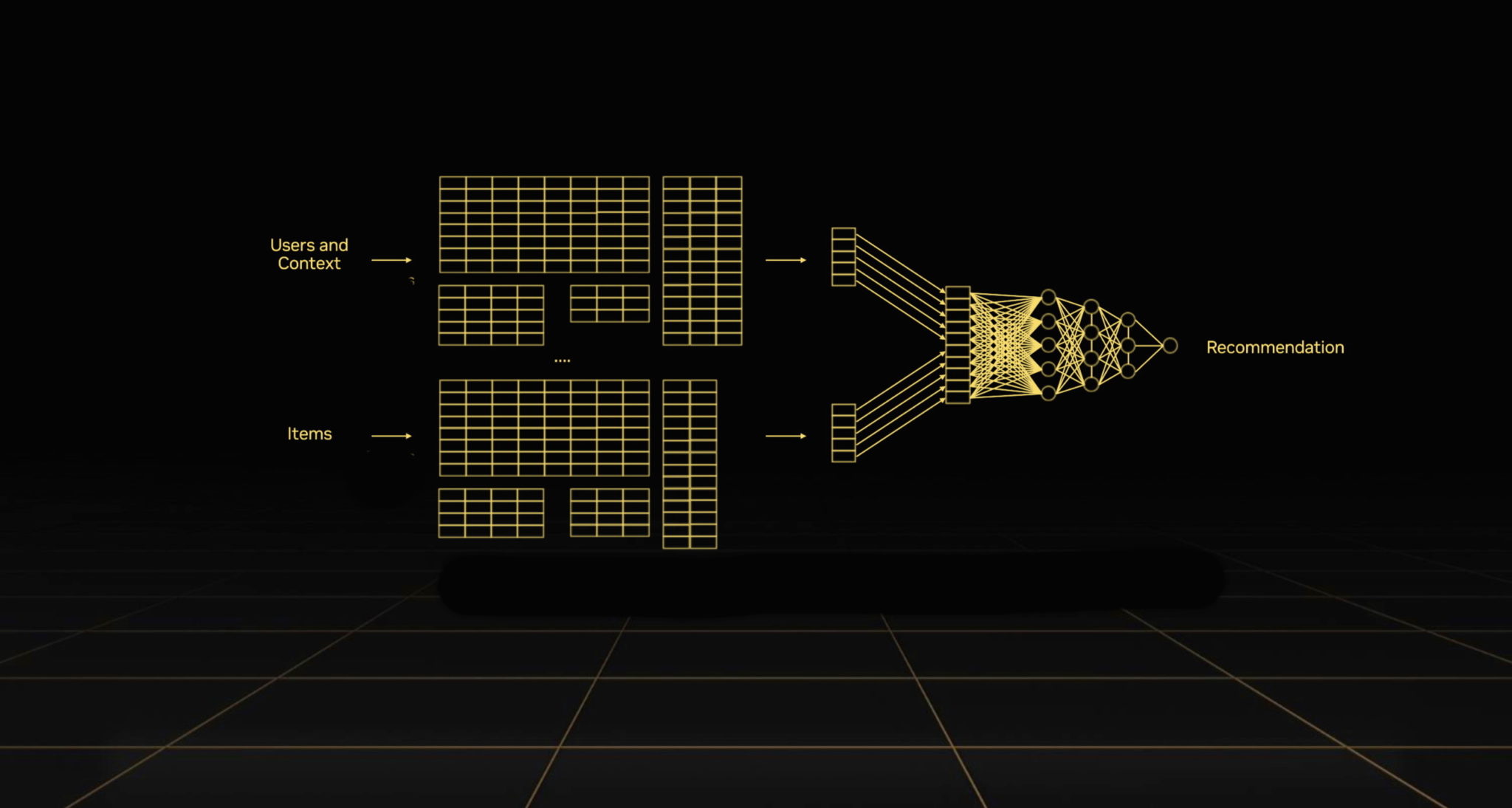
Recommender systems, the economic engines of the internet, are getting a new turbocharger: the NVIDIA Grace Hopper Superchip.
Every day, recommenders serve up trillions of search results, ads, products, music and news stories to billions of people. They’re among the most important AI models of our time because they’re incredibly effective at finding in the internet’s pandemonium the pearls users want.
These machine learning pipelines run on data, terabytes of it. The more data recommenders consume, the more accurate their results and the more return on investment they deliver.
To process this data tsunami, companies are already adopting accelerated computing to personalize services for their customers. Grace Hopper will take their advances to the next level.
GPUs Drive 16% More Engagement
Pinterest, the image-sharing social media company, was able to move to 100x larger recommender models by adopting NVIDIA GPUs. That increased engagement by 16% for its more than 400 million users.
“Normally, we would be happy with a 2% increase, and 16% is just a beginning,” a software engineer at the company said in a recent blog. “We see additional gains — it opens a lot of doors for opportunities.”
Recommenders consume tens of terabytes of embeddings, data tables that provide context for making accurate predictions.
The next generation of the NVIDIA AI platform promises even greater gains for companies processing massive datasets with super-sized recommender models.
Because data is the fuel of AI, Grace Hopper is designed to pump more data through recommender systems than any other processor on the planet.
NVLink Accelerates Grace Hopper
Grace Hopper achieves this because it’s a superchip — two chips in one unit, sharing a superfast chip-to-chip interconnect. It’s an Arm-based NVIDIA Grace CPU and a Hopper GPU that communicate over NVIDIA NVLink-C2C.
What’s more, NVLink also connects many superchips into a super system, a computing cluster built to run terabyte-class recommender systems.
NVLink carries data at a whopping 900 gigabytes per second — 7x the bandwidth of PCIe Gen 5, the interconnect most leading edge upcoming systems will use.
That means Grace Hopper feeds recommenders 7x more of the embeddings — data tables packed with context — that they need to personalize results for users.
More Memory, Greater Efficiency
The Grace CPU uses LPDDR5X, a type of memory that strikes the optimal balance of bandwidth, energy efficiency, capacity and cost for recommender systems and other demanding workloads. It provides 50% more bandwidth while using an eighth of the power per gigabyte of traditional DDR5 memory subsystems.
Any Hopper GPU in a cluster can access Grace’s memory over NVLink. It’s a feature of Grace Hopper that provides the largest pools of GPU memory ever.
In addition, NVLink-C2C requires just 1.3 picojoules per bit transferred, giving it more than 5x the energy efficiency of PCIe Gen 5.
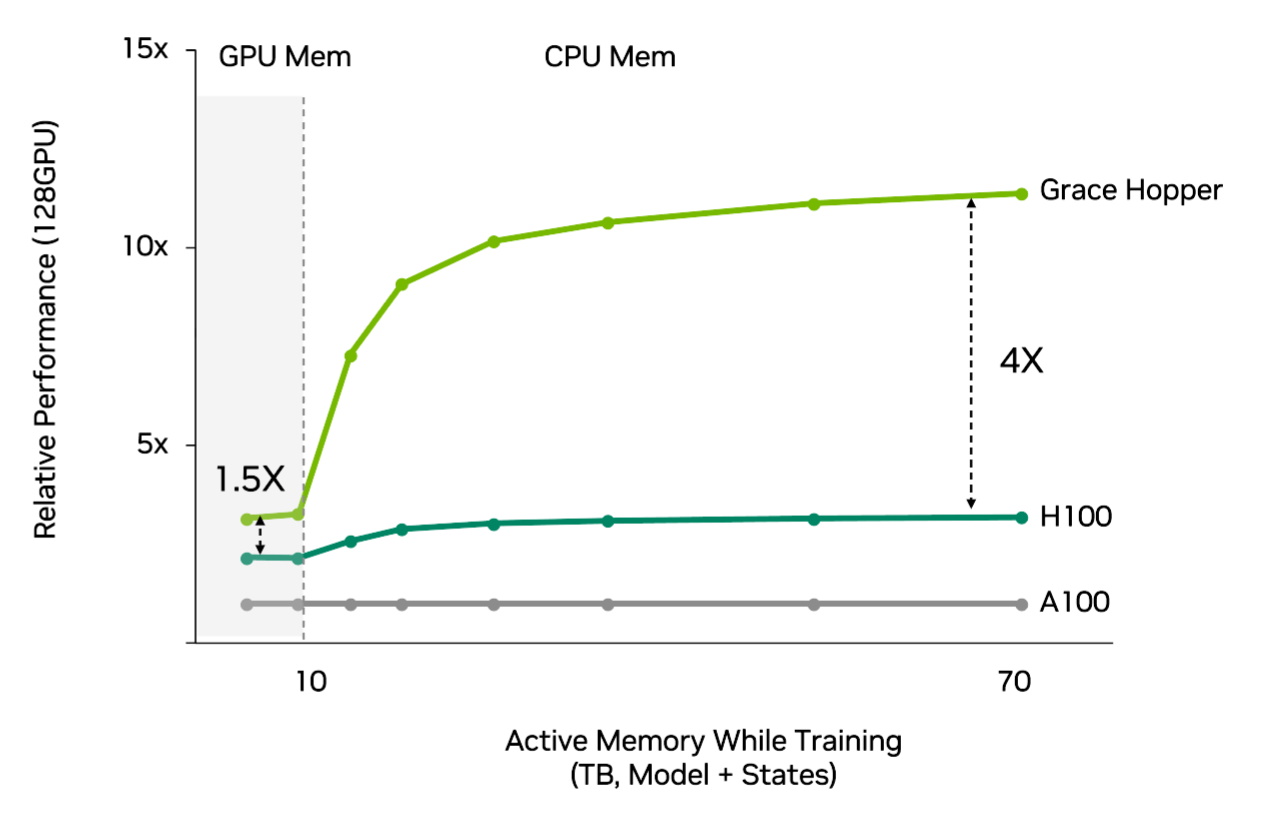
The overall result is recommenders get a further up to 4x more performance and greater efficiency using Grace Hopper than using Hopper with traditional CPUs (see chart below).
All the Software You Need
The Grace Hopper Superchip runs the full stack of NVIDIA AI software used in some of the world’s largest recommender systems today.
NVIDIA Merlin is the rocket fuel of recommenders, a collection of models, methods and libraries for building AI systems that can provide better predictions and increase clicks.
As scientists probe for new insights about DNA, proteins and other building blocks of life, the NVIDIA BioNeMo framework — announced today at NVIDIA GTC — will accelerate their research.
NVIDIA BioNeMo is a framework for training and deploying large biomolecular language models at supercomputing scale — helping scientists better understand disease and find therapies for patients. The large language model (LLM) framework will support chemistry, protein, DNA and RNA data formats.
It’s part of the NVIDIA Clara Discovery collection of frameworks, applications and AI models for drug discovery.
Just as AI is learning to understand human languages with LLMs, it’s also learning the languages of biology and chemistry. By making it easier to train massive neural networks on biomolecular data, NVIDIA BioNeMo helps researchers discover new patterns and insights in biological sequences — insights that researchers can connect to biological properties or functions, and even human health conditions.
NVIDIA BioNeMo provides a framework for scientists to train large-scale language models using bigger datasets, resulting in better-performing neural networks. The framework will be available in early access on NVIDIA NGC, a hub for GPU-optimized software.
In addition to the language model framework, NVIDIA BioNeMo has a cloud API service that will support a growing list of pretrained AI models.
Scientists using natural language processing models for biological data today often train relatively small neural networks that require custom preprocessing. By adopting BioNeMo, they can scale up to LLMs with billions of parameters that capture information about molecular structure, protein solubility and more.
BioNeMo is an extension of the NVIDIA NeMo Megatron framework for GPU-accelerated training of large-scale, self-supervised language models. It’s domain specific, designed to support molecular data represented in the SMILES notation for chemical structures, and in FASTA sequence strings for amino acids and nucleic acids.
“The framework allows researchers across the healthcare and life sciences industry to take advantage of their rapidly growing biological and chemical datasets,” said Mohammed AlQuraishi, founding member of the OpenFold Consortium and assistant professor at Columbia University’s Department of Systems Biology. “This makes it easier to discover and design therapeutics that precisely target the molecular signature of a disease.”
BioNeMo Service Features LLMs for Chemistry and Biology
For developers looking to quickly get started with LLMs for digital biology and chemistry applications, the NVIDIA BioNeMo LLM service will include four pretrained language models. These are optimized for inference and will be available under early access through a cloud API running on NVIDIA DGX Foundry.
ESM-1: This protein LLM, originally published by Meta AI Labs, processes amino acid sequences to generate representations that can be used to predict a wide variety of protein properties and functions. It also improves scientists’ ability to understand protein structure.
OpenFold: The public-private consortium creating state-of-the-art protein modeling tools will make its open-source AI pipeline accessible through the BioNeMo service.
MegaMolBART: Trained on 1.4 billion molecules, this generative chemistry model can be used for reaction prediction, molecular optimization and de novo molecular generation.
ProtT5: The model, developed in a collaboration led by the Technical University of Munich’s RostLab and including NVIDIA, extends the capabilities of protein LLMs like ESM-1b to sequence generation.
In the future, researchers using the BioNeMo LLM service will be able to customize the LLM models for higher accuracy on their applications in a few hours — with fine-tuning and new techniques such as p-tuning, a training method that requires a dataset with just a few hundred examples instead of millions.
Startups, Researchers and Pharma Adopting NVIDIA BioNeMo
A wave of experts in biotech and pharma are adopting NVIDIA BioNeMo to support drug discovery research.
AstraZeneca and NVIDIA have used the Cambridge-1 supercomputer to develop the MegaMolBART model included in the BioNeMo LLM service. The global biopharmaceuticals company will use the BioNeMo framework to help train some of the world’s largest language models on datasets of small molecules, proteins and, soon, DNA.
Researchers at the Broad Institute of MIT and Harvard are working with NVIDIA to develop next-generation DNA language models using the BioNeMo framework. These models will be integrated into Terra, a cloud platform co-developed by the Broad Institute, Microsoft and Verily that enables biomedical researchers to share, access and analyze data securely and at scale. The AI models will also be added to the BioNeMo service’s collection.
The OpenFold consortium plans to use the BioNeMo framework to advance its work developing AI models that can predict molecular structures from amino acid sequences with near-experimental accuracy.
Peptone is focused on modeling intrinsically disordered proteins — proteins that lack a stable 3D structure. The company is working with NVIDIA to develop versions of the ESM model using the NeMo framework, which BioNeMo is also based on. The project, which is scheduled to run on NVIDIA’s Cambridge-1 supercomputer, will advance Peptone’s drug discovery work.
Evozyne, a Chicago-based biotechnology company, combines engineering and deep learning technology to design novel proteins to solve long-standing challenges in therapeutics and sustainability.
“The BioNeMo framework is an enabling technology to efficiently leverage the power of LLMs for data-driven protein design within our design-build-test cycle,” said Andrew Ferguson, co-founder and head of computation at Evozyne. “This will have an immediate impact on our design of novel functional proteins, with applications in human health and sustainability.”
“As we see the ever-widening adoption of large language models in the protein space, being able to efficiently train LLMs and quickly modulate model architectures is becoming hugely important,” said Istvan Redl, machine learning lead at Peptone, a biotech startup in the NVIDIA Inception program. “We believe that these two engineering aspects — scalability and rapid experimentation — are exactly what the BioNeMo framework could provide.”
Promising to help process images faster and more efficiently at a vast scale, NVIDIA introduced CV-CUDA, an open-source library for building accelerated end-to-end computer vision and image processing pipelines.
The majority of internet traffic is video. Increasingly, this video will be augmented by AI special effects and computer graphics.
To add to this complexity, fast-growing social media and video-sharing services are experiencing growing cloud computing costs and bottlenecks in their AI-based imaging processing and computer vision pipelines.
CV-CUDA accelerates AI special effects such as relighting, reposing, blurring backgrounds and super resolution.
NVIDIA GPUs already accelerate the inference portion of AI computer vision pipelines. But pre- and post-processing using traditional computer vision tools gobble up time and computing power.
CV-CUDA gives developers more than 50 high-performance computer vision algorithms, a development framework that makes it easy to implement custom kernels and zero-copy interfaces to remove bottlenecks in the AI pipeline.
The result is higher throughput and lower cloud-computing costs. CV-CUDA can process 10x as many streams on a single GPU.
All this helps developers move much faster when tackling video content creation, 3D worlds, image-based recommender systems, image recognition and video conferencing.
Video content creation platforms must process, enhance and moderate millions of video streams daily and ensure mobile-based users have the best experience running their apps on any phone.
For those building 3D worlds or metaverse applications, CV-CUDA is anticipated to enable tasks to help build or extend 3D worlds and their components.
In image understanding and recognition, CV-CUDA can significantly speed up the pipelines running at hyperscale, allowing mobile users to enjoy sophisticated and responsive image recognition applications.
And in video conferencing, CV-CUDA can support sophisticated augmented reality-based features. These features could involve complex AI pipelines requiring numerous pre- and post-processing steps.
CV-CUDA accelerates pre- and post-processing pipelines through hand-optimized CUDA kernels and natively integrates into C/C++, Python and common deep learning frameworks, such as PyTorch.
CV-CUDA will be one of the core technologies that can accelerate AI workflows in NVIDIA Omniverse, a virtual world simulation and collaboration platform for 3D workflows.
Developers can get early access to code in December, with a beta release set for March.
In her 18 years as a competitive figure skater, Bettina Heim learned to land a lutz with speed and grace. Now, armed with a Ph.D. in quantum computing, she’s helping Microsoft Azure Quantum carve out a position at the cutting edge of cloud services.
“I’ve always been attracted to interesting problems and working hard to achieve a goal,” said Heim, a principal software engineering manager at Microsoft. “That’s why I was drawn to quantum computing, where there’s a huge potential to benefit society by creating a completely new tool beyond today’s classical systems.”
Last winter, Azure Quantum — in collaboration with Quantinuum, Quantum Circuits Inc., Rigetti Computing and Oak Ridge National Lab — demonstrated how classical and quantum systems can work together to tackle big problems, a capability it aims to deliver to any cloud user.
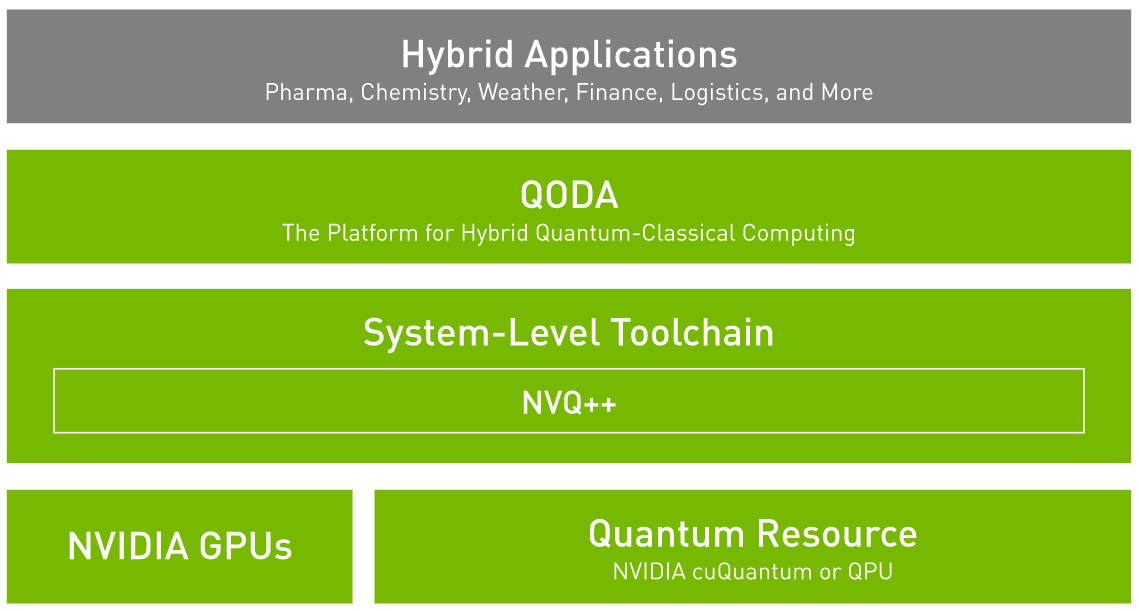
To get there, it’s embracing tools such as NVIDIA QODA, an open, universal programming environment that will link GPUs and quantum processors in future hybrid systems.
“QODA will help us take that next step of offering a robust integration of very different systems and developer tools,” said Heim, a Swiss national now based in Seattle.
Quantum’s Software Foundation
Laying the software foundation for quantum computers is the focus of the QIR Alliance that Heim chairs.
The industry group oversees work on a common interface between quantum programming languages and targeted quantum computers. QIR enables developers to use tools like QODA to build apps that run on hybrid quantum computers to accelerate scientific discovery.
That’s a huge leap for a sector where developers are used to writing the equivalent of assembler programs that directly address the specifics of each system.
“It’s important to have tools that don’t require deep knowledge of quantum systems, so we’re collaborating with companies like NVIDIA to engage and inspire a broad field of developers,” she said.
“QODA and cuQuantum provide a great step ahead for the field by taking advantage of classical HPC resources for quantum development,” she added, referring to NVIDIA cuQuantum, a software library for running quantum-circuit simulations on GPU-accelerated systems.
An Expanding Quantum Ecosystem
The collaboration with Microsoft to expand the QIR ecosystem and integrate NVIDIA’s toolset with Azure Quantum is one among many. Dozens of companies are adopting cuQuantum to accelerate quantum research on today’s classical computers and QODA to program tomorrow’s hybrid classical-quantum systems.
For example, Rigetti Computing will let developers use QODA to program its superconducting quantum computers. And software specialist Classiq will use QODA to optimize performance of its quantum algorithms.
QODA provides a unified programming model for hybrid quantum-classical computers.
The companies join quantum hardware providers IQM Quantum Computers, Pasqal, Quantinuum, Quantum Brilliance and Xanadu, which announced collaborations using QODA in July. They support a broad range of qubit technologies that reinforce QODA’s role as a unified platform enabling all hybrid quantum-classical systems.
In addition, QODA has support from software providers QC Ware and Zapata Computing and four supercomputing centers: Forschungszentrum Jülich, Lawrence Berkeley National Laboratory, Oak Ridge National Laboratory and RIKEN in Japan.
Industry Research Rides cuQuantum
Meanwhile, the applications for quantum circuit simulations on cuQuantum are expanding.
BMW Group identified more than 40 automotive use cases for quantum computing in a paper last year. This year, it used cuQuantum’s cuStateVec library as part of its work on a benchmark for quantum applications.
The automaker hosted a global challenge in collaboration with Amazon Web Services (AWS) to show ways quantum systems can address the sector’s toughest optimization, AI and material science problems. In a sign of the broad interest in the technology, the challenge attracted 70 teams.
In Japan, the Fujifilm Informatics Research Laboratory is using cuQuantum to build quantum circuits with startup blueqat. The collaboration aims to create simulations of large-scale quantum circuits to accelerate Fujifilm’s R&D.
Developers can use cuQuantum to create accurate simulations of hundreds of qubits on a single NVIDIA A100 Tensor Core GPU, and thousands of qubits on a supercomputing cluster.
Quantum Expands in the Cloud
Oracle Cloud services will let developers create quantum-circuit simulations on GPUs. It’s making available on the Oracle Cloud Marketplace the DGX cuQuantum Appliance, a container with all the components needed to run cuQuantum jobs.
Likewise, AWS announced the availability of cuQuantum in its Braket service. It also demonstrated on Braket how cuQuantum can provide up to a 900x speedup on quantum machine learning workloads.
Consulting firms are also showing the potential of quantum computing accelerated with NVIDIA software.
AI Gets a Quantum Boost
Deloitte will use cuQuantum and QODA to take natural language processing to new heights in customer service. It will employ high-dimensional datasets to let systems interpret full sentences.
In other projects, it will explore how cuQuantum can speed drug discovery and unravel complex optimization problems in structured medical data.
The R&D group at SoftServe, a global IT consulting and services company, is using cuQuantum in several application areas including drug discovery and the optimization of emergency logistics. It also runs the software in quantum simulations of finance such as forecasting trends in stock prices and automating financial portfolio management.
The research efforts join those from existing collaborators, including Google Quantum AI and IonQ, that announced support for cuQuantum at its launch in late 2021.
Learn More at GTC
Learn more by watching GTC sessions that give an overview of quantum-accelerated supercomputing, its ecosystem and its applications in the pharmaceutical industry.
And to get the big picture, watch NVIDIA founder and CEO Jensen Huang’s GTC keynote below.
The NVIDIA DRIVE ecosystem is pulling further ahead of the pack with intelligent, software-defined vehicles powered by the high-performance, scalable compute solutions announced today at NVIDIA GTC.
Premium electric-mobility brand ZEEKR will be the first customer for the next-generation NVIDIA DRIVE Thor centralized AI computer, with production starting in 2025. Momentum also continues for the current-generation DRIVE Orin, as electric vehicle maker Xpeng and autonomous vehicle company QCraft announced new models built on the platform.
The NVIDIA DRIVE in-vehicle AI compute platform is scalable, so companies can seamlessly use current software development on future vehicle generations.
The DRIVE platform is architected for safety. NVIDIA has invested over 15,000 engineering years in safety systems and processes. Five million lines of code have been safety assessed, and the company’s platforms are designed for ASIL D and ISO 26262 compliance.
The industry is validating these high-performance, automotive-grade technologies, with plans to build software-defined vehicles on both current- and future-generation platforms.
Turbocharged EV Development
Founded last year, ZEEKR is hitting the ground sprinting.
The premium EV brand is part of Geely Auto Group, one of the leading automakers in China. In 2021 alone, the Geely sold nearly 1.5 million vehicles.
ZEEKR’s first model, the 001, began production last year, and the automaker aims to sell 650,000 intelligent vehicles by 2025 to meet accelerating demand for EVs. The brand is designing vehicles that provide customers an immersive, AI-enabled experience — with innovation as standard.
The ZEEKR 001
ZEEKR has selected the centralized DRIVE Thor platform to power automated-driving functions, as well as infotainment and cluster. Thor delivers up to 2,000 teraflops of AI performance and cutting-edge AI features, unifying these intelligent functions on a single platform.
These features include highly automated driving capabilities, parking, digital instrument cluster and infotainment. The unified architecture is expected to achieve even greater efficiency and lower overall system cost.
ZEEKR has already selected DRIVE Orin for its in-house advanced driver-assistance development. With the forward-compatible DRIVE platform, ZEEKR can seamlessly leverage its current development investments on DRIVE Orin to DRIVE Thor for its long-term production roadmap and beyond.
Pulling Ahead With AI Performance
As NVIDIA puts the pedal to the metal on AI compute performance, the industry continues to innovate on the current-generation DRIVE Orin platform.
Earlier this week, Xpeng took the wraps off its G9 electric SUV, built on DRIVE Orin to deliver an enhanced driving experience.
The Xpeng G9
The G9 features dual DRIVE Orin configurations, delivering 508 trillion operations per second of performance for address-to-address automated driving. It also supports intelligent functions such as autonomous parking and can safely handle side streets, toll booths and more.
Autonomous-solutions provider QCraft also announced this week that its latest-generation self-driving platform built on DRIVE Orin will begin public operations this month in a robotaxi fleet in China.
The NVIDIA DRIVE ecosystem revs onward with the scalable, high-performance AI compute platform, enabling automakers to develop vehicles and technology miles ahead of their time.
Posted by Douglas Yarrington (Google TPgM), James Rubin (Google PM), Neal Vaidya (NVIDIA TME), Jay Rodge (NVIDIA PMM)
Together, NVIDIA and Google are delighted to announce new milestones and plans to optimize TensorFlow and JAX for the Ampere and recently announced Hopper GPU architectures by leveraging the power of XLA: a performant, flexible and extensible ML compiler built by Google. We will deepen our ongoing collaboration with dedicated engineering teams focused on delivering improved performance in currently available A100 GPUs. NVIDIA and Google will also jointly support unique features in the recently announced H100 GPU, including the Transformer Engine with support for hardware-accelerated 8-bit floating-point (FP8) data types and the transformer library.
We are announcing improved performance in TensorFlow, new NVIDIA GPU-specific features in XLA and the first release of JAX for multi-node, multi-GPU training, which will significantly improve large language model (LLM) training. We expect the Hopper architecture to be especially popular for LLMs.
NVIDIA H100 Tensor Core GPU
XLA for GPU
Google delivers high performance with LLMs on NVIDIA GPUs because of a notable technology, XLA, which supports all leading ML frameworks, such as TensorFlow, JAX, and PyTorch. Over 90% of Google’s ML compilations – across research and production, happen on XLA. These span the gamut of ML use cases, from ultra-large scale model training at DeepMind and Google Research, to optimized deployments across our products, to edge inferencing at Waymo.
XLA’s deep feature set accelerates large language model performance and is solving most large model challenges seen in the industry today. For example, a feature unique to XLA, SPMD, automates most of the work needed to partition models across multiple cores and devices, making large model training significantly more scalable and performant. XLA can also automatically recognize and select the most optimal hand-written library implementation for your target backend, like cuDNN for CUDA chipsets. Otherwise, XLA can natively generate optimized code for performant execution.
We’ve been collaborating with NVIDIA on several exciting features and integrations that will further optimize LLMs for GPUs. We recently enabled collectives such as all-reduce to run in parallel to compute. This has resulted in a significant reduction in end to end latency for customers. Furthermore, we enabled support for bfloat16, which has resulted in compute gains of 4.5x over 32 bit floating point while retaining the same dynamic range of values.
Our joint efforts mean that XLA integrates even more deeply with NVIDIA’s AI tools and can better leverage NVIDIA’s suite of AI hardware optimized libraries. In Q1 2023, we will release a XLA-cuDNN Graph API integration, which provides customers with optimized fusion of convolution/matmul operations and multi-headed attention in transformers for improved use of memory and faster GPU kernel execution. As a result, overheads drop significantly and performance improves notably.
TensorFlow for GPU
TensorFlow recently released distributed tensors (or DTensors) to enable Tensor storage across devices like NVIDIA GPUs while allowing programs to manipulate them seamlessly. The goal of DTensor is to make parallelizing large-scale TensorFlow models across multiple devices easy, understandable, and fast. DTensors are a drop-in replacement for local TensorFlow tensors and scale well to large clusters. In addition, the DTensor project improves the underlying TensorFlow execution and communication primitives, and they are available for use today!
We are also collaborating with NVIDIA on several exciting new features in TensorFlow that leverage GPUs, including supporting the new FP8 datatype which should yield a significant improvement in training times for transformer models, when using the Hopper H100 GPU.
JAX for GPU
Google seeks to empower every developer with purpose-built tools for every step of the ML workflow. That includes TensorFlow for robust, production-ready models and JAX with highly optimized capabilities for cutting-edge research. We are pleased to announce the unique collaboration between NVIDIA and Google engineering teams to enhance TensorFlow and JAX for large deep-learning models, like LLMs. Both frameworks fully embrace NVIDIA A100 GPUs, and will support the recently-announced H100 GPUs in the future.
One of the key advantages of JAX is the ease of achieving superior hardware utilization with industry-leading FLOPs across the accelerators. Through our collaboration with NVIDIA, we are translating these advantages to GPU using some XLA compiler magic. Specifically, we are leveraging XLA for operator fusion, improving GSPMD for GPU to support generalized data and model parallelism and optimizing for cross-host NVLink.
Future Plans
NVIDIA and Google are pleased with all the progress shared in this post, and are excited to hear from community members about their experience using TensorFlow and JAX, by leveraging the power of XLA for Ampere (A100) and Hopper (H100) GPUs.
TensorFlow is also available in the NVIDIA GPU Cloud (NGC) as a docker container that contains a validated set of libraries that enable and optimize GPU performance, with JAX NGC container coming soon later this year.
Thank you!
Contributors:Frederic Bastien (NVIDIA), Abhishek Ratna (Google), Sean Lee (NVIDIA), Nathan Luehr (NVIDIA), Ayan Moitra (NVIDIA), Yash Katariya (Google), Peter Hawkins (Google), Skye Wanderman-Milne (Google), David Majnemer (Google), Stephan Herhut (Google), George Karpanov (Google), Mahmoud Soliman (NVIDIA), Yuan Lin (NVIDIA), Vartika Singh (NVIDIA), Vinod Grover (NVIDIA), Pooya Jannaty (NVIDIA), Paresh Kharya (NVIDIA), Santosh Bhavani (NVIDIA)
Robotics developers can span global teams testing for navigation of environments, underscoring the importance of easy access to simulation software for quick input and iterations.
At GTC today, NVIDIA founder and CEO Jensen Huang announced that the Isaac Sim robotics simulation platform is now available on the cloud.
Developers will have three options to access it. It will soon be available on the new NVIDIA Omniverse Cloud platform, a suite of services that enables developers to design and use metaverse applications from anywhere. It’s available now on AWS RoboMaker, a cloud-based simulation service for robotics development and testing. And, developers can download it from NVIDIA NGC and deploy it to any public cloud.
With these choices for accessing Isaac Sim in the cloud, individuals and teams can develop, test and train AI-enabled robots at scale and in the workflow that fits their needs. And it comes at a time when the need is greater than ever.
Consider that the mobile robotics market is expected to grow 9x worldwide from $13 billion in 2021 to over $123 billion in 2030, according to ABI Research.
“NVIDIA’s move to provide its visual computing capabilities as an autonomous robot training platform in the cloud should further enable the growing number of companies and developers building next-generation intelligent machines for numerous applications,” said Rob Enderle, principal analyst for the Enderle Group.
Scaling Simulations
Using Isaac Sim in the cloud, roboticists will be able to generate large datasets from physically accurate sensor simulations to train the AI-based perception models on their robots. The synthetic data generated in these simulations improves the model performance and provides training data that often can’t be collected in the real world.
Developers can now test the robot’s software by launching batches of parallel simulations that exercise the software stack in numerous environments and across varying conditions to ensure that the robots perform as designed. Continuous testing and continuous delivery, or CI/CD, of the evolving robotics software stack is an important component of successful robotics deployments.
Isaac Sim in the cloud will make it easy to meet the most compute-intensive simulation tasks like CI/CD and synthetic data generation.
The upcoming release of Isaac Sim will include NVIDIA cuOpt, a real-time fleet task-assignment and route-planning engine for optimizing robot path planning. Tapping into the accelerated performance of the cloud, teams can make dynamic, data-driven decisions, whether designing the ideal warehouse layout or optimizing active operations.
Remote Collaboration and Improved Access
Developing robots is a multidisciplinary endeavor. Mechanical engineers, electrical engineers, computer scientists and AI engineers come together to build the robot. With Isaac Sim in the cloud, these teams can be located across the globe and still able to share a virtual world in which to simulate and train robots.
Running Isaac Sim in the cloud means that developers will no longer be tied to a powerful workstation to run simulations. Any device will be able to set up, manage and review the results of simulations.
Results can be shared outside of the simulation team with potential partners, customers and co-workers.
Content creation is booming at an unprecedented rate.
Whether it’s a 3D artist sculpting a beautiful piece of art or an aspiring influencer editing their next hit TikTok, more than 110 million professional and hobbyist artists worldwide are creating content on laptops and desktops.
NVIDIA Studio is meeting the moment with new GeForce RTX 40 Series GPUs, 110 RTX-accelerated apps, as well as the Studio suite of software, validated systems, dedicated Studio Drivers for creators, and software development kits to help artists create at the speed of their imagination.
On display during today’s NVIDIA GTC keynote, new GeForce RTX 40 Series GPUs and incredible AI tools — powered by the ultra-efficient NVIDIA Ada Lovelace architecture — are making content creation faster and easier than ever.
The new GeForce RTX 4090 brings a massive boost in performance, third-generation RT Cores, fourth-generation Tensor Cores, an eighth-generation NVIDIA Dual AV1 Encoder and 24GB of Micron G6X memory capable of reaching 1TB/s bandwidth. The GeForce RTX 4090 is up to 2x faster than a GeForce RTX 3090 Ti in 3D rendering, AI and video exports.
The GeForce RTX 4080 comes in two variants — 16GB and 12GB — so creators can choose the optimal memory capacity based on their projects’ needs. The RTX GeForce 4080 16GB is up to 1.5x faster than the RTX 3080 Ti.
The keynote kicked off with a breathtaking demo, NVIDIA Racer RTX, built in NVIDIA Omniverse, an open platform for virtual collaboration and real-time photorealistic simulation. The demo showcases the latest NVIDIA technologies with real-time full ray tracing — in 4K resolution at 60 frames per second (FPS), running with new DLSS 3 technology — and hyperrealistic physics.
It’s a blueprint for the next generation of content creation and game development, where worlds are no longer prebaked, but physically accurate, full simulations.
In addition to benefits for 3D creators, we’ve introduced near-magical RTX and AI tools for game modders — the creators of the PC gaming community — with the Omniverse application RTX Remix, which has been used to turn RTX ON in Portal with RTX, free downloadable content for Valve’s classic hit, Portal.
Video editors and livestreamers are getting a massive boost, too. New dual encoders cut video export times nearly in half. Live streamers get encoding benefits with the eighth-generation NVIDIA Encoder, including support for AV1 encoding.
Groundbreaking AI technology, like AI image generators and new video-editing tools in DaVinci Resolve, are ushering in a new wave of creativity. Beyond-fast GeForce RTX 4090 and 4080 graphics cards will power the next step in the AI revolution, delivering up to a 2x increase in AI performance over the previous generation.
A New Paradigm for 3D
GeForce RTX 40 Series GPUs and DLSS 3 deliver big boosts in performance for 3D artists, so they can create in fully ray-traced environments with accurate physics and realistic materials all in real time, without proxies.
DLSS 3 uses AI-powered fourth-generation RTX Tensor Cores, and a new Optical Flow Accelerator on GeForce RTX 40 Series GPUs, to generate additional frames and dramatically increase FPS. This improves smoothness and speeds up movement in the viewport for those working in 3D applications such as NVIDIA Omniverse, Unity and Unreal Engine 5.
Performance testing conducted by NVIDIA in September 2022 with desktops equipped with Intel Core i9-12900K with UHD 770, 64 GB RAM. NVIDIA Driver 521.58, Windows 11. Autodesk Maya with Autodesk Arnold 2022 renderer performance measures render time of the NVIDIA SOL 3D model. Blender 2.93 measures render time of various scenes using Blender OpenData benchmark, with the OptiX render engine. Render time of various scenes with Redshift version 3.0.45.
NVIDIA Omniverse, included in the NVIDIA Studio software suite, takes creativity and collaboration even further. A new Omniverse application, RTX Remix, is putting powerful new tools in the hands of game modders.
Modders — the millions of creators in the gaming world who are responsible for driving billions of game mod downloads annually — can use the app to remaster a large library of compatible DirectX 8 and 9 titles, including one of the world’s most modded games, The Elder Scrolls III: Morrowind. As a test, NVIDIA artists updated a Morrowind scene in stunning ray tracing with DLSS 3 and enhanced assets.
It starts with the magical capture tool. With one click, capture geometry, materials, lighting and cameras in the Universal Scene Description format. AI texture tools bring assets up to date, with super resolution and physically based materials. Assets are easily customizable in real time using Omniverse Connectors for Autodesk Maya, Blender and more.
RTX Remix enables artists to easily make incredible mods with ray tracing and DLSS for classic games.
Modders can collaborate in Omniverse connected apps and view changes in RTX Remix to replace assets throughout entire games. RTX Remix features a state-of-the-art ray tracer, DLSS 3 and more, making it easy to reimagine classics with incredible graphics.
RTX mods work alongside existing mods, meaning a large breadth of content on sites like Nexus Mods is ready to be updated with dazzling RTX. Sign up to be notified when RTX Remix is available.
The robust capabilities of this new modding platform were used to create Portal with RTX.
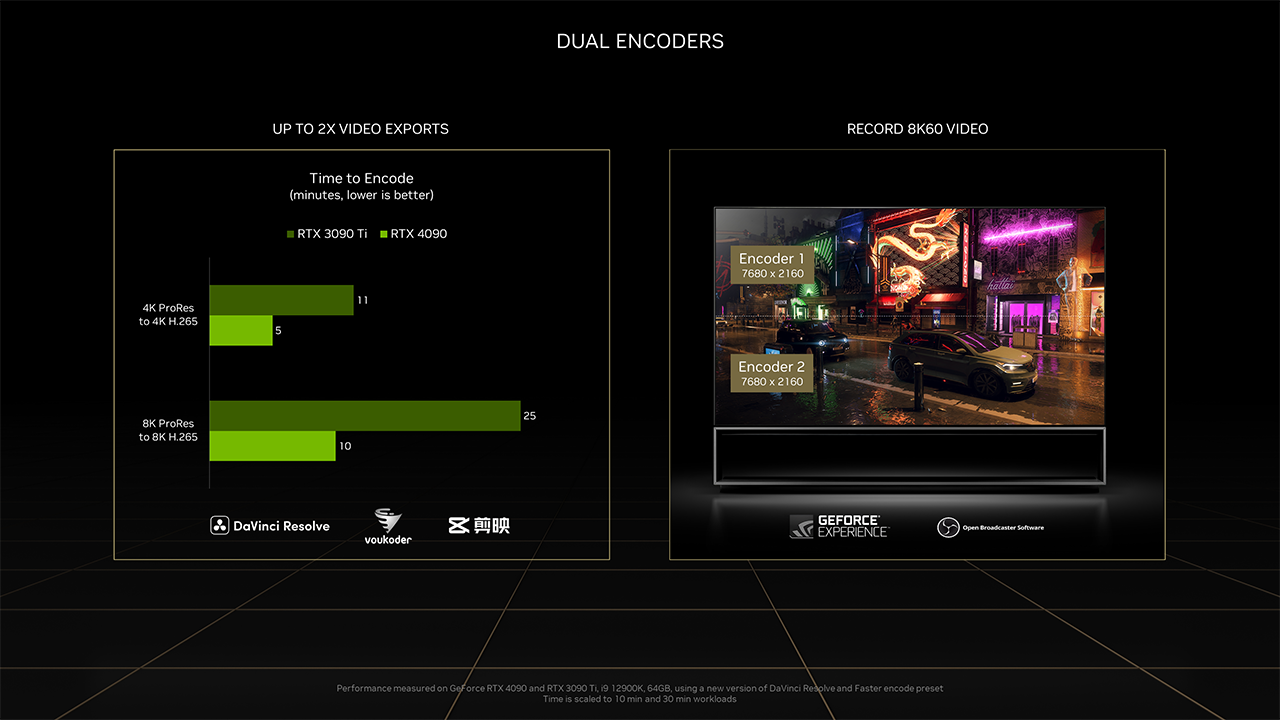
Video production is getting a significant boost with GeForce RTX 40 Series GPUs. The feeling of being stuck on pause while waiting for videos to export gets dramatically reduced with the GeForce RTX 40 Series’ new dual encoders, which slash export times nearly in half.
The dual encoders can work in tandem, dividing work automatically between them to double output. They’re also capable of recording up to 8K, 60 FPS content in real time via GeForce Experience and OBS Studio to make stunning gameplay videos.
Dual encoders can record up to 8K, 60 FPS content in real time via GeForce Experience and OBS Studio.
Blackmagic Design’s DaVinci Resolve, the popular Voukoder plugin for Adobe Premiere Pro, and Jianying — the top video editing app in China — are all enabling AV1 support, as well as a dual encoder through encode presets. Expect dual encoder and AV1 availability for these apps in October. And we’re working with popular video-effects app Notch to enable AV1, as well as Topaz to enable AV1 and the dual encoder.
AI tools are changing the speed at which video work gets done. Professionals can now automate tedious tasks, while aspiring filmmakers can add stylish effects with ease. Rotoscoping — the process of highlighting a part of motion footage, typically done frame by frame — can now be done nearly instantaneously with the AI-powered “Object Select Mask” tool in Blackmagic Design’s DaVinci Resolve. With GeForce RTX 40 Series GPUs, this feature is 70% faster than with the previous generation.
“The new GeForce RTX 40 Series GPUs are going to supercharge the speed at which our users are able to produce video through the power of AI and dual encoding — completing their work in a fraction of the time,” said Rohit Gupta, director of software development at Blackmagic Design.
Content creators using GeForce RTX 40 Series GPUs also benefit from speedups to existing integrations in top video-editing apps. GPU-accelerated effects and decoding save immeasurable time by enabling work with ultra-high-resolution RAW footage in real time in REDCINE-X PRO, DaVinci Resolve and Adobe Premiere Pro, without the need for proxies.
AV1 Brings Encoding Benefits to Livestreamers and More
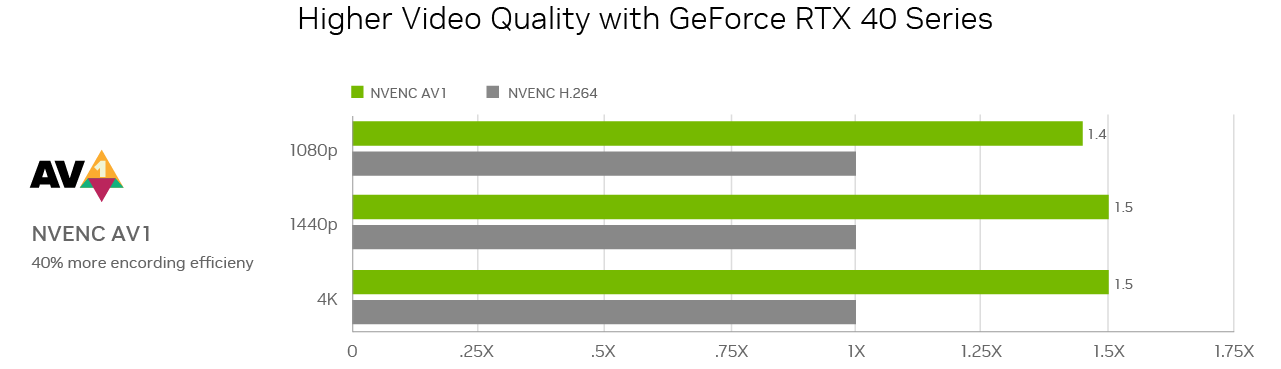
The open video encoding format AV1 is the biggest leap in encoding since H.264 was released nearly two decades ago. The GeForce RTX 40 Series features the eighth-generation NVIDIA video encoder, NVENC for short, now with support for AV1.
Performance testing conducted by NVIDIA in September 2022, using desktops equipped with Intel Core i9-12900K with UHD 770, 32GB RAM. NVIDIA Driver 521.58, Windows 11. Encoding quality is measured as BD-SNR using seventh-generation NVENC with H.264, and eighth-generation NVENC with AV1, both at the maximum-quality P7 preset.
For livestreamers, the new AV1 encoder delivers 40% better efficiency. This means livestreams will appear as if bandwidth was increased by 40% — a big boost in image quality. AV1 also adds support for advanced features like high dynamic range.
NVIDIA collaborated with OBS Studio to add AV1 — on top of the recently released HEVC and HDR support — within its next software release, expected in October. OBS is also optimizing encoding pipelines to reduce overhead by 35% for all NVIDIA GPUs. The new release will additionally feature updated NVIDIA Broadcast effects, including noise and room echo removal, as well as improvements to virtual background.
We’ve also worked with Discord to enable end-to-end livestreams with AV1. In an update releasing later this year, Discord will enable its users to use AV1 to dramatically improve screen sharing, be it for game play, school work or hangouts with friends.
To make the deployment of AV1 seamless for developers, NVIDIA is making it available in the NVIDIA Video Codec SDK 12 in October. Developers can also access the NVENC AV1 directly with Microsoft Media Framework, through Google Chrome and Chromium, as well as in FFMPEG.
Benefits to livestreamers go beyond AV1 encoding on GeForce RTX 40 Series GPUs. The SDKs that power NVIDIA Broadcast are available to developers, enabling native feature support for Logitech, Corsair and Elgato devices, or advanced workflows in OBS and Notch software. At GTC, NVIDIA updated and introduced new AI-powered effects:
The popular Virtual Background feature now includes temporal information, so random objects in the background will no longer create distractions by flashing in and out. It will be available in the next version of OBS Studio.
Face Expression Estimation is a new feature that allows apps to accurately track facial expressions for face meshes, even with the simplest of webcams. It’s hugely beneficial to VTubers and can be found in the next version of VTube Studio.
Eye Contact allows creators, like podcasters, to appear as if they’re looking directly at the camera — highly useful for when the user is reading a script or looking away to engage with viewers in the chat window.
The Making of ‘Racer RTX’
To showcase the technological advancements made possible by GeForce RTX 40 Series GPUs, a global team of NVIDIANs, led by creative director Gabriele Leone, created a stunning new technology demo, Racer RTX.
The team recreated city streets in West Los Angeles, turning them into a lifelike radio-controlled car track.
Leone and team set out to one-up the fully playable, physics-based Marbles at Night RTX demo. With improved GPU performance and breakthrough advancements in NVIDIA Omniverse, Racer RTX lets the user explore different sandbox environments, highlighting the amazing 3D worlds that artists are now able to create.
The demo is a look into the next generation of content creation, “where virtually everything is simulated,” Leone said. “Soon, there’s going to be no need to bake lighting — content will be fully simulated, aided by incredibly powerful GeForce RTX 40 Series GPUs.”
The Omniverse real-time editor empowered the artists on the project to create lights, design materials, rig physics, adjust elements and see updates immediately. They moved objects, added new geometry, changed surface types and tweaked physics.
In a traditional rasterized workflow, levels and lighting need to be baked. And in a typical art environment, only one person can work on a level at a time, leading to painstaking iteration that greatly slows the creation process. These challenges were overcome with Omniverse.
Animating behavior is also a complex and manual process for creators. Using NVIDIA MDL-based materials, Leone turned on PhysX in Omniverse, and each surface and object was automatically textured and modeled to behave as it would in real life. Ram a baseball, for example, and it’ll roll away and interact with other objects until it runs out of momentum.
“Racer RTX” offers a glimpse into the future of content creation, where worlds are no longer prebaked.
Working with GeForce RTX 40 Series GPUs and DLSS 3 meant the team could modify its worlds through a fully ray-traced design viewport in 4K at 60 FPS — 4x the FPS of a GeForce RTX 3090 Ti.
And the team is just getting started. The Racer RTX demo will be available for developers and creators to download, explore and tweak in November. Get familiar with Omniverse ahead of the release.
With all these astounding advancements in AI and GPU-accelerated features for the NVIDIA Studio platform, it’s the perfect time to upgrade for gamers, 3D artists, video editors and live steamers. And battle-tested monthly NVIDIA Studio Drivers help any creator feel like a professional — download the September Driver.
Stay Tuned for the Latest Studio News
Keep up to date on the latest creator news, creative app updates, AI-powered workflows and featured In the NVIDIA Studio artists by visiting the NVIDIA Studio blog.
GeForce RTX 4090 GPUs launch on Wednesday, Oct. 12, followed by the GeForce RTX 4080 graphics cards in November. Visit GeForce.com for further information.
NVIDIA today introduced the NVIDIA IGX platform for medical edge AI use cases, bringing advanced security and safety to intelligent machines and human-machine collaboration.
IGX is a hardware and software platform that delivers secure, low-latency AI inference to meet the clinical demand for instant insights from a range of devices and sensors for medical applications, including robotic-assisted surgery and patient monitoring.
The IGX platform supports NVIDIA Clara Holoscan, a domain-specific platform that allows medical-device developers to bridge edge, on-premises data center and cloud services. This integration enables the rapid development of new, software-defined devices that bring the latest AI applications directly into the operating room.
They’re among more than 70 medical device companies, medical centers and startups already using Clara Holoscan to advance their efforts to deploy AI applications in clinical settings.
Robotic Surgery Startups Accelerate Time to Market
Activ Surgical has selected NVIDIA Clara Holoscan to accelerate development of its AI and augmented-reality solution for real-time surgical guidance. The Boston-based company’s ActivSight technology allows surgeons to view critical physiological structures and functions, like blood flow, that cannot be seen with the naked eye.
By integrating this information into surgical imaging systems, the company aims to reduce surgical complication rates, improving patient care and safety.
“NVIDIA Clara Holoscan will help us optimize precious engineering resources and go to market faster,” says Tom Calef, chief technology officer at Activ Surgical. “With Clara Holoscan and NVIDIA IGX, we envision that our intraoperative AI solution will transform the collective surgical experience with data-driven insights, helping make world-class surgery accessible for all.”
Paris-based robotic surgery company Moon Surgical is designing Maestro, an accessible, adaptive surgical-assistant robotics system that works with the equipment and workflows that operating rooms already have in place.
“NVIDIA has all the hardware and software figured out, with an optimized architecture and libraries,” said Anne Osdoit, CEO of Moon Surgical. “Clara Holoscan helps us not worry about things we typically spend a lot of time working on in the medical-device development cycle.”
The company has instead been able to focus its engineering resources on AI algorithms and other unique features. Adopting Clara Holoscan saved them time and resources, helping them compress their development timeline.
London-based Proximie is building a telepresence platform to enable real-time, remote surgeon collaboration. Clara Holoscan will allow the company to provide local video processing in the operating room, improving performance for users while maintaining data privacy and lowering cloud-computing costs.
“We are delighted to work with NVIDIA to strengthen the health ecosystem and further our mission to connect operating rooms globally,” said Dr. Nadine Hachach-Haram, founder and CEO of Proximie. “Thanks to this collaboration, we are able to provide the most immersive experience possible and deliver a resilient digital solution, with which operating-room devices all over the world can communicate with each other and capture valuable insights.”
Proximie is already deployed in more than 500 operating rooms around the world, and has recorded tens of thousands of surgical procedures to date.
Medical-Grade Compliance in Edge AI
The NVIDIA IGX platform is powered by NVIDIA IGX Orin, the world’s most powerful, compact and energy-efficient AI supercomputer for medical devices. IGX Orin developer kits will be available early next year.
IGX features industrial-grade components designed for medical certification, making it easier to take medical devices from clinical trials to real-world deployment.
Embedded-computing manufacturers ADLINK, Advantech, Dedicated Computing, Kontron, Leadtek, MBX, Onyx, Portwell, Prodrive Technologies and YUAN will be among the first to build products based on NVIDIA IGX for the medical device industry.
Learn more about the NVIDIA IGX platform in a special address by Kimberly Powell, NVIDIA’s vice president of healthcare, at GTC. Register free for the virtual conference, which runs through Thursday, Sept. 22.
NVIDIA today introduced the IGX edge AI computing platform for secure, safe autonomous systems.
IGX brings together hardware with programmable safety extensions, commercial operating-system support and powerful AI software — enabling organizations to safely and securely deliver AI in support of human-machine collaboration.
The all-in-one platform enables next-level safety, security and perception for use cases in healthcare, as well as in industrial edge AI.
Robots and autonomous systems are used to create “factories of the future,” where humans and robots work side by side, leading to improved efficiency for manufacturing, logistics and other workflows.
Such autonomous machines have built-in functional safety capabilities to ensure intelligent spaces stay clear of collisions and other safety threats.
NVIDIA IGX enhances this functional safety, using AI sensors around the environment to add proactive-safety alerts — which identify safety concerns before an incident occurs — in addition to existing reactive-safety abilities, which mitigate safety threats.
“Safety has long been a top priority for industrial organizations,” said Riccardo Mariani, vice president of industry safety at NVIDIA. “What’s new is that we’re using AI across sensors in a factory to create a centralized view, which can improve safety by providing additional inputs to the intelligent machines and autonomous mobile robots operating in the environment.”
For sensitive settings in which humans and machines collaborate — like factories, distribution centers and warehouses — intelligent systems’ safety and security features are especially critical.
Proactive Safety for the Industrial Edge
Three layers of functional safety exist at the industrial edge.
First, reactive safety is the mitigation of safety threats and events after they occur. For example, if a human walked into a robot’s direct route, the bot might stop, slow or shut down to avoid a collision.
This type of safety mechanism already exists in autonomous machines, per standard regulations. But reactive stops of an intelligent machine or factory line result in unplanned downtime, which for some manufacturers can cost hundreds of thousands of dollars per hour.
Second, proactive safety is the identification of potential safety concerns before breaches happen. NVIDIA IGX is focused on enabling organizations to add this safety layer to intelligent environments, further protecting workers and saving costs. It delivers high-performance, proactive-safety capabilities that are built into its hardware and software.
For example, with IGX-powered proactive safety at play, cameras in the warehouse might see a human heading into the path of a robot. It could signal the bot to change routes and avoid being in the same field of movement, preventing the collision altogether. IGX can also alert employees and other robots in the area, rerouting them to eliminate the risk of a backup across the factory.
And third, predictive safety is the anticipation of future exposure to safety threats based on past performance data. In this case, organizations can use simulation and digital twins to identify patterns of intersections or improve a factory layout to reduce the number of safety incidents.
One of the first companies to use IGX at the edge is Siemens, a technology leader in industrial automation and digitalization, which is working with NVIDIA on a vision for autonomous factories. Siemens is collaborating with NVIDIA to expand its work across industrial computing, including with digital twins and for the industrial metaverse.
Siemens is already adding next-level perception into its edge-based applications through NVIDIA Metropolis. With millions of sensors in factories, Metropolis connects entire fleets of robots and IoT devices to bring AI into industrial environments, making it one of the key application frameworks for edge AI running on top of the IGX platform.
Zero-Trust Security, High Performance and Long-Term Support
In addition to safety requirements, edge AI deployments have unique security needs compared to systems in data centers or the cloud — since humans and machines operate side by side in edge environments.
The IGX platform has a hardened, end-to-end security architecture that starts at the system level and expands through over-the-air updates from the cloud. Advanced networking and a dedicated security controller are paired with NVIDIA Fleet Command, which brings secure edge AI management and orchestration from the cloud.
The first product offering of the IGX platform is NVIDIA IGX Orin, the world’s most powerful, compact and energy-efficient AI system for accelerating the development of autonomous industrial machines and medical devices.
IGX Orin developer kits will be available early next year. Each includes an integrated GPU and CPU for high-performance AI compute, as well as an NVIDIA ConnectX-7 SmartNIC to deliver high-performance networking with ultra-low latency and advanced security.
IGX also brings up to 10 years of full-stack support from NVIDIA and leading partners.
Learn more about IGX and other technology breakthroughs by watching the latest GTC keynote address by NVIDIA founder and CEO Jensen Huang: