
On June 2, 2021, don’t miss the opportunity to hear from some of the brightest minds in machine learning (ML) at the free virtual AWS Machine Learning Summit. Machine learning is one of the most disruptive technologies we will encounter in our generation. It’s improving customer experience, creating more efficiencies in operations, and spurring new innovations and discoveries like helping researchers discover new vaccines and aiding autonomous drones to sail our world’s oceans. But we’re just scratching the surface about what is possible. This Summit, which is open to all and free to attend, brings together industry luminaries, AWS customers, and leading ML experts to share the latest in machine learning. You’ll learn about the latest science breakthroughs in ML, how ML is impacting business, best practices in building ML, and how to get started now without prior ML expertise.
Hear from ML leaders from across AWS, Amazon, and the industry, including Swami Sivasubramanian, VP of AI and Machine Learning, AWS; Bratin Saha, VP of Machine Learning, AWS; and Yoelle Maarek, VP of Research, Alexa Shopping, who will share a keynote on how we’re applying customer-obsessed science to advance ML. Andrew Ng, founder and CEO of Landing AI and founder of deeplearning.ai, will join Swami Sivasubramanian in a fireside chat about the future of ML, the skills that are fundamental for the next generation of ML practitioners, and how we can bridge the gap from proof of concept to production in ML. You’ll also get an inside look at trends in deep learning and natural language in a powerhouse fireside chat with Amazon distinguished scientists Alex Smola and Bernhard Schölkopf, and Alexa AI senior principal scientist Dilek Hakkani-Tur.
Pick from over 30 session across four tracks, which all offer something for anyone who is interested in ML. Advanced practitioners and data scientists can learn about scientific breakthroughs and dive deep into the tools for building ML. Business and technical leaders can learn from their peers about implementing organization-wide ML initiatives. And developers can learn how to perform ML without needing any experience.
The science of machine learning
Advanced practitioners will get a technical deep dive into the groundbreaking work that ML scientists within AWS, Amazon, and beyond are doing to advance the science of ML in areas including computer vision, natural language processing, bias, and more. Speakers include two Amazon Scholars, Michael Kearns and Kathleen McKeown. Kearns a professor in the Computer and Information Science department at the University of Pennsylvania, where he holds the National Center Chair. He is co-author of the book “The Ethical Algorithm: The Science of Socially Aware Algorithm Design,” and joined Amazon as a scholar June 2020. McKeown is the Henry and Gertrude Rothschild professor of computer science at Columbia University, and the founding director of the school’s Data Science Institute. She joined Amazon as a scholar in 2019.
The impact of machine learning
Business leaders will learn from AWS customers that are leading the way in ML adoption. Customers including 3M, AstraZeneca, Vanguard, and Latent Space will share how they’re applying ML to create efficiencies, deliver new revenue streams, and launch entirely new products and business models. You’ll get best practices for scaling ML in an organization and showing impact.
How machine learning is done
Data scientists and ML developers will get practical deep dives into tools that can speed up the entire ML lifecycle, from building to training to deploying ML models. Sessions include how to choose the right algorithms, more accurate and speedy data prep, model explainability, and more.
Machine learning: no expertise required
If you’re a developer who wants to apply ML and AI to a use case but doesn’t have the expertise, this track is for you. Learn how to use AWS AI services and other tools to get started with your ML project right away, for use cases including contact center intelligence, personalization, intelligent document processing, business metrics analysis, computer vision, and more.
For more details, visit the website.
About the Author
 Laura Jones is a product marketing lead for AWS AI/ML where she focuses on sharing the stories of AWS’s customers and educating organizations on the impact of machine learning. As a Florida native living and surviving in rainy Seattle, she enjoys coffee, attempting to ski and enjoying the great outdoors.
Laura Jones is a product marketing lead for AWS AI/ML where she focuses on sharing the stories of AWS’s customers and educating organizations on the impact of machine learning. As a Florida native living and surviving in rainy Seattle, she enjoys coffee, attempting to ski and enjoying the great outdoors.


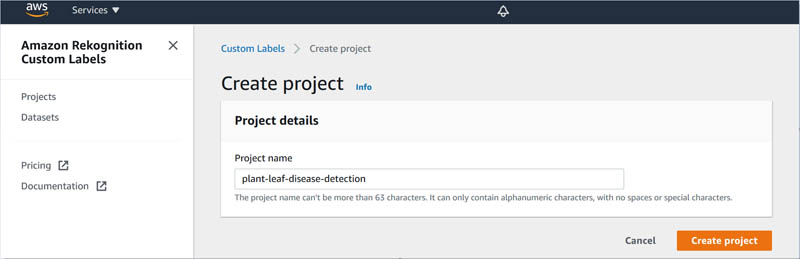


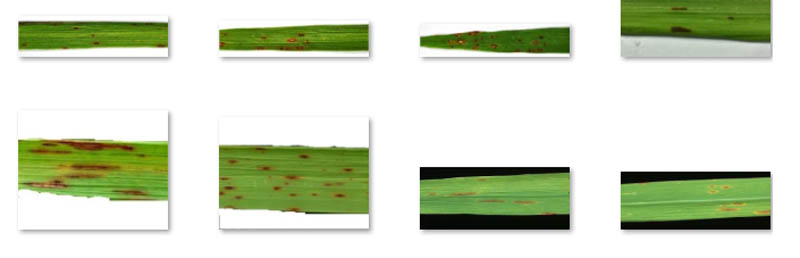


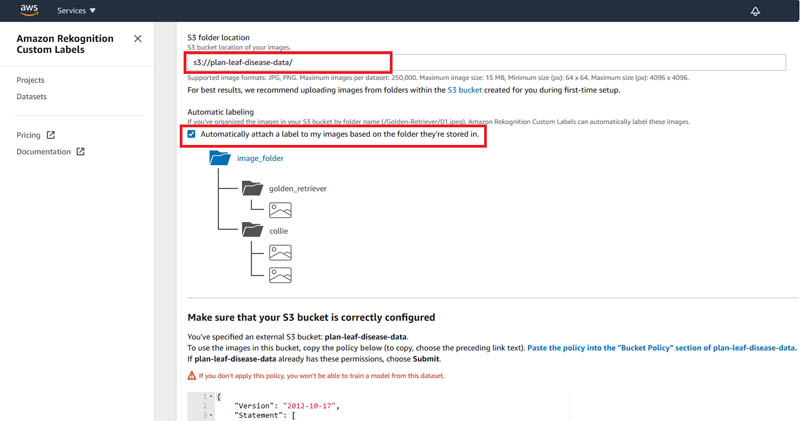

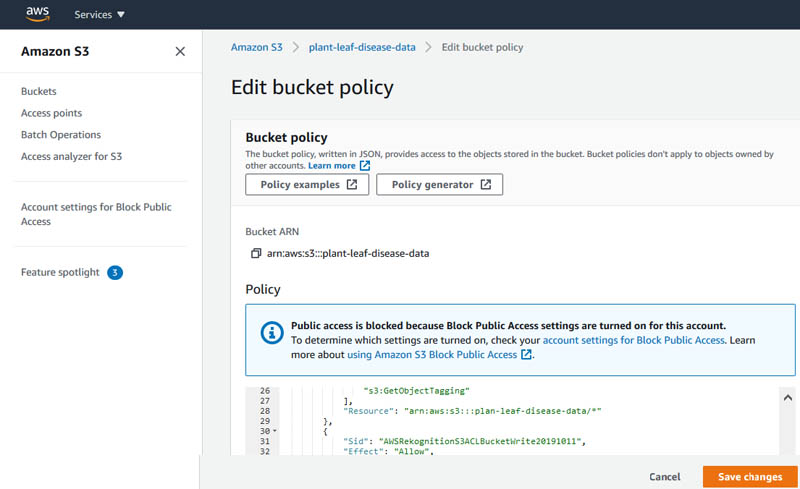

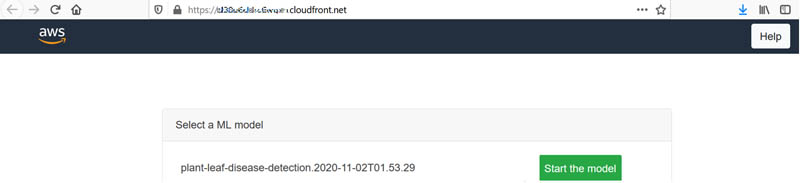
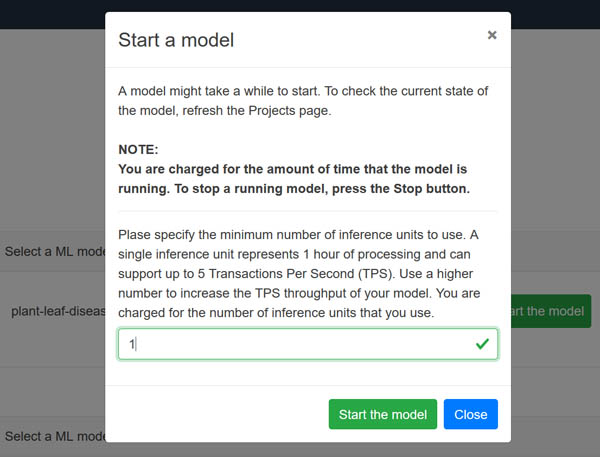
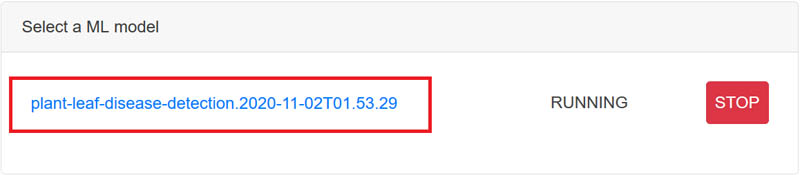
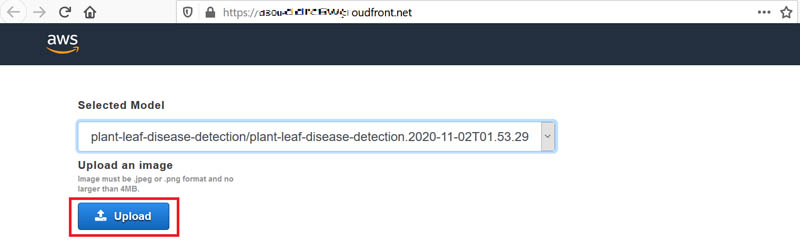

 Dhiraj Thakur is a Solutions Architect with Amazon Web Services. He works with AWS customers and partners to provide guidance on enterprise cloud adoption, migration, and strategy. He is passionate about technology and enjoys building and experimenting in the analytics and AI/ML space.
Dhiraj Thakur is a Solutions Architect with Amazon Web Services. He works with AWS customers and partners to provide guidance on enterprise cloud adoption, migration, and strategy. He is passionate about technology and enjoys building and experimenting in the analytics and AI/ML space. Sameer Goel is a Solutions Architect in Seattle, who drives customer success by building prototypes on cutting-edge initiatives. Prior to joining AWS, Sameer graduated with a master’s degree from NEU Boston, with a concentration in data science. He enjoys building and experimenting with AI/ML projects on Raspberry Pi.
Sameer Goel is a Solutions Architect in Seattle, who drives customer success by building prototypes on cutting-edge initiatives. Prior to joining AWS, Sameer graduated with a master’s degree from NEU Boston, with a concentration in data science. He enjoys building and experimenting with AI/ML projects on Raspberry Pi.
 Geoff Murase is a Senior Product Marketing Manager for AWS EC2 accelerated computing instances, helping customers meet their compute needs by providing access to hardware-based compute accelerators such as Graphics Processing Units (GPUs) or Field Programmable Gate Arrays (FPGAs). In his spare time, he enjoys playing basketball and biking with his family.
Geoff Murase is a Senior Product Marketing Manager for AWS EC2 accelerated computing instances, helping customers meet their compute needs by providing access to hardware-based compute accelerators such as Graphics Processing Units (GPUs) or Field Programmable Gate Arrays (FPGAs). In his spare time, he enjoys playing basketball and biking with his family.