Amazon’s product search engine indexes billions of products, serves hundreds of millions of customers worldwide, and is one of the most heavily used services in the world. The Amazon Search team develops machine learning (ML) technology that powers the Amazon.com search engine and helps customers search effortlessly. To deliver a great customer experience and operate at the massive scale required by the Amazon.com search engine, this team is always looking for ways to build more cost-effective systems with real-time latency and throughput requirements. The team constantly explores hardware and compilers optimized for deep learning to accelerate model training and inference, while reducing operational costs across the board.
In this post, we describe how Amazon Search uses AWS Inferentia, a high-performance accelerator purpose built by AWS to accelerate deep learning inference workloads. The team runs low-latency ML inference with Transformer-based NLP models on AWS Inferentia-based Amazon Elastic Compute Cloud (Amazon EC2) Inf1 instances, and saves up to 85% in infrastructure costs while maintaining strong throughput and latency performance.
Deep learning for duplicate and query intent prediction
Searching the Amazon Marketplace is a multi-task, multi-modal problem, dealing with several inputs such as ASINs (Amazon Standard Identification Number, a 10-digit alphanumeric number that uniquely identifies products), product images, textual descriptions, and queries. To create a tailored user experience, predictions from many models are used for different aspects of search. This is a challenge because the search system has thousands of models with tens of thousands of transactions per second (TPS) at peak load. We focus on two components of that experience:
-
Customer-perceived duplicate predictions – To show the most relevant list of products that match a user’s query, it’s important to identify products that customers have a hard time differentiating between
-
Query intent prediction – To adapt the search page and product layout to better suit what the customer is looking for, it’s important to predict the intent and type of the user’s query (for example, a media-related query, help query, and other query types)
Both of these predictions are made using Transformer model architectures, namely BERT-based models. In fact, both share the same BERT-based model as a basis, and each one stacks a classification/regression head on top of this backbone.
Duplicate prediction takes in various textual features for a pair of evaluated products as inputs (such as product type, title, description, and so on) and is computed periodically for large datasets. This model is trained end to end in a multi-task fashion. Amazon SageMaker Processing jobs are used to run these batch workloads periodically to automate their launch and only pay for the processing time that is used. For this batch workload use case, the requirement for inference throughput was 8,800 total TPS.
Intent prediction takes the user’s textual query as input and is needed in real time to dynamically serve everyday traffic and enhance the user experience on the Amazon Marketplace. The model is trained on a multi-class classification objective. This model is then deployed on Amazon Elastic Container Service (Amazon ECS), which enables quick auto scaling and easy deployment definition and management. Because this is a real-time use case, it required the P99 latency to be under 10 milliseconds to ensure a delightful user experience.
AWS Inferentia and the AWS Neuron SDK
EC2 Inf1 instances are powered by AWS Inferentia, the first ML accelerator purpose built by AWS to accelerate deep learning inference workloads. Inf1 instances deliver up to 2.3 times higher throughput and up to 70% lower cost per inference than comparable GPU-based EC2 instances. You can keep training your models using your framework of choice (PyTorch, TensorFlow, MXNet), and then easily deploy them on AWS Inferentia to benefit from the built-in performance optimizations. You can deploy a wide range of model types using Inf1 instances, from image recognition, object detection, natural language processing (NLP), and modern recommender models.
AWS Neuron is a software development kit (SDK) consisting of a compiler, runtime, and profiling tools that optimize the ML inference performance of the EC2 Inf1 instances. Neuron is natively integrated with popular ML frameworks such as TensorFlow and PyTorch. Therefore, you can deploy deep learning models on AWS Inferentia with the same familiar APIs provided by your framework of choice, and benefit from the boost in performance and lowest cost-per-inference in the cloud.
Since its launch, the Neuron SDK has continued to increase the breadth of models it supports while continuing to improve performance and reduce inference costs. This includes NLP models (BERTs), image classification models (ResNet, VGG), and object detection models (OpenPose and SSD).
Deploy on Inf1 instances for low latency, high throughput, and cost savings
The Amazon Search team wanted to save costs while meeting their high throughput requirement on duplication prediction, and the low latency requirement on query intent prediction. They chose to deploy on AWS Inferentia-based Inf1 instances and not only met the high performance requirements, but also saved up to 85% on inference costs.
Customer-perceived duplicate predictions
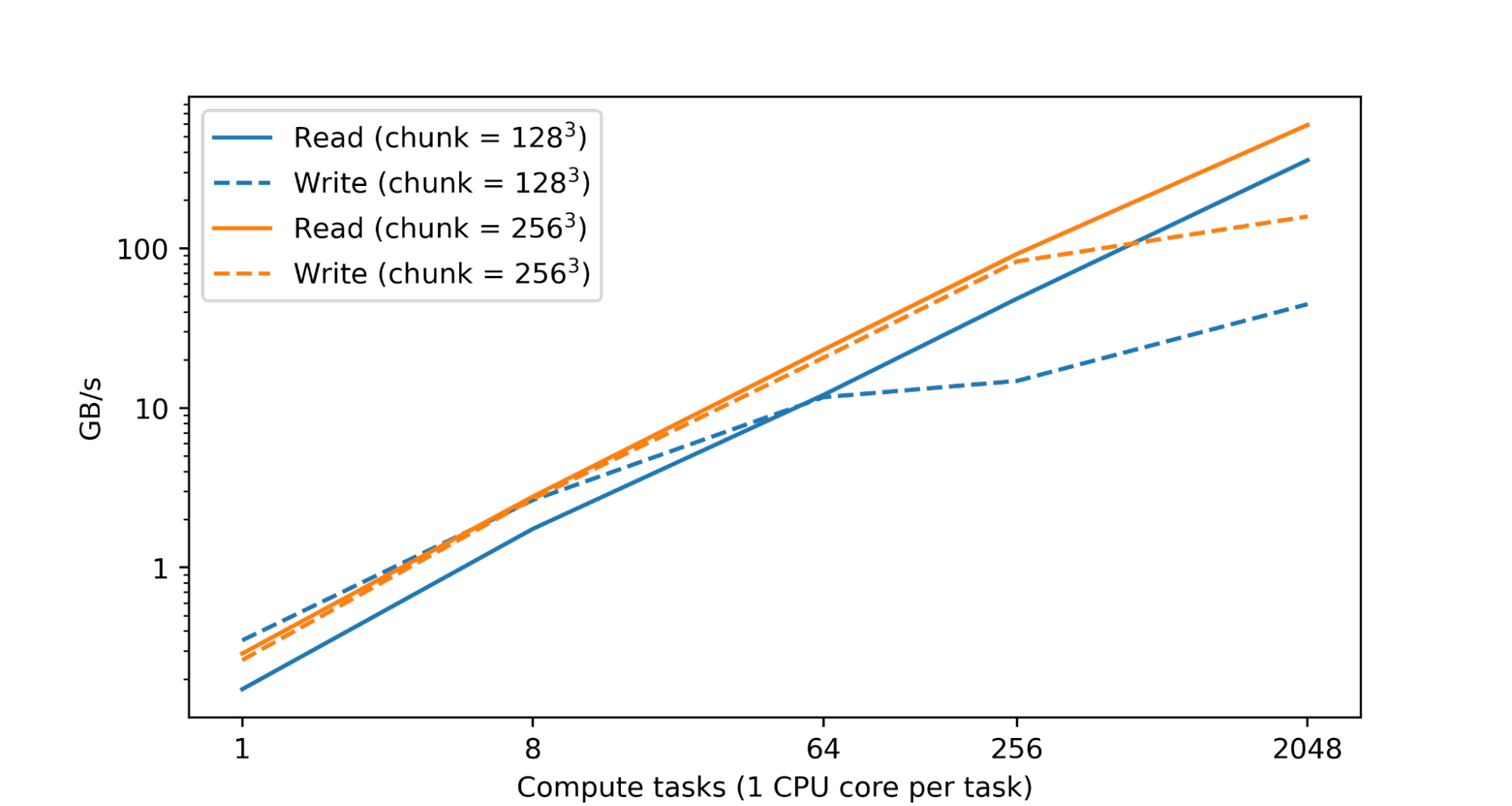
Prior to the usage of Inf1, a dedicated Amazon EMR cluster was running using CPU-based instances. Without relying on hardware acceleration, a large number of instances were necessary to meet the high throughput requirement of 8,800 total transactions per second. The team switched to inf1.6xlarge instances, each with 4 AWS Inferentia accelerators, and 16 NeuronCores (4 cores per AWS Inferentia chip). They traced the Transformer-based model for a single NeuronCore and loaded one mode per NeuronCore to maximize throughput. By taking advantage of the 16 available NeuronCores, they decreased inference costs by 85% (based on the current public Amazon EC2 on-demand pricing).
Query intent prediction
Given the P99 latency requirement of 10 milliseconds or less, the team loaded the model to every available NeuronCore on inf1.6xlarge instances. You can easily do this with PyTorch Neuron using the torch.neuron.DataParallel API. With the Inf1 deployment, the model latency was 3 milliseconds, end-to-end latency was approximately 10 milliseconds, and maximum throughput at peak load reached 16,000 TPS.
Get started with sample compilation and deployment code
The following is some sample code to help you get started on Inf1 instances and realize the performance and cost benefits like the Amazon Search team. We show how to compile and perform inference with a PyTorch model, using PyTorch Neuron.
First, the model is compiled with torch.neuron.trace():
m = torch.jit.load(f="./cpu_model.pt", map_location=torch.device('cpu'))
m.eval()
model_neuron = torch.neuron.trace(
m,
inputs,
compiler_workdir="work_" + str(cores) + "_" + str(batch_size),
compiler_args=[
'--fp32-cast=all', '--neuroncore-pipeline-cores=' + str(cores)
])
model_neuron.save("m5_batch" + str(batch_size) + "_cores" + str(cores) +
"_with_extra_op_and_fp32cast.pt")
For the full list of possible arguments to the trace method, refer to PyTorch-Neuron trace Python API. As you can see, compiler arguments can be passed to the torch.neuron API directly. All FP32 operators are cast to BF16 with --fp32-cast=all, providing the highest performance while preserving dynamic range. More casting options are available to let you control the performance to model precision trade-off. The models used for both use cases were compiled for a single NeuronCore (no pipelining).
We then load the model on Inferentia with torch.jit.load, and use it for prediction. The Neuron runtime automatically loads the model to NeuronCores.
cm_cpd_preprocessing_jit = torch.jit.load(f=CM_CPD_PROC,
map_location=torch.device('cpu'))
cm_cpd_preprocessing_jit.eval()
m5_model = torch.jit.load(f=CM_CPD_M5)
m5_model.eval()
input = get_input()
with torch.no_grad():
batch_cm_cpd = cm_cpd_preprocessing_jit(input)
input_ids, attention_mask, position_ids, valid_length, token_type_ids = (
batch_cm_cpd['input_ids'].type(torch.IntTensor),
batch_cm_cpd['attention_mask'].type(torch.HalfTensor),
batch_cm_cpd['position_ids'].type(torch.IntTensor),
batch_cm_cpd['valid_length'].type(torch.IntTensor),
batch_cm_cpd['token_type_ids'].type(torch.IntTensor))
model_res = m5_model(input_ids, attention_mask, position_ids, valid_length,
token_type_ids)
Conclusion
The Amazon Search team was able to reduce their inference costs by 85% using AWS Inferentia-based Inf1 instances, under heavy traffic and demanding performance requirements. AWS Inferentia and the Neuron SDK provided the team the flexibility to optimize the deployment process separately from training, and put forth a shallow learning curve via well-rounded tools and familiar framework APIs.
You can unlock performance and cost benefits by getting started with the sample code provided in this post. Also, check out the end-to-end tutorials to run ML models on Inferentia with PyTorch and TensorFlow.
About the authors
 João Moura is an AI/ML Specialist Solutions Architect at Amazon Web Services. He is mostly focused on NLP use cases and helping customers optimize deep learning model training and deployment. He is also an active proponent of ML-specialized hardware and low-code ML solutions.
João Moura is an AI/ML Specialist Solutions Architect at Amazon Web Services. He is mostly focused on NLP use cases and helping customers optimize deep learning model training and deployment. He is also an active proponent of ML-specialized hardware and low-code ML solutions.
 Weiqi Zhang is a Software Engineering Manager at Search M5, where he works on productizing large-scale models for Amazon machine learning applications. His interests include information retrieval and machine learning infrastructure.
Weiqi Zhang is a Software Engineering Manager at Search M5, where he works on productizing large-scale models for Amazon machine learning applications. His interests include information retrieval and machine learning infrastructure.
 Jason Carlson is a Software Engineer for developing machine learning pipelines to help reduce the number of stolen search impressions due to customer-perceived duplicates. He mostly works with Apache Spark, AWS, and PyTorch to help deploy and feed/process data for ML models. In his free time, he likes to read and go on runs.
Jason Carlson is a Software Engineer for developing machine learning pipelines to help reduce the number of stolen search impressions due to customer-perceived duplicates. He mostly works with Apache Spark, AWS, and PyTorch to help deploy and feed/process data for ML models. In his free time, he likes to read and go on runs.
 Shaohui Xi is an SDE at the Search Query Understanding Infra team. He leads the effort for building large-scale deep learning online inference services with low latency and high availability. Outside of work, he enjoys skiing and exploring good foods.
Shaohui Xi is an SDE at the Search Query Understanding Infra team. He leads the effort for building large-scale deep learning online inference services with low latency and high availability. Outside of work, he enjoys skiing and exploring good foods.
 Zhuoqi Zhang is a Software Development Engineer at the Search Query Understanding Infra team. He works on building model serving frameworks to improve latency and throughput for deep learning online inference services. Outside of work, he likes playing basketball, snowboarding, and driving.
Zhuoqi Zhang is a Software Development Engineer at the Search Query Understanding Infra team. He works on building model serving frameworks to improve latency and throughput for deep learning online inference services. Outside of work, he likes playing basketball, snowboarding, and driving.
 Haowei Sun is a software engineer in the Search Query Understanding Infra team. She works on designing APIs and infrastructure supporting deep learning online inference services. Her interests include service API design, infrastructure setup, and maintenance. Outside of work, she enjoys running, hiking, and traveling.
Haowei Sun is a software engineer in the Search Query Understanding Infra team. She works on designing APIs and infrastructure supporting deep learning online inference services. Her interests include service API design, infrastructure setup, and maintenance. Outside of work, she enjoys running, hiking, and traveling.
 Jaspreet Singh is an Applied Scientist on the M5 team, where he works on large-scale foundation models to improve the customer shopping experience. His research interests include multi-task learning, information retrieval, and representation learning.
Jaspreet Singh is an Applied Scientist on the M5 team, where he works on large-scale foundation models to improve the customer shopping experience. His research interests include multi-task learning, information retrieval, and representation learning.
 Shruti Koparkar is a Senior Product Marketing Manager at AWS. She helps customers explore, evaluate, and adopt EC2 accelerated computing infrastructure for their machine learning needs.
Shruti Koparkar is a Senior Product Marketing Manager at AWS. She helps customers explore, evaluate, and adopt EC2 accelerated computing infrastructure for their machine learning needs.
Read More













 Jyothi Goudar is Partner Solutions Architect Manager at AWS. She works closely with global system integrator partner to enable and support customers moving their workloads to AWS.
Jyothi Goudar is Partner Solutions Architect Manager at AWS. She works closely with global system integrator partner to enable and support customers moving their workloads to AWS. Jay Rao is a Principal Solutions Architect at AWS. He enjoys providing technical and strategic guidance to customers and helping them design and implement solutions on AWS.
Jay Rao is a Principal Solutions Architect at AWS. He enjoys providing technical and strategic guidance to customers and helping them design and implement solutions on AWS.




 NVIDIA GeForce NOW (@NVIDIAGFN)
NVIDIA GeForce NOW (@NVIDIAGFN) 