Lilian Weng works on Applied AI Research at OpenAI.OpenAI Blog
Auto Machine Translation and Synchronization for “Dive into Deep Learning”
A system built on Amazon Translate reduces the workload of human translators.Read More
Get to production-grade data faster by using new built-in interfaces with Amazon SageMaker Ground Truth Plus
Launched at AWS re:Invent 2021, Amazon SageMaker Ground Truth Plus helps you create high-quality training datasets by removing the undifferentiated heavy lifting associated with building data labeling applications and managing the labeling workforce. All you do is share data along with labeling requirements, and Ground Truth Plus sets up and manages your data labeling workflow based on these requirements. From there, an expert workforce that is trained on a variety of machine learning (ML) tasks labels your data. You don’t even need deep ML expertise or knowledge of workflow design and quality management to use Ground Truth Plus.
Today, we are excited to announce the launch of new built-in interfaces on Ground Truth Plus. With this new capability, multiple Ground Truth Plus users can now create a new project and batch, share data, and receive data using the same AWS account through self-serve interfaces. This enables you to accelerate the development of high-quality training datasets by reducing project set up time. Additionally, you can control fine-grained access to your data by scoping your AWS Identity and Access Management (IAM) role permissions to match your individual level of Amazon Simple Storage Service (Amazon S3) access, and you always have the option to revoke access to certain buckets.
Until now, you had to reach out to your Ground Truth Plus operations program manager (OPM) to create new data labeling projects and batches. This process had some restrictions because it allowed only one user to request a new project and batch—if multiple users within the organization were using the same AWS account, then only one user could request a new data labeling project and batch using the Ground Truth Plus console. Additionally, the process created artificial delays in kicking off the labeling process due to multiple manual touchpoints and troubleshooting required in case of issues. Separately, all the projects used the same IAM role for accessing data. Therefore, to run projects and batches that needed access to different data sources such as different Amazon S3 buckets, you had to rely on your Ground Truth Plus OPM to provide your account specific S3 policies, which you had to manually apply to your S3 buckets. This entire operation was manually intensive resulting in operational overheads.
This post walks you through steps to create a new project and batch, share data, and receive data using the new self-serve interfaces to efficiently kickstart the labeling process. This post assumes that you are familiar with Ground Truth Plus. For more information, see Amazon SageMaker Ground Truth Plus – Create Training Datasets Without Code or In-house Resources.
Solution overview
We demonstrate how to do the following:
- Update existing projects
- Request a new project
- Set up a project team
- Create a batch
Prerequisites
Before you get started, make sure you have the following prerequisites:
- An AWS account
- An IAM user with access to create IAM roles
- The Amazon S3 URI of the bucket where your labeling objects are stored
Update existing projects
If you have a Ground Truth Plus project before the launch (December 9, 2022) of the new features described in this post, then you need to create and share an IAM role so that you can use these features with your existing Ground Truth Plus project. If you’re a new user of Ground Truth Plus, you can skip this section.
To create an IAM role, complete the following steps:
- On the IAM console, choose Create role.
- Select Custom trust policy.
- Specify the following trust relationship for the role:
- Choose Next.
- Choose Create policy.
- On the JSON tab, specify the following policy. Update the Resource property by specifying two entries for each bucket: one with just the bucket ARN, and another with the bucket ARN followed by
/*. For example, replace <your-input-s3-arn> witharn:aws:s3:::my-bucket/myprefix/and <your-input-s3-arn>/* witharn:aws:s3:::my-bucket/myprefix/*. - Choose Next: Tags and Next: Review.
- Enter the name of the policy and an optional description.
- Choose Create policy.
- Close this tab and go back to the previous tab to create your role.
On the Add permissions tab, you should see the new policy you created (refresh the page if you don’t see it).
- Select the newly created policy and choose Next.
- Enter a name (for example,
GTPlusExecutionRole) and optionally a description of the role. - Choose Create role.
- Provide the role ARN to your Ground Truth Plus OPM, who will then update your existing project with this newly created role.
Request a new project
To request a new project, complete the following steps:
- On the Ground Truth Plus console, navigate to the Projects section.
This is where all your projects are listed.
- Choose Request project.
The Request project page is your opportunity to provide details that will help us schedule an initial consultation call and set up your project.
- In addition to specifying general information like the project name and description, you must specify the project’s task type and whether it contains personally identifiable information (PII).
To label your data, Ground Truth Plus needs temporary access to your raw data in an S3 bucket. When the labeling process is complete, Ground Truth Plus delivers the labeling output back to your S3 bucket. This is done through an IAM role. You can either create a new role, or you can navigate to the IAM console to create a new role (refer to the previous section for instructions).
- If you choose to create a role, choose Enter a custom IAM role ARN and enter your IAM role ARN, which is in the format of
arn:aws:iam::<YourAccountNumber>:role/<RoleName>. - To use the built-in tool, on the drop-down menu under IAM Role, choose Create a new role.
- Specify the bucket location of your labeling data. If you don’t know the location of your labeling data or if you don’t have any labeling data uploaded, select Any S3 bucket, which will give Ground Truth Plus access to all your account’s buckets.
- Choose Create to create the role.
Your IAM role will allow Ground Truth Plus, identified as sagemaker-ground-truth-plus.amazonaws.com in the role’s trust policy, to run the following actions on your S3 buckets:
- Choose Request project to complete the request.

A Ground Truth Plus OPM will schedule an initial consultation call with you to discuss your data labeling project requirements and pricing.
Set up a project team
After you request a project, you need to create a project team to log in to your project portal. A project team provides access to the members from your organization or team to track projects, view metrics, and review labels. You can use the option Invite new members by email or Import members from existing Amazon Cognito user groups. In this post, we show how to import members from existing Amazon Cognito user groups to add users to your project team.
- On the Ground Truth Plus console, navigate to the Project team section.
- Choose Create project team.
- Choose Import members from existing Amazon Cognito user groups.
- Choose an Amazon Cognito user pool.
User pools require a domain and an existing user group.
- Choose an app client.
We recommend using a client generated by Amazon SageMaker.
- Choose a user group from your pool to import members.
- Choose Create project team.

You can add more team members after creating the project team by choosing Invite new members on the Members page of the Ground Truth Plus console.
Create a batch
After you have successfully submitted the project request and created a project team, you can access the Ground Truth Plus project portal by clicking Open project portal on the Ground Truth Plus console.
You can use the project portal to create batches for a project, but only after the project’s status has changed to Request approved.
- View a project’s details and batches by choosing the project name.
 A page titled with the project name opens.
A page titled with the project name opens. - In the Batches section, choose Create batch.

- Enter a batch name and optional description.
- Enter the S3 locations of the input and output datasets.
To ensure the batch is created successfully, you must meet the following requirements:
-
- The S3 bucket and prefix should exist, and the total number of files should be greater than 0
- The total number of objects should be less than 10,000
- The size of each object should be less than 2 GB
- The total size of all objects combined is less than 100 GB
- The IAM role provided to create a project has permission to access the input bucket, output bucket, and S3 files that are used to create the batch
- The files under the provided S3 location for the input datasets should not be encrypted by AWS Key Management Service (AWS KMS)
- Choose Submit.

Your batch status will show as Request submitted. After Ground Truth Plus has temporary access to your data, AWS experts will set up data labeling workflows and operate them on your behalf, which will change the batch status to In-progress. When the labeling is complete, the batch status changes from In-progress to Ready for review. If you want to review your labels before receiving the labels then choose Review batch. From there, you have an option to choose Accept batch to receive your labeled data.
Conclusion
This post showed you how multiple Ground Truth Plus users can now create a new project and batch, share data, and receive data using the same AWS account through new self-serve interfaces. This new capability allows you to kickstart your labeling projects faster and reduces operational overhead. We also demonstrated how you can control fine-grained access to data by scoping your IAM role permissions to match your individual level of access.
We encourage you to try out this new functionality, and connect with the Machine Learning & AI community if you have any questions or feedback!
About the authors
 Manish Goel is the Product Manager for Amazon SageMaker Ground Truth Plus. He is focused on building products that make it easier for customers to adopt machine learning. In his spare time, he enjoys road trips and reading books.
Manish Goel is the Product Manager for Amazon SageMaker Ground Truth Plus. He is focused on building products that make it easier for customers to adopt machine learning. In his spare time, he enjoys road trips and reading books.
 Karthik Ganduri is a Software Development Engineer at Amazon AWS, where he works on building ML tools for customers and internal solutions. Outside of work, he enjoys clicking pictures.
Karthik Ganduri is a Software Development Engineer at Amazon AWS, where he works on building ML tools for customers and internal solutions. Outside of work, he enjoys clicking pictures.
 Zhuling Bai is a Software Development Engineer at Amazon AWS. She works on developing large scale distributed systems to solve machine learning problems.
Zhuling Bai is a Software Development Engineer at Amazon AWS. She works on developing large scale distributed systems to solve machine learning problems.
 Aatef Baransy is a Frontend engineer at Amazon AWS. He writes fast, reliable, and thoroughly tested software to nurture and grow the industry’s most cutting-edge AI applications.
Aatef Baransy is a Frontend engineer at Amazon AWS. He writes fast, reliable, and thoroughly tested software to nurture and grow the industry’s most cutting-edge AI applications.
 Mohammad Adnan is a Senior Engineer for AI and ML at AWS. He was part of many AWS service launch, notably Amazon Lookout for Metrics and AWS Panorama. Currently, he is focusing on AWS human-in-the-loop offerings (AWS SageMaker’s Ground truth, Ground truth plus and Augmented AI). He is a clean code advocate and a subject-matter expert on server-less and event-driven architecture. You can follow him on LinkedIn, mohammad-adnan-6a99a829.
Mohammad Adnan is a Senior Engineer for AI and ML at AWS. He was part of many AWS service launch, notably Amazon Lookout for Metrics and AWS Panorama. Currently, he is focusing on AWS human-in-the-loop offerings (AWS SageMaker’s Ground truth, Ground truth plus and Augmented AI). He is a clean code advocate and a subject-matter expert on server-less and event-driven architecture. You can follow him on LinkedIn, mohammad-adnan-6a99a829.

Top Food Stories From 2022: Meet 4 Startups Putting AI on the Plate
This holiday season, feast on the bounty of food-themed stories NVIDIA Blog readers gobbled up in 2022.
Startups in the retail industry — and particularly in quick-service restaurants — are using NVIDIA AI and robotics technology to make it easier to order food in drive-thrus, find beverages on store shelves and have meals delivered. They’re accelerated by NVIDIA Inception, a program that offers go-to-market support, expertise and technology for cutting-edge startups.
For those who prefer eye candy, artists also recreated a ramen restaurant using the NVIDIA Omniverse platform for creating and operating metaverse applications.
AI’ll Take Your Order: Conversational AI at the Drive-Thru

Toronto startup HuEx is developing a conversational AI assistant to handle order requests at the drive-thru speaker box. The real-time voice service, which runs on the NVIDIA Jetson edge AI platform, transcribes voice orders to text for staff members to fulfill.
The technology, integrated with the existing drive-thru headset system, allows for team members to hear the orders and jump in to assist if needed. It’s in pilot tests to help support service at popular Canadian fast-service chains.
Hungry for AI: Automated Ordering Addresses Restaurant Labor Crunch
 San Diego-based startup Vistry is tackling a growing labor shortage among quick-service restaurants with an AI-enabled, automated order-taking solution. The system, built with the NVIDIA Riva software development kit, uses natural language processing for menu understanding and speech — plus recommendation systems to enable faster, more accurate order-taking and more relevant, personalized offers.
San Diego-based startup Vistry is tackling a growing labor shortage among quick-service restaurants with an AI-enabled, automated order-taking solution. The system, built with the NVIDIA Riva software development kit, uses natural language processing for menu understanding and speech — plus recommendation systems to enable faster, more accurate order-taking and more relevant, personalized offers.
Vistry is also using the NVIDIA Metropolis application framework to create computer vision applications that can help automate curbside check-ins, speed up drive-thrus and predict the time it takes to prepare a customer’s order. Its tools are powered by NVIDIA Jetson and NVIDIA A2 Tensor Core GPUs.
Dinner Delivered: Cartken Deploys Sidewalk Robots
 Oakland-based startup Cartken is deploying NVIDIA Jetson-enabled sidewalk robots for last-mile deliveries of coffee and meals. Its autonomous mobile robot technology is used to deliver Grubhub orders to students at the University of Arizona and Ohio State — and Starbucks goods in malls in Japan.
Oakland-based startup Cartken is deploying NVIDIA Jetson-enabled sidewalk robots for last-mile deliveries of coffee and meals. Its autonomous mobile robot technology is used to deliver Grubhub orders to students at the University of Arizona and Ohio State — and Starbucks goods in malls in Japan.
The Inception member relies on the NVIDIA Jetson AGX Orin module to run six cameras that aid in simultaneous localization and mapping, navigation, and wheel odometry.
AI’s Never Been More Convenient: Restocking Robot Rolls Out in Japan
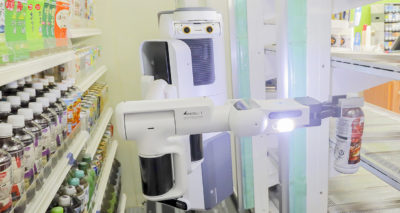 Telexistence, an Inception startup based in Tokyo, is deploying hundreds of NVIDIA AI-powered robots to restock shelves at FamilyMart, a leading Japanese convenience store chain. The robots handle repetitive tasks like refilling beverage displays, which frees up retail staff to interact with customers.
Telexistence, an Inception startup based in Tokyo, is deploying hundreds of NVIDIA AI-powered robots to restock shelves at FamilyMart, a leading Japanese convenience store chain. The robots handle repetitive tasks like refilling beverage displays, which frees up retail staff to interact with customers.
For AI model training, the team relied on NVIDIA DGX systems. The robot uses the NVIDIA Jetson AGX Xavier for AI processing at the edge, and the NVIDIA Jetson TX2 module to transmit video-streaming data.
Bonus: Savor a Virtual Bowlful of NVIDIA Omniverse
NVIDIA technology isn’t just accelerating food-related applications for the restaurant industry — it’s also powering tantalizing virtual scenes complete with mouth-watering, calorie-free dishes.
Two dozen NVIDIA artists and freelancers around the globe showcased the capabilities of NVIDIA Omniverse by recreating a Tokyo ramen shop in delicious detail — including simmering pots of noodles, steaming dumplings and bottled drinks.
The scene, created to highlight NVIDIA RTX-powered real-time rendering and physics simulation capabilities, consists of more than 22 million triangles, 350 unique textured models and 3,000 4K-resolution texture maps.
The post Top Food Stories From 2022: Meet 4 Startups Putting AI on the Plate appeared first on NVIDIA Blog.

New State-of-the-Art Quantized Models Added in TF Model Garden

Posted by Jaehong Kim, Fan Yang, Shixin Luo, and Jiyang Kang

The TensorFlow Model Garden provides implementations of many state-of-the-art machine learning models for vision and natural language processing, and workflow tools to let you quickly configure and run those models on standard datasets. These models are implemented using modern best practices.
Previously, we have announced the quantization aware training (QAT) support for various on-device vision models using TensorFlow Model Optimization Toolkit (TFMOT). In this post, we introduce new SOTA models optimized using QAT in object detection, semantic segmentation, and natural language processing.
RetinaNet+MobileNetV2
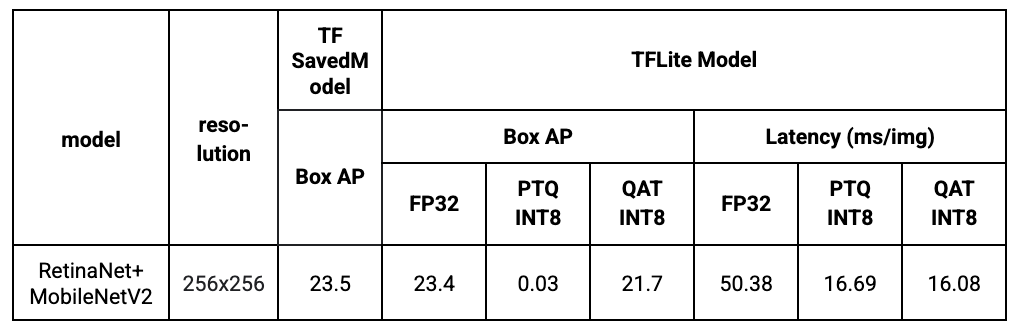
A new QAT supported object detection model has been added to the Model Garden. Specifically, we use a MobileNetV2 with 1x depth multiplier as the backbone and a lightweight RetinaNet as the decoder. MobileNetV2 is a widely used mobile model backbone and we have provided QAT support since our last release. RetinaNet is the SOTA one-stage detection framework used for detection tasks and we make it more efficient on mobile devices by using separable convolution and reducing the number of filters. We train the model from scratch without any pre-trained checkpoints.
Results show that with QAT, we can successfully preserve the model quality while reducing the latency significantly. In comparison, post-training quantization (PTQ) does not work out-of-the-box smoothly due to the complexity of the RetinaNet decoder, thus leading to low box average precision (AP).
Table 1. Box AP and latency comparison of the RetinaNet models. Latency is measured on a Samsung Galaxy S21 using 1-thread CPU. FP32 refers to the unquantized floating point TFLite model. PTQ INT8 refers to full integer post-training quantization. QAT INT8 refers to the quantized QAT model.
 |
The QAT support for object detection model is critical to many on-device use cases, such as product recognition using hand-held devices, enabling a more pleasant user journey.
MOSAIC
MOSAIC is a neural network architecture for efficient and accurate semantic image segmentation on mobile devices. With a simple asymmetric encoder-decoder structure which consists of an efficient multi-scale context encoder and a light-weight hybrid decoder to recover spatial details from aggregated information, MOSAIC achieves better balanced performance while considering accuracy and computational cost. MLCommons MLPerf adopted MOSAIC as the new industry standard model for mobile image segmentation benchmark.
We have added QAT support for MOSAIC as part of the open source release. In Table 2, we provide the benchmark comparison between DeepLabv3+ and MOSAIC. We can clearly observe that MOSAIC achieves better performance (mIoU: mean intersection-over-union) with significantly lower latency. The negligible gap between QAT INT8 and FP32 also demonstrates the effectiveness of QAT. Please refer to the paper for more benchmark results.
Table 2. mIoU and latency comparison of a MobileNet Multi-HW AVG + MOSAIC. Latency is measured on a Samsung Galaxy S21 using 1-thread CPU. FP32 refers to the unquantized floating point TFLite model. PTQ INT8 refers to full integer post-training quantization. QAT INT8 refers to the quantized QAT model.
 |
MOSAIC is designed using commonly supported neural operations, and can be easily deployed to diverse mobile hardware platforms for efficient and accurate semantic image segmentation.
MobileBERT
MobileBERT is a thin version of BERT_LARGE, while equipped with bottleneck structures and a carefully designed balance between self-attentions and feed-forward networks. (code)
We applied QAT to the MobileBERT model to show our QAT toolkit can apply to the Transformer based mode, which has become very popular these days.
Table 3. F1 score and latency comparison of a MobileBERT. Latency is measured on a Samsung Galaxy S21 using 1-thread CPU. FP32 refers to the unquantized floating point TFLite model. PTQ INT8 refers to full integer post-training quantization. QAT INT8 refers to the quantized QAT model.

Apply QAT on MobileBERT to enable mobile use-case for the NLP model, such as next word prediction or answer generation. This model only trained on Q&A tasks but it can leverage other on-device NLP tasks.
Next steps
In this post, we expanded the coverage of QAT support and introduced new state-of-the-art quantized models in Model Garden for object detection, semantic segmentation, and natural language processing. TensorFlow practitioners can easily utilize these SOTA quantized models for their problems achieving lower latency or smaller model size with minimal accuracy loss.
To learn more about the Model Garden and its Model Optimization Toolkit support, check out the following blog posts:
- Introducing the Model Garden for TensorFlow 2
- Adding Quantization-aware Training and Pruning to the TensorFlow Model Garden
Model Garden provides implementation of various vision and language models, and the pipeline to train models from scratch or from checkpoints. To get started with Model Garden, you can check out the examples in the Model Garden Official repository. Model libraries in this repository are optimized for fast performance and actively maintained by Google engineers. Simple colab examples for training and inference using these models are also provided.
Acknowledgements
We would like to thank everyone who contributed to this work including the Model Garden team, Model Optimization team and Google Research team. Special thanks to Abdullah Rashwan, Yeqing Li, Hongkun Yu from the Model Garden team; Jaesung Chung from the Model Optimization team, Weijun Wang from the Google Research team.

Toy Jensen Rings in Holidays With AI-Powered ‘Jingle Bells’
In a moment of pure serendipity, Lah Yileh Lee and Xinting Lee, a pair of talented singers who often stream their performances online, found themselves performing in a public square in Taipei when NVIDIA founder and CEO Jensen Huang happened upon them.
Huang couldn’t resist joining in, cheering on their serenade as they recorded Lady Gaga’s “Always Remember Us This Way.”
The resulting video quickly went viral, as did a follow-up video from the pair, who sang Lady Gaga’s “Hold My Hand,” the song Huang originally requested.
Toy Jensen Created Using NVIDIA Omniverse Avatar Cloud Engine
Now, with the help of his AI-driven avatar, Toy Jensen, Huang has come up with a playful holiday-themed response.
NVIDIA’s creative team quickly developed a holiday performance by TJ, a tech demo showcasing core technologies that are part of the NVIDIA Omniverse Avatar Cloud Engine, or ACE, platform.
Omniverse ACE is a collection of cloud-native AI microservices and workflows for developers to easily build, customize and deploy engaging and interactive avatars.
Unlike current avatar development, which requires expertise, specialized equipment, and manually intensive workflows, Omniverse ACE is built on top of the Omniverse platform and NVIDIA’s Unified Compute Framework, or UCF, which makes it possible to quickly create and configure AI pipelines with minimal coding.
“It’s a really amazing technology, and the fact that we can do this is phenomenal,” said Cyrus Hogg, an NVIDIA technical program manager.
To make it happen, NVIDIA’s team used a recently developed voice conversion model to extract the voice of a professional singer from a sample provided by them and turn it into TJ’s voice – originally developed by training on hours of real world recordings. They used the musical notes from that sample and applied them to the digital voice of TJ to make the avatar sing the same notes and with the same rhythm as the original singer.
NVIDIA Omniverse Generative AI – Audio2Face, Audio2Gesture Enable Realistic Facial Expressions, Body Movements
Then the team used NVIDIA Omniverse ACE along with Omniverse Audio2Face and Audio2Gesture technologies to generate realistic facial expressions and body movements for the animated performance based on TJ’s audio alone.
While the team behind Omniverse ACE technologies spent years developing and fine-tuning the technology showcased in the performance, turning the music track they created into a polished video took just hours.
Toy Jensen Delights Fans With ‘Jingle Bells’ Performance
That gave them plenty of time to ensure an amazing performance.
They even collaborated with Jochem van der Saag, a composer and producer who has worked with Michael Bublé and David Foster, to create the perfect backing track for TJ to sing along to.
“We have van der Saag composing the song, and he’s gonna also orchestrate it for us,” said Hogg. “So that’s a really great addition to the team. And we’re really excited to have him on board.”
ACE Could Revolutionize Virtual Experiences
The result is the perfect showcase for NVIDIA Omniverse ACE and the applications it could have in various industries — for virtual events, online education and customer service, as well as in creating personalized avatars for video games, social media and virtual reality experiences. NVIDIA Omniverse ACE will be available soon to early-access partners.
The post Toy Jensen Rings in Holidays With AI-Powered ‘Jingle Bells’ appeared first on NVIDIA Blog.
Popular deep-learning book from Amazon authors gets update
Google JAX Python library implementation and new topics added; volume 1 of book to be published by Cambridge University Press.Read More

Make Your Spirit Merry and Bright With Hit Games on GeForce NOW This Holiday Season
Gear up for some festive fun this GFN Thursday with some of the GeForce NOW community’s top picks of games to play during the holidays, as well as a new title joining the GeForce NOW library this week.
And, following the recent update that enabled Ubisoft Connect account syncing with GeForce NOW, select Ubisoft+ Multi-Access subscribers are receiving a one-month GeForce NOW Priority membership for free. Keep an eye out for an email from Ubisoft to subscribers eligible for the promotion and read more details.
Top Picks to Play During the Holidays
With over 1,400 titles streaming from the cloud and more coming every week, there’s a game for everyone to enjoy this holiday. We asked which games members were most looking forward to playing, and the GeForce NOW community responded with their top picks.
Gamers are diving into all of the action with hit games like the next-gen update for The Witcher 3: Wild Hunt, Battlefield 2042 and Mass Effect.
“Battlefield 2042 highlights what the RTX 3080 tier is ALL about,” said Project Storm. “High performance in the cloud with ultra-low latency.”
“The Mass Effect saga is an epic journey,” said Tartan Troot. “Certainly some of the best role-playing games you can play GeForce NOW.”
The Witcher 3 Complete Edition on the 3080 tier
— ConfidesConch (@ConchConfides) December 14, 2022
Watch Dogs 2, Witcher 3, Cyberpunk. I’m an old gamer, but still enjoy a few hours a week video gaming.
— Lee Friend (@iamleefriend) December 14, 2022
For some, it’s all about the immersion. Members are visiting darker and fantastic worlds in Marvel’s Midnight Suns and Warhammer 40,000: Darktide. Many are fighting zombie hoards in Dying Light 2, while others are taking the path of revenge in SIFU.
“For me, it’s the story that draws me into a game,” said N7_Spectres. “So those games that I’ve been playing this year have been Marvel’s Midnight Suns and Warhammer 40,000: Darktide.”
“I’ve had so many good experiences in the cloud with GeForce NOW this year … games such as Dying Light 2 and SIFU have been in their element on the RTX 3080 membership,” said ParamedicGames from Cloudy With Games.
Destiny 2, Fortnite and going to start Sniper 3.
— GhostStrats Cloud Gaming
(@GhostStrats) December 15, 2022



Gamers who crave competition called out favorites like Destiny 2 and Rocket League. Many mentioned their love for Fortnite, streaming with touch controls on mobile devices.
“The best game to stream on GFN this year has been Destiny 2,” said Nads614. “Being able to set those settings to the maximum and see the quality and the performance is great — I love it.”
“Rocket League still remains the best game I’ve ever played on GFN,” said Aluneth. “Started playing on a bad laptop in 2017 and then moved on to GFN for a better experience.”
“GeForce NOW RTX 3080 works so well to play Fortnite with support for 120 frames per second and ridiculously fast response time, making the cloud gaming platform an affordable, very competitive platform like no other,” said DrSpaceman.
Other titles mentioned frequently include Genshin Impact, Apex Legends and Marvel’s Midnight Suns for gamers wanting to play characters with fantastic abilities. Games like the Assassin’s Creed series and Cyberpunk 2077 are popular options for immersive worlds. And members wanting to partner up and play with others should try It Takes Two for a fun-filled, collaborative experience.

Speaking of playing together, the perfect last-minute present for a gamer in your life is the gift of being able to play all of these titles on any device.
Grab a GeForce NOW RTX 3080 or Priority membership digital gift card to power up devices with the kick of a full gaming rig, priority access to gaming servers, extended session lengths and RTX ON to take supported games to the next level of rendering quality. Check out the GeForce NOW membership page for more information on benefits.
Here for the Holidays

This GFN Thursday brings new in-game content. Roam around explosive Jurassic streets with dinosaurs and buy properties to become the most famous real-estate mogul of Dino City in the new MONOPOLY Madness downloadable content.
And, as the perfect tree topper, members can look for the following new title streaming this week:
- Dinkum (Steam)
Before celebrating the holidays with great gaming, share a little cheer by telling us who Santa should spoil this season. Let us know on Twitter.
Tag someone Santa should give this to…
pic.twitter.com/spSdeN8zoF
—
NVIDIA GeForce NOW (@NVIDIAGFN) December 21, 2022
The post Make Your Spirit Merry and Bright With Hit Games on GeForce NOW This Holiday Season appeared first on NVIDIA Blog.

Scaling Vision Model Training Platforms with PyTorch
TL;DR: We demonstrate the use of PyTorch with FairScale’s FullyShardedDataParallel (FSDP) API in writing large vision transformer models. We discuss our techniques for scaling and optimizing these models on a GPU cluster. The goal of this platform scaling effort is to enable research at scale. This blog does not discuss model accuracy, new model architectures, or new training recipes.
1. Introduction
Latest vision research [1, 2] demonstrates model scaling as a promising research direction. In this project, we aim to enable our platforms to train massive vision transformer (ViT) [3] models. We present our work on scaling the largest trainable ViT from 1B to 120B parameters in FAIR vision platforms. We wrote ViT in PyTorch and leveraged its support for large-scale, distributed training on a GPU cluster.
In the rest of this blog, we will first discuss the main challenges, namely scalability, optimization, and numerical stability. Then we will discuss how we tackle them with techniques including data and model parallelism, automatic mixed precision, kernel fusion, and bfloat16. Finally, we present our results and conclude.
2. Main Challenges
2.1 Scalability
The key scalability challenge is to efficiently shard a model’s operations and state across multiple GPUs. A 100B parameter model requires ~200GB of RAM just for parameters, assuming fp16 representation. So, it is impossible to fit the model on a single GPU (A100 has at most 80GB RAM). Therefore, we need some way to efficiently shard a model’s data (input, parameters, activations, and optimizer state) across multiple GPUs.
Another aspect of this problem is to scale without significantly changing the training recipe. E.g. Certain representation learning recipes use a global batch size of up to 4096 beyond which we start to see accuracy degradation. We cannot scale to more than 4096 GPUs without using some form of tensor or pipeline parallelism.
2.2 Optimization
The key optimization challenge is to maintain high GPU utilization even as we scale the number of model parameters and flops. When we scale models to teraflops and beyond, we start to hit major bottlenecks in our software stack that super-linearly increase training time and reduce accelerator utilization. We require hundreds or thousands of GPUs to run just a single experiment. Improvements in accelerator utilization can lead to significant reductions in cost and improve fleet utilization. It enables us to fund more projects and run more experiments in parallel.
2.3 Numerical Stability
The key stability challenge is to avoid numerical instability and divergence at large scale. We empirically observed in our experiments that the training instability gets severe and hard to deal with when we scale up model sizes, data, batch sizes, learning rate, etc. Vision Transformers particularly face training instability even at a lower parameter threshold. E.g., we find it challenging to train even ViT-H (with just 630M parameters) in mixed-precision mode without using strong data augmentation. We need to study the model properties and training recipes to make sure that the models train stably and converge.
3. Our Solutions
Figure 1 depicts our solutions to each of the challenges.
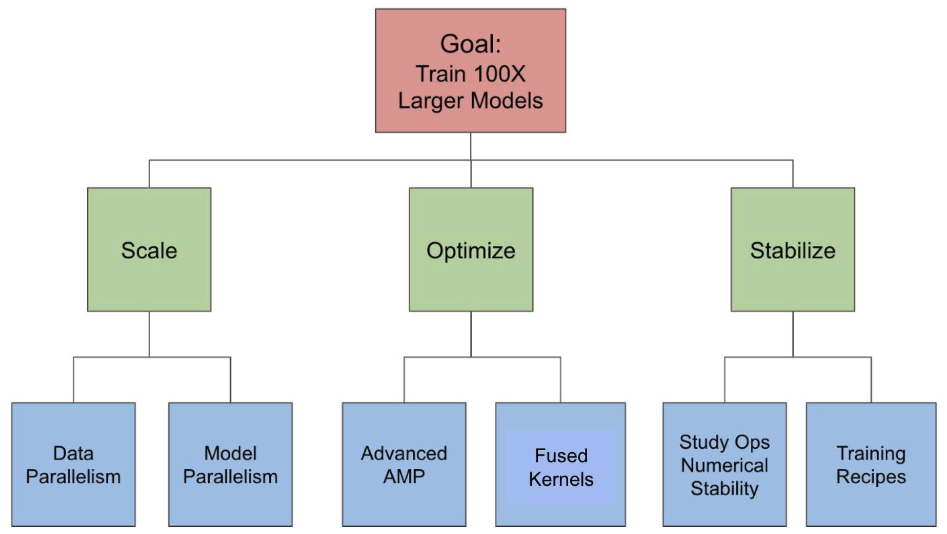
3.1 Addressing scaling challenges with data parallelism and model parallelism
We apply various forms of data and model parallelism to enable fitting very large models in GPU memory.
We use FairScale’s FullyShardedDataParallel (FSDP) API [4], based on PyTorch, to shard parameters, gradients, and optimizer state across multiple GPUs, thereby reducing the memory footprint per GPU. This process consists of the following three steps:
-
Step 1: We wrapped the entire model in a single FSDP instance. This shards the model parameters at the end of a forward pass and gathers parameters at the beginning of a forward pass. This enabled us to scale ~3x from 1.5B to 4.5B parameters.
-
Step 2: We experimented with wrapping individual model layers in separate FSDP instances. This nested wrapping further reduced the memory footprint by sharding and gathering parameters of individual model layers instead of an entire model. The peak memory is then determined by an individually wrapped transformer block in GPU memory in this mode instead of the entire model.
-
Step 3: We used activation-checkpoint to reduce the memory consumption by activations. It saves the input tensors and discards the intermediate activation tensors during the forward pass. These are recomputed during the backward pass.
In addition, we experimented with model-parallelism techniques such as pipeline parallelism [5], which allow us to scale to more GPUs without increasing the batch size.
3.2 Addressing optimization challenges with advanced AMP and kernel fusion
Advanced AMP
Automatic Mixed Precision (AMP) [6] training refers to training models using a lower precision of bits than FP32 or the default but still maintaining accuracy. We experimented with three levels of AMP as described below:
-
AMP O1: This refers to training in mixed precision where weights are in FP32 and some operations are in FP16. With AMP O1, the ops that might impact accuracy remain in FP32 and are not autocasted to FP16.
-
AMP O2: This refers to training in mixed precision but with more weights and ops in FP16 than in O1. Weights do not implicitly remain in FP32 and are cast to FP16. A copy of the master weights is maintained in the FP32 precision that is used by the optimizer. If we want the normalization layer weights in FP32 then we need to explicitly use layer wrapping to ensure that.
-
Full FP16: This refers to training in full FP16 where weights and operations are in FP16. FP16 is challenging to enable for training due to convergence issues.
We found that AMP O2 with LayerNorm wrapping in FP32 leads to the best performance without sacrificing accuracy.
Kernel Fusion
- To reduce GPU kernel launch overhead and increase GPU work granularity, we experimented with kernel fusions, including fused dropout and fused layer-norm, using the xformers library [7].
3.3 Addressing stability challenges by studying ops numerical stability and training recipes
BFloat16 in general but with LayerNorm in FP32
The bfloat16 (BF16) [8] floating-point format provides the same dynamic range as FP32 with a memory footprint identical to FP16. We found that we could train models in the BF16 format using the same set of hyperparameters as in FP32, without special parameter tuning. Nevertheless, we found that we need to keep LayerNorm in FP32 mode in order for the training to converge.
3.4 Final training recipe
A summary of the final training recipe.
- Wrap the outer model in an FSDP instance. Enable parameter sharding after the forward pass.
- Wrap individual ViT blocks with activation checkpointing, nested FSDP wrapping, and parameter flattening.
- Enable mixed precision mode (AMP O2) with bfloat16 representation. Maintain the optimizer state in FP32 precision to enhance numerical stability.
- Wrap normalization layers like LayerNorm in FP32 for better numerical stability.
- Maximize the Nvidia TensorCore utilization by keeping matrix dimensions to be multiple of 8. For More details check Nvidia Tensor Core Performance Guide.
4. Results
In this section, we show the scaling results of ViT on three types of tasks: (1) image classification, (2) object detection (3) video understanding. Our key result is that we are able to train massive ViT backbones across these vision tasks after applying the discussed scaling and optimization techniques. This enables vision research at a much larger scale. We trained the models to convergence to verify that we maintain the current baselines even with all the optimizations. A common trend in Figures 2, 3, 4 is that we are able to train up to 25B-param models with an epoch time of less than 4 hours on 128 A100 GPUs. The 60B and 120B models are relatively slower to train.
Figure 2 shows the image-classification scaling result. It plots the epoch time for training ViTs on ImageNet using 128 A100-80GB GPUs with different model sizes.
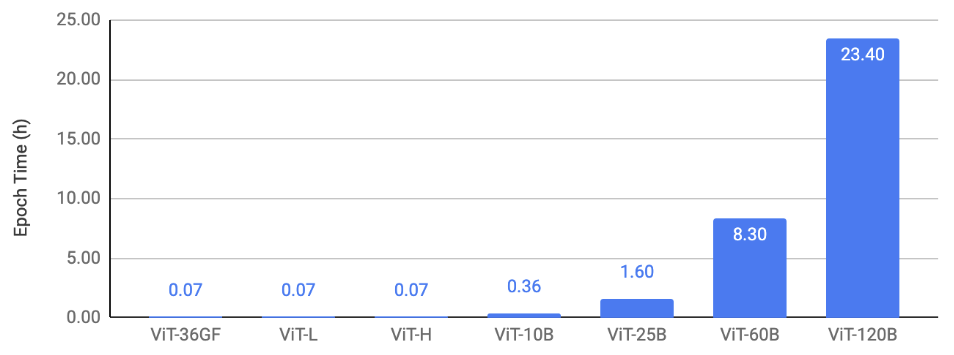
Figure 2: Image-classification scaling result.
Figure 3 shows the object-detection scaling result. It plots the epoch time for training ViTDet [9] with different ViT backbones on COCO using 128 A100-80GB GPUs.
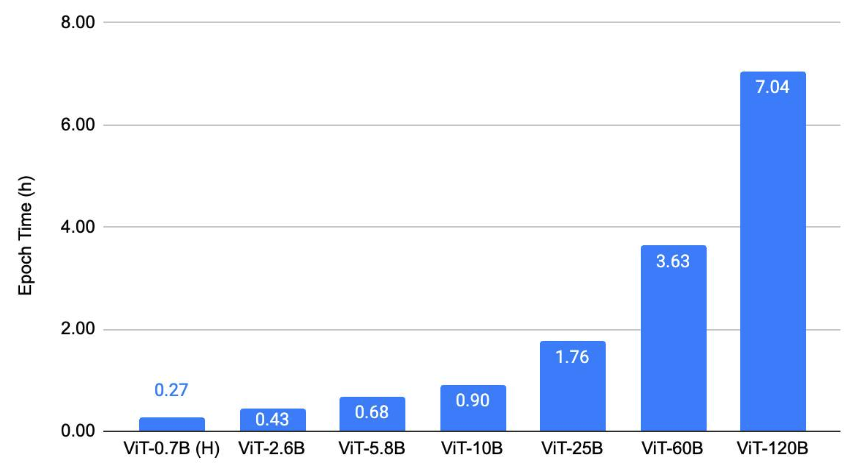
Figure 3: Object-detection scaling result.
Figure 4 shows the video-understanding scaling result. It plots the epoch time for training MViTv2 [10] models on Kinetics 400 [11] using 128 V100 (32 GB) GPUs in FP32.
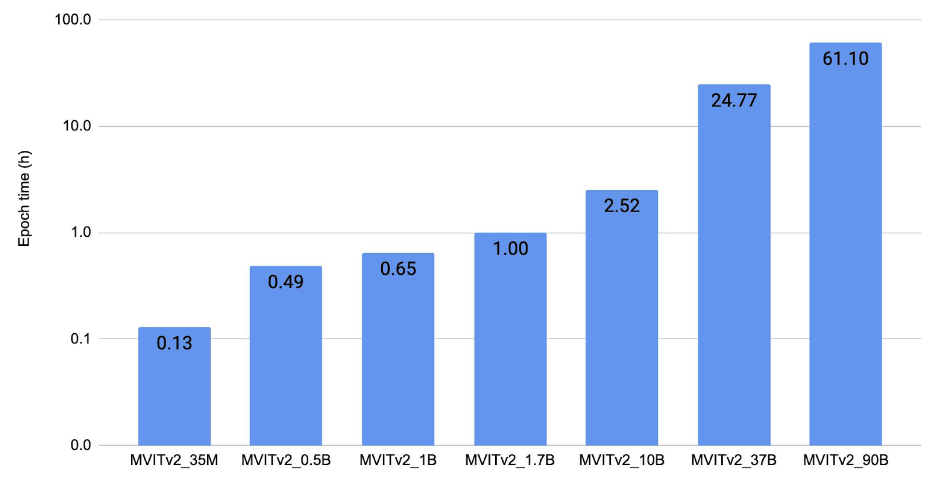
Figure 4: Video-understanding scaling result.
Figure 5 shows the optimization result with the ViT-H model in Figure 2 on 8 A100-40GB GPUs.
Three versions are used: (1) the baseline uses PyTorch’s DDP [12] with AMP O1, (2) FSDP + AMP-O2 + other optimizations, and (3) FSDP + FP16 + other optimizations. These optimizations altogether speed up the training by up to 2.2x.
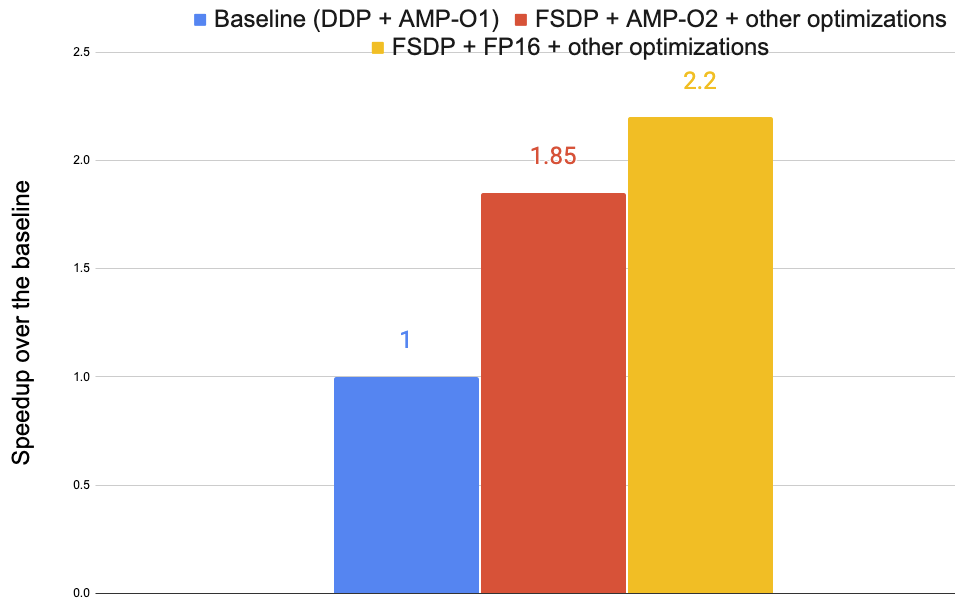
Figure 5: Training speedups from various optimizations.
5. Concluding Remarks
We have demonstrated the use of PyTorch with FairScale’s FullyShardedDataParallel (FSDP) API in writing large vision transformer models. We discuss our techniques for scaling and optimizing these models on a GPU cluster. We hope that this article can motivate others to develop large-scale ML models with PyTorch and its ecosystem.
References
[1] Masked Autoencoders Are Scalable Vision Learners [2] Revisiting Weakly Supervised Pre-Training of Visual Perception Models [3] An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale [4] fairscale.nn.FullyShardedDataParallel [5] Pipeline parallelism in PyTorch [6] Automatic Mixed Precision (AMP) in PyTorch [7] xformers [8] The bfloat16 numerical format [9] Exploring Plain Vision Transformer Backbones for Object Detection [10] MViTv2: Improved Multiscale Vision Transformers for Classification and Detection [11] https://www.deepmind.com/open-source/kinetics [12] Getting Started with Distributed Data Parallel (DDP)The future of time-series forecasting, with RFP winner B. Aditya Prakash
From time to time, Meta invites academics to propose research in specific areas that align with our mission of building community and bringing the world closer together.Read More