Today, social media is a huge source of news. Users rely on platforms like Facebook and Twitter to consume news. For certain industries such as insurance companies, first respondents, law enforcement, and government agencies, being able to quickly process news about relevant events occurring can help them take action while these events are still unfolding.
It’s not uncommon for organizations trying to extract value from text data to look for a solution that doesn’t involve the training of a complex NLP (natural language processing) model. For those organizations, using a pre-trained NLP model is more practical. Furthermore, if the chosen model doesn’t satisfy their success metrics, organizations want to be able to easily pick another model and reassess.
At present, it’s easier than ever to extract information from text data thanks to the following:
- The rise of state-of-the art, general-purpose NLP architectures such as transformers
- The ability that developers and data scientists have to quickly build, train, and deploy machine learning (ML) models at scale on the cloud with services like Amazon SageMaker
- The availability of thousands of pre-trained NLP models in hundreds of languages and with support for multiple frameworks provided by the community in platforms like Hugging Face Hub
In this post, we show you how to build a real-time alert system that consumes news from Twitter and classifies the tweets using a pre-trained model from the Hugging Face Hub. You can use this solution for zero-shot classification, meaning you can classify tweets at virtually any set of categories, and deploy the model with SageMaker for real-time inference.
Alternatively, if you’re looking for insights into your customer’s conversations and deepen brand awareness by analyzing social media interactions, we encourage you to check out the AI-Driven Social Media Dashboard. The solution uses Amazon Comprehend, a fully managed NLP service that uncovers valuable insights and connections in text without requiring machine learning experience.
Zero-shot learning
The fields of NLP and natural language understanding (NLU) have rapidly evolved to address use cases involving text classification, question answering, summarization, text generation, and more. This evolution has been possible, in part, thanks to the rise of state-of-the art, general-purpose architectures such as transformers, but also the availability of more and better-quality text corpora available for the training of such models.
The transformer architecture is a complex neural network that requires domain expertise and a huge amount of data in order to be trained from scratch. A common practice is to take a pre-trained state-of-the-art transformer like BERT, RoBERTa, T5, GPT-2, or DistilBERT and fine-tune (transfer learning) the model to a specific use case.
Nevertheless, even performing transfer learning on a pre-trained NLP model can often be a challenging task, requiring large amounts of labeled text data and a team of experts to curate the data. This complexity prevents most organizations from using these models effectively, but zero-shot learning helps ML practitioners and organizations overcome this shortcoming.
Zero-shot learning is a specific ML task in which a classifier learns on one set of labels during training, and then during inference is evaluated on a different set of labels that the classifier has never seen before. In NLP, you can use a zero-shot sequence classifier trained on a natural language inference (NLI) task to classify text without any fine-tuning. In this post, we use the popular NLI BART model bart-large-mnli to classify tweets. This is a large pre-trained model (1.6 GB), available on the Hugging Face model hub.
Hugging Face is an AI company that manages an open-source platform (Hugging Face Hub) with thousands of pre-trained NLP models (transformers) in more than 100 different languages and with support for different frameworks such as TensorFlow and PyTorch. The transformers library helps developers and data scientists get started in complex NLP and NLU tasks such as classification, information extraction, question answering, summarization, translation, and text generation.
AWS and Hugging Face have been collaborating to simplify and accelerate the adoption of NLP models. A set of Deep Learning Containers (DLCs) for training and inference in PyTorch or TensorFlow, and Hugging Face estimators and predictors for the SageMaker Python SDK are now available. These capabilities help developers with all levels of expertise get started with NLP easily.
Overview of solution
We provide a working solution that fetches tweets in real time from selected Twitter accounts. For the demonstration of our solution, we use three accounts, Amazon Web Services (@awscloud), AWS Security (@AWSSecurityInfo), and Amazon Science (@AmazonScience), and classify their content into one of the following categories: security, database, compute, storage, and machine learning. If the model returns a category with a confidence score greater than 40%, a notification is sent.
In the following example, the model classified a tweet from Amazon Web Services in the machine learning category, with a confidence score of 97%, generating an alert.
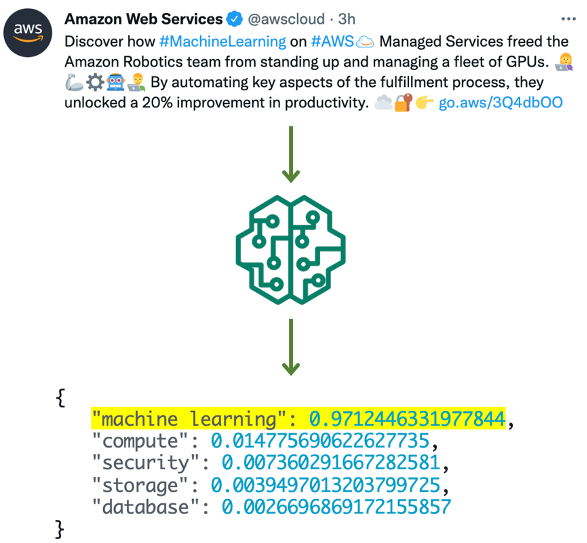
The solution relies on a Hugging Face pre-trained transformer model (from the Hugging Face Hub) to classify tweets based on a set of labels that are provided at inference time—the model doesn’t need to be trained. The following screenshots show more examples and how they were classified.
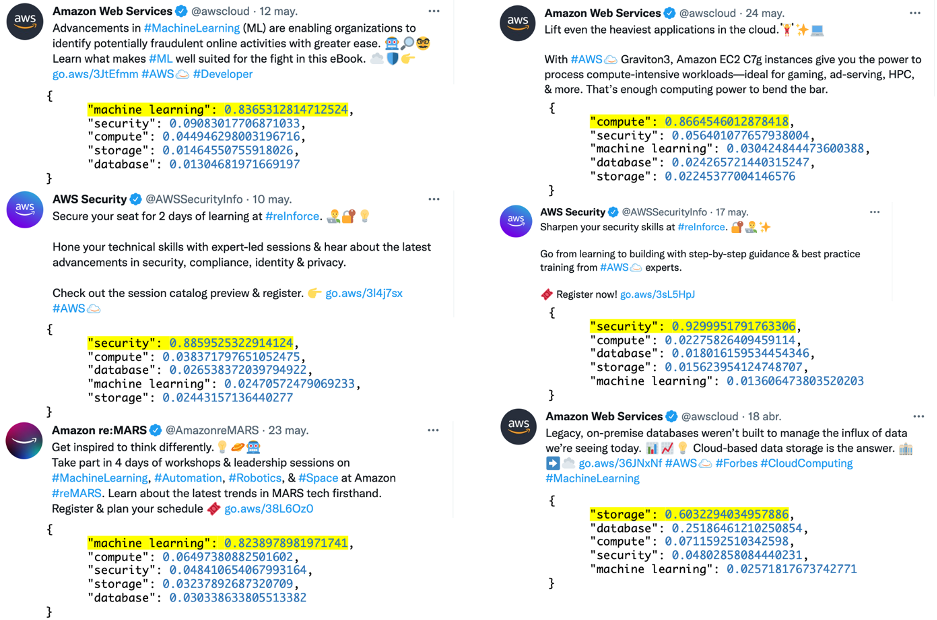
We encourage you to try the solution for yourself. Simply download the source code from the GitHub repository and follow the deployment instructions in the README file.
Solution architecture
The solution keeps an open connection to Twitter’s endpoint and, when a new tweet arrives, sends a message to a queue. A consumer reads messages from the queue, calls the classification endpoint, and, depending on the results, notifies the end user.
The following is the architecture diagram of the solution.
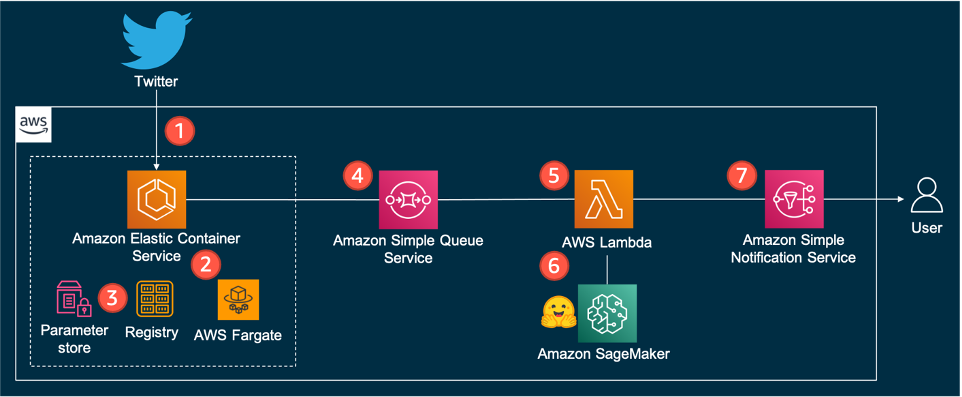
The solution workflow consists of the following components:
- The solution relies on Twitter’s Stream API to get tweets that match the configured rules (tweets from the accounts of interest) in real time. To do so, an application running inside a container keeps an open connection to Twitter’s endpoint. Refer to Twitter API for more details.
- The container runs on Amazon Elastic Container Service (Amazon ECS), a fully managed container orchestration service that makes it easy for you to deploy, manage, and scale containerized applications. A single task runs on a serverless infrastructure managed by AWS Fargate.
- The Twitter Bearer token is securely stored in AWS Systems Manager Parameter Store, a capability of AWS Systems Manager that provides secure, hierarchical storage for configuration data and secrets. The container image is hosted on Amazon Elastic Container Registry (Amazon ECR), a fully managed container registry offering high-performance hosting.
- Whenever a new tweet arrives, the container application puts the tweet into an Amazon Simple Queue Service (Amazon SQS) queue. Amazon SQS is a fully managed message queuing service that enables you to decouple and scale microservices, distributed systems, and serverless applications.
- The logic of the solution resides in an AWS Lambda function. Lambda is a serverless, event-driven compute service. The function consumes new tweets from the queue and classifies them by calling an endpoint.
- The endpoint relies on a Hugging Face model and is hosted on SageMaker. The endpoint runs the inference and outputs the class of the tweet.
- Depending on the classification, the function generates a notification through Amazon Simple Notification Service (Amazon SNS), a fully managed messaging service. You can subscribe to the SNS topic, and multiple destinations can receive that notification (see Amazon SNS event destinations). For instance, you can deliver the notification to inboxes as email messages (see Email notifications).
Deploy Hugging Face models with SageMaker
You can select any of the over 10,000 publicly available models from the Hugging Face Model Hub and deploy them with SageMaker by using Hugging Face Inference DLCs.
When using AWS CloudFormation, you select one of the publicly available Hugging Face Inference Containers and configure the model and the task. This solution uses the facebook/bart-large-mnli model and the zero-shot-classification task, but you can choose any of the models under Zero-Shot Classification on the Hugging Face Model Hub. You configure those by setting the HF_MODEL_ID and HF_TASK environment variables in your CloudFormation template, as in the following code:
SageMakerModel:
Type: AWS::SageMaker::Model
Properties:
ExecutionRoleArn: !GetAtt SageMakerModelRole.Arn
PrimaryContainer:
Image: 763104351884.dkr.ecr.us-east-1.amazonaws.com/huggingface-pytorch-inference:1.7-transformers4.6-cpu-py36-ubuntu18.04
Environment:
HF_MODEL_ID: facebook/bart-large-mnli
HF_TASK: zero-shot-classification
SAGEMAKER_CONTAINER_LOG_LEVEL: 20
SAGEMAKER_REGION: us-east-1
Alternatively, if you’re not using AWS CloudFormation, you can achieve the same results with few lines of code. Refer to Deploy models to Amazon SageMaker for more details.
To classify the content, you just call the SageMaker endpoint. The following is a Python code snippet:
endpoint_name = os.environ['ENDPOINT_NAME']
labels = os.environ['ENDPOINT_NAME']
data = {
'inputs': tweet,
'parameters': {
'candidate_labels': labels,
'multi_class': False
}
}
response = sagemaker.invoke_endpoint(EndpointName=endpoint_name,
ContentType='application/json',
Body=json.dumps(data))
response_body = json.loads(response['Body'].read())
Note the False value for the multi_class parameter to indicate that the sum of all the probabilities for each class will add up to 1.
Solution improvements
You can enhance the solution proposed here by storing the tweets and the model results. Amazon Simple Storage Service (Amazon S3), an object storage service, is one option. You can write tweets, results, and other metadata as JSON objects into an S3 bucket. You can then perform ad hoc queries against that content using Amazon Athena, an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL.
You can use the history not only to extract insights but also to train a custom model. You can use Hugging Face support to train a model with your own data with SageMaker. Learn more on Run training on Amazon SageMaker.
Real-world use cases
Customers are already experimenting with Hugging Face models on SageMaker. Seguros Bolívar, a Colombian financial and insurance company founded in 1939, is an example.
“We developed a threat notification solution for customers and insurance brokers. We use Hugging Face pre-trained NLP models to classify tweets from relevant accounts to generate notifications for our customers in near-real time as a prevention strategy to help mitigate claims. A claim occurs because customers are not aware of the level of risk they are exposed to. The solution allows us to generate awareness in our customers, turning risk into something measurable in concrete situations.”
– Julian Rico, Chief of Research and Knowledge at Seguros Bolívar.
Seguros Bolívar worked with AWS to re-architecture their solution; it now relies on SageMaker and resembles the one described in this post.
Conclusion
Zero-shot classification is ideal when you have little data to train a custom text classifier or when you can’t afford to train a custom NLP model. For specialized use cases, when text is based on specific words or terms, it’s better to go with a supervised classification model based on a custom training set.
In this post, we showed you how to build a news classifier using a Hugging Face zero-shot model on AWS. We used Twitter as our news source, but you can choose a news source that is more suitable to your specific needs. Furthermore, you can easily change the model, just specify your chosen model in the CloudFormation template.
For the source code, refer to the GitHub repository It includes the full setup instructions. You can clone, change, deploy, and run it yourself. You can also use it as a starting point and customize the categories and the alert logic or build another solution for a similar use case.
Please give it a try, and let us know what you think. As always, we’re looking forward to your feedback. You can send it to your usual AWS Support contacts, or in the AWS Forum for SageMaker.
About the authors
 David Laredo is a Prototyping Architect at AWS Envision Engineering in LATAM, where he has helped develop multiple machine learning prototypes. Previously he has worked as a Machine Learning Engineer and has been doing machine learning for over 5 years. His areas of interest are NLP, time series, and end-to-end ML.
David Laredo is a Prototyping Architect at AWS Envision Engineering in LATAM, where he has helped develop multiple machine learning prototypes. Previously he has worked as a Machine Learning Engineer and has been doing machine learning for over 5 years. His areas of interest are NLP, time series, and end-to-end ML.
 Rafael Werneck is a Senior Prototyping Architect at AWS Envision Engineering, based in Brazil. Previously, he worked as a Software Development Engineer on Amazon.com.br and Amazon RDS Performance Insights.
Rafael Werneck is a Senior Prototyping Architect at AWS Envision Engineering, based in Brazil. Previously, he worked as a Software Development Engineer on Amazon.com.br and Amazon RDS Performance Insights.
 Vikram Elango is an AI/ML Specialist Solutions Architect at Amazon Web Services, based in Virginia, USA. Vikram helps financial and insurance industry customers with design and thought leadership to build and deploy machine learning applications at scale. He is currently focused on natural language processing, responsible AI, inference optimization, and scaling ML across the enterprise. In his spare time, he enjoys traveling, hiking, cooking, and camping with his family.
Vikram Elango is an AI/ML Specialist Solutions Architect at Amazon Web Services, based in Virginia, USA. Vikram helps financial and insurance industry customers with design and thought leadership to build and deploy machine learning applications at scale. He is currently focused on natural language processing, responsible AI, inference optimization, and scaling ML across the enterprise. In his spare time, he enjoys traveling, hiking, cooking, and camping with his family.
Read More



















