The adoption of multimodal interactions by Voice Assistants (VAs) is growing rapidly to enhance human-computer interactions. Smartwatches have now incorporated trigger-less methods of invoking VAs, such as Raise To Speak (RTS), where the user raises their watch and speaks to VAs without an explicit trigger. Current state-of-the-art RTS systems rely on heuristics and engineered Finite State Machines to fuse gesture and audio data for multimodal decision-making. However, these methods have limitations, including limited adaptability, scalability, and induced human biases. In this work, we…Apple Machine Learning Research
Collaborative Machine Learning Model Building with Families Using Co-ML
Existing novice-friendly machine learning (ML) modeling tools center around a solo user experience, where a single user collects only their own data to build a model. However, solo modeling experiences limit valuable opportunities for encountering alternative ideas and approaches that can arise when learners work together; consequently, it often precludes encountering critical issues in ML around data representation and diversity that can surface when different perspectives are manifested in a group-constructed data set. To address this issue, we created Co-ML – a tablet-based app for learners…Apple Machine Learning Research
Use Amazon SageMaker Canvas to build machine learning models using Parquet data from Amazon Athena and AWS Lake Formation
Data is the foundation for machine learning (ML) algorithms. One of the most common formats for storing large amounts of data is Apache Parquet due to its compact and highly efficient format. This means that business analysts who want to extract insights from the large volumes of data in their data warehouse must frequently use data stored in Parquet.
To simplify access to Parquet files, Amazon SageMaker Canvas has added data import capabilities from over 40 data sources, including Amazon Athena, which supports Apache Parquet.
Canvas provides connectors to AWS data sources such as Amazon Simple Storage Service (Amazon S3), Athena, and Amazon Redshift. In this post, we describe how to query Parquet files with Athena using AWS Lake Formation and use the output Canvas to train a model.
Solution overview
Athena is a serverless, interactive analytics service built on open-source frameworks, supporting open table and file formats. Many teams are turning to Athena to enable interactive querying and analyze their data in the respective data stores without creating multiple data copies.
Athena allows applications to use standard SQL to query massive amounts of data on an S3 data lake. Athena supports various data formats, including:
- CSV
- TSV
- JSON
- text files
- Open-source columnar formats, such as ORC and Parquet
- Compressed data in Snappy, Zlib, LZO, and GZIP formats
Parquet files organize the data into columns and use efficient data compression and encoding schemes for fast data storage and retrieval. You can reduce the import time in Canvas by using Parquet files for bulk data imports and with specific columns.
Lake Formation is an integrated data lake service that makes it easy for you to ingest, clean, catalog, transform, and secure your data and make it available for analysis and ML. Lake Formation automatically manages access to the registered data in Amazon S3 through services including AWS Glue, Athena, Amazon Redshift, Amazon QuickSight, and Amazon EMR using Zeppelin notebooks with Apache Spark to ensure compliance with your defined policies.
In this post, we show you how to import Parquet data to Canvas from Athena, where Lake Formation enables data governance.
To illustrate, we use the operations data of a consumer electronics business. We create a model to estimate the demand for electronic products using their historical time series data.
This solution is illustrated in three steps:
- Set up the Lake Formation.
- Grant Lake Formation access permissions to Canvas.
- Import the Parquet data to Canvas using Athena.
- Use the imported Parquet data to build ML models with Canvas.
The following diagram illustrates the solution architecture.
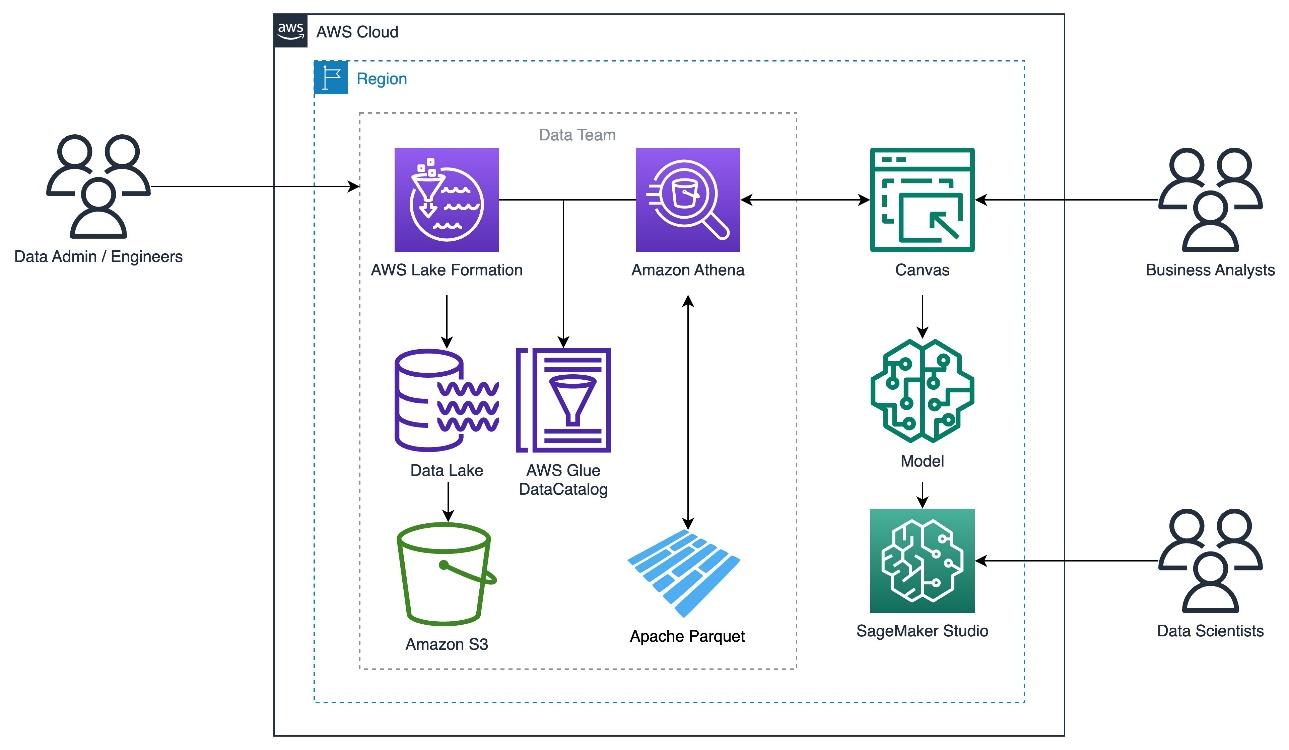
Set up the Lake Formation database
The steps listed here form a one-time setup to show you the data lake hosting the Parquet data, which can be consumed by your analysts to gain insights using Canvas. Either cloud engineers or administrators can best perform these prerequisites. Analysts can go directly to Canvas and import the data from Athena.
The data used in this post consist of two datasets sourced from Amazon S3. These datasets have been generated synthetically for this post.
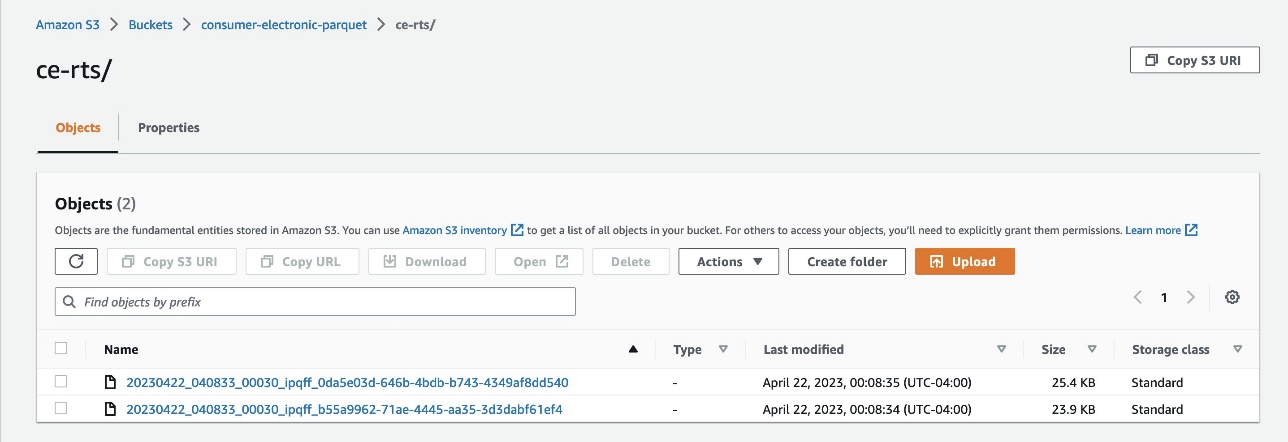
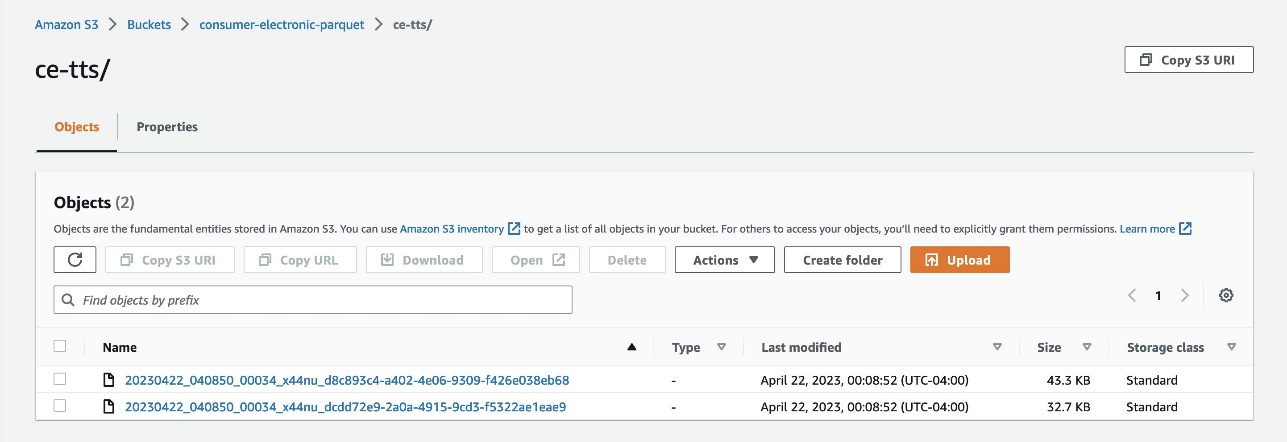
- Consumer Electronics Target Time Series (TTS) – The historical data of the quantity to forecast is called the Target Time Series (TTS). In this case, it’s the demand for an item.
- Consumer Electronics Related Time Series (RTS) – Other historical data that is known at exactly the same time as every sales transaction is called the Related Time Series (RTS). In our use case, it’s the price of an item. An RTS dataset includes time series data that isn’t included in a TTS dataset and might improve the accuracy of your predictor.
- Upload data to Amazon S3 as Parquet files from these two folders:
- ce-rts – Contains Consumer Electronics Related Time Series (RTS).
- ce-tts – Contains Consumer Electronics Target Time Series (TTS).
- Create a data lake with Lake Formation.
- On the Lake Formation console, create a database called
consumer-electronics.
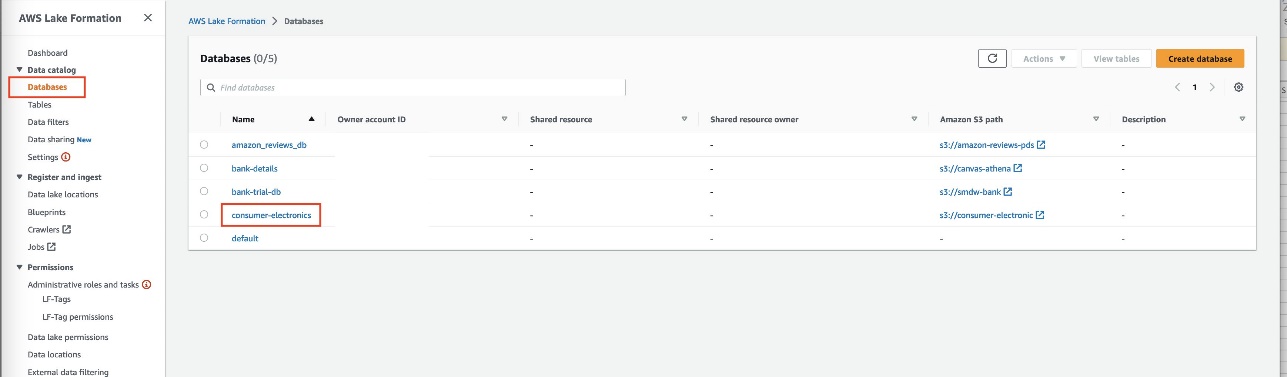
- Create two tables for the consumer electronics dataset with the names
ce-rts-Parquetandce-tts-Parquetwith the data sourced from the S3 bucket.
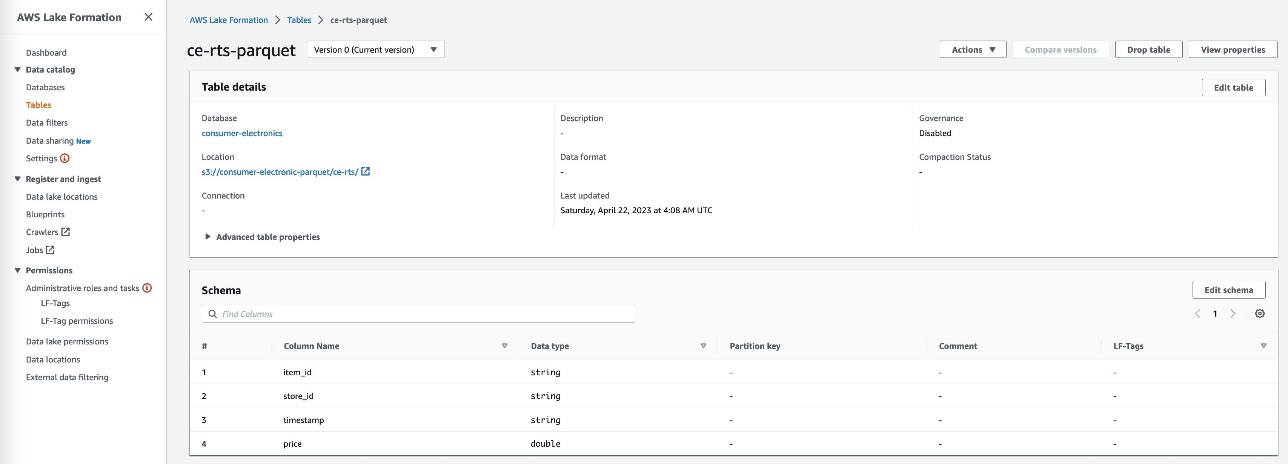
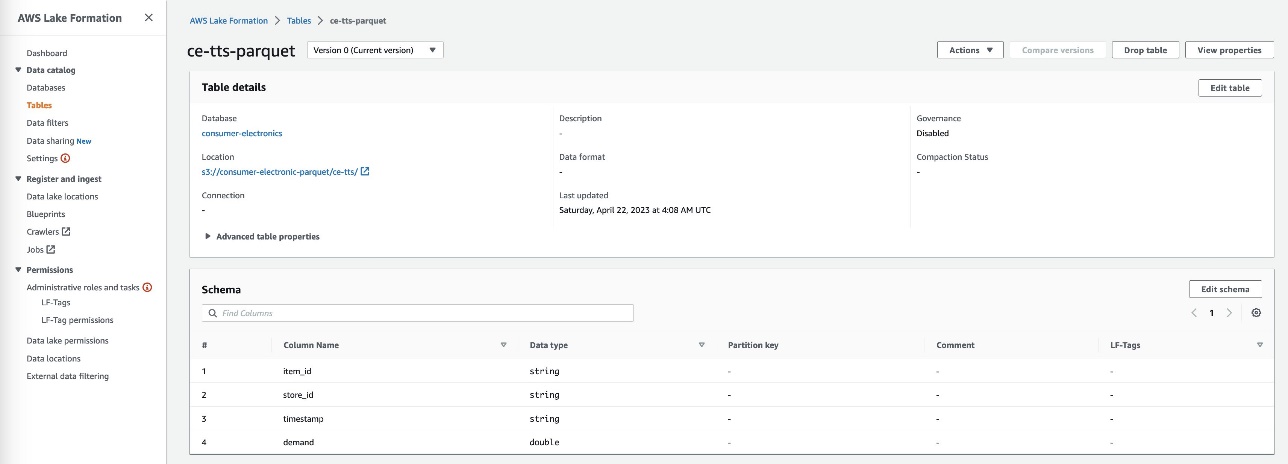
We use the database we created in this step in a later step to import the Parquet data into Canvas using Athena.
Grant Lake Formation access permissions to Canvas
This is a one-time setup to be done by either cloud engineers or administrators.
- Grant data lake permissions to access Canvas to access the consumer-electronics Parquet data.
- In the SageMaker Studio domain, view the Canvas user’s details.
- Copy the execution role name.
- Make sure the execution role has enough permissions to access the following services:
- Canvas.
- The S3 bucket where Parquet data is stored.
- Athena to connect from Canvas.
- AWS Glue to access the Parquet data using the Athena connector.
- In Lake Formation, choose Data Lake permissions in the navigation pane.
- Choose Grant.
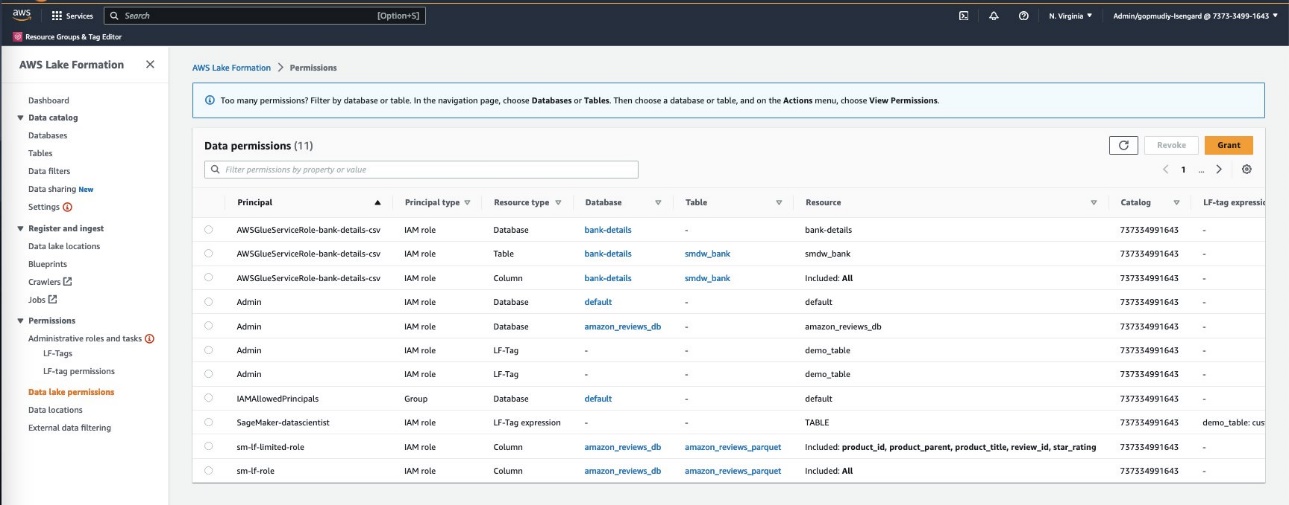
- For Principals, select IAM users and roles to provide Canvas access to your data artifacts.
- Specify your SageMaker Studio domain user’s execution role.
- Specify the database and tables.
- Choose Grant.
You can grant granular actions on the tables, columns, and data. This option provides granular access configuration of your sensitive data by the segregation of roles you have defined.
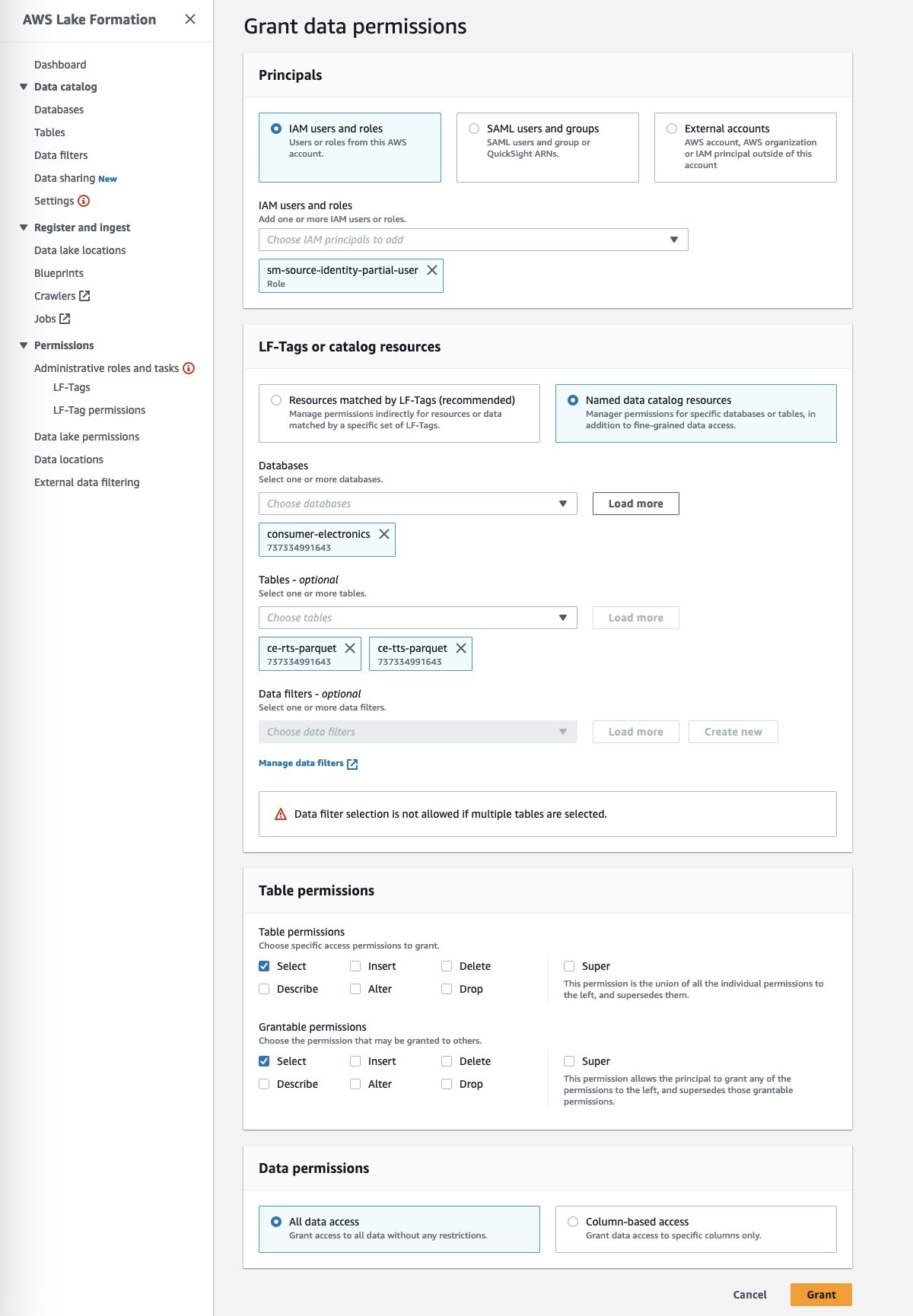
After you set up the required environment for the Canvas and Athena integration, proceed to the next step to import the data into Canvas using Athena.
Import data using Athena
Complete the following steps to import the Lake Formation-managed Parquet files:
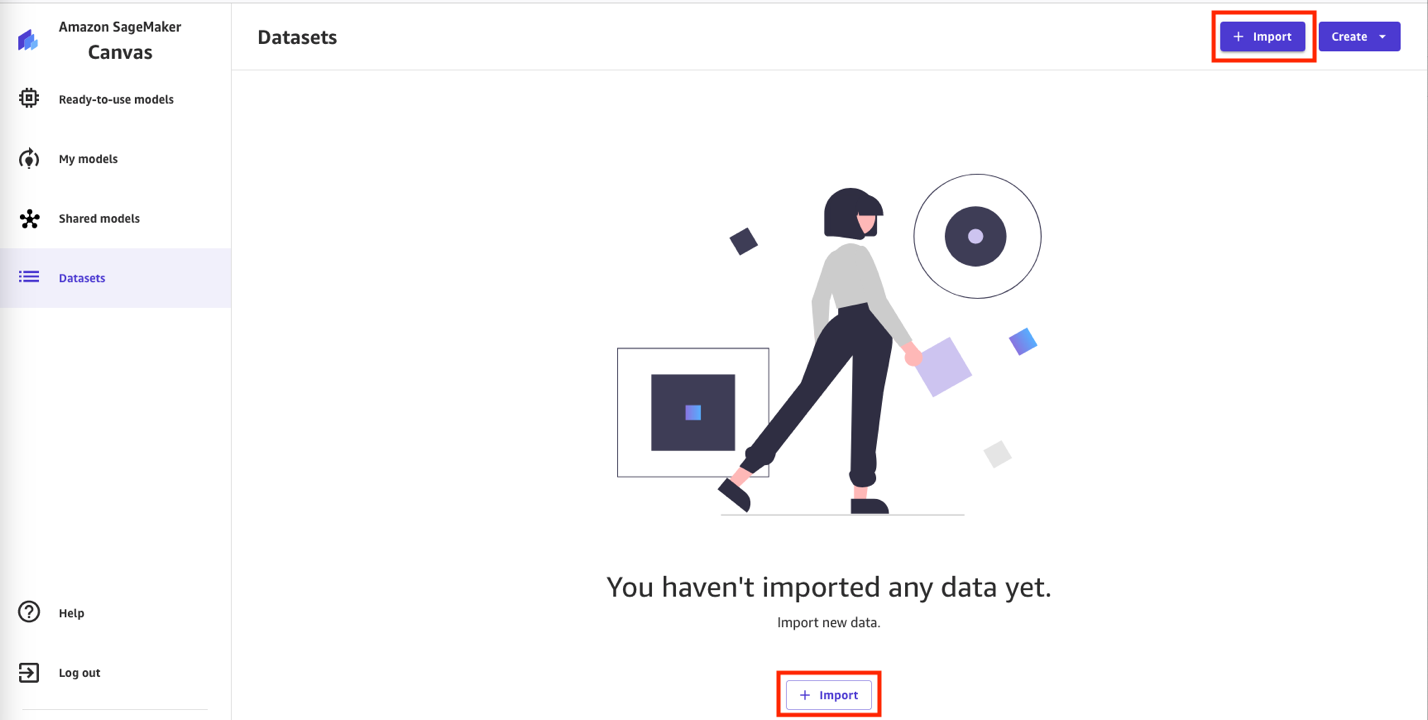
- In Canvas, choose Datasets in the navigation pane.
- Choose + Import to import the Parquet datasets managed by Lake Formation.
- Choose Athena as the data source.
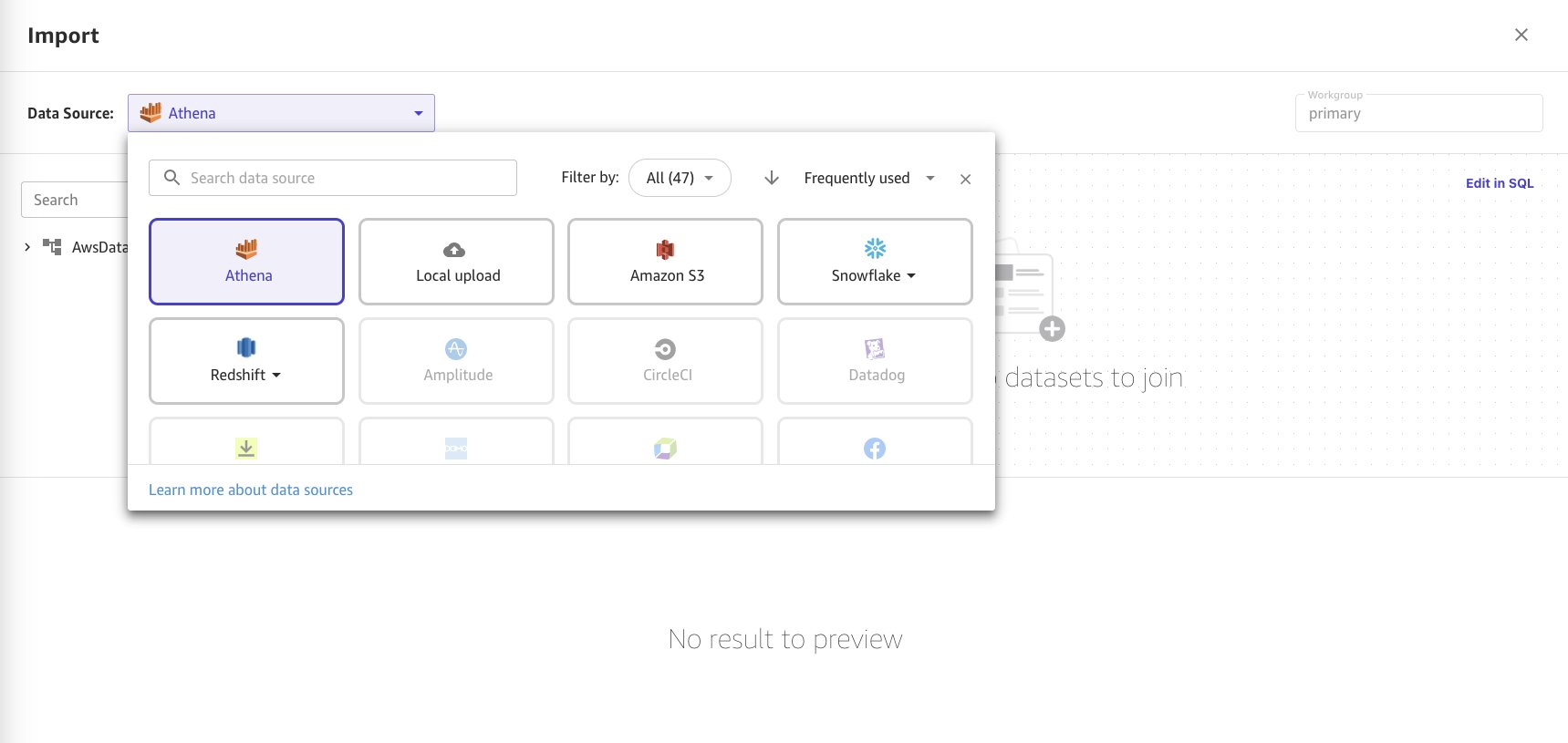
- Choose the
consumer-electronicsdataset in Parquet format from the Athena data catalog and table details in the menu. - Import the two datasets. Drag and drop the data source to select the first one.

When you drag and drop the dataset, the data preview appears in the bottom frame of the page.
- Choose Import data.
- Enter
consumer-electronics-rtsas the name for the dataset you’re importing.
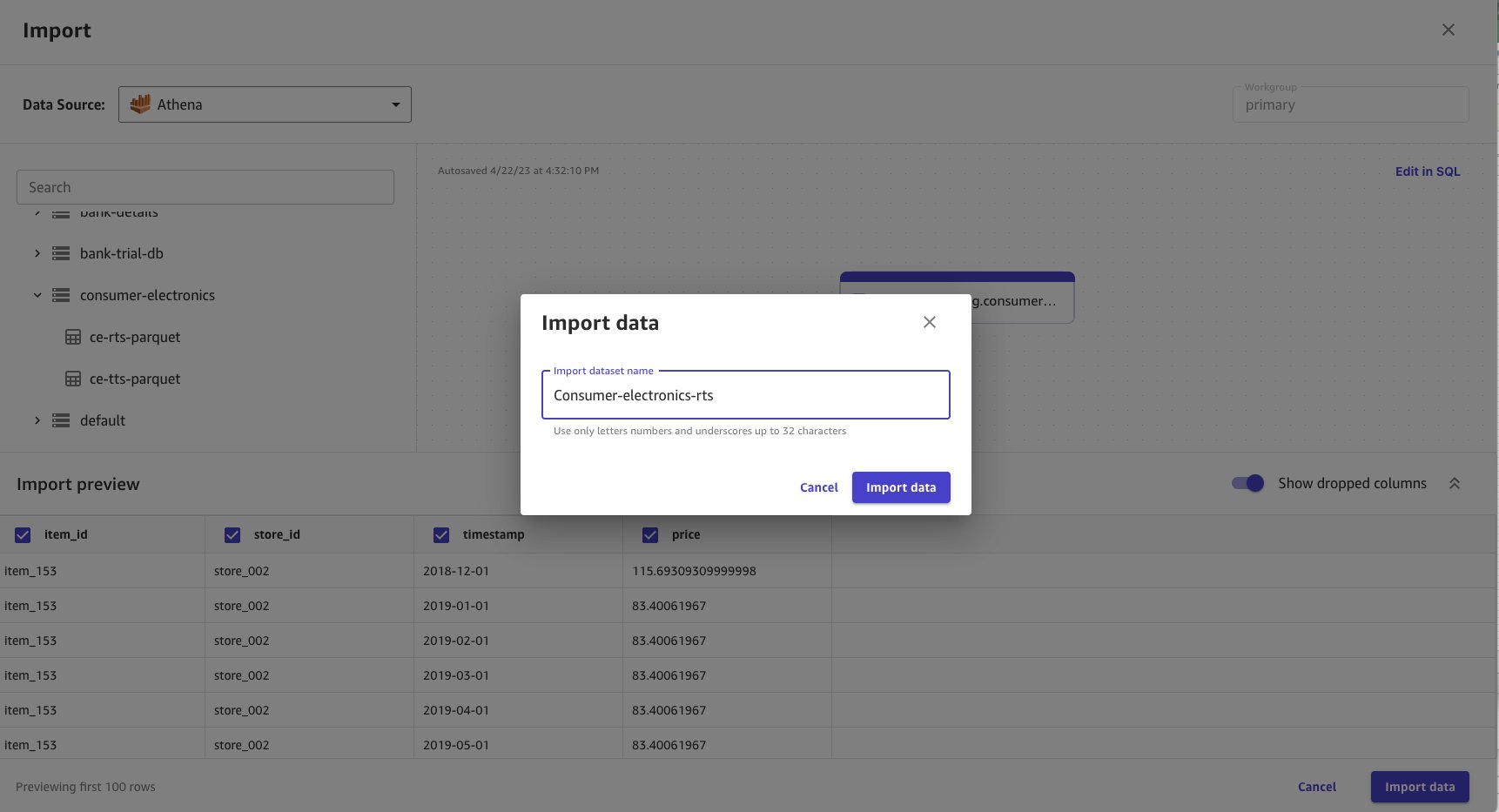
Data import takes time based on the data size. The dataset in this example is small, so the import takes a few seconds. When the data import is completed, the status turns from Processing to Ready.
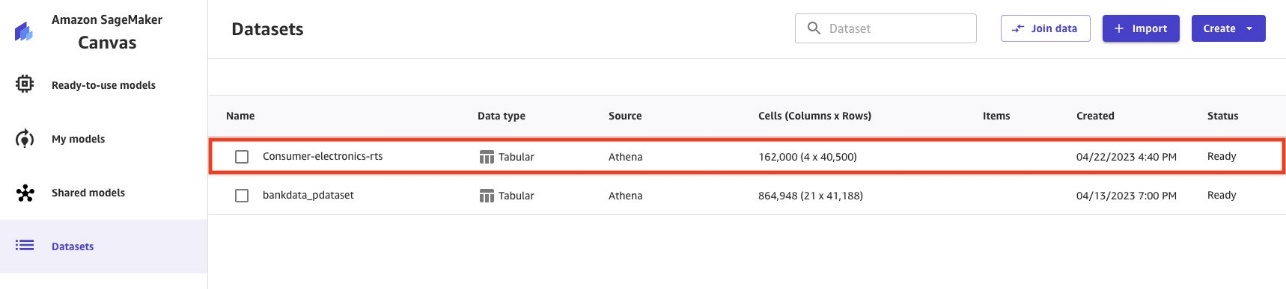
- Repeat the import process for the second dataset (
ce-tts).
When the ce-tts Parquet data is imported, the Datasets pageshow both datasets.
The imported datasets contain targeted and related time series data. The RTS dataset can help deep learning models improve forecast accuracy.
Let’s join the datasets to prepare for our analysis.
- Select the datasets.
- Choose Join data.
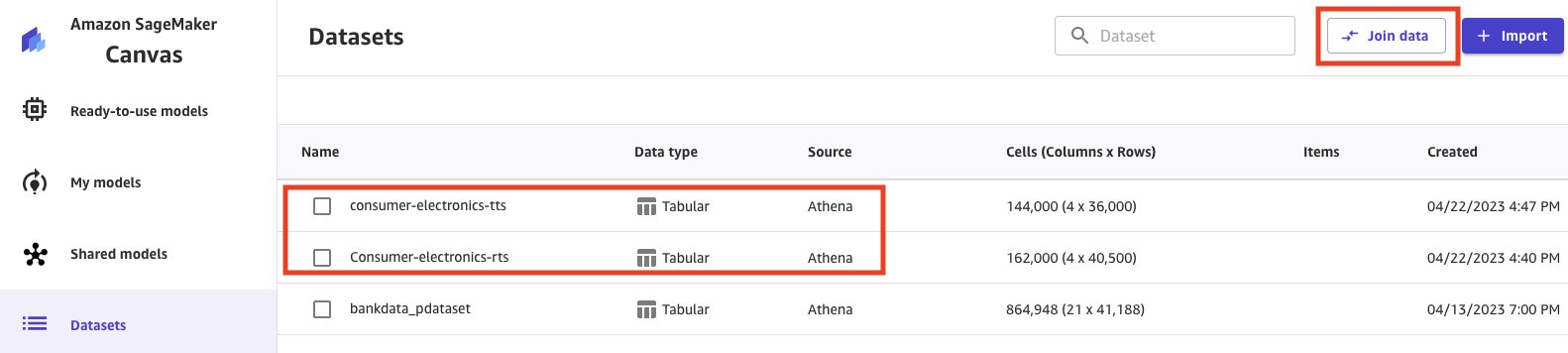
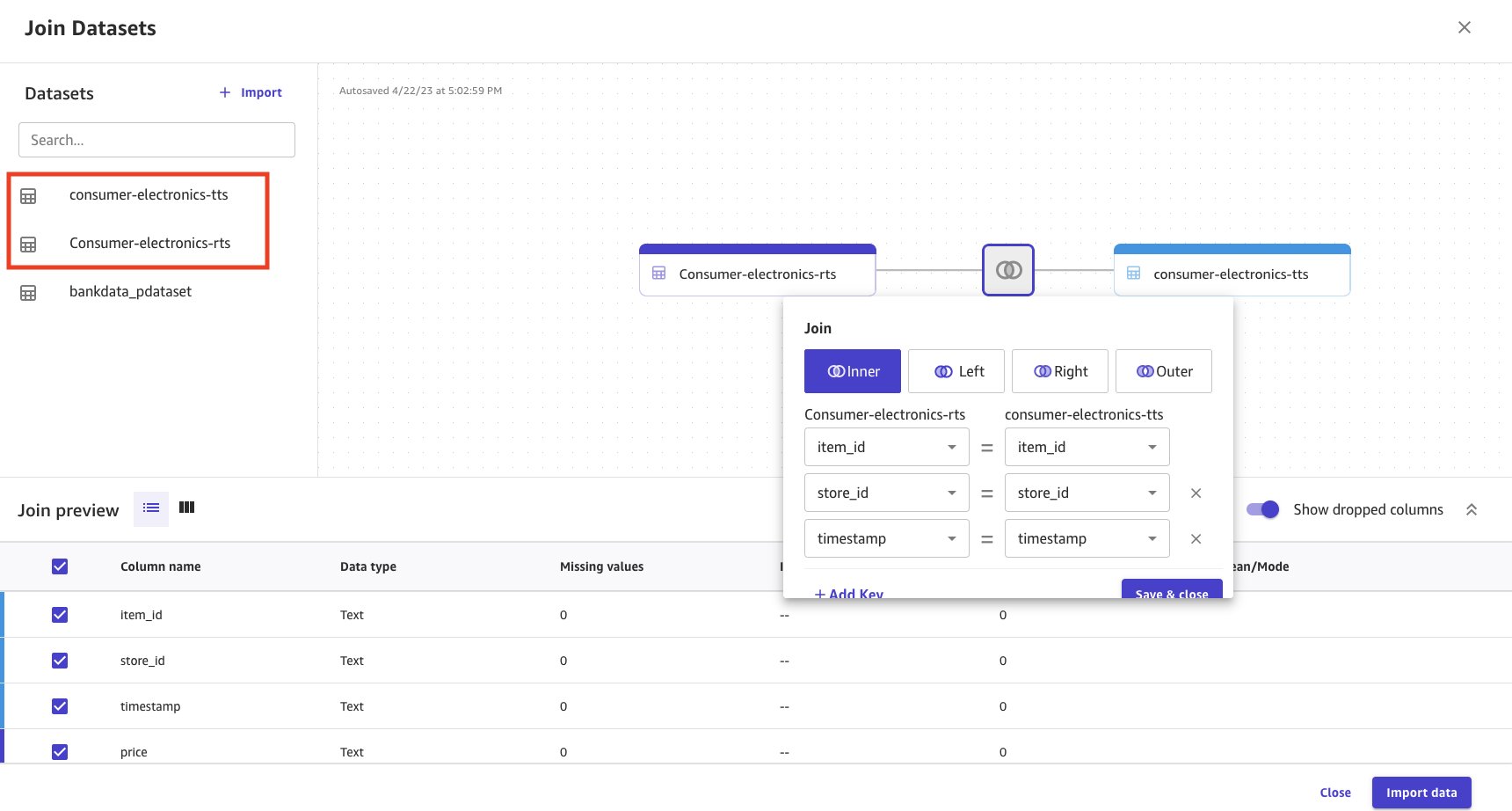
- Select and drag both the datasets to the center pane, which applies an inner join.
- Choose the Join icon to see the join conditions applied and to make sure the inner join is applied and the right columns are joined.
- Choose Save & close to apply the join condition.
- Provide a name for the joined dataset.
- Choose Import data.
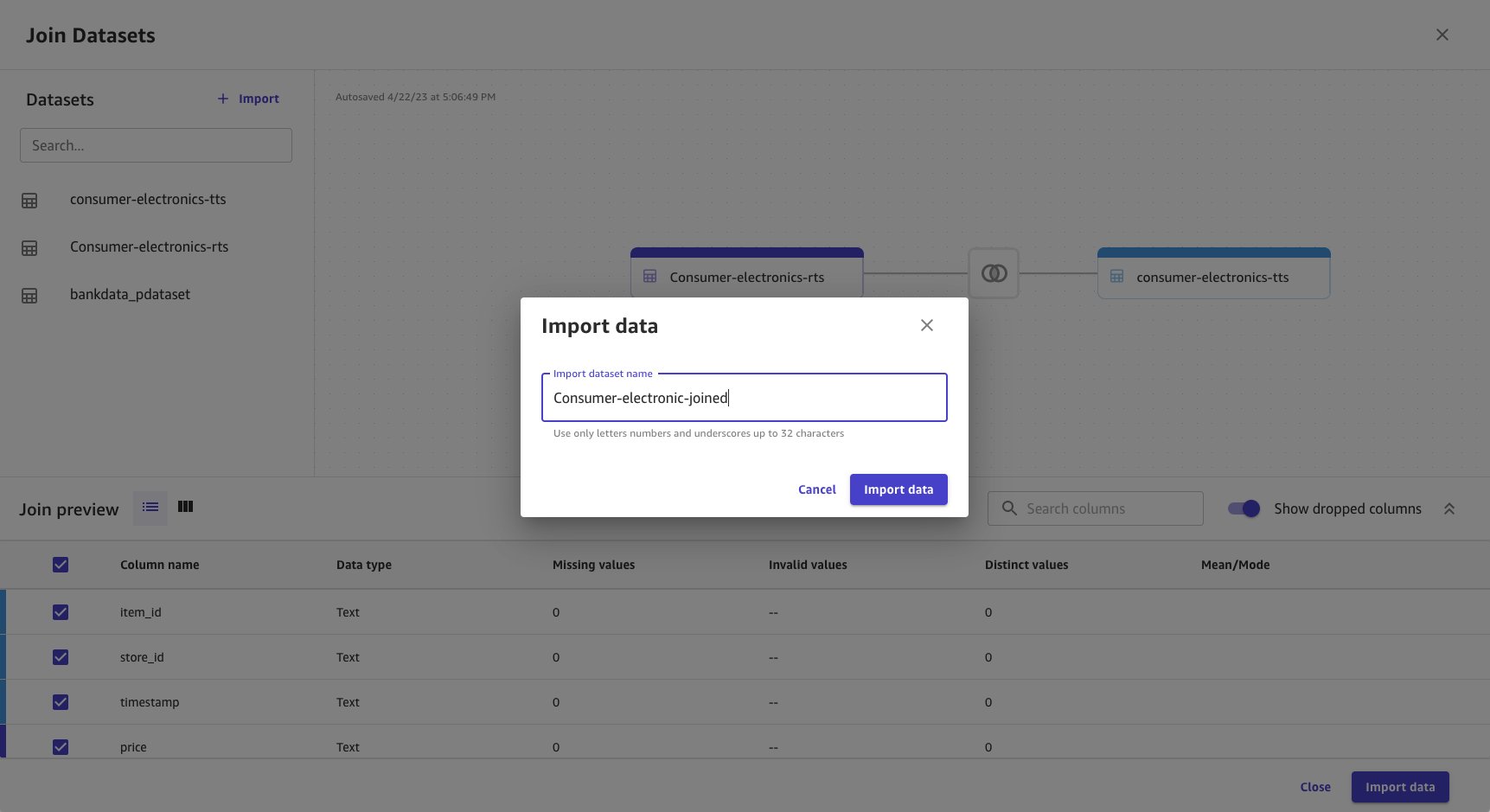
Joined data is imported and created as a new dataset. The joined dataset source is shown as Join.
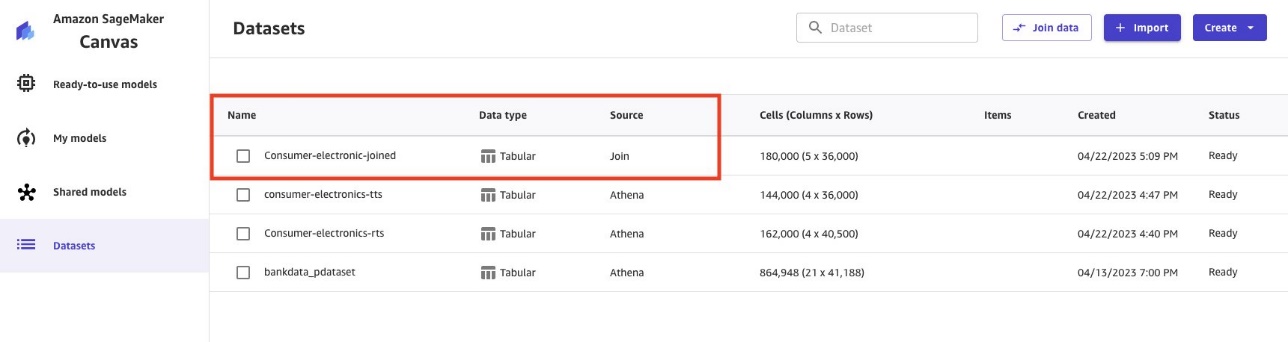
Use the Parquet data to build ML models with Canvas
The Parquet data from Lake Formation is now available on Canvas. Now you can run your ML analysis on the data.
- Choose Create a custom model in Ready-to-use models from Canvas after successfully importing the data.
- Enter a name for the model.
- Select your problem type (for this post, Predictive analysis).
- Choose Create.
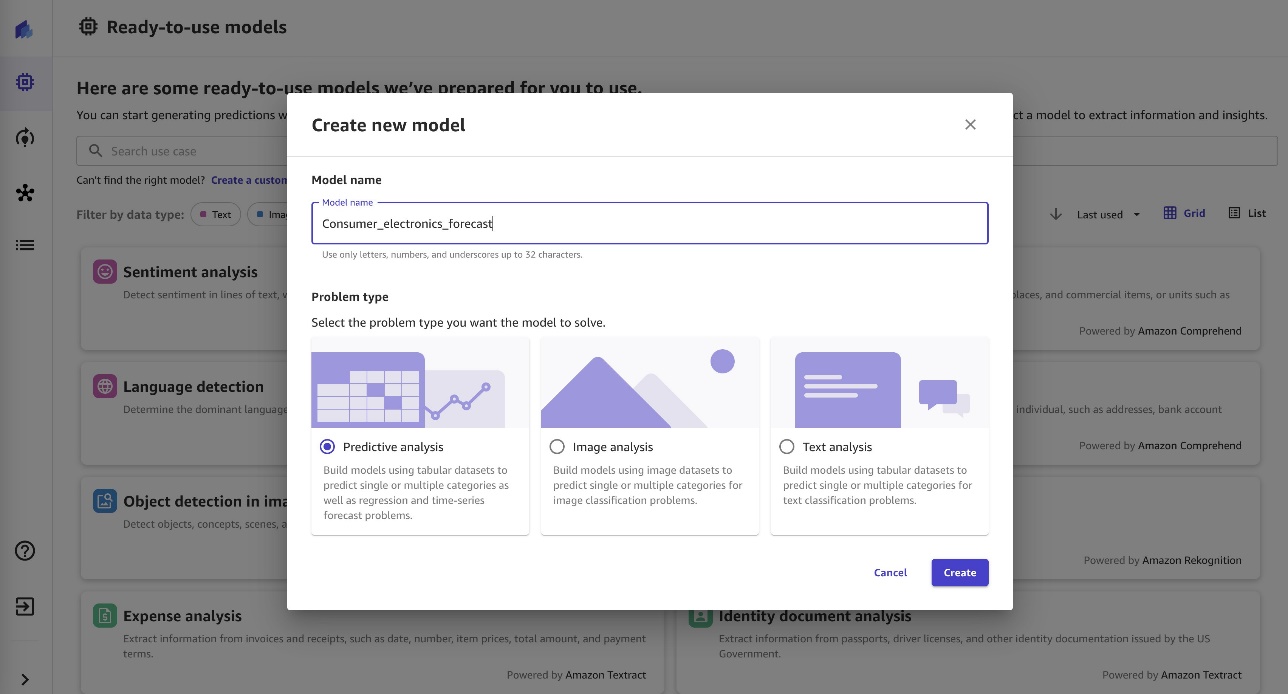
- Select the
consumer-electronic-joineddataset to train the model to predict the demand for electronic items.
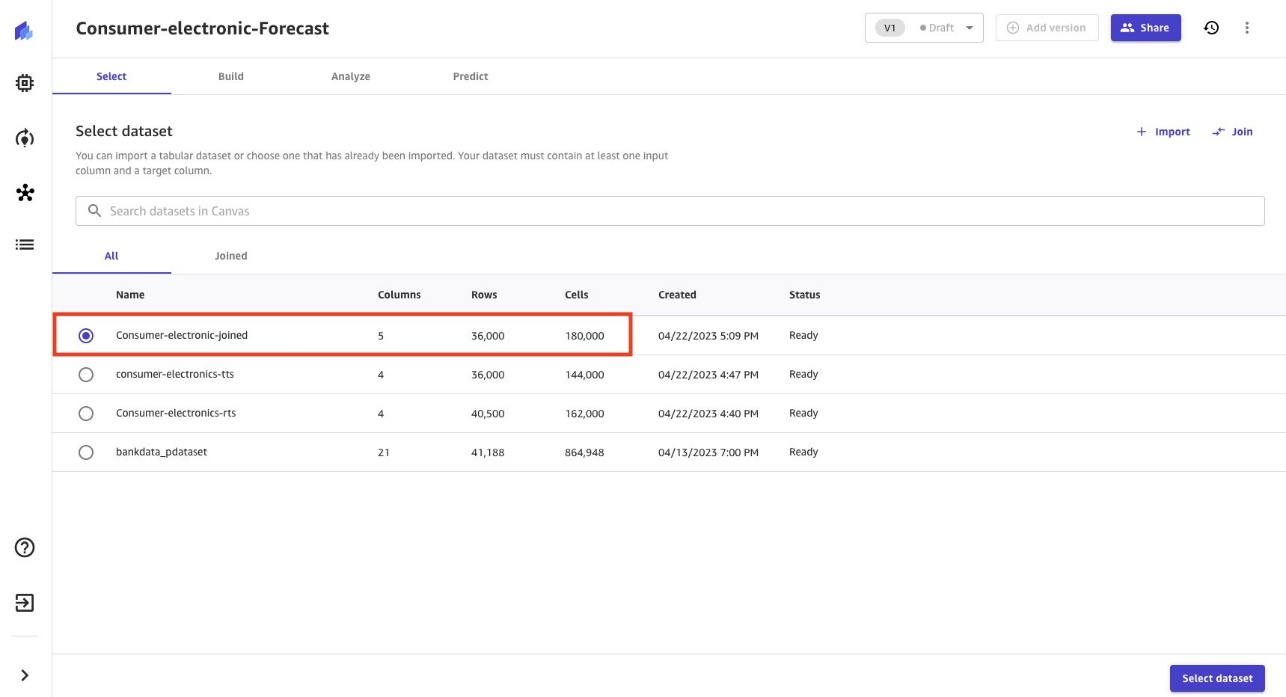
- Select demand as the target column to forecast demand for consumer electronic items.
Based on the data provided to Canvas, the Model type is automatically derived as Time series forecasting and provides a Configure time series model option.
- Choose the Configure time series model link to provide time series model options.
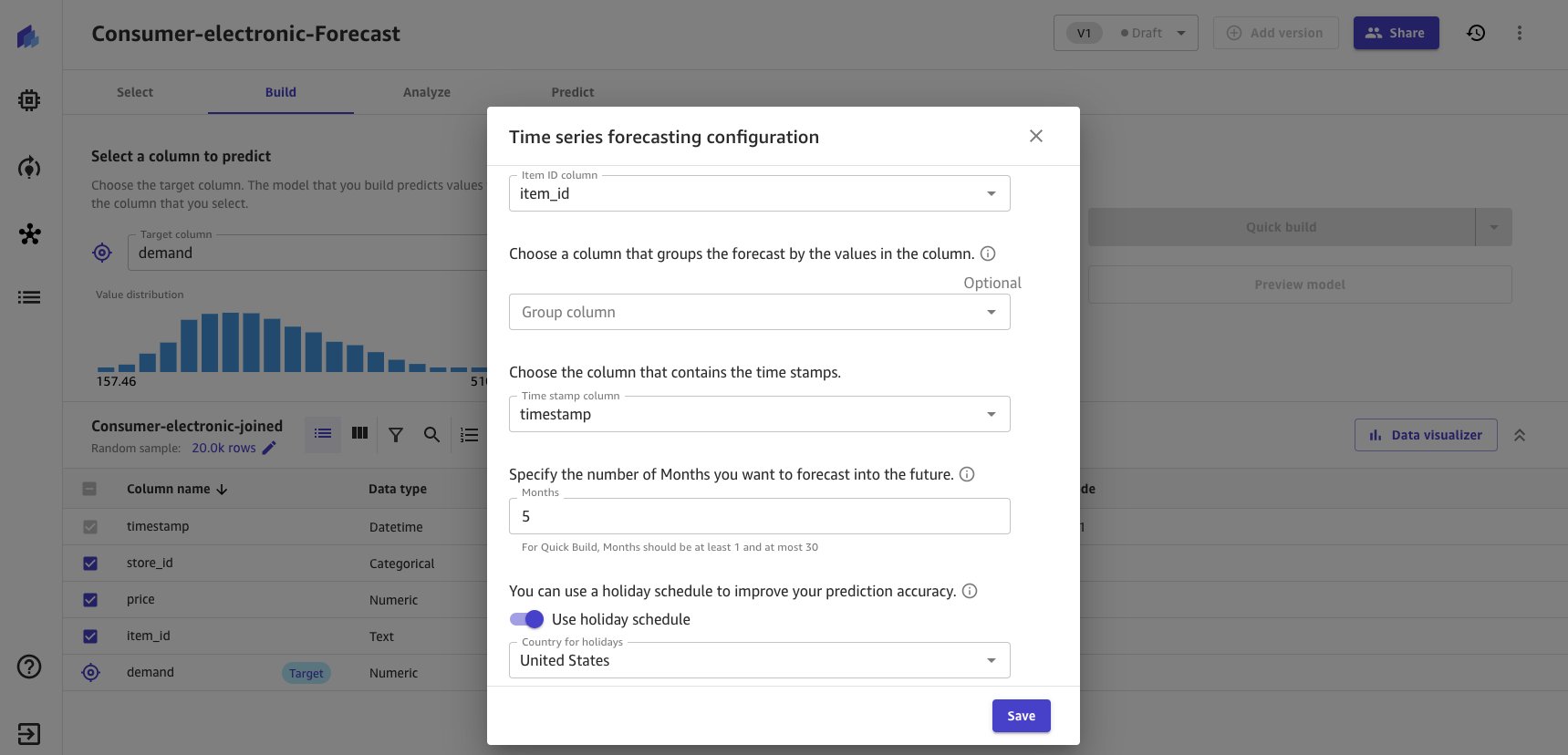
- Enter forecasting configurations as shown in the following screenshot.
- Exclude group column because no logical grouping is executed for the dataset.
For building the model, Canvas offers two build options. Choose the option as per your preference. Quick build generally takes around 15–20 minutes, whereas Standard takes around 4 hours.
-
- Quick build – Builds a model in a fraction of the time compared to a standard build; potential accuracy is exchanged for speed
- Standard build – Builds the best model from an optimized process powered by AutoML; speed is exchanged for greatest accuracy
- For this post, we choose Quick build for illustrative purposes.

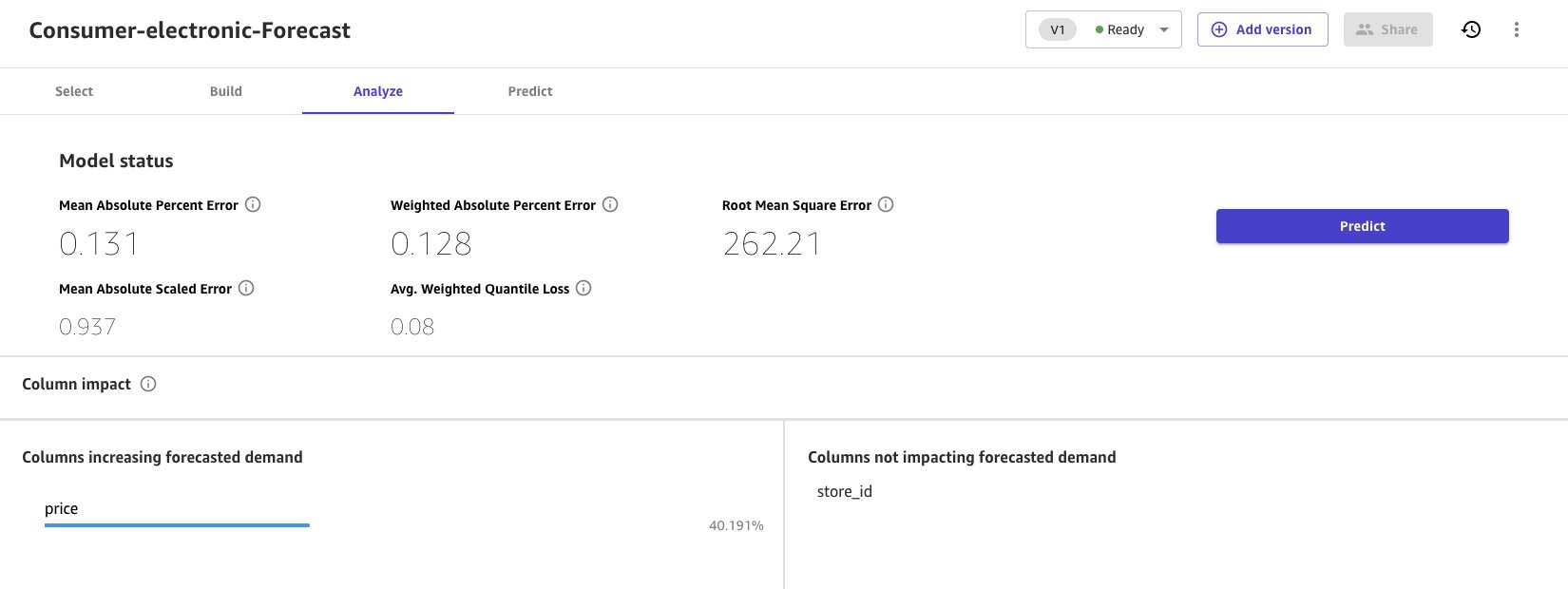
When the quick build is completed, the model evaluation metrics are presented in the Analyze section.
- Choose Predict to run a single prediction or batch prediction.
Clean up
Log out from Canvas to avoid future charges.
Conclusion
Enterprises have data in data lakes in various formats, including the highly efficient Parquet format. Canvas has launched more than 40 data sources, including Athena, from which you can easily pull data in various formats from data lakes. To learn more, refer to Import data from over 40 data sources for no-code machine learning with Amazon SageMaker Canvas.
In this post, we took Lake Formation-managed Parquet files and imported them into Canvas using Athena. The Canvas ML model forecasted the demand of consumer electronics using historical demand and price data. Thanks to a user-friendly interface and vivid visualizations, we completed this without writing a single line of code. Canvas now allows business analysts to use Parquet files from data engineering teams and build ML models, conduct analysis, and extract insights independently of data science teams.
To learn more about Canvas, refer to Predict types of machine failures with no-code machine learning using Canvas. Refer to Announcing Amazon SageMaker Canvas – a Visual, No Code Machine Learning Capabilities for Business Analysts for more information on creating ML models with a no-code solution.
About the authors
 Gopi Mudiyala is a Senior Technical Account Manager at AWS. He helps customers in the Financial Services industry with their operations in AWS. As a machine learning enthusiast, Gopi works to help customers succeed in their ML journey. In his spare time, he likes to play badminton, spend time with family, and travel.
Gopi Mudiyala is a Senior Technical Account Manager at AWS. He helps customers in the Financial Services industry with their operations in AWS. As a machine learning enthusiast, Gopi works to help customers succeed in their ML journey. In his spare time, he likes to play badminton, spend time with family, and travel.
 Hariharan Suresh is a Senior Solutions Architect at AWS. He is passionate about databases, machine learning, and designing innovative solutions. Prior to joining AWS, Hariharan was a product architect, core banking implementation specialist, and developer, and worked with BFSI organizations for over 11 years. Outside of technology, he enjoys paragliding and cycling.
Hariharan Suresh is a Senior Solutions Architect at AWS. He is passionate about databases, machine learning, and designing innovative solutions. Prior to joining AWS, Hariharan was a product architect, core banking implementation specialist, and developer, and worked with BFSI organizations for over 11 years. Outside of technology, he enjoys paragliding and cycling.

Amazon SageMaker Automatic Model Tuning now automatically chooses tuning configurations to improve usability and cost efficiency
Amazon SageMaker Automatic Model Tuning has introduced Autotune, a new feature to automatically choose hyperparameters on your behalf. This provides an accelerated and more efficient way to find hyperparameter ranges, and can provide significant optimized budget and time management for your automatic model tuning jobs.
In this post, we discuss this new capability and some of the benefits it brings.
Hyperparameter overview
When training any machine learning (ML) model, you are generally dealing with three types of data: input data (also called the training data), model parameters, and hyperparameters. You use the input data to train your model, which in effect learns your model parameters. During the training process, your ML algorithms are trying to find the optimal model parameters based on data while meeting the goals of your objective function. For example, when a neural network is trained, the weight of the network nodes is learned from the training, and indicates how much impact it has on the final prediction. These weights are the model parameters.
Hyperparameters, on the other hand, are parameters of a learning algorithm and not the model itself. The number of hidden layers and the number of nodes are some of the examples of hyperparameters you can set for a neural network. The difference between model parameters and hyperparameters is that model parameters are learned during the training process, whereas hyperparameters are set prior to the training and remain constant during the training process.
Pain points
SageMaker automatic model tuning, also called hyperparameter tuning, runs many training jobs on your dataset using a range of hyperparameters that you specify. It can accelerate your productivity by trying many variations of a model. It looks for the best model automatically by focusing on the most promising combinations of hyperparameter values within the ranges that you specify. However, to get good results, you must choose the right ranges to explore.
But how do you know what the right range is to begin with? With hyperparameter tuning jobs, we are assuming that the optimal set of hyperparameters lies within the range that we specified. What happens if the chosen range is not right, and the optimal hyperparameter actually falls outside of the range?
Choosing the right hyperparameters requires experience with the ML technique you are using and understanding how its hyperparameters behave. It’s important to understand the hyperparameter implications because every hyperparameter that you choose to tune has the potential to increase the number of trials required for a successful tuning job. You need to strike an optimal trade-off between resources allocated to the tuning job and achieving the goals you’ve set.
The SageMaker Automatic Model Tuning team is constantly innovating on behalf of our customers to optimize their ML workloads. AWS recently announced support of new completion criteria for hyperparameter optimization: the max runtime criteria, which is a budget control completion criteria that can be used to bound cost and runtime. Desired target metrics, improvement monitoring, and convergence detection monitors the performance of the model and assists with early stopping if the models don’t improve after a defined number of training jobs. Autotune is a new feature of automatic model tuning that helps save you time and reduce wasted resources on finding optimal hyperparameter ranges.
Benefits of Autotune and how automatic model tuning alleviates those pain points
Autotune is a new configuration in the CreateHyperParameterTuningJob API and in the HyperparameterTuner SageMaker Python SDK that alleviates the need to specify the hyperparameter ranges, tuning strategy, objective metrics, or the number of jobs that were required as part of the job definition. Autotune automatically chooses the optimal configurations for your tuning job, helps prevent wasted resources, and accelerates productivity.
The following example showcases how many of the parameters are not necessary when using Autotune.
The following code creates a hyperparameter tuner using the SageMaker Python SDK without Autotune:
The following example showcases how many of the parameters are not necessary when using Autotune:
If you are using API, the equivalent code would be as follows:
The code example illustrates some of the key benefits of Autotune:
- A key choice for a tuning job is which hyperparameters to tune and their ranges. Autotune makes this choice for you based on a list of hyperparameters that you provide. Using the previous example, the hyperparameters that Autotune can choose to be tunable are
lrandbatch-size. - Autotune will automatically select the hyperparameter ranges on your behalf. Autotune uses best practices as well as internal benchmarks for selecting the appropriate ranges.
- Autotune automatically selects the strategy on how to choose the combinations of hyperparameter values to use for the training job.
- Early stopping is enabled by default when using Autotune. When using early stopping, SageMaker stops training jobs launched by the hyperparameter tuning job when they are unlikely to perform better than previously completed training jobs to avoid additional resource utilization.
- Maximum expected resources to be consumed by the tuning job (parallel jobs, max runtime, and so on) will be calculated and set in the tuning job record as soon as the tuning job is created. Such reserved resources will not increase during the course of the tuning job; this will maintain an upper bound of cost and duration of the tuning job that is easily predictable by the user. A max runtime of 48 hours will be used by default.
You can override any settings chosen automatically by Autotune. As an example, if you specify your own hyperparameter ranges, those will be used alongside the inferred ranges. Any user-specified hyperparameter range will take precedence over the same named inferred ranges:
Autotune generates a set of settings as part of the tuning job. Any customer-specified settings that have the same name will override the Autotune-selected settings. Any customer-provided settings (that aren’t the same as the named Autotune settings) are added in addition to the Autotune-selected settings.
Inspecting parameters chosen by Autotune
Autotune reduces the time you would normally have spent in deciding on the initial set of hyperparameters to tune. But how do you get insights into what hyperparameter values Autotune ended up choosing? You can get information about decisions made for you in the description of the running tuning job (in the response of the DescribeHyperParameterTuningJob operation). After you submit a request to create a tuning job, the request is processed, and all missing fields are set by Autotune. All set fields are reported in the DescribeHyperParameterTuningJob operation.
Alternatively, you can inspect HyperparameterTuner class fields to see the settings chosen by Autotune.
The following is an XGBoost example of how you may use the DescribeHyperParameterTuningJob to inspect the hyperparameters chosen by Autotune.
First, we create a tuning job with automatic model tuning:
After the tuning job is created successfully, we can discover what settings Autotune chose. For example, we can describe the tuning job by the name given by it from hp_tuner:
Then we can inspect the generated response to review the settings chosen by Autotune on our behalf.
If the current tuning job settings are not satisfactory, you can stop the tuning job:
hp_tuner.stop()
Conclusion
SageMaker Automatic Model Tuning allows you to reduce the time to tune a model by automatically searching for the best hyperparameter configuration within the ranges that you specify. However, choosing the right hyperparameter ranges can be a time-consuming process and can have direct implications on your training cost and duration.
In this post, we discussed how you can now use Autotune, a new feature introduced as part of automatic model tuning, to automatically pick an initial set of hyperparameter ranges on your behalf. This can reduce the time it takes for you to get started with your model tuning process. Additionally, you can evaluate the ranges picked by Autotune and adjust them according to your needs.
We also showed how Autotune can automatically pick the optimal parameter settings on your behalf, such as the number of training jobs, the strategy to choose the hyperparameter combinations, and enabling early stopping by default. This can result in significantly optimized budget and time bounds that are easily predictable.
To learn more, refer to Perform Automatic Model Tuning with SageMaker.
About the Authors
 Jas Singh is a Senior Solutions Architect helping public sector customers achieve their business outcomes through architecting and implementing innovative and resilient solutions at scale. Jas has over 20 years of experience in designing and implementing mission-critical applications and holds a master’s degree in computer science from Baylor University.
Jas Singh is a Senior Solutions Architect helping public sector customers achieve their business outcomes through architecting and implementing innovative and resilient solutions at scale. Jas has over 20 years of experience in designing and implementing mission-critical applications and holds a master’s degree in computer science from Baylor University.
Gopi Mudiyala is a Senior Technical Account Manager at AWS. He helps customers in the Financial Services industry with their operations in AWS. As a machine learning enthusiast, Gopi works to help customers succeed in their ML journey. In his spare time, he likes to play badminton, spend time with family, and travel.
 Raviteja Yelamanchili is an Enterprise Solutions Architect with Amazon Web Services based in New York. He works with large financial services enterprise customers to design and deploy highly secure, scalable, reliable, and cost-effective applications on the cloud. He brings over 11 years of risk management, technology consulting, data analytics, and machine learning experience. When he is not helping customers, he enjoys traveling and playing PS5.
Raviteja Yelamanchili is an Enterprise Solutions Architect with Amazon Web Services based in New York. He works with large financial services enterprise customers to design and deploy highly secure, scalable, reliable, and cost-effective applications on the cloud. He brings over 11 years of risk management, technology consulting, data analytics, and machine learning experience. When he is not helping customers, he enjoys traveling and playing PS5.
 Iaroslav Shcherbatyi is a Machine Learning Engineer at AWS. He works mainly on improvements to the Amazon SageMaker platform and helping customers best use its features. In his spare time, he likes to go to gym, do outdoor sports such as ice skating or hiking, and to catch up on new AI research.
Iaroslav Shcherbatyi is a Machine Learning Engineer at AWS. He works mainly on improvements to the Amazon SageMaker platform and helping customers best use its features. In his spare time, he likes to go to gym, do outdoor sports such as ice skating or hiking, and to catch up on new AI research.

Train a Large Language Model on a single Amazon SageMaker GPU with Hugging Face and LoRA
This post is co-written with Philipp Schmid from Hugging Face.
We have all heard about the progress being made in the field of large language models (LLMs) and the ever-growing number of problem sets where LLMs are providing valuable insights. Large models, when trained over massive datasets and several tasks, are also able to generalize well over tasks that they aren’t trained specifically for. Such models are called foundation models, a term first popularized by the Stanford Institute for Human-Centered Artificial Intelligence. Even though these foundation models are able to generalize well, especially with the help of prompt engineering techniques, often the use case is so domain specific, or the task is so different, that the model needs further customization. One approach to improve performance of a large model for a specific domain or task is to further train the model with a smaller, task-specific dataset. Although this approach, known as fine-tuning, successfully improves the accuracy of LLMs, it requires modifying all of the model weights. Fine-tuning is much faster than the pre-training of a model thanks to the much smaller dataset size, but still requires significant computing power and memory. Fine-tuning modifies all the parameter weights of the original model, which makes it expensive and results in a model that is the same size as the original.
To address these challenges, Hugging Face introduced the Parameter-Efficient Fine-Tuning library (PEFT). This library allows you to freeze most of the original model weights and replace or extend model layers by training an additional, much smaller, set of parameters. This makes training much less expensive in terms of required compute and memory.
In this post, we show you how to train the 7-billion-parameter BloomZ model using just a single graphics processing unit (GPU) on Amazon SageMaker, Amazon’s machine learning (ML) platform for preparing, building, training, and deploying high-quality ML models. BloomZ is a general-purpose natural language processing (NLP) model. We use PEFT to optimize this model for the specific task of summarizing messenger-like conversations. The single-GPU instance that we use is a low-cost example of the many instance types AWS provides. Training this model on a single GPU highlights AWS’s commitment to being the most cost-effective provider of AI/ML services.
The code for this walkthrough can be found on the Hugging Face notebooks GitHub repository under the sagemaker/24_train_bloom_peft_lora folder.
Prerequisites
In order to follow along, you should have the following prerequisites:
- An AWS account.
- A Jupyter notebook within Amazon SageMaker Studio or SageMaker notebook instances.
- You will need access to the SageMaker ml.g5.2xlarge instance type, containing a single NVIDIA A10G GPU. On the AWS Management Console, navigate to Service Quotas for SageMaker and request a 1-instance increase for the following quotas: ml.g5.2xlarge for training job usage and ml.g5.2xlarge for training job usage.
- After your requested quotas are applied to your account, you can use the default Studio Python 3 (Data Science) image with a ml.t3.medium instance to run the notebook code snippets. For the full list of available kernels, refer to Available Amazon SageMaker Kernels.
Set up a SageMaker session
Use the following code to set up your SageMaker session:
Load and prepare the dataset
We use the samsum dataset, a collection of 16,000 messenger-like conversations with summaries. The conversations were created and written down by linguists fluent in English. The following is an example of the dataset:
To train the model, you need to convert the inputs (text) to token IDs. This is done by a Hugging Face Transformers tokenizer. For more information, refer to Chapter 6 of the Hugging Face NLP Course.
Convert the inputs with the following code:
Before starting training, you need to process the data. Once it’s trained, the model will take a set of text messages as the input and generate a summary as the output. You need to format the data as a prompt (the messages) with a correct response (the summary). You also need to chunk examples into longer input sequences to optimize the model training. See the following code:
Now you can use the FileSystem integration to upload the dataset to Amazon Simple Storage Service (Amazon S3):
Fine-tune BLOOMZ-7B with LoRA and bitsandbytes int-8 on SageMaker
The Hugging Face BLOOMZ-7B model card indicates its initial training was distributed over 8 nodes with 8 A100 80 GB GPUs and 512 GB memory CPUs each. This computing configuration is not readily accessible, is cost-prohibitive to consumers, and requires expertise in distributed training performance optimization. SageMaker lowers the barriers to replication of this setup through its distributed training libraries; however, the cost of comparable eight on-demand ml.p4de.24xlarge instances would be $376.88 per hour. Furthermore, the fully trained model consumes about 40 GB of memory, which exceeds the available memory of many individual consumer available GPUs and requires strategies to address for large model inferencing. As a result, full fine-tuning of the model for your task over multiple model runs and deployment would require significant compute, memory, and storage costs on hardware that isn’t readily accessible to consumers.
Our goal is to find a way to adapt BLOOMZ-7B to our chat summarization use case in a more accessible and cost-effective way while maintaining accuracy. To enable our model to be fine-tuned on a SageMaker ml.g5.2xlarge instance with a single consumer-grade NVIDIA A10G GPU, we employ two techniques to reduce the compute and memory requirements for fine-tuning: LoRA and quantization.
LoRA (Low Rank Adaptation) is a technique that significantly reduces the number of model parameters and associated compute needed for fine-tuning to a new task without a loss in predictive performance. First, it freezes your original model weights and instead optimizes smaller rank-decomposition weight matrices to your new task rather than updating the full weights, and then injects these adapted weights back into the original model. Consequently, fewer weight gradient updates means less compute and GPU memory during fine-tuning. The intuition behind this approach is that LoRA allows LLMs to focus on the most important input and output tokens while ignoring redundant and less important tokens. To deepen your understanding of the LoRA technique, refer to the original paper LoRA: Low-Rank Adaptation of Large Language Models.
In addition to the LoRA technique, you use the bitsanbytes Hugging Face integration LLM.int8() method to quantize out the frozen BloomZ model, or reduce the precision of the weight and bias values, by rounding them from float16 to int8. Quantization reduces the needed memory for BloomZ by about four times, which enables you to fit the model on the A10G GPU instance without a significant loss in predictive performance. To deepen your understanding of how int8 quantization works, its implementation in the bitsandbytes library, and its integration with the Hugging Face Transformers library, see A Gentle Introduction to 8-bit Matrix Multiplication for transformers at scale using Hugging Face Transformers, Accelerate and bitsandbytes.
Hugging Face has made LoRA and quantization accessible across a broad range of transformer models through the PEFT library and its integration with the bitsandbytes library. The create_peft_config() function in the prepared script run_clm.py illustrates their usage in preparing your model for training:
With LoRA, the output from print_trainable_parameters()indicates we were able to reduce the number of model parameters from 7 billion to 3.9 million. This means that only 5.6% of the original model parameters need to be updated. This significant reduction in compute and memory requirements allows us to fit and train our model on the GPU without issues.
To create a SageMaker training job, you will need a Hugging Face estimator. The estimator handles end-to-end SageMaker training and deployment tasks. SageMaker takes care of starting and managing all the required Amazon Elastic Compute Cloud (Amazon EC2) instances for you. Additionally, it provides the correct Hugging Face training container, uploads the provided scripts, and downloads the data from our S3 bucket into the container at the path /opt/ml/input/data. Then, it starts the training job. See the following code:
You can now start your training job using the .fit() method and passing the S3 path to the training script:
Using LoRA and quantization makes fine-tuning BLOOMZ-7B to our task affordable and efficient with SageMaker. When using SageMaker training jobs, you only pay for GPUs for the duration of model training. In our example, the SageMaker training job took 20,632 seconds, which is about 5.7 hours. The ml.g5.2xlarge instance we used costs $1.515 per hour for on-demand usage. As a result, the total cost for training our fine-tuned BLOOMZ-7B model was only $8.63. Comparatively, full fine-tuning of the model’s 7 billion weights would cost an estimated $600, or 6,900% more per training run, assuming linear GPU scaling on the original computing configuration outlined in the Hugging Face model card. In practice, this would further vary depending upon your training strategy, instance selection, and instance pricing.
We could also further reduce our training costs by using SageMaker managed Spot Instances. However, there is a possibility this would result in the total training time increasing due to Spot Instance interruptions. See Amazon SageMaker Pricing for instance pricing details.
Deploy the model to a SageMaker endpoint for inference
With LoRA, you previously adapted a smaller set of weights to your new task. You need a way to combine these task-specific weights with the pre-trained weights of the original model. In the run_clm.py script, the PEFT library merge_and_unload() method takes care of merging the base BLOOMZ-7B model with the updated adapter weights fine-tuned to your task to make them easier to deploy without introducing any inference latency compared to the original model.
In this section, we go through the steps to create a SageMaker model from the fine-tuned model artifact and deploy it to a SageMaker endpoint for inference. First, you can create a Hugging Face model using your new fine-tuned model artifact for deployment to a SageMaker endpoint. Because you previously trained the model with a SageMaker Hugging Face estimator, you can deploy the model immediately. You could instead upload the trained model to an S3 bucket and use them to create a model package later. See the following code:
As with any SageMaker estimator, you can deploy the model using the deploy() method from the Hugging Face estimator object, passing in the desired number and type of instances. In this example, we use the same G5 instance type equipped with a single NVIDIA A10g GPU that the model was fine-tuned on in the previous step:
It may take 5–10 minutes for the SageMaker endpoint to bring your instance online and download your model in order to be ready to accept inference requests.
When the endpoint is running, you can test it by sending a sample dialog from the dataset test split. First load the test split using the Hugging Face Datasets library. Next, select a random integer for index slicing a single test sample from the dataset array. Using string formatting, combine the test sample with a prompt template into a structured input to guide our model’s response. This structured input can then be combined with additional model input parameters into a formatted sample JSON payload. Finally, invoke the SageMaker endpoint with the formatted sample and print the model’s output summarizing the sample dialog. See the following code:
Clean up
Now that you’ve tested your model, make sure that you clean up the associated SageMaker resources to prevent continued charges:
Summary
In this post, you used the Hugging Face Transformer, PEFT, and the bitsandbytes libraries with SageMaker to fine-tune a BloomZ large language model on a single GPU for $8 and then deployed the model to a SageMaker endpoint for inference on a test sample. SageMaker offers multiple ways to use Hugging Face models; for more examples, check out the AWS Samples GitHub.
To continue using SageMaker to fine-tune foundation models, try out some of the techniques in the post Architect personalized generative AI SaaS applications on Amazon SageMaker. We also encourage you to learn more about Amazon Generative AI capabilities by exploring JumpStart, Amazon Titan models, and Amazon Bedrock.
About the Authors
 Philipp Schmid is a Technical Lead at Hugging Face with the mission to democratize good machine learning through open source and open science. Philipp is passionate about productionizing cutting-edge and generative AI machine learning models. He loves to share his knowledge on AI and NLP at various meetups such as Data Science on AWS, and on his technical blog.
Philipp Schmid is a Technical Lead at Hugging Face with the mission to democratize good machine learning through open source and open science. Philipp is passionate about productionizing cutting-edge and generative AI machine learning models. He loves to share his knowledge on AI and NLP at various meetups such as Data Science on AWS, and on his technical blog.
 Robert Fisher is a Sr. Solutions Architect for Healthcare and Life Sciences customers. He works closely with customers to understand how AWS can help them solve problems, especially in the AI/ML space. Robert has many years of experience in software engineering across a range of industry verticals including medical devices, fintech, and consumer-facing applications.
Robert Fisher is a Sr. Solutions Architect for Healthcare and Life Sciences customers. He works closely with customers to understand how AWS can help them solve problems, especially in the AI/ML space. Robert has many years of experience in software engineering across a range of industry verticals including medical devices, fintech, and consumer-facing applications.
 Doug Kelly is an AWS Sr. Solutions Architect that serves as a trusted technical advisor to top machine learning startups in verticals ranging from machine learning platforms, autonomous vehicles, to precision agriculture. He is member of the AWS ML technical field community where he specializes in supporting customers with MLOps and ML inference workloads.
Doug Kelly is an AWS Sr. Solutions Architect that serves as a trusted technical advisor to top machine learning startups in verticals ranging from machine learning platforms, autonomous vehicles, to precision agriculture. He is member of the AWS ML technical field community where he specializes in supporting customers with MLOps and ML inference workloads.
Announcing the launch of new Hugging Face LLM Inference containers on Amazon SageMaker
This post is co-written with Philipp Schmid and Jeff Boudier from Hugging Face.
Today, as part of Amazon Web Services’ partnership with Hugging Face, we are excited to announce the release of a new Hugging Face Deep Learning Container (DLC) for inference with Large Language Models (LLMs). This new Hugging Face LLM DLC is powered by Text Generation Inference (TGI), an open source, purpose-built solution for deploying and serving Large Language Models. TGI enables high-performance text generation using Tensor Parallelism and dynamic batching for the most popular open-source LLMs, including StarCoder, BLOOM, GPT-NeoX, StableLM, Llama, and T5.
Large Language Models are growing in popularity but can be difficult to deploy
LLMs have emerged as the leading edge of artificial intelligence, captivating developers and enthusiasts alike with their ability to comprehend and generate human-like text across diverse domains. These powerful models, such as those based on the GPT and T5 architectures, have experienced an unprecedented surge in popularity for a broad set of applications, including language understanding, conversational experiences, and automated writing assistance. As a result, companies across industries are seizing the opportunity to unlock their potential and offer new LLM-powered experiences in their applications.
Hosting LLMs at scale presents a unique set of complex engineering challenges. To provide an ideal user experience, an LLM hosting service should provide adequate response times while scaling to a large number of concurrent users. Given the high resource requirements of large models, general-purpose inference frameworks may not provide the optimizations required to maximize the utilization of available resources and provide the best possible performance.
Some of these optimizations include:
- Tensor parallelism to distribute the computation across multiple accelerators
- Model quantization to reduce the memory footprint of the model
- Dynamic batching of inference requests to improve throughput, and many others.
The Hugging Face LLM DLC provides these optimizations out of the box and makes it easier to host LLM models at scale.
Hugging Face’s Text Generation Inference simplifies LLM deployment
TGI is an open source, purpose-built solution for deploying Large Language Models (LLMs). It incorporates optimizations including tensor parallelism for faster multi-GPU inference, dynamic batching to boost overall throughput, and optimized transformers code using flash-attention for popular model architectures including BLOOM, T5, GPT-NeoX, StarCoder, and LLaMa.
With the new Hugging Face LLM Inference DLCs on Amazon SageMaker, AWS customers can benefit from the same technologies that power highly concurrent, low latency LLM experiences like HuggingChat, OpenAssistant, and Inference API for LLM models on the Hugging Face Hub, while enjoying SageMaker’s managed service capabilities, such as autoscaling, health checks, and model monitoring.
Get started with TGI on SageMaker Hosting
Let’s walk through a code example that deploys a GPT NeoX 20B parameter model on a SageMaker Endpoint. You can find our complete example notebook here.
First, make sure that the latest version of SageMaker SDK is installed:
Then, we import the SageMaker Python SDK and instantiate a sagemaker_session to find the current region and execution role.
Next we retrieve the LLM image URI. We use the helper function get_huggingface_llm_image_uri() to generate the appropriate image URI for the Hugging Face Large Language Model (LLM) inference. The function takes a required parameter backend and several optional parameters. The backend specifies the type of backend to use for the model, the values can be “lmi” and “huggingface”. “lmi” stands for SageMaker Large Model Inference backend and “huggingface” refers to using Hugging Face TGI backend that is used in this tutorial.
Now that we have the image uri, the next step is to configure the model object. We specify a unique name, the image_uri for the managed TGI container, and the execution role for the endpoint. Additionally, we specify a number of environment variables including the HF_MODEL_ID which corresponds to the model from the HuggingFace Hub that will be deployed, and the HF_TASK which configures the inference task to be performed by the model.
You should also define SM_NUM_GPUS, which specifies the tensor parallelism degree of the model. Tensor parallelism can be used to split the model across multiple GPUs, which is necessary when working with LLMs that are too big for a single GPU. To learn more about tensor parallelism with inference, see our previous blog post. Here, you should set SM_NUM_GPUS to the number of available GPUs on your selected instance type. For example, in this tutorial, we set SM_NUM_GPUS to 4 because our selected instance type ml.g4dn.12xlarge has 4 available GPUs.
Note that you can optionally reduce the memory and computational footprint of the model by setting the HF_MODEL_QUANTIZE environment variable to “true”, but this lower weight precision could affect the quality of the output for some models.
Next, we invoke the deploy method to deploy the model.
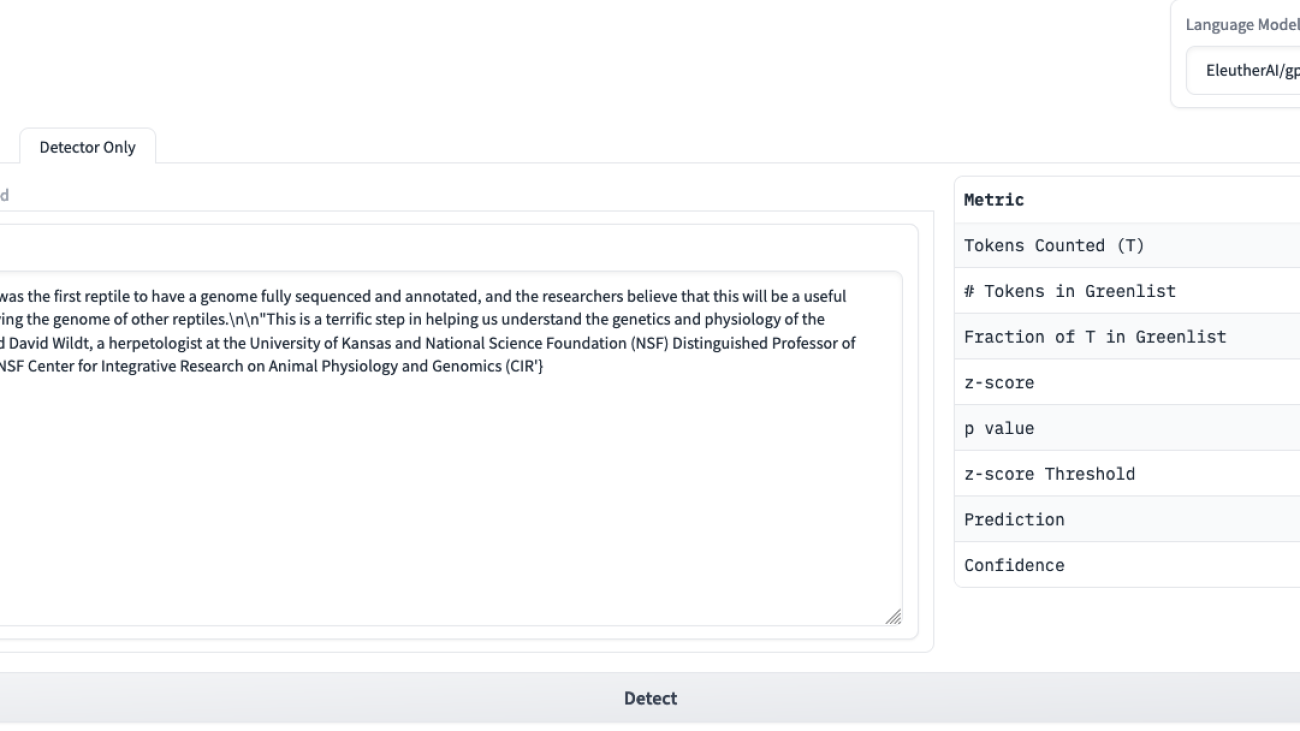
Once the model is deployed, we can invoke it to generate text. We pass an input prompt and run the predict method to generate a text response from the LLM running in the TGI container.
We receive the following auto-generated text response:.
To mitigate the risk of potential exploitation of Generative AI capabilities by automated bots, the response is watermarked. Such watermarked responses can be easily detected by algorithms, promoting the responsible use of Generative AI.

Once we are done experimenting, we delete the endpoint and the model resources.
Conclusion and next steps
Deploying Large Language Models using Hugging Face’s Text Generation Inference and SageMaker Hosting is a straightforward solution for hosting open source models like GPT-NeoX, Flan-T5-XXL, StarCoder or LLaMa. The state of the art LLMs are deployed within the secure managed SageMaker environment, and AWS customers can benefit from Large Language Models while keeping full control over their implementation, and without sending their data over to a third-party API.
In the tutorial, we demonstrated the deployment of GPT-NeoX using the new Hugging Face LLM Inference DLC, leveraging the power of 4 GPUs on a SageMaker ml.g4dn.12xlarge instance. With this approach, users can effortlessly harness the capabilities of state-of-the-art language models, enabling a wide range of applications and advancements in natural language processing.
As a next step, you can learn more about Hugging Face LLM Inference on SageMaker with the following resources:
About the authors
 Philipp Schmid is a Technical Lead at Hugging Face with the mission to democratize good machine learning through open source and open science. Philipp is passionate about productionizing cutting-edge & generative AI machine learning models.
Philipp Schmid is a Technical Lead at Hugging Face with the mission to democratize good machine learning through open source and open science. Philipp is passionate about productionizing cutting-edge & generative AI machine learning models.
 Jeff Boudier builds products at Hugging Face, the #1 open platform for AI builders. Previously Jeff was a co-founder of Stupeflix, acquired by GoPro, where he served as director of Product Management, Product Marketing, Business Development and Corporate Development.
Jeff Boudier builds products at Hugging Face, the #1 open platform for AI builders. Previously Jeff was a co-founder of Stupeflix, acquired by GoPro, where he served as director of Product Management, Product Marketing, Business Development and Corporate Development.
 Robert Van Dusen is a Senior Product Manager with Amazon SageMaker. He leads deep learning model optimization for applications such as large model inference.
Robert Van Dusen is a Senior Product Manager with Amazon SageMaker. He leads deep learning model optimization for applications such as large model inference.
 Qing Lan is a Software Development Engineer in AWS. He has been working on several challenging products in Amazon, including high performance ML inference solutions and high performance logging system. Qing’s team successfully launched the first Billion-parameter model in Amazon Advertising with very low latency required. Qing has in-depth knowledge on the infrastructure optimization and Deep Learning acceleration.
Qing Lan is a Software Development Engineer in AWS. He has been working on several challenging products in Amazon, including high performance ML inference solutions and high performance logging system. Qing’s team successfully launched the first Billion-parameter model in Amazon Advertising with very low latency required. Qing has in-depth knowledge on the infrastructure optimization and Deep Learning acceleration.
 Simon Zamarin is an AI/ML Solutions Architect whose main focus is helping customers extract value from their data assets. In his spare time, Simon enjoys spending time with family, reading sci-fi, and working on various DIY house projects.
Simon Zamarin is an AI/ML Solutions Architect whose main focus is helping customers extract value from their data assets. In his spare time, Simon enjoys spending time with family, reading sci-fi, and working on various DIY house projects.
 Xin Yang is a Software Development Engineer at AWS. She has been working on deploying and optimizing deep learning inference systems. Her work spans both the realms of real-time inference and scalable offline inference solutions. In her spare time, Xin enjoys reading and hiking.
Xin Yang is a Software Development Engineer at AWS. She has been working on deploying and optimizing deep learning inference systems. Her work spans both the realms of real-time inference and scalable offline inference solutions. In her spare time, Xin enjoys reading and hiking.
 Gagan Singh is a Senior Technical Account Manager at AWS helping digital native startups maximize business success. He helps customers with adoption and optimization of real-time, multi-model ML inferencing endpoints using Amazon SageMaker. In his spare time, Gagan enjoys trekking in the Himalayas and listening to music.
Gagan Singh is a Senior Technical Account Manager at AWS helping digital native startups maximize business success. He helps customers with adoption and optimization of real-time, multi-model ML inferencing endpoints using Amazon SageMaker. In his spare time, Gagan enjoys trekking in the Himalayas and listening to music.
How epic was that shot? Opportunity Analysis brings data to the debate
Learn about the science behind the brand-new NHL EDGE IQ stat that debuted in April 2023.Read More

Validating Large Language Models with ReLM
ReLM enables writing tests that are guaranteed to come from the set of valid strings, such as dates. Without ReLM, LLMs are free to complete prompts with non-date answers, which are difficult to assess.
TL;DR: While large language models (LLMs) have been touted for their ability to generate natural-sounding text, there are concerns around potential negative effects of LLMs such as data memorization, bias, and inappropriate language. We introduce ReLM (MLSys ’23), a system for validating and querying LLMs using standard regular expressions. We demonstrate via validation tasks on memorization, bias, toxicity, and language understanding that ReLM achieves up to (15times) higher system efficiency, (2.5times) data efficiency, and increased prompt-tuning coverage compared to state-of-the-art ad-hoc queries.
The Winners and Losers in Sequence Prediction
Consider playing a video game (perhaps in your youth). You randomly enter the following sequence in your controller:






Suddenly, your character becomes invincible. You’ve discovered the “secret” sequence that the game developer used for testing the levels. After this point in time, everything you do is trivial—the game is over, you win.
I claim that using large language models (LLMs) to generate text content is similar to playing a game with such secret sequences. Rather than getting surprised to see a change in game state, users of LLMs may be surprised to see a response that is not quite right. It’s possible the LLM violates someone’s privacy, encodes a stereotype, contains explicit material, or hallucinates an event. However, unlike the game, it may be difficult to even reason about how that sequence manifested.
LLMs operate over tokens (i.e., integers), which are translated via the tokenizer to text. For encoding systems such as Byte-Pair Encoding (BPE), each token maps to 1+ characters. Using the controller analogy, an LLM is a controller having 50000+ “buttons”, and certain buttons operate as “macros” over the string space. For example, ⇑ could represent and ⇓could represent , enabling the same code to be represented with ⇑⇓. Importantly, the LLM is unaware of this equivalence mapping—a single edit changing to would invalidate ⇑ being substituted into the sequence. Writing “the” instead of “The” could result in a different response from the LLM, even though the difference is stylistic to humans. These tokenization artifacts combined with potential shortcomings in the LLM’s internal reasoning create a minefield of unassuming LLM “bugs”.
The possibility that a model may deviate from the “correct” set of sequences motivates LLM validation—the task of evaluating a model’s behavior among many axes so that shortcomings can be identified and addressed. The problem can be much worse than our game example—when we expect a single sequence, nearly all sequences are incorrect, a process that exponentially diverges as a function of the sequence length. Intuitively, it gets much harder to output the right sequence when the sequence length grows—correctly “dancing” is easier than . In the lab, it’s hard to notice the consequences of generating an incorrect sequence, but as society embraces LLMs for more serious tasks (e.g., writing emails, filing taxes), we’ll want to have more confidence that they work as intended.
Short of formal verification, the best validation mechanism we have is to build comprehensive test suites for characterizing model behavior over a set of input sequences. Benchmarking efforts such as HeLM are continuing to increase the scope of LLM validation by providing a gamut of test sequences. While I strongly agree with the motivation, I ask: Should we be rethinking how tests themselves are written? Can we systematically generalize sequences to high-level patterns such that test writers don’t have to reason about all the peculiar LLM implementation details that we just discussed?
Background: Prompting LLMs
With game codes, the code is entered through the controller. The result, on the other hand, is reflected in the game state (i.e., your character becomes invincible, which I represent with a good outcome ✓). But how does this analogy hold for LLMs?
⇒✓
For autoregressive LLMs, typically the input is a sequence and the output is a sequence, and both of these are in the same space (e.g., strings of human language). For example, prompting the model with the word “The” would perhaps be followed by “ cat” in the sense that it is either likely or simply possible according to the LLM and the sampling procedure.
Ⓣⓗⓔ⇒ ⓒⓐⓣ
If “ cat” is considered a good answer, then we “won” the sequence lottery (represented by ✓). If the sequence is considered a bad answer e.g., the misspelling ” kAt”, then we lost (represented by ✗).
Ⓣⓗⓔ ⓒⓐⓣ⇒✓
Ⓣⓗⓔ ⓚⒶⓣ⇒✗
Keep in mind that the token-level encoding is not unique for a given string sequence, so the above LLM examples will have many representations. The number of representations compounds with the size of the reference strings e.g., all the possible misspellings of ” cat”. Furthermore, the LLM will output a distribution over good and bad sequences, so we’d like to summarize them e.g., by measuring what percentage of sequences are good.
Problem: Testing LLMs
As test designers, our goal is to quantitatively measure some aspect of the LLM’s behavior. As we are studying a general notion of tests, we’ll introduce a small amount of formalism to argue our points. Let us call a test, (T), which takes a model, (M), and returns a boolean represented with 0 (bad answer) or 1 (good answer).
$$T: M → {0, 1}$$
For classification tasks, (T) represents whether the model, (M), classified a particular example correctly; the average of these tests is reported with test accuracy. Since correct classification boils down to the predicted class ((y_text{pred}:=M(x))) matching the ground-truth class ((y)), this test can be implemented in one line of code.
y_pred == y
What does (T) look like for LLMs? Let’s say we want to test if “The” is followed by “ cat”. Constructing such a test is straightforward, because we can just check if the statement is true. We can imagine (x) representing “The” and (y) representing “ cat”. If (y) is sampled from some distribution (i.e., it’s a random variable), we can get many samples to compute the mean score. Depending on the application, we may or may not be interested in including all the encodings discussed previously as well as possible variations of the base pattern e.g., misspellings.
Because of the potentially massive number of sequences involved in a test, LLM tests are both more difficult to express and evaluate, leading to tests with insufficient coverage. For example, if we happened to miss some prompt that does lead to “ cat”, our test had a false negative—it concluded it was not possible when it actually was. If we were to check if “ cat” is the most likely string following “The”, we may get false positives in the omitted cases where “ kAt” was more likely. The test designer must carefully consider trading off such sources of error with the implementation and execution complexity of the test.
With traditional string-level APIs, it’s difficult to make testing trade-offs without rewriting the testing logic altogether—one has to write testing code that explicitly samples from the distribution of interest (e.g., the choice of encodings and misspellings). For example, a privacy-oriented user would want you to be reasonably sure that the LLM couldn’t emit their private information, even with the presence of encoding or misspelling artifacts. Such a minor change in the test’s scope would result in dramatic changes to the underlying test implementation. To make matters worse, testing becomes even more difficult when the base pattern of interest is a combinatorial object, such as integers, dates, URL strings, and phone numbers—sets too large to enumerate.
Example: Does GPT-2XL know George Washington’s birth date?
To give a concrete example of false positives and false negatives, let’s consider a simple test of knowledge: Does the LLM know George Washington’s birth date? As shown in the figure below, we formulate this ‘test’ by asking the model to rank 4 choices. Such multiple-choice questions are common in today’s benchmark suites because they are simple to implement. However, 4 choices do not cover all birth dates; what if the model was lucky enough to eliminate the other 3 answers and just guess? That would be a false positive. As shown below, the correct date of February 22, 1732, is chosen by the model because it is the most likely; thus this test concludes the model does know the birth date.

We can also try free response, as shown in in the following figure. However, the most likely reply is not a date and thus penalizes the model for being more general than the test task—a possible false negative. “this day in 1732” and “a farm” are reasonable completions for the fill-in-the-blank, yet an automated test system would mark them as not matching the solution set.

A more natural alternative, and one that we explore via our work in ReLM (MLSys ’23), would be to only consider answers that follow a specific date-related format. The way we evaluate this query is by constraining generation to be of the form <Month> <Day>, <Year>, as if we had a “complete” multiple choice solution set, which is too large to enumerate. Because this pattern contains exactly all the solutions of interest, the test minimizes spurious conclusions due to false positives and false negatives. In doing so, we confirm a true negative—GPT-2XL believes George Washington was born on July 4, 1732. That’s of course factually incorrect, but we didn’t trick ourselves into thinking the LLM knew the answer when it didn’t.

While we don’t have the space to exactly write out how to run these queries in ReLM, you can rest assured that you’ll find the above example in our code.
The Case for ReLM
Regular expressions describe the regular languages and are a way of specifying text patterns. Many text-processing tools, such as grep, use regular expressions to locate patterns in text. At a high level, regular languages can describe patterns using the primitives of string literals, disjunction (“OR”), and repetitions. For the purpose of this blog, you can think of regular languages as allowing you to interpolate between a 4-way multiple choice (e.g., A OR B OR C OR D) and one with a combinatorial explosion of choices in a free-response (e.g., all strings of length (N)). At the implementation level, regular expressions can be expressed with an equivalent directed graph, called an automaton, that represents all sequences via the edge transitions in the graph.
ReLM is a Regular Expression engine for Language Models. As shown below, ReLM is an automaton-based constrained decoding system on top of the LLM. Users of ReLM construct queries that encompass the test pattern and how to execute it. Because the user explicitly describes the pattern of interest, ReLM can avoid doing extra work that results in false negatives. Additionally, since the user describes variations of the pattern (e.g., encodings and misspellings), ReLM can cover often-ignored elements in the test set, avoiding false positives. We can essentially describe any pattern or mutation of the pattern as long as the effects can be correctly propagated to the final automaton. Thankfully, there is a rich theory on ways to perform operations on automata (e.g., including misspellings and rewrites), which we utilize when compiling the final automaton. Thus, the user can 1) exactly specify large sets of interest and 2) cover the tokenization artifacts mentioned in the introduction.

Since the same query pattern can be used for many execution parameters, a single test encoded as a regular expression can lead to a variety of analyses. For example, the query in the above figure could be modified to include all misspellings of the base pattern as well as all the encodings. Additionally, the user can choose between sampling from the test set or finding the most likely sequence in it. Our paper’s results exploring queries surrounding memorization (extracting URLs), gender bias (measuring distributional bias in professions), toxicity (extracting offensive words), and language understanding (completing the correct answer) show that ReLM achieves up to (15times) higher system efficiency in extracting memorized URLs, (2.5times) data efficiency in extracting offensive content, and increased statistical and prompt-tuning coverage compared to state-of-the-art ad-hoc queries.
Our results indicate that subtle differences in query specification can yield dramatically different results. For example, we find that randomly sampling from a URL prefix “https://www.” tends to generate invalid or duplicated URLs. ReLM avoids such inefficiency by returning strings matching the valid URL pattern sorted by likelihood. Likewise, searching over the space of all encodings as well as misspellings enables the (2.5times) data efficiency in extracting toxic content from the LLM and results in different results on the gender bias task. Finally, we can recover prompt tuning behavior on the LAMBADA dataset by modifying the regular expression pattern, demonstrating that even language understanding tasks can benefit from such pattern specification.
Conclusion
In this blog, we outlined why it’s important to think of LLM tests in terms of patterns rather than individual sequences. Our work introduces ReLM, a Regular Expression engine for Language Models, to enable test writers to easily write LLM tests that can be described via pattern matching. If you’re interested in learning more about ReLM and how it can reduce the burden of LLM validation, please check out our paper (MLSys ’23) as well as our open-source code.
DISCLAIMER: All opinions expressed in this post are those of the author and do not represent the views of CMU.
Microsoft Bing Speeds Ad Delivery With NVIDIA Triton
Jiusheng Chen’s team just got accelerated.
They’re delivering personalized ads to users of Microsoft Bing with 7x throughput at reduced cost, thanks to NVIDIA Triton Inference Server running on NVIDIA A100 Tensor Core GPUs.
It’s an amazing achievement for the principal software engineering manager and his crew.
Tuning a Complex System
Bing’s ad service uses hundreds of models that are constantly evolving. Each must respond to a request within as little as 10 milliseconds, about 10x faster than the blink of an eye.
The latest speedup got its start with two innovations the team delivered to make AI models run faster: Bang and EL-Attention.
Together, they apply sophisticated techniques to do more work in less time with less computer memory. Model training was based on Azure Machine Learning for efficiency.
Flying With NVIDIA A100 MIG
Next, the team upgraded the ad service from NVIDIA T4 to A100 GPUs.
The latter’s Multi-Instance GPU (MIG) feature lets users split one GPU into several instances.
Chen’s team maxed out the MIG feature, transforming one physical A100 into seven independent ones. That let the team reap a 7x throughput per GPU with inference response in 10ms.
Flexible, Easy, Open Software
Triton enabled the shift, in part, because it lets users simultaneously run different runtime software, frameworks and AI modes on isolated instances of a single GPU.
The inference software comes in a software container, so it’s easy to deploy. And open-source Triton — also available with enterprise-grade security and support through NVIDIA AI Enterprise — is backed by a community that makes the software better over time.
Accelerating Bing’s ad system with Triton on A100 GPUs is one example of what Chen likes about his job. He gets to witness breakthroughs with AI.
While the scenarios often change, the team’s goal remains the same — creating a win for its users and advertisers.

Accelerating the Accelerator: Scientist Speeds CERN’s HPC With GPUs, AI
Editor’s note: This is part of a series profiling researchers advancing science with high performance computing.
Maria Girone is expanding the world’s largest network of scientific computers with accelerated computing and AI.
Since 2002, the Ph.D. in particle physics has worked on a grid of systems across 170 sites in more than 40 countries that support CERN’s Large Hadron Collider (LHC), itself poised for a major upgrade.
A high-luminosity version of the giant accelerator (HL-LHC) will produce 10x more proton collisions, spawning exabytes of data a year. That’s an order of magnitude more than it generated in 2012 when two of its experiments uncovered the Higgs boson, a subatomic particle that validated scientists’ understanding of the universe.
The Call of Geneva
Girone loved science from her earliest days growing up in Southern Italy.
“In college, I wanted to learn about the fundamental forces that govern the universe, so I focused on physics,” she said. “I was drawn to CERN because it’s where people from different parts of the world work together with a common passion for science.”
Tucked between Lake Geneva and the Jura mountains, the European Organization for Nuclear Research is a nexus for more than 12,000 physicists.
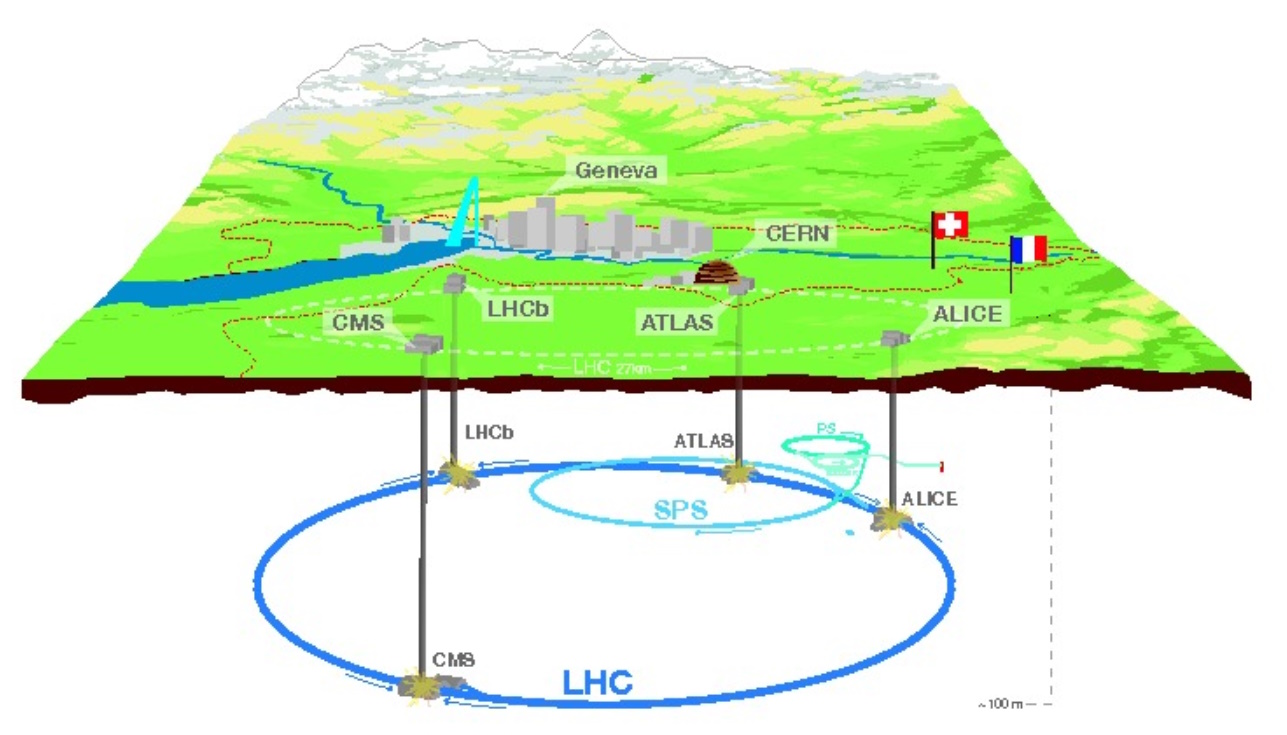
Its 27-kilometer ring is sometimes called the world’s fastest racetrack because protons careen around it at 99.9999991% the speed of light. Its superconducting magnets operate near absolute zero, creating collisions that are briefly millions of times hotter than the sun.
Opening the Lab Doors
In 2016, Girone was named CTO of CERN openlab, a group that gathers academic and industry researchers to accelerate innovation and tackle future computing challenges. It works closely with NVIDIA through its collaboration with E4 Computer Engineering, a specialist in HPC and AI based in Italy.
In one of her initial acts, Girone organized the CERN openlab’s first workshop on AI.
Industry participation was strong and enthusiastic about the technology. In their presentations, physicists explained the challenges ahead.
“By the end of the day we realized we were from two different worlds, but people were listening to each other, and enthusiastically coming up with proposals for what to do next,” she said.
A Rising Tide of Physics AI
Today, the number of publications on applying AI across the whole data processing chain in high-energy physics is rising, Girone reports. The work attracts young researchers who see opportunities to solve complex problems with AI, she said.
Meanwhile, researchers are also porting physics software to GPU accelerators and using existing AI programs that run on GPUs.
“This wouldn’t have happened so quickly without the support of NVIDIA working with our researchers to solve problems, answer questions and write articles,” she said. “It’s been extremely important to have people at NVIDIA who appreciate how science needs to evolve in tandem with technology, and how we can make use of acceleration with GPUs.”
Energy efficiency is another priority for Girone’s team.
“We’re working on experiments on a number of projects like porting to lower power architectures, and we look forward to evaluating the next generation of lower power processors,” she said.
Digital Twins and Quantum Computers
To prepare for the HL-LHC, Girone, named head of CERN openlab in March, seeks new ways to accelerate science with machine learning and accelerated computing. Other tools are on the near and far horizons, too.
The group recently won funding to prototype an engine for building digital twins. It will provide services for physicists, as well as researchers in fields from astronomy to environmental science.

CERN also launched a collaboration among academic and industry researchers in quantum computing. The technology could advance science and lead to better quantum systems, too.
A Passion for Diversity
In another act of community-making, Girone was among four co-founders of a Swiss chapter of the Women in HPC group. It will help define specific actions to support women in every phase of their careers.
“I’m passionate about creating diverse teams where everyone feels they contribute and belong — it’s not just a checkbox about numbers, you want to realize a feeling of belonging,” she said.
Girone was among thousands of physicists who captured some of that spirit the day CERN announced the Higgs boson discovery.
She recalls getting up at 4 a.m. to queue for a seat in the main auditorium. It couldn’t hold all the researchers and guests who arrived that day, but the joy of accomplishment followed her and others watching the event from a nearby hall.
“I knew the contribution I made,” she said. “I was proud being among the many authors of the paper, and my parents and my kids felt proud, too.”
Check out other profiles in this series: