Guilherme Pereira, a 2019 Amazon Research Award recipient, is researching methods to improve a robot’s ability to work autonomously.Read More
Optimize your inference jobs using dynamic batch inference with TorchServe on Amazon SageMaker
In deep learning, batch processing refers to feeding multiple inputs into a model. Although it’s essential during training, it can be very helpful to manage the cost and optimize throughput during inference time as well. Hardware accelerators are optimized for parallelism, and batching helps saturate the compute capacity and often leads to higher throughput.
Batching can be helpful in several scenarios during model deployment in production. Here we broadly categorize them into two use cases:
- Real-time applications where several inference requests are received from different clients and are dynamically batched and fed to the serving model. Latency is usually important in these use cases.
- Offline applications where several inputs or requests are batched on the client side and sent to the serving model. Higher throughput is often the objective for these use cases, which helps manage the cost. Example use cases include video analysis and model evaluation.
Amazon SageMaker provides two popular options for your inference jobs. For real-time applications, SageMaker Hosting uses TorchServe as the backend serving library that handles the dynamic batching of the received requests. For offline applications, you can use SageMaker batch transform jobs. In this post, we go through an example of each option to help you get started.
Because TorchServe is natively integrated with SageMaker via the SageMaker PyTorch inference toolkit, you can easily deploy a PyTorch model onto TorchServe using SageMaker Hosting. There may be also times when you need to customize your environment further using custom Docker images. In this post, we first show how to deploy a real-time endpoint using the native SageMaker PyTorch inference toolkit and configuring the batch size to optimize throughput. In the second example, we demonstrate how to use a custom Docker image to configure advanced TorchServe configurations that aren’t available as an environment variable to optimize your batch inference job.
Best practices for batch inference
Batch processing can increase throughput and optimize your resources because it helps complete a larger number of inferences in a certain amount of time at the expense of latency. To optimize model deployment for higher throughput, the general guideline is to increase the batch size until throughput decreases. This most often suits offline applications, where several inputs are batched (such as video frames, images, or text) to get prediction outputs.
For real-time applications, latency is often a main concern. There’s a trade-off between higher throughput and increased batch size and latency; you may need to adjust as needed to meet your latency SLA. In terms of best practices on the cloud, the cost per a certain number of inferences is a helpful guideline in making an informed decision that meets your business needs. One contributing factor in managing the cost is choosing the right accelerator. For more information, see Choose the best AI accelerator and model compilation for computer vision inference with Amazon SageMaker.
TorchServe dynamic batching on SageMaker
TorchServe is the native PyTorch library for serving models in production at scale. It’s a joint development from Facebook and AWS. TorchServe allows you to monitor, add custom metrics, support multiple models, scale up and down the number of workers through secure management APIs, and provide inference and explanation endpoints.
To support batch processing, TorchServe provides a dynamic batching feature. It aggregates the received requests within a specified time frame, batches them together, and sends the batch for inference. The received requests are processed through the handlers in TorchServe. TorchServe has several default handlers, and you’re welcome to author a custom handler if your use case isn’t covered. When using a custom handler, make sure that the batch inference logic has been implemented in the handler. An example of a custom handler with batch inference support is available on GitHub.
You can configure dynamic batching using two settings, batch_size and max_batch_delay, either through environment variables in SageMaker or through the config.properties file in TorchServe (if using a custom container). TorchServe uses any of the settings that comes first, either the maximum batch size (batch_size) or specified time window to wait for the batch of requests through max_batch_delay.
With TorchServe integrations with SageMaker, you can now deploy PyTorch models natively on SageMaker, where you can define a SageMaker PyTorch model. You can add custom model loading, inference, and preprocessing and postprocessing logic in a script passed as an entry point to the SageMaker PyTorch (see the following example code). Alternatively, you can use a custom container to deploy your models. For more information, see The SageMaker PyTorch Model Server.
You can set the batch size for PyTorch models on SageMaker through environment variables. If you choose to use a custom container, you can bundle settings in config.properties with your model when packaging your model in TorchServe. The following code snippet shows an example how to set the batch size using environment variables and how to deploy a PyTorch model on SageMaker:
In the code snippet, model_artifact refers to all the required files for loading back the trained model, which is archived in a .tar file and pushed into an Amazon Simple Storage Service (Amazon S3) bucket. The inference.py is similar to the TorchServe custom handler; it has several functions that you can override to accommodate the model initialization, preprocessing and postprocessing of received requests, and inference logic.
The following notebook shows a full example of deploying a Hugging Face BERT model.
If you need a custom container, you can build a custom container image and push it to the Amazon Elastic Container Registry (Amazon ECR) repository. The model artifact in this case can be a TorchServe .mar file that bundles the model artifacts along with handler. We demonstrate this in the next section, where we use a SageMaker batch transform job.
SageMaker batch transform job
For offline use cases where requests are batched from a data source such as a dataset, SageMaker provides batch transform jobs. These jobs enable you to read data from an S3 bucket and write the results to a target S3 bucket. For more information, see Use Batch Transform to Get Inferences from Large Datasets. A full example of batch inference using batch transform jobs can be found in the following notebook, where we use a machine translation model from the FLORES competition. In this example, we show how to use a custom container to score our model using SageMaker. Using a custom inference container allows you to further customize your TorchServe configuration. In this example, we want to change and disable JSON decoding, which we can do through the TorchServe config.properties file.
When using a custom handler for TorchServe, we need to make sure that the handler implements the batch inference logic. Each handler can have custom functions to perform preprocessing, inference, and postprocessing. An example of a custom handler with batch inference support is available on GitHub.
We use our custom container to bundle the model artifacts with the handler as we do in TorchServe (making a .mar file). We also need an entry point to the Docker container that starts TorchServe with the batch size and JSON decoding set in config.properties. We demonstrate this in the example notebook.
The SageMaker batch transform job requires access to the input files from an S3 bucket, where it divides the input files into mini batches and sends them for inference. Consider the following points when configuring the batch transformation job:
- Place the input files (such as a dataset) in an S3 bucket and set it as a data source in the job settings.
- Assign an S3 bucket in which to save the results of the batch transform job.
- Set BatchStrategy to
MultiRecordandSplitTypetoLineif you need the batch transform job to make mini batches from the input file. If it can’t automatically split the dataset into mini batches, you can divide it into mini batches by putting each batch in a separate input file, placed in the data source S3 bucket. - Make sure that the batch size fits into the memory. SageMaker usually handles this automatically; however, when dividing batches manually, this needs to be tuned based on the memory.
The following code is an example for a batch transform job:
When we use the preceding settings and launch our transform job, it reads the input files from the source S3 bucket in batches and sends them for inference. The results are written back to the S3 bucket specified to the outputs.
The following code snippet shows how to create and launch a job using the preceding settings:
Conclusion
In this post, we reviewed the two modes SageMaker offers for online and offline inference. The former uses dynamic batching provided in TorchServe to batch the requests from multiple clients. The latter uses a SageMaker transform job to batch the requests from input files in an S3 bucket and run inference.
We also showed how to serve models on SageMaker using native SageMaker PyTorch inference toolkit container images, and how to use custom containers for use cases that require advanced TorchServe configuration settings.
As TorchServe continues to evolve to address the needs of the PyTorch community, new features are integrated into SageMaker to provide performant ways for serving models in production. For more information, check out the TorchServe GitHub repo and the SageMaker examples.
About the Authors
 Phi Nguyen is a solutions architect at AWS helping customers with their cloud journey with a special focus on data lake, analytics, semantics technologies and machine learning. In his spare time, you can find him biking to work, coaching his son’s soccer team or enjoying nature walk with his family.
Phi Nguyen is a solutions architect at AWS helping customers with their cloud journey with a special focus on data lake, analytics, semantics technologies and machine learning. In his spare time, you can find him biking to work, coaching his son’s soccer team or enjoying nature walk with his family.
 Nikhil Kulkarni is a software developer with AWS Machine Learning, focusing on making machine learning workloads more performant on the cloud and is a co-creator of AWS Deep Learning Containers for training and inference. He’s passionate about distributed Deep Learning Systems. Outside of work, he enjoys reading books, fiddling with the guitar and making pizza.
Nikhil Kulkarni is a software developer with AWS Machine Learning, focusing on making machine learning workloads more performant on the cloud and is a co-creator of AWS Deep Learning Containers for training and inference. He’s passionate about distributed Deep Learning Systems. Outside of work, he enjoys reading books, fiddling with the guitar and making pizza.
 Hamid Shojanazeri is a Partner Engineer at Pytorch working on OSS high performance model optimization and serving. Hamid holds a P.h.D in Computer vision and worked as a researcher in multimedia labs in Australia, Malaysia and NLP lead in Opus.ai. He likes to find simpler solutions to hard problems and is an art enthusiast in his spare time.
Hamid Shojanazeri is a Partner Engineer at Pytorch working on OSS high performance model optimization and serving. Hamid holds a P.h.D in Computer vision and worked as a researcher in multimedia labs in Australia, Malaysia and NLP lead in Opus.ai. He likes to find simpler solutions to hard problems and is an art enthusiast in his spare time.
 Geeta Chauhan leads AI Partner Engineering at Meta AI with expertise in building resilient, anti-fragile, large scale distributed platforms for startups and Fortune 500s. Her team works with strategic partners, machine learning leaders across the industry and all major cloud service providers for building and launching new AI product services and experiences; and taking PyTorch models from research to production.. She is a winner of Women in IT – Silicon Valley – CTO of the year 2019, an ACM Distinguished Speaker and thought leader on topics ranging from Ethics in AI, Deep Learning, Blockchain, IoT. She is passionate about promoting use of AI for Good.
Geeta Chauhan leads AI Partner Engineering at Meta AI with expertise in building resilient, anti-fragile, large scale distributed platforms for startups and Fortune 500s. Her team works with strategic partners, machine learning leaders across the industry and all major cloud service providers for building and launching new AI product services and experiences; and taking PyTorch models from research to production.. She is a winner of Women in IT – Silicon Valley – CTO of the year 2019, an ACM Distinguished Speaker and thought leader on topics ranging from Ethics in AI, Deep Learning, Blockchain, IoT. She is passionate about promoting use of AI for Good.
Graph-based recommendation system with Neptune ML: An illustration on social network link prediction challenges
Recommendation systems are one of the most widely adopted machine learning (ML) technologies in real-world applications, ranging from social networks to ecommerce platforms. Users of many online systems rely on recommendation systems to make new friendships, discover new music according to suggested music lists, or even make ecommerce purchase decisions based on the recommended products. In social networks, one common use case is to recommend new friends to a user based on the users’ other connections. Users with common friends likely know each other. Therefore, they should have a higher score for a recommendation system to propose if they haven’t been connected yet.
Social networks can naturally be expressed in a graph, where the nodes represent people, and the connections between people, such as friendship or co-workers, are represented by edges. The following illustrates one such social network. Let’s imagine that we have a social network with the members (nodes) Bill, Terry, Henry, Gary, and Alistair. Their relationships are represented by a link (edge), and each person’s interests, such as sports, arts, games, and comics, are represented by node properties.
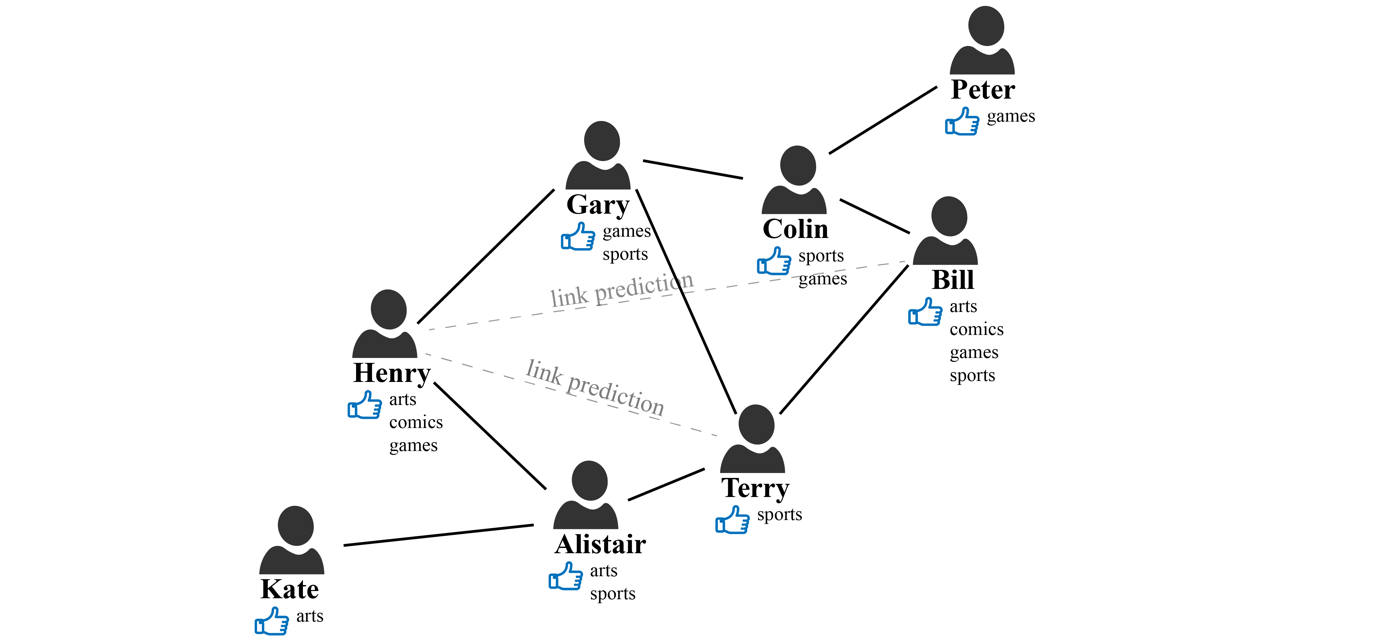
The objective here is to predict if there is a potential missing link between members. For example, should we recommend a connection between Henry and Terry? Looking at the graph, we can see that they have two mutual friends, Gary and Alistair. Therefore, there is a good chance that Henry and Terry either already knew each other or may get to know each other soon. How about Henry and Bill? They don’t have any mutual friends, but they do have some weak connection through their friends’ connections. In addition, they both have similar interests in arts, comics, and games. Should we promote this connection? All of these questions and intuitions are the core logic of social network recommendation systems.
One possible way to do this is recommending relationships based on graph exploration. In graph query languages, such as Apache TinkerPop Gremlin, the implementation of rule sets such as counting common friends, is relatively easy, and it can be used to determine the link between Henry and Terry. However, these rule sets will be very complicated when we want account for other attributes such as node properties, connection strength, etc. Let’s imagine a rule set to determine the link between Henry and Bill. This rule set must account for their common interests and their weak connections through certain paths in the graph. To increase robustness, we might also need to add a distance factor to favor strong connections and penalize the weak ones. Similarly, we would want a factor to favor common interests. Soon, the rule sets that can reveal complex hidden patterns will become impossible to enumerate.
ML technology lets us discover hidden patterns by learning algorithms. One example is XGBoost, which is widely used for classification or regression tasks. However, algorithms such as XGBoost use a conventional ML approach based on a tabular data format. These approaches aren’t optimized for graph data structures, and they require complex feature engineering to cope with these data patterns.
In the preceding social network example, the graph interaction information is critical to improving the recommendation accuracy. Graph Neural Network (GNN) is a deep learning (DL) framework that can be applied to graph data to perform edge-level, node-level, or graph-level prediction tasks. GNNs can leverage individual node characteristics as well as graph structure information when learning the graph representation and underlying patterns. Therefore, in recent years, GNN-based methods have set new standards on many recommender system benchmarks. See more detailed information in recent research papers: A Comprehensive Survey on Graph Neural Networks and Graph Learning based Recommender Systems: A Review.
The following is one famous example of such a use case. Researchers and engineers at Pinterest have trained Graph Convolutional Neural Networks for Web-Scale Recommender Systems, called PinSage, with three billion nodes representing pins and boards, and 18 billion edges. PinSage generates high-quality embeddings that represent pins (visual bookmarks to online content). These can be used for a wide range of downstream recommendation tasks, such as nearest-neighbor lookups in the learned embedding space for content discovery and recommendations.
In this post, we will walk you through how to use GNNs for recommendation use cases by casting this as a link prediction problem. We’ll also illustrate how Neptune ML can facilitate implementation. We will also provide sample code on GitHub to train your first GNN with Neptune ML, and make recommendation inferences on the demo graph through link prediction tasks.
Link prediction with Graph Neural Networks
Considering the previous social network example, we would like to recommend new friends to Henry. Both Terry and Bill would be good candidates. Terry has more common friends (Gary, Alistair) with Henry but no common interests. While Bill shares common interests (arts, comics, games) with Henry, but no common friends. Which one would be a better recommendation? When framed as a link prediction problem, the task is to assign a score to any possible link between the two nodes. The higher the link score, the more likely this recommendation will converge. By learning link structures already present in the graph, a link prediction model can generalize new link predictions that ‘complete’ the graph.
The parameters of the function f that predicts the link score is learned during the training phase. Since the function f makes a prediction for any two nodes in the graph, the feature vectors associated with the nodes are essential to the learning process. To predict the link score between Henry and Bill, we have a set of raw data features (arts, comics, games) that can represent Henry and Bill. We transform this, along with the connections in the graph, using a GNN network to form new representations known as node embeddings. We can also supplement or replace the initial raw features with vectors from an embedding lookup table that can be learned during the training process. Ideally, the embedded features for Henry and Bill should represent their interests as well as their topological information from the graph.
How GNNs work
A GNN transforms the initial node features to node embeddings by using a technique called message passing. The message passing process is illustrated in the following figure. In the beginning, the node attributes or features are converted into numerical attributes. In our case, we do one-hot encoding of the categorical features (Henry’s interests: arts, comics, games). Then, the first layer of GNN aggregates all of the neighbors’ (Gary and Alistair) raw features (in black) to form a new set of features (in yellow). A common approach is the linear transformation of all of the neighboring features, then aggregate them through a normalized sum, and pass the results into a non-linear activation function, such as ReLU, to generate a new vector set. The following figure illustrates how message passing works for node Henry. H, the GNN message passing algorithm, will compute representations for all of the graph nodes. These are later used as the input features for the second layer.
The second layer of a GNN repeats the same process. It takes the previously computed feature (in yellow) from the first layer as input, aggregates all of Gary and Alistair’s neighbors’ new embedded features, and generates second layer feature vectors for Henry (in orange). As you can see, by repeating the message passing mechanism, we extended the feature aggregation to 2-hop neighbors. In our illustration, we limit ourselves to 2-hop neighbors, but extending into 3-hop neighbors can be done in the same way by adding another GNN layer.
The final embeddings from Henry and Bill (in orange) are used for computing the score. During the training process, the link score is defined as 1 when the edge exists between the two nodes (positive sample), and as 0 when the edges between the two nodes don’t exist (negative sample). Then, the error or loss between the actual score and the prediction f(e1,e2) is back-propagated into previous layers to adjust the weights. Once the training is finished, we can rely on the embedded feature vectors for each node to compute their link scores with our function f.

In this example, we simplified the learning task on a homogeneous graph, where all of the nodes and edges are of the same type. For example, all of the nodes in the graph are the “People” type, and all of the edges are the “friends with” type. However, the learning algorithm also supports heterogeneous graphs with different node and edge types. We can extend the previous use case to recommend products to different users that share similar interactions and interests. See more details in this research paper: Modeling Relational Data with Graph Convolutional Networks.
At AWS re:Invent 2020, we introduced Amazon Neptune ML, which lets our customers train ML models on graph data, without necessarily having deep ML expertise. In this example, with the help of Neptune ML, we will show you how to build your own recommender system on graph data.
Train your Graph Convolution Network with Amazon Neptune ML
Neptune ML uses graph neural network technology to automatically create, train, and deploy ML models on your graph data. Neptune ML supports common graph prediction tasks, such as node classification and regression, edge classification and regression, and link prediction.
It is powered by:
- Amazon Neptune: a fast, reliable, and fully managed graph database, which is optimized for storing billions of relationships and querying the graph with millisecond latency. Amazon Neptune supports three open standards for building graph applications: Apache TinkerPop Gremlin, RDF SPARQL, and openCypher. Learn more at Overview of Amazon Neptune Features.
- Amazon SageMaker: a fully managed service that provides every developer and data scientist with the ability to prepare build, train, and deploy ML models quickly.
- Deep Graph Library (DGL): an open-source, high-performance, and scalable Python package for DL on graphs. It provides fast and memory-efficient message passing primitives for training Graph Neural Networks. Neptune ML uses DGL to automatically choose and train the best ML model for your workload. This enables you to make ML-based predictions on graph data in hours instead of weeks.
The easiest way to get started with Neptune ML is to use the AWS CloudFormation quickstart template. The template installs all of the necessary components, including a Neptune DB cluster, and sets up the network configurations, IAM roles, and associated SageMaker notebook instance with pre-populated notebook samples for Neptune ML.
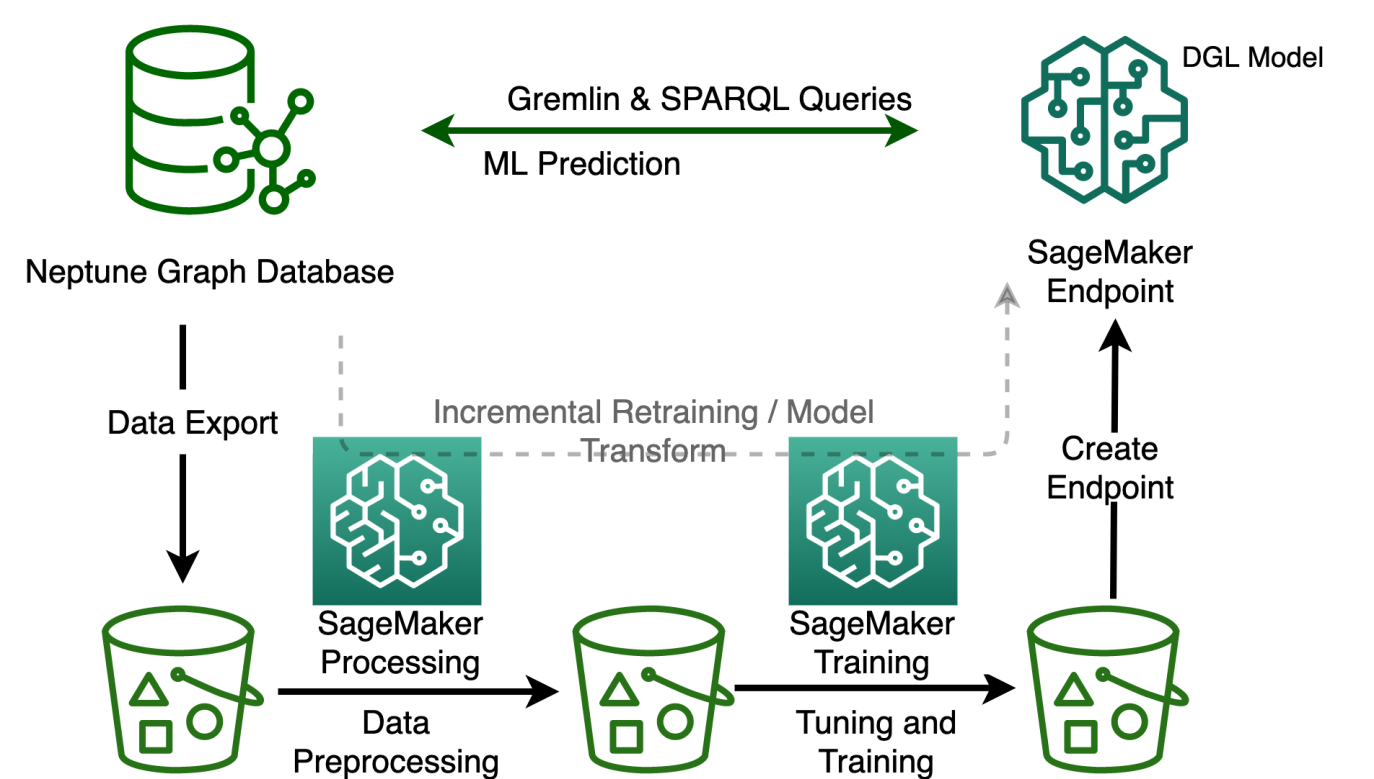
The following figure illustrates different steps for Neptune ML to train a GNN-based recommendation system. Let’s zoom in on each step and explore what it involves:
-
Data export configuration
The first step in our Neptune ML process is to export the graph data from the Neptune cluster. We must specify the parameters and model configuration for the data export task. We use the Neptune workbench for all of the configurations and commends. The workbench lets us work with the Neptune DB cluster using Jupyter notebooks hosted by Amazon SageMaker. In addition, it provides a number of magic commands in the notebooks that save a great deal of time and effort. Here is our example of export parameters:
In export_params, we must configure the basic setup, such as the Neptune cluster and output Amazon Simple Storage Service (S3) path for exported data storage. The configuration specified in additionalParams is the type of ML task to perform. In this example, link prediction is optionally used to predict a particular edge type (User—FRIEND—User). If no target type is specified, then Neptune ML will assume that the task is Link Prediction. The parameters also specify details about the data stored in our graph and how the ML model will interpret that data (we have “User” as node, and “interests” as node property).
To run each step in the ML building process, simply use Neptune workbench commands. The Neptune workbench contains a line magic and a cell magic that can save you a lot of time managing these steps. To run the data export, use the Neptune workbench command: %neptune_ml export start
Once the export job completes, we will have the Neptune graph exported into CSV format and stored in an S3 bucket. There will be two types of files: nodes.csv and edges.csv. A file named training-data-configuration.json will also be generated which has the configuration needed for Neptune ML to perform model training.
See Export data from Neptune for Neptune ML for more information.
-
Data preprocessing
Neptune ML performs feature extraction and encoding as part of the data-processing steps. Common types of property pre-processing include: encoding categorical features through one-hot encoding, bucketing numerical features, or using word2vec to encode a string property or other free-form text property values.
In our example, we will simply use the property “interests”. Neptune ML encodes the values as multi-categorical. However, if a categorical value is complex (more than three words per node), then Neptune ML infers the property type to be text and uses the text_word2vec encoding.
To run data preprocessing, use the following Neptune notebook magic command: %neptune_ml dataprocessing start
At the end of this step, a DGL graph is generated from the exported dataset for use by the model training step. Neptune ML automatically tunes the model with Hyperparameter Optimization Tuning jobs defined in training-data-configuration.json. We can download and modify this file to tune the model’s hyperparameters, such as batch-size, num-hidden, num-epochs, dropout, etc. Here is a sample configuration.json file.
See Processing the graph data exported from Neptune for training for more information.
-
Model training
The next step is the automated training of the GNN model. The model training is done in two stages. The first stage uses a SageMaker Processing job to generate a model training strategy. This is a configuration set that specifies what type of model and model hyperparameter ranges will be used for the model training.
Then, a SageMaker hyperparameter tuning job will be launched. The SageMaker Hyperparameter Tuning Optimization job runs a pre-specified number of model training job trials on the processed data, tries different hyperparameter combinations according to the model-hpo-configuration.json file, and stores the model artifacts generated by the training in the output Amazon S3 location.
To start the training step, you can use the %neptune_ml training start command.
Once all of the training jobs are complete, the Hyperparameter tuning job will save the artifacts from the best performing model, which will be used for inference.
At the end of the training, Neptune ML will instruct SageMaker to save the trained model, the raw embeddings calculated for the nodes and edges, and the mapping information between the embeddings and node indices.
See Training a model using Neptune ML for more information.
-
Create an inference endpoint in Amazon SageMaker
Now that the graph representation is learned, we can deploy the learned model behind an endpoint to perform inference requests. The model input will be the User for which we need to generate friends’ recommendations, along with the edge type, and the output will be the list of the likely recommended friends for that user.
To deploy the model to the SageMaker endpoint instance, use the %neptune_ml endpoint create command.
-
Query the ML model using Gremlin
Once the endpoint is ready, we can use it for graph inference queries. Neptune ML supports graph inference queries in Gremlin or SPARQL. In our example, we can now check the friends recommendation with Neptune ML on User “Henry”. It requires nearly the same syntax to traverse the edge, and it lists the other Users that are connected to Henry through the FRIEND connection.
Neptune#ml.prediction returns the connection determined by Neptune ML predictions by using the model that we just trained on the social graph. Bill is returned just like our expectation.
Here is another sample prediction query that is used to predict the top eight users that are most likely to connect with Henry:
The results are ranked from stronger connection to weaker, where link Henry — FRIEND — Colin and Henry — FRIEND — Terry is also proposed. This proposition is through graph-based ML where complex interaction patterns on graph can be explored.
See Gremlin inference queries in Neptune ML for more information.
Model transform or retraining when graph data changes
Another question you might ask is: what if my social network changes, or if I want to make recommendations for newly added users? In these scenarios, where you have continuously changing graphs, you may need to update ML predictions with the newest graph data. The generated model artifacts after training are directly tied to the training graph. This means that the inference endpoint must be updated once the entities in the original training graph changes.
However, you don’t need to retrain the whole model to make predictions on the updated graph. With an incremental model inference workflow, you only need to export the Neptune DB data, perform an incremental data preprocessing, run a model batch transform job, and then update the inference endpoint. The model-transform step takes the trained model from the main workflow and the results of the incremental data preprocessing step as inputs. Then it outputs a new model artifact to use for inference. This new model artifact is created from the up-to-date graph data.
One special focus here is for the model-transform step command. It can compute model artifacts on graph data that was not used for model training. The node embeddings are re-computed and any existing node embeddings are overridden. Neptune ML applies the learned GNN encoder from the previous trained model to the new graph data nodes with their new features. Therefore, the new graph data must be processed using the same feature encodings, and it must adhere to the same graph schema as the original graph data. See more Neptune ML implementation details at Generating new model artifacts.
Moreover, you can retrain the whole model if the graph changes dramatically, or if the previously trained model could no longer accurately represent the underlying interactions. In this case, re-using the learned model parameters on a new graph cannot guarantee a similar model performance. You must retrain your model on the new graph. To accelerate the hyperparameters search, Neptune ML can leverage the information from the previous model training task with warm start: the results of previous training jobs are used to select good combinations of hyperparameters to search over the new tuning job.
See workflows for handling evolving graph data for more details.
Conclusion
In this post, you have seen how Neptune ML and GNNs can help you make recommendations on graph data using a link prediction task by combining information from the complex interaction patterns in the graph.
Link prediction is one way of implementing a recommendation system on graph. You can construct your recommender in many other ways. You can use the embeddings learned during link prediction training to cluster the nodes into different segments in an unsupervised manner, and recommend items to the one belonging to the same segment. Furthermore, you can obtain the embeddings and feed them into a downstream similarity-based recommendation system as an input feature. Now this additional input feature also encodes the semantic information derived from graph and can provide significant improvements to the overall precision of the system. Learn more about Amazon Neptune ML by visiting the website or feel free to ask questions in the comments!
About the Authors
 Yanwei Cui, PhD, is a Machine Learning Specialist Solutions Architect at AWS. He started machine learning research at IRISA (Research Institute of Computer Science and Random Systems), and has several years of experience building artificial intelligence powered industrial applications in computer vision, natural language processing and online user behavior prediction. At AWS, he shares the domain expertise and helps customers to unlock business potentials, and to drive actionable outcomes with machine learning at scale. Outside of work, he enjoys reading and traveling.
Yanwei Cui, PhD, is a Machine Learning Specialist Solutions Architect at AWS. He started machine learning research at IRISA (Research Institute of Computer Science and Random Systems), and has several years of experience building artificial intelligence powered industrial applications in computer vision, natural language processing and online user behavior prediction. At AWS, he shares the domain expertise and helps customers to unlock business potentials, and to drive actionable outcomes with machine learning at scale. Outside of work, he enjoys reading and traveling.
 Will Badr is a Principal AI/ML Specialist SA who works as part of the global Amazon Machine Learning team. Will is passionate about using technology in innovative ways to positively impact the community. In his spare time, he likes to go diving, play soccer and explore the Pacific Islands.
Will Badr is a Principal AI/ML Specialist SA who works as part of the global Amazon Machine Learning team. Will is passionate about using technology in innovative ways to positively impact the community. In his spare time, he likes to go diving, play soccer and explore the Pacific Islands.
World Record-Setting DNA Sequencing Technique Helps Clinicians Rapidly Diagnose Critical Care Patients
Cutting down the time needed to sequence and analyze a patient’s whole genome from days to hours isn’t just about clinical efficiency — it can save lives.
By accelerating every step of this process — from collecting a blood sample to sequencing the whole genome to identifying variants linked to diseases — a research team led by Stanford University took just hours to find a pathogenic variant and make a definitive diagnosis in a three-month-old infant with a rare seizure-causing genetic disorder. A traditional gene panel analysis ordered at the same time took two weeks to return results.
This ultra-rapid sequencing method, detailed today in the New England Journal of Medicine, helped clinicians manage the epilepsy case by providing insight about the infant’s seizure types and treatment response to anti-seizure medications.
The method set the first Guinness World Record for fastest DNA sequencing technique: five hours and 2 minutes. It was developed by researchers from Stanford University, NVIDIA, Oxford Nanopore Technologies, Google, Baylor College of Medicine and the University of California at Santa Cruz.
The researchers accelerated both base calling and variant calling using NVIDIA GPUs on Google Cloud. Variant calling, the process of identifying the millions of variants in a genome, was also sped up with NVIDIA Clara Parabricks, a computational genomics application framework.
Euan Ashley, MB ChB, DPhil, the paper’s corresponding author and a professor of medicine, of genetics and of biomedical data science at Stanford University School of Medicine, will be speaking at NVIDIA GTC, which runs online March 21-24.
Racing Against Time, Making Clinical Impact
Identifying genetic variants associated with a specific disease is a classic needle-in-the-haystack problem, often requiring researchers to comb through a person’s genome of 3 billion base pairs to find a single change that causes the disease.
It’s a lengthy process: A typical whole human genome sequencing diagnostic test takes six to eight weeks. Even rapid turnaround tests take two or three days. In many cases, this can be too slow to make a difference in treatment of a critically ill patient.
By optimizing the diagnosis pipeline to take only 7-10 hours, clinicians can more quickly identify genetic clues that inform patient care plans. In this pilot project, genomes were sequenced for a dozen patients, most of them children, at Stanford Health Care and Lucile Packard Children’s Hospital Stanford.
In five of the cases, the team found diagnostic variants that were reviewed by physicians and used to inform clinical decisions including heart transplant and drug prescription.
“Genomic information can provide rich insights and enable a clearer picture to be built,” said Gordon Sanghera, CEO of Oxford Nanopore Technologies. “A workflow which could deliver this information in near real time has the potential to provide meaningful benefits in a variety of settings in which rapid access to information is critical.”
AI Calls It: Identifying Variants with Clara Parabricks
The researchers found ways to optimize every step of the pipeline, including speeding up sample preparation and using nanopore sequencing on Oxford Nanopore’s PromethION Flow Cells to generate more than 100 gigabases of data per hour.
This sequencing data was sent to NVIDIA Tensor Core GPUs in a Google Cloud computing environment for base calling — the process of turning raw signals from the device into a string of A, T, G and C nucleotides — and alignment in near real time. Distributing the data across cloud GPU instances helped minimize latency.
Next, the scientists had to find tiny variations within the DNA sequence that could cause a genetic disorder. Known as variant calling, this stage was sped up with Clara Parabricks using a GPU-accelerated version of PEPPER-Margin-DeepVariant, a pipeline developed in a collaboration between Google and UC Santa Cruz’s Computational Genomics Laboratory.
DeepVariant uses convolutional neural networks for highly accurate variant calling. The GPU-accelerated DeepVariant Germline Pipeline software in Clara Parabricks provides results at 10x the speed of native DeepVariant instances, decreasing the time to identify disease-causing variants.
“Together with our collaborators and some of the world’s leaders in genomics, we were able to develop a rapid sequencing analysis workflow that has already shown tangible clinical benefits,” said NVIDIA’s Mehrzad Samadi, who co-led the creation of Parabricks and co-authored the New England Journal of Medicine article. “These are the kinds of high-impact problems we live to solve.”
Read the full publication in the New England Journal of Medicine and get started with a 90-day trial of NVIDIA Clara Parabricks, which can help analyze a whole human genome in under 30 minutes.
Subscribe to NVIDIA healthcare news here.
The post World Record-Setting DNA Sequencing Technique Helps Clinicians Rapidly Diagnose Critical Care Patients appeared first on The Official NVIDIA Blog.
Secure access to Amazon SageMaker Studio with AWS SSO and a SAML application
Cloud security at AWS is the highest priority. Amazon SageMaker Studio offers various mechanisms to protect your data and code using integration with AWS security services like AWS Identity and Access Management (IAM), AWS Key Management Service (AWS KMS), or network isolation with Amazon Virtual Private Cloud (Amazon VPC).
Customers in highly regulated industries, like financial services, can set up Studio in VPC only mode to enable network isolation and disable internet access from Studio notebooks. You can use IAM integration with Studio to control which users have access to resources like Studio notebooks, the Studio IDE, or Amazon SageMaker training jobs.
A popular use case is to restrict access to the Studio IDE to only users from inside a specified network CIDR range or a designated VPC. You can achieve this by implementing IAM identity-based SageMaker policies and attaching those policies to the IAM users or groups that require those permissions. However, the SageMaker domain must be configured with IAM authentication mode, because the IAM identity-based policies aren’t supported in AWS Single Sign-On (SSO) authentication mode.
Many customers use AWS SSO to enable centralized workforce identity control and provide a consistent user sign-in experience. This post shows how to implement this use case while keeping AWS SSO capabilities to access Studio.
Solution overview
When you set up a SageMaker domain in VPC-only mode and specify the subnets and security groups, SageMaker creates elastic network interfaces (ENIs) that are associated with your security groups in the specified subnets. ENIs allow your training containers to connect to resources in your VPC.
In this mode, the direct internet access from notebooks is completely disabled, and all the traffic is routed through an ENI in your private VPC. This also includes traffic from Studio UI widgets and interfaces—such as experiment management, autopilot, and model monitor—to their respective backend SageMaker APIs. AWS recommends using VPC only mode to exercise fine-grained control on network access of Studio.
The first challenge is that even though Studio is deployed with no internet connectivity, Studio IDE can still be accessed from anywhere, assuming access to the AWS Management Console and Studio is granted to an IAM principal. This situation isn’t acceptable if you want to fully isolate Studio from a public network and contain all communication within a tightly controlled private VPC.
To address this challenge and disable any access to Studio IDE except from a designated VPC or a CIDR range, you can use the CreatePresignedDomainUrl SageMaker API. The IAM role or user used to call this API defines the permissions to access Studio. Now you can use IAM identity-based policies to implement the desired access configuration. For example, to enable access only from a designated VPC, add the following condition to the IAM policy, associated with an IAM principal, which is used to generate a presigned domain URL:
To enable access only from a designated VPC endpoint or endpoints, specify the following condition:
Use the following condition to restrict access from a designated CIDR range:
The second challenge is this that IAM-based access control works only when the SageMaker domain is configured in IAM authentication mode; you can’t use it when the SageMaker domain is deployed in AWS SSO mode. The next section shows how to address these challenges and implement IAM-based access control with AWS SSO access to Studio.
Architecture overview
Studio is published as a SAML application, which is assigned to a specific SageMaker Studio user profile. Users can conveniently access Studio directly from the AWS SSO portal, as shown in the following screenshot.

The solution integrates with a custom SAML 2.0 application as the mechanism to trigger the user authentication for Studio. It requires that the custom SAML application is configured with the Amazon API Gateway endpoint URL as its Assertion Consumer Service (ACS), and needs mapping attributes containing the AWS SSO user ID as well as the SageMaker domain ID.
The API Gateway endpoint calls an AWS Lambda function that parses the SAML response to extract the domain ID and user ID and use them to generate a Studio presigned URL. The Lambda function finally performs a redirection via an HTTP 302 response to sign in the user in Studio.
An IAM policy controls the network environment that Studio users are allowed to log in from, which includes restricting conditions as described in the previous section. This IAM policy is attached to the Lambda function. The IAM policy contains a permission to call the sagemaker:CreatePresignedDomainURL API for a specific user profile only:
The following diagram shows the solution architecture.

The solution deploys a SageMaker domain into your private VPC and VPC endpoints to access Studio, SageMaker runtime, and the SageMaker API via a private connection without need for an internet gateway. The VPC endpoints are configured with private DNS enabled (PrivateDnsEnabled=True) to associate a private hosted zone with your VPC. This enables Studio to access the SageMaker API using the default public DNS name api.sagemaker.<Region>.amazonaws.com resolved to the private IP address of the endpoint rather than using the VPC endpoint URL.
You need to add VPC endpoints to your VPC if you want to access any other AWS services like Amazon Simple Storage Service (Amazon S3), Amazon Elastic Container Registry (Amazon ECR), AWS Security Token Service (AWS STS), AWS CloudFormation, or AWS CodeCommit.
You can fully control permissions used to generate the presigned URL and any other API calls with IAM policies attached to the Lambda function execution role or control access to any used AWS service via VPC endpoint policies. For examples of using IAM policies to control access to Studio and SageMaker API, refer to Control Access to the SageMaker API by Using Identity-based Policies.
Although the solution requires the Studio domain to be deployed in IAM mode, it does allow for AWS SSO to be used as the mechanism for end users to log in to Studio.
The following subsections contain detailed descriptions of the main solution components.
API Gateway
The API Gateway endpoint acts as the target for the application ACS URL configured in the custom SAML 2.0 application. The endpoint is private, and has a resource called /saml and a POST method with integration request configured as Lambda proxy. The solution uses a VPC endpoint with a configured com.amazonaws.<region>.execute-api DNS name to call this API endpoint from within the VPC.
AWS SSO
A custom SAML 2.0 application is configured with the API Gateway endpoint URL https:/{ restapi-id}.execute-api.amazonaws.com/saml as its application ACS URL, and uses attribute mappings with the following requirements:
- User identifier:
- User attribute in the application – user name
-
Maps user attribute in AWS SSO –
${user:AD_GUID}
- SageMaker domain ID identifier:
-
User attribute in the application –
domain-id - Maps user attribute in AWS SSO – Domain ID for the Studio instance
-
User attribute in the application –
The application implements the access control for an AWS SSO user by provisioning a Studio user profile with the name equal to the AWS SSO user ID.
Lambda function
The solution configures a Lambda function as an invocation point for the API Gateway /saml resource. The function parses the SAMLResponse sent by AWS SSO, extracts the domain-id as well as the user name, and calls the createPresignedDomainUrl SageMaker API to retrieve the Studio URL and token and redirect the user to log in using an HTTP 302 response. The Lambda function has a specific IAM policy attached to its execution role that allows the sagemaker:createPresignedDomainUrl action only when it’s requested from a specific network CIDR range using the VpcSourceIp condition.
The Lambda function doesn’t have any logic to validate the SAML response, for example to check a signature. However, because the API Gateway endpoint serving as the ACS is private or internal only, it’s not mandatory for this proof of concept environment.
Deploy the solution
The GitHub repository provides the full source code for the end-to-end solution.
To deploy the solution, you must have administrator (or power user) permissions for an AWS account, and install the AWS Command Line Interface (AWS CLI) and AWS SAM CLI and minimum Python 3.8.
The solution supports deployment to three AWS Regions: eu-west-1, eu-central-1, and us-east-1. Make sure you select one of these Regions for deployment.
To start testing the solution, you must complete the following deployment steps from the solution’s GitHub README file:
- Set up AWS SSO if you don’t have it configured.
- Deploy the solution using the SAM application.
- Create a new custom SAML 2.0 application.
After you complete the deployment steps, you can proceed with the solution test.
Test the solution
The solution simulates two use cases to demonstrate the usage of AWS SSO and SageMaker identity-based policies:
- Positive use case – A user accesses Studio from within a designated CIDR range through a VPC endpoint
- Negative use case – A user accesses Studio from a public IP address
To test these use cases, the solution created three Amazon Elastic Compute Cloud (Amazon EC2) instances:
- Private host – An EC2 Windows instance in a private subnet that is able to access Studio (your on-premises secured environment)
- Bastion host – An EC2 Linux instance in the public subnet used to establish an SSH tunnel into the private host on the private network
- Public host – An EC2 Windows instance in a public subnet to demonstrate that the user can’t access Studio from an unauthorized IP address
Test Studio access from an authorized network
Follow these steps to perform the test:
- To access the EC2 Windows instance on the private network, run the command provided as the value of the SAM output key
TunnelCommand. Make sure that the private key of the key pair specified in the parameter is in the directory where the SSH tunnel command runs from. The command creates an SSH tunnel from the local computer onlocalhost:3389to the EC2 Windows instance on the private network. See the following example code: - On your local desktop or notebook, open a new RDP connection (for example using Microsoft Remote Desktop) using
localhostas the target remote host. This connection is tunneled via the bastion host to the private EC2 Windows instance. Use the user nameAdministratorand password from the stack outputSageMakerWindowsPassword. - Open the Firefox web browser from the remote desktop.
- Navigate and log in to the AWS SSO portal using the credentials associated with the user name that you specified as the
ssoUserNameparameter. - Choose the SageMaker Secure Demo AWS SSO application from the AWS SSO portal.
You’re redirected to the Studio IDE in a new browser window.

Test Studio access from an unauthorized network
Now follow these steps to simulate access from an unauthorized network:
- Open a new RDP connection on the IP provided in the
SageMakerWindowsPublicHostSAML output. - Open the Firefox web browser from the remote desktop.
- Navigate and log in to the AWS SSO portal using the credentials associated with the user name that was specified as the
ssoUserNameparameter. - Choose the SageMaker Secure Demo AWS SSO application from the AWS SSO portal.
This time you receive an unauthorized access message.

Clean up
To avoid charges, you must remove all solution-provisioned and manually created resources from your AWS account. Follow the instructions in the solution’s README file.
Conclusion
We demonstrated that by introducing a middleware authentication layer between the end user and Studio, we can control the environment that user is allowed to access Studio from and explicitly block every other unauthorized environment.
To further tighten security, you can add an IAM policy to a user role to prevent access to Studio from the console. If you use AWS Organizations, you can implement the following service control policy for the organizational units or accounts that need access to Studio:
Although the solution described in this post uses API Gateway and Lambda, you can explore other ways such as an EC2 instance with an instance role using the same permission validation workflow as described or even an independent system to handle user authentication and authorization and generate a Studio presigned URL.
Further reading
Securing access to Studio is an active research topic, and there are other relevant posts on similar approaches. Refer to the following posts on the AWS Machine Learning Blog to learn more about other services and architectures you can use:
- Launch Amazon SageMaker Studio from external applications using presigned URLs
- Building secure Amazon SageMaker access URLs with AWS Service Catalog
- Mitigate data leakage through the use of AppStream 2.0 and end-to-end auditing
- Understanding Amazon SageMaker notebook instance networking configurations and advanced routing options
- Securing Amazon SageMaker Studio connectivity using a private VPC
About the Authors
 Jerome Bachelet is a Solutions Architect at Amazon Web Services. He thrives on helping customers get the most value out of AWS to achieve their business objectives. Jerome has over 10 years of experience working with data protection and data security solutions. Besides being in the cloud, Jerome enjoys travels and quality time with his wife and 2 daughters in the Geneva, Switzerland area.
Jerome Bachelet is a Solutions Architect at Amazon Web Services. He thrives on helping customers get the most value out of AWS to achieve their business objectives. Jerome has over 10 years of experience working with data protection and data security solutions. Besides being in the cloud, Jerome enjoys travels and quality time with his wife and 2 daughters in the Geneva, Switzerland area.
 Yevgeniy Ilyin is a Solutions Architect at AWS. He has over 20 years of experience working at all levels of software development and solutions architecture and has used programming languages from COBOL and Assembler to .NET, Java, and Python. He develops and codes cloud native solutions with a focus on big data, analytics, and data engineering.
Yevgeniy Ilyin is a Solutions Architect at AWS. He has over 20 years of experience working at all levels of software development and solutions architecture and has used programming languages from COBOL and Assembler to .NET, Java, and Python. He develops and codes cloud native solutions with a focus on big data, analytics, and data engineering.
EzPC: Increased data security in the AI model validation process
From manufacturing and logistics to agriculture and transportation, the expansion of artificial intelligence (AI) in the last decade has revolutionized a multitude of industries—examples include enhancing predictive analytics on the manufacturing floor and making microclimate predictions so that farmers can respond and save their crops in time. The adoption of AI is expected to accelerate in the coming years, underscoring the need for an efficient adoption process that preserves data privacy.
Currently, organizations that want to adopt AI into their workflow go through the process of model validation, in which they test, or validate, AI models from multiple vendors before selecting the one that best fits their needs. This is usually done with a test dataset that the organization provides. Unfortunately, the two options that are currently available for model validation are insufficient; both risk the exposure of data.
One of these options entails the AI vendor sharing their model with the organization, which can then validate the model on its test dataset. However, by doing this, the AI vendor risks exposing its intellectual property, which it undoubtedly wants to protect. The second option, equally risky, involves the organization sharing its test dataset with the AI vendor. This is problematic on two fronts. First, it risks exposing a dataset with sensitive information. Additionally, there’s the risk that the AI vendor will use the test dataset to train the AI model, thereby “over-fitting” the model to the test dataset to show credible results. To accurately assess how an AI model performs on a test dataset, it’s critical that the model not be trained on it. Currently, these concerns are addressed by complex legal agreements, often taking several months to draft and execute, creating a substantial delay in the AI adoption process.
The risk of data exposure and the need for legal agreements are compounded in the healthcare domain, where patient data—which makes up the test dataset—is incredibly sensitive, and there are strict privacy regulations with which both organizations must comply. Additionally, not only does the vendor’s AI model contain proprietary intellectual property information, but it may also include sensitive patient information as part of the training data that was used to develop it. This makes for a challenging predicament. On one hand, healthcare organizations want to quickly adopt AI due to its enormous potential in such applications as understanding health risks in patients, predicting and diagnosing diseases, and developing personalized health intervention. On the other hand, there’s a fast-growing list of AI vendors in the healthcare space to choose from (currently over 200), making the cumulative legal paperwork of AI validation daunting.
EzPC: Easy Secure Multi-Party Computation
We’re very interested in accelerating the AI model validation process while also ensuring dataset and model privacy. For this reason, we built Easy Secure Multi-party Computation (EzPC). This open-source framework is the result of a collaboration among researchers with backgrounds in cryptography, programming languages, machine learning (ML), and security. At its core, EzPC is based on secure multiparty computation (MPC)—a suite of cryptographic protocols that enable multiple parties to collaboratively compute a function on their private data without revealing that data to one other or any other party. This functionality makes AI model validation an ideal use case for MPC.
However, while MPC has been around for almost four decades, it’s rarely deployed because building scalable and efficient MPC protocols requires deep cryptography expertise. Additionally, while MPC performs well when computing small or simple stand-alone functions, combining several different kinds of functions—which is fundamental to ML applications—is much harder and inefficient if done without a specialized skillset.
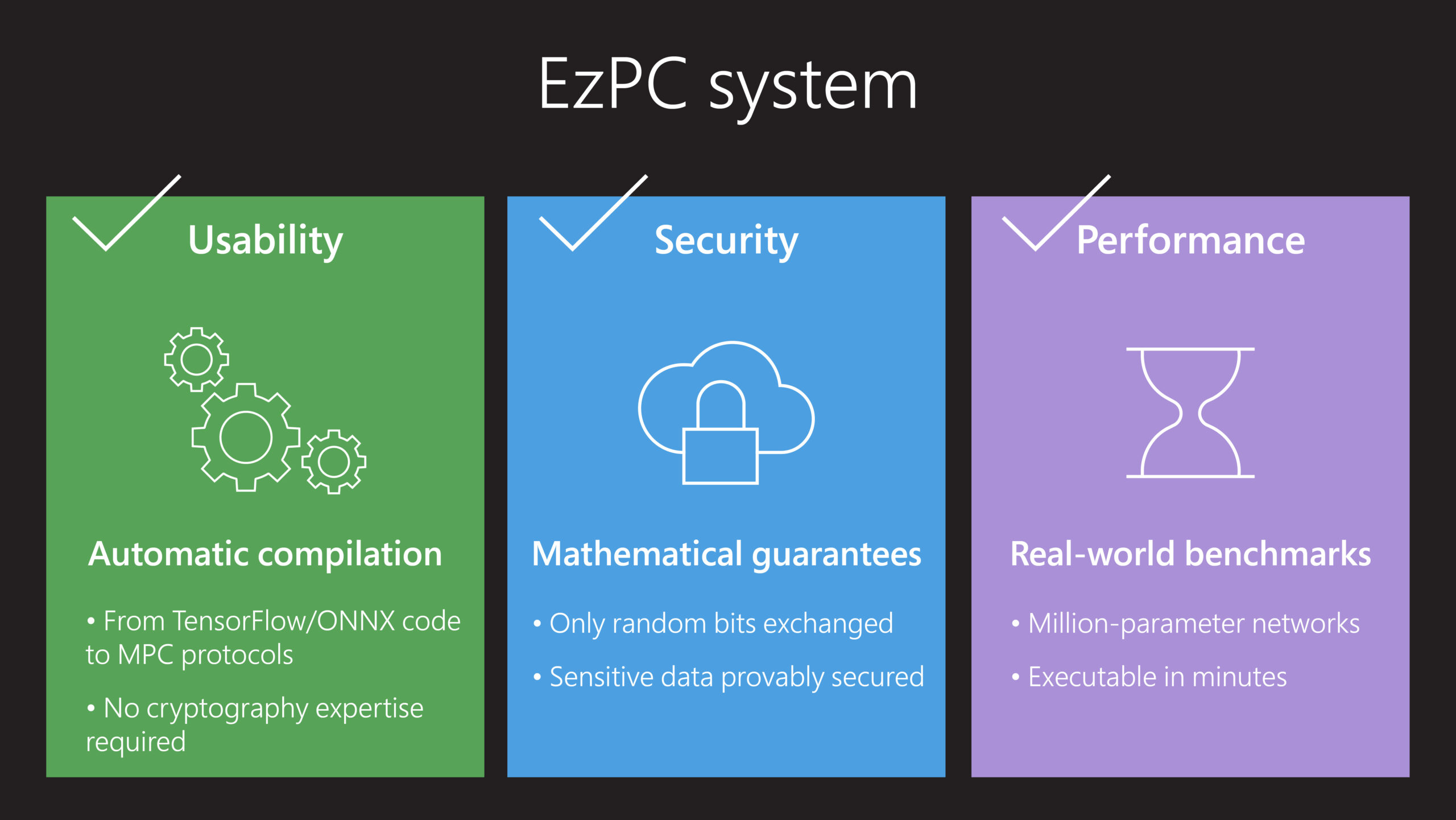
EzPC solves these problems, making it easy for all developers, not just cryptography experts, to use MPC as a building block in their applications while providing high computational performance. Two innovations are at the core of EzPC. First, a modular compiler called CrypTFlow takes as input TensorFlow or Open Neural Network Exchange (ONNX) code for ML inference and automatically generates C-like code, which can then be compiled into various MPC protocols. This compiler is both “MPC-aware” and optimized, ensuring that the MPC protocols are efficient and scalable. The second innovation is a suite of highly performant cryptographic protocols for securely computing complex ML functions.
EzPC in practice: Multi-institution medical imaging AI validation
In a recent collaboration with researchers at Stanford University and the Centre for Advanced Research in Imaging, Neuroscience & Genomics (CARING), the EzPC team built a system using EzPC to address the need for secure and performant AI model validation. The team from Stanford University had developed a widely acclaimed 7-million parameter DenseNet-121 AI model trained on the CheXpert dataset to predict certain lung diseases from chest X-rays, while a team from CARING created a labeled test dataset of five hundred patient images. The goal was to test the accuracy of the CheXpert model on CARING’s test dataset while preserving the privacy of both the model and the test data.
With this test, EzPC enabled the first-ever secure validation of a production-grade AI model, proving that it’s not necessary to share data to accurately perform AI model validation. Additionally, the performance overheads of the secure validation were reasonable and practical for the application. In particular, it took 15 minutes to perform secure inference on a single image from the test data between two standard cloud virtual machines, which was about 3000x longer than the time needed to test an image without the added security that EzPC provides. Running all the images from the test data took a total of five days with a nominal overall cost (Multi-institution encrypted medical imaging AI validation without data sharing.
Spotlight: Academic programs

Working with the academic community
Looking ahead: Standardizing privacy technology and applications beyond healthcare
With EzPC, MPC technology is now practical and accessible enough to be run on complex AI workloads, making it a game-changer in data collaboration and enabling organizations in all industries, not only healthcare, to select the best AI models for their use cases while simultaneously protecting data and model confidentiality. We want to encourage the use of EzPC with the awareness that it’s possible to validate AI models without sharing data. In doing so, we can prevent the risk of data exposure and potentially overcome current barriers in data collaboration.
Moreover, this technology has the potential to impact the negotiation of complex legal agreements required for the AI model validation process. It’s our hope that these types of legal agreements as well as legislation that aims to protect sensitive and proprietary information can incorporate the understanding that—when using the latest privacy-preserving technology—it’s not necessary to share this type of information to compute functions on joint data.
In addition to AI model validation, EzPC can be applied to a number of different scenarios where it’s essential to maintain data privacy. We’ve successfully evaluated EzPC to securely compute a variety of algorithms across such domains as phishing detection, personalized radiotherapy, speech to keywords, and analytics.
EzPC is open source under MIT license on GitHub. Discover the latest developments on the EzPC research project page, where you can read our publications and watch videos to learn more.
The post EzPC: Increased data security in the AI model validation process appeared first on Microsoft Research.
Elevated Entertainment: SHIELD Experience 9.0 Upgrade Rolling Out Now
SHIELD Software Experience Upgrade 9.0 is rolling out to all NVIDIA SHIELD TVs, delivering the Android 11 operating system and more.
An updated Gboard — the Google Keyboard — allows people to use their voices and the Google Assistant to discover content in all search boxes.
Additional permissions let users customize privacy across apps, including a new “only this time” option to grant temporary, one-time permissions.
SHIELD also adds support for aptX-compatible Bluetooth headsets. This, in addition to existing support for LDAC headsets, gives customers more options for higher quality listening options.
Browse the release notes for a complete list of upgrades and look for the upgrade notification, which will hit SHIELD TV homescreens starting today.
Stream On
Exciting new app releases and updates bring new and improved content to SHIELD TV-powered home theaters.
Google Play Movies & TV adds stunning Dolby Vision HDR for unparalleled cinematic experiences on SHIELD TV.
SHIELD owners can connect digital movie catalogs from Amazon, Apple TV and VUDU using Movies Anywhere and watch from a single place on Google Play Movies & TV.

Stream limitless entertainment from popular apps like IMDb TV and Apple TV on SHIELD TV, at up to 4K HDR.
IMDb TV delivers thousands of movies, binge-worthy TV shows and IMDb Originals like Leverage: Redemption and Alex Rider. Best of all, they’re always free.
With Apple TV, stream a robust library of Apple Originals in 4K Dolby Vision and Dolby Atmos. Buy or rent over 100,000 movies and shows — including Ted Lasso and The Morning Show — from the largest selection of 4K HDR titles.
Browse the Google Play Store app for the latest updates from Disney+, Paramount+, YouTube TV and Peloton for thousands of live and on-demand workouts.
The Next Generation of GeForce NOW
Gamers around the globe are upgrading their SHIELD TVs into a powerful GeForce RTX 3080-class gaming rig, unlocking extraordinary 4K HDR graphics exclusively on SHIELD, as well as immersive 7.1 surround sound, with the new GeForce NOW RTX 3080 membership.

GeForce NOW Founders members are eligible for an exclusive discount on the RTX 3080 membership. They can retain their Founders benefits — including “Founders for Life” pricing — if they decide to revert back to their original membership. Find more information and sign up at geforcenow.com.
The SHIELD update provides all GeForce NOW members with new benefits. Twitch has been updated to enable simultaneous gaming and streaming in high quality. Support for additional Bluetooth keyboards and mice has been added as well.
SHIELD TV pairs with Xbox One and Series X, Sony PlayStation DualSense and DualShock, and Scuf controllers, allowing for a bring-your-own-controller cloud gaming experience on GeForce NOW.
Bonus Streaming
Google is offering new, U.S.-based SHIELD TV owners six months of Peacock Premium at no additional cost. Unlock everything Premium has to offer. Watch movies and shows like The Office and Parks and Recreation, exclusive originals such as Yellowstone and AP Bio, and live sports including WWE and English Premier League soccer.
To redeem this offer, new SHIELD owners must set up a new Google account or log into a preexisting one, subscribe through the Peacock Premium banner on the For You or Apps tab, and provide a valid form of payment.

It’s an exciting time for SHIELD owners. What are you looking forward to most? Let us know in the comments or on Twitter.
The post Elevated Entertainment: SHIELD Experience 9.0 Upgrade Rolling Out Now appeared first on The Official NVIDIA Blog.
How new machine learning techniques could improve MRI scans
Amazon Research Award recipient Jonathan Tamir is focusing on deriving better images faster.Read More
Industrial automation at Tyson with computer vision, AWS Panorama, and Amazon SageMaker
This is the first in a two-part blog series on how Tyson Foods, Inc., is utilizing Amazon SageMaker and AWS Panorama to automate industrial processes at their meat packing plants by bringing the benefits of artificial intelligence applications at the edge. In part one, we discuss an inventory counting application for packaging lines. In part two, we discuss a vision-based anomaly detection solution at the edge for predictive maintenance of industrial equipment.
As one of the largest processors and marketers of chicken, beef, and pork in the world, Tyson Foods, Inc., is known for bringing innovative solutions to their production and packing plants. In Feb 2020, Tyson announced its plan to bring Computer Vision (CV) to its chicken plants and launched a pilot with AWS to pioneer efforts on inventory management. Tyson collaborated with Amazon ML Solutions Lab to create a state-of-the-art chicken tray counting CV solution that provides real-time insights into packed inventory levels. In this post, we provide an overview of the AWS architecture and a complete walkthrough of the solution to demonstrate the key components in the tray counting pipeline set up at Tyson’s plant. We will focus on the data collection and labeling, training, and deploying of CV models at the edge using Amazon SageMaker, Apache MXNet Gluon, and AWS Panorama.
Operational excellence is a key priority at Tyson Foods. Tyson employs strict quality assurance (QA) measures in their packaging lines, ensuring that only those packaged products that pass their quality control protocols are shipped to its customers. In order to meet customer demand and to stay ahead of any production issue, Tyson closely monitors packed chicken tray counts. However, current manual techniques to count chicken trays that pass QA are not accurate and do not present a clear picture of over/under production levels. Alternate strategies such as monitoring hourly total weight of production per rack does not provide immediate feedback to the plant employees. With a chicken processing capacity of 45,000,000 head per week, production accuracy and efficiency are critical to Tyson’s business. CV can be effectively used in such scenarios to accurately estimate the amount of chicken processed in real-time, empowering employees to identify potential bottlenecks in packaging and production lines as they occur. This enables implementation of corrective measures and improves production efficiency.
Streaming and processing on-premise video streams at the cloud for CV applications requires high network bandwidth and provisioning of relevant infrastructure. This can be a cost prohibitive task. AWS Panorama removes these requirements and enables Tyson to process video streams at the edge on the AWS Panorama Appliance. It reduces latency to/from the cloud and bandwidth costs, while providing an easy-to-use interface for managing devices and applications at the edge.
Object detection is one of the most commonly used CV algorithms that can localize the position of objects in images and videos. This technology is currently being used in various real-life applications such as pedestrian spotting in autonomous vehicles, detecting tumors in medical scans, people counting systems to monitor footfall in retail spaces, amongst others. It is also crucial for inventory management use cases, such as meat tray counting for Tyson, to reduce waste by creating a feedback loop with production processes, cost savings, and delivery of customer shipments on time.
The following sections of this blog post outline how we use live-stream videos from one of the Tyson Foods plants to train an object detection model using Amazon SageMaker. We then deploy it at the edge with the AWS Panorama device.
AWS Panorama
AWS Panorama is a machine learning(ML) appliance that allows organizations to bring CV to on-premise cameras to make predictions locally with high accuracy and low latency. The AWS Panorama Appliance is a hardware device that allows you to run applications that use ML to collect data from video streams, output video with text and graphical overlays, and interact with other AWS services. The appliance can run multiple CV models against multiple video streams in parallel and output the results in real time. It is designed for use in commercial and industrial settings.
The AWS Panorama Appliance enables you to run self-contained CV applications at the edge, without sending images to the AWS Cloud. You can also use the AWS SDK on the AWS Panorama Appliance to integrate with other AWS services and use them to track data from the application over time. To build and deploy applications, you use the AWS Panorama Application CLI. The CLI is a command line tool that generates default application folders and configuration files, builds containers with Docker, and uploads assets.
AWS Panorama supports models built with Apache MXNet, DarkNet, GluonCV, Keras, ONNX, PyTorch, TensorFlow, and TensorFlow Lite. Refer to this blog post to learn more about building applications on AWS Panorama. During the deployment process AWS Panorama takes care of compiling the model specific to the edge platform through Amazon SageMaker Neo compilation. The inference results can be routed to AWS services such as Amazon S3, Amazon CloudWatch or integrated with on-premise line-of-business applications. The deployment logs are stored in Amazon CloudWatch.
To track any change in inference script logic or trained model, one can create a new version of the application. Application versions are immutable snapshots of an application’s configuration. AWS Panorama saves previous versions of your applications so that you can roll back updates that aren’t successful, or run different versions on different appliances.
For more information, refer to the AWS Panorama page. To learn more about building sample applications, refer to AWS Panorama Samples.
Approach

A plant employee continuously fills-in packed chicken trays into plastic bins and stacks them over time, as show in the preceding figure. We want to be able to detect and count the total number of trays across all the bins stacked vertically.
A trained object detection model can predict bounding boxes of all the trays placed in a bin at every video frame. This can be used to gauge tray counts in a bin at a given instance. We also know that at any point in time, only one bin is being filled with packed trays; the tray counts continuously oscillate from high (during filling) to low (when a new bin obstructs the view of filled bin).
With this knowledge, we adopt the following strategy to count total number of chicken trays:
- Maintain two different counters – local and global. Global counter maintains total trays binned and local counter stores maximum number of trays placed in a new bin.
- Update local counter as new trays are placed in the bin.
- Detect a new bin event in the following ways:
- The tray count in a given frame goes to zero. (or)
- The stream of tray numbers in the last n frames drops continuously.
- Once the new bin event is detected, add the local counter value to global counter.
- Reset local counter to zero.
We tested this algorithm on several hours of video and got consistent results.
Training an object detection model with Amazon SageMaker
Dataset creation:
Capturing new images for labeling jobs
We collected image samples from the packaging line using the AWS Panorama Appliance. The script to process images and save them was packaged as an application and deployed on AWS Panorama. The application collects video frames from an on-premise camera set up near the packaging zone and saves them at 60 seconds intervals to an Amazon S3 bucket; this prevents capturing similar images in the video sequence that are a few seconds apart. We also mask out adjacent regions in the image that are not relevant for the use-case.
We labeled the chicken trays with bounding boxes using Amazon SageMaker Ground Truth’s streaming labeling job. We also set up an Amazon S3 Event notification that publishes object-created events to an Amazon Simple Notification Service (SNS) topic, which acts as the input source for the labeling job. When the AWS Panorama application script saves an image to an S3 bucket, an event notification is published to the SNS topic, which then sends this image to the labeling job. As the annotators label every incoming image, Ground Truth saves the labels into a manifest file, which contains S3 path of the image as well as coordinates of chicken tray bounding boxes.
We perform several data augmentations (for example: random noise, random contrast and brightness, channel shuffle) on the labeled images to make the model robust to variations in real-life. The original and augmented images were combined to form a unified dataset.
Model Training:

Once the labeling job is completed, we manually trigger an AWS Lambda function. This Lambda function bundles images and their corresponding labels from the output manifest into an LST file. Our training and test files had images collected from different packaging lines to prevent any data leak in evaluation. The Lambda function then triggers an Amazon SageMaker training job.
We use SageMaker Script Mode, which allows you to bring your own training algorithms and directly train models while staying within the user-friendly confines of Amazon SageMaker. We train models like SSD, Yolo-v3 (for real-time inference latency) with various backbone network combinations from GluonCV Model Zoo for object detection in script-mode. Neural networks have the tendency to overfit training data, leading to poor out-of-sample results. GluonCV provides image normalization and image augmentations, such as randomized image flipping and cropping, to help reduce overfitting during training. The model training code is containerized and uses the Docker image in our AWS Elastic Container Registry. The training job takes the S3 image folder and LST file paths as inputs and saves the best model artifact (.params and .json) to S3 upon completion.
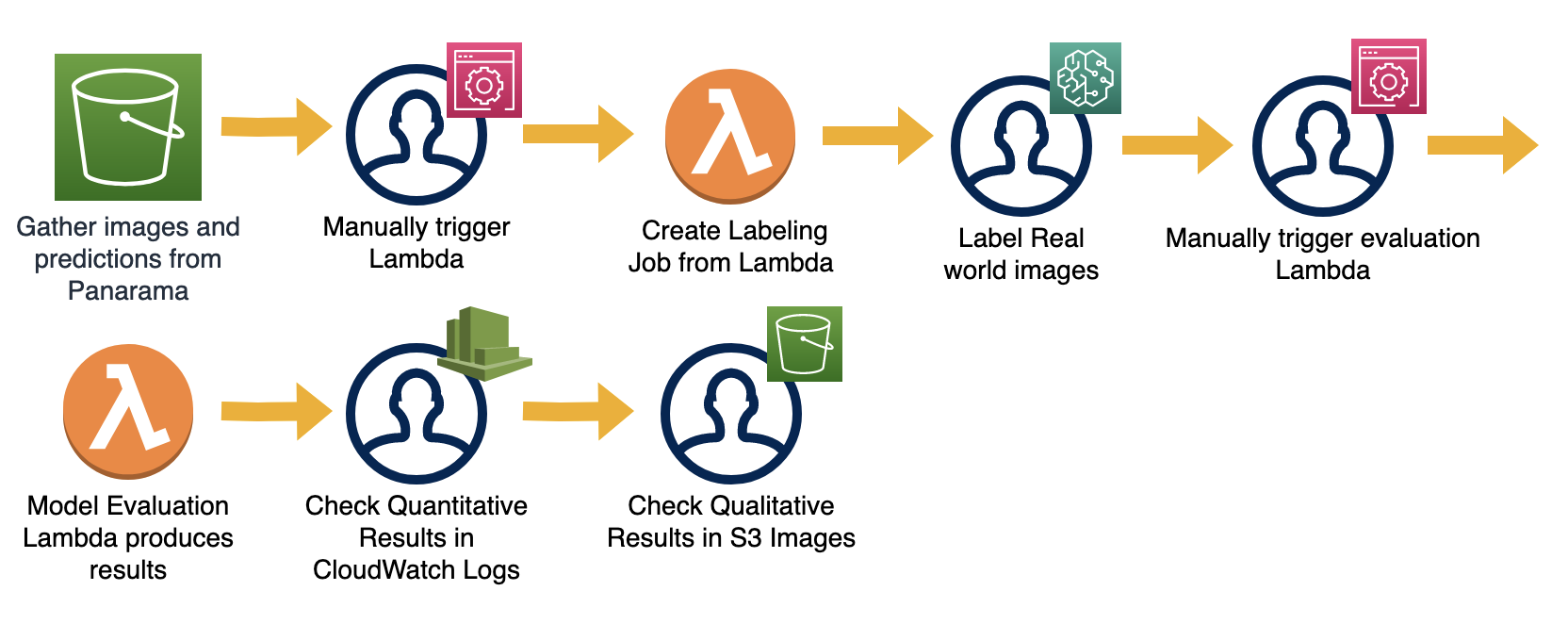
Model Evaluation Pipeline
The top-2 models based on our test set were SSD-resnet50 and Yolov3-darketnet53, with a mAP score of 0.91 each. We also performed real-world testing by deploying an inference application on AWS Panorama device along with the trained model. The inference script saves the predictions and video frames to an Amazon S3 bucket. We created another SageMaker Ground Truth job for annotating ground truth and then performed additional quantitative model evaluation. The ground truth and predicted bounding box labels on images were saved in S3 for qualitative evaluation. The models were able to generalize on the real-world data and yielded consistent performance similar to that on our test-set.
You can find full, end-to-end examples of creating custom training jobs, training state-of-the-art object detection models, implementing Hyperparameter Optimization (HPO), and model deployment on Amazon SageMaker on the AWS Labs GitHub repo.
Deploying meat-tray counting application

Production Architecture
Before deployment, we package all our assets – model, inference script, camera and global variable configuration into a single container as mentioned in this blog post. Our continuous integration and continuous deployment (CI/CD) pipeline updates any change in the inference script as a new application version. Once the new application version is published, we deploy it programmatically using boto3 SDK in Python.
Upon application deployment, AWS Panorama first creates an AWS SageMaker Neo Compilation job to compile the model for the AWS Panorama device. The inference application script imports the compiled-model on the device and performs chicken-tray detection at every frame. In addition to SageMaker Neo-Compilation, we enabled post-training quantization by adding a os.environ['TVM_TENSORRT_USE_FP16'] = '1' flag in the script. This reduces the size of model weights from float 32 to float 16, decreasing model size by half and improving latency without degradation in performance. The inference results are captured in AWS SiteWise Monitor through MQTT messages from the AWS Panorama device via AWS IoT core. The results are then pushed to Amazon S3 and visualized in Amazon QuickSight Dashboards. The plant managers and employees can directly view these dashboards to understand throughput of every packaging line in real-time.
Conclusion
By combining AWS Cloud service like Amazon SageMaker, Amazon S3 and edge service like AWS Panorama, Tyson Foods Inc., is infusing artificial intelligence to automate human-intensive industrial processes like inventory counting in its manufacturing plants. Real-time edge inference capabilities enable Tyson to identify over/under production and dynamically adjust their production flow to maximize efficiency. Furthermore, by owning the AWS Panorama device at the edge, Tyson is also able to save costs associated with expensive network bandwidth to transfer video files to the cloud and can now process all their video/image assets locally in their network.
This blog post provides you with an end-end edge application overview and reference architectures for developing a CV application with AWS Panorama. We discussed 3 different aspects of building an edge CV application.
- Data: Data collection, processing and labeling using AWS Panorama and Amazon SageMaker Ground Truth.
- Model: Model training and evaluation using Amazon SageMaker and AWS Lambda
- Application Package: Bundling trained model, scripts and configuration files for AWS Panorama.
Stay tuned for part two of this series on how Tyson is using AWS Panorama for CV based predictive maintenance of industrial machines.
Click here to start your journey with AWS Panorama. To learn more about collaborating with ML Solutions Lab, see Amazon Machine Learning Solutions Lab.
About the Authors
 Divya Bhargavi is a data scientist at the Amazon ML Solutions Lab where she works with customers across various verticals and applies creative problem solving to generate value for customers with state-of-the-art ML/AI solutions.
Divya Bhargavi is a data scientist at the Amazon ML Solutions Lab where she works with customers across various verticals and applies creative problem solving to generate value for customers with state-of-the-art ML/AI solutions.
 Dilip Subramaniam is a Senior Developer with the Emerging Technologies team at Tyson Foods. He is passionate about building large-scale distributed applications to solve business problems and simplify processes using his knowledge in Software Development, Machine Learning, and Big Data.
Dilip Subramaniam is a Senior Developer with the Emerging Technologies team at Tyson Foods. He is passionate about building large-scale distributed applications to solve business problems and simplify processes using his knowledge in Software Development, Machine Learning, and Big Data.