Coordinated automation could improve traffic flow, boost efficiency, and slash emissions. A combination of machine learning, big data, and Amazon Web Services is making this future possible.Read More
Announcing PyTorch Developer Day 2021
We are excited to announce PyTorch Developer Day (#PTD2), taking place virtually from December 1 & 2, 2021. Developer Day is designed for developers and users to discuss core technical developments, ideas, and roadmaps.

Event Details
Technical Talks Live Stream – December 1, 2021
Join us for technical talks on a variety of topics, including updates to the core framework, new tools and libraries to support development across a variety of domains, responsible AI and industry use cases. All talks will take place on December 1 and will be live streamed on PyTorch channels.
Stay up to date by following us on our social channels: Twitter, Facebook, or LinkedIn.
Poster Exhibition & Networking – December 2, 2021
On the second day, we’ll be hosting an online poster exhibition on Gather.Town. There will be opportunities to meet the authors and learn more about their PyTorch projects as well as network with the community. This poster and networking event is limited to people composed of PyTorch maintainers and contributors, long-time stakeholders and experts in areas relevant to PyTorch’s future. Conversations from the networking event will strongly shape the future of PyTorch. As such, invitations are required to attend the networking event.
Apply for an invitation to the networking event by clicking here.
Call for Content Now Open
Submit your poster abstracts today! Please send us the title and brief summary of your project, tools and libraries that could benefit PyTorch researchers in academia and industry, application developers, and ML engineers for consideration. The focus must be on academic papers, machine learning research, or open-source projects related to PyTorch development, Responsible AI or Mobile. Please no sales pitches. Deadline for submission is September 24, 2021.
You can submit your poster abstract during your application & registration process here.
Visit the event website for more information and we look forward to having you at PyTorch Developer Day. For any questions about the event, contact pytorch@fbreg.com.
How to train large graph neural networks efficiently
New method enables two- to 14-fold speedups over best-performing predecessors.Read More
‘Think a lot, and think big’
How Minghui He turned her Amazon internship into a full-time research scientist role.Read More
Inside the DPU: Talk Describes an Engine Powering Data Center Networks
The tech world this week gets its first look under the hood of the NVIDIA BlueField data processing unit. The chip invented the category of the DPU last year, and it’s already being embraced by cloud services, supercomputers and many OEMs and software partners.
Idan Burstein, a principal architect leading our Israel-based BlueField design team, will describe the DPU’s architecture at Hot Chips, an annual conference that draws many of the world’s top microprocessor designers.
The talk will unveil a silicon engine for accelerating modern data centers. It’s an array of hardware accelerators and general-purpose Arm cores that speed networking, security and storage jobs.
Those jobs include virtualizing data center hardware while securing and smoothing the flow of network traffic. It’s work that involves accelerating in hardware a growing alphabet soup of tasks fundamental to running a data center, such as:
- IPsec, TLS, AES-GCM, RegEx and Public Key Acceleration for security
- NVMe-oF, RAID and GPUDirect Storage for storage
- RDMA, RoCE, SR-IOV, VXLAN, VirtIO and GPUDirect RDMA for networking, and
- Offloads for video streaming and time-sensitive communications
These workloads are growing faster than Moore’s law and already consume a third of server CPU cycles. DPUs pack purpose-built hardware to run these jobs more efficiently, making more CPU cores available for data center applications.
DPUs deliver virtualization and advanced security without compromising bare-metal performance. Their uses span the gamut from cloud computing and media streaming to storage, edge processing and high performance computing.
NVIDIA CEO Jensen Huang describes DPUs as “one of the three major pillars of computing going forward … The CPU is for general-purpose computing, the GPU is for accelerated computing and the DPU, which moves data around the data center, does data processing.”
A Full Plug-and-Play Stack
The good news for users is they don’t have to master the silicon details that may fascinate processor architects at Hot Chips. They can simply plug their existing software into familiar high-level software interfaces to harness the DPU’s power.
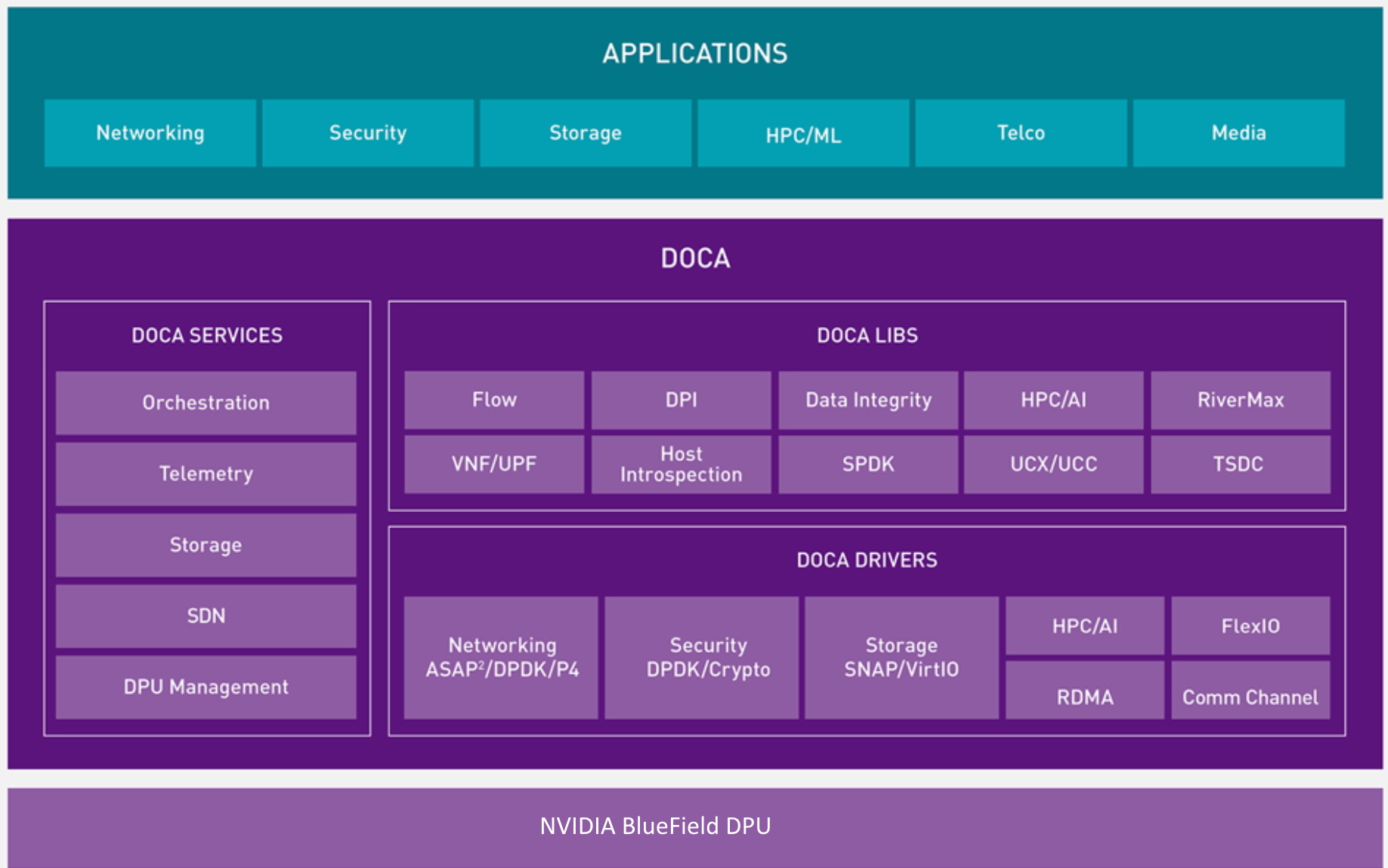
Those APIs are bundled into the DPU’s software stack called NVIDIA DOCA. It includes drivers, libraries, tools, documentation, example applications and a runtime environment for provisioning, deploying and orchestrating services on thousands of DPUs across the data center.
We’ve already received requests for early access to DOCA from hundreds of organizations, including several of the world’s industry leaders.
DPUs Deliver for Data Centers, Clouds
The architecture described at Hot Chips is moving into several of the world’s largest clouds as well as a TOP500 supercomputer and integrated with next-generation firewalls. It will soon be available in systems from several top OEMs supported with software from more than a dozen other partners.
Today, multiple cloud service providers around the world are using or preparing to deploy BlueField DPUs to provision compute instances securely.
BlueField Powers Supercomputers, Firewalls
The University of Cambridge tapped into the DPU’s efficiencies to debut in June the fastest academic system in the U.K., a supercomputer that hit No. 3 on the Green500 list of the world’s most energy-efficient systems.
It’s the world’s first cloud-native supercomputer, letting researchers share virtual resources with privacy and security while not compromising performance.
With the VM-Series Next-Generation Firewall from Palo Alto Networks, every data center can now access the DPU’s security capabilities. The VM-Series NGFW can be accelerated with BlueField-2 to inspect network flows that were previously impossible or impractical to track.
The DPU will soon be available in systems from ASUS, Atos, Dell Technologies, Fujitsu, GIGABYTE, H3C, Inspur, Quanta/QCT and Supermicro, several of which announced plans at Computex in May.
More than a dozen software partners will support the NVIDIA BlueField DPUs, including:
- VMware, with Project Monterey, which introduces DPUs to the more than 300,000 organizations that rely on VMware for its speed, resilience and security.
- Red Hat, with an upcoming developer’s kit for Red Hat Enterprise Linux and Red Hat OpenShift, used by 95 percent of the Fortune 500.
- Canonical, in Ubuntu Linux, the most popular operating system among public clouds.
- Check Point Software Technologies, in products used by more than 100,000 organizations worldwide to prevent cyberattacks.
Other partners include Cloudflare, DDN, Excelero, F5, Fortinet, Guardicore, Juniper Networks, NetApp, Vast Data and WekaIO.
The support is broad because the opportunity is big.
“Every single networking chip in the world will be a smart networking chip … And that’s what the DPU is. It’s a data center on a chip,” said Collette Kress, NVIDIA’s CFO, in a May earnings call, predicting every server will someday sport a DPU.
DPU-Powered Networks on the Horizon
Market watchers at Dell’Oro Group forecast the number of smart networking ports shipped will nearly double from 4.4 million in 2020 to 7.4 million by 2025.
Gearing up for that growth, NVIDIA announced at GTC its roadmap for the next two generations of DPUs.
The BlueField-3, sampling next year, will drive networks up to 400 Gbit/second and pack the muscle of 300 x86 cores. The BlueField-4 will deliver an order of magnitude more performance with the addition of NVIDIA AI computing technologies.
What’s clear from the market momentum and this week’s Hot Chips talk is just as it has in AI, NVIDIA is now setting the pace in accelerated networking.
The post Inside the DPU: Talk Describes an Engine Powering Data Center Networks appeared first on The Official NVIDIA Blog.
Make History This GFN Thursday: ‘HUMANKIND’ Arrives on GeForce NOW
This GFN Thursday brings in the highly anticipated magnum opus from SEGA and Amplitude Studios, HUMANKIND, as well as exciting rewards to redeem for members playing Eternal Return.
There’s also updates on the newest Fortnite Season 7 game mode, “Impostors,” streaming on GeForce NOW.
Plus, there are nine games in total coming to the cloud this week.
The Future is in Your Hands
It’s time to make history. The exciting new turn-based historical strategy game HUMANKIND released this week and is streaming on GeForce NOW.
In HUMANKIND, you’ll be rewriting the entire narrative of human history and combining cultures to create a civilization as unique as you are. Combine up to 60 historical cultures as you lead your people from the Ancient to the Modern Age. From humble origins as a Neolithic tribe, transition to the Ancient Era as the Babylonians, become the Classical era Mayans, the Medieval Umayyads, the Early Modern-era British, and so on. Create a custom leader from these backgrounds to pave the way to the future.
Players will encounter historical events and make impactful moral decisions to develop the world as they see fit. Explore the natural wonders, discover scientific breakthroughs and make remarkable creations to leave your mark on the world. Master tactical turn-based battles and command your assembled armies to victory against strangers and friends in multiplayer matches of up to eight players. For every discovery, every battle and every deed, players gain fame — and the player with the most fame wins the game.
An awesome extra, unlock unique characters based on popular content creators, like GeForce NOW streamer BurkeBlack, by watching their HUMANKIND streams for unique drops.

Gamers have been eagerly anticipating the release of HUMANKIND, and members will be able to experience this awesome new PC game when streaming on low-powered PCs, Macs, Chromebooks, SHIELD TVs or Android and iOS mobile devices with the power of GeForce NOW.
“GeForce NOW can invite even more players to experience the HUMANKIND journey,” said Romain de Waubert, studio head and chief creative officer at Amplitude Studios. “The service quickly and easily brings gamers into HUMANKIND with beautiful PC graphics on nearly any device.”
Tell your story your way. Play HUMANKIND this week on GeForce NOW and determine where you’ll take history.
Reap the Rewards
Playing games on GeForce NOW is great, and so is getting rewarded for playing.
The GeForce NOW rewards program is always looking to give members access to awesome rewards. This week brings a custom skin and custom emote for Eternal Return.
Getting rewarded for streaming games on the cloud is easy. Members should make sure to check the box for Rewards in the GeForce NOW account portal and opt in to receive newsletters for future updates and upcoming reward spoils.
Impostors Infiltrate Fortnite
Chapter 2 Season 7 of Fortnite also delivered a thrilling, new game mode. Members can play Fortnite “Impostors,” which recently was released on August 17.
Play in matches between four to 10 players of Agents versus Impostors on a brand new map – The Bridge. Agents win by completing minigame assignments to fill their progress bar or revealing all Impostors hiding among the team by calling discussions and voting out suspicious behavior.
While keeping their identity a secret, up to two Impostors will seek to eliminate enough Agents to overtake The Bridge. They can hide their status by completing assignments, which will benefit the progress of the Agent team, and have sneaky sabotage abilities to create chaos.
Whether playing as an Agent or as an Impostor, this game is set to be a great time. Stream it today on GeForce NOW.
It’s Game Time

As always, GFN Thursday means new games coming to the cloud every week. Members can look forward to being able to stream these nine titles joining the GeForce NOW library:
- Yooka-Laylee (free on Epic Games Store, August 19)
- Greak: Memories of Azur (day-and-date release on Steam, August 17)
- HUMANKIND (day-and-date release on Steam and Epic Games Store, August 17)
- RiMS Racing (day-and-date release on Steam and Epic Games Store, August 19)
- Recompile (day-and-date release on Steam and Epic Games Store, August 19)
- The Architect: Paris (Steam)
- Arid (Steam)
- Road 96 (Steam and Epic Games Store)
- Wargame: European Escalation (Steam)
With all of these new games, it’s always a good time to play. Speaking of time, we’ve got a question about your favorite games:
past, present, or future
what’s your favorite time period to play in?
—
NVIDIA GeForce NOW (@NVIDIAGFN) August 18, 2021
Let us know on Twitter or in the comments below.
The post Make History This GFN Thursday: ‘HUMANKIND’ Arrives on GeForce NOW appeared first on The Official NVIDIA Blog.
Migrate your work to an Amazon SageMaker notebook instance with Amazon Linux 2
Amazon SageMaker notebook instances now support Amazon Linux 2, so you can now create a new Amazon SageMaker notebook instance to start developing your machine learning (ML) models with the latest updates. An obvious question is: what do I need to do to migrate my work from an existing notebook instance that runs on Amazon Linux to a new notebook instance with Amazon Linux 2? In this post, we describe an approach to migrate your work from an existing notebook instance to a new notebook instance.
Solution overview
The following diagram shows an overview of the components in a SageMaker notebook instance and how the migration takes place. Note that this solution isn’t limited to a particular version of an Amazon Linux image in the source and destination instance. Therefore, we denote the notebook instance that has existing work and data as an existing or source instance, and to refer the notebook instance that we migrate existing work and data to as a new or destination instance.
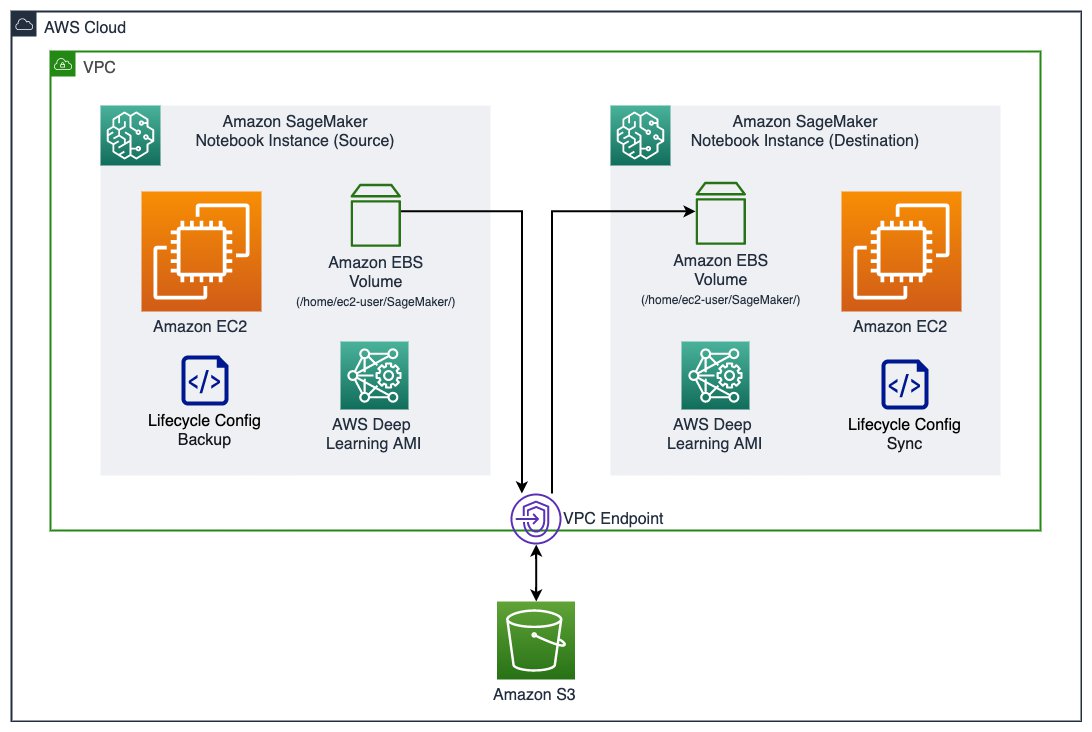
A SageMaker notebook instance consists of an Amazon Elastic Compute Cloud (Amazon EC2) instance with an Amazon Elastic Block Storage (Amazon EBS) volume attached, running an image built on top of the AWS Deep Learning AMI. The EBS volume (attached on /home/ec2-user/SageMaker/) is where you save any code, notebooks, or data persistently inside a notebook instance, and is subject to the migration to a new instance. In this solution, we use an Amazon Simple Storage Service (Amazon S3) bucket to store backup snapshots of an existing EBS volume. We then use lifecycle configurations to create a backup snapshot of the source EBS volume and synchronize a snapshot to the destination instance. You can easily indicate the S3 bucket name and the desired snapshot by tagging the instances.
When using the lifecycle configuration, you don’t need to open and be inside a notebook instance to initiate the backup or sync. It allows an administrator to script the migration process for all notebook instances for an organization.
In many cases, your notebook instance could run in an Amazon Virtual Private Cloud (Amazon VPC) and not have a direct internet access. The communication to the S3 bucket goes through an Amazon S3 VPC gateway endpoint.
Prerequisites
To get started with your migration, you need to set up the following prerequisites:
- SageMaker execution roles – The AWS Identity and Access Management (IAM) execution role for the existing instance should have
s3:CreateBucket,s3:GetObject,s3:PutObject, ands3:ListBucketto the bucket for backup. The execution role for the new instance should haves3:GetObject,s3:PutObject, ands3:ListBucketfor the same bucket (required byaws s3 sync). - Networking – If your notebook instances don’t have direct internet access, and are in placed in a VPC, you need the following VPC endpoints attached to the VPC:
- SageMaker notebook instance lifecycle configuration – You need the following lifecycle configuration scripts:
- File system – If you have mounted a file system in
/home/ec2-user/SageMaker/in the source instance either from Amazon Elastic File System (Amazon EFS) or Amazon FSx for Lustre, make sure you unmount it before proceeding. The file system can be simply mounted again onto the new instance and should not be subject to migration, which helps avoid unnecessary overhead. Refer to the relevant instructions to unmount an Amazon EFS file system or FSx for Lustre file system).
Create lifecycle configurations
First, we need to create two lifecycle configurations: one to create backup from the source instance, and another to synchronize a specific backup to a destination instance.
- On the Lifecycle configurations page on the SageMaker console, choose Create configuration.

- For Name, enter a name for the backup.
- On the Start notebook tab in the Scripts section, enter the code from on-start.sh.
- Leave the Create notebook tab empty.
- Choose Create configuration.

You have just created one lifecycle configuration, and are redirected to the list of all your lifecycle configurations. Let’s create our second configuration.
- Choose Create configuration.
- For Name, enter a name for your sync.
- On the Create notebook tab in the Scripts section, enter the code from on-create.sh.
- Leave the Start notebook tab empty.
- Choose Create configuration.
We have created two lifecycle configurations: one for backing up your EBS volume to Amazon S3, and another to synchronize the backup from Amazon S3 to the EBS volume. We need to attach the former to an existing notebook instance, and the latter to a new notebook instance.
Back up an existing notebook instance
You can only attach a lifecycle configuration to an existing notebook instance when it’s stopped. If your instance is still running, stop it before completing the following steps. Also, it will be safer to perform the backup process when all your notebook kernels and processes on the instance are shut down.
- On the Notebook instances page on the SageMaker console, choose your instance to see its detailed information.
- Choose Stop to stop the instance.
The instance may take a minute or two to transition to the Stopped state.
- After the instance stops, choose Edit.
- In Additional configuration, for Lifecycle configuration, choose backup-ebs.
- Choose Update notebook instance.
You can monitor the instance details while it’s being updated.
We need to tag the instance to provide the lifecycle configuration script where the backup S3 bucket is.
- In the Tags section, choose Edit.
- Add a tag with the key ebs-backup-bucket, which matches what the lifecycle configuration script expects.
- The value is a bucket of your choice, for example sagemaker-ebs-backup-<region>-<account_id>.
Make sure the attached execution role allows sufficient permission to perform aws s3 sync to the bucket.
- Choose Save.
You should see the following tag details.

- Choose Start at the top of the page to start the instance.
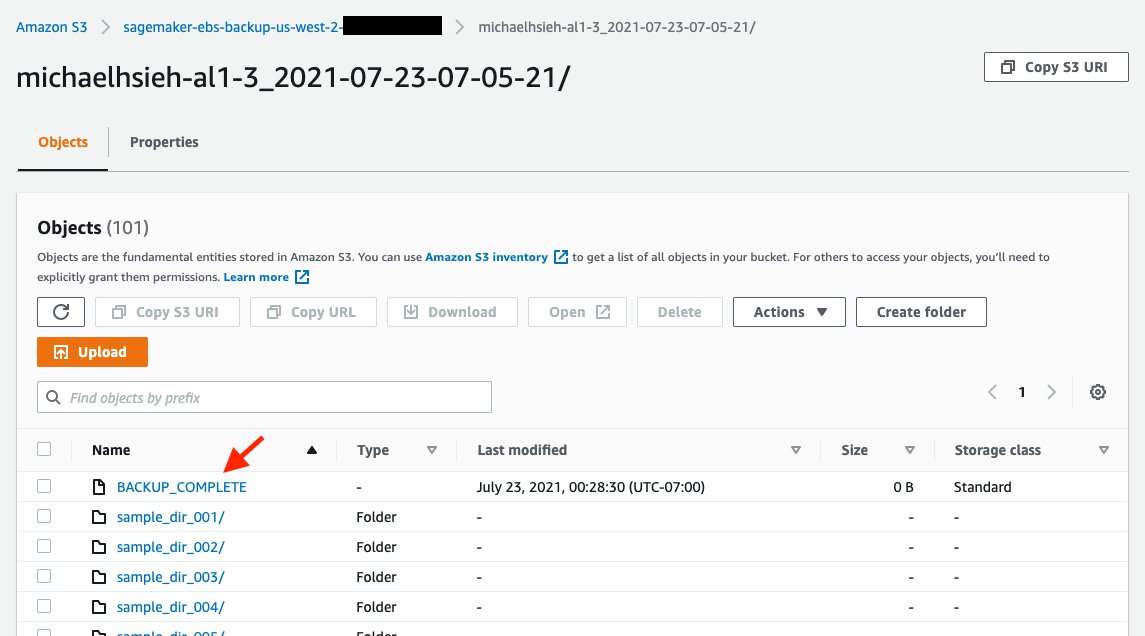
When the instance is starting, on-start.sh from the backup-ebs lifecycle configuration begins, and starts the backup process to create a complete snapshot of /home/ec2-user/SageMaker/ in s3://<ebs-backup-bucket>/<source-instance-name>_<snapshot-timestamp>/. The length of the backup process depends on the total size of your data in the volume.
The backup process is run with a nohup in the background during the instance startup. This means that there is no guarantee that when the instance becomes InService, the backup process is complete. To know when the backup is complete, you should see the file /home/ec2-user/SageMaker/BACKUP_COMPLETE created, and you should see the same in s3://<ebs-backup-bucket>/<source-instance-name>_<snapshot-timestamp>/.
Synchronize from a snapshot to a new instance
When the backup is complete, you can create a new instance and download the backup snapshot with the following steps:
- On the SageMaker console, on the Notebook instances page, create a new instance.
- In Additional configuration, for Lifecycle configuration, choose sync-from-s3.

- Make sure that Volume size in GB is equal to or greater than that of the source instance.
- For Platform identifier, choose notebook-al2-v1 if you’re migrating to an instance with Amazon Linux 2.
- Use an IAM execution role that has sufficient permission to perform
aws s3 syncfrom the backup bucketebs-backup-bucket. - Choose the other options according to your needs or based on the source instance.
- If you need to host this instance in a VPC and with Direct internet access disabled, you need to follow the prerequisites to attach the S3 VPC endpoint and SageMaker API VPC endpoint to your VPC.
- Add the following two tags. The keys have to match what is expected in the lifecycle configuration script.
- Key:
ebs-backup-bucket, value:<ebs-backup-bucket>. - Key:
backup-snapshot, value:<source-instance-name>_<snapshot-timestamp>.
- Key:
- Choose Create notebook instance.

When your new instance starts, on-create.sh in the sync-from-s3 lifecycle configuration performs aws s3 sync to get the snapshot indicated in the tags from s3://<ebs-backup-bucket>/<source-instance-name>_<snapshot-timestamp>/ down to /home/ec2-user/SageMaker/. Again, the length of the sync process depends on the total size of your data in the volume.
The sync process is run with a nohup in the background during the instance creation. This means that there is no guarantee that when the instance becomes InService, the sync process is complete. To know when the backup is complete, you should see the file /home/ec2-user/SageMaker/SYNC_COMPLETE created in the new instance.
Considerations
Consider the following when performing the backup and sync operations:
- You can expect the time to back up and sync to be approximately the same. The time for backup and sync depends on the size of
/home/ec2-user/SageMaker/. If it takes 5 minutes for you to back up a source instance, you can expect 5 minutes for the sync. - If you no longer need to create a snapshot for a source instance, consider detaching the lifecycle configuration from the instance. Because the backup script is attached to the Start notebook tab in a lifecycle configuration, the script runs every time you start the source instance. You can detach a lifecycle configuration by following the same steps we showed to back up an existing notebook instance, but in Additional configuration, for Lifecycle configuration, choose No configuration.
- For security purposes, you should limit the bucket access within the policy of the attached execution role. Because both the source and destination instances are dedicated to the same data scientist, you can allow access to a specific S3 bucket in the IAM execution role (see Add Additional Amazon S3 Permissions to an SageMaker Execution Role) and attach the role to both source and destination instances for a data scientist. For more about data protection see Data Protection in Amazon SageMaker.
When migrating from Amazon Linux to Amazon Linux 2 in a SageMaker notebook instance, there are significant conda kernel changes, as described in the announcement. You should take actions to adopt your code and notebooks that depend on kernels that are no longer supported in Amazon Linux 2.
Conclusion
In this post, we shared a solution to create an EBS volume backup from an existing SageMaker notebook instance and synchronize the backup to a new notebook instance. This helps you migrate your work on an existing notebook instance to a new instance with Amazon Linux 2, as we announced the support of Amazon Linux 2 in SageMaker notebook instances. We walked you through the steps on the SageMaker console, and also discussed some considerations when performing the steps in this post. Now you should be able to continue your ML development in a notebook instance with Amazon Linux 2 and regular updates and patches. Happy coding!
About the Author
 Michael Hsieh is a Senior AI/ML Specialist Solutions Architect. He works with customers to advance their ML journey with a combination of AWS ML offerings and his ML domain knowledge. As a Seattle transplant, he loves exploring the great mother nature the region has to offer, such as the hiking trails, scenery kayaking in the SLU, and the sunset at the Shilshole Bay.
Michael Hsieh is a Senior AI/ML Specialist Solutions Architect. He works with customers to advance their ML journey with a combination of AWS ML offerings and his ML domain knowledge. As a Seattle transplant, he loves exploring the great mother nature the region has to offer, such as the hiking trails, scenery kayaking in the SLU, and the sunset at the Shilshole Bay.
Amazon SageMaker notebook instances now support Amazon Linux 2
Today, we’re excited to announce that Amazon SageMaker notebook instances support Amazon Linux 2. You can now choose Amazon Linux 2 for your new SageMaker notebook instance to take advantage of the latest update and support provided by Amazon Linux 2.
SageMaker notebook instances are fully managed Jupyter Notebooks with pre-configured development environments for data science and machine learning. Data scientists and developers can spin up SageMaker Notebooks to interactively explore, visualize and prepare data, and build and deploy models on SageMaker.
Introduced in 2017, Amazon Linux 2 is the next generation of Amazon Linux, a Linux server operating system from AWS first launched in September 2010. Amazon Linux 2 provides a secure, stable, and high-performance runtime environment to develop and run cloud and enterprise applications. With Amazon Linux 2, you get an environment that offers long-term support with access to the latest innovations in the Linux offering. AWS provides long-term security and maintenance updates for the Amazon Linux 2 AMI while the Amazon Linux AMI ended its standard support on December 31, 2020 and has entered a maintenance support phase.
In this post, we show you what your new experience with an Amazon Linux 2 based SageMaker notebook instance looks like. We also share the support plan for Amazon Linux based notebook instances. To learn how to migrate your work from an Amazon Linux based notebook instance to a new Amazon Linux 2 based notebook instance, see our next post Migrate your work to an Amazon SageMaker notebook instance with Amazon Linux 2.
What’s new with Amazon Linux 2 based notebook instances
For a data scientist using SageMaker notebook instances, the major difference is the notebook kernels available in the instance. Because Python 2 has been sunset since January 1, 2020, the kernels with Python 2.x are no longer available in the Amazon Linux 2 based notebook instance. You need to port your code and notebooks from Python 2 to Python 3 before using the same code with python3.x kernels.
Another set of kernels that are no longer provided within the Amazon Linux 2 based instance are Chainer kernels (conda_chainer_p27 and conda_chainer_p36). Chainer has been in a maintenance phase since December 5, 2019, when the last major upgrade to v7 was released. Chainer users are encouraged to follow the migration guide provided by Chainer to port the Chainer code into PyTorch and use the conda_pytorch_p36 or conda_pytorch_latest_p37 in the notebook instance.
SageMaker notebook instances use AMIs that are built on top of the AWS Deep Learning AMI. Therefore, you can find detailed release notes and differences in the AWS Deep Learning AMI (Amazon Linux) and AWS Deep Learning AMI (Amazon Linux 2).
The Amazon Linux 2 option in SageMaker notebook instances is now available in AWS Regions in which SageMaker notebook instances are available.
Support plan for Amazon Linux on SageMaker notebook instances
On August 18, 2021, we’re rolling out the Amazon Linux 2 AMI option for users on SageMaker notebook instances. You have the option to launch a notebook instance with the Amazon Linux 2 AMI while the Amazon Linux AMI remains as the default during the setup.
Your existing notebook instances launched before August 18, 2021 will continue to run with Amazon Linux AMI. All notebook instances with either the Amazon Linux AMI or Amazon Linux 2 AMI will continue to receive version updates and security patches when instances are restarted.
On April 18, 2022, the default AMI option when creating a new notebook instance will switch to the Amazon Linux 2 AMI, but we’ll still keep the Amazon Linux AMI as an option. A new notebook instance with the Amazon Linux AMI will use the last snapshot of the Amazon Linux AMI created on April 18, 2022 and will no longer receive any version updates and security patches when restarted. An existing notebook instance with the Amazon Linux AMI, when restarted, will receive a one-time update to the last snapshot of the Amazon Linux AMI created on April 18, 2022 and will no longer receive any version updates and security patches afterwards.
Set up an Amazon Linux 2 based SageMaker notebook instance
You can set up a SageMaker notebook instance with the Amazon Linux 2 AMI using the SageMaker console (see Create a Notebook Instance) or the AWS Command Line Interface (AWS CLI).
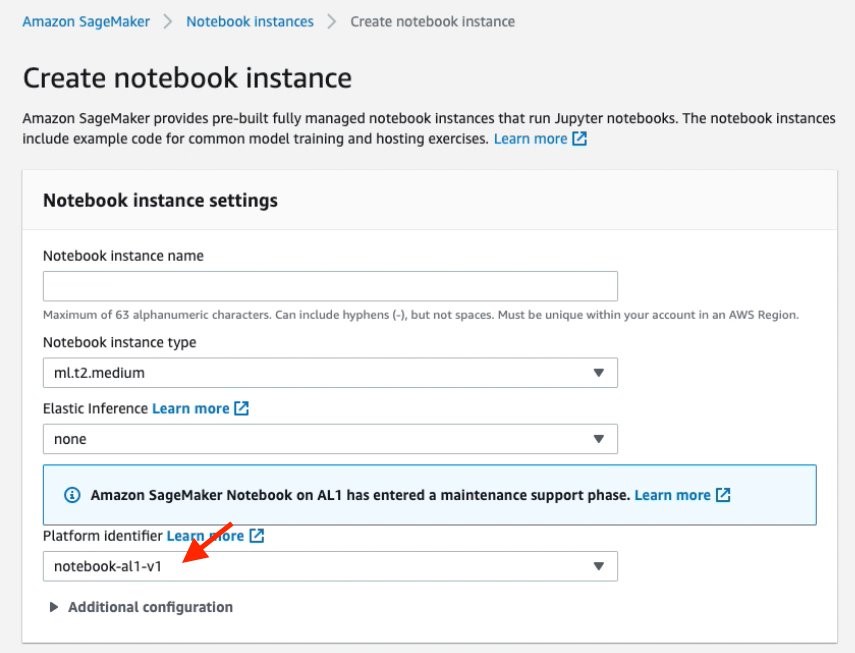
When using the SageMaker console, you have a new option, Platform identifier, to choose the Amazon Linux AMI version. notebook-al2-v1 refers to the Amazon Linux 2 AMI, and notebook-al1-v1 refers to the Amazon Linux AMI. As described in the previous section, the default is notebook-al1-v1 until April 18, 2022, and will switch to notebook-al2-v1 on April 18, 2022.
If you prefer to create a notebook instance with the AWS CLI, you can use the new argument platform-identifier to indicate the choice for the Amazon Linux AMI version. Similarly, notebook-al2-v1 refers to the Amazon Linux 2 AMI, and notebook-al1-v1 refers to the Amazon Linux AMI. For example, a command to create an instance with the Amazon Linux 2 AMI looks like the following command:
aws sagemaker create-notebook-instance
--region region
--notebook-instance-name instance-name
--instance-type ml.t3.medium
--role-arn sagemaker-execution-role-arn
--platform-identifier notebook-al2-v1 Next steps
If you want to move your existing work to a new notebook instance, see our next post, Migrate your work to an Amazon SageMaker notebook instance with Amazon Linux 2. You can learn how to migrate your work and data on an existing notebook instance to a new, Amazon Linux 2 based instance.
Conclusion
Today, we announced SageMaker notebook instance support for the Amazon Linux 2 AMI and showed you how to create a notebook instance with the Amazon Linux 2 AMI. We also showed you the major differences for developers when using an Amazon Linux 2 based notebook instance. You can start your new ML development on an Amazon Linux 2 based notebook instance or try out Amazon SageMaker Studio, the first integrated development environment (IDE) for ML.
If you have any questions and feedback regarding Amazon Linux 2, please speak to your AWS support contact or post a message in the Amazon Linux Discussion Forum and SageMaker Discussion Forum.
About the Authors
Michael Hsieh is a Senior AI/ML Specialist Solutions Architect. He works with customers to advance their ML journey with a combination of Amazon Machine Learning offerings and his ML domain knowledge. As a Seattle transplant, he loves exploring the great nature the region has to offer, such as the hiking trails, scenery kayaking in the SLU, and the sunset at the Shilshole Bay.
 Sam Liu is a Product Manager at Amazon Web Services (AWS) focusing on AI/ML infrastructure and tooling. Beyond that, he has 10 years of experience building machine learning applications in various industries. In his spare time, he enjoys golf and international traveling.
Sam Liu is a Product Manager at Amazon Web Services (AWS) focusing on AI/ML infrastructure and tooling. Beyond that, he has 10 years of experience building machine learning applications in various industries. In his spare time, he enjoys golf and international traveling.
 Jun Lyu is a Software Engineer on the SageMaker Notebooks team. He has a Master’s degree in engineering from Duke University. He has been working for Amazon since 2015 and has contributed to AWS services like Amazon Machine Learning, Amazon SageMaker Notebooks, and Amazon SageMaker Studio. In his spare time, he enjoys spending time with his family, reading, cooking, and playing video games.
Jun Lyu is a Software Engineer on the SageMaker Notebooks team. He has a Master’s degree in engineering from Duke University. He has been working for Amazon since 2015 and has contributed to AWS services like Amazon Machine Learning, Amazon SageMaker Notebooks, and Amazon SageMaker Studio. In his spare time, he enjoys spending time with his family, reading, cooking, and playing video games.
Announcing the winners of the 2021 Statistics for Improving Insights, Models, and Decisions request for proposals
In April 2021, Facebook launched the 2021 Statistics for Improving Insights, Models, and Decisions request for proposals live at The Web Conference. Today, we’re announcing the winners of this award.
VIEW RFPAt Facebook, our research teams strive to improve decision-making for a business that touches the lives of billions of people across the globe. Making advances in data science methodologies helps us make the best decisions for our community, products, and infrastructure.
This RFP is a continuation of the 2019 and 2020 RFPs in applied statistics. Through this series of RFPs, the Facebook Core Data Science team, Infrastructure Data Science team, and Statistics and Privacy team aim to foster further innovation and deepen their collaboration with academia in applied statistics, in areas including, but not limited to, the following:
- Learning and evaluation under uncertainty
- Statistical models of complex social processes
- Causal inference with observational data
- Algorithmic auditing
- Performance regression detection and attribution
- Forecasting for aggregated time series
- Privacy-aware statistics for noisy, distributed data sets
The team reviewed 134 high-quality proposals and are pleased to announce the 10 winning proposals below, as well as the 15 finalists. Thank you to everyone who took the time to submit a proposal, and congratulations to the winners.
Research award winners
Breaking the accuracy-privacy-communication trilemma in federated analytics
Ayfer Ozgur (Stanford University)
Certifiably private, robust, and explainable federated learning
Bo Li, Han Zhao (University of Illinois Urbana-Champaign)
Experimental design in market equilibrium
Stefan Wager, Evan Munro, Kuang Xu (Stanford University)
Learning to trust graph neural networks
Claire Donnat (University of Chicago)
Negative-unlabeled learning for online datacenter straggler prediction
Michael Carbin, Henry Hoffmann, Yi Ding (Massachusetts Institute of Technology)
Non-parametric methods for calibrated hierarchical time-series forecasting
B. Aditya Prakash, Chao Zhang (Georgia Institute of Technology)
Privacy in personalized federated learning and analytics
Suhas Diggavi (University of California Los Angeles)
Reducing simulation-to-reality gap as remedy to learning under uncertainty
Mahsa Baktashmotlagh (University of Queensland)
Reducing the theory-practice gap in private and distributed learning
Ambuj Tewari (University of Michigan)
Robust wait-for graph inference for performance diagnosis
Ryan Huang (Johns Hopkins University)
Finalists
An integrated framework for learning and optimization over networks
Eric Balkanski, Adam Elmachtoub (Columbia University)
Auditing bias in large-scale language models
Soroush Vosoughi (Dartmouth College)
Cross-functional experiment prioritization with decision maker in-the-loop
Emma McCoy, Bryan Liu (Imperial College London)
Data acquisition and social network intervention codesign: Privacy and equity
Amin Rahimian (University of Pittsburgh)
Efficient and practical A/B testing for multiple nonstationary experiments
Nicolò Cesa-Bianchi, Nicola Gatti (Università degli Studi di Milano)
Empirical Bayes deep neural networks for predictive uncertainty
Xiao Wang, Yijia Liu (Purdue University)
Global forecasting framework for large scale hierarchical time series
Rob Hyndman, Christoph Bergmeir, Kasun Bandara, Shanika Wickramasuriya (Monash University)
High-dimensional treatments in causal inference
Kosuke Imai (Harvard University)
Nowcasting time series aggregates: Textual machine learning analysis
Eric Ghysels (University of North Carolina at Chapel Hill)
Online sparse deep learning for large-scale dynamic systems
Faming Liang, Dennis KJ Lin, Qifan Song (Purdue University)
Optimal use of data for reliable off-policy policy evaluation
Hongseok Namkoong (Columbia University)
Principled uncertainty quantification for deep neural networks
Tengyu Ma, Ananya Kumar, Jeff Haochen (Stanford University)
Reliable causal inference with continual learning
Sheng Li (University of Georgia)
Training individual-level machine learning models on noisy aggregated data
Martine De Cock, Steven Golob (University of Washington Tacoma)
Understanding instance-dependent label noise: Learnability and solutions
Yang Liu (University of California Santa Cruz)
The post Announcing the winners of the 2021 Statistics for Improving Insights, Models, and Decisions request for proposals appeared first on Facebook Research.
A crossword puzzle with a big purpose
Before the pandemic, Alicia Chang was working on a new project. “I was experimenting with non-traditional ways to help teach Googlers the AI Principles,” she says. Alicia is a technical writer on the Engineering Education team focused on designing learning experiences to help Googlers learn about our AI Principles and how to apply them in their own work.
The challenge for Alicia would be how many people she needed to educate. “There are so many people spread over different locations, time zones, countries!” But when the world started working from home, she was inspired by the various workarounds people were using to connect virtually.

Alicia Chang
“I started testing out activities like haiku-writing contests and online trivia,” Alicia says. “Then one day a friend mentioned an online escape room activity someone had arranged for a COVID-safe birthday gathering. Something really clicked with me when she mentioned that, and I started to think about designing an immersive learning experience.” Alicia decided to research how some of the most creative, dedicated people deliver information: She looked at what teachers were doing.
Alicia soon stumbled upon a YouTube video about using Google Sheets to create a crossword puzzle, so she decided to make her own — and Googlers loved it. Since the crossword was such a success, Alicia decided to make more interactive games. She used Google Forms to create a fun “Which AI Principle are you?” quiz, and Google Docs to make a word search. Then there’s the Emoji Challenge, where players have to figure out which AI Principles a set of emoji describe. All of this became part of what is now known as the Responsible Innovation Challenge, a set of various puzzle activities built with Google products — including Forms, Sheets, Docs and Sites — that focus on teaching Google’s AI Principles.

The purpose of the Responsible Innovation Challenge is to introduce Google’s AI Principles to new technical hires in onboarding courses, and to help Googlers put the AI Principles into practice in everyday product development situations. The first few puzzles are fairly simple and help players remember and recall the Principles, which serve as a practical framework for responsible innovation. As Googlers start leveling up, the puzzles get a bit more complex.. There’s even a bonus level where Googlers are asked to think about various technical resources and tools they can use to develop AI responsibly by applying them in their existing workflow when creating a machine learning model.
Alicia added a points system and a leaderboard with digital badges — and even included prizes. “I noticed that people were motivated by some friendly competition. Googlers really got involved and referred their coworkers to play, too,” she says. “We had over 1,000 enroll in the first 30 days alone!” To date, more than 2,800 Googlers have participated from across 41 countries, and people continue to sign up.
It’s been encouraging for Alicia to see how much Googlers are enjoying the puzzles, especially when screen time burnout is all too real. Most importantly, though, she’s thrilled that more people are learning about Google’s AI Principles. “Each of the billions of people who use Google products has a unique story and life experience,” Alicia says. “And that’s what we want to think about so we can make the best products for individual people.”