OpenAI Blog
GPT-4 API general availability and deprecation of older models in the Completions API
GPT-3.5 Turbo, DALL·E and Whisper APIs are also generally available, and we are releasing a deprecation plan for older models of the Completions API, which will retire at the beginning of 2024.OpenAI Blog
Highlight text as it’s being spoken using Amazon Polly
Amazon Polly is a service that turns text into lifelike speech. It enables the development of a whole class of applications that can convert text into speech in multiple languages.
This service can be used by chatbots, audio books, and other text-to-speech applications in conjunction with other AWS AI or machine learning (ML) services. For example, Amazon Lex and Amazon Polly can be combined to create a chatbot that engages in a two-way conversation with a user and performs certain tasks based on the user’s commands. Amazon Transcribe, Amazon Translate, and Amazon Polly can be combined to transcribe speech to text in the source language, translate it to a different language, and speak it.
In this post, we present an interesting approach for highlighting text as it’s being spoken using Amazon Polly. This solution can be used in many text-to-speech applications to do the following:
- Add visual capabilities to audio in books, websites, and blogs
- Increase comprehension when customers are trying to understand the text rapidly as it’s being spoken
Our solution gives the client (the browser, in this example), the ability to know what text (word or sentence) is being spoken by Amazon Polly at any instant. This enables the client to dynamically highlight the text as it’s being spoken. Such a capability is useful for providing visual aid to speech for the use cases mentioned previously.
Our solution can be extended to perform additional tasks besides highlighting text. For example, the browser can show images, play music, or perform other animations on the front end as the text is being spoken. This capability is useful for creating dynamic audio books, educational content, and richer text-to-speech applications.
Solution overview
At its core, the solution uses Amazon Polly to convert a string of text into speech. The text can be input from the browser or through an API call to the endpoint exposed by our solution. The speech generated by Amazon Polly is stored as an audio file (MP3 format) in an Amazon Simple Storage Service (Amazon S3) bucket.
However, using the audio file alone, the browser can’t find what parts of the text are being spoken at any instant because we don’t have granular information on when each word is spoken.
Amazon Polly provides a way to obtain this using speech marks. Speech marks are stored in a text file that shows the time (measured in milliseconds from start of the audio) when each word or sentence is spoken.
Amazon Polly returns speech mark objects in a line-delimited JSON stream. A speech mark object contains the following fields:
- Time – The timestamp in milliseconds from the beginning of the corresponding audio stream
- Type – The type of speech mark (sentence, word, viseme, or SSML)
- Start – The offset in bytes (not characters) of the start of the object in the input text (not including viseme marks)
- End – The offset in bytes (not characters) of the object’s end in the input text (not including viseme marks)
- Value – This varies depending on the type of speech mark:
- SSML – <mark> SSML tag
- Viseme – The viseme name
- Word or sentence – A substring of the input text as delimited by the start and end fields
For example, the sentence “Mary had a little lamb” can give you the following speech marks file if you use SpeechMarkTypes = [“word”, “sentence”] in the API call to obtain the speech marks:
The word “had” (at the end of line 3) begins 373 milliseconds after the audio stream begins, starts at byte 5, and ends at byte 8 of the input text.
Architecture overview
The architecture of our solution is presented in the following diagram.
Highlight Text as it’s spoken, using Amazon Polly
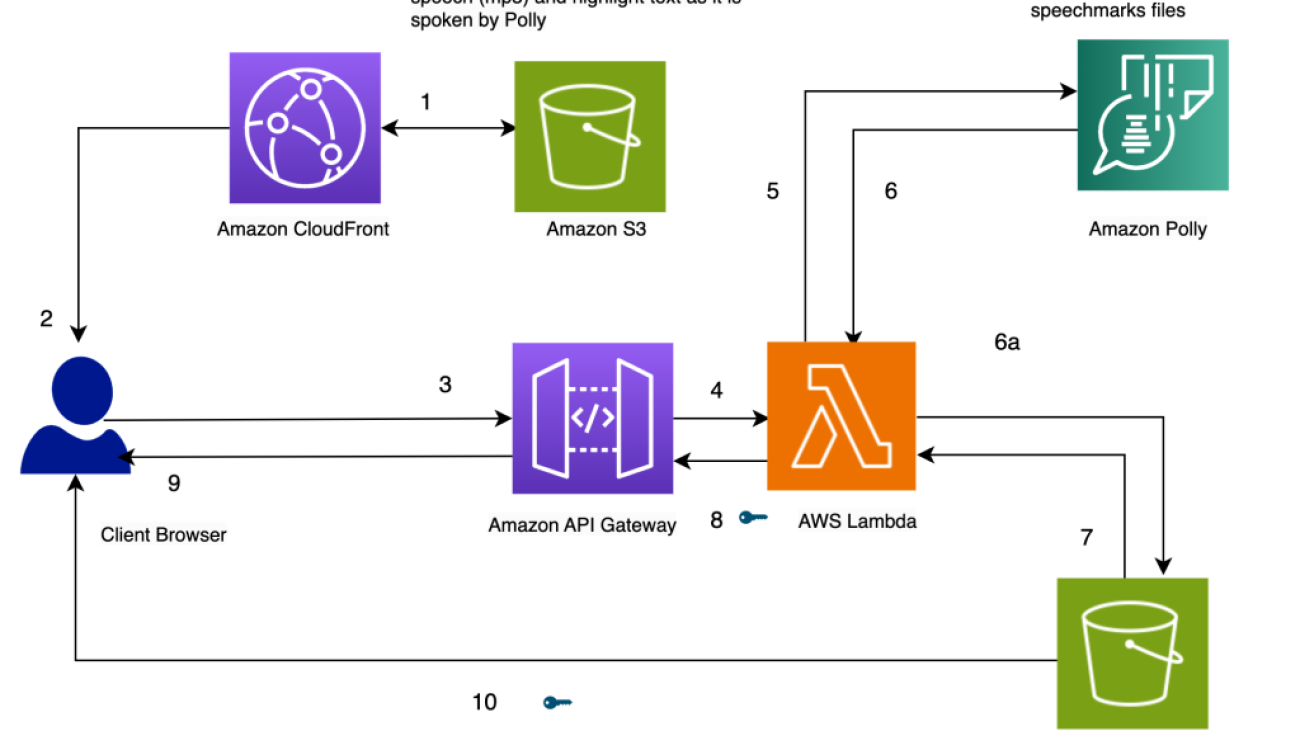
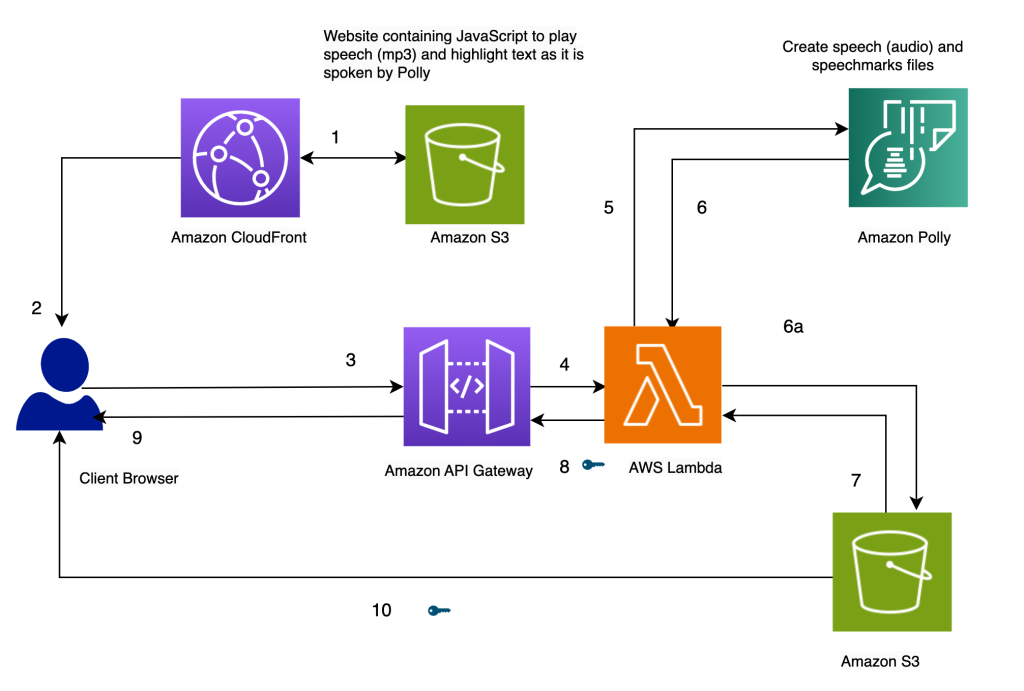
Our website for the solution is stored on Amazon S3 as static files (JavaScript, HTML), which are hosted in Amazon CloudFront (1) and served to the end-user’s browser (2).
When the user enters text in the browser through a simple HTML form, it’s processed by JavaScript in the browser. This calls an API (3) through Amazon API Gateway, to invoke an AWS Lambda function (4). The Lambda function calls Amazon Polly (5) to generate speech (audio) and speech marks (JSON) files. Two calls are made to Amazon Polly to fetch the audio and speech marks files. The calls are made using JavaScript async functions. The output of these calls is the audio and speech marks files, which are stored in Amazon S3 (6a). To avoid multiple users overwriting each others’ files in the S3 bucket, the files are stored in a folder with a timestamp. This minimizes the chances of two users overwriting each others’ files in Amazon S3. For a production release, we can employ more robust approaches to segregate users’ files based on user ID or timestamp and other unique characteristics.
The Lambda function creates pre-signed URLs for the speech and speech marks files and returns them to the browser in the form of an array (7, 8, 9).
When the browser sends the text file to the API endpoint (3), it gets back two pre-signed URLs for the audio file and the speech marks file in one synchronous invocation (9). This is indicated by the key symbol next to the arrow.
A JavaScript function in the browser fetches the speech marks file and the audio from their URL handles (10). It sets up the audio player to play the audio. (The HTML audio tag is used for this purpose).
When the user clicks the play button, it parses the speech marks retrieved in the earlier step to create a series of timed events using timeouts. The events invoke a callback function, which is another JavaScript function used to highlight the spoken text in the browser. Simultaneously, the JavaScript function streams the audio file from its URL handle.
The result is that the events are run at the appropriate times to highlight the text as it’s spoken while the audio is being played. The use of JavaScript timeouts provides us the synchronization of the audio with the highlighted text.
Prerequisites
To run this solution, you need an AWS account with an AWS Identity and Access Management (IAM) user who has permission to use Amazon CloudFront, Amazon API Gateway, Amazon Polly, Amazon S3, AWS Lambda, and AWS Step Functions.
Use Lambda to generate speech and speech marks
The following code invokes the Amazon Polly synthesize_speech function two times to fetch the audio and speech marks file. They’re run as asynchronous functions and coordinated to return the result at the same time using promises.
On the JavaScript side, the text highlighting is done by highlighter(start, finish, word) and the timed events are set by setTimers():
Alternative approaches
Instead of the previous approach, you can consider a few alternatives:
- Create both the speech marks and audio files inside a Step Functions state machine. The state machine can invoke the parallel branch condition to invoke two different Lambda functions: one to generate speech and another to generate speech marks. The code for this can be found in the using-step-functions subfolder in the Github repo.
- Invoke Amazon Polly asynchronously to generate the audio and speech marks. This approach can be used if the text content is large or the user doesn’t need a real-time response. For more details about creating long audio files, refer to Creating Long Audio Files.
- Have Amazon Polly create the presigned URL directly using the
generate_presigned_urlcall on the Amazon Polly client in Boto3. If you go with this approach, Amazon Polly generates the audio and speech marks newly every time. In our current approach, we store these files in Amazon S3. Although these stored files aren’t accessible from the browser in our version of the code, you can modify the code to play previously generated audio files by fetching them from Amazon S3 (instead of regenerating the audio for the text again using Amazon Polly). We have more code examples for accessing Amazon Polly with Python in the AWS Code Library.
Create the solution
The entire solution is available from our Github repo. To create this solution in your account, follow the instructions in the README.md file. The solution includes an AWS CloudFormation template to provision your resources.
Cleanup
To clean up the resources created in this demo, perform the following steps:
- Delete the S3 buckets created to store the CloudFormation template (Bucket A), the source code (Bucket B) and the website (
pth-cf-text-highlighter-website-[Suffix]). - Delete the CloudFormation stack
pth-cf. - Delete the S3 bucket containing the speech files (
pth-speech-[Suffix]). This bucket was created by the CloudFormation template to store the audio and speech marks files generated by Amazon Polly.
Summary
In this post, we showed an example of a solution that can highlight text as it’s being spoken using Amazon Polly. It was developed using the Amazon Polly speech marks feature, which provides us markers for the place each word or sentence begins in an audio file.
The solution is available as a CloudFormation template. It can be deployed as is to any web application that performs text-to-speech conversion. This would be useful for adding visual capabilities to audio in books, avatars with lip-sync capabilities (using viseme speech marks), websites, and blogs, and for aiding people with hearing impairments.
It can be extended to perform additional tasks besides highlighting text. For example, the browser can show images, play music, and perform other animations on the front end while the text is being spoken. This capability can be useful for creating dynamic audio books, educational content, and richer text-to-speech applications.
We welcome you to try out this solution and learn more about the relevant AWS services from the following links. You can extend the functionality for your specific needs.
About the Author
 Varad G Varadarajan is a Trusted Advisor and Field CTO for Digital Native Businesses (DNB) customers at AWS. He helps them architect and build innovative solutions at scale using AWS products and services. Varad’s areas of interest are IT strategy consulting, architecture, and product management. Outside of work, Varad enjoys creative writing, watching movies with family and friends, and traveling.
Varad G Varadarajan is a Trusted Advisor and Field CTO for Digital Native Businesses (DNB) customers at AWS. He helps them architect and build innovative solutions at scale using AWS products and services. Varad’s areas of interest are IT strategy consulting, architecture, and product management. Outside of work, Varad enjoys creative writing, watching movies with family and friends, and traveling.
Predict vehicle fleet failure probability using Amazon SageMaker Jumpstart
Predictive maintenance is critical in automotive industries because it can avoid out-of-the-blue mechanical failures and reactive maintenance activities that disrupt operations. By predicting vehicle failures and scheduling maintenance and repairs, you’ll reduce downtime, improve safety, and boost productivity levels.
What if we could apply deep learning techniques to common areas that drive vehicle failures, unplanned downtime, and repair costs?
In this post, we show you how to train and deploy a model to predict vehicle fleet failure probability using Amazon SageMaker JumpStart. SageMaker Jumpstart is the machine learning (ML) hub of Amazon SageMaker, providing pre-trained, publicly available models for a wide range of problem types to help you get started with ML. The solution outlined in the post is available on GitHub.
SageMaker JumpStart solution templates
SageMaker JumpStart provides one-click, end-to-end solutions for many common ML use cases. Explore the following use cases for more information on available solution templates:
- Demand forecasting
- Credit rating prediction
- Fraud detection
- Computer vision
- Extract and analyze data from documents
- Predictive maintenance
- Churn prediction
- Personalized recommendations
- Reinforcement learning
- Healthcare and life sciences
- Financial pricing
The SageMaker JumpStart solution templates cover a variety of use cases, under each of which several different solution templates are offered (the solution in this post, Predictive Maintenance for Vehicle Fleets, is in the Solutions section). Choose the solution template that best fits your use case from the SageMaker JumpStart landing page. For more information on specific solutions under each use case and how to launch a SageMaker JumpStart solution, see Solution Templates.
Solution overview
The AWS predictive maintenance solution for automotive fleets applies deep learning techniques to common areas that drive vehicle failures, unplanned downtime, and repair costs. It serves as an initial building block for you to get to a proof of concept in a short period of time. This solution contains data preparation and visualization functionality within SageMaker and allows you to train and optimize the hyperparameters of deep learning models for your dataset. You can use your own data or try the solution with a synthetic dataset as part of this solution. This version processes vehicle sensor data over time. A subsequent version will process maintenance record data.
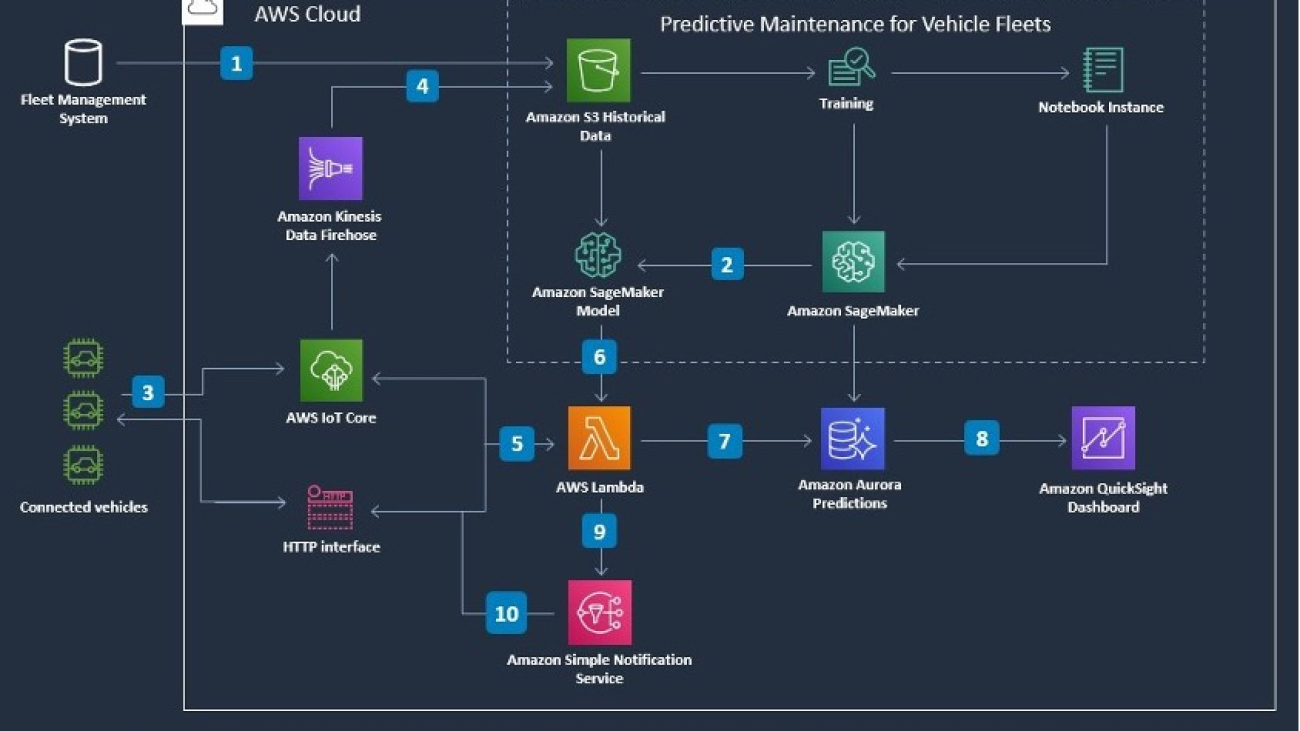
The following diagram demonstrates how you can use this solution with SageMaker components. As part of the solution, the following services are used:
- Amazon S3 – We use Amazon Simple Storage Service (Amazon S3) to store datasets
- SageMaker notebook – We use a notebook to preprocess and visualize the data, and to train the deep learning model
- SageMaker endpoint – We use the endpoint to deploy the trained model

The workflow includes the following steps:
- An extract of historical data is created from the Fleet Management System containing vehicle data and sensor logs.
- After the ML model is trained, the SageMaker model artifact is deployed.
- The connected vehicle sends sensor logs to AWS IoT Core (alternatively, via an HTTP interface).
- Sensor logs are persisted via Amazon Kinesis Data Firehose.
- Sensor logs are sent to AWS Lambda for querying against the model to make predictions.
- Lambda sends sensor logs to Sagemaker model inference for predictions.
- Predictions are persisted in Amazon Aurora.
- Aggregate results are displayed on an Amazon QuickSight dashboard.
- Real-time notifications on the predicted probability of failure are sent to Amazon Simple Notification Service (Amazon SNS).
- Amazon SNS sends notifications back to the connected vehicle.
The solution consists of six notebooks:
- 0_demo.ipynb – A quick preview of our solution
- 1_introduction.ipynb – Introduction and solution overview
- 2_data_preparation.ipynb – Prepare a sample dataset
- 3_data_visualization.ipynb – Visualize our sample dataset
- 4_model_training.ipynb – Train a model on our sample dataset to detect failures
- 5_results_analysis.ipynb – Analyze the results from the model we trained
Prerequisites
Amazon SageMaker Studio is the integrated development environment (IDE) within SageMaker that provides us with all the ML features that we need in a single pane of glass. Before we can run SageMaker JumpStart, we need to set up SageMaker Studio. You can skip this step if you already have your own version of SageMaker Studio running.
The first thing we need to do before we can use any AWS services is to make sure we have signed up for and created an AWS account. Then we create an administrative user and a group. For instructions on both steps, refer to Set Up Amazon SageMaker Prerequisites.
The next step is to create a SageMaker domain. A domain sets up all the storage and allows you to add users to access SageMaker. For more information, refer to Onboard to Amazon SageMaker Domain. This demo is created in the AWS Region us-east-1.
Finally, you launch SageMaker Studio. For this post, we recommend launching a user profile app. For instructions, refer to Launch Amazon SageMaker Studio.
To run this SageMaker JumpStart solution and have the infrastructure deployed to your AWS account, you need to create an active SageMaker Studio instance (see Onboard to Amazon SageMaker Studio). When your instance is ready, use the instructions in SageMaker JumpStart to launch the solution. The solution artifacts are included in this GitHub repository for reference.
Launch the SageMaker Jumpstart solution
To get started with the solution, complete the following steps:
- On the SageMaker Studio console, choose JumpStart.

- On the Solutions tab, choose Predictive Maintenance for Vehicle Fleets.

- Choose Launch.

It takes a few minutes to deploy the solution. - After the solution is deployed, choose Open Notebook.

If you’re prompted to select a kernel, choose PyTorch 1.8 Python 3.6 for all notebooks in this solution.
Solution preview
We first work on the 0_demo.ipynb notebook. In this notebook, you can get a quick preview of what the outcome will look like when you complete the full notebook for this solution.
Choose Run and Run All Cells to run all cells in SageMaker Studio (or Cell and Run All in a SageMaker notebook instance). You can run all the cells in each notebook one after the other. Ensure all the cells finish processing before moving to the next notebook.

This solution relies on a config file to run the provisioned AWS resources. We generate the file as follows:
We have some sample time series input data consisting of a vehicle’s battery voltage and battery current over time. Next, we load and visualize the sample data. As shown in the following screenshots, the voltage and current values are on the Y axis and the readings (19 readings recorded) are on the X axis.



We have previously trained a model on this voltage and current data that predicts the probability of vehicle failure and have deployed the model as an endpoint in SageMaker. We will call this endpoint with some sample data to determine the probability of failure in the next time period.
Given the sample input data, the predicted probability of failure is 45.73%.
To move to the next stage, choose Click here to continue.

Introduction and solution overview
The 1_introduction.ipynb notebook provides an overview of the solution and stages, and a look into the configuration file that has content definition, data sampling period, train and test sample count, parameters, location, and column names for generated content.
After you review this notebook, you can move to the next stage.
Prepare a sample dataset
We prepare a sample dataset in the 2_data_preparation.ipynb notebook.
We first generate the configuration file for this solution:
The config properties are as follows:
You can define your own dataset or use our scripts to generate a sample dataset:
You can merge the sensor data and fleet vehicle data together:
We can now move to data visualization.
Visualize our sample dataset
We visualize our sample dataset in 3_data_vizualization.ipynb. This solution relies on a config file to run the provisioned AWS resources. Let’s generate the file similar to the previous notebook.
The following screenshot shows our dataset.

Next, let’s build the dataset:
Now that the dataset is ready, let’s visualize the data statistics. The following screenshot shows the data distribution based on vehicle make, engine type, vehicle class, and model.

Comparing the log data, let’s look at an example of the mean voltage across different years for Make E and C (random).
The mean of voltage and current is on the Y axis and the number of readings is on the X axis.
- Possible values for log_target: [‘make’, ‘model’, ‘year’, ‘vehicle_class’, ‘engine_type’]
- Randomly assigned value for
log_target: make
- Randomly assigned value for
- Possible values for log_target_value1: [‘Make A’, ‘Make B’, ‘Make E’, ‘Make C’, ‘Make D’]
- Randomly assigned value for
log_target_value1: Make B
- Randomly assigned value for
- Possible values for log_target_value2: [‘Make A’, ‘Make B’, ‘Make E’, ‘Make C’, ‘Make D’]
- Randomly assigned value for
log_target_value2: Make D
- Randomly assigned value for
Based on the above, we assume log_target: make, log_target_value1: Make B and log_target_value2: Make D

The following graphs break down the mean of the log data.

The following graphs visualize an example of different sensor log values against voltage and current.

Train a model on our sample dataset to detect failures
In the 4_model_training.ipynb notebook, we train a model on our sample dataset to detect failures.
Let’s generate the configuration file similar to the previous notebook, and then proceed with training configuration:
Analyze the results from the model we trained
In the 5_results_analysis.ipynb notebook, we get data from our hyperparameter tuning job, visualize metrics of all the jobs to identify the best job, and build an endpoint for the best training job.
Let’s generate the configuration file similar to the previous notebook and visualize the metrics of all the jobs. The following plot visualizes test accuracy vs. epoch.

The following screenshot shows the hyperparameter tuning jobs we ran.

You can now visualize data from the best training job (out of the four training jobs) based on the test accuracy (red).
As we can see in the following screenshots, the test loss declines and AUC and accuracy increase with epochs.


Based on the visualizations, we can now build an endpoint for the best training job:
After we build the endpoint, we can test the predictor by passing it sample sensor logs:
Given the sample input data, the predicted probability of failure is 34.60%.
Clean up
When you’ve finished with this solution, make sure that you delete all unwanted AWS resources. On the Predictive Maintenance for Vehicle Fleets page, under Delete solution, choose Delete all resources to delete all the resources associated with the solution.

You need to manually delete any extra resources that you may have created in this notebook. Some examples include the extra S3 buckets (to the solution’s default bucket) and the extra SageMaker endpoints (using a custom name).
Customize the solution
Our solution is simple to customize. To modify the input data visualizations, refer to sagemaker/3_data_visualization.ipynb. To customize the machine learning, refer to sagemaker/source/train.py and sagemaker/source/dl_utils/network.py. To customize the dataset processing, refer to sagemaker/1_introduction.ipynb on how to define the config file.
Additionally, you can change the configuration in the config file. The default configuration is as follows:
The config file has the following parameters:
fleet_info_fn,fleet_sensor_logs_fn,fleet_dataset_fn,train_dataset_fn, andtest_dataset_fndefine the location of dataset filesvehicle_id_column,timestamp_column,target_column, andperiod_columndefine the headers for columnsdataset_size,chunksize,processing_chunksize,period_ms, andwindow_lengthdefine the properties of the dataset
Conclusion
In this post, we showed you how to train and deploy a model to predict vehicle fleet failure probability using SageMaker JumpStart. The solution is based on ML and deep learning models and allows a wide variety of input data including any time-varying sensor data. Because every vehicle has different telemetry on it, you can fine-tune the provided model to the frequency and type of data that you have.
To learn more about what you can do with SageMaker JumpStart, refer to the following:
- Visual inspection automation using Amazon SageMaker JumpStart
- Run automatic model tuning with Amazon SageMaker JumpStart
- Get started with generative AI on AWS using Amazon SageMaker JumpStart
Resources
- Amazon SageMaker Developer Guide
- SageMaker JumpStart Developer Guide
- Perform Automatic Model Tuning with SageMaker
- SageMaker JumpStart predictive maintenance solution
About the Authors
 Rajakumar Sampathkumar is a Principal Technical Account Manager at AWS, providing customers guidance on business-technology alignment and supporting the reinvention of their cloud operation models and processes. He is passionate about cloud and machine learning. Raj is also a machine learning specialist and works with AWS customers to design, deploy, and manage their AWS workloads and architectures.
Rajakumar Sampathkumar is a Principal Technical Account Manager at AWS, providing customers guidance on business-technology alignment and supporting the reinvention of their cloud operation models and processes. He is passionate about cloud and machine learning. Raj is also a machine learning specialist and works with AWS customers to design, deploy, and manage their AWS workloads and architectures.

NVIDIA CEO, European Generative AI Execs Discuss Keys to Success
Three leading European generative AI startups joined NVIDIA founder and CEO Jensen Huang this week to talk about the new era of computing.
More than 500 developers, researchers, entrepreneurs and executives from across Europe and further afield packed into the Spindler and Klatt, a sleek, riverside gathering spot in Berlin.
Huang started the reception by touching on the message he delivered Monday at the Berlin Summit for Earth Virtualization Engines (EVE), an international collaboration focused on climate science. He shared details of NVIDIA’s Earth-2 initiative and how accelerated computing, AI-augmented simulation and interactive digital twins drive climate science research.
Before sitting down for a fireside chat with the founders of the three startups, Huang introduced some “special guests” to the audience — four of the world’s leading climate modeling scientists, who he called the “unsung heroes” of saving the planet.
“These scientists have dedicated their careers to advancing climate science,” said Huang. “With the vision of EVE, they are the architects of the new era of climate science.”
Taking on Formidable Forces
“There is an enormous amount of AI startups in Germany, and I’m delighted to see it,” Huang said. “You’re in a brand-new computing era, and when that happens, everybody’s on square one.”
Huang welcomed to the stage the founders from Blackshark.ai, Magic and DeepL. Planetary management, artificial general intelligence, or AGI, and language translation are some ways the startups use generative AI.
- Blackshark.ai uses AI and hyperscaling distributed spatial computing to turn 2D images into data-rich 3D worlds.
- Magic is building an AGI software engineer, enabling small teams to write code significantly faster and more cheaply.
- DeepL aims to help everything communicate with everybody else with its AI-powered translation tool.
All three companies make solutions that could be seen as going up against products from established companies.

“Why did you take on such formidable forces?” Huang asked the founders.
Blackshark co-founder and CEO Michael Putz shared that the startup’s product is similar to what you might see in Google Earth.
But Blackshark claimed its coverage of the planet is 100%, compared to Google Earth’s 20%. And while Google might take a few months to update parts of its map, Blackshark only needs three days, Putz said.
Magic co-founder, CEO and AI lead Eric Steinberger explained how his company is trying to build an AGI AI software engineer that will work as though it were a team of humans.
He said it’ll remember conversations from months ago and can be messaged via an app like any other engineer. Rather than creating an alternative to existing solutions, Magic sees itself as trying to build something categorically different.
“It’s hard to build, but if we can get it right, we’re in an even playing field, even up against the giants,” said Steinberger.
DeepL founder and CEO Jaroslav Kutylowski said his company’s work was initially an intellectual challenge. “Could they do better than Google?” the team asked themselves. To Kutylowski, that sounded like fun.
Intuition, Efficiency and Resilience
Steinberger got a chuckle from the audience as he asked Huang about his decision-making process in driving NVIDIA forward. “You’re right, either always or almost always. How do you make those decisions before it’s obvious?”
“That’s a hard question,” Huang responded.
Huang talked about the intuition that comes from decision-making, saying, in his case, it comes from life and industrial experience. In NVIDIA’s case, he said it comes from having a lot of ideas “cooking” simultaneously.
He explained that with the invention of the GPU, the intention was never to replace the CPU but to make the GPU part of the next great computer by taking a full-stack approach.
With data centers and the cloud, Putz asked for advice on the best approach for startups when it comes to computing.
NVIDIA joined the “fabless semiconductor” industry, where there was very little capital required for a factory to funnel resources into R&D teams of 30-50 engineers instead of 500 like a more traditional semiconductor company.
Today, Huang explained, with the software 2.0 generation, startups can’t spend all their money on engineers — they need to save some to prototype and refine their software.
And it’s important to use the right tools to do the work for cost-efficient workloads. A CPU might be cheaper than a GPU per instance, but running a workload on a GPU will take “10x less time,” he said.
Kutylowski asked about the most significant challenges NVIDIA and Huang have faced along the company’s 30-year journey.
“I go into things with the attitude of, ‘How hard can it be? Well, it turns out it’s super hard,” Huang answered. “But if somebody else can do it, why can’t I?”
The answer includes the right attitude, self-confidence, the willingness to learn, and not setting an expectation of perfection from day one, he said. “Being resilient as you fail to the point where you eventually succeed — that’s when you learn,” Huang said.

XPENG Unleashes G6 Coupe SUV for Mainstream Market
China electric vehicle maker XPENG Motors has announced its new G6 coupe SUV — featuring an NVIDIA-powered intelligent advanced driver assistance system — is now available to the China market.
The G6 is XPENG’s first model featuring the company’s proprietary Smart Electric Platform Architecture (SEPA) 2.0, which aims to reduce development and manufacturing costs and shorten R&D cycles since the modular architecture will be compatible with future models.

The electric SUV also features the XPENG Navigation Guided Pilot (XNGP), a full scenario-based intelligent assisted driving system. It’s powered by the cutting-edge NVIDIA DRIVE Orin compute and XPENG’s full-stack software developed in-house.
The XNGP system first made its debut in the EV maker’s flagship G9 SUV, touting a safe, reliable, advanced driving experience behind the wheel.
Next-Level Driving Experience for All
The G6 comes in five trim levels, ranging in price from $29,021-$38,285 (RMB 209,900-276,900), making it accessible for the mainstream market.
Featuring a high-voltage 800V silicon-carbide platform and 3C battery, the G6 is built to go up to 469 miles on one charge and can reach speeds up to 125 miles per hour (202 kph). With XPENG’s DC fast charger, drivers can get up to 186 miles of charge in just 10 minutes.
The G6 model comes with two NVIDIA DRIVE Orin systems-on-a-chip (SOCs), which deliver 508 trillion operations per second (TOPS) of high-peformance compute for real-time processing of data streaming in from the vehicle’s 31 driving sensors.

Upping the Ante
The XNGP driving system makes the G6 a standout among today’s EV landscape as automakers jockey for position in the highly competitive China market. In fact, XPENG predicts this latest model will become the top-selling electric SUV in the country.
With the XNGP’s point-to-point automated cruise assistance, drivers need only set the destination and monitor the traffic conditions with hands resting on the steering wheel, while the vehicle takes the wheel, performing a host of scenario-based actions. These include cruising on main urban roads, autonomously changing lanes, congestion avoidance, emergency braking, on- and off-ramp driving, highway driving, parking, and more.
The G6’s ability to safely navigate all these driving scenarios is enabled by its comprehensive sensor suite, which includes multiple lidars, cameras, mmWave and ultrasonic radars for a 360-degree surround view of the car’s environment. As a result, this redundant and diverse multi-sensor fusion set helps enable safe, intelligent driving decisions under a variety of urban driving conditions.
With plans for the G6 to roll out to key European markets by next year, XPENG designed this state-of-the-art coupe SUV to meet both C-NCAP and E-NCAP safety standards.
Based on the more than 35,000 preorders reported for the G6 after its reveal at Auto Shanghai earlier this year, drivers are eager to get moving in this latest offering from XPENG’s software-defined fleet.
“Who we are shapes what we say and how we say it”
Amazon Research Award recipient Shrikanth Narayanan is on a mission to make inclusive human-AI conversational experiences.Read More

A Change in the Weather: AI, Accelerated Computing Promise Faster, More Efficient Predictions
The increased frequency and severity of extreme weather and climate events could take a million lives and cost $1.7 trillion annually by 2050, according to the Munich Reinsurance Company.
This underscores a critical need for accurate weather forecasting, especially with the rise in severe weather occurrences such as blizzards, hurricanes and heatwaves. AI and accelerated computing are poised to help.
More than 180 weather modeling centers employ robust high performance computing (HPC) infrastructure to crunch traditional numerical weather prediction (NWP) models. These include the European Center for Medium-Range Weather Forecasts (ECMWF), which operates on 983,040 CPU cores, and the U.K. Met Office’s supercomputer, which uses more than 1.5 million CPU cores and consumes 2.7 megawatts of power.
Rethinking HPC Design
The global push toward energy efficiency is urging a rethink of HPC system design. Accelerated computing, harnessing the power of GPUs, offers a promising, energy-efficient alternative that speeds up computations.
NVIDIA GPUs have made a significant impact on globally adopted weather models, including those from ECMWF, the Max Planck Institute for Meteorology, the German Meteorological Service and the National Center for Atmospheric Research.
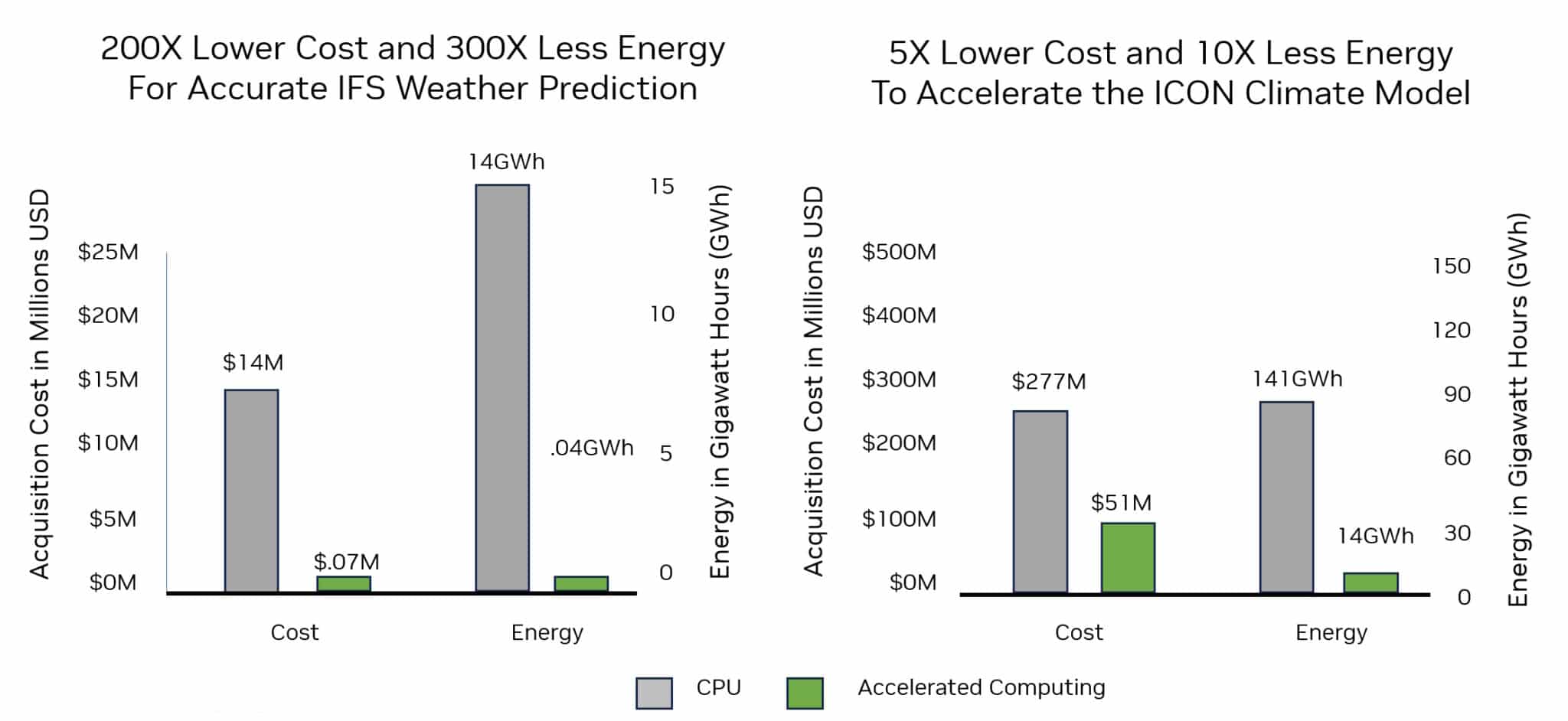
GPUs enhance performance up to 24x, improve energy efficiency, and reduce costs and space requirements.
“To make reliable weather predictions and climate projections a reality within power budget limits, we rely on algorithmic improvements and hardware where NVIDIA GPUs are an alternative to CPUs,” said Oliver Fuhrer, head of numerical prediction at MeteoSwiss, the Swiss national office of meteorology and climatology.
AI Model Boosts Speed, Efficiency
NVIDIA’s AI-based weather-prediction model FourCastNet offers competitive accuracy with orders of magnitude greater speed and energy efficiency compared with traditional methods. FourCastNet rapidly produces week-long forecasts and allows for the generation of large ensembles — or groups of models with slight variations in starting conditions — for high-confidence, extreme weather predictions.
For example, based on historical data, FourCastNet accurately predicted the temperatures on July 5, 2018, in Ouargla, Algeria — Africa’s hottest recorded day.
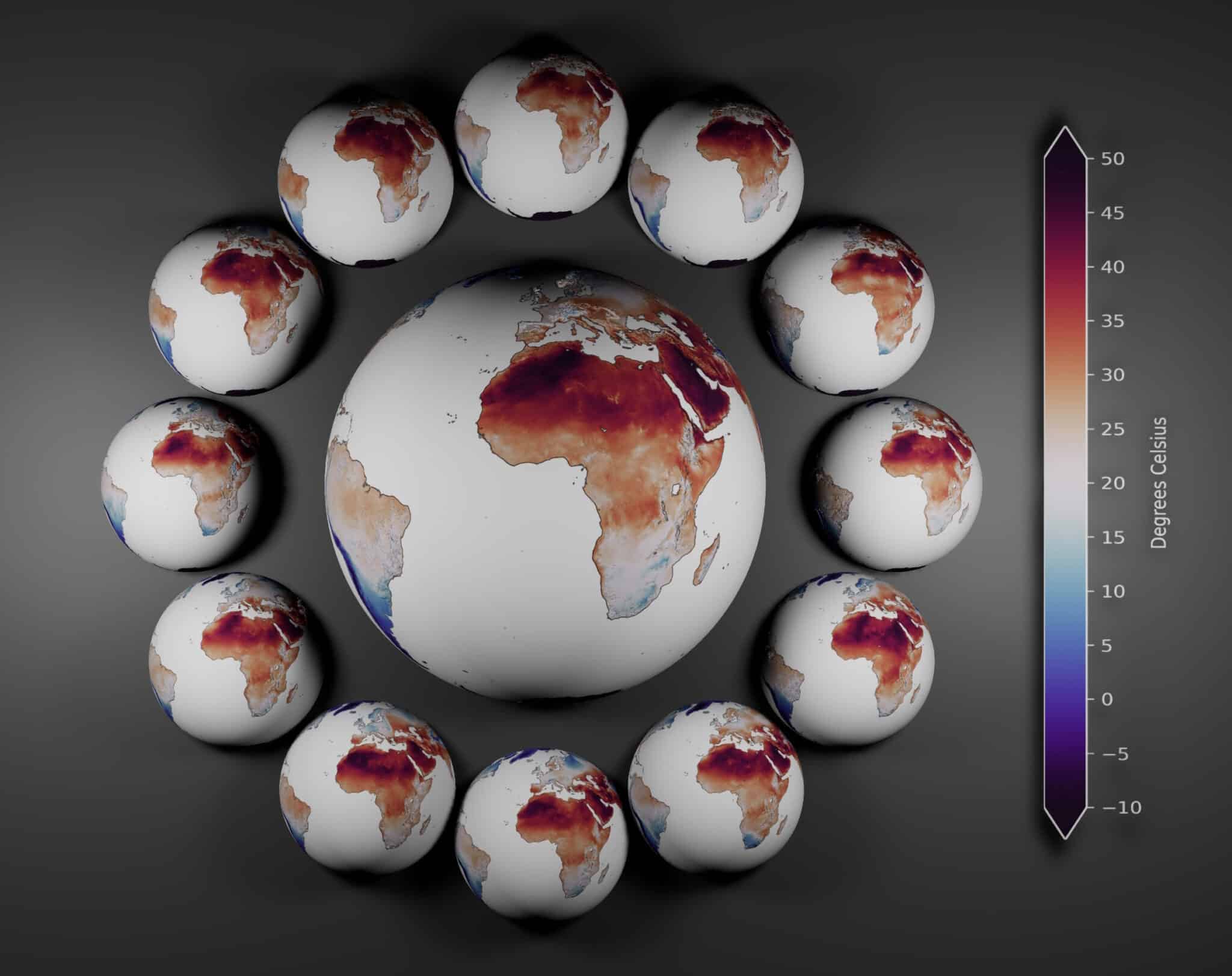
Using NVIDIA GPUs, FourCastNet quickly and accurately generated 1,000 ensemble members, outpacing traditional models. A dozen of the members accurately predicted the high temperatures in Algeria based on data from three weeks before it occurred.
This marked the first time the FourCastNet team predicted a high-impact event weeks in advance, demonstrating AI’s potential for reliable weather forecasting with lower energy consumption than traditional weather models.
FourCastNet uses the latest AI advances, such as transformer models, to bridge AI and physics for groundbreaking results. It’s about 45,000x faster than traditional NWP models. And when trained, FourCastNet consumes 12,000x less energy to produce a forecast than the Europe-based Integrated Forecast System, a gold-standard NWP model.
“NVIDIA FourCastNet opens the door to the use of AI for a wide variety of applications that will change the shape of the NWP enterprise,” said Bjorn Stevens, director of the Max Planck Institute for Meteorology.
Expanding What’s Possible
In an NVIDIA GTC session, Stevens described what’s possible now with the ICON climate research tool. The Levante supercomputer, using 3,200 CPUs, can simulate 10 days of weather in 24 hours, Stevens said. In contrast, the JUWELS Booster supercomputer, using 1,200 NVIDIA A100 Tensor Core GPUs, can run 50 simulated days in the same amount of time.
Scientists are looking to study climate effects 300 years into the future, which means systems need to be 20x faster, Stevens added. Embracing faster technology like NVIDIA H100 Tensor Core GPUs and simpler code could get us there, he said.
Researchers now face the challenge of striking the optimal balance between physical modeling and machine learning to produce faster, more accurate climate forecasts. A ECMWF blog published last month describes this hybrid approach, which relies on machine learning for initial predictions and physical models for data generation, verification and system refinement.
Such an integration — delivered with accelerated computing — could lead to significant advancements in weather forecasting and climate science, ushering in a new era of efficient, reliable and energy-conscious predictions.
Learn more about how accelerated computing and AI boost climate science through these resources:
- NVIDIA one-pager: Predicting the Weather With AI
- NVIDIA one-pager: Faster Weather Predictions
- NVIDIA resource page: Sustainable Computing
- NVIDIA technical blog: AI for a Scientific Computing Revolution
Unlocking the AI-powered opportunity in the UK
 AI is the most profound technology that humanity is working on today. It’s a critical part of solving big societal challenges and helping to make our everyday lives bett…Read More
AI is the most profound technology that humanity is working on today. It’s a critical part of solving big societal challenges and helping to make our everyday lives bett…Read More
Introducing Superalignment
We need scientific and technical breakthroughs to steer and control AI systems much smarter than us. To solve this problem within four years, we’re starting a new team, co-led by Ilya Sutskever and Jan Leike, and dedicating 20% of the compute we’ve secured to date to this effort. We’re looking for excellent ML researchers and engineers to join us.OpenAI Blog