In our recent paper, we explore how populations of deep reinforcement learning (deep RL) agents can learn microeconomic behaviours, such as production, consumption, and trading of goods. We find that artificial agents learn to make economically rational decisions about production, consumption, and prices, and react appropriately to supply and demand changes.Read More
Emergent Bartering Behaviour in Multi-Agent Reinforcement Learning
In our recent paper, we explore how populations of deep reinforcement learning (deep RL) agents can learn microeconomic behaviours, such as production, consumption, and trading of goods. We find that artificial agents learn to make economically rational decisions about production, consumption, and prices, and react appropriately to supply and demand changes.Read More
Enhance the caller experience with hints in Amazon Lex
We understand speech input better if we have some background on the topic of conversation. Consider a customer service agent at an auto parts wholesaler helping with orders. If the agent knows that the customer is looking for tires, they’re more likely to recognize responses (for example, “Michelin”) on the phone. Agents often pick up such clues or hints based on their domain knowledge and access to business intelligence dashboards. Amazon Lex now supports a hints capability to enhance the recognition of relevant phrases in a conversation. You can programmatically provide phrases as hints during a live interaction to influence the transcription of spoken input. Better recognition drives efficient conversations, reduces agent handling time, and ultimately increases customer satisfaction.
In this post, we review the runtime hints capability and use it to implement verification of callers based on their mother’s maiden name.
Overview of the runtime hints capability
You can provide a list of phrases or words to help your bot with the transcription of speech input. You can use these hints with built-in slot types such as first and last names, street names, city, state, and country. You can also configure these for your custom slot types.
You can use the capability to transcribe names that may be difficult to pronounce or understand. For example, in the following sample conversation, we use it to transcribe the name “Loreck.”
Conversation 1
IVR: Welcome to ACME bank. How can I help you today?
Caller: I want to check my account balance.
IVR: Sure. Which account should I pull up?
Caller: Checking
IVR: What is the account number?
Caller: 1111 2222 3333 4444
IVR: For verification purposes, what is your mother’s maiden name?
Caller: Loreck
IVR: Thank you. The balance on your checking account is 123 dollars.
Words provided as hints are preferred over other similar words. For example, in the second sample conversation, the runtime hint (“Smythe”) is selected over a more common transcription (“Smith”).
Conversation 2
IVR: Welcome to ACME bank. How can I help you today?
Caller: I want to check my account balance.
IVR: Sure. Which account should I pull up?
Caller: Checking
IVR: What is the account number?
Caller: 5555 6666 7777 8888
IVR: For verification purposes, what is your mother’s maiden name?
Caller: Smythe
IVR: Thank you. The balance on your checking account is 456 dollars.
If the name doesn’t match the runtime hint, you can fail the verification and route the call to an agent.
Conversation 3
IVR: Welcome to ACME bank. How can I help you today?
Caller: I want to check my account balance.
IVR: Sure. Which account should I pull up?
Caller: Savings
IVR: What is the account number?
Caller: 5555 6666 7777 8888
IVR: For verification purposes, what is your mother’s maiden name?
Caller: Jane
IVR: There is an issue with your account. For support, you will be forwarded to an agent.
Solution overview
Let’s review the overall architecture for the solution (see the following diagram):
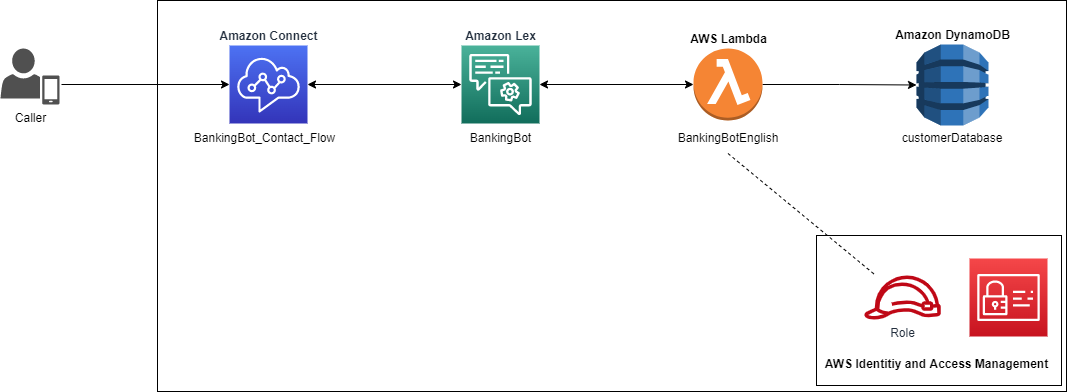
- We use an Amazon Lex bot integrated with an Amazon Connect contact flow to deliver the conversational experience.
- We use a dialog codehook in the Amazon Lex bot to invoke an AWS Lambda function that provides the runtime hint at the previous turn of the conversation.
- For the purposes of this post, the mother’s maiden name data used for authentication is stored in an Amazon DynamoDB table.
- After the caller is authenticated, the control is passed to the bot to perform transactions (for example, check balance)
In addition to the Lambda function, you can also send runtime hints to Amazon Lex V2 using the PutSession, RecognizeText, RecognizeUtterance, or StartConversation operations. The runtime hints can be set at any point in the conversation and are persisted at every turn until cleared.
Deploy the sample Amazon Lex bot
To create the sample bot and configure the runtime phrase hints, perform the following steps. This creates an Amazon Lex bot called BankingBot, and one slot type (accountNumber).
- Download the Amazon Lex bot.
- On the Amazon Lex console, choose Actions, Import.
- Choose the file
BankingBot.zipthat you downloaded, and choose Import. - Choose the bot
BankingBoton the Amazon Lex console. - Choose the language English (GB).
- Choose Build.
- Download the supporting Lambda code.
- On the Lambda console, create a new function and select Author from scratch.
- For Function name, enter
BankingBotEnglish. - For Runtime, choose Python 3.8.
- Choose Create function.
- In the Code source section, open
lambda_function.pyand delete the existing code. - Download the function code and open it in a text editor.
- Copy the code and enter it into the empty function code field.
- Choose deploy.
- On the Amazon Lex console, select the bot
BankingBot. - Choose Deployment and then Aliases, then choose the alias
TestBotAlias. - On the Aliases page, choose Languages and choose English (GB).
- For Source, select the bot
BankingBotEnglish. - For Lambda version or alias, enter
$LATEST. - On the DynamoDB console, choose Create table.
- Provide the name as
customerDatabase. - Provide the partition key as
accountNumber. - Add an item with
accountNumber: “1111222233334444”andmothersMaidenName “Loreck”. - Add item with
accountNumber: “5555666677778888”andmothersMaidenName “Smythe”. - Make sure the Lambda function has permissions to read from the DynamoDB table
customerDatabase. - On the Amazon Connect console, choose Contact flows.
- In the Amazon Lex section, select your Amazon Lex bot and make it available for use in the Amazon Connect contact flow.
- Download the contact flow to integrate with the Amazon Lex bot.
- Choose the contact flow to load it into the application.
- Make sure the right bot is configured in the “Get Customer Input” block.
- Choose a queue in the “Set working queue” block.
- Add a phone number to the contact flow.
- Test the IVR flow by calling in to the phone number.
Test the solution
You can now call in to the Amazon Connect phone number and interact with the bot.
Conclusion
Runtime hints allow you to influence the transcription of words or phrases dynamically in the conversation. You can use business logic to identify the hints as the conversation evolves. Better recognition of the user input allows you to deliver an enhanced experience. You can configure runtime hints via the Lex V2 SDK. The capability is available in all AWS Regions where Amazon Lex operates in the English (Australia), English (UK), and English (US) locales.
To learn more, refer to runtime hints.
About the Authors
 Kai Loreck is a professional services Amazon Connect consultant. He works on designing and implementing scalable customer experience solutions. In his spare time, he can be found playing sports, snowboarding, or hiking in the mountains.
Kai Loreck is a professional services Amazon Connect consultant. He works on designing and implementing scalable customer experience solutions. In his spare time, he can be found playing sports, snowboarding, or hiking in the mountains.
 Anubhav Mishra is a Product Manager with AWS. He spends his time understanding customers and designing product experiences to address their business challenges.
Anubhav Mishra is a Product Manager with AWS. He spends his time understanding customers and designing product experiences to address their business challenges.
 Sravan Bodapati is an Applied Science Manager at AWS Lex. He focuses on building cutting edge Artificial Intelligence and Machine Learning solutions for AWS customers in ASR and NLP space. In his spare time, he enjoys hiking, learning economics, watching TV shows and spending time with his family.
Sravan Bodapati is an Applied Science Manager at AWS Lex. He focuses on building cutting edge Artificial Intelligence and Machine Learning solutions for AWS customers in ASR and NLP space. In his spare time, he enjoys hiking, learning economics, watching TV shows and spending time with his family.
Broom, Broom: WeRide Revs Up Self-Driving Street Sweepers Powered by NVIDIA
When it comes to safety, efficiency and sustainability, autonomous vehicles are delivering a clean sweep.
Autonomous vehicle company and NVIDIA Inception member WeRide this month began a public road pilot of its Robo Street Sweepers. The vehicles, designed to perform round-the-clock cleaning services, are built on the high-performance, energy-efficient compute of NVIDIA.
The fleet of 50 vehicles is sweeping, sprinkling and spraying disinfectant in Guangzhou, China, all without a human driver at the wheel. The robo-sweepers run on a cloud-based fleet management platform that automatically schedules and dispatches vehicles using real-time information on daily traffic and routes.
Street sweeping is a critical municipal service. In addition to keeping dirt and debris off the road, it helps ensure trash and hazardous materials don’t flow into storm drains and pollute local waterways.
As cities grow, applying autonomous driving technology to street cleaning vehicles enables these fleets to run more efficiently and maintain cleaner and healthier public spaces.
Sweep Smarts
While street sweepers typically operate at lower speeds and in more constrained environments than robotaxis, trucks or other autonomous vehicles, they still require robust AI compute to safely operate.
Street cleaning vehicles must be able to drive in dense urban traffic, as well as in low-visibility conditions, such as nighttime and early morning. In addition, they have to detect and classify objects in the road as they clean.
To do so without a human at the wheel, these vehicles must process massive amounts of data from onboard sensors in real time. Redundant and diverse deep neural networks (DNNs) must work together to accurately perceive relevant information from this sensor data.
As a high-performance, software-defined AI compute platform, NVIDIA’s solution is designed to handle the large number of applications and DNNs that run simultaneously in autonomous vehicles, while achieving systemic safety standards.
A Model Lineup
The WeRide Robo Street Sweepers are the latest in the company’s stable of autonomous vehicles and its second purpose-built and mass-produced self-driving vehicle model.
WeRide has been developing autonomous technology on NVIDIA since 2017, building robotaxis, mini robobuses and robovans with the goal of accelerating intelligent urban transportation.
Its robotaxis have already provided more than 350,000 rides for 180,000 passengers since 2019, while its mini robobuses began pilot operations to the public in January.
The company is currently building its next-generation self-driving solutions on NVIDIA DRIVE Orin, using the high-performance AI compute platform to commercialize its autonomous lineup.
And with the addition of these latest vehicles, WeRide’s fleets are set to make a clean sweep.
The post Broom, Broom: WeRide Revs Up Self-Driving Street Sweepers Powered by NVIDIA appeared first on NVIDIA Blog.
Q&A with UIUC professor Lav Varshney, the AI expert behind sustainable concrete collaboration with Meta
For May, we nominated Lav Varshney, an associate professor in the Department of Electrical and Computer Engineering and the Coordinated Science Laboratory at University of […]Read More
Training a Tokenizer for Free with Private Federated Learning
Federated learning with differential privacy, i.e. private federated learning (PFL), makes it possible to train models on private data distributed across users’ devices without harming privacy. PFL is efficient for models, such as neural networks, that have a fixed number of parameters, and thus a fixed-dimensional gradient vector. Such models include neural-net language models, but not tokenizers, the topic of this work. Training a tokenizer requires frequencies of words from an unlimited vocabulary, and existing methods for finding an unlimited vocabulary need a separate privacy budget.
A…Apple Machine Learning Research
Run automatic model tuning with Amazon SageMaker JumpStart
In December 2020, AWS announced the general availability of Amazon SageMaker JumpStart, a capability of Amazon SageMaker that helps you quickly and easily get started with machine learning (ML). In March 2022, we also announced the support for APIs in JumpStart. JumpStart provides one-click fine-tuning and deployment of a wide variety of pre-trained models across popular ML tasks, as well as a selection of end-to-end solutions that solve common business problems. These features remove the heavy lifting from each step of the ML process, making it simpler to develop high-quality models and reducing time to deployment.
In this post, we demonstrate how to run automatic model tuning with JumpStart.
SageMaker automatic model tuning
Traditionally, ML engineers implement a trial and error method to find the right set of hyperparameters. Trial and error involves running multiple jobs sequentially or in parallel while provisioning the resources needed to run the experiment.
With SageMaker automatic model tuning, ML engineers and data scientists can offload the time-consuming task of optimizing their model and let SageMaker run the experimentation. SageMaker takes advantage of the elasticity of the AWS platform to efficiently and concurrently run multiple training simulations on a dataset and find the best hyperparameters for a model.
SageMaker automatic model tuning finds the best version of a model by running many training jobs on your dataset using the algorithm and ranges of hyperparameters that you specify. It then chooses the hyperparameter values that result in a model that performs the best, as measured by a metric that you choose.
Automatic model tuning uses either a Bayesian (default) or a random search strategy to find the best values for hyperparameters. Bayesian search treats hyperparameter tuning like a regression problem. When choosing the best hyperparameters for the next training job, it considers everything that it knows about the problem so far and allows the algorithm to exploit the best-known results.
In this post, we use the default Bayesian search strategy to demonstrate the steps involved in running automatic model tuning with JumpStart using the LightGBM model.
JumpStart currently supports 10 example notebooks with automatic model tuning. It also supports four popular algorithms for tabular data modeling. The tasks and links to their sample notebooks are summarized in the following table.
Solution overview
This technical workflow gives an overview of the different Amazon Sagemaker features and steps needed to automatically tune a JumpStart model.
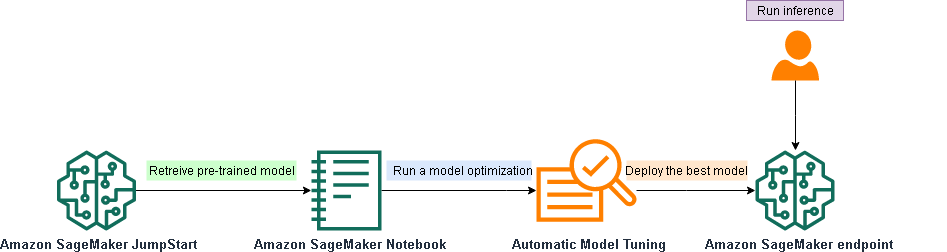
In the following sections, we provide a step-by-step walkthrough of how to run automatic model tuning with JumpStart using the LightGBM algorithm. We provide an accompanying notebook for this walkthrough.
We walk through the following high-level steps:
- Retrieve the JumpStart pre-trained model and images container.
- Set static hyperparameters.
- Define the tunable hyperparameter ranges.
- Initialize the automatic model tuning.
- Run the tuning job.
- Deploy the best model to an endpoint.
Retrieve the JumpStart pre-trained model and images container
In this section, we choose the LightGBM classification model for fine-tuning. We use the ml.m5.xlarge instance type on which the model is run. We then retrieve the training Docker container, the training algorithm source, and the pre-trained model. See the following code:
training_instance_type = "ml.m5.xlarge"
# Retrieve the docker image
train_image_uri = image_uris.retrieve(
region=None,
framework=None,
model_id=train_model_id,
model_version=train_model_version,
image_scope=train_scope,
instance_type=training_instance_type,
)
# Retrieve the training script
train_source_uri = script_uris.retrieve(
model_id=train_model_id, model_version=train_model_version, script_scope=train_scope
)
# Retrieve the pre-trained model tarball to further fine-tune
train_model_uri = model_uris.retrieve(
model_id=train_model_id, model_version=train_model_version, model_scope=train_scope
)
Set static hyperparameters
We now retrieve the default hyperparameters for this LightGBM model, as preconfigured by JumpStart. We also override the num_boost_round hyperparameter with a custom value.
# Retrieve the default hyper-parameters for fine-tuning the model
hyperparameters = hyperparameters.retrieve_default(
model_id=train_model_id, model_version=train_model_version
)
# [Optional] Override default hyperparameters with custom valuesDefine the tunable hyperparameter ranges
Next we define the hyperparameter ranges to be optimized by automatic model tuning. We define the hyperparameter name as expected by the model and then the ranges of values to be tried for this hyperparameter. Automatic model tuning draws samples (equal to the max_jobs parameter) from the space of hyperparameters, using a technique called Bayesian search. For each drawn hyperparameter sample, the tuner creates a training job to evaluate the model with that configuration. See the following code:
hyperparameter_ranges = {
"learning_rate": ContinuousParameter(1e-4, 1, scaling_type="Logarithmic"),
"num_boost_round": IntegerParameter(2, 30),
"early_stopping_rounds": IntegerParameter(2, 30),
"num_leaves": IntegerParameter(10, 50),
"feature_fraction": ContinuousParameter(0, 1),
"bagging_fraction": ContinuousParameter(0, 1),
"bagging_freq": IntegerParameter(1, 10),
"max_depth": IntegerParameter(5, 30),
"min_data_in_leaf": IntegerParameter(5, 50),
}Initialize the automatic model tuning
We start by creating an Estimator object with all the required assets that define the training job, such as the pre-trained model, the training image, and the training script. We then define a HyperparameterTuner object to interact with SageMaker hyperparameter tuning APIs.
The HyperparameterTuner accepts as parameters the Estimator object, the target metric based on which the best set of hyperparameters is decided, the total number of training jobs (max_jobs) to start for the hyperparameter tuning job, and the maximum parallel training jobs to run (max_parallel_jobs). Training jobs are run with the LightGBM algorithm, and the hyperparameter values that has the minimal mlogloss metric is chosen. For more information about configuring automatic model tuning, see Best Practices for Hyperparameter Tuning.
# Create SageMaker Estimator instance
tabular_estimator = Estimator(
role=aws_role,
image_uri=train_image_uri,
source_dir=train_source_uri,
model_uri=train_model_uri,
entry_point="transfer_learning.py",
instance_count=1,
instance_type=training_instance_type,
max_run=360000,
hyperparameters=hyperparameters,
output_path=s3_output_location,
)
tuner = HyperparameterTuner(
estimator=tabular_estimator,
objective_metric_name="multi_logloss",
hyperparameter_ranges=hyperparameter_ranges,
metric_definitions=[{"Name": "multi_logloss", "Regex": "multi_logloss: ([0-9\.]+)"}],
strategy="Bayesian",
max_jobs=10,
max_parallel_jobs=2,
objective_type="Minimize",
base_tuning_job_name=training_job_name,
)In the preceding code, we tell the tuner to run at most 10 experiments (max_jobs) and only two concurrent experiments at a time (max_parallel_jobs). Both of these parameters keep your cost and training time under control.
Run the tuning job
To launch the SageMaker tuning job, we call the fit method of the hyperparameter tuner object and pass the Amazon Simple Storage Service (Amazon S3) path of the training data:
tuner.fit({"training": training_dataset_s3_path}, logs=True)While automatic model tuning searches for the best hyperparameters, you can monitor their progress either on the SageMaker console or on Amazon CloudWatch. When training is complete, the best model’s fine-tuned artifacts are uploaded to the Amazon S3 output location specified in the training configuration.
Deploy the best model to an endpoint
When the tuning job is complete, the best model has been selected and stored in Amazon S3. We now can deploy that model by calling the deploy method of the HyperparameterTuner object and passing the needed parameters, such as the number of instances to be used for the created endpoint, their type, the image to be deployed, and the script to run:
tuner.deploy(
initial_instance_count=1,
instance_type=inference_instance_type,
entry_point="inference.py",
image_uri=deploy_image_uri,
source_dir=deploy_source_uri,
endpoint_name=endpoint_name,
enable_network_isolation=True
)We can now test the created endpoint by making inference requests. You can follow the rest of the process in the accompanying notebook.
Conclusion
With automatic model tuning in SageMaker, you can find the best version of your model by running training jobs on the provided dataset with one of the supported algorithms. Automatic model tuning allows you to reduce the time to tune a model by automatically searching for the best hyperparameter configuration within the hyperparameter ranges that you specify.
In this post, we showed the value of running automatic model tuning on a JumpStart pre-trained model using SageMaker APIs. We used the LightGBM algorithm and defined a maximum of 10 training jobs. We also provided links to example notebooks showcasing the ML frameworks that support JumpStart model optimization.
For more details on how to optimize a JumpStart model with automatic model tuning, refer to our example notebook.
About the Author
 Doug Mbaya is a Senior Partner Solution architect with a focus in data and analytics. Doug works closely with AWS partners, helping them integrate data and analytics solution in the cloud.
Doug Mbaya is a Senior Partner Solution architect with a focus in data and analytics. Doug works closely with AWS partners, helping them integrate data and analytics solution in the cloud.
 Kruthi Jayasimha Rao is a Partner Solutions Architect in the Scale-PSA team. Kruthi conducts technical validations for Partners enabling them progress in the Partner Path.
Kruthi Jayasimha Rao is a Partner Solutions Architect in the Scale-PSA team. Kruthi conducts technical validations for Partners enabling them progress in the Partner Path.
 Giannis Mitropoulos is a Software Development Engineer for SageMaker Automatic Model Tuning.
Giannis Mitropoulos is a Software Development Engineer for SageMaker Automatic Model Tuning.
 Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He is an active researcher in machine learning and statistical inference and has published many papers in NeurIPS, ICML, ICLR, JMLR, and ACL conferences.
Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He is an active researcher in machine learning and statistical inference and has published many papers in NeurIPS, ICML, ICLR, JMLR, and ACL conferences.
Image classification and object detection using Amazon Rekognition Custom Labels and Amazon SageMaker JumpStart
In the last decade, computer vision use cases have been a growing trend, especially in industries like insurance, automotive, ecommerce, energy, retail, manufacturing, and others. Customers are building computer vision machine learning (ML) models to bring operational efficiencies and automation to their processes. Such models help automate the classification of images or detection of objects of interest in images that are specific and unique to your business.
To simplify the ML model building process, we introduced Amazon SageMaker JumpStart in December 2020. JumpStart helps you quickly and easily get started with ML. It provides one-click deployment and fine-tuning of a wide variety of pre-trained models, as well as a selection of end-to-end solutions. This removes the heavy lifting from each step of the ML process, making it easier to develop high-quality models and reducing time to deployment. However, it requires you to have some prior knowledge to help in model selection from a catalog of over 200 pre-trained computer vision models. You then have to benchmark the model performance with different hyperparameter settings and select the best model to be deployed in production.
To simplify this experience and allow developers with little to no ML expertise to build custom computer vision models, we’re releasing a new example notebook within JumpStart that uses Amazon Rekognition Custom Labels, a fully managed service to build custom computer vision models. Rekognition Custom Labels builds off of the pre-trained models in Amazon Rekognition, which are already trained on tens of millions of images across many categories. Instead of thousands of images, you can get started with a small set of training images (a few hundred or less) that are specific to your use case. Rekognition Custom Labels abstracts away the complexity involved in building a custom model. It automatically inspects the training data, selects the right ML algorithms, selects the instance type, trains multiple candidate models with different hyperparameters, and outputs the best trained model. Rekognition Custom Labels also provides an easy-to-use interface from the AWS Management Console for the entire ML workflow, including labeling images, training, deploying a model, and visualizing the test results.
This example notebook within JumpStart using Rekognition Custom Labels solves any image classification or object detection computer vision ML task, making it easy for customers familiar with Amazon SageMaker to build a computer vision solution that best fits your use case, requirements, and skillset.
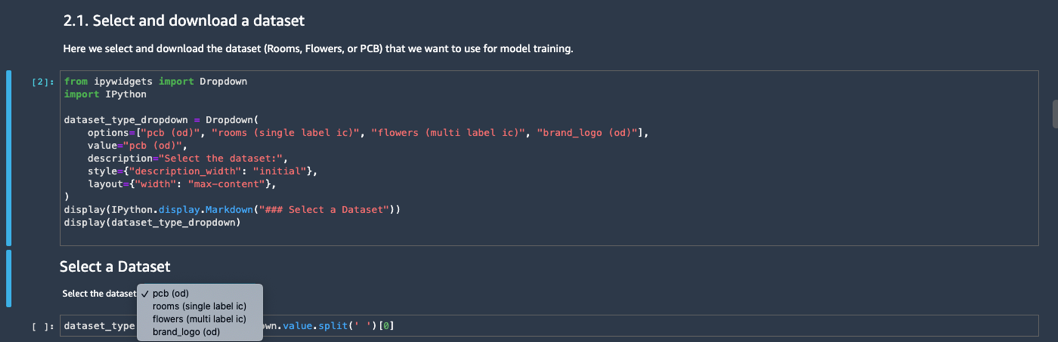
In this post, we provide step-by-step directions to use this example notebook within JumpStart. The notebook demonstrates how to easily use Rekognition Custom Labels existing training and inference APIs to create an image classification model, a multi-label classification model, and an object detection model. To make it easy for you to get started, we have provided example datasets for each model.
Train and deploy a computer vision model using Rekognition Custom Labels
In this section, we locate the desired notebook in JumpStart, and demonstrate how to train and run inference on the deployed endpoint.
Let’s start from the Amazon SageMaker Studio Launcher.
- On the Studio Launcher, choose Go to SageMaker JumpStart.

The JumpStart landing page has sections for carousels for solutions, text models, and vision models. It also has a search bar. - In the search bar, enter
Rekognition Custom Labelsand choose the Rekognition Custom Labels for Vision notebook.

The notebook opens in read-only mode. - Choose Import Notebook to import the notebook into your environment.

The notebook provides a step-by-step guide for training and running inference using Rekognition Custom Labels from the JumpStart console. It provides the following four sample datasets to demonstrate single- and multi-label image classification and object detection.
-
-
Single-label image classification – This dataset demonstrates how to classify images as belonging to one of a set of predefined labels. For example, real estate companies can use Rekognition Custom Labels to categorize their images of living rooms, backyards, bedrooms, and other household locations. The following is a sample image from this dataset, which is included as part of the notebook.

-
Multi-label image classification – This dataset demonstrates how to classify images into multiple categories, such as the color, size, texture, and type of a flower. For example, plant growers can use Rekognition Custom Labels to distinguish between different types of flowers and if they are healthy, damaged, or infected. The following image is an example from this dataset.

-
Object detection – This dataset demonstrates object localization to locate parts used in production or manufacturing lines. For example, in the electronics industry, Rekognition Custom Labels can help count the number of capacitors on a circuit board. The following image is an example from this dataset.

-
Brand and logo detection – This dataset demonstrates locating logos or brands in an image. For example, in the media industry, an object detection model can help identify the location of sponsor logos in photographs. The following is a sample image from this dataset.
-
Single-label image classification – This dataset demonstrates how to classify images as belonging to one of a set of predefined labels. For example, real estate companies can use Rekognition Custom Labels to categorize their images of living rooms, backyards, bedrooms, and other household locations. The following is a sample image from this dataset, which is included as part of the notebook.
- Follow the steps in the notebook by running each cell.
This notebook demonstrates how you can use a single notebook to address both image classification and object detection use cases via the Rekognition Custom label APIs.
As you proceed with the notebook, you have the option to select one of the aforementioned sample datasets. We encourage you to try running the notebook for each of the datasets.
Conclusion
In this post, we showed you how to use the Rekognition Custom Labels APIs to build an image classification or an object detection computer vision model to classify and identify objects in images that are specific to your business needs. To train a model, you can get started by providing tens to hundreds of labeled images instead of thousands. Rekognition Custom Labels simplifies the model training by taking care of parameter choices such as such as machine type, algorithm type, or algorithm-specific hyperparameters (including the number of layers in the network, learning rate, and batch size). Rekognition Custom Labels also simplifies hosting of a trained model and provides a simple operation for performing inference with a trained model.
Rekognition Custom Labels provides an easy-to-use console experience for the training process, model management, and visualization of dataset images. We encourage you learn more about Rekognition Custom Labels and try it out with your business-specific datasets.
To get started, you can navigate to the Rekognition Custom Labels example notebook in SageMaker JumpStart.
About the Authors
 Pashmeen Mistry is the Senior Product Manager for Amazon Rekognition Custom Labels. Outside of work, Pashmeen enjoys adventurous hikes, photography, and spending time with his family.
Pashmeen Mistry is the Senior Product Manager for Amazon Rekognition Custom Labels. Outside of work, Pashmeen enjoys adventurous hikes, photography, and spending time with his family.
 Abhishek Gupta is the Senior AI Services Solution Architect at AWS. He helps customers design and implement computer vision solutions.
Abhishek Gupta is the Senior AI Services Solution Architect at AWS. He helps customers design and implement computer vision solutions.
Intelligently search your Jira projects with Amazon Kendra Jira cloud connector
Organizations use agile project management platforms such as Atlassian Jira to enable teams to collaborate to plan, track, and ship deliverables. Jira captures organizational knowledge about the workings of the deliverables in the issues and comments logged during project implementation. However, making this knowledge easily and securely available to users is challenging due to it being fragmented across issues belonging to different projects and sprints. Additionally, because different stakeholders such as developers, test engineers, and project managers contribute to the same issue by logging it and then adding attachments and comments, traditional keyword-based search is rendered ineffective when searching for information in Jira projects.
You can now use the Amazon Kendra Jira cloud connector to index issues, comments, and attachments in your Jira projects, and search this content using Amazon Kendra intelligent search, powered by machine learning (ML).
This post shows how to use the Amazon Kendra Jira cloud connector to configure a Jira cloud instance as a data source for an Amazon Kendra index, and intelligently search the contents of the projects in it. We use an example of Jira projects where team members collaborate by creating issues and adding information to them in the form of descriptions, comments, and attachments throughout the issue lifecycle.
Solution overview
A Jira instance has one or more projects, where each project has team members working on issues in that project. Each team member has set of permissions about the operations they can perform with respect to different issues in the project they belong to. Team members can create new issues, or add more information to the issues in the form of attachments and comments, as well as change the status of an issue from its opening to closure throughout the issue lifecycle defined for that project. A project manager creates sprints, assigns issues to specific sprints, and assigns owners to issues. During the course of the project, the knowledge captured in these issues keeps evolving.
In our solution, we configure a Jira cloud instance as a data source to an Amazon Kendra search index using the Amazon Kendra Jira connector. Based on the configuration, when the data source is synchronized, the connector crawls and indexes the content from the projects in the Jira instance. Optionally, you can configure it to index the content based on the change log. The connector also collects and ingests access control list (ACL) information for each issue, comment, and attachment. The ACL information is used for user context filtering, where search results for a query are filtered by what a user has authorized access to.
Prerequisites
To try out the Amazon Kendra connector for Jira using this post as a reference, you need the following:
- An AWS account with privileges to create AWS Identity and Access Management (IAM) roles and policies. For more information, see Overview of access management: Permissions and policies and policies for Jira data sources.
- Basic knowledge of AWS and working knowledge of Jira administration.
- Admin access to a Jira cloud instance.
Jira instance configuration
This section describes the Jira configuration used to demonstrate how to configure an Amazon Kendra data source using the Jira connector, ingest the data from the Jira projects into the Amazon Kendra index, and make search queries. You can use your own Jira instance for which you have admin access or create a new project and carry out the steps to try out the Amazon Kendra connector for Jira.
In our example Jira instance, we created two projects to demonstrate that the search queries made by users return results from only the projects to which they have access. We used data from the following public domain projects to simulate the use case of real-life software development projects:
- AWS CLI Community Contributions GitHub project
- A project from the popular Deep Learning Library PyTorch

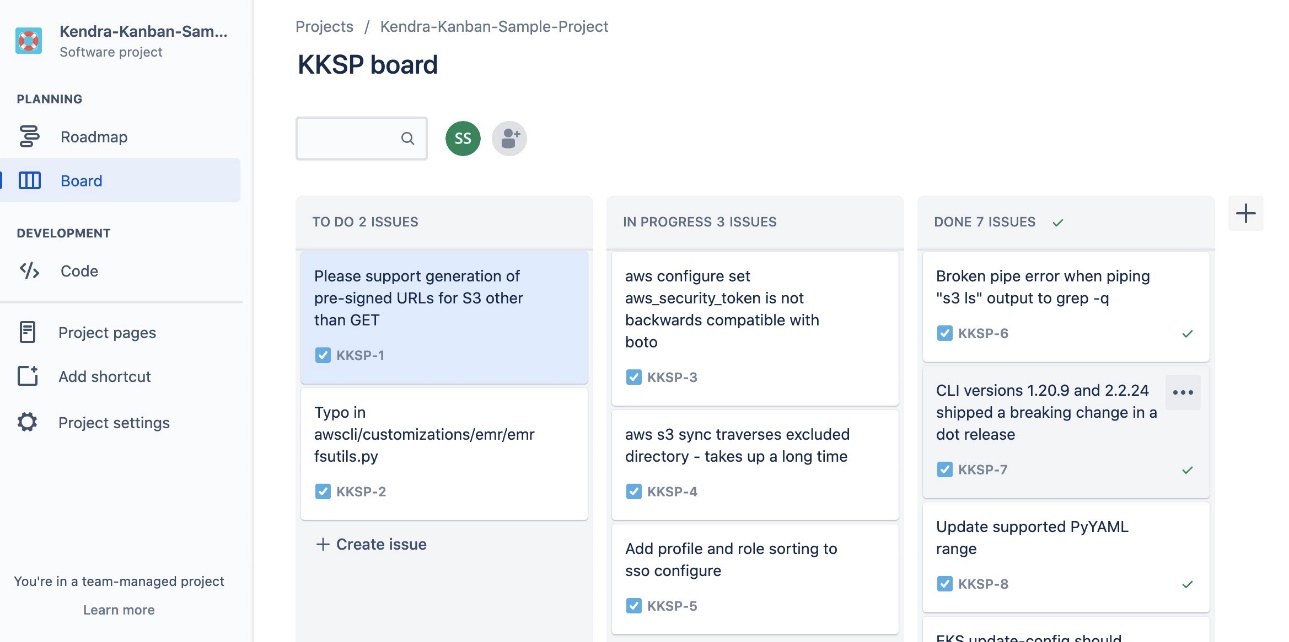
The following is a screenshot of our Kanban-style board for project 1.
Create an API token for the Jira instance
To get the API token needed to configure the Amazon Kendra Jira connector, complete the following steps:
- Log in to https://id.atlassian.com/manage/api-tokens.
- Choose Create API token.
- In the dialog box that appears, enter a label for your token and choose Create.
- Choose Copy and enter the token on a temporary notepad.
You can’t copy this token again, and you need it to configure the Amazon Kendra Jira connector.
Configure the data source using the Amazon Kendra connector for Jira
To add a data source to your Amazon Kendra index using the Jira connector, you can use an existing index or create a new index. Then complete the following steps. For more information on this topic, refer to Amazon Kendra Developer Guide.
- On the Amazon Kendra console, open your index and choose Data sources in the navigation pane.
- Choose Add data source.
- Under Jira, choose Add connector.

- In the Specify data source details section, enter the details of your data source and choose Next.
- In the Define access and security section, for Jira Account URL, enter the URL of your Jira cloud instance.
- Under Authentication, you have two options:
- Choose Create to add a new secret using the Jira API token you copied from your Jira instance and use the email address used to log in to Jira as the Jira ID. (This is the option we choose for this post.)
- Use an existing AWS Secrets Manager secret that has the API token for the Jira instance you want the connector to access.
- For IAM role, choose Create a new role or choose an existing IAM role configured with appropriate IAM policies to access the Secrets Manager secret, Amazon Kendra index, and data source.

- Choose Next.

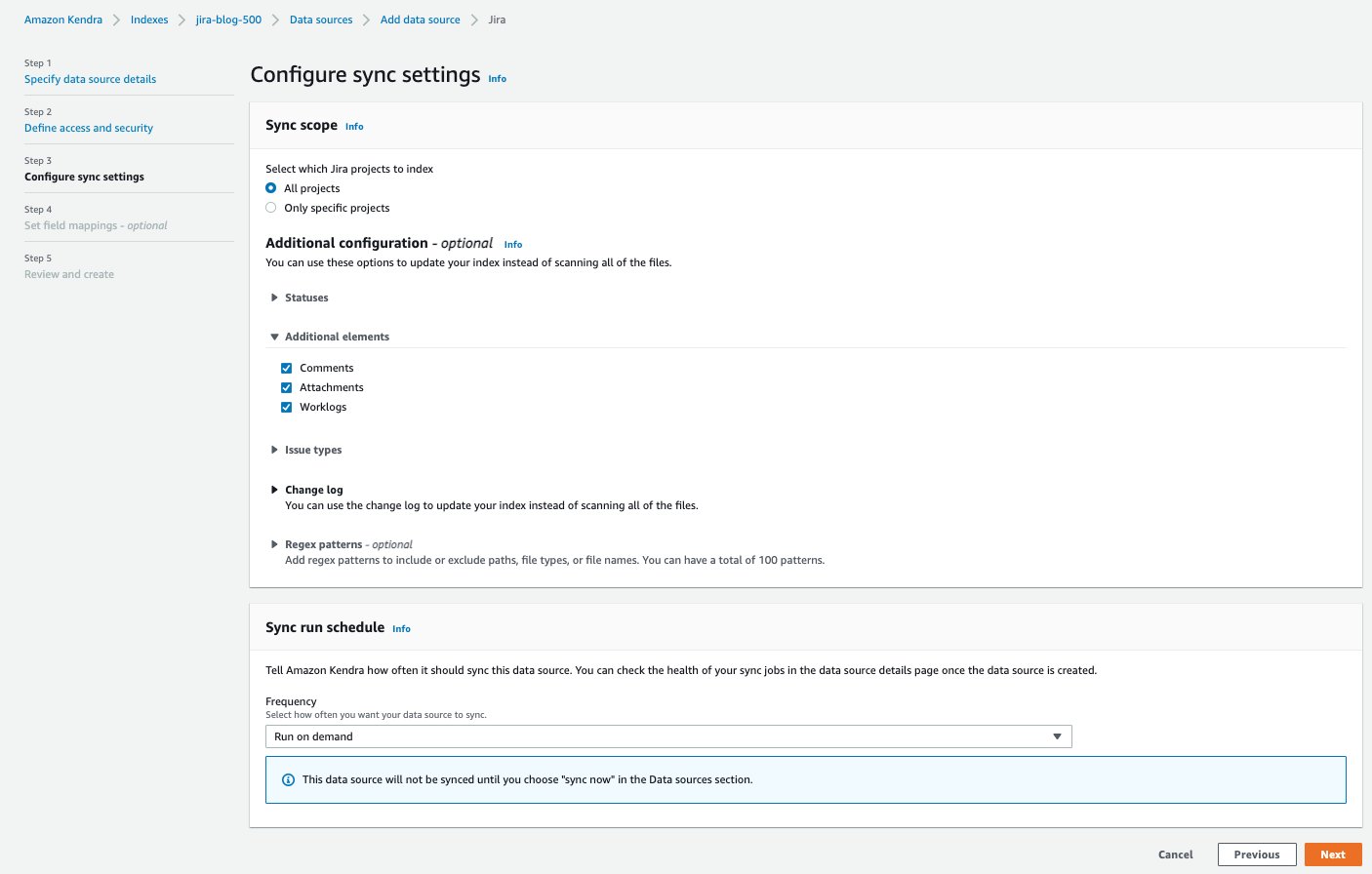
- In the Configure sync settings section, provide information about your sync scope and run schedule.
- Choose Next.
- In the Set field mappings section, you can optionally configure the field mappings, or how the Jira field names are mapped to Amazon Kendra attributes or facets.
- Choose Next.
- Review your settings and confirm to add the data source.
- After the data source is added, choose Data sources in the navigation pane, select the newly added data source, and choose Sync now to start data source synchronization with the Amazon Kendra index.
The sync process can take about 10–15 minutes. Let’s now enable access control for the Amazon Kendra index. - In the navigation pane, choose your index.
- In the middle pane, choose the User access control tab.
- Choose Edit settings and change the settings to look like the following screenshot.
- Choose Next and then choose Update.

Perform intelligent search with Amazon Kendra
Before you try searching on the Amazon Kendra console or using the API, make sure that the data source sync is complete. To check, view the data sources and verify if the last sync was successful.

- To start your search, on the Amazon Kendra console, choose Search indexed content in the navigation pane.
You’re redirected to the Amazon Kendra Search console. - Expand Test query with an access token and choose Apply token.

- For Username, enter the email address associated with your Jira account.
- Choose Apply.

Now we’re ready to search our index. Let’s use the query “where does boto3 store security tokens?”

In this case, Kendra provides a suggested answer from one of the cards in our Kanban project on Jira.
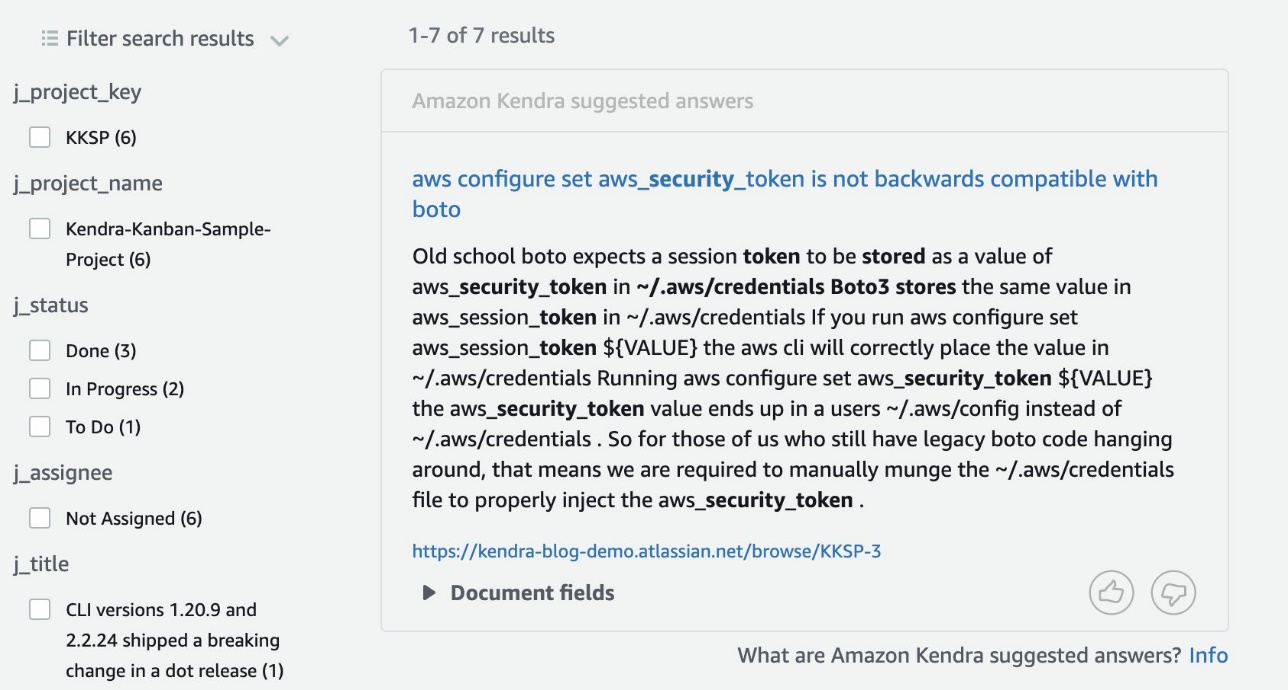
Note that this is also a suggested answer pointing to an issue discussing AWS security tokens and Boto3. You may also build search experience with multiple data sources including SDK documentation and wikis with Amazon Kendra, and present results and related links accordingly. The following screenshot shows another search query made against the same index.

Note that when we apply a different access token (associate the search with a different user), the search results are restricted to projects that this user has access to.

Lastly, we can also use filters relevant to Jira in our search. First, we navigate to our index’s Facet definition page and check Facetable for j_status, j_assignee, and j_project_name. For every search, we can then filter by these fields, as shown in the following screenshot.

Clean up
To avoid incurring future costs, clean up the resources you created as part of this solution. If you created a new Amazon Kendra index while testing this solution, delete it. If you only added a new data source using the Amazon Kendra connector for Jira, delete that data source.
Conclusion
With the Amazon Kendra Jira connector, your organization can make invaluable knowledge in your Jira projects available to your users securely using intelligent search powered by Amazon Kendra.
To learn more about the Amazon Kendra Jira connector, refer to the Amazon Kendra Jira connector section of the Amazon Kendra Developer Guide.
For more information on other Amazon Kendra built-in connectors to popular data sources, refer to Unravel the knowledge in Slack workspaces with intelligent search using the Amazon Kendra Slack connector and Search for knowledge in Quip documents with intelligent search using the Quip connector for Amazon Kendra.
About the Authors
 Shreyas Subramanian is an AI/ML specialist Solutions Architect, and helps customers by using Machine Learning to solve their business challenges on the AWS Cloud.
Shreyas Subramanian is an AI/ML specialist Solutions Architect, and helps customers by using Machine Learning to solve their business challenges on the AWS Cloud.
 Abhinav Jawadekar is a Principal Solutions Architect focused on Amazon Kendra in the AI/ML language services team at AWS. Abhinav works with AWS customers and partners to help them build intelligent search solutions on AWS.
Abhinav Jawadekar is a Principal Solutions Architect focused on Amazon Kendra in the AI/ML language services team at AWS. Abhinav works with AWS customers and partners to help them build intelligent search solutions on AWS.
The Intel®3D Athlete Tracking (3DAT) scalable architecture deploys pose estimation models using Amazon Kinesis Data Streams and Amazon EKS
This blog post is co-written by Jonathan Lee, Nelson Leung, Paul Min, and Troy Squillaci from Intel.
In Part 1 of this post, we discussed how Intel®3DAT collaborated with AWS Machine Learning Professional Services (MLPS) to build a scalable AI SaaS application. 3DAT uses computer vision and AI to recognize, track, and analyze over 1,000 biomechanics data points from standard video. It allows customers to create rich and powerful biomechanics-driven products, such as web and mobile applications with detailed performance data and three-dimensional visualizations.
In Part 2 of this post, we dive deeper into each stage of the architecture. We explore the AWS services used to meet the 3DAT design requirements, including Amazon Kinesis Data Streams and Amazon Elastic Kubernetes Service (Amazon EKS), in order to scalably deploy the necessary pose estimation models for this software as a service (SaaS) application.
Architecture overview
The primary goal of the MLPS team was to productionalize the 2D and 3D pose estimation model pipelines and create a functional and scalable application. The following diagram illustrates the solution architecture.

The complete architecture is broken down into five major components:
- User application interface layers
- Database
- Workflow orchestration
- Scalable pose estimation inference generation
- Operational monitoring
Let’s go into detail on each component, their interactions, and the rationale behind the design choices.
User application interface layers
The following diagram shows the application interface layers that provide user access and control of the application and its resources.

These access points support different use cases based on different customer personas. For example, an application user can submit a job via the CLI, whereas a developer can build an application using the Python SDK and embed pose estimation intelligence into their applications. The CLI and SDK are built as modular components—both layers are wrappers of the API layer, which is built using Amazon API Gateway to resolve the API calls and associated AWS Lambda functions, which take care of the backend logic associated with each API call. These layers were a crucial component for the Intel OTG team because it opens up a broad base of customers that can effectively use this SaaS application.
API layer
The solution has a core set of nine APIs, which correspond to the types of objects that operate on this platform. Each API has a Python file that defines the API actions that can be run. The creation of new objects is automatically assigned an object ID sequentially. The attributes of these objects are stored and tracked in the Amazon Aurora Serverless database using this ID. Therefore, the API actions tie back to functions that are defined in a central file that contains the backend logic for querying the Aurora database. This backend logic uses the Boto3 Amazon RDS DataService client to access the database cluster.
The one exception is the /job API, which has a create_job method that handles video submission for creating a new processing job. This method starts the AWS Step Functions workflow logic for running the job. By passing in a job_id, this method uses the Boto3 Step Functions client to call the start_execution method for a specified stateMachineARN (Amazon Resource Name).
The eight object APIs have the methods and similar access pattern as summarized in the following table.
| Method Type | Function Name | Description |
| GET | list_[object_name]s |
Selects all objects of this type from the database and displays. |
| POST | create_[object] |
Inserts a new object record with required inputs into the database. |
| GET | get_[object] |
Selects object attributes based on the object ID from the database and displays. |
| PUT | update_[object] |
Updates an existing object record with the required inputs. |
| DELETE | delete_[object] |
Deletes an existing object record from the database based on object ID. |
The details of the nine APIs are as follows:
- /user – A user is the identity of someone authorized to submit jobs to this application. The creation of a user requires a user name, user email, and group ID that the user belongs to.
- /user_group – A user group is a collection of users. Every user group is mapped to one project and one pipeline parameter set. To have different tiers (in terms of infrastructural resources and pipeline parameters), users are divided into user groups. Each user can belong to only one user group. The creation of a user group requires a project ID, pipeline parameter set ID, user group name, and user group description. Note that user groups are different from user roles defined in the AWS account. The latter is used to provide different level of access based on their access roles (for example admin).
-
/project – A project is used to group different sets of infrastructural resources together. A project is associated with a single
project_cluster_url(Aurora cluster) for recording users, jobs, and other metadata, aproject_queue_arn(Kinesis Data Streams ARN), and a compute runtime environment (currently controlled via Cortex) used for running inference on the frame batches or postprocessing on the videos. Each user group is associated to one project, and this mechanism is how different tiers are enabled in terms of latency and compute power for different groups of users. The creation of a project requires a project name, project cluster URL, and project queue ARN. - /pipeline – A pipeline is associated with a single configuration for a sequence of processing containers that perform video processing in the Amazon EKS inference generation cluster coordinated by Cortex (see the section on video processing inference generation for more details). Typically, this consists of three containers: preprocessing and decoding, object detection, and pose estimation. For example, the decode and object detection step are the same for the 2D and 3D pipelines, but swapping out the last container using either HRNet or 3DMPPE results in the parameter set for 2D vs. 3D processing pipelines. You can create new configurations to define possible pipelines that can be used for processing, and it requires as input a new Python file in the Cortex repo that details the sequence of model endpoints call that define that pipeline (see the section on video processing inference generation). The pipeline endpoint is the Cortex endpoint that is called to process a single frame. The creation of a pipeline requires a pipeline name, pipeline description, and pipeline endpoint.
- /pipeline_parameter_set – A pipeline parameter set is a flexible JSON collection of multiple parameters (a pipeline configuration runtime) for a particular pipeline, and is added to provide flexibility for future customization when multiple pipeline configuration runtimes are required. User groups can be associated with a particular pipeline parameter set, and its purpose is to have different groups of parameters per user group and per pipeline. This was an important forward-looking addition for Intel OTG to build in customization that supports portability as different customers, particularly ISVs, start using the application.
- /pipeline_parameters – A single collection of pipeline parameters is an instantiation of a pipeline parameter set. This makes it a 1:many mapping of a pipeline parameter set to pipeline parameters. This API requires a pipeline ID to associate with the set of pipeline parameters that enables the creation of a pipeline for a 1:1 mapping of pipeline parameters to the pipeline. The other inputs required by this API are a pipeline parameter set ID, pipeline parameters value, and pipeline parameters name.
-
/video – A video object is used to define individual videos that make up a .zip package submitted during a job. This file is broken up into multiple videos after submission. A video is related to the
job_idfor the job where the .zip package is submitted, and Amazon Simple Storage Service (Amazon S3) paths for the location of the raw separated videos and the postprocessing results of each video. The video object also contains a video progress percentage, which is consistently updated during processing of individual frame batches of that video, as well as a video status flag for complete or not complete. The creation of a video requires a job ID, video path, video results path, video progress percentage, and video status. -
/frame_batch – A
frame_batchobject is a mini-batch of frames created by sampling a single video. Separating a video into regular-sized frame batches provides a lever to tune latency and increases parallelization and throughput. This is the granular unit that is run through Kinesis Data Streams for inference. A creation of a frame batch requires a video ID, frame batch start number, frame batch end number, frame batch input path, frame batch results path, and frame batch status. -
/job – This interaction API is used for file submission to start a processing job. This API has a different function from other object APIs because it’s the direct path to interact with the video processing backend Step Functions workflow coordination and Amazon EKS cluster. This API requires a user ID, project ID, pipeline ID, pipeline parameter set ID, job parameters, and job status. In the job parameters, an input file path is specified, which is the location in Amazon S3 where the .zip package of videos to be processed is located. File upload is handled with the
upload_handlermethod, which generates a presigned S3 URL for the user to place a file. A WORKFLOW_STATEMACHINE_ARN is an environment variable that is passed to thecreate_jobAPI to specify where a video .zip package with an input file path is submitted to start a job.
The following table summarizes the API’s functions.
| Method Type | Function | Description |
| GET | list_jobs |
Selects all jobs from the database and displays. |
| POST | create_ job |
Inserts a new job record with user ID, project ID, pipeline ID, pipeline parameter set ID, job results path, job parameters, and job status. |
| GET | get_ job |
Selects job attributes based on job ID from the database and displays. |
| GET | upload_handler |
Generates a presigned S3 URL as the location for the .zip file upload. Requires an S3 bucket name and expects an application/zip file type. |
Python SDK layer
Building upon the APIs, the team created a Python SDK client library as a wrapper to make it easier for developers to access the API methods. They used the open-source Poetry, which handles Python packaging and dependency management. They created a client.py file that contains functions wrapping each of the APIs using the Python requests library to handle API requests and exceptions.
For developers to launch the Intel 3DAT SDK, they need to install and build the Poetry package. Then, they can add a simple Python import of intel_3dat_sdk to any Python code.
To use the client, you can create an instance of the client, specifying the API endpoint:
You can then use the client to call the individual methods such as the create_pipeline method (see the following code), taking in the proper arguments such as pipeline name and pipeline description.
CLI layer
Similarly, the team built on the APIs to create a command line interface for users who want to access the API methods with a straightforward interface without needing to write Python code. They used the open-source Python package Click (Command Line Interface Creation Kit). The benefits of this framework are the arbitrary nesting of commands, automatic help page generation, and support of lazy loading of subcommands at runtime. In the same client.py file as in the SDK, each SDK client method was wrapped using Click and the required method arguments were converted to command line flags. The flag inputs are then used when calling the SDK command.
To launch the CLI, you can use the CLI configure command. You’re prompted for the endpoint URL:
Now you can use the CLI to call different commands related to the API methods, for example:
Database
As a database, this application uses Aurora Serverless to store metadata associated with each of the APIs with MYSQL as the database engine. Choosing the Aurora Serverless database service adheres to the design principle to minimize infrastructural overhead by utilizing serverless AWS services when possible. The following diagram illustrates this architecture.
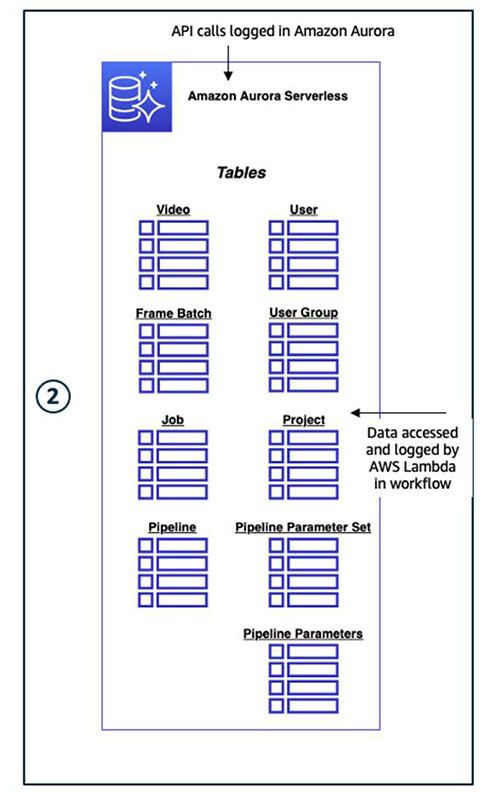
The serverless engine mode meets the intermittent usage pattern because this application scales up to new customers and workloads are still uncertain. When launching a database endpoint, a specific DB instance size isn’t required, only a minimum and maximum range for cluster capacity. Aurora Serverless handles the appropriate provisioning of a router fleet and distributes the workload amongst the resources. Aurora Serverless automatically performs backup retention for a minimum of 1 day up to 35 days. The team optimized for safety by setting the default to the maximum value of 35.
In addition, the team used the Data API to handle access to the Aurora Serverless cluster, which doesn’t require a persistent connection, and instead provides a secure HTTP endpoint and integration with AWS SDKs. This feature uses AWS Secrets Manager to store the database credentials so there is no need to explicitly pass credentials. CREATE TABLE scripts were written in .sql files for each of the nine tables that correspond to the nine APIs. Because this database contained all the metadata and state of objects in the system, the API methods were run using the appropriate SQL commands (for example select * from Job for the list_jobs API) and passed to the execute_statement method from the Amazon RDS client in the Data API.
Workflow orchestration
The functional backbone of the application was handled using Step Functions to coordinate the workflow, as shown in the following diagram.

The state machine consisted of a sequence of four Lambda functions, which starts when a job is submitted using the create_job method from the job API. The user ID, project ID, pipeline ID, pipeline parameter set ID, job results path, job parameters, and job status are required for job creation. You can first upload a .zip package of video files using the upload_handler method from the job API to generate a presigned S3 URL. During job submission, the input file path is passed via the job parameters, to specify the location of the file. This starts the run of the workflow state machine, triggering four main steps:
- Initializer Lambda function
- Submitter Lambda function
- Completion Check Lambda function
- Collector Lambda function
Initializer Lambda function
The main function of the Initializer is to separate the .zip package into individual video files and prepare them for the Submitter. First, the .zip file is downloaded, and then each individual file, including video files, is unzipped and extracted. The videos, preferably in .mp4 format, are uploaded back into an S3 bucket. Using the create_video method in the video API, a video object is created with the video path as input. This inserts data on each video into the Aurora database. Any other file types, such as JSON files, are considered metadata and similarly uploaded, but no video object is created. A list of the names of files and video files extracted is passed to the next step.
Submitter Lambda function
The Submitter function takes the video files that were extracted by the Initializer and creates mini-batches of video frames as images. Most current computer vision models in production have been trained on images so even when video is processed, they’re first separated into image frames before model inference. This current solution using a state-of-the-art pose estimation model is no different—the frame batches from the Submitter are passed to Kinesis Data Streams to initiate the inference generation step.
First, the video file is downloaded by the Lambda function. The frame rate and number of frames is calculated using the FileVideoStream module from the imutils.video processing library. The frames are extracted and grouped according to a specified mini-batch size, which is one of the key tunable parameters of this pipeline. Using the Python pickle library, the data is serialized and uploaded to Amazon S3. Subsequently, a frame batch object is created and the metadata entry is created in the Aurora database. This Lambda function was built using a Dockerfile with dependencies on opencv-python, numpy, and imutils libraries.
Completion Check Lambda function
The Completion Check function continues to query the Aurora database to see, for each video in the .zip package for this current job, how many frame batches are in the COMPLETED status. When all frame batches for all videos are complete, then this check process is complete.
Collector Lambda function
The Collector function takes the outputs of the inferences that were performed on each frame during the Consumer stage and combines them across a frame batch and across a video. The combined merged data is then upload to an S3 bucket. The function then invokes the Cortex postprocessing API for a particular ML pipeline in order to perform any postprocessing computations, and adds the aggregated results by video to the output bucket. Many of these metrics are calculated across frames, such as speed, acceleration, and joint angle, so this calculation needs to be performed on the aggregated data. The main outputs include body key points data (aggregated into CSV format), BMA calculations (such as acceleration), and visual overlay of key points added to each frame in an image file.
Scalable pose estimation inference generation
The processing engine that powers the scaling of ML inference happens in this stage. It involves three main pieces, each with have their own concurrency levers that can be tuned for latency tradeoffs (see the following diagram).

This architecture allows for experimentation in testing latency gains, as well as flexibility for the future when workloads may change with different mixes of end-user segments that access the application.
Kinesis Data Streams
The team chose Kinesis Data Streams because it’s typically used to handle streaming data, and in this case is a good fit because it can handle frame batches in a similar way to provide scalability and parallelization. In the Submitter Lambda function, the Kinesis Boto3 client is used, with the put_record method passing in the metadata associated with a single frame batch, such as the frame batch ID, frame batch starting frame, frame batch ending frame, image shape, frame rate, and video ID.
We defined various job queue and Kinesis data stream configurations to set levels of throughput that tie back to the priority level of different user groups. Access to different levels of processing power is linked by passing a project queue ARN when creating a new project using the project API. Every user group is then linked to a particular project during user group creation. Three default stream configurations are defined in the AWS Serverless Application Model (AWS SAM) infrastructure template:
-
Standard –
JobStreamShardCount -
Priority –
PriorityJobStreamShardCount -
High priority –
HighPriorityJobStreamShardCount
The team used a few different levers to differentiate the processing power of each stream or tune the latency of the system, as summarized in the following table.
| Lever | Description | Default value |
| Shard | A shard is native to Kinesis Data Streams; it’s the base unit of throughput for ingestion. The default is 1MB/sec, which equates to 1,000 data records per second. | 2 |
KinesisBatchSize |
The maximum number of records that Kinesis Data Streams retrieves in a single batch before invoking the consumer Lambda function. | 1 |
KinesisParallelizationFactor |
The number of batches to process from each shard concurrently. | 1 |
| Enhanced fan-out | Data consumers who have enhanced fan-out activated have a dedicated ingestion throughput per consumer (such as the default 1MB/sec) instead of sharing throughput across consumers. | Off |
Consumer Lambda function
From the perspective of Kinesis Data Streams, a data consumer is an AWS service that retrieves data from a data stream shard as data is generated in a stream. This application uses a Consumer Lambda function, which is invoked when messages are passed from the data stream queues. Each Consumer function processes one frame batch by performing the following steps. First, a call is made to the Cortex processor API synchronously, which is the endpoint that hosts the model inference pipeline (see the next section regarding Amazon EKS with Cortex for more details). The results are stored in Amazon S3, and an update is made to the database by changing the status of the processed frame batch to Complete. Error handling is built in to manage the Cortex API call with a retry loop to handle any 504 errors from the Cortex cluster, with number of retries set to 5.
Amazon EKS with Cortex for ML inference
The team used Amazon EKS, a managed Kubernetes service in AWS, as the compute engine for ML inference. A design choice was made to use Amazon EKS to host ML endpoints, giving the flexibility of running upstream Kubernetes with the option of clusters both fully managed in AWS via AWS Fargate, or on-premises hardware via Amazon EKS Anywhere. This was a critical piece of functionality desired by Intel OTG, which provided the option to hook up this application to specialized on-premises hardware, for example.
The three ML models that were the building blocks for constructing the inference pipelines were a custom Yolo model (for object detection), a custom HRNet model (for 2D pose estimation), and a 3DMPPE model (for 3D pose estimation) (see the previous ML section for more details). They used the open-source Cortex library to handle deployment and management of ML inference pipeline endpoints, and launching and deployment of the Amazon EKS clusters. Each of these models were packaged up into Docker containers—model files were stored in Amazon S3 and model images were stored in Amazon Elastic Container Registry (Amazon ECR)—and deployed as Cortex Realtime APIs. Versions of the model containers that run on CPU and GPU were created to provide flexibility for the type of compute hardware. In the future, if additional models or model pipelines need to be added, they can simply create additional Cortex Realtime APIs.
They then constructed inference pipelines by composing together the Cortex Realtime model APIs into Cortex Realtime pipeline APIs. A single Realtime pipeline API consisted of calling a sequence of Realtime model APIs. The Consumer Lambda functions treated a pipeline API as a black box, using a single API call to retrieve the final inference output for an image. Two pipelines were created: a 2D pipeline and a 3D pipeline.
The 2D pipeline combines a decoding preprocessing step, object detection using a custom Yolo model to locate the athlete and produce bounding boxes, and finally a custom HRNet model for creating 2D key points for pose estimation.

The 3D pipeline combines a decoding preprocessing step, object detection using a custom Yolo model to locate the athlete and produce bounding boxes, and finally a 3DMPPE model for creating 3D key points for pose estimation.

After generating inferences on a batch of frames, each pipeline also includes a separate postprocessing Realtime Cortex endpoint that generates three main outputs:
- Aggregated body key points data into a single CSV file
- BMA calculations (such as acceleration)
- Visual overlay of key points added to each frame in an image file
The Collector Lambda function submits the appropriate metadata associated with a particular video, such as the frame IDs and S3 locations of the pose estimation inference outputs, to the endpoint to generate these postprocessing outputs.
Cortex is designed to be integrated with Amazon EKS, and only requires a cluster configuration file and a simple command to launch a Kubernetes cluster:
Another lever for performance tuning was the instance configuration for the compute clusters. Three tiers were created with varying mixes of M5 and G4dn instances, codified as .yaml files with specifications such as cluster name, Region, and instance configuration and mix. M5 instances are lower-cost CPU-based and G4dn are higher cost GPU-based to provide some cost/performance tradeoffs.
Operational monitoring
To maintain operational logging standards, all Lambda functions include code to record and ingest logs via Amazon Kinesis Data Firehose. For example, every frame batch processed from the Submitter Lambda function is logged with the timestamp, name of action, and Lambda function response JSON and saved to Amazon S3. The following diagram illustrates this step in the architecture.

Deployment
Deployment is handled using AWS SAM, an open-source framework for building serverless applications in AWS. AWS SAM enables infrastructure design, including functions, APIs, databases, and event source mappings to be codified and easily deployed in new AWS environments. During deployment, the AWS SAM syntax is translated into AWS CloudFormation to handle the infrastructure provisioning.
A template.yaml file contains the infrastructure specifications along with tunable parameters, such as Kinesis Data Streams latency levers detailed in the preceding sections. A samconfig.toml file contains deployment parameters such as stack name, S3 bucket name where application files like Lambda function code is stored, and resource tags for tracking cost. A deploy.sh shell script with the simple commands is all that is required to build and deploy the entire template:
User work flow
To sum up, after the infrastructure has been deployed, you can follow this workflow to get started:
- Create an Intel 3DAT client using the client library.
- Use the API to create a new instance of a pipeline corresponding to the type of processing that is required, such as one for 3D pose estimation.
- Create a new instance of a project, passing in the cluster ARN and Kinesis queue ARN.
- Create a new instance of a pipeline parameter set.
- Create a new instance of pipeline parameters that map to the pipeline parameter set.
- Create a new user group that is associated with a project ID and a pipeline parameter set ID.
- Create a new user that is associated with the user group.
- Upload a .zip file of videos to Amazon S3 using a presigned S3 URL generated by the upload function in the job API.
- Submit a
create_jobAPI call, with job parameters that specify location of the video files. This starts the processing job.
Conclusion
The application is now live and ready to be tested with athletes and coaches alike. Intel OTG is excited to make innovative pose estimation technology using computer vision accessible for a variety of users, from developers to athletes to software vendor partners.
The AWS team is passionate about helping customers like Intel OTG accelerate their ML journey, from the ideation and discovery stage with ML Solutions Lab to the hardening and deployment stage with AWS ML ProServe. We will all be watching closely at the 2021 Tokyo Olympics this summer to envision all the progress that ML can unlock in sports.
Get started today! Explore your use case with the services mentioned in this post and many others on the AWS Management Console.
About the Authors
 Han Man is a Senior Manager- Machine Learning & AI at AWS based in San Diego, CA. He has a PhD in engineering from Northwestern University and has several years of experience as a management consultant advising clients in manufacturing, financial services, and energy. Today he is passionately working with customers from a variety of industries to develop and implement machine learning & AI solutions on AWS. He enjoys following the NBA and playing basketball in his spare time.
Han Man is a Senior Manager- Machine Learning & AI at AWS based in San Diego, CA. He has a PhD in engineering from Northwestern University and has several years of experience as a management consultant advising clients in manufacturing, financial services, and energy. Today he is passionately working with customers from a variety of industries to develop and implement machine learning & AI solutions on AWS. He enjoys following the NBA and playing basketball in his spare time.
 Iman Kamyabi is an ML Engineer with AWS Professional Services. He has worked with a wide range of AWS customers to champion best practices in setting up repeatable and reliable ML pipelines.
Iman Kamyabi is an ML Engineer with AWS Professional Services. He has worked with a wide range of AWS customers to champion best practices in setting up repeatable and reliable ML pipelines.
 Jonathan Lee is the Director of Sports Performance Technology, Olympic Technology Group at Intel. He studied the application of machine learning to health as an undergrad at UCLA and during his graduate work at University of Oxford. His career has focused on algorithm and sensor development for health and human performance. He now leads the 3D Athlete Tracking project at Intel.
Jonathan Lee is the Director of Sports Performance Technology, Olympic Technology Group at Intel. He studied the application of machine learning to health as an undergrad at UCLA and during his graduate work at University of Oxford. His career has focused on algorithm and sensor development for health and human performance. He now leads the 3D Athlete Tracking project at Intel.
 Nelson Leung is the Platform Architect in the Sports Performance CoE at Intel, where he defines end-to-end architecture for cutting-edge products that enhance athlete performance. He also leads the implementation, deployment and productization of these machine learning solutions at scale to different Intel partners.
Nelson Leung is the Platform Architect in the Sports Performance CoE at Intel, where he defines end-to-end architecture for cutting-edge products that enhance athlete performance. He also leads the implementation, deployment and productization of these machine learning solutions at scale to different Intel partners.
 Troy Squillaci is a DecSecOps engineer at Intel where he delivers professional software solutions to customers through DevOps best practices. He enjoys integrating AI solutions into scalable platforms in a variety of domains.
Troy Squillaci is a DecSecOps engineer at Intel where he delivers professional software solutions to customers through DevOps best practices. He enjoys integrating AI solutions into scalable platforms in a variety of domains.
 Paul Min is an Associate Solutions Architect Intern at Amazon Web Services (AWS), where he helps customers across different industry verticals advance their mission and accelerate their cloud adoption. Previously at Intel, he worked as a Software Engineering Intern to help develop the 3D Athlete Tracking Cloud SDK. Outside of work, Paul enjoys playing golf and can be heard singing.
Paul Min is an Associate Solutions Architect Intern at Amazon Web Services (AWS), where he helps customers across different industry verticals advance their mission and accelerate their cloud adoption. Previously at Intel, he worked as a Software Engineering Intern to help develop the 3D Athlete Tracking Cloud SDK. Outside of work, Paul enjoys playing golf and can be heard singing.