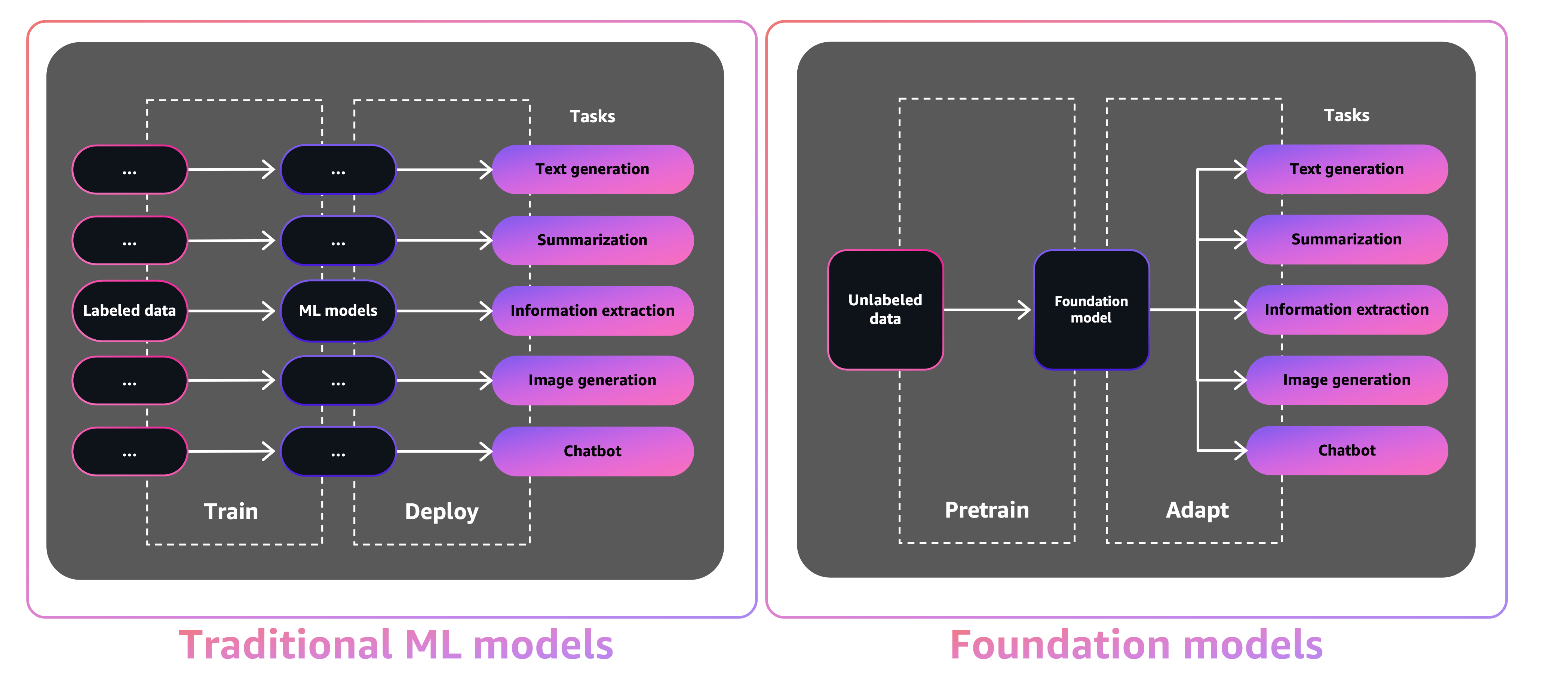
Intelligent document processing (IDP) is a technology that automates the processing of high volumes of unstructured data, including text, images, and videos. IDP offers a significant improvement over manual methods and legacy optical character recognition (OCR) systems by addressing challenges such as cost, errors, low accuracy, and limited scalability, ultimately leading to better outcomes for organizations and stakeholders.
Natural language processing (NLP) is one of the recent developments in IDP that has improved accuracy and user experience. However, despite these advances, there are still challenges to overcome. For instance, many IDP systems are not user-friendly or intuitive enough for easy adoption by users. Additionally, several existing solutions lack the capability to adapt to changes in data sources, regulations, and user requirements through continuous improvement and updates.
Enhancing IDP through dialogue involves incorporating dialogue capabilities into IDP systems. By enabling users to interact with IDP systems in a more natural and intuitive way, through multi-round dialogue by adjusting inaccurate information or adding missing information aided with task automation, these systems can become more efficient, accurate, and user-friendly.
In this post, we explore an innovative approach to IDP that utilizes a dialogue-guided query solution using Amazon Foundation Models and SageMaker JumpStart.
Solution overview
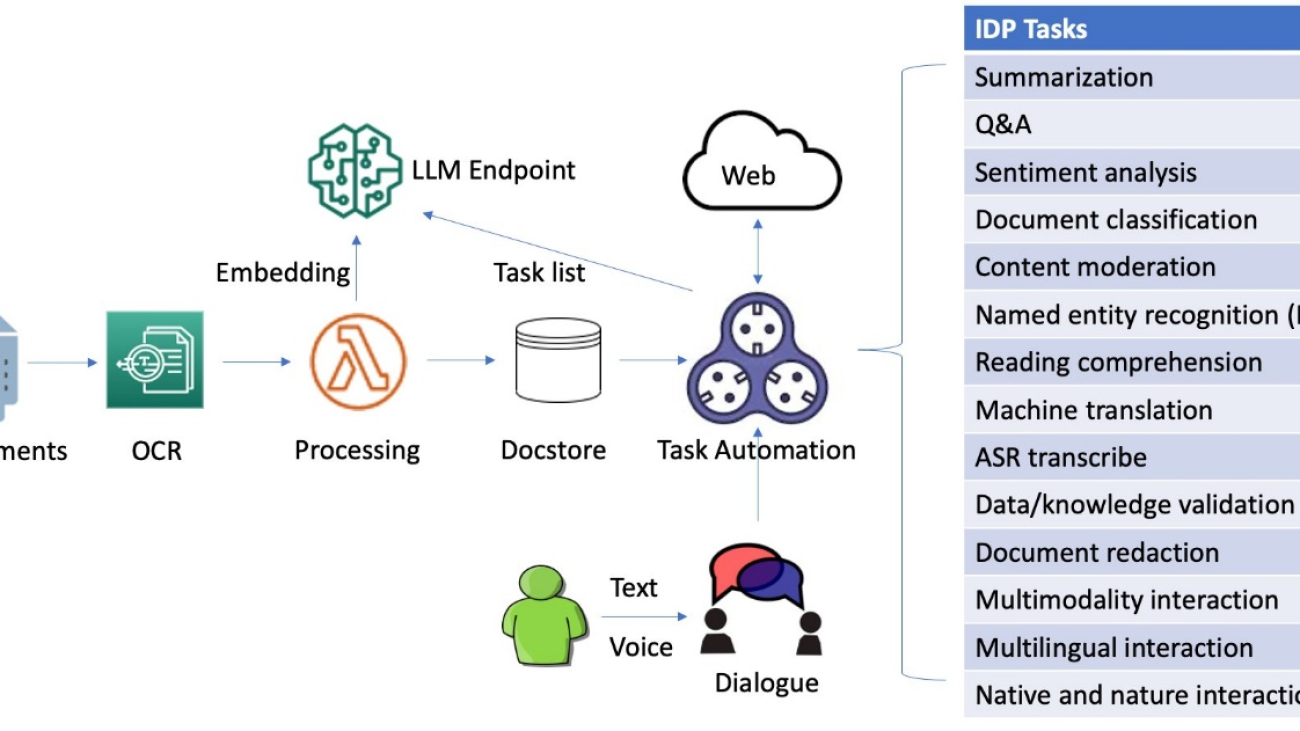
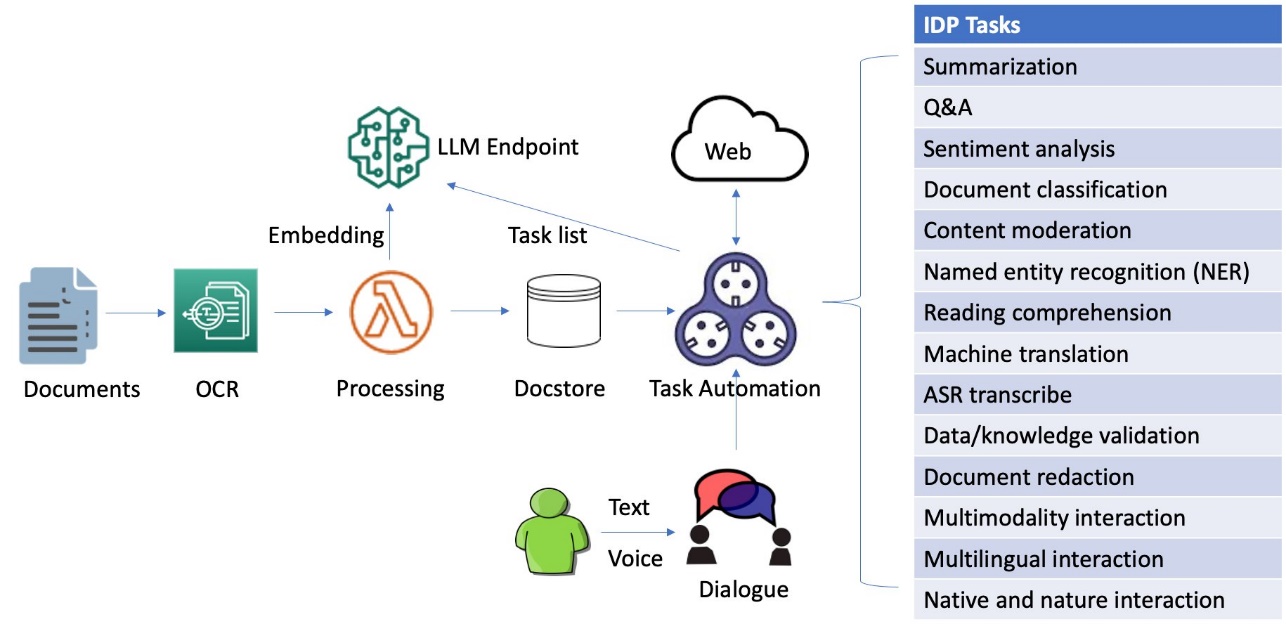
This innovative solution combines OCR for information extraction, a local deployed large language model (LLM) for dialogue and autonomous tasking, VectorDB for embedding subtasks, and LangChain-based task automation for integration with external data sources to transform the way businesses process and analyze document contexts. By harnessing generative AI technologies, organizations can streamline IDP workflows, enhance user experience, and boost overall efficiency.
The following video highlights the dialogue-guided IDP system by processing an article authored by the Federal Reserve Board of Governors, discussing the collapse of Silicon Valley Bank in March 2023.
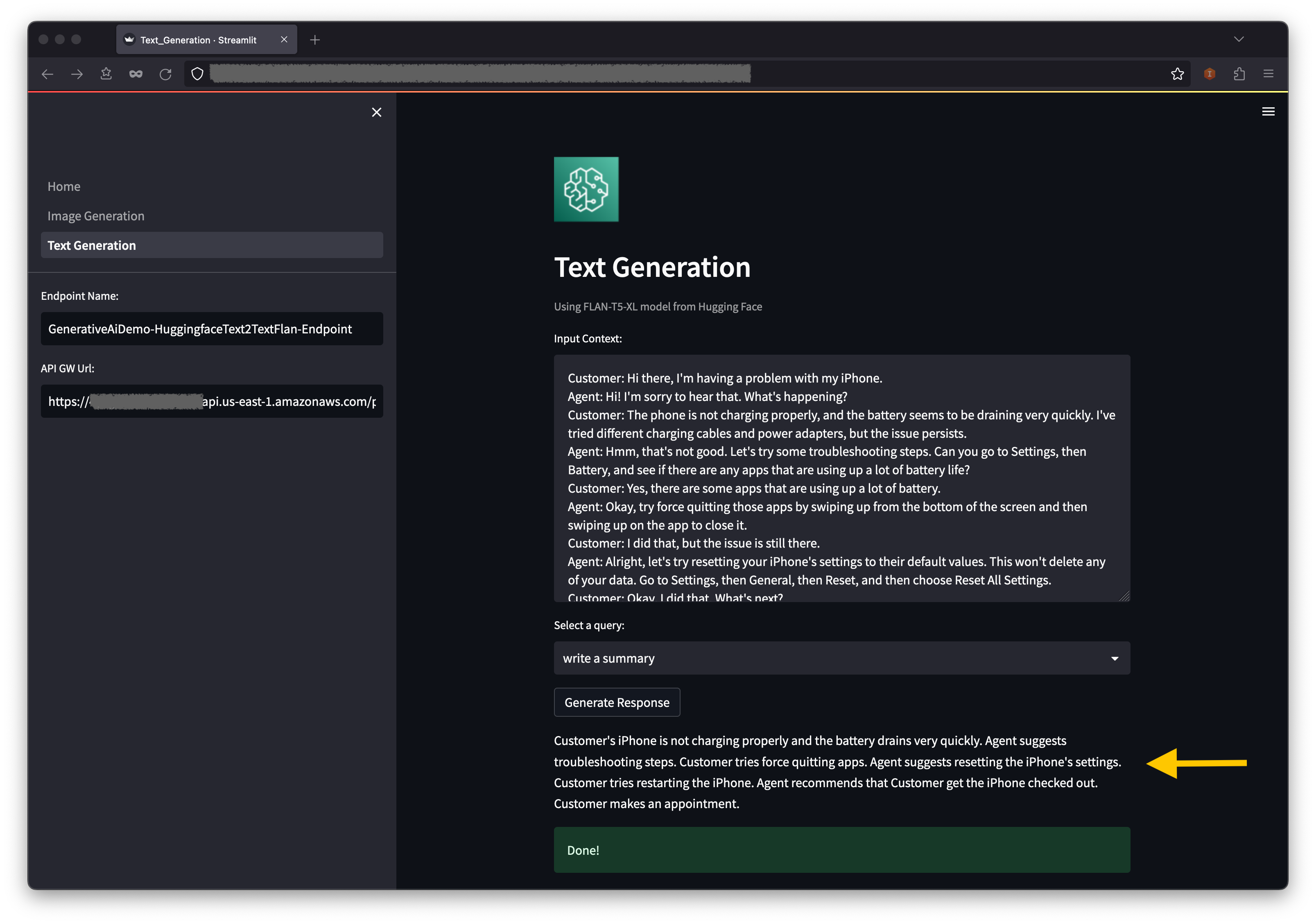
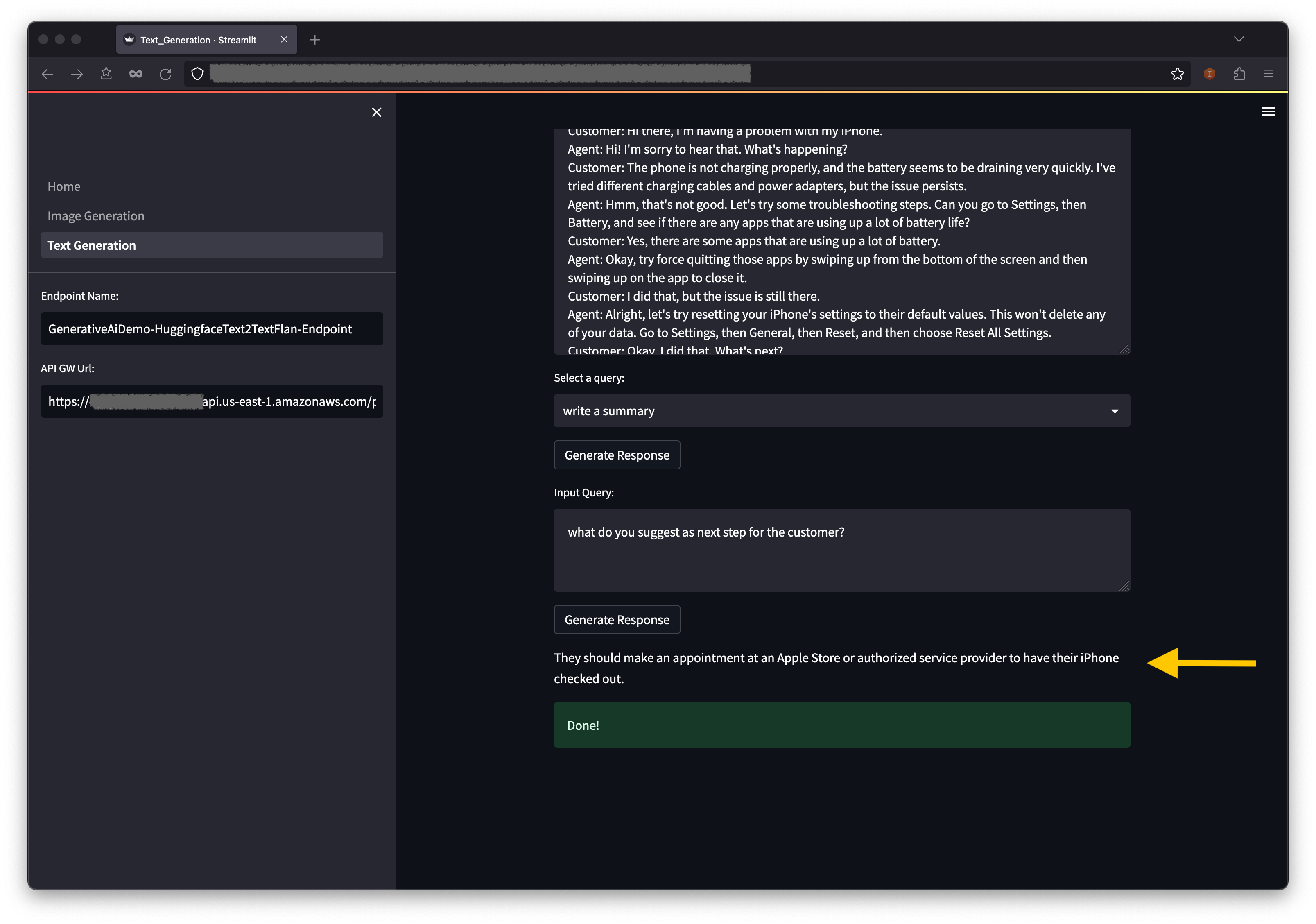
The system is capable of processing images, large PDF, and documents in other format and answering questions derived from the content via interactive text or voice inputs. If a user needs to inquire beyond the document’s context, the dialogue-guided IDP can create a chain of tasks from the text prompt and then reference external and up-to-date data sources for relevant answers. Additionally, it supports multi-round conversations and accommodates multilingual exchanges, all managed through dialogue.
Deploy your own LLM using Amazon foundation models
One of the most promising developments in generative AI is the integration of LLMs into dialogue systems, opening up new avenues for more intuitive and meaningful exchanges. An LLM is a type of AI model designed to understand and generate human-like text. These models are trained on massive amounts of data and consist of billions of parameters, allowing them to perform various language-related tasks with high accuracy. This transformative approach facilitates a more natural and productive interaction, bridging the gap between human intuition and machine intelligence. A key advantage of local LLM deployment lies in its ability to enhance data security without submitting data outside to third-party APIs. Moreover, you can fine-tune your chosen LLM with domain-specific data, resulting in a more accurate, context-aware, and natural language understanding experience.
The Jurassic-2 series from AI21 Labs, which are based on the instruct-tuned 178-billion-parameter Jurassic-1 LLM, are integral parts of the Amazon foundation models available through Amazon Bedrock. The Jurassic-2 instruct was specifically trained to manage prompts that are instructions only, known as zero-shot, without the need for examples, or few-shot. This method provides the most intuitive interaction with LLMs, and it’s the best approach to understand the ideal output for your task without requiring any examples. You can efficiently deploy the pre-trained J2-jumbo-instruct, or other Jurassic-2 models available on AWS Marketplace, into your own own virtual private cloud (VPC) using Amazon SageMaker. See the following code:
import ai21, sagemaker
# Define endpoint name
endpoint_name = "sagemaker-soln-j2-jumbo-instruct"
# Define real-time inference instance type. You can also choose g5.48xlarge or p4de.24xlarge instance types
# Please request P instance quota increase via <a href="https://console.aws.amazon.com/servicequotas/home" target="_blank" rel="noopener">Service Quotas console</a> or your account manager
real_time_inference_instance_type = ("ml.p4d.24xlarge")
# Create a Sgaemkaer endpoint then deploy a pre-trained J2-jumbo-instruct-v1 model from AWS Market Place.
model_package_arn = "arn:aws:sagemaker:us-east-1:865070037744:model-package/j2-jumbo-instruct-v1-0-20-8b2be365d1883a15b7d78da7217cdeab"
model = ModelPackage(
role=sagemaker.get_execution_role(),
model_package_arn=model_package_arn,
sagemaker_session=sagemaker.Session()
)
# Deploy the model
predictor = model.deploy(1, real_time_inference_instance_type,
endpoint_name=endpoint_name,
model_data_download_timeout=3600,
container_startup_health_check_timeout=600,
)After the endpoint has been successfully deployed within your own VPC, you can initiate an inference task to verify that the deployed LLM is functioning as anticipated:
response_jumbo_instruct = ai21.Completion.execute(
sm_endpoint=endpoint_name,
prompt="Explain deep learning algorithms to 8th graders",
numResults=1,
maxTokens=100,
temperature=0.01 #subject to reduce “hallucination” by using common words.
)Document processing, embedding, and indexing
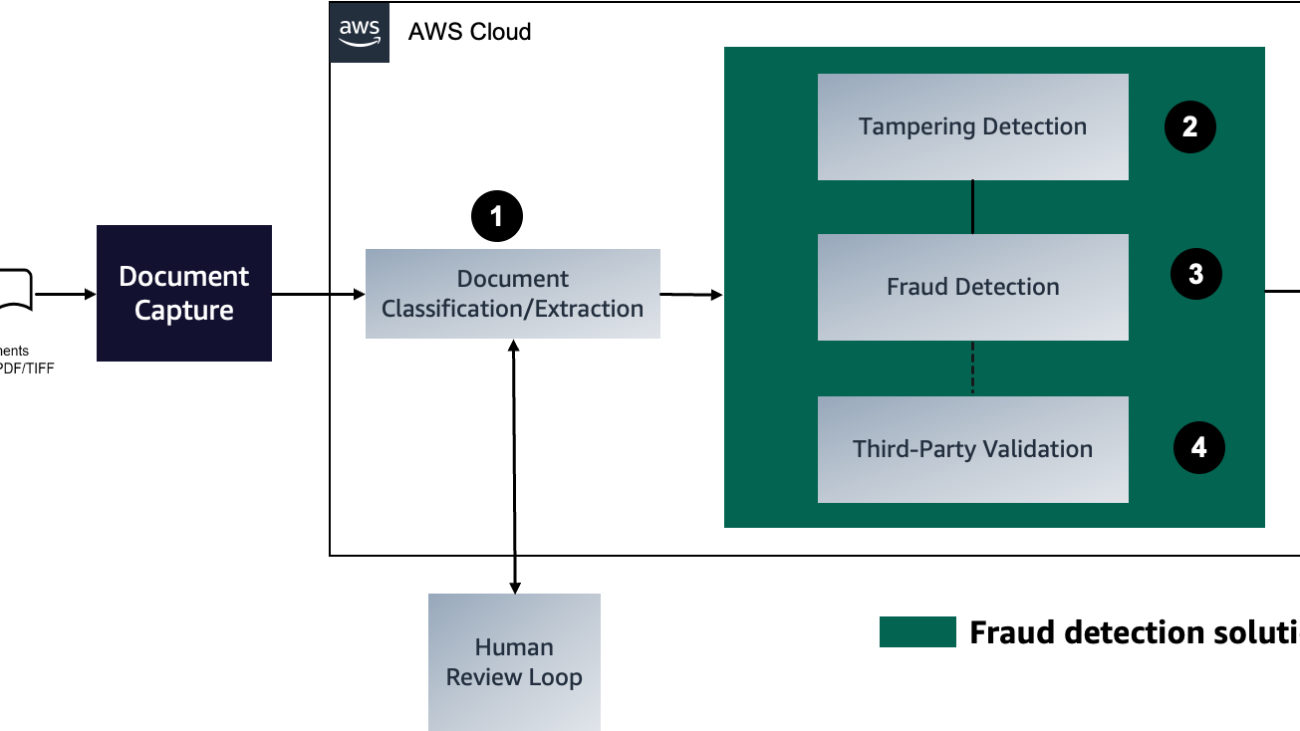
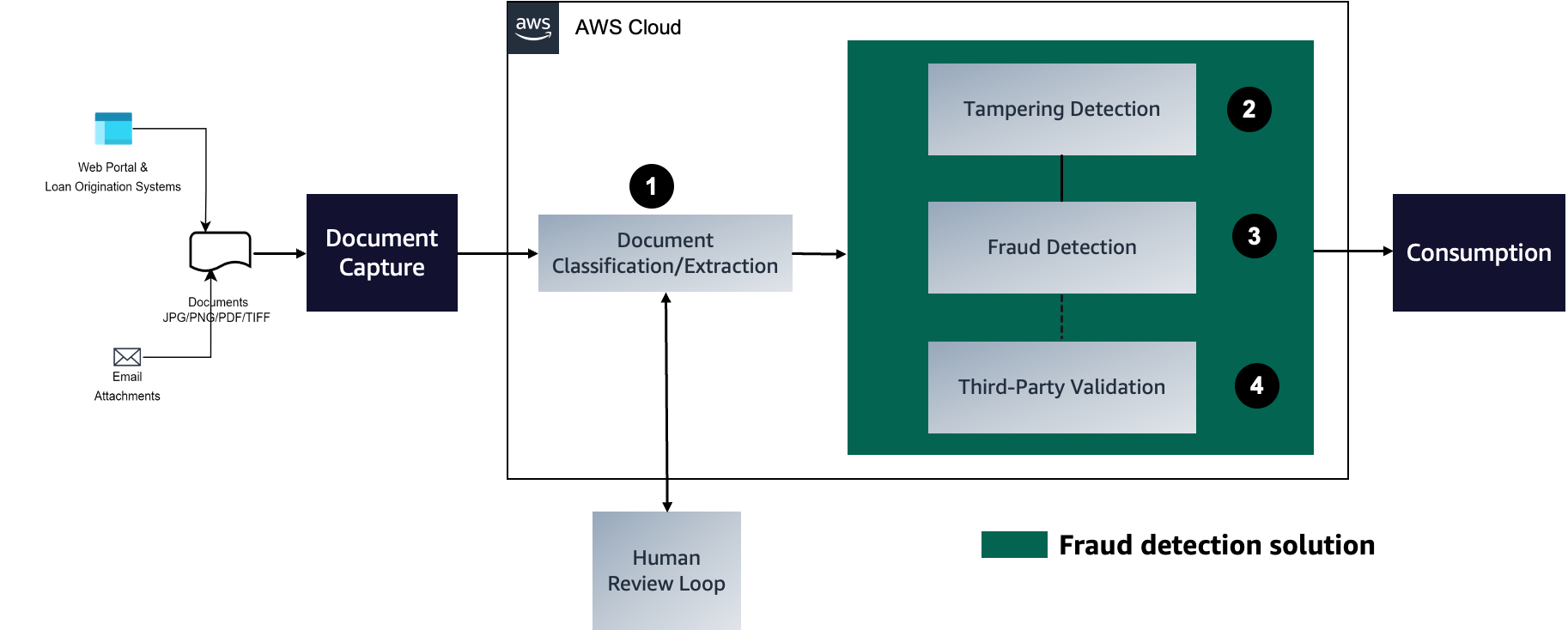
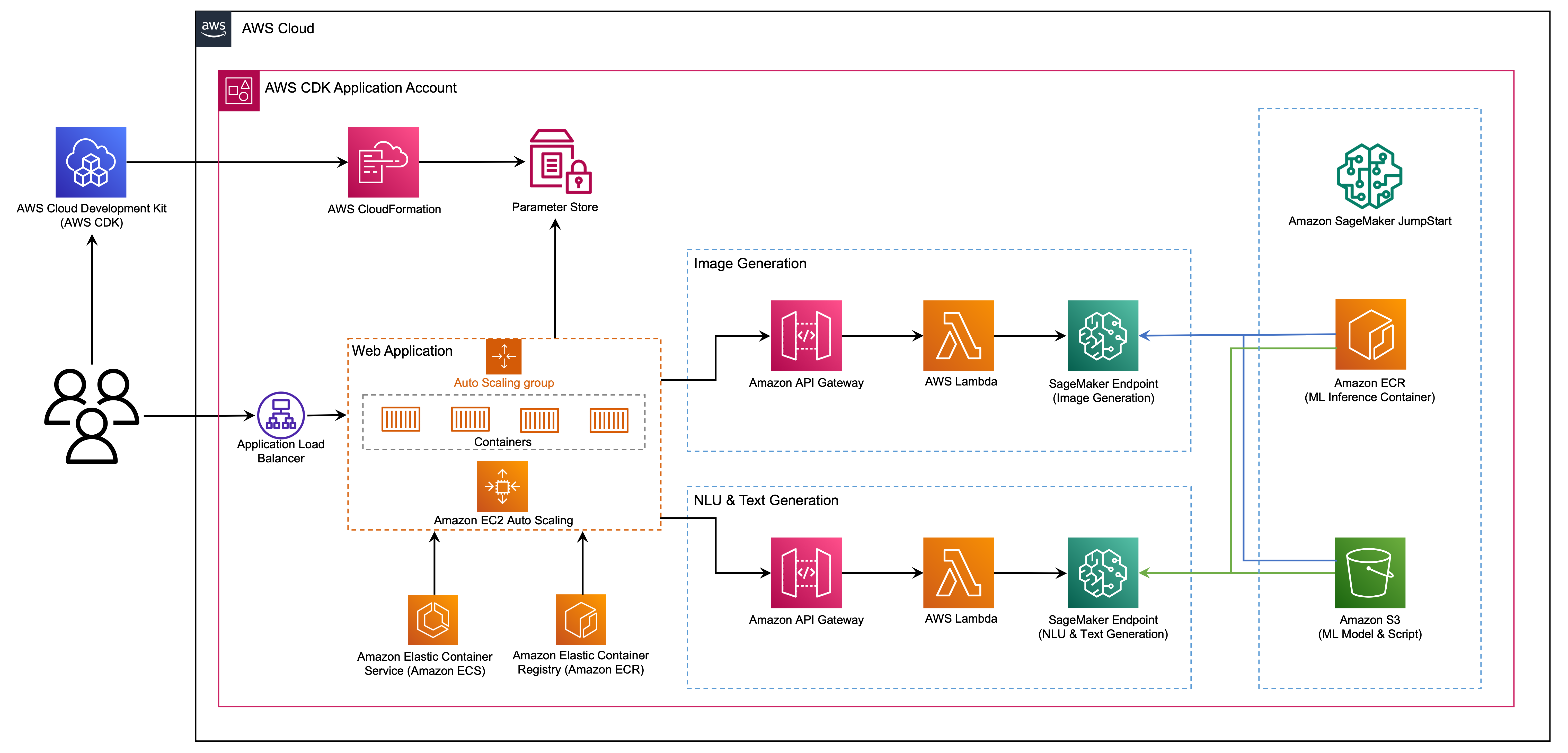
We delve into the process of building an efficient and effective search index, which forms the foundation for intelligent and responsive dialogues to guide document processing. To begin, we convert documents from various formats into text content using OCR and Amazon Textract. We then read this content and fragment it into smaller pieces, ideally around the size of a sentence each. This granular approach allows for more precise and relevant search results, because it enables better matching of queries against individual segments of a page rather than the entire document. To further enhance the process, we use embeddings such as the sentence transformers library from Hugging Face, which generates vector representations (encoding) of each sentence. These vectors serve as a compact and meaningful representation of the original text, enabling efficient and accurate semantic matching functionality. Finally, we store these vectors in a vector database for similarity search. This combination of techniques lays the groundwork for a novel document processing framework that delivers accurate and intuitive results for users. The following diagram illustrates this workflow.
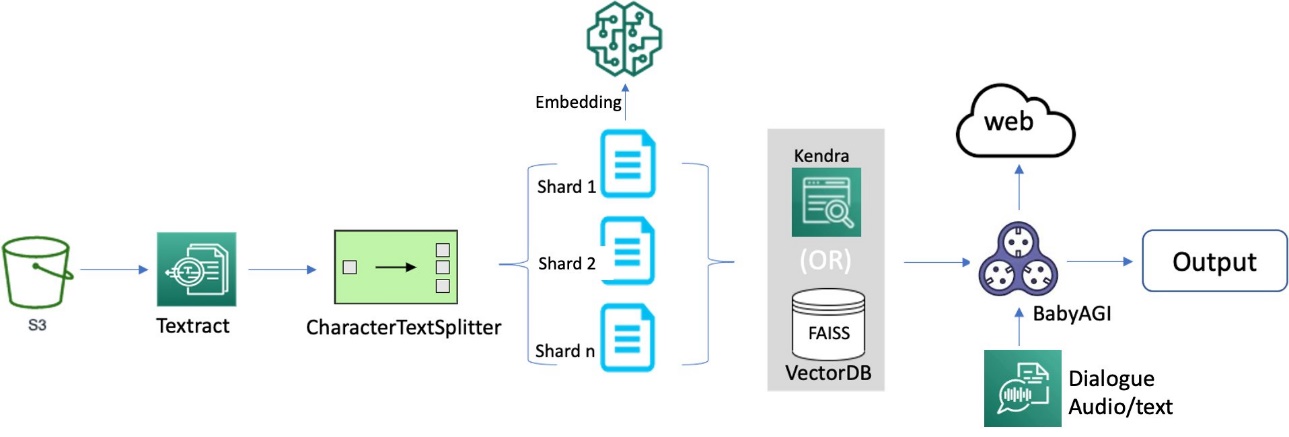
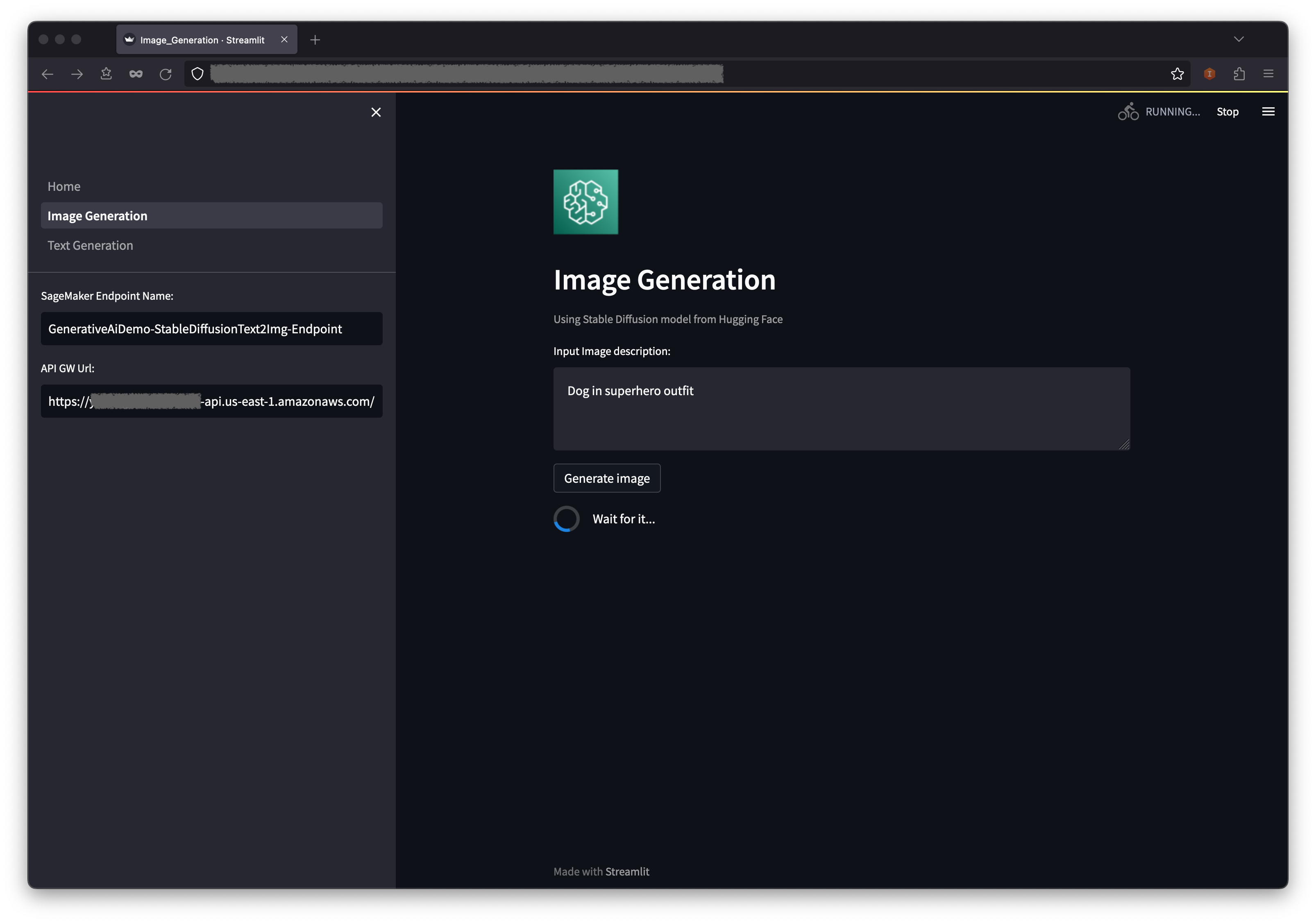
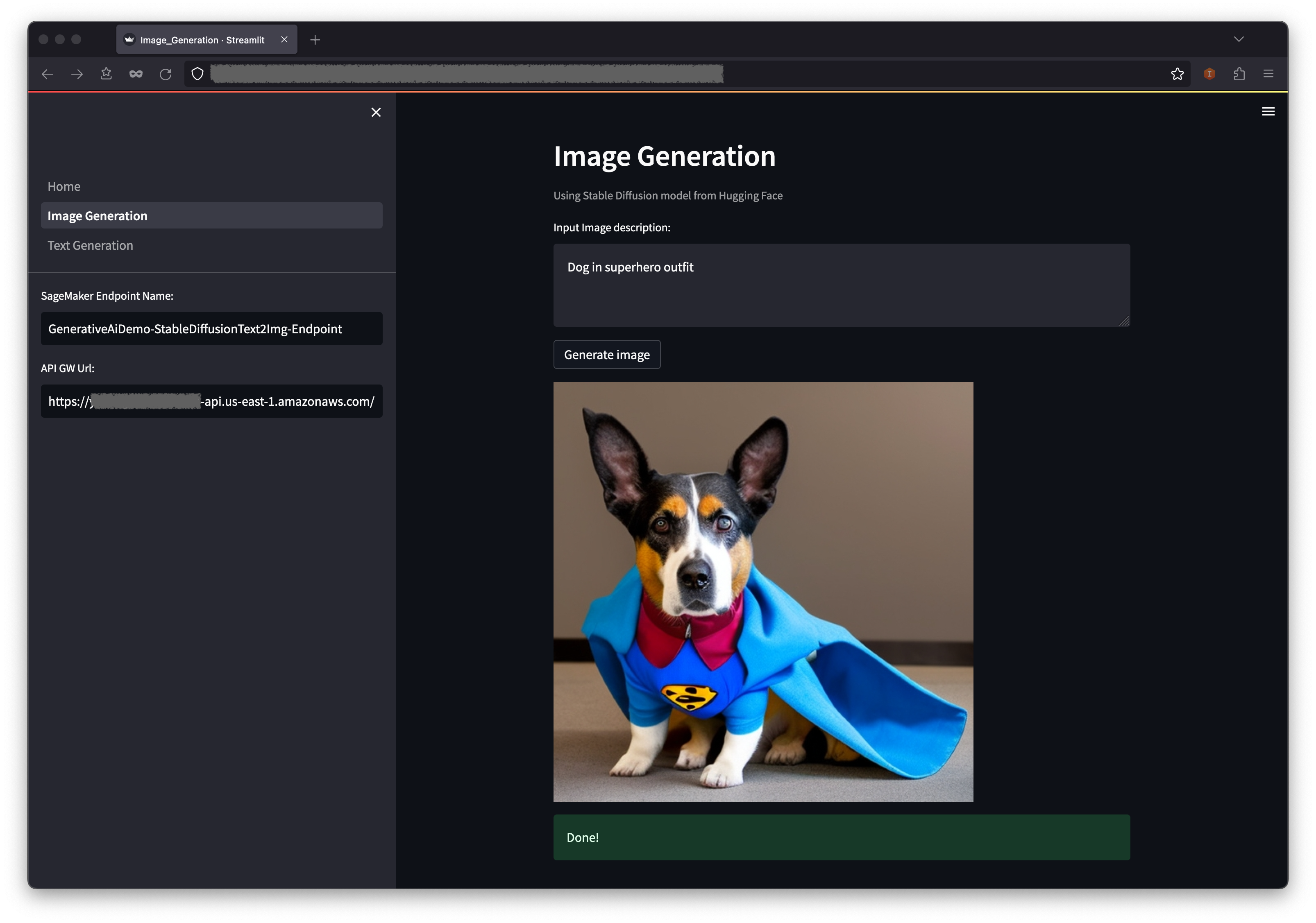
OCR serves as a crucial element in the solution, allowing for the retrieval of text from scanned documents or pictures. We can use Amazon Textract for extracting text from PDF or image files. This managed OCR service is capable of identifying and examining text in multi-page documents, including those in PDF, JPEG or TIFF formats, such as invoices and receipts. The processing of multi-page documents occurs asynchronously, making it advantageous for handling extensive, multi-page documents. See the following code:
def pdf_2_text(input_pdf_file, history):
history = history or []
key = 'input-pdf-files/{}'.format(os.path.basename(input_pdf_file.name))
try:
response = s3_client.upload_file(input_pdf_file.name, default_bucket_name, key)
except ClientError as e:
print("Error uploading file to S3:", e)
s3_object = {'Bucket': default_bucket_name, 'Name': key}
response = textract_client.start_document_analysis(
DocumentLocation={'S3Object': s3_object},
FeatureTypes=['TABLES', 'FORMS']
)
job_id = response['JobId']
while True:
response = textract_client.get_document_analysis(JobId=job_id)
status = response['JobStatus']
if status in ['SUCCEEDED', 'FAILED']:
break
time.sleep(5)
if status == 'SUCCEEDED':
with open(output_file, 'w') as output_file_io:
for block in response['Blocks']:
if block['BlockType'] in ['LINE', 'WORD']:
output_file_io.write(block['Text'] + 'n')
with open(output_file, "r") as file:
first_512_chars = file.read(512).replace("n", "").replace("r", "").replace("[", "").replace("]", "") + " [...]"
history.append(("Document conversion", first_512_chars))
return history, historyWhen dealing with large documents, it’s crucial to break them down into more manageable pieces for easier processing. In the case of LangChain, this means dividing each document into smaller segments, such as 1,000 tokens per chunk with an overlap of 100 tokens. To achieve this smoothly, LangChain utilizes specialized splitters designed specifically for this purpose:
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders import TextLoader
separator = 'n'
overlap_count = 100. # overlap count between the splits
chunk_size = 1000 # Use a fixed split unit size
loader = TextLoader(output_file)
documents = loader.load()
text_splitter = CharacterTextSplitter(separator=separator, chunk_overlap=overlap_count, chunk_size=chunk_size, length_function=len)
texts = text_splitter.split_documents(documents)The duration needed for embedding can fluctuate based on the size of the document; for example, it could take roughly 10 minutes to finish. Although this time frame may not be substantial when dealing with a single document, the ramifications become more notable when indexing hundreds of gigabytes as opposed to just hundreds of megabytes. To expedite the embedding process, you can implement sharding, which enables parallelization and consequently enhances efficiency:
from langchain.document_loaders import ReadTheDocsLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from sentence_transformers import SentenceTransformer
import numpy as np
import ray
from embeddings import LocalHuggingFaceEmbeddings
# Define number of splits
db_shards = 10
loader = TextLoader(output_file)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1000,
chunk_overlap = 100,
length_function = len,
)
@ray.remote()
def process_shard(shard):
embeddings = LocalHuggingFaceEmbeddings('multi-qa-mpnet-base-dot-v1')
result = Chroma.from_documents(shard, embeddings)
return result
# Read the doc content and split them into chunks.
chunks = text_splitter.create_documents([doc.page_content for doc in documents], metadatas=[doc.metadata for doc in documents])
# Embed the doc chunks into vectors.
shards = np.array_split(chunks, db_shards)
futures = [process_shard.remote(shards[i]) for i in range(db_shards)]
texts = ray.get(futures)Now that we have obtained the smaller segments, we can continue to represent them as vectors through embeddings. Embeddings, a technique in NLP, generate vector representations of text prompts. The Embedding class serves as a unified interface for interacting with various embedding providers, such as SageMaker, Cohere, Hugging Face, and OpenAI, which streamlines the process across different platforms. These embeddings are numeric portrayals of ideas transformed into number sequences, allowing computers to effortlessly comprehend the connections between these ideas. See the following code:
# Choose a SageMaker deployed local LLM endpoint for embedding
llm_embeddings = SagemakerEndpointEmbeddings(
endpoint_name=<endpoint_name>,
region_name=<region>,
content_handler=content_handler
)After creating the embeddings, we need to utilize a vectorstore to store the vectors. Vectorstores like Chroma are specially engineered to construct indexes for quick searches in high-dimensional spaces later on, making them perfectly suited for our objectives. As an alternative, you can use FAISS, an open-source vector clustering solution for storing vectors. See the following code:
from langchain.vectorstores import Chroma
# Store vectors in Chroma vectorDB
docsearch_chroma = Chroma.from_documents(texts, llm_embeddings)
# Alternatively you can choose FAISS vectorstore
from langchain.vectorstores import FAISS
docsearch_faiss = FAISS.from_documents(texts, llm_embeddings)You can also use Amazon Kendra to index enterprise content and produce precise answers. As a fully managed service, Amazon Kendra offers ready-to-use semantic search features for advanced document and passage ranking. With the high-accuracy search in Amazon Kendra, you can obtain the most pertinent content and documents to optimize the quality of your payload. This results in superior LLM responses compared to traditional or keyword-focused search methods. For more information, refer to Quickly build high-accuracy Generative AI applications on enterprise data using Amazon Kendra, LangChain, and large language models.
Interactive multilingual voice input
Incorporating interactive voice input into document search offers a myriad of advantages that enhance the user experience. By enabling users to verbally articulate search terms, document search becomes more natural and intuitive, making it simpler and quicker for users to find the information they need. Voice input can bolster the precision of search results, because spoken search terms are less susceptible to spelling or grammatical errors. Interactive voice input renders document search more inclusive, catering to a broader spectrum of users with different language speakers and culture background.
The Amazon Transcribe Streaming SDK enables you to perform audio-to-speech recognition by integrating directly with Amazon Transcribe simply with a stream of audio bytes and a basic handler. As an alternative, you can deploy the whisper-large model locally from Hugging Face using SageMaker, which offers improved data security and better performance. For details, refer to the sample notebook published on the GitHub repo.
# Choose ASR using a locally deployed Whisper-large model from Hugging Face
image = sagemaker.image_uris.retrieve(
framework='pytorch',
region=region,
image_scope='inference',
version='1.12',
instance_type='ml.g4dn.xlarge',
)
model_name = f'sagemaker-soln-whisper-model-{int(time.time())}'
whisper_model_sm = sagemaker.model.Model(
model_data=model_uri,
image_uri=image,
role=sagemaker.get_execution_role(),
entry_point="inference.py",
source_dir='src',
name=model_name,
)
# Audio transcribe
transcribe = whisper_endpoint.predict(audio.numpy())The above demonstration video shows how voice commands, in conjunction with text input, can facilitate the task of document summarization through interactive conversation.
Guiding NLP tasks through multi-round conversations
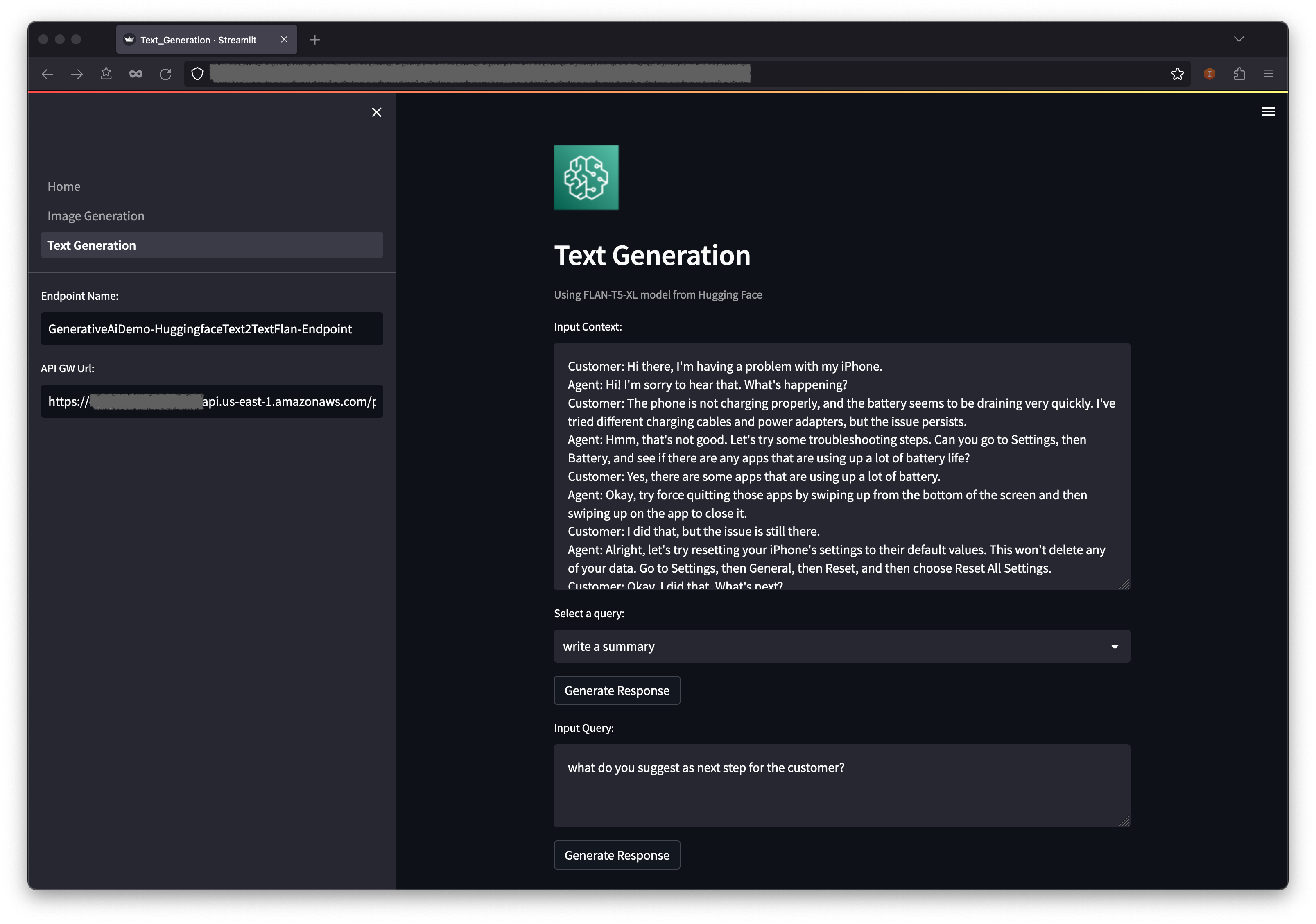
Memory in language models maintains a concept of state throughout a user’s interactions. This involves processing a sequence of chat messages to extract and transform knowledge. Memory types vary, but each can be understood using standalone functions and within a chain. Memory can return multiple data points, such as recent messages or message summaries, in the form of strings or lists. This post focuses on the simplest memory form, buffer memory, which stores all prior messages, and demonstrates its usage with modular utility functions and chains.
The LangChain’s ChatMessageHistory class is a crucial utility for memory modules, providing convenient methods to save and retrieve human and AI messages by remembering all previous chat interactions. It’s ideal for managing memory externally from a chain. The following code is an example of applying a simple concept in a chain by introducing ConversationBufferMemory, a wrapper for ChatMessageHistory. This wrapper extracts messages into a variable, allowing them to be represented as a string:
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(return_messages=True)LangChain works with many popular LLM providers such as AI21 Labs, OpenAI, Cohere, Hugging Face, and more. For this example, we use a locally deployed AI21 Labs’ Jurassic-2 LLM wrapper using SageMaker. AI21 Studio also provides API access to Jurassic-2 LLMs.
from langchain import PromptTemplate, SagemakerEndpoint
from langchain.llms.sagemaker_endpoint import ContentHandlerBase
from langchain.chains.question_answering import load_qa_chain
prompt= PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
class ContentHandler(ContentHandlerBase):
content_type = "application/json"
accepts = "application/json"
def transform_input(self, prompt: str, model_kwargs: Dict) -- bytes:
input_str = json.dumps({prompt: prompt, **model_kwargs})
return input_str.encode('utf-8')
def transform_output(self, output: bytes) -- str:
response_json = json.loads(output.read().decode("utf-8"))
return response_json[0]["generated_text"]
content_handler = ContentHandler()
llm_ai21=SagemakerEndpoint(
endpoint_name=endpoint_name,
credentials_profile_name=f'aws-credentials-profile-name',
region_name="us-east-1",
model_kwargs={"temperature":0},
content_handler=content_handler)
qa_chain = VectorDBQA.from_chain_type(
llm=llm_ai21,
chain_type='stuff',
vectorstore=docsearch,
verbose=True,
memory=ConversationBufferMemory(return_messages=True)
)
response = qa_chain(
{'query': query_input},
return_only_outputs=True
)In the event that the process is unable to locate an appropriate response from the original documents in response to a user’s inquiry, the integration of a third-party URL or ideally a task-driven autonomous agent with external data sources significantly enhances the system’s ability to access a vast array of information, ultimately improving context and providing more accurate and current results.
With AI21’s preconfigured Summarize run method, a query can access a predetermined URL, condense its content, and then carry out question and answer tasks based on the summarized information:
# Call AI21 API to query the context of a specific URL for Q&A
ai21.api_key = "<YOUR_API_KEY>"
url_external_source = "<your_source_url>"
response_url = ai21.Summarize.execute(
source=url_external_source,
sourceType="URL" )
context = "<concate_document_and_response_url>"
question = "<query>"
response = ai21.Answer.execute(
context=context,
question=question,
sm_endpoint=endpoint_name,
maxTokens=100,
)For additional details and code examples, refer to the LangChain LLM integration document as well as the task-specific API documents provided by AI21.
Task automation using BabyAGI
The task automation mechanism allows the system to process complex queries and generate relevant responses, which greatly improves the validity and authenticity of document processing. LangCain’s BabyAGI is a powerful AI-powered task management system that can autonomously create, prioritize, and run tasks. One of the key features is its ability to interface with external sources of information, such as the web, databases, and APIs. One way to use this feature is to integrate BabyAGI with Serpapi, a search engine API that provides access to search engines. This integration allows BabyAGI to search the web for information related to tasks, allowing BabyAGI to access a wealth of information beyond the input documents.
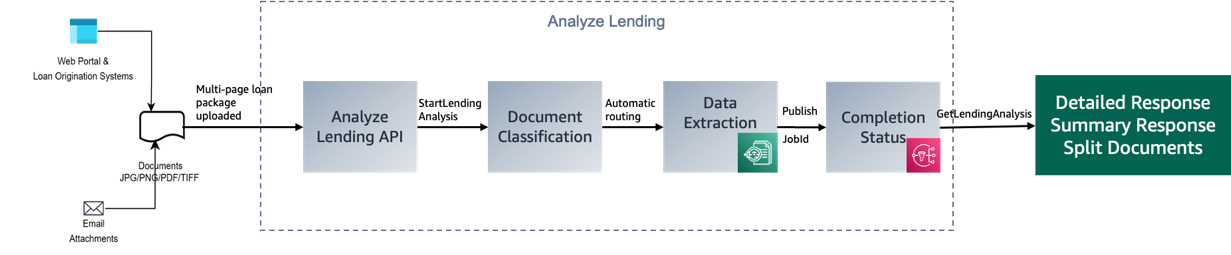
BabyAGI’s autonomous tasking capacity is fueled by an LLM, a vector search database, an API wrapper to external links, and the LangChain framework, allowing it to run a broad spectrum of tasks across various domains. This enables the system to proactively carry out tasks based on user interactions, streamlining the document processing pipeline that incorporates external sources and creating a more efficient, smooth experience. The following diagram illustrates the task automation process.
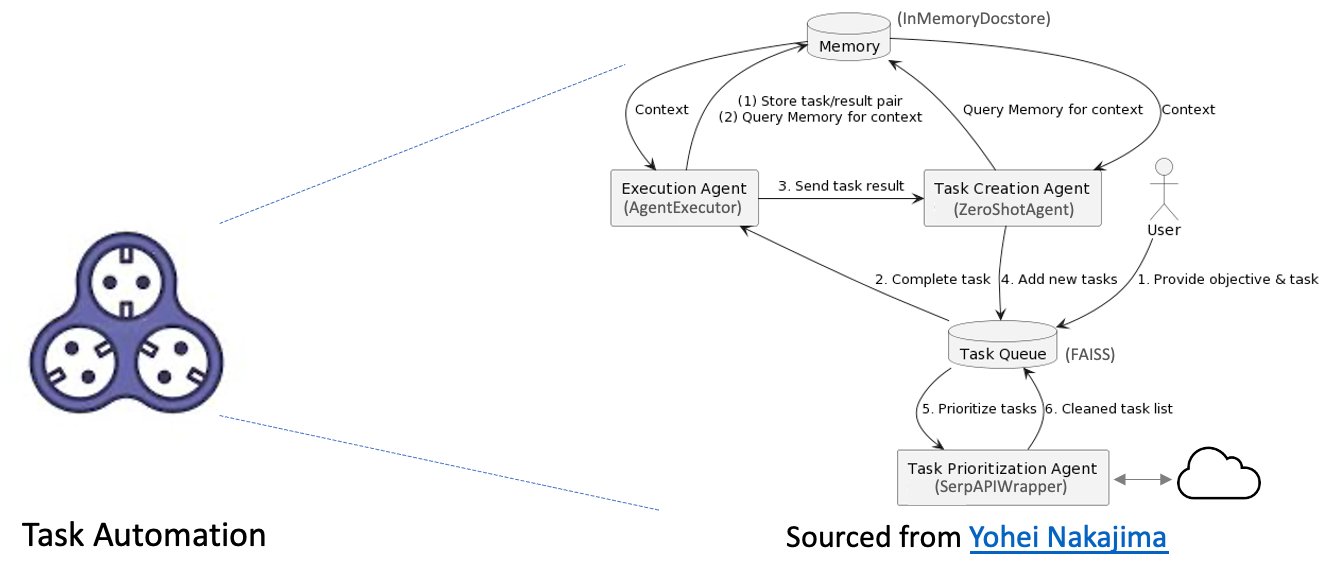
This process includes the following components:
- Memory – The memory stores all the information that BabyAGI needs to complete its tasks. This includes the task itself, as well as any intermediate results or data that BabyAGI has generated.
- Execution agent – The execution agent is responsible for carrying out the tasks that are stored in the memory. It does this by accessing the memory, retrieving the relevant information, and then taking the necessary steps to complete the task.
- Task creation agent – The task creation agent is responsible for generating new tasks for BabyAGI to complete. It does this by analyzing the current state of the memory and identifying any gaps in knowledge or understanding. When a gap has been identified, the task creation agent generates a new task that will help BabyAGI fill that gap.
- Task queue – The task queue is a list of all of the tasks that BabyAGI has been assigned. The tasks are added to the queue in the order in which they were received.
- Task prioritization agent – The task prioritization agent is responsible for determining the order in which BabyAGI should complete its tasks. It does this by analyzing the tasks in the queue and identifying the ones that are most important or urgent. The tasks that are most important are placed at the front of the queue, and the tasks that are least important are placed at the back of the queue.
See the following code:
from babyagi import BabyAGI
from langchain.docstore import InMemoryDocstore
import faiss
# Set temperatur=0 to generate the most frequent words, instead of more “poetically free” behavior.
new_query = """
What happened to the First Republic Bank? Will the FED take the same action as it did on SVB's failure?
"""
# Enable verbose logging and use a fixed embedding size.
verbose = True
embedding_size = 1536
# Using FAISS vector cluster for vectore store
index = faiss.IndexFlatL2(embedding_size)
vectorstore = FAISS(llm_embeddings.embed_query, index, InMemoryDocstore({}), {})
# Choose 1 iteration for demo and 1>N>10 for real. If None, it will loop indefinitely
max_iterations: Optional[int] = 2
# Call bayagi class for task automation
baby_agi = BabyAGI.from_llm(
llm=llm_embedding, vectorstore=vectorstore, verbose=verbose, max_iterations=max_iterations<br />)
response = baby_agi({"objective": new_query})Let’s examine the tasks gathered and their outcomes from a single iteration, used for demonstration purposes, to accomplish the objective in response to the user’s inquiry. BabyAGI operates through a continuous cycle of the following steps:
- A task creation agent formulates a new task.
- The new task is incorporated into the task queue.
- The task prioritization agent establishes the sequence in which tasks should be tackled.
- The run agent accomplishes the task.
- The task outcome is saved in the memory.
- The cycle repeats.
This iterative process enables BabyAGI to learn and develop over time. As it successfully completes an increasing number of tasks, BabyAGI’s knowledge and comprehension of the world expand. Consequently, it can generate and efficiently run more intricate and advanced tasks. By augmenting the iteration count, you can enhance the outcome through the reorganization of the task list, which focuses on the goal and the outcome of preceding tasks, ultimately yielding more pertinent and precise responses.
See the following example output:
*****TASK LIST*****
1: Make a todo list
*****NEXT TASK*****
1: Make a todo list
> Entering new AgentExecutor chain...
Thought: I need to research the First Republic Bank and the FED's action
Action: Search
Action Input: What happened to the First Republic Bank? Will the FED take the same
action as it did on SVB's failure?
Observation: First Republic's failure was due to a run on deposits following the
collapse of Silicon Valley Bank and Signature Bank. JPMorgan Chase acquired
First Republic Bank on May 1, 2023. If you had insured or uninsured money in First Republic accounts, your funds are safe and now managed by JPMorgan Chase.
Thought: I need to research the FED's action on SVB's failure
Action: Search
Action Input: What action did the FED take on SVB's failure?
Observation: The Hutchins Center explains how the Federal Reserve has responded to the
March 2023 failures of Silicon Valley Bank and Signature Bank.
Thought: I now know the final answer
Final Answer: The FED responded to the March 2023 failures of Silicon Valley Bank and <br />Signature Bank by providing liquidity to the banking system. JPMorgan
Chase acquired First Republic Bank on May 1, 2023, and if you had insured
or uninsured money in First Republic accounts, your funds are safe and
now managed by JPMorgan Chase.
> Finished chain.
*****TASK RESULT*****
The Federal Reserve responded to the March 2023 failures of Silicon Valley Bank and Signature Bank by providing liquidity to the banking system. It is unclear what action the FED will take in response to the failure of First Republic Bank.
***TASK LIST***
2: Research the timeline of First Republic Bank's failure.
3: Analyze the Federal Reserve's response to the failure of Silicon Valley Bank and Signature Bank.
4: Compare the Federal Reserve's response to the failure of Silicon Valley Bank and Signature Bank to the Federal Reserve's response to the failure of First Republic Bank.
5: Investigate the potential implications of the Federal Reserve's response to the failure of First Republic Bank.
6: Identify any potential risks associated with the Federal Reserve's response to the failure of First Republic Bank.<br />*****NEXT TASK*****
2: Research the timeline of First Republic Bank's failure.
> Entering new AgentExecutor chain...
Will the FED take the same action as it did on SVB's failure?
Thought: I should search for information about the timeline of First Republic Bank's failure and the FED's action on SVB's failure.
Action: Search
Action Input: Timeline of First Republic Bank's failure and FED's action on SVB's failure
Observation: March 20: The FDIC decides to break up SVB and hold two separate auctions for its traditional deposits unit and its private bank after failing ...
Thought: I should look for more information about the FED's action on SVB's failure.
Action: Search
Action Input: FED's action on SVB's failure
Observation: The Fed blamed failures on mismanagement and supervisory missteps, compounded by a dose of social media frenzy.
Thought: I now know the final answer.
Final Answer: The FED is likely to take similar action on First Republic Bank's failure as it did on SVB's failure, which was to break up the bank and hold two separate auctions for its traditional deposits unit and its private bank.</p><p>> Finished chain.
*****TASK RESULT*****
The FED responded to the March 2023 failures of ilicon Valley Bank and Signature Bank
by providing liquidity to the banking system. JPMorgan Chase acquired First Republic
Bank on May 1, 2023, and if you had insured or uninsured money in First Republic
accounts, your funds are safe and now managed by JPMorgan Chase.*****TASK ENDING*****With BabyAGI for task automation, the dialogue-guided IDP system showcased its effectiveness by going beyond the original document’s context to address the user’s query about the Federal Reserve’s potential actions concerning the First Republic Bank’s failure, which occurred in late April 2023, 1 month after the sample publication, in comparison to SVB’s failure. To achieve this, the system generated a to-do list and completed tasks sequentially. It investigated the circumstances surrounding the First Republic Bank’s failure, pinpointed potential risks tied to the Federal Reserve’s response, and compared it to the response to SVB’s failure.
Although BabyAGI remains a work in progress, it carries the promise of revolutionizing machine interactions, inventive thinking, and problem resolution. As BabyAGI’s learning and enhancement persist, it will be capable of producing more precise, insightful, and inventive responses. By empowering machines to learn and evolve autonomously, BabyAGI could facilitate their assistance in a broad spectrum of tasks, ranging from mundane chores to intricate problem-solving.
Constraints and limitations
Dialogue-guided IDP offers a promising approach to enhancing the efficiency and effectiveness of document analysis and extraction. However, we must acknowledge its current constraints and limitations, such as the need for data bias avoidance, hallucination mitigation, the challenge of handling complex and ambiguous language, and difficulties in understanding context or maintaining coherence in longer conversations.
Additionally, it’s important to consider confabulations and hallucinations in AI-generated responses, which may lead to the creation of inaccurate or fabricated information. To address these challenges, ongoing developments are focusing on refining LLMs with better natural language understanding capabilities, incorporating domain-specific knowledge and developing more robust context-aware models. Building an LLM from scratch can be costly and time-consuming; however, you can employ several strategies to improve existing models:
- Fine-tuning a pre-trained LLM on specific domains for more accurate and relevant outputs
- Integrating external data sources known to be safe during inference for enhanced contextual understanding
- Designing better prompts to elicit more precise responses from the model
- Using ensemble models to combine outputs from multiple LLMs, averaging out errors and minimizing hallucination chances
- Building guardrails to prevent models from veering off into undesired areas while ensuring apps respond with accurate and appropriate information
- Conducting supervised fine-tuning with human feedback, iteratively refining the model for increased accuracy and reduced hallucination.
By adopting these approaches, AI-generated responses can be made more reliable and valuable.
The task-driven autonomous agent offers significant potential across various applications, but it is vital to consider key risks before adopting the technology. These risks include:
- Data privacy and security breaches due to reliance on the selected LLM provider and vectorDB
- Ethical concerns arising from biased or harmful content generation
- Dependence on model accuracy, which may lead to ineffective task completion or undesired results
- System overload and scalability issues if task generation outpaces completion, requiring proper task sequencing and parallel management
- Misinterpretation of task prioritization based on the LLM’s understanding of task importance
- The authenticity of the data it received from the web
Addressing these risks is crucial for responsible and successful application, allowing us to maximize the benefits of AI-powered language models while minimizing potential risks.
Conclusions
The dialogue-guided solution for IDP presents a groundbreaking approach to document processing by integrating OCR, automatic speech recognition, LLMs, task automation, and external data sources. This comprehensive solution enables businesses to streamline their document processing workflows, making them more efficient and intuitive. By incorporating these cutting-edge technologies, organizations can not only revolutionize their document management processes, but also bolster decision-making capabilities and considerably boost overall productivity. The solution offers a transformative and innovative means for businesses to unlock the full potential of their document workflows, ultimately driving growth and success in the era of generative AI. Refer to SageMaker Jumpstart for other solutions and Amazon Bedrock for additional generative AI models.
The authors would like to sincerely express their appreciation to Ryan Kilpatrick, Ashish Lal, and Kristine Pearce for their valuable inputs and contributions to this work. They also acknowledge Clay Elmore for the code sample provided on Github.
About the authors
 Alfred Shen is a Senior AI/ML Specialist at AWS. He has been working in Silicon Valley, holding technical and managerial positions in diverse sectors including healthcare, finance, and high-tech. He is a dedicated applied AI/ML researcher, concentrating on CV, NLP, and multimodality. His work has been showcased in publications such as EMNLP, ICLR, and Public Health.
Alfred Shen is a Senior AI/ML Specialist at AWS. He has been working in Silicon Valley, holding technical and managerial positions in diverse sectors including healthcare, finance, and high-tech. He is a dedicated applied AI/ML researcher, concentrating on CV, NLP, and multimodality. His work has been showcased in publications such as EMNLP, ICLR, and Public Health.
 Dr. Vivek Madan is an Applied Scientist with the Amazon SageMaker JumpStart team. He got his PhD from University of Illinois at Urbana-Champaign and was a Post Doctoral Researcher at Georgia Tech. He is an active researcher in machine learning and algorithm design and has published papers in EMNLP, ICLR, COLT, FOCS, and SODA conferences.
Dr. Vivek Madan is an Applied Scientist with the Amazon SageMaker JumpStart team. He got his PhD from University of Illinois at Urbana-Champaign and was a Post Doctoral Researcher at Georgia Tech. He is an active researcher in machine learning and algorithm design and has published papers in EMNLP, ICLR, COLT, FOCS, and SODA conferences.
 Dr. Li Zhang is a Principal Product Manager-Technical for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms, a service that helps data scientists and machine learning practitioners get started with training and deploying their models, and uses reinforcement learning with Amazon SageMaker. His past work as a principal research staff member and master inventor at IBM Research has won the test of time paper award at IEEE INFOCOM.
Dr. Li Zhang is a Principal Product Manager-Technical for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms, a service that helps data scientists and machine learning practitioners get started with training and deploying their models, and uses reinforcement learning with Amazon SageMaker. His past work as a principal research staff member and master inventor at IBM Research has won the test of time paper award at IEEE INFOCOM.
 Dr. Changsha Ma is an AI/ML Specialist at AWS. She is a technologist with a PhD in Computer Science, a master’s degree in Education Psychology, and years of experience in data science and independent consulting in AI/ML. She is passionate about researching methodological approaches for machine and human intelligence. Outside of work, she loves hiking, cooking, hunting food, mentoring college students for entrepreneurship, and spending time with friends and families.
Dr. Changsha Ma is an AI/ML Specialist at AWS. She is a technologist with a PhD in Computer Science, a master’s degree in Education Psychology, and years of experience in data science and independent consulting in AI/ML. She is passionate about researching methodological approaches for machine and human intelligence. Outside of work, she loves hiking, cooking, hunting food, mentoring college students for entrepreneurship, and spending time with friends and families.
 Anup Ravindranath is a Senior Solutions Architect at Amazon Web Services (AWS) based in Toronto, Canada working with Financial Services organizations. He helps customers to transform their businesses and innovate on cloud.
Anup Ravindranath is a Senior Solutions Architect at Amazon Web Services (AWS) based in Toronto, Canada working with Financial Services organizations. He helps customers to transform their businesses and innovate on cloud. Vinnie Saini is a Senior Solutions Architect at Amazon Web Services (AWS) based in Toronto, Canada. She has been helping Financial Services customers transform on cloud, with AI and ML driven solutions laid on strong foundational pillars of Architectural Excellence.
Vinnie Saini is a Senior Solutions Architect at Amazon Web Services (AWS) based in Toronto, Canada. She has been helping Financial Services customers transform on cloud, with AI and ML driven solutions laid on strong foundational pillars of Architectural Excellence.
 Hemant Singh is a Machine Learning Engineer with experience in Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He got his masters from Courant Institute of Mathematical Sciences and B.Tech from IIT Delhi. He has experience in working on a diverse range of machine learning problems within the domain of natural language processing, computer vision, and time series analysis.
Hemant Singh is a Machine Learning Engineer with experience in Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He got his masters from Courant Institute of Mathematical Sciences and B.Tech from IIT Delhi. He has experience in working on a diverse range of machine learning problems within the domain of natural language processing, computer vision, and time series analysis. Rachna Chadha is a Principal Solutions Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that the ethical and responsible use of AI can improve society in future and bring economic and social prosperity. In her spare time, Rachna likes spending time with her family, hiking, and listening to music.
Rachna Chadha is a Principal Solutions Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that the ethical and responsible use of AI can improve society in future and bring economic and social prosperity. In her spare time, Rachna likes spending time with her family, hiking, and listening to music. Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.






 What does TTQ mean to you
What does TTQ mean to you



















































 Ashish Lagwankar is a Senior Enterprise Solutions Architect at AWS. His core interests include AI/ML, serverless, and container technologies. Ashish is based in the Boston, MA, area and enjoys reading, outdoors, and spending time with his family.
Ashish Lagwankar is a Senior Enterprise Solutions Architect at AWS. His core interests include AI/ML, serverless, and container technologies. Ashish is based in the Boston, MA, area and enjoys reading, outdoors, and spending time with his family.

 Vik is a Partner in the Cloud & Data practice at PwC Canada He earned a PhD in Information Science from the University of Toronto. He is convinced that there is a telepathic connection between his biological neural network and the artificial neural networks that he trains on SageMaker. Connect with him on
Vik is a Partner in the Cloud & Data practice at PwC Canada He earned a PhD in Information Science from the University of Toronto. He is convinced that there is a telepathic connection between his biological neural network and the artificial neural networks that he trains on SageMaker. Connect with him on  Kyle is a Partner in the Cloud & Data practice at PwC Canada, along with his crack team of tech alchemists, they weave enchanting MLOPs solutions that mesmerize clients with accelerated business value. Armed with the power of artificial intelligence and a sprinkle of wizardry, Kyle turns complex challenges into digital fairy tales, making the impossible possible. Connect with him on
Kyle is a Partner in the Cloud & Data practice at PwC Canada, along with his crack team of tech alchemists, they weave enchanting MLOPs solutions that mesmerize clients with accelerated business value. Armed with the power of artificial intelligence and a sprinkle of wizardry, Kyle turns complex challenges into digital fairy tales, making the impossible possible. Connect with him on  Francois is a Principal Advisory Consultant with AWS Professional Services Canada and the Canadian practice lead for Data and Innovation Advisory. He guides customers to establish and implement their overall cloud journey and their data programs, focusing on vision, strategy, business drivers, governance, target operating models, and roadmaps. Connect with him on
Francois is a Principal Advisory Consultant with AWS Professional Services Canada and the Canadian practice lead for Data and Innovation Advisory. He guides customers to establish and implement their overall cloud journey and their data programs, focusing on vision, strategy, business drivers, governance, target operating models, and roadmaps. Connect with him on 
 Hantzley Tauckoor is an APJ Partner Solutions Architecture Leader based in Singapore. He has 20 years’ experience in the ICT industry spanning multiple functional areas, including solutions architecture, business development, sales strategy, consulting, and leadership. He leads a team of Senior Solutions Architects that enable partners to develop joint solutions, build technical capabilities, and steer them through the implementation phase as customers migrate and modernize their applications to AWS.
Hantzley Tauckoor is an APJ Partner Solutions Architecture Leader based in Singapore. He has 20 years’ experience in the ICT industry spanning multiple functional areas, including solutions architecture, business development, sales strategy, consulting, and leadership. He leads a team of Senior Solutions Architects that enable partners to develop joint solutions, build technical capabilities, and steer them through the implementation phase as customers migrate and modernize their applications to AWS. Kwonyul Choi is a CTO at BABITALK, a Korean beauty care platform startup, based in Seoul. Prior to this role, Kownyul worked as Software Development Engineer at AWS with a focus on AWS CDK and Amazon SageMaker.
Kwonyul Choi is a CTO at BABITALK, a Korean beauty care platform startup, based in Seoul. Prior to this role, Kownyul worked as Software Development Engineer at AWS with a focus on AWS CDK and Amazon SageMaker. Arunprasath Shankar is a Senior AI/ML Specialist Solutions Architect with AWS, helping global customers scale their AI solutions effectively and efficiently in the cloud. In his spare time, Arun enjoys watching sci-fi movies and listening to classical music.
Arunprasath Shankar is a Senior AI/ML Specialist Solutions Architect with AWS, helping global customers scale their AI solutions effectively and efficiently in the cloud. In his spare time, Arun enjoys watching sci-fi movies and listening to classical music. Satish Upreti is a Migration Lead PSA and Security SME in the partner organization in APJ. Satish has 20 years of experience spanning on-premises private cloud and public cloud technologies. Since joining AWS in August 2020 as a migration specialist, he provides extensive technical advice and support to AWS partners to plan and implement complex migrations.
Satish Upreti is a Migration Lead PSA and Security SME in the partner organization in APJ. Satish has 20 years of experience spanning on-premises private cloud and public cloud technologies. Since joining AWS in August 2020 as a migration specialist, he provides extensive technical advice and support to AWS partners to plan and implement complex migrations.


.gif)
.gif)


