Posted by Ivan Grishchenko, Valentin Bazarevsky, Ahmed Sabie, Jason Mayes, Google
With the rise in interest around health and fitness, we have seen a growing number of TensorFlow.js users take their first steps in 2021 with our existing body related ML models, such as face mesh, body pose, and hand pose estimation.
Today we are launching two new highly optimized body segmentation models that are both accurate and fast as part of our updated body-segmentation and pose APIs in TensorFlow.js.
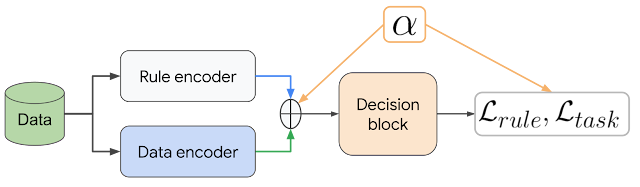
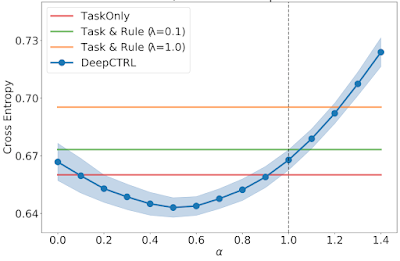
First is the BlazePose GHUM pose estimation model that now has additional support for segmentation. This model is part of our unified pose-detection API offering that can perform full body segmentation and 3D pose estimation simultaneously as shown in the animation below. It’s well suited for bodies in full view further away from the camera accurately capturing the feet and legs regions for example.
|
 |
The second model we are releasing is Selfie Segmentation that is well suited for cases where someone is directly in front of a webcam on a video call (<2 meters). This model that is part of our unified body-segmentation API can have higher accuracy across the upper body as shown in the animation below, but may be less accurate for the lower body in some situations.

Both of these new models could enable a whole host of creative applications orientated around the human body that could drive next generation web apps. For example, the BlazePose GHUM Pose model may power services like digitally teleporting your presence anywhere in the world, estimating body measurements for a virtual tailor, or creating special effects for music videos and more, the possibilities are endless. In contrast the Selfie Segmentation model could enable user friendly features on web based video calls like the demo above where you can change or blur the background accurately.
Prior to this launch, many of our users may have tried our BodyPix model, which was state of the art when it launched. With today’s release, our two new models offer a much higher FPS and fidelity across devices for a variety of use cases.
Body Segmentation API Installation
The body-segmentation API provides two runtimes for the Selfie Segmentation model, namely the MediaPipe runtime and TensorFlow.js runtime.
To install the API and runtime library, you can either use the <script> tag in your html file or use NPM.
Through script tag:
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-backend-webgl">
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/body-segmentation">
<!-- Optional: Include below scripts if you want to use TensorFlow.js runtime. -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-converter">
<!-- Optional: Include below scripts if you want to use MediaPipe runtime. -->
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/selfie_segmentation">Through NPM:
yarn add @tensorflow/tfjs-core @tensorflow/tfjs-backend-webgl
yarn add @tensorflow-models/body-segmentation
# Run below commands if you want to use TensorFlow.js runtime.
yarn add @tensorflow/tfjs-converter
# Run below commands if you want to use MediaPipe runtime.
yarn add @mediapipe/selfie_segmentation
To reference the API in your JS code, it depends on how you installed the library.
If installed through script tag, you can reference the library through the global namespace bodySegmentation.
If installed through NPM, you need to import the libraries first:
import '@tensorflow/tfjs-backend-core';
import '@tensorflow/tfjs-backend-webgl';
import * as bodySegmentation from '@tensorflow-models/body-segmentation';
// Uncomment the line below if you want to use TensorFlow.js runtime.
// import '@tensorflow/tfjs-converter';
// Uncomment the line below if you want to use MediaPipe runtime.
// import '@mediapipe/selfie_segmentation';
Try it yourself!
First, you need to create a segmenter:
const model = bodySegmentation.SupportedModels.MediaPipeSelfieSegmentation; // or 'BodyPix'
const segmenterConfig = {
runtime: 'mediapipe', // or 'tfjs'
modelType: 'general' // or 'landscape'
};
segmenter = await bodySegmentation.createSegmenter(model, segmenterConfig);Choose a modelType that fits your application needs, there are two options for you to choose from: general, and landscape. From landscape to general, the accuracy increases while the inference speed decreases. Please try our live demo to compare different configurations.
Once you have a segmenter, you can pass in a video stream, static image, or TensorFlow.js tensors to segment people:
const video = document.getElementById('video');
const people = await segmenter.segmentPeople(video);How to use the output?
The people result above represents an array of the found segmented people in the image frame. However, each model has its own semantics for a given segmentation.
For Selfie Segmentation, the array will be exactly of length 1, where the single segmentation corresponds to all people in the image frame. For each segmentation, it contains maskValueToLabel and mask properties detailed below.
The mask field stores an object which provides access to the underlying results of the segmentation. You can then utilize the provided asynchronous conversion functions such as toCanvasImageSource, toImageData, and toTensor depending on the desired output type that you want for efficiency.
It should be noted that different models have different internal representations of data. Therefore converting from one form to another may be expensive. In the name of efficiency, you can call getUnderlyingType to determine what form the segmentation is in already so you may choose to keep it in the same form for faster results.
The semantics of the RGBA values of the mask are as follows: the image mask is the same size as the input image, where green and blue channels are always set to 0. Different red values denote different body parts (see maskValueToLabel key below). Different alpha values denote the probability of a pixel being a body part pixel (0 being lowest probability and 255 being highest).
maskValueToLabel maps pixel’s red channel value to the segmented part name for that pixel. This is not necessarily the same across different models (for example SelfieSegmentation will always return ‘person’ since it does not distinguish individual body parts, whereas a model like BodyPix would return the name of individual body parts that it can distinguish for each segmented pixel). See below output snippet for example:
[
{
maskValueToLabel: (maskValue: number) => { return 'person' },
mask: {
toCanvasImageSource(): ...
toImageData(): ...
toTensor(): ...
getUnderlyingType(): ...
}
}
]
We also provide an optional utility function that you can use to render the result of the segmentation. Use the toBinaryMask function to convert the segmentation to an ImageData object.
This function takes 5 parameters, the last 4 being optional:
- Segmentation results from segmentPeople call above.
- Foreground color – an object representing the RGBA values to use for rendering foreground pixels.
- Background color – object with RGBA values for background pixels
- Draw Contour – boolean value if to draw a contour line around the body of the found person.
- Foreground threshold – at what point a pixel should be considered a foreground pixel vs background pixel. This is a floating point value from 0 to 1.
Once you have the imageData object from toBinaryMask you can use the drawMask function to render it to a canvas of your choice.
Example code for using these two functions is shown below:
const foregroundColor = {r: 0, g: 0, b: 0, a: 0};
const backgroundColor = {r: 0, g: 0, b: 0, a: 255};
const drawContour = true;
const foregroundThreshold = 0.6;
const backgroundDarkeningMask = await bodySegmentation.toBinaryMask(people, foregroundColor, backgroundColor, drawContour, foregroundThreshold);
const opacity = 0.7;
const maskBlurAmount = 3; // Number of pixels to blur by.
const canvas = document.getElementById('canvas');
const people = await bodySegmentation.drawMask(canvas, video, backgroundDarkeningMask, opacity, maskBlurAmount);Pose Detection API Usage
To load and use the BlazePose GHUM model please reference the unified Pose API documentation. This model has three outputs:
- 2D keypoints
- 3D keypoints
- Segmentation for each found pose.
If you need to grab the segmentation from the pose results, you can simply grab a reference to that pose’s segmentation property a shown:
const poses = await detector.estimatePoses(video);
const firstSegmentation = poses.length > 0 ? poses[0].segmentation : null;
Models deep dive
BlazePose GHUM and MediaPipe Selfie Segmentation models segment the prominent humans in the frame. Both run in real-time across laptops and smartphones but vary in intended applications as discussed at the start of this blog. Selfie Segmentation focuses on selfie effects and conferencing for closeup cases (< 2m) where as BlazePose GHUM specializes in full-body cases like yoga, fitness, dance and works up to 4 meters from the camera.
 |
| Selfie Segmentation |
Selfie Segmentation model predicts binary segmentation mask of foreground with humans. The pipeline is structured to run entirely on GPU, from image acquisition over neural network inference to rendering the segmented result on the screen. It avoids slow CPU-GPU syncs and achieves the maximum performance. Variations of the model are powering background replacement in Google Meet and a more general model is now available in TensorFlow.js and MediaPipe.
 |
| BlazePose GHUM 2D landmarks and body segmentation |
BlazePose GHUM model now provides a body segmentation mask in addition to 2D and 3D landmarks introduced earlier. Having a single model that predicts both outputs gives us two gains. First, it allows outputs to supervise and improve each other as landmarks give semantic structure while segmentation focuses on edges. Second, it guarantees that predicted mask and points belong to the same person, which is hard to achieve with separate models. As BlazePose GHUM model runs only on the ROI crop of a person (vs. full image), segmentation mask quality depends only on the effective resolution within the ROI and doesn’t change a lot when moving closer or further from the camera.
|
Conference |
ASL |
Yoga |
Dance |
HIIT |
|
|
BlazePose GHUM (full) |
95.50% |
96.52% |
94.73% |
94.55% |
95.16% |
|
Selfie Segmentation (256×256) |
97.60% |
97.88% |
80.66% |
86.33% |
85.53% |
BlazePose GHUM and Selfie Segmentation IOUs across different domains
MediaPipe and TensorFlow.js runtime
There are some pros and cons of using each runtime. As shown in the performance tables below, the MediaPipe runtime provides faster inference speed on desktop, laptop and android phones. The TensorFlow.js runtime provides faster inference speed on iPhones and iPads.
FPS numbers here are the time taken to perform the inference through the model and wait for the GPU and CPU to sync. This is done to ensure the GPU has fully finished for benchmarking purposes, but for pure-GPU production pipelines no waiting is needed, so your numbers may be higher still. For pure GPU pipeline, if you are using the MediaPipe runtime, just use await mask.toCanvasImageSource(), and if you are using the TF.js runtime, reference this example on how to use texture directly to stay on GPU for rendering effects.
Benchmarks
Selfie segmentation model
|
MacBook Pro 15” 2019. Intel core i9. AMD Radeon Pro Vega 20 Graphics. (FPS) |
iPhone 11 (FPS – CPU Only for MediaPipe) |
Pixel 6 Pro (FPS) |
Desktop PC Intel i9-10900K. Nvidia GTX 1070 GPU. (FPS) |
|
|
MediaPipe Runtime With WASM & GPU Accel. |
125 | 130 |
31 | 21 |
35 | 33 |
185 | 225 |
|
TFJS Runtime With WebGL backend. |
74 | 45 |
42 | 30 |
25 | 23 |
80 | 62 |
Inference speed of Selfie Segmentation across different devices and runtimes. The first number in each cell is for the landscape model, and the second number is for the general model.
BlazePose GHUM model
|
MacBook Pro 15” 2019. Intel core i9. AMD Radeon Pro Vega 20 Graphics. (FPS) |
iPhone 11 (FPS – CPU Only for MediaPipe) |
Pixel 6 Pro (FPS) |
Desktop PC Intel i9-10900K. Nvidia GTX 1070 GPU. (FPS) |
|
|
MediaPipe Runtime With WASM & GPU Accel |
70 | 59 | 31 |
8 | 5 | 1 |
22 | 19 | 10 |
123 | 112 | 70 |
|
TFJS Runtime With WebGL backend. |
42 | 36 | 22 |
14 | 12 | 8 |
12 | 10 | 6 |
35 | 33 | 26 |
Inference speed of BlazePose GHUM full body segmentation across different devices and runtimes. The first number in each cell is the lite model, second number is the full model, and third number is the heavy version of the model. Note that the segmentation output can be turned off by setting enableSegmentation to false in the model parameters, which would increase the model performance.
Looking to the future
We are constantly working on new features and quality improvements of our tech (for instance this is the third BlazePose GHUM update in the last year after initial 2D release and consequent 3D update), so expect new exciting updates in the near future.
Acknowledgements
We would like to acknowledge our colleagues who participated in or sponsored creating Selfie Segmentation, BlazePose GHUM and building the APIs: Siargey Pisarchyk, Tingbo Hou, Artsiom Ablavatski, Karthik Raveendran, Eduard Gabriel Bazavan, Andrei Zanfir, Cristian Sminchisescu, Chuo-Ling Chang, Matthias Grundmann, Michael Hays, Tyler Mullen, Na Li, Ping Yu.