All-neural, end-to-end ASR systems gained rapid interest from the speech recognition community. Such systems convert speech input to text units using a single trainable neural network model. E2E models require large amounts of paired speech text data that is expensive to obtain. The amount of data available varies across different languages and dialects. It is critical to make use of all these data so that both low resource languages and high resource languages can be improved. When we want to deploy an ASR system for a new application domain, the amount of domain specific training data is…Apple Machine Learning Research
Automated reasoning at Amazon: a conversation
To mark the occasion of the eighth Federated Logic Conference (FloC), Amazon’s Byron Cook, Daniel Kröning, and Marijn Heule discussed automated reasoning’s prospects.Read More
MLOps at the edge with Amazon SageMaker Edge Manager and AWS IoT Greengrass
Internet of Things (IoT) has enabled customers in multiple industries, such as manufacturing, automotive, and energy, to monitor and control real-world environments. By deploying a variety of edge IoT devices such as cameras, thermostats, and sensors, you can collect data, send it to the cloud, and build machine learning (ML) models to predict anomalies, failures, and more. However, if the use case requires real-time prediction, you need to enrich your IoT solution with ML at the edge (ML@Edge) capabilities. ML@Edge is a concept that decouples the ML model’s lifecycle from the app lifecycle and allows you to run an end-to-end ML pipeline that includes data preparation, model building, model compilation and optimization, model deployment (to a fleet of edge devices), model execution, and model monitoring and governing. You deploy the app once and run the ML pipeline as many times as you need.
As you can imagine, to implement all the steps proposed by the ML@Edge concept is not trivial. There are many questions that developers need to address in order to implement a complete ML@Edge solution, for example:
- How do I operate ML models on a fleet (hundreds, thousands, or millions) of devices at the edge?
- How do I secure my model while deploying and running it at the edge?
- How do I monitor my model’s performance and retrain it, if needed?
In this post, you learn how to answer all these questions and build an end-to-end solution for automating your ML@Edge pipeline. You’ll see how to use Amazon SageMaker Edge Manager, Amazon SageMaker Studio, and AWS IoT Greengrass v2 to create an MLOps (ML Operations) environment that automates the process of building and deploying ML models to large fleets of edge devices.
In the next sections, we present a reference architecture that details all the components and workflows required to build a complete solution for MLOps focused on edge workloads. Then we dive deep into the steps this solution runs automatically to build and prepare a new model. We also show you how to prepare the edge devices to start deploying, running, and monitoring ML models, and demonstrate how to monitor and maintain the ML models deployed to your fleet of devices.
Solution overview
Productionization of robust ML models requires the collaboration of multiple personas, such as data scientists, ML engineers, data engineers, and business stakeholders, under a semi-automate infrastructure following specific operations (MLOps). Also, the modularization of the environment is important in order to give all these different personas the flexibility and agility to develop or improve (independently of the workflow) the component for which they are responsible. An example of such an infrastructure consists of multiple AWS accounts that enable this collaboration and productionization of the ML models both in the cloud and to the edge devices. In the following reference architecture, we show how we organized the multiple accounts and services that compose this end-to-end MLOps platform for building ML models and deploying them at the edge.
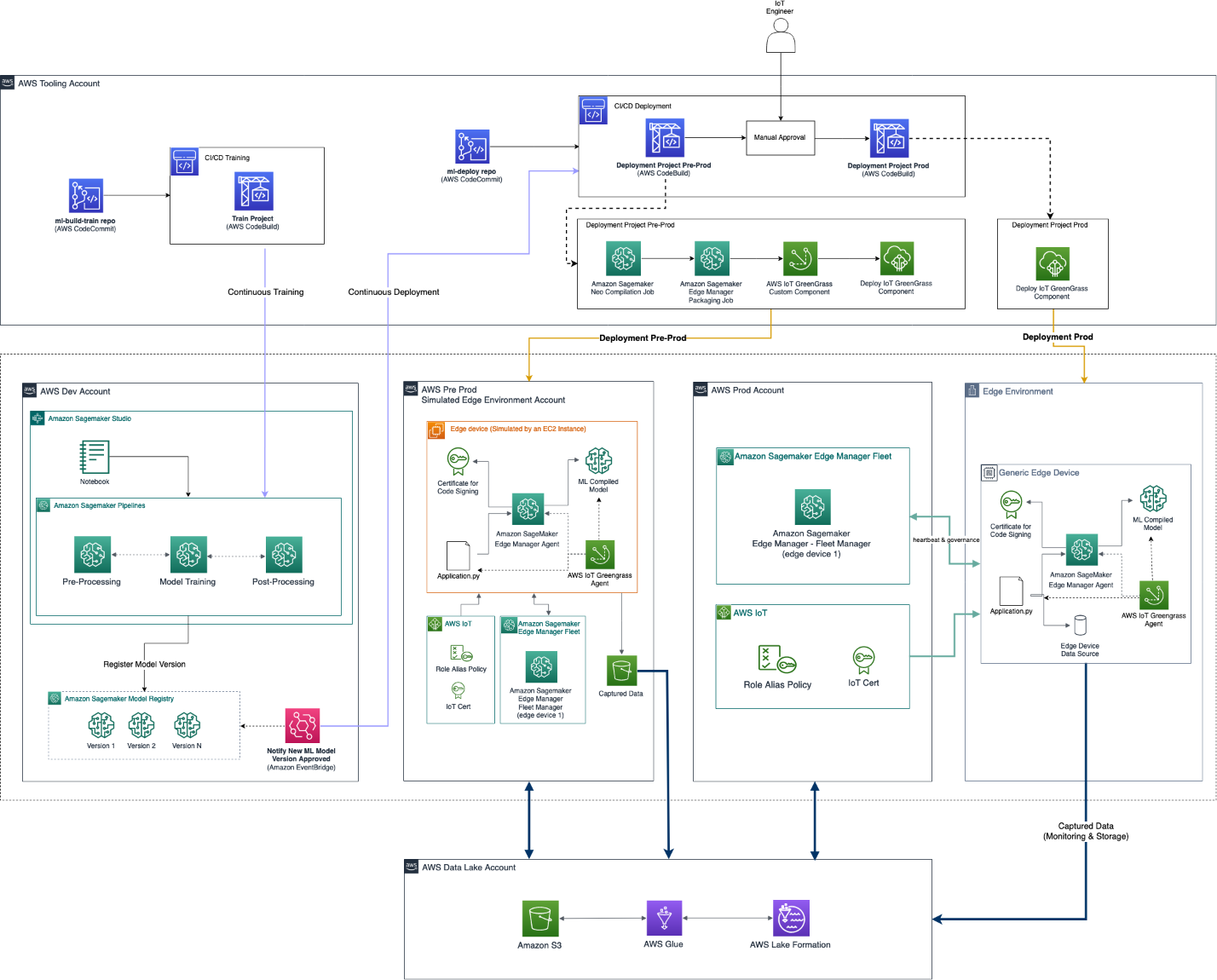
This solution consists of the following accounts:
- Data lake account – Data engineers ingest, store, and prepare data from multiple data sources, including on-premise databases and IoT devices.
- Tooling account – IT operators manage and check CI/CD pipelines for automated continuous delivery and deployment of ML model packages across the pre-production and production accounts for remote edge devices. Runs of CI/CD pipelines are automated through the usage of Amazon EventBridge, which monitors change status events of ML models and targets AWS CodePipeline.
- Experimentation and development account – Data scientists can conduct research and experiment with multiple modeling techniques and algorithms to solve business problems based on ML, creating proof of concept solutions. ML engineers and data scientists collaborate to scale a proof of concept, creating automated workflows using Amazon SageMaker Pipelines to prepare data and build, train, and package ML models. The deployment of the pipelines is driven via CI/CD pipelines, while the version control of the models is achieved using the Amazon SageMaker model registry. Data scientists evaluate the metrics of multiple model versions and request the promotion of the best model to production by triggering the CI/CD pipeline.
- Pre-production account – Before the promotion of the model to the production environment, the model needs to be tested to ensure robustness in a simulation environment. Therefore, the pre-production environment is a simulator of the production environment, in which SageMaker model endpoints are deployed and tested automatically. Test methods might include an integration test, stress test, or ML-specific tests on inference results. In this case, the production environment isn’t a SageMaker model endpoint but an edge device. To simulate an edge device in pre-production, two approaches are possible: use an Amazon Elastic Compute Cloud (Amazon EC2) instance with the same hardware characteristics, or use an in-lab testbed consisting of the actual devices. With this infrastructure, the CI/CD pipeline deploys the model to the corresponding simulator and conducts the multiple tests automatically. After the tests run successfully, the CI/CD pipeline requires manual approval (for example, from the IoT stakeholder to promote the model to production).
- Production account – In the case of hosting the model on the AWS Cloud, the CI/CD pipeline deploys a SageMaker model endpoint on the production account. In this case, the production environment consists of multiple fleets of edge devices. Therefore, the CI/CD pipeline uses Edge Manager to deploy the models to the corresponding fleet of devices.
- Edge devices – Remote edge devices are hardware devices that can run ML models using Edge Manager. It allows the application on those devices to manage the models, run inference against the models, and capture data securely into Amazon Simple Storage Service (Amazon S3).
SageMaker projects help you to automate the process of provisioning resources inside each of these accounts. We don’t dive deep into this feature, but to learn more about how to build a SageMaker project template that deploys ML models across accounts, check out Multi-account model deployment with Amazon SageMaker Pipelines.
Pre-production account: Digital twin
After the training process, the resulting model needs to be evaluated. In the pre-production account, you have a simulated Edge device. It represents the digital twin of the edge device on which the ML model runs in production. This environment has the dual purpose of performing the classic tests (such as unit, integration, and smoke) and to be a playground for the development team. This device is simulated using an EC2 instance where all the components needed to manage the ML model were deployed.
The involved services are as follows:
- AWS IoT Core – We use AWS IoT Core to create AWS IoT thing objects, create a device fleet, register the device fleet so it can interact with the cloud, create X.509 certificates to authenticate edge devices to AWS IoT Core, associate the role alias with AWS IoT Core that was generated when the fleet has created, get an AWS account-specific endpoint for the credential provider, get an official Amazon Root CA file, and upload the Amazon CA file to Amazon S3.
- Amazon Sagemaker Neo – Sagemaker Neo automatically optimizes machine learning models for inference to run faster with no loss in accuracy. It supports machine learning model already built with DarkNet, Keras, MXNet, PyTorch, TensorFlow, TensorFlow-Lite, ONNX, or XGBoost and trained in Amazon SageMaker or anywhere else. Then you choose your target hardware platform, which can be a SageMaker hosting instance or an edge device based on processors from Ambarella, Apple, ARM, Intel, MediaTek, Nvidia, NXP, Qualcomm, RockChip, Texas Instruments, or Xilinx.
- Edge Manager – We use Edge Manager to register and manage the edge device within the Sagemaker fleets. Fleets are collections of logically grouped devices you can use to collect and analyze data. Besides, Edge Manager packager, packages the optimized model and create an AWS IoT Greengrass V2 component that can directly be deployed. You can use Edge Manager to operate ML models on a fleet of smart cameras, smart speakers, robots, and other SageMaker device fleets.
- AWS IoT Greengrass V2 – AWS IoT Greengrass allows you to deploy components into the simulated devices using an EC2 instance. By using the AWS IoT Greengrass V2 agent in the EC2 instances, we can simplify the access, management, and deployment of the Edge Manager agent and model to devices. Without AWS IoT Greengrass V2, setting up devices and fleets to use Edge Manager requires you to manually copy the agent from an S3 release bucket. With AWS IoT Greengrass V2 and Edge Manager integration, it’s possible to use AWS IoT Greengrass V2 components. Components are pre-built software modules that can connect edge devices to AWS services or third-party service via AWS IoT Greengrass.
- Edge Manager agent – The Edge Manager agent is deployed via AWS IoT Greengrass V2 in the EC2 instance. The agent can load multiple models at a time and make inference with loaded models on edge devices. The number of models the agent can load is determined by the available memory on the device.
- Amazon S3 – We use an S3 bucket to store the inference captured data from the Edge Manager agent.
We can define a pre-production account as a digital twin for testing ML models before moving them into real edge devices. This offers the following benefits:
- Agility and flexibility – Data scientists and ML engineers need to quickly validate if the ML model and associated scripts (preprocessing and inference scripts) will work on the device edge. However, IoT and data science departments in large enterprises may be different entities. By identically replicating the technology stack in the cloud, data scientists and ML engineers can iterate and consolidate artifacts prior to deployment.
- Accelerated risk assessment and production time – Deployment on the edge device is the final stage of the process. After you validate everything in an isolated and self-contained environment, secure it to be adherent to the specifications required by the edge in terms of quality, performance, and integration. This helps avoid further involvement of other people in the IoT department to fix and iterate on artifact versions.
- Improved team collaboration and enhanced quality and performance – Development team can immediately assess the impact of the ML model by analyzing edge hardware metrics and measuring the level of interactions with third-party tools (eg. I/O rate). Then, the IoT team is only responsible for deployment to the production environment, and can be confident that the artifacts are accurate for a production environment.
- Integrated playground for testing – Given the target of ML models, the pre-production environment in a traditional workflow should be represented by an edge device outside the cloud environment. This introduces another level of complexity. Integrations are needed to collect metrics and feedback. Instead, by using the digital twin simulated environment, interactions are reduced and time to market is shortened.
Production account and edge environment
After the tests are complete and the artifact stability is achieved, you can proceed to production deployment through the pipelines. Artifact deployment occurs programmatically after an operator has approved the artifact. However, access to the AWS Management Console is granted to operators in read-only mode to be able to monitor metadata associated with the fleets and therefore have insight into the version of the deployed ML model and other metrics associated with the lifecycle.
Edge device fleets belong to the AWS production account. This account has specific security and networking configurations to allow communication between the cloud and edge devices. The main AWS services deployed in the production account are Edge Manager, which is responsible for managing all the device fleets, collecting data, and operating ML models, and AWS IoT Core, which manages IoT thing objects, certificates, role alias, and endpoints.
At the same time, we need to configure an edge device with the services and components to manage ML models. The main components are as follows:
- AWS IoT Greengrass V2
- An Edge Manager agent
- AWS IoT certificates
- Application.py, which is responsible for orchestrating the inference process (retrieving information from the edge data source and performing inference using the Edge Manager agent and loaded ML model)
- A connection to Amazon S3 or the data lake account to store inferenced data
Automated ML pipeline
Now that you know more about the organization and the components of the reference architecture, we can dive deeper into the ML pipeline that we use to build, train, and evaluate the ML model inside the development account.
A pipeline (built using Amazon SageMaker Model Building Pipelines) is a series of interconnected steps that is defined by a JSON pipeline definition. This pipeline definition encodes a pipeline using a Directed Acyclic Graph (DAG). This DAG gives information on the requirements for and relationships between each step of your pipeline. The structure of a pipeline’s DAG is determined by the data dependencies between steps. These data dependencies are created when the properties of a step’s output are passed as the input to another step.
To enable data science teams to easily automate the creation of new versions of ML models, it’s important to introduce validation steps and automated data for continuously feeding and improving ML models, as well as model monitoring strategies for enabling pipeline triggering. The following diagram shows an example pipeline.
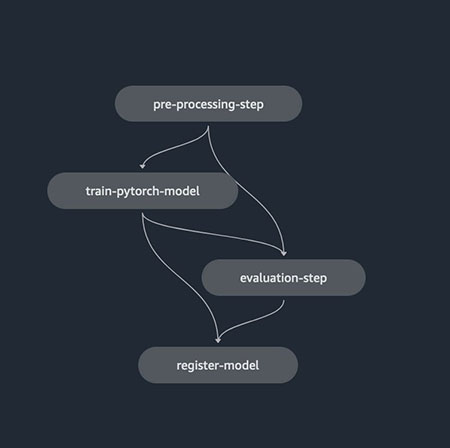
For enabling automations and MLOps capabilities, it’s important to create modular components for creating reusable code artifacts that can be sharable across different steps and ML use cases. This enables you to quickly move the implementation from an experimentation phase to a production phase by automating the transition.
The steps for defining an ML pipeline for enabling the continuous training and versioning of ML models are as follows:
- Preprocessing – The process of data cleaning, feature engineering, and dataset creation for training the ML algorithm
- Training – The process of training the developed ML algorithm for generating a new version of the ML model artifact
- Evaluation – The process of evaluation of the generated ML model, for extracting key metrics related to the model behavior on new data not seen during the training phase
- Registration – The process of versioning the new trained ML model artifact by linking the metrics extracted with the generated artifact
You can see more details of how to build a SageMaker pipeline in the following notebook.
Trigger CI/CD pipelines using EventBridge
When you finish building the model, you can start the deployment process. The last step of the SageMaker pipeline defined in the previous section registers a new version of the model in the specific SageMaker model registry group. The deployment of a new version of the ML model is managed using the model registry status. By manually approving or rejecting an ML model version, this step raises an event that is captured by EventBridge. This event can then start a new pipeline (CI/CD this time) for creating a new version of the AWS IoT Greengrass component that is then deployed to the pre-production and production accounts. The following screenshot shows our defined EventBridge rule.

This rule monitors the SageMaker model package group by looking for updates of model packages in the status Approved or Rejected.
The EventBridge rule is then configured to target CodePipeline, which starts the workflow of creating a new AWS IoT Greengrass component by using Amazon SageMaker Neo and Edge Manager.
Optimize ML models for the target architecture
Neo allows you to optimize ML models for performing inference on edge devices (and in the cloud). It automatically optimizes the ML models for better performance based on the target architecture, and decouples the model from the original framework, allowing you to run it on a lightweight runtime.
Refer to the following notebook for an example of how to compile a PyTorch Resnet18 model using Neo.
Build the deployment package by including the AWS IoT Greengrass component
Edge Manager allows you to manage, secure, deploy, and monitor models to a fleet of edge devices. In the following notebook, you can see more details of how to build a minimalist fleet of edge devices and run some experiments with this feature.
After you configure the fleet and compile the model, you need to run an Edge Manager packaging job, which prepares the model to be deployed to the fleet. You can start a packaging job by using the Boto3 SDK. For our parameters, we use the optimized model and model metadata. By adding the following parameters to OutputConfig, the job also prepares an AWS IoT Greengrass V2 component with the model:
PresetDeploymentTypePresetDeploymentConfig
See the following code:
Deploy ML models at the edge at scale
Now it’s time to deploy the model to your fleet of edge devices. First, we need to ensure that we have the necessary AWS Identity and Access Management (IAM) permissions to provision our IoT devices and are able to deploy components to it. We require two basic elements to start onboarding devices into our IoT platform:
- IAM policy – This policy allows for the automatic provisioning of such devices, attached to the user or role performing the provisioning. It should have IoT write permissions to create the IoT thing and group, as well as to attach the necessary policies to the device. For more information, refer to Minimal IAM policy for installer to provision resources.
- IAM role – this role is attached to the IoT things and groups that we create. You can create this role at provisioning time with basic permissions, but it will lack features like access to Amazon S3 or AWS Key Management Service (AWS KMS) that might be needed later. You can create this role beforehand and reuse it when we provision the device. For more information, refer to Authorize core devices to interact with AWS.
AWS IoT Greengrass installation and provisioning
After we have the IAM policy and role in place, we’re ready to install AWS IoT Greengrass Core software with automatic resource provisioning. Although it’s possible to provision the IoT resources following manual steps, there is the convenient procedure of automatically provisioning these resources during the installation of the AWS IoT Greengrass v2 nucleus. This is the preferred option to quickly onboard new devices into the platform. Besides default-jdk, other packages are required to be installed, such as curl, unzip, and python3.
When we provision our device, the IoT thing name must be exactly the same as the edge device defined in Edge Manager, otherwise data won’t be captured to the destination S3 bucket.
The installer can create the AWS IoT Greengrass role and alias during the installation if they don’t exist. However, they’ll be created with minimal permissions and will require manually adding more policies to interact with other services such as Amazon S3. We recommend creating these IAM resources beforehand as shown earlier, and then reuse them as you onboard new devices into the account.
Model and inference component packaging
After our code has been developed, we can deploy both the code (for inference) and our ML models as components into our devices.
After the ML model is trained in SageMaker, you can optimize the model with Neo using a Sagemaker compilation job. The resulting compiled model artifacts, can then be packaged into a GreenGrass V2 component using the Edge Manager packager. Then, it can be registered as a custom component in the My Components section on the AWS IoT Greengrass console. This component already contains the necessary lifecycle commands to download and decompress the model artifact in our device, so that the inference code can load it up to send the images captured through it.
Regarding the inference code, we must create a component using the console or AWS Command Line Interface (AWS CLI). First, we pack our source inference code and necessary dependencies to Amazon S3. After we upload the code, we can create our component using a recipe in .yaml or JSON like the following example:
This example recipe shows the name and description of our component, as well as the necessary prerequisites before our run script command. The recipe unpacks the artifact in a work folder environment in the device, and we use that path to run our inference code. The AWS CLI command to create such recipe is:
You can now see this component created on the AWS IoT Greengrass console.
Beware of the fact that the component version matters, and it must be specified in the recipe file. Repeating the same version number will return an error.
After our model and inference code have been set up as components, we’re ready to deploy them.
Deploy the application and model using AWS IoT Greengrass
In the previous sections, you learned how to package the inference code and the ML models. Now we can create a deployment with multiple components that include both components and configurations needed for our inference code to interact with the model in the edge device.
The Edge Manager agent is the component that should be installed on each edge device in order enable all the Edge Manager capabilities. On the SageMaker console, we have a device fleet defined, which has an associated S3 bucket. All edge devices associated with the fleet will capture and report their data to this S3 path. The agent can be deployed as a component in AWS IoT Greengrass v2, which makes it easier to install and configure than if the agent were deployed in standalone mode. When deploying the agent as a component, we need to specify its configuration parameters, namely the device fleet and S3 path.
We create a deployment configuration with the custom components for the model and code we just created. This setup is defined in a JSON file that lists the deployment name and target, as well as the components in the deployment. We can add and update the configuration parameters of each component, such as in the Edge Manager agent, where we specify the fleet name and bucket.
It’s worth noting that we have added not only the model, inference components, and agent, but also the AWS IoT Greengrass CLI and nucleus as components. The former can help debug certain deployments locally on the device. The latter is added into the deployment to configure the necessary network access from the device itself if needed (for example, proxy settings), and also in case you want to perform an OTA upgrade of the AWS IoT Greengrass v2 nucleus. The nucleus isn’t deployed because it’s installed in the device, and only the configuration update will be applied (unless an upgrade is in place). To deploy, we simply need to run the following command over the preceding configuration. Remember to set up the target ARN to which the deployment will be applied (an IoT thing or IoT group). We can also deploy these components from the console.
Monitor and manage ML models deployed to the edge
Now that your application is running on the edge devices, it’s time to understand how to monitor the fleet to improve governance, maintenance, and visibility. On the SageMaker console, choose Edge Manager in the navigation pane, then choose Edge device fleets. From here, choose your fleet.
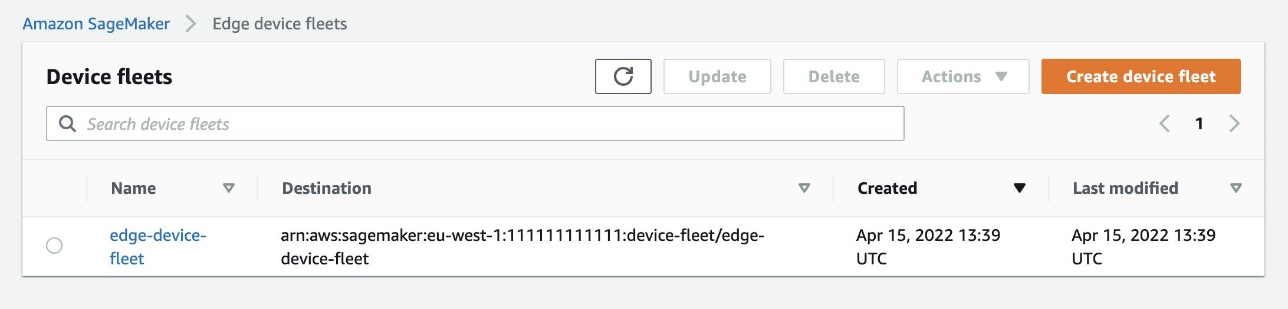
On the fleet’s detail page, you can see some metadata of the models that are running on each device of your fleet. Fleet report is generated every 24 hours.
Data captured by each device through the Edge Agent is sent to an S3 bucket in json lines format (JSONL). The process of sending captured data is managed from an application standpoint. You are therefore free to decide whether to send this data, how and how often.
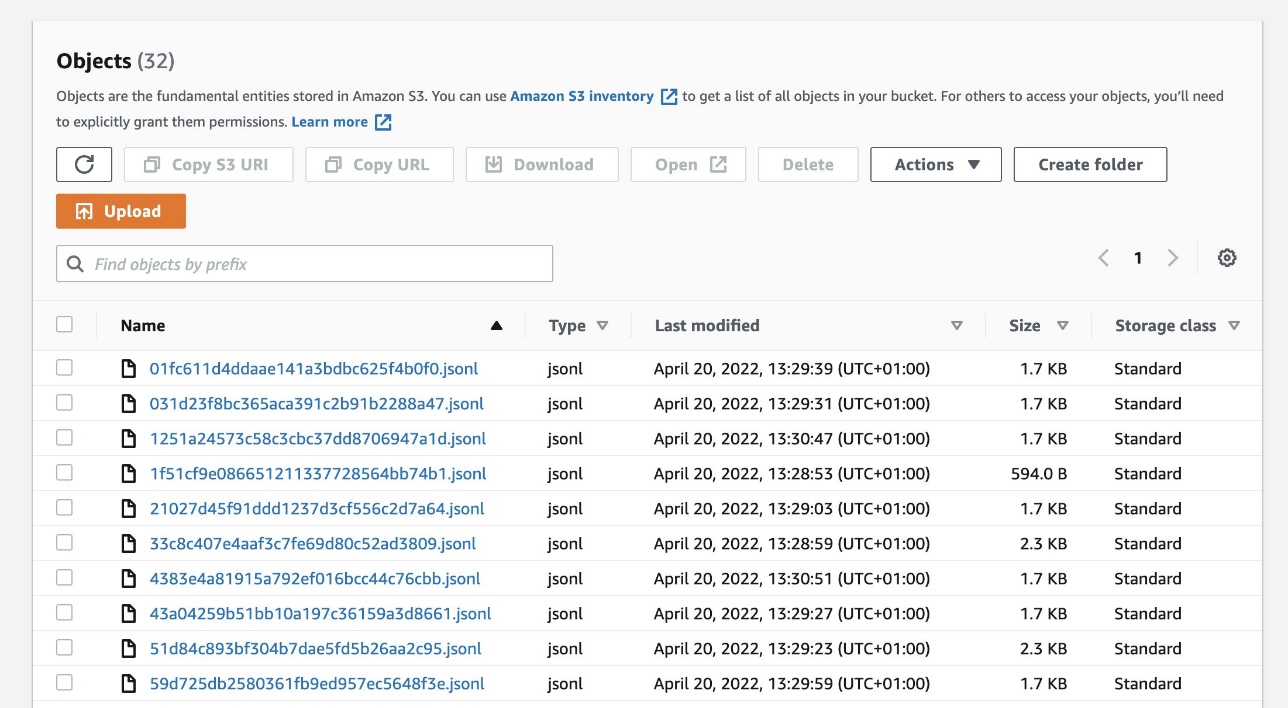
You can use this data for many things, such as monitoring data drift and model quality, building a new dataset, enriching a data lake, and more. A simple example of how to utilize this data is when you identify some data drift in the way users are interacting with your application and you need to train a new model. You then build a new dataset with the captured data and copy it back to the development account. This can automatically start a new run of your environment that builds a new model and redeploys it to the whole fleet to keep the performance of the deployed solution.
Conclusion
In this post, you learned how to build a complete solution that combines MLOps and ML@Edge using AWS services. Building such a solution is not trivial, but we hope the reference architecture presented in this post can inspire and help you build a solid architecture for your own business challenges. You can also use just the parts or modules of this architecture that integrate with your existing MLOps environment. By prototyping one single module at a time and using the appropriate AWS services to address each piece of this challenge, you can learn how to build a robust MLOps environment and also further simplify the final architecture.
As a next step, we encourage you to try out Sagemaker Edge Manager to manage your ML at edge lifecycle. For more information on how Edge Manager works, see Deploy models at the edge with SageMaker Edge Manager .
About the authors
 Bruno Pistone is an AI/ML Specialist Solutions Architect for AWS based in Milan. He works with customers of any size on helping them to to deeply understand their technical needs and design AI and Machine Learning solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. His field of expertice are Machine Learning end to end, Machine Learning Industrialization and MLOps. He enjoys spending time with his friends and exploring new places, as well as travelling to new destinations.
Bruno Pistone is an AI/ML Specialist Solutions Architect for AWS based in Milan. He works with customers of any size on helping them to to deeply understand their technical needs and design AI and Machine Learning solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. His field of expertice are Machine Learning end to end, Machine Learning Industrialization and MLOps. He enjoys spending time with his friends and exploring new places, as well as travelling to new destinations.
 Matteo Calabrese is an AI/ML Customer Delivery Architect in AWS Professional Services team. He works with EMEA large enterprises on AI/ML projects, helping them in proposition, design, deliver, scale, and optimize ML production workloads. His main expertise are ML Operation (MLOps) and Machine Learning at Edge. His goal is shortening their time to value and accelerate business outcomes by providing AWS best practices. In his spare time, he enjoys hiking and traveling.
Matteo Calabrese is an AI/ML Customer Delivery Architect in AWS Professional Services team. He works with EMEA large enterprises on AI/ML projects, helping them in proposition, design, deliver, scale, and optimize ML production workloads. His main expertise are ML Operation (MLOps) and Machine Learning at Edge. His goal is shortening their time to value and accelerate business outcomes by providing AWS best practices. In his spare time, he enjoys hiking and traveling.
 Raúl Díaz García is a Sr Data Scientist in AWS Professional Services team. He works with large enterprise customers across EMEA, where he helps them enable solutions related to Computer Vision and Machine Learning in the IoT space.
Raúl Díaz García is a Sr Data Scientist in AWS Professional Services team. He works with large enterprise customers across EMEA, where he helps them enable solutions related to Computer Vision and Machine Learning in the IoT space.
 Sokratis Kartakis is a Senior Machine Learning Specialist Solutions Architect for Amazon Web Services. Sokratis focuses on enabling enterprise customers to industrialize their Machine Learning (ML) solutions by exploiting AWS services and shaping their operating model, i.e. MLOps foundation, and transformation roadmap leveraging best development practices. He has spent 15+ years on inventing, designing, leading, and implementing innovative end-to-end production-level ML and Internet of Things (IoT) solutions in the domains of energy, retail, health, finance/banking, motorsports etc. Sokratis likes to spend his spare time with family and friends, or riding motorbikes.
Sokratis Kartakis is a Senior Machine Learning Specialist Solutions Architect for Amazon Web Services. Sokratis focuses on enabling enterprise customers to industrialize their Machine Learning (ML) solutions by exploiting AWS services and shaping their operating model, i.e. MLOps foundation, and transformation roadmap leveraging best development practices. He has spent 15+ years on inventing, designing, leading, and implementing innovative end-to-end production-level ML and Internet of Things (IoT) solutions in the domains of energy, retail, health, finance/banking, motorsports etc. Sokratis likes to spend his spare time with family and friends, or riding motorbikes.
 Samir Araújo is an AI/ML Solutions Architect at AWS. He helps customers creating AI/ML solutions which solve their business challenges using AWS. He has been working on several AI/ML projects related to computer vision, natural language processing, forecasting, ML at the edge, and more. He likes playing with hardware and automation projects in his free time, and he has a particular interest for robotics.
Samir Araújo is an AI/ML Solutions Architect at AWS. He helps customers creating AI/ML solutions which solve their business challenges using AWS. He has been working on several AI/ML projects related to computer vision, natural language processing, forecasting, ML at the edge, and more. He likes playing with hardware and automation projects in his free time, and he has a particular interest for robotics.
How to Start a Career in AI
How do I start a career as a deep learning engineer? What are some of the key tools and frameworks used in AI? How do I learn more about ethics in AI?
Everyone has questions, but the most common questions in AI always return to this: how do I get involved?
Cutting through the hype to share fundamental principles for building a career in AI, a group of AI professionals gathered at NVIDIA’s GTC conference in the spring offered what may be the best place to start.
Each panelist, in a conversation with NVIDIA’s Louis Stewart, head of strategic initiatives for the developer ecosystem, came to the industry from very different places.
Watch the session on demand.
But the speakers — Katie Kallot, NVIDIA’s former head of global developer relations and emerging areas; David Ajoku, founder of startup aware.ai; Sheila Beladinejad, CEO of Canada Tech; and Teemu Roos, professor at the University of Helsinki — returned again and again to four basic principles.
1) Start With Networking and Mentorship
The best way to start, Ajoku explained, is to find people who are where you want to be in five years.
And don’t just look for them online — on Twitter and LinkedIn. Look for opportunities to connect with others in your community and at professional events who are going where you want to be.
“You want to find people you admire, find people who walk the path you want to be on over the next five years,” Ajoku said. “It doesn’t just come to you; you have to go get it.”
At the same time, be generous about sharing what you know with others. “You want to find people who will teach, and in teaching, you will learn,” he added.
But the best place to start is knowing that reaching out is okay.
“When I started my career in computer science, I didn’t even know I should be seeking a mentor,” Beladinejad said, echoing remarks from the other panelists.
“I learned not to be shy, to ask for support and seek help whenever you get stuck on something — always have the confidence to approach your professors and classmates,” she added.
2) Get Experience
Kallot explained that the best way to learn is by doing.
She got a degree in political science and learned about technology — including how to code — while working in the industry.
She started out as a sales and marketing analyst, then leaped to a product manager role.
“I had to learn everything about AI in three months, and at the same time I had to learn to use the product, I had to learn to code,” she said.
The best experience, explained Roos, is to surround yourself with people on the same learning journey, whether they’re learning online or in person.
“Don’t do it alone. If you can, grab your friends, grab your colleagues, maybe start a study group and create a curriculum,” he said. “Meet once a week, twice a week — it’s much more fun that way.”
3) Develop Soft Skills
You’ll also need the communications skills to explain what you’re learning, and doing, in AI as you progress.
“Practice talking about technical topics to non-technical audiences,” Stewart said.
Ajoku recommended learning and practicing public speaking.
Ajoku took an acting class at Carnegie Mellon University. Similarly, Roos took an improv comedy class.
Others on the panel learned to perform, publicly, through dance and sports.
“The more you’re cross-trained, the more comfortable you’re going to be and the better you’re going to be able to express yourself in any environment,” Stewart said.
4) Define Your Why
The most important element, however, comes from within, the panelists said.
They urged listeners to find a reason, something that drives them to stay motivated on their journey.
For some, it’s environmental issues. Others are driven by a desire to make technology more accessible. Or to help make the industry more inclusive, panelists said.
“It’s helpful for anyone if you have a topic that you’re passionate about,” Beladinejad said. “That would help keep you going, keep your motivation up.”
Whatever you do, “do it with passion,” Stewart said. “Do it with purpose.”
Burning Questions
Throughout the conversation, thousands of virtual attendees submitted more than 350 questions about how to get started in their AI careers.
Among them:
What’s the best way to learn about deep learning?
The NVIDIA Deep Learning Institute offers a huge variety of hands-on courses.
Even more resources for new and experienced developers alike are available through the NVIDIA Developer program, which includes resources for those pursuing higher education and research.
Massive open online courses — or MOOCs — have made learning about technical subjects more accessible than ever. One panelist suggested looking for classes taught by Stanford Professor Andrew Ng on Coursera.
“There are many MOOC courses out there, YouTube videos and books — I highly recommend finding a study buddy as well,” another wrote.
“Join technical and professional networks … get some experience through volunteering, participating in a Kaggle competition, etc.”
What are some of the most prevalent tools and frameworks used in machine learning and AI in industry? Which ones are crucial to landing a first job or internship in the field?
The best way to figure out which technologies you want to start with, one panelist suggested, is to think about what you want to do.
Another suggested, however, that learning Python isn’t a bad place to begin.
“A lot of today’s AI tools are based on Python,” they wrote. “You can’t go wrong by mastering Python.”
“The technology is evolving rapidly, so many of today’s AI developers are constantly learning new things. Having software fundamentals like data structures and common languages like Python and C++ will help set you up to ‘learn on the job,’” another added.
What’s the best way to start getting experience in the field? Do personal projects count as experience?
Student clubs, online developer communities, volunteering and personal projects are all a great way to gain hands-on experience, panelists wrote.
And definitely include personal projects on your resume, another added.
Is there an age limit for getting involved in AI?
Age isn’t at all a barrier, whether you’re just starting out or transitioning from another field, panelists wrote.
Build a portfolio for yourself so you can better demonstrate your skills and abilities — that’s what should count.
Employers should be able to easily realize your potential and skills.
I want to build a tech startup with some form of AI as the engine driving the solution to solve an as-yet-to-be-determined problem. What pointers do you have for entrepreneurs?
Entrepreneurs should apply to be a part of NVIDIA Inception.
The program provides free benefits, such as technical support, go-to-market support, preferred pricing on hardware and access to its VC alliance for funding.
Which programming language is best for AI?
Python is widely used in deep learning, machine learning and data science. The programming language is at the center of a thriving ecosystem of deep learning frameworks and developer tools. It’s predominantly used for training complex models and for real-time inference for web-based services.
C/C++ is a popular programming language for self-driving cars which is used for deploying models for real-time inference.
Those getting started, though, will want to make sure they’re familiar with a broad array of tools, not just Python.
The NVIDIA Deep Learning Institute’s beginner self-paced courses can be one of the best ways to get oriented.
Learn More at GTC
At NVIDIA GTC, a global AI conference running Sept. 19-22, hear firsthand from professionals about how they got started in their careers.
Register for free now — and check out the sessions How to Be a Deep Learning Engineer and 5 Paths to a Career in AI.
Learn the AI essentials from NVIDIA fast: check out the “getting started” resources to explore the fundamentals of today’s hottest technologies on our learning series page.
The post How to Start a Career in AI appeared first on NVIDIA Blog.
National Science Foundation and Amazon announce latest Fairness in AI grant projects
Thirteen new projects focus on ensuring fairness in AI algorithms and the systems that incorporate them.Read More
National Science Foundation and Amazon announce latest Fairness in AI grant projects
Thirteen new projects focus on ensuring fairness in AI algorithms and the systems that incorporate them.Read More
Meta graphics research at SIGGRAPH 2022
Meta graphics research at SIGGRAPH 2022Read More
Domenico Giannone’s never-ending drive to learn more from economic data
How the Amazon Supply Chain Optimization Technologies principal economist uses his expertise in time series econometrics to forecast aggregate demand.Read More
NVIDIA Instant NeRF Wins Best Paper at SIGGRAPH, Inspires Creative Wave Amid Tens of Thousands of Downloads
3D content creators are clamoring for NVIDIA Instant NeRF, an inverse rendering tool that turns a set of static images into a realistic 3D scene.
Since its debut earlier this year, tens of thousands of developers around the world have downloaded the source code and used it to render spectacular scenes, sharing eye-catching results on social media.
The research behind Instant NeRF is being honored as a best paper at SIGGRAPH — which runs Aug. 8-11 in Vancouver and online — for its contribution to the future of computer graphics research. One of just five papers selected for this award, it’s among 17 papers and workshops with NVIDIA authors that are being presented at the conference, covering topics spanning neural rendering, 3D simulation, holography and more.
NVIDIA recently held an Instant NeRF sweepstakes, asking developers to share 3D scenes created with the software for a chance to win a high-end NVIDIA GPU. Hundreds participated, posting 3D scenes of landmarks like Stonehenge, their backyards and even their pets.
Among the creators using Instant NeRF are:
Through the Looking Glass: Karen X. Cheng and James Perlman
San Francisco-based creative director Karen X. Cheng is working with software engineer James Perlman to render 3D scenes that test the boundaries of what Instant NeRF can create.
The duo has used Instant NeRF to create scenes that explore reflections within a mirror (shown above) and handle complex environments with multiple people — like a group enjoying ramen at a restaurant.
“The algorithm itself is groundbreaking — the fact that you can render a physical scene with higher fidelity than normal photogrammetry techniques is just astounding,” Perlman said. “It’s incredible how accurately you can reconstruct lighting, color differences or other tiny details.”

“It even makes mistakes look artistic,” said Cheng. “We really lean into that, and play with training a scene less sometimes, experimenting with 1,000, or 5,000 or 50,000 iterations. Sometimes I’ll prefer the ones trained less because the edges are softer and you get an oil-painting effect.”
Using prior tools, it would take them three or four days to train a “decent-quality” scene. With Instant NeRF, the pair can churn out about 20 a day, using an NVIDIA RTX A6000 GPU to render, train and preview their 3D scenes.
With rapid rendering comes faster iteration.
“Being able to render quickly is very necessary for the creative process. We’d meet up and shoot 15 or 20 different versions, run them overnight and then see what’s working,” said Cheng. “Everything we’ve published has been shot and reshot a dozen times, which is only possible when you can run several scenes a day.”
Preserving Moments in Time: Hugues Bruyère
Hugues Bruyère, partner and chief of innovation at Dpt., a Montreal-based creative studio, uses Instant NeRF daily.
“3D captures have always been of strong interest to me because I can go back to those volumetric reconstructions and move in them, adding an extra dimension of meaning to them,” he said.
Bruyère rendered 3D scenes with Instant NeRF using the data he’d previously captured for traditional photogrammetry relying on mirrorless digital cameras, smartphones, 360 cameras and drones. He uses an NVIDIA GeForce RTX 3090 GPU to render his Instant NeRF scenes.
Bruyère believes Instant NeRF could be a powerful tool to help preserve and share cultural artifacts through online libraries, museums, virtual-reality experiences and heritage-conservation projects.
“The aspect of capturing itself is being democratized, as camera and software solutions become cheaper,” he said. “In a few months or years, people will be able to capture objects, places, moments and memories and have them volumetrically rendered in real time, shareable and preserved forever.”
Using pictures taken with a smartphone, Bruyère created an Instant NeRF render of an ancient marble statue of Zeus from an exhibition at Toronto’s Royal Ontario Museum.
Stepping Into Remote Scenes: Jonathan Stephens
Jonathan Stephens, chief evangelist for spatial computing company EveryPoint, has been exploring Instant NeRF for both creative and practical applications.
EveryPoint reconstructs 3D scenes such as stockpiles, railyards and quarries to help businesses manage their resources. With Instant NeRF, Stephens can capture a scene more completely, allowing clients to freely explore a scene. He uses an NVIDIA GeForce RTX 3080 GPU to run scenes rendered with Instant NeRF.
“What I really like about Instant NeRF is that you quickly know if your render is working,” Stephens said. “With a large photogrammetry set, you could be waiting hours or days. Here, I can test out a bunch of different datasets and know within minutes.”
Visit the NVIDIA Technical Blog for a tutorial from Stephens on getting started with NVIDIA Instant NeRF.
Stephens has also experimented with making NeRFs using footage from lightweight devices like smart glasses. Instant NeRF could turn his low-resolution, bumpy footage from walking down the street into a smooth 3D scene.
Find NVIDIA at SIGGRAPH
Tune in for a special address by NVIDIA CEO Jensen Huang and other senior leaders on Tuesday, Aug. 9, at 9 a.m. PT to hear about the research and technology behind AI-powered virtual worlds.
NVIDIA is also presenting a score of in-person and virtual sessions for SIGGRAPH attendees, including:
- The Next Evolution of Universal Scene Description (USD) for Building Virtual Worlds
- Real-Time Collaboration in Ray-Traced VR
- Meet the Researchers: How to Use NVIDIA Kaolin in Your 3D Deep Learning Workflows
- The Future of Extended Reality: How Immersion Will Change Everything
Learn how to create with Instant NeRF in the hands-on demo, NVIDIA Instant NeRF — Getting Started With Neural Radiance Fields. Instant NeRF will also be part of SIGGRAPH’s “Real-Time Live” showcase — where in-person attendees can vote for a winning project.
For more interactive sessions, the NVIDIA Deep Learning Institute is offering free hands-on training with NVIDIA Omniverse and other 3D graphics technologies for in-person conference attendees.
And peek behind the scenes of NVIDIA GTC in the documentary premiere, The Art of Collaboration: NVIDIA, Omniverse, and GTC, taking place Aug. 10 at 10 a.m. PT, to learn how NVIDIA’s creative, engineering and research teams used the company’s technology to deliver the visual effects in the latest GTC keynote address.
Find out more about NVIDIA at SIGGRAPH, and see a full schedule of events and sessions in this show guide.
The post NVIDIA Instant NeRF Wins Best Paper at SIGGRAPH, Inspires Creative Wave Amid Tens of Thousands of Downloads appeared first on NVIDIA Blog.
auton-survival: An Open-Source Package for Regression, Counterfactual Estimation, Evaluation and Phenotyping Censored Time-to-Event Data
![]()

Real-world decision-making often requires reasoning about when an event will occur. The overarching goal of such reasoning is to help aid decision-making for optimal triage and subsequent intervention. Such problems involving estimation of Times-to-an-Event frequently arise across multiple application areas, including,
Healthcare and Bio-informatics: More commonly known as ‘Survival Analysis‘ involves prognostication of an adverse physiological event like a stroke, the onset of cancer, re-hospitalization, and mortality. Time-to-event or survival analysis can be used to proactively mitigate adverse outcomes and extend the longevity of patients.
Internet Marketing and e-commerce: Models employed for estimating customer churn and retention in large commercial organizations are essentially time-to-event regression models and help determine best practices to maximize customer retention.
Predictive Maintenance: Reliability engineering and systems safety research involves the use of remaining useful life prediction models to help extend the longevity of machinery and equipment by proactive part and component replacement.
Finance and Actuarial and Sciences: Time-to-Event models are ubiquitous in the estimation of optimal financial strategies for setting insurance premiums, as well as estimating credit defaulting behavior.
Real-world decision-making often requires reasoning about when an event will occur. The overarching goal of such reasoning is to help aid decision-making for optimal triage and subsequent intervention. Such problems involving estimation of Times-to-an-Event frequently arise across multiple application areas, including,
Healthcare and Bio-informatics: More commonly known as ‘Survival Analysis‘ involves prognostication of an adverse physiological event like a stroke, the onset of cancer, re-hospitalization, and mortality. Time-to-event or survival analysis can be used to proactively mitigate adverse outcomes and extend the longevity of patients.
Internet Marketing and e-commerce: Models employed for estimating customer churn and retention in large commercial organizations are essentially time-to-event regression models and help determine best practices to maximize customer retention.
Predictive Maintenance: Reliability engineering and systems safety research involves the use of remaining useful life prediction models to help extend the longevity of machinery and equipment by proactive part and component replacement.
Finance and Actuarial and Sciences: Time-to-Event models are ubiquitous in the estimation of optimal financial strategies for setting insurance premiums, as well as estimating credit defaulting behavior.
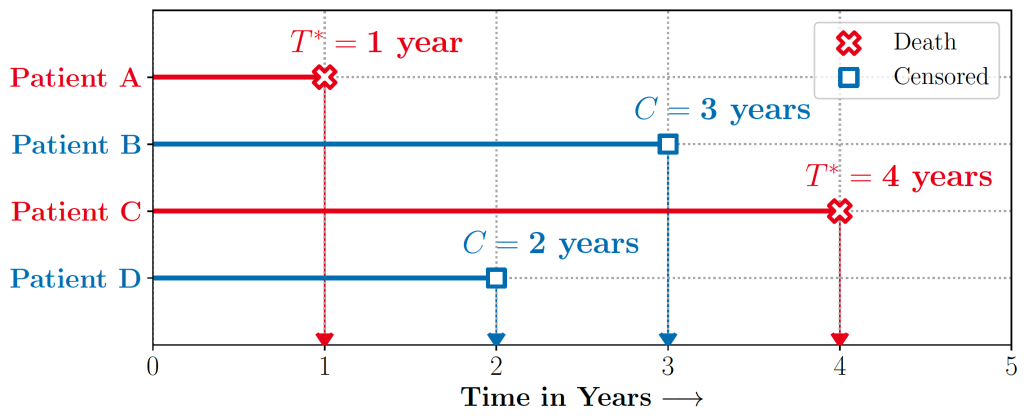
Figure 1 illustrates a typical example of a Time-to-Event problem in healthcare. The challenge of working with time-to-event data is compounded by the fact that as evidenced in the figure, such data typically includes individuals whose outcomes are unobserved, or ‘censored,’ either due to a loss of follow-up or end of the study.
Discretizing time-to-event outcomes to predict if an event will occur is a common approach in standard machine learning. However, this neglects temporal context, which could result in models that misestimate and lead to poorer generalization.
The auton-survival Package
In our recent Machine Learning for Healthcare ’22 paper, we present auton-survival – a comprehensive Python code repository of user-friendly, machine learning tools for working with censored time-to-event data. This package includes an exclusive suite of workflows for a range of tasks from data pre-processing and regression modeling to model evaluation. auton-survival includes an API similar to the scikit-learn package (Pedregosa et al., 2011), making its adoption easy for users with machine learning experience in Python. Additionally, to promote the usability of the package and rapid prototyping of solutions for both machine learning and clinical researchers, we include detailed documentation as well as example notebooks.
Time-to-Event Regression
Time-to-Event or Survival regression can be used to estimate the conditional probability of an event occurring within a specified time period or event-horizon. A time-to-event estimation problem thus reduces to estimating the conditional distribution of survival:
( mathbb{E}[1{T > t}|X = x] = mathbb{P}(T > t|X = x) = 1 − mathbb{P}(T ≤ t|X = x) )
Note that ( X) is a set of covariates, and ( T ) refers to the distribution of the censored survival time ( T = text{min}(T^∗, C) ) where ( T^∗ ) is the distribution of the true time-to-event and ( C ) is the distribution of the censoring time. Assuming conditional independence between ( T ) and ( C ) (ie., ( T ⊥ C|X )) allows identification of the distribution of ( mathbb{P}(T |X) ).
Survival regression naturally allows accounting for censored data. In the case of survival regression, the likelihood ( ell ) under censoring is given as
( ell ({x, t, δ}) ∝ mathbb{P}(T = t|X = x)^δmathbb{P}(T > t|X = x)^{1−δ} ).
Here ( x in mathbb{R}^d ) are the covariates, ( t in mathbb{R}^{+} ) is the event or censoring time and ( delta in {0, 1} ) is a binary indicator denoting if the individual was censored. For the censored individuals, the likelihood corresponds to the probability that the event takes place beyond the time horizon, ( t, mathbb{P}(T > t|X = x) ) also known as the ‘survival function‘.
Broadly, the popular approaches for learning estimators of survival in the presence of censoring can be categorized into:
- Parametric: Assume that time-to-event distribution ( mathbb{P}(T) ) adheres to a known parametric distribution, such as Weibull or Log-Normal.
- Non-Parametric: Involve learning kernels or similarity functions of the input covariates followed by a non-parametric (Kaplan-Meier or Nelson-Aalen) estimation of the survival rate weighted with the learned kernel.
- Semi-Parametric: As with Cox Proportional Hazards models, feature interactions are learned through a parametric model followed by a non-parametric estimation of the base survival (hazard) rate.
Estimators of Survival [Notebook] [Docs]
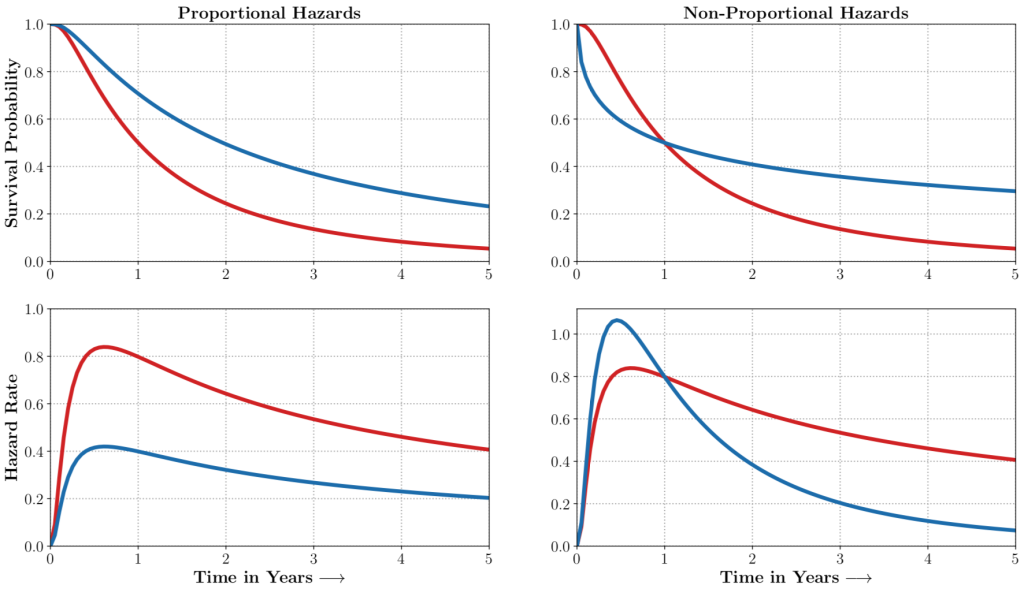
auton-survival includes flexible estimators of time-to-events in the presence of non-proportional hazards.Complex multimodal data often observed in healthcare and other applications, bring a multitude of challenges to traditional machine learning. auton-survival allows a simple interface to use deep neural networks and representation learning to model such complex data.
auton-survival includes extensions to the standard Cox Proportional Hazards (CPH) (Cox, 1972) involving deep representation learning (Faraggi and Simon, 1995; Katzman et al., 2018) as well as latent variable survival regression models, Deep Cox Mixtures (DCM), and Deep Survival Machines (DSM) (Nagpal et al., 2021 a,b) that ease the strong assumptions of proportional hazards shown in Figure 2 by modeling the time-to-event distribution as a fixed size mixture.
The SurvivalModel Class
The package provides a convenient SurvivalModel class that enables rapid experimentation via a consistent API that wraps multiple alternative regression estimators. In addition to the models mentioned above, the SurvivalModel class includes Random Survival Forests (RSF) (Ishwaran et al., 2008), which is a popular non-parametric survival model.
Hyperparameter tuning for model selection can be streamlined with the SurvivalRegressionCV class to apply ( K-text{fold} ) cross-validation over a user-specified hyperparameter grid.
Time-Varying Survival Regression
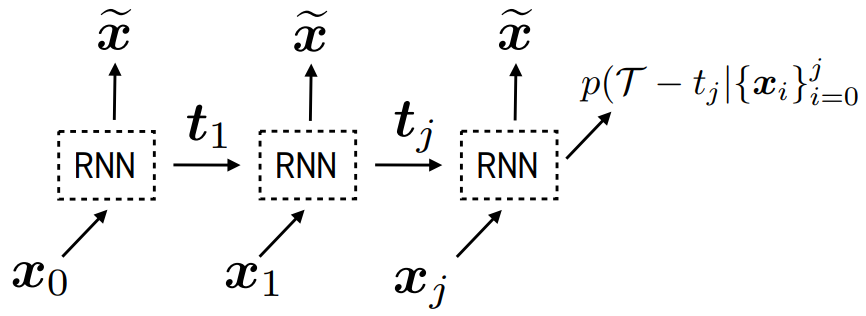
Real-world data often consists of multiple time-dependent observations per individual or time-varying covariates. auton-survival is equipped to handle time-varying covariates for survival analysis with auto-regressive deep learning models that allow learning temporal dependencies when estimating time-to-event outcomes. Implementations of time-varying DSM and Deep Cox Proportional Hazards model involve the use of RNNs, LSTMs, or GRUs (Chung et al., 2014; Hochreiter and Schmidhuber, 1997) for time-varying survival regression as shown in Figure 3.
Counterfactual Estimators of Survival
Decision support often requires reasoning about ‘what if’ scenarios regarding the effect of different treatments on outcomes. In observational settings, outcomes and treatment assignments may share common causes. Adjusting for such confounding factors is crucial when performing causal inference. auton-survival includes counterfactual survival regression as a tool for causal inference that accounts for confounding factors when estimating the effect of treatment on survival. Counterfactual survival regression involves fitting separate regression models on the treated and control populations and computing survival rates across treatment arms. Under the standard causal inference assumption of strong ignorability, the time-to-event outcome under intervention ( text{do}(A = a) ) can then be estimated as
(hat{S}big(t|text{do}(A = a)big) = mathop{mathbb{E}}_{X} big[hat{mathbb{E}}[1{T > t}|X = x, A = a] big] )
where (hat{mathbb{E}}[1{T > t}|X = x, A = a]) is just an estimate of the conditional expectation of survival learnt on the population under intervention ( (A=a) ).
Consider the data from the large SEER Cancer Incidence registry (Ries et al., 1975). When stratified by region (Figure 4a), there is an apparent disparity in survival rates. We demonstrate the use of counterfactual regression to provide insight into whether these discrepancies can be attributed to the geographic region or other socio-economic or physiological confounding factors that affect both belonging to these regions and the outcomes. To adjust estimates of survival with counterfactual estimation, we train two separate Deep Cox models on data from Greater California and Louisiana as counterfactual regressors. The fitted regressors are then applied to estimate the survival curves for each instance, which are then averaged over treatment groups to compute the domain-specific survival rate. Figure 4b presents the counterfactual survival rates compared with the survival rates obtained from a Kaplan-Meier estimator. The Kaplan-Meier estimator does not adjust for confounding factors and overestimates treatment effect, as evidenced by the extent that survival rates differ between regions. Alternatively, counterfactual regression adjusts for confounding factors and predicts more similar survival rates between regions.
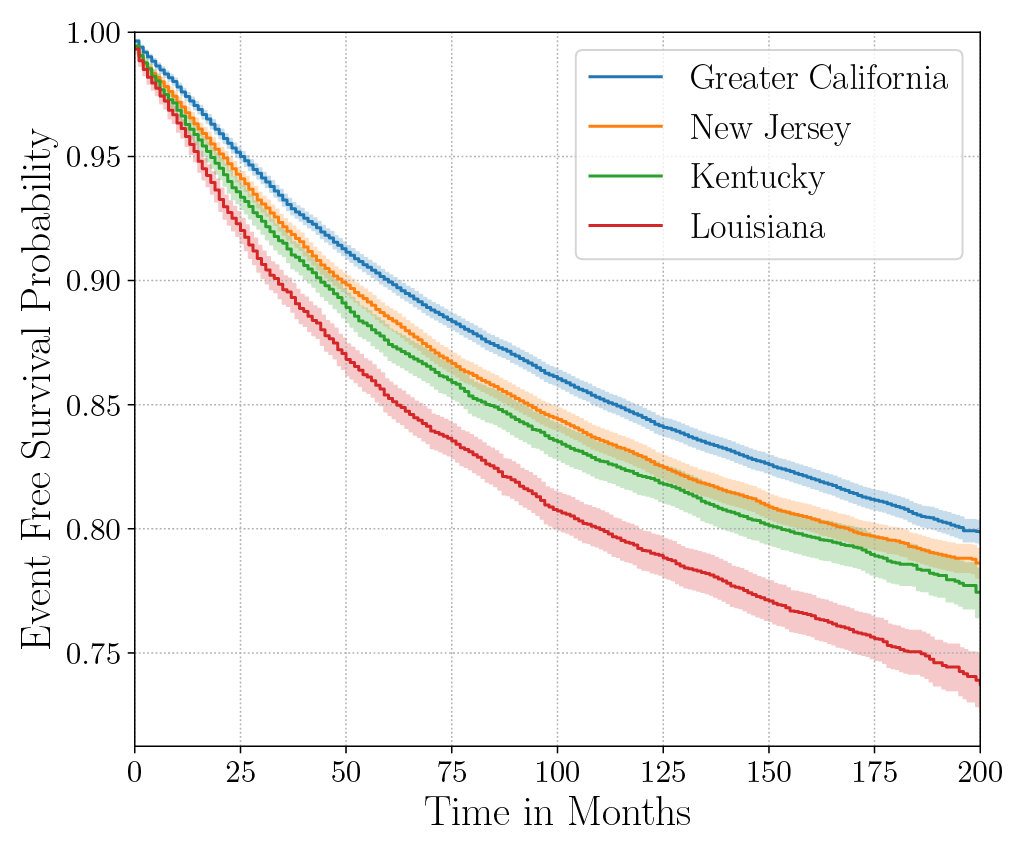
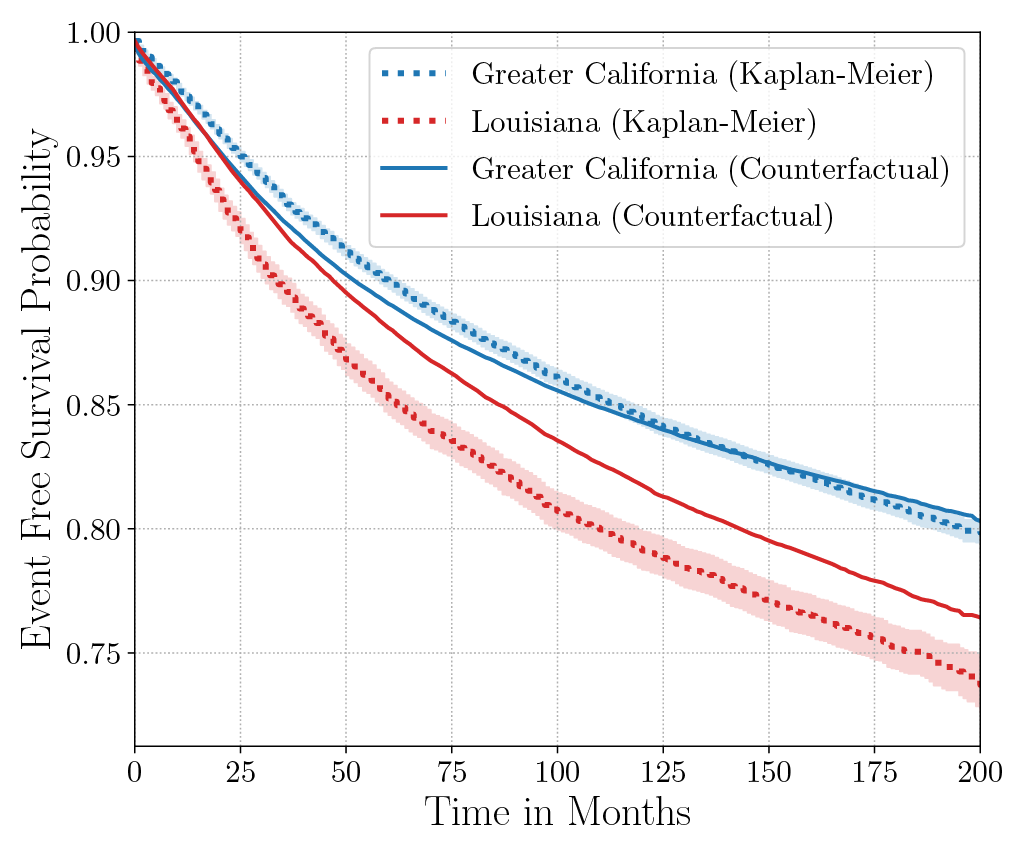
discrepancies in the Kaplan-Meier estimated survival rates when stratified by the geographic
region (left). The Kaplan-Meier estimator overestimates the effect of region on mortality compared with the counterfactual regression model, which reduces discrepancy in survival rates between regions (right).
Phenotyping Censored Survival Data [Notebook] [Docs]
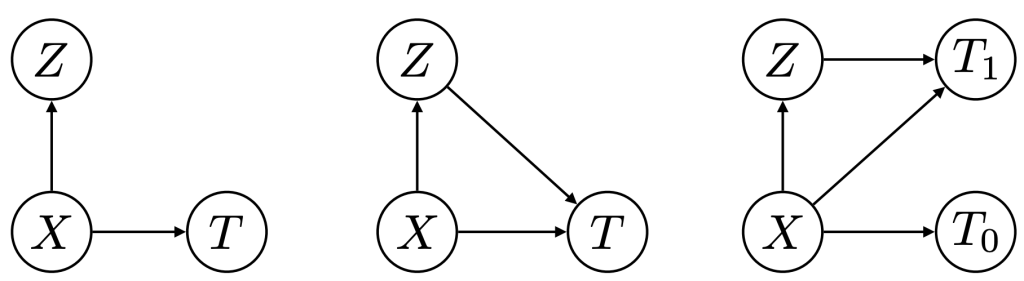
Figure 5: Phenotypers in auton-survival: ( X ) represents the covariates, ( T ) the time-to-event, and ( Z ) is the phenotype to be inferred.
Survival rates differ across groups of individuals with heterogeneous characteristics. Identifying groups of patients with similar survival rates can be used to derive insight into practices and interventions that can help improve longevity for such groups. While domain knowledge can help identify such subgroups, in practice there could be potentially complex, non-linear feature interactions that determine assignment to subgroups, making identification difficult. In auton-survival, we refer to this group identification and survival assessment as phenotyping.
Our package offers multiple approaches to phenotyping that involve either the use of specific domain knowledge, as in the case of the intersectional phenotyper, or a completely unsupervised approach that clusters subjects based on the observed covariates. Additionally, auton-survival also offers phenotypers that explicitly involve supervision in the form of the observed outcomes and counterfactuals inform the learned phenotypes to better stratify the data. Directed Acyclic Graphical representations of probabilistic phenotypers in auton-survival are shown in Figure 5.
- Intersectional Phenotyping: Recovers groups, or phenotypes, of individuals over exhaustive combinations of user-specified categorical and numerical features.
- Unsupervised Phenotyping: Identifies groups of individuals based on structured similarity in the feature space by first performing dimensionality reduction of the input covariates, followed by clustering. The estimated probability of an individual belonging to a latent group is computed as the distance to the cluster normalized by the sum of distances to other clusters.
- Supervised Phenotyping: Identifies latent groups of individuals with similar survival outcomes conditioned on outcomes. This approach can be performed as a direct consequence of training the DSM and DCM latent variable survival estimators.
- Counterfactual Phenotyping: Identifies groups of individuals that demonstrate enhanced or diminished treatment effects (Chirag et al., 2022).
Figure 6 presents the Kaplan-Meier survival curves of the phenogroups extracted from SUPPORT (Knaus et al., 1995) using the unsupervised and supervised phenotyping. The intersecting survival curves suggest the phenotypers’ ability to recover phenogroups that do not strictly adhere to assumptions of Proportional Hazards. From Figure 7, it can be inferred that supervised phenotyping extracts phenogroups with higher discriminative power as indicated by the contrasting Kaplan-Meier estimates of phenogroup level survival.


Figure 6: Kaplan-Meier survival curves of the phenogroups extracted from SUPPORT using the unsupervised and supervised phenotyping.
Treatment Effect Estimation
auton-survival offers additional tools to analyze the effect of an intervention on outcomes by computing propensity-adjusted treatment effects in terms of the following metrics through bootstrap resampling of the dataset with replacement:
- Hazard Ratio: Assuming the proportional hazards assumptions holds, the treatment effect can be measured as the ratio of hazard rates between the treatment and control arms.
- Time at Risk (TaR) (Figure 7a): The treatment effect can be measured as the difference in time-to-event at a specified level of risk.
- Risk at Time (Figure 7b): The treatment effect can be measured as the difference in risk at a specified time horizon.
- Restricted Mean Survival Time (RMST) (Figure 7c): The treatment effect can be measured as the difference in the expected (or mean) time-to-event conditioned on a specified time horizon.
Propensity-adjustment allows an alternative approach to estimate treatment effects of potential confounders that influence both treatment assignment and the outcome. Not adjusting for treatment propensity could result in misestimations of treatment effects.



Figure 7: Treatment effects measured in terms of the difference in metrics computed for
treatment and control groups including (a) the time at a specified level of risk (b) risk at a
certain time and (c) the expected survival time over a truncated time horizon.
auton-survival allows adjusting for treatment propensity with computation of treatment effects bootstrapped with sample weights. When the specified sample weights are propensity scores, such as obtained from a classification model, the bootstrapped distribution treatment effect converges to the Inverse Propensity of Treatment Weighting (IPTW) Thompson-Horvitz estimate of the population Average Treatment Effect.
(mathbb{ATE}(mathcal{D}^*, f) = mathbb{E}_{x sim mathcal{D}^*} big[mathbb{E} [f_1(x) – f_0(x) | X = x]big] ; quad mathcal{D}^* sim frac{1}{widehat{mathbb{P}}(A|X)} cdot mathbb{P}^*(mathcal{D}) )
In a second analysis of the effect of geographical region on breast cancer mortality using data from the SEER cancer registry (Ries et al., 1975), we compare treatment effects before and after adjusting for confounding factors by inverse propensity weighting. Similar to the previous analysis with counterfactual regression, we consider the regions of “Greater California” and “Louisiana” as the binary “treatment” in question. To adjust treatment effects for confounding factors, we first trained a logistic regression with an ( ell_2 ) penalty by regressing the geographical region on the set of confounding variables. The estimated propensity scores are then employed as sampling weights for the treatment effects in terms of hazard ratios, restricted mean survival time (RMST), and risk difference as in Figure 8. Adjusting for region propensity noticeably mitigates differences in treatment effects, indicating that mortality due to breast cancer is likely explained by confounding socio-economic and physiological factors rather than solely the geographic region.



Figure 8: Estimated probability densities of the bootstrapped treatment effects treatment effects before (blue) and after (red) adjusting for treatment propensity by inverse propensity weighting.
Conclusion
We present auton-survival, an open-source Python package encapsulating multiple pipelines to work with censored time-to-event data. Such data is ubiquitous in many fields, including healthcare and the maintenance of equipment. Through continuous collaboration with the machine learning for healthcare community, we aim to better aid machine learning research in efforts to create a robust, comprehensive repository of rigorous tools for reproducible analysis of censored time-to-event data.
Authors
Chirag Nagpal
PhD Candidate, Auton Lab
@nagpalchirag
cs.cmu.edu/~chiragn
Willa Potosnak
Research Intern and
Incoming PhD Student, Auton Lab
potosnakw.github.io
References
[1] Nagpal, C., Potosnak, W. and Dubrawski, A., 2022. auton-survival: an Open-Source Package for Regression, Counterfactual Estimation, Evaluation and Phenotyping with Censored Time-to-Event Data. arXiv preprint arXiv:2204.07276.
[2] Fabian Pedregosa, Ga¨el Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, et al. Scikit-learn: Machine learning in python. the Journal of machine Learning research, 12: 2825–2830, 2011.
[3] D. R. Cox. Regression models and life-tables. Journal of the Royal Statistical Society. Series B (Methodological), 34(2):187–220, 1972.
[4] David Faraggi and Richard Simon. A neural network model for survival data. Statistics in medicine, 14(1):73–82, 1995.
[5] Jared L Katzman, Uri Shaham, Alexander Cloninger, Jonathan Bates, Tingting Jiang, and Yuval Kluger. Deepsurv: personalized treatment recommender system using a cox proportional hazards deep neural network. BMC medical research methodology, 18(1): 1–12, 2018.
[6] Nagpal, C., Li, X. and Dubrawski, A., 2021a. Deep survival machines: Fully parametric survival regression and representation learning for censored data with competing risks. IEEE Journal of Biomedical and Health Informatics, 25(8), pp.3163-3175.
[7] Nagpal, C., Yadlowsky, S., Rostamzadeh, N. and Heller, K., 2021b, October. Deep Cox mixtures for survival regression. In Machine Learning for Healthcare Conference (pp. 674-708). PMLR.
[8] H. Ishwaran, Udaya B. Kogalur, Eugene H. Blackstone, and Michael S. Lauer. Random survival forests. The Annals of Applied Statistics, 2(3), 2008.
[9] Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, and Yoshua Bengio. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555, 2014.
[10] Sepp Hochreiter and J¨urgen Schmidhuber. Long short-term memory. Neural computation, 9 (8):1735–1780, 1997.
[11] LAG Ries, D Melbert, M Krapcho, DG Stinchcomb, N Howlader, MJ Horner, A Mariotto, BA Miller, EJ Feuer, SF Altekruse, et al. Seer cancer statistics review, 1975–2005. Bethesda, MD: National Cancer Institute, 2999, 2008.
[12] Nagpal, C., Goswami, M., Dufendach, K. and Dubrawski, A., 2022. Counterfactual Phenotyping with Censored Time-to-Events. arXiv preprint arXiv:2202.11089.
[13] W. A. Knaus, Harrell F. E., Lynn J, and et al. The support prognostic model: Objective estimates of survival for seriously ill hospitalized adults. Annals of Internal Medicine, 122: 191–203, 1995.