This post is co-authored by Tristan Miller from Best Egg.
Best Egg is a leading financial confidence platform that provides lending products and resources focused on helping people feel more confident as they manage their everyday finances. Since March 2014, Best Egg has delivered $22 billion in consumer personal loans with strong credit performance, welcomed almost 637,000 members to the recently launched Best Egg Financial Health platform, and empowered over 180,000 cardmembers who carry the new Best Egg Credit Card in their wallet.
Amazon SageMaker is a fully managed machine learning (ML) service providing various tools to build, train, optimize, and deploy ML models. SageMaker provides automated model tuning, which manages the undifferentiated heavy lifting of provisioning and managing compute infrastructure to run several iterations and select the optimized model candidate from training.
To help you efficiently tune your required hyperparameters and determine the best-performing model, this post will discuss how Best Egg used SageMaker hyperparameter tuning with warm pools and achieved a three-fold improvement in model training time.
Use case overview
Risk credit analysts use credit rating models when lending or offering a credit card to customers by taking a variety of user attributes into account. This statistical model generates a final score, or Good Bad Indicator (GBI), which determines whether to approve or reject a credit application. ML insights facilitate decision-making. To assess the risk of credit applications, ML uses various data sources, thereby predicting the risk that a customer will be delinquent.
The challenge
A significant problem in the financial sector is that there is no universally accepted method or structure for dealing with the overwhelming array of possibilities that must be considered at any one time. It’s difficult to standardize the tools that teams use in order to promote transparency and tracking across the board. The application of ML can help those in the finance industry make better judgments regarding pricing, risk management, and consumer behavior. Data scientists train multiple ML algorithms to examine millions of consumer data records, identify anomalies, and evaluate if a person is eligible for credit.
SageMaker can run automated hyperparameter tuning based on multiple optimization techniques such as grid search, Bayesian, random search, and Hyperband. Automatic model tuning makes it easy to zero in on the optimal model configuration, freeing up time and money for better use elsewhere in the financial sector. As part of hyperparameter tuning, SageMaker runs several iterations of the training code on the training dataset with various hyperparameter combinations. SageMaker then determines the best model candidate with the optimal hyperparameters based on the objective metric configured.
Best Egg was able to automate hyperparameter tuning with the automated hyperparameter optimization (HPO) feature of SageMaker and parallelize it. However, each hyperparameter tuning job could take hours, and selecting the best model candidate took many hyperparameter tuning jobs run over the course of several days. Hyperparameter tuning jobs could be slow due to the nature of the iterative tasks that HPO runs under the hood. Every time a training job is initiated, new resource provisioning occurs, which consumes a significant amount of time before the training actually begins. This is a common problem that data scientists face when training their models. Time efficiency was a major pain point because these long-running training jobs were impeding productivity and data scientists were stuck on these jobs for hours.
Solution overview
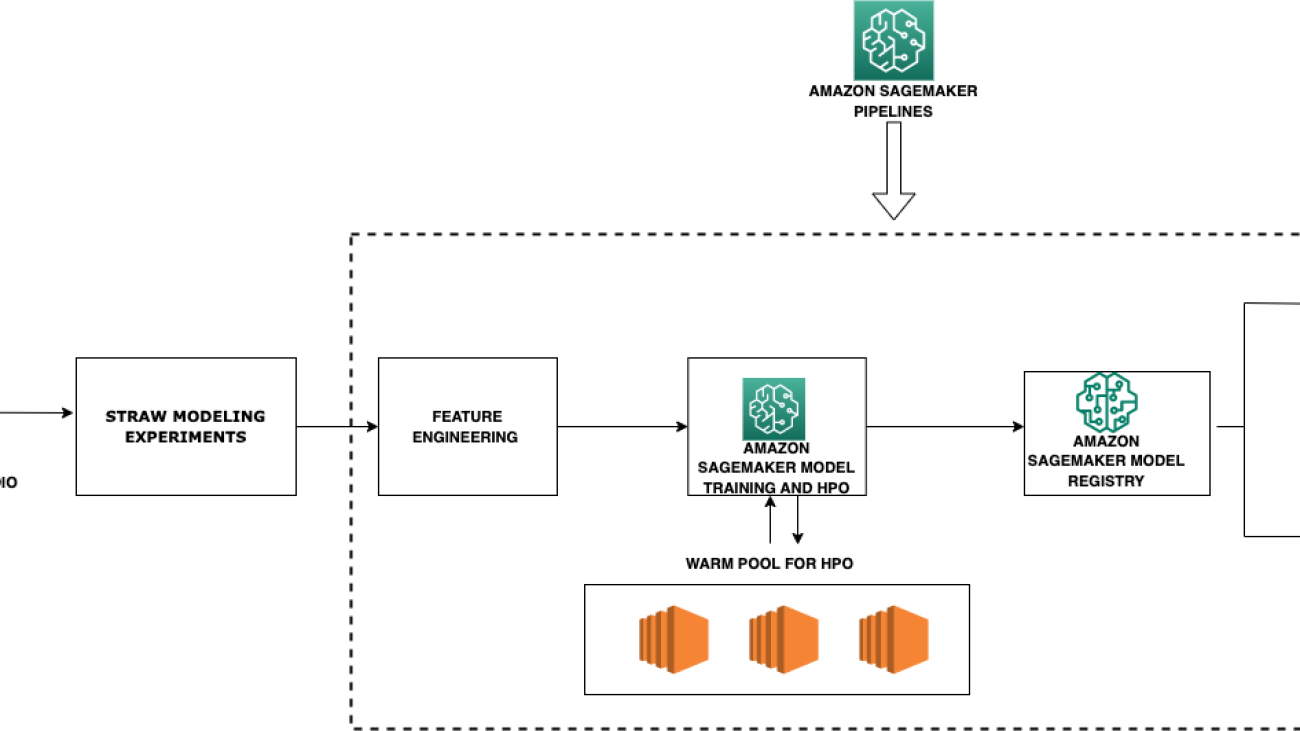
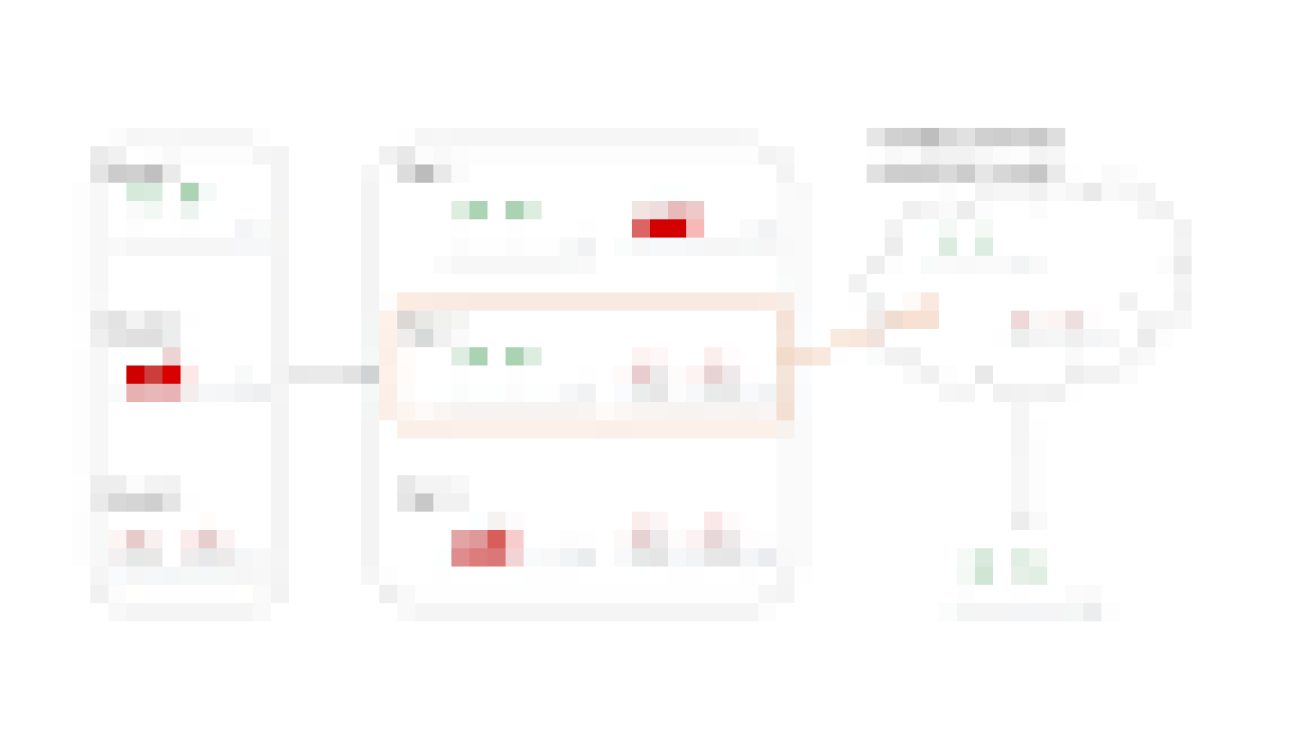
The following diagram represents the different components used in this solution.

The Best Egg data science team uses Amazon SageMaker Studio for building and running Jupyter notebooks. SageMaker processing jobs run feature engineering pipelines on the input dataset to generate features. Best Egg trains multiple credit models using classification and regression algorithms. The data science team must sometimes work with limited training data in the order of tens of thousands of records given the nature of their use cases. Best Egg runs SageMaker training jobs with automated hyperparameter tuning powered by Bayesian optimization. To reduce variance, Best Egg uses k-fold cross validation as part of their custom container to evaluate the trained model.
The trained model artifact is registered and versioned in the SageMaker model registry. Inference is run in two ways—real time and batch—based on the user requirements. The trained model artifact is hosted on a SageMaker real-time endpoint using the built-in auto scaling and load balancing features. The model is also scored through batch transform jobs scheduled on a daily basis. The whole pipeline is orchestrated through Amazon SageMaker Pipelines, consisting of a sequence of steps such as a processing step for feature engineering, a tuning step for training and automated model tuning, and a model step for registering the artifact.
With respect to the core problem of long-running hyperparameter tuning jobs, Best Egg explored the recently released warm pools feature managed by SageMaker. SageMaker Managed Warm Pools allows you to retain and reuse provisioned infrastructure after the completion of a training job to reduce latency for repetitive workloads, such as iterative experimentation or consecutively running jobs where specific job configuration parameters like instance type or count match with the previous runs. This allowed Best Egg to reuse the existing infrastructure for their repetitive training jobs without wasting time on infrastructure provisioning.
Deep Dive into Model Tuning and Benefits of Warm Pools
SageMaker Automated Model Tuning leverages Warm Pools by default for any tuning job as of August 2022 (announcement). This makes it straightforward to reap the benefits of Warm Pools as you just need to launch a tuning job and SageMaker Automatic Model Tuning will automatically use Warm Pools between subsequent training jobs launched as part of the tuning. When each training job completes, the provisioned resources are kept alive in a warm pool so that the next training job launched as part of the tuning will start on the same pool with minimal startup overhead.
The below workflow depicts a series of training job runs using warm pool.
- After the first training job is complete, the instances used for training are retained in the warm pool cluster.
- The next training job triggered will use the instance in the warm pool to run, eliminating the cold start time needed to prepare the instance to start up.
- Likewise, if more training jobs come in with instance type, instance count, volume & networking criteria similar to the warm pool cluster resources, then the matched instances will be used for running the jobs.
- Once the training job is completed, the instances will be retained in the warm pool waiting for new jobs.
- The maximum length of time that a warm pool cluster can continue running consecutive training jobs is 7 days.
- As long as the cluster is healthy and the warm pool is within the specified time duration, the warm pool status is
Available. - The warm pool stays
Availableuntil it identifies a matching training job for reuse. If the warm pool status isTerminated, then this is the end of the warm pool lifecycle.
- As long as the cluster is healthy and the warm pool is within the specified time duration, the warm pool status is
The following diagram illustrates this workflow.

How Best Egg benefitted: Improvements and data points
Best Egg noticed that with warm pools, their training jobs on SageMaker were running faster by a factor of 3. In one credit model project, the best model was selected from eight different HPO jobs, each of which had 40 iterations with five parallel jobs at a time. Each iteration took about 1 minute to compute, whereas without warm pools they typically took 5 minutes each. In total, the process took 2 hours of computation time, with additional input from the data scientist adding up to about half a business day. Without warm pools, we estimate that the computation would have taken 6 hours alone, likely spread out over the course of 2–3 business days.
Summary
In conclusion, this post discussed elements of Best Egg’s business and the company’s ML landscape. We reviewed how Best Egg was able to speed up its model training and tuning by enabling warm pools for their hyperparameter tuning jobs on SageMaker. We also explained how simple it is to implement warm pools for your training jobs with a simple configuration. At AWS, we recommend our readers start exploring warm pools for iterative and repetitive training jobs.
About the Authors
 Tristan Miller is a Lead Data Scientist at Best Egg. He builds and deploys ML models to make important underwriting and marketing decisions. He develops bespoke solutions to address specific problems, as well as automation to increase efficiency and scale. He is also a skilled origamist.
Tristan Miller is a Lead Data Scientist at Best Egg. He builds and deploys ML models to make important underwriting and marketing decisions. He develops bespoke solutions to address specific problems, as well as automation to increase efficiency and scale. He is also a skilled origamist.

Valerio Perrone is an Applied Science Manager at AWS. He leads the science and engineering team owning the service for automatic model tuning across Amazon SageMaker. Valerio’s expertise lies in developing algorithms for large-scale machine learning and statistical models, with a focus on data-driven decision making and the democratization of artificial intelligence

Ganapathi Krishnamoorthi is a Senior ML Solutions Architect at AWS. Ganapathi provides prescriptive guidance to startup and enterprise customers, helping them design and deploy cloud applications at scale. He is specialized in machine learning and is focused on helping customers use AI/ML for their business outcomes. When not at work, he enjoys exploring the outdoors and listening to music
 Ajjay Govindaram is a Sr. Solutions Architect at AWS. He works with strategic customers who are using AI/ML to solve complex business problems. His experience lies in providing technical direction as well as design assistance for modest to large-scale AI/ML application deployments. His knowledge ranges from application architecture to big data, analytics, and machine learning. He enjoys listening to music while resting, experiencing the outdoors, and spending time with his loved ones.
Ajjay Govindaram is a Sr. Solutions Architect at AWS. He works with strategic customers who are using AI/ML to solve complex business problems. His experience lies in providing technical direction as well as design assistance for modest to large-scale AI/ML application deployments. His knowledge ranges from application architecture to big data, analytics, and machine learning. He enjoys listening to music while resting, experiencing the outdoors, and spending time with his loved ones.

Hariharan Suresh is a Senior Solutions Architect at AWS. He is passionate about databases, machine learning, and designing innovative solutions. Prior to joining AWS, Hariharan was a product architect, core banking implementation specialist, and developer, and worked with BFSI organizations for over 11 years. Outside of technology, he enjoys paragliding and cycling.
















 Dhiraj Thakur is a Solutions Architect with Amazon Web Services. He works with AWS customers and partners to provide guidance on enterprise cloud adoption, migration, and strategy. He is passionate about technology and enjoys building and experimenting in the analytics and AI/ML space.
Dhiraj Thakur is a Solutions Architect with Amazon Web Services. He works with AWS customers and partners to provide guidance on enterprise cloud adoption, migration, and strategy. He is passionate about technology and enjoys building and experimenting in the analytics and AI/ML space.



 Pinak Panigrahi works with customers to build machine learning driven solutions to solve strategic business problems on AWS. When not occupied with machine learning, he can be found taking a hike, reading a book or catching up with sports.
Pinak Panigrahi works with customers to build machine learning driven solutions to solve strategic business problems on AWS. When not occupied with machine learning, he can be found taking a hike, reading a book or catching up with sports. Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.
Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.


 Dr. Vivek Madan is an Applied Scientist with the Amazon SageMaker JumpStart team. He got his PhD from University of Illinois at Urbana-Champaign and was a Post Doctoral Researcher at Georgia Tech. He is an active researcher in machine learning and algorithm design and has published papers in EMNLP, ICLR, COLT, FOCS, and SODA conferences.
Dr. Vivek Madan is an Applied Scientist with the Amazon SageMaker JumpStart team. He got his PhD from University of Illinois at Urbana-Champaign and was a Post Doctoral Researcher at Georgia Tech. He is an active researcher in machine learning and algorithm design and has published papers in EMNLP, ICLR, COLT, FOCS, and SODA conferences. Heiko Hotz is a Senior Solutions Architect for AI & Machine Learning with a special focus on Natural Language Processing (NLP), Large Language Models (LLMs), and Generative AI. Prior to this role, he was the Head of Data Science for Amazon’s EU Customer Service. Heiko helps our customers being successful in their AI/ML journey on AWS and has worked with organizations in many industries, including Insurance, Financial Services, Media and Entertainment, Healthcare, Utilities, and Manufacturing. In his spare time Heiko travels as much as possible.
Heiko Hotz is a Senior Solutions Architect for AI & Machine Learning with a special focus on Natural Language Processing (NLP), Large Language Models (LLMs), and Generative AI. Prior to this role, he was the Head of Data Science for Amazon’s EU Customer Service. Heiko helps our customers being successful in their AI/ML journey on AWS and has worked with organizations in many industries, including Insurance, Financial Services, Media and Entertainment, Healthcare, Utilities, and Manufacturing. In his spare time Heiko travels as much as possible.