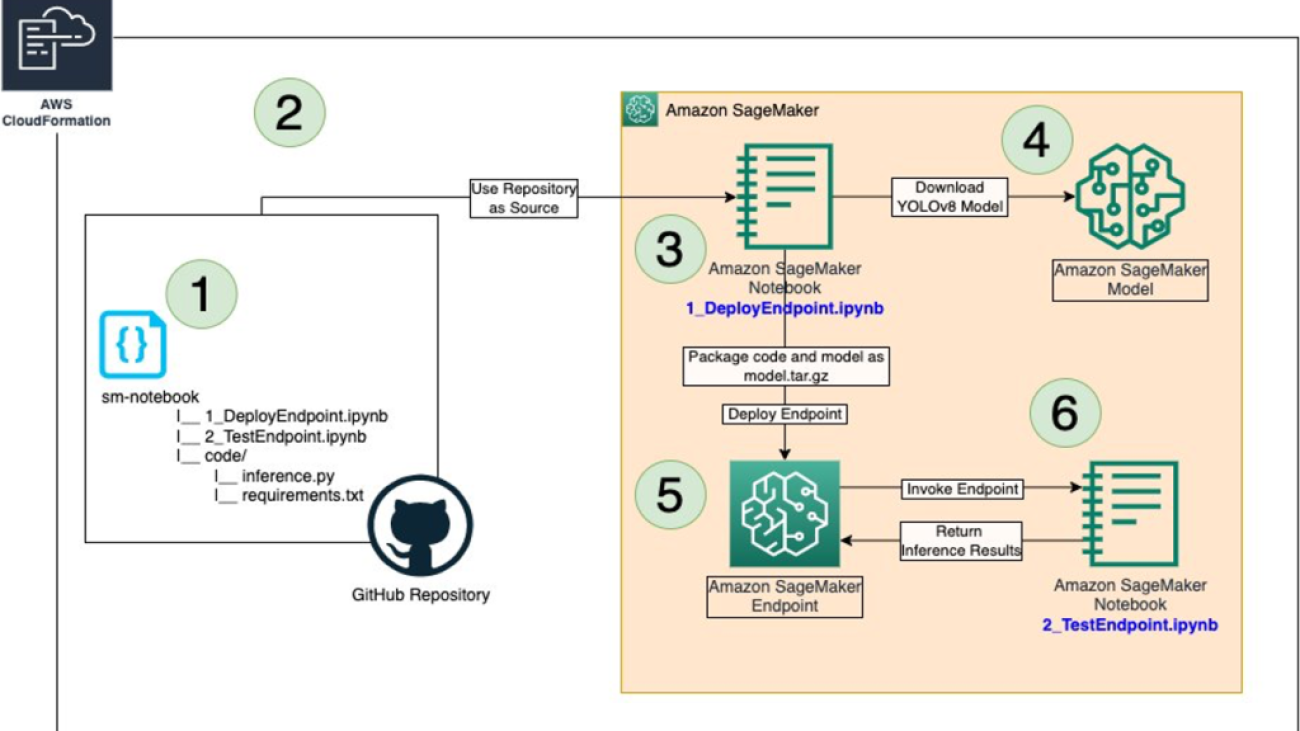
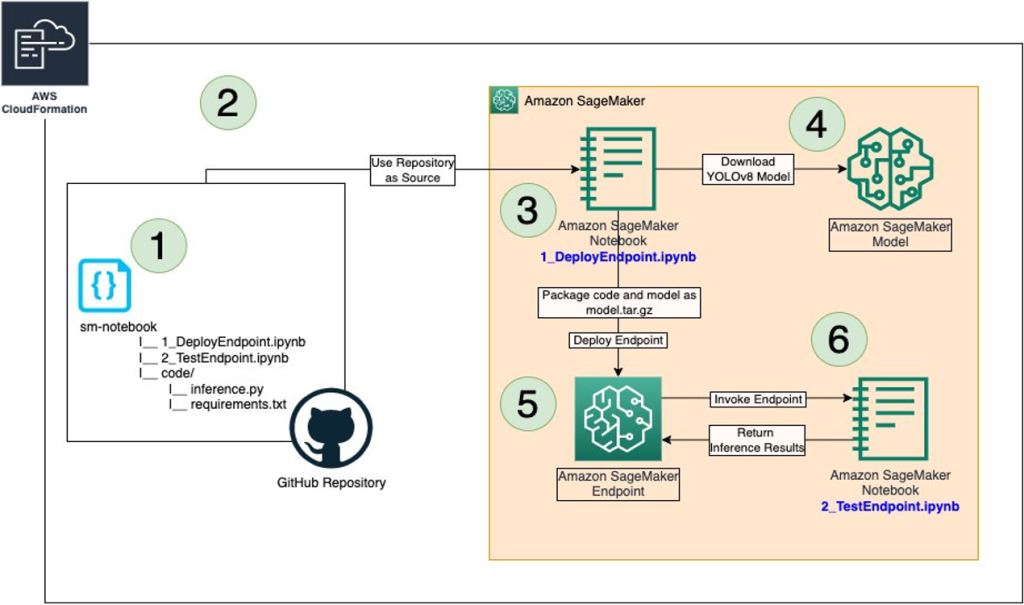
This post presents and compares options and recommended practices on how to manage Python packages and virtual environments in Amazon SageMaker Studio notebooks. A public GitHub repo provides hands-on examples for each of the presented approaches.
Amazon SageMaker Studio is a web-based, integrated development environment (IDE) for machine learning (ML) that lets you build, train, debug, deploy, and monitor your ML models. Studio provides all the tools you need to take your models from data preparation to experimentation to production while boosting your productivity.
Studio notebooks are collaborative Jupyter notebooks that you can launch quickly because you don’t need to set up compute instances and file storage beforehand. When you open a notebook in Studio, you are prompted to set up your environment by choosing a SageMaker image, a kernel, an instance type, and, optionally, a lifecycle configuration script that runs on image startup.
For more details on Studio notebook concepts and other aspects of the architecture, refer to Dive deep into Amazon SageMaker Studio Notebooks architecture.
Studio notebooks are designed to support you in all phases of your ML development, for example, ideation, experimentation, and operationalization of an ML workflow. Studio comes with pre-built images that include the latest Amazon SageMaker Python SDK and, depending on the image type, other specific packages and resources, such as Spark, MXNet, or PyTorch framework libraries, and their required dependencies. Each image can host one or multiple kernels, which can be different virtual environments for development.
To ensure the best fit for your development process and phases, access to specific or latest ML frameworks, or to fulfil data access and governance requirements, you can customize the pre-built notebook environments or create new environments using your own images and kernels.
This post considers the following approaches for customizing Studio environments by managing packages and creating Python virtual environments in Studio notebooks:
- Use a custom Studio KernelGateway app image
- Use Studio notebook lifecycle configurations
- Use the Studio Amazon Elastic File System (Amazon EFS) volume to persist Conda environments
- Use
pip install
Studio KernelGateway apps and notebooks kernels
One of the main differences of Studio notebooks architecture compared to SageMaker notebook instances is that Studio notebook kernels run in a Docker container, called a SageMaker image container, rather than hosted directly on Amazon Elastic Compute Cloud (Amazon EC2) instances, which is the case with SageMaker notebook instances.
The following diagram shows the relations between KernelGateway, notebook kernels, and SageMaker images. (For more information, see Use Amazon SageMaker Studio Notebooks.)

Because of this difference, there are some specifics of how you create and manage virtual environments in Studio notebooks, for example usage of Conda environments or persistence of ML development environments between kernel restarts.
The following sections explain each of four environment customization approaches in detail, provide hands-on examples, and recommend use cases for each option.
Prerequisites
To get started with the examples and try the customization approaches on your own, you need an active SageMaker domain and at least one user profile in the domain. If you don’t have a domain, refer to the instructions in Onboard to Amazon SageMaker Domain.
Studio KernelGateway custom app images
A Studio KernelGateway app image is a Docker container that identifies the kernels, language packages, and other dependencies required to run a Jupyter notebook in Studio. You use these images to create environments that you then run Jupyter notebooks on. Studio provides many built-in images for you to use.
If you need different functionality, specific frameworks, or library packages, you can bring your own custom images (BYOI) to Studio.
You can create app images and image versions, attach image versions to your domain, and make an app available for all domain users or for specific user profiles. You can manage app images via the SageMaker console, the AWS SDK for Python (Boto3), and the AWS Command Line Interface (AWS CLI). The custom image needs to be stored in an Amazon Elastic Container Registry (Amazon ECR) repository.
The main benefits of this approach are a high level of version control and reproducibility of an ML runtime environment and immediate availability of library packages because they’re installed in the image. You can implement comprehensive tests, governance, security guardrails, and CI/CD automation to produce custom app images. Having snapshots of development environments facilitates and enforces your organization’s guardrails and security practices.
The provided notebook implements an app image creation process for Conda-based environments. The notebook demonstrates how you can create multi-environment images so the users of the app can have a selection of kernels they can run their notebooks on.
Configure a custom app image
You must run this notebook as a SageMaker notebook instance to allow using Docker locally and run Docker commands in the notebook. Alternatively to using notebook instances or shell scripts, you can use the Studio Image Build CLI to work with Docker in Studio. The Studio Image Build CLI lets you build SageMaker-compatible Docker images directly from your Studio environments by using AWS CodeBuild.
If you don’t have a SageMaker notebook instance, follow the instructions in Create an Amazon SageMaker Notebook Instance to get started.
You must also ensure that the execution role you use for a notebook instance has the required permissions for Amazon ECR and SageMaker domain operations:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ecr:CompleteLayerUpload",
"ecr:GetAuthorizationToken",
"ecr:UploadLayerPart",
"ecr:InitiateLayerUpload",
"ecr:BatchCheckLayerAvailability",
"ecr:PutImage",
"ecr:CreateRepository",
"ecr:ListImages"
],
"Resource": "arn:aws:ecr:<REGION>:<ACCOUNT ID>:repository/<YOUR REPOSITORY NAME>"
}
]
}
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"sagemaker:UpdateDomain"
],
"Resource": "arn:aws:sagemaker:<REGION>:<ACCOUNT ID>:domain/<YOUR DOMAIN ID>"
}
]
}
To create a custom image with two kernels, each with their own Conda virtual environment, the notebook implements the following steps:
- Define the Conda environments. The Conda environment must have a Jupyter kernel package installed, for example,
ipykernel for Python kernel.
- Define a Dockerfile. Consider the custom SageMaker image specifications when creating your own image.
- Build a Docker image compatible with Studio and push the image into the ECR repository.
- Create a SageMaker image with the Docker image from the ECR repository and create an initial image version. Every time you update the image in Amazon ECR, a new image version must be created.
- Update an existing SageMaker domain to use this image. For this operation, the execution role needs the
UpdateDomain permission. The image is immediately available to all user profiles of the domain. If you want to make the image available only for a specific user profile, you can use the UpdateUserProfile API call instead of UpdateDomain.
- Launch the custom image in Studio. Start a new notebook and choose the new image on the image selection drop-down menu.
Studio automatically recognizes the Conda environments in your image as corresponding kernels in the kernel selection drop-down menu in the Set up notebook environment widget.

Refer to these sample notebooks for more examples and use cases on custom app image implementation.
Clean up
To avoid charges, you must stop the active SageMaker notebook instances. For instructions, refer to Clean up.
Implement an automated image authoring process
As already mentioned, you can use the Studio Image Build CLI to implement an automated CI/CD process of app image creation and deployment with CodeBuild and sm-docker CLI. It abstracts the setup of your Docker build environments by automatically setting up the underlying services and workflow necessary for building Docker images.
Recommended use cases
The custom app image approach is a good fit for the following scenarios when using a Studio notebook environment:
- Stable and controlled environments for production or sensitive development use
- Environments without internet access, where you want to pre-package all needed resources and libraries into the image
- High environment reuse ratio and low rate of changes in the environments
- High scale of data science operations, dozens or hundreds of developers or teams who need access to standardized custom environments
- Use libraries that can’t be configured on the SageMaker first-party images
- Requirements to use custom images for a different OS or different programming language
- Centralized governance and environment development using automated CI/CD pipelines
Limitations of this approach
This approach requires a multi-step image creation process including tests, which might be overkill for smaller or very dynamic environments. Furthermore, consider the following limitations of the approach:
- An upfront effort is needed to add new packages or create new versions of an image. As mitigation, you can customize the existing custom image with pip, even if it’s not persistent.
- Attaching a new custom image or adding a new version to the domain requires the
UpdateDomain permission, which isn’t normally attached to the user profile execution role. We recommend using an automated pipeline with a dedicated execution role to perform this operation or give the permission to update a domain to a dedicated admin user or role.
- A high manual effort for image authoring is involved. We recommend implementing an automated pipeline if you produce and update custom images frequently.
- If you use Conda environments, you might encounter issues with it in Docker environment. For an example, refer to Activating a Conda environment in your Dockerfile. Not all Conda commands may work in the notebook virtual environment. However, this Studio customization approach is not limited to Conda-based environments.
- You can’t manually switch between Conda environments in the notebook; you must switch kernels in the notebook environment setup widget.
Also consider that there are default quotas of 30 custom images per domain and 5 images per user profile. These are soft limits and can be increased.
The next sections describe more lightweight approaches that may be a better fit for other use cases.
Studio notebook lifecycle configurations
Studio lifecycle configurations define a shell script that runs at each restart of the kernel gateway application and can install the required packages. The main benefit is that a data scientist can choose which script to run to customize the container with new packages. This option doesn’t require rebuilding the container and in most cases doesn’t require a custom image at all because you can customize the pre-built ones.
Set up a lifecycle configuration process
This process takes around 5 minutes to complete. The post demonstrates how to use the lifecycle configurations via the SageMaker console. The provided notebook shows how to implement the same programmatically using Boto3.
- On the SageMaker console, choose Lifecycle configurations in the navigation pane.
- On the Studio tab, choose Create configuration.

The first step to create the lifecycle configuration is to select the type.
- For this use case of installing dependencies each time a Jupyter kernel gateway app is created, choose Jupyter kernel gateway app and choose Next.

- For Name, enter a name for the configuration.
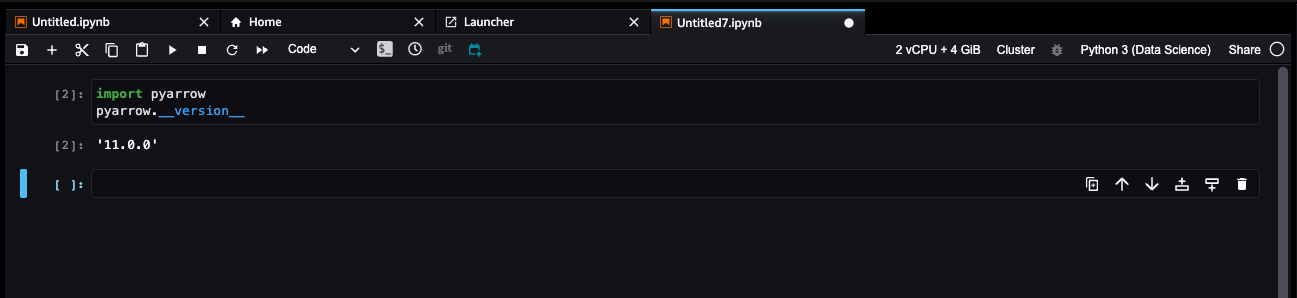
- In the Scripts section, define the script to be run when the kernel starts. For this example, the PyArrow library will be installed with the following script:
# This script installs a single pip package on a SageMaker Studio Kernel Application
#!/bin/bash
set -eux
# PARAMETERS
PACKAGE=pyarrow
pip install --upgrade $PACKAGE
- Choose Create Configuration.

Now that the configuration has been created, it needs to be attached to a domain or user profile. When attached to the domain, all user profiles in that domain inherit it, whereas when attached to a user profile, it is scoped to that specific profile. For this walkthrough, we use the Studio domain route.
- Choose Domains in the navigation pane and open your existing domain.
- On the Environment tab, in the Lifecycle configurations for personal Studio apps section, choose Attach.

- For Source, select Existing configuration.
- Select the lifecycle configuration you created and choose Attach to domain.

Now that all the configuration is done, it’s time to test the script within Studio.
- Launch Studio and on the Launcher tab, locate the Notebooks and compute resources section, and choose Change environment to select the lifecycle configuration you created.

- For Start-up script, choose the lifecycle configuration you created, then choose Select.

- Choose Create notebook.
You can also set the Lifecycle configuration to be run by default in the Lifecycle configurations for personal Studio apps section of the Domain page.
Within the new notebook, the dependencies installed in the startup script will be available.
Recommended use cases
This approach is lightweight but also powerful because it allows you to control the setup of your notebook environment via shell scripts. The use cases that best fit this approach are the following:
- Integrating package installations in the notebook lifecycle configuration that must run at each kernel start.
- Environments without internet access. Use lifecycle configurations to set up an environment to access local or security artifact and package repositories, such as AWS CodeArtifact.
- If you already use lifecycle configurations, you can extend them to include package install.
- Installation of a few additional packages on top of built-in or custom app images.
- When you need a shorter time to market than with custom app images.
Limitations of this approach
The main limitations are a high effort to manage lifecycle configuration scripts at scale and slow installation of packages. Depending on how many packages are installed and how large they are, the lifecycle script might even timeout. There are also limited options for ad hoc script customization by users, such as data scientists or ML engineers, due to permissions of the user profile execution role.
Refer to SageMaker Studio Lifecycle Configuration Samples for more samples and use cases.
Persist Conda environments to the Studio EFS volume
SageMaker domains and Studio use an EFS volume as a persistent storage layer. You can save your Conda environments on this EFS volume. These environments are persistent between kernel, app, or Studio restart. Studio automatically picks up all environments as KernelGateway kernels.
This is a straightforward process for a data scientist, but there is a 1-minute delay for the environment to appear in the list of selectable kernels. There also might be issues with using environments for kernel gateway apps that have different compute requirements, for example a CPU-based environment on a GPU-based app.
Refer to Custom Conda environments on SageMaker Studio for detailed instructions. The post’s GitHub repo also contains a notebook with the step-by-step guide.
Create persistent Conda environments on a Studio EFS volume
This walkthrough should take around 10 minutes.
- On Studio, choose Home in the navigation pane.
- Choose Open Launcher.

- Within the Launcher, locate the Notebooks and compute resources section.
- Check that the SageMaker image selected is a Conda-supported first-party kernel image such as “Data Science.”
- Choose Open image terminal to open a terminal window with a new kernel.

A message displays saying “Starting image terminal…” and after a few moments, the new terminal will open in a new tab.
- Within the terminal, run the following commands:
mkdir -p ~/.conda/envs
conda create --yes -p ~/.conda/envs/custom
conda activate ~/.conda/envs/custom
conda install -y ipykernel
conda config --add envs_dirs ~/.conda/envs
These commands will take about 3 minutes to run and will create a directory on the EFS volume to store the Conda environments, create the new Conda environment and activate it, install the ipykernel dependencies (without this dependency this solution will not work), and finally create a Conda configuration file (.condarc), which contains the reference to the new Conda environment directory. Because this is a new Conda environment, no additional dependencies are installed. To install other dependencies, you can modify the conda install line or wait for the following commands to finish and install any additional dependencies while inside the Conda environment.
- For this example, we install the NumPy library by running the following command in the terminal window:
conda install -y numpy
python -c "import numpy; print(numpy.version.version)"
Now that the Conda environment is created and the dependencies are installed, you can create a notebook that uses this Conda environment persisted on Amazon EFS.
- On the Studio Launcher, choose Create notebook.

- From the new notebook, choose the “Python 3 (Data Science)” kernel.

- For Kernel, choose the newly created Conda environment, then choose Select.
If at first there is no option for the new Conda environment, this could be because it takes a few minutes to propagate.

Back within the notebook, the kernel name will have changed in the top right-hand corner, and within a cell you can test that the dependencies installed are available.

Recommended use cases
The following use cases are the best fit for this approach:
- Environments without internet access, with all dependencies pre-installed in the persisted Conda environments
- Ad hoc environments that need persistence between kernel sessions
- Testing of custom SageMaker images in Studio before creating a Docker image and pushing to Amazon ECR
Limitations of this approach
Although this approach has practical uses, consider the following limitations:
- There might be performance issues with Amazon EFS on many small files, which is very common when managing Python packages.
- It may be challenging to share persistent environments between Studio user profiles.
- It may be challenging to reuse persistent environments.
- It may be challenging to address management at scale.
- The approach works only with specific Conda-based first-party SageMaker images, for example “Data Science,” “Data Science 2.0,” and “Data Science 3.0.” For a list of all available images, refer to Available Amazon SageMaker Images.
Pip install
You can install packages directly into the default Conda environment or the default Python environment.
Create a setup.py or requirements.txt file with all required dependencies and run %pip install .-r requirement.txt. You have to run this command every time you restart the kernel or recreate an app.
This approach is recommended for ad hoc experimentation because these environments are not persistent.
For more details about using the pip install command and limitations, refer to Install External Libraries and Kernels in Amazon SageMaker Studio.
Recommended use cases
This approach is a standard way to install packages to customize your notebook environment. The recommended use cases are limited to non-production use for ad hoc experimentation in a notebook:
- Ad hoc experimentation in Studio notebooks
- Non-productive and non-sensitive environments, sandbox environments
- Environments with internet access
Limitations of this approach
The main limitations of this approach are:
- Some enterprise environments block all egress and ingress internet connections and you can’t use
pip install to pull Python packages or need to configure an offline mode
- Lower reproducibility of environments
- Need to wait until packages are downloaded and installed
- No persistence between image restarts
Conclusion
SageMaker Studio offers a broad range of possible customization of development environments. Each user role such as a data scientist; an ML, MLOps, or DevOps engineer; and an administrator can choose the most suitable approach based on their needs, place in the development cycle, and enterprise guardrails.
The following table summarizes the presented approaches along with their preferred use cases and main limitations.
| Approach |
Persistence |
Best Fit Use Cases |
Limitations |
| Bring your own image |
Permanent, transferrable between user profiles and domains |
- Need for a stable, reproduceable, shareable, and centrally managed ML runtime
- Reuse the same image for Studio development, and SageMaker processing and training jobs
- Enterprise ML runtime golden images with built-in security controls and guardrails
|
- Multi-step manual authoring process or needs an automated build and test pipeline
|
| Lifecycle configurations |
Permanent, transferrable between user profiles and domains |
- Need for a centrally managed, reproduceable, and shareable environment
- Need for installation of a few additional packages on top of an existing environment
|
- Time limit for environment installation
- Effort and challenges for managing at scale
|
| Conda environments on the Studio EFS volume |
Permanent, not transferrable between user profiles or domains |
- Fast experimentation in a notebook with a need for persistence, reuse, and reproducibility of environments
- Single-user self-managed environments
|
- Works only with some kernels
- Performance issues with many small files
- Can’t share environments between users
|
| Pip install |
Transient, no persistence between image or Studio restarts, not transferrable between user profiles or domains |
- Fast experimentation in a notebook
- Single-user self-managed environments
- Non-productive environments
|
- Low reproducibility of environments
- Potentially long package download and installation times
- No persistence
|
It’s still Day 1. The real-world virtual environment and Python management is far more complex than these four approaches, but this post helps you with the first steps for developing your own use case.
You can find more use cases, details, and hands-on examples in the following resources:
About the authors
 Yevgeniy Ilyin is a Solutions Architect at Amazon Web Services (AWS). He has over 20 years of experience working at all levels of software development and solutions architecture and has used programming languages from COBOL and Assembler to .NET, Java, and Python. He develops and codes cloud native solutions with a focus on big data, analytics, and data engineering.
Yevgeniy Ilyin is a Solutions Architect at Amazon Web Services (AWS). He has over 20 years of experience working at all levels of software development and solutions architecture and has used programming languages from COBOL and Assembler to .NET, Java, and Python. He develops and codes cloud native solutions with a focus on big data, analytics, and data engineering.
 Alex Grace is a Solutions Architect at Amazon Web Services (AWS) who looks after Fintech Digital Native Businesses. Based in London, Alex works with a few of the UK’s leading Fintechs and enjoys supporting their use of AWS to solve business problems and fuel future growth. Previously, Alex has worked as a software developer and tech lead at Fintech startups in London and has more recently been specialising in AWS’ machine learning solutions.
Alex Grace is a Solutions Architect at Amazon Web Services (AWS) who looks after Fintech Digital Native Businesses. Based in London, Alex works with a few of the UK’s leading Fintechs and enjoys supporting their use of AWS to solve business problems and fuel future growth. Previously, Alex has worked as a software developer and tech lead at Fintech startups in London and has more recently been specialising in AWS’ machine learning solutions.
Read More





 Kevin Song is a Data Scientist at AWS Professional Services. He holds a PhD in Biophysics and has more than five years of industry experience in building computer vision and machine learning solutions.
Kevin Song is a Data Scientist at AWS Professional Services. He holds a PhD in Biophysics and has more than five years of industry experience in building computer vision and machine learning solutions. Romil Shah is an IoT Edge Data Scientist at AWS Professional Services. Romil has more than six years of industry experience in computer vision, machine learning, and IoT edge devices. He is involved in helping customers optimize and deploy their machine learning models for edge devices in an industrial setup.
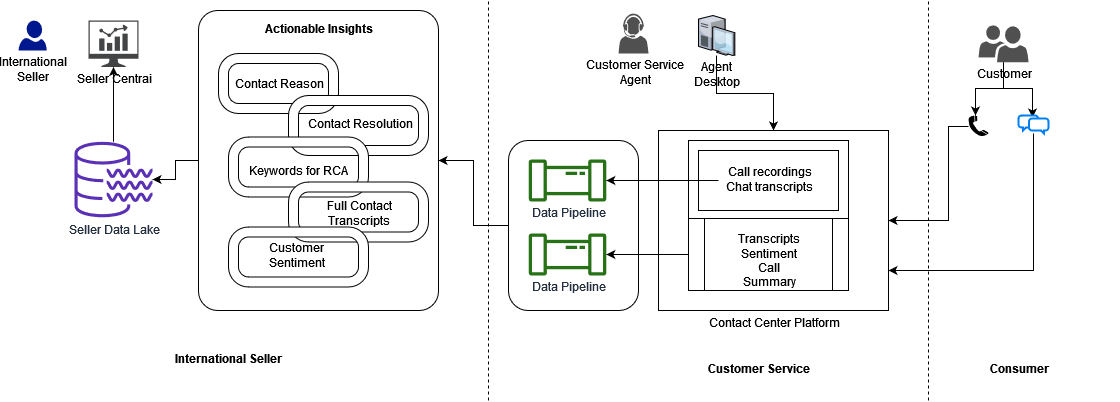
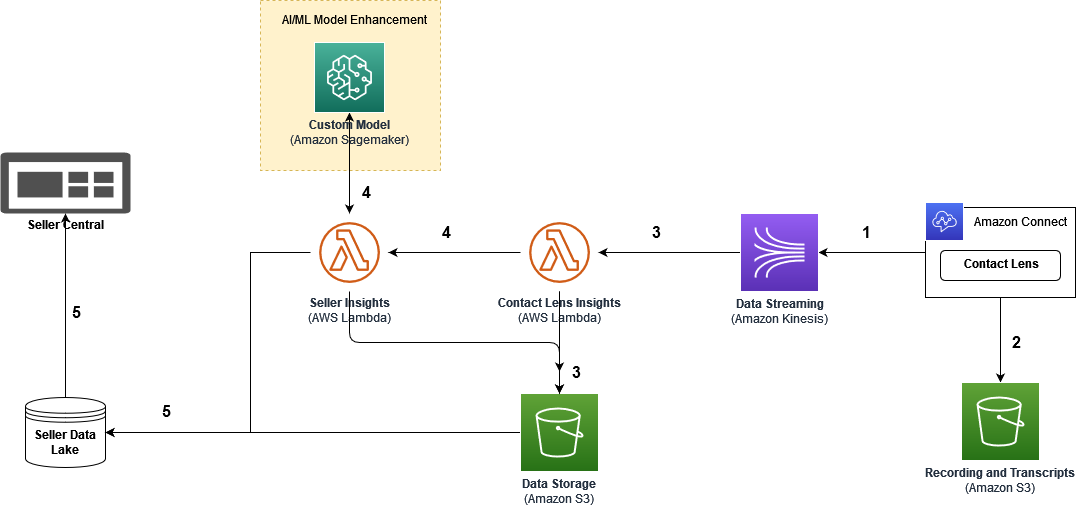
Romil Shah is an IoT Edge Data Scientist at AWS Professional Services. Romil has more than six years of industry experience in computer vision, machine learning, and IoT edge devices. He is involved in helping customers optimize and deploy their machine learning models for edge devices in an industrial setup.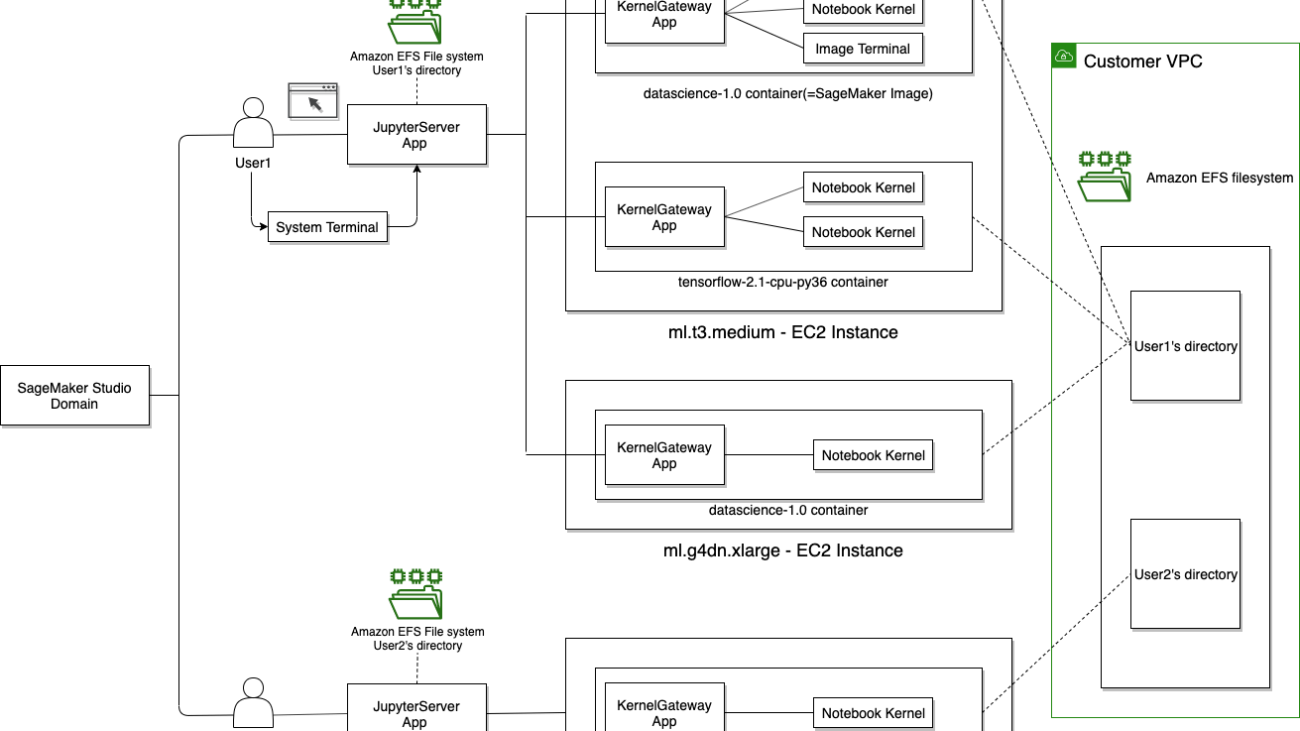





 Yunfei Bai is a Senior Solutions Architect at AWS. With the background in AI/ML, Data Science and Analytics, Yunfei helps customers adopt AWS services to deliver business results. He designs AI/ML and Data Analytics solutions that overcome complex technical challenges and drive strategic objectives. Yunfei is a PhD in Electronic and Electrical Engineering . Outside of work, Yunfei enjoys reading and music.
Yunfei Bai is a Senior Solutions Architect at AWS. With the background in AI/ML, Data Science and Analytics, Yunfei helps customers adopt AWS services to deliver business results. He designs AI/ML and Data Analytics solutions that overcome complex technical challenges and drive strategic objectives. Yunfei is a PhD in Electronic and Electrical Engineering . Outside of work, Yunfei enjoys reading and music. Burak Gozluklu is a Principal ML Specialist Solutions Architect located in Boston, MA. Burak has +15 years of industry experience in simulation modeling, data science and ML technology. He helps global customers adopting AWS technologies and especially, AI/ML solutions to achieve their business objectives. Burak has a PhD in Aerospace Eng. from METU, MS in Systems Engineering and post-doc on system dynamics from MIT in Cambridge, MA. Burak is passionate about yoga and meditation.
Burak Gozluklu is a Principal ML Specialist Solutions Architect located in Boston, MA. Burak has +15 years of industry experience in simulation modeling, data science and ML technology. He helps global customers adopting AWS technologies and especially, AI/ML solutions to achieve their business objectives. Burak has a PhD in Aerospace Eng. from METU, MS in Systems Engineering and post-doc on system dynamics from MIT in Cambridge, MA. Burak is passionate about yoga and meditation. Chelsea Cai is a Senior Product Manager at Amazon’s International Seller Growth (ISG) organization, where she works for Customer Service by Amazon service (CSBA) helping 3P sellers improve their customer service/CX through Amazon CS technology and worldwide organizations. In her spare time, she likes philosophy, psychology, swimming, hiking, good food, and spending time with her family and friends.
Chelsea Cai is a Senior Product Manager at Amazon’s International Seller Growth (ISG) organization, where she works for Customer Service by Amazon service (CSBA) helping 3P sellers improve their customer service/CX through Amazon CS technology and worldwide organizations. In her spare time, she likes philosophy, psychology, swimming, hiking, good food, and spending time with her family and friends. Abhishek Kumar is a Senior Product Manager at Amazon’s International Seller Growth (ISG) organization, where he develops software platforms and applications to help global 3P sellers manage their Amazon business. In his free time, Abhishek enjoys traveling, learning Italian, and exploring European cultures and cuisines with his extended Italian family.
Abhishek Kumar is a Senior Product Manager at Amazon’s International Seller Growth (ISG) organization, where he develops software platforms and applications to help global 3P sellers manage their Amazon business. In his free time, Abhishek enjoys traveling, learning Italian, and exploring European cultures and cuisines with his extended Italian family.






















 Senthil Ramachandran is an Enterprise Solutions Architect at AWS, supporting customers in the US North East. He is primarily focused on Cloud adoption and Digital Transformation in Financial Services Industry. Senthil’s area of interest is AI, especially Deep Learning and Machine Learning. He focuses on application automations with continuous learning and improving human enterprise experience. Senthil enjoys watching Autosport, Soccer and spending time with his family.
Senthil Ramachandran is an Enterprise Solutions Architect at AWS, supporting customers in the US North East. He is primarily focused on Cloud adoption and Digital Transformation in Financial Services Industry. Senthil’s area of interest is AI, especially Deep Learning and Machine Learning. He focuses on application automations with continuous learning and improving human enterprise experience. Senthil enjoys watching Autosport, Soccer and spending time with his family.