For our midyear update, we’d like to share three of our best practices based on this guidance and what we’ve done in our pre-launch design, reviews and development of ge…Read More

A fail-in-place approach for sustainable server operations
This research paper was presented at the 17th USENIX Symposium on Operating Systems Design and Implementation (OSDI), a premier forum for discussing the design, implementation, and implications of systems software.

Cloud platforms aim to provide a seamless user experience, alleviating the challenge and complexity of managing physical servers in datacenters. Hardware failures are one such challenge, as individual server components can fail independently, and while failures affecting individual customers are rare, cloud platforms encounter a substantial volume of server failures. Currently, when a single component in a server fails, the entire server needs to be serviced by a technician. This all-or-nothing operating model is increasingly becoming a hindrance to achieving cloud sustainability goals.
Finding a sustainable server repair solution
A sustainable cloud platform should be water-positive and carbon-negative. Water consumption in datacenters primarily arises from the need for cooling, and liquid cooling has emerged as a potential solution for waterless cooling. Paradoxically, liquid cooling also increases the complexity and time required to repair servers. Therefore, reducing the demand for repairs becomes essential to achieving water-positive status.
To become carbon-negative, Microsoft has been procuring renewable energy for its datacenters since 2016. Currently, Azure’s carbon emissions largely arise during server manufacturing, as indicated in Microsoft’s carbon emission report. Extending the lifetime of servers, which Microsoft has recently done to a minimum of six years, is a key strategy to reduce server-related carbon emissions. However, longer server lifetimes highlight the importance of server repairs, which not only contribute significantly to costs but also to carbon emissions. Moreover, sourcing replacement components can sometimes pose challenges. Consequently, finding ways to minimize the need for repairs becomes crucial.
Spotlight: On-Demand EVENT

Microsoft Research Summit 2022
On-Demand
Watch now to learn about some of the most pressing questions facing our research community and listen in on conversations with 120+ researchers around how to ensure new technologies have the broadest possible benefit for humanity.
Reducing server repairs by 60% with Hyrax
To support Microsoft sustainability goals, our paper, “Hyrax: Fail-in-Place Server Operation in Cloud,” proposes that cloud platforms adopt a fail-in-place paradigm where servers with faulty components continue to host virtual machines (VMs) without the need for immediate repairs. With this approach, cloud platforms could significantly reduce repair requirements, decreasing costs and carbon emissions at the same time. However, implementing fail-in-place in practice poses several challenges.
First, we want to ensure graceful degradation, where faulty components are identified and deactivated in a controlled manner. Second, deactivating common components like dual in-line memory modules (DIMMs) can significantly impact server performance due to reduced memory interleaving. It is crucial to prevent VM customers from experiencing loss in performance resulting from these deactivations. Finally, the cloud platform must be capable of using the capacity of servers with deactivated components, necessitating algorithmic changes in VM scheduling and structural adjustments in the cloud control plane.
To address these challenges, our paper introduces Hyrax, the first implementation of fail-in-place for cloud compute servers. Through a multi-year study of component failures across five server generations, we found that existing servers possess sufficient redundancy to overcome the most common types of server component failures. We propose effective mechanisms for component deactivation that can mitigate a wide range of possibilities, including issues like corroded connectors or chip failures. Additionally, Hyrax introduces a degraded server state and scheduling optimizations to the production control plane, enabling effective utilization of servers with deactivated components, as illustrated in Figure 1.
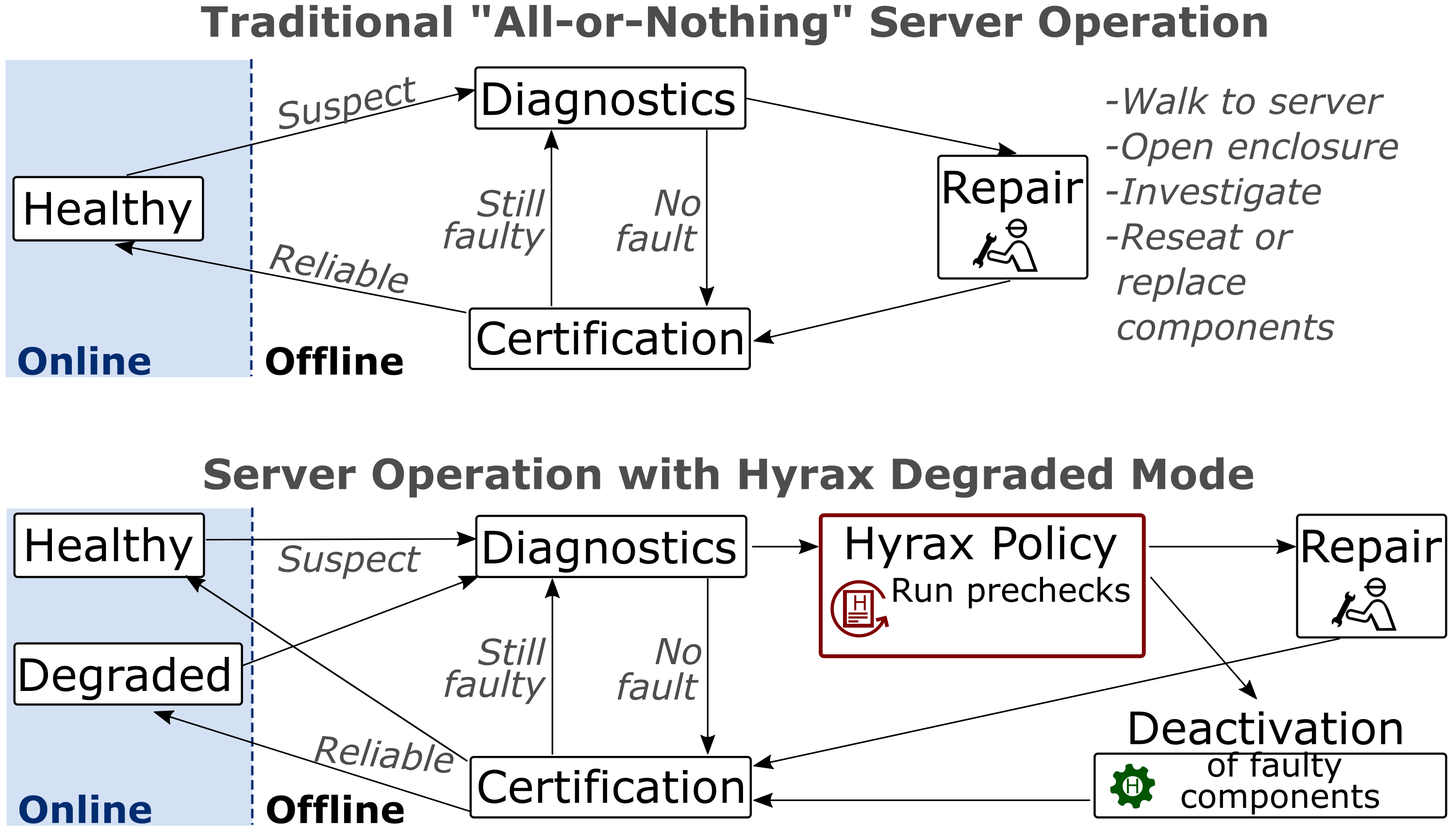
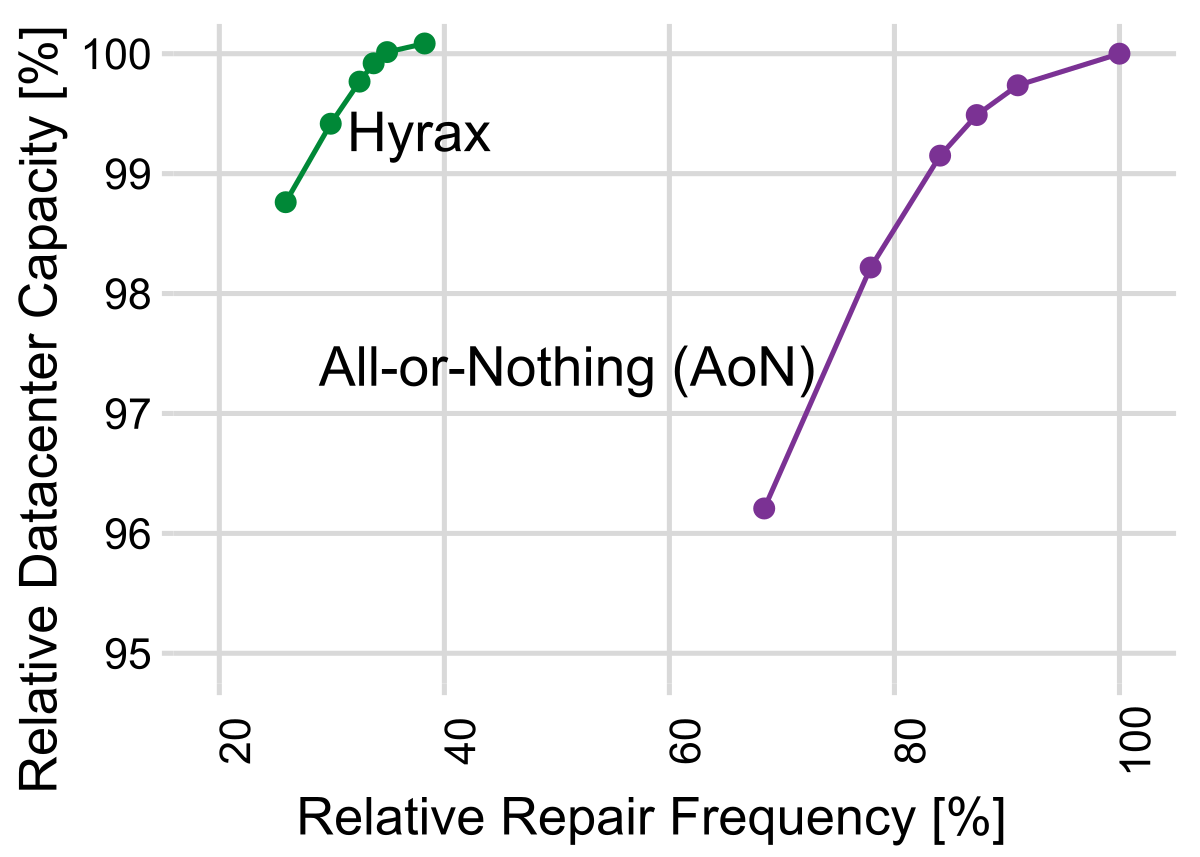
Our results demonstrate that Hyrax achieves a 60 percent reduction in repair demand without compromising datacenter capacity, as shown in Figure 2. This reduction in repairs leads to a 5 percent decrease in embodied carbon emissions over a typical six-year deployment period, as fewer replacement components are needed. In a subsequent study, we show that Hyrax enables servers to run for 30 percent longer, resulting in a proportional reduction in embodied carbon. We also demonstrate that Hyrax does not impact VM performance.
Deactivating memory modules without impacting performance
One of Hyrax’s key technical challenges is the need to deactivate components at the firmware level, as software-based deactivations prove to be insufficient. This requirement requires addressing previously unexplored performance implications.
A good example is the deactivation of a memory module, specifically a DIMM. To understand DIMM deactivation, it is important to consider how CPUs access memory, which is usually hidden from software. This occurs at the granularity of a cache line, which is 64 bytes and resides on a single DIMM. Larger data is divided into cache lines and distributed among all DIMMs connected to a CPU in a round-robin fashion. This interleaving mechanism ensures that while one DIMM is handling cache line N, another DIMM serves cache line N+1. From a software standpoint, memory is typically presented as a uniform address space that encompasses all cache lines across all the DIMMs attached to the CPU. Accessing any portion of this address space is equally fast in terms of memory bandwidth. Figure 3 shows an example of a server with six memory channels populated with two 32-GB DIMMs each. From the software perspective, the entire 384 GB of address space appears indistinguishable and offers a consistent 120 GB/sec bandwidth.
However, deactivating a DIMM causes the interleaving policy to reconfigure in unexpected ways. Figure 3 demonstrates this scenario, where the second DIMM on channel B (B2) has been identified as faulty and subsequently deactivated. Consequently, three different parts of the address space exhibit different characteristics: 120 GB/sec (six-way interleaving), 80 GB/sec (four-way interleaving), and 20 GB/sec (one-way interleaving). These performance differences are invisible to software and naively scheduling VMs on such a server can lead to variable performance, a suboptimal outcome.
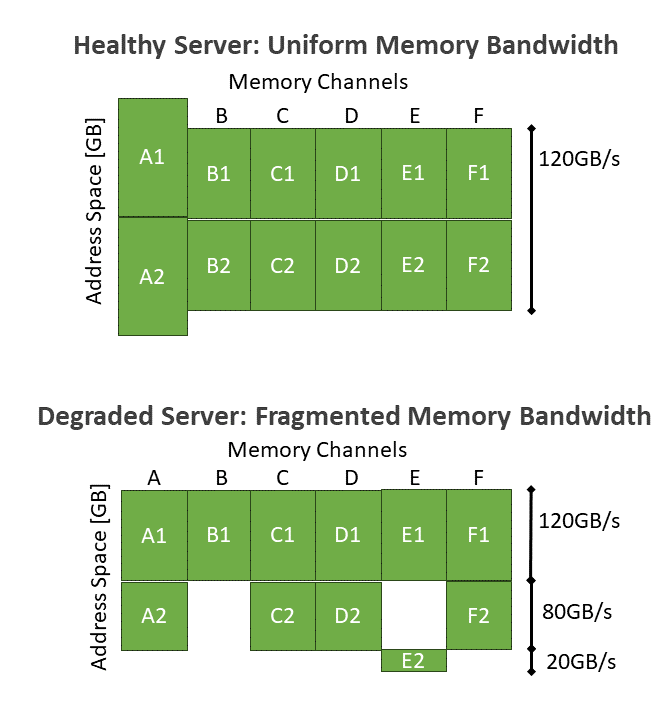
Hyrax enables cloud platforms to work around this issue by scheduling VMs on only the parts of the address space that offer sufficient performance for that VM’s requirements. Our paper discusses how this works in more detail.
Implications and looking forward
Hyrax is the first fail-in-place system for cloud computing servers, paving the way for future improvements. One potential enhancement involves reconsidering the approach to memory regions with 20 GB/sec memory bandwidth. Instead of using them only for small VMs, we could potentially allocate these regions to accommodate large data structures, such as by adding buffers for input-output devices that require more than 20 GB/sec of bandwidth.
Failing-in-place offers significant flexibility when it comes to repairs. For example, instead of conducting daily repair trips to individual servers scattered throughout a datacenter, we are exploring the concept of batching repairs, where technicians would visit a row of server racks once every few weeks to address issues across multiple servers simultaneously. By doing so, we can save valuable time and resources while creating new research avenues for optimizing repair schedules that intelligently balance capacity loss and repair efforts.
Achieving sustainability goals demands collective efforts across society. In this context, we introduce fail-in-place as a research direction for both datacenter hardware and software systems, directly tied to water and carbon efficiency. Beyond refining the fail-in-place concept itself and exploring new server designs, this new paradigm also opens up new pathways for improving maintenance processes using an environmentally friendly approach.
The post A fail-in-place approach for sustainable server operations appeared first on Microsoft Research.

How AI Is Powering the Future of Clean Energy
AI is improving ways to power the world by tapping the sun and the wind, along with cutting-edge technologies.
The latest episode in the I AM AI video series showcases how artificial intelligence can help optimize solar and wind farms, simulate climate and weather, enhance power grid reliability and resilience, advance carbon capture and power fusion breakthroughs.
It’s all enabled by NVIDIA and its energy-conscious partners, as they use and develop technology breakthroughs for a cleaner, safer, more sustainable future.
Homes and businesses need access to reliable, affordable fuel and electricity to power day-to-day activities.
Renewable energy sources — such as sunlight, wind and water — are scaling in deployments and available capacity. But they also burden legacy power grids built for traditional one-way power flow: from generation plants through transmission and distribution lines to end customers.
The latest advancements in AI and accelerated computing enable energy companies and utilities to balance power supply and demand in real time and manage distributed energy resources, all while lowering monthly bills to consumers.
The enterprises and startups featured in the new I AM AI video, and below, are using such innovations for a variety of clean energy use cases.
Power-Generation Site Optimization
Companies are turning to AI to improve maintenance of renewable power-generation sites.
For example, reality capture platform DroneDeploy is using AI to evaluate solar farm layouts, maximize energy generated per site and automatically monitor the health of solar panels and other equipment in the field.
Renewable energy company Siemens Gamesa is working with NVIDIA to apply AI surrogate models to optimize its offshore wind farms to output maximum power at minimal cost. Together, the companies are exploring neural super resolution powered by the NVIDIA Omniverse and NVIDIA Modulus platforms to accelerate high-resolution wake simulation by 4,000x compared with traditional methods–from 40 days to just 15 minutes.
Italy-based THE EDGE COMPANY, a member of the NVIDIA Metropolis vision AI partner ecosystem, is tracking endangered birds near offshore wind farms to provide operators with real-time suggestions that can help prevent collisions and protect the at-risk species.
Grid Infrastructure Maintenance
Energy grids also benefit from AI, which can help keep their infrastructure safe and efficient.
NVIDIA Metropolis partner Noteworthy AI deployed smart cameras powered by the NVIDIA Jetson platform for edge AI and robotics on Ohio-based utility FirstEnergy’s field trucks. Along with AI-enhanced computer vision, the cameras automate manual inspections of millions of power lines, poles and mounted devices.
Orbital Sidekick, a member of the NVIDIA Inception program for cutting-edge startups, has used hyperspectral imagery and edge AI to detect hundreds of suspected gas and hydrocarbon leaks across the globe. This protects worker health and safety while preventing costly accidents.
And Sweden-based startup Eneryield is using AI to detect signal anomalies in undersea cables, predict equipment failures to avoid costly repairs and enhance reliability of generated power.
Climate and Weather Simulation
AI and digital twins are unleashing a new wave of climate research, offering accurate, physics-informed weather modeling, high-resolution simulations of Earth and more.
NVIDIA Inception member Open Climate Fix built transformer-based AI models trained on terabytes of satellite data. Through granular, near-term forecasts of sunny and cloudy conditions over the U.K.’s solar panels, the nonprofit product lab has improved predictions of solar-energy generation by 3x. This reduces electricity produced using fossil fuels and helps decarbonize the country’s grid.
Plus, a team of researchers from the California Institute of Technology, Stanford University, and NVIDIA developed a neural operator architecture called Nested FNO to simulate pressure levels during carbon storage in a fraction of a second while doubling accuracy on certain tasks. This can help industries decarbonize and achieve emission-reduction goals.
And Lawrence Livermore National Laboratory demonstrated the first successful application of nuclear fusion — considered the holy grail of clean energy — and used AI to simulate experimental results.
Learn more about AI for autonomous operations and grid modernization in energy.

Gear Up and Game On: Gearbox’s ‘Remnant II’ Streaming on GeForce NOW
Get ready for Gunfire Games and Gearbox Publishing’s highly anticipated Remnant II, available for members to stream on GeForce NOW at launch. It leads eight new games coming to the cloud gaming platform.
Ultimate and Priority members, make sure to grab the Guild Wars 2 rewards, available now through Thursday, Aug. 31. Visit the GeForce NOW Rewards portal and opt in to rewards.
Strange New Worlds

Kick off the weekend with one of the hottest new games in the cloud. Remnant II from Gunfire Games and Gearbox Publishing, sequel to the hit game Remnant: From the Ashes, is newly launched in the cloud for members to stream.
Go head to head against new deadly creatures and god-like bosses while exploring terrifying new worlds with different types of creatures, weapons and items. With various stories woven throughout, each playthrough will be different from the last, making each experience unique for endless replayability.
Find secrets and unlock different Archetypes, each with their own special set of abilities. Members can brave it alone or team up with buddies to explore the depths of the unknown and stop an evil from destroying reality itself. Just remember — friendly fire is on, so pick your squad wisely.
Upgrade to an Ultimate membership to play Remnant II and more than 1,600 titles at RTX 4080 quality, with support for 4K 120 frames per second gameplay and ultrawide resolutions. Ultimate and Priority members can also experience higher frame rates with DLSS technology for AI-powered graphics on their RTX-powered cloud gaming rigs.
Reward Yourself

Ultimate and Priority members can now grab their free, exclusive rewards for Guild Wars 2, featuring the “Always Prepared” and “Booster” bundles, available through the end of August.
The “Always Prepared” bundle includes ten Transmutation Charges to change character appearance, a Revive Orb that returns a player to 50% health at their current location and a top hat to add style to the character. On top of that, the “Booster” bundle includes an Item Booster, Karma Booster, Experience Booster, a 10-Slot Bag and a Black Lion Miniature Claim Ticket, which can be exchanged in game for a mini-pet of choice.
Visit the GeForce NOW Rewards portal to update the settings to receive special offers and in-game goodies. Better hurry — these rewards are available for a limited time on a first-come, first-served basis.
Grab them in time for the fourth expansion of Guild Wars 2, coming to GeForce NOW at launch on Tuesday, Aug. 22. The “Secrets of the Obscure” paid expansion includes a new storyline, powerful combat options, new mount abilities and more.
Racing Into the Weekend

Remnant II is one of the eight games available this week on GeForce NOW. Check out the complete list of new games:
- Remnant II (New release on Steam, July 25)
- Let’s School (New release on Steam, July 26)
- Grand Emprise: Time Travel Survival (New release on Steam, July 27)
- MotoGP23 (Steam)
- OCTOPATH TRAVELER (Epic Games Store)
- Pro Cycling Manager 2023 (Steam)
- Riders Republic (Steam)
- Starship Troopers: Extermination (Steam)
What are you planning to play this weekend? Let us know on Twitter or in the comments below.
It’s up to you to save humanity from the Root. Which Archetype are you choosing:
Challenger
Medic
Gunslinger
Handler
Hunter
—
NVIDIA GeForce NOW (@NVIDIAGFN) July 26, 2023
IBM Joins the PyTorch Foundation as a Premier Member
The PyTorch Foundation, part of The Linux Foundation, is pleased to announce that IBM has joined as a premier member.
![]()
The foundation serves as a neutral space for the deep learning community to collaborate on the open source PyTorch framework and ecosystem. With its extensive industry expertise and leadership in open source and AI, IBM is committed to actively contributing to the PyTorch community.
IBM offers a comprehensive portfolio of enterprise AI solutions and recently released watsonx, its next-generation data and AI platform. IBM’s watsonx platform leverages PyTorch to offer an enterprise-grade software stack for end-to-end training and fine-tuning of AI foundation models.
“By joining the PyTorch Foundation, we aim to contribute our expertise and resources to further advance PyTorch’s capabilities and make AI more accessible in hybrid cloud environments with flexible hardware options,” said Priya Nagpurkar, Vice President, Hybrid Cloud Platform and Developer Productivity, IBM Research. “We intend for our collaboration with PyTorch to bring the power of foundation models and generative AI to enterprises using the watsonx platform to drive business transformation.”
IBM and PyTorch have already collaborated on two projects. The first enables foundation models with billions of parameters to train efficiently on standard cloud networking infrastructure, such as Ethernet networking. Together, IBM and PyTorch have also worked on ways to make checkpointing for AI training considerably more cost-effective, by fixing the distributed checkpointing within PyTorch to support certain types of object storage.
“We’re happy to welcome IBM as a premier member. IBM’s expertise and dedication to advancing the field of artificial intelligence align perfectly with the mission of the PyTorch community,” said PyTorch Foundation Executive Director Ibrahim Haddad. “Their commitment to open collaboration and innovation will strengthen our collective efforts to empower developers and researchers worldwide.”
As a premier member, IBM is granted one seat to the PyTorch Foundation Governing Board. The Board sets policy through our bylaws, mission and vision statements, describing the overarching scope of foundation initiatives, technical vision, and direction.

We’re happy to welcome Raghu Ganti, Principal Research Scientist at IBM Research, to our board. Raghu co-leads IBM Research’s foundation model training and validation platform, built on Red Hat OpenShift. His team primarily contributes to the PyTorch training components, with the mission of democratizing training and validation of foundation models.
To learn more about how you can be a part of the PyTorch Foundation, visit our website.

Use Stable Diffusion XL with Amazon SageMaker JumpStart in Amazon SageMaker Studio
Today we are excited to announce that Stable Diffusion XL 1.0 (SDXL 1.0) is available for customers through Amazon SageMaker JumpStart. SDXL 1.0 is the latest image generation model from Stability AI. SDXL 1.0 enhancements include native 1024-pixel image generation at a variety of aspect ratios. It’s designed for professional use, and calibrated for high-resolution photorealistic images. SDXL 1.0 offers a variety of preset art styles ready to use in marketing, design, and image generation use cases across industries. You can easily try out these models and use them with SageMaker JumpStart, a machine learning (ML) hub that provides access to algorithms, models, and ML solutions so you can quickly get started with ML.
In this post, we walk through how to use SDXL 1.0 models via SageMaker JumpStart.
What is Stable Diffusion XL 1.0 (SDXL 1.0)
SDXL 1.0 is the evolution of Stable Diffusion and the next frontier for generative AI for images. SDXL is capable of generating stunning images with complex concepts in various art styles, including photorealism, at quality levels that exceed the best image models available today. Like the original Stable Diffusion series, SDXL is highly customizable (in terms of parameters) and can be deployed on Amazon SageMaker instances.
The following image of a lion was generated using SDXL 1.0 using a simple prompt, which we explore later in this post.

The SDXL 1.0 model includes the following highlights:
- Freedom of expression – Best-in-class photorealism, as well as an ability to generate high-quality art in virtually any art style. Distinct images are made without having any particular feel that is imparted by the model, ensuring absolute freedom of style.
- Artistic intelligence – Best-in-class ability to generate concepts that are notoriously difficult for image models to render, such as hands and text, or spatially arranged objects and people (for example, a red box on top of a blue box).
- Simpler prompting – Unlike other generative image models, SDXL requires only a few words to create complex, detailed, and aesthetically pleasing images. No more need for paragraphs of qualifiers.
- More accurate – Prompting in SDXL is not only simple, but more true to the intention of prompts. SDXL’s improved CLIP model understands text so effectively that concepts like “The Red Square” are understood to be different from “a red square.” This accuracy allows much more to be done to get the perfect image directly from text, even before using the more advanced features or fine-tuning that Stable Diffusion is famous for.
What is SageMaker JumpStart
With SageMaker JumpStart, ML practitioners can choose from a broad selection of state-of-the-art models for use cases such as content writing, image generation, code generation, question answering, copywriting, summarization, classification, information retrieval, and more. ML practitioners can deploy foundation models to dedicated SageMaker instances from a network isolated environment and customize models using SageMaker for model training and deployment. The SDXL model is discoverable today in Amazon SageMaker Studio and, as of this writing, is available in us-east-1, us-east-2, us-west-2, eu-west-1, ap-northeast-1, and ap-southeast-2 Regions.
Solution overview
In this post, we demonstrate how to deploy SDXL 1.0 to SageMaker and use it to generate images using both text-to-image and image-to-image prompts.
SageMaker Studio is a web-based integrated development environment (IDE) for ML that lets you build, train, debug, deploy, and monitor your ML models. For more details on how to get started and set up SageMaker Studio, refer to Amazon SageMaker Studio.
Once you are in the SageMaker Studio UI, access SageMaker JumpStart and search for Stable Diffusion XL. Choose the SDXL 1.0 model card, which will open up an example notebook. This means you will be only be responsible for compute costs. There is no associated model cost. Closed weight SDXL 1.0 offers SageMaker optimized scripts and container with faster inference time and can be run on smaller instance compared to the open weight SDXL 1.0. The example notebook will walk you through steps, but we also discuss how to discover and deploy the model later in this post.
In the following sections, we show how you can use SDXL 1.0 to create photorealistic images with shorter prompts and generate text within images. Stable Diffusion XL 1.0 offers enhanced image composition and face generation with stunning visuals and realistic aesthetics.
Stable Diffusion XL 1.0 parameters
The following are the parameters used by SXDL 1.0:
- cfg_scale – How strictly the diffusion process adheres to the prompt text.
- height and width – The height and width of image in pixel.
- steps – The number of diffusion steps to run.
- seed – Random noise seed. If a seed is provided, the resulting generated image will be deterministic.
- sampler – Which sampler to use for the diffusion process to denoise our generation with.
- text_prompts – An array of text prompts to use for generation.
- weight – Provides each prompt a specific weight
For more information, refer to the Stability AI’s text to image documentation.
The following code is a sample of the input data provided with the prompt:
All examples in this post are based on the sample notebook for Stability Diffusion XL 1.0, which can be found on Stability AI’s GitHub repo.
Generate images using SDXL 1.0
In the following examples, we focus on the capabilities of Stability Diffusion XL 1.0 models, including superior photorealism, enhanced image composition, and the ability to generate realistic faces. We also explore the significantly improved visual aesthetics, resulting in visually appealing outputs. Additionally, we demonstrate the use of shorter prompts, enabling the creation of descriptive imagery with greater ease. Lastly, we illustrate how the text in images is now more legible, further enriching the overall quality of the generated content.
The following example shows using a simple prompt to get detailed images. Using only a few words in the prompt, it was able to create a complex, detailed, and aesthetically pleasing image that resembles the provided prompt.

Next, we show the use of the style_preset input parameter, which is only available on SDXL 1.0. Passing in a style_preset parameter guides the image generation model towards a particular style.
Some of the available style_preset parameters are enhance, anime, photographic, digital-art, comic-book, fantasy-art, line-art, analog-film, neon-punk, isometric, low-poly, origami, modeling-compound, cinematic, 3d-mode, pixel-art, and tile-texture. This list of style presets is subject to change; refer to the latest release and documentation for updates.
For this example, we use a prompt to generate a teapot with a style_preset of origami. The model was able to generate a high-quality image in the provided art style.

Let’s try some more style presets with different prompts. The next example shows a style preset for portrait generation using style_preset="photographic" with the prompt “portrait of an old and tired lion real pose.”

Now let’s try the same prompt (“portrait of an old and tired lion real pose”) with modeling-compound as the style preset. The output image is a distinct image made without having any particular feel that is imparted by the model, ensuring absolute freedom of style.

Multi-prompting with SDXL 1.0
As we have seen, one of the core foundations of the model is the ability to generate images via prompting. SDXL 1.0 supports multi-prompting. With multi-prompting, you can mix concepts together by assigning each prompt a specific weight. As you can see in the following generated image, it has a jungle background with tall bright green grass. This image was generated using the following prompts. You can compare this to a single prompt from our earlier example.

Spatially aware generated images and negative prompts
Next, we look at poster design with a detailed prompt. As we saw earlier, multi-prompting allows you to combine concepts to create new and unique results.
In this example, the prompt is very detailed in terms of subject position, appearance, expectations, and surroundings. The model is also trying to avoid images that have distortion or are poorly rendered with the help of a negative prompt. The image generated shows spatially arranged objects and subjects.
text = “A cute fluffy white cat stands on its hind legs, peering curiously into an ornate golden mirror. But in the reflection, the cat sees not itself, but a mighty lion. The mirror illuminated with a soft glow against a pure white background.”

Let’s try another example, where we keep the same negative prompt but change the detailed prompt and style preset. As you can see, the generated image not only spatially arranges objects, but also changes the style presets with attention to details like the ornate golden mirror and reflection of the subject only.

Face generation with SDXL 1.0
In this example, we show how SDXL 1.0 creates enhanced image composition and face generation with realistic features such as hands and fingers. The generated image is of a human figure created by AI with clearly raised hands. Note the details in the fingers and the pose. An AI-generated image such as this would otherwise have been amorphous.

Text generation using SDXL 1.0
SDXL is primed for complex image design workflows that include generation of text within images. This example prompt showcases this capability. Observe how clear the text generation is using SDXL and notice the style preset of cinematic.

Discover SDXL 1.0 from SageMaker JumpStart
SageMaker JumpStart onboards and maintains foundation models for you to access, customize, and integrate into your ML lifecycles. Some models are open weight models that allow you to access and modify model weights and scripts, whereas some are closed weight models that don’t allow you to access them to protect the IP of model providers. Closed weight models require you to subscribe to the model from the AWS Marketplace model detail page, and SDXL 1.0 is a model with closed weight at this time. In this section, we go over how to discover, subscribe, and deploy a closed weight model from SageMaker Studio.
You can access SageMaker JumpStart by choosing JumpStart under Prebuilt and automated solutions on the SageMaker Studio Home page.
From the SageMaker JumpStart landing page, you can browse for solutions, models, notebooks, and other resources. The following screenshot shows an example of the landing page with solutions and foundation models listed.
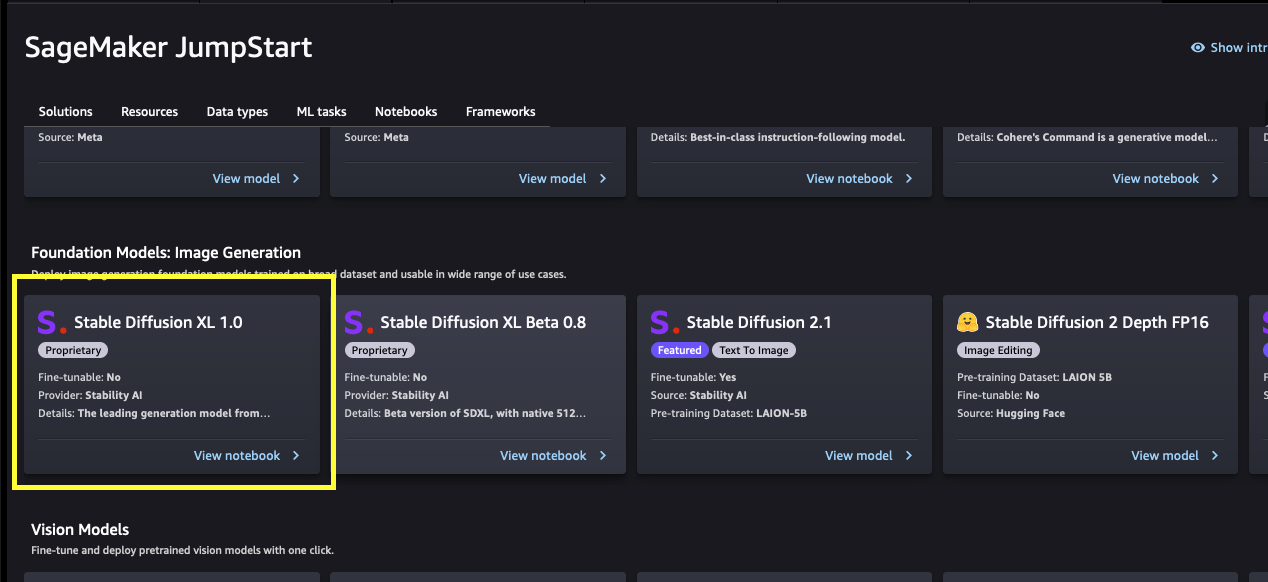
Each model has a model card, as shown in the following screenshot, which contains the model name, if it is fine-tunable or not, the provider name, and a short description about the model. You can find the Stable Diffusion XL 1.0 model in the Foundation Model: Image Generation carousel or search for it in the search box.
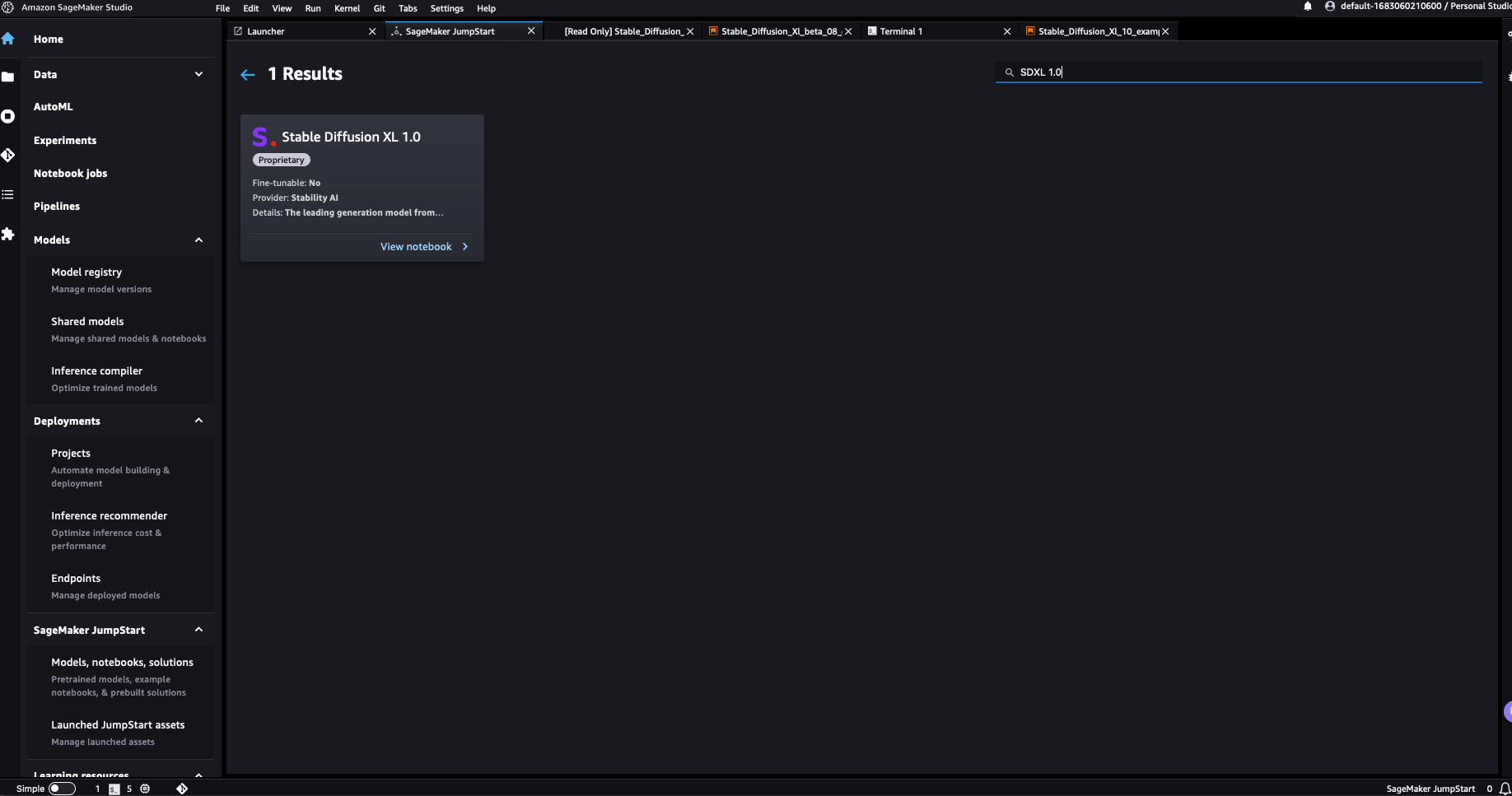
You can choose Stable Diffusion XL 1.0 to open an example notebook that walks you through how to use the SDXL 1.0 model. The example notebook opens as read-only mode; you need to choose Import notebook to run it.

After importing the notebook, you need to select the appropriate notebook environment (image, kernel, instance type, and so on) before running the code.
Deploy SDXL 1.0 from SageMaker JumpStart
In this section, we walk through how to subscribe and deploy the model.
- Open the model listing page in AWS Marketplace using the link available from the example notebook in SageMaker JumpStart.
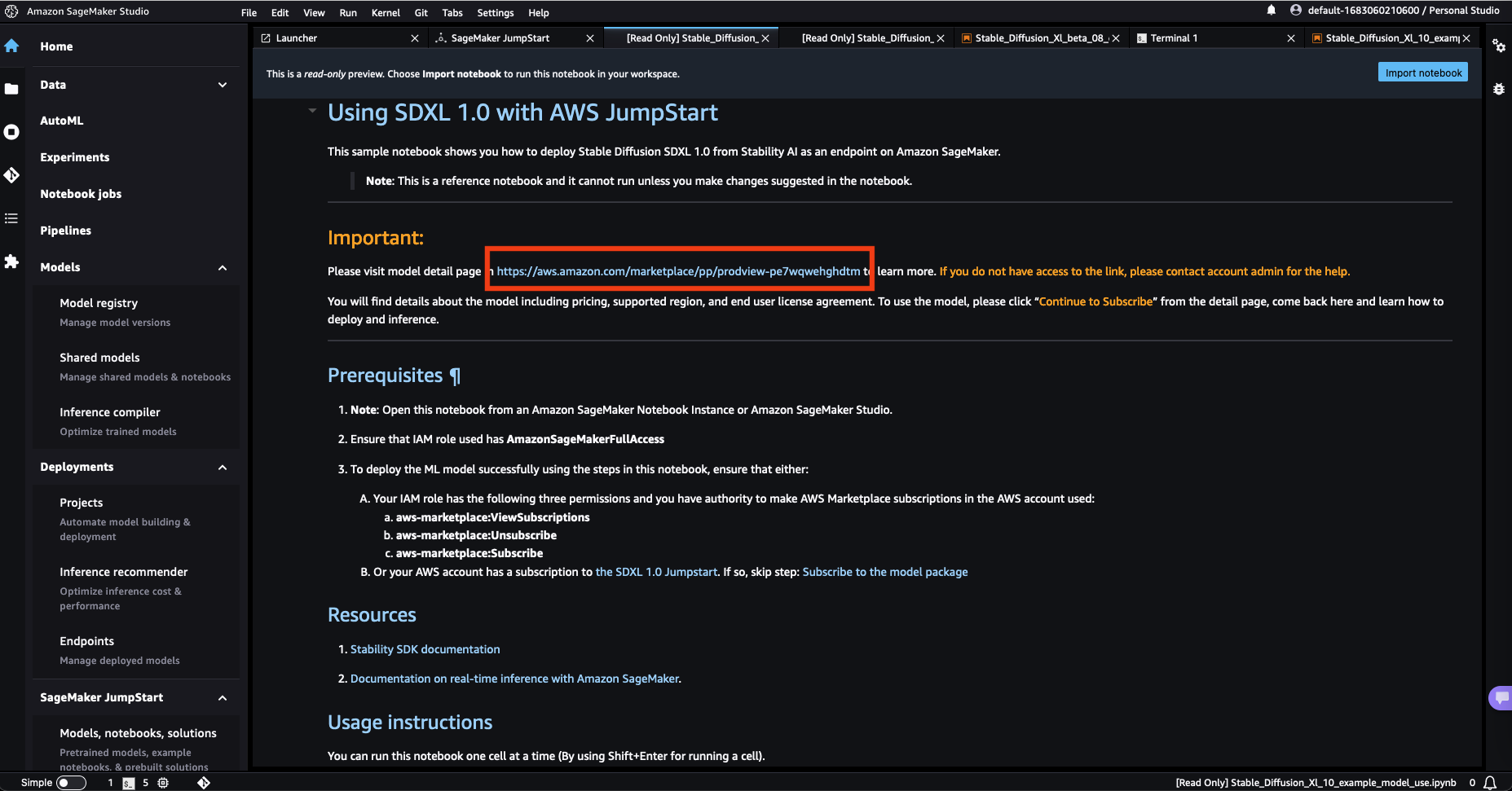
- On the AWS Marketplace listing, choose Continue to subscribe.
If you don’t have the necessary permissions to view or subscribe to the model, reach out to your AWS administrator or procurement point of contact. Many enterprises may limit AWS Marketplace permissions to control the actions that someone can take in the AWS Marketplace Management Portal.
- Choose Continue to Subscribe.
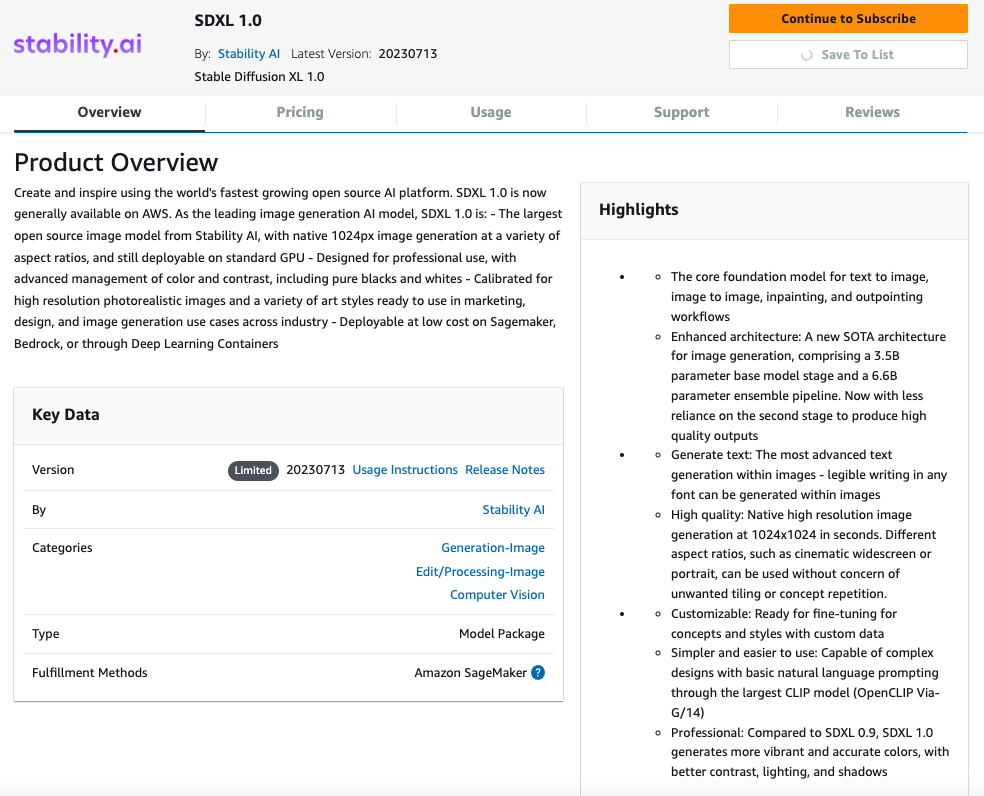
- On the Subscribe to this software page, review the pricing details and End User Licensing Agreement (EULA). If agreeable, choose Accept offer.
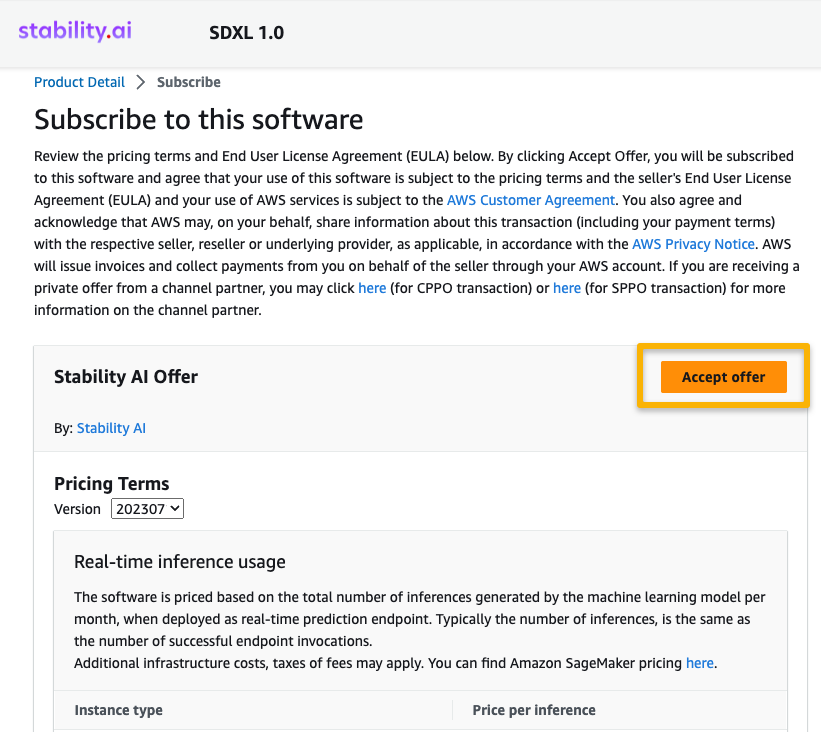
- Choose Continue to configuration to start configuring your model.
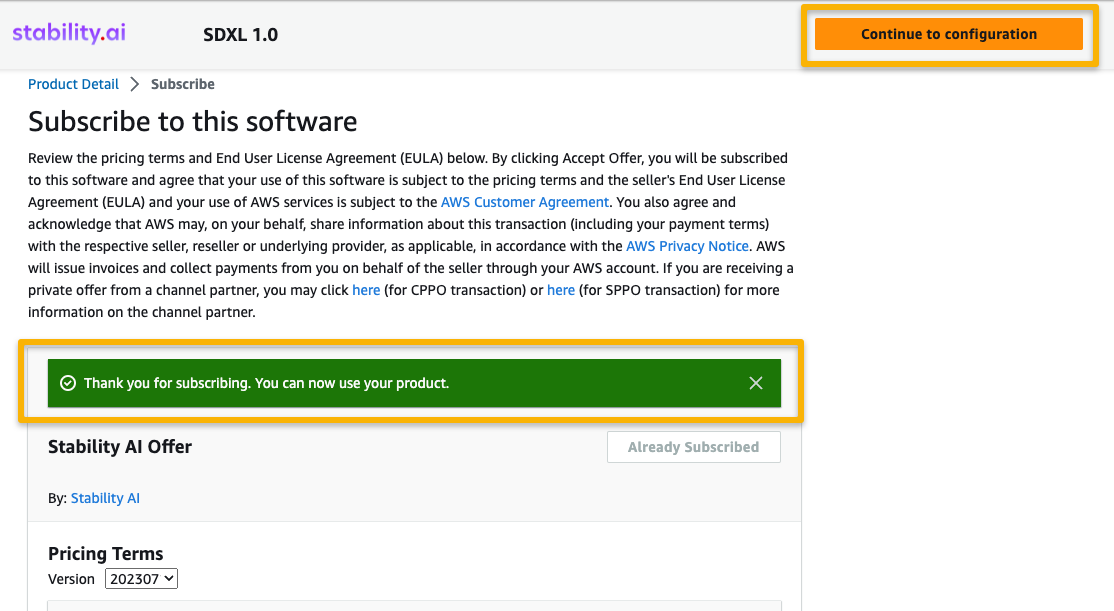
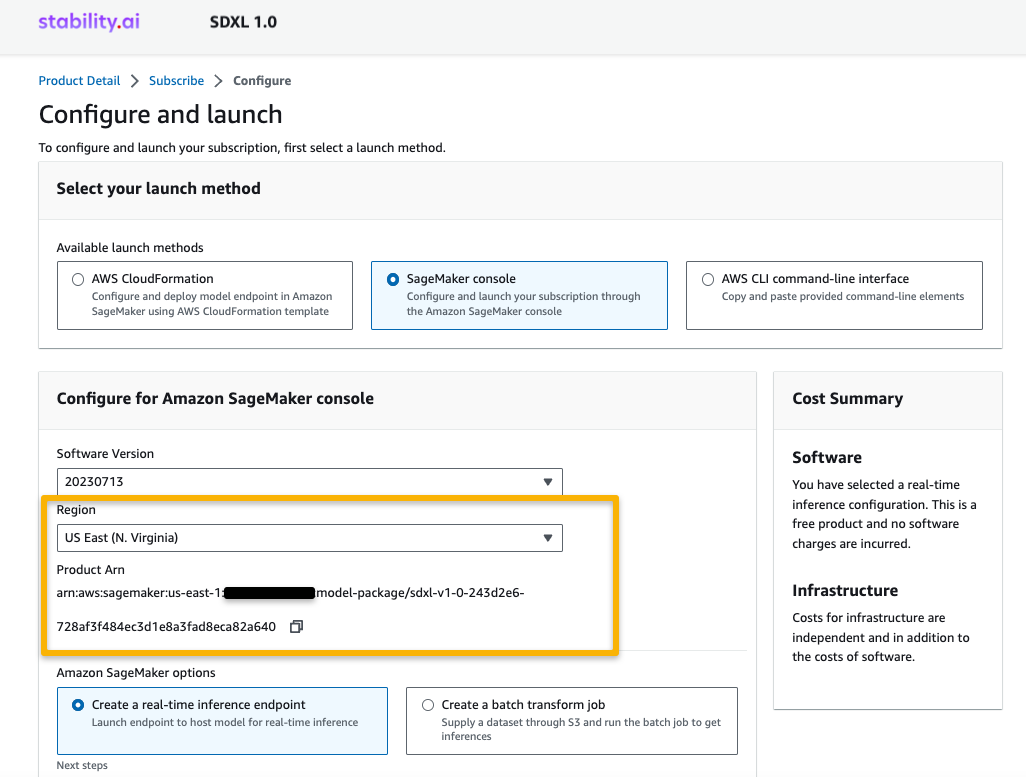
- Choose a supported Region.
You will see a product ARN displayed. This is the model package ARN that you need to specify while creating a deployable model using Boto3.
- Copy the ARN corresponding to your Region and specify the same in the notebook’s cell instruction.
ARN information may be already available in the example notebook.
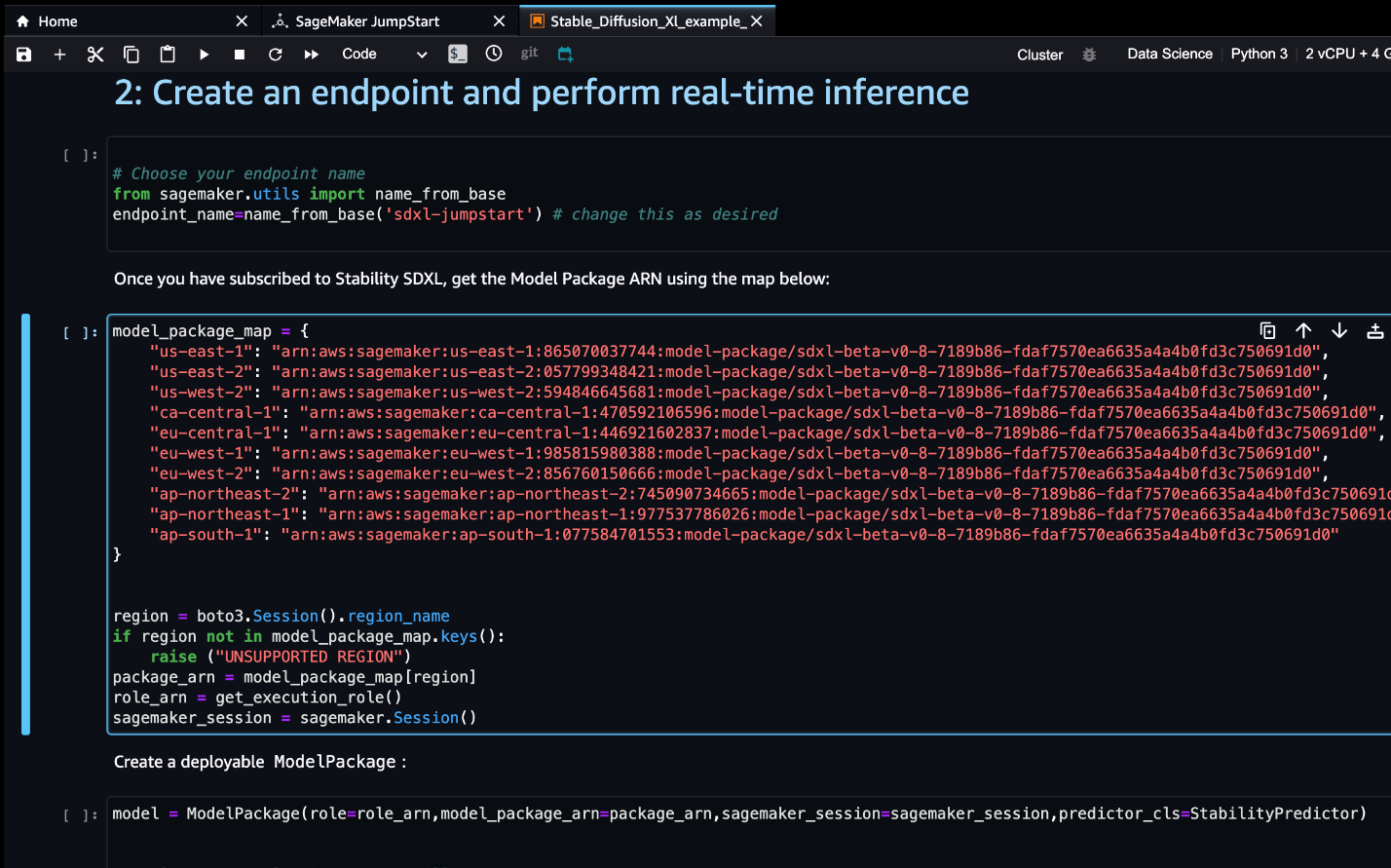
- Now you’re ready to start following the example notebook.
You can also continue from AWS Marketplace, but we recommend following the example notebook in SageMaker Studio to better understand how deployment works.
Clean up
When you’ve finished working, you can delete the endpoint to release the Amazon Elastic Compute Cloud (Amazon EC2) instances associated with it and stop billing.
Get your list of SageMaker endpoints using the AWS CLI as follows:
Then delete the endpoints:
Conclusion
In this post, we showed you how to get started with the new SDXL 1.0 model in SageMaker Studio. With this model, you can take advantage of the different features offered by SDXL to create realistic images. Because foundation models are pre-trained, they can also help lower training and infrastructure costs and enable customization for your use case.
Resources
- SageMaker JumpStart
- JumpStart Foundation Models
- SageMaker JumpStart product page
- SageMaker JumpStart model catalog
About the authors
 June Won is a product manager with SageMaker JumpStart. He focuses on making foundation models easily discoverable and usable to help customers build generative AI applications.
June Won is a product manager with SageMaker JumpStart. He focuses on making foundation models easily discoverable and usable to help customers build generative AI applications.
 Mani Khanuja is an Artificial Intelligence and Machine Learning Specialist SA at Amazon Web Services (AWS). She helps customers using machine learning to solve their business challenges using the AWS. She spends most of her time diving deep and teaching customers on AI/ML projects related to computer vision, natural language processing, forecasting, ML at the edge, and more. She is passionate about ML at edge, therefore, she has created her own lab with self-driving kit and prototype manufacturing production line, where she spends lot of her free time.
Mani Khanuja is an Artificial Intelligence and Machine Learning Specialist SA at Amazon Web Services (AWS). She helps customers using machine learning to solve their business challenges using the AWS. She spends most of her time diving deep and teaching customers on AI/ML projects related to computer vision, natural language processing, forecasting, ML at the edge, and more. She is passionate about ML at edge, therefore, she has created her own lab with self-driving kit and prototype manufacturing production line, where she spends lot of her free time.
 Nitin Eusebius is a Sr. Enterprise Solutions Architect at AWS with experience in Software Engineering , Enterprise Architecture and AI/ML. He works with customers on helping them build well-architected applications on the AWS platform. He is passionate about solving technology challenges and helping customers with their cloud journey.
Nitin Eusebius is a Sr. Enterprise Solutions Architect at AWS with experience in Software Engineering , Enterprise Architecture and AI/ML. He works with customers on helping them build well-architected applications on the AWS platform. He is passionate about solving technology challenges and helping customers with their cloud journey.
 Suleman Patel is a Senior Solutions Architect at Amazon Web Services (AWS), with a special focus on Machine Learning and Modernization. Leveraging his expertise in both business and technology, Suleman helps customers design and build solutions that tackle real-world business problems. When he’s not immersed in his work, Suleman loves exploring the outdoors, taking road trips, and cooking up delicious dishes in the kitchen.
Suleman Patel is a Senior Solutions Architect at Amazon Web Services (AWS), with a special focus on Machine Learning and Modernization. Leveraging his expertise in both business and technology, Suleman helps customers design and build solutions that tackle real-world business problems. When he’s not immersed in his work, Suleman loves exploring the outdoors, taking road trips, and cooking up delicious dishes in the kitchen.
 Dr. Vivek Madan is an Applied Scientist with the Amazon SageMaker JumpStart team. He got his PhD from University of Illinois at Urbana-Champaign and was a Post Doctoral Researcher at Georgia Tech. He is an active researcher in machine learning and algorithm design and has published papers in EMNLP, ICLR, COLT, FOCS, and SODA conferences.
Dr. Vivek Madan is an Applied Scientist with the Amazon SageMaker JumpStart team. He got his PhD from University of Illinois at Urbana-Champaign and was a Post Doctoral Researcher at Georgia Tech. He is an active researcher in machine learning and algorithm design and has published papers in EMNLP, ICLR, COLT, FOCS, and SODA conferences.

NVIDIA H100 GPUs Now Available on AWS Cloud
AWS users can now access the leading performance demonstrated in industry benchmarks of AI training and inference.
The cloud giant officially switched on a new Amazon EC2 P5 instance powered by NVIDIA H100 Tensor Core GPUs. The service lets users scale generative AI, high performance computing (HPC) and other applications with a click from a browser.
The news comes in the wake of AI’s iPhone moment. Developers and researchers are using large language models (LLMs) to uncover new applications for AI almost daily. Bringing these new use cases to market requires the efficiency of accelerated computing.
The NVIDIA H100 GPU delivers supercomputing-class performance through architectural innovations including fourth-generation Tensor Cores, a new Transformer Engine for accelerating LLMs and the latest NVLink technology that lets GPUs talk to each other at 900GB/sec.
Scaling With P5 Instances
Amazon EC2 P5 instances are ideal for training and running inference for increasingly complex LLMs and computer vision models. These neural networks drive the most demanding and compute-intensive generative AI applications, including question answering, code generation, video and image generation, speech recognition and more.
P5 instances can be deployed in hyperscale clusters, called EC2 UltraClusters, made up of high-performance compute, networking and storage in the cloud. Each EC2 UltraCluster is a powerful supercomputer, enabling customers to run their most complex AI training and distributed HPC workloads across multiple systems.
So customers can run at scale applications that require high levels of communications between compute nodes, the P5 instance sports petabit-scale non-blocking networks, powered by AWS EFA, a 3,200 Gbps network interface for Amazon EC2 instances.
With P5 instances, machine learning applications can use the NVIDIA Collective Communications Library to employ as many as 20,000 H100 GPUs.
NVIDIA AI Enterprise helps users make the most of P5 instancesoptimize P5 instances. It’s a full-stack suite of software that includes more than 100 frameworks, pretrained models, AI workflows and tools to tune AI infrastructure.
Designed to streamline the development and deployment of AI applications, NVIDIA AI Enterprise addresses the complexities of building and maintaining a high-performance, secure, cloud-native AI software platform. Available in the AWS Marketplace, it offers continuous security monitoring, regular and timely patching of common vulnerabilities and exposures, API stability, and enterprise support as well as access to NVIDIA AI experts.
What Customers Are Saying
NVIDIA and AWS have collaborated for more than a dozen years to bring GPU acceleration to the cloud. The new P5 instances, the latest example of that collaboration, represents a major step forward to deliver the cutting-edge performance that enables developers to invent the next generation of AI.
Here are some examples of what customers are already saying:
Anthropic builds reliable, interpretable and steerable AI systems that will have many opportunities to create value commercially and for public benefit.
“While the large, general AI systems of today can have significant benefits, they can also be unpredictable, unreliable and opaque, so our goal is to make progress on these issues and deploy systems that people find useful,” said Tom Brown, co-founder of Anthropic. “We expect P5 instances to deliver substantial price-performance benefits over P4d instances, and they’ll be available at the massive scale required for building next-generation LLMs and related products.”
Cohere, a leading pioneer in language AI, empowers every developer and enterprise to build products with world-leading natural language processing (NLP) technology while keeping their data private and secure.
“Cohere leads the charge in helping every enterprise harness the power of language AI to explore, generate, search for and act upon information in a natural and intuitive manner, deploying across multiple cloud platforms in the data environment that works best for each customer,” said Aidan Gomez, CEO of Cohere. “NVIDIA H100-powered Amazon EC2 P5 instances will unleash the ability of businesses to create, grow and scale faster with its computing power combined with Cohere’s state-of-the-art LLM and generative AI capabilities.”
For its part, Hugging Face is on a mission to democratize good machine learning.
“As the fastest growing open-source community for machine learning, we now provide over 150,000 pretrained models and 25,000 datasets on our platform for NLP, computer vision, biology, reinforcement learning and more,” said Julien Chaumond, chief technology officer and co-founder of Hugging Face. “We’re looking forward to using Amazon EC2 P5 instances via Amazon SageMaker at scale in UltraClusters with EFA to accelerate the delivery of new foundation AI models for everyone.”
Today, more than 450 million people around the world use Pinterest as a visual inspiration platform to shop for products personalized to their taste, find ideas and discover inspiring creators.
“We use deep learning extensively across our platform for use cases such as labeling and categorizing billions of photos that are uploaded to our platform, and visual search that provides our users the ability to go from inspiration to action,” said David Chaiken, chief architect at Pinterest. “We’re looking forward to using Amazon EC2 P5 instances featuring NVIDIA H100 GPUs, AWS EFA and UltraClusters to accelerate our product development and bring new empathetic AI-based experiences to our customers.”
Learn more about new AWS P5 instances powered by NVIDIA H100.
Flag harmful language in spoken conversations with Amazon Transcribe Toxicity Detection
The increase in online social activities such as social networking or online gaming is often riddled with hostile or aggressive behavior that can lead to unsolicited manifestations of hate speech, cyberbullying, or harassment. For example, many online gaming communities offer voice chat functionality to facilitate communication among their users. Although voice chat often supports friendly banter and trash talking, it can also lead to problems such as hate speech, cyberbullying, harassment, and scams. Flagging harmful language helps organizations keep conversations civil and maintain a safe and inclusive online environment for users to create, share, and participate freely. Today, many companies rely solely on human moderators to review toxic content. However, scaling human moderators to meet these needs at a sufficient quality and speed is expensive. As a result, many organizations risk facing high user attrition rates, reputational damage, and regulatory fines. In addition, moderators are often psychologically impacted by reviewing the toxic content.
Amazon Transcribe is an automatic speech recognition (ASR) service that makes it easy for developers to add speech-to-text capability to their applications. Today, we are excited to announce Amazon Transcribe Toxicity Detection, a machine learning (ML)-powered capability that uses both audio and text-based cues to identify and classify voice-based toxic content across seven categories, including sexual harassment, hate speech, threats, abuse, profanity, insults, and graphic language. In addition to text, Toxicity Detection uses speech cues such as tones and pitch to hone in on toxic intent in speech.
This is an improvement from standard content moderation systems that are designed to focus only on specific terms, without accounting for intention. Most enterprises have an SLA of 7–15 days to review content reported by users because moderators must listen to lengthy audio files to evaluate if and when the conversation became toxic. With Amazon Transcribe Toxicity Detection, moderators only review the specific portion of the audio file flagged for toxic content (vs. the entire audio file). The content human moderators must review is reduced by 95%, enabling customers to reduce their SLA to just a few hours, as well as enable them to proactively moderate more content beyond just what’s flagged by the users. It will allow enterprises to automatically detect and moderate content at scale, provide a safe and inclusive online environment, and take action before it can cause user churn or reputational damage. The models used for toxic content detection are maintained by Amazon Transcribe and updated periodically to maintain accuracy and relevance.
In this post, you’ll learn how to:
- Identify harmful content in speech with Amazon Transcribe Toxicity Detection
- Use the Amazon Transcribe console for toxicity detection
- Create a transcription job with toxicity detection using the AWS Command Line Interface (AWS CLI) and Python SDK
- Use the Amazon Transcribe toxicity detection API response
Detect toxicity in audio chat with Amazon Transcribe Toxicity Detection
Amazon Transcribe now provides a simple, ML-based solution for flagging harmful language in spoken conversations. This feature is especially useful for social media, gaming, and general needs, eliminating the need for customers to provide their own data to train the ML model. Toxicity Detection classifies toxic audio content into the following seven categories and provides a confidence score (0–1) for each category:
- Profanity – Speech that contains words, phrases, or acronyms that are impolite, vulgar, or offensive.
- Hate speech – Speech that criticizes, insults, denounces, or dehumanizes a person or group on the basis of an identity (such as race, ethnicity, gender, religion, sexual orientation, ability, and national origin).
- Sexual – Speech that indicates sexual interest, activity, or arousal using direct or indirect references to body parts, physical traits, or sex.
- Insults – Speech that includes demeaning, humiliating, mocking, insulting, or belittling language. This type of language is also labeled as bullying.
- Violence or threat – Speech that includes threats seeking to inflict pain, injury, or hostility toward a person or group.
- Graphic – Speech that uses visually descriptive and unpleasantly vivid imagery. This type of language is often intentionally verbose to amplify a recipient’s discomfort.
- Harassment or abusive – Speech intended to affect the psychological well-being of the recipient, including demeaning and objectifying terms.
You can access Toxicity Detection either via the Amazon Transcribe console or by calling the APIs directly using the AWS CLI or the AWS SDKs. On the Amazon Transcribe console, you can upload the audio files you want to test for toxicity and get results in just a few clicks. Amazon Transcribe will identify and categorize toxic content, such as harassment, hate speech, sexual content, violence, insults, and profanity. Amazon Transcribe also provides a confidence score for each category, providing valuable insights into the content’s toxicity level. Toxicity Detection is currently available in the standard Amazon Transcribe API for batch processing and supports US English language.
Amazon Transcribe console walkthrough
To get started, sign in to the AWS Management Console and go to Amazon Transcribe. To create a new transcription job, you need to upload your recorded files into an Amazon Simple Storage Service (Amazon S3) bucket before they can be processed. On the audio settings page, as shown in the following screenshot, enable Toxicity detection and proceed to create the new job. Amazon Transcribe will process the transcription job in the background. As the job progresses, you can expect the status to change to COMPLETED when the process is finished.
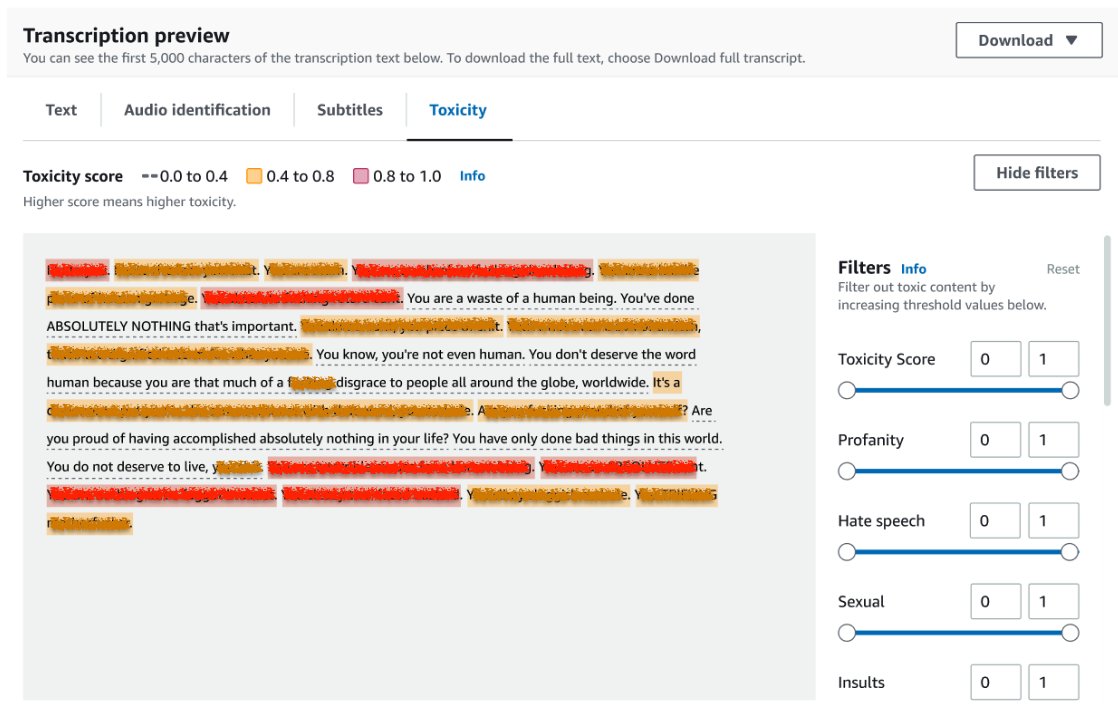
To review the results of a transcription job, choose the job from the job list to open it. Scroll down to the Transcription preview section to check results on the Toxicity tab. The UI shows color-coded transcription segments to indicate the level of toxicity, determined by the confidence score. To customize the display, you can use the toggle bars in the Filters pane. These bars allow you to adjust the thresholds and filter the toxicity categories accordingly.
The following screenshot has covered portions of the transcription text due to the presence of sensitive or toxic information.
Transcription API with a toxicity detection request
In this section, we guide you through creating a transcription job with toxicity detection using programming interfaces. If the audio file is not already in an S3 bucket, upload it to ensure access by Amazon Transcribe. Similar to creating a transcription job on the console, when invoking the job, you need to provide the following parameters:
- TranscriptionJobName – Specify a unique job name.
- MediaFileUri – Enter the URI location of the audio file on Amazon S3. Amazon Transcribe supports the following audio formats: MP3, MP4, WAV, FLAC, AMR, OGG, or WebM
- LanguageCode – Set to
en-US. As of this writing, Toxicity Detection only supports US English language. - ToxicityCategories – Pass the
ALLvalue to include all supported toxicity detection categories.
The following are examples of starting a transcription job with toxicity detection enabled using Python3:
You can invoke the same transcription job with toxicity detection using the following AWS CLI command:
Transcription API with toxicity detection response
The Amazon Transcribe toxicity detection JSON output will include the transcription results in the results field. Enabling toxicity detection adds an extra field called toxicityDetection under the results field. toxicityDetection includes a list of transcribed items with the following parameters:
- text – The raw transcribed text
- toxicity – A confidence score of detection (a value between 0–1)
- categories – A confidence score for each category of toxic speech
- start_time – The start position of detection in the audio file (seconds)
- end_time – The end position of detection in the audio file (seconds)
The following is a sample abbreviated toxicity detection response you can download from the console:
Summary
In this post, we provided an overview of the new Amazon Transcribe Toxicity Detection feature. We also described how you can parse the toxicity detection JSON output. For more information, check out the Amazon Transcribe console and try out the Transcription API with Toxicity Detection.
Amazon Transcribe Toxicity Detection is now available in the following AWS Regions: US East (Ohio), US East (N. Virginia), US West (Oregon), Asia Pacific (Sydney), Europe (Ireland), and Europe (London). To learn more, visit Amazon Transcribe.
Learn more about content moderation on AWS and our content moderation ML use cases. Take the first step towards streamlining your content moderation operations with AWS.
About the author
 Lana Zhang is a Senior Solutions Architect at AWS WWSO AI Services team, specializing in AI and ML for content moderation, computer vision, and natural language processing. With her expertise, she is dedicated to promoting AWS AI/ML solutions and assisting customers in transforming their business solutions across diverse industries, including social media, gaming, e-commerce, and advertising & marketing.
Lana Zhang is a Senior Solutions Architect at AWS WWSO AI Services team, specializing in AI and ML for content moderation, computer vision, and natural language processing. With her expertise, she is dedicated to promoting AWS AI/ML solutions and assisting customers in transforming their business solutions across diverse industries, including social media, gaming, e-commerce, and advertising & marketing.
 Sumit Kumar is a Sr Product Manager, Technical at AWS AI Language Services team. He has 10 years of product management experience across a variety of domains and is passionate about AI/ML. Outside of work, Sumit loves to travel and enjoys playing cricket and Lawn-Tennis.
Sumit Kumar is a Sr Product Manager, Technical at AWS AI Language Services team. He has 10 years of product management experience across a variety of domains and is passionate about AI/ML. Outside of work, Sumit loves to travel and enjoys playing cricket and Lawn-Tennis.

Maximize Stable Diffusion performance and lower inference costs with AWS Inferentia2
Generative AI models have been experiencing rapid growth in recent months due to its impressive capabilities in creating realistic text, images, code, and audio. Among these models, Stable Diffusion models stand out for their unique strength in creating high-quality images based on text prompts. Stable Diffusion can generate a wide variety of high-quality images, including realistic portraits, landscapes, and even abstract art. And, like other generative AI models, Stable Diffusion models require powerful computing to provide low-latency inference.
In this post, we show how you can run Stable Diffusion models and achieve high performance at the lowest cost in Amazon Elastic Compute Cloud (Amazon EC2) using Amazon EC2 Inf2 instances powered by AWS Inferentia2. We look at the architecture of a Stable Diffusion model and walk through the steps of compiling a Stable Diffusion model using AWS Neuron and deploying it to an Inf2 instance. We also discuss the optimizations that the Neuron SDK automatically makes to improve performance. You can run both Stable Diffusion 2.1 and 1.5 versions on AWS Inferentia2 cost-effectively. Lastly, we show how you can deploy a Stable Diffusion model to an Inf2 instance with Amazon SageMaker.
The Stable Diffusion 2.1 model size in floating point 32 (FP32) is 5 GB and 2.5 GB in bfoat16 (BF16). A single inf2.xlarge instance has one AWS Inferentia2 accelerator with 32 GB of HBM memory. The Stable Diffusion 2.1 model can fit on a single inf2.xlarge instance. Stable Diffusion is a text-to-image model that you can use to create images of different styles and content simply by providing a text prompt as an input. To learn more about the Stable Diffusion model architecture, refer to Create high-quality images with Stable Diffusion models and deploy them cost-efficiently with Amazon SageMaker.
How the Neuron SDK optimizes Stable Diffusion performance
Before we can deploy the Stable Diffusion 2.1 model on AWS Inferentia2 instances, we need to compile the model components using the Neuron SDK. The Neuron SDK, which includes a deep learning compiler, runtime, and tools, compiles and automatically optimizes deep learning models so they can run efficiently on Inf2 instances and extract full performance of the AWS Inferentia2 accelerator. We have examples available for Stable Diffusion 2.1 model on the GitHub repo. This notebook presents an end-to-end example of how to compile a Stable Diffusion model, save the compiled Neuron models, and load it into the runtime for inference.
We use StableDiffusionPipeline from the Hugging Face diffusers library to load and compile the model. We then compile all the components of the model for Neuron using torch_neuronx.trace() and save the optimized model as TorchScript. Compilation processes can be quite memory-intensive, requiring a significant amount of RAM. To circumvent this, before tracing each model, we create a deepcopy of the part of the pipeline that’s being traced. Following this, we delete the pipeline object from memory using del pipe. This technique is particularly useful when compiling on instances with low RAM.
Additionally, we also perform optimizations to the Stable Diffusion models. UNet holds the most computationally intensive aspect of the inference. The UNet component operates on input tensors that have a batch size of two, generating a corresponding output tensor also with a batch size of two, to produce a single image. The elements within these batches are entirely independent of each other. We can take advantage of this behavior to get optimal latency by running one batch on each Neuron core. We compile the UNet for one batch (by using input tensors with one batch), then use the torch_neuronx.DataParallel API to load this single batch model onto each core. The output of this API is a seamless two-batch module: we can pass to the UNet the inputs of two batches, and a two-batch output is returned, but internally, the two single-batch models are running on the two Neuron cores. This strategy optimizes resource utilization and reduces latency.
Compile and deploy a Stable Diffusion model on an Inf2 EC2 instance
To compile and deploy the Stable Diffusion model on an Inf2 EC2 instance, sign to the AWS Management Console and create an inf2.8xlarge instance. Note that an inf2.8xlarge instance is required only for the compilation of the model because compilation requires a higher host memory. The Stable Diffusion model can be hosted on an inf2.xlarge instance. You can find the latest AMI with Neuron libraries using the following AWS Command Line Interface (AWS CLI) command:
For this example, we created an EC2 instance using the Deep Learning AMI Neuron PyTorch 1.13 (Ubuntu 20.04). You can then create a JupyterLab lab environment by connecting to the instance and running the following steps:
A notebook with all the steps for compiling and hosting the model is located on GitHub.
Let’s look at the compilation steps for one of the text encoder blocks. Other blocks that are part of the Stable Diffusion pipeline can be compiled similarly.
The first step is to load the pre-trained model from Hugging Face. The StableDiffusionPipeline.from_pretrained method loads the pre-trained model into our pipeline object, pipe. We then create a deepcopy of the text encoder from our pipeline, effectively cloning it. The del pipe command is then used to delete the original pipeline object, freeing up the memory that was consumed by it. Here, we are quantizing the model to BF16 weights:
This step involves wrapping our text encoder with the NeuronTextEncoder wrapper. The output of a compiled text encoder module will be of dict. We convert it to a list type using this wrapper:
We initialize PyTorch tensor emb with some values. The emb tensor is used as example input for the torch_neuronx.trace function. This function traces our text encoder and compiles it into a format optimized for Neuron. The directory path for the compiled model is constructed by joining COMPILER_WORKDIR_ROOT with the subdirectory text_encoder:
The compiled text encoder is saved using torch.jit.save. It’s stored under the file name model.pt in the text_encoder directory of our compiler’s workspace:
The notebook includes similar steps to compile other components of the model: UNet, VAE decoder, and VAE post_quant_conv. After you have compiled all the models, you can load and run the model following these steps:
- Define the paths for the compiled models.
- Load a pre-trained
StableDiffusionPipelinemodel, with its configuration specified to use the bfloat16 data type. - Load the UNet model onto two Neuron cores using the
torch_neuronx.DataParallelAPI. This allows data parallel inference to be performed, which can significantly speed up model performance. - Load the remaining parts of the model (
text_encoder,decoder, andpost_quant_conv) onto a single Neuron core.
You can then run the pipeline by providing input text as prompts. The following are some pictures generated by the model for the prompts:
- Portrait of renaud sechan, pen and ink, intricate line drawings, by craig mullins, ruan jia, kentaro miura, greg rutkowski, loundraw

- Portrait of old coal miner in 19th century, beautiful painting, with highly detailed face painting by greg rutkowski

- A castle in the middle of a forest

Host Stable Diffusion 2.1 on AWS Inferentia2 and SageMaker
Hosting Stable Diffusion models with SageMaker also requires compilation with the Neuron SDK. You can complete the compilation ahead of time or during runtime using Large Model Inference (LMI) containers. Compilation ahead of time allows for faster model loading times and is the preferred option.
SageMaker LMI containers provide two ways to deploy the model:
- A no-code option where we just provide a
serving.propertiesfile with the required configurations - Bring your own inference script
We look at both solutions and go over the configurations and the inference script (model.py). In this post, we demonstrate the deployment using a pre-compiled model stored in an Amazon Simple Storage Service (Amazon S3) bucket. You can use this pre-compiled model for your deployments.
Configure the model with a provided script
In this section, we show how to configure the LMI container to host the Stable Diffusion models. The SD2.1 notebook available on GitHub. The first step is to create the model configuration package per the following directory structure. Our aim is to use the minimal model configurations needed to host the model. The directory structure needed is as follows:
Next, we create the serving.properties file with the following parameters:
The parameters specify the following:
- option.model_id – The LMI containers use s5cmd to load the model from the S3 location and therefore we need to specify the location of where our compiled weights are.
- option.entryPoint – To use the built-in handlers, we specify the transformers-neuronx class. If you have a custom inference script, you need to provide that instead.
- option.dtype – This specifies to load the weights in a specific size. For this post, we use BF16, which further reduces our memory requirements vs. FP32 and lowers our latency due to that.
- option.tensor_parallel_degree – This parameter specifies the number of accelerators we use for this model. The AWS Inferentia2 chip accelerator has two Neuron cores and so specifying a value of 2 means we use one accelerator (two cores). This means we can now create multiple workers to increase the throughput of the endpoint.
- option.engine – This is set to Python to indicate we will not be using other compilers like DeepSpeed or Faster Transformer for this hosting.
Bring your own script
If you want to bring your own custom inference script, you need to remove the option.entryPoint from serving.properties. The LMI container in that case will look for a model.py file in the same location as the serving.properties and use that to run the inferencing.
Create your own inference script (model.py)
Creating your own inference script is relatively straightforward using the LMI container. The container requires your model.py file to have an implementation of the following method:
Let’s examine some of the critical areas of the attached notebook, which demonstrates the bring your own script function.
Replace the cross_attention module with the optimized version:
These are the names of the compiled weights file we used when creating the compilations. Feel free to change the file names, but make sure your weights file names match what you specify here.
Then we need to load them using the Neuron SDK and set these in the actual model weights. When loading the UNet optimized weights, note we are also specifying the number of Neuron cores we need to load these onto. Here, we load to a single accelerator with two cores:
Running the inference with a prompt invokes the pipe object to generate an image.
Create the SageMaker endpoint
We use Boto3 APIs to create a SageMaker endpoint. Complete the following steps:
- Create the tarball with just the serving and the optional
model.pyfiles and upload it to Amazon S3. - Create the model using the image container and the model tarball uploaded earlier.
- Create the endpoint config using the following key parameters:
- Use an
ml.inf2.xlargeinstance. - Set
ContainerStartupHealthCheckTimeoutInSecondsto 240 to ensure the health check starts after the model is deployed. - Set
VolumeInGBto a larger value so it can be used for loading the model weights that are 32 GB in size.
- Use an
Create a SageMaker model
After you create the model.tar.gz file and upload it to Amazon S3, we need to create a SageMaker model. We use the LMI container and the model artifact from the previous step to create the SageMaker model. SageMaker allows us to customize and inject various environment variables. For this workflow, we can leave everything as default. See the following code:
Create the model object, which essentially creates a lockdown container that is loaded onto the instance and used for inferencing:
Create a SageMaker endpoint
In this demo, we use an ml.inf2.xlarge instance. We need to set the VolumeSizeInGB parameters to provide the necessary disk space to load the model and the weights. This parameter is applicable to instances supporting the Amazon Elastic Block Store (Amazon EBS) volume attachment. We can leave the model download timeout and container startup health check to a higher value, which will give adequate time for the container to pull the weights from Amazon S3 and load into the AWS Inferentia2 accelerators. For more details, refer to CreateEndpointConfig.
Lastly, we create a SageMaker endpoint:
Invoke the model endpoint
This is a generative model, so we pass in the prompt that the model uses to generate the image. The payload is of the type JSON:
Benchmarking the Stable Diffusion model on Inf2
We ran a few tests to benchmark the Stable Diffusion model with BF 16 data type on Inf2, and we are able to derive latency numbers that rival or exceed some of the other accelerators for Stable Diffusion. This, coupled with the lower cost of AWS Inferentia2 chips, makes this an extremely valuable proposition.
The following numbers are from the Stable Diffusion model deployed on an inf2.xl instance. For more information about costs, refer to Amazon EC2 Inf2 Instances.
| Model | Resolution | Data type | Iterations | P95 Latency (ms) | Inf2.xl On-Demand cost per hour | Inf2.xl (Cost per image) |
| Stable Diffusion 1.5 | 512×512 | bf16 | 50 | 2,427.4 | $0.76 | $0.0005125 |
| Stable Diffusion 1.5 | 768×768 | bf16 | 50 | 8,235.9 | $0.76 | $0.0017387 |
| Stable Diffusion 1.5 | 512×512 | bf16 | 30 | 1,456.5 | $0.76 | $0.0003075 |
| Stable Diffusion 1.5 | 768×768 | bf16 | 30 | 4,941.6 | $0.76 | $0.0010432 |
| Stable Diffusion 2.1 | 512×512 | bf16 | 50 | 1,976.9 | $0.76 | $0.0004174 |
| Stable Diffusion 2.1 | 768×768 | bf16 | 50 | 6,836.3 | $0.76 | $0.0014432 |
| Stable Diffusion 2.1 | 512×512 | bf16 | 30 | 1,186.2 | $0.76 | $0.0002504 |
| Stable Diffusion 2.1 | 768×768 | bf16 | 30 | 4,101.8 | $0.76 | $0.0008659 |
Conclusion
In this post, we dove deep into the compilation, optimization, and deployment of the Stable Diffusion 2.1 model using Inf2 instances. We also demonstrated deployment of Stable Diffusion models using SageMaker. Inf2 instances also deliver great price performance for Stable Diffusion 1.5. To learn more about why Inf2 instances are great for generative AI and large language models, refer to Amazon EC2 Inf2 Instances for Low-Cost, High-Performance Generative AI Inference are Now Generally Available. For performance details, refer to Inf2 Performance. Check out additional examples on the GitHub repo.
Special thanks to Matthew Mcclain, Beni Hegedus, Kamran Khan, Shruti Koparkar, and Qing Lan for reviewing and providing valuable inputs.
About the Authors
![]() Vivek Gangasani is a Senior Machine Learning Solutions Architect at Amazon Web Services. He works with machine learning startups to build and deploy AI/ML applications on AWS. He is currently focused on delivering solutions for MLOps, ML inference, and low-code ML. He has worked on projects in different domains, including natural language processing and computer vision.
Vivek Gangasani is a Senior Machine Learning Solutions Architect at Amazon Web Services. He works with machine learning startups to build and deploy AI/ML applications on AWS. He is currently focused on delivering solutions for MLOps, ML inference, and low-code ML. He has worked on projects in different domains, including natural language processing and computer vision.
 K.C. Tung is a Senior Solution Architect in AWS Annapurna Labs. He specializes in large deep learning model training and deployment at scale in cloud. He has a Ph.D. in molecular biophysics from the University of Texas Southwestern Medical Center in Dallas. He has spoken at AWS Summits and AWS Reinvent. Today he helps customers to train and deploy large PyTorch and TensorFlow models in AWS cloud. He is the author of two books: Learn TensorFlow Enterprise and TensorFlow 2 Pocket Reference.
K.C. Tung is a Senior Solution Architect in AWS Annapurna Labs. He specializes in large deep learning model training and deployment at scale in cloud. He has a Ph.D. in molecular biophysics from the University of Texas Southwestern Medical Center in Dallas. He has spoken at AWS Summits and AWS Reinvent. Today he helps customers to train and deploy large PyTorch and TensorFlow models in AWS cloud. He is the author of two books: Learn TensorFlow Enterprise and TensorFlow 2 Pocket Reference.
 Rupinder Grewal is a Sr Ai/ML Specialist Solutions Architect with AWS. He currently focuses on serving of models and MLOps on SageMaker. Prior to this role he has worked as Machine Learning Engineer building and hosting models. Outside of work he enjoys playing tennis and biking on mountain trails.
Rupinder Grewal is a Sr Ai/ML Specialist Solutions Architect with AWS. He currently focuses on serving of models and MLOps on SageMaker. Prior to this role he has worked as Machine Learning Engineer building and hosting models. Outside of work he enjoys playing tennis and biking on mountain trails.

In search of a generalizable method for source-free domain adaptation

Deep learning has recently made tremendous progress in a wide range of problems and applications, but models often fail unpredictably when deployed in unseen domains or distributions. Source-free domain adaptation (SFDA) is an area of research that aims to design methods for adapting a pre-trained model (trained on a “source domain”) to a new “target domain”, using only unlabeled data from the latter.
Designing adaptation methods for deep models is an important area of research. While the increasing scale of models and training datasets has been a key ingredient to their success, a negative consequence of this trend is that training such models is increasingly computationally expensive, out of reach for certain practitioners and also harmful for the environment. One avenue to mitigate this issue is through designing techniques that can leverage and reuse already trained models for tackling new tasks or generalizing to new domains. Indeed, adapting models to new tasks is widely studied under the umbrella of transfer learning.
SFDA is a particularly practical area of this research because several real-world applications where adaptation is desired suffer from the unavailability of labeled examples from the target domain. In fact, SFDA is enjoying increasing attention [1, 2, 3, 4]. However, albeit motivated by ambitious goals, most SFDA research is grounded in a very narrow framework, considering simple distribution shifts in image classification tasks.
In a significant departure from that trend, we turn our attention to the field of bioacoustics, where naturally-occurring distribution shifts are ubiquitous, often characterized by insufficient target labeled data, and represent an obstacle for practitioners. Studying SFDA in this application can, therefore, not only inform the academic community about the generalizability of existing methods and identify open research directions, but can also directly benefit practitioners in the field and aid in addressing one of the biggest challenges of our century: biodiversity preservation.
In this post, we announce “In Search for a Generalizable Method for Source-Free Domain Adaptation”, appearing at ICML 2023. We show that state-of-the-art SFDA methods can underperform or even collapse when confronted with realistic distribution shifts in bioacoustics. Furthermore, existing methods perform differently relative to each other than observed in vision benchmarks, and surprisingly, sometimes perform worse than no adaptation at all. We also propose NOTELA, a new simple method that outperforms existing methods on these shifts while exhibiting strong performance on a range of vision datasets. Overall, we conclude that evaluating SFDA methods (only) on the commonly-used datasets and distribution shifts leaves us with a myopic view of their relative performance and generalizability. To live up to their promise, SFDA methods need to be tested on a wider range of distribution shifts, and we advocate for considering naturally-occurring ones that can benefit high-impact applications.
Distribution shifts in bioacoustics
Naturally-occurring distribution shifts are ubiquitous in bioacoustics. The largest labeled dataset for bird songs is Xeno-Canto (XC), a collection of user-contributed recordings of wild birds from across the world. Recordings in XC are “focal”: they target an individual captured in natural conditions, where the song of the identified bird is at the foreground. For continuous monitoring and tracking purposes, though, practitioners are often more interested in identifying birds in passive recordings (“soundscapes”), obtained through omnidirectional microphones. This is a well-documented problem that recent work shows is very challenging. Inspired by this realistic application, we study SFDA in bioacoustics using a bird species classifier that was pre-trained on XC as the source model, and several “soundscapes” coming from different geographical locations — Sierra Nevada (S. Nevada); Powdermill Nature Reserve, Pennsylvania, USA; Hawai’i; Caples Watershed, California, USA; Sapsucker Woods, New York, USA (SSW); and Colombia — as our target domains.
This shift from the focalized to the passive domain is substantial: the recordings in the latter often feature much lower signal-to-noise ratio, several birds vocalizing at once, and significant distractors and environmental noise, like rain or wind. In addition, different soundscapes originate from different geographical locations, inducing extreme label shifts since a very small portion of the species in XC will appear in a given location. Moreover, as is common in real-world data, both the source and target domains are significantly class imbalanced, because some species are significantly more common than others. In addition, we consider a multi-label classification problem since there may be several birds identified within each recording, a significant departure from the standard single-label image classification scenario where SFDA is typically studied.
 |
| Illustration of the “focal → soundscapes” shift. In the focalized domain, recordings are typically composed of a single bird vocalization in the foreground, captured with high signal-to-noise ratio (SNR), though there may be other birds vocalizing in the background. On the other hand, soundscapes contain recordings from omnidirectional microphones and can be composed of multiple birds vocalizing simultaneously, as well as environmental noises from insects, rain, cars, planes, etc. |
| Audio files |
Focal domain |
Soundscape domain1 |
||
| Spectogram images |  |
 |
| Illustration of the distribution shift from the focal domain (left) to the soundscape domain (right), in terms of the audio files (top) and spectrogram images (bottom) of a representative recording from each dataset. Note that in the second audio clip, the bird song is very faint; a common property in soundscape recordings where bird calls aren’t at the “foreground”. Credits: Left: XC recording by Sue Riffe (CC-BY-NC license). Right: Excerpt from a recording made available by Kahl, Charif, & Klinck. (2022) “A collection of fully-annotated soundscape recordings from the Northeastern United States” [link] from the SSW soundscape dataset (CC-BY license). |
State-of-the-art SFDA models perform poorly on bioacoustics shifts
As a starting point, we benchmark six state-of-the-art SFDA methods on our bioacoustics benchmark, and compare them to the non-adapted baseline (the source model). Our findings are surprising: without exception, existing methods are unable to consistently outperform the source model on all target domains. In fact, they often underperform it significantly.
As an example, Tent, a recent method, aims to make models produce confident predictions for each example by reducing the uncertainty of the model’s output probabilities. While Tent performs well in various tasks, it doesn’t work effectively for our bioacoustics task. In the single-label scenario, minimizing entropy forces the model to choose a single class for each example confidently. However, in our multi-label scenario, there’s no such constraint that any class should be selected as being present. Combined with significant distribution shifts, this can cause the model to collapse, leading to zero probabilities for all classes. Other benchmarked methods like SHOT, AdaBN, Tent, NRC, DUST and Pseudo-Labelling, which are strong baselines for standard SFDA benchmarks, also struggle with this bioacoustics task.
 |
| Evolution of the test mean average precision (mAP), a standard metric for multilabel classification, throughout the adaptation procedure on the six soundscape datasets. We benchmark our proposed NOTELA and Dropout Student (see below), as well as SHOT, AdaBN, Tent, NRC, DUST and Pseudo-Labelling. Aside from NOTELA, all other methods fail to consistently improve the source model. |
Introducing NOisy student TEacher with Laplacian Adjustment (NOTELA)
Nonetheless, a surprisingly positive result stands out: the less celebrated Noisy Student principle appears promising. This unsupervised approach encourages the model to reconstruct its own predictions on some target dataset, but under the application of random noise. While noise may be introduced through various channels, we strive for simplicity and use model dropout as the only noise source: we therefore refer to this approach as Dropout Student (DS). In a nutshell, it encourages the model to limit the influence of individual neurons (or filters) when making predictions on a specific target dataset.
DS, while effective, faces a model collapse issue on various target domains. We hypothesize this happens because the source model initially lacks confidence in those target domains. We propose improving DS stability by using the feature space directly as an auxiliary source of truth. NOTELA does this by encouraging similar pseudo-labels for nearby points in the feature space, inspired by NRC’s method and Laplacian regularization. This simple approach is visualized below, and consistently and significantly outperforms the source model in both audio and visual tasks.
 |
 |
| NOTELA in action. The audio recordings are forwarded through the full model to obtain a first set of predictions, which are then refined through Laplacian regularization, a form of post-processing based on clustering nearby points. Finally, the refined predictions are used as targets for the noisy model to reconstruct. |
Conclusion
The standard artificial image classification benchmarks have inadvertently limited our understanding of the true generalizability and robustness of SFDA methods. We advocate for broadening the scope and adopt a new assessment framework that incorporates naturally-occurring distribution shifts from bioacoustics. We also hope that NOTELA serves as a robust baseline to facilitate research in that direction. NOTELA’s strong performance perhaps points to two factors that can lead to developing more generalizable models: first, developing methods with an eye towards harder problems and second, favoring simple modeling principles. However, there is still future work to be done to pinpoint and comprehend existing methods’ failure modes on harder problems. We believe that our research represents a significant step in this direction, serving as a foundation for designing SFDA methods with greater generalizability.
Acknowledgements
One of the authors of this post, Eleni Triantafillou, is now at Google DeepMind. We are posting this blog post on behalf of the authors of the NOTELA paper: Malik Boudiaf, Tom Denton, Bart van Merriënboer, Vincent Dumoulin*, Eleni Triantafillou* (where * denotes equal contribution). We thank our co-authors for the hard work on this paper and the rest of the Perch team for their support and feedback.
1Note that in this audio clip, the bird song is very faint; a common property in soundscape recordings where bird calls aren’t at the “foreground”. ↩