Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to prepare data and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate data preparation in machine learning (ML) workflows without writing any code.
SageMaker Data Wrangler supports Snowflake, a popular data source for users who want to perform ML. We launch the Snowflake direct connection from the SageMaker Data Wrangler in order to improve the customer experience. Before the launch of this feature, administrators were required to set up the initial storage integration to connect with Snowflake to create features for ML in Data Wrangler. This includes provisioning Amazon Simple Storage Service (Amazon S3) buckets, AWS Identity and Access Management (IAM) access permissions, Snowflake storage integration for individual users, and an ongoing mechanism to manage or clean up data copies in Amazon S3. This process is not scalable for customers with strict data access control and a large number of users.
In this post, we show how Snowflake’s direct connection in SageMaker Data Wrangler simplifies the administrator’s experience and data scientist’s ML journey from data to business insights.
Solution overview
In this solution, we use SageMaker Data Wrangler to speed up data preparation for ML and Amazon SageMaker Autopilot to automatically build, train, and fine-tune the ML models based on your data. Both services are designed specifically to increase productivity and shorten time to value for ML practitioners. We also demonstrate the simplified data access from SageMaker Data Wrangler to Snowflake with direct connection to query and create features for ML.
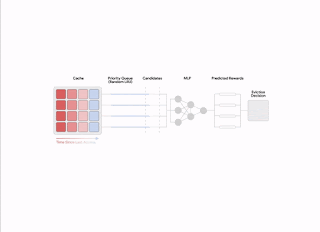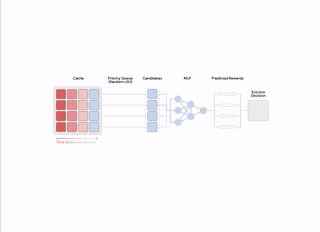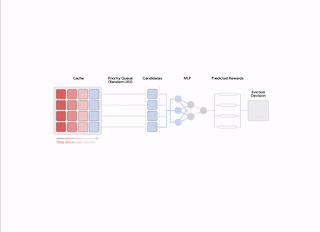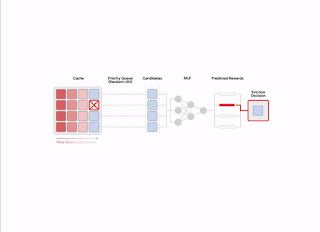
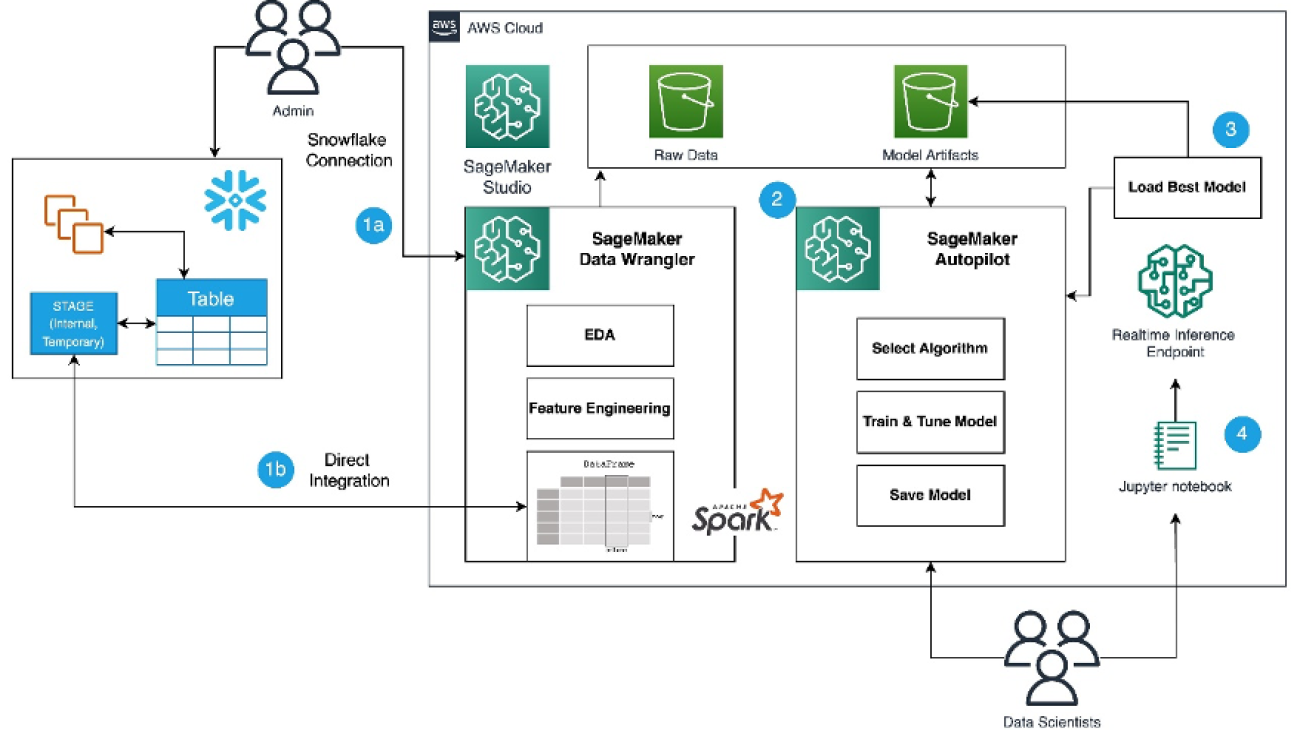
Refer to the diagram below for an overview of the low-code ML process with Snowflake, SageMaker Data Wrangler, and SageMaker Autopilot.
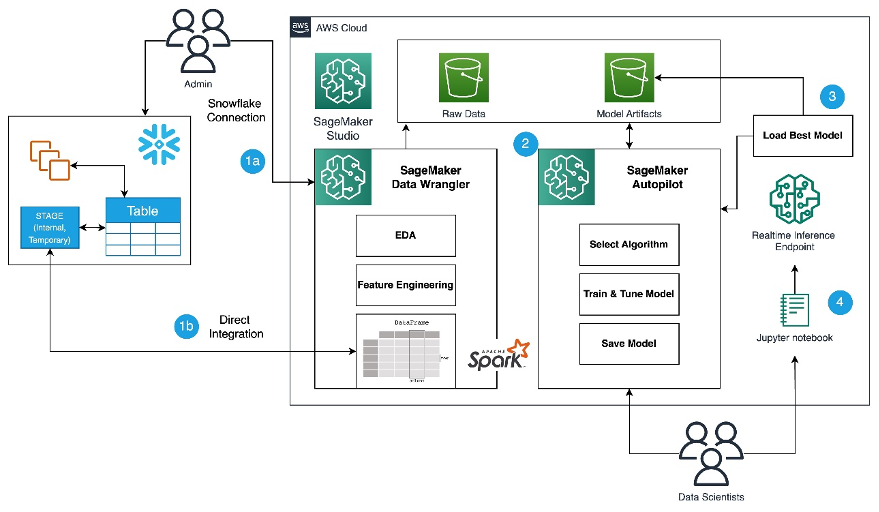
The workflow includes the following steps:
- Navigate to SageMaker Data Wrangler for your data preparation and feature engineering tasks.
- Set up the Snowflake connection with SageMaker Data Wrangler.
- Explore your Snowflake tables in SageMaker Data Wrangler, create a ML dataset, and perform feature engineering.
- Train and test the models using SageMaker Data Wrangler and SageMaker Autopilot.
- Load the best model to a real-time inference endpoint for predictions.
- Use a Python notebook to invoke the launched real-time inference endpoint.
Prerequisites
For this post, the administrator needs the following prerequisites:
Data scientists should have the following prerequisites
Lastly, you should prepare your data for Snowflake
- We use credit card transaction data from Kaggle to build ML models for detecting fraudulent credit card transactions, so customers are not charged for items that they didn’t purchase. The dataset includes credit card transactions in September 2013 made by European cardholders.
- You should use the SnowSQL client and install it in your local machine, so you can use it to upload the dataset to a Snowflake table.
The following steps show how to prepare and load the dataset into the Snowflake database. This is a one-time setup.
Snowflake table and data preparation
Complete the following steps for this one-time setup:
- First, as the administrator, create a Snowflake virtual warehouse, user, and role, and grant access to other users such as the data scientists to create a database and stage data for their ML use cases:
-- Use the role SECURITYADMIN to create Role and User
USE ROLE SECURITYADMIN;
-- Create a new role 'ML Role'
CREATE OR REPLACE ROLE ML_ROLE COMMENT='ML Role';
GRANT ROLE ML_ROLE TO ROLE SYSADMIN;
-- Create a new user and password and grant the role to the user
CREATE OR REPLACE USER ML_USER PASSWORD='<REPLACE_PASSWORD>'
DEFAULT_ROLE=ML_ROLE
DEFAULT_WAREHOUSE=ML_WH
DEFAULT_NAMESPACE=ML_WORKSHOP.PUBLIC
COMMENT='ML User';
GRANT ROLE ML_ROLE TO USER ML_USER;
-- Grant privliges to role
USE ROLE ACCOUNTADMIN;
GRANT CREATE DATABASE ON ACCOUNT TO ROLE ML_ROLE;
--Create Warehouse for AI/ML work
USE ROLE SYSADMIN;
CREATE OR REPLACE WAREHOUSE ML_WH
WITH WAREHOUSE_SIZE = 'XSMALL' AUTO_SUSPEND = 120 AUTO_RESUME = true INITIALLY_SUSPENDED = TRUE;
GRANT ALL ON WAREHOUSE ML_WH TO ROLE ML_ROLE;
- As the data scientist, let’s now create a database and import the credit card transactions into the Snowflake database to access the data from SageMaker Data Wrangler. For illustration purposes, we create a Snowflake database named
SF_FIN_TRANSACTION:
-- Select the role and the warehouse
USE ROLE ML_ROLE;
USE WAREHOUSE ML_WH;
-- Create the DB to import the financial transactions
CREATE DATABASE IF NOT EXISTS sf_fin_transaction;
-- Create CSV File Format
create or replace file format my_csv_format
type = csv
field_delimiter = ','
skip_header = 1
null_if = ('NULL', 'null')
empty_field_as_null = true
compression = gzip;
- Download the dataset CSV file to your local machine and create a stage to load the data into the database table. Update the file path to point to the downloaded dataset location before running the PUT command for importing the data to the created stage:
-- Create a Snowflake named internal stage to store the transactions csv file
CREATE OR REPLACE STAGE my_stage
FILE_FORMAT = my_csv_format;
-- Import the file in to the stage
-- This command needs be run from SnowSQL client and not on WebUI
PUT file:///Users/*******/Downloads/creditcard.csv @my_stage;
-- Check whether the import was successful
LIST @my_stage;
- Create a table named
credit_card_transactions:
-- Create table and define the columns mapped to the csv transactions file
create or replace table credit_card_transaction (
Time integer,
V1 float, V2 float, V3 float,
V4 float, V5 float, V6 float,
V7 float, V8 float, V9 float,
V10 float,V11 float,V12 float,
V13 float,V14 float,V15 float,
V16 float,V17 float,V18 float,
V19 float,V20 float,V21 float,
V22 float,V23 float,V24 float,
V25 float,V26 float,V27 float,
V28 float,Amount float,
Class varchar(5)
);
- Import the data into the created table from the stage:
-- Import the transactions in to a new table named 'credit_card_transaction'
copy into credit_card_transaction from @my_stage ON_ERROR = CONTINUE;
-- Check whether the table was successfully created
select * from credit_card_transaction limit 100;
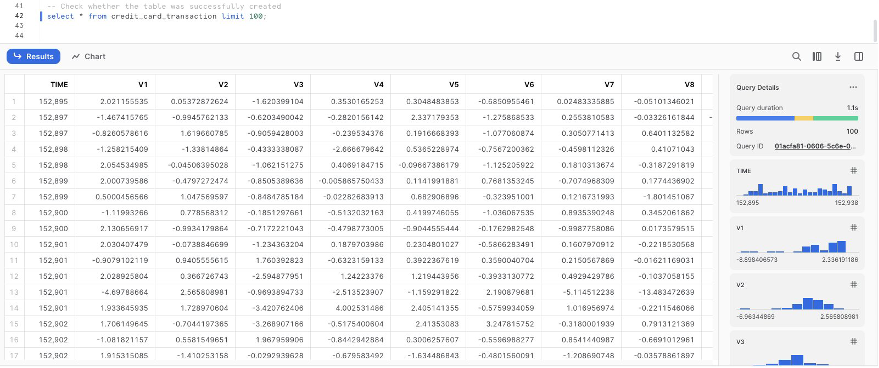
Set up the SageMaker Data Wrangler and Snowflake connection
After we prepare the dataset to use with SageMaker Data Wrangler, let us create a new Snowflake connection in SageMaker Data Wrangler to connect to the sf_fin_transaction database in Snowflake and query the credit_card_transaction table:
- Choose Snowflake on the SageMaker Data Wrangler Connection page.
- Provide a name to identify your connection.
- Select your authentication method to connect with the Snowflake database:
- If using basic authentication, provide the user name and password shared by your Snowflake administrator. For this post, we use basic authentication to connect to Snowflake using the user credentials we created in the previous step.
- If you are using OAuth, provide your identity provider credentials.
SageMaker Data Wrangler by default queries your data directly from Snowflake without creating any data copies in S3 buckets. SageMaker Data Wrangler’s new usability enhancement uses Apache Spark to integrate with Snowflake to prepare and seamlessly create a dataset for your ML journey.
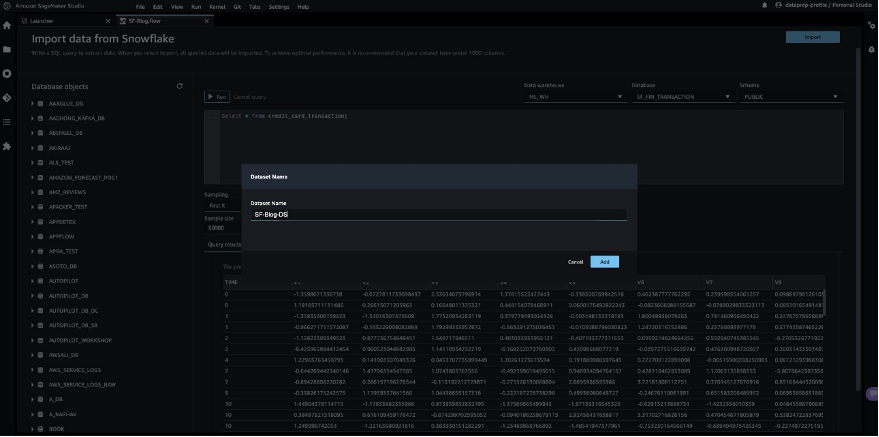
So far, we have created the database on Snowflake, imported the CSV file into the Snowflake table, created Snowflake credentials, and created a connector on SageMaker Data Wrangler to connect to Snowflake. To validate the configured Snowflake connection, run the following query on the created Snowflake table:
select * from credit_card_transaction;
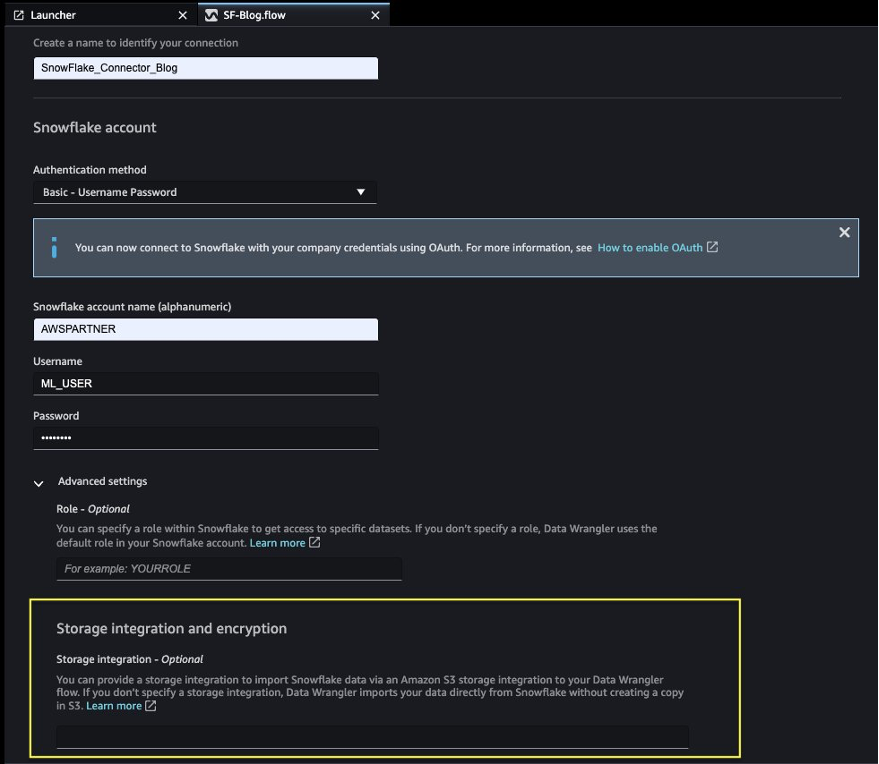
Note that the storage integration option that was required before is now optional in the advanced settings.
Explore Snowflake data
After you validate the query results, choose Import to save the query results as the dataset. We use this extracted dataset for exploratory data analysis and feature engineering.
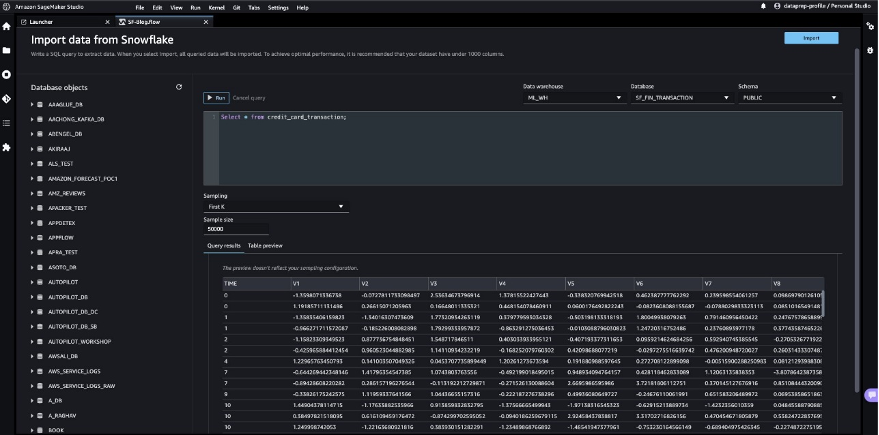
You can choose to sample the data from Snowflake in the SageMaker Data Wrangler UI. Another option is to download complete data for your ML model training use cases using SageMaker Data Wrangler processing jobs.
Perform exploratory data analysis in SageMaker Data Wrangler
The data within Data Wrangler needs to be engineered before it can be trained. In this section, we demonstrate how to perform feature engineering on the data from Snowflake using SageMaker Data Wrangler’s built-in capabilities.
First, let’s use the Data Quality and Insights Report feature within SageMaker Data Wrangler to generate reports to automatically verify the data quality and detect abnormalities in the data from Snowflake.
You can use the report to help you clean and process your data. It gives you information such as the number of missing values and the number of outliers. If you have issues with your data, such as target leakage or imbalance, the insights report can bring those issues to your attention. To understand the report details, refer to Accelerate data preparation with data quality and insights in Amazon SageMaker Data Wrangler.
After you check out the data type matching applied by SageMaker Data Wrangler, complete the following steps:
- Choose the plus sign next to Data types and choose Add analysis.
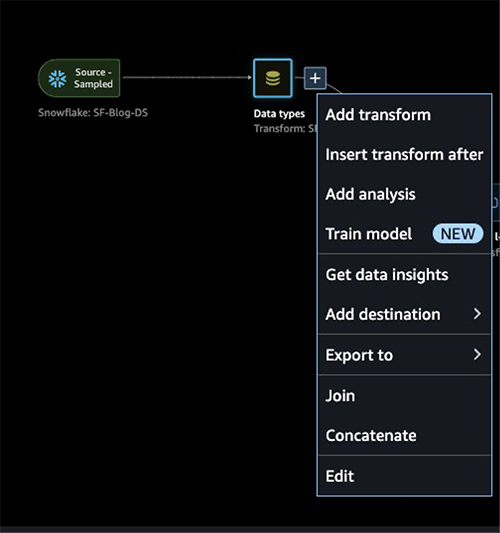
- For Analysis type, choose Data Quality and Insights Report.
- Choose Create.
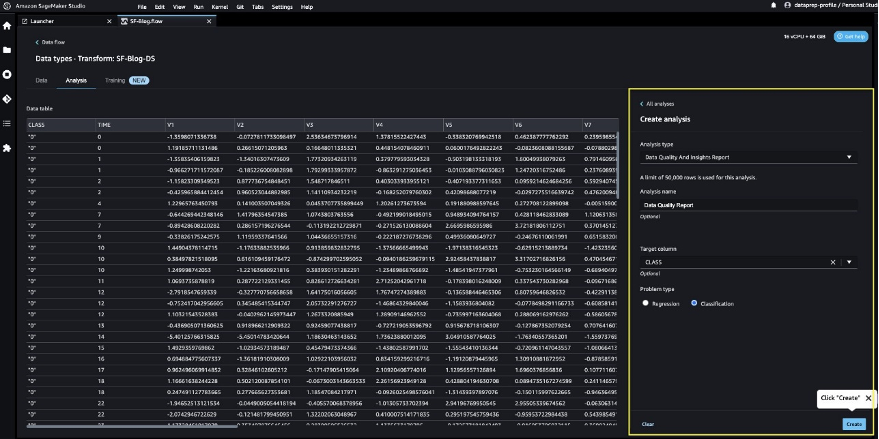
- Refer to the Data Quality and Insights Report details to check out high-priority warnings.
You can choose to resolve the warnings reported before proceeding with your ML journey.
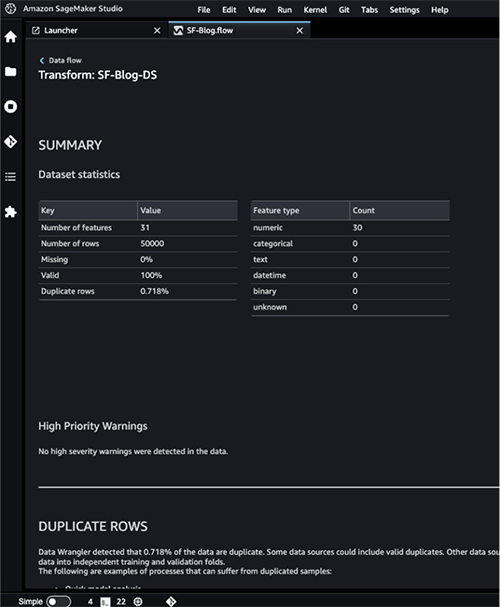
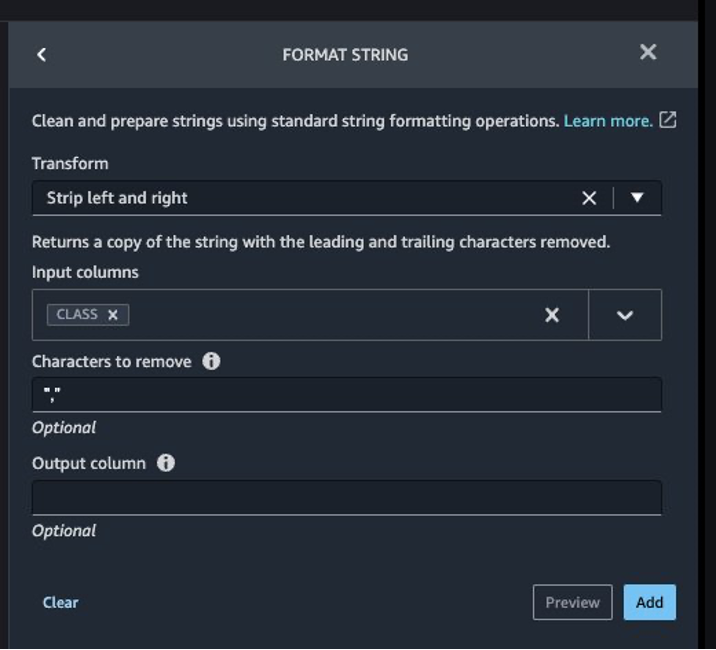
The target column Class to be predicted is classified as a string. First, let’s apply a transformation to remove the stale empty characters.
- Choose Add step and choose Format string.
- In the list of transforms, choose Strip left and right.
- Enter the characters to remove and choose Add.
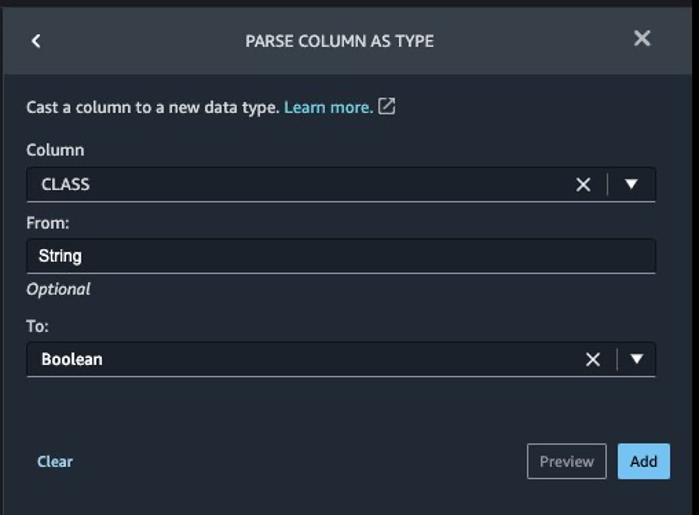
Next, we convert the target column Class from the string data type to Boolean because the transaction is either legitimate or fraudulent.
- Choose Add step.
- Choose Parse column as type.
- For Column, choose
Class.
- For From, choose String.
- For To, choose Boolean.
- Choose Add.
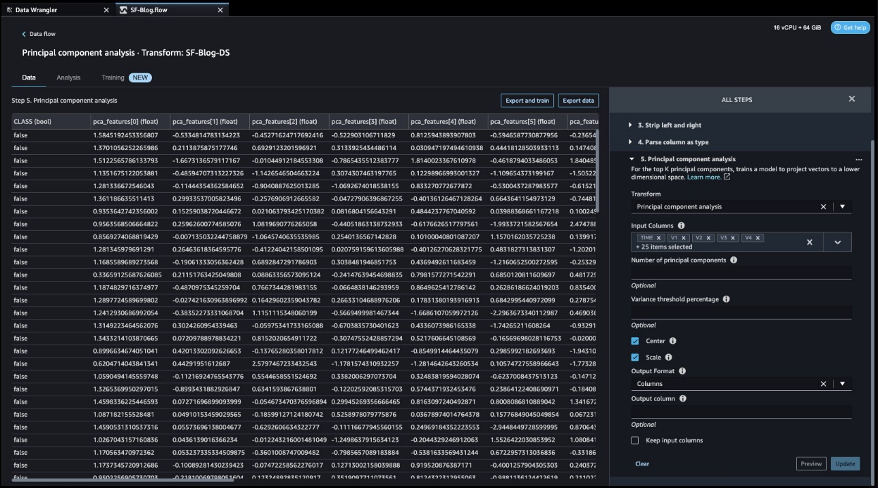
After the target column transformation, we reduce the number of feature columns, because there are over 30 features in the original dataset. We use Principal Component Analysis (PCA) to reduce the dimensions based on feature importance. To understand more about PCA and dimensionality reduction, refer to Principal Component Analysis (PCA) Algorithm.
- Choose Add step.
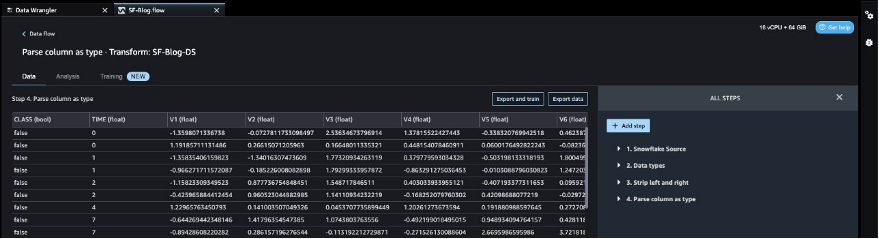
- Choose Dimensionality Reduction.
- For Transform, choose Principal component analysis.
- For Input columns, choose all the columns except the target column
Class.
- Choose the plus sign next to Data flow and choose Add analysis.
- For Analysis type, choose Quick Model.
- For Analysis name, enter a name.
- For Label, choose
Class.
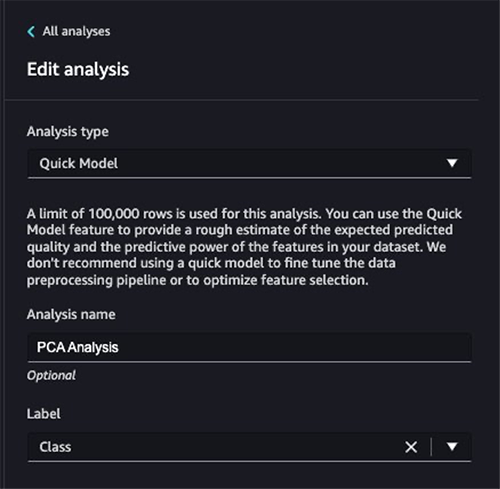
- Choose Run.
Based on the PCA results, you can decide which features to use for building the model. In the following screenshot, the graph shows the features (or dimensions) ordered based on highest to lowest importance to predict the target class, which in this dataset is whether the transaction is fraudulent or valid.
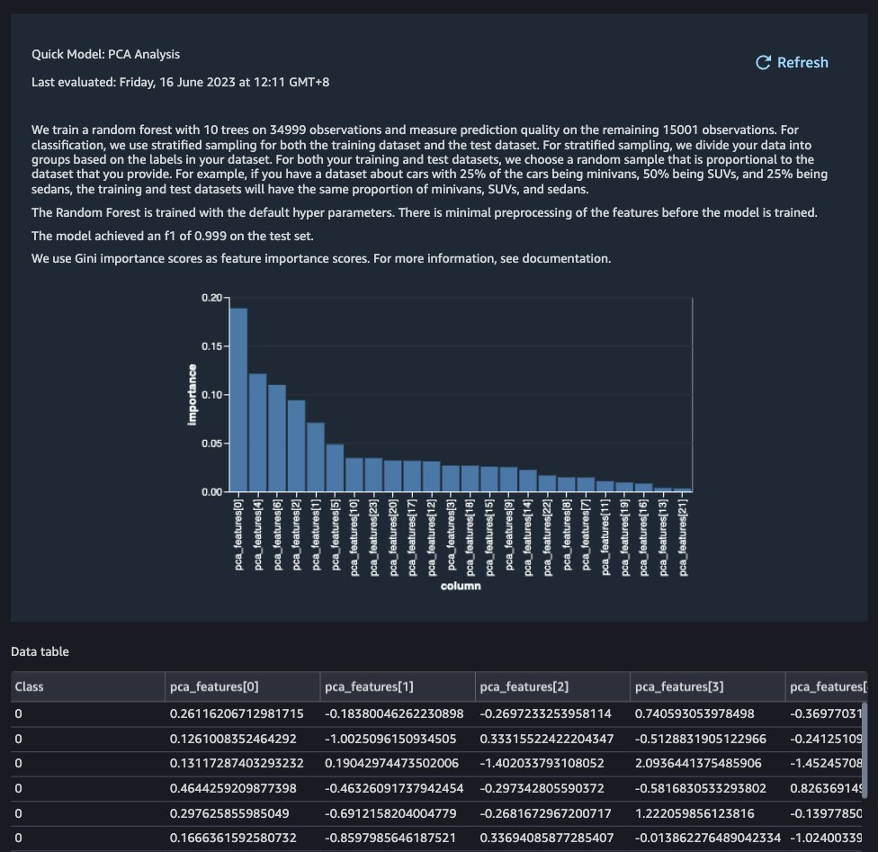
You can choose to reduce the number of features based on this analysis, but for this post, we leave the defaults as is.
This concludes our feature engineering process, although you may choose to run the quick model and create a Data Quality and Insights Report again to understand the data before performing further optimizations.
Export data and train the model
In the next step, we use SageMaker Autopilot to automatically build, train, and tune the best ML models based on your data. With SageMaker Autopilot, you still maintain full control and visibility of your data and model.
Now that we have completed the exploration and feature engineering, let’s train a model on the dataset and export the data to train the ML model using SageMaker Autopilot.
- On the Training tab, choose Export and train.
We can monitor the export progress while we wait for it to complete.
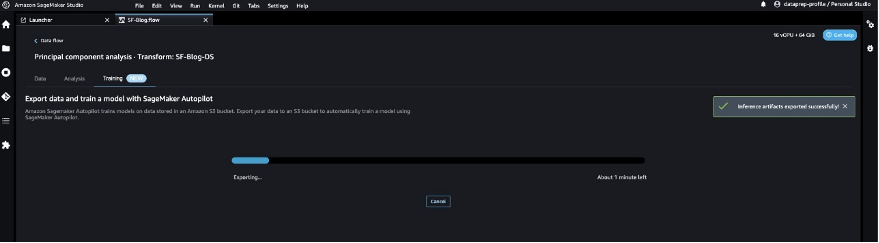
Let’s configure SageMaker Autopilot to run an automated training job by specifying the target we want to predict and the type of problem. In this case, because we’re training the dataset to predict whether the transaction is fraudulent or valid, we use binary classification.
- Enter a name for your experiment, provide the S3 location data, and choose Next: Target and features.
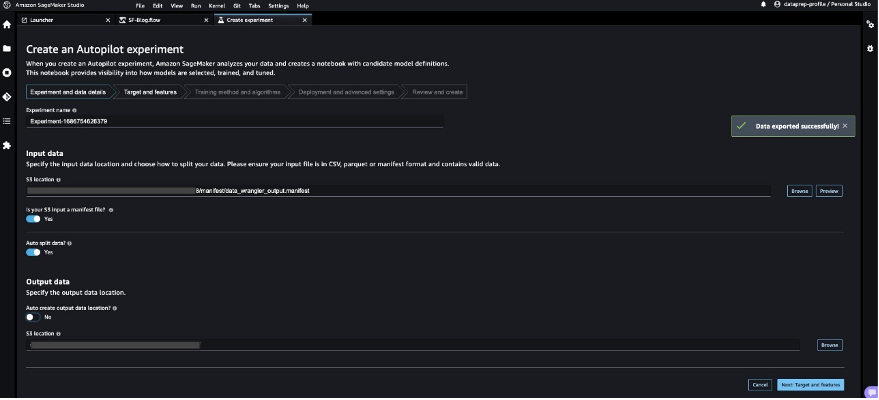
- For Target, choose
Class as the column to predict.
- Choose Next: Training method.
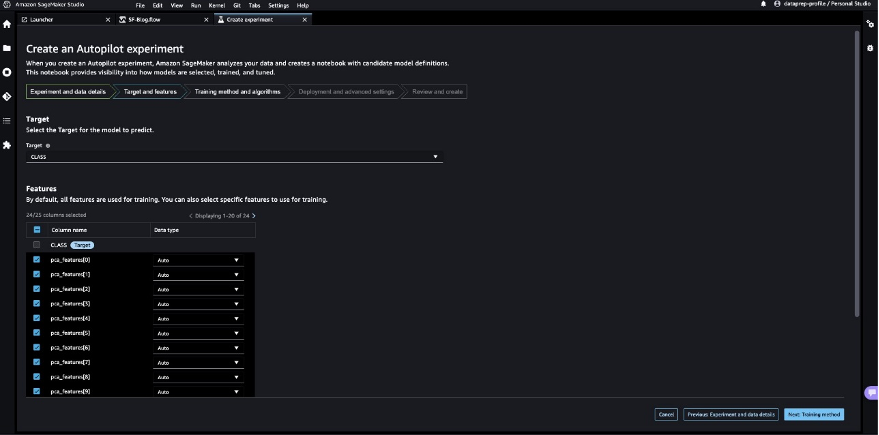
Let’s allow SageMaker Autopilot to decide the training method based on the dataset.
- For Training method and algorithms, select Auto.
To understand more about the training modes supported by SageMaker Autopilot, refer to Training modes and algorithm support.
- Choose Next: Deployment and advanced settings.
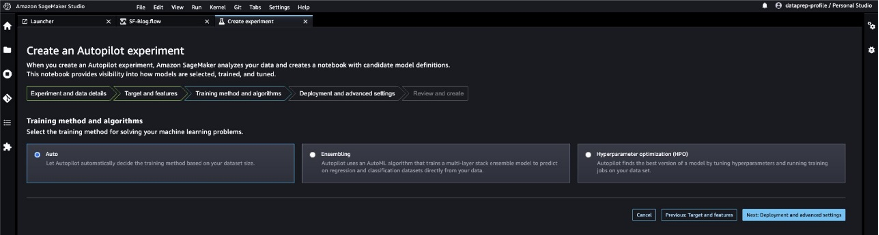
- For Deployment option, choose Auto deploy the best model with transforms from Data Wrangler, which loads the best model for inference after the experimentation is complete.
- Enter a name for your endpoint.
- For Select the machine learning problem type, choose Binary classification.
- For Objection metric, choose F1.
- Choose Next: Review and create.
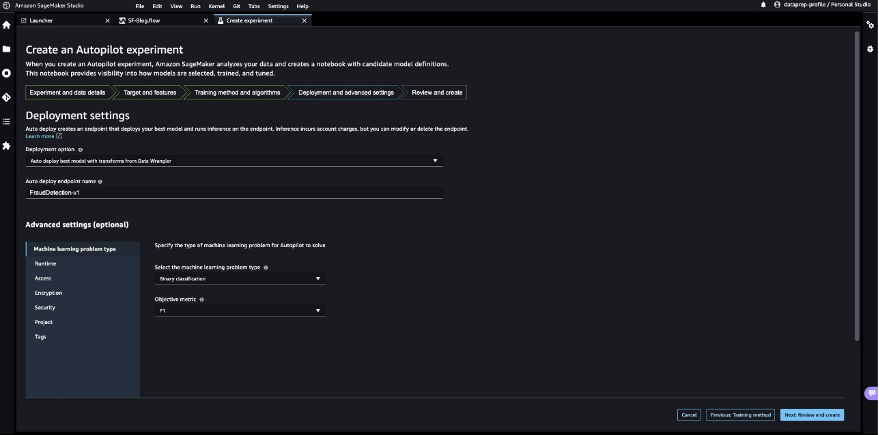
- Choose Create experiment.
This starts an SageMaker Autopilot job that creates a set of training jobs that uses combinations of hyperparameters to optimize the objective metric.
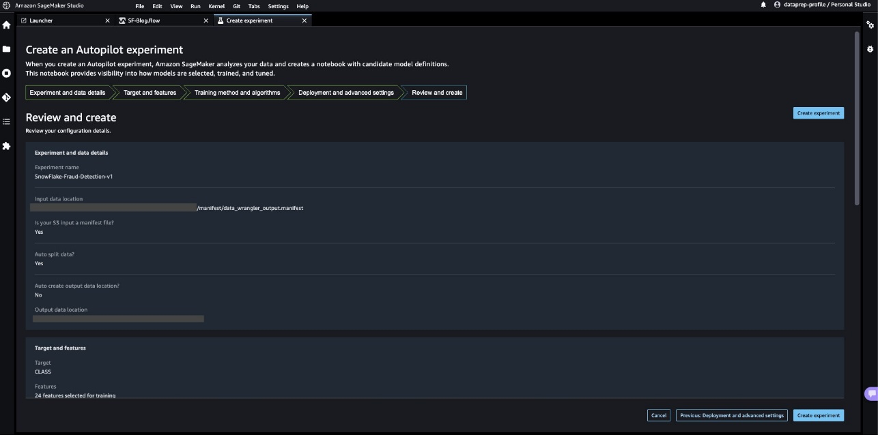
Wait for SageMaker Autopilot to finish building the models and evaluation of the best ML model.
Launch a real-time inference endpoint to test the best model
SageMaker Autopilot runs experiments to determine the best model that can classify credit card transactions as legitimate or fraudulent.
When SageMaker Autopilot completes the experiment, we can view the training results with the evaluation metrics and explore the best model from the SageMaker Autopilot job description page.
- Select the best model and choose Deploy model.
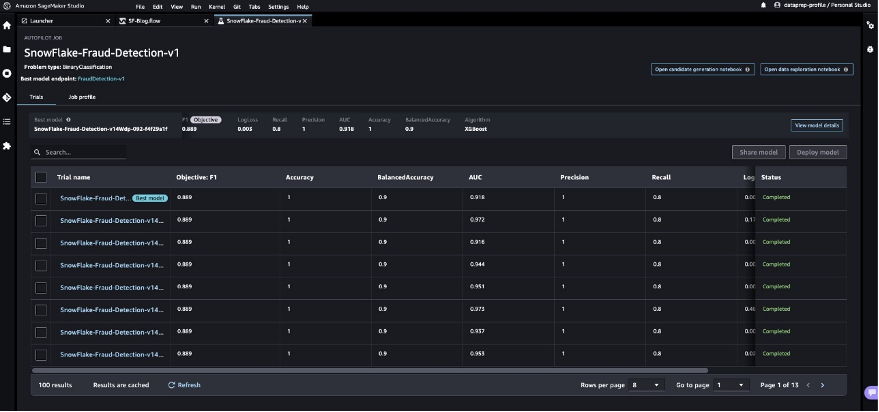
We use a real-time inference endpoint to test the best model created through SageMaker Autopilot.
- Select Make real-time predictions.
When the endpoint is available, we can pass the payload and get inference results.
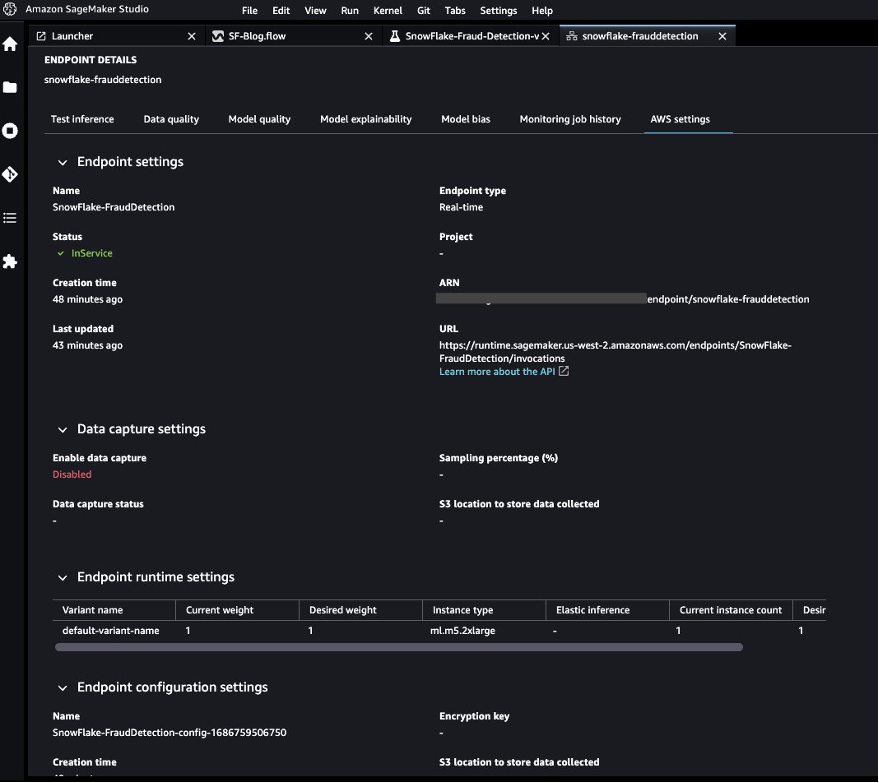
Let’s launch a Python notebook to use the inference endpoint.
- On the SageMaker Studio console, choose the folder icon in the navigation pane and choose Create notebook.
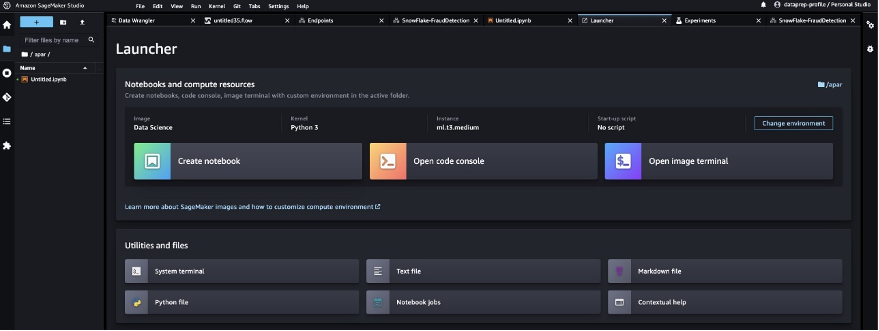
- Use the following Python code to invoke the deployed real-time inference endpoint:
# Library imports
import os
import io
import boto3
import json
import csv
#: Define the endpoint's name.
ENDPOINT_NAME = 'SnowFlake-FraudDetection' # replace the endpoint name as per your config
runtime = boto3.client('runtime.sagemaker')
#: Define a test payload to send to your endpoint.
payload = {
"body": {
"TIME": 152895,
"V1": 2.021155535,
"V2": 0.05372872624,
"V3": -1.620399104,
"V4": 0.3530165253,
"V5": 0.3048483853,
"V6": -0.6850955461,
"V7": 0.02483335885,
"V8": -0.05101346021,
"V9": 0.3550896835,
"V10": -0.1830053153,
"V11": 1.148091498,
"V12": 0.4283365505,
"V13": -0.9347237892,
"V14": -0.4615291327,
"V15": -0.4124343184,
"V16": 0.4993445934,
"V17": 0.3411548305,
"V18": 0.2343833846,
"V19": 0.278223588,
"V20": -0.2104513475,
"V21": -0.3116427235,
"V22": -0.8690778214,
"V23": 0.3624146958,
"V24": 0.6455923598,
"V25": -0.3424913329,
"V26": 0.1456884618,
"V27": -0.07174890419,
"V28": -0.040882382,
"AMOUNT": 0.27
}
}
#: Submit an API request and capture the response object.
response = runtime.invoke_endpoint(
EndpointName=ENDPOINT_NAME,
ContentType='text/csv',
Body=str(payload)
)
#: Print the model endpoint's output.
print(response['Body'].read().decode())
The output shows the result as false, which implies the sample feature data is not fraudulent.

Clean up
To make sure you don’t incur charges after completing this tutorial, shut down the SageMaker Data Wrangler application and shut down the notebook instance used to perform inference. You should also delete the inference endpoint you created using SageMaker Autopilot to prevent additional charges.
Conclusion
In this post, we demonstrated how to bring your data from Snowflake directly without creating any intermediate copies in the process. You can either sample or load your complete dataset to SageMaker Data Wrangler directly from Snowflake. You can then explore the data, clean the data, and perform featuring engineering using SageMaker Data Wrangler’s visual interface.
We also highlighted how you can easily train and tune a model with SageMaker Autopilot directly from the SageMaker Data Wrangler user interface. With SageMaker Data Wrangler and SageMaker Autopilot integration, we can quickly build a model after completing feature engineering, without writing any code. Then we referenced SageMaker Autopilot’s best model to run inferences using a real-time endpoint.
Try out the new Snowflake direct integration with SageMaker Data Wrangler today to easily build ML models with your data using SageMaker.
About the authors
 Hariharan Suresh is a Senior Solutions Architect at AWS. He is passionate about databases, machine learning, and designing innovative solutions. Prior to joining AWS, Hariharan was a product architect, core banking implementation specialist, and developer, and worked with BFSI organizations for over 11 years. Outside of technology, he enjoys paragliding and cycling.
Hariharan Suresh is a Senior Solutions Architect at AWS. He is passionate about databases, machine learning, and designing innovative solutions. Prior to joining AWS, Hariharan was a product architect, core banking implementation specialist, and developer, and worked with BFSI organizations for over 11 years. Outside of technology, he enjoys paragliding and cycling.
 Aparajithan Vaidyanathan is a Principal Enterprise Solutions Architect at AWS. He supports enterprise customers migrate and modernize their workloads on AWS cloud. He is a Cloud Architect with 23+ years of experience designing and developing enterprise, large-scale and distributed software systems. He specializes in Machine Learning & Data Analytics with focus on Data and Feature Engineering domain. He is an aspiring marathon runner and his hobbies include hiking, bike riding and spending time with his wife and two boys.
Aparajithan Vaidyanathan is a Principal Enterprise Solutions Architect at AWS. He supports enterprise customers migrate and modernize their workloads on AWS cloud. He is a Cloud Architect with 23+ years of experience designing and developing enterprise, large-scale and distributed software systems. He specializes in Machine Learning & Data Analytics with focus on Data and Feature Engineering domain. He is an aspiring marathon runner and his hobbies include hiking, bike riding and spending time with his wife and two boys.
 Tim Song is a Software Development Engineer at AWS SageMaker, with 10+ years of experience as software developer, consultant and tech leader he has demonstrated ability to deliver scalable and reliable products and solve complex problems. In his spare time, he enjoys the nature, outdoor running, hiking and etc.
Tim Song is a Software Development Engineer at AWS SageMaker, with 10+ years of experience as software developer, consultant and tech leader he has demonstrated ability to deliver scalable and reliable products and solve complex problems. In his spare time, he enjoys the nature, outdoor running, hiking and etc.
 Bosco Albuquerque is a Sr. Partner Solutions Architect at AWS and has over 20 years of experience in working with database and analytics products from enterprise database vendors and cloud providers. He has helped large technology companies design data analytics solutions and has led engineering teams in designing and implementing data analytics platforms and data products.
Bosco Albuquerque is a Sr. Partner Solutions Architect at AWS and has over 20 years of experience in working with database and analytics products from enterprise database vendors and cloud providers. He has helped large technology companies design data analytics solutions and has led engineering teams in designing and implementing data analytics platforms and data products.
Read More





 Akash Bhatia is a Principal Solution Architect with experience spanning multiple industries, including Manufacturing, Automotive, Retail ,and Space and Technology. Currently working in Amazon Web Services Enterprise Segments, Akash works closely with a diverse range of clients, including Fortune 100 companies and start-ups, to facilitate their cloud migration journey. In addition to his technical expertise, Akash has led product and program management, having successfully overseen numerous large-scale initiatives throughout his career.
Akash Bhatia is a Principal Solution Architect with experience spanning multiple industries, including Manufacturing, Automotive, Retail ,and Space and Technology. Currently working in Amazon Web Services Enterprise Segments, Akash works closely with a diverse range of clients, including Fortune 100 companies and start-ups, to facilitate their cloud migration journey. In addition to his technical expertise, Akash has led product and program management, having successfully overseen numerous large-scale initiatives throughout his career. Ram Vittal is a Principal ML Solutions Architect at AWS. He has over 20 years of experience architecting and building distributed, hybrid, and cloud applications. He is passionate about building secure and scalable AI/ML and big data solutions to help enterprise customers with their cloud adoption and optimization journey to improve their business outcomes. In his spare time, he enjoys riding motorcycle, playing tennis, and photography.
Ram Vittal is a Principal ML Solutions Architect at AWS. He has over 20 years of experience architecting and building distributed, hybrid, and cloud applications. He is passionate about building secure and scalable AI/ML and big data solutions to help enterprise customers with their cloud adoption and optimization journey to improve their business outcomes. In his spare time, he enjoys riding motorcycle, playing tennis, and photography. Ozan Eken is a Senior Product Manager at Amazon Web Services. He has over 15 years of experience in consulting and product management. He is passionate about building governance products, and Admin capabilities in Machine Learning for enterprise customers. Outside of work, he likes exploring different outdoor activities and watching soccer.
Ozan Eken is a Senior Product Manager at Amazon Web Services. He has over 15 years of experience in consulting and product management. He is passionate about building governance products, and Admin capabilities in Machine Learning for enterprise customers. Outside of work, he likes exploring different outdoor activities and watching soccer.






 Tingyi Li is an Enterprise Solutions Architect from AWS based out in Stockholm, Sweden supporting the Nordics customers. She enjoys helping customers with the architecture, design, and development of cloud-optimized infrastructure solutions. She is specialized in AI and Machine Learning and is interested in empowering customers with intelligence in their AI/ML applications. In her spare time, she is also a part-time illustrator who writes novels and plays the piano.
Tingyi Li is an Enterprise Solutions Architect from AWS based out in Stockholm, Sweden supporting the Nordics customers. She enjoys helping customers with the architecture, design, and development of cloud-optimized infrastructure solutions. She is specialized in AI and Machine Learning and is interested in empowering customers with intelligence in their AI/ML applications. In her spare time, she is also a part-time illustrator who writes novels and plays the piano. Demir Catovic is a Machine Learning Engineer from AWS based in Zurich, Switzerland. He engages with customers and helps them implement scalable and fully-functional ML applications. He is passionate about building and productionizing machine learning applications for customers and is always keen to explore around new trends and cutting-edge technologies in the AI/ML world.
Demir Catovic is a Machine Learning Engineer from AWS based in Zurich, Switzerland. He engages with customers and helps them implement scalable and fully-functional ML applications. He is passionate about building and productionizing machine learning applications for customers and is always keen to explore around new trends and cutting-edge technologies in the AI/ML world.