Today she’s helping Amazon to better formulate how to more efficiently transport packages through the middle mile of its complex delivery network.Read More
Google at ICCV 2021
Posted by Cat Armato, Program Manager, Google Research
The International Conference on Computer Vision 2021 (ICCV 2021), one of the world’s premier conferences on computer vision, starts this week. A Champion Sponsor and leader in computer vision research, Google will have a strong presence at ICCV 2021 with more than 50 research presentations and involvement in the organization of a number of workshops and tutorials.
If you are attending ICCV this year, we hope you’ll check out the work of our researchers who are actively pursuing the latest innovations in computer vision. Learn more about our research being presented in the list below (Google affilitation in bold).
Organizing Committee
Diversity and Inclusion Chair: Negar Rostamzadeh
Area Chairs: Andrea Tagliasacchi, Boqing Gong, Ce Liu, Dilip Krishnan, Jordi Pont-Tuset, Michael Rubinstein, Michael S. Ryoo, Negar Rostamzadeh, Noah Snavely, Rodrigo Benenson, Tsung-Yi Lin, Vittorio Ferrari
Publications
MosaicOS: A Simple and Effective Use of Object-Centric Images for Long-Tailed Object Detection
Cheng Zhang, Tai-Yu Pan, Yandong Li, Hexiang Hu, Dong Xuan, Soravit Changpinyo, Boqing Gong, Wei-Lun Chao
Learning to Resize Images for Computer Vision Tasks
Hossein Talebi, Peyman Milanfar
Joint Representation Learning and Novel Category Discovery on Single- and Multi-Modal Data
Xuhui Jia, Kai Han, Yukun Zhu, Bradley Green
Explaining in Style: Training a GAN to Explain a Classifier in StyleSpace
Oran Lang, Yossi Gandelsman, Michal Yarom, Yoav Wald, Gal Elidan, Avinatan Hassidim, William T. Freeman, Phillip Isola, Amir Globerson, Michal Irani, Inbar Mosseri
Learning Fast Sample Re-weighting without Reward Data
Zizhao Zhang, Tomas Pfister
Contrastive Multimodal Fusion with TupleInfoNCE
Yunze Liu, Qingnan Fan, Shanghang Zhang, Hao Dong, Thomas Funkhouser, Li Yi
Learning Temporal Dynamics from Cycles in Narrated Video
Dave Epstein*, Jiajun Wu, Cordelia Schmid, Chen Sun
Patch Craft: Video Denoising by Deep Modeling and Patch Matching
Gregory Vaksman, Michael Elad, Peyman Milanfar
How to Train Neural Networks for Flare Removal
Yicheng Wu*, Qiurui He, Tianfan Xue, Rahul Garg, Jiawen Chen, Ashok Veeraraghavan, Jonathan T. Barron
Learning to Reduce Defocus Blur by Realistically Modeling Dual-Pixel Data
Abdullah Abuolaim*, Mauricio Delbracio, Damien Kelly, Michael S. Brown, Peyman Milanfar
Hybrid Neural Fusion for Full-Frame Video Stabilization
Yu-Lun Liu, Wei-Sheng Lai, Ming-Hsuan Yang, Yung-Yu Chuang, Jia-Bin Huang
A Dark Flash Normal Camera
Zhihao Xia*, Jason Lawrence, Supreeth Achar
Efficient Large Scale Inlier Voting for Geometric Vision Problems
Dror Aiger, Simon Lynen, Jan Hosang, Bernhard Zeisl
Big Self-Supervised Models Advance Medical Image Classification
Shekoofeh Azizi, Basil Mustafa, Fiona Ryan*, Zachary Beaver, Jan Freyberg, Jonathan Deaton, Aaron Loh, Alan Karthikesalingam, Simon Kornblith, Ting Chen, Vivek Natarajan, Mohammad Norouzi
Physics-Enhanced Machine Learning for Virtual Fluorescence Microscopy
Colin L. Cooke, Fanjie Kong, Amey Chaware, Kevin C. Zhou, Kanghyun Kim, Rong Xu, D. Michael Ando, Samuel J. Yang, Pavan Chandra Konda, Roarke Horstmeyer
Retrieve in Style: Unsupervised Facial Feature Transfer and Retrieval
Min Jin Chong, Wen-Sheng Chu, Abhishek Kumar, David Forsyth
Deep Survival Analysis with Longitudinal X-Rays for COVID-19
Michelle Shu, Richard Strong Bowen, Charles Herrmann, Gengmo Qi, Michele Santacatterina, Ramin Zabih
MUSIQ: Multi-Scale Image Quality Transformer
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, Feng Yang
imGHUM: Implicit Generative Models of 3D Human Shape and Articulated Pose
Thiemo Alldieck, Hongyi Xu, Cristian Sminchisescu
Deep Hybrid Self-Prior for Full 3D Mesh Generation
Xingkui Wei, Zhengqing Chen, Yanwei Fu, Zhaopeng Cui, Yinda Zhang
Differentiable Surface Rendering via Non-Differentiable Sampling
Forrester Cole, Kyle Genova, Avneesh Sud, Daniel Vlasic, Zhoutong Zhang
A Lazy Approach to Long-Horizon Gradient-Based Meta-Learning
Muhammad Abdullah Jamal, Liqiang Wang, Boqing Gong
ViViT: A Video Vision Transformer
Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid
The Surprising Impact of Mask-Head Architecture on Novel Class Segmentation (see the blog post)
Vighnesh Birodkar, Zhichao Lu, Siyang Li, Vivek Rathod, Jonathan Huang
Generalize Then Adapt: Source-Free Domain Adaptive Semantic Segmentation
Jogendra Nath Kundu, Akshay Kulkarni, Amit Singh, Varun Jampani, R. Venkatesh Babu
Unified Graph Structured Models for Video Understanding
Anurag Arnab, Chen Sun, Cordelia Schmid
The Many Faces of Robustness: A Critical Analysis of Out-of-Distribution Generalization
Dan Hendrycks, Steven Basart, Norman Mu, Saurav Kadavath, Frank Wang, Evan Dorundo, Rahul Desai, Tyler Zhu, Samyak Parajuli, Mike Guo, Dawn Song, Jacob Steinhardt, Justin Gilmer
Learning Rare Category Classifiers on a Tight Labeling Budget
Ravi Teja Mullapudi, Fait Poms, William R. Mark, Deva Ramanan, Kayvon Fatahalian
Composable Augmentation Encoding for Video Representation Learning
Chen Sun, Arsha Nagrani, Yonglong Tian, Cordelia Schmid
Multi-Task Self-Training for Learning General Representations
Golnaz Ghiasi, Barret Zoph, Ekin D. Cubuk, Quoc V. Le, Tsung-Yi Lin
With a Little Help From My Friends: Nearest-Neighbor Contrastive Learning of Visual Representations
Debidatta Dwibedi, Yusuf Aytar, Jonathan Tompson, Pierre Sermanet, Andrew Zisserman
Understanding Robustness of Transformers for Image Classification
Srinadh Bhojanapalli, Ayan Chakrabarti, Daniel Glasner, Daliang Li, Thomas Unterthiner, Andreas Veit
Impact of Aliasing on Generalization in Deep Convolutional Networks
Cristina Vasconcelos, Hugo Larochelle, Vincent Dumoulin, Rob Romijnders, Nicolas Le Roux, Ross Goroshin
von Mises-Fisher Loss: An Exploration of Embedding Geometries for Supervised Learning
Tyler R. Scott*, Andrew C. Gallagher, Michael C. Mozer
Contrastive Learning for Label Efficient Semantic Segmentation
Xiangyun Zhao*, Raviteja Vemulapalli, Philip Andrew Mansfield, Boqing Gong, Bradley Green, Lior Shapira, Ying Wu
Interacting Two-Hand 3D Pose and Shape Reconstruction from Single Color Image
Baowen Zhang, Yangang Wang, Xiaoming Deng, Yinda Zhang, Ping Tan, Cuixia Ma, Hongan Wang
Telling the What While Pointing to the Where: Multimodal Queries for Image Retrieval
Soravit Changpinyo, Jordi Pont-Tuset, Vittorio Ferrari, Radu Soricut
SO-Pose: Exploiting Self-Occlusion for Direct 6D Pose Estimation
Yan Di, Fabian Manhardt, Gu Wang, Xiangyang Ji, Nassir Navab, Federico Tombari
Patch2CAD: Patchwise Embedding Learning for In-the-Wild Shape Retrieval from a Single Image
Weicheng Kuo, Anelia Angelova, Tsung-Yi Lin, Angela Dai
NeRD: Neural Reflectance Decomposition From Image Collections
Mark Boss, Raphael Braun, Varun Jampani, Jonathan T. Barron, Ce Liu, Hendrik P.A. Lensch
THUNDR: Transformer-Based 3D Human Reconstruction with Markers
Mihai Zanfir, Andrei Zanfir, Eduard Gabriel Bazavan, William T. Freeman, Rahul Sukthankar, Cristian Sminchisescu
Discovering 3D Parts from Image Collections
Chun-Han Yao, Wei-Chih Hung, Varun Jampani, Ming-Hsuan Yang
Multiresolution Deep Implicit Functions for 3D Shape Representation
Zhang Chen*, Yinda Zhang, Kyle Genova, Sean Fanello, Sofien Bouaziz, Christian Hane, Ruofei Du, Cem Keskin, Thomas Funkhouser, Danhang Tang
AI Choreographer: Music Conditioned 3D Dance Generation With AIST++ (see the blog post)
Ruilong Li*, Shan Yang, David A. Ross, Angjoo Kanazawa
Learning Object-Compositional Neural Radiance Field for Editable Scene Rendering
Bangbang Yang, Han Zhou, Yinda Zhang, Hujun Bao, Yinghao Xu, Guofeng Zhang, Yijin Li, Zhaopeng Cui
VariTex: Variational Neural Face Textures
Marcel C. Buhler, Abhimitra Meka, Gengyan Li, Thabo Beeler, Otmar Hilliges
Pathdreamer: A World Model for Indoor Navigation (see the blog post)
Jing Yu Koh, Honglak Lee, Yinfei Yang, Jason Baldridge, Peter Anderson
4D-Net for Learned Multi-Modal Alignment
AJ Piergiovanni, Vincent Casser, Michael S. Ryoo, Anelia Angelova
Episodic Transformer for Vision-and-Language Navigation
Alexander Pashevich*, Cordelia Schmid, Chen Sun
Graph-to-3D: End-to-End Generation and Manipulation of 3D Scenes Using Scene Graphs
Helisa Dhamo, Fabian Manhardt, Nassir Navab, Federico Tombari
Unconditional Scene Graph Generation
Sarthak Garg, Helisa Dhamo, Azade Farshad, Sabrina Musatian, Nassir Navab, Federico Tombari
Panoptic Narrative Grounding
Cristina González, Nicolás Ayobi, Isabela Hernández, José Hernández, Jordi Pont-Tuset, Pablo Arbeláez
Cross-Camera Convolutional Color Constancy
Mahmoud Afifi*, Jonathan T. Barron, Chloe LeGendre, Yun-Ta Tsai, Francois Bleibel
Defocus Map Estimation and Deblurring from a Single Dual-Pixel Image
Shumian Xin*, Neal Wadhwa, Tianfan Xue, Jonathan T. Barron, Pratul P. Srinivasan, Jiawen Chen, Ioannis Gkioulekas, Rahul Garg
COMISR: Compression-Informed Video Super-Resolution
Yinxiao Li, Pengchong Jin, Feng Yang, Ce Liu, Ming-Hsuan Yang, Peyman Milanfar
Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields
Jonathan T. Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo Martin-Brualla, Pratul P. Srinivasan
Nerfies: Deformable Neural Radiance Fields
Keunhong Park*, Utkarsh Sinha, Jonathan T. Barron, Sofien Bouaziz, Dan B Goldman, Steven M. Seitz, Ricardo Martin-Brualla
Baking Neural Radiance Fields for Real-Time View Synthesis
Peter Hedman, Pratul P. Srinivasan, Ben Mildenhall, Jonathan T. Barron, Paul Debevec
Stacked Homography Transformations for Multi-View Pedestrian Detection
Liangchen Song, Jialian Wu, Ming Yang, Qian Zhang, Yuan Li, Junsong Yuan
COTR: Correspondence Transformer for Matching Across Images
Wei Jiang, Eduard Trulls, Jan Hosang, Andrea Tagliasacchi, Kwang Moo Yi
Large Scale Interactive Motion Forecasting for Autonomous Driving: The Waymo Open Motion Dataset
Scott Ettinger, Shuyang Cheng, Benjamin Caine, Chenxi Liu, Hang Zhao, Sabeek Pradhan, Yuning Chai, Ben Sapp, Charles R. Qi, Yin Zhou, Zoey Yang, Aurélien Chouard, Pei Sun, Jiquan Ngiam, Vijay Vasudevan, Alexander McCauley, Jonathon Shlens, Dragomir Anguelov
Low-Shot Validation: Active Importance Sampling for Estimating Classifier Performance on Rare Categories
Fait Poms, Vishnu Sarukkai, Ravi Teja Mullapudi, Nimit S. Sohoni, William R. Mark, Deva Ramanan, Kayvon Fatahalian
Vector Neurons: A General Framework for SO(3)-Equivariant Networks
Congyue Deng, Or Litany, Yueqi Duan, Adrien Poulenard, Andrea Tagliasacchi, Leonidas J. Guibas
SLIDE: Single Image 3D Photography with Soft Layering and Depth-Aware Inpainting
Varun Jampani, Huiwen Chang, Kyle Sargent, Abhishek Kar, Richard Tucker, Michael Krainin, Dominik Kaeser, William T. Freeman, David Salesin, Brian Curless, Ce Liu
DeepPanoContext: Panoramic 3D Scene Understanding with Holistic Scene Context Graph and Relation-Based Optimization
Cheng Zhang, Zhaopeng Cui, Cai Chen, Shuaicheng Liu, Bing Zeng, Hujun Bao, Yinda Zhang
Infinite Nature: Perpetual View Generation of Natural Scenes from a Single Image
Andrew Liu, Richard Tucker, Varun Jampani, Ameesh Makadia, Noah Snavely, Angjoo Kanazawa
Workshops (only Google affiliations are noted)
Visual Inductive Priors for Data-Efficient Deep Learning Workshop
Speakers: Ekin Dogus Cubuk, Chelsea Finn
Instance-Level Recognition Workshop
Organizers: Andre Araujo, Cam Askew, Bingyi Cao, Jack Sim, Tobias Weyand
Unsup3D: Unsupervised 3D Learning in the Wild
Speakers: Adel Ahmadyan, Noah Snavely, Tali Dekel
Embedded and Real-World Computer Vision in Autonomous Driving (ERCVAD 2021)
Speakers: Mingxing Tan
Adversarial Robustness in the Real World
Speakers: Nicholas Carlini
Neural Architectures: Past, Present and Future
Speakers: Been Kim, Hanxiao Liu Organizers: Azade Nazi, Mingxing Tan, Quoc V. Le
Computational Challenges in Digital Pathology
Organizers: Craig Mermel, Po-Hsuan Cameron Chen
Interactive Labeling and Data Augmentation for Vision
Speakers: Vittorio Ferrari
Map-Based Localization for Autonomous Driving
Speakers: Simon Lynen
DeeperAction: Challenge and Workshop on Localized and Detailed Understanding of Human Actions in Videos
Speakers: Chen Sun Advisors: Rahul Sukthankar
Differentiable 3D Vision and Graphics
Speakers: Angjoo Kanazawa
Deep Multi-Task Learning in Computer Vision
Speakers: Chelsea Finn
Computer Vision for AR/VR
Speakers: Matthias Grundmann, Ira Kemelmacher-Shlizerman
GigaVision: When Gigapixel Videography Meets Computer Vision
Organizers: Feng Yang
Human Interaction for Robotic Navigation
Speakers: Peter Anderson
Advances in Image Manipulation Workshop and Challenges
Organizers: Ming-Hsuan Yang
More Exploration, Less Exploitation (MELEX)
Speakers: Angjoo Kanazawa
Structural and Compositional Learning on 3D Data
Speakers: Thomas Funkhouser, Kyle Genova Organizers: Fei Xia
Simulation Technology for Embodied AI
Organizers: Li Yi
Video Scene Parsing in the Wild Challenge Workshop
Speakers: Liang-Chieh (Jay) Chen
Structured Representations for Video Understanding
Organizers: Cordelia Schmid
Closing the Loop Between Vision and Language
Speakers: Cordelia Schmid
Segmenting and Tracking Every Point and Pixel: 6th Workshop on Benchmarking Multi-Target Tracking
Organizers: Jun Xie, Liang-Chieh Chen
AI for Creative Video Editing and Understanding
Speakers: Angjoo Kanazawa, Irfan Essa
BEHAVIOR: Benchmark for Everyday Household Activities in Virtual, Interactive, and Ecological Environments
Speakers: Chelsea Finn Organizers: Fei Xia
Computer Vision for Automated Medical Diagnosis
Organizers: Maithra Raghu
Computer Vision for the Factory Floor
Speakers: Cordelia Schmid
Tutorials (only Google affiliations are noted)
Towards Robust, Trustworthy, and Explainable Computer Vision
Speakers: Sara Hooker
Multi-Modality Learning from Videos and Beyond
Organizers: Arsha Nagrani
Tutorial on Large Scale Holistic Video Understanding
Organizers: David Ross
Efficient Video Understanding: State of the Art, Challenges, and Opportunities
Organizers: Arsha Nagrani
* Indicates work done while at Google

How DermAssist uses TensorFlow.js for on-device image quality checks
Posted by Miles Hutson and Aaron Loh, Google Health
At Google I/O in May, we previewed our DermAssist web application designed to help people understand issues related to their skin. The tool is designed to be easy to use. Upon opening it, users are expected to take three images of their skin, hair, or nail concern from multiple angles, and provide some additional information about themselves and their condition.
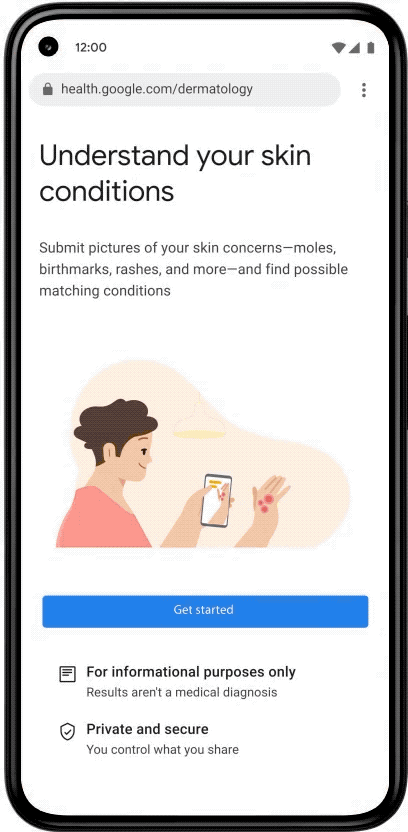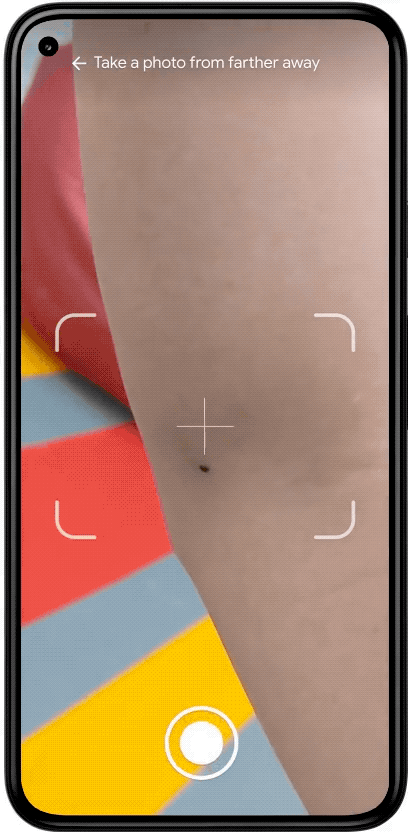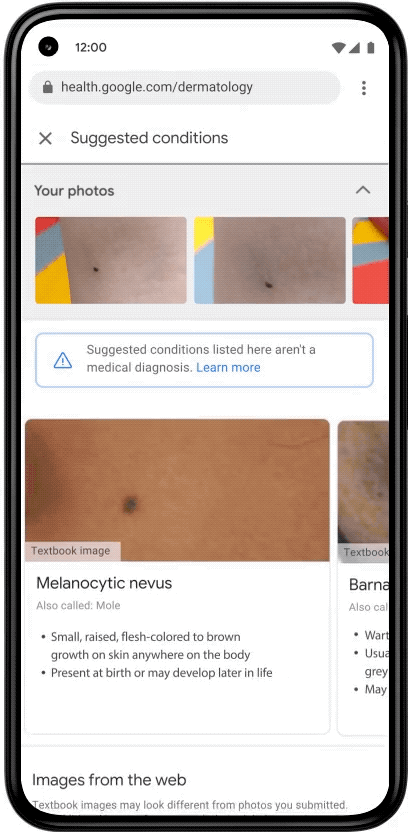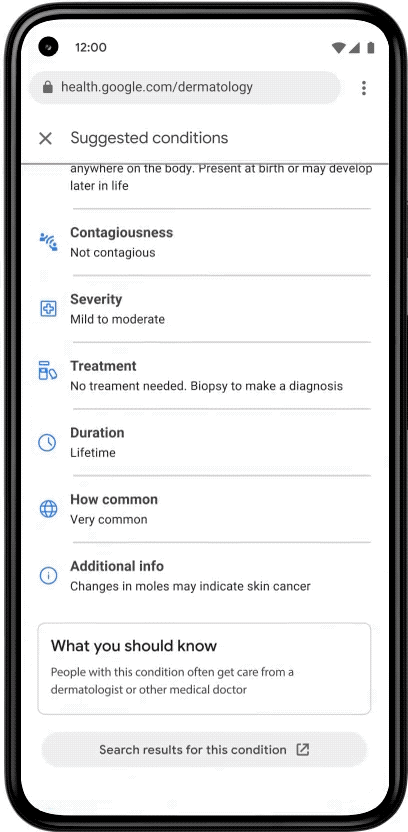 |
| This product has been CE marked as a Class I medical device in the EU. It is not available in the United States. |
We recognize that when users take pictures on their phone, some images could be blurry or have poor lighting. To address this, we initially added a “quality check” after images had been uploaded, which would prompt people to retake an image when necessary. However, these prompts could be a frustrating experience for them, depending on their upload speed, how long they took to acquire the image, and the multiple retakes it might require to pass the quality check.
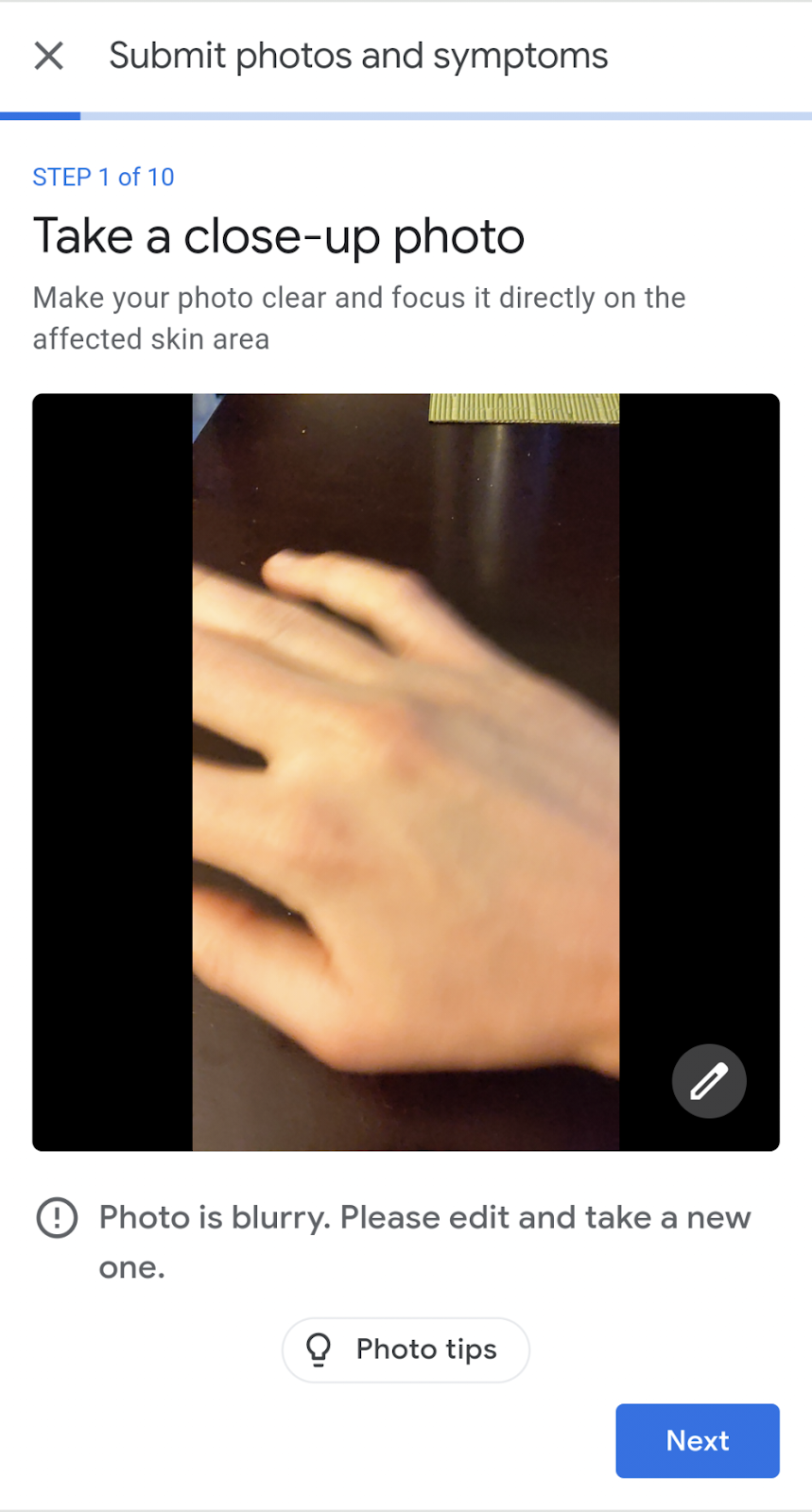 |
| Letting the user know they uploaded an image with insufficient quality and advising them to retake it before they proceed. |
To improve their experience, we decided to give users image quality feedback both on-device as they line up a photo, and when they review the photo before uploading. The way this feature works can be seen below. As the user lines up their camera for a shot, they may get a notification that their environment has a lighting issue (right image). Or, they may be notified that they took a blurry photo as they moved their camera (left image); the model helpfully lets them know their image is blurred before they go to the trouble of uploading it. They can decide to go back and correct the issue without the need to upload the image.
 |
 |
Examples of poor lighting or blurry images that obtain real time feedback so the user knows to take a new photo
Developing the Model
When developing the model, it was important to ensure that the model could comfortably run on-device. One such architecture designed for that purpose is MobileNetV2, which we selected as the backbone for the model.
Our discussions with dermatologists highlighted recurrent issues with image quality, such as the image being too blurry, too badly lit, or inappropriate for interpreting skin diseases. We curated several datasets to tackle those issues, which also informed the outputs of the model. The datasets included a crowdsourced data collection, public datasets, data obtained from tele-dermatology services, and synthetically generated images, many of which were further labeled by trained human graders. Combined, we trained the model on more than 30k images.
We trained the model with multiple binary heads, one for each quality issue. In the diagram below, we see how the input image is fed into a MobileNet feature extractor. This feature embedding is then fed to multiple distinct fully connected layers, producing a binary output (yes/no), each corresponding to a certain quality issue.

The infrastructure we used to train the model was built using TensorFlow, and exported models in the standard SavedModel format.
Translating the model to TensorFlow.js
Our team’s infrastructure for training models makes use of TensorFlow examples, which meant that the exported SavedModel had nodes for loading and preprocessing TensorFlow Examples.
TensorFlow.js at present does not support such preprocessing nodes. Therefore, we modified the signature of the SavedModel to use the image input node after the preprocessing nodes as input to the model. We re-implemented the processing in our Angular integration below.
Having rebuilt the SavedModel in the correct format for conversion, we employed the TensorFlow.js converter to convert it to the TensorFlow.js model format, which consists of a JSON file identifying the model topology, as well as the weights in sharded bin files.
tensorflowjs_converter --input_format=keras /path/to/tfjs/signature/ /path/to/write/tfjs_modelIntegrating TensorFlow.js with Observables and the Image Capture API
With the model trained, serialized, and made available for TensorFlow.js, it might feel like the job is pretty much done. However, we still had to integrate the TensorFlow.js model into our Angular 2 web application. While doing that, we had the goal that the model would ultimately be exposed as an API similar to other components. A good abstraction would allow frontend engineers to work with the TensorFlow.js model as they would work with any other part of the application, rather than as a unique component.
To begin, we created a wrapper class around the model ImageQualityPredictor. This Typescript class exposed only two methods:
- A static method
createImageQualityPredictorthat, given a URL for the model, returns a promise for anImageQualityPredictor. - A
makePredictionmethod that takes ImageData and returns an array of quality predictions above a given threshold.
We found that the implementation of makePrediction was key for abstracting the inner workings of our model. The result of calling execute on our model was an array of Tensors representing yes/no probabilities for each binary head. But we didn’t want the downstream application code to be responsible for the delicate task of thresholding these tensors and connecting them back to the heads’ descriptions. Instead, we moved these details inside of our wrapper class. The final return value to the caller was instead an interface ImageQualityPrediction.
export interface ImageQualityPrediction {
score: number;
qualityIssue: QualityIssue;
}
In order to make sure that a single ImageQualityPredictor was shared across the application, we in turn wrapped ImageQualityPredictor in a singleton ImageQualityModelService. This service handled the initialization of the predictor and tracked if the predictor already had a request in progress. It also contained helper methods for extracting frames from the ImageCapture API that our camera feature is built on and translating QualityIssue to plain English strings.
Finally, we combined the CameraService and our ImageQualityModelService in an ImageQualityService. The final product exposed for use in any given front end component is a simple observable that provides text describing any quality issues.
@Injectable()
export class ImageQualityService {
readonly realTimeImageQualityText$: Observable;
constructor(
private readonly cameraService: CameraService,
private readonly imageQualityModelService: ImageQualityModelService) {
const retrieveText = () =>
this.imageQualityModelService.runModel(this.cameraService.grabFrame());
this.realTimeImageQualityText$ =
interval(REFRESH_INTERVAL_MS)
.pipe(
filter(() => !imageQualityModelService.requestInProgress),
mergeMap(retrieveText),
);
}
// ...
}
This lends itself well to Angular’s normal templating system, accomplishing our goal of making a TensorFlow.js model in Angular as easy to work with as any other component for front end engineers. For example, a suggestion chip can be as easy to include in a component as
<suggestive-chip *ngIf="(imageQualityText$ | async) as text"
>{{text}}</suggestive-chip>Looking Ahead
With helping users to capture better pictures in mind, we developed an on-device image quality check for the DermAssist app to provide real-time guidance on image intake. Part of making users’ lives easier is making sure that this model works fast enough such that we can show a notification as quickly as possible while they’re taking a picture. For us, this means finding ways to reduce the model size in order to reduce the time it takes to load on a user’s device. Possible techniques to further advance this goal may be model quantization, or attempts at model distillation into smaller architectures.
To learn more about the DermAssist application, check out our blog post from Google I/O.
To learn more about TensorFlow.js, you can visit the main site here, also be sure to check out the tutorials and guide.
How the second-gen Echo Buds got smaller and better
Take a behind-the-scenes look at the unique challenges the engineering teams faced, and how they used scientific research to drive fundamental innovation.Read More
Stacking our way to more general robots
Picking up a stick and balancing it atop a log or stacking a pebble on a stone may seem like simple — and quite similar — actions for a person. However, most robots struggle with handling more than one such task at a time. Manipulating a stick requires a different set of behaviours than stacking stones, never mind piling various dishes on top of one another or assembling furniture. Before we can teach robots how to perform these kinds of tasks, they first need to learn how to interact with a far greater range of objects. As part of DeepMind’s mission and as a step toward making more generalisable and useful robots, we’re exploring how to enable robots to better understand the interactions of objects with diverse geometries.Read More
Stacking our way to more general robots
Introducing RGB-Stacking as a new benchmark for vision-based robotic manipulation.Read More
TensorFlow Model Optimization Toolkit — Collaborative Optimization API
A guest post by Mohamed Nour Abouelseoud and Elena Zhelezina at Arm.
This blog post introduces collaborative techniques for machine learning model optimization for edge devices, proposed and contributed by Arm to the TensorFlow Model Optimization Toolkit, available starting from release v0.7.0.
The main idea of the collaborative optimization pipeline is to apply the different optimization techniques in the TensorFlow Model Optimization Toolkit one after another while maintaining the balance between compression and accuracy required for deployment. This leads to significant reduction in the model size and could improve inference speed given framework and hardware-specific support such as that offered by the Arm Ethos-N and Ethos-U NPUs.
This work is a part of the toolkit’s roadmap to support the development of smaller and faster ML models. You can see previous posts on post-training quantization, quantization-aware training, sparsity, and clustering for more background on the toolkit and what it can do.
What is Collaborative Optimization? And why?
The motivation behind collaborative optimization remains the same as that behind the Model Optimization Toolkit (TFMOT) in general, which is to enable model conditioning and compression for improving deployment to edge devices. The push towards edge computing and endpoint-oriented AI creates high demand for such tools and techniques. The Collaborative Optimization API stacks all of the available techniques for model optimization to take advantage of their cumulative effect and achieve the best model compression while maintaining required accuracy.
Given the following optimization techniques, various combinations for deployment are possible:
- Weight pruning
- Weight clustering
- Quantization
In other words, it is possible to apply one or both of pruning and clustering, followed by post-training quantization or QAT before deployment.
The challenge in combining these techniques is that the APIs don’t consider previous ones, with each optimization and fine-tuning process not preserving the results of the preceding technique. This spoils the overall benefit of simultaneously applying them; i.e., clustering doesn’t preserve the sparsity introduced by the pruning process and the fine-tuning process of QAT loses both the pruning and clustering benefits. To overcome these problems, we introduce the following collaborative optimization techniques:
- Sparsity preserving clustering: clustering API that ensures a zero cluster, preserving the sparsity of the model.
- Sparsity preserving quantization aware training (PQAT): QAT training API that preserves the sparsity of the model.
- Cluster preserving quantization aware training (CQAT): QAT training API that does re-clustering and preserves the same number of centroids.
- Sparsity and cluster preserving quantization aware training (PCQAT): QAT training API that preserves the sparsity and number of clusters of a model trained with sparsity-preserving clustering.
Considered together, along with the option of post-training quantization instead of QAT, these provide several paths for deployment, visualized in the following deployment tree, where the leaf nodes are deployment-ready models, meaning they are fully quantized and in TFLite format. The green fill indicates steps where retraining/fine-tuning is required and a dashed red border highlights the collaborative optimization steps. The technique used to obtain a model at a given node is indicated in the corresponding label.

The direct, quantization-only (post-training or QAT) deployment path is omitted in the figure above.
The idea is to reach the fully optimized model at the third level of the above deployment tree; however, any of the other levels of optimization could prove satisfactory and achieve the required inference latency, compression, and accuracy target, in which case no further optimization is needed. The recommended training process would be to iteratively go through the levels of the deployment tree applicable to the target deployment scenario and see if the model fulfils the optimization requirements and, if not, use the corresponding collaborative optimization technique to compress the model further and repeat until the model is fully optimized (pruned, clustered, and quantized), if needed.
To further unlock the improvements in memory usage and speed at inference time associated with collaborative optimization, specialized run-time or compiler software and dedicated machine learning hardware is required. Examples include the Arm ML Ethos-N driver stack for the Ethos-N processor and the Ethos-U Vela compiler for the Ethos-U processor. Both examples currently require quantizing and converting optimized Keras models to TensorFlow Lite first.
The figure below shows the density plots of a sample weight kernel going through the full collaborative optimization pipeline.
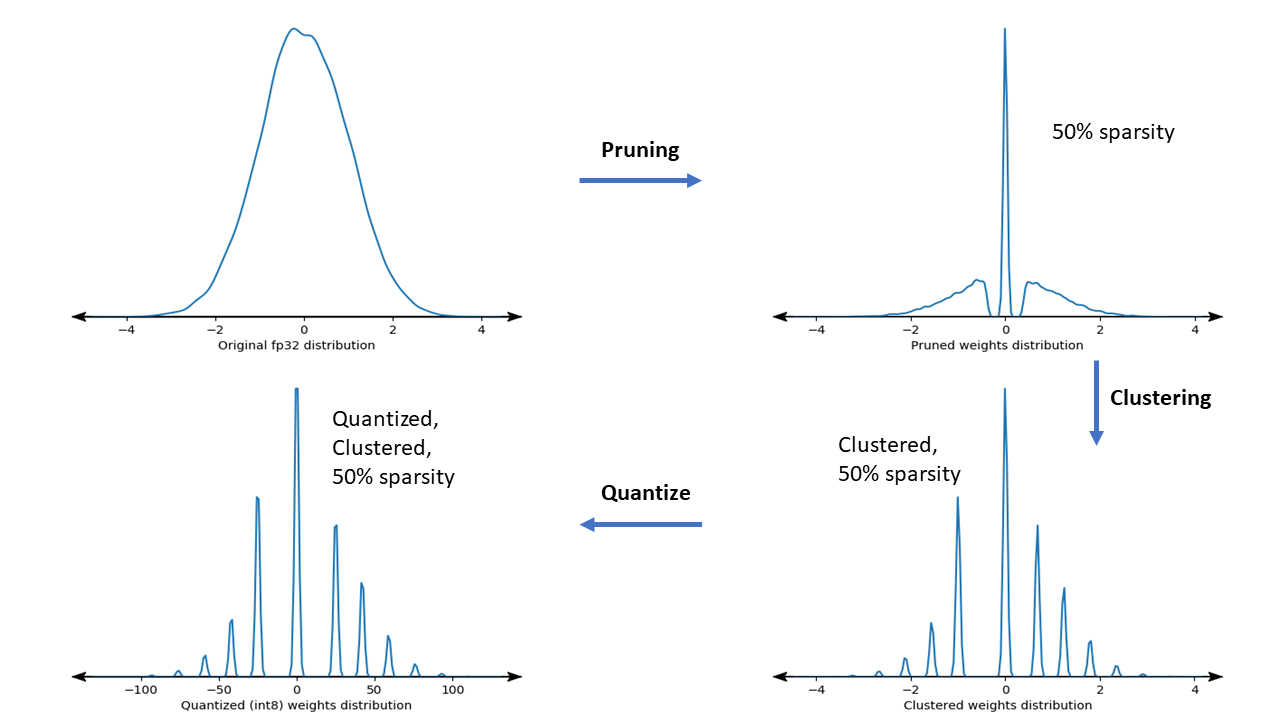
The result is a quantized deployment model with a reduced number of unique values as well as a significant number of sparse weights, depending on the target sparsity specified at training time. This results in substantial model compression advantages and significantly reduced inference latency on specialized hardware.
Compression and accuracy results
The tables below show the results of running several experiments on popular models, demonstrating the compression benefits vs. accuracy loss incurred by applying these techniques. More aggressive optimizations can be applied, but at the cost of accuracy. Though the table below includes measurements for TensorFlow Lite models, similar benefits are observed for other serialization formats.
Sparsity-preserving Quantization aware training (PQAT)
|
Model |
Metric |
Baseline |
Pruned Model (50% sparsity) |
QAT Model |
PQAT Model |
|
DS-CNN-L |
FP32 Top-1 Accuracy |
95.23% |
94.80% |
(Fake INT8) 94.721% |
(Fake INT8) 94.128% |
|
INT8 Top-1 Accuracy |
94.48% |
93.80% |
94.72% |
94.13% |
|
|
Compression |
528,128 → 434,879 (17.66%) |
528,128 → 334,154 (36.73%) |
512,224 → 403,261 (21.27%) |
512,032 → 303,997 (40.63%) |
|
|
MobileNet_v1 on ImageNet |
FP32 Top-1 Accuracy |
70.99% |
70.11% |
(Fake INT8) 70.67% |
(Fake INT8) 70.29% |
|
INT8 Top-1 Accuracy |
69.37% |
67.82% |
70.67% |
70.29% |
|
|
Compression |
4,665,520 → 3,880,331 (16.83%) |
4,665,520 → 2,939,734 (37.00%) |
4,569,416 → 3,808,781 (16.65%) |
4,569,416 → 2,869,600 (37.20%) |
Note: DS-CNN-L is a keyword spotting model designed for edge devices. More can be found in Arm’s ML Examples repository.
Cluster-preserving Quantization aware training (CQAT)
|
Model |
Metric |
Baseline |
Clustered Model |
QAT Model |
CQAT Model |
|
MobileNet_v1 on CIFAR-10 |
FP32 Top-1 Accuracy |
94.88% |
94.48% (16 clusters) |
(Fake INT8) 94.80% |
(Fake INT8) 94.60% |
|
INT8 Top-1 Accuracy |
94.65% |
94.41% (16 clusters) |
94.77% |
94.52% |
|
|
Size |
3,000,000 |
2,000,000 |
2,840,000 |
1,940,000 |
|
|
MobileNet_v1 on ImageNet |
FP32 Top-1 Accuracy |
71.07% |
65.30% (32 clusters) |
(Fake INT8) 70.39% |
(Fake INT8) 65.35% |
|
INT8 Top-1 Accuracy |
69.34% |
60.60% (32 clusters) |
70.35% |
65.42% |
|
|
Compression |
4,665,568 → 3,886,277 (16.7%) |
4,665,568 → 3,035,752 (34.9%) |
4,569,416 → 3,804,871 (16.7%) |
4,569,472 → 2,912,655 (36.25%) |
Sparsity and cluster preserving quantization aware training (PCQAT)
|
Model |
Metric |
Baseline |
Pruned Model (50% sparsity) |
QAT Model |
Pruned Clustered Model |
PCQAT Model |
|
DS-CNN-L |
FP32 Top-1 Accuracy |
95.06% |
94.07% |
(Fake INT8) 94.85% |
93.76% (8 clusters) |
(Fake INT8) 94.28% |
|
INT8 Top-1 Accuracy |
94.35% |
93.80% |
94.82% |
93.21% (8 clusters) |
94.06% |
|
|
Compression |
506,400 → 425,006 (16.07%) |
506,400 → 317,937 (37.22%) |
507,296 → 424,368 (16.35%) |
506,400 → 205,333 (59.45%) |
507,296 → 201,744 (60.23%) |
|
|
MobileNet_v1 on ImageNet |
FP32 Top-1 Accuracy |
70.98% |
70.49% |
(Fake INT8) 70.88% |
67.64% (16 clusters) |
(Fake INT8) 67.80% |
|
INT8 Top-1 Accuracy |
70.37% |
69.85% |
70.87% |
66.89% (16 clusters) |
68.63%
|
|
|
Compression |
4,665,552 → 3,886,236 (16.70%) |
4,665,552 → 2,909,148 (37.65%) |
4,569,416 → 3,808,781 (16.65%) |
4,665,552 → 2,013,010 (56.85%) |
4,569472 → 1,943,957 (57.46%) |
Applying PCQAT
To apply PCQAT, you will need to first use the pruning API to prune the model, then chain it with clustering using the sparsity-preserving clustering API. After that, the QAT API is used along with the custom collaborative optimization quantization scheme. An example is shown below.
import tensorflow_model_optimization as tfmot
model = build_your_model()
# prune model
model_for_pruning = tfmot.sparsity.keras.prune_low_magnitude(model, ...)
model_for_pruning.fit(...)
# pruning wrappers must be stripped before clustering
stripped_pruned_model = tfmot.sparsity.keras.strip_pruning(pruned_model)
After pruning the model, cluster and fit as below.
# Sparsity preserving clustering
from tensorflow_model_optimization.python.core.clustering.keras.experimental import (cluster)
# Specify your clustering parameters along
# with the `preserve_sparsity` flag
clustering_params = {
...,
'preserve_sparsity': True
}
# Cluster and fine-tune as usual
cluster_weights = cluster.cluster_weights
sparsity_clustered_model = cluster_weights(stripped_pruned_model_copy, **clustering_params)
sparsity_clustered_model.compile(...)
sparsity_clustered_model.fit(...)
# Strip clustering wrappers before the PCQAT step
stripped_sparsity_clustered_model = tfmot.clustering.keras.strip_clustering(sparsity_clustered_model)
Then apply PCQAT.
pcqat_annotate_model = quantize.quantize_annotate_model(stripped_sparsity_clustered_model )
pcqat_model = quantize.quantize_apply(quant_aware_annotate_model,scheme=default_8bit_cluster_preserve_quantize_scheme.Default8BitClusterPreserveQuantizeScheme(preserve_sparsity=True))
pcqat_model.compile(...)
pcqat_model.fit(...)The example above shows the training process to achieve a fully optimized PCQAT model, for the other techniques, please refer to the CQAT, PQAT, and sparsity-preserving clustering example notebooks. Note that the API used for PCQAT is the same as that of CQAT, the only difference being the use of the preserve_sparsity flag to ensure that the zero cluster is preserved during training. The PQAT API usage is similar but uses a different, sparsity preserving, quantization scheme.
Acknowledgments
The features and results presented in this post are the work of many people including the Arm ML Tooling team and our collaborators in Google’s TensorFlow Model Optimization Toolkit team.
From Arm – Anton Kachatkou, Aron Virginas-Tar, Ruomei Yan, Saoirse Stewart, Peng Sun, Elena Zhelezina, Gergely Nagy, Les Bell, Matteo Martincigh, Benjamin Klimczak, Thibaut Goetghebuer-Planchon, Tamás Nyíri, Johan Gras.
From Google – David Rim, Frederic Rechtenstein, Alan Chiao, Pulkit Bhuwalka
What made me want to fight for fair AI
My life has always involved centering the voices of those historically marginalized in order to foster equitable communities. Growing up, I lived in a small suburb just outside of Cleveland, Ohio and I was fortunate enough to attend Laurel School, an all-girls school focused on encouraging young women to think critically and solve difficult world problems. But my lived experience at school was so different from kids who lived even on my same street. I was grappling with watching families around me contend with an economic recession, losing any financial security that they had and I wanted to do everything I could to change that. Even though my favorite courses at the time were engineering and African American literature, I was encouraged to pursue economics.
I was fortunate enough to continue my education at Princeton University, first starting in the economics department. Unfortunately, I struggled to find the connections between what I was learning and the challenges I saw my community and people of color in the United States facing through the economic crisis. Interestingly enough, it was through an art and social justice movements class in the School of Architecture that I found my fit. Everyday, I focused on building creative solutions to difficult community problems through qualitative research, received feedback and iterated. The deeper I went into my studies, the more I realized that my passion was working with locally-based researchers and organizations to center their voices in designing solutions to complex and large-scale problems. It wasn’t until I came to Google, that I realized this work directly translated to human-centered design and community-based participatory research. My undergraduate studies culminated in the creation of a social good startup focused on providing fresh produce to food deserts in central New Jersey, where our team interviewed over 100 community members and leaders, secured a $16,000 grant, and provided pounds of free fresh produce to local residents.
Already committed to a Ph.D. program in Social Policy at Brandeis University, I channeled my passion for social enterprise and solving complex problems into developing research skills. Knowing that I ultimately did not want to go into academia, I joked with my friends that the job I was searching for didn’t exist yet, but hopefully it would by the time I graduated. I knew that my heart was equal parts in understanding technology and in closing equity gaps, but I did not know how I would be able to do both.
Through Brandeis, I found language to the experiences of family and friends who had lost financial stability during the Great Recession and methodologies for how to research systematic inequalities across human identity. It was in this work that I witnessed Angela Glover-Blackwell, founder of PolicyLink speak for the first time. From her discussion on highlighting community-based equitable practices, I knew I had to support her work. Through their graduate internship program in Oakland, I was able to bridge the gap between research and application – I even found a research topic for my dissertation! And then Mike Brown was shot.
Mike was from the midwest, just like me. He reminded me of my cousins, friends from my block growing up. The experience of watching what happened to Mike Brown so publically, gave weight to the research and policies that I advocated for in my Ph.D. program and at work – it somehow made it more personal than my experience with the Great Recession. At Brandeis, I led a town hall interviewing the late Civil Rights activist and politician Julian Bond, where I still remember his admonishment to shift from talk to action, and to have clear and centralized values and priorities from which to guide equity. In the background of advocating for social justice, I used my work grading papers and teaching courses as a graduate teaching assistant to supplement my doctoral grant – including graduate courses on “Ethics, Rights, and Development” and “Critical Race Theory.”
The next summer I had the privilege of working at a think tank now known as Prosperity Now, supporting local practitioners and highlighting their findings at the national level. This amazing experience was coupled with meeting my now husband, who attended my aunt and uncle’s church. By the end of the summer, my work and personal experiences in DC had become so important that I decided to stay. Finished with my coursework at Brandeis, I wrote my dissertation in the evenings as I shifted to a more permanent position at the Center for Global Policy Solutions, led by Dr. Maya Rockeymoore. I managed national research projects and then brought the findings to the hill for policymakers to make a case for equitable policies like closing the racial wealth gap. Knocking on doors in Capitol buildings taught me the importance of finding shared language and translating research into measurable change.
By the end of 2016, I was a bit burned out by my work on the hill and welcomed the transition of marriage and moving to Los Angeles. The change of scenery allowed me to finally hone my technical skills as a Program Manager for the LA-based ed tech non profit, 9 Dots. I spent my days partnering with school districts, principals, teaching fellows and software developers to provide CS education to historically underserved students. The ability to be a part of a group that created a hybrid working space for new parents was icing on the cake. Soon after, I got a call from a recruiter at Google.
It had been almost a year since Google’s AI Principles had been publicly released and they were searching for candidates that had a deep understanding of socio-technical research and program management to operationalize the Principles. Every role and research pursuit that I’d followed led to my dream role – Senior Strategist focused on centering the voices of historically underrepresented and marginalized communities in machine learning through research and collaboration.
During my time at Google, I’ve had the opportunity to develop an internal workshop focused on equitable and inclusive language practices, which led to a collaboration with UC Berkeley’s Center for Equity, Gender, and Leadership; launch the Equitable AI Research Roundtable along with Jamila Smith-Loud and external experts focused on equitable cross-disciplinary research practices (including PolicyLink!); and present on Google’s work in Responsible AI at industry-wide conferences like MozFest. With all that I’ve learned, I’m still determined to bring more voices to the table. My work in Responsible AI has led me to building out globally-focused resources for machine learning engineers, analysts, and product decision makers. When we center the experiences of our users – the communities who faced the economic recession with grit and resilience, those who searched for insights from Civil Rights leaders, and developed shared language to inspire inclusion – all else will follow. I’m honored to be one of many at Google driving the future of responsible and equitable AI for all.
Amazon Robotics AI leaders believe now is a ‘particularly good time’ to explore careers in robotics
Siddhartha Srinivasa, director of Amazon Robotics AI, and Nia Jetter, Amazon Robotics AI senior principal technologist, discuss inspiration, their roles at Amazon, and tips for pursuing a robotics career.Read More
Stanford AI Lab Papers at ICCV 2021
![]()
The International Conference on Computer Vision (ICCV 2021)
will be hosted virtually next week. We’re excited to share all the work from SAIL that will be presented, and you’ll find links to papers, videos and blogs below. Feel free to reach out to the contact authors directly to learn more about the work that’s happening at Stanford!
List of Accepted Papers
GLoRIA: A Multimodal Global-Local Representation Learning Framework for Label-efficient Medical Image Recognition
Authors: Mars Huang
Contact: mschuang@stanford.edu
Keywords: medical image, self-supervised learning, multimodal fusion
3D Shape Generation and Completion Through Point-Voxel Diffusion
Authors: Linqi Zhou, Yilun Du, Jiajun Wu
Contact: linqizhou@stanford.edu
Links: Paper | Video | Website
Keywords: diffusion, shape generation
CAPTRA: CAtegory-level Pose Tracking for Rigid and Articulated Objects from Point Clouds
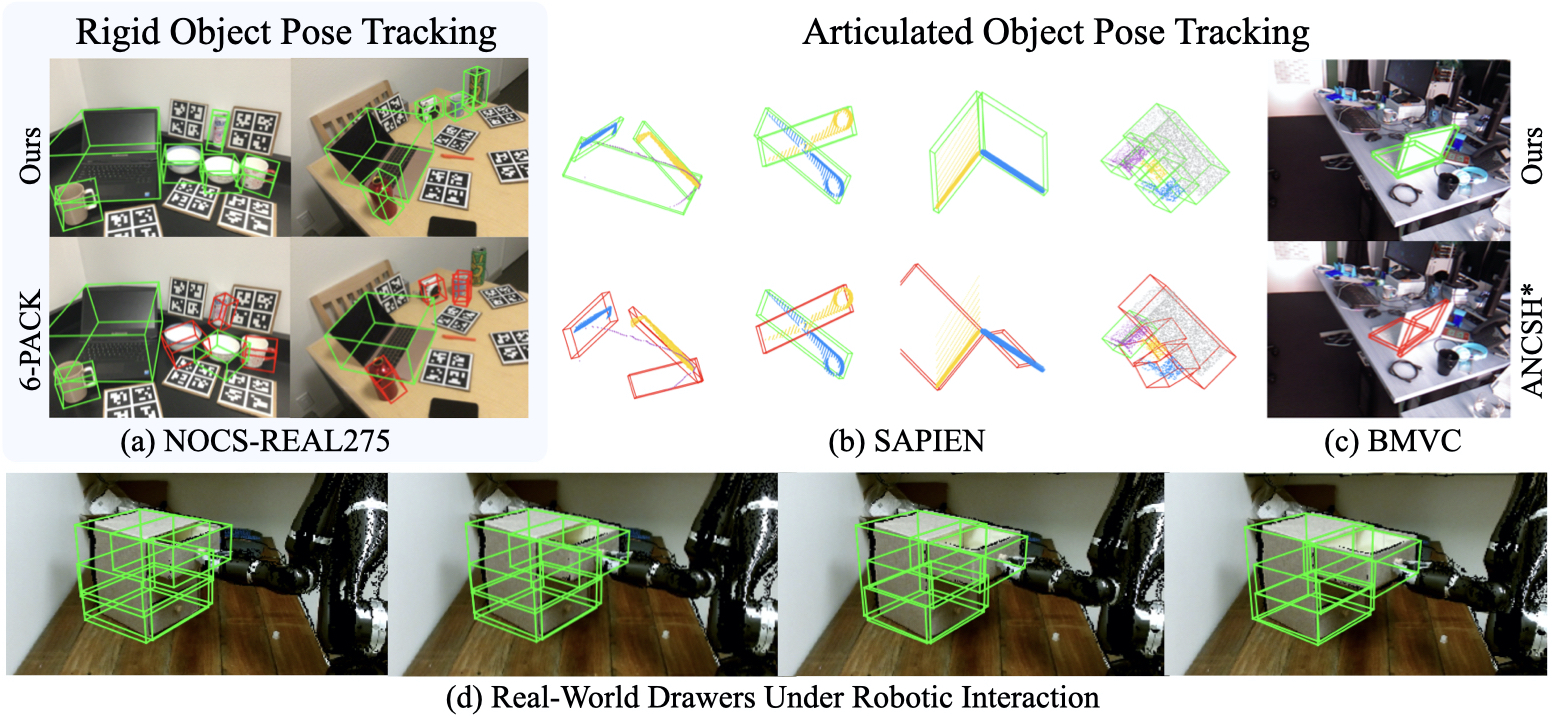
Authors: Yijia Weng*, He Wang*, Qiang Zhou, Yuzhe Qin, Yueqi Duan, Qingnan Fan, Baoquan Chen, Hao Su, Leonidas J. Guibas
Contact: yijiaw@stanford.edu
Award nominations: Oral Presentation
Links: Paper | Video | Website
Keywords: category-level object pose tracking, articulated objects
Detecting Human-Object Relationships in Videos
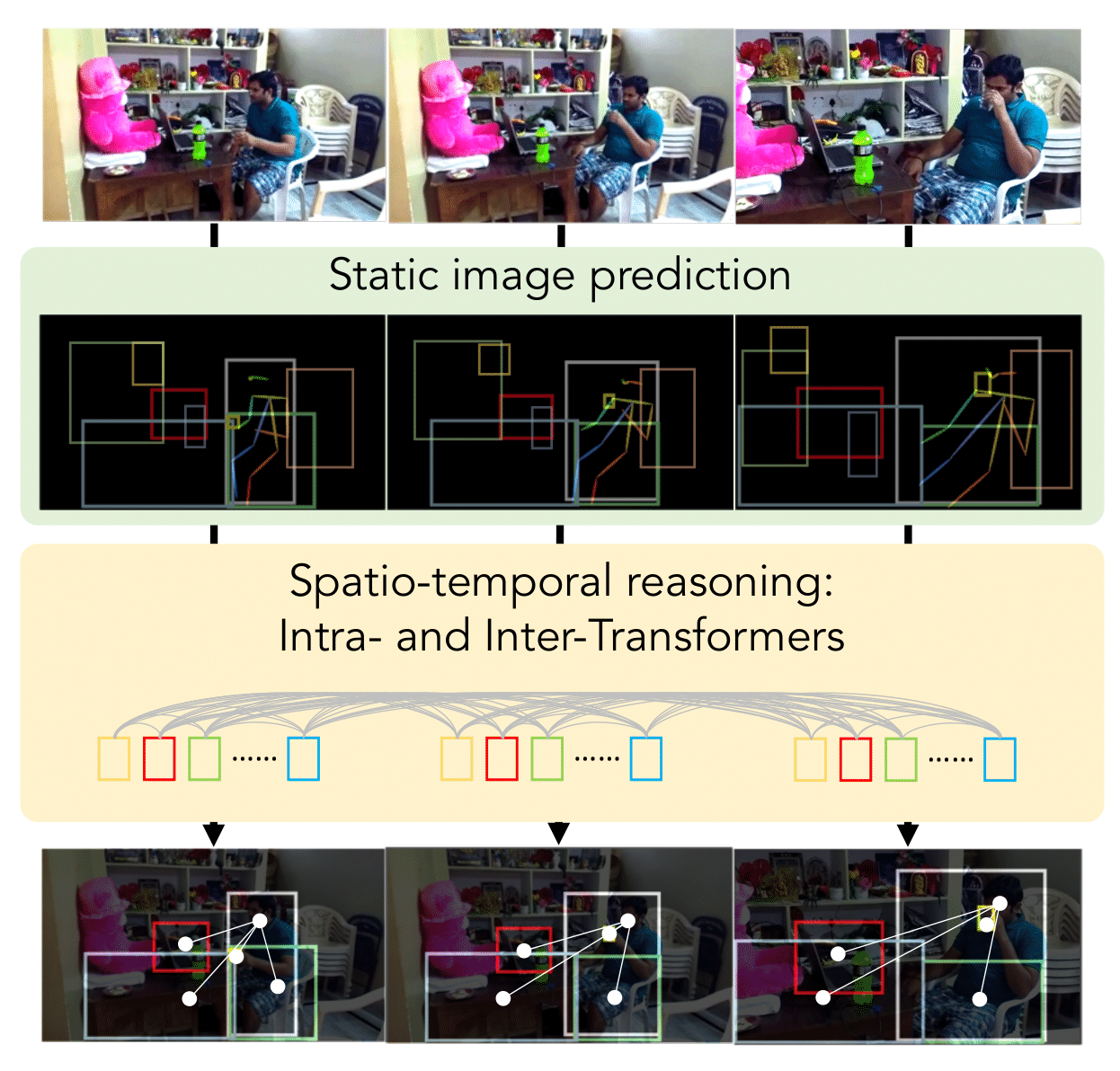
Authors: Jingwei Ji, Rishi Desai, Juan Carlos Niebles
Contact: jingweij@cs.stanford.edu
Links: Paper
Keywords: human-object relationships, video, detection, transformer, spatio-temporal reasoning
Geography-Aware Self-Supervised Learning
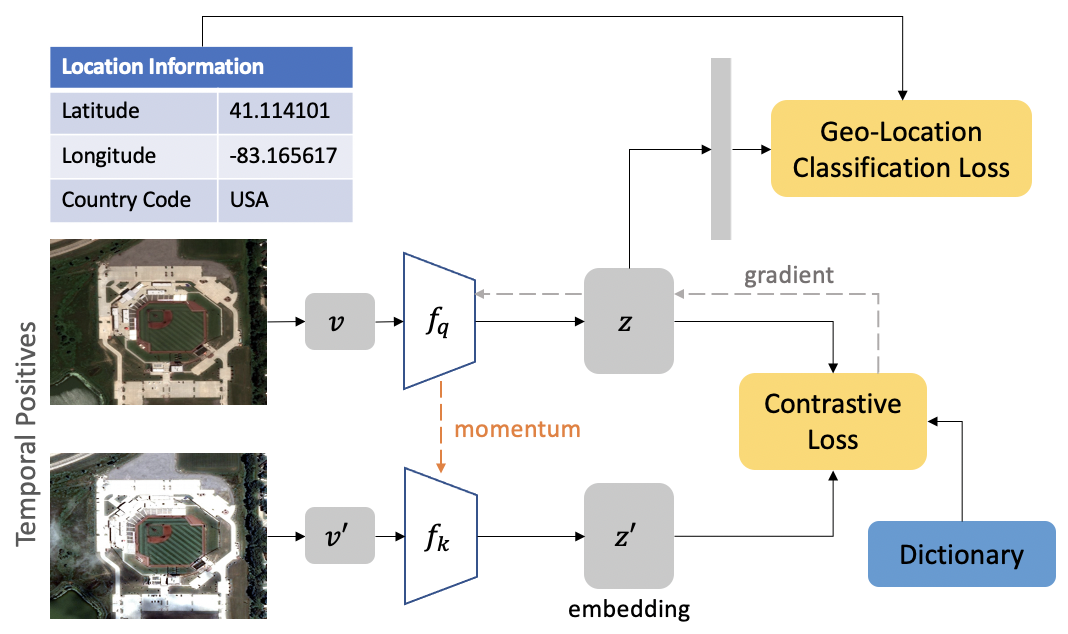
Authors: Kumar Ayush, Burak Uzkent, Chenlin Meng, Kumar Tanmay, Marshall Burke, David Lobell, Stefano Ermon
Contact: kayush@cs.stanford.edu, chenlin@stanford.edu
Links: Paper | Website
Keywords: self-supervised learning, contrastive learning, remote sensing, spatio-temporal, classification, object detection, segmentation
HuMoR: 3D Human Motion Model for Robust Pose Estimation
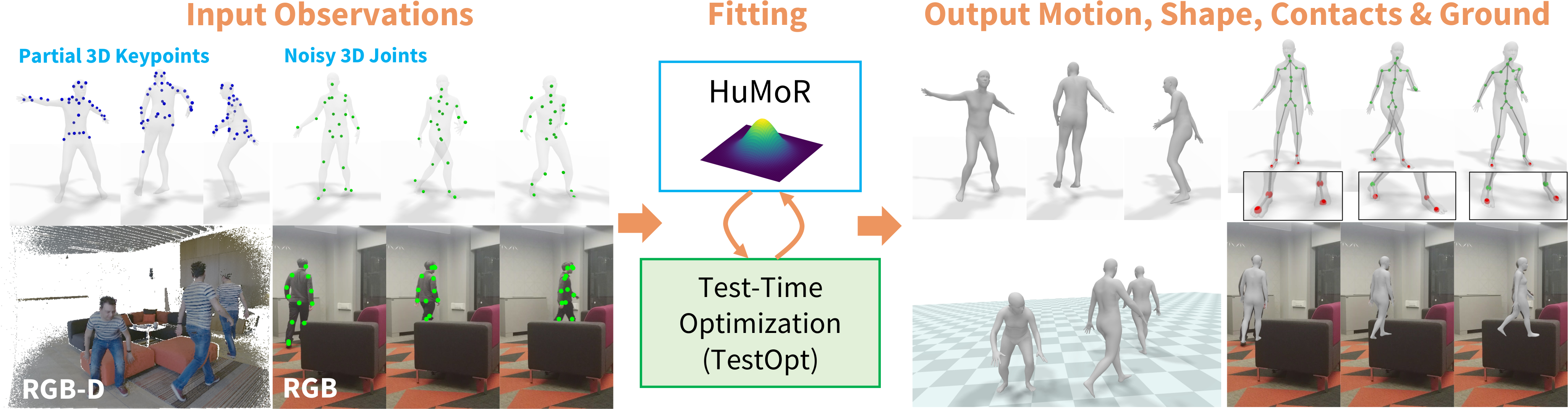
Authors: Davis Rempe, Tolga Birdal, Aaron Hertzmann, Jimei Yang, Srinath Sridhar, Leonidas Guibas
Contact: drempe@stanford.edu
Award nominations: Oral Presentation
Links: Paper | Website
Keywords: 3d human pose estimation; 3d human motion; generative modeling
Learning Privacy-preserving Optics for Human Pose Estimation
Authors: Carlos Hinojosa, Juan Carlos Niebles, Henry Arguello
Contact: carlos.hinojosa@saber.uis.edu.co
Links: Paper | Website
Keywords: computational photography; fairness, accountability, transparency, and ethics in vision; gestures and body pose
Learning Temporal Dynamics from Cycles in Narrated Video
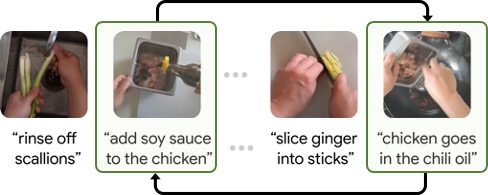
Authors: Dave Epstein, Jiajun Wu, Cordelia Schmid, Chen Sun
Contact: jiajunwu@cs.stanford.edu
Links: Paper | Website
Keywords: multi-modal learning, cycle consistency, video
Vector Neurons: A General Framework for SO(3)-Equivariant Networks
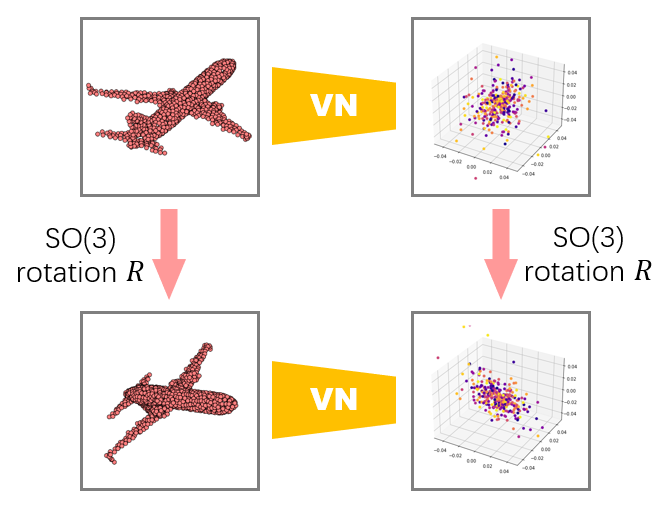
Authors: Congyue Deng, Or Litany, Yueqi Duan, Adrien Poulenard, Andrea Tagliasacchi, Leonidas Guibas
Contact: congyue@stanford.edu
Links: Paper | Video | Website
Keywords: pointcloud network, rotation equivariance, rotation invariance
Neural Radiance for 4D View Synthesis and Video Processing

Authors: Yilun Du, Yinan Zhang, Hong-Xing Yu, Joshua B. Tenenbaum, Jiajun Wu
Contact: jiajunwu@cs.stanford.edu
Links: Paper | Website
Keywords: 4d representation, neural rendering, video processing
Where2Act: From Pixels to Actions for Articulated 3D Objects
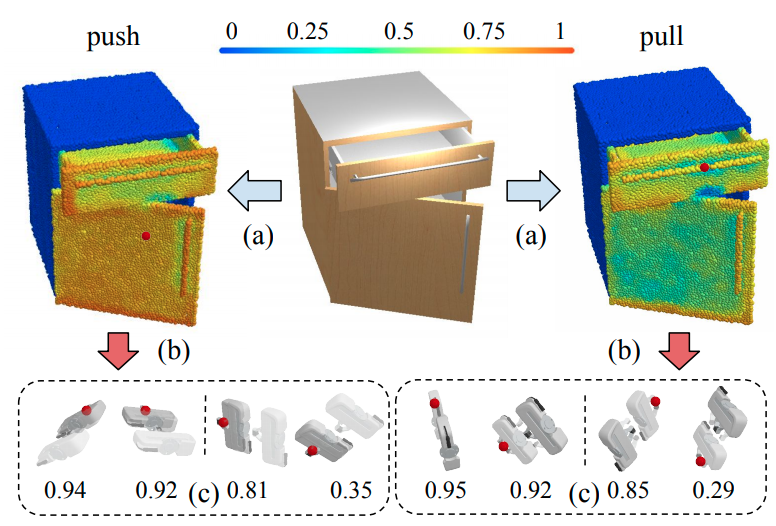
Authors: Kaichun Mo, Leonidas J. Guibas, Mustafa Mukadam, Abhinav Gupta, Shubham Tulsiani
Contact: kaichunm@stanford.edu
Links: Paper | Website
Keywords: 3d computer vision, robotic vision, affordance learning, robot learning
Low-Shot Validation: Active Importance Sampling for Estimating Classifier Performance on Rare Categories
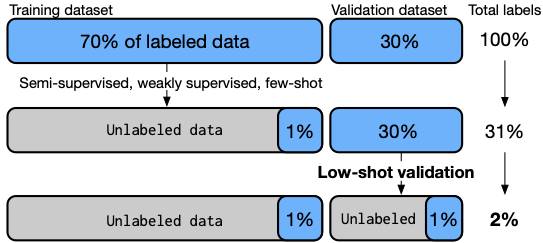
Authors: Fait Poms*, Vishnu Sarukkai*, Ravi Teja Mullapudi, Nimit S. Sohoni, William R. Mark, Deva Ramanan, Kayvon Fatahalian
Contact: sarukkai@stanford.edu
Links: Paper | Blog | Video
Keywords: model evaluation, active learning
We look forward to seeing you at ICCV 2021!