Five teams to compete for $500,000 first prize; winners will be announced in August 2021.Read More
WILDS: A Benchmark of in-the-Wild Distribution Shifts

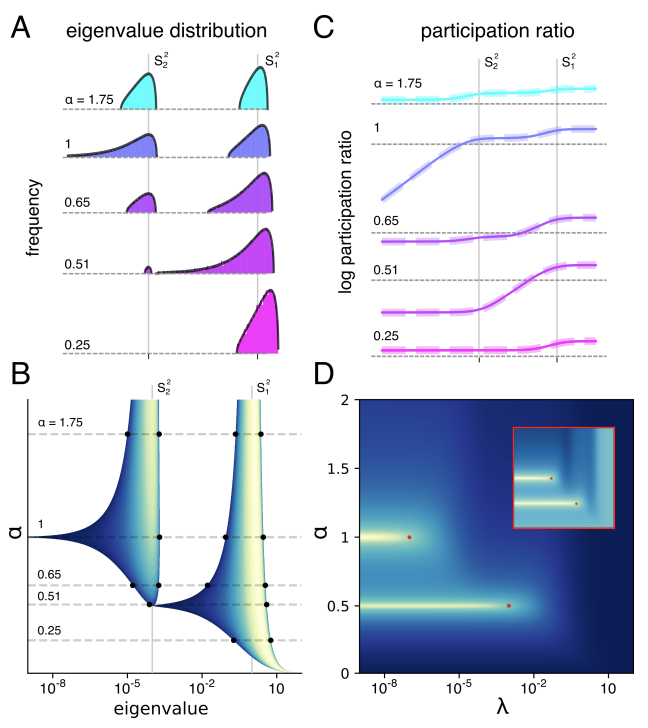
One of the most common assumptions in machine learning (ML) is that the training and test data are independently and identically distributed (i.i.d.). For example, we might collect some number of data points and then randomly split them, assigning half to the training set and half to the test set.
However, this assumption is often broken in ML systems deployed in the wild. In real-world applications, distribution shifts— instances where a model is trained on data from one distribution but then deployed on data from a different distribution— are ubiquitous. For example, in medical applications, we might train a diagnosis model on patients from a few hospitals, and then deploy it more broadly to hospitals outside the training set 1; and in wildlife monitoring, we might train an animal recognition model on images from one set of camera traps and then deploy it to new camera traps 2.
A large body of prior work has shown that these distribution shifts can significantly degrade model performance in a variety of real-world ML applications: models can perform poorly out-of-distribution, despite achieving high in-distribution performance 3. To be able to reliably deploy ML models in the wild, we urgently need to develop methods for training models that are robust to real-world distribution shifts.
The WILDS benchmark
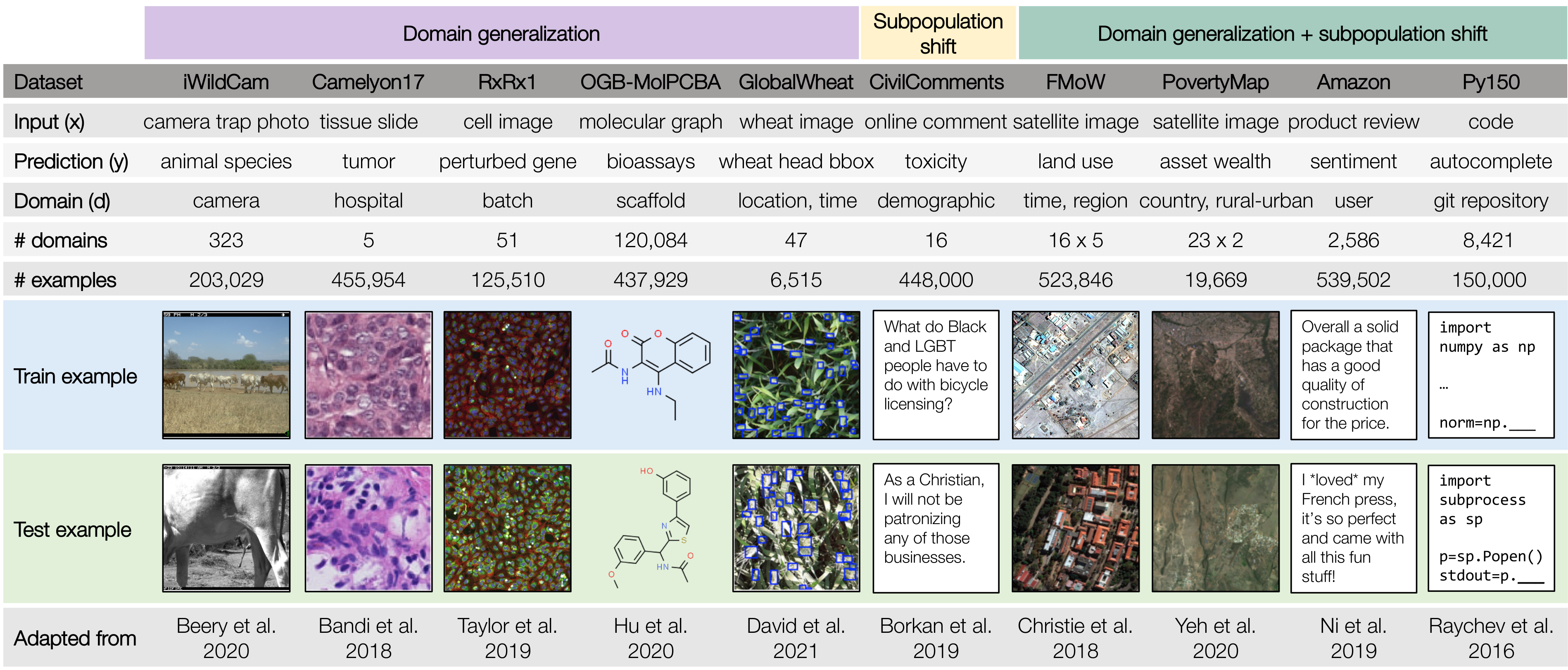
To facilitate the development of ML models that are robust to real-world distribution shifts, our ICML 2021 paper presents WILDS, a curated benchmark of 10 datasets that reflect natural distribution shifts arising from different cameras, hospitals, molecular scaffolds, experiments, demographics, countries, time periods, users, and codebases.
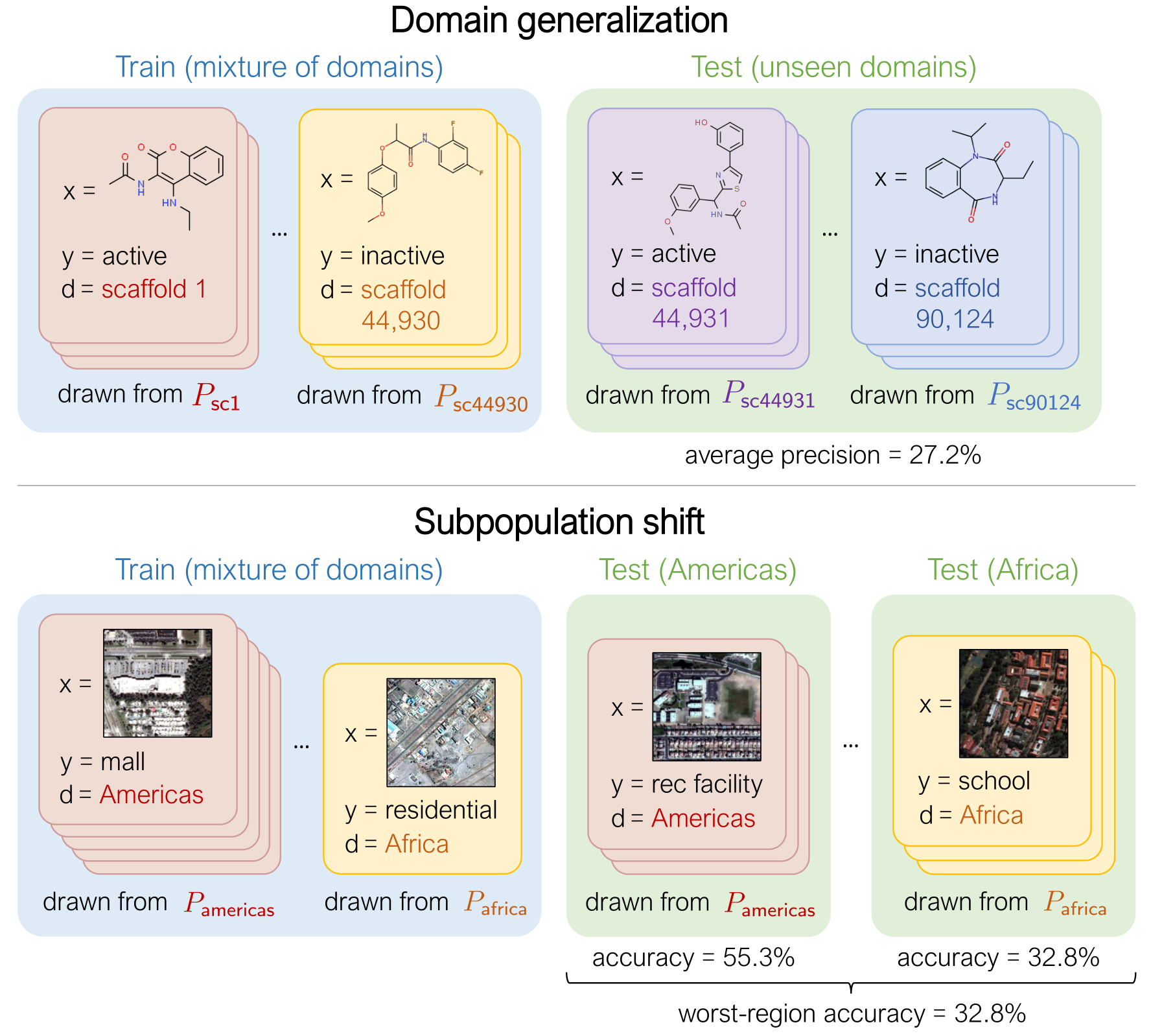
The WILDS datasets cover two common types of distribution shifts: domain generalization and subpopulation shift.
In domain generalization, the training and test distributions comprise data from related but distinct domains. The figure shows an example from the OGB-MolPCBA dataset 4 in WILDS, where the task is to predict the biochemical properties of molecules, and the goal is to generalize to molecules with different molecular scaffolds that have not been seen in the training set.
In subpopulation shift, we consider test distributions that are subpopulations of the training distribution, and seek to perform well even on the worst-case subpopulation. As an example, consider the CivilComments-WILDS dataset 5, where the task is toxicity classification on online text comments. Standard models perform well on average but poorly on comments that mention certain minority demographic groups (e.g., they might be likely to erroneously flag innocuous comments mentioning Black people as toxic), and we seek to train models that can perform equally well on comments that correspond to different demographic subpopulations.
Finally, some datasets exhibit both types of distribution shifts. For example, the second example in the figure above is from the FMoW-WILDS dataset 6, where there is both a domain generalization problem over time (the training set consists of satellite images taken before 2013, while the test images were taken after 2016) as well as a subpopulation shift problem over different geographical regions (we seek to do well over all regions).
Selection criteria for WILDS datasets
WILDS builds on extensive data collection efforts by domain experts working on applying ML methods in their application areas, and who are often forced to grapple with distribution shifts to make progress in their applications. To design WILDS, we worked with these experts to identify, select, and adapt datasets that fulfilled the following criteria:
-
Real-world relevance. The training/test splits and evaluation metrics are motivated by real-world scenarios and chosen in conjunction with domain experts. By focusing on realistic distribution shifts, WILDS complements existing distribution shift benchmarks, which have largely studied shifts that are cleanly characterized but are not likely to arise in real-world deployments. For example, many recent papers have studied datasets with shifts induced by synthetic transformations, such as changing the color of MNIST digits 7. Though these are important testbeds for systematic studies, model robustness need not transfer across shifts—e.g., a method that improves robustness on a standard vision dataset can consistently harm robustness on real-world satellite imagery datasets 8. So, in order to evaluate and develop methods for real-world distribution shifts, benchmarks like WILDS that capture shifts in the wild serve as an important complement to more synthetic benchmarks.
-
Distribution shifts with large performance gaps. The train/test splits reflect shifts that substantially degrade model performance, i.e., with a large gap between in-distribution and out-of-distribution performance. Measuring the in-distribution versus out-of-distribution gap is an important but subtle problem, as it relies on carefully constructing an appropriate in-distribution setting. We discuss its complexities and our approach in more detail in the paper.
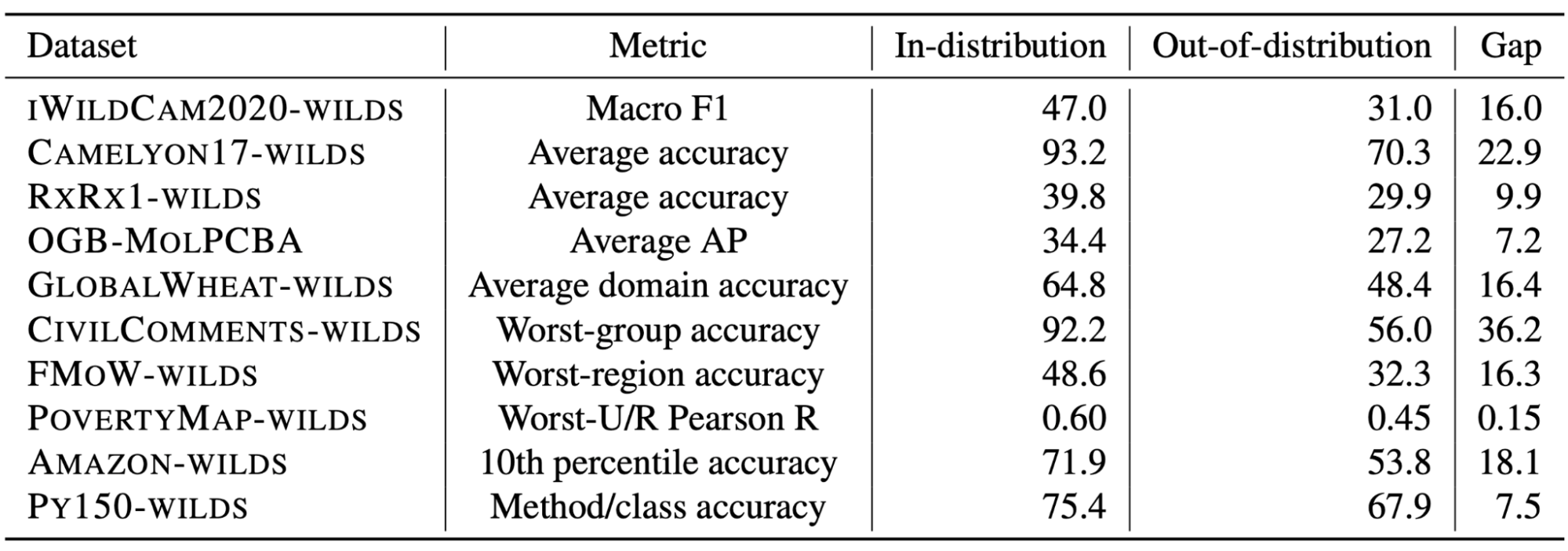
Apart from the 10 datasets in WILDS, we also survey distribution shifts that occur in other application areas—algorithmic fairness and policing, medicine and healthcare, genomics, natural language and speech processing, education, and robotics—and discuss examples of datasets from these areas that we considered but did not include in WILDS. We investigated datasets in autonomous driving, fairness in policing, and computational biology, but either did not observe substantial performance drops or found that performance disparities arose from factors beyond distribution shifts.
Using WILDS
To make it easy to work with WILDS and to enable systematic comparisons between approaches, we developed an open-source Python package that fully automates data loading and evaluation. This package also contains default models and hyperparameters that can easily reproduce all of the baseline numbers we have in our paper. The package is simple to install—just run pip install wilds—and straightforward to use with any PyTorch-based algorithms and models:

We are also hosting a public leaderboard at https://wilds.stanford.edu/leaderboard/ to track the state of the art in algorithms for learning robust models. In our paper, we benchmarked several existing algorithms for learning robust models, but found that they did not consistently improve upon standard models trained with empirical risk minimization (i.e., minimizing the average loss). We thus believe that there is substantial room for developing algorithms and model architectures that can close the gaps between in-distribution and out-of-distribution performance on the WILDS datasets.
Just in the past few months, WILDS has been used to develop methods for domain generalization—such as Fish, which introduces an inter-domain gradient matching objective and is currently state-of-the-art on our leaderboard for several datasets 9, and a Model-Based Domain Generalization (MBDG) approach that uses generative modeling 10—as well as for subpopulation shift settings through environment inference 11 or a variant of distributionally robust optimization 12. WILDS has also been used to develop methods for out-of-distribution calibration 13, uncertainty measurement 14, gradual domain adaptation 15, and self-training 16.
Finally, it has also been used to study out-of-distribution selective classification 17, and to investigate the relationship between in-distribution and out-of-distribution generalization 18.
However, we have only just begun to scratch the surface of how we can train models that are robust to the distribution shifts that are unavoidable in real-world applications, and we’re excited to see what the ML research community will come up with. If you’re interested in trying WILDS out, please check out https://wilds.stanford.edu, and let us know if you have any questions or feedback.
We’ll be presenting WILDS at ICML at 6pm Pacific Time on Thursday, July 22, 2021, with the poster session from 9pm to 11pm Pacific Time on the same day. If you’d like to find out more, please drop by https://icml.cc/virtual/2021/poster/10117! (The link requires ICML registration.)
Acknowledgements
WILDS is a large collaborative effort by researchers from Stanford, UC Berkeley, Cornell, INRAE, the University of Saskatchewan, the University of Tokyo, Recursion, Caltech, and Microsoft Research. This blog post is based on the WILDS paper:
WILDS: A Benchmark of in-the-Wild Distribution Shifts. Pang Wei Koh*, Shiori Sagawa*, Henrik Marklund, Sang Michael Xie, Marvin Zhang, Akshay Balsubramani, Weihua Hu, Michihiro Yasunaga, Richard Lanas Phillips, Irena Gao, Tony Lee, Etienne David, Ian Stavness, Wei Guo, Berton A. Earnshaw, Imran S. Haque, Sara Beery, Jure Leskovec, Anshul Kundaje, Emma Pierson, Sergey Levine, Chelsea Finn, and Percy Liang. ICML 2021.
We are grateful to the many people who generously volunteered their time and expertise to advise us on WILDS.
-
J. R. Zech, M. A. Badgeley, M. Liu, A. B. Costa, J. J. Titano, and E. K. Oermann. Variable generalization performance of a deep learning model to detect pneumonia in chest radiographs: A cross-sectional study. In PLOS Medicine, 2018. ↩
-
S. Beery, G. V. Horn, and P. Perona. Recognition in terra incognita. In European Conference on Computer Vision (ECCV), pages 456–473, 2018. ↩
-
J. Quiñonero-Candela, M. Sugiyama, A. Schwaighofer, and N. D. Lawrence. Dataset shift in machine learning. The MIT Press, 2009. ↩
-
W. Hu, M. Fey, M. Zitnik, Y. Dong, H. Ren, B. Liu, M. Catasta, and J. Leskovec. Open Graph Benchmark: Datasets for machine learning on graphs. In Advances in Neural Information Processing Systems (NeurIPS), 2020. ↩
-
D. Borkan, L. Dixon, J. Sorensen, N. Thain, and L. Vasserman. Nuanced metrics for measuring unintended bias with real data for text classification. In WWW, pages 491–500, 2019. ↩
-
G. Christie, N. Fendley, J. Wilson, and R. Mukherjee. Functional map of the world. In Computer Vision and Pattern Recognition (CVPR), 2018. ↩
-
B. Kim, H. Kim, K. Kim, S. Kim, and J. Kim, 2019. Learning not to learn: Training deep neural networks with biased data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 9012-9020). ↩
-
S. M. Xie, A. Kumar, R. Jones, F. Khani, T. Ma, and P. Liang. In-N-Out: Pre-training and self-training using auxiliary information for out-of-distribution robustness. In International Conference on Learning Representations (ICLR), 2021. ↩
-
Y. Shi, J. Seely, P. H. Torr, N. Siddharth, A. Hannun, N. Usunier, and G. Synnaeve. Gradient Matching for Domain Generalization. arXiv preprint arXiv:2104.09937, 2021. ↩
-
A Robey, H. Hassani, and G. J. Pappas. Model-Based Robust Deep Learning. arXiv preprint arXiv:2005.10247, 2020. ↩
-
E. Creager, J. H. Jacobsen, and R. Zemel. Environment inference for invariant learning. In International Conference on Machine Learning, 2021. ↩
-
E. Liu, B. Haghgoo, A. Chen, A. Raghunathan, P. W. Koh, S. Sagawa, P. Liang, and C. Finn. Just Train Twice: Improving group robustness without training group information. In International Conference on Machine Learning (ICML), 2021. ↩
-
Y. Wald, A. Feder, D. Greenfeld, and U. Shalit. On calibration and out-of-domain generalization. arXiv preprint arXiv:2102.10395, 2021. ↩
-
E. Daxberger, A., Kristiadi, A., Immer, R., Eschenhagen, M., Bauer, and P. Hennig. Laplace Redux–Effortless Bayesian Deep Learning. arXiv preprint arXiv:2106.14806, 2021. ↩
-
S. Abnar, R. V. D. Berg, G. Ghiasi, M. Dehghani, N., Kalchbrenner, and H. Sedghi. Gradual Domain Adaptation in the Wild: When Intermediate Distributions are Absent. arXiv preprint arXiv:2106.06080, 2021. ↩
-
J. Chen, F. Liu, B. Avci, X. Wu, Y. Liang, and S. Jha. Detecting Errors and Estimating Accuracy on Unlabeled Data with Self-training Ensembles. arXiv preprint arXiv:2106.15728, 2021. ↩
-
E. Jones, S. Sagawa, P. W. Koh, A. Kumar, and P. Liang. Selective classification can magnify disparities across groups. In International Conference on Learning Representations (ICLR), 2021. ↩
-
J. Miller, R. Taori, A. Raghunathan, S. Sagawa, P. W. Koh, V. Shankar, P. Liang, Y. Carmon, and L. Schmidt. Accuracy on the line: on the strong correlation between out-of-distribution and in-distribution generalization. In International Conference on Machine Learning (ICML), 2021. ↩
NVIDIA CEO Awarded Lifetime Achievement Accolade by Asian American Engineer of the Year
NVIDIA CEO Jensen Huang was today conferred the Distinguished Lifetime Achievement Award by Asian American Engineer of the Year, an annual event that recognizes outstanding Asian American scientists, engineers and role models.
In a virtual ceremony, Huang was awarded for his contributions as “a visionary and innovator in parallel computing technology that accelerates the realization of AI computing.” He also spoke of his experience as an immigrant and an Asian American.
“It is strange to accept a lifetime achievement award because I feel like I’m just getting started – and NVIDIA indeed is,” Huang said. “Still, I’m grateful and deeply honored to receive this award, which I share with my colleagues at NVIDIA.”
Past recipients of the Distinguished Lifetime Achievement Award include Nobel laureates, astronauts and key corporate executives like TSMC founder Morris Chang. The event was hosted by the nonprofit Chinese Institute of Engineers/USA, part of the DiscoverE Diversity Council.
“I was fortunate to have had a front-row seat at the creation of the computer industry,” Huang said, reflecting on the early days of NVIDIA and the birth of GPU-accelerated computing. “We dreamed of solving grand computing challenges and even imagined that we would be a major computing company one day.”
Since the company’s first chip, Huang explained, scene complexity in computer graphics has increased around 500 million times. Beyond the field of graphics, GPU acceleration has been channeled into high performance computing and AI to address previously impossible problems in areas such as molecular biology.
“After nearly three decades, it is gratifying to see this computing approach demonstrate astonishing results, embraced by software developers and computer makers worldwide, become an essential instrument of scientists and the engine of modern AI,” Huang said. “There has never been a more exciting time to be an engineer.”
Huang also took the opportunity to share his thoughts as a first-generation immigrant amid a recent rash of violent attacks on Asian Americans in the wake of the pandemic.
“Like other immigrants, Asian Americans make up the fabric of America, have benefited from but also contributed significantly to building this great country,” he said. “Though America is not perfect, it’s hard as a first-generation immigrant not to feel a deep sense of gratitude for the opportunities she offered. I only hope America offers future generations the same opportunities she afforded me.”
The post NVIDIA CEO Awarded Lifetime Achievement Accolade by Asian American Engineer of the Year appeared first on The Official NVIDIA Blog.
Stanford AI Lab Papers and Talks at ICML 2021
![]()
The International Conference on Machine Learning (ICML) 2021 is being hosted virtually from July 18th – July 24th. We’re excited to share all the work from SAIL that’s being presented, and you’ll find links to papers, videos and blogs below. Feel free to reach out to the contact authors directly to learn more about the work that’s happening at Stanford!
List of Accepted Papers
Deep Reinforcement Learning amidst Continual Structured Non-Stationarity
Authors: Annie Xie, James Harrison, Chelsea Finn
Contact: anniexie@stanford.edu
Keywords: deep reinforcement learning, non-stationarity
Just Train Twice: Improving Group Robustness without Training Group Information
Authors: Evan Zheran Liu*, Behzad Haghgoo*, Annie S. Chen*, Aditi Raghunathan, Pang Wei Koh, Shiori Sagawa, Percy Liang, Chelsea Finn
Contact: evanliu@cs.stanford.edu
Links: Paper | Video
Keywords: robustness, spurious correlations

A theory of high dimensional regression with arbitrary correlations between input features and target functions: sample complexity, multiple descent curves and a hierarchy of phase transitions
Authors: Gabriel Mel, Surya Ganguli
Contact: sganguli@stanford.edu
Links: Paper
Keywords: high dimensional statistics, random matrix theory, regularization
Accelerating Feedforward Computation via Parallel Nonlinear Equation Solving
Authors: Yang Song, Chenlin Meng, Renjie Liao, Stefano Ermon
Contact: songyang@stanford.edu
Links: Paper | Website
Keywords: parallel computing, autoregressive models, densenets, rnns

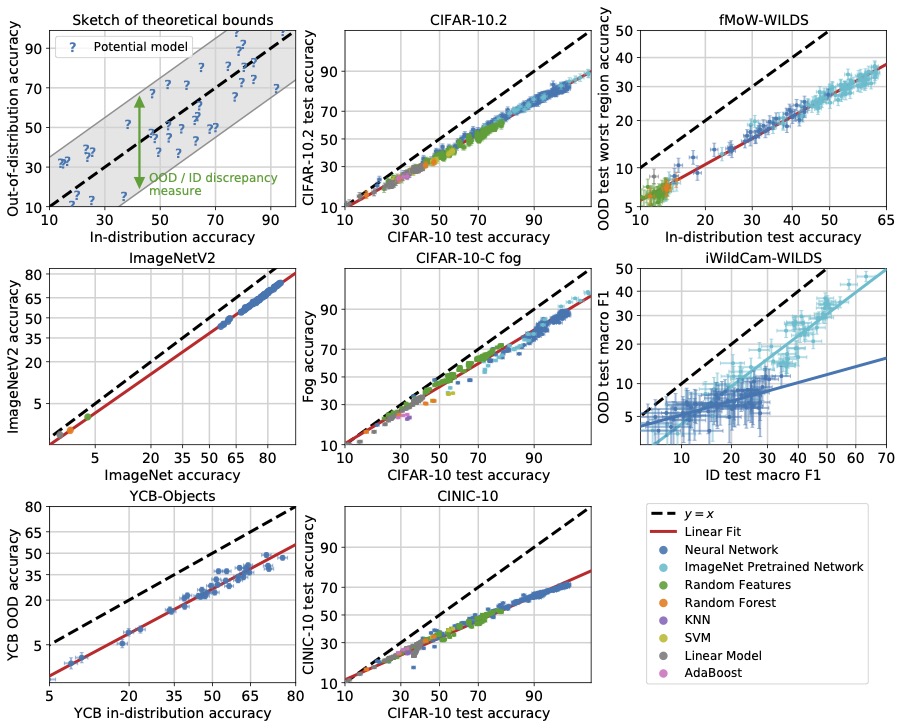
Accuracy on the Line: on the Strong Correlation Between Out-of-Distribution and In-Distribution Generalization
Authors: John Miller, Rohan Taori, Aditi Raghunathan, Shiori Sagawa, Pang Wei Koh, Vaishaal Shankar, Percy Liang, Yair Carmon, Ludwig Schmidt
Contact: rtaori@stanford.edu
Links: Paper
Keywords: out of distribution, generalization, robustness, distribution shift, machine learning
Bayesian Algorithm Execution: Estimating Computable Properties of Black-box Functions Using Mutual Information
Authors: Willie Neiswanger, Ke Alexander Wang, Stefano Ermon
Contact: neiswanger@cs.stanford.edu
Links: Paper | Blog Post | Video | Website
Keywords: bayesian optimization, experimental design, algorithm execution, information theory

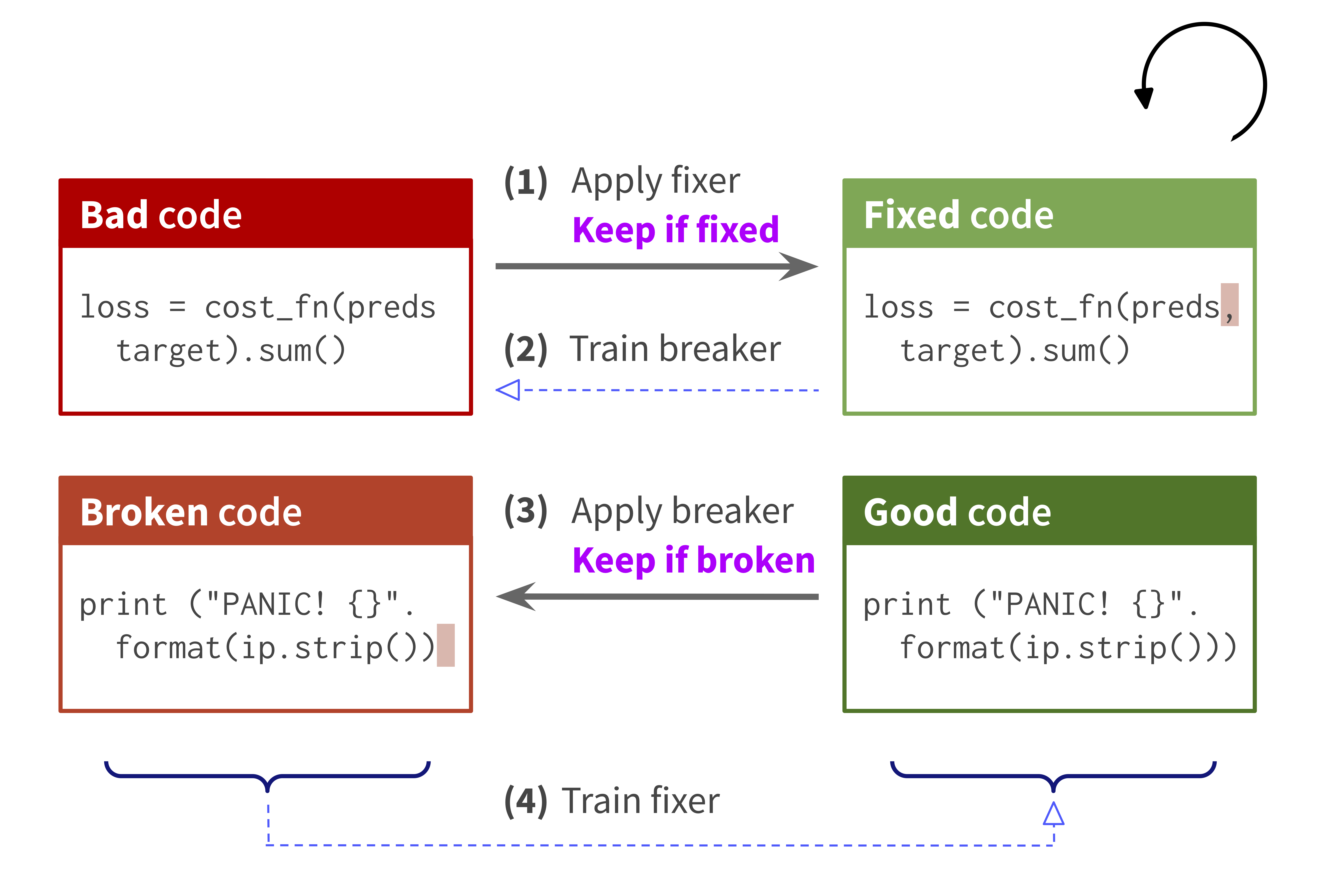
Break-It-Fix-It: Unsupervised Learning for Program Repair
Authors: Michihiro Yasunaga, Percy Liang
Contact: myasu@cs.stanford.edu
Links: Paper | Website
Keywords: program repair, unsupervised learning, translation, domain adaptation, self-supervised learning
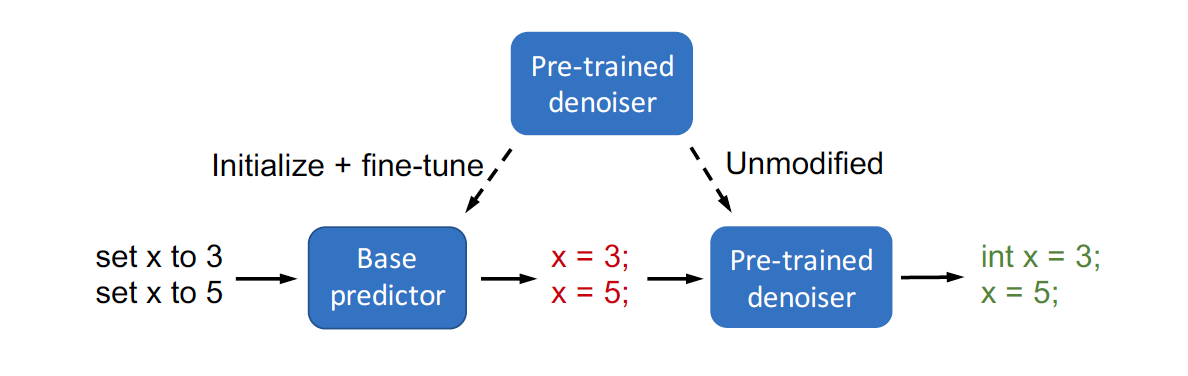
Composed Fine-Tuning: Freezing Pre-Trained Denoising Autoencoders for Improved Generalization
Authors: Sang Michael Xie, Tengyu Ma, Percy Liang
Contact: xie@cs.stanford.edu
Links: Paper | Website
Keywords: fine-tuning, adaptation, freezing, ood generalization, structured prediction, semi-supervised learning, unlabeled outputs
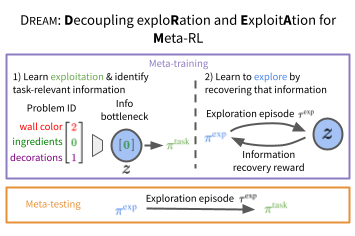
Decoupling Exploration and Exploitation for Meta-Reinforcement Learning without Sacrifices
Authors: Evan Zheran Liu, Aditi Raghunathan, Percy Liang, Chelsea Finn
Contact: evanliu@cs.stanford.edu
Links: Paper | Blog Post | Video | Website
Keywords: meta-reinforcement learning, exploration
Exponential Lower Bounds for Batch Reinforcement Learning: Batch RL can be Exponentially Harder than Online RL
Authors: Andrea Zanette
Contact: zanette@stanford.edu
Links: Paper | Video
Keywords: reinforcement learning, lower bounds, linear value functions, off-policy evaluation, policy learning
Federated Composite Optimization
Authors: Honglin Yuan, Manzil Zaheer, Sashank Reddi
Contact: yuanhl@cs.stanford.edu
Links: Paper | Video | Website
Keywords: federated learning, distributed optimization, convex optimization

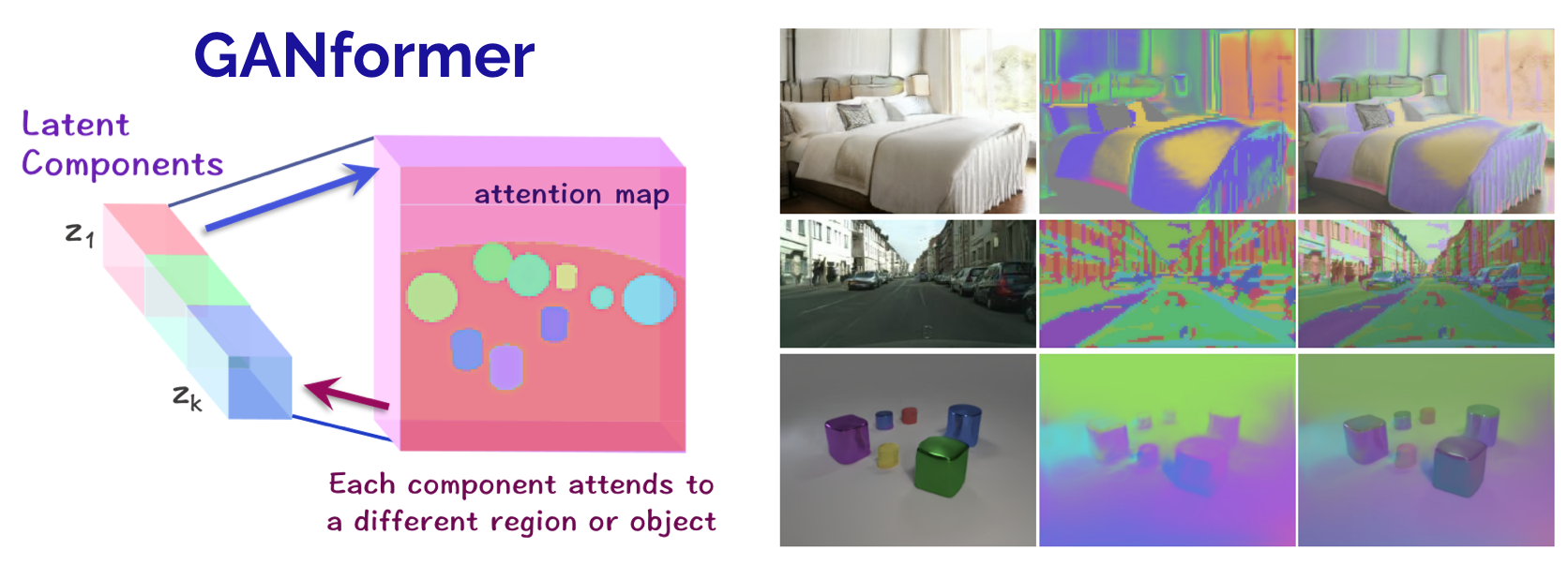
Generative Adversarial Transformers
Authors: Drew A. Hudson, C. Lawrence Zitnick
Contact: dorarad@stanford.edu
Links: Paper | Website
Keywords: gans, transformers, compositionality, attention, bottom-up, top-down, disentanglement, object-oriented, representation learning, scenes
Improving Generalization in Meta-learning via Task Augmentation
Authors: Huaxiu Yao, Longkai Huang, Linjun Zhang, Ying Wei, Li Tian, James Zou, Junzhou Huang, Zhenhui Li
Contact: huaxiu@cs.stanford.edu
Links: Paper
Keywords: meta-learning
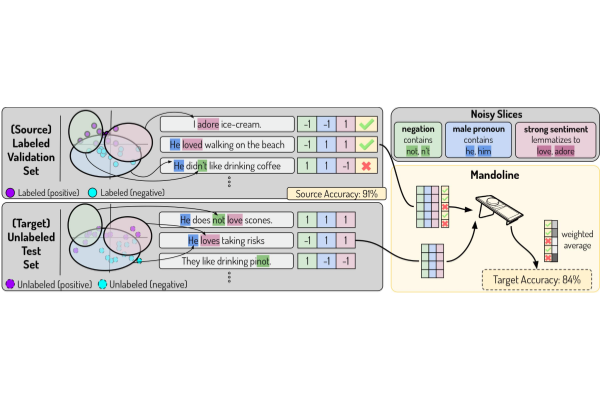
Mandoline: Model Evaluation under Distribution Shift
Authors: Mayee Chen, Karan Goel, Nimit Sohoni, Fait Poms, Kayvon Fatahalian, Christopher Ré
Contact: mfchen@stanford.edu
Links: Paper
Keywords: evaluation, distribution shift, importance weighting
Memory-Efficient Pipeline-Parallel DNN Training
Authors: Deepak Narayanan
Contact: deepakn@stanford.edu
Links: Paper
Keywords: distributed training, pipeline model parallelism, large language model training
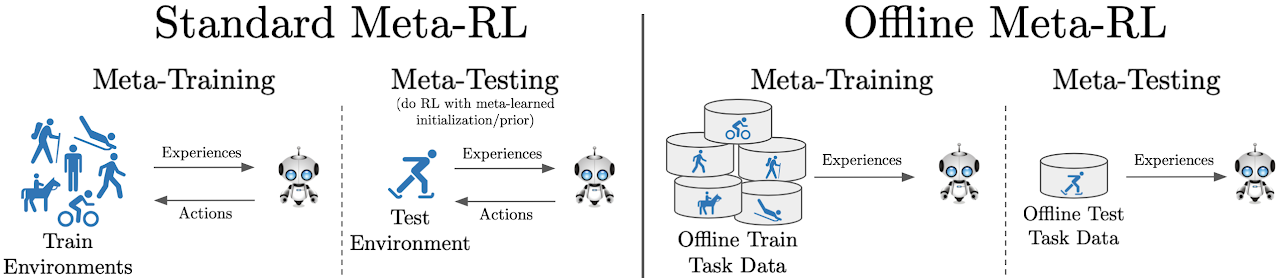
Offline Meta-Reinforcement Learning with Advantage Weighting
Authors: Eric Mitchell, Rafael Rafailov, Xue Bin Peng, Sergey Levine, Chelsea Finn
Contact: em7@stanford.edu
Links: Paper | Website
Keywords: meta-rl offline rl batch meta-learning
SECANT: Self-Expert Cloning for Zero-Shot Generalization of Visual Policies
Authors: Linxi Fan, Guanzhi Wang, De-An Huang, Zhiding Yu, Li Fei-Fei, Yuke Zhu, Anima Anandkumar
Contact: jimfan@cs.stanford.edu
Links: Paper | Website
Keywords: reinforcement learning, computer vision, sim-to-real, robotics, simulation

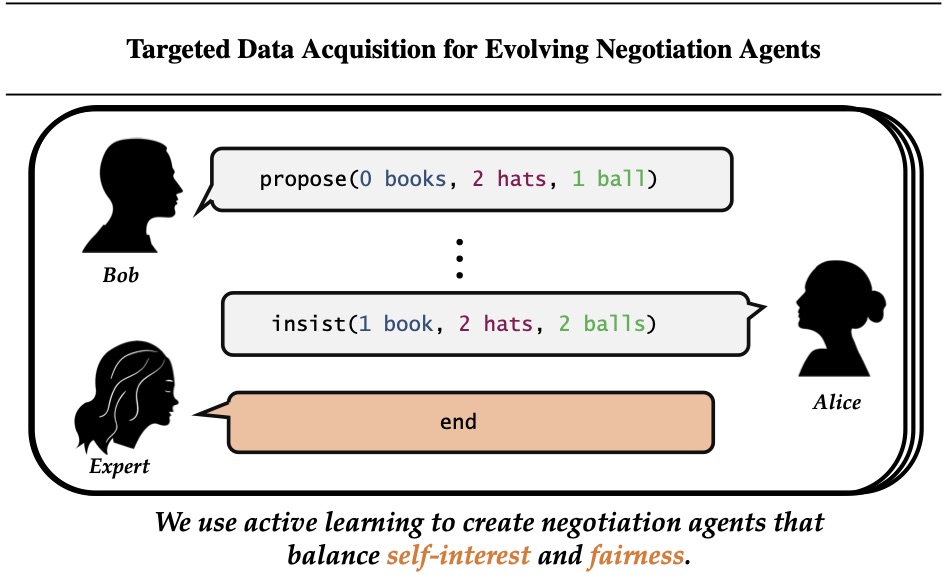
Targeted Data Acquisition for Evolving Negotiation Agents
Authors: Minae Kwon, Siddharth Karamcheti, Mariano-Florentino Cuéllar, Dorsa Sadigh
Contact: minae@cs.stanford.edu
Links: Paper | Video
Keywords: negotiation, targeted data acquisition, active learning
Understanding self-supervised Learning Dynamics without Contrastive Pairs
Authors: Yuandong Tian, Xinlei Chen, Surya Ganguli
Contact: sganguli@stanford.edu
Links: Paper
Keywords: self-supervised learning
WILDS: A Benchmark of in-the-Wild Distribution Shifts
Authors: Pang Wei Koh*, Shiori Sagawa*, Henrik Marklund, Sang Michael Xie, Marvin Zhang, Akshay Balsubramani, Weihua Hu, Michihiro Yasunaga, Richard Lanas Phillips, Irena Gao, Tony Lee, Etienne David, Ian Stavness, Wei Guo, Berton A. Earnshaw, Imran S. Haque, Sara Beery, Jure Leskovec, Anshul Kundaje, Emma Pierson, Sergey Levine, Chelsea Finn, Percy Liang
Contact: pangwei@cs.stanford.edu, ssagawa@cs.stanford.edu
Links: Paper | Website
Keywords: robustness, distribution shifts, benchmark

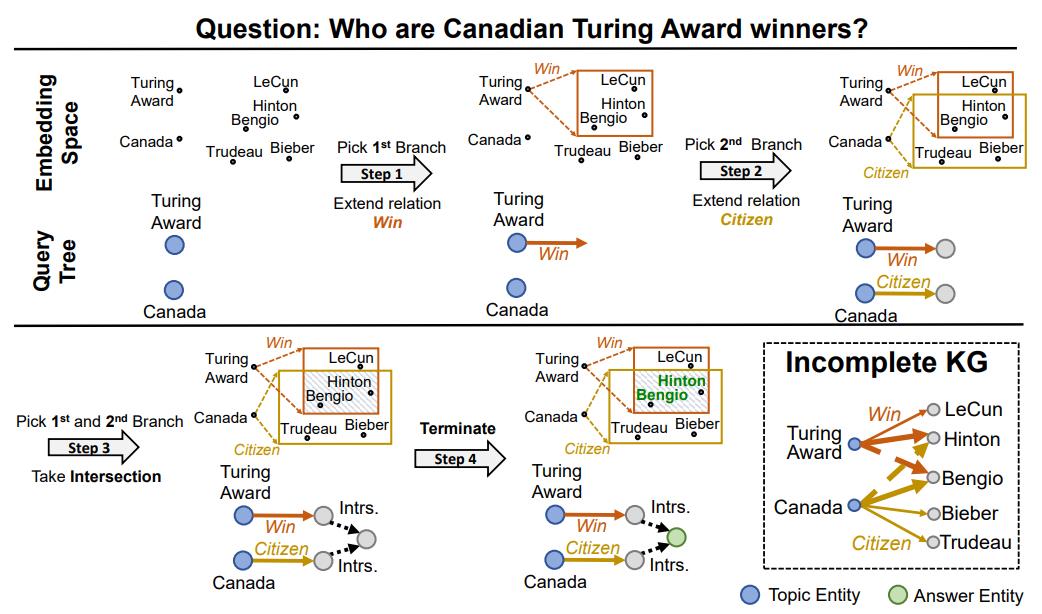
LEGO: Latent Execution-Guided Reasoning for Multi-Hop Question Answering on Knowledge Graphs
Authors: Hongyu Ren, Hanjun Dai, Bo Dai, Xinyun Chen, Michihiro Yasunaga, Haitian Sun, Dale Schuurmans, Jure Leskovec, Denny Zhou
Contact: hyren@cs.stanford.edu
Keywords: knowledge graphs, question answering, multi-hop reasoning
We look forward to seeing you at ICML 2021!
High Fidelity Image Generation Using Diffusion Models
Posted by Jonathan Ho, Research Scientist and Chitwan Saharia, Software Engineer, Google Research, Brain Team
Natural image synthesis is a broad class of machine learning (ML) tasks with wide-ranging applications that pose a number of design challenges. One example is image super-resolution, in which a model is trained to transform a low resolution image into a detailed high resolution image (e.g., RAISR). Super-resolution has many applications that can range from restoring old family portraits to improving medical imaging systems. Another such image synthesis task is class-conditional image generation, in which a model is trained to generate a sample image from an input class label. The resulting generated sample images can be used to improve performance of downstream models for image classification, segmentation, and more.
Generally, these image synthesis tasks are performed by deep generative models, such as GANs, VAEs, and autoregressive models. Yet each of these generative models has its downsides when trained to synthesize high quality samples on difficult, high resolution datasets. For example, GANs often suffer from unstable training and mode collapse, and autoregressive models typically suffer from slow synthesis speed.
Alternatively, diffusion models, originally proposed in 2015, have seen a recent revival in interest due to their training stability and their promising sample quality results on image and audio generation. Thus, they offer potentially favorable trade-offs compared to other types of deep generative models. Diffusion models work by corrupting the training data by progressively adding Gaussian noise, slowly wiping out details in the data until it becomes pure noise, and then training a neural network to reverse this corruption process. Running this reversed corruption process synthesizes data from pure noise by gradually denoising it until a clean sample is produced. This synthesis procedure can be interpreted as an optimization algorithm that follows the gradient of the data density to produce likely samples.
Today we present two connected approaches that push the boundaries of the image synthesis quality for diffusion models — Super-Resolution via Repeated Refinements (SR3) and a model for class-conditioned synthesis, called Cascaded Diffusion Models (CDM). We show that by scaling up diffusion models and with carefully selected data augmentation techniques, we can outperform existing approaches. Specifically, SR3 attains strong image super-resolution results that surpass GANs in human evaluations. CDM generates high fidelity ImageNet samples that surpass BigGAN-deep and VQ-VAE2 on both FID score and Classification Accuracy Score by a large margin.
SR3: Image Super-Resolution
SR3 is a super-resolution diffusion model that takes as input a low-resolution image, and builds a corresponding high resolution image from pure noise. The model is trained on an image corruption process in which noise is progressively added to a high-resolution image until only pure noise remains. It then learns to reverse this process, beginning from pure noise and progressively removing noise to reach a target distribution through the guidance of the input low-resolution image..
With large scale training, SR3 achieves strong benchmark results on the super-resolution task for face and natural images when scaling to resolutions 4x–8x that of the input low-resolution image. These super-resolution models can further be cascaded together to increase the effective super-resolution scale factor, e.g., stacking a 64×64 → 256×256 and a 256×256 → 1024×1024 face super-resolution model together in order to perform a 64×64 → 1024×1024 super-resolution task.
We compare SR3 with existing methods using human evaluation study. We conduct a Two-Alternative Forced Choice Experiment where subjects are asked to choose between the reference high resolution image, and the model output when asked the question, “Which image would you guess is from a camera?” We measure the performance of the model through confusion rates (% of time raters choose the model outputs over reference images, where a perfect algorithm would achieve a 50% confusion rate). The results of this study are shown in the figure below.
 |
| Above: We achieve close to 50% confusion rate on the task of 16×16 → 128×128 faces, outperforming state-of-the-art face super-resolution methods PULSE and FSRGAN. Below: We also achieve a 40% confusion rate on the much more difficult task of 64×64 → 256×256 natural images, outperforming the regression baseline by a large margin. |
CDM: Class-Conditional ImageNet Generation
Having shown the effectiveness of SR3 in performing natural image super-resolution, we go a step further and use these SR3 models for class-conditional image generation. CDM is a class-conditional diffusion model trained on ImageNet data to generate high-resolution natural images. Since ImageNet is a difficult, high-entropy dataset, we built CDM as a cascade of multiple diffusion models. This cascade approach involves chaining together multiple generative models over several spatial resolutions: one diffusion model that generates data at a low resolution, followed by a sequence of SR3 super-resolution diffusion models that gradually increase the resolution of the generated image to the highest resolution. It is well known that cascading improves quality and training speed for high resolution data, as shown by previous studies (for example in autoregressive models and VQ-VAE-2) and in concurrent work for diffusion models. As demonstrated by our quantitative results below, CDM further highlights the effectiveness of cascading in diffusion models for sample quality and usefulness in downstream tasks, such as image classification.
 |
| Example of the cascading pipeline that includes a sequence of diffusion models: the first generates a low resolution image, and the rest perform upsampling to the final high resolution image. Here the pipeline is for class-conditional ImageNet generation, which begins with a class-conditional diffusion model at 32×32 resolution, followed by 2x and 4x class-conditional super-resolution using SR3. |
 |
| Selected generated images from our 256×256 cascaded class-conditional ImageNet model. |
Along with including the SR3 model in the cascading pipeline, we also introduce a new data augmentation technique, which we call conditioning augmentation, that further improves the sample quality results of CDM. While the super-resolution models in CDM are trained on original images from the dataset, during generation they need to perform super-resolution on the images generated by a low-resolution base model, which may not be of sufficiently high quality in comparison to the original images. This leads to a train-test mismatch for the super-resolution models. Conditioning augmentation refers to applying data augmentation to the low-resolution input image of each super-resolution model in the cascading pipeline. These augmentations, which in our case include Gaussian noise and Gaussian blur, prevents each super-resolution model from overfitting to its lower resolution conditioning input, eventually leading to better higher resolution sample quality for CDM.
Altogether, CDM generates high fidelity samples superior to BigGAN-deep and VQ-VAE-2 in terms of both FID score and Classification Accuracy Score on class-conditional ImageNet generation. CDM is a pure generative model that does not use a classifier to boost sample quality, unlike other models such as ADM and VQ-VAE-2. See below for quantitative results on sample quality.
 |
| Class-conditional ImageNet FID scores at the 256×256 resolution for methods that do not use extra classifiers to boost sample quality. BigGAN-deep is reported at its best truncation value. (Lower is better.) |
 |
| ImageNet classification accuracy scores at the 256×256 resolution, measuring the validation set accuracy of a classifier trained on generated data. CDM generated data attains significant gains over existing methods, closing the gap in classification accuracy between real and generated data. (Higher is better.) |
Conclusion
With SR3 and CDM, we have pushed the performance of diffusion models to state-of-the-art on super-resolution and class-conditional ImageNet generation benchmarks. We are excited to further test the limits of diffusion models for a wide variety of generative modeling problems. For more information on our work, please visit Image Super-Resolution via Iterative Refinement and Cascaded Diffusion Models for High Fidelity Image Generation.
Acknowledgements:
We thank our co-authors William Chan, Mohammad Norouzi, Tim Salimans, and David Fleet, and we are grateful for research discussions and assistance from Ben Poole, Jascha Sohl-Dickstein, Doug Eck, and the rest of the Google Research, Brain Team. Thanks to Tom Small for helping us with the animations.

Real-World ML with Coral: Manufacturing
Posted by Michael Brooks, Coral
For over 3 years, Coral has been focused on enabling privacy-preserving Edge ML with low-power, high performance products. We’ve released many examples and projects designed to help you quickly accelerate ML for your specific needs. One of the most common requests we get after exploring the Coral models and projects is: How do we move to production?
With this in mind we’re introducing the first of our use-case specific demos. These demos are intended to to take full advantage of the Coral Edge TPU™ with high performance, production-quality code that is easily customizable to meet your ML requirements. In this demo we focus on use cases that are specific to manufacturing; worker safety and quality grading / visual inspection.
Demo Overview
The Coral manufacturing demo targets a x86 or powerful ARM64 system with OpenGL acceleration that processes and displays two simultaneous inputs. The default demo, using the included example videos, looks like this:

The two examples being run are:
- Worker Safety: Performs generic person detection (powered by COCO-trained SSDLite MobileDet) and then runs a simple algorithm to detect bounding box collisions to see if a person is in an unsafe region.
- Visual Inspection: Performs apple detection (using the same COCO-trained SSDLite MobileDet from Worker Safety) and then crops the frame to the detected apple and runs a retrained MobileNetV2 that classifies fresh vs rotten apples.
By combining these two examples, we are able to demonstrate multiple Coral features that can enable this processing, including:
- Co-compilation
- Cascading models (using the output of one model to feed another)
- Classification retraining
- Real time processing of multiple inputs
Creating The Demo
When designing a new ML application, it is critical to ensure that you can meet your latency and accuracy requirements. With the two applications described here, we went through the following process to choose models, train these models, and deploy to the EdgeTPU – this process should be used when beginning any Coral application.
Choosing the Models
When deciding on a model to use, the new Coral Model Page is the best place to start. For this demo, we know that we need a detection model (which will be used for detection of both people and apples) as well as a classification model.
Detection
When picking a detection model from the Detection Model Page, there are four aspects to a model we want to look for:
- Training Dataset: In the case of the models page, all of our normal detection models use the COCO dataset. Referring to the labels, we can find both apples and people, so we can use just the one model for both detection tasks.
- Latency: We will need to run at least 3 inferences per frame and need this to keep up with our input (30 FPS). This means we need our detection to be as fast as possible. From the models page, we can see two good options: SSD MobileNet v2 (7.4 ms) and MobileDet (8.0 ms). This is the first point where we see the clear advantage of Coral – looking at the benchmarks at the bottom of our x86+USB CTS Output we can see even on a powerful workstation this would be 90 ms and 123 ms respectively.
- Accuracy/Precision: We also want as accurate a model as possible. This is evaluated using the primary challenge metric from COCO evaluation metrics. We see here MobileDet (32.8%) clearly outpeforms MobileNet V2 (25.7%).
- Size: In order to fully co-compile this detection model with the classification model below, we need to ensure that we can fit both models in the 8MB of cache on the Edge TPU. This means we want as small a model as possible. MobileDet is 5.1 MB vs MobileNet V2 is 6.6 MB.
With the above considerations, we chose SSDLite MobileDet.
Classification
For the fresh-or-rotten apple classification, there are many more options on the Coral Classification Page. What we want to check is the same:
- Training Dataset: We’ll be retraining on our new dataset, so this isn’t critical in this application.
- Latency: We want the classification to be as fast as possible. Luckily many of the models on our page are extremely fast relative to the 30 FPS frame rate we demand. With this in mind we can eliminate all the Inception models and ResNet-50.
- Accuracy: Accuracy for Top-1 and Top-5 is provided. We want to be as accurate as possible for Top-1 (since we are only checking fresh vs rotten) – but still need to consider latency. With this in mind we eliminate MobileNet v1.
- Size: As mentioned above, we want to ensure we can fit both the detection and classification models (or as much as possible) so we can easily eliminate the EfficientNet options.
This leaves us with MobileNet v2 and MobileNet v3. We opted for v2 due to existing tutorials on retraining this model.
Retraining Classification
With the model decisions taken care of, now we need to retain the classification model to identify fresh and rotten apples. Coral.ai offers training tutorials in CoLab (uses post-training quantization) and Docker (uses quantization aware training) formats – but we’ve also included the retraining python script in this demo’s repo.
Our Fresh/Rotten data comes from the “Fruits fresh and rotten for classification” dataset – we simply omit everything but apples.
In our script, we first load the standard Keras MobileNetV2 – freezing the first 100 layers and adding a few extra layers at the end:
base_model = tf.keras.applications.MobileNetV2(input_shape=input_shape,
include_top=False,
classifier_activation='softmax',
weights='imagenet')
# Freeze first 100 layers
base_model.trainable = True
for layer in base_model.layers[:100]:
layer.trainable = False
model = tf.keras.Sequential([
base_model,
tf.keras.layers.Conv2D(filters=32, kernel_size=3, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.Dense(units=2, activation='softmax')
])
model.compile(loss='categorical_crossentropy',
optimizer=tf.keras.optimizers.RMSprop(lr=1e-5),
metrics=['accuracy'])
print(model.summary())Next, with the dataset download into ./dataset we train our model:
train_datagen = ImageDataGenerator(rescale=1./255,
zoom_range=0.3,
rotation_range=50,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
val_datagen = ImageDataGenerator(rescale=1./255)
dataset_path = './dataset'
train_set_path = os.path.join(dataset_path, 'train')
val_set_path = os.path.join(dataset_path, 'test')
batch_size = 64
train_generator = train_datagen.flow_from_directory(train_set_path,
target_size=input_size,
batch_size=batch_size,
class_mode='categorical')
val_generator = val_datagen.flow_from_directory(val_set_path,
target_size=input_size,
batch_size=batch_size,
class_mode='categorical')
epochs = 15
history = model.fit(train_generator,
steps_per_epoch=train_generator.n // batch_size,
epochs=epochs,
validation_data=val_generator,
validation_steps=val_generator.n // batch_size,
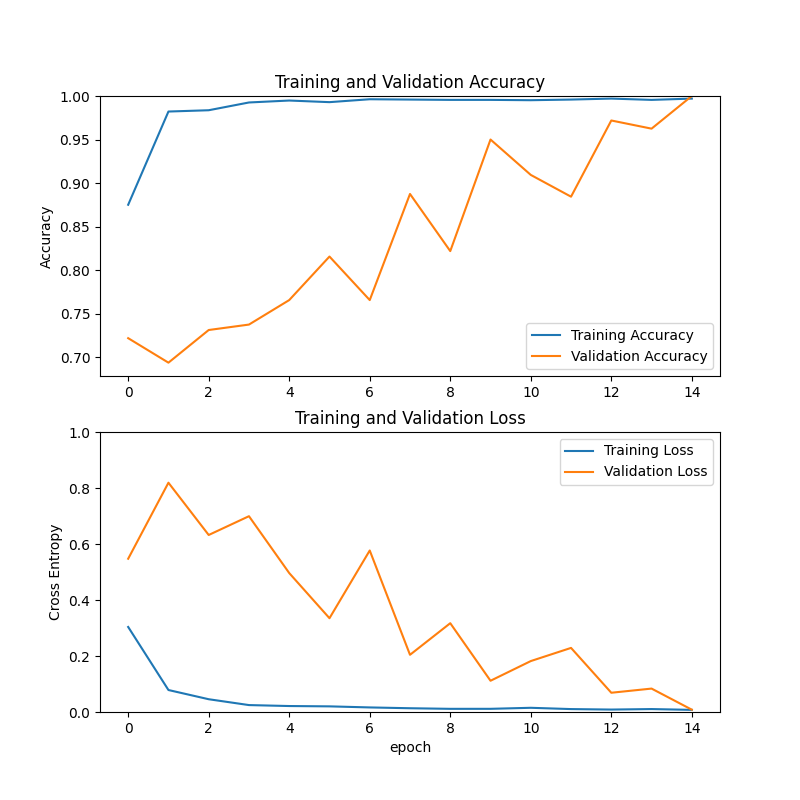
verbose=1)Note that we’re only using 15 epochs. When retraining on another dataset it is very likely more will be required. With the apple dataset, we can see this model quickly hits very high accuracy numbers:
For your own dataset and model more epochs will likely be needed (the script will generate the above plots for validation).
We now have a Keras model that works for our apple quality inspector. In order to run this on a Coral Edge TPU, the model must be quantized and converted to TF Lite. We’ll do this using post-training quantization – quantizing based on a representative dataset after training:
def representative_data_gen():
dataset_list = tf.data.Dataset.list_files('./dataset/test/*/*')
for i in range(100):
image = next(iter(dataset_list))
image = tf.io.read_file(image)
image = tf.io.decode_jpeg(image, channels=3)
image = tf.image.resize(image, input_size)
image = tf.cast(image / 255., tf.float32)
image = tf.expand_dims(image, 0)
yield [image]
model.input.set_shape((1,) + model.input.shape[1:])
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_data_gen
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.target_spec.supported_types = [tf.int8]
converter.inference_input_type = tf.uint8
converter.inference_output_type = tf.uint8
tflite_model = converter.convert()The script will then compile the model and evaluate both the Keras and TF Lite models – but we’ll need to take one extra step beyond the script: We must use the Edge TPU Compiler to co-compile the classification model with our detection model.
Co-compiling the models
We now have two quantized TF Lite models: classifier.tflite and the default CPU model for MobileDet taken from the Coral model page. We can compile them together to ensure that they share the same caching token – when either model is requested the parameter data will already be cached. This simply requires passing both models to the compiler:
edgetpu_compiler ssdlite_mobiledet_coco_qat_postprocess.tflite classifier.tflite
Edge TPU Compiler version 15.0.340273435
Models compiled successfully in 1770 ms.
Input model: ssdlite_mobiledet_coco_qat_postprocess.tflite
Input size: 4.08MiB
Output model: ssdlite_mobiledet_coco_qat_postprocess_edgetpu.tflite
Output size: 5.12MiB
On-chip memory used for caching model parameters: 4.89MiB
On-chip memory remaining for caching model parameters: 2.74MiB
Off-chip memory used for streaming uncached model parameters: 0.00B
Number of Edge TPU subgraphs: 1
Total number of operations: 125
Operation log: ssdlite_mobiledet_coco_qat_postprocess_edgetpu.log
Model successfully compiled but not all operations are supported by the Edge TPU. A percentage of the model will instead run on the CPU, which is slower. If possible, consider updating your model to use only operations supported by the Edge TPU. For details, visit g.co/coral/model-reqs.
Number of operations that will run on Edge TPU: 124
Number of operations that will run on CPU: 1
See the operation log file for individual operation details.
Input model: classifier.tflite
Input size: 3.07MiB
Output model: classifier_edgetpu.tflite
Output size: 3.13MiB
On-chip memory used for caching model parameters: 2.74MiB
On-chip memory remaining for caching model parameters: 0.00B
Off-chip memory used for streaming uncached model parameters: 584.06KiB
Number of Edge TPU subgraphs: 1
Total number of operations: 72
Operation log: classifier_edgetpu.log
See the operation log file for individual operation details.There are two things to note in this log. First is that we see one operation is run on the CPU for the detection model – this is expected. The TF Lite SSD PostProcess will always run on CPU. Second, we couldn’t quite fit everything on the on-chip memory, the classifier has 584 kB of off-chip memory needed. This is fine – we’ve substantially reduced the amount of IO time needed. Both models will now be in the same folder, but because we co-compiled them they are aware of each other and the cache will persist parameters for both models.
Customizing For Your Application
The demo is optimized and ready for customization and deployment. It can be cross compiled for other architectures (currently it’s only for x86 or ARM64) and statically links libedgetpu to allow this binary to be deployed to many different Linux systems with an Edge TPU.
There are many things that can be done to customize the model to your application:
- The quickest changes are the inputs, which can be adjusted via the
--visual_inspection_inputand--worker_safety_inputflags. The demo accepts mp4 files and V4L2 camera devices. - The worker safety demo can be further improved with more complicated keepout algorithms (including consideration of angle/distance from camera) as well as retraining on overhead data. Currently the demo checks only the bottom of the bounding box, but the flag
--safety_check_whole_boxcan be used to compare to the whole box (for situations like overhead cameras). - The apple inspection demonstrates simple quality grading / inspection – this cascaded model approach (using detection to determine bounding boxes and feeding into another model) can be applied to many different uses. By retraining the detection and classification model this can be customized for your application.
Conclusion
The Coral Manufacturing Demo demonstrates how Coral can be used in a production environment to solve multiple ML needs. The Coral accelerator provides a low-cost and low-power way to add enough ML compute to run both tasks in parallel without over-burdening the host. We hope that you can use the Coral Manufacturing Demo as a starting point to bringing Coral intelligence into your own manufacturing environment.
To learn more about ways edge ML can be used to benefit day to day operations across a variety of industries, visit our Industries page. For more information about Coral Products and Partner products with Coral integrated, please visit us at Coral.ai.
A conversation with James Whitfield, Amazon Visiting Academic, on quantum computing
Dartmouth College professor is focusing on broader educational efforts with customers and other stakeholders.Read More
Facebook Fellow Spotlight: Pioneering self-monitoring networks at scale
Each year, PhD students from around the world apply for the Facebook Fellowship, a program designed to encourage and support promising doctoral students who are engaged in innovative and relevant research in areas related to computer science and engineering at an accredited university.
As a continuation of our Fellowship spotlight series, we’re highlighting 2020 Facebook Fellow in Networking and Connectivity, Nofel Yaseen.
Nofel is a fourth-year PhD student at the University of Pennsylvania, advised by Vincent Liu. Nofel’s research interests lie in the broad areas of distributed systems and networking, in addition to a number of related topics. His recent work aims to design a fine-grained network measurement tool and to see how we can use those measurements to understand network traffic patterns.
Nofel is fascinated by the internet and how it allows us to communicate worldwide, from anywhere, at any time. “The sheer complexity of the network system deployed to keep the world online intrigues me to understand it more,” he says.
This led Nofel to pursue a PhD in network systems, where he could explore the many types of devices deployed to various systems — servers, switches, and network functions. Through his research, a question emerged: How do we currently monitor networks, and is there a way to monitor them more effectively?
“Networks keep getting larger and larger, and as they expand, we need more innovation to handle the scale and growth of the network,” Nofel explains. As networks grow, the question of how to monitor network status and performance becomes more complex. Humans can only monitor so much, and the reality of expanding networks necessitates a tool that can automate network monitoring. These questions led him and his collaborators to the creation of a tool called Speedlight, a fine-grained network measurement tool that can help us better understand network traffic patterns.
Speedlight has been deployed and tested in small topology, but Nofel hopes to scale his work on Speedlight to address the needs of larger networks. “Networks are constantly evolving, and will require more research and innovation to bring new solutions that can handle huge networks,” he says, and scaling network monitoring tools will need to address challenges in deployment and traffic. Through the Facebook Research Fellowship, Nofel has connected with Facebook engineers in an effort to understand the industry problems that larger data centers face in terms of monitoring so he can focus his work more intensely.
“I asked myself, ‘How can networks be self-driving?’” he says. “How can they monitor and debug by themselves? How do operators select what to deploy in their own data centers? How do they choose what to run and what not to run?” Nofel is excited to pursue additional research and investigate how networks can integrate machine learning and deep learning into further evolutions of monitoring, as they are a natural extension to develop self-monitoring networks.
To learn more about Nofel Yaseen and his research, visit his website.
The post Facebook Fellow Spotlight: Pioneering self-monitoring networks at scale appeared first on Facebook Research.
Speeding Up Reinforcement Learning with a New Physics Simulation Engine
Posted by C. Daniel Freeman, Senior Software Engineer and Erik Frey, Staff Software Engineer, Google Research
Reinforcement learning (RL) is a popular method for teaching robots to navigate and manipulate the physical world, which itself can be simplified and expressed as interactions between rigid bodies1 (i.e., solid physical objects that do not deform when a force is applied to them). In order to facilitate the collection of training data in a practical amount of time, RL usually leverages simulation, where approximations of any number of complex objects are composed of many rigid bodies connected by joints and powered by actuators. But this poses a challenge: it frequently takes millions to billions of simulation frames for an RL agent to become proficient at even simple tasks, such as walking, using tools, or assembling toy blocks.
While progress has been made to improve training efficiency by recycling simulation frames, some RL tools instead sidestep this problem by distributing the generation of simulation frames across many simulators. These distributed simulation platforms yield impressive results that train very quickly, but they must run on compute clusters with thousands of CPUs or GPUs which are inaccessible to most researchers.
In “Brax – A Differentiable Physics Engine for Large Scale Rigid Body Simulation”, we present a new physics simulation engine that matches the performance of a large compute cluster with just a single TPU or GPU. The engine is designed to both efficiently run thousands of parallel physics simulations alongside a machine learning (ML) algorithm on a single accelerator and scale millions of simulations seamlessly across pods of interconnected accelerators. We’ve open sourced the engine along with reference RL algorithms and simulation environments that are all accessible via Colab. Using this new platform, we demonstrate 100-1000x faster training compared to a traditional workstation setup.
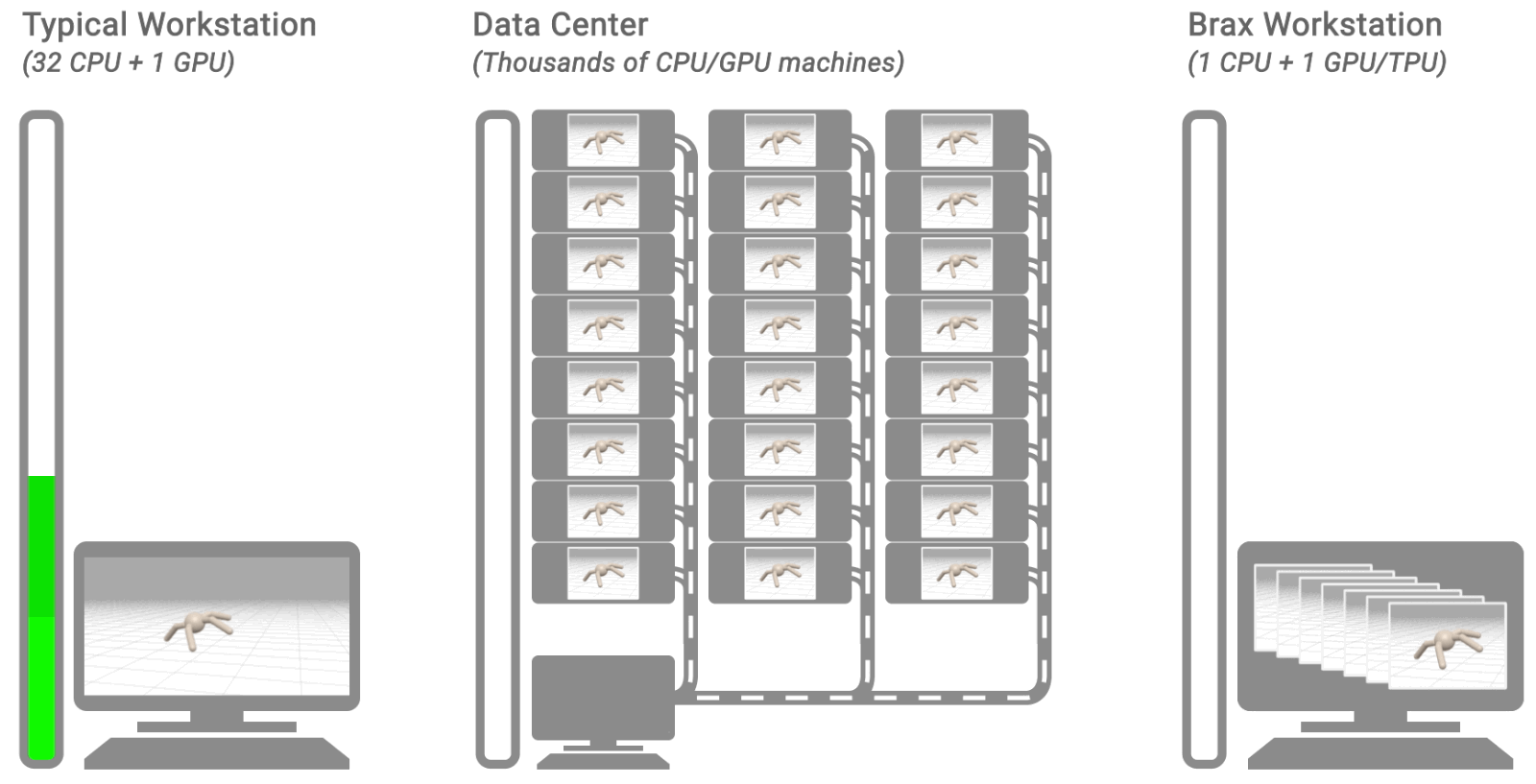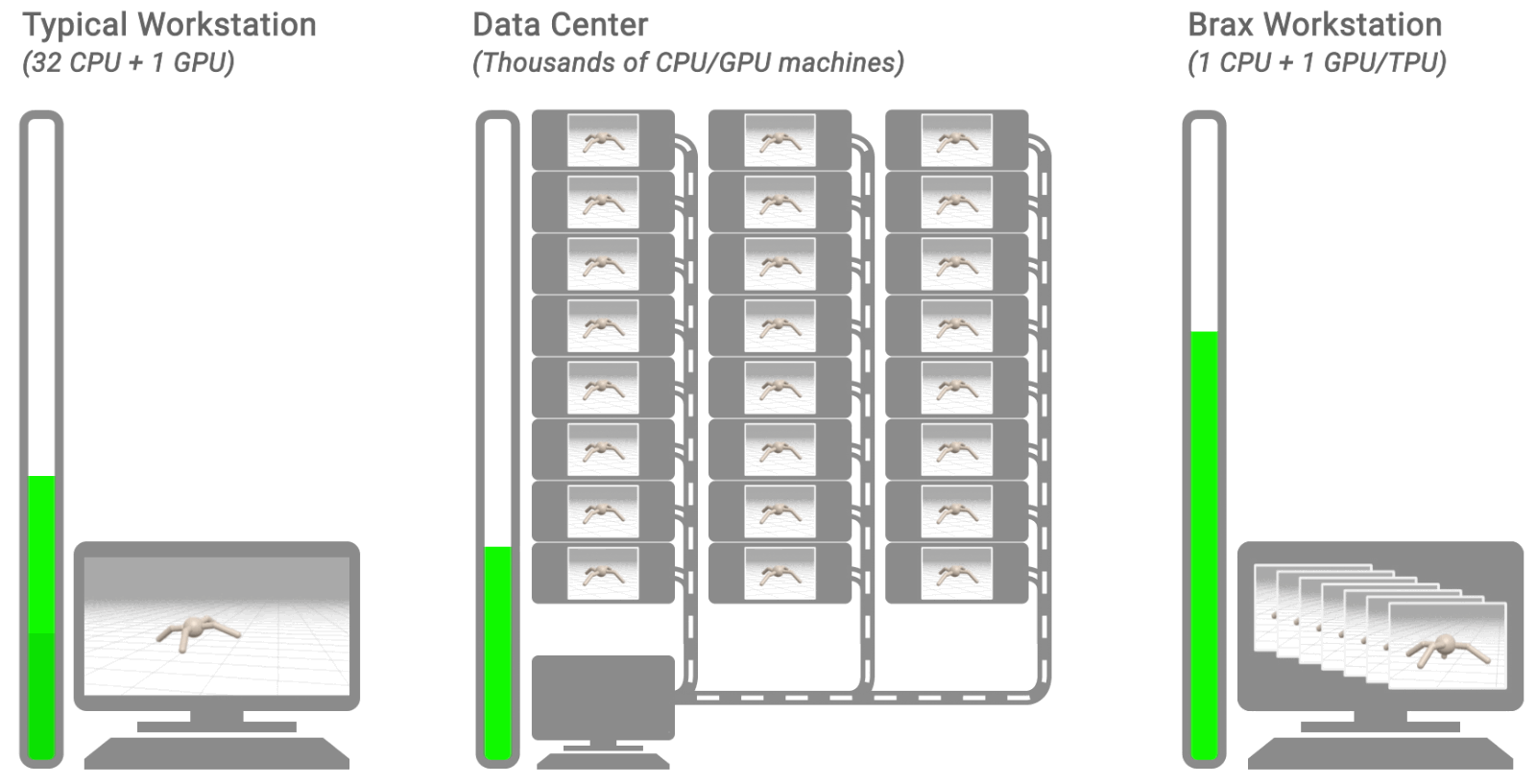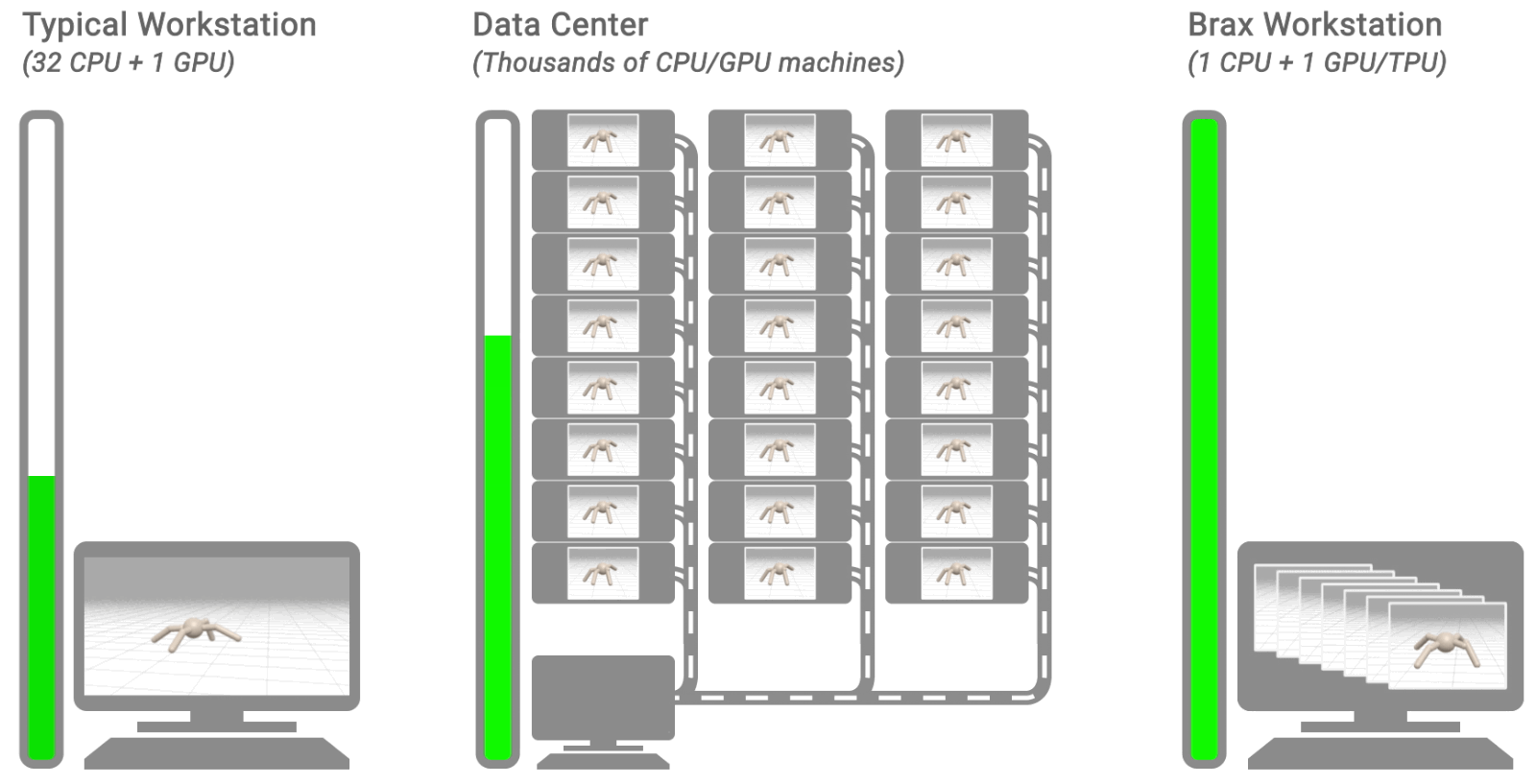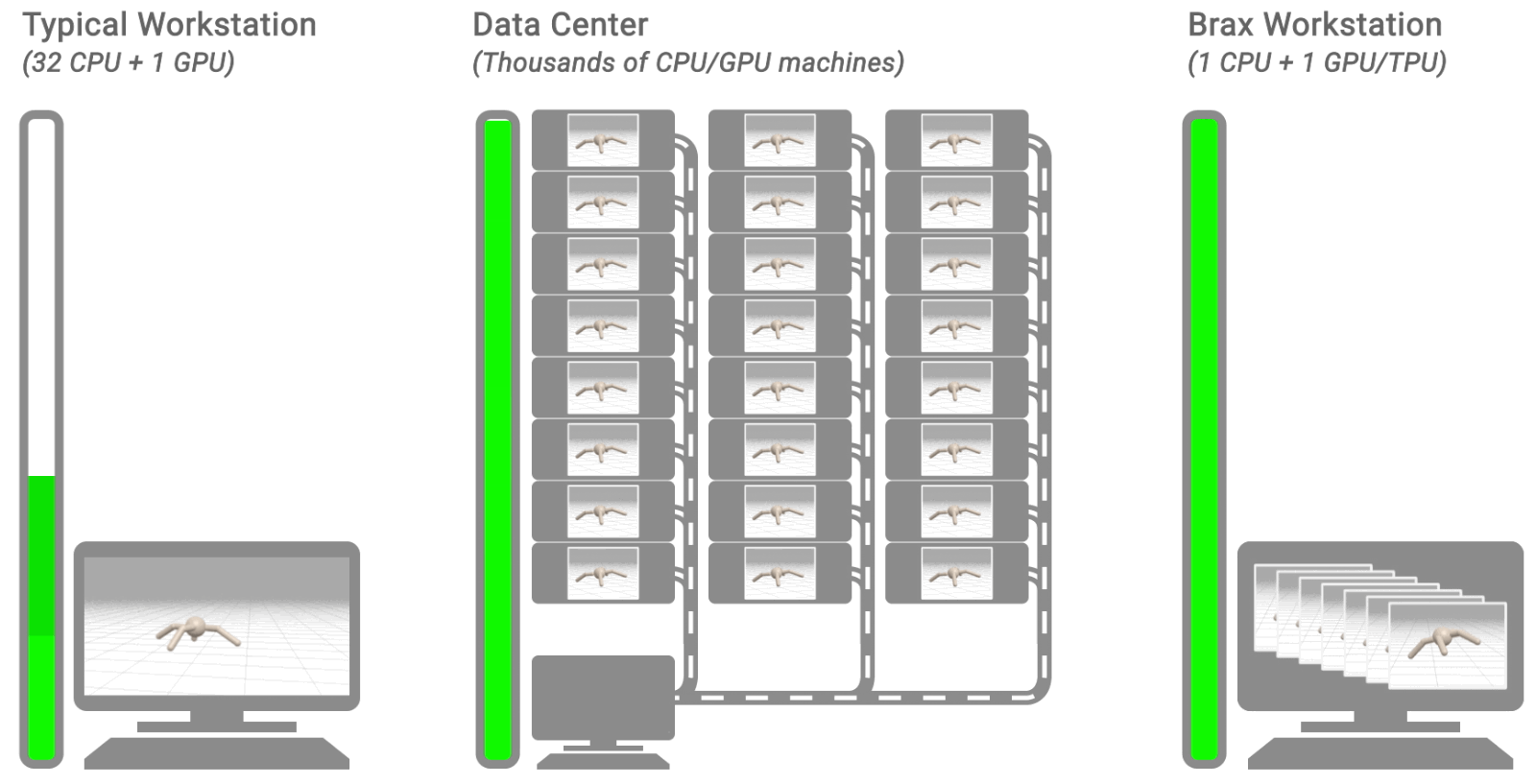 |
| Three typical RL workflows. The left shows a typical workstation flow: on a single machine, with the environment on CPU, training takes hours or days. The middle shows a typical distributed simulation flow: training takes minutes by farming simulation out to thousands of machines. The right shows the Brax flow: learning and large batch simulation occur side by side on a single CPU/GPU chip. |
Physics Simulation Engine Design Opportunities
Rigid body physics are used in video games, robotics, molecular dynamics, biomechanics, graphics and animation, and other domains. In order to accurately model such systems, simulators integrate forces from gravity, motor actuation, joint constraints, object collisions, and others to simulate the motion of a physical system across time.
 |
| Simulation of three spherical bodies, a wall, two joints, and one actuator. For each simulation timestep, forces and torques are integrated together to update the positions, rotations, and velocities of each physical body. |
Taking a closer look at how most physics simulation engines are designed today, there are a few large opportunities to improve efficiency. As we noted above, a typical robotics learning pipeline places a single learner in a tight feedback with many simulations in parallel, but upon analyzing this architecture, one finds that:
- This layout imposes an enormous latency bottleneck. Because the data must travel over the network within a datacenter, the learner must wait for 10,000+ nanoseconds to fetch experience from the simulator. Were this experience instead already on the same device as the learner’s neural network, latency would drop to <1 nanosecond.
- The computation necessary for training the agent (one simulation step, followed by one update of the agent’s neural network) is overshadowed by the computation spent packaging the data (i.e., marshalling data within the engine, then into a wire format such as protobuf, then into TCP buffers, and then undoing all these steps on the learner side).
- The computations happening within each simulator are remarkably similar, but not exactly the same.
Brax Design
In response to these observations, Brax is designed so that its physics calculations are exactly the same across each of its thousands of parallel environments by ensuring that the simulation is free of branches (i.e., simulation “if” logic that diverges as a result of the environment state). An example of a branch in a physics engine is the application of a contact force between a ball and a wall: different code paths will execute depending on whether the ball is touching the wall. That is, if the ball contacts the wall, separate code for simulating the ball’s bounce off the wall will execute. Brax employs a mix of the following three strategies to avoid branching:
- Replace the discrete branching logic with a continuous function, such as approximating the ball-wall contact force using a signed distance function. This approach results in the most efficiency gains.
- Evaluate the branch during JAX’s just-in-time compile. Many branches based on static properties of the environment, such as whether it’s even possible for two objects to collide, may be evaluated prior to simulation time.
- Run both sides of the branch during simulation but then select only the required results. Because this executes some code that isn’t ultimately used, it wastes operations compared to the above.
Once the calculations are guaranteed to be exactly uniform, the entire training architecture can be reduced in complexity to be executed on a single TPU or GPU. Doing so removes the computational overhead and latency of cross-machine communication. In practice, these changes lower the cost of training by 100x-1000x for comparable workloads.
Brax Environments
Environments are tiny packaged worlds that define a task for an RL agent to learn. Environments contain not only the means to simulate a world, but also functions, such as how to observe the world and the definition of the goal in that world.
A few standard benchmark environments have emerged in recent years for testing new RL algorithms and for evaluating the impact of those algorithms using metrics commonly understood by research scientists. Brax includes four such ready-to-use environments that come from the popular OpenAI gym: Ant, HalfCheetah, Humanoid, and Reacher.
 |
 |
 |
 |
| From left to right: Ant, HalfCheetah, Humanoid, and Reacher are popular baseline environments for RL research. |
Brax also includes three novel environments: dexterous manipulation of an object (a popular challenge in robotics), generalized locomotion (an agent that goes to a target placed anywhere around it), and a simulation of an industrial robot arm.
 |
 |
 |
| Left: Grasp, a claw hand that learns dexterous manipulation. Middle: Fetch, a toy, box-like dog learns a general goal-based locomotion policy. Right: Simulation of UR5e, an industrial robot arm. |
Performance Benchmarks
The first step for analyzing Brax’s performance is to measure the speed at which it can simulate large batches of environments, because this is the critical bottleneck to overcome in order for the learner to consume enough experience to learn quickly.
These two graphs below show how many physics steps (updates to the state of the environment) Brax can produce as it is tasked with simulating more and more environments in parallel. The graph on the left shows that Brax scales the number of steps per second linearly with the number of parallel environments, only hitting memory bandwidth bottlenecks at 10,000 environments, which is not only enough for training single agents, but also suitable for training entire populations of agents. The graph on the right shows two things: first, that Brax performs well not only on TPU, but also on high-end GPUs (see the V100 and P100 curves), and second, that by leveraging JAX’s device parallelism primitives, Brax scales seamlessly across multiple devices, reaching hundreds of millions of physics steps per second (see the TPUv3 8×8 curve, which is 64 TPUv3 chips directly connected to each other over a high speed interconnect) .
 |
| Left: Scaling of the simulation steps per second for each Brax environment on a 4×2 TPU v3. Right: Scaling of the simulation steps per second for several accelerators on the Ant environment. |
Another way to analyze Brax’s performance is to measure its impact on the time it takes to run a reinforcement learning experiment on a single workstation. Here we compare Brax training the popular Ant benchmark environment to its OpenAI counterpart, powered by the MuJoCo physics engine.
In the graph below, the blue line represents a standard workstation setup, where a learner runs on the GPU and the simulator runs on the CPU. We see that the time it takes to train an ant to run with reasonable proficiency (a score of 4000 on the y axis) drops from about 3 hours for the blue line, to about 10 seconds using Brax on accelerator hardware. It’s interesting to note that even on CPU alone (the grey line), Brax performs more than an order of magnitude faster, benefitting from learner and simulator both sitting in the same process.
 |
| Brax’s optimized PPO versus a standard GPU-backed PPO learning the MuJoCo-Ant-v2 environment, evaluated for 10 million steps. Note the x-axis is log-wallclock-time in seconds. Shaded region indicates lowest and highest performing seeds over 5 replicas, and solid line indicates mean. |
Physics Fidelity
Designing a simulator that matches the behavior of the real world is a known hard problem that this work does not address. Nevertheless, it is useful to compare Brax to a reference simulator to ensure it is producing output that is at least as valid. In this case, we again compare Brax to MuJoCo, which is well-regarded for its simulation quality. We expect to see that, all else being equal, a policy has a similar reward trajectory whether trained in MuJoCo or Brax.
 |
| MuJoCo-Ant-v2 vs. Brax Ant, showing the number of environment steps plotted against the average episode score achieved for the environment. Both environments were trained with the same standard implementation of SAC. Shaded region indicates lowest and highest performing seeds over five runs, and solid line indicates the mean. |
These curves show that as the reward rises at about the same rate for both simulators, both engines compute physics with a comparable level of complexity or difficulty to solve. And as both curves top out at about the same reward, we have confidence that the same general physical limits apply to agents operating to the best of their ability in either simulation.
We can also measure Brax’s ability to conserve linear momentum, angular momentum, and energy.
 |
| Linear momentum (left), angular momentum (middle), and energy (right) non-conservation scaling for Brax as well as several other physics engines. The y-axis indicates drift from the expected calculation (higher is smaller drift, which is better), and the x axis indicates the amount of time being simulated. |
This measure of physics simulation quality was first proposed by the authors of MuJoCo as a way to understand how the simulation drifts off course as it is tasked with computing larger and larger time steps. Here, Brax performs similarly as its neighbors.
Conclusion
We invite researchers to perform a more qualitative measure of Brax’s physics fidelity by training their own policies in the Brax Training Colab. The learned trajectories are recognizably similar to those seen in OpenAI Gym.
Our work makes fast, scalable RL and robotics research much more accessible — what was formerly only possible via large compute clusters can now be run on workstations, or for free via hosted Google Colaboratory. Our Github repository includes not only the Brax simulation engine, but also a host of reference RL algorithms for fast training. We can’t wait to see what kind of new research Brax enables.
Acknowledgements
We’d like to thank our paper co-authors: Anton Raichuk, Sertan Girgin, Igor Mordatch, and Olivier Bachem. We also thank Erwin Coumans for advice on building physics engines, Blake Hechtman and James Bradbury for providing optimization help with JAX and XLA, and Luke Metz and Shane Gu for their advice. We’d also like to thank Vijay Sundaram, Wright Bagwell, Matt Leffler, Gavin Dodd, Brad Mckee, and Logan Olson, for helping to incubate this project.
1 Due to the complexity of the real world, there is also ongoing research exploring the physics of deformable bodies. ↩
A Sparkle in Their AIs: Students Worldwide Rev Robots with Jetson Nano
Every teacher has a story about the moment a light switched on for one of their students.
David Tseng recalls a high school senior in Taipei excited at a summer camp to see a robot respond instantly when she updated her software. After class, she had a lot of questions and later built an AI-powered security system that let her friends — but not her parents — into her room.
“Before the class, she said she was not very interested in college, but now she’s majoring in computer science and she’s in my class as a freshman,” said Tseng, an assistant professor at the National Taiwan University of Science and Technology and founder of CAVEDU, a company that runs youth programs using robotics.
Echoes Out of Africa
A teacher in Tunisia who’s run many robotics events for young people tells a similar story.
“A couple of my students started their own robotics startup, AviaGeek Consulting, and a couple others got internships at an aircraft manufacturer in Tunisia thanks to what they learned and practiced,” said Khlaifia Bilel, an assistant professor of data science at an aviation school near Tunis, who started a student program to build tiny satellites using Jetson products.
“Thanks, NVIDIA, for changing the life of my kids,” he said in a talk at GTC in April.
Planting Seeds on the Farm
Tony Foster, a 4H program volunteer in Kansas, put one of the first Jetson Nano 2GB developer kits into the hands of an 11-year-old.
“She was in a rural area with no programming classes in her junior high school, so we sent her everything she needed and now she’s building a robot that can run a maze and she wants to take it to science fairs and robotics competitions,” he said in a GTC talk (watch a replay free with registration).
Foster, a 4H member since he was seven years old, believes the middle-school years are the best time to plant seeds. “These hands-on opportunities help children grow and learn — and they have results that last a lifetime,” he said.
A Celebration of Learning
On this World Youth Skills Day, we celebrate kids finding their way in the world.

So far this year, 250 organizations around the globe have expressed interest in using NVIDIA’s educational tools in their curriculum. As part of a grant program, the company has given hundreds of Jetson Nano developer kits to educators in colleges, schools and nonprofit groups.
Our work with the Boys & Girls Clubs of Western Pennsylvania’s AI Pathways Institute also helps expand access to AI and robotics education to more students, particularly in traditionally underrepresented communities.
Released in October, the Jetson Nano 2GB Developer Kit packs quite a punch for its size — a whopping 472 gigaflops of AI performance. That’s enough to run Linux and CUDA software as well as AI training and inference jobs.
Students Get Certified in AI
The hardware is just the half of it. NVIDIA also certifies students and educators in AI skills through its Deep Learning Institute (DLI). Eight-hour classes require attendees to demonstrate their skills by building a working project, and they help them do it through online courses, videos and a repository of code to get started.
The curriculum is being embraced around the world from high schools in Korea to universities in Japan and Europe. For example, at Spain’s University of Málaga, more than a dozen students attended a three-day workshop, seven are now certified AI specialists and the university is looking to integrate Jetson into its curriculum.
In Taiwan last year when the pandemic was not a factor, Tseng ran nearly 20 events with 300 participants and a competition that drew seven teams of high schoolers — work that led to 200 people earning DLI certificates.
Teacher Gives Program an A+
A recent weekend event for educators drew more than 100 attendees including 30 college professors, some from fashion, hospitality and economics departments.

“Schools are encouraging teachers to merge AI into their courses, so they are eager to find suitable content and DLI is very suitable because the documentation is good and it helps them get going right away,” said Tseng, whose company published a book in traditional Chinese to add to the curriculum.
The weekend event drew kudos from one of the professors who attended.
“Thanks to leaders like NVIDIA providing so many wonderful platforms and tools, I am more confident to teach AI in my next semester courses,” said Cheng-Ling Ying, a professor at Jinwen University of Science and Technology.
Making a Difference in Young Lives
Each teacher, each event sends out ripples that affect many young lives.
Back in Kansas, Foster said 4H STEM programs like the ones he runs now “really helped me on my path to become a computer system engineer working at Dell.”
Today, he’s one of 6,000 volunteers in a university extension program that serves 75,000 youth across five counties. “We want to empower youth … to make decisions about their future and go where they want in jobs and careers,” he said.
To learn more about how NVIDIA promotes youth and vocational education go to Jetson for AI Education.
The post A Sparkle in Their AIs: Students Worldwide Rev Robots with Jetson Nano appeared first on The Official NVIDIA Blog.