance with a single GPU to instances with four and eight GPUs, respectively.
Deploy the trained model to a remote endpoint
To deploy your trained model remotely, you need to prepare, build, and push a custom serving container and deploy this custom container for serving via the SageMaker SDK.
Build and push the custom serving container
We use the SageMaker inference container as a base image. This image includes a pre-installed PyTorch model server to host your PyTorch model, so no additional configuration or installation is required. For more information about the Docker files and shell scripts to push and build the containers, see the GitHub repo.
For this post, we build Detectron2 for the Volta and Turing chip architectures. Volta architecture is used to run SageMaker batch transform on P3 instance types. If you need real-time prediction, you should use G4 instance types because they provide optimal price-performance compromise. Amazon Elastic Compute Cloud (Amazon EC2) G4 instances provide the latest generation NVIDIA T4 GPUs, AWS custom Intel Cascade Lake CPUs, up to 100 Gbps of networking throughput, and up to 1.8 TB of local NVMe storage and direct access to GPU libraries such as CUDA and CuDNN.
Run batch transform jobs on the test set
The SageMaker Python SDK gives a simple way of running inference on a batch of images. You can get the predictions on the SKU-110K test set by running the following code:
model = PyTorchModel(
name = "d2-sku110k-model",
model_data=training_job_artifact,
role=role,
sagemaker_session = sm_session,
entry_point="predict_sku110k.py",
source_dir="container_serving",
image_uri=serve_image_uri,
framework_version="1.6.0",
code_location=f"s3://{bucket}/{prefix_code}",
)
transformer = model.transformer(
instance_count=1,
instance_type="ml.p3.2xlarge", # "ml.p2.xlarge"
output_path=inference_output,
max_payload=16
)
transformer.transform(
data=test_channel,
data_type="S3Prefix",
content_type="application/x-image",
wait=False,
)
The batch transform saves the predictions to an S3 bucket. You can evaluate your trained models by comparing the predictions to the ground truth. We use the pycocotools library to compute the metrics that official competitions use to evaluate object detection algorithms. The authors who published the SKU-110k dataset took into account three measures in their paper “Precise Detection in Densely Packed Scenes” (Goldman et al.):
- Average Precision (AP) at 0.5:0.95 Intersection over Union (IoU)
- AP at 75% IoU, i.e. AP75
- Average Recall (AR) at 0.5:0.95 IoU
You can refer to the COCO website for the whole list of metrics that characterize the performance of an object detector on the COCO dataset. The following table compares the results from the paper to those obtained on SageMaker with Detectron2.
| |
|
AP |
AP75 |
AR |
| From paper by Goldman et al. |
RetinaNet |
0.46 |
0.39 |
0.53 |
| Faster-RCNN |
0.04 |
0.01 |
0.05 |
| Custom Method |
0.49 |
0.56 |
0.55 |
| Detectron2 on Amazon SageMaker |
RetinaNet |
0.47 |
0.54 |
0.55 |
| Faster-RCNN |
0.49 |
0.53 |
0.55 |
We use SageMaker hyperparameter tuning jobs to optimize the hyperparameters of the object detectors. Faster-RCNN has the same performance in terms of AP and AR compared with the model proposed by Goldman et al. that is specifically conceived for object detection in dense scenes. Our Faster-RCNN loses three points on the AP75. However, this may be an acceptable performance decrease according to the business use case. Moreover, the advantage of our solution is that is doesn’t require any custom implementation because it only relies on Detecron2 modules. This proves that you can use Detectron2 to train at scale with SageMaker object detectors that compete with state-of-the-art solutions in challenging contexts such as dense scenes.
Summary
This post only scratches the surface of what is possible when deploying Detectron2 on the SageMaker platform. We hope that you found this introductory use case useful and we look forward to seeing what you build on AWS with this new tool in your ML toolset!
About the Authors
 Vadim Dabravolski is Sr. AI/ML Architect at AWS. Areas of interest include distributed computations and data engineering, computer vision, and NLP algorithms. When not at work, he is catching up on his reading list (anything around business, technology, politics, and culture) and jogging in NYC boroughs.
Vadim Dabravolski is Sr. AI/ML Architect at AWS. Areas of interest include distributed computations and data engineering, computer vision, and NLP algorithms. When not at work, he is catching up on his reading list (anything around business, technology, politics, and culture) and jogging in NYC boroughs.
 Paolo Irrera is a Data Scientist at the Amazon Machine Learning Solutions Lab where he helps customers address business problems with ML and cloud capabilities. He holds a PhD in Computer Vision from Telecom ParisTech, Paris.
Paolo Irrera is a Data Scientist at the Amazon Machine Learning Solutions Lab where he helps customers address business problems with ML and cloud capabilities. He holds a PhD in Computer Vision from Telecom ParisTech, Paris.
Read More
 Michael Robinson is a Lead Data Scientist at Koch Ag & Energy Solutions, LLC (KAES). His work focuses on computer vision, acoustic, and data engineering. He leverages technical knowledge to solve unique challenges for KAES. In his spare time, he enjoys golfing, photography and traveling.
Michael Robinson is a Lead Data Scientist at Koch Ag & Energy Solutions, LLC (KAES). His work focuses on computer vision, acoustic, and data engineering. He leverages technical knowledge to solve unique challenges for KAES. In his spare time, he enjoys golfing, photography and traveling. Dave Kroening is an IT Leader with Koch Ag & Energy Solutions, LLC (KAES). His work focuses on building out a vision and strategy for initiatives that can create long term value. This includes exploring, assessing, and developing opportunities that have a potential to disrupt the Operating capability within KAES. He and his team also help to discover and experiment with technologies that can create a competitive advantage. In his spare time he enjoys spending time with his family, snowboarding, and racing.
Dave Kroening is an IT Leader with Koch Ag & Energy Solutions, LLC (KAES). His work focuses on building out a vision and strategy for initiatives that can create long term value. This includes exploring, assessing, and developing opportunities that have a potential to disrupt the Operating capability within KAES. He and his team also help to discover and experiment with technologies that can create a competitive advantage. In his spare time he enjoys spending time with his family, snowboarding, and racing. Mehdi Noori is a Data Scientist at the Amazon ML Solutions Lab, where he works with customers across various verticals, and helps them to accelerate their cloud migration journey, and to solve their ML problems using state-of-the-art solutions and technologies. Mehdi attended MIT as a postdoctoral researcher and obtained his Ph.D. in Engineering from UCF.
Mehdi Noori is a Data Scientist at the Amazon ML Solutions Lab, where he works with customers across various verticals, and helps them to accelerate their cloud migration journey, and to solve their ML problems using state-of-the-art solutions and technologies. Mehdi attended MIT as a postdoctoral researcher and obtained his Ph.D. in Engineering from UCF. Xin Chen is a senior manager at Amazon ML Solutions Lab, where he leads the Automotive Vertical and helps AWS customers across different industries identify and build machine learning solutions to address their organization’s highest return-on-investment machine learning opportunities. Xin obtained his Ph.D. in Computer Science and Engineering from the University of Notre Dame.
Xin Chen is a senior manager at Amazon ML Solutions Lab, where he leads the Automotive Vertical and helps AWS customers across different industries identify and build machine learning solutions to address their organization’s highest return-on-investment machine learning opportunities. Xin obtained his Ph.D. in Computer Science and Engineering from the University of Notre Dame. Yunzhi Shi is a data scientist at the Amazon ML Solutions Lab where he helps AWS customers address business problems with AI and cloud capabilities. Recently, he has been building computer vision, search, and forecast solutions for customers from various industrial verticals. Yunzhi obtained his Ph.D. in Geophysics from the University of Texas at Austin.
Yunzhi Shi is a data scientist at the Amazon ML Solutions Lab where he helps AWS customers address business problems with AI and cloud capabilities. Recently, he has been building computer vision, search, and forecast solutions for customers from various industrial verticals. Yunzhi obtained his Ph.D. in Geophysics from the University of Texas at Austin. Dan Volk is a Data Scientist at Amazon ML Solutions Lab, where he helps AWS customers across various industries accelerate their AI and cloud adoption. Dan has worked in several fields including manufacturing, aerospace, and sports and holds a Masters in Data Science from UC Berkeley.
Dan Volk is a Data Scientist at Amazon ML Solutions Lab, where he helps AWS customers across various industries accelerate their AI and cloud adoption. Dan has worked in several fields including manufacturing, aerospace, and sports and holds a Masters in Data Science from UC Berkeley. Brant Swidler is the Technical Product Manager for Amazon Lookout for Equipment. He focuses on leading product development including data science and engineering efforts. Brant comes from an Industrial background in the oil and gas industry and has a B.S. in Mechanical and Aerospace Engineering from Washington University in St. Louis and an MBA from the Tuck school of business at Dartmouth.
Brant Swidler is the Technical Product Manager for Amazon Lookout for Equipment. He focuses on leading product development including data science and engineering efforts. Brant comes from an Industrial background in the oil and gas industry and has a B.S. in Mechanical and Aerospace Engineering from Washington University in St. Louis and an MBA from the Tuck school of business at Dartmouth.
















 Joe Fontaine is the Marketing Program Manager for AWS AI/ML Developer Devices. He is passionate about making machine learning more accessible to all through hands-on educational experiences. Outside of work he enjoys freeride mountain biking, aerial cinematography, and exploring the wilderness with his dogs. He is proud to be a recent inductee to the “rad dads” club.
Joe Fontaine is the Marketing Program Manager for AWS AI/ML Developer Devices. He is passionate about making machine learning more accessible to all through hands-on educational experiences. Outside of work he enjoys freeride mountain biking, aerial cinematography, and exploring the wilderness with his dogs. He is proud to be a recent inductee to the “rad dads” club.