This GFN Thursday delivers more gr-EA-t games as two new titles from Electronic Arts join the GeForce NOW library.
Gamers can now enjoy Need for Speed HEAT and Plants vs. Zombies Garden Warfare 2 streaming from GeForce NOW to underpowered PCs, Macs, Chromebooks, SHIELD TV and mobile devices.
It’s all part of the eight total games coming to the cloud, starting your weekend off right.
Newest Additions From Electronic Arts
Get ready to play more beloved hits from EA this week.
The Electronic Arts collection expands this week with two new titles streaming on GeForce NOW, including Need for Speed HEAT.
Hustle by day and risk it all at night in Need for Speed HEAT (Steam and Origin). Compete and level up in the daytime race scene, then use the prize money to customize cars and ramp up the action in illicit, nighttime street races that build your reputation as you go up against the Cops swarming the city.
Ready the Peashooters and prepare for plant-based battle against zombies in Plants vs Zombies Garden Warfare 2 (Origin). This time, bring the fight to the zombies and help the plants reclaim a zombie-filled Suburbia from the clutches of Dr. Zomboss.
Stream these new additions and more Electronic Arts games across all your devices with unrivaled performance from the cloud and latency so low that it feels local by upgrading to the power of a GeForce NOW RTX 3080 membership.
All of the Games Coming This Week
Yippee ki-yay, gamers. Stream the immersive open-world title Ranch Simulator on GeForce NOW today.
In addition, members can look for the eight total new games ready to stream this week:
And, in case you missed it, members have been loving the new, instant-play free game demos streaming on GeForce NOW. Try out some of the hit titles streaming on the service and the top tech that comes with Priority and RTX 3080 membership features, like RTX in Ghostrunner and DLSS in Chorus, before purchasing the full PC versions.
Jump in with the newest instant play free demo arriving this week with Terraformers: First Steps on Mars – the prologue to the game Terraformers – before the full game releases next week.
Speaking of jumping in, we’ve got a question to start your weekend gaming off. Let us know your answer on Twitter or in the comments below.
SOS you’re stranded on a desert island with a GFN-enabled device and 3 games, which 3 do you pick?
You can establish feature stores to provide a central repository for machine learning (ML) features that can be shared with data science teams across your organization for training, batch scoring, and real-time inference. Data science teams can reuse features stored in the central repository, avoiding the need to reengineer feature pipelines for different projects and as a result eliminating rework and duplication.
To satisfy security and compliance needs, you may need granular control over how these shared ML features are accessed. These needs often go beyond table- and column-level access control to individual row-level access control. For example, you may want to let account representatives see rows from a sales table for only their accounts and mask the prefix of sensitive data like credit card numbers. Fine-grained access controls are needed to protect feature store data and grant access based on an individual’s role. This is specifically important for customers and stakeholders in industries that are required to audit access to feature data and ensure the right level of security is in place.
The following architecture uses Lake Formation to implement row-, column-, or cell-level access to limit which feature groups or features within a feature group can be accessed by a data scientist working in Amazon SageMaker Studio. Although we focus on restricting access to users working in Studio, the same approach is applicable for users accessing the offline feature store using services like Amazon Athena.
Feature Store is a purpose-built solution for ML feature management that helps data science teams reuse ML features across teams and models, serve features for model predictions at scale with low latency, and train and deploy new models more quickly and effectively.
Lake Formation is a fully managed service that helps you build, secure, and manage data lakes, and provide access control for data in the data lake. Lake Formation supports the following security levels:
Row-level permissions – Restricts access to specific rows based on data compliance and governance policies
Column-level permissions – Restricts access to specific columns based on data filters
Cell-level permissions – Combines both row- and column-level controls by allowing you access to specific rows and columns on the database tables
Lake Formation also provides centralized auditing and compliance reporting by identifying which principals accessed what data, when, and through which services.
By combining Feature Store and Lake Formation, you can implement granular access to ML features on your existing offline feature store.
In this post, we provide an approach for use cases in which you have created feature groups in Feature Store and need to provide access to your data science teams for feature exploration and creating models for their projects. At a high level, a Lake Formation admin defines and creates a permission model in Lake Formation and assigns it to individual Studio users or groups of users.
We walk you through the following steps:
Register the offline feature store in Lake Formation.
Create the Lake Formation data filters for fine-grained access control.
Grant feature groups (tables) and features (columns) permissions.
Prerequisites
To implement this solution, you need to create a Lake Formation admin user in IAM and sign in as that admin user. For instructions, refer to Create a Data Lake Administrator.
We begin with setting up test data using synthetic grocery orders from synthetically generated customer lists using the Faker Python library. You can try it yourself by following the module on GitHub. For each customer, the notebook generates between 1–10 orders, with products purchased in each order. Then you can use the following notebook to create the three feature groups for the customers, products, and orders datasets in the feature store. Before creating the feature groups, make sure that your Studio environment is set up in your AWS account. For instructions, refer to Onboard to Amazon SageMaker Domain.
The goal is to illustrate how to use Feature Store to store the features and use Lake Formation to control access to these features. The following screenshot shows the definition of the orders feature group using the Studio console.
Feature Store uses an Amazon Simple Storage Service (Amazon S3) bucket in your account to store offline data. You can use query engines like Athena against the offline data store in Amazon S3 to extract training datasets or to analyze feature data, and you can join more than one feature group in a single query. Feature Store automatically builds the AWS Glue Data Catalog for feature groups during feature group creation, which allows you to use this catalog to access and query the data from the offline store using Athena or open-source tools like Presto.
Register the offline feature store in Lake Formation
To start using Lake Formation permissions with your existing Feature Store databases and tables, you must revoke the Super permission from the IAMAllowedPrincipals group on the database and the associated feature group tables in Lake Formation.
In the navigation pane, under Data Catalog, choose Databases.
Select the database sagemaker_featurestore, which is the database associated to the offline feature store.
Because Feature Store automatically builds an AWS Glue Data Catalog when you create the feature groups, the offline feature store is visible as a database in Lake Formation.
On the Actions menu, choose Edit.
On the Edit database page, if you want Lake Formation permissions to work for newly created feature groups too and not have to revoke the IAMAllowedPrincipals for each table, deselect Use only IAM access control for new tables in this database, then choose Save.
On the Databases page, select the sagemaker_featurestore database.
On the Actions menu, choose View permissions.
Select the IAMAllowedPrincipals group and choose Revoke.
Similarly, you need to perform these steps for all feature group tables that are associated to your offline feature store.
In the navigation pane, under Data Catalog, choose Tables.
Select table with your feature group name.
On the Actions menu, choose View permissions.
Select the IAMAllowedPrincipals group and choose Revoke.
To switch the offline feature store to the Lake Formation permission model, you need to turn on Lake Formation permissions for the Amazon S3 location of the offline feature store. For this, you have to register the Amazon S3 location.
In the navigation pane, under Register and Ingest, choose Data lake locations.
Choose Register location.
Select the location of the offline feature store in Amazon S3 for the Amazon S3 path.
The location is the S3Uri that was provided in the feature group’s offline store configuration and can be found in the DescribeFeatureGroup API’s ResolvedOutputS3Uri field.
Select the default AWSServiceRoleForLakeFormationDataAccess IAM role and choose Register location.
Lake Formation integrates with AWS Key Management Service (AWS KMS); this approach also works with Amazon S3 locations that have been encrypted with an AWS managed key or with the recommended approach of a customer managed key. For further reading, refer to Registering an encrypted Amazon S3 location.
Create Lake Formation data filters for fine-grained access control
You can implement row-level and cell-level security by creating data filters. You select a data filter when you grant the SELECT Lake Formation permission on tables. In this case, we use this capability to implement a set of filters that limit access to feature groups and specific features within a feature group.
Let’s use the following figure to explain how data filters work. The figure shows two feature groups: customers and orders. A row-level data filter is applied to the customers feature group, resulting in only records where feature1 = ‘12’ is being returned. Similarly, access to the orders feature group is restricted using a cell-level data filter to only feature records where feature2 = ‘22’, as well as excluding feature 1 from the resulting dataset.
To create a new data filter, in the navigation pane on the Lake Formation console, under Data Catalog, choose Data filters and then choose Create new filter.
When you select Access to all columns and provide a row filter expression, you’re establishing row-level security (row filtering) only. In this example, we create a filter that limits access to a data scientist to only records in the orders feature group based on the value of the feature customer_id ='C7782'.
When you include or exclude specific columns and also provide a row filter expression, you’re establishing cell-level security (cell filtering). In this example, we create a filter that limits access to a data scientist to certain features of a feature group (we exclude sex and is_married) and a subset of the records in the customers feature group based on the value of the feature (customer_id ='C3126').
The following screenshot shows the data filters created.
Grant feature groups (tables) and features (columns) permission
In this section, you grant granular access control and permissions defined in Lake Formation to a SageMaker user by assigning the data filter to the SageMaker execution role associated to the user who originally created the feature groups. The SageMaker execution role is created as part of the SageMaker Studio domain setup and by default starts with AmazonSageMaker-ExecutionRole-*. You need to give this role permissions on Lake Formation APIs (GetDataAccess, StartQueryPlanning, GetQueryState, GetWorkUnits, and GetWorkUnitResults) and AWS Glue APIs (GetTables and GetDatabases) in IAM in order for it to be able to access the data.
Create the following policy in IAM, name the policy LakeFormationDataAccess, and attach it to the SageMaker execution role. You also need to attach the AmazonAthenaFullAccess policy to access Athena.
Next, you need to grant access to the Feature Store database and specific feature group table to the SageMaker execution role and assign it one of the data filters created previously. To grant data permissions inside Lake Formation, in the navigation pane, under Permissions, choose Data Lake Permissions, then choose Grant. The following screenshot demonstrates how to grant permissions with a data filter for row-level access to a SageMaker execution role.
Similarly, you can grant permissions with the data filter created for cell-level access to the SageMaker execution role.
Test Feature Store access
In this section, you validate the access controls set up in Lake Formation using a Studio notebook. This implementation uses the Feature Store Python SDK and Athena to query data from the offline feature store that has been registered in Lake Formation.
First, you test row-level access by creating an Athena query for your feature group orders with the following code. The table_name is the AWS Glue table that is automatically generated by Feature Store.
Only records with customer_id = ‘C7782’ are returned as per the data filters created in Lake Formation.
Secondly, you test cell-level access by creating an Athena query for your feature group customers with the following code. The table_name is the AWS Glue table that is automatically generated by Feature Store.
Only records with customer_id ='C3126' are returned as per the data filters created in Lake Formation. In addition, the features sex and is_married aren’t visible.
With this approach, you can implement granular permission access control to an offline feature store. With the Lake Formation permission model, you can limit access to certain feature groups or specific features within a feature group for individuals based on their role in the organization.
To explore the complete code example, and to try it out in your own account, see the GitHub repo.
Conclusion
SageMaker Feature Store provides a purpose-built feature management solution to help organizations scale ML development across business units and data science teams. In this post, we explained how you can use Lake Formation to implement fine-grained access control for your offline feature store. Give it a try, and let us know what you think in comments.
About the Authors
Arnaud Lauer is a Senior Partner Solutions Architect in the Public Sector team at AWS. He enables partners and customers to understand how best to use AWS technologies to translate business needs into solutions. He brings more than 16 years of experience in delivering and architecting digital transformation projects across a range of industries, including the public sector, energy, and consumer goods. Artificial intelligence and machine learning are some of his passions. Arnaud holds 12 AWS certifications, including the ML Specialty Certification.
Ioan Catana is an Artificial Intelligence and Machine Learning Specialist Solutions Architect at AWS. He helps customers develop and scale their ML solutions in the AWS Cloud. Ioan has over 20 years of experience, mostly in software architecture design and cloud engineering.
Swagat Kulkarni is a Senior Solutions Architect at AWS and an AI/ML enthusiast. He is passionate about solving real-world problems for customers with cloud-native services and machine learning. Swagat has over 15 years of experience delivering several digital transformation initiatives for customers across multiple domains including retail, travel and hospitality and healthcare. Outside of work, Swagat enjoys travel, reading, and meditating.
Charu Sareen is a Sr. Product Manager for Amazon SageMaker Feature Store. Prior to AWS, she was leading growth and monetization strategy for SaaS services at VMware. She is a data and machine learning enthusiast and has over a decade of experience spanning product management, data engineering, and advanced analytics. She has a bachelor’s degree in Information Technology from National Institute of Technology, India and an MBA from University of Michigan, Ross School of Business.
Goodhart’s law famously says: “When a measure becomes a target, it ceases to be a good measure.” Although originally from economics, it’s something we have to grapple with at OpenAI when figuring out how to optimize objectives that are difficult or costly to measure. It’s often necessary to introduce some proxy objective that’s easier or cheaper to measure, but when we do this, we need to be careful not to optimize it too much.
For example, as part of our work to align models like GPT-3 with human intent and values, we would like to optimize things like “How helpful is this response?”, or “How factually accurate is this claim?”. These are complex objectives that require humans to carefully check things over. For this reason, we train a model to predict these human preferences, known as a reward model, and use the reward model’s predictions as a proxy objective. But it’s important to keep track of how well the true objective is being optimized.
In this post we’ll look at some of the mathematics behind how we do this. We’ll focus on a setting that is particularly clean to analyze, in which we have access to the true objective. In practice, even human preferences can fail to measure what we really care about, but we’re setting that issue aside in this post.
Best-of-$n$ sampling
There are many ways in which one could optimize the proxy objective, but perhaps the simplest is best-of-$n$ sampling, also known as rejection sampling or reranking. We simply sample $n$ times and take the one that scores the highest according to the proxy objective.
Although this method is very simple, it can actually be competitive with more advanced techniques such as reinforcement learning, albeit at the cost of more inference-time compute. For example, in WebGPT, our best-of-$64$ model outperformed our reinforcement learning model, perhaps in part because the best-of-$64$ model got to browse many more websites. Even applying best-of-$4$ provided a significant boost to human preferences.
In addition, best-of-$n$ sampling has reliable performance and is straightforward to analyze mathematically, making it well-suited to empirical studies of Goodhart’s law and related phenomena.
The mathematics of best-of-$n$ sampling
Let’s study best-of-$n$ sampling more formally. Suppose we have some sample space $S$ (such as the set of possible question-answer pairs), some probability distribution $P$ over $S$, a true objective (or “reward”) $R_{text{true}}:Stomathbb R$, and a proxy objective $R_{text{proxy}}:Stomathbb R$. Let’s say that we somehow optimize $R_{text{proxy}}$ and thereby obtain some new distribution $P^prime$. Then:
The expectation $mathbb E_{x^primesim P^prime}left[R_{text{true}}left(x^primeright)right]$ measures how well we have optimized the true objective.
The KL divergence $D_{text{KL}}left(P^primeparallel Pright)$ measures how much optimization we have done. For example, if $P^prime$ is obtained by taking the first sample from $P$ that lies in some subset $S^primesubseteq S$, then this KL divergence is just the negative log probability that a sample from $P$ lies in $S^prime$.
It turns out that in the case of best-of-$n$ sampling, both of these quantities can be estimated efficiently using samples from $P$.
Let’s look at the expectation first. The naive approach is to use a Monte Carlo estimator: run best-of-$n$ sampling many times, measure the true objective on those samples, and average the results. However, there is a better estimator. If we have $Ngeq n$ samples from $P$ overall, then we can simultaneously consider every possible subset of these samples of size $n$, weight each sample by the number of subsets for which it is the best according to the proxy objective, and then take the weighted average true objective score. This weight is just the binomial coefficient $binom{k-1}{n-1}$, where $k$ is the rank of the sample under the proxy objective, from $1$ (worst) up to $N$ (best).[1] As well as using samples more efficiently, this also allows us to reuse samples for different values of $n$.
As for the KL divergence, surprisingly, this turns out to have an exact formula that works for any continuous probability distribution $P$ (i.e., as long as $P$ has no point masses). One might naively guess that the answer is $log n$, since best-of-$n$ is doing something like taking the top $frac 1n$ of the distribution, and this is roughly correct: the exact answer is $log n-frac{n-1}n$.[2]
Together, these estimators allow us to easily analyze how the true objective varies with the amount of optimization applied to the proxy objective.
Best-of-$n$ performance for WebGPT, with shaded regions representing $pm 1$ standard error, and the KL axis following a square root scale. Here, the original distribution ($P$) is given by the 175B model trained using behavior cloning, the proxy objective used to compute best-of-$n$ ($R_{text{proxy}}$) is given by the training reward model, and we consider three putatively “true” objectives ($R_{text{true}}$): the training reward model itself, a validation reward model trained on held-out data, and actual human preferences. There isn’t much over-optimization of the proxy objective, but we would expect there to be at higher KLs.
Going beyond best-of-$n$ sampling
The main limitation of best-of-$n$ sampling is that the KL divergence grows logarithmically with $n$, so it is only suitable for applying a small amount of optimization.
To apply more optimization, we typically use reinforcement learning. In the settings we’ve studied so far, such as summarization, we’ve typically been able to reach a KL of around 10 nats using reinforcement learning before the true objective starts to decrease due to Goodhart’s law. We’d have to take $n$ to be around 60,000 to reach this KL using best-of-$n$, and we hope to be able to reach much larger KLs than this with improvements to our reward modeling and reinforcement learning practices.
However, not all nats are equal. Empirically, for small KL budgets, best-of-$n$ better optimizes both the proxy and the true objectives than reinforcement learning. Intuitively, best-of-$n$ is the “brute force” approach, making it more information-theoretically efficient than reinforcement learning, but less computationally efficient at large KLs.[3]
We’re actively studying the scaling properties of proxy objectives as part of our work to align our models with human intent and values. If you’d like to help us with this research, we’re hiring!
Aimed at driving diversity and inclusion in artificial intelligence, the MIT Stephen A. Schwarzman College of Computing is launching Break Through Tech AI, a new program to bridge the talent gap for women and underrepresented genders in AI positions in industry.
Break Through Tech AI will provide skills-based training, industry-relevant portfolios, and mentoring to qualified undergraduate students in the Greater Boston area in order to position them more competitively for careers in data science, machine learning, and artificial intelligence. The free, 18-month program will also provide each student with a stipend for participation to lower the barrier for those typically unable to engage in an unpaid, extra-curricular educational opportunity.
“Helping position students from diverse backgrounds to succeed in fields such as data science, machine learning, and artificial intelligence is critical for our society’s future,” says Daniel Huttenlocher, dean of the MIT Schwarzman College of Computing and Henry Ellis Warren Professor of Electrical Engineering and Computer Science. “We look forward to working with students from across the Greater Boston area to provide them with skills and mentorship to help them find careers in this competitive and growing industry.”
The college is collaborating with Break Through Tech — a national initiative launched by Cornell Tech in 2016 to increase the number of women and underrepresented groups graduating with degrees in computing — to host and administer the program locally. In addition to Boston, the inaugural artificial intelligence and machine learning program will be offered in two other metropolitan areas — one based in New York hosted by Cornell Tech and another in Los Angeles hosted by the University of California at Los Angeles Samueli School of Engineering.
“Break Through Tech’s success at diversifying who is pursuing computer science degrees and careers has transformed lives and the industry,” says Judith Spitz, executive director of Break Through Tech. “With our new collaborators, we can apply our impactful model to drive inclusion and diversity in artificial intelligence.”
The new program will kick off this summer at MIT with an eight-week, skills-based online course and in-person lab experience that teaches industry-relevant tools to build real-world AI solutions. Students will learn how to analyze datasets and use several common machine learning libraries to build, train, and implement their own ML models in a business context.
Following the summer course, students will be matched with machine-learning challenge projects for which they will convene monthly at MIT and work in teams to build solutions and collaborate with an industry advisor or mentor throughout the academic year, resulting in a portfolio of resume-quality work. The participants will also be paired with young professionals in the field to help build their network, prepare their portfolio, practice for interviews, and cultivate workplace skills.
“Leveraging the college’s strong partnership with industry, Break Through AI will offer unique opportunities to students that will enhance their portfolio in machine learning and AI,” says Asu Ozdaglar, deputy dean of academics of the MIT Schwarzman College of Computing and head of the Department of Electrical Engineering and Computer Science. Ozdaglar, who will be the MIT faculty director of Break Through Tech AI, adds: “The college is committed to making computing inclusive and accessible for all. We’re thrilled to host this program at MIT for the Greater Boston area and to do what we can to help increase diversity in computing fields.”
Break Through Tech AI is part of the MIT Schwarzman College of Computing’s focus to advance diversity, equity, and inclusion in computing. The college aims to improve and create programs and activities that broaden participation in computing classes and degree programs, increase the diversity of top faculty candidates in computing fields, and ensure that faculty search and graduate admissions processes have diverse slates of candidates and interviews.
“By engaging in activities like Break Through Tech AI that work to improve the climate for underrepresented groups, we’re taking an important step toward creating more welcoming environments where all members can innovate and thrive,” says Alana Anderson, assistant dean for diversity, equity and inclusion for the Schwarzman College of Computing.
Posted by Jeffrey Zhao and Raghav Gupta, Software Engineers, Google Research
Modern conversational agents need to integrate with an ever-increasing number of services to perform a wide variety of tasks, from booking flights and finding restaurants, to playing music and telling jokes. Adding this functionality can be difficult — for each new task, one needs to collect new data and retrain the models that power the conversational agent. This is because most task-oriented dialogue (TOD) models are trained on a single task-specific ontology. An ontology is generally represented as a list of possible user intents (e.g., if the user wants to book a flight, if the user wants to play some music, etc.) and possible parameter slots to extract from the conversation (e.g., the date of the flight, the name of a song, and so on). A rigid ontology can be limiting, preventing the model from generalizing to new tasks or domains. For instance, a TOD model trained on a certain ontology only knows the intents in that ontology, and lacks the ability to generalize its knowledge to unseen intents. This is true even for new ontologies that overlap with ones already known to the agent — for example, if an agent already knows how to book train tickets, adding the ability to book airline tickets would require training on completely new data. Ideally, the agent should be able to leverage its existing knowledge from one ontology, and apply it to new ones.
New benchmarks, such as the the Schema Guided Dialogue (SGD) dataset, have been designed to evaluate the ability to generalize to unseen tasks, by distilling each ontology into a schema of slots and intents. In the SGD setting, TOD models are trained on multiple schemas, and evaluated on how well they generalize to unseen ones — instead of how well they overfit to a single ontology. However, recent work shows the top models still have room for improvement.
To address this problem, we introduce two different sequence-to-sequence approaches toward zero-shot transfer for dialogue modeling, presented in the papers “Description-Driven Task-Oriented Dialogue” and “Show, Don’t Tell: Demonstrations Outperform Descriptions for Schema-Guided Task-Oriented Dialogue”. Both models condition on additional contextual information, either slot and intent descriptions, or single demonstrative examples. Results obtained on multiple dialogue state tracking benchmarks show that by doing away with the fixed schemas and ontologies, these new approaches lead to state-of-the-art results on the dialogue state tracking task with more efficient models. The source code for the described approaches can be found here.
Background: Dialogue State Tracking To address the challenge of zero-shot transfer for dialogue models, we focus on the problem of Dialogue State Tracking (DST). DST is a fundamental problem for conversational agents, in which a model predicts the belief state of a conversation, i.e., the agent’s understanding of the user’s indicated preferences. The belief state is typically modeled as an assignment of values to slots for which the user has indicated a preference in the conversation. An example is shown below.
An example conversation and its ground truth slots and intents for dialogue state tracking. Here, the active user intent is “Book a train”, and pertinent information for booking this train is recorded in the slot values.
Description-Driven Task-Oriented Dialogue In our first paper, we introduce Description-Driven Dialogue State Tracking (D3ST), a DST model that leverages slot and intent descriptions when making predictions about the belief state. D3ST is built on top of the T5 sequence-to-sequence language model, which was shown in previous work to be pretrained effectively for DST problems.
D3ST prompts the input sequence with slot and intent descriptions, allowing the T5 model to attend to both this contextual information and the conversation. Its ability to generalize comes from the formulation of these descriptions. Instead of using a name for each slot, we assign a random index for every slot. For categorical slots (i.e., slots that only take values from a small, predefined set), possible values are also arbitrarily enumerated and then listed. The same is done with intents, and together these descriptions form the schema representation to be included in the input string. This is concatenated with the conversation text and fed into the T5 model. The target output is the belief state and user intent, again identified by their assigned indices. An example is shown below.
An example of the D3ST input and output format. The red text contains slot descriptions, while the blue text contains intent descriptions. The yellow text contains the conversation utterances.
This forces the model to predict conversation contexts using a slot’s index, and not that specific slot. By randomizing the index we assign to each slot between different examples, we prevent the model from learning specific schema information. The slot with index 0 could be the “Train Departure” slot in one example, and the “Train Destination” in another — as such, the model is encouraged to use the slot description given in index 0 to find the correct value, and discouraged from overfitting to a specific schema. With this setup, a model that sees enough different tasks or domains will learn to generalize the action of belief state tracking and intent prediction.
Show Don’t Tell In our subsequent paper, “Show, Don’t Tell: Demonstrations Outperform Descriptions for Schema-Guided Task-Oriented Dialogue”, we employ a single annotated dialogue example that demonstrates the possible slots and values in a conversation, instead of relying on slot descriptions. In this sense, we “show” the semantics of the schema rather than “tell” the model through descriptions — hence the name “Show Don’t Tell” (SDT). SDT is also built on T5, and improves zero-shot performance beyond D3ST.
n example of the SDT input and output format. The text in red contains the demonstrative example, while the text in blue contains its ground truth belief state. The actual conversation for the model to predict is in yellow. While the D3ST prompt relies entirely on slot descriptions, the SDT prompt contains a concise example dialogue followed by the expected dialogue state annotations, resulting in more direct supervision.
The rationale for SDT’s single example demonstration is simple: there can still be ambiguities that are not fully captured in a slot or intent description, and require a concrete example to demonstrate. Moreover, from a developer’s standpoint, creating short dialogue examples to describe a schema can often be easier than writing descriptions that fully capture the meaning behind each slot and intent.
Benchmark Results We evaluate both D3ST and SDT on a number of benchmarks, most notably the SGD dataset, which tests zero-shot generalization to unseen schemas in its test set. We evaluate our state tracking models on joint goal accuracy (JGA), the fraction of dialogue turns for which the model predicts an exactly correct belief state.
Both of our models either match or outperform existing state-of-the-art baselines (T5DST and paDST) at comparable model sizes, as shown below. In general, SDT performs slightly better than D3ST. Note that our models can be trained on different sizes of the underlying T5 language model. In addition, while the baseline models can only make predictions for one slot per forward pass, both our models can decode the entire dialogue state in a single forward pass — a much more efficient method in both training and inference.
Joint Goal Accuracy on the SGD dataset plotted against model size for existing baselines and our proposed models D3ST and SDT. Note that paDST* includes additional data augmentation.
Additional metrics are reported in both papers. D3ST exhibits state-of-the-art quality on the MultiWOZ dataset, with 75.9% JGA on MultiWOZ 2.4. Both D3ST and SDT show state-of-the-art performance in the MultiWOZ cross-domain leave-one-out setting. In addition, both D3ST and SDT were evaluated using the SGD-X dataset, and demonstrated strong robustness to linguistic variations in schema. These benchmarks all indicate that D3ST and SDT are state-of-the-art TOD models, with the ability to generalize to unseen tasks and domains.
Zero-Shot Capability D3ST and SDT sometimes demonstrate a surprising ability to generalize to unseen tasks, and we saw many interesting examples when trying completely new dialogues with the model. We’ve included one such example below:
A D3ST model trained on the SGD dataset makes predictions (right) for an unseen meta conversation (left) about creating this blog post. The model predicts a completely correct belief state, even though it is not fine-tuned on anything related to blogs, authors or NLP.
Future Work These papers demonstrate the feasibility of a zero-shot TOD system that can generalize to unseen tasks or domains. However, we’ve limited ourselves to the DST problem for now — we plan to extend this research to enable zero-shot dialogue policy modeling, allowing TOD systems to take actions following arbitrary instructions. In addition, the current input format can often lead to long input sequences, which can be slow for inference — we’re exploring new and more efficient methods to encode schema information.
Acknowledgements This post reflects the combined work of Jeffrey Zhao, Raghav Gupta, Harrison Lee, Mingqiu Wang, Dian Yu, Yuan Cao, and Abhinav Rastogi. We’d like to thank Yonghui Wu and Izhak Shafran for their continued advice and guidance.
Amazon Lex can add powerful automation to contact center solutions, so you can enable self-service via interactive voice response (IVR) interactions or route calls to the appropriate agent based on caller input. These capabilities can increase customer satisfaction by streamlining the user experience, and improve containment rates in the contact center.
In both the self-service and call routing scenarios, you may need to configure the bot so that it can obtain information commonly required in customer service calls. For example, to enable a self-service experience when the caller requests a transfer from their checking account to their savings account, you may have to first get their account ID.
Bots are more effective at processing a response if they know the related request or prompt (for example, “What is your account ID?”). Amazon Lex provides comprehensive dialog management capabilities, so that context can be maintained across a conversation. However, sometimes the initial prompt may occur before the Amazon Lex bot is engaged.
In the case of an IVR solution, for example, the welcome prompt (“Welcome to ACME bank. To get started, can you tell me your account ID?”) may be defined in the client (Amazon Connect) contact flow. In this case, the Amazon Lex bot isn’t aware that you already prompted the user for their account ID. This could be a source of ambiguity for the bot (imagine if someone called you and started a conversation by saying, “123456”).
To create the best customer experience in cases like this, we recommend that you provide your Amazon Lex bot with details about the prompt. In this post, we show a simple way to inform Amazon Lex about details such as a prior prompt already provided to the user.
Solution overview
For this example, we use an Amazon Lex bot that provides self-service capabilities as part of an Amazon Connect contact flow. When the user calls in on their phone, they’re prompted for their account ID (for example, a six-digit number). We demonstrate how the Amazon Connect contact flow passes context about the information requested (in this case, the AccountId slot) to the Amazon Lex bot. As a best practice, we recommend setting the Amazon Lex dialog state to “slot elicitation” any time a user is prompted for a slot value.
We use the following sample banking interaction to model our Amazon Lex bot:
IVR: Hi, welcome to ACME bank customer service. To get started, please tell me your account ID.
User: 123456.
IVR: Thanks. How can I help? You can check account balances, transfer funds, and order checks.
User: What’s my balance in checking?
IVR: The balance for your checking account is $875. Is there anything else I can help you with?
User: No thanks, that’s it.
IVR: Okay, thanks for contacting us today. We appreciate your business!
Let’s deploy an Amazon Lex bot to see how this works.
Solution architecture
In this sample solution, we use AWS CloudFormation to deploy an Amazon Lex bot with an AWS Lambda fulfillment function, along with an example Amazon Connect contact flow that is integrated with the bot. The welcome prompt (“Welcome to ACME bank. To get started, please tell me your account ID.”) is configured in a “Play prompt” block in the contact flow.
The contact flow uses a Lambda helper function to inform Amazon Lex that the user has been prompted for a slot value. This is done via an “Invoke AWS Lambda function” block in the contact flow. The helper function makes a call to the Amazon Lex put-session API, to tell Amazon Lex to elicit for the account ID slot value. See the following code:
Next, control passes to the “Get customer input” block in the contact flow to trigger the Amazon Lex bot. Because the bot is ready for the account ID slot, the conversation is more efficient. You can also handle scenarios where the caller doesn’t have the requested information, by creating an intent to respond to inputs such as “I don’t know.” Although the bot is expecting a number (account ID), if the user provides a different response, the appropriate intent is triggered.
Prerequisites
Before deploying this solution, you should have the following prerequisites:
To deploy the solution, complete the following steps:
Sign in to the AWS Management Console in your AWS account, and choose the following link:
This launches a new CloudFormation stack to create the example banking bot.
For Stack name, enter a name (for example, lex-elicit-slot-example).
For ConnectInstanceARN, enter the ARN (Amazon Resource Name) for the Amazon Connect instance you’ll use for testing the solution.
Leave the other parameters at their default or change them as needed.
Choose Next.
Add any tags you may want for your stack (this step is optional).
Choose Next.
Review the stack details and select the check box to acknowledge that IAM resources will be created.
Choose Create stack.
After a few minutes, your stack is complete, and includes the following resources:
A Lex bot, including a published version with an alias (Development-Alias)
A Lambda fulfillment function for the bot (BotHandler)
A Lambda helper function, which calls the Amazon Lex put-session API to enable slot elicitation mode (SlotElicitor)
A CloudWatch Logs log group for Amazon Lex conversation logs (optional)
Required IAM roles
A custom resource that adds a sample contact flow to your Amazon Connect instance
Test the bot on the Amazon Lex console
At this point, you can try the example interaction on the Amazon Lex console. You should see the sample bot with the name that you specified in the CloudFormation template (banking-bot-sample).
On the Amazon Lex console, choose this bot and choose Bot versions in the navigation pane.
Choose Version 1, then choose Intents in the navigation pane.
You can see a list of intents.
Choose Test.
Select Development-Alias and choose Confirm.
The test window opens.
Try “What’s my balance?” to get started. You can also say “order some checks,” “transfer 100 dollars,” and “goodbye.”
You will be prompted for an account ID.
Test the bot with Amazon Connect
Now let’s try this with voice using an Amazon Connect instance. We have already configured a sample contact flow in your Amazon Connect instance.
All you need to do is set up a phone number and associate it with this contact flow. To do this, follow these steps:
On the Amazon Connect console, open your instance by choosing Access URL and logging in to the instance.
On the Dashboard, choose View phone numbers.
Choose Claim a number.
Choose a country on the Country drop-down menu, and choose a number.
For Description, enter a description, such as Example contact flow that elicits a slot with Amazon Lex.
For Contact flow, choose the contact flow you just created.
Choose Save.
You’re now ready to call in to your Amazon Connect instance to test your bot using voice. Just dial the number on your phone and give it a try!
Clean up
You may want to clean up the resources created as part of the CloudFormation template when you’re done using the bot, to avoid incurring ongoing charges. To do this, delete the CoudFormation Stack.
Conclusion
Amazon Lex offers powerful automated speech recognition (ASR) and natural language understanding (NLU) capabilities that you can use to capture information from your users to provide automated, self-service functionality, or to route callers to the right agents. Amazon Lex uses slot elicitation to collect information commonly needed in a customer service call. It’s important to provide the bot details on the type of information it should be expecting at the right times—in some cases, even on the first turn of a conversation. You can incorporate this technique in your own Amazon Lex conversation flows.
About the Authors
Brian Yost is a Senior Technical Program manager on the AWS Lex team. In his spare time, he enjoys mountain biking, home brewing, and tinkering with technology.
Perovskites are a family of materials that are currently the leading contender to potentially replace today’s silicon-based solar photovoltaics. They hold the promise of panels that are far thinner and lighter, that could be made with ultra-high throughput at room temperature instead of at hundreds of degrees, and that are cheaper and easier to transport and install. But bringing these materials from controlled laboratory experiments into a product that can be manufactured competitively has been a long struggle.
Manufacturing perovskite-based solar cells involves optimizing at least a dozen or so variables at once, even within one particular manufacturing approach among many possibilities. But a new system based on a novel approach to machine learning could speed up the development of optimized production methods and help make the next generation of solar power a reality.
The system, developed by researchers at MIT and Stanford University over the last few years, makes it possible to integrate data from prior experiments, and information based on personal observations by experienced workers, into the machine learning process. This makes the outcomes more accurate and has already led to the manufacturing of perovskite cells with an energy conversion efficiency of 18.5 percent, a competitive level for today’s market.
The research is reported today in the journal Joule, in a paper by MIT professor of mechanical engineering Tonio Buonassisi, Stanford professor of materials science and engineering Reinhold Dauskardt, recent MIT research assistant Zhe Liu, Stanford doctoral graduate Nicholas Rolston, and three others.
Perovskites are a group of layered crystalline compounds defined by the configuration of the atoms in their crystal lattice. There are thousands of such possible compounds and many different ways of making them. While most lab-scale development of perovskite materials uses a spin-coating technique, that’s not practical for larger-scale manufacturing, so companies and labs around the world have been searching for ways of translating these lab materials into a practical, manufacturable product.
“There’s always a big challenge when you’re trying to take a lab-scale process and then transfer it to something like a startup or a manufacturing line,” says Rolston, who is now an assistant professor at Arizona State University. The team looked at a process that they felt had the greatest potential, a method called rapid spray plasma processing, or RSPP.
The manufacturing process would involve a moving roll-to-roll surface, or series of sheets, on which the precursor solutions for the perovskite compound would be sprayed or ink-jetted as the sheet rolled by. The material would then move on to a curing stage, providing a rapid and continuous output “with throughputs that are higher than for any other photovoltaic technology,” Rolston says.
“The real breakthrough with this platform is that it would allow us to scale in a way that no other material has allowed us to do,” he adds. “Even materials like silicon require a much longer timeframe because of the processing that’s done. Whereas you can think of [this approach as more] like spray painting.”
Within that process, at least a dozen variables may affect the outcome, some of them more controllable than others. These include the composition of the starting materials, the temperature, the humidity, the speed of the processing path, the distance of the nozzle used to spray the material onto a substrate, and the methods of curing the material. Many of these factors can interact with each other, and if the process is in open air, then humidity, for example, may be uncontrolled. Evaluating all possible combinations of these variables through experimentation is impossible, so machine learning was needed to help guide the experimental process.
But while most machine-learning systems use raw data such as measurements of the electrical and other properties of test samples, they don’t typically incorporate human experience such as qualitative observations made by the experimenters of the visual and other properties of the test samples, or information from other experiments reported by other researchers. So, the team found a way to incorporate such outside information into the machine learning model, using a probability factor based on a mathematical technique called Bayesian Optimization.
Using the system, he says, “having a model that comes from experimental data, we can find out trends that we weren’t able to see before.” For example, they initially had trouble adjusting for uncontrolled variations in humidity in their ambient setting. But the model showed them “that we could overcome our humidity challenges by changing the temperature, for instance, and by changing some of the other knobs.”
The system now allows experimenters to much more rapidly guide their process in order to optimize it for a given set of conditions or required outcomes. In their experiments, the team focused on optimizing the power output, but the system could also be used to simultaneously incorporate other criteria, such as cost and durability — something members of the team are continuing to work on, Buonassisi says.
The researchers were encouraged by the Department of Energy, which sponsored the work, to commercialize the technology, and they’re currently focusing on tech transfer to existing perovskite manufacturers. “We are reaching out to companies now,” Buonassisi says, and the code they developed has been made freely available through an open-source server. “It’s now on GitHub, anyone can download it, anyone can run it,” he says. “We’re happy to help companies get started in using our code.”
Already, several companies are gearing up to produce perovskite-based solar panels, even though they are still working out the details of how to produce them, says Liu, who is now at the Northwestern Polytechnical University in Xi’an, China. He says companies there are not yet doing large-scale manufacturing, but instead starting with smaller, high-value applications such as building-integrated solar tiles where appearance is important. Three of these companies “are on track or are being pushed by investors to manufacture 1 meter by 2-meter rectangular modules [comparable to today’s most common solar panels], within two years,” he says.
‘The problem is, they don’t have a consensus on what manufacturing technology to use,” Liu says. The RSPP method, developed at Stanford, “still has a good chance” to be competitive, he says. And the machine learning system the team developed could prove to be important in guiding the optimization of whatever process ends up being used.
“The primary goal was to accelerate the process, so it required less time, less experiments, and less human hours to develop something that is usable right away, for free, for industry,” he says.
“Existing work on machine-learning-driven perovskite PV fabrication largely focuses on spin-coating, a lab-scale technique,” says Ted Sargent, University Professor at the University of Toronto, who was not associated with this work, which he says demonstrates “a workflow that is readily adapted to the deposition techniques that dominate the thin-film industry. Only a handful of groups have the simultaneous expertise in engineering and computation to drive such advances.” Sargent adds that this approach “could be an exciting advance for the manufacture of a broader family of materials” including LEDs, other PV technologies, and graphene, “in short, any industry that uses some form of vapor or vacuum deposition.”
The team also included Austin Flick and Thomas Colburn at Stanford and Zekun Ren at the Singapore-MIT Alliance for Science and Technology (SMART). In addition to the Department of Energy, the work was supported by a fellowship from the MIT Energy Initiative, the Graduate Research Fellowship Program from the National Science Foundation, and the SMART program.
The principal research scientist shares lessons learned during her life journey from a small farm to working on optimizing Amazon’s distribution network.Read More
In deep learning and machine learning, having a large enough dataset is key to training a system and getting it to produce results.
So what does a ML researcher do when there just isn’t enough publicly accessible data?
Enter the MLCommons Association, a global engineering consortium with the aim of making ML better for everyone.
MLCommons recently announced the general availability of the People’s Speech Dataset, a 30,000 hour English-language conversational speech dataset, and the Multilingual Spoken Words Corpus, an audio speech dataset with over 340,000 keywords in 50 languages, to help advance ML research.
On this episode of NVIDIA’s AI Podcast, host Noah Kravitz spoke with David Kanter, founder and executive director of MLCommons, and NVIDIA senior AI developer technology engineer David Galvez, about the democratization of access to speech technology and how ML Commons is helping advance the research and development of machine learning for everyone.
Remote work has made us more reliant on virtual conferencing platforms, including Zoom, Skype and Microsoft Teams. Sam Liang, CEO of Otter.ai, explains how his company enhances the virtual meeting experience for all users.
When large organizations require translation services, there’s no room for the amusing errors often produced by automated apps. Lilt CEO Spence Green aims to correct that using a human-in-the-loop process to achieve fast, accurate and affordable translation.
From active noise cancellation to digital assistants that are always listening for your commands, audio is perhaps one of the most important but often overlooked aspects of modern technology in our daily lives. Dr. Chris Mitchell, CEO and founder of Audio Analytic, discusses the challenges, and the fun, involved in teaching machines to listen.
Subscribe to the AI Podcast: Now available on Amazon Music
In “Just Tech: Centering Community-Driven Innovation at the Margins,” Senior Principal Researcher Mary L. Gray explores how technology and community intertwine and the role technology can play in supporting community-driven innovation and community-based organizations. Dr. Gray and her team are working to bring computer science, engineering, social science, and communities together to boost societal resilience in ongoing work with Project Resolve. She’ll talk with organizers, academics, technology leaders, and activists to understand how to develop tools and frameworks of support alongside members of these communities.
In this episode of the series, Dr. Gray and Dr. Sasha Costanza-Chock, scholar, designer, and activist, explore design justice, a framework for analyzing design’s power to perpetuate—or take down—structural inequality and a community of practice dedicated to creating a more equitable and sustainable world through inclusive, thoughtful, and respectful design processes. They also discuss how critical thinkers and makers from social movements have influenced technology design and science and technology studies (STS), how challenging the assumptions that drive who tech is built for will create better experiences for most of the planet, and how a deck of tarot-inspired cards is encouraging radically wonderful sociotechnical futures.
MARY GRAY: Welcome to the Microsoft Research Podcast series “Just Tech: Centering Community-Driven Innovation at the Margins.” I’m Mary Gray, a Senior Principal Researcher at our New England lab in Cambridge, Massachusetts. I use my training as an anthropologist and communication media scholar to study people’s everyday uses of technology. In March 2020, I took all that I’d learned about app-driven services that deliver everything from groceries to telehealth to study how a coalition of community-based organizations in North Carolina might develop better tech to deliver the basic needs and health support to those hit hardest by the pandemic. Our research together, called Project Resolve, aims to create a new approach to community-driven innovation—one that brings computer science, engineering, the social sciences, and community expertise together to accelerate the roles that communities and technologies could play in boosting societal resilience. For this podcast, I’ll be talking with researchers, activists, and nonprofit leaders about the promises and challenges of what it means to build technology with rather than for society.
[MUSIC ENDS]
My guest for this episode is Dr. Sasha Costanza-Chock,a researcher, activist, and designerwho works to support community-ledprocesses that build shared power,dismantle the matrix of domination,and advance ecological survival.They are the director of research and designat Algorithmic Justice League,a faculty associate with the Berkman Klein Center for Internet & Society at Harvard University,and a member of the steering committee of the Design Justice Network.Sasha’s most recent book, DesignJustice:Community-LedPracticestoBuildtheWorldsWeNeed, was recently a 2021Engineering and Technology PROSE Award finalistand has been cited widely across disciplines.Welcome, Sasha.
SASHA COSTANZA-CHOCK: Thanks, Mary. I’m excited to be here.
GRAY: Can you tell us a little bit about how you define designjustice?
COSTANZA-CHOCK: Design justice is a term—you know, I didn’t create this term; it comes out of a community of practice called the Design Justice Network. But I have kind of chronicled the emergence of this community of practice and some of the ways of thinking about design and power and technology that have sort of come out of that community.And I’ve also done some work sort of tracing the history of different ways that people have thought about design and social justice, really.So, in the book, I did offer a tentative definition, kind of a two-part definition.So, on the one hand, design justice is a framework for analysis about how design distributes benefits and burdens between various groups of people.And in particular, design justice is a way to focus explicitly on the ways that design can reproduce or challenge the matrix of domination, which is Patricia Hill Collins’ term for white supremacy, heteropatriarchy, capitalism, ableism, settler colonialism, and other forms of structural inequality. And also, design justice is a growing community of practice of people who are focused on ensuring more equitable distribution of design’s benefits and burdens, more meaningful participation in design decisions and processes, and also recognition of already existing, community-based, Indigenous, and diasporic design traditions and knowledge and practices.
GRAY: Yeah. What are those disciplines we’re missing when we think about building and building for and with justice at the center of our attention?
COSTANZA-CHOCK: It’s interesting.I think for me, um, so design and technology design in particular, I think, for me, practice came first.So, you know, learning the basics of how to code, building websites, working with the Indymedia network. Indymedia was a kind of global network of hackers and activists and social movement networks who leveraged the power of what was then the nascent internet, um, to try and create a globalized news network for social movements. I became a project manager for various open-source projects for a while.I had a lot of side gigs along my educational pathway.So that was sort of more sort of practice.So, that’s where I learned, you know, how do you run a software project?How do you motivate and organize people?I came later to reading about and learning more about sort of that long history of design theory and history.And then, sort of technology design stuff, I was always looking at it along the way, but started diving deeper more recently. So, my—my first job after my doctorate was, you know, I—I received a position at MIT.Um, and so I came to MIT to the comparative media studies department,set up my collaborative design studio, and I would say, yeah, at MIT, I became more exposed to the HCI literature, spent more time reading STS work,and, in particular, was drawn to feminist science and technology studies.You know, MIT’s a very alienating place in a lot of ways and there’s a small but excellent, you know, community of scholars there who take, you know, various types of critical approaches to thinking about technology design and development and—and sort of the histories of—of technology and sociotechnical systems.And so, kind of through that period, from 2011 up until now, I spent more time engaging with—with that work, and yeah, got really inspired by feminist STS. I also—parallel to my academic formation and training—was always reading theory and various types of writing from within social movement circles, stuff that sometimes is published in academic presses or in peer-review journals and sometimes totally isn’t, but, to me, is often equally or even more valuable if you’re interested in theorizing social movement activity than the stuff that comes sort of primarily from the academy or from social movement studies as a subfield of sociology.
GRAY: Mm-hmm.
COSTANZA-CHOCK: Um, so I was like, you know, always reading all kinds of stuff that I thought was really exciting that came out of movements.So, reading everything that AK Press publishes, reading stuff from Autonomia, and sort of the—the Italian sort of autonomous Marxist tradition. But also in terms of pedagogy, I’m a big fan of Freire.And I didn’t encounter Freire through the academy; it was through, you know, community organizing work.So, community organizers that I was connected to were all reading Freire and reading other sort of critical and radical thinkers and scholars.
GRAY: So, wait.Hold the phone.
COSTANZA-CHOCK: OK. [LAUGHS]
GRAY: You didn’t actually—I mean, there wasn’t a class where PedagogyoftheOppressed was taught in your training?I’m just, now, am like “Really?” That’s—
COSTANZA-CHOCK: I don’t think so.Yeah.
GRAY: Wow.
COSTANZA-CHOCK: Yeah, because I didn’t have formal training in education.It was certainly referenced, but the place where I did, you know, study group on it was in movement spaces, not in the academy.Same with bell hooks. I mean, bell hooks, there would be, like, the occasional essay in, like—I did undergraduate cultural studies stuff. Marjorie Garber, you know, I think—
GRAY: Yeah.
COSTANZA-CHOCK: had like an essay or two on her syllabus, um—
GRAY: Yeah.
COSTANZA-CHOCK: —of bell hooks.Um so, I remember encountering bell hooks early on, but reading more of her work came later and through movement spaces.And so, then, what I didn’t see was a lot of people—although, increasingly now, I think this is happening—you know, putting that work into dialogue with design studies and with science and technology studies.And so, that’s what I—that’s what I get really excited by, is the evolution of that.
GRAY: And—and maybe to that point, I feel like you have, dare I say, “mainstreamed” Patricia Hill Collins in computer science and engineering circles that I travel.Like, to hear colleagues say “the matrix of domination,” they’re reading it through you, which is wonderful.They’re reading—they’re reading what that means. And design justice really puts front and center this critical approach.Can you tell us about how you came to that framework and put it in the center of your work for design justice?
COSTANZA-CHOCK:Patricia Hill Collinsdevelops the term in the ’90s. Um, the “matrix of domination” is her phrase.Um, she elaborates on it in, you know, her text, uh, BlackFeministThought.And of course, she’s the past president of the American Sociological Association.Towering figure, um, in some fields, but, you know, maybe not as much in computer science and HCI, and other, you know, related fields.But I think unjustly so.And so, part of what I’m really trying to do at the core of the DesignJustice book was put insights from her and other Black feminist thinkers and other critical scholars in dialogue with some core, for me, in particular, HCI concepts,um, although I think it does, you know, go broader than that.The matrix of domination was really useful to me when I was learning to think about power and resistance, how does power and privilege operate. You know, this is a concept that says you can’t only think about one axis of inequality at a time.You can’t just talk about race or just talk about gender—you can’t just talk about class—because they operate together.Of course, another key term that connects with matrix of domination is “intersectionality” from Kimberlé Crenshaw.She talks about it in the context of legal theory, where she’s looking at how the legal system is not set up to actually protect people who bear the brunt of oppression.And she talks about these, you know, classic cases where Black women can’t claim discrimination under the law at a company which defends itself by saying, “Well, we’ve hired Black people.”And what they mean is they’ve hired some Black men.And they say, “And we’ve also hired women.”But they mean white women. And so, it’s not legally actionable.The Black women have no standing or claim to discriminationbecause Black women aren’t protected under anti-discrimination law in the United States of America.And so that is sort of like a grounding that leads to this, you know, the conversation.The matrix of domination is an allied concept.And to me, it’s just incredibly useful because I thought that it could translate well, in some ways, into technical fields because there’s a geometry and there’s a mental picture.There’s an image that it’s relatively easy to generate for engineers, I think, of saying, “OK, well, OK, your x-axis is class. [LAUGHS] Your y-axis is gender.Your z-axis is race.This is a field.And somewhere within that, you’re located. And also, everyone is located somewhere in there, and where you’re located has an influence on how difficult the climb is.”And so when we’re designing technologies—and whether it’s, you know, interface design, or it’s an automated decision system—you know, you have to think about if this matrix is set up to unequally distribute, through its topography, burdens and benefits to different types of people depending on how they are located in this matrix, at this intersection.Is that correct?You know, do you want to keep doing that, or do you want to change it up so that it’s more equitable?And I think that that’s been a very useful and powerful concept. And I think, for me, part of it maybe did come through pedagogy.You know, I was teaching MIT undergraduates—most of them are majoring in computer science these days—and so I had to find ways to get them to think about power using conceptual language that they could connect with, and I found that this resonated.
GRAY: Yeah.And since the book has come out—and I, you know, it’s been received by many different scholarly communities and activist communities—has your own definition of design justice changed at—at all?Or even the ways you think about that matrix?
COSTANZA-CHOCK: That’s a great question.I think that one of the things that happened for me in the process of writing the book is I went a lot deeper into reading and listening and thinking more about disability and how crucial, you know, disability and ableism are, how important they are as sort of axes of power and resistance, also as sources of knowledge.So, like, disability justice and disabled communities of various kinds being key places for innovation, both of devices and tools and also of processes of care.And just, there’s so much phenomenal sort of work that’s coming, you know, through the disability justice lens that I really was influenced by in the writing of the book.
GRAY: So another term that seems central in the book is “codesign.”And I think formany folks listening, they might already have an idea of what that is.But can you say a bit more about what you mean by codesign, and just how that term relates to design justice for you?
COSTANZA-CHOCK: I mean, to be entirely honest with you, I think that when I arrived at MIT, I was sort of casting around for a term that I could use to frame a studio course that I wanted to set up that would both signal what the approach was going to be while also being palatable to the administration and not scaring people away.Um, and so I settled on “codesign” as a term that felt really friendly and inclusive and was a broad enough umbrella to enable the types of partnerships with community-based organizations and social movement groups, um, that I wanted to provide scaffolding for in that class.It’s not that I think “codesign” is bad. You know, there’s a whole rich history of writing and thinking and practice, you know, in codesign.I think I just worry that like so many things—I don’t know if it’s that the term is loose enough that it allows for certain types of design practices that I don’t really believe in or support or that I’m critical of or if it’s just that it started meaning more of one thing, um, and then, over time, it became adopted—as many things do become adopted—um, by the broader logics of multinational capitalist design firms and their clients. But I don’t necessarily use the term that much in my own practice anymore.
GRAY: I want to understand what you felt was useful about that term when you first started applying it to your own work and why you’ve moved away from it. What are good examples of, for you, a practice of codesign that stays committed to design justice, and what are some examples of what worries you about the ambiguity of what’s expected of somebody doing codesign?
COSTANZA-CHOCK: So, I mean, there—there’s lots of terms in, like, a related conceptual space, right?So, there’s codesign, participatory design, human-centered design, design justice.I think if we really get into it, each has its own history and sort of there are conferences associated with each.There are institutions connected to each.And there are internal debates within those communities about, you know, what counts and what doesn’t.I think, for me, you know, codesign remains broad enough to include both what I would consider to be sort of design justice practice, where, you know, a community is actually leading the process and people with different types of design and engineering skills might be supporting or responding to that community leadership.But it’s also broad enough to include what I call in the book, you know, more extractive design processes, where what happens is, you know, typically a design shop or consultant working for a multinational brand parachutes into a place, a community, a group of people, runs some design workshops, maybe—maybe does some observation, maybe does some focus groups, generates a whole bunch of ideas about the types of products or product changes that people would like to see, and then gathers that information and extracts it from that community, brings it back to headquarters, and then maybe there are some product changes or some new features or a rollout of something new that gets marketed back to people.And so in that modality, you know, some people might call an extractive process where you’re just doing one or a few workshops with people “codesign” because you have community collaborators, you have community input of some kind; you’re not only sitting in the lab making something.But the community participation is what I would call thin.It’s potentially extractive.The benefit may be minimal to the people who have been involved in that process.And most of the benefits accrue back either to the design shop that’s getting paid really well to do this or ultimately back to headquarters—to the brand that decided to sort of initiate the process.And I’m interested in critiquing extractive processes, but I’m most interested in trying to learn from people who are trying to do something different, people who are already in practice saying, “I don’t want to just be doing knowledge extraction.I want to think about how my practice can contribute to a more just and equitable and sustainable world.”And in some ways, people are, you know, figuring it out as we go along, right?Um, but I’m trying to be attentive to people trying to create other types of processes that mirror, in the process, the kinds of worlds that we want to create.
GRAY: So, it seems like one of the challenges that you bring up in the book is precisely design at—at some point is thinking about particular people and particular—often referred to as “users’”— journeys.And I wanted to—to step back and ask you, you know, you note in the book that there’s a—a default in design that tends to think about the “unmarked user.”And I’m quoting you here. That’s a “(cis)male, white, heterosexual, ‘able-bodied,’ literate, college educated, not a young child, not elderly.”Definitely, they have broadband access.They’ve got a smartphone.Um, maybe they have a personal jet, I don’t know.That part was not a quote of you. [LAUGHTER] But, you know, you’re really clear that there’s this—this default, this presumed user, ubiquitous user.Um, what are the limits for you to designing for an unmarked user, but then how do you contend with this thinking so specifically about people can also be quite, to your earlier point about intersectionality, quite flattening?
COSTANZA-CHOCK: Well, I think the unmarked user is a really well-known and well-documented problem.Unfortunately, it often, it—it applies—you don’t have to be a member of all those categories as an unmarked user to design for the unmarked user when you’re in sort of a professional design context.And that’s for a lot of different reasons that we don’t have that much time to get into, but basically hegemony. [LAUGHTER] So, um—and the problem with that—like, there’s lots of problems with that—one is that it means that we’re organizing so much time and energy and effort in all of our processes to kind of, like, design and build everything from, you know, industrial design and new sort of, you know, objects to interface design to service design, and, you know, if we build everything for the already most privileged group of people in the world, then the matrix of domination just kind of continues to perpetuate itself.Then we don’t move the world towards a more equitable place.And we create bad experiences, frankly, for the majority of people on the planet.Because the majority of people on planet Earth don’t belong to that sort of default, unmarked user that’s hegemonic.Most people on planet Earth aren’t white; they’re actually not cis men.Um, at some point most people on planet Earth will be disabled or will have an impairment.They may not identify as Disabled, capital D.Most people on planet Earth aren’t college educated.Um, and so on and so forth.So, we’re really excluding the majority of people if we don’t actively and regularly challenge the assumption of who we should be building things for.
GRAY: So, what do you say to the argument that, “Well, tech companies, those folks who are building, they just need to hire more diverse engineers, diverse designers—they need a different set of people at the table—and then they’ll absolutely be able to anticipate what a—a broader range of humanity needs, what more people on Earth might need.”
COSTANZA-CHOCK: I think this is a “yes, and” answer.So, absolutely, tech companies [LAUGHS] need to hire more diverse engineers, designers, CEOs; investors need to be more diverse, et cetera, et cetera, et cetera. You know, the tech industry still has pretty terrible statistics, and the further you go up the corporate hierarchy, the worse it gets.So that absolutely needs to change, and unfortunately, right now, it’s just, you know, every few years, everyone puts out their diversity numbers.There’s a slow crawl sometimes towards improvement; sometimes it backslides.But we’re not seeing the shifts that we—we need to see, so it’s like hiring, retention, promotion, everything.I am a huge fan of all those things.They do need to happen. And a—a much more diverse and inclusive tech industry will create more diverse and inclusive products.I wouldn’t say that’s not true.I just don’t think that employment diversity is enough to get us towards an equitable, just, and ecologically sustainable planet.And the reason why is because the entire tech industry right now is organized around the capitalist system.And unfortunately, the capitalist system is a resource-extractive system, which is acting as if we have infinite resources on a finite planet.And so, we’re just continually producing more stuff and more things and building more server farms and creating more energy-intensive products and software tools and machine learning models and so on and so on and so on.So at some point, we’re going to have to figure out a way to organize our economic system in a way that’s not going to destroy the planet and result in the end of homo sapiens sapiens along with most of the other species on the planet.And so unfortunately, employment diversity within multicultural, neoliberal capitalism will not address that problem.
GRAY: I could not agree more.And I don’t want this conversation to end. I really hope you’ll come back and join me for another conversation, Sasha.It’s been unbelievable to be able to spend even a little bit of time with you.So, thank you for—for sharing your thoughts with us today.
COSTANZA-CHOCK: Well, thank you so much for having me.I always enjoy talking with you, Mary.And I hope that, yeah, we’ll continue this either in a podcast or just over a cup of tea.
[MUSIC PLAYS UNDER DIALOGUE]
GRAY: Looking forward to it.And as always, thanks to our listeners for tuning in.If you’d like to learn more—wait, wait, wait, wait!There’s just so much to talk about. [MUSIC IS WARPED AND ENDS] Not long after our initial conversation,Sasha said she was willing to have more discussion.Sasha, thanks for rejoining us.
COSTANZA-CHOCK: Of course.It’s always a pleasure to talk with you, Mary.
GRAY: In our first conversation, we had a chance to explore design justiceas a framework and a practiceand your book of the same name, which has inspired many.I’d love to know how your experience in design justice informs your current role with the Algorithmic Justice League.
COSTANZA-CHOCK:So I am currently the director of researchand design at the Algorithmic Justice League. The Algorithmic Justice League, or AJL for short,is an organization that was founded by Dr. Joy Buolamwini, and our mission is to raise awarenessabout the impacts of AI,equip advocates with empirical research,build the voice and choice of the most impacted communities,and galvanize researchers, policymakers,and industry practitioners to mitigate AI harms and biases,and so we like to talk about how we’re building a movementto shift the AI ecosystem towards more equitableand accountable AI. And my role in AJL is to lead up our research efforts and also,at the moment, product design.Uh,we’re a small team.We’re sort of in start-up mode.Uh, we’re hiring various, you know, director-level rolesand building out the teams that are responsiblefor different functions,and so it’s a very exciting time to be part of the organization.I’m very proud of the work that we’re doing.
GRAY: So you have both product design and researchhappening under the same roofin what sounds like a super-hero setting.That’s what we should take away—and that you’re hiring.I think listeners need to hear that. How do you keep research and product design happening in a setting that usually you have to pick one or the other in a nonprofit. How are you making those come together?
COSTANZA-CHOCK: Well, to be honest,most nonprofits don’t really have a product design arm.I mean, there are some that do,but it’s not necessarily a standard, you know, practice. I think what we are trying to do, though,as an organization—you know, we’re very uniquely positionedbecause we play a storytelling role,and so we’re influencing the public conversationabout bias and harms in algorithmic decision systems,and probably the most visible placethat that, you know, has happenedis in the film CodedBias. It premiered at Sundance,then it aired on PBS,and it’s now available on Netflix,and that film follows Dr. Buolamwini’s journey from,you know, a grad student at the MIT Media Labwho has an experience of facial recognition technologybasically failing on her dark skin, and it follows her journeyas she learns more about how the technology works,how it was trained, why it’s failing,and ultimately is then sort of, you know, testifying in U.S. Congressabout the way that these toolsare systematically biased against women and peoplewith darker skin tones, skin types,and also against trans and gender nonconforming people,and that these toolsshould not be deployed in production environments,especially where it’s going to cause significant impacts to people’s lives. Over the past couple years, we’ve seen a lot of real-world examples of the harms that facial recognition technologies, or FRTs, can create. These types of bias and harm are happening constantlynot only in facial recognition technologiesbut in automated decision systems of many different kinds,and there are so many scholars and advocacy organizationsand, um, community groups that are now kind of emergingto make that more visible and to organizeto try and block the deployment of systemswhen they’re really harmful or at the very leasttry and ensure that there’s more communityoversight of these toolsand also to set some standards in place,best practices, external auditing and impact assessmentso that especially as public agenciesstart to purchase these systems and roll them out,you know, we have oversight and accountability.
GRAY: So, April 15 is around the corner, Tax Day, and there was a recent bit of news around what seems like a harmless use of technology and use of identification for taxes that you very much, um, along with other activists and organizations, uh, brought public attention to the concerns over sharing IDs as a part of our—of our tax process. Can you just tell the audience a little bit about what happened, and what did you stop?
COSTANZA-CHOCK: Absolutely.So, um, ID.me is a, uh, private companythat sells identity verification services,and they have a number of different waysthat they do identity verification,including, uh, facial recognition technologywhere they compare basicallya live video or selfie to a picture IDthat’s previously been uploaded and stored in the system.They managed to secure contracts with many government agencies,including a number of federal agenciesand about 30 state agencies, as well.And a few weeks ago,it came out that the IRS had given a contract to ID.me and that people were going to have to scan our facesto access our tax records.Now, the problem with this—there are a lot of problems with this,but one of the problems is that we knowthat facial recognition technologyis systematically biased against some groups of peoplewho are protected by the Civil Rights Act,so, uh, against Black people and people with darker skin tonesin general, uh, against women,and the systems perform least wellon darker skinned type women.And so what this means is that if you’re, say, a Black womanor if you’re a trans person, it would be more likelythat the verification process would fail for youin a way that is very systematic and has—you know, we have pretty good documentationabout the failure rates,both in false positives and false negatives.The best science shows that these toolsare systematically biased against some people,and so for it to be deployed in contractsby a public agency for something that’s going to affect everybodyin the United States of America and is going to affect Black people and Black womenspecifically most, uh, is really, really problematicand opens the ground to civil rights lawsuits,to Federal Trade Commission action,among a number of other, you know, possible problems.So when we at the Algorithmic Justice League learned that ID.me had this partnership with the IRSand that this was all going to roll outin advance of this year’s tax season,uh, we thought this is really a problemand maybe this is something that we could move the needle on,and so we got togetherwith a whole bunch of other organizations like Fightfor the Futureand the Electronic Privacy Information Center, and basically, all of these organizationsstarted working with all cylinders firing,including public campaigns, op-eds, social media,and back channeling to various peoplewho work inside different agenciesin the federal government like the White House Office of Science and Technology Policy,the Federal Trade Commission,other contacts that we have in different agencieskind of saying, “Did you know that this system—this multi-million-dollar contract for verificationthat the IRS is about to unleash on all taxpayers—is known to have outcomes that disproportionately disadvantage Black people and women and trans and gender nonconforming people?” And in a nutshell, it workedto a degree. So the IRS announced that they would not beusing the facial recognition verification option that ID.me offers, and a number of other federal agencies announcedthat they would be looking more closely at the contractsand exploringwhether they wanted to actually roll this out,and what’s happening now is that at the state level through public records requests and other actions,um, you know, different organizationsare now looking state by state and findingand turning up all these examples of how this same toolwas used to basically deny accessto unemployment benefits for people,to deny access to services for veterans.There are now, I think, around 700 documented examplesthat came from public records requests of peoplesaying that they tried to verify their access, um, especially to unemployment benefits using the ID.me service, and they could not verify,and when they were told to take the backup option,which is to talk with a live agent, the company, you know,was rolling out this system with contractsso quickly that they hadn’t built up their human workforce,so when people’s automated verification was failing,there were these extremely long wait times like weeks or, in some cases,months for people to try and get verified.
GRAY: Well, and I mean, this is—I feel like the past always comes back to haunt us, right,because we have so many cases where it’s, in hindsight,seems really obvious that we’re going to have a systemthat will fail because of the training datathat might have created the model.We are seeing so many cases where training datasetsthat have been the tried-and-true standardsare now being taken off the shelfbecause we can tell that there are too many errorsand too few theories to understand the models we haveto keep using the same models the same way that we haveused them in the past,and I’m wondering what you make of this continued desireto keep reaching for the training dataand pouring more data inor seeing some way to offset the bias. What’s the value of looking for the bias versus setting up guardrails for where we apply a decision-making system in the first place?
COSTANZA-CHOCK: Sure. I mean, I think—let me start by sayingthat I do think it’s useful and valuable for people to do research to try and better understandthe ways in which automated decision systems are biased,the different points in the life cycle where bias creeps in. And I do think it’s useful and valuablefor people to look at bias and try and reduce it.And also, that’s not the be all and end all,and at the Algorithmic Justice League,we are really trying to get people to shiftthe conversation from bias to harmbecause bias is one but not the only waythat algorithmic systems can be harmful to people.So a good example of that would be, we could talk about recidivism risk prediction,which there’s been a lot of attention to that, you know, ever since the—the ProPublica articlesand the analysis of—that’s come out about, uh, COMPAS, which is, you know, the scoring system that’s usedwhen people are being detained pre-trial and a courtis making a decisionabout whether the person should be allowed out on bailor whether they should be detained until their trial. And these risk scoring tools,it turns out thatthey’re systematically biased against Black people,and they tend to overpredict the rate at whichBlack people will recidivate or will—will re-offend during the, you know,the periodthat they’re out and underpredict the rate at which white people, you know, would do so.So there’s one strand of researchers and advocateswho would say,“Well, we need to make this better.We need to fix that system, and it should be less biased,and we want a system that more perfectly—more perfectly does predictionand also more equitably distributesboth false positives and false negatives.”You can’t actually maximize both of those things.You kind of have to make difficult decisions about do youwant it to, um, have more false positivesor more false negatives.You have to sort of make decisions about that.But then there’s a whole nother strand of people like, you know, the Carceral Technology Resistance Network,who would just say, “Hold on a minute.Why are we talking about reducing biasin a pre-trial detention risk-scoring tool?We should be talking about why are we locking people up at all,and especially why are we locking people upbefore they’ve been sentenced for anything?” So rather than saying let’s build a better tool that can help us,you know, manage pre-trial detention,we should just be saying we should absolutely minimize pre-trial detentionto only the most extreme casesthat—where there’s clear evidence and a clear,you know, present danger that the person will immediatelybe harming themselves or—or—or someone else,and that should be something that, you know, a judge can decidewithout the need of a risk score.
GRAY: When you’re describing the consequencesof a false positive or a false negative,I’m struck by, um, how cold the calculation can sound,and then when I think about the implications,you’re saying we have to decide do we let more people we might suspectcould create harms leave a courtroomor put in jail people we could not possibly know how many more of themwould not versus would commit some kind of act between nowand when they’re sentenced.And so, I’m just really struck by the weightiness of that,uh, if I was trying to think about developing a technologythat was going to try and reduce that harmand deliberate which is more harmful.I’m just saying that out loud because I—I feel like thoseare those moments where I see two strands of worksyou’re calling out and two strands of workyou’re pointing outthat sometimes do seem in fundamental tension, right?That we would not want to build systemsthat perpetuate an approachthat tries to take a better guessat whether to retain someonebefore they’ve been convicted of anything.
COSTANZA-CHOCK: Yeah, so I think, like,in certain cases, like in criminal,you know, in the criminal legal system,you know, we want to sort of step outfrom the question that’s posed to us,where people are saying,“Well, what approach should we useto make this tool less biasedor even less harmful,” if they’re using that frame.And we want to step back and say,“Well, what are the other things that we need to invest into ensure that we can minimize the number of peoplewho are being locked up in cages?”Because that’s clearly a horrible thing to do to people,and it’s not making us safer or happier or better,and it’s systematically and disproportionately deployedagainst people of color.In other domains, it’s very different,and this is why I think, you know, it can be very tricky.We don’t want to collapse the conversationabout AI and algorithmic decision systems,and there are some things that we can say,you know, at a very high level about these tools,but at the end of the day, a lot of the times,I think that it comes down to the specific domainand context and tool that we’re talking about.So then we could say, well, let’s lookat another field like dermatology, right?And you would say, well, there’s a whole bunch of researchersworking hard to try and develop better diagnostic toolsfor skin conditions, early detection of cancer. And so it turns out that the existing datasets of skin conditions heavily undersample the wide diversity of human skin typesthat are out there in the world and overrepresent white skin, and so these tools perform way better, um, you know,for people who are, uh, raced as white, uh, under the current, you know, logicof the construction of—of racial identities.So there’s a case where we could say, “Well, yeah, here inclusion makes sense.”Not everybody would say this, but a lot of us would say this is a case where it is a good idea to say, “Well, what we need to do is go out and create much better,far more inclusive datasets of various skin conditionsacross many different skin types, you know,should be people from all across the world and different climatesand locations and skin types and conditions,and we should better train these diagnostic tools,which potentially could really both democratize access to,you know, dermatology diagnostics and could also help with earlier detection of,you know, skin conditionsthat people could take action on, you know.Now, we could step out of that logic for a moment and say,“Well, no, what we should really do is make surethat there’s enough resources so that there are dermatologists in every communitythat people can easily see for freebecause they’re always going to do, you know,a better job than, you know, these apps could ever do,”and I wouldn’t disagree with that statement,and also, to me, this is a casewhere that’s a “both/and” proposition, you know.If we have apps that people can use to do self-diagnosticand if they reach a certain threshold of accuracyand they’re equitable across different skin types,then that could really save a lot of people’s lives,um, and then in the longer run,yes, we need to dramatically overhaul our—our medical systemand so on and so forth. But I don’t think that those goals are incompatible,whereas in another domain like the criminal legal system,I think that investing heavily in the developmentof so-called predictive crime technologies of various kinds, I don’t think that that’s compatible with decarcerationand the long-term project of abolition.
GRAY: I love that you’ve reframed itas a matter of compatibilitycause I—what I really appreciate about your workis that you’re—you keep the tension.I mean you—that you really insist on us being willing to grapple with and stay vigilantabout what could go wrong without saying don’t do it at all,and I’ve found that really inspiring. Um …
COSTANZA-CHOCK: Well—
GRAY: Yeah, please.
COSTANZA-CHOCK: Can I—can I say one more thingabout that, though?I mean, I do—yes,and also there’s a whole nother question here, right?So, you know, is—is this tool harmful?And then there’s also—there’s a democracy question, which is, were people consulted?Do people want this thing?Even if it does a good job, you know,um, and even if it is equitable.And because there’s a certain type of harm,which is, uh, a procedural harm,which is if an automated decision system is deployed against people’s consent or against people’s ideaabout what they think should be happeningin a just interaction with the decision maker, then that’s a type of harm that’s also being done.And so, we really need to think about not onlyhow can we make AI systems less harmfuland less biased, among the various types of harm that can happen,but also more accountable, and how can we ensurethat there is democratic and community oversightover whether systems are deployed at all,whether these contracts are entered into by public agencies,and whether people can opt outif they want to from the automated decision systemor whether it’s something that’s being forced on us.
GRAY: Could you talk a little bitabout the work you’re doing around bounties as a way of thinking about harms in algorithmic systems?
COSTANZA-CHOCK: So at the Algorithmic Justice League,one of the projectsI’ve been working on over the last year culminated in a recently released report,which is called “Bug Bounties for Algorithmic Harms? Lessons from cybersecurity vulnerability disclosure for algorithmic harms discovery, disclosure, and redress,” and it’s a co-authored paper by AJL researchers Josh Kenway, Camille François, myself, Deb Raji, and Dr. Joy Buolamwini. And so, basically, we got some resourcesfrom the Sloan and Rockefeller foundationsto explore this question of couldwe apply bug bounty programs to areas beyond cybersecurity,including algorithmic harm discovery and disclosure?In the early days of cybersecurity,hackers were often in this positionof finding bugs in software,and they would then tell the companies about it,and then the companies would sue them or denythat it was happening or try and shut them down in—in various ways.And over time,that kind of evolved into what we have now,which is a system where, you know, it was once considereda radical new thing to pay hackers to findand tell you about bugs in your—in your systems,and now it’s a quite common thing,and most major tech companies, uh, do this. And so very recently,a few companies have started adoptingthat model to look beyond security bugs.So, for example, you know, we found an early examplewhere Rockstar Games offered a bountyfor anyone who could demonstratehow their cheat detection algorithms might be flawed because they didn’t want to mistakenly flag peopleas cheating in game if they weren’t. And then there was an example where Twitter basically observedthat Twitter userswere conducting a sort of open participatory auditon Twitter’s image saliency and cropping algorithm,which was sort of—when you uploaded an image to Twitter,it would crop the image in a way that it thought would generate the most engagement,and so people noticed that there were some problems with that.It seemed to be cropping outBlack people to favor white people, um,and a number of other things.So Twitter users kind of demonstrated this,and then Twitter engineers replicated those findingsand published a paper about it, and then a few months later, they ran a bounty program, um, in partnershipwith the platform HackerOne,and they sort of launched it at—at DEF CONand said, “We will offer prizes to people who can demonstrate the ways that our image crop system, um,might be biased.”So this was a biased bounty.So we explored the whole history of bug bounty programs.We explored these more recent attempts to apply bug bountiesto algorithmic bias and harms,and we interviewed key people in the field,and we developed a design frameworkfor better vulnerability disclosure mechanisms. We developed a case study of Twitter’s bias bounty pilot.We developed a set of 25 design lessons for people to createimproved bug bounty programs in the future. And you can read all about that stuff at ajl.org/bugs.
GRAY: I—I feel like you’ve reviveda certain, um, ’90s sentiment of “this is our internet; let’s pick up the trash.”It just has a certain, um, kind of collaborative feel to itthat I—that I really appreciate.So, with the time we have left, I would love to hear about oracles and transfeminism. What’s exciting you about oracles and transfeminist technologies these days?
COSTANZA-CHOCK:So it can be really overwhelming to constantlybe working to expose the harms of these systemsthat are being deployed everywhere,in every domain of life, all the time,to uncover the harms,to get people to talk about what’s happened,to try and push back against contractsthat have already been signed,and to try and get, you know,lawmakers that are concerned with a thousand other thingsto pass bills that will rein in the worst of these tools.So I think for me, personally, it’s really importantto also find spaces for play and for visioningand for speculative design and for radical imagination.And so, one of the projects that I’m really enjoying latelyis called the Oracle for Transfeminist Technologies,and it’s a partnership between Coding Rights,which is a Brazil-based hacker feminist organization,and the Design Justice Network,and the Oracle is a hands-on card deckthat we designed to help us useas a tool to collectively envision and share ideasfor transfeminist technologies from the far future. And this idea kind of bubbled up from conversations between Joana Varon,who’s the directoress of Coding Rights,and myself and a number of other peoplewho are in kind of transnational hacker feminist networks,and we were kind of thinking about how, throughout history,human beings have always useda number of different divination techniques,like tarot decks,to understand the present and to reshape our destiny,and so we created a card deck called the Oracle for Transfeminist Technologies that has values cards,objects cards, bodies and territories cards,and situations cards,and the values are various transfeminist values,like autonomy and solidarityand nonbinary thought and decolonialityand a number of other transfeminist values.The objects are everyday objectslike backpacks or bread or belts or lipstick,and the bodies and territories cards,well, that’s a spoiler, so I can’t tell you what’s in them.
GRAY:[LAUGHS]
COSTANZA-CHOCK:Um, and the situations cards are kind of scenariosthat you might have to confront.And so what happens is basicallypeople take this card deck—and there’s both a physical version of the card deck,and there’s also a virtual version of thisthat we developed using a—a Miro board,a virtual whiteboard,but we created the cards inside the whiteboard—and people get dealt a hand, um,and either individually or in small groups,you get one or several values, an object, a people/places card,or a bodies/territory card and a situation,and then what you have to dois create a technology rooted in your valuesand—that somehow engages with the objectthat you’re dealt that will help people dealwith the situation, um, from the future.And so people come up with all kindsof really wonderful things that, um—and—and they illustrate these.So they create kind of hand-drawn blueprints or mockupsfor what these technologies are likeand then short descriptions of them and how they work.And so people have created thingslike community compassion probiotics thatconnect communities through a mycelial networkand the bacteria develop a horizontal governancein large groups,where each bacteria is linked to a personto maintain accountability to the whole,and it measures emotional and affective temperatureand supports equitable distribution of careby flattening hierarchies.Or people created, um, a—
GRAY:[LAUGHS]Right now, every listener is, like, Googling,looking feverishly online for these—for the, the Oracle.Where—where do we find this deck?Where—please, tell us.
COSTANZA-CHOCK: So you can—you can just Google“the Oracle for Transfeminist Technologies”or you can go to transfeministech.codingrights.org. So people create these fantastic technologies,and what’s really fun, right, is that a lot of them,of course, you know, we could create something like that now.And so our dream with the Oracle in its next stagewould be to move from the completely speculative design,you know, on paper piece to a prototyping lab,where we would start prototypingsome of the transfeminist technologies from the future and see how soon we can bring them into the present.
GRAY: I remember being so delightedby a very, very, very early version of this, and it was the tactileness of it was just amazing, like,to be able to play with the cards and dream together.So that’s—I’m so excited to hearthat you’re doing that work.That’s—that is inspiring.I’m just smiling.I don’t know if you can hear it through the radio, but, uh—wow, I just said “radio.” [LAUGHTER]
[MUSIC PLAYS UNDER DIALOGUE]
COSTANZA-CHOCK: It is a radio.A radio in another name.
GRAY: I guess it is a radio.That’s true. A radio by another name.Oh, Sasha, I could—I could really spend all day talking with you. Thank you for wandering back into the studio.
COSTANZA-CHOCK: Thank you.It’s really a pleasure.And next time, it’ll be in person with tea.
GRAY: Thanks to our listeners for tuning in. If you’d like to learn more about community-driven innovation, check out the other episodes in our “Just Tech” series. Also, be sure to subscribe for new episodes of the Microsoft Research Podcast wherever you listen to your favorite shows.


SOS
NVIDIA GeForce NOW (@NVIDIAGFN) April 13, 2022

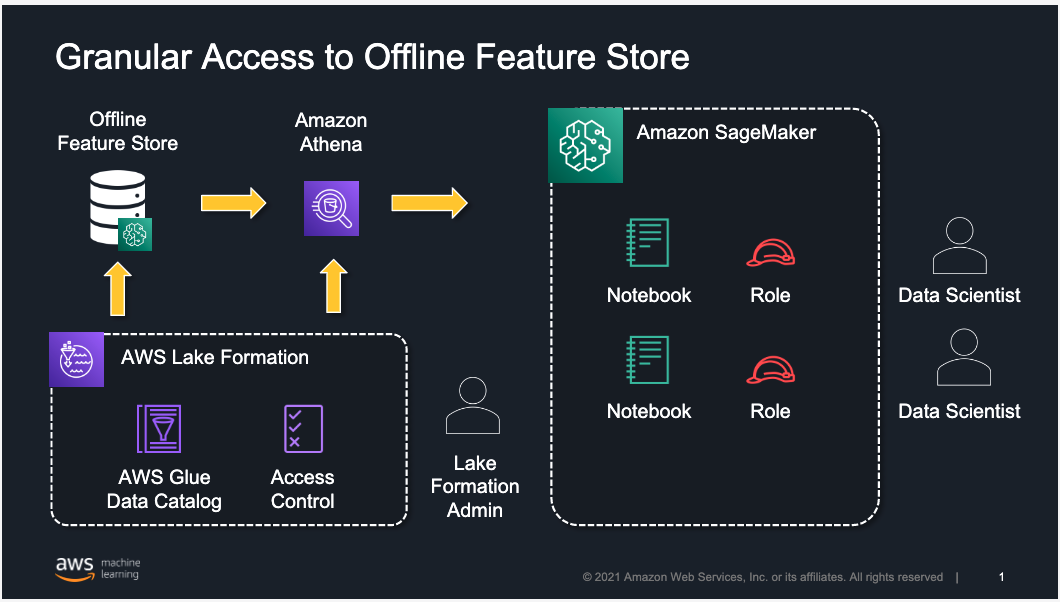
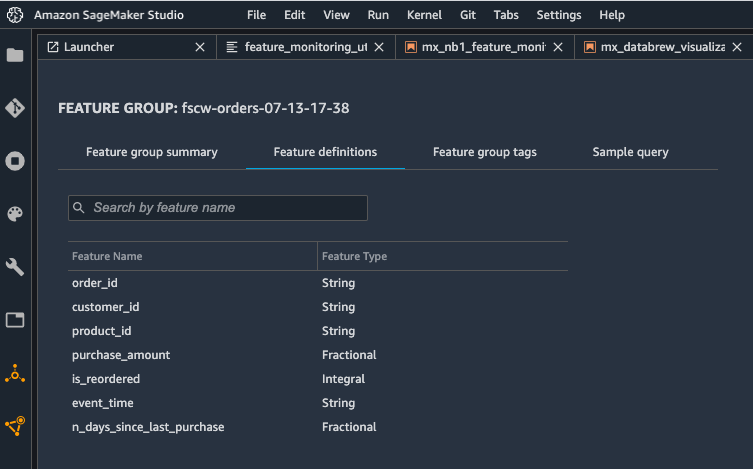




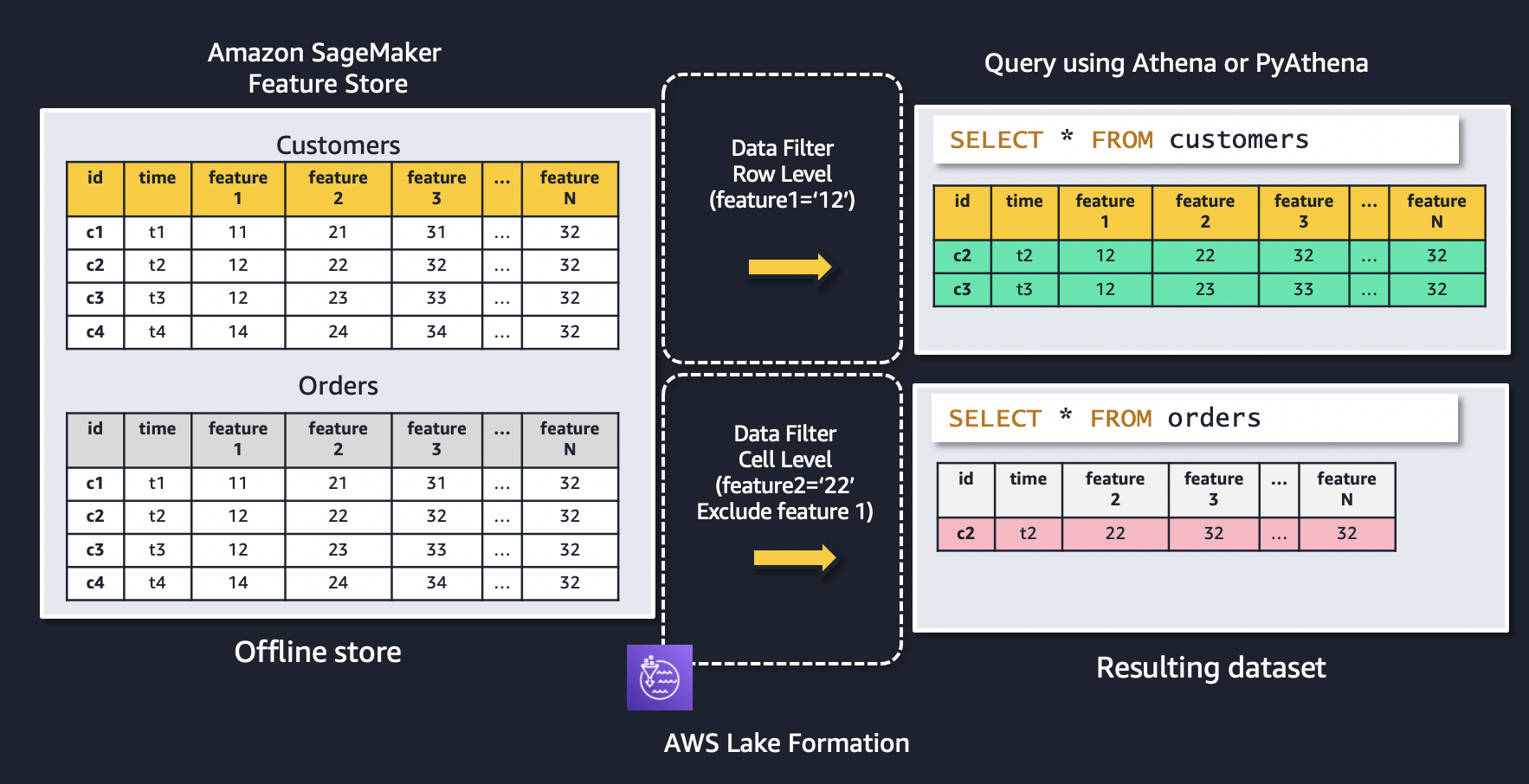

















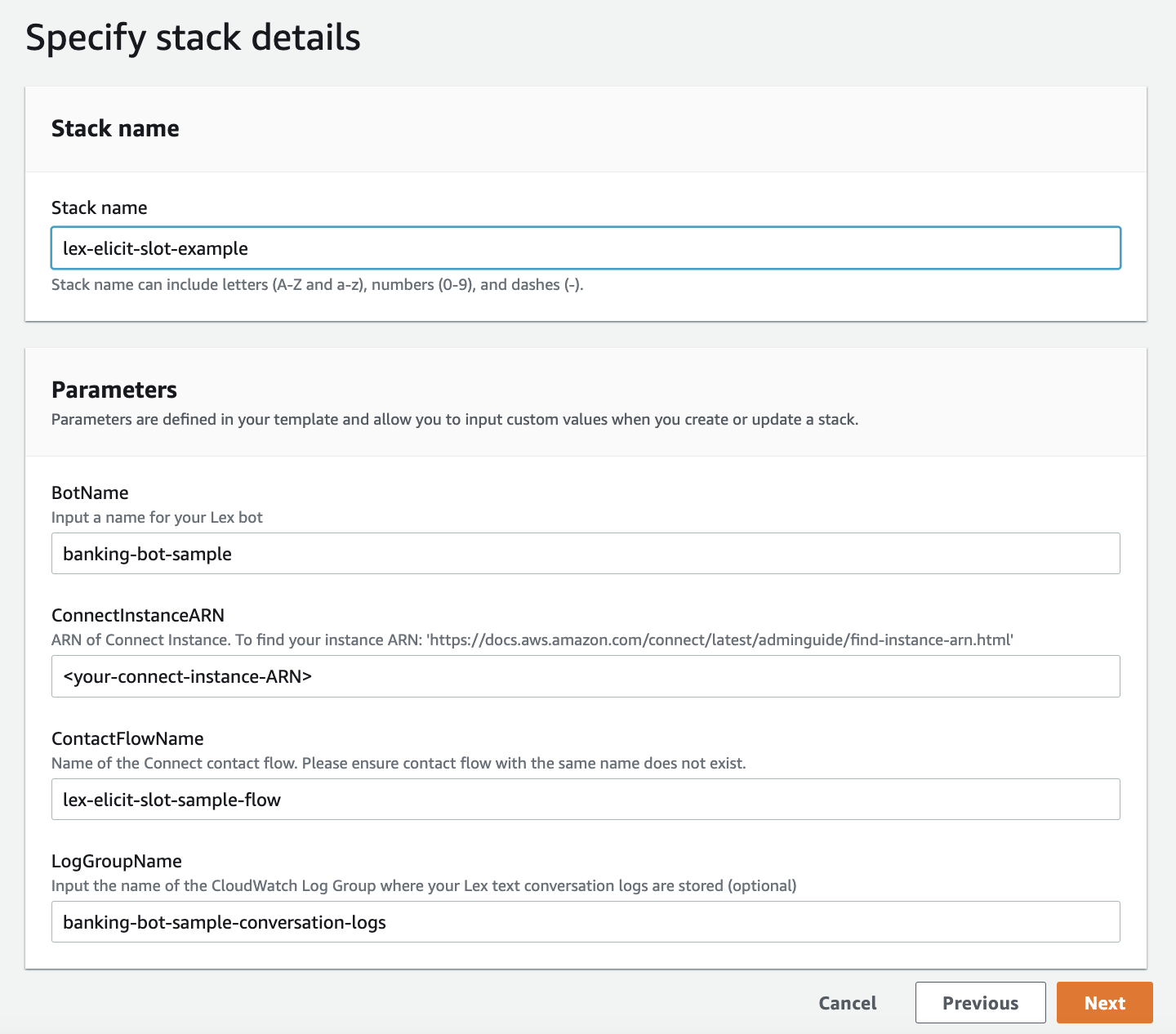
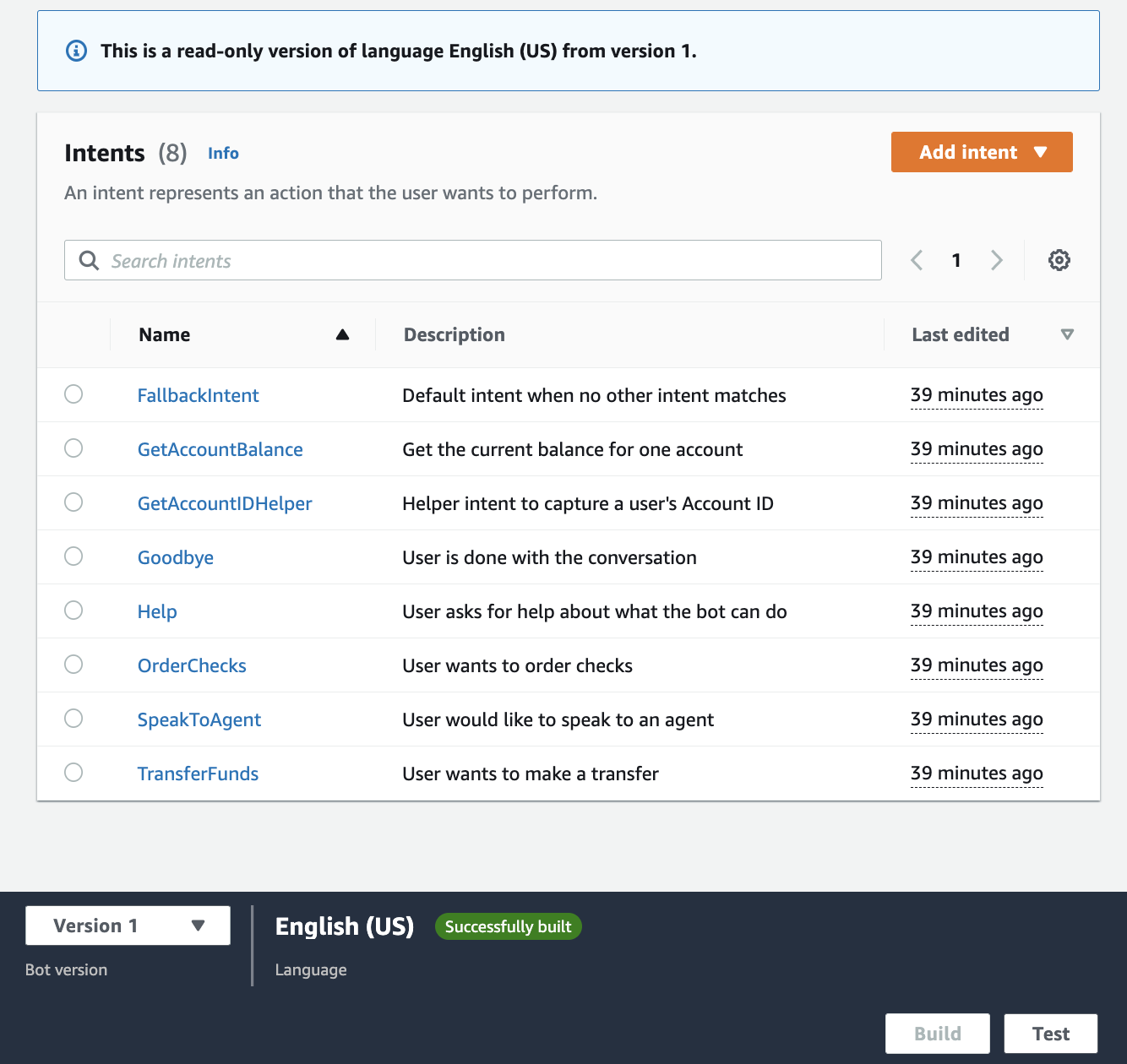
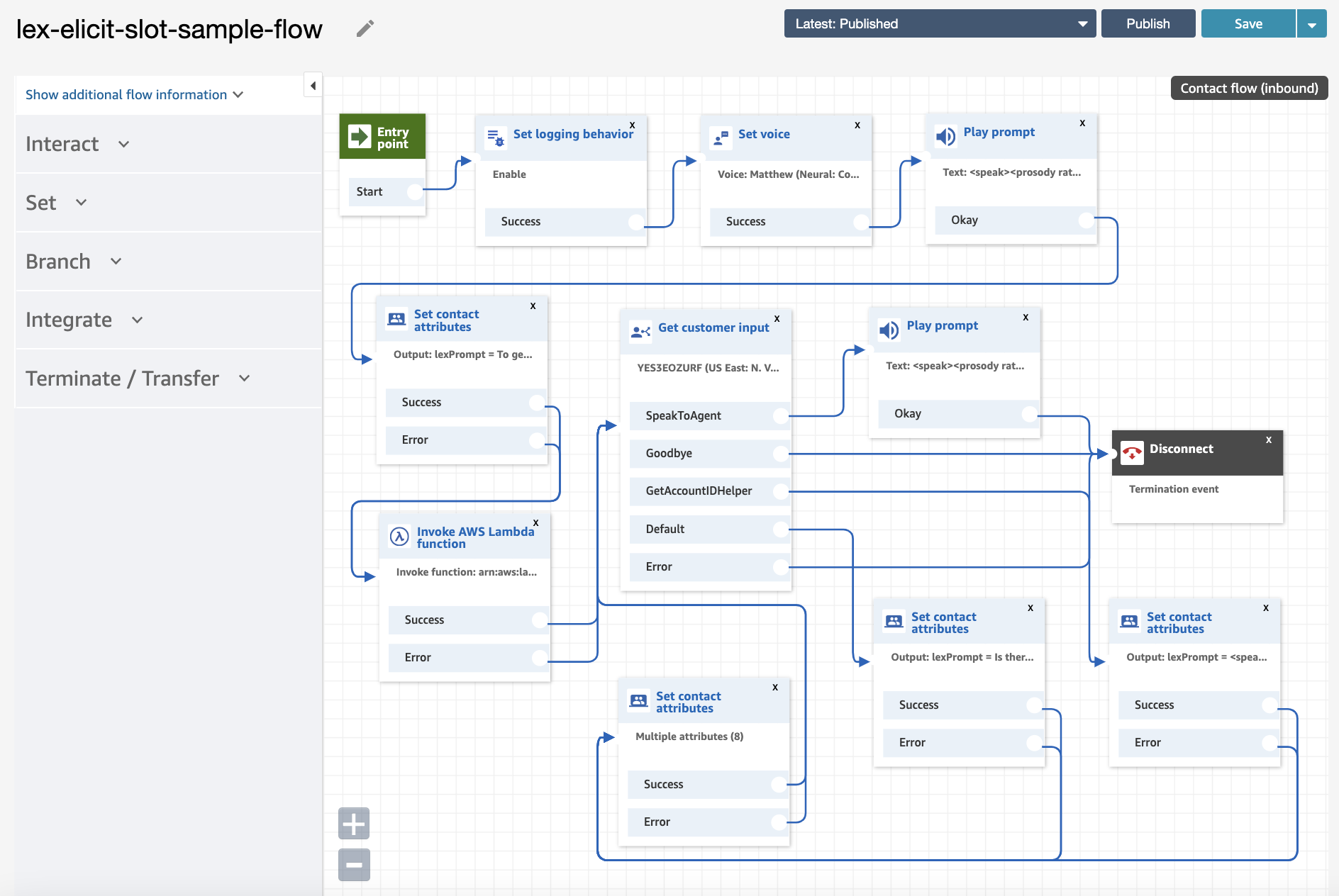



 Brian Yost is a Senior Technical Program manager on the AWS Lex team. In his spare time, he enjoys mountain biking, home brewing, and tinkering with technology.
Brian Yost is a Senior Technical Program manager on the AWS Lex team. In his spare time, he enjoys mountain biking, home brewing, and tinkering with technology.