Voice assistants help users make phone calls, send messages, create events, navigate, and do a lot more. However, assistants have limited capacity to understand their users’ context. In this work, we aim to take a step in this direction. Our work dives into a new experience for users to refer to phone numbers, addresses, email addresses, URLs, and dates on their phone screens. Our focus lies in reference understanding, which becomes particularly interesting when multiple similar texts are present on screen, similar to visual grounding. We collect a dataset and propose a lightweight…Apple Machine Learning Research
How Alexa learned to speak with an Irish accent
With little training data and no mapping of speech to phonemes, Amazon researchers used voice conversion to generate Irish-accented training data in Alexa’s own voice.Read More

AI, Digital Twins to Unleash Next Wave of Climate Research Innovation
AI and accelerated computing will help climate researchers achieve the miracles they need to achieve breakthroughs in climate research, NVIDIA founder and CEO Jensen Huang said during a keynote Monday at the Berlin Summit for the Earth Virtualization Engines initiative.
“Richard Feynman once said that “what I can’t create, I don’t understand” and that’s the reason why climate modeling is so important,” Huang told 180 attendees at the Harnack House in Berlin, a storied gathering place for the region’s scientific and research community.
“And so the work that you do is vitally important to policymakers to researchers to the industry,” he added.
To advance this work, the Berlin Summit brings together participants from around the globe to harness AI and high-performance computing for climate prediction.
In his talk, Huang outlined three miracles that will have to happen for climate researchers to achieve their goals, and touched on NVIDIA’s own efforts to collaborate with climate researchers and policymakers with its Earth-2 efforts.
The first miracle required will be to simulate the climate fast enough, and with a high enough resolution – on the order of just a couple of square kilometers.
The second miracle needed will be the ability to pre-compute vast quantities of data.
The third miracle needed is the ability to visualize all this data interactively with NVIDIA Omniverse to “put it in the hands of policymakers, businesses, companies, and researchers.”
The Next Wave of Climate and Weather Innovation
The Earth Virtualization Engines initiative, known as EVE, is an international collaboration that brings together digital infrastructure focused on climate science, HPC and AI aiming to provide, for the first time, easily accessible kilometer-scale climate information to sustainably manage the planet.
“The reason why Earth-2 and EVE found each other at the perfect time is because Earth-2 was based on 3 fundamental breakthroughs,” Huang said.
The initiative promises to accelerate the pace of advances, advocating coordinated climate projections at 2.5-km resolution. It’s an enormous challenge, but it’s one that builds on a huge base of advancements over the past 25 years.
A sprawling suite of applications already benefits from accelerated computing, including ICON, IFS, NEMO, MPAS, WRF-G and more — and much more computing power for such applications is coming.
The NVIDIA GH200 Grace Hopper Superchip is a breakthrough accelerated CPU designed from the ground up for giant-scale AI and high-performance computing applications. It delivers up to 10x higher performance for applications running terabytes of data.
It’s built to scale, and by connecting large numbers of these chips together, NVIDIA can offer systems with the power efficiency to accelerate the work of researchers at the cutting edge of climate research. “To the software it looks like one giant processor,” Huang said.
To help researchers put vast quantities of data to work, quickly, to unlock understanding, Huang spoke about NVIDIA Modulus, an open-source framework for building training and fine-tuning physics-based machine learning model, and FourCastNet, a global, data-driven weather forecasting model, and how the latest AI-driven models can learn physics from real-world data.
Using raw data alone, FourCastNet is able to learn the principles governing complex weather patterns. Huang showed how FourCastNet was able to accurately predict the path of Hurricane Harvey by modeling the Coriolis force, the effect of the Earth’s rotation, on the storm.
Such models, when tethered to regular “checkpoints” created by traditional simulation, allow for more detailed, long-range forecasts. Huang then demonstrated how some of the FourCastNet ensemble’s models, running on NVIDIA GPUs, anticipated an unprecedented North African heatwave.
By running FourCastNet in Modulus, NVIDIA was able to generate 21-day weather trajectories of 1,000 ensemble members in one-tenth the time it previously took to do a single ensemble — and with 1,000x less energy consumption.
Lastly, NVIDIA technologies promise to help all this knowledge become more accessible with digital twins able to create interactive models of increasingly complex systems – from Amazon warehouses to the way 5G signals propagate in dense urban environments.
Huang then showed a stunning, high-resolution interactive visualization of global-scale climate data in the cloud, zooming in from a view of the globe to a detailed view of Berlin. This approach can work to predict climate and weather in locations as diverse as Berlin, Tokyo and Buenos Aires, Huang said.
Earth: The Final Frontier
To help meet challenges such as these, Huang outlined how NVIDIA is building more powerful systems for training AI models, simulating physical problems and interactive visualization.
“These new types of supercomputers are just coming online,” Huang said. “This is as fresh a computing technology as you can imagine.”
Huang ended his talk by thanking key researchers from across the field and playfully suggesting a mission statement for EVE.
“Earth, the final frontier, these are the voyages of EVE,” Huang said. Its “mission is to push the limits of computing in service of climate modeling, to seek out new methods and technologies to study the global-to-local state of the climate to inform today the impact of mitigation and adaptation to Earth’s tomorrow, to boldly go where no one has gone before.”
For more on Earth-2, visit https://www.nvidia.com/en-us/high-performance-computing/earth-2/
Retain original PDF formatting to view translated documents with Amazon Textract, Amazon Translate, and PDFBox
Companies across various industries create, scan, and store large volumes of PDF documents. In many cases, the content is text-heavy and often written in a different language and requires translation. To address this, you need an automated solution to extract the contents within these PDFs and translate them quickly and cost-efficiently.
Many businesses have diverse global users and need to translate text to enable cross-lingual communication between them. This is a manual, slow, and expensive human effort. There’s a need to find a scalable, reliable, and cost-effective solution to translate documents while retaining the original document formatting.
For verticals such as healthcare, due to regulatory requirements, the translated documents require an additional human in the loop to verify the validity of the machine-translated document.
If the translated document doesn’t retain the original formatting and structure, it loses its context. This can make it difficult for a human reviewer to validate and make corrections.
In this post, we demonstrate how to create a new translated PDF from a scanned PDF while retaining the original document structure and formatting using a geometry-based approach with Amazon Textract, Amazon Translate, and Apache PDFBox.
Solution overview
The solution presented in this post uses the following components:
- Amazon Textract – A fully managed machine learning (ML) service that automatically extracts printed text, handwriting, and other data from scanned documents that goes beyond simple optical character recognition (OCR) to identify, understand, and extract data from forms and tables. Amazon Textract can detect text in a variety of documents, including financial reports, medical records, and tax forms.
- Amazon Translate – A neural machine translation service that delivers fast, high-quality, and affordable language translation. Amazon Translate provides high-quality on-demand and batch translation capabilities across more than 2,970 language pairs, while decreasing your translation costs.
- PDF Translate – An open-source library written in Java and published on AWS Samples in GitHub. This library contains logic to generate translated PDF documents in your desired language with Amazon Textract and Amazon Translate. It also uses the open-source Java library Apache PDFBox to create PDF documents. There are similar PDF processing libraries available in other programming languages, for example Node PDFBox.
While performing machine translations, you may have situations where you wish to preserve specific sections of text from being translated, such as names or unique identifiers. Amazon Translate allows tag modifications, which allows you to specify what text should not be translated. Amazon Translate also supports formality customization, which allows you to customize the level of formality in your translation output.
For details on Amazon Textract limits, refer to Quotas in Amazon Textract.
The solution is restricted to the languages that can be extracted by Amazon Textract, which currently supports English, Spanish, Italian, Portuguese, French, and German. These languages are also supported by Amazon Translate. For the full list of languages supported by Amazon Translate, refer to Supported languages and language codes.
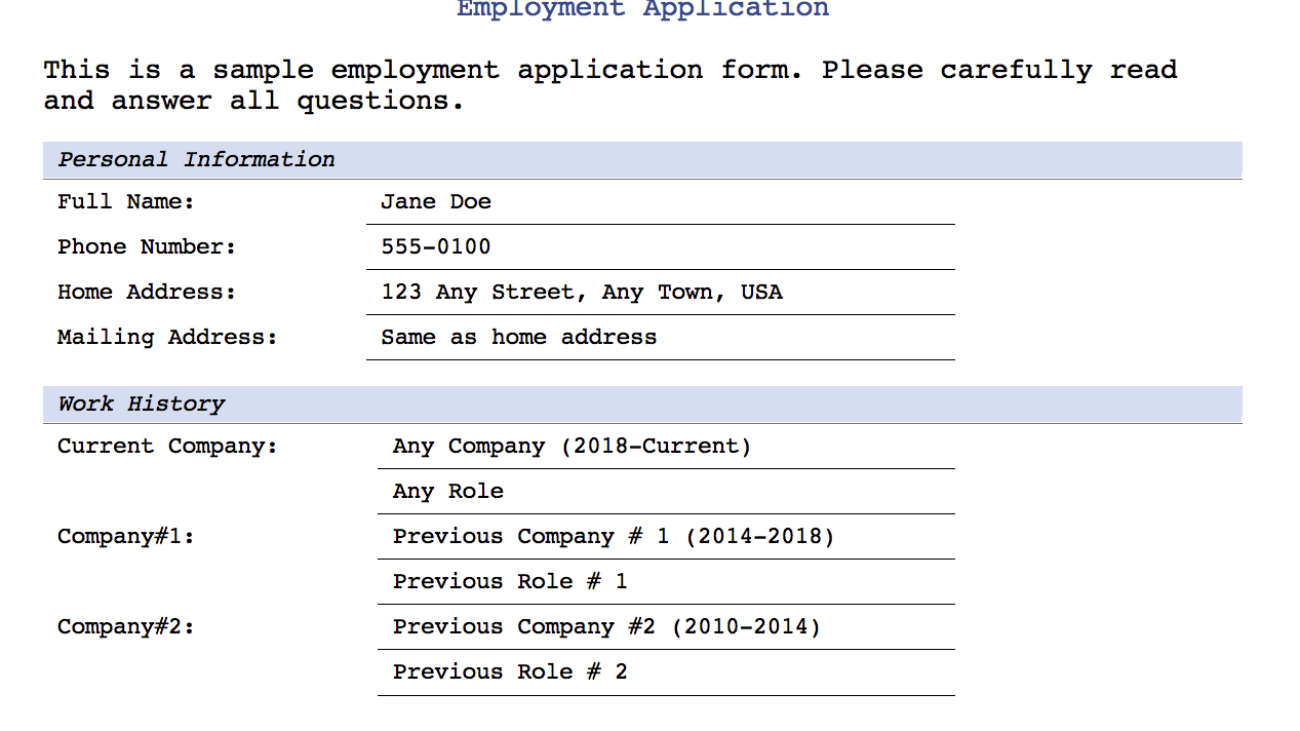
We use the following PDF to demonstrate translating the text from English to Spanish. The solution also supports generating the translated document without any formatting. The position of the translated text is maintained. The source and translated PDF documents can also be found in the AWS Samples GitHub repo.
In the following sections, we demonstrate how to run the translation code on a local machine and look at the translation code in more detail.

Prerequisites
Before you get started, set up your AWS account and the AWS Command Line Interface (AWS CLI). For access to any AWS Services such as Textract and Translate, appropriate IAM permissions are needed. We recommend utilizing least privilege permissions. To learn more about IAM permissions see Policies and permissions in IAM as well as How Amazon Textract works with IAM and How Amazon Translate works with IAM.
Run the translation code on a local machine
This solution focuses on the standalone Java code to extract and translate a PDF document. This is for easier testing and customizations to get the best-rendered translated PDF document. The code can then be integrated into an automated solution to deploy and run in AWS. See Translating PDF documents using Amazon Translate and Amazon Textract for a sample architecture that uses Amazon Simple Storage Service (Amazon S3) to store the documents and AWS Lambda to run the code.
To run the code on a local machine, complete the following steps. The code examples are available on the GitHub repo.
- Clone the GitHub repo:
- Run the following command:
- Run the following command to translate from English to Spanish:
Two translated PDF documents are created in the documents folder, with and without the original formatting (SampleOutput-es.pdf and SampleOutput-min-es.pdf).
Code to generate the translated PDF
The following code snippets show how to take a PDF document and generate a corresponding translated PDF document. It extracts the text using Amazon Textract and creates the translated PDF by adding the translated text as a layer to the image. It builds on the solution shown in the post Generating searchable PDFs from scanned documents automatically with Amazon Textract.
The code first gets each line of text with Amazon Textract. Amazon Translate is used to get translated text and save the geometry of the translated text.
The font size is calculated as follows and can easily be configured:
The translated PDF is created from the saved geometry and translated text. Changes to the color of the translated text can easily be configured.
The following image shows the document translated into Spanish with the original formatting (SampleOutput-es.pdf).
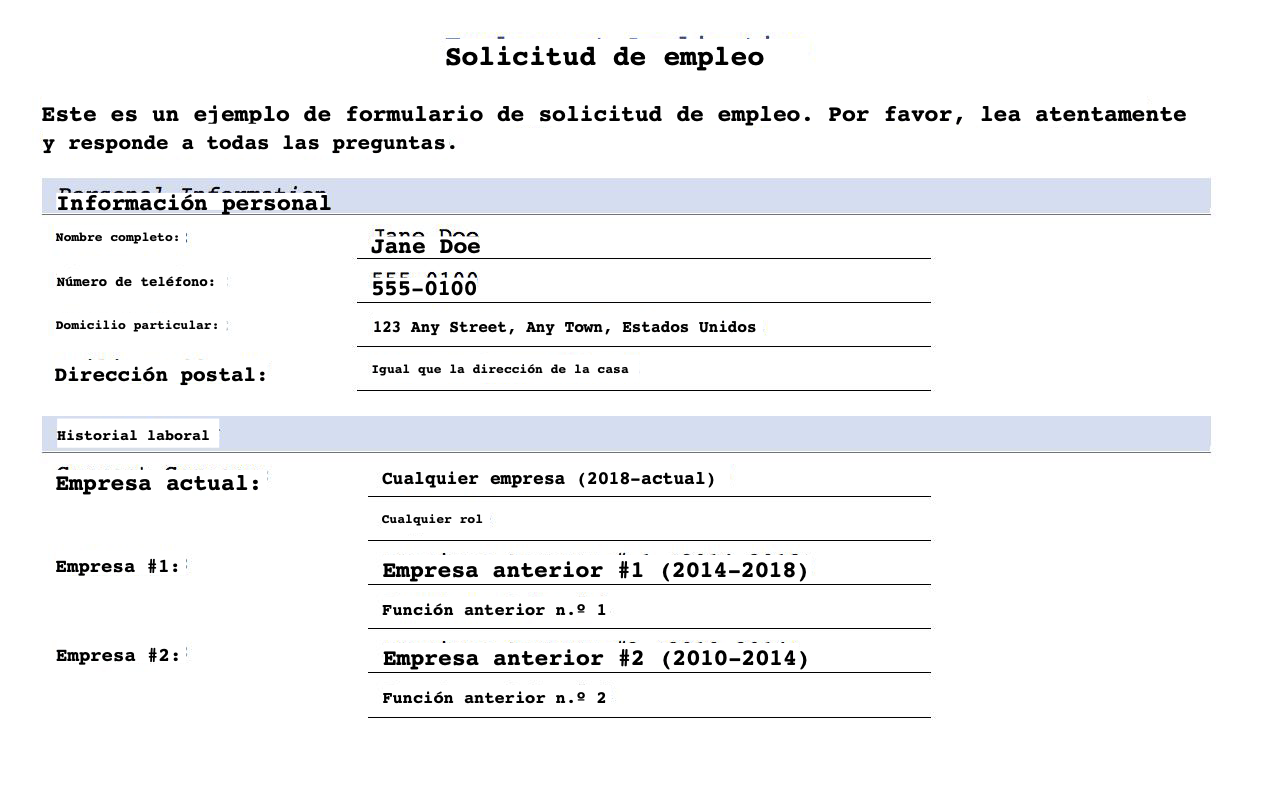
The following image shows the translated PDF in Spanish without any formatting (SampleOutput-min-es.pdf).

Processing time
The employment application pdf took about 10 seconds to extract, process and render the translated pdf. The processing time for text heavy document such as the Declaration of Independence PDF took less than a minute.
Cost
With Amazon Textract, you pay as you go based on the number of pages and images processed. With Amazon Translate, you pay as you go based on the number of text characters that are processed. Refer to Amazon Textract pricing and Amazon Translate pricing for actual costs.
Conclusion
This post showed how to use Amazon Textract and Amazon Translate to generate translated PDF documents while retaining the original document structure. You can optionally postprocess Amazon Textract results to improve the quality of the translation, for example extracted words can be passed through ML-based spellchecks such as SymSpell for data validation, or clustering algorithms can be used to preserve reading order. You can also use Amazon Augmented AI (Amazon A2I) to build human review workflows where you can use your own private workforce to review the original and translated PDF documents to provide more accuracy and context. See Designing human review workflows with Amazon Translate and Amazon Augmented AI and Building a multi-lingual document translation workflow with domain-specific and language-specific customization to get started.
About the Authors
 Anubha Singhal is a Senior Cloud Architect at Amazon Web Services in the AWS Professional Services organization.
Anubha Singhal is a Senior Cloud Architect at Amazon Web Services in the AWS Professional Services organization.
 Sean Lawrence was formerly a Front End Engineer at AWS. He specialized in front end development in the AWS Professional Services organization and the Amazon Privacy team.
Sean Lawrence was formerly a Front End Engineer at AWS. He specialized in front end development in the AWS Professional Services organization and the Amazon Privacy team.
Auto-labeling module for deep learning-based Advanced Driver Assistance Systems on AWS
In computer vision (CV), adding tags to identify objects of interest or bounding boxes to locate the objects is called labeling. It’s one of the prerequisite tasks to prepare training data to train a deep learning model. Hundreds of thousands of work hours are spent generating high-quality labels from images and videos for various CV use cases. You can use Amazon SageMaker Data Labeling in two ways to create these labels:
- Amazon SageMaker Ground Truth Plus – This service provides an expert workforce that is trained on ML tasks and can help meet your data security, privacy, and compliance requirements. You upload your data, and the Ground Truth Plus team creates and manages data labeling workflows and the workforce on your behalf.
- Amazon SageMaker Ground Truth – Alternatively, you can manage your own data labeling workflows and workforce to label data.
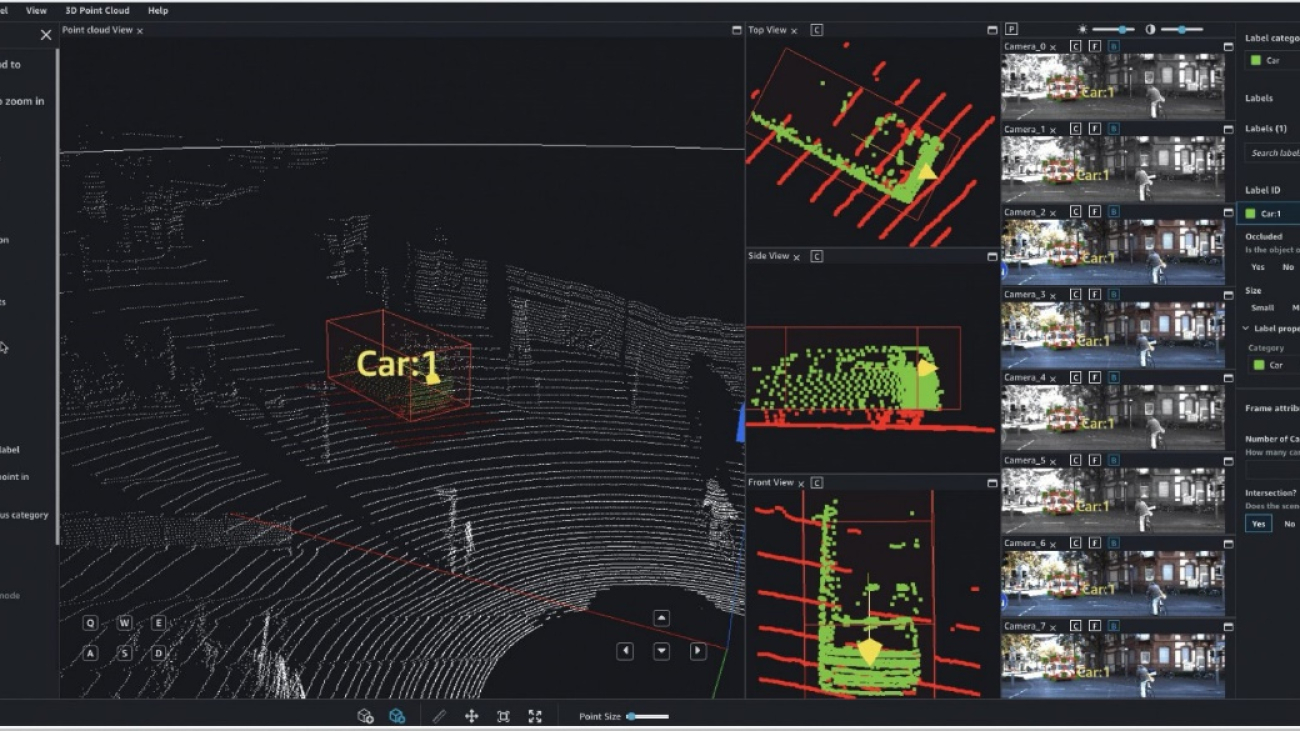
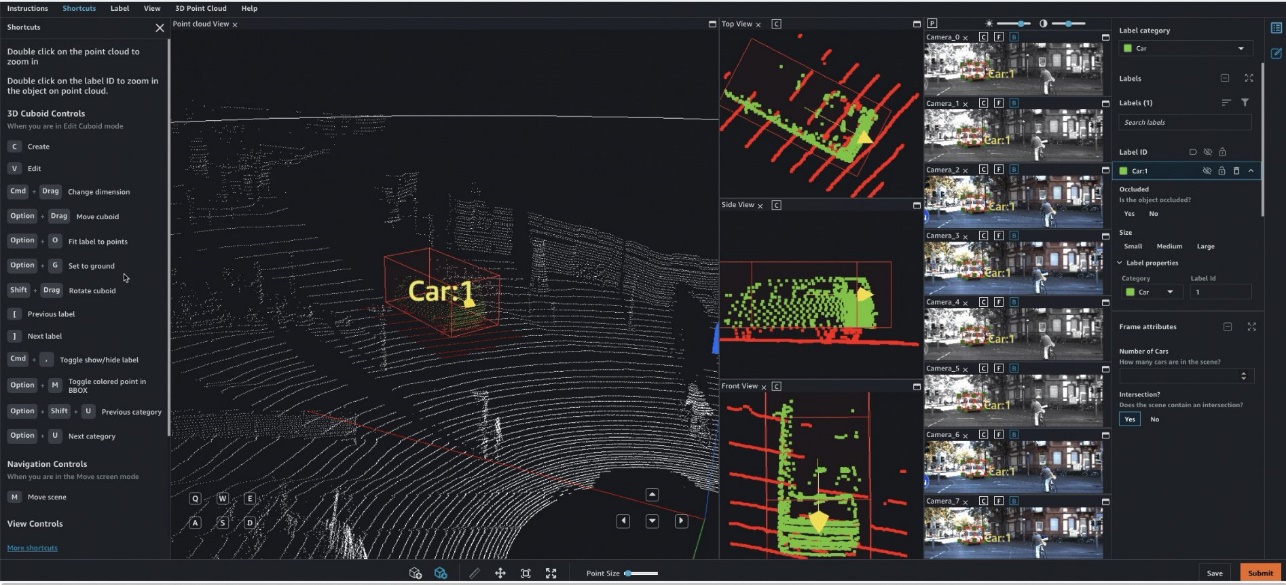
Specifically, for deep learning-based autonomous vehicle (AV) and Advanced Driver Assistance Systems (ADAS), there is a need to label complex multi-modal data from scratch, including synchronized LiDAR, RADAR, and multi-camera streams. For example, the following figure shows a 3D bounding box around a car in the Point Cloud view for LiDAR data, aligned orthogonal LiDAR views on the side, and seven different camera streams with projected labels of the bounding box.
AV/ADAS teams need to label several thousand frames from scratch, and rely on techniques like label consolidation, automatic calibration, frame selection, frame sequence interpolation, and active learning to get a single labeled dataset. Ground Truth supports these features. For a full list of features, refer to Amazon SageMaker Data Labeling Features. However, it can be challenging, expensive, and time-consuming to label tens of thousands of miles of recorded video and LiDAR data for companies that are in the business of creating AV/ADAS systems. One technique used to solve this problem today is auto-labeling, which is highlighted in the following diagram for a modular functions design for ADAS on AWS.

In this post, we demonstrate how to use SageMaker features such as Amazon SageMaker JumpStart models and asynchronous inference capabilities along with Ground Truth’s functionality to perform auto-labeling.
Auto-labeling overview
Auto-labeling (sometimes referred to as pre-labeling) occurs before or alongside manual labeling tasks. In this module, the best-so-far model trained for a particular task (for example, pedestrian detection or lane segmentation) is used to generate high-quality labels. Manual labelers simply verify or adjust the automatically created labels from the resulting dataset. This is easier, faster and cheaper than labeling these large datasets from scratch. Downstream modules such as the training or validation modules can use these labels as is.
Active learning is another concept that is closely related to auto-labeling. It’s a machine learning (ML) technique that identifies data that should be labeled by your workers. Ground Truth’s automated data labeling functionality is an example of active learning. When Ground Truth starts an automated data labeling job, it selects a random sample of input data objects and sends them to human workers. When the labeled data is returned, it’s used to create a training set and a validation set. Ground Truth uses these datasets to train and validate the model used for auto-labeling. Ground Truth then runs a batch transform job to generate labels for unlabeled data, along with confidence scores for new data. Labeled data with low confidence scores is sent to human labelers. This process of training, validating, and batch transform is repeated until the full dataset is labeled.
In contrast, auto-labeling assumes that a high-quality, pre-trained model exists (either privately within the company, or publicly in a hub). This model is used to generate labels that can be trusted and used for downstream tasks such as label verification tasks, training, or simulation. This pre-trained model in the case of AV/ADAS systems is deployed onto the car at the edge, and can be used within large-scale, batch inference jobs on the cloud to generate high-quality labels.
JumpStart provides pretrained, open-source models for a wide range of problem types to help you get started with machine learning. You can use JumpStart to share models within your organization. Let’s get started!
Solution overview
For this post, we outline the major steps without going over every cell in our example notebook. To follow along or try it on your own, you can run the Jupyter notebook in Amazon SageMaker Studio.
The following diagram provides a solution overview.
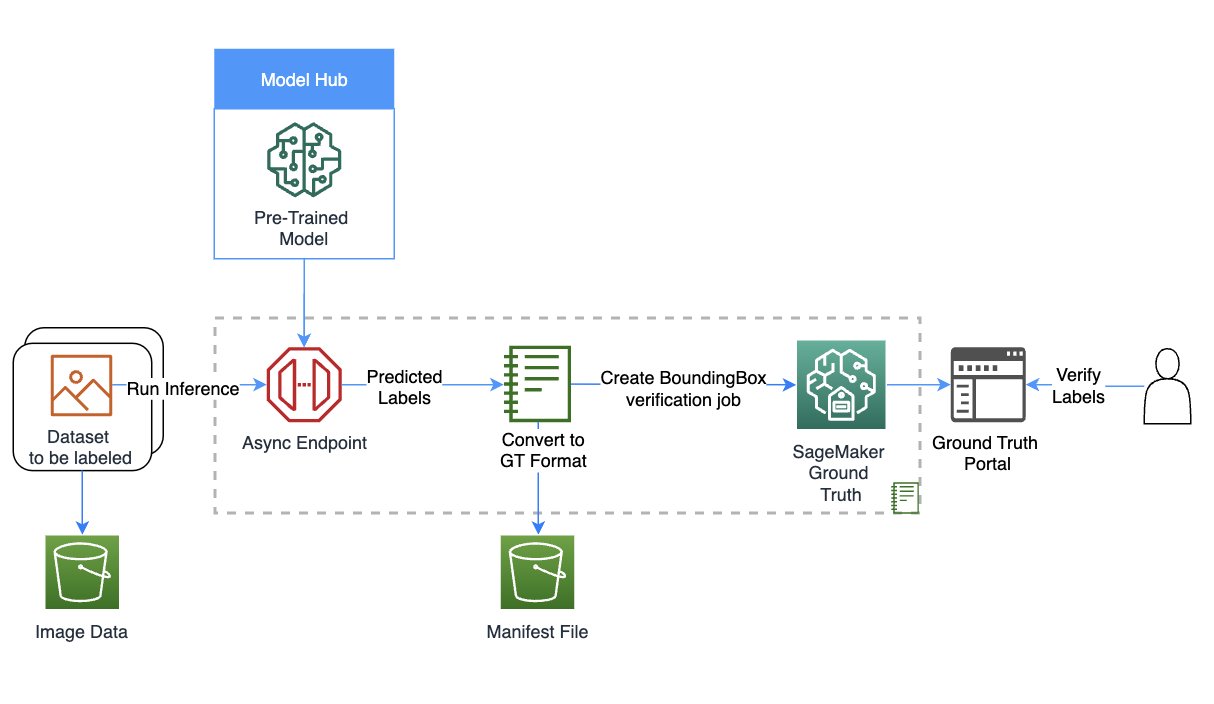
Set up the role and session
For this example, we used a Data Science 3.0 kernel in Studio on an ml.m5.large instance type. First, we do some basic imports and set up the role and session for use later in the notebook:
Create your model using SageMaker
In this step, we create a model for the auto-labeling task. You can choose from three options to create a model:
- Create a model from JumpStart – With JumpStart, we can perform inference on the pre-trained model, even without fine-tuning it first on a new dataset
- Use a model shared via JumpStart with your team or organization – You can use this option if you want to use a model developed by one of the teams within your organization
- Use an existing endpoint – You can use this option if you have an existing model already deployed in your account
To use the first option, we select a model from JumpStart (here, we use mxnet-is-mask-rcnn-fpn-resnet101-v1d-coco. A list of models is available in the models_manifest.json file provided by JumpStart.
We use this JumpStart model that is publicly available and trained on the instance segmentation task, but you are free to use a private model as well. In the following code, we use the image_uris, model_uris, and script_uris to retrieve the right parameter values to use this MXNet model in the sagemaker.model.Model API to create the model:
Set up asynchronous inference and scaling
Here we set up an asynchronous inference config before deploying the model. We chose asynchronous inference because it can handle large payload sizes and can meet near-real-time latency requirements. In addition, you can configure the endpoint to auto scale and apply a scaling policy to set the instance count to zero when there are no requests to process. In the following code, we set max_concurrent_invocations_per_instance to 4. We also set up auto scaling such that the endpoint scales up when needed and scales down to zero after the auto-labeling job is complete.
Download data and perform inference
We use the Ford Multi-AV Seasonal dataset from the AWS Open Data Catalog.
First, we download and prepare the date for inference. We have provided preprocessing steps to process the dataset in the notebook; you can change it to process your dataset. Then, using the SageMaker API, we can start the asynchronous inference job as follows:
This may take up to 30 minutes or more depending on how much data you have uploaded for asynchronous inference. You can visualize one of these inferences as follows:

Convert the asynchronous inference output to a Ground Truth input manifest
In this step, we create an input manifest for a bounding box verification job on Ground Truth. We upload the Ground Truth UI template and label categories file, and create the verification job. The notebook linked to this post uses a private workforce to perform the labeling; you can change this if you’re using other types of workforces. For more details, refer to the full code in the notebook.
Verify labels from the auto-labeling process in Ground Truth
In this step, we complete the verification by accessing the labeling portal. For more details, refer to here.
When you access the portal as a workforce member, you will be able to see the bounding boxes created by the JumpStart model and make adjustments as required.

You can use this template to repeat auto-labeling with many task-specific models, potentially merge labels, and use the resulting labeled dataset in downstream tasks.
Clean up
In this step, we clean up by deleting the endpoint and the model created in previous steps:
Conclusion
In this post, we walked through an auto-labeling process involving JumpStart and asynchronous inference. We used the results of the auto-labeling process to convert and visualize labeled data on a real-world dataset. You can use the solution to perform auto-labeling with many task-specific models, potentially merge labels, and use the resulting labeled dataset in downstream tasks. You can also explore using tools like the Segment Anything Model for generating segment masks as part of the auto-labeling process. In future posts in this series, we will cover the perception module and segmentation. For more information on JumpStart and asynchronous inference, refer to SageMaker JumpStart and Asynchronous inference, respectively. We encourage you to reuse this content for use cases beyond AV/ADAS, and reach out to AWS for any help.
About the authors
 Gopi Krishnamurthy is a Senior AI/ML Solutions Architect at Amazon Web Services based in New York City. He works with large Automotive customers as their trusted advisor to transform their Machine Learning workloads and migrate to the cloud. His core interests include deep learning and serverless technologies. Outside of work, he likes to spend time with his family and explore a wide range of music.
Gopi Krishnamurthy is a Senior AI/ML Solutions Architect at Amazon Web Services based in New York City. He works with large Automotive customers as their trusted advisor to transform their Machine Learning workloads and migrate to the cloud. His core interests include deep learning and serverless technologies. Outside of work, he likes to spend time with his family and explore a wide range of music.
 Shreyas Subramanian is a Principal AI/ML specialist Solutions Architect, and helps customers by using Machine Learning to solve their business challenges using the AWS platform. Shreyas has a background in large scale optimization and Machine Learning, and in use of Machine Learning and Reinforcement Learning for accelerating optimization tasks.
Shreyas Subramanian is a Principal AI/ML specialist Solutions Architect, and helps customers by using Machine Learning to solve their business challenges using the AWS platform. Shreyas has a background in large scale optimization and Machine Learning, and in use of Machine Learning and Reinforcement Learning for accelerating optimization tasks.

Leonardo da Vinci: Inside a genius mind
 28 institutions from around the world join forces to showcase Leonardo da Vinci’s unparalleled legacy, blending art, science, and AI innovationRead More
28 institutions from around the world join forces to showcase Leonardo da Vinci’s unparalleled legacy, blending art, science, and AI innovationRead More