*=Authors contributed equally
Machine learning (ML) models can fail in unexpected ways in the real world, but not all model failures are equal. With finite time and resources, ML practitioners are forced to prioritize their model debugging and improvement efforts. Through interviews with 13 ML practitioners at Apple, we found that practitioners construct small targeted test sets to estimate an error’s nature, scope, and impact on users. We built on this insight in a case study with machine translation models, and developed Angler, an interactive visual analytics tool to help practitioners…Apple Machine Learning Research
Hunting speculative information leaks with Revizor
Spectre and Meltdown are two security vulnerabilities that affect the vast majority of CPUs in use today. CPUs, or central processing units, act as the brains of a computer, directing the functions of its other components. By targeting a feature of the CPU implementation that optimizes performance, attackers could access sensitive data previously considered inaccessible.
For example, Spectre exploits speculative execution—an aggressive strategy for increasing processing speed by postponing certain security checks. But it turns out that before the CPU performs the security check, attackers might have already extracted secrets via so-called side-channels. This vulnerability went undetected for years before it was discovered and mitigated in 2018. Security researchers warned that thieves could use it to target countless computers, phones and mobile devices. Researchers began hunting for more vulnerabilities, and they continue to find them. But this process is manual and progress came slowly. With no tools available to help them search, researchers had to analyze documentation, read through patents, and experiment with different CPU generations.
A group of researchers from Microsoft and academic partners began exploring a method for systematically finding and analyzing CPU vulnerabilities. This effort would produce a tool called Revizor (REV-izz-or), which automatically detects microarchitectural leakage in CPUs—with no prior knowledge about the internal CPU components. Revizor achieves this by differentiating between expected and unexpected information leaks on the CPU.
Spotlight: Microsoft Research Podcast

AI Frontiers: The Physics of AI with Sébastien Bubeck
What is intelligence? How does it emerge and how do we measure it? Ashley Llorens and machine learning theorist Sébastian Bubeck discuss accelerating progress in large-scale AI and early experiments with GPT-4.
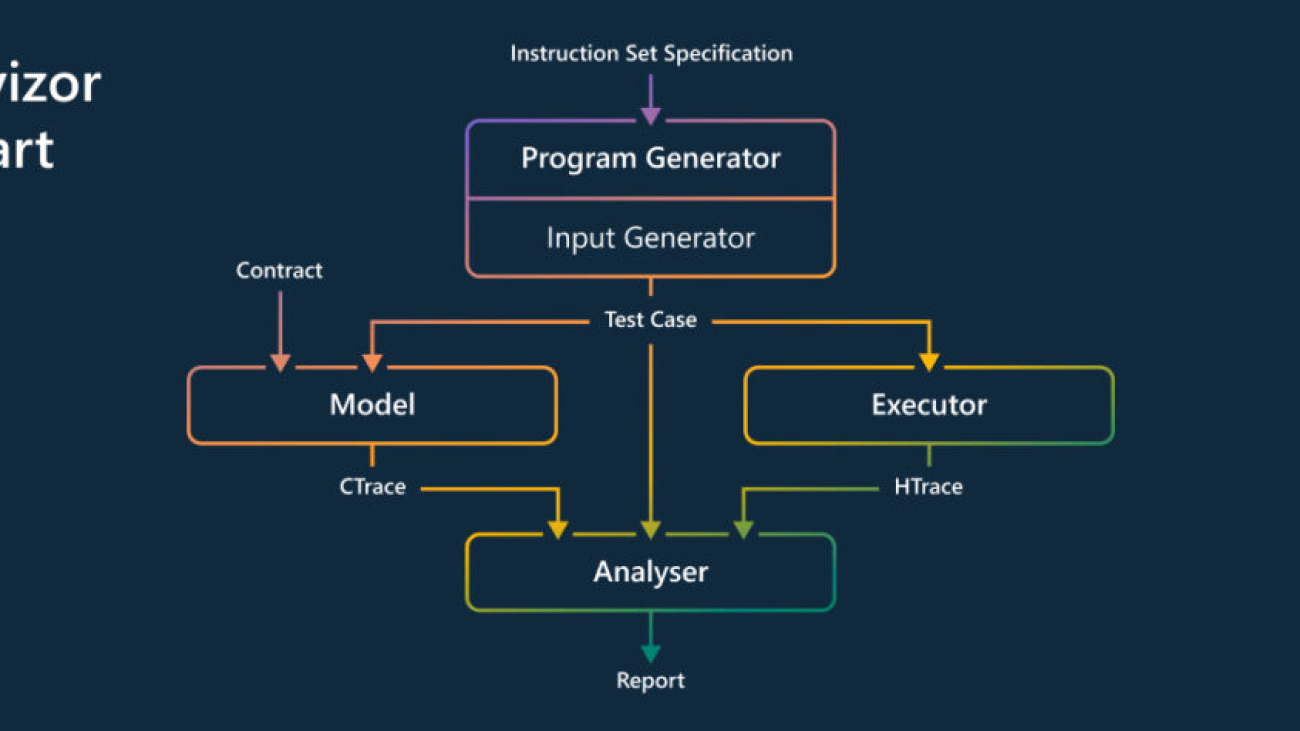
The Revizor process begins by describing what is expected from the CPU in a so-called “leakage contract.” Revizor then searches the CPU to find any violations of this contract. It creates random programs, runs them on the CPU, records the information they expose, and compares the information with the contract. When it finds a mismatch that violates the contract, it reports it as a potential vulnerability.
Details were published in 2022 in the paper: Revizor: Testing Black-box CPUs against Speculation Contracts.
To demonstrate Revizor’s effectiveness, the researchers tested a handful of commercial CPUs and found several known vulnerabilities, including Spectre, MDS, and LVI, as well as several previously unknown variants.
However, the search was still slow, which hindered the discovery of entirely new classes of leaks. The team identified the root causes of the performance limitations, and proposed techniques to overcome them, improving the testing speed by up to two orders of magnitude. The improvements are described in a newly published paper: Hide and Seek with Spectres: Efficient discovery of speculative information leaks with random testing.
These improvements supported a testing campaign of unprecedented depth on Intel and AMD CPUs. In the process, the researchers found two types of previously unknown speculative leaks (affecting string comparison and division) that had escaped previous analyses—both manual and automated. These results show that work which previously required persistent hacking and painstaking manual labor can now be automated and rapidly accelerated.
The team began working with the Microsoft Security Response Center and hardware vendors, and together they continue to find vulnerabilities so they can be closed before they are discovered by hackers—thereby protecting customers from risk.
Revizor is part of Project Venice, which investigates novel mechanisms for the secure sharing and partitioning of computing resources, together with techniques for specifying and rigorously validating their resilience to side-channel attacks.
The post Hunting speculative information leaks with Revizor appeared first on Microsoft Research.

AI Frontiers: Models and Systems with Ece Kamar

Episode 138 | April 13, 2023
Powerful new large-scale AI models like GPT-4 are showing dramatic improvements in reasoning, problem-solving, and language capabilities. This marks a phase change for artificial intelligence—and a signal of accelerating progress to come.
In this Microsoft Research Podcast series, AI scientist and engineer Ashley Llorens hosts conversations with his collaborators and colleagues about what these new models—and the models that will come next—mean for our approach to creating, understanding, and deploying AI, its applications in areas such as health care and education, and its potential to benefit humanity.
The third episode features Ece Kamar, deputy lab director at Microsoft Research Redmond. Kamar draws on decades of experience in AI research and an opportunity she and Microsoft colleagues had to evaluate and experiment with GPT-4 prior to its release in discussing the capabilities and limitations of today’s large-scale models. She explores the short-term mitigation techniques she and her team are using to make these models viable components of the AI systems that give them purpose and shares the long-term research questions that will help maximize their value.
Learn more:
- Sparks of Artificial General Intelligence: Early experiments with GPT-4
Publication, March 2023 - ToxiGen: A Large-Scale Machine-Generated Dataset for Adversarial and Implicit Hate Speech Detection
Publication, May 2022 - AI and Microsoft Research
Learn more about the breadth of AI research at Microsoft - GitHub Copilot
Product page
Transcript
[MUSIC PLAYS]Ashley Llorens: I’m Ashley Llorens with Microsoft Research. I’ve spent the last 20 years working in AI and machine learning, but I’ve never felt more fortunate to work in the field than at this moment. The development of increasingly powerful large-scale models is accelerating the advancement of AI. Most recently, GPT-4 is exhibiting surprising new abilities like problem-solving and translation across languages and domains.
In this podcast series, I’ll share conversations with fellow researchers about our impressions of GPT-4, the nature of intelligence, and ultimately how innovations like these can have the greatest benefit for humanity.
Today we’re sitting down with Ece Kamar, deputy lab director at Microsoft Research in Redmond. In the months leading up to the release of GPT-4, Ece and her team leverage their many years of experience in AI research to evaluate the model and to help understand and mitigate its limitations.
So the experiences it powers can bring the greatest benefit to the people that use them.
Welcome to AI Frontiers.
All right, why don’t we just jump right in.
Ece Kamar: Okay.
Llorens: Okay.
Kamar: Take it over.
[MUSIC FADES]Llorens: All right, so I want to start at a place that I think will be close to your heart, and that is with the difference between a model and a system. But let me, let me paint the picture a little bit, right. So machine learning is a process through which we create something called a model, which is learned from data. The model is a kind of program that maps inputs to outputs, be it language, images, etc. In deep learning, the models are some variant of an artificial neural network. And finally, in the current era of large-scale AI, these models can have hundreds of billions of parameters or more. But there’s a model, and then there’s a system. The system is the thing that gets deployed when we put out a product or something. So, Ece, from your perspective, what’s the difference between a model as described here and a system?
Ece Kamar: Yeah, that’s, that’s something that I’m thinking so much about these days because we are all getting very excited about the emerging capabilities we see in the latest models—what they can do, what kind of questions we can ask them, the generalizability, the interactive power, even some of the reasoning capabilities that are surprising just to be able to get them with that input-output mapping that, Ashley, you’ve been talking about. However, when you think about it, these models on their own, they don’t really have a purpose. They are just trying to replicate what they have seen in these massive data sources. And the thing that has been driving me as a researcher, even from my earlier days, has been the purpose: why are we building technology, and what is the purpose behind it? And the main difference between a system and a model is a system has a purpose. We build these systems for a particular reason that—in particular, the reason I care very much about is providing value to people who use these systems. So in terms of that distinction, I am spending a lot of time these days thinking about system design with the purpose of enabling, augmenting people, and these systems will have these latest models as building blocks. No question about it. They are so powerful in terms of synthesizing information, having a cohesive, interesting conversation. But at the same time, they are not enough. To be helpful to people, we have additional capabilities like knowing about that individual, learning from that individual, having an understanding of the goals that the individual would like to have. So we are trying to get to that system architecture, the system design that can actually make that input-output model a very crucial part of a much bigger, uh, purpose.
Llorens: Maybe next we can go into the system lifecycle. So there’s a way that a system component like a model becomes part, uh, of a larger system that eventually gets deployed. So tell me about that lifecycle. What’s that like from your experience?
Kamar: From my experience, actually, the larger system you really care about is the hybrid human-AI system because at the end of the day, what we really care about is not how great a system is alone, like an AI system is alone, but we care very much about how well that partnership is working between the human and the AI system. And right now, we have some systems out in the world that are actually already providing a lot of value for. For example, Copilot is a great example of this—the GitHub Copilot—where as you’re writing code, it can make suggestions for you and you can accept or reject them. At the same time, this is really missing some very crucial abilities in it because we are still in the very early days of this copilot-AI revolution. So what are some of the capabilities we are missing? Copilot still doesn’t really have a very good understanding of me as a developer. What are the particular habits I have? What kind of code I love to write? Maybe I care very much about the interpretability of my code by others when I’m not in that project anymore. It is not necessarily a preference that Copilot has about me. I think soon enough it will because I think we are going to get to a world where these AI systems will know a lot about us, our goals, our preferences, our intentions, our habits. And then they are going to become a lot more helpful to us. The other thing that’s not happening with the current systems is that they are not learning from feedback. As individuals, when we are part of teams—let’s say I’m working with you, which we do, all the time—I learn about you; you give me your feedback. You say, “Next time, don’t do that. Maybe don’t consider doing it that way.” I take that into account. I get better at what I do because I learn from you. So the more we build these self-feeding feedback loops into our AI systems, they are going to have a better understanding of us as users, but also they are going to be able to provide more value for us.
Llorens: The first time I used GPT-4, I asked it a question that was inspired by my own work in underwater robotics. I asked it how far away I could hear a sound generated underwater in the ocean. The response took me completely by surprise. The model pointed out that more information was needed, like how temperature would affect the speed of sound through the water. It suggested I consider using a sonar array. It went ahead and made its own assumptions about those things and then gave me an answer. The reasoning was breathtaking to me. I knew for a fact it hadn’t been explicitly trained to do any of that. It challenged my notion of the value of being able to do this kind of reasoning as a researcher.
So maybe we can actually start with the model and your experience of it. The capabilities and limitations. But why don’t we just start with your first impressions of it?
Kamar: It was surprising, mainly because I have been working in the AI space for almost like, I don’t want to say it, but two decades. So we have been all thinking about new models, new architectures, what is coming in AI; we always had in mind these kind of ambitious goals for AI. For me, it has always been these AI assistants that come and help us with whatever we are doing, even from the early days it has been that. But always that aspiration never really landed because when we tried to build these systems, they became narrow that they did not really match what, as users, we needed from them. And when I saw GPT-4 and started interacting with it, I saw some mind-blowing capabilities that I thought I wouldn’t see for many years to come. And one of the surprises was how quickly we get here. So that’s kind of No. 1. And we can talk a lot more about like what are those surprising abilities, but second, immediately, my mind goes to, what can we do with this? Because first of all, there’s so much potential now we have in terms of bringing that vision of helping people into reality.
But second of all, because I also care a lot about responsibility, “Oh, my god, this powerful model will come with so much responsibility.” What, as Microsoft, we build with this plus what others will be able to build with this model or maybe models [that] will come next, that’s going to matter a lot for not only for us as researchers, not only for users, but our society overall.
So the other reaction I had was like, what can go wrong and what can we do to prevent those negative consequences from happening? And that’s going to be a long journey that we are going to be on.
Llorens: Sure. Let’s get further into those surprising capabilities.
Kamar: Yeah, sure. So one of the very surprising capabilities is how general purpose these models are at the moment. I can prompt it to write code, write poems. I can ask—I’m Turkish. I can ask questions in Turkish and I can get very fluid responses in Turkish. It can actually write me beautiful poems about sunset in Cappadocia in Turkish, which is like, oh my god, this is already creating an emotional reaction, right, when I’m interacting with it. And then, though, you get into much more practical tasks. For example, how do I turn some of my thoughts into, into writing? Um, how can I customize my voice for different audiences? And the model seems to know about these things and can help me, but not producing a final result, but bringing me to a point where I can be a lot more productive.
So that general-purpose nature of it, like I can go from writing a poem—which I’m terrible at it—to writing academic papers—I think I’m better at that—and helping me throughout the spectrum when I’m not good at something, when I’m kind of good at something. That is just showing me so much potential, such a big spectrum.
But the other thing is the interactivity. It is not this static tool where I basically ask one thing, it gives me one answer, and I’m kind of done, like whatever I can do with that one turn is all I get. It is actually the opposite. It gives me a response and I can actually instruct it further. I can talk about my preferences, how I would like that to be changed for something that’s a much better fit for my needs.
And as a person, I may not be able to articulate my needs at the beginning clearly, so that interaction of being able to see what it can do and asking further is just making it a much, much more capable tool. And the other thing is the reasoning capabilities. What I mean by that is that, you know, for the last few years, as these larger models came out and came out, we all said, OK, this is pretty powerful, but it is still just like repeating patterns it has seen in the, in the internet. And one of the—you know, I think some of my colleagues used the term—was “stochastic parrots.” It’s just repeating things back to you. And what we are seeing with GPT-4—and I think it’s just the phase transition; we’re at this point in this phase transition and these capabilities are going to get stronger and stronger—is that the capabilities for synthesis, compiling information together to get into new insights that may not exist. I’m not claiming all of those insights are correct, but they are giving people sparks that they can further think about and build on. Also, it can reason about multiple steps. It’s not a planner yet, but it has the basics of top-level reasoning where we can start from a point towards the goal and we can collaborate to work towards a plan to get there.
And those are all very powerful things, especially when we think about building an AI system that can take somebody’s goals and turn them into actions.
Llorens: So you mentioned, planning as a limitation of the model, but let’s just talk about, you know, maybe more fully about the limitations that, that you see in, the in the current, current model, current state of the art.
Kamar: You know, a lot of people, when they think about these limitations, they see these as reasons not to invest in these technologies at all. I look at it from a different perspective. I see these as pieces of the puzzle that we need to invent and put in place. So we started this conversation with the distinction between the model and the system. The model is a very powerful piece of this puzzle, but we are also, as we are building these systems—like Bing is a great example, the GitHub Copilot is another example—we are seeing what they can do, but we are seeing a lot about what they cannot do, and that is giving us, as researchers, ideas about new puzzle pieces we need to invent so that we can come to this architecture.
So a huge limitation, hallucinations. I think that is top of mind for a lot of us. These models are learning from large datasets on the internet, they don’t have fresh information. They are not able to separate reliable information from unreliable information. And also because these models are general-purpose tools, sometimes we want to use them for creating something new that doesn’t exist on the internet, for example, writing a brand-new poem that nobody else wrote before. But sometimes you want them as information retrieval engines, where the biggest requirement is being correct in terms of that information coming back. So we are all learning, like, how can we understand the purpose, turn it into prompts, and then figure out the best way to instruct these models so that, so that we are getting our desired behavior in return, but also how can we actually, in the future, specialize these models in a way that we can have versions that are much less prone to hallucinations?
How can we ground them with the right context and know how to communicate that intent well, so that I can be assured that whenever they are giving me information, giving me facts when I need the facts, they are giving me the right facts? We are at the very beginning of solving this puzzle. But in my mind, this is not a limitation.
This is actually showing me a lot of problems, research problems, to invest in.
Llorens: So, Ece, you’re a leader here at Microsoft Research. You’ve got a team, and your team, uh, is instrumental in this process of turning the model into a system, uh, for some of these applications. And I guess you’ve talked about understanding the purpose—systems have a purpose—and maybe there’s aspects of the system design that mitigate or deal with some of the limitations in order to make it fit for that purpose.
You mentioned grounding, for example, as one of those methods, but can you just get deeper maybe into grounding and some of the other techniques that you use to, again, turn the model into a system?
Kamar: Yeah, definitely. We have been working with different teams across Microsoft as some of these technologies find their way into products, both understanding the limitations but also helping to overcome those limitations, um, with existing techniques. Of course, there’s a lot to be invented, but right now we still have some things in our capabilities list that we can apply to make these problems mitigated, up to some extent.
Just to give a few examples, right, when we are giving search results, instead of just using GPT-4 to produce that result, we are actually getting better, more accurate results when the top search results are provided as context to the models for them to create their generations. So that is one technique that is currently implemented. That is an example of grounding, grounding with that context. You can imagine that for another application, let’s say for writing an email for you, here we can ground with your past emails written to the same person; we can ground based on your personal documents. For example, if I’m writing you an email about this podcast, you probably have an outline or a document where we have previously discussed some of these ideas. That becomes important grounding so that that email represents my voice, represents my thoughts, but it actually becomes a way for me to just do things faster and more efficiently. So those are some examples of the grounding. The other thing we have in our toolbox these days is how we talk to the model. This is called prompting. A lot of people are talking about prompting because we are discovering new ways to communicate with these models as developers.
If you remember back in the day, um, the way a developer would talk to a machine learning model was giving labeled data. Here’s an example: True, false. Here’s an example: True, false. Now our communication channel with the model in terms of developing systems is increasing. Our bandwidth is so much higher. Now we can talk to the model in natural language.
The problem with this is this is, uh, not a perfect specification. However, still, the way I can instruct the model carries a lot of power. So when we are building systems with prompting, we can tell the model, instruct the model, that whenever the model is talking about a fact, it should cite the source of that material. This has two particular benefits. One benefit is that this is instructing the model that everything the model says should be coming from a source and the links should be there. Of course, I’m not claiming that we are doing this perfectly, but it’s a step in that direction. But second, and even the more important reason is, we are giving people accountability to check. As I said, none of the systems we are trying to build are there to automate the role of the human being.
It is all about complementarity and augmentation and enablement. So when we are building a system, giving results to the human, the goal is always having the human in the driver’s seat, having the human control what is being generated, and by providing sources in the results, that is one way we can enable the user, because then the user can go to these links and check.
These are just some of the things that we are currently inventing as, you know, short-term ideas to mitigate these problems as much as possible. But also we have to think about long-term solutions that can really make these problems go away. We are not there yet, but as a researcher, I’m very excited about the potential.
Llorens: I’d love to just drill into this notion of specification for a moment. You mentioned the complementarity, you mentioned the intent to have these systems amplify human agency, and with that stewardship of the system comes the expression of intent. And you know, you mentioned maybe even in the era before machine learning, the way to express intent was through a very explicitly written program and, you know, kind of machine learning for more narrow systems, it’s identifying labels for data. And now we have natural language as a means of specification, and you called it an imperfect means of specification. So can you just maybe take us a little deeper into that thought?
Kamar: Yeah. So we have been talking about what we are seeing in the latest models in GPT-4 as a phase transition. We haven’t arrived at the best possible model, and we haven’t arrived at the best possible way to communicate with that model. We are at this very specific point in our history where we are saying, “OK, our models are getting really capable and that communication channel has opened up.
Now I can talk to it in natural language.” I personally don’t think that this very noisy way of just communicating things in natural language as a way of prompts is the final product of how we are going to be talking to our AI systems. However, it is a way, and with iteration, we can become more precise. So let me tell you this.
Let’s say I want this AI system to write me an email to you. The simple prompt could be, “Write me an email to Ashley, and it should talk about this and this.” I can see the result. Immediately, I can see what I don’t like about it. Imagine I could say more specification, right, I can say, “Oh, don’t mention this; include this, as well. The tone should be this way and not that way.”
These are all additional specifications I may not think about when I’m just prompting the model, but over time, I may get better and better in terms of really specifying my preferences, my intent. So right now, we’re in this very noisy process of almost like trial and error. We are trying something, looking at the result; if we don’t like it, we come up with a correction. I think over time we can really compile these experiences—how people are specifying things into these models—and that can pave the way for much better communication methods. Again, we don’t have the answers yet, but I’m also, I’m also not thinking that these prompts are the best way to interact.
Llorens: And as I learn to specify my intent to a particular model, how much does that knowledge or that skill of prompting this model in an effective way translate when I pick up another model or maybe, you know, another iteration on the same model. Do I have to relearn it every time?
Kamar: Ideally not, because we all want to be consistent. Uh, we don’t want our experiences to go away just because we are starting over with a new model. Again, so far, a lot of the model developments have been guided by numbers—how big the models are, how accurate they are, how did they do on certain benchmarks. Now, as these models are enabling real systems for humans, we need to bring in other criteria that are human-centered, that can not only be explained by how well you predict the next word, but it is about what you said. How can I get consistency in the way I communicate with this model? How does this model learn better about me? How this model can capture the right context about me? So I think we are at the beginning of understanding those human-centered considerations we want to have in these models and somehow incorporate them into the way these models are trained.
Llorens: Earlier you mentioned responsibility, you know, that, that Microsoft, you know, has a responsibility, you know, when we put these systems out in the world. As researchers and engineers, um, we have some stewardship of that responsibility in the design process, and throughout the lifecycle. How has that manifested here, you know, for GPT-4 in the applications that you’ve worked on? How does that aspect of responsibility enter into the system design and engineering for you?
Kamar: In a very similar way to how we have been thinking about responsible AI for the last five, six years. It is a journey, and with every model, including GPT-4, the first step, is understanding—understanding the capabilities, understanding the limitations, understanding what can go wrong and what can we do in a short term to prevent those negative effects to be as little as possible.
So from the early days of Microsoft’s interaction with GPT-4, uh, me and many of my colleagues have been involved. We started playing with it. We started observing what it can do, what it cannot do, started documenting all of those capabilities. And now you need to take a step back and say, “OK, what can I say about the risks?” Because you observe the instances, but there are these higher-level risks that you should be considerate about. So it became obvious that hallucination was an issue. The other issue is something we call manipulation. The fact that these models don’t have a good understanding of what they don’t know, but at the same time, they can also not admit that they don’t have the right answer, and they may actually even try to convince you as the user that what they are providing is the right one.
So we started thinking what kind of mitigations we can bring in place to make these problems as little as possible. Of course, another consideration is offensive language, biases, content moderation. So that’s another, another factor that a lot of my colleagues have been involved with from the early days. And we worked closely across the company in terms of putting practices in place.
Sometimes this is content moderation modules. Sometimes this is prompt engineering to get hallucinations to be as low as possible. Sometimes it is really thinking about those high-level guidelines you can give to the systems to make these risks as low as possible. So we have been very heavily involved from the beginning, and we are also putting our ideas into publications to share with the wider world, because not everybody—we are aware that not everybody will have as much experience as we have with these models.
So how can we actually capture our experience and share with our academic colleagues so that we can all think about these problems together? So now I think we have some understanding. Again, now this is distilling the longer-term research questions and getting our teams to focus on those.
Llorens: You know, another important phase of the research lifecycle or the system lifecycle is the test and evaluation. So you design a system; you conceptualize it; you develop it. At some point, you know—put some mitigations in place, perhaps like the ones you suggested. Um, at some point, then you have to test it. How does that happen, uh, with these, with this kind of a system, this kind of general-purpose system?
Kamar: Yeah. So, you know, just thinking about traditional machine learning, testing was always a very core part of the way we built machine learning. You would collect some data, you would make part of that data training and you would have part of that data as test set, and then you would have a call to measure for every model you’re building from, from Day 1.
That is no longer the case with these generative models, especially as we get into this “prompt something and you have your application development” culture. There are really big questions about how we evaluate these models. The insight there is that because these models are generative, they can also be used for creating test data. So on the topic of hallucination, for example, we have been using GPT-4 for simulating dialogues fed by, um, queries, common queries, and also get the model to check if some certain risks like hallucinations are happening.
So this is giving us a partly automated, GPT-4–powered evaluation pipeline that, of course, needs to have human eyes on it because not everything the machine generates or validates is always correct. But this gives us a loop to be able to generate data at scale and do evaluation. But, of course, not all problems are equally vital for our society.
There are certain things that carry a lot more weight than others. For example, even on the topic of hallucinations, if a search engine is providing wrong guidance on a critical health query, that is a much bigger risk. So this is why another important part of the evaluation is red teaming. How can we bring human eyes onto the system in the most critical ways and actually get them to check what the systems are doing?
So again, we are at the early days of figuring out what evaluation is going to look like for this new generation of models. Again, human-AI partnership is going to play a key role in the way we evaluate these systems. We see that generative capabilities of these models are powerful for creating data. Human eyes are always going to be important as the final checkers of what is right and what is wrong.
And we just need to build these techniques and make them part of the way we build AI systems with these latest models.
Llorens: I want to ask you about a term, uh, the term agent. Um, you, you kind of referenced it earlier, but I want to come back to it, and I want to come back to it in the context of what your vision for the future is for, I’ll say, AI models and systems that we use, that we create from those models.
What is that vision, and what does that vision have to do with agents?
Kamar: You know, the word agent comes from agency, and the question is what does agency mean for an AI system? It is the fact that they are aware, they can act, and they can learn. So those are the three main capabilities we want to have in our AI systems. Just to take a bit deeper into this: being aware—again, we are building these agents not to act independently in the world. We are building them to partner with people and help people with their tasks. So when we talk about them being aware, we are talking about being aware of their users, being aware of their needs, being aware of their goals, and also being aware of the information on the world so that they don’t have to start from scratch. The other part is action—taking action on behalf of their users.
And here I think we are going to see a lot more interesting scenarios going forward in terms of what the AI systems can do in partnership with people. Right now, we are seeing writing documents, collecting information from the web, and presenting them, but in the future, what other creative things AI systems and humans can do together?
What other tasks that you just don’t want to do and you want the AI to take over with your accountability and control, of course. So that’s the part of the acting we need to figure out. And the other part that is very important is learning. We talked about GitHub Copilot, which is a wonderful AI application that so many people are getting value in the world.
At the same time, we are not only talking about GitHub Copilot getting better at code completion; we are talking about GitHub Copilot getting better in terms of providing value for people. So in terms of like getting better, we have to figure out what does that human-centered reward we can provide to these AI systems just in terms of the value people get—what has been good, what has been bad—and use that reward signal to teach the machine how to act better in the world. Those are all part of the framework we have for this AI agent. And just to reiterate, this is always going to have these very powerful models as a building block. But as you can imagine, we will need other components to get there.
[MUSIC]Llorens: Thanks, Ece. Well, I’m certainly excited by the technologies we have today, and I’m excited for the vision that you’ve articulated for the future. So, yeah, really appreciate you sharing that vision with us today, and thanks for spending the time.
Kamar: Thank you.
The post AI Frontiers: Models and Systems with Ece Kamar appeared first on Microsoft Research.

Hunting speculative information leaks with Revizor
Spectre and Meltdown are two security vulnerabilities that affect the vast majority of CPUs in use today. CPUs, or central processing units, act as the brains of a computer, directing the functions of its other components. By targeting a feature of the CPU implementation that optimizes performance, attackers could access sensitive data previously considered inaccessible.
For example, Spectre exploits speculative execution—an aggressive strategy for increasing processing speed by postponing certain security checks. But it turns out that before the CPU performs the security check, attackers might have already extracted secrets via so-called side-channels. This vulnerability went undetected for years before it was discovered and mitigated in 2018. Security researchers warned that thieves could use it to target countless computers, phones and mobile devices. Researchers began hunting for more vulnerabilities, and they continue to find them. But this process is manual and progress came slowly. With no tools available to help them search, researchers had to analyze documentation, read through patents, and experiment with different CPU generations.
A group of researchers from Microsoft and academic partners began exploring a method for systematically finding and analyzing CPU vulnerabilities. This effort would produce a tool called Revizor (REV-izz-or), which automatically detects microarchitectural leakage in CPUs—with no prior knowledge about the internal CPU components. Revizor achieves this by differentiating between expected and unexpected information leaks on the CPU.
Spotlight: Microsoft Research Podcast
AI Frontiers: The Physics of AI with Sébastien Bubeck
What is intelligence? How does it emerge and how do we measure it? Ashley Llorens and machine learning theorist Sébastian Bubeck discuss accelerating progress in large-scale AI and early experiments with GPT-4.
The Revizor process begins by describing what is expected from the CPU in a so-called “leakage contract.” Revizor then searches the CPU to find any violations of this contract. It creates random programs, runs them on the CPU, records the information they expose, and compares the information with the contract. When it finds a mismatch that violates the contract, it reports it as a potential vulnerability.
Details were published in 2022 in the paper: Revizor: Testing Black-box CPUs against Speculation Contracts.
To demonstrate Revizor’s effectiveness, the researchers tested a handful of commercial CPUs and found several known vulnerabilities, including Spectre, MDS, and LVI, as well as several previously unknown variants.
However, the search was still slow, which hindered the discovery of entirely new classes of leaks. The team identified the root causes of the performance limitations, and proposed techniques to overcome them, improving the testing speed by up to two orders of magnitude. The improvements are described in a newly published paper: Hide and Seek with Spectres: Efficient discovery of speculative information leaks with random testing.
These improvements supported a testing campaign of unprecedented depth on Intel and AMD CPUs. In the process, the researchers found two types of previously unknown speculative leaks (affecting string comparison and division) that had escaped previous analyses—both manual and automated. These results show that work which previously required persistent hacking and painstaking manual labor can now be automated and rapidly accelerated.
The team began working with the Microsoft Security Response Center and hardware vendors, and together they continue to find vulnerabilities so they can be closed before they are discovered by hackers—thereby protecting customers from risk.
Revizor is part of Project Venice, which investigates novel mechanisms for the secure sharing and partitioning of computing resources, together with techniques for specifying and rigorously validating their resilience to side-channel attacks.
The post Hunting speculative information leaks with Revizor appeared first on Microsoft Research.

New GeForce RTX 4070 GPU Dramatically Accelerates Creativity
Editor’s note: This post is part of our weekly In the NVIDIA Studio series, which celebrates featured artists, offers creative tips and tricks, and demonstrates how NVIDIA Studio technology improves creative workflows. We’re also deep diving on new GeForce RTX 40 Series GPU features, technologies and resources, and how they dramatically accelerate content creation.
The GeForce RTX 4070 GPU, the latest in the 40 Series lineup, is available today starting at $599.
It comes backed by NVIDIA Studio technologies, including hardware acceleration for 3D, video and AI workflows; optimizations for RTX hardware in over 110 popular creative apps; and exclusive NVIDIA Studio apps like Omniverse, Broadcast, Canvas and RTX Remix.
VLC media player added RTX Video Super Resolution to automatically upscale video to 4K resolution and beyond. GeForce RTX 40 and 30 Series GPU owners will immediately benefit from improved virtual fidelity.
The RTX Remix runtime for remastering classic games is now available as open source on GitHub. It empowers the mod development community to extend Remix’s game compatibility and feature set.
Creators can install the new April NVIDIA Studio Driver, supporting these latest updates and more, available for download today.
Plus, see how NVIDIA’s Hauler piece came to life using the Omniverse USD Composer app, this week In the NVIDIA Studio.
A Creator’s Dream
The GeForce RTX 4070 joins NVIDIA’s lineup of GPUs, featuring 12GB of ultra-fast GDDR6X VRAM with advancements of the NVIDIA Ada Lovelace architecture, primed to supercharge all content-creation workflows.

Like other GeForce RTX 40 Series GPUs, the GeForce RTX 4070 is much more efficient than previous-generation products, using 23% less power than the GeForce RTX 3070 Ti. Negligible amounts of power are used when the GPU is idle, or used for web browsing or watching videos, thanks to power-consumption enhancements in the GeForce RTX 40 Series.
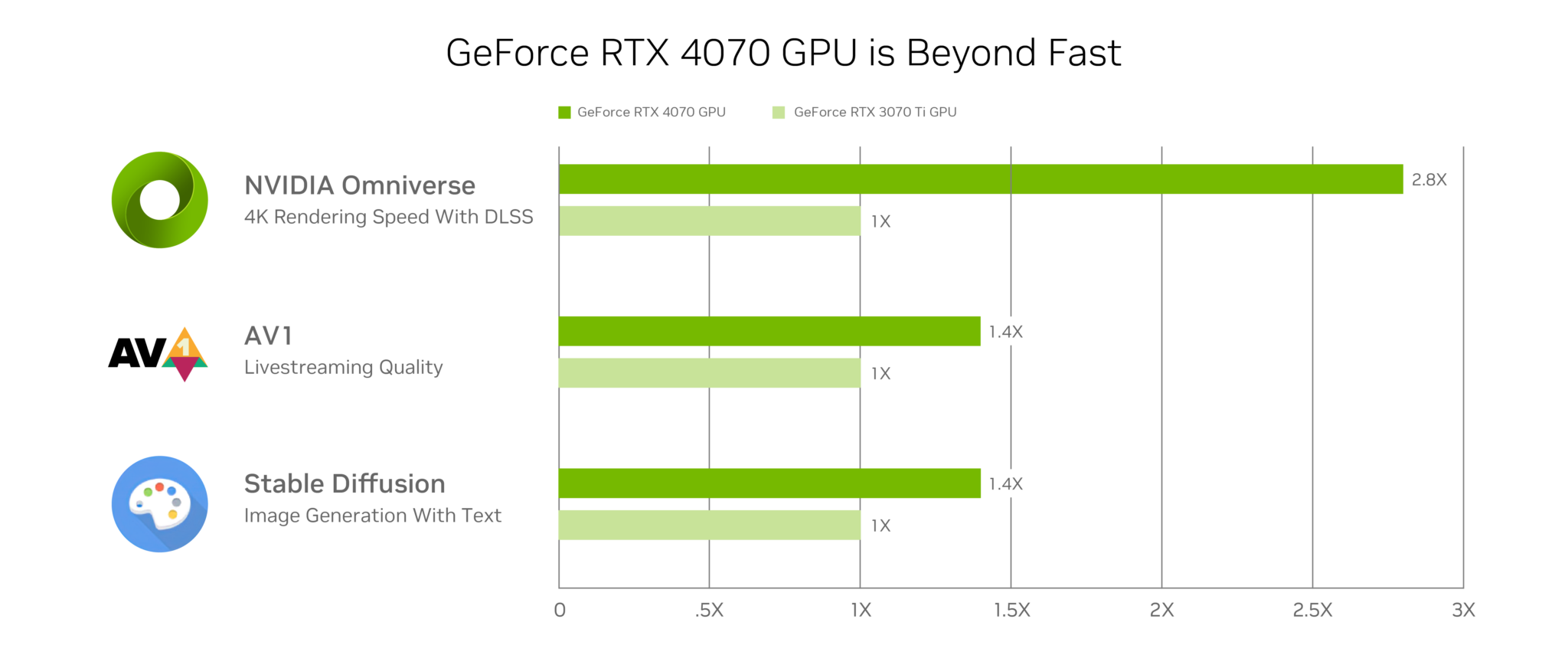
3D modelers rendering 4K scenes with the AI-powered DLSS 3 technology in NVIDIA Omniverse, a platform for creating and operating metaverse applications, can expect 2.8x faster performance than with the GeForce RTX 3070 Ti.
Broadcasters deploying the eighth-generation NVIDIA video encoder, NVENC, with support for AV1, will enjoy 40% better efficiency. Livestreams will appear as if bitrate was increased by 40% — a big boost in image quality for popular broadcast apps like OBS Studio.
Plus, AI enthusiasts using the Stable Diffusion deep learning model can generate detailed images conditioned on text descriptions 1.4x faster with the GeForce RTX 4070.
RTX Video Super Resolution Comes to VLC Media Player
VLC media player, a popular, free and open-source multimedia player for Windows PCs, has added RTX Video Super Resolution to intelligently upscale video to 4K resolutions and beyond.
Owners of RTX 40 and 30 Series GPUs can now play local video on VLC with crisper edges and noticeably reduced compression artifacts.

Access is quick and easy. Begin by downloading the full version of VLC. Once installed, open the NVIDIA Control Panel, navigate to Adjust video image settings and enable Super Resolution under RTX video enhancement.
Ready for RTX Remix Runtime
RTX Remix, the newest app in the NVIDIA Studio suite, is a revolutionary modding tool used to enhance classic DirectX 8 and 9 games with full ray tracing, AI-enhanced textures and other graphics improvements.
Remix is composed of two core components: a creator toolkit and a custom, open-source runtime.
The Remix creator toolkit, built on Omniverse and used to develop the hit remastered game Portal With RTX, allows modders to assign new assets and lights within their scene and use AI tools to rebuild the look of any asset. The RTX Remix creator toolkit will be available in early access soon.
Remix runtime captures every element of a game scene, replacing assets at playback and injecting RTX technologies, such as path tracing, DLSS 3 and Reflex, into the game. Mod developers are already using the RTX Remix runtime from Portal With RTX to create experimental remastered scenes in numerous classic games.
Remix runtime is ready to download on GitHub. Learn more about Remix runtime and its potential to transform game development.
The Remarkable Rocket Man
NVIDIA’s project Hauler launched to test the sheer amount of instancing that could occur in a unified project.
Instancing, aka referencing, refers to the mass duplication of a model with minor variations, essential for populating massive 3D worlds with many detailed objects while maintaining realism. It’s useful for creating scenes, say, in a forest with hundreds of trees, or in this instance, in outer space with thousands of asteroids.
Lead NVIDIA artist Rogelio Olguin, who has over 25 years of experience in the gaming industry, teamed up with colleagues to build a massive scene, rich with asteroids. Olguin loves a good challenge.
“I feel that one of the trappings of artists at times is that if you lose exploration and learning, you will just get stuck,” said the artist. “It’s important to explore and work on areas you’re not good at as an artist to improve.”

The team gathered reference materials from movies, shows and anime before putting it all together in a shared board for the team to add and edit. The collaborative board included thumbnail sketch storyboards made in Adobe Photoshop and preliminary concept art.

The vast number of asteroids were procedurally created in SideFX Houdini, taking advantage of the RTX-accelerated Karma XPU renderer, which enables fast rendering of complex 3D models and simulations. It was all made possible by his GeForce RTX GPU.

Next, Maxon’s ZBrush was used to sculpt the main asteroids. The Drop 3D function was especially helpful in increasing the density of local meshes while maintaining high-resolution details.

Then came the animation phase in SideFX Houdini, building animations of the large and tiny cloud-based asteroids alike to ensure constant movement and rotation.
Olguin stressed the importance of his GeForce RTX 40 Series GPU. “Virtually every part of the process relied on RTX GPU technology, including path-traced rendering,” he said. “Without RTX acceleration, this piece would have been impossible.”

With all components in place, the team worked in Omniverse USD Composer (formerly known as Create) to assemble complex, physically accurate simulations. They collaboratively edited 3D scenes in real time with ease.
“Having a beast of a machine has sped up what I can do. I would dread going back to a slower machine.” — Rogelio Olguin.
“The primary benefit of using Omniverse USD Composer was being able to quickly see what I was doing, and place and compose our shots quickly, which made this so simple to work on,“ said Olguin.
USD Composer works with the Universal Scene Description (USD) format, enabling artists to choose their 3D app of choice. It supports Autodesk Maya, SideFX Houdini, Trimble SketchUp and more. It also removes pipeline bottlenecks, so there’s no need for artists to constantly download, reformat, upload and download again.
After all, using USD Composer to collaborate in 3D is just comet sense.
Stay tuned for more updates on Hauler. For more artistic inspiration from Olguin, check out his ArtStation page.

AV1 encoding support is coming to YouTube via OBS. GeForce RTX GPU owners broadcasting on YouTube can expect increased streaming quality. This feature is currently in beta and will be available as a general release in the near future.
Follow NVIDIA Studio on Instagram, Twitter and Facebook. Access tutorials on the Studio YouTube channel and get updates directly in your inbox by subscribing to the Studio newsletter. Learn more about Omniverse on Instagram, Medium, Twitter and YouTube for additional resources and inspiration. Check out the Omniverse forums, and join our Discord server and Twitch channel to chat with the community.

A Gripping New Adventure: GeForce NOW Brings Titles From Bandai Namco Europe to the Cloud, Including ‘Little Nightmares’ Series
A new adventure with publisher Bandai Namco Europe kicks off this GFN Thursday. Some of its popular titles lead seven new games joining the cloud this week.
Plus, gamers can play them on more devices than ever, with native 4K streaming for GeForce NOW available on select LG Smart TVs.
Better Together

Bandai Namco is no stranger to delivering hit games. And GeForce NOW delivers high-performance cloud game streaming, making it the ultimate way to play the publisher’s high-quality titles.
“Our collaboration with NVIDIA will allow more players to enjoy Bandai Namco titles like ‘Little Nightmares’ across their devices, thanks to the power of the GeForce NOW cloud,” said Anthony Macare, senior director of digital business and customer experience at Bandai Namco Europe.
It’s the perfect time to jump into the Little Nightmares series, the critically acclaimed puzzle-platformer games set in a dark, nightmarish world. Confront childhood fears and help Six, a brave young girl escape The Maw — a vast, mysterious vessel inhabited by corrupted souls looking for their next meal— in Little Nightmares.
Then play as Mono, a boy with a paper bag on his head looking for answers, in Little Nightmares II. With Six as a guide, face a host of new threats on the way to discover the dark secrets of The Signal Tower. The Enhanced Edition of Little Nightmares II adds an extra layer of eerie realism with RTX ON, which Ultimate and Priority members can select after launching the game from Steam.
Little Nightmares and Little Nightmares II, Get Even and 11-11 Memories Retold are the first of many Bandai Namco titles arriving to the cloud this week.
Life’s Good in 4K

Head on over to gaming on the big screen with LG Smart TVs. The Gaming Shelf on LG 2020-2022 TVs and the Game Quick Card on 2023 TVs already prominently feature GeForce NOW titles right on the home page, providing members with effortless discoverability to stream over 1,000 games directly from their LG Smart TVs.
To further enhance the user experience for Ultimate members, native 4K streaming through GeForce NOW is freshly available on select LG 2023 Smart TVs such as the flagship OLED B3, C3 and G3 models. Ultimate members in over 80 supported countries can jump right into their favorite PC titles in pixel-perfect 4K resolution with exclusive access to GeForce NOW’s fastest servers and eight-hour gaming sessions. Members won’t ever need to leave the spot in front of their LG TVs, except maybe to stock up on more snacks.
LG Smart TVs feature lifelike picture quality and high refresh rates so members can enjoy stunning games like Dying Light 2 and Cyberpunk 2077 in 4K — no need for a console nor worries about hardware requirements. It’s one of the easiest ways to try out the new Ray Tracing: Overdrive Mode update for Cyberpunk 2077, which adds full ray tracing, or path tracing, further enhancing the visual fidelity of Night City’s neon-soaked streets and beyond. The update is available now, so upgrade to Ultimate today to check out all the streaming goodness.
Gimme Gimme More
New ways to stream, plus seven new games this week. Here’s the full list:
- MORDHAU (New release on Epic Games Store, free on April 13)
- DE-EXIT – Eternal Matters (New release on Steam, April 14)
- 11-11 Memories Retold (Steam)
- canVERSE (Steam)
- Get Even (Steam)
- Little Nightmares (Steam)
- Little Nightmares II (Steam)
Finally, let the fun and games begin, starting by answering this week’s GFN Thursday question in the comments below, or on Facebook and Twitter.
What’s your go-to horror game?
—
NVIDIA GeForce NOW (@NVIDIAGFN) April 12, 2023


Announcing New Tools for Building with Generative AI on AWS
The seeds of a machine learning (ML) paradigm shift have existed for decades, but with the ready availability of scalable compute capacity, a massive proliferation of data, and the rapid advancement of ML technologies, customers across industries are transforming their businesses. Just recently, generative AI applications like ChatGPT have captured widespread attention and imagination. We are truly at an exciting inflection point in the widespread adoption of ML, and we believe most customer experiences and applications will be reinvented with generative AI.
AI and ML have been a focus for Amazon for over 20 years, and many of the capabilities customers use with Amazon are driven by ML. Our e-commerce recommendations engine is driven by ML; the paths that optimize robotic picking routes in our fulfillment centers are driven by ML; and our supply chain, forecasting, and capacity planning are informed by ML. Prime Air (our drones) and the computer vision technology in Amazon Go (our physical retail experience that lets consumers select items off a shelf and leave the store without having to formally check out) use deep learning. Alexa, powered by more than 30 different ML systems, helps customers billions of times each week to manage smart homes, shop, get information and entertainment, and more. We have thousands of engineers at Amazon committed to ML, and it’s a big part of our heritage, current ethos, and future.
At AWS, we have played a key role in democratizing ML and making it accessible to anyone who wants to use it, including more than 100,000 customers of all sizes and industries. AWS has the broadest and deepest portfolio of AI and ML services at all three layers of the stack. We’ve invested and innovated to offer the most performant, scalable infrastructure for cost-effective ML training and inference; developed Amazon SageMaker, which is the easiest way for all developers to build, train, and deploy models; and launched a wide range of services that allow customers to add AI capabilities like image recognition, forecasting, and intelligent search to applications with a simple API call. This is why customers like Intuit, Thomson Reuters, AstraZeneca, Ferrari, Bundesliga, 3M, and BMW, as well as thousands of startups and government agencies around the world, are transforming themselves, their industries, and their missions with ML. We take the same democratizing approach to generative AI: we work to take these technologies out of the realm of research and experiments and extend their availability far beyond a handful of startups and large, well-funded tech companies. That’s why today I’m excited to announce several new innovations that will make it easy and practical for our customers to use generative AI in their businesses.
Building with Generative AI on AWS
Generative AI and foundation models
Generative AI is a type of AI that can create new content and ideas, including conversations, stories, images, videos, and music. Like all AI, generative AI is powered by ML models—very large models that are pre-trained on vast amounts of data and commonly referred to as Foundation Models (FMs). Recent advancements in ML (specifically the invention of the transformer-based neural network architecture) have led to the rise of models that contain billions of parameters or variables. To give a sense for the change in scale, the largest pre-trained model in 2019 was 330M parameters. Now, the largest models are more than 500B parameters—a 1,600x increase in size in just a few years. Today’s FMs, such as the large language models (LLMs) GPT3.5 or BLOOM, and the text-to-image model Stable Diffusion from Stability AI, can perform a wide range of tasks that span multiple domains, like writing blog posts, generating images, solving math problems, engaging in dialog, and answering questions based on a document. The size and general-purpose nature of FMs make them different from traditional ML models, which typically perform specific tasks, like analyzing text for sentiment, classifying images, and forecasting trends.
FMs can perform so many more tasks because they contain such a large number of parameters that make them capable of learning complex concepts. And through their pre-training exposure to internet-scale data in all its various forms and myriad of patterns, FMs learn to apply their knowledge within a wide range of contexts. While the capabilities and resulting possibilities of a pre-trained FM are amazing, customers get really excited because these generally capable models can also be customized to perform domain-specific functions that are differentiating to their businesses, using only a small fraction of the data and compute required to train a model from scratch. The customized FMs can create a unique customer experience, embodying the company’s voice, style, and services across a wide variety of consumer industries, like banking, travel, and healthcare. For instance, a financial firm that needs to auto-generate a daily activity report for internal circulation using all the relevant transactions can customize the model with proprietary data, which will include past reports, so that the FM learns how these reports should read and what data was used to generate them.
The potential of FMs is incredibly exciting. But, we are still in the very early days. While ChatGPT has been the first broad generative AI experience to catch customers’ attention, most folks studying generative AI have quickly come to realize that several companies have been working on FMs for years, and there are several different FMs available—each with unique strengths and characteristics. As we’ve seen over the years with fast-moving technologies, and in the evolution of ML, things change rapidly. We expect new architectures to arise in the future, and this diversity of FMs will set off a wave of innovation. We’re already seeing new application experiences never seen before. AWS customers have asked us how they can quickly take advantage of what is out there today (and what is likely coming tomorrow) and quickly begin using FMs and generative AI within their businesses and organizations to drive new levels of productivity and transform their offerings.
Announcing Amazon Bedrock and Amazon Titan models, the easiest way to build and scale generative AI applications with FMs
Customers have told us there are a few big things standing in their way today. First, they need a straightforward way to find and access high-performing FMs that give outstanding results and are best-suited for their purposes. Second, customers want integration into applications to be seamless, without having to manage huge clusters of infrastructure or incur large costs. Finally, customers want it to be easy to take the base FM, and build differentiated apps using their own data (a little data or a lot). Since the data customers want to use for customization is incredibly valuable IP, they need it to stay completely protected, secure, and private during that process, and they want control over how their data is shared and used.
We took all of that feedback from customers, and today we are excited to announce Amazon Bedrock, a new service that makes FMs from AI21 Labs, Anthropic, Stability AI, and Amazon accessible via an API. Bedrock is the easiest way for customers to build and scale generative AI-based applications using FMs, democratizing access for all builders. Bedrock will offer the ability to access a range of powerful FMs for text and images—including Amazon’s Titan FMs, which consist of two new LLMs we’re also announcing today—through a scalable, reliable, and secure AWS managed service. With Bedrock’s serverless experience, customers can easily find the right model for what they’re trying to get done, get started quickly, privately customize FMs with their own data, and easily integrate and deploy them into their applications using the AWS tools and capabilities they are familiar with (including integrations with Amazon SageMaker ML features like Experiments to test different models and Pipelines to manage their FMs at scale) without having to manage any infrastructure.
Bedrock customers can choose from some of the most cutting-edge FMs available today. This includes the Jurassic-2 family of multilingual LLMs from AI21 Labs, which follow natural language instructions to generate text in Spanish, French, German, Portuguese, Italian, and Dutch. Claude, Anthropic’s LLM, can perform a wide variety of conversational and text processing tasks and is based on Anthropic’s extensive research into training honest and responsible AI systems. Bedrock also makes it easy to access Stability AI’s suite of text-to-image foundation models, including Stable Diffusion (the most popular of its kind), which is capable of generating unique, realistic, high-quality images, art, logos, and designs.
One of the most important capabilities of Bedrock is how easy it is to customize a model. Customers simply point Bedrock at a few labeled examples in Amazon S3, and the service can fine-tune the model for a particular task without having to annotate large volumes of data (as few as 20 examples is enough). Imagine a content marketing manager who works at a leading fashion retailer and needs to develop fresh, targeted ad and campaign copy for an upcoming new line of handbags. To do this, they provide Bedrock a few labeled examples of their best performing taglines from past campaigns, along with the associated product descriptions, and Bedrock will automatically start generating effective social media, display ad, and web copy for the new handbags. None of the customer’s data is used to train the underlying models, and since all data is encrypted and does not leave a customer’s Virtual Private Cloud (VPC), customers can trust that their data will remain private and confidential.
Bedrock is now in limited preview, and customers like Coda are excited about how fast their development teams have gotten up and running. Shishir Mehrotra, Co-founder and CEO of Coda, says, “As a longtime happy AWS customer, we’re excited about how Amazon Bedrock can bring quality, scalability, and performance to Coda AI. Since all our data is already on AWS, we are able to quickly incorporate generative AI using Bedrock, with all the security and privacy we need to protect our data built-in. With over tens of thousands of teams running on Coda, including large teams like Uber, the New York Times, and Square, reliability and scalability are really important.”
We have been previewing Amazon’s new Titan FMs with a few customers before we make them available more broadly in the coming months. We’ll initially have two Titan models. The first is a generative LLM for tasks such as summarization, text generation (for example, creating a blog post), classification, open-ended Q&A, and information extraction. The second is an embeddings LLM that translates text inputs (words, phrases or possibly large units of text) into numerical representations (known as embeddings) that contain the semantic meaning of the text. While this LLM will not generate text, it is useful for applications like personalization and search because by comparing embeddings the model will produce more relevant and contextual responses than word matching. In fact, Amazon.com’s product search capability uses a similar embeddings model among others to help customers find the products they’re looking for. To continue supporting best practices in the responsible use of AI, Titan FMs are built to detect and remove harmful content in the data that customers provide for customization, reject inappropriate content in the user input, and filter the models’ outputs that contain inappropriate content (such as hate speech, profanity, and violence).
Bedrock makes the power of FMs accessible to companies of all sizes so that they can accelerate the use of ML across their organizations and build their own generative AI applications because it will be easy for all developers. We think Bedrock will be a massive step forward in democratizing FMs, and our partners like Accenture, Deloitte, Infosys, and Slalom are building practices to help enterprises go faster with generative AI. Independent Software Vendors (ISVs) like C3 AI and Pega are excited to leverage Bedrock for easy access to its great selection of FMs with all of the security, privacy, and reliability they expect from AWS.
Announcing the general availability of Amazon EC2 Trn1n instances powered by AWS Trainium and Amazon EC2 Inf2 instances powered by AWS Inferentia2, the most cost-effective cloud infrastructure for generative AI
Whatever customers are trying to do with FMs—running them, building them, customizing them—they need the most performant, cost-effective infrastructure that is purpose-built for ML. Over the last five years, AWS has been investing in our own silicon to push the envelope on performance and price performance for demanding workloads like ML training and Inference, and our AWS Trainium and AWS Inferentia chips offer the lowest cost for training models and running inference in the cloud. This ability to maximize performance and control costs by choosing the optimal ML infrastructure is why leading AI startups, like AI21 Labs, Anthropic, Cohere, Grammarly, Hugging Face, Runway, and Stability AI run on AWS.
Trn1 instances, powered by Trainium, can deliver up to 50% savings on training costs over any other EC2 instance, and are optimized to distribute training across multiple servers connected with 800 Gbps of second-generation Elastic Fabric Adapter (EFA) networking. Customers can deploy Trn1 instances in UltraClusters that can scale up to 30,000 Trainium chips (more than 6 exaflops of compute) located in the same AWS Availability Zone with petabit scale networking. Many AWS customers, including Helixon, Money Forward, and the Amazon Search team, use Trn1 instances to help reduce the time required to train the largest-scale deep learning models from months to weeks or even days while lowering their costs. 800 Gbps is a lot of bandwidth, but we have continued to innovate to deliver more, and today we are announcing the general availability of new, network-optimized Trn1n instances, which offer 1600 Gbps of network bandwidth and are designed to deliver 20% higher performance over Trn1 for large, network-intensive models.
Today, most of the time and money spent on FMs goes into training them. This is because many customers are only just starting to deploy FMs into production. However, in the future, when FMs are deployed at scale, most costs will be associated with running the models and doing inference. While you typically train a model periodically, a production application can be constantly generating predictions, known as inferences, potentially generating millions per hour. And these predictions need to happen in real-time, which requires very low-latency and high-throughput networking. Alexa is a great example with millions of requests coming in every minute, which accounts for 40% of all compute costs.
Because we knew that most of the future ML costs would come from running inferences, we prioritized inference-optimized silicon when we started investing in new chips a few years ago. In 2018, we announced Inferentia, the first purpose-built chip for inference. Every year, Inferentia helps Amazon run trillions of inferences and has saved companies like Amazon over a hundred million dollars in capital expense already. The results are impressive, and we see many opportunities to keep innovating as workloads will only increase in size and complexity as more customers integrate generative AI into their applications.
That’s why we’re announcing today the general availability of Inf2 instances powered by AWS Inferentia2, which are optimized specifically for large-scale generative AI applications with models containing hundreds of billions of parameters. Inf2 instances deliver up to 4x higher throughput and up to 10x lower latency compared to the prior generation Inferentia-based instances. They also have ultra-high-speed connectivity between accelerators to support large-scale distributed inference. These capabilities drive up to 40% better inference price performance than other comparable Amazon EC2 instances and the lowest cost for inference in the cloud. Customers like Runway are seeing up to 2x higher throughput with Inf2 than comparable Amazon EC2 instances for some of their models. This high-performance, low-cost inference will enable Runway to introduce more features, deploy more complex models, and ultimately deliver a better experience for the millions of creators using Runway.
Announcing the general availability of Amazon CodeWhisperer, free for individual developers
We know that building with the right FMs and running Generative AI applications at scale on the most performant cloud infrastructure will be transformative for customers. The new wave of experiences will also be transformative for users. With generative AI built-in, users will be able to have more natural and seamless interactions with applications and systems. Think of how we can unlock our mobile phones just by looking at them, without needing to know anything about the powerful ML models that make this feature possible.
One area where we foresee the use of generative AI growing rapidly is in coding. Software developers today spend a significant amount of their time writing code that is pretty straightforward and undifferentiated. They also spend a lot of time trying to keep up with a complex and ever-changing tool and technology landscape. All of this leaves developers less time to develop new, innovative capabilities and services. Developers try to overcome this by copying and modifying code snippets from the web, which can result in inadvertently copying code that doesn’t work, contains security vulnerabilities, or doesn’t track usage of open source software. And, ultimately, searching and copying still takes time away from the good stuff.
Generative AI can take this heavy lifting out of the equation by “writing” much of the undifferentiated code, allowing developers to build faster while freeing them up to focus on the more creative aspects of coding. This is why, last year, we announced the preview of Amazon CodeWhisperer, an AI coding companion that uses a FM under the hood to radically improve developer productivity by generating code suggestions in real-time based on developers’ comments in natural language and prior code in their Integrated Development Environment (IDE). Developers can simply tell CodeWhisperer to do a task, such as “parse a CSV string of songs” and ask it to return a structured list based on values such as artist, title, and highest chart rank. CodeWhisperer provides a productivity boost by generating an entire function that parses the string and returns the list as specified. Developer response to the preview has been overwhelmingly positive, and we continue to believe that helping developers code could end up being one of the most powerful uses of generative AI we’ll see in the coming years. During the preview, we ran a productivity challenge, and participants who used CodeWhisperer completed tasks 57% faster, on average, and were 27% more likely to complete them successfully than those who didn’t use CodeWhisperer. This is a giant leap forward in developer productivity, and we believe this is only the beginning.
Today, we’re excited to announce the general availability of Amazon CodeWhisperer for Python, Java, JavaScript, TypeScript, and C#—plus ten new languages, including Go, Kotlin, Rust, PHP, and SQL. CodeWhisperer can be accessed from IDEs such as VS Code, IntelliJ IDEA, AWS Cloud9, and many more via the AWS Toolkit IDE extensions. CodeWhisperer is also available in the AWS Lambda console. In addition to learning from the billions of lines of publicly available code, CodeWhisperer has been trained on Amazon code. We believe CodeWhisperer is now the most accurate, fastest, and most secure way to generate code for AWS services, including Amazon EC2, AWS Lambda, and Amazon S3.
Developers aren’t truly going to be more productive if code suggested by their generative AI tool contains hidden security vulnerabilities or fails to handle open source responsibly. CodeWhisperer is the only AI coding companion with built-in security scanning (powered by automated reasoning) for finding and suggesting remediations for hard-to-detect vulnerabilities, such as those in the top ten Open Worldwide Application Security Project (OWASP), those that don’t meet crypto library best practices, and others. To help developers code responsibly, CodeWhisperer filters out code suggestions that might be considered biased or unfair, and CodeWhisperer is the only coding companion that can filter and flag code suggestions that resemble open source code that customers may want to reference or license for use.
We know generative AI is going to change the game for developers, and we want it to be useful to as many as possible. This is why CodeWhisperer is free for all individual users with no qualifications or time limits for generating code! Anyone can sign up for CodeWhisperer with just an email account and become more productive within minutes. You don’t even have to have an AWS account. For business users, we’re offering a CodeWhisperer Professional Tier that includes administration features like single sign-on (SSO) with AWS Identity and Access Management (IAM) integration, as well as higher limits on security scanning.
Building powerful applications like CodeWhisperer is transformative for developers and all our customers. We have a lot more coming, and we are excited about what you will build with generative AI on AWS. Our mission is to make it possible for developers of all skill levels and for organizations of all sizes to innovate using generative AI. This is just the beginning of what we believe will be the next wave of ML powering new possibilities for you.
Resources
Check out the following resources to learn more about generative AI on AWS and these announcements:
- Explore generative AI on AWS
- An introduction to generative AI: Read what Werner Vogels, Amazon.com CTO, has to say about Generative AI
- Demystifying generative AI: Listen to Werner Vogels and I discuss the impact of generative AI to businesses
- Learn about Amazon Bedrock, the easiest way to build and scale generative AI applications with FMs
- Learn about Amazon Titan, high-performing FMs from Amazon to innovate responsibly
- Discover the new AWS Trainium based Trn1n instance and the AWS Inferentia based Inf2 instance
- Learn how you can use Amazon CodeWhisperer as your coding companion
About the author
 Swami Sivasubramanian is Vice President of Data and Machine Learning at AWS. In this role, Swami oversees all AWS Database, Analytics, and AI & Machine Learning services. His team’s mission is to help organizations put their data to work with a complete, end-to-end data solution to store, access, analyze, and visualize, and predict.
Swami Sivasubramanian is Vice President of Data and Machine Learning at AWS. In this role, Swami oversees all AWS Database, Analytics, and AI & Machine Learning services. His team’s mission is to help organizations put their data to work with a complete, end-to-end data solution to store, access, analyze, and visualize, and predict.
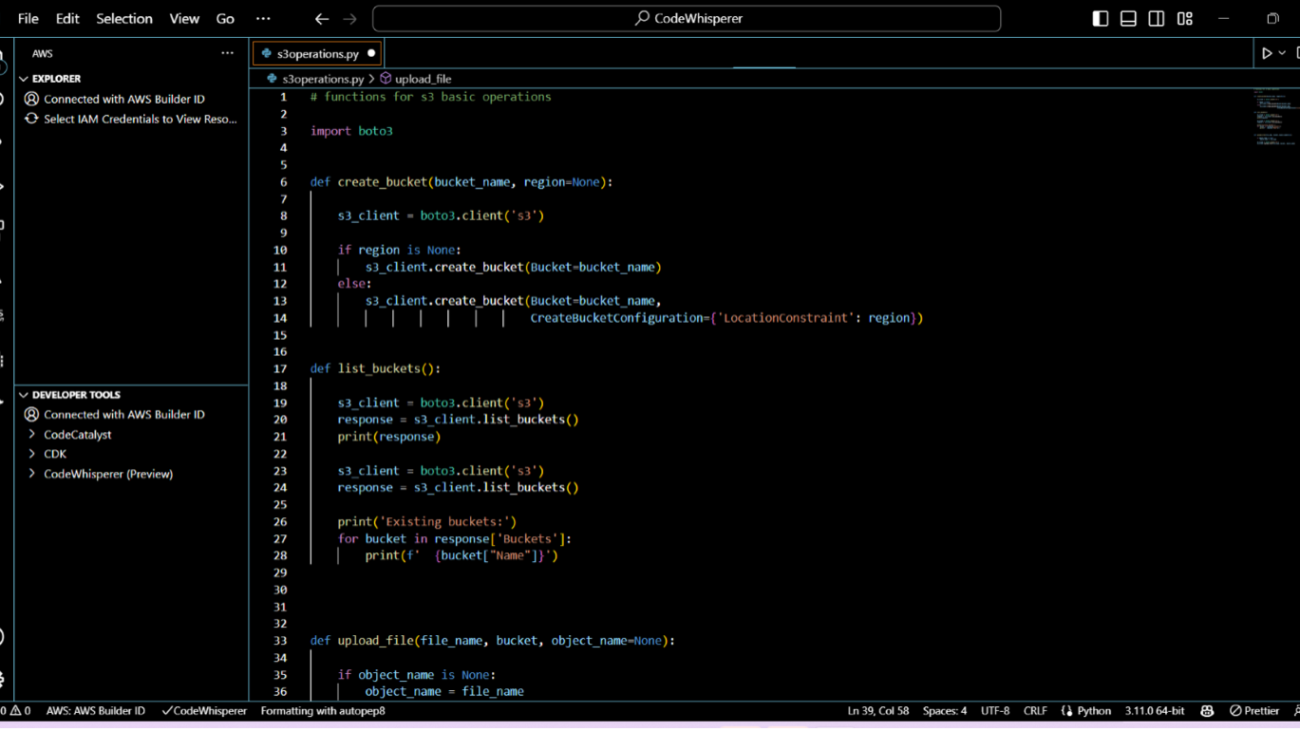
How Accenture is using Amazon CodeWhisperer to improve developer productivity
Amazon CodeWhisperer is an AI coding companion that helps improve developer productivity by generating code recommendations based on their comments in natural language and code in the integrated development environment (IDE). CodeWhisperer accelerates completion of coding tasks by reducing context-switches between the IDE and documentation or developer forums. With real-time code recommendations from CodeWhisperer, you can stay focused in the IDE and finish your coding tasks faster.
CodeWhisperer is powered by a Large Language Model (LLM) that is trained on billions of lines of code, and as a result, has learned how to write code in 15 programming languages. You can simply write a comment that outlines a specific task in plain English, such as “upload a file to S3.” Based on this, CodeWhisperer automatically determines which cloud services and public libraries are best suited for the specified task, builds the specific code on the fly, and recommends the generated code snippets directly in the IDE. Moreover, CodeWhisperer seamlessly integrates with your Visual Studio Code and JetBrains IDEs so that you can stay focused and never leave the IDE. At the time of this writing, CodeWhisperer supports Java, Python, JavaScript, TypeScript, C#, Go, Ruby, Rust, Scala, Kotlin, PHP, C, C++, Shell, and SQL.
In this post, we illustrate how Accenture uses CodeWhisperer in practice to improve developer productivity.
“Accenture is using Amazon CodeWhisperer to accelerate coding as part of our software engineering best practices initiative in our Velocity platform,” says Balakrishnan Viswanathan, Senior Manager, Tech Architecture at Accenture. “The Velocity team was looking for ways to improve developer productivity. After searching for multiple options, we came across Amazon CodeWhisperer to reduce our development efforts by 30% and we are now focusing more on improving security, quality, and performance.”
Benefits of CodeWhisperer
The Accenture Velocity team has been using CodeWhisperer to accelerate their artificial intelligence (AI) and machine learning (ML) projects. The following summary highlights the benefits:
- The team is spending less time creating boilerplate and repetitive code patterns, and more time on what matters: building great software
- CodeWhisperer empowers developers to responsibly use AI to create syntactically correct and secure applications
- The team can generate entire functions and logical code blocks without having to search for and customize code snippets from the web
- They can accelerate onboarding for novice developers or developers working with an unfamiliar codebase
- They can detect security threats early in the development process by shifting the security scanning left to the developer’s IDE
In the following sections, we discuss some of the ways that the Accenture Velocity team has been using CodeWhisperer in more detail.
Onboarding developers on new projects
CodeWhisperer helps developers unfamiliar with AWS to ramp up faster on projects that use AWS services. New developers in Accenture were able to write code for AWS services such as Amazon Simple Storage Service (Amazon S3) and Amazon DynamoDB. In a short amount of time, they were able to be productive and contribute to the project. CodeWhisperer assisted developers by providing code blocks or line-by-line suggestions. It is also context-aware. Changing the instructions (comments) to be more specific results in CodeWhisperer generating more relevant code.
Writing boilerplate code
Developers were able to use CodeWhisperer to complete prerequisites. They were able to create a preprocessing data class just by typing “class to create preprocessing script for ML data.” Writing the preprocessing script took only a couple of minutes, and CodeWhisperer was able to generate entire code blocks.
Helping developers code in unfamiliar languages
A Java user new to the team was able to easily start writing Python code with the help of CodeWhisperer without worrying about the syntax.
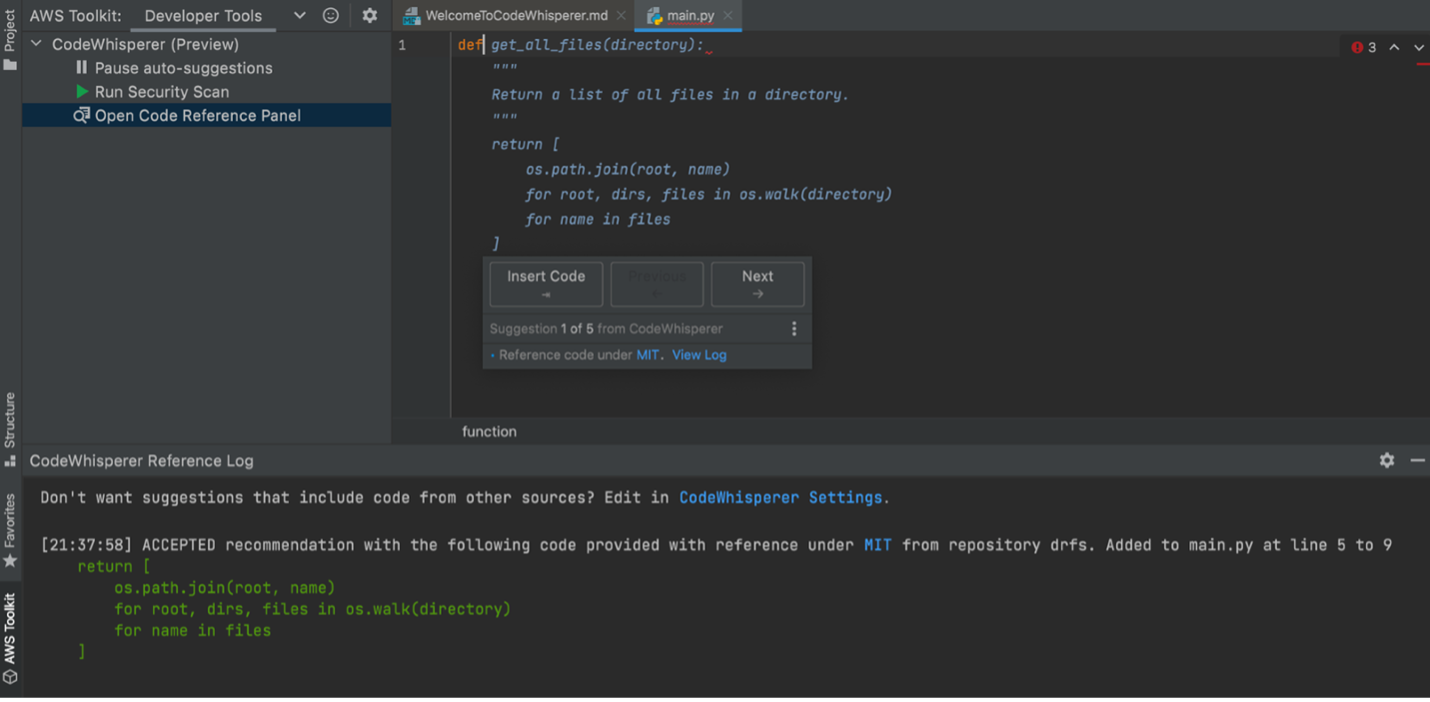
Detecting security vulnerabilities in the code
Developers were able to detect security issues by choosing Run security scan in their IDE. Detailed insights on the security issues found are provided directly in the IDE. This helps developers detect and fix issues early.
“As a developer, using CodeWhisperer enables you to write code more quickly,” says Nino Leenus, AI Engineering Consultant at Accenture. “In addition, CodeWhisperer will help you code more accurately by eliminating typos and other typical errors with the aid of artificial intelligence. For a developer, writing the same code multiple times is tedious. By recommending the subsequent code pieces that you may need, AI code completion technologies reduce such repetitious coding.”
Conclusion
This post introduces CodeWhisperer, an AI coding companion by Amazon. The tool uses ML models trained on large datasets to provide suggestions and autocompletion for code, as well as generate entire functions and classes based on natural language descriptions. This post also highlights some of the benefits seen by Accenture when using CodeWhisperer, such as increased productivity and the ability to reduce the time and effort required for common coding tasks. You can activate CodeWhisperer in your favorite IDE today. CodeWhisperer automatically generates suggestions based on your existing code and comments. Visit Amazon CodeWhisperer to get started.
About the Authors
 Balakrishnan Viswanathan is an AI/ML Solution Architect at Accenture. Collaborating with AABG, he devises and executes cutting-edge cloud-based strategies to tackle various AI/ML related challenges. Bala’s interests lie in both cooking and Photoshop, which he is passionate about.
Balakrishnan Viswanathan is an AI/ML Solution Architect at Accenture. Collaborating with AABG, he devises and executes cutting-edge cloud-based strategies to tackle various AI/ML related challenges. Bala’s interests lie in both cooking and Photoshop, which he is passionate about.
 Shikhar Kwatra is an AI/ML specialist solutions architect at Amazon Web Services, working with a leading Global System Integrator. He has earned the title of one of the Youngest Indian Master Inventors with over 500 patents in the AI/ML and IoT domains. Shikhar aids in architecting, building, and maintaining cost-efficient, scalable cloud environments for the organization, and supports the GSI partner in building strategic industry solutions on AWS. Shikhar enjoys playing guitar, composing music, and practicing mindfulness in his spare time.
Shikhar Kwatra is an AI/ML specialist solutions architect at Amazon Web Services, working with a leading Global System Integrator. He has earned the title of one of the Youngest Indian Master Inventors with over 500 patents in the AI/ML and IoT domains. Shikhar aids in architecting, building, and maintaining cost-efficient, scalable cloud environments for the organization, and supports the GSI partner in building strategic industry solutions on AWS. Shikhar enjoys playing guitar, composing music, and practicing mindfulness in his spare time.
 Ankur Desai is a Principal Product Manager within the AWS AI Services team.
Ankur Desai is a Principal Product Manager within the AWS AI Services team.
 Nino Leenus is an AI Consultant at Accenture. She is expertise on developing End-to-End Machine learning solutions and its deployment using cloud. She is curious about latest tools and technologies in ML-Ops field. She loves traveling and trekking.
Nino Leenus is an AI Consultant at Accenture. She is expertise on developing End-to-End Machine learning solutions and its deployment using cloud. She is curious about latest tools and technologies in ML-Ops field. She loves traveling and trekking.
A new, unique AI dataset for animating amateur drawings
When we released our Animated Drawings Demo in late 2021, we invited people to opt in to contribute to a dataset of in-the-wild amateur drawings.Read More