There is an increasing adoption of machine learning for encoding data into vectors to serve online recommendation and search use cases. As a result, recent data management systems propose augmenting query processing with online vector similarity search. In this work, we explore vector similarity search in the context of Knowledge Graphs (KGs). Motivated by the tasks of finding related KG queries and entities for past KG query workloads, we focus on hybrid vector similarity search (hybrid queries for short) where part of the query corresponds to vector similarity search and part of the query…Apple Machine Learning Research
Text is All You Need: Personalizing ASR Models using Controllable Speech Synthesis
Adapting generic speech recognition models to specific individuals is a challenging problem due to the scarcity of personalized data. Recent works have proposed boosting the amount of training data using personalized text-to-speech synthesis. Here, we ask two fundamental questions about this strategy: when is synthetic data effective for personalization, and why is it effective in those cases? To address the first question, we adapt a state-of-the-art automatic speech recognition (ASR) model to target speakers from four benchmark datasets representative of different speaker types. We show that…Apple Machine Learning Research

UniPi: Learning universal policies via text-guided video generation
Building models that solve a diverse set of tasks has become a dominant paradigm in the domains of vision and language. In natural language processing, large pre-trained models, such as PaLM, GPT-3 and Gopher, have demonstrated remarkable zero-shot learning of new language tasks. Similarly, in computer vision, models like CLIP and Flamingo have shown robust performance on zero-shot classification and object recognition. A natural next step is to use such tools to construct agents that can complete different decision-making tasks across many environments.
However, training such agents faces the inherent challenge of environmental diversity, since different environments operate with distinct state action spaces (e.g., the joint space and continuous controls in MuJoCo are fundamentally different from the image space and discrete actions in Atari). This environmental diversity hampers knowledge sharing, learning, and generalization across tasks and environments. Furthermore, it is difficult to construct reward functions across environments, as different tasks generally have different notions of success.
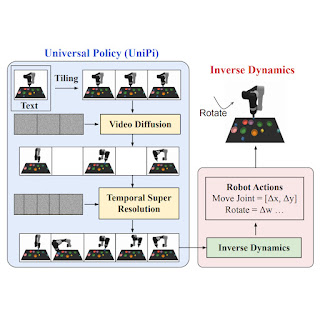
In “Learning Universal Policies via Text-Guided Video Generation”, we propose a Universal Policy (UniPi) that addresses environmental diversity and reward specification challenges. UniPi leverages text for expressing task descriptions and video (i.e., image sequences) as a universal interface for conveying action and observation behavior in different environments. Given an input image frame paired with text describing a current goal (i.e., the next high-level step), UniPi uses a novel video generator (trajectory planner) to generate video with snippets of what an agent’s trajectory should look like to achieve that goal. The generated video is fed into an inverse dynamics model that extracts underlying low-level control actions, which are then executed in simulation or by a real robot agent. We demonstrate that UniPi enables the use of language and video as a universal control interface for generalizing to novel goals and tasks across diverse environments.
 |
| Video policies generated by UniPi. |
 |
| UniPi may be applied to downstream multi-task settings that require combinatorial language generalization, long-horizon planning, or internet-scale knowledge. In the bottom example, UniPi takes the image of the white robot arm from the internet and generates video snippets according to the text description of the goal. |
UniPi implementation
To generate a valid and executable plan, a text-to-video model must synthesize a constrained video plan starting at the current observed image. We found it more effective to explicitly constrain a video synthesis model during training (as opposed to only constraining videos at sampling time) by providing the first frame of each video as explicit conditioning context.
At a high level, UniPi has four major components: 1) consistent video generation with first-frame tiling, 2) hierarchical planning through temporal super resolution, 3) flexible behavior synthesis, and 4) task-specific action adaptation. We explain the implementation and benefit of each component in detail below.
Video generation through tiling
Existing text-to-video models like Imagen typically generate videos where the underlying environment state changes significantly throughout the duration. To construct an accurate trajectory planner, it is important that the environment remains consistent across all time points. We enforce environment consistency in conditional video synthesis by providing the observed image as additional context when denoising each frame in the synthesized video. To achieve context conditioning, UniPi directly concatenates each intermediate frame sampled from noise with the conditioned observed image across sampling steps, which serves as a strong signal to maintain the underlying environment state across time.
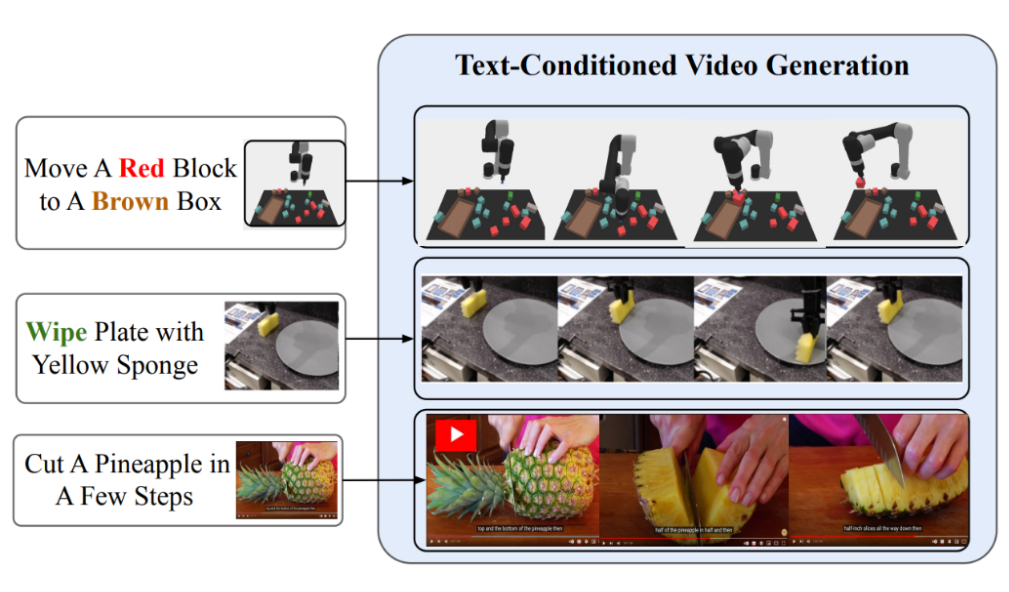 |
| Text-conditional video generation enables UniPi to train general purpose policies on a wide range of data sources (simulated, real robots and YouTube). |
Hierarchical planning
When constructing plans in high-dimensional environments with long time horizons, directly generating a set of actions to reach a goal state quickly becomes intractable due to the exponential growth of the underlying search space as the plan gets longer. Planning methods often circumvent this issue by leveraging a natural hierarchy in planning. Specifically, planning methods first construct coarse plans (the intermediate key frames spread out across time) operating on low-dimensional states and actions, which are then refined into plans in the underlying state and action spaces.
Similar to planning, our conditional video generation procedure exhibits a natural temporal hierarchy. UniPi first generates videos at a coarse level by sparsely sampling videos (“abstractions”) of desired agent behavior along the time axis. UniPi then refines the videos to represent valid behavior in the environment by super-resolving videos across time. Meanwhile, coarse-to-fine super-resolution further improves consistency via interpolation between frames.
 |
| Given an input observation and text instruction, we plan a set of images representing agent behavior. Images are converted to actions using an inverse dynamics model. |
Flexible behavioral modulation
When planning a sequence of actions for a given sub-goal, one can readily incorporate external constraints to modulate a generated plan. Such test-time adaptability can be implemented by composing a probabilistic prior incorporating properties of the desired plan to specify desired constraints across the synthesized action trajectory, which is also compatible with UniPi. In particular, the prior can be specified using a learned classifier on images to optimize a particular task, or as a Dirac delta distribution on a particular image to guide a plan towards a particular set of states. To train the text-conditioned video generation model, we utilize the video diffusion algorithm, where pre-trained language features from the Text-To-Text Transfer Transformer (T5) are encoded.
Task-specific action adaptation
Given a set of synthesized videos, we train a small task-specific inverse dynamics model to translate frames into a set of low-level control actions. This is independent from the planner and can be done on a separate, smaller and potentially suboptimal dataset generated by a simulator.
Given the input frame and text description of the current goal, the inverse dynamics model synthesizes image frames and generates a control action sequence that predicts the corresponding future actions. An agent then executes inferred low-level control actions via closed-loop control.
Capabilities and evaluation of UniPi
We measure the task success rate on novel language-based goals, and find that UniPi generalizes well to both seen and novel combinations of language prompts, compared to baselines such as Transformer BC, Trajectory Transformer (TT), and Diffuser.
 |
| UniPi generalizes well to both seen and novel combinations of language prompts in Place (e.g., “place X in Y”) and Relation (e.g., “place X to the left of Y”) tasks. |
Below, we illustrate generated videos on unseen combinations of goals. UniPi is able to synthesize a diverse set of behaviors that satisfy unseen language subgoals:
 |
| Generated videos for unseen language goals at test time. |
Multi-environment transfer
We measure the task success rate of UniPi and baselines on novel tasks not seen during training. UniPi again outperforms the baselines by a large margin:
 |
| UniPi generalizes well to new environments when trained on a set of different multi-task environments. |
Below, we illustrate generated videos on unseen tasks. UniPi is further able to synthesize a diverse set of behaviors that satisfy unseen language tasks:
 |
| Generated video plans on different new test tasks in the multitask setting. |
Real world transfer
Below, we further illustrate generated videos given language instructions on unseen real images. Our approach is able to synthesize a diverse set of different behaviors which satisfy language instructions:
 |
Using internet pre-training enables UniPi to synthesize videos of tasks not seen during training. In contrast, a model trained from scratch incorrectly generates plans of different tasks:
 |
To evaluate the quality of videos generated by UniPi when pre-trained on non-robot data, we use the Fréchet Inception Distance (FID) and Fréchet Video Distance (FVD) metrics. We used Contrastive Language-Image Pre-training scores (CLIPScores) to measure the language-image alignment. We demonstrate that pre-trained UniPi achieves significantly higher FID and FVD scores and a better CLIPScore compared to UniPi without pre-training, suggesting that pre-training on non-robot data helps with generating plans for robots. We report the CLIPScore, FID, and VID scores for UniPi trained on Bridge data, with and without pre-training:
| Model (24×40) | CLIPScore ↑ | FID ↓ | FVD ↓ | ||||||||
| No pre-training | 24.43 ± 0.04 | 17.75 ± 0.56 | 288.02 ± 10.45 | ||||||||
| Pre-trained | 24.54 ± 0.03 | 14.54 ± 0.57 | 264.66 ± 13.64 |
| Using existing internet data improves video plan predictions under all metrics considered. |
The future of large-scale generative models for decision making
The positive results of UniPi point to the broader direction of using generative models and the wealth of data on the internet as powerful tools to learn general-purpose decision making systems. UniPi is only one step towards what generative models can bring to decision making. Other examples include using generative foundation models to provide photorealistic or linguistic simulators of the world in which artificial agents can be trained indefinitely. Generative models as agents can also learn to interact with complex environments such as the internet, so that much broader and more complex tasks can eventually be automated. We look forward to future research in applying internet-scale foundation models to multi-environment and multi-embodiment settings.
Acknowledgements
We’d like to thank all remaining authors of the paper including Bo Dai, Hanjun Dai, Ofir Nachum, Joshua B. Tenenbaum, Dale Schuurmans, and Pieter Abbeel. We would like to thank George Tucker, Douglas Eck, and Vincent Vanhoucke for the feedback on this post and on the original paper.

Research Focus: Week of April 10, 2023

Welcome to Research Focus, a series of blog posts that highlights notable publications, events, code/datasets, new hires and other milestones from across the research community at Microsoft.
NEW RESEARCH
Snape: Reliable and Low-Cost Computing with Mixture of Spot and On-Demand VMs
To improve the utilization of computing resources, cloud providers often offer underutilized capacity at a discount, but with lower guarantees of availability. However, many customers hesitate to take full advantage of such offerings (such as spot virtual machines), even though they can provide scalability and lower costs for workloads that can handle interruptions.
In a new paper: Snape: Reliable and Low-Cost Computing with Mixture of Spot and On-Demand VMs,
researchers from Microsoft propose an intelligent framework to optimize customer cost while maintaining resource availability by dynamically mixing on-demand VMs with spot VMs. Snape is composed with a reliable model for predicting the eviction rate of spot VMs from the production trace and an intelligent constrained reinforcement learning (CRL) framework for learning the best mixture policy, given the predicted eviction rate and other service signals.
This proactive design enables an online decision-making system for dynamically adjusting the mixture of on-demand and spot VMs and ensures that a more aggressive and cheaper policy is only adopted when the reliability is high (low predicted eviction rates of spot VM). Experiments across different configurations show that Snape achieves 44% savings compared to the policy of using only on-demand VMs, and at the same time, maintains 99.96% availability—2.77% higher than with a policy of using only spot VMs.
SPOTLIGHT: AI focus area

AI and Microsoft Research
Learn more about the breadth of AI research at Microsoft
NEW RESEARCH
Embracing Noise: How can systems be designed and created with and for noise?
Noise—as a term used to describe data as not meaningful or useful to a system—is a helpful concept in fields like data science, machine learning, and AI. It can help make data manageable, for example by allowing “noisy” data points to be identified and removed so the data can be streamlined to fit a computational structure. But unlike computer systems, which operate with explicit definitions and discrete structures, people have varying boundaries and perceptions of what is meaningful. This presents choices that involve noise. For example, what specific input will we be expecting and what remaining potential input will be considered noise? What constitutes valid input, and what are the consequences of deciding that something is “invalid”?
In a new paper: Embracing Data Noise, Microsoft researcher Ida Larsen-Ledet examines conceptualization, acceptance, and use of noise; including what may be gained from viewing seemingly undesirable output as noise with potential.
When designing computing systems, removing or reducing noise can be the right choice – for example, in safety-critical environments. But noise shouldn’t be uncritically disregarded. If we look at noise in a nuanced way, we may be better able to apply it in useful ways.
NEW RESEARCH
DOTE: Rethinking (Predictive) WAN Traffic Engineering
Uncertainty about future network traffic trends presents a crucial real-world challenge for routing, especially over wide-area networks where bandwidth is expensive, and applications have stringent quality-of-service requirements. In a new paper, DOTE: Rethinking (Predictive) WAN Traffic Engineering, researchers from Microsoft Research teamed up with researchers from the Hebrew University and the Technion to explore a new design point for traffic engineering on wide-area networks (WANs): directly optimizing traffic flow on the WAN using only historical data.
The novel algorithmic framework of DOTE combines stochastic optimization and deep learning to identify appropriate routing using as input only historical traffic demands. Intrinsically, the technique picks up on patterns in traffic demands at the scale of large WANs, allowing it to identify high-quality routing without predicting future demands. The research shows this method provably converges to the global optimum in well-studied theoretical models and demonstrates the performance benefits through extensive analyses of empirical data from operational networks, including Microsoft’s backbone network.
OPPORTUNITY
Predoctoral Research Assistant (contract) – Computational Social Science
Microsoft Research New York City seeks a recent college graduate for a contingent Predoctoral Research Assistant position in computational social science (CSS). Our Predoctoral Research Assistant program is aimed at candidates seeking research experience prior to pursuing a PhD in fields related to CSS.
Our computational social science group is widely recognized as a leading center of CSS research. Our research lies at the intersection of computer science, statistics, and social sciences, and uses large-scale demographic, behavioral, and network data to investigate human activity and relationships. Apply by May 5 for a one-year assignment beginning in Summer 2023, with a possibility to extend to a total of 18 months.
The post Research Focus: Week of April 10, 2023 appeared first on Microsoft Research.

Research Focus: Week of April 10, 2023
Welcome to Research Focus, a series of blog posts that highlights notable publications, events, code/datasets, new hires and other milestones from across the research community at Microsoft.
NEW RESEARCH
Snape: Reliable and Low-Cost Computing with Mixture of Spot and On-Demand VMs
To improve the utilization of computing resources, cloud providers often offer underutilized capacity at a discount, but with lower guarantees of availability. However, many customers hesitate to take full advantage of such offerings (such as spot virtual machines), even though they can provide scalability and lower costs for workloads that can handle interruptions.
In a new paper: Snape: Reliable and Low-Cost Computing with Mixture of Spot and On-Demand VMs,
researchers from Microsoft propose an intelligent framework to optimize customer cost while maintaining resource availability by dynamically mixing on-demand VMs with spot VMs. Snape is composed with a reliable model for predicting the eviction rate of spot VMs from the production trace and an intelligent constrained reinforcement learning (CRL) framework for learning the best mixture policy, given the predicted eviction rate and other service signals.
This proactive design enables an online decision-making system for dynamically adjusting the mixture of on-demand and spot VMs and ensures that a more aggressive and cheaper policy is only adopted when the reliability is high (low predicted eviction rates of spot VM). Experiments across different configurations show that Snape achieves 44% savings compared to the policy of using only on-demand VMs, and at the same time, maintains 99.96% availability—2.77% higher than with a policy of using only spot VMs.
Spotlight: Microsoft Research Podcast

AI Frontiers: The Physics of AI with Sébastien Bubeck
What is intelligence? How does it emerge and how do we measure it? Ashley Llorens and machine learning theorist Sébastian Bubeck discuss accelerating progress in large-scale AI and early experiments with GPT-4.
NEW RESEARCH
Embracing Noise: How can systems be designed and created with and for noise?
Noise—as a term used to describe data as not meaningful or useful to a system—is a helpful concept in fields like data science, machine learning, and AI. It can help make data manageable, for example by allowing “noisy” data points to be identified and removed so the data can be streamlined to fit a computational structure. But unlike computer systems, which operate with explicit definitions and discrete structures, people have varying boundaries and perceptions of what is meaningful. This presents choices that involve noise. For example, what specific input will we be expecting and what remaining potential input will be considered noise? What constitutes valid input, and what are the consequences of deciding that something is “invalid”?
In a new paper: Embracing Data Noise, Microsoft researcher Ida Larsen-Ledet examines conceptualization, acceptance, and use of noise; including what may be gained from viewing seemingly undesirable output as noise with potential.
When designing computing systems, removing or reducing noise can be the right choice – for example, in safety-critical environments. But noise shouldn’t be uncritically disregarded. If we look at noise in a nuanced way, we may be better able to apply it in useful ways.
NEW RESEARCH
DOTE: Rethinking (Predictive) WAN Traffic Engineering
Uncertainty about future network traffic trends presents a crucial real-world challenge for routing, especially over wide-area networks where bandwidth is expensive, and applications have stringent quality-of-service requirements. In a new paper, DOTE: Rethinking (Predictive) WAN Traffic Engineering, researchers from Microsoft Research teamed up with researchers from the Hebrew University and the Technion to explore a new design point for traffic engineering on wide-area networks (WANs): directly optimizing traffic flow on the WAN using only historical data.
The novel algorithmic framework of DOTE combines stochastic optimization and deep learning to identify appropriate routing using as input only historical traffic demands. Intrinsically, the technique picks up on patterns in traffic demands at the scale of large WANs, allowing it to identify high-quality routing without predicting future demands. The research shows this method provably converges to the global optimum in well-studied theoretical models and demonstrates the performance benefits through extensive analyses of empirical data from operational networks, including Microsoft’s backbone network.
OPPORTUNITY
Predoctoral Research Assistant (contract) – Computational Social Science
Microsoft Research New York City seeks a recent college graduate for a contingent Predoctoral Research Assistant position in computational social science (CSS). Our Predoctoral Research Assistant program is aimed at candidates seeking research experience prior to pursuing a PhD in fields related to CSS.
Our computational social science group is widely recognized as a leading center of CSS research. Our research lies at the intersection of computer science, statistics, and social sciences, and uses large-scale demographic, behavioral, and network data to investigate human activity and relationships. Apply by May 5 for a one-year assignment beginning in Summer 2023, with a possibility to extend to a total of 18 months.
The post Research Focus: Week of April 10, 2023 appeared first on Microsoft Research.
Deploy a predictive maintenance solution for airport baggage handling systems with Amazon Lookout for Equipment
This is a guest post co-written with Moulham Zahabi from Matarat.
Probably everyone has checked their baggage when flying, and waited anxiously for their bags to appear at the carousel. Successful and timely delivery of your bags depends on a massive infrastructure called the baggage handling system (BHS). This infrastructure is one of the key functions of successful airport operations. Successfully handling baggage and cargo for departing and arriving flights is critical to ensure customer satisfaction and deliver airport operational excellence. This function is heavily dependent on the continuous operation of the BHS and the effectiveness of maintenance operations. As the lifeline of the airports, a BHS is a linear asset that can exceed 34,000 meters in length (for a single airport) handling over 70 million bags annually, making it one of the most complex automated systems and a vital component of airport operations.
Unplanned downtime of a baggage handling system, whether be it a conveyor belt, carousel, or sorter unit, can disrupt airport operations. Such disruption is bound to create an unpleasant passenger experience and possibly impose penalties on airport service providers.
The prevalent challenge with maintaining a baggage handling system is how to operate an integrated system of over 7,000 assets and over a million setpoints continuously. These systems also handle millions of bags in different shapes and sizes. It’s safe to assume that baggage handling systems are prone to error. Because the elements function in a closed loop, if one element breaks down, it affects the entire line. Traditional maintenance activities rely on a sizable workforce distributed across key locations along the BHS dispatched by operators in the event of an operational fault. Maintenance teams also rely heavily on supplier recommendations to schedule downtime for preventive maintenance. Determining if preventive maintenance activities are properly implemented or monitoring the performance of this type of asset may be unreliable and doesn’t reduce the risk of unanticipated downtime.
Spare parts management is an additional challenge as lead times are increasing due to global supply chain disruptions, yet inventory replenishment decisions are based on historical trends. In addition, these trends don’t incorporate the volatile dynamic environment of operating BHS assets as they age. To address these challenges, a seismic shift needs to happen in maintenance strategies—moving from a reactive to proactive mindset. This shift requires operators to utilize the latest technology to streamline maintenance activities, optimize operations, and minimize operating expenses.
In this post, we describe how AWS Partner Airis Solutions used Amazon Lookout for Equipment, AWS Internet of Things (IoT) services, and CloudRail sensor technologies to provide a state-of-the-art solution to address these challenges.
Baggage handling system overview
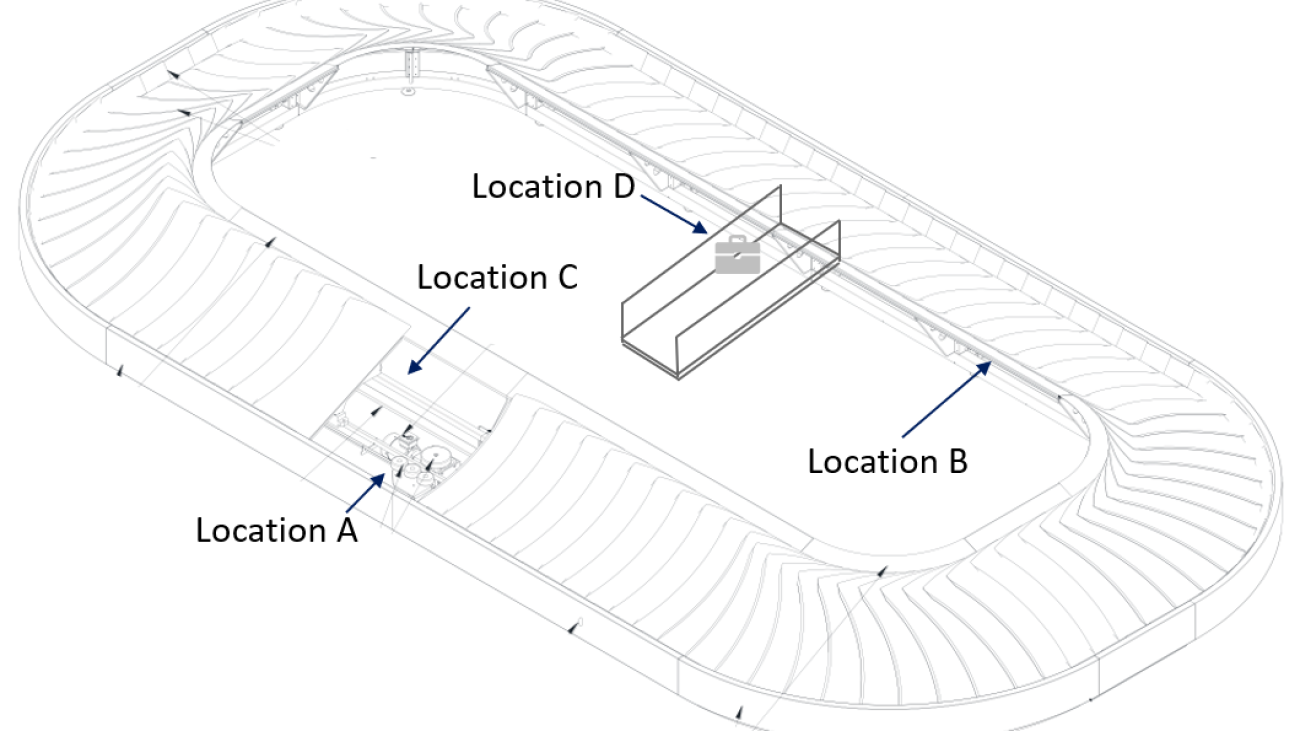
The following diagram and table illustrate the measurements taken across a typical carousel in King Khalid International Airport in Riyadh.

Data is collected at the different locations illustrated in the diagram.
| Sensor Type | Business value | Datasets | Location |
| IO Link Speed Sensors | Homogeneous Carousel Speed | PDV1 (1 per min) | C |
|
Vibration Sensor with Integrated Temperature Sensor |
Loose Screw, Shaft Misaligned, Bearing Damage, Motor Winding Damage |
Fatigue (v-RMS) (m/s) Impact (a-Peak) (m/s^2) Friction (a-RMS) (m/s^2) Temperature (C) Crest |
A and B |
| Distance PEC Sensor | Baggage Throughput | Distance (cm) | D |
The following images show the environment and monitoring equipment for the various measurements.

Vibration sensor mounted on one of the conveyor motors |

Proximity probe measuring carousel speed |
|

Line of sight of the baggage throughput counter (using a distance sensor) |

Thermal image of one of the conveyor motors |
|
Solution overview
The predictive maintenance system (PdMS) for baggage handling systems is a reference architecture that aids airport maintenance operators in their journey to have data as an enabler in improving unplanned downtime. It contains building blocks to accelerate the development and deployment of connected sensors and services. The PdMS includes AWS services to securely manage the lifecycle of edge compute devices and BHS assets, cloud data ingestion, storage, machine learning (ML) inference models, and business logic to power proactive equipment maintenance in the cloud.
This architecture was built from lessons learned while working with airport operations over several years. The proposed solution was developed with the support of Northbay Solutions, an AWS Premier Partner, and can be deployed to airports of all sizes and scales to thousands of connected devices within 90 days.
The following architecture diagram exposes the underlying components used to build the predictive maintenance solution:

We use the following services to assemble our architecture:
- CloudRail.DMC is a software as a service (SaaS) solution by the German IoT expert CloudRail GmbH. This organization manages fleets of globally distributed edge gateways. With this service, industrial sensors, smart meters, and OPC UA servers can be connected to an AWS data lake with just a few clicks.
- AWS IoT Core lets you connect billions of IoT devices and route trillions of messages to AWS services without managing infrastructure. It securely transmits messages to and from all of your IoT devices and applications with low latency and high throughput. We use AWS IoT Core to connect to the CloudRail sensors and forward their measurements to the AWS Cloud.
- AWS IoT Analytics is a fully managed service that makes it easy to run and operationalize sophisticated analytics on massive volumes of IoT data without having to worry about the cost and complexity typically required to build an IoT analytics platform. It’s an easy way to run analytics on IoT data to gain accurate insights.
- Amazon Lookout for Equipment analyzes data from equipment sensors to create an ML model automatically for your equipment based on asset specific data—no data science skills necessary. Lookout for Equipment analyzes incoming sensor data in real time and accurately identifies early warning signals that could lead to unexpected downtime.
- Amazon QuickSight allows everyone in the organization to understand the data by asking questions in natural language, visualizing information through interactive dashboards, and automatically looking for patterns and outliers powered by ML.
As illustrated in the following diagram, this architecture enables sensor data to flow to operational insights.

Data points are collected using IO-Link sensors: IO-Link is a standardized interface to enable seamless communication from the control level of an industrial asset (in our case, the baggage handling system) to the sensor level. This protocol is used to feed sensor data into a CloudRail edge gateway and loaded into AWS IoT Core. The latter then provides equipment data to ML models to identify operational and equipment issues that can be used to determine optimal timing for asset maintenance or replacement without incurring unnecessary costs.
Data collection
Retrofitting existing assets and their controls systems to the cloud remains a challenging approach for operators of equipment. Adding secondary sensors provides a fast and secure way to acquire the necessary data while not interfering with existing systems. Therefore, it’s easier, faster, and non-invasive compared to the direct connection of a machine’s PLCs. Additionally, retrofitted sensors can be selected to precisely measure the data points required for specific failure modes.
With CloudRail, every industrial IO-Link sensor can be connected to AWS services like AWS IoT Core, AWS IoT SiteWise, or AWS IoT Greengrass within a few seconds through a cloud-based device management portal (CloudRail.DMC). This enables IoT experts to work from centralized locations and onboard physical systems that are globally distributed. The solution solves the challenges of data connectivity for predictive maintenance systems through an easy plug-and-play mechanism.
The gateway acts as the Industrial Demilitarized Zone (IDMZ) between the equipment (OT) and the cloud service (IT). Through an integrated fleet management application, CloudRail ensures that the latest security patches are rolled out automatically to thousands of installations.
The following image shows an IO-Link sensor and the CloudRail edge gateway (in orange):

Training an anomaly detection model
Organizations from most industrial segments see modern maintenance strategies moving away from the run-to-failure, reactive approaches and progressing towards more predictive methods. However, moving to a condition-based or predictive maintenance approach requires data collected from sensors installed throughout facilities. Using historical data captured by these sensors in conjunction with analytics helps identify precursors to equipment failures, which allows maintenance personnel to act accordingly before breakdown.
Predictive maintenance systems rely on the capability to identify when failures could occur. Equipment OEMs usually provide datasheets for their equipment and recommend monitoring certain operational metrics based on near-perfect conditions. However, these conditions are rarely realistic because of the natural wear of the asset, the environmental conditions it operates in, its past maintenance history, or just the way you need to operate it to achieve your business outcomes. For instance, two identical motors (make, model, production date) were installed in the same carousel for this proof of concept. These motors operated at different temperature ranges due to different weather exposure (one part of the conveyor belt on the inside and the other outside of the airport terminal).
Motor 1 operated in a temperature ranging from 32–35°C. Vibration velocity RMS can change due to motor fatigue (for example, alignment errors or imbalance problems). As shown in the following figure, this motor shows fatigue levels ranging between 2–6, with some peaks at 9.
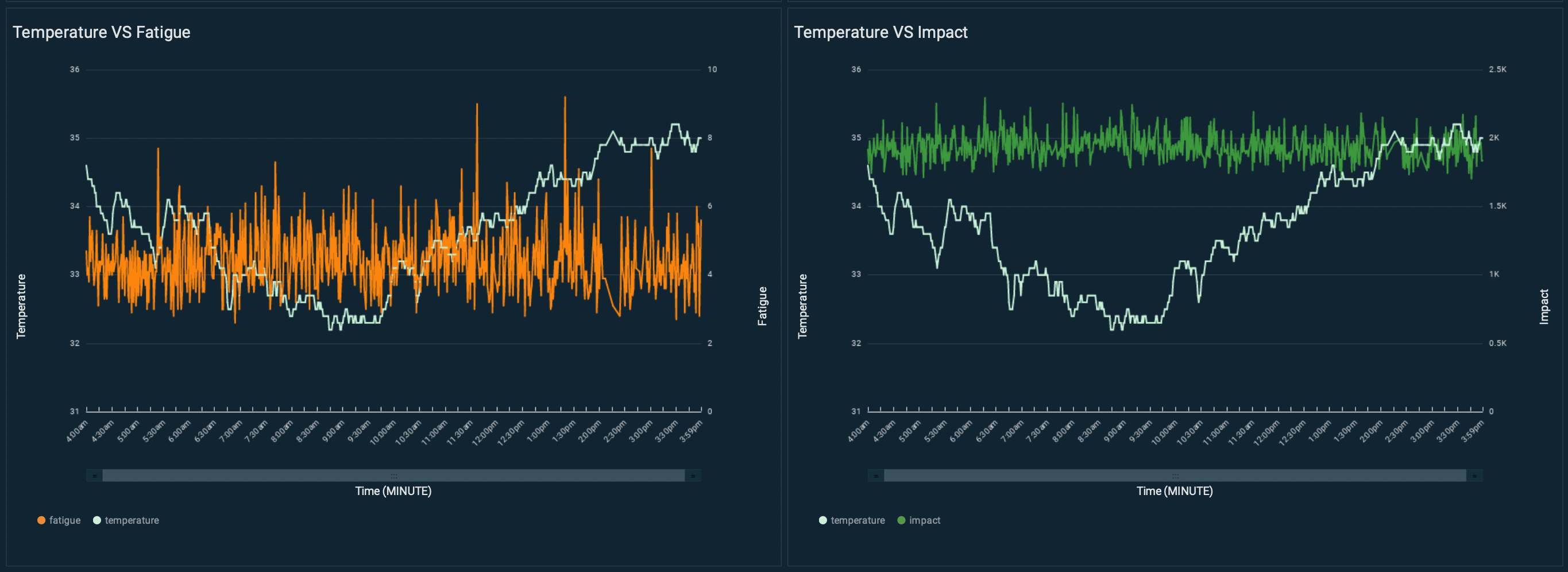
Motor 2 operated in a cooler environment, where the temperature was ranging between 20–25°C. In this context, motor 2 shows fatigue levels between 4–8, with some peaks at 10:

Most ML approaches expect very specific domain knowledge and information (often difficult to obtain) that must be extracted from the way you operate and maintain each asset (for example, failure degradation patterns). This work needs to be performed each time you want to monitor a new asset, or if the asset conditions change significantly (such as when you replace a part). This means that a great model delivered at the prototyping phase will likely see a performance hit when rolled out on other assets, drastically reducing the accuracy of the system and in the end, losing the end-users’ confidence. This may also cause many false positives, and you would need the skills necessary to find your valid signals in all the noise.
Lookout for Equipment only analyzes your time series data to learn the normal relationships between your signals. Then, when these relationships start to deviate from the normal operating conditions (captured at training state), the service will flag the anomaly. We found that strictly using historical data for each asset lets you focus on technologies that can learn the operating conditions that will be unique to a given asset in the very environment it’s operating in. This lets you deliver predictions supporting root cause analysis and predictive maintenance practices at a granular, per-asset level and macro level (by assembling the appropriate dashboard to let you get an overview of multiple assets at once). This is the approach we took and the reason we decided to use Lookout for Equipment.
Training strategy: Addressing the cold start challenge
The BHS we targeted wasn’t instrumented at first. We installed CloudRail sensors to start collecting new measurements from our system, but this meant we only had a limited historical depth to train our ML model. We addressed the cold start challenge in this case by recognizing that we are building a continuously improving system. After the sensors were installed, we collected an hour of data and duplicated this information to start using Lookout for Equipment as soon as possible and test our overall pipeline.
As expected, the first results were quite unstable because the ML model was exposed to a very small period of operations. This meant that any new behavior not seen during the first hour would be flagged. When looking at the top-ranking sensors, the temperature on one of the motors seemed to be the main suspect (T2_MUC_ES_MTRL_TMP in orange in the following figure). Because the initial data capture was very narrow (1 hour), over the course of the day, the main change was coming from the temperature values (which is consistent with the environmental conditions at that time).

When matching this with the environmental conditions around this specific conveyor belt, we confirmed that the outside temperature increased severely, which, in turn, increased the temperature measured by this sensor. In this case, after the new data (accounting for the outside temperature increase) is incorporated into the training dataset, it will be part of the normal behavior as captured by Lookout for Equipment and similar behavior in the future will be less likely to raise any events.
After 5 days, the model was retrained and the false positive rates immediately fell drastically:

Although this cold start problem was an initial challenge to obtain actionable insights, we used this opportunity to build a retraining mechanism the end-user can trigger easily. A month into the experimentation, we trained a new model by duplicating a month’s worth of sensor data into 3 months. This continued to reduce the false positive rates as the model was exposed to a broader set of conditions. A similar false positive rate drop happened after this retraining: the condition modeled by the system was closer to what users are experiencing in real life. After 3 months, we finally had a dataset that we could use without using this duplication trick.
From now on, we will launch a retraining every 3 months and, as soon as possible, will use up to 1 year of data to account for the environmental condition seasonality. When deploying this system on other assets, we will be able to reuse this automated process and use the initial training to validate our sensor data pipeline.
After the model was trained, we deployed the model and started sending live data to Lookout for Equipment. Lookout for Equipment lets you configure a scheduler that wakes up regularly (for example, every hour) to send fresh data to the trained model and collect the results.
Now that we know how to train, improve, and deploy a model, let’s look at the operational dashboards implemented for the end-users.
Data visualization and insights
End-users need a way to extract more value from their operational data to better improve their asset utilization. With QuickSight, we connected the dashboard to the raw measurement data provided by our IoT system, allowing users to compare and contrast key pieces of equipment on a given BHS.
In the following dashboard, users can check the key sensors used to monitor the condition of the BHS and obtain period-over-period metrics changes.
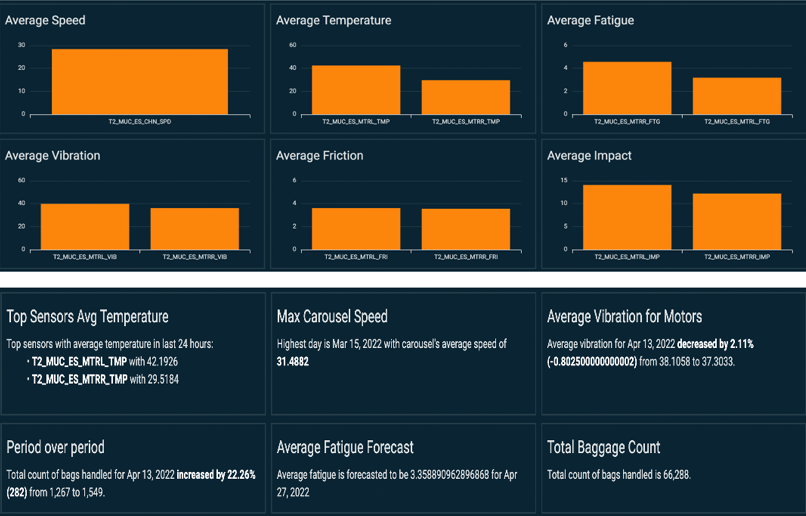
In the preceding plot, users can visualize any unexpected imbalance of the measurement for each motor (left and right plots for temperature, fatigue, vibration, friction, and impact). At the bottom, key performance indicators are summarized, with forecast and period-over-period trends called out.
End-users can access information for the following purposes:
- View historical data in intervals of 2 hours up to 24 hours.
- Extract raw data via CSV format for external integration.
- Visualize asset performance over a set period of time.
- Produce insights for operational planning and improve asset utilization.
- Perform correlation analysis. In the following plot, the user can visualize several measurements (such as motor fatigue vs. temperature, or baggage throughput vs. carousel speed) and use this dashboard to better inform the next best maintenance action.

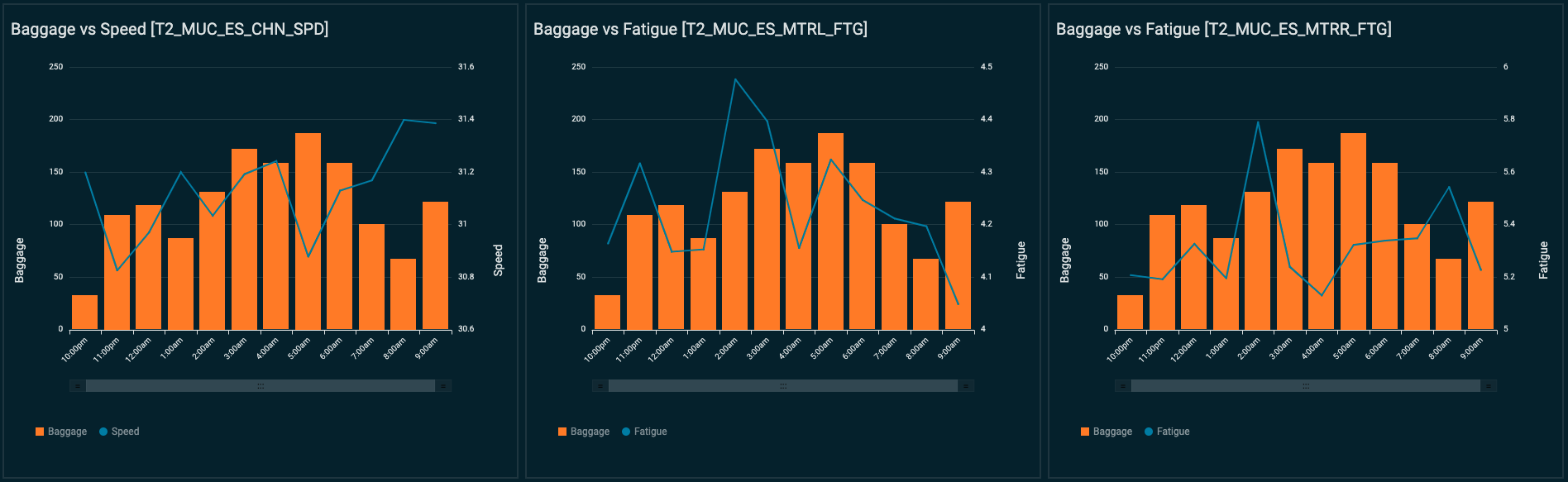
Eliminating noise from the data
After a few weeks, we noticed that Lookout for Equipment was emitting some events thought to be false positives.

When analyzing these events, we discovered irregular drops in the speed of the carousel motor.

We met with the maintenance team and they informed us these stops were either emergency stops or planned downtime maintenance activities. With this information, we labeled the emergency stops as anomalies and fed them to Lookout for Equipment, while the planned downtimes were considered normal behavior for this carousel.
Understanding such scenarios where abnormal data can be influenced by controlled external actions is critical to improve the anomaly detection model accuracy over time.
Smoke testing
After a few hours from retraining the model and achieving relatively no anomalies, our team physically stressed the assets, which was immediately detected by the system. This is a common request from users because they need to familiarize themselves with the system and how it reacts.

We built our dashboard to allow end-users to visualize historical anomalies with an unlimited period. Using a business intelligence service let them organize their data at will, and we have found that bar charts over a 24-hour period or pie charts are the best way to get a good view of the condition of the BHS. In addition to the dashboards that users can view whenever they need, we set up automated alerts sent to a designated email address and via text message.
Extracting deeper insights from anomaly detection models
In the future, we intend to extract deeper insights from the anomaly detection models trained with Lookout for Equipment. We will continue to use QuickSight to build an expanded set of widgets. For instance, we have found that the data visualization widgets exposed in the GitHub samples for Lookout for Equipment allow us to extract even more insights from the raw outputs of our models.

Results
Reactive maintenance in baggage handling systems translates to the following:
- Lower passenger satisfaction due to lengthy wait times or damaged baggage
- Lower asset availability due to the unplanned failures and inventory shortage of critical spare parts
- Higher operating expenses due to rising inventory levels in addition to higher maintenance costs
Evolving your maintenance strategy to incorporate reliable, predictive analytics into the cycle of decision-making aims to improve asset operation and help avoid forced shutdowns.

The monitoring equipment was installed locally in 1 day and configured completely remotely by IoT experts. The cloud architecture described in the solution overview was then successfully deployed within 90 days. A fast implementation time proves the benefits proposed to the end-user, quickly leading to a shift in maintenance strategy from human-based reactive (fixing breakdowns) to machine-based, data-driven proactive (preventing downtimes).
Conclusion
The cooperation between Airis, CloudRail, Northbay Solutions, and AWS led to new achievement at the King Khalid International Airport (see the press release for more details). As part of their digital transformation strategy, the Riyadh Airport plans on further deployments to cover other electro-mechanical systems like passenger boarding bridges and HVAC systems.
If you have comments about this post, please submit them in the comments section. If you have questions about this solution or its implementation, please start a new thread on re:Post, where AWS experts and the broader community can support you.
About the authors
 Moulham Zahabi is an aviation specialist with over 11 years of experience in designing and managing aviation projects, and managing critical airport assets in the GCC region. He is also one of the co-founders of Airis-Solutions.ai, which aims to lead the aviation industry’s digital transformation through innovative AI/ML solutions for airports and logistical centers. Today, Moulham is heading the Asset Management Directorate in the Saudi Civil Aviation Holding Company (Matarat).
Moulham Zahabi is an aviation specialist with over 11 years of experience in designing and managing aviation projects, and managing critical airport assets in the GCC region. He is also one of the co-founders of Airis-Solutions.ai, which aims to lead the aviation industry’s digital transformation through innovative AI/ML solutions for airports and logistical centers. Today, Moulham is heading the Asset Management Directorate in the Saudi Civil Aviation Holding Company (Matarat).
 Fauzan Khan is a Senior Solutions Architect working with public sector customers, providing guidance to design, deploy, and manage their AWS workloads and architectures. Fauzan is passionate about helping customers adopt innovative cloud technologies in the area of HPC and AI/ML to address business challenges. Outside of work, Fauzan enjoys spending time in nature.
Fauzan Khan is a Senior Solutions Architect working with public sector customers, providing guidance to design, deploy, and manage their AWS workloads and architectures. Fauzan is passionate about helping customers adopt innovative cloud technologies in the area of HPC and AI/ML to address business challenges. Outside of work, Fauzan enjoys spending time in nature.
 Michaël Hoarau is an AI/ML Specialist Solutions Architect at AWS who alternates between data scientist and machine learning architect, depending on the moment. He is passionate about bringing the AI/ML power to the shop floors of his industrial customers and has worked on a wide range of ML use cases, ranging from anomaly detection to predictive product quality or manufacturing optimization. He published a book on time series analysis in 2022 and regularly writes about this topic on LinkedIn and Medium. When not helping customers develop the next best machine learning experiences, he enjoys observing the stars, traveling, or playing the piano.
Michaël Hoarau is an AI/ML Specialist Solutions Architect at AWS who alternates between data scientist and machine learning architect, depending on the moment. He is passionate about bringing the AI/ML power to the shop floors of his industrial customers and has worked on a wide range of ML use cases, ranging from anomaly detection to predictive product quality or manufacturing optimization. He published a book on time series analysis in 2022 and regularly writes about this topic on LinkedIn and Medium. When not helping customers develop the next best machine learning experiences, he enjoys observing the stars, traveling, or playing the piano.

Modulate makes voice chat safer while reducing infrastructure costs by a factor of 5 with Amazon EC2 G5g instances
This is a guest post by Carter Huffman, CTO and Co-founder at Modulate.
Modulate is a Boston-based startup on a mission to build richer, safer, more inclusive online gaming experiences for everyone. We’re a team of world-class audio experts, gamers, allies, and futurists who are eager to build a better online world and make voice chat safer for all players. We’re doing just that with ToxMod, our proactive, voice-native moderation platform. Game publishers and developers use ToxMod to proactively moderate voice chat in their games according to their own content policies, codes of conduct, and community guidelines.
We chose AWS for the scalability and elasticity that our application needed as well as the great customer service it offers. Using Amazon Elastic Compute Cloud (Amazon EC2) G5g instances featuring NVIDIA T4G Tensor Core GPUs as the infrastructure for ToxMod has helped us lower our costs by a factor of 5 (compared to G4dn instances) while achieving our goals on throughput and latency. As a nimble startup, we can reinvest these cost savings into further innovation to help serve our mission. In this post, we cover our use case, challenges, and alternative paths, and a brief overview of our solution using AWS.
The changing metaverse and need for ToxMod

Modern online games and metaverse platforms have become far more social than their predecessors. Historically, games have focused on providing a specific curated experience to players. Today, they have evolved to be more of a communal space, where players and their friends can congregate and choose a variety of experiences to partake in. With this evolution, toxicity and verbal abuse can often ruin otherwise great online experiences.
In fact, according to a recent study from the Anti-Defamation League, toxicity in games is worse than ever: exposure to white supremacist ideologies in games more than doubled in 2022. Over three-quarters of adult gamers reported experiencing severe harassment in online games. More than 17 million young gamers were exposed to harm and harassment in the past year. The problem is only getting worse, and with upcoming regulations that will require studios to take a more active role in managing and reporting on toxicity, the need for proactive voice moderation is more urgent than ever.
ToxMod helps game publishers and platforms proactively moderate their voice chat according to their own policies and guidelines, keeping their communities safe and positive. ToxMod runs a series of machine learning (ML) models that analyze the emotional, textual, and conversational aspects of voice conversations to determine if there are any violations of the publisher’s or platform’s content policies. Violations are flagged to human moderators who can take action against bad actors. Our ML models include emotion detection, transcription, and NLP-powered conversational analysis that categorizes violations and provides a rank score to determine how confident it is that a violation has occurred. These detections occur in real time and enable game publishers to proactively moderate their communities as toxicity is occurring, preventing harm to players and dangerous conversations from escalating.
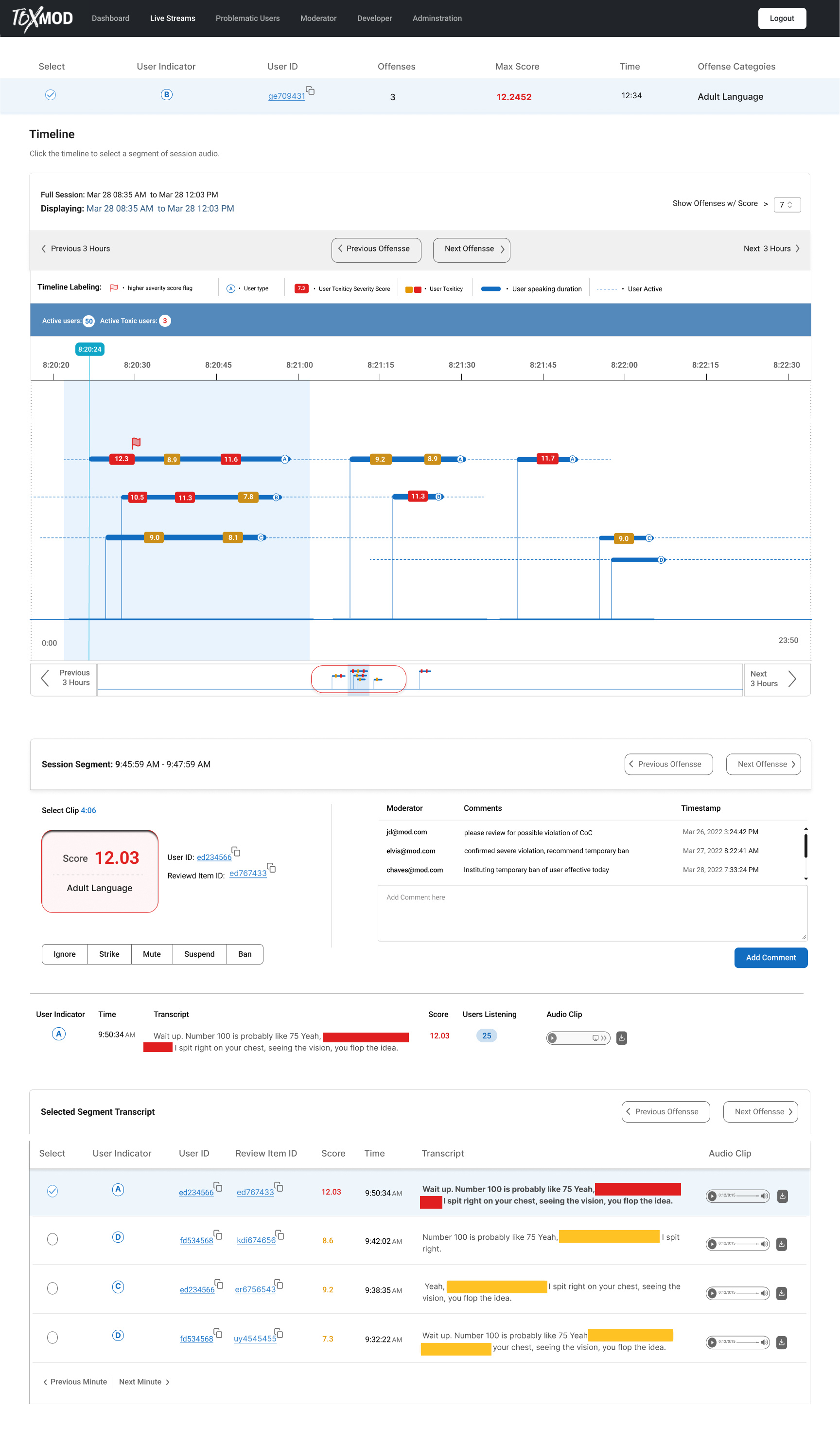
Economic and technical considerations
We have two types of constraints: economic and technical. On the economic side, our problem is variable demand and the uncertain scale of the required compute infrastructure. In the games industry, developers and publishers launch games with minimal margins and only scale up as the game becomes more successful. That success can mean that our largest customers are processing millions of hours of voice chat per month. ToxMod’s costs scale with the number of hours of audio processed, which is very dynamic based on players’ behavior and external factors affecting a game’s popularity. Operating our own servers to power ToxMod is prohibitively expensive in terms of both cost and team bandwidth. On-premise servers lack this scalability and would often go underutilized, meaning the right choice for ToxMod is the cloud. With AWS, we can dynamically scale to match our customers’ demand while keeping costs at a minimum.
On the technical side, as with building any voice process application, we need to strike a balance between latency and throughput. Some of our users want the ability to address situations that may arise in their communities within a minute or two of them happening. To meet our latency budgets, we go as low level as possible. We happen to have a lot of experience with ARM devices because a lot of the ToxMod code base runs on client-side devices that often run on an ARM processor. The EC2 G5g instances powered by NVIDIA T4G Tensor Core GPUs and featuring AWS Graviton2 processors were a natural fit for some of the custom neural network inference code that had developed for client-side usage.
EC2 G5g instances for cost-efficiency and AWS reliability
With these considerations, we decided to use G5g instances as the infrastructure for ToxMod because they are cost-effective and provide familiar environments to test and deploy our models. This choice ultimately helped us lower our costs by a factor of 5 (compared to G4dn instances). To be able to iterate quickly, we needed a compute environment that was familiar to our data scientists and ML engineers. We were able to get our machine image with all the relevant drivers, libraries, and environment variables running on G5g instances within a day. We started off on G4dn instances, and our initial tests on G5g enabled us to lower our costs by 40%. Many of our most expensive models to run are GPU-bound, so we were able to further optimize our costs by right-sizing to an instance size that enabled us to maximize the CPU utilization while still having access to a single GPU.
Beyond G5g instances working particularly well for our configuration, we knew we could count on AWS’s technical support and account management to help us resolve issues quickly and maintain extremely high uptime while experiencing highly variable load. When we started, we were spending less than double digits per month, and yet a real person reached out to learn about our use case and a team of people worked with us to make our application not only work, but work in the most cost-efficient manner.
Overview of our solution
ToxMod’s solution begins with audio ingestion, which is accomplished through integration of our SDK into a game’s or platform’s voice chat infrastructure. The use of an SDK (over an API or other interface) is critical because when you process audio, you have to be extremely resource-efficient. For any single audio stream, we need to process it and hand it back to the rest of the system quickly or customers will encounter glitches in the audio, which is something we want to avoid at all costs. A lot of things can cause glitches—including memory allocation, garbage collection, and system calls—so we’ve developed the ToxMod SDK to ensure the smoothest audio processing possible.
From the SDK, voice chats are encoded in short buffers and sent over the internet. On the ingestion side, we buffer a couple of seconds of audio, and we try to find natural break points in voice conversations before sending the package to the AWS Cloud, where we save the incoming data via AWS Lambda functions. From there, analysis of the audio conversation is done via processing on G5g instances running our variety of ML audio models. We minimize overhead by batching all the packets we receive and sending those off to the GPUs in the G5g instances. The G5g instances are fed through queues of audio clips to process, which we have hooked up to auto scaling groups that efficiently scale up or down as traffic varies throughout the day.
Looking ahead
ToxMod is built for studios of all sizes, from small indie dev teams to AAA, multi-team developers and publishers. Today, we’re better positioned than ever to provide the level of support, product development, and robust features that enterprise teams at the largest studios expect from their software partners. With multilingual support for 18 languages, 24/7 enterprise-grade support, available single-tenant licenses for studios with multiple games, and the support of the scalable ML infrastructure that AWS provides, we’re here to help AAA studios make voice chat safe for their players.
If you would like to learn more about how EC2 G5g instances can help you cost-effectively deploy your ML workloads, refer to Amazon EC2 G5g instances.
About the Authors
 Carter Huffman is the CTO and co-founder of Modulate, a voice technology startup that aims to fight online toxicity and enhance voice communication in games. He has a background in physics, machine learning, and data analysis, and previously worked at NASA’s Jet Propulsion Laboratory. He is passionate about understanding and manipulating human speech using deep neural networks. He graduated from MIT with a Bachelor of Science in Physics.
Carter Huffman is the CTO and co-founder of Modulate, a voice technology startup that aims to fight online toxicity and enhance voice communication in games. He has a background in physics, machine learning, and data analysis, and previously worked at NASA’s Jet Propulsion Laboratory. He is passionate about understanding and manipulating human speech using deep neural networks. He graduated from MIT with a Bachelor of Science in Physics.
 Shruti Koparkar is a Senior Product Marketing Manager at AWS. She helps customers explore, evaluate, and adopt EC2 accelerated computing infrastructure for their machine learning needs.
Shruti Koparkar is a Senior Product Marketing Manager at AWS. She helps customers explore, evaluate, and adopt EC2 accelerated computing infrastructure for their machine learning needs.
Secure your Amazon Kendra indexes with the ACL using a JWT shared secret key
Globally, many organizations have critical business data dispersed among various content repositories, making it difficult to access this information in a streamlined and cohesive manner. Creating a unified and secure search experience is a significant challenge for organizations because each repository contains a wide range of document formats and access control mechanisms.
Amazon Kendra is an intelligent enterprise search service that allows users to search across different content repositories. Customers are responsible for authenticating and authorizing users to gain access to their search application, and Amazon Kendra enables secure search for enterprise applications, making sure that the results of a user’s search query only include documents the user is authorized to read. Amazon Kendra can easily validate the identity of individual users as well as user groups who perform searches with the addition of secure search tokens. By adding user tokens for secure search, performing access-based filtered searches in Amazon Kendra is simplified and secured. You can securely pass user access information in the query payload instead of using attribute filters to accomplish this. With this feature, Amazon Kendra can validate the token information and automatically apply it to the search results for accurate and secure access-based filtering.
Amazon Kendra supports token-based user access control using the following token types:
- Open ID
- JWT with a shared secret
- JWT with a public key
- JSON
Previously, we saw a demonstration of token-based user access control in Amazon Kendra with Open ID. In this post, we demonstrate token-based user access control in Amazon Kendra with JWT with a shared secret. JWT, or JSON Web Token, is an open standard used to share security information between a client and a server. It contains encoded JSON objects, including a set of claims. JWTs are signed using a cryptographic algorithm to ensure that the claims can’t be altered after the token is issued. JWTs are useful in scenarios regarding authorization and information exchange.
JWTs consist of three parts separated by dots (.):
- Header – It contains parts like type of the token, which is JWT, the signing algorithm being used, such as HMAC SHA256 or RSA, and an optional key identifier.
- Payload – This contains several key-value pairs, called claims, which are issued by the identity provider. In addition to several claims relating to the issuance and expiration of the token, the token can also contain information about the individual principal and tenant.
- Signature – To create the signature part, you take the encoded header, the encoded payload, a secret, the algorithm specified in the header, and sign that.
Therefore, a JWT looks like the following:
The following is a sample header:
The following is the sample payload:
The JWT is created with a secret key, and that secret key is private to you, which means you will never reveal that to the public or inject it inside the JWT. When you receive a JWT from the client, you can verify the JWT with the secret key stored on the server. Any modification to the JWT will result in verification (JWT validation) failure.
This post demonstrates the sample use of a JWT using a shared access key and its usage to secure Amazon Kendra indexes with access controls. In production, you use a secure authentication service provider of your choice and based on your requirements to generate JWTs.
To learn more about JWTs, refer to Introduction to JSON Web Tokens.
Solution overview
Similar to the post with Open ID, this solution is designed for a set of users and groups to make search queries to a document repository, and results are returned only from those documents that are authorized for access within that group. The following table outlines which documents each user is authorized to access for our use case. The documents being used in this example are a subset of AWS public documents.
| User | Group | Document Type Authorized for Access |
| Guest | . | Blogs |
| Patricia | Customer | Blogs, user guides |
| James | Sales | Blogs, user guides, case studies |
| John | Marketing | Blogs, user guides, case studies, analyst reports |
| Mary | Solutions Architect | Blogs, user guides, case studies, analyst reports, whitepapers |
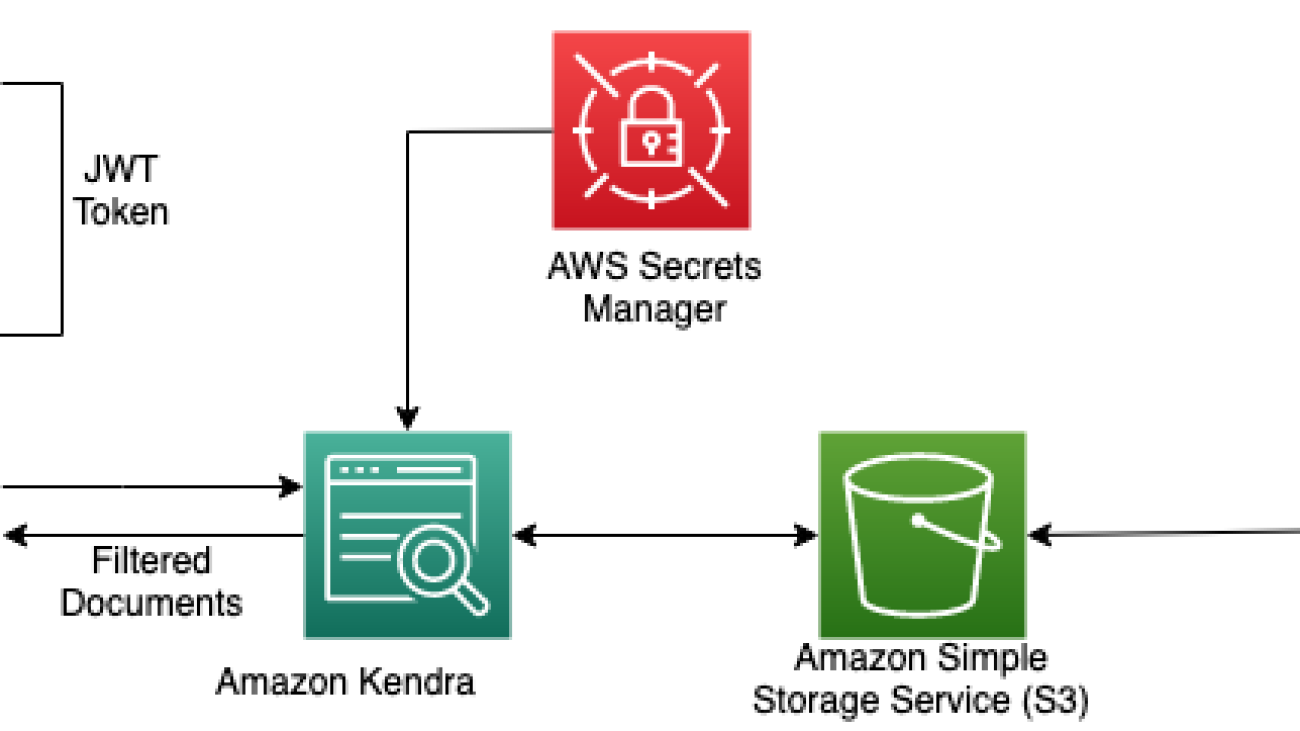
The following diagram illustrates the creation of a JWT with a shared access key to control access to users to the specific documents in the Amazon Kendra index.
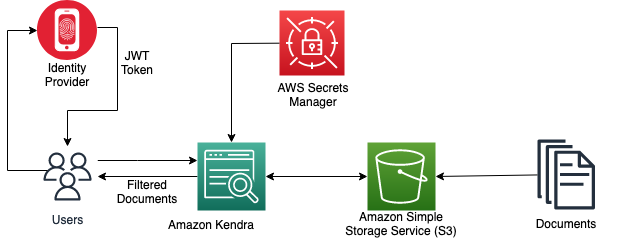
When an Amazon Kendra index receives a query API call with a user access token, it validates the token using a shared secret key (stored securely in AWS Secrets Manager) and gets parameters such as username and groups in the payload. The Amazon Kendra index filters the search results based on the stored Access Control List (ACL) and the information received in the user’s JWT. These filtered results are returned in response to the query API call made by the application.
Prerequisites
In order to follow the steps in this post, make sure you have the following:
- Basic knowledge of AWS.
- An AWS account with access to Amazon Simple Storage Service (Amazon S3), Amazon Kendra, and Secrets Manager.
- An S3 bucket to store your documents. For more information, see Creating a bucket and the Amazon S3 User Guide.
Generate a JWT with a shared secret key
The following sample Java code shows how to create a JWT with a shared secret key using the open-source jsonwebtoken package. In production, you will be using a secure authentication service provider of your choice and based on your requirements to generate JWTs.
We pass the username and groups information as claims in the payload, sign the JWT with the shared secret, and generate a JWT specific for that user. Provide a 256 bit string as your secret and retain the value of the base64 URL encoded shared secret to use in a later step.
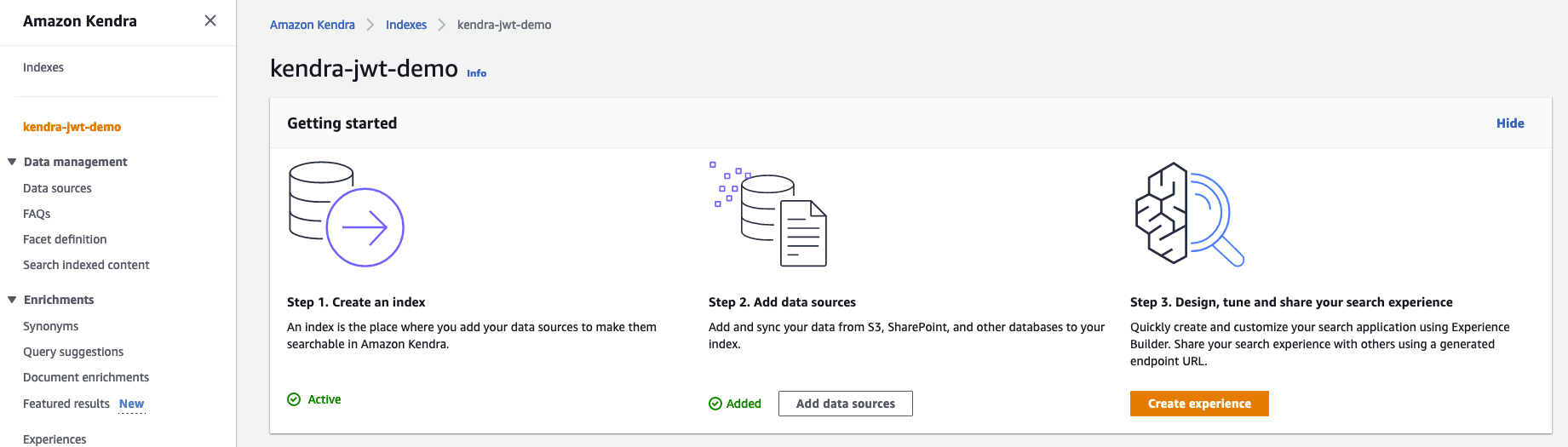
Create an Amazon Kendra index with a JWT shared secret
For instructions on creating an Amazon Kendra index, refer to Creating an index. Note down the AWS Identity and Access Management (IAM) role that you created during the process. Provide the role access to the S3 bucket and Secrets Manager following the principle of least privilege. For example policies, refer to Example IAM identity-based policies. After you create the index, your Amazon Kendra console should look like the following screenshot.
Complete the following steps to add your secret:
- On the Amazon Kendra console, navigate to the User access control tab on your index detail page.
- Choose Edit settings.
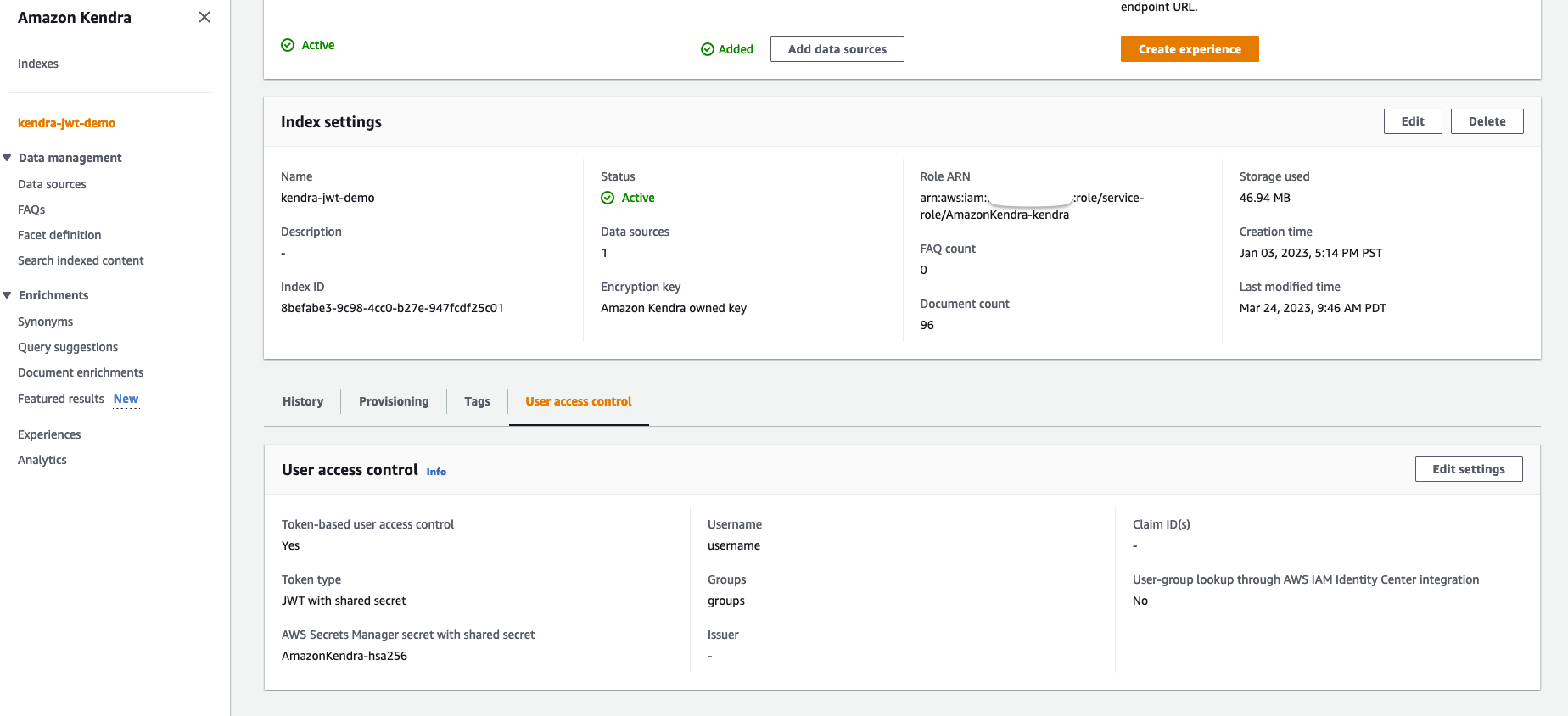
- Because we’re implementing token-based access control, select Yes under Access control settings.

- Under Token configuration, choose JWT with shared secret for Token type.
- For Type of secret, choose New.
- For Secret name, enter
AmazonKendra-jwt-shared-secretor any name of your choice. - For Key ID, enter the key ID to match your JWT that you created in the sample Java code.
- For Algorithm, choose the HS256 algorithm.
- For Shared secret, enter your retained base64 URL encoded secret generated from the Java code previously.
- Choose Save secret.
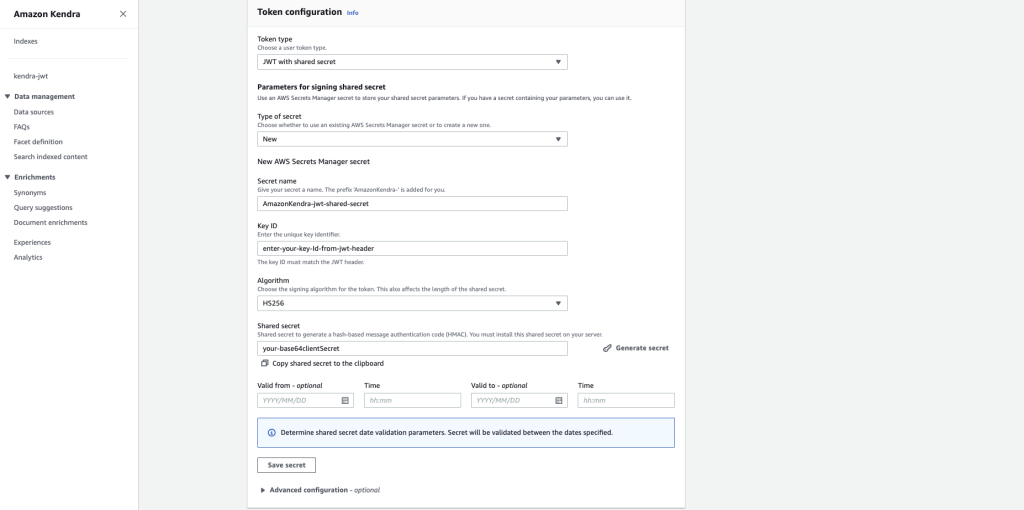
The secret will now be stored in Secrets Manager as a JSON Web Key Set (JWKS). You can locate it on the Secrets Manager console. For more details, refer to Using a JSON Web Token (JWT) with a shared secret.
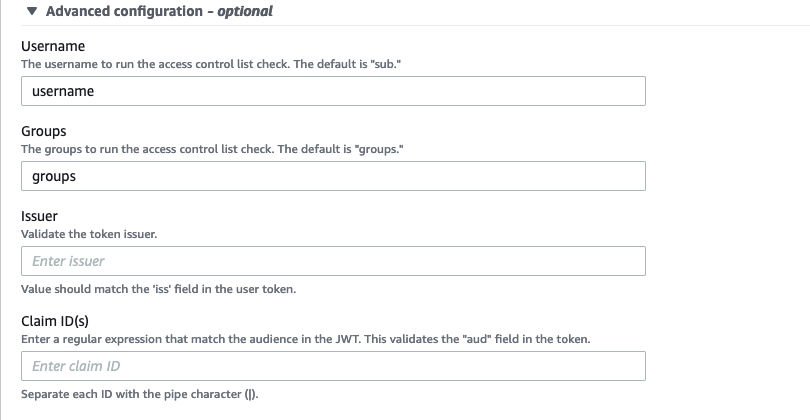
- Expand the Advanced configuration section.
In this step, we set up the user name and groups that will be extracted from JWT claims and matched with the ACL when the signature is valid.
- For Username¸ enter username.
- For Groups, enter groups.
- Leave the optional fields as default.
- Choose Next, then choose Update.
Prepare your S3 bucket as a data source
To prepare an S3 bucket as a data source, create an S3 bucket. In the terminal with the AWS Command Line Interface (AWS CLI) or AWS CloudShell, run the following commands to upload the documents and metadata to the data source bucket:
The documents being queried are stored in an S3 bucket. Each document type has a separate folder: blogs, case-studies, analyst-reports, user-guides, and white-papers. This folder structure is contained in a folder named Data. Metadata files including the ACLs are in a folder named Meta.
We use the Amazon Kendra S3 connector to configure this S3 bucket as the data source. When the data source is synced with the Amazon Kendra index, it crawls and indexes all documents as well as collects the ACLs and document attributes from the metadata files. To learn more about ACLs using metadata files, refer to Amazon S3 document metadata. For this example, we use the custom attribute DocumentType to denote the type of the document. After the upload, your S3 bucket structure should look like the following screenshot.

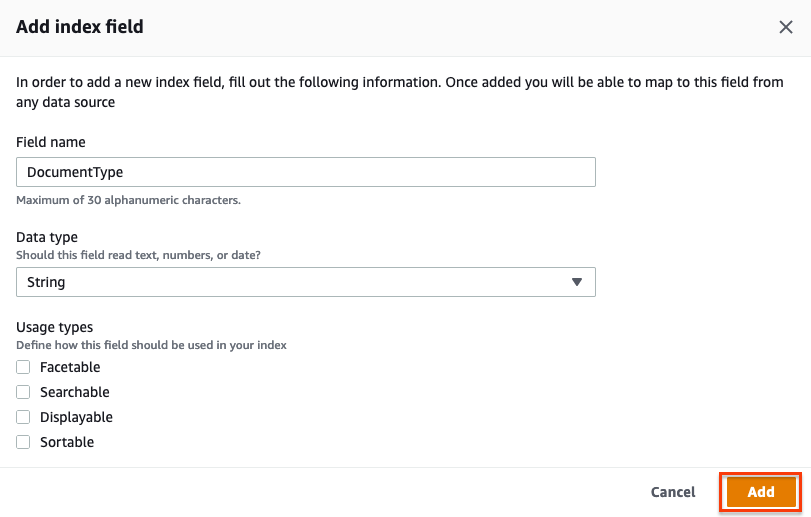
To set the custom attribute DocumentType, complete the following steps:
- Choose your Kendra index and choose Facet definition in the navigation pane.
- Choose Add field.

- For Field name, enter
DocumentType. - For Data type, choose String.
- Choose Add.
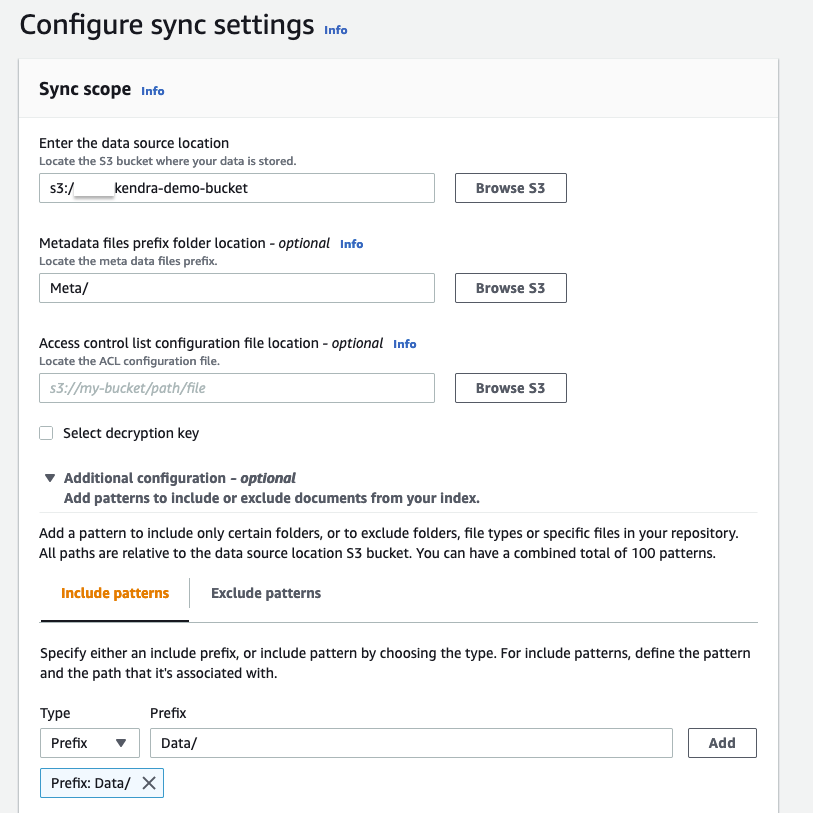
Now you can ingest documents from the bucket you created to the Amazon Kendra index using the S3 connector. For full instructions, refer to Ingesting Documents through the Amazon Kendra S3 Connector.
- In the Configure sync settings section, for Enter the data source location, enter your S3 bucket (
s3://kendra-demo-bucket/). - For Metadata files prefix folder location, enter
Meta/. - Expand Additional configuration.
- On the Include patterns tab, for Prefix, enter
Data/.
For more information about supported connectors, see Connectors.
- Choose Next, then Next again, then Update.
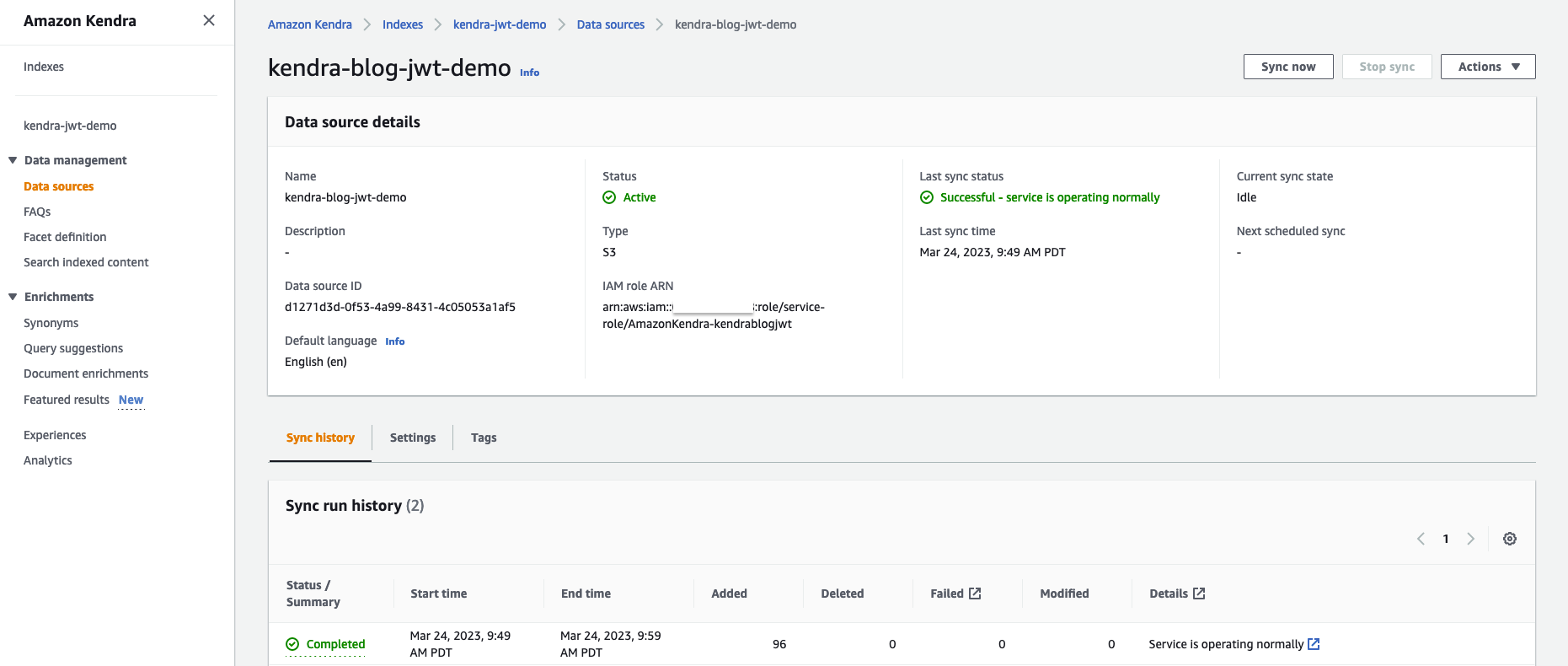
- Wait for the data source to be created, then select the data source and choose Sync now.
The data source sync can take 10–15 minutes to complete. When your sync is complete, Last sync status should show as Successful.
Query an Amazon Kendra index
To run a test query on your index, complete the following steps:
- On the Amazon Kendra console, choose Search indexed content in the navigation pane.
- Expand Test query with an access token.
- Choose Apply token.
- We can generate a JWT for the user and group. In this example, we create a JWT for the
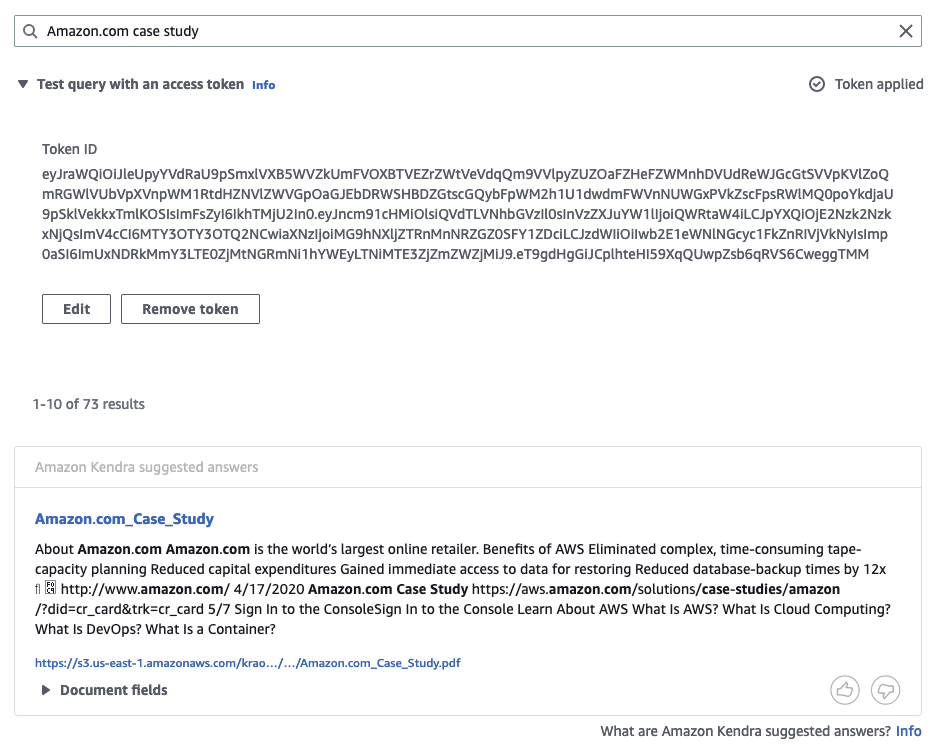
AWS-SAgroup. We replace username as Mary and groups asAWS-SAin the JWT generation step. - Enter the generated token and choose Apply.
Based on the ACL, we should be results from all the folders: blogs, user guides, case studies, analyst reports, and whitepapers.

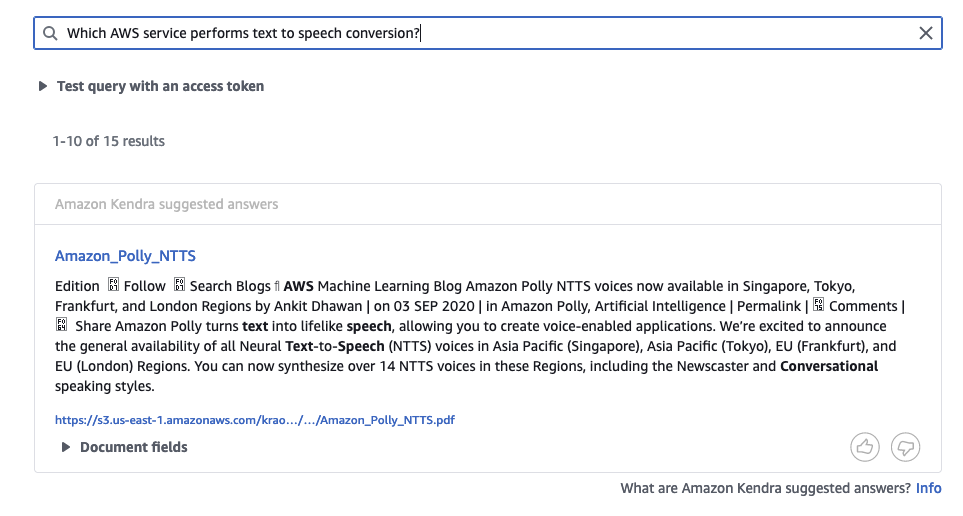
Similarly, when logged in as James from the AWS-Sales group and passing the corresponding JWT, we have access to only blogs, user guides, and case studies.
We can also search the index as a guest without passing a token. The guest is only able to access contents in the blogs folder.
Experiment using other queries you can think of while logged in as different users and groups and observe the results.
Clean up
To avoid incurring future costs, clean up the resources you created as part of this solution. To delete the Amazon Kendra index and S3 bucket created while testing the solution, refer to Cleanup. To delete the Secrets Manager secret, refer to Delete an AWS Secrets Manager secret.
Conclusion
In this post, we saw how Amazon Kendra can perform secure searches that only return search results based on user access. With the addition of a JWT with a shared secret key, we can easily validate the identity of individual users as well as user groups who perform searches. This similar approach can be extended to a JWT with a public key. To learn more, refer to Using a JSON Web Token (JWT) with a shared secret.
About the Authors
 Nitin Eusebius is a Sr. Enterprise Solutions Architect at AWS with over 18 years of experience in Software Engineering and Enterprise Architecture. He works with customers on helping them build well-architected applications on the AWS platform. He is passionate about solving technology challenges and helping customers with their cloud journey.
Nitin Eusebius is a Sr. Enterprise Solutions Architect at AWS with over 18 years of experience in Software Engineering and Enterprise Architecture. He works with customers on helping them build well-architected applications on the AWS platform. He is passionate about solving technology challenges and helping customers with their cloud journey.
 Kruthi Jayasimha Rao is a Partner Solutions Architect with a focus in AI and ML. She provides technical guidance to AWS Partners in following best practices to build secure, resilient, and highly available solutions in the AWS Cloud.
Kruthi Jayasimha Rao is a Partner Solutions Architect with a focus in AI and ML. She provides technical guidance to AWS Partners in following best practices to build secure, resilient, and highly available solutions in the AWS Cloud.
 Ishaan Berry is a Software Engineer at Amazon Web Services, working on Amazon Kendra, an enterprise search engine. He is passionate about security and has worked on key components of Kendra’s Access Control features over the past 2 years.
Ishaan Berry is a Software Engineer at Amazon Web Services, working on Amazon Kendra, an enterprise search engine. He is passionate about security and has worked on key components of Kendra’s Access Control features over the past 2 years.
 Akash Bhatia is a Principal Solutions architect with AWS. His current focus is helping enterprise customers achieve their business outcomes through architecting and implementing innovative and resilient solutions at scale. He has been working in technology for over 15 years at companies ranging from Fortune 100 to start-ups in Manufacturing, Aerospace and Retail verticals.
Akash Bhatia is a Principal Solutions architect with AWS. His current focus is helping enterprise customers achieve their business outcomes through architecting and implementing innovative and resilient solutions at scale. He has been working in technology for over 15 years at companies ranging from Fortune 100 to start-ups in Manufacturing, Aerospace and Retail verticals.
How Games24x7 transformed their retraining MLOps pipelines with Amazon SageMaker
This is a guest blog post co-written with Hussain Jagirdar from Games24x7.
Games24x7 is one of India’s most valuable multi-game platforms and entertains over 100 million gamers across various skill games. With “Science of Gaming” as their core philosophy, they have enabled a vision of end-to-end informatics around game dynamics, game platforms, and players by consolidating orthogonal research directions of game AI, game data science, and game user research. The AI and data science team dive into a plethora of multi-dimensional data and run a variety of use cases like player journey optimization, game action detection, hyper-personalization, customer 360, and more on AWS.
Games24x7 employs an automated, data-driven, AI powered framework for the assessment of each player’s behavior through interactions on the platform and flags users with anomalous behavior. They’ve built a deep-learning model ScarceGAN, which focuses on identification of extremely rare or scarce samples from multi-dimensional longitudinal telemetry data with small and weak labels. This work has been published in CIKM’21 and is open source for rare class identification for any longitudinal telemetry data. The need for productionization and adoption of the model was paramount to create a backbone behind enabling responsible game play in their platform, where the flagged users can be taken through a different journey of moderation and control.
In this post, we share how Games24x7 improved their training pipelines for their responsible gaming platform using Amazon SageMaker.
Customer challenges
The DS/AI team at Games24x7 used multiple services provided by AWS, including SageMaker notebooks, AWS Step Functions, AWS Lambda, and Amazon EMR, for building pipelines for various use cases. To handle the drift in data distribution, and therefore to retrain their ScarceGAN model, they discovered that the existing system needed a better MLOps solution.
In the previous pipeline through Step Functions, a single monolith codebase ran data preprocessing, retraining, and evaluation. This became a bottleneck in troubleshooting, adding, or removing a step, or even in making some small changes in the overall infrastructure. This step-function instantiated a cluster of instances to extract and process data from S3 and the further steps of pre-processing, training, evaluation would run on a single large EC2 instance. In scenarios where the pipeline failed at any step the whole workflow needed to be restarted from the beginning, which resulted in repeated runs and increased cost. All the training and evaluation metrics were inspected manually from Amazon Simple Storage Service (Amazon S3). There was no mechanism to pass and store the metadata of the multiple experiments done on the model. Due to the decentralized model monitoring, thorough investigation and cherry-picking the best model required hours from the data science team. Accumulation of all these efforts had resulted in lower team productivity and increased overhead. Additionally, with a fast-growing team, it was very challenging to share this knowledge across the team.
Because MLOps concepts are very extensive and implementing all the steps would need time, we decided that in the first stage we would address the following core issues:
- A secure, controlled, and templatized environment to retrain our in-house deep learning model using industry best practices
- A parameterized training environment to send a different set of parameters for each retraining job and audit the last-runs
- The ability to visually track training metrics and evaluation metrics, and have metadata to track and compare experiments
- The ability to scale each step individually and reuse the previous steps in cases of step failures
- A single dedicated environment to register models, store features, and invoke inferencing pipelines
- A modern toolset that could minimize compute requirements, drive down costs, and drive sustainable ML development and operations by incorporating the flexibility of using different instances for different steps
- Creating a benchmark template of state-of-the-art MLOps pipeline that could be used across various data science teams
Games24x7 started evaluating other solutions, including Amazon SageMaker Studio Pipelines. The already existing solution through Step Functions had limitations. Studio pipelines had the flexibility of adding or removing a step at any point of time. Also, the overall architecture and their data dependencies between each step can be visualized through DAGs. The evaluation and fine-tuning of the retraining steps became quite efficient after we adopted different Amazon SageMaker functionalities such as the Amazon SageMaker Studio, Pipelines, Processing, Training, model registry and experiments and trials. The AWS Solution Architecture team showed great deep dive and was really instrumental in the design and implementation of this solution.
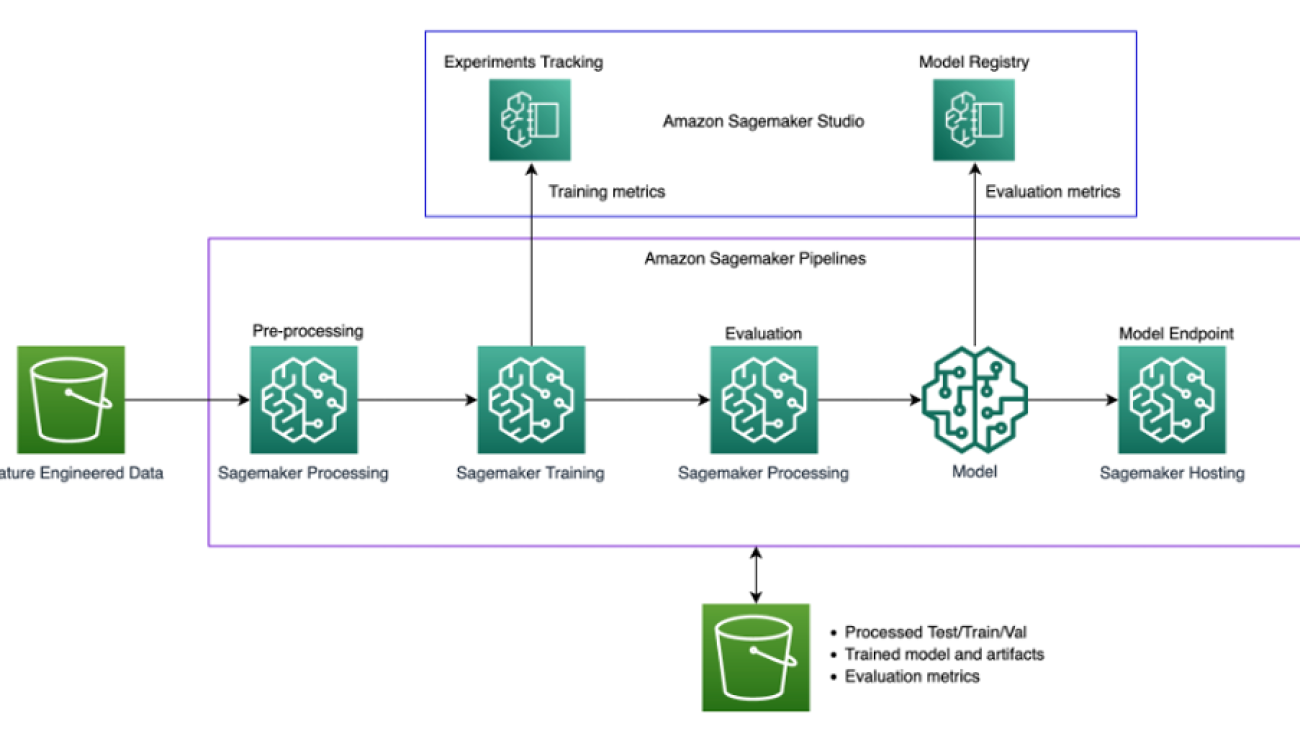
Solution overview
The following diagram illustrates the solution architecture.

The solution uses a SageMaker Studio environment to run the retraining experiments. The code to invoke the pipeline script is available in the Studio notebooks, and we can change the hyperparameters and input/output when invoking the pipeline. This is quite different from our earlier method where we had all the parameters hard coded within the scripts and all the processes were inextricably linked. This required modularization of the monolithic code into different steps.
The following diagram illustrates our original monolithic process.

Modularization
In order to scale, track, and run each step individually, the monolithic code needed to be modularized. Parameters, data, and code dependencies between each step were removed, and shared modules for the shared components across the steps was created. An illustration of the modularization is shown below:-

For every single module , testing was done locally using SageMaker SDK’s Script mode for training, processing and evaluation which required minor changes in the code to run with SageMaker. The local mode testing for deep learning scripts can be done either on SageMaker notebooks if already being used or by using Local Mode using SageMaker Pipelines in case of directly starting with Pipelines. This helps in validating if our custom scripts will run on SageMaker instances.
Each module was then tested in isolation using SageMaker Training/processing SDK’s using Script mode and ran them in a sequence manually using the SageMaker instances for each step like below training step:
Amazon S3 was used to get the source data to process and then store the intermediate data, data frames, and NumPy results back to Amazon S3 for the next step. After the integration testing between individual modules for pre-processing, training, evaluation was complete, the SageMaker Pipeline SDK’s which is integrated with the SageMaker Python SDK’s that we already used in the above steps, allowed us to chain all these modules programmatically by passing the input parameters, data, metadata and output of each step as an input to the next steps.
We could re-use the previous Sagemaker Python SDK code to run the modules individually into Sagemaker Pipeline SDK based runs. The relationships between each steps of the pipeline are determined by the data dependencies between steps.
The final steps of the pipeline are as follows:
- Data preprocessing
- Retraining
- Evaluation
- Model registration

In the following sections, we discuss each of the steps in more detail when run with the SageMaker Pipeline SDK’s.
Data preprocessing
This step transforms the raw input data and preprocesses and splits into train, validation, and test sets. For this processing step, we instantiated a SageMaker processing job with TensorFlow Framework Processor, which takes our script, copies the data from Amazon S3, and then pulls a Docker image provided and maintained by SageMaker. This Docker container allowed us to pass our library dependencies in the requirements.txt file while having all the TensorFlow libraries already included, and pass the path for source_dir for the script. The train and validation data goes to the training step, and the test data gets forwarded to the evaluation step. The best part of using this container was that it allowed us to pass a variety of inputs and outputs as different S3 locations, which could then be passed as a step dependency to the next steps in the SageMaker pipeline.
Retraining
We wrapped the training module through the SageMaker Pipelines TrainingStep API and used already available deep learning container images through the TensorFlow Framework estimator (also known as Script mode) for SageMaker training. Script mode allowed us to have minimal changes in our training code, and the SageMaker pre-built Docker container handles the Python, Framework versions, and so on. The ProcessingOutputs from the Data_Preprocessing step were forwarded as the TrainingInput of this step.
All the hyperparameters were passed through the estimator through a JSON file. For every epoch in our training, we were already sending our training metrics through stdOut in the script. Because we wanted to track the metrics of an ongoing training job and compare them with previous training jobs, we just had to parse this StdOut by defining the metric definitions through regex to fetch the metrics from StdOut for every epoch.
It was interesting to understand that SageMaker Pipelines automatically integrates with SageMaker Experiments API, which by default creates an experiment, trial, and trial component for every run. This allows us to compare training metrics like accuracy and precision across multiple runs as shown below.

For each training job run, we generate four different models to Amazon S3 based on our custom business definition.
Evaluation
This step loads the trained models from Amazon S3 and evaluates on our custom metrics. This ProcessingStep takes the model and the test data as its input and dumps the reports of the model performance on Amazon S3.
We’re using custom metrics, so in order to register these custom metrics to the model registry, we needed to convert the schema of the evaluation metrics stored in Amazon S3 as CSV to the SageMaker Model quality JSON output. Then we can register the location of this evaluation JSON metrics to the model registry.
The following screenshots show an example of how we converted a CSV to Sagemaker Model quality JSON format.


Model registration
As mentioned earlier, we were creating multiple models in a single training step, so we had to use a SageMaker Pipelines Lambda integration to register all four models into a model registry. For a single model registration we can use the ModelStep API to create a SageMaker model in registry. For each model, the Lambda function retrieves the model artifact and evaluation metric from Amazon S3 and creates a model package to a specific ARN, so that all four models can be registered into a single model registry. The SageMaker Python APIs also allowed us to send custom metadata that we wanted to pass to select the best models. This proved to be a major milestone for productivity because all the models can now be compared and audited from a single window. We provided metadata to uniquely distinguish the model from each other. This also helped in approving a single model with the help of peer-reviews and management reviews based on model metrics.
The above code block shows an example of how we added metadata through model package input to the model registry along with the model metrics.
The screenshot below shows how easily we can compare metrics of different model versions once they are registered.

Pipeline Invocation
The pipeline can be invoked through EventBridge , Sagemaker Studio or the SDK itself. The invocation runs the jobs based on the data dependencies between steps.
Conclusion
In this post, we demonstrated how Games24x7 transformed their MLOps assets through SageMaker pipelines. The ability to visually track training metrics and evaluation metrics, with parameterized environment, scaling the steps individually with the right processing platform and a central model registry proved to be a major milestone in standardizing and advancing to an auditable, reusable, efficient, and explainable workflow. This project is a blueprint across different data science teams and has increased the overall productivity by allowing members to operate, manage, and collaborate with best practices.
If you have a similar use case and want to get started then we would recommend to go through SageMaker Script mode and the SageMaker end to end examples using Sagemaker Studio. These examples have the technical details which has been covered in this blog.
A modern data strategy gives you a comprehensive plan to manage, access, analyze, and act on data. AWS provides the most complete set of services for the entire end-to-end data journey for all workloads, all types of data and all desired business outcomes. In turn, this makes AWS the best place to unlock value from your data and turn it into insight.
About the Authors
 Hussain Jagirdar is a Senior Scientist – Applied Research at Games24x7. He is currently involved in research efforts in the area of explainable AI and deep learning. His recent work has involved deep generative modeling, time-series modeling, and related subareas of machine learning and AI. He is also passionate about MLOps and standardizing projects that demand constraints such as scalability, reliability, and sensitivity.
Hussain Jagirdar is a Senior Scientist – Applied Research at Games24x7. He is currently involved in research efforts in the area of explainable AI and deep learning. His recent work has involved deep generative modeling, time-series modeling, and related subareas of machine learning and AI. He is also passionate about MLOps and standardizing projects that demand constraints such as scalability, reliability, and sensitivity.
 Sumir Kumar is a Solutions Architect at AWS and has over 13 years of experience in technology industry. At AWS, he works closely with key AWS customers to design and implement cloud based solutions that solve complex business problems. He is very passionate about data analytics and machine learning and has a proven track record of helping organizations unlock the full potential of their data using AWS Cloud.
Sumir Kumar is a Solutions Architect at AWS and has over 13 years of experience in technology industry. At AWS, he works closely with key AWS customers to design and implement cloud based solutions that solve complex business problems. He is very passionate about data analytics and machine learning and has a proven track record of helping organizations unlock the full potential of their data using AWS Cloud.
How Amazon scientists are driving success for Alexa in the car
Dozens of models now have the popular voice assistant on board for help with navigation and other tasks.Read More