If you’ve had the opportunity to build a search application for unstructured data (i.e., wiki, informational web sites, self-service help pages, internal documentation, etc.) using open source or commercial-off-the-shelf search engines, then you’re probably familiar with the inherent accuracy challenges involved in getting relevant search results. The intended meaning of both query and document can be lost because the search is reduced to matching component keywords and terms. Consequently, while you get results that may contain the right words, they aren’t always relevant to the user. You need your search engine to be smarter so it can rank documents based on matching the meaning or semantics of the content to the intention of the user’s query.
Amazon Kendra provides a fully managed intelligent search service that automates document ingestion and provides highly accurate search and FAQ results based on content across many data sources. If you haven’t migrated to Amazon Kendra and would like to improve the quality of search results, you can use Amazon Kendra Intelligent Ranking for self-managed OpenSearch on your existing search solution.
We’re delighted to introduce the new Amazon Kendra Intelligent Ranking for self-managed OpenSearch, and its companion plugin for the OpenSearch search engine! Now you can easily add intelligent ranking to your OpenSearch document queries, with no need to migrate, duplicate your OpenSearch indexes, or rewrite your applications. The difference between Amazon Kendra Intelligent Ranking for self-managed OpenSearch and the fully managed Amazon Kendra service is that while the former provides powerful semantic re-ranking for the search results, the later provides additional search accuracy improvements and functionality such as incremental learning, question answering, FAQ matching, and built-in connectors. For more information about the fully managed service, please visit the Amazon Kendra service page.
With Amazon Kendra Intelligent Ranking for self-managed OpenSearch, previous results like this:
Query: What is the address of the White House?
Hit1 (best): The president delivered an address to the nation from the White House today.
Hit2: The White House is located at: 1600 Pennsylvania Avenue NW, Washington, DC 20500
become like this:
Query: What is the address of the White House?
Hit1 (best): The White House is located at: 1600 Pennsylvania Avenue NW, Washington, DC 20500
Hit2: The president delivered an address to the nation from the White House today.
In this post, we show you how to get started with Amazon Kendra Intelligent Ranking for self-managed OpenSearch, and we provide a few examples that demonstrate the power and value of this feature.
Components of Amazon Kendra Intelligent Ranking for self-managed OpenSearch
Prerequisites
For this tutorial, you’ll need a bash terminal on Linux, Mac, or Windows Subsystem for Linux, and an AWS account. Hint: consider using an Amazon Cloud9 instance or an Amazon Elastic Compute Cloud (Amazon EC2) instance.
You will:
- Install Docker, if it’s not already installed on your system.
- Install the latest AWS Command Line Interface (AWS CLI), if it’s not already installed.
- Create and start OpenSearch containers, with the Amazon Kendra Intelligent Ranking plugin enabled.
- Create test indexes, and load some sample documents.
- Run some queries, with and without intelligent ranking, and be suitably impressed by the differences!
Install Docker
If Docker (i.e., docker and docker-compose) is not already installed in your environment, then install it. See Get Docker for directions.
Install the AWS CLI
If you don’t already have the latest version of the AWS CLI installed, then install and configure it now (see AWS CLI Getting Started). Your default AWS user credentials must have administrator access, or ask your AWS administrator to add the following policy to your user permissions:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "kendra-ranking:*",
"Resource": "*"
}
]
}
Create and start OpenSearch using the Quickstart script
Download the search_processing_kendra_quickstart.sh script:
wget https://raw.githubusercontent.com/msfroh/search-relevance/quickstart-script/helpers/search_processing_kendra_quickstart.sh
chmod +x search_processing_kendra_quickstart.sh
Make it executable:
chmod +x ./search_processing_kendra_quickstart.sh
The quickstart script:
- Creates an Amazon Kendra Intelligent Ranking Rescore Execution Plan in your AWS account.
- Creates Docker containers for OpenSearch and its Dashboards.
- Configures OpenSearch to use the Kendra Intelligent Ranking Service.
- Starts the OpenSearch services.
- Provides helpful guidance for using the service.
Use the --help option to see the command line options:
./search_processing_kendra_quickstart.sh --help
Now, execute the script to automate the Amazon Kendra and OpenSearch setup:
./search_processing_kendra_quickstart.sh --create-execution-plan
That’s it! OpenSearch and OpenSearch Dashboard containers are now up and running.
Read the output message from the quickstart script, and make a note of the directory where you can run the handy docker-compose commands, and the cleanup_resources.sh script.
Try a test query to validate you can connect to your OpenSearch container:
curl -XGET --insecure -u 'admin:admin' 'https://localhost:9200'
Note that if you get the error curl(35):OpenSSL SSL_connect: SSL_ERROR_SYSCALL in connection to localhost:9200, it means that OpenSearch is still coming up. Please wait for a couple of minutes for OpenSearch to be ready and try again.
Create test indexes and load sample documents
The script below is used to create an index and load sample documents. Save it on your computer as bulk_post.sh:
#!/bin/bash
curl -u admin:admin -XPOST https://localhost:9200/_bulk --insecure --data-binary @$1 -H 'Content-Type: application/json'
Save the data files below as tinydocs.jsonl:
{ "create" : { "_index" : "tinydocs", "_id" : "tdoc1" } }
{"title": "WhiteHouse1", "body": "The White House is located at: 1600 Pennsylvania Avenue NW, Washington, DC 20500"}
{ "create" : { "_index" : "tinydocs", "_id" : "tdoc2" } }
{"title": "WhiteHouse2", "body": "The president delivered an address to the nation from the White House today."}
And save the data file below as dstinfo.jsonl:
(This data is adapted from Daylight Saving Time article).
{ "create" : { "_index" : "dstinfo", "_id" : "dst1" } }
{"title": "Daylight Saving Time", "body": "Daylight saving time begins on the second Sunday in March at 2 a.m., and clocks are set an hour ahead, according to the Farmers’ Almanac. It lasts for eight months and ends on the first Sunday in November, when clocks are set back an hour at 2 a.m."}
{ "create" : { "_index" : "dstinfo", "_id" : "dst2" } }
{"title":"History of daylight saving time", "body": "Founding Father Benjamin Franklin is often deemed the brain behind daylight saving time after a letter he wrote in 1784 to a Parisian newspaper, according to the Farmers’ Almanac. But Franklin’s letter suggested people simply change their routines and schedules — not the clocks — to the sun’s cycles. Perhaps surprisingly, daylight saving time had a soft rollout in the United States in 1883 to solve issues with railroad accidents, according to the U.S. Bureau of Transportation Services. It was instituted across the United States in 1918, according to the Congressional Research Service. In 2005, Congress changed it to span from March to November instead of its original timeframe of April to October."}
{ "create" : { "_index" : "dstinfo", "_id" : "dst3" } }
{"title": "Daylight saving time participants", "body":"The United States is one of more than 70 countries that follow some form of daylight saving time, according to World Data. States can individually decide whether or not to follow it, according to the Farmers’ Almanac. Arizona and Hawaii do not, nor do parts of northeastern British Columbia in Canada. Puerto Rico and the Virgin Islands, both U.S. territories, also don’t follow daylight saving time, according to the Congressional Research Service."}
{ "create" : { "_index" : "dstinfo", "_id" : "dst4" } }
{"title":"Benefits of daylight saving time", "body":"Those in favor of daylight saving time, whether eight months long or permanent, also vouch that it increases tourism in places such as parks or other public attractions, according to National Geographic. The longer days can keep more people outdoors later in the day."}
Make the script executable:
Now use the bulk_post.sh script to create indexes and load the data by running the two commands below:
./bulk_post.sh tinydocs.jsonl
./bulk_post.sh dstinfo.jsonl
Run sample queries
Prepare query scripts
OpenSearch queries are defined in JSON using the OpenSearch query domain specific language (DSL). For this post, we use the Linux curl command to send queries to our local OpenSearch server using HTTPS.
To make this easy, we’ve defined two small scripts to construct our query DSL and send it to OpenSearch.
The first script creates a regular OpenSearch text match query on two document fields – title and body. See OpenSearch documentation for more on the multi-match query syntax. We’ve kept the query very simple, but you can experiment later with defining alternate types of queries.
Save the script below as query_nokendra.sh:
#!/bin/bash
curl -XGET "https://localhost:9200/$1/_search?pretty" -u 'admin:admin' --insecure -H 'Content-Type: application/json' -d'
{
"query": {
"multi_match": {
"fields": ["title", "body"],
"query": "'"$2"'"
}
},
"size": 20
}
'
The second script is similar to the first one, but this time we add a query extension to instruct OpenSearch to invoke the Amazon Kendra Intelligent Ranking plugin as a post-processing step to re-rank the original results using the Amazon Kendra Intelligent Ranking service.
The size property determines how many OpenSearch result documents are sent to Kendra for re-ranking. Here, we specify a maximum of 20 results for re-ranking. Two properties, title_field (optional) and body_field (required), specify the document fields used for intelligent ranking.
Save the script below as query_kendra.sh:
#!/bin/bash
curl -XGET "https://localhost:9200/$1/_search?pretty" -u 'admin:admin' --insecure -H 'Content-Type: application/json' -d'
{
"query": {
"multi_match": {
"fields": ["title", "body"],
"query": "'"$2"'"
}
},
"size": 20,
"ext": {
"search_configuration": {
"result_transformer": {
"kendra_intelligent_ranking": {
"order": 1,
"properties": {
"title_field": "title",
"body_field": "body"
}
}
}
}
}
}
'
Make both scripts executable:
chmod +x ./query_*kendra.sh
Run initial queries
Start with a simple query on the tinydocs index, to reproduce the example used in the post introduction.
Use the query_nokendra.sh script to search for the address of the White House:
./query_nokendra.sh tinydocs "what is the address of White House"
You see the results shown below. Observe the order of the two results, which are ranked by the score assigned by the OpenSearch text match query. Although the top scoring result does contain the keywords address and White House, it’s clear the meaning doesn’t match the intent of the question. The keywords match, but the semantics do not.
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.1619741,
"hits" : [
{
"_index" : "tinydocs",
"_id" : "tdoc2",
"_score" : 1.1619741,
"_source" : {
"title" : "Whitehouse2",
"body" : "The president delivered an address to the nation from the White House today."
}
},
{
"_index" : "tinydocs",
"_id" : "tdoc1",
"_score" : 1.0577903,
"_source" : {
"title" : "Whitehouse1",
"body" : "The White House is located at: 1600 Pennsylvania Avenue NW, Washington, DC 20500"
}
}
]
}
}
Now let’s run the query with Amazon Kendra Intelligent Ranking, using the query_kendra.sh script:
./query_kendra.sh tinydocs "what is the address of White House"
This time, you see the results in a different order as shown below. The Amazon Kendra Intelligent Ranking service has re-assigned the score values, and assigned a higher score to the document that more closely matches the intention of the query. From a keyword perspective, this is a poorer match because it doesn’t contain the word address; however, from a semantic perspective it’s the better response. Now you see the benefit of using the Amazon Kendra Intelligent Ranking plugin!
{
"took" : 522,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 2,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.3798389,
"hits" : [
{
"_index" : "tinydocs",
"_id" : "tdoc1",
"_score" : 0.3798389,
"_source" : {
"title" : "Whitehouse1",
"body" : "The White House is located at: 1600 Pennsylvania Avenue NW, Washington, DC 20500"
}
},
{
"_index" : "tinydocs",
"_id" : "tdoc2",
"_score" : 0.25906953,
"_source" : {
"title" : "Whitehouse2",
"body" : "The president delivered an address to the nation from the White House today."
}
}
]
}
}
Run additional queries and compare search results
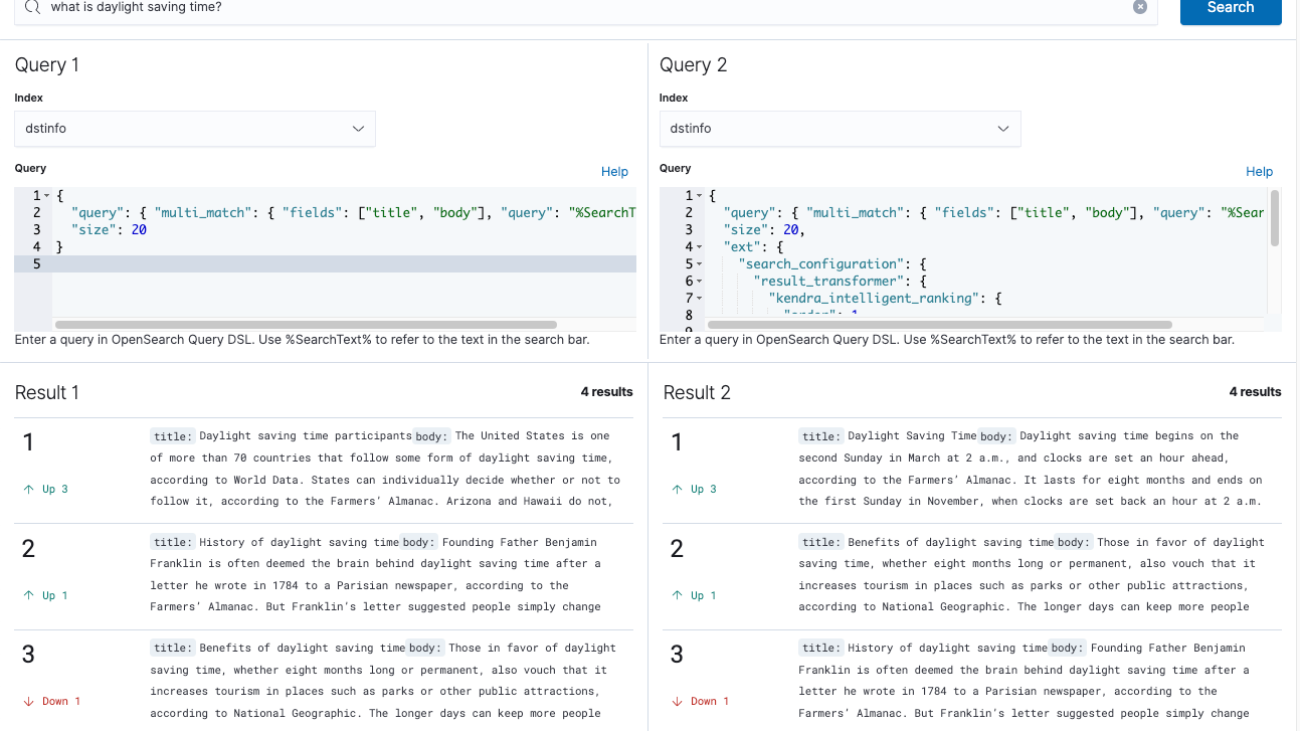
Try the dstinfo index now, to see how the same concept works with different data and queries. While you can use the scripts query_nokendra.sh and query_kendra.sh to make queries from the command line, let’s use instead the OpenSearch Dashboards Compare Search Results Plugin to run queries and compare search results.
Paste the local Dashboards URL into your browser: http://localhost:5601/app/searchRelevance – / to access the dashboard comparison tool. Use the default credentials: Username: admin, Password: admin.
In the search bar, enter: what is daylight saving time?
For the Query 1 and Query 2 index, select dstinfo.
Copy the DSL query below and paste it in the Query panel under Query 1. This is a keyword search query.
{
"query": { "multi_match": { "fields": ["title", "body"], "query": "%SearchText%" } },
"size": 20
}
Now copy the DSL query below and paste it in the Query panel under Query 2. This query invokes the Amazon Kendra Intelligent Ranking plugin for self-managed OpenSearch to perform semantic re-ranking of the search results.
{
"query": { "multi_match": { "fields": ["title", "body"], "query": "%SearchText%" } },
"size": 20,
"ext": {
"search_configuration": {
"result_transformer": {
"kendra_intelligent_ranking": {
"order": 1,
"properties": { "title_field": "title", "body_field": "body" }
}
}
}
}
}
Choose the Search button to run the queries and observe the search results. In Result 1, the hit ranked last is probably actually the most relevant response to this query. In Result 2, the output from Amazon Kendra Intelligent Ranking has the most relevant answer correctly ranked first.

Now that you have experienced Amazon Kendra Intelligent Ranking for self-managed OpenSearch, experiment with a few queries of your own. Use the data we have already loaded or use the bulk_post.sh script to load your own data.
Explore the Amazon Kendra ranking rescore API
As you’ve seen from this post, the Amazon Kendra Intelligent Ranking plugin for OpenSearch can be conveniently used for semantic re-ranking of your search results. However, if you use a search service that doesn’t support the Amazon Kendra Intelligent Ranking plugin for self-managed OpenSearch, then you can use the Rescore function from the Amazon Kendra Intelligent Ranking API directly.
Try this API using the search results from the example query we used above: what is the address of the White House?
First, find your Execution Plan Id by running:
aws kendra-ranking list-rescore-execution-plans
The JSON below contains the search query, and the two results that were returned by the original OpenSearch match query, with their original OpenSearch scores. Replace {kendra-execution-plan_id} with your Execution Plan Id (from above) and save it as rescore_input.json:
{
"RescoreExecutionPlanId": "{kendra-execution-plan_id}",
"SearchQuery": "what is the address of White House",
"Documents": [
{ "Id": "tdoc1", "Title": "Whitehouse1", "Body": "The president delivered an address to the nation from the White House today.", "OriginalScore": 1.4484794 },
{ "Id": "tdoc2", "Title": "Whitehouse2", "Body": "The White House is located at: 1600 Pennsylvania Avenue NW, Washington, DC 20500", "OriginalScore": 1.2401118 }
]
}
Run the CLI command below to re-score this list of documents using the Amazon Kendra Intelligent Ranking service:
aws kendra-ranking rescore --cli-input-json "`cat rescore_input.json`"
The output of a successful execution of this will look as below.
{
"ResultItems": [
{
"Score": 0.39321771264076233,
"DocumentId": "tdoc2"
},
{
"Score": 0.328217089176178,
"DocumentId": "tdoc1"
}
],
"RescoreId": "991459b0-ca9e-4ba8-b0b3-1e8e01f2ad15"
}
As expected, the document tdoc2 (containing the text body “The White House is located at: 1600 Pennsylvania Avenue NW, Washington, DC 20500”) now has the higher ranking, as it’s the semantically more relevant response for the query. The ResultItems list in the output contains each input DocumentId with its new Score, ranked in descending order of Score.
Clean up
When you’re done experimenting, shut down, and remove your Docker containers and Rescore Execution Plan by running the cleanup_resources.sh script created by the Quickstart script, e.g.:
./opensearch-kendra-ranking-docker.xxxx/cleanup_resources.sh
Conclusion
In this post, we showed you how to use Amazon Kendra Intelligent Ranking plugin for self-managed OpenSearch to easily add intelligent ranking to your OpenSearch document queries to dramatically improve the relevance ranking of the results, while using your existing OpenSearch search engine deployments.
You can also use the Amazon Kendra Intelligent Ranking Rescore API directly to intelligently re-score and rank results from your own applications.
Read the Amazon Kendra Intelligent Ranking for self-managed OpenSearch documentation to learn more about this feature, and start planning to apply it in your production applications.
About the Authors
 Abhinav Jawadekar is a Principal Solutions Architect focused on Amazon Kendra in the AI/ML language services team at AWS. Abhinav works with AWS customers and partners to help them build intelligent search solutions on AWS.
Abhinav Jawadekar is a Principal Solutions Architect focused on Amazon Kendra in the AI/ML language services team at AWS. Abhinav works with AWS customers and partners to help them build intelligent search solutions on AWS.
 Bob Strahan is a Principal Solutions Architect in the AWS Language AI Services team.
Bob Strahan is a Principal Solutions Architect in the AWS Language AI Services team.
Read More



pic.twitter.com/lXiFLROhQh










 Here we notice
Here we notice 

 If you start experiencing errors even with this hardware setup, make sure to monitor
If you start experiencing errors even with this hardware setup, make sure to monitor  Marc Karp is a ML Architect with the SageMaker Service team. He focuses on helping customers design, deploy and manage ML workloads at scale. In his spare time, he enjoys traveling and exploring new places.
Marc Karp is a ML Architect with the SageMaker Service team. He focuses on helping customers design, deploy and manage ML workloads at scale. In his spare time, he enjoys traveling and exploring new places. Ram Vegiraju is a ML Architect with the SageMaker Service team. He focuses on helping customers build and optimize their AI/ML solutions on Amazon SageMaker. In his spare time, he loves traveling and writing.
Ram Vegiraju is a ML Architect with the SageMaker Service team. He focuses on helping customers build and optimize their AI/ML solutions on Amazon SageMaker. In his spare time, he loves traveling and writing.