Apple Machine Learning Research

10 helpful ways to use Bard
 Check out 10 ways Bard can help you get things done, from brainstorming ideas to planning trip itineraries.Read More
Check out 10 ways Bard can help you get things done, from brainstorming ideas to planning trip itineraries.Read More
Microsoft at KDD 2023: Advancing health at the speed of AI
This content was given as a keynote at the Workshop of Applied Data Science for Healthcare and covered during a tutorial at the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, a premier forum for advancement, education, and adoption of the discipline of knowledge discovering and data mining.
-
Group
Real-world Evidence
Recent and noteworthy advancements in generative AI and large language models (LLMs) are leading to profound transformations in various domains. This blog explores how these breakthroughs can accelerate progress in precision health. In addition to the keynote I delivered, “Applications and New Fronters of Generative Models for Healthcare,” it includes part of a tutorial (LS-21) being given at KDD 2023. This tutorial surveys the broader research area of “Precision Health at the Age of Large Language Models,” delivered by Sheng Zhang, Javier González Hernández, Tristan Naumann, and myself.
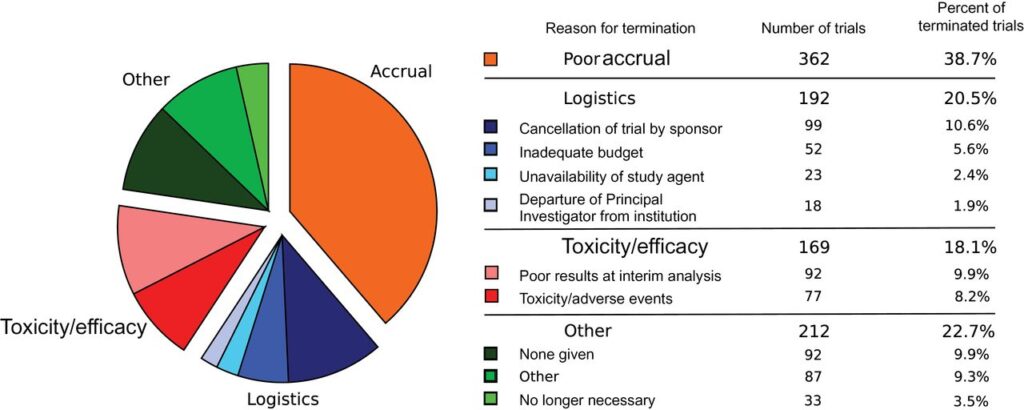
A longstanding objective within precision health is the development of a continuous learning system capable of seamlessly integrating novel information to enhance healthcare delivery and expedite advancements in biomedicine. The National Academy of Medicine has gathered leading experts to explore this key initiative, as documented in its Learning Health System series. However, the current state of health systems is far removed from this ideal. The burden of extensive unstructured data and labor-intensive manual processing hinder progress. This is evident, for instance, in the context of cancer treatment, where the traditional standard of care frequently falls short, leaving clinical trials as a last resort. Yet a lack of awareness renders these trials inaccessible, with only 3 percent of US patients finding a suitable trial. This enrollment deficiency contributes to nearly 40 percent of trial failures, as shown in Figure 1. Consequently, the process of drug discovery is exceedingly slow, demanding billions of dollars and a timeline of over a decade.
On an encouraging note, advances in generative AI provide unparalleled opportunities in harnessing real-world observational data to improve patient care—a long-standing goal in the realm of real-world evidence (RWE), which the US Food and Drug Administration (FDA) relies on to monitor and evaluate post-market drug safety. Large language models (LLMs) like GPT-4 have the capability of “universal structuring,” enabling efficient abstraction of patient information from clinical text at a large scale. This potential can be likened to the transformative impact LLMs are currently making in other domains, such as software development and productivity tools.
Microsoft Research Podcast

Collaborators: Holoportation communication technology with Spencer Fowers and Kwame Darko
communication technology with Spencer Fowers and Kwame Darko
Spencer Fowers and Kwame Darko break down how the technology behind Holoportation and the telecommunication device being built around it brings patients and doctors together when being in the same room isn’t an easy option and discuss the potential impact of the work.
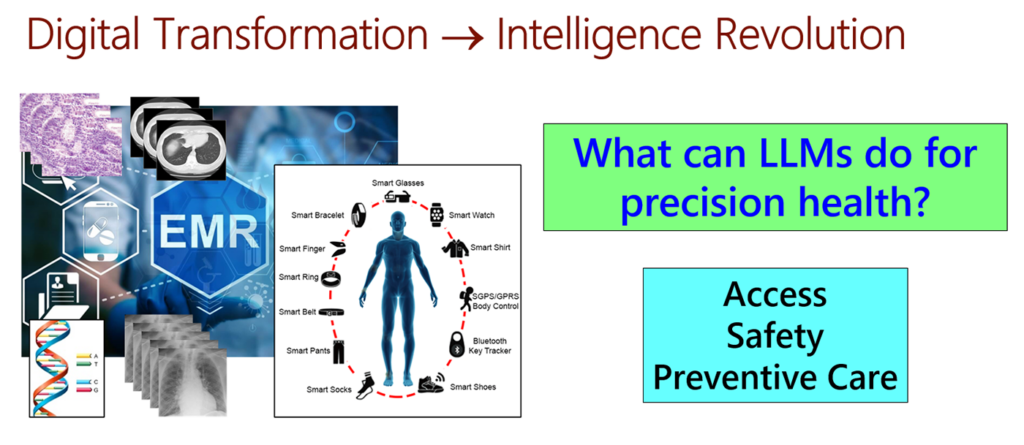
Digital transformation leads to an intelligence revolution
The large-scale digitization of human knowledge on the internet has facilitated the pretraining of powerful large language models. As a result, we are witnessing revolutionary changes in general software categories like programming and search. Similarly, the past couple of decades have seen rapid digitization in biomedicine, with advancements like sequencing technologies, electronic medical records (EMRs), and health sensors. By unleashing the power of generative AI in the field of biomedicine, we can achieve similarly amazing transformations in precision health, as shown in Figure 2.
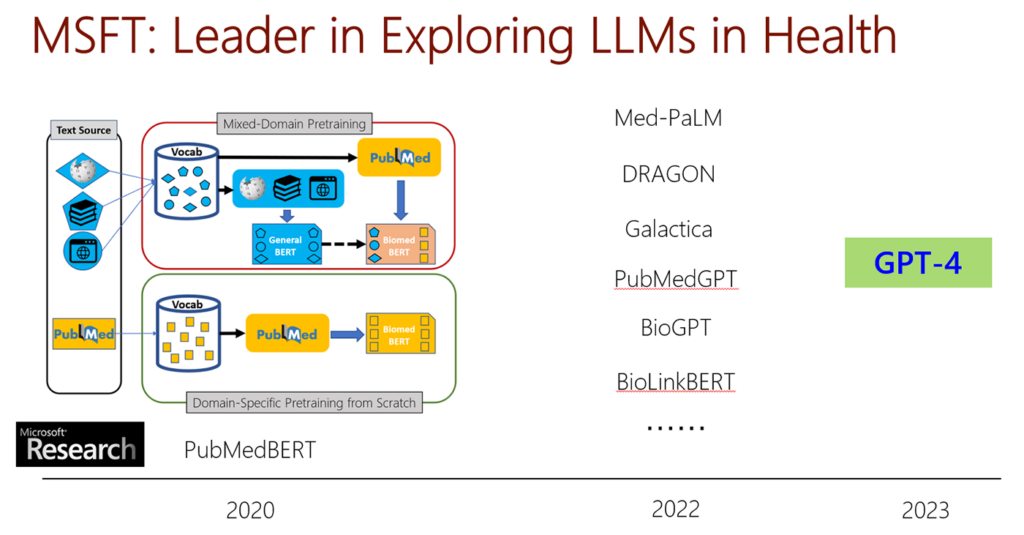
Microsoft is at the forefront of exploring the applications of LLMs in the health field, as depicted in Figure 3. Our PubMedBERT models, pretrained on biomedical abstracts and full texts, were released three years ago. They have sparked immense interest in biomedical pretraining and continue to receive an overwhelming number of downloads each month, with over one million in July 2023 alone. Numerous recent investigations have followed suit, delving deeper into this promising direction. Now, with next-generation models like GPT-4 being widely accessible, progress can be further accelerated.
Although pretrained on general web content, GPT-4 has demonstrated impressive competence in biomedical tasks straightaway and has the potential to perform previously unseen natural language processing (NLP) tasks in the biomedical domain with exceptional accuracy. Notably, research studies show that GPT-4 can achieve expert-level performance on medical question-answer datasets, like MedQA (USMLE exam), without the need for costly task-specific fine-tuning or intricate self-refinement.
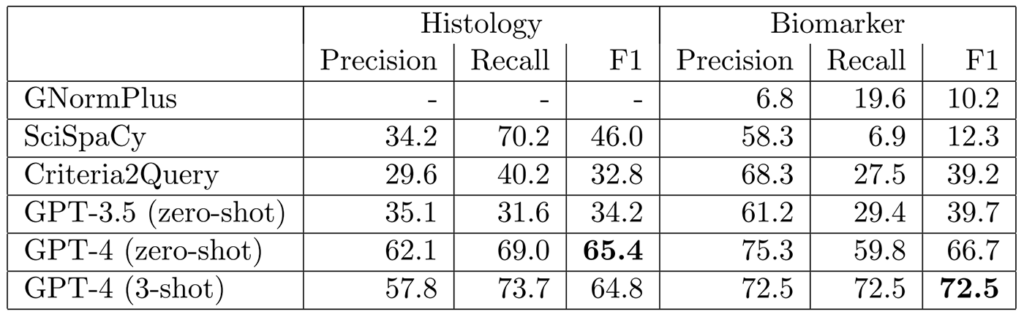
Similarly, with simple prompts, GPT-4 can effectively structure complex clinical trial matching logic from eligibility criteria, surpassing prior state-of-the-art systems like Criteria2Query, which were specifically designed for this purpose, as shown in Figure 4.
Transforming real-world data into a discovery engine
In the context of clinical trial matching, besides structuring trial eligibility criteria, the bigger challenge lies in structuring patient records at scale. Cancer patients may have hundreds of notes where critical information like histopathology or staging may be scattered across multiple entries, as shown in Figure 5. To tackle this, Microsoft and Providence, a large US-based health system, have developed state-of-the-art self-supervised LLMs like OncoBERT to extract such details. More recently, preliminary studies have found that GPT-4 can also excel at structuring such vital information. Drawing on these advancements, we developed a research system for clinical trial matching, powered by LLMs. This system is now used daily on a molecular tumor board at Providence, as well as in high-profile trials such as this adoptive T-cell trial, as reported by the New York Times.
Clinical trial matching is important in its own right, and the same underlying technologies can be used to unlock other beneficial applications. For example, in collaboration with Providence researchers, we demonstrated how real-world data can be harnessed to simulate prominent lung cancer trials under various eligibility settings. By combining the structuring capabilities of LLMs with state-of-the-art causal inference methods, we effectively transform real-world data into a discovery engine. This enables instant evaluation of clinical hypotheses, with applications spanning clinical trial design, synthetic control, post-market surveillance, comparative effectiveness, among others.
Towards precision health copilots
The significance of generative AI lies not in achieving incremental improvements, but in enabling entirely new possibilities in applications. LLM’s universal structuring capability allows for the scaling of RWE generation from patient data at the population level. Additionally, LLMs can serve as “universal annotators,” generating examples from unlabeled data to train high-performance student models. Furthermore, LLMs possess remarkable reasoning capabilities, functioning as “universal reasoners” and accelerating causal discovery from real-world data at the population level. These models can also fact-check their own answers, providing easily verifiable rationale to enhance their accuracy and facilitate human-in-the-loop verification and interactive learning.
Beyond textual data, there is immense growth potential for LLMs in health applications, particularly when dealing with multimodal and longitudinal patient data. Crucial patient information may reside in various information-rich modalities, such as imaging and multi-omics. We have explored pretraining large biomedical multimodal models by assembling the largest collection of public biomedical image-text pairs from biomedical research articles, comprising 15 million images and over 30 million image-text pairs. Recently, we investigated using GPT-4 to generate instruction-following data to train a multimodal conversational copilot called LLaVA-Med, enabling researchers to interact with biomedical imaging data. Additionally, we are collaborating with clinical stakeholders to train LMMs for precision immuno-oncology, utilizing multimodal fusion to combine EMRs, radiology images, digital pathology, and multi-omics in longitudinal data on cancer patients.
Our ultimate aspiration is to develop precision health copilots that empower all stakeholders in biomedicine and scale real-world evidence generation, optimizing healthcare delivery and accelerating discoveries. We envision a future where clinical research and care are seamlessly integrated, where every clinical observation instantly updates a patient’s health status, and decisions are supported by population-level patient-like-me information. Patients in need of advanced intervention are continuously evaluated for just-in-time clinical trial matching. Life sciences researchers have access to a global real-world data dashboard in real time, initiating in silico trials to generate and test counterfactual hypotheses. Payors and regulators base approval and care decisions on the most comprehensive and up-to-date clinical evidence at the finest granular level. This vision embodies the dream of evidence-based precision health. Generative AI, including large language models, will play a pivotal role in propelling us towards this exciting and transformative future.
The post Microsoft at KDD 2023: Advancing health at the speed of AI appeared first on Microsoft Research.
Build a centralized monitoring and reporting solution for Amazon SageMaker using Amazon CloudWatch
Amazon SageMaker is a fully managed machine learning (ML) platform that offers a comprehensive set of services that serve end-to-end ML workloads. As recommended by AWS as a best practice, customers have used separate accounts to simplify policy management for users and isolate resources by workloads and account. However, when more users and teams are using the ML platform in the cloud, monitoring the large ML workloads in a scaling multi-account environment becomes more challenging. For better observability, customers are looking for solutions to monitor the cross-account resource usage and track activities, such as job launch and running status, which is essential for their ML governance and management requirements.
SageMaker services, such as Processing, Training, and Hosting, collect metrics and logs from the running instances and push them to users’ Amazon CloudWatch accounts. To view the details of these jobs in different accounts, you need to log in to each account, find the corresponding jobs, and look into the status. There is no single pane of glass that can easily show this cross-account and multi-job information. Furthermore, the cloud admin team needs to provide individuals access to different SageMaker workload accounts, which adds additional management overhead for the cloud platform team.
In this post, we present a cross-account observability dashboard that provides a centralized view for monitoring SageMaker user activities and resources across multiple accounts. It allows the end-users and cloud management team to efficiently monitor what ML workloads are running, view the status of these workloads, and trace back different account activities at certain points of time. With this dashboard, you don’t need to navigate from the SageMaker console and click into each job to find the details of the job logs. Instead, you can easily view the running jobs and job status, troubleshoot job issues, and set up alerts when issues are identified in shared accounts, such as job failure, underutilized resources, and more. You can also control access to this centralized monitoring dashboard or share the dashboard with relevant authorities for auditing and management requirements.
Overview of solution
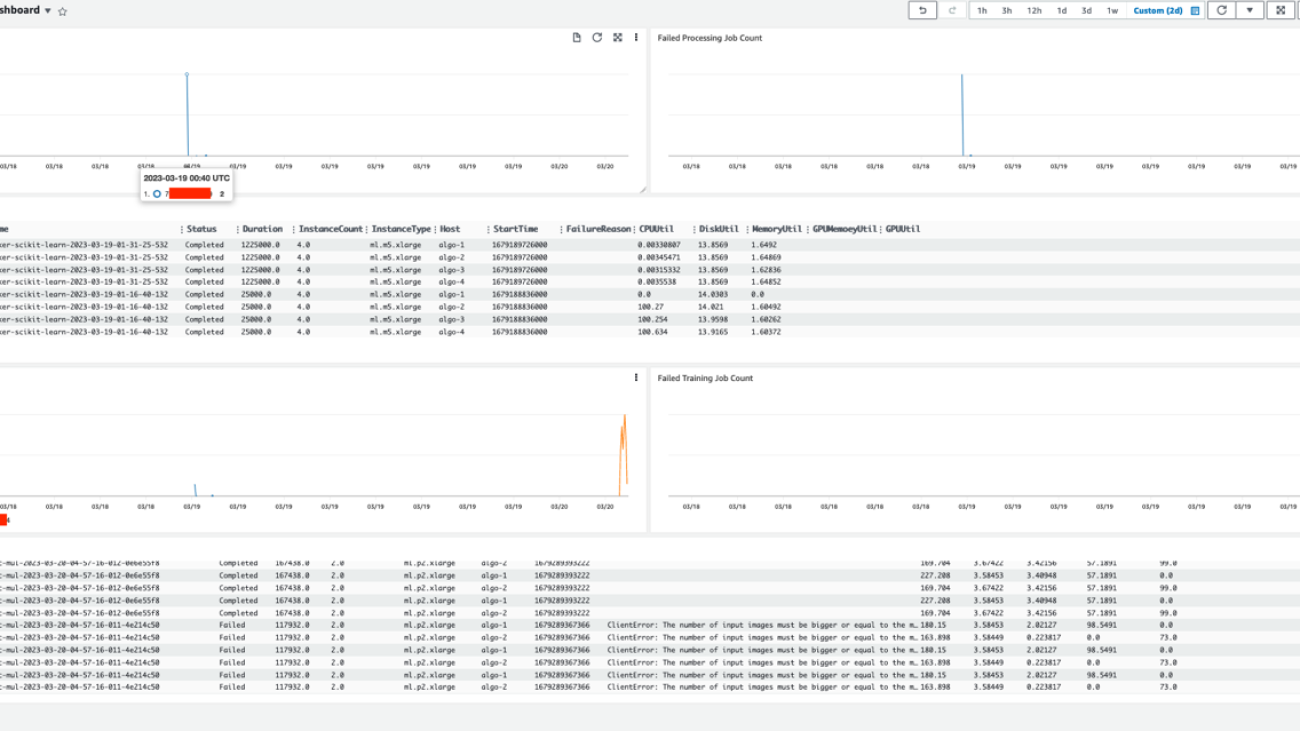
This solution is designed to enable centralized monitoring of SageMaker jobs and activities across a multi-account environment. The solution is designed to have no dependency on AWS Organizations, but can be adopted easily in an Organizations or AWS Control Tower environment. This solution can help the operation team have a high-level view of all SageMaker workloads spread across multiple workload accounts from a single pane of glass. It also has an option to enable CloudWatch cross-account observability across SageMaker workload accounts to provide access to monitoring telemetries such as metrics, logs, and traces from the centralized monitoring account. An example dashboard is shown in the following screenshot.

The following diagram shows the architecture of this centralized dashboard solution.

SageMaker has native integration with the Amazon EventBridge, which monitors status change events in SageMaker. EventBridge enables you to automate SageMaker and respond automatically to events such as a training job status change or endpoint status change. Events from SageMaker are delivered to EventBridge in near-real time. For more information about SageMaker events monitored by EventBridge, refer to Automating Amazon SageMaker with Amazon EventBridge. In addition to the SageMaker native events, AWS CloudTrail publishes events when you make API calls, which also streams to EventBridge so that this can be utilized by many downstream automation or monitoring use cases. In our solution, we use EventBridge rules in the workload accounts to stream SageMaker service events and API events to the monitoring account’s event bus for centralized monitoring.
In the centralized monitoring account, the events are captured by an EventBridge rule and further processed into different targets:
- A CloudWatch log group, to use for the following:
- Auditing and archive purposes. For more information, refer to the Amazon CloudWatch Logs User Guide.
- Analyzing log data with CloudWatch Log Insights queries. CloudWatch Logs Insights enables you to interactively search and analyze your log data in CloudWatch Logs. You can perform queries to help you more efficiently and effectively respond to operational issues. If an issue occurs, you can use CloudWatch Logs Insights to identify potential causes and validate deployed fixes.
- Support for the CloudWatch Metrics Insights query widget for high-level operations in the CloudWatch dashboard, adding CloudWatch Insights Query to dashboards, and exporting query results.
- An AWS Lambda function to complete the following tasks:
- Perform custom logic to augment SageMaker service events. One example is performing a metric query on the SageMaker job host’s utilization metrics when a job completion event is received.
- Convert event information into metrics in certain log formats as ingested as EMF logs. For more information, refer to Embedding metrics within logs.
The example in this post is supported by the native CloudWatch cross-account observability feature to achieve cross-account metrics, logs, and trace access. As shown at the bottom of the architecture diagram, it integrates with this feature to enable cross-account metrics and logs. To enable this, necessary permissions and resources need to be created in both the monitoring accounts and source workload accounts.
You can use this solution for either AWS accounts managed by Organizations or standalone accounts. The following sections explain the steps for each scenario. Note that within each scenario, steps are performed in different AWS accounts. For your convenience, the account type to perform the step is highlighted at the beginning each step.
Prerequisites
Before starting this procedure, clone our source code from the GitHub repo in your local environment or AWS Cloud9. Additionally, you need the following:
- Node.js 14.15.0 (or later) and nmp installed
- The AWS Command Line Interface (AWS CLI) version 2 installed
- The AWS CDK Toolkit
- Docker Engine installed (in running state when performing the deployment procedures)

Deploy the solution in an Organizations environment
If the monitoring account and all SageMaker workload accounts are all in the same organization, the required infrastructure in the source workload accounts is created automatically via an AWS CloudFormation StackSet from the organization’s management account. Therefore, no manual infrastructure deployment into the source workload accounts is required. When a new account is created or an existing account is moved into a target organizational unit (OU), the source workload infrastructure stack will be automatically deployed and included in the scope of centralized monitoring.
Set up monitoring account resources
We need to collect the following AWS account information to set up the monitoring account resources, which we use as the inputs for the setup script later on.
| Input | Description | Example |
| Home Region | The Region where the workloads run. | ap-southeast-2 |
| Monitoring account AWS CLI profile name | You can find the profile name from ~/.aws/config. This is optional. If not provided, it uses the default AWS credentials from the chain. |
. |
| SageMaker workload OU path | The OU path that has the SageMaker workload accounts. Keep the / at the end of the path. |
o-1a2b3c4d5e/r-saaa/ou-saaa-1a2b3c4d/ |
To retrieve the OU path, you can go to the Organizations console, and under AWS accounts, find the information to construct the OU path. For the following example, the corresponding OU path is o-ye3wn3kyh6/r-taql/ou-taql-wu7296by/.

After you retrieve this information, run the following command to deploy the required resources on the monitoring account:
You can get the following outputs from the deployment. Keep a note of the outputs to use in the next step when deploying the management account stack.

Set up management account resources
We need to collect the following AWS account information to set up the management account resources, which we use as the inputs for the setup script later on.
| Input | Description | Example |
| Home Region | The Region where the workloads run. This should be the same as the monitoring stack. | ap-southeast-2 |
| Management account AWS CLI profile name | You can find the profile name from ~/.aws/config. This is optional. If not provided, it uses the default AWS credentials from the chain. |
. |
| SageMaker workload OU ID | Here we use just the OU ID, not the path. | ou-saaa-1a2b3c4d |
| Monitoring account ID | The account ID where the monitoring stack is deployed to. | . |
| Monitoring account role name | The output for MonitoringAccountRoleName from the previous step. |
. |
| Monitoring account event bus ARN | The output for MonitoringAccountEventbusARN from the previous step. |
. |
| Monitoring account sink identifier | The output from MonitoringAccountSinkIdentifier from the previous step. |
. |
You can deploy the management account resources by running the following command:
Deploy the solution in a non-Organizations environment
If your environment doesn’t use Organizations, the monitoring account infrastructure stack is deployed in a similar manner but with a few changes. However, the workload infrastructure stack needs to be deployed manually into each workload account. Therefore, this method is suitable for an environment with a limited number of accounts. For a large environment, it’s recommended to consider using Organizations.
Set up monitoring account resources
We need to collect the following AWS account information to set up the monitoring account resources, which we use as the inputs for the setup script later on.
| Input | Description | Example |
| Home Region | The Region where the workloads run. | ap-southeast-2 |
| SageMaker workload account list | A list of accounts that run the SageMaker workload and stream events to the monitoring account, separated by commas. | 111111111111,222222222222 |
| Monitoring account AWS CLI profile name | You can find the profile name from ~/.aws/config. This is optional. If not provided, it uses the default AWS credentials from the chain. |
. |
We can deploy the monitoring account resources by running the following command after you collect the necessary information:
We get the following outputs when the deployment is complete. Keep a note of the outputs to use in the next step when deploying the management account stack.
Set up workload account monitoring infrastructure
We need to collect the following AWS account information to set up the workload account monitoring infrastructure, which we use as the inputs for the setup script later on.
| Input | Description | Example |
| Home Region | The Region where the workloads run. This should be the same as the monitoring stack. | ap-southeast-2 |
| Monitoring account ID | The account ID where the monitoring stack is deployed to. | . |
| Monitoring account role name | The output for MonitoringAccountRoleName from the previous step. |
. |
| Monitoring account event bus ARN | The output for MonitoringAccountEventbusARN from the previous step. |
. |
| Monitoring account sink identifier | The output from MonitoringAccountSinkIdentifier from the previous step. |
. |
| Workload account AWS CLI profile name | You can find the profile name from ~/.aws/config. This is optional. If not provided, it uses the default AWS credentials from the chain. |
. |
We can deploy the monitoring account resources by running the following command:
Visualize ML tasks on the CloudWatch dashboard
To check if the solution works, we need to run multiple SageMaker processing jobs and SageMaker training jobs on the workload accounts that we used in the previous sections. The CloudWatch dashboard is customizable based on your own scenarios. Our sample dashboard consists of widgets for visualizing SageMaker Processing jobs and SageMaker Training jobs. All jobs for monitoring workload accounts are displayed in this dashboard. In each type of job, we show three widgets, which are the total number of jobs, the number of failing jobs, and the details of each job. In our example, we have two workload accounts. Through this dashboard, we can easily find that one workload account has both processing jobs and training jobs, and another workload account only has training jobs. As with the functions we use in CloudWatch, we can set the refresh interval, specify the graph type, and zoom in or out, or we can run actions such as download logs in a CSV file.
Customize your dashboard
The solution provided in the GitHub repo includes both SageMaker Training job and SageMaker Processing job monitoring. If you want to add more dashboards to monitor other SageMaker jobs, such as batch transform jobs, you can follow the instructions in this section to customize your dashboard. By modifying the index.py file, you can customize the fields what you want to display on the dashboard. You can access all details that are captured by CloudWatch through EventBridge. In the Lambda function, you can choose the necessary fields that you want to display on the dashboard. See the following code:
To customize the dashboard or widgets, you can modify the source code in the monitoring-account-infra-stack.ts file. Note that the field names you use in this file should be the same as those (the keys of job_detail) defined in the Lambda file:
After you modify the dashboard, you need to redeploy this solution from scratch. You can run the Jupyter notebook provided in the GitHub repo to rerun the SageMaker pipeline, which will launch the SageMaker Processing jobs again. When the jobs are finished, you can go to the CloudWatch console, and under Dashboards in the navigation pane, choose Custom Dashboards. You can find the dashboard named SageMaker-Monitoring-Dashboard.
Clean up
If you no longer need this custom dashboard, you can clean up the resources. To delete all the resources created, use the code in this section. The cleanup is slightly different for an Organizations environment vs. a non-Organizations environment.
For an Organizations environment, use the following code:
For a non-Organizations environment, use the following code:
Alternatively, you can log in to the monitoring account, workload account, and management account to delete the stacks from the CloudFormation console.
Conclusion
In this post, we discussed the implementation of a centralized monitoring and reporting solution for SageMaker using CloudWatch. By following the step-by-step instructions outlined in this post, you can create a multi-account monitoring dashboard that displays key metrics and consolidates logs related to their various SageMaker jobs from different accounts in real time. With this centralized monitoring dashboard, you can have better visibility into the activities of SageMaker jobs across multiple accounts, troubleshoot issues more quickly, and make informed decisions based on real-time data. Overall, the implementation of a centralized monitoring and reporting solution using CloudWatch offers an efficient way for organizations to manage their cloud-based ML infrastructure and resource utilization.
Please try out the solution and send us the feedback, either in the AWS forum for Amazon SageMaker, or through your usual AWS contacts.
To learn more about the cross-account observability feature, please refer to the blog Amazon CloudWatch Cross-Account Observability
About the Authors
 Jie Dong is an AWS Cloud Architect based in Sydney, Australia. Jie is passionate about automation, and loves to develop solutions to help customer improve productivity. Event-driven system and serverless framework are his expertise. In his own time, Jie loves to work on building smart home and explore new smart home gadgets.
Jie Dong is an AWS Cloud Architect based in Sydney, Australia. Jie is passionate about automation, and loves to develop solutions to help customer improve productivity. Event-driven system and serverless framework are his expertise. In his own time, Jie loves to work on building smart home and explore new smart home gadgets.
 Melanie Li, PhD, is a Senior AI/ML Specialist TAM at AWS based in Sydney, Australia. She helps enterprise customers build solutions using state-of-the-art AI/ML tools on AWS and provides guidance on architecting and implementing ML solutions with best practices. In her spare time, she loves to explore nature and spend time with family and friends.
Melanie Li, PhD, is a Senior AI/ML Specialist TAM at AWS based in Sydney, Australia. She helps enterprise customers build solutions using state-of-the-art AI/ML tools on AWS and provides guidance on architecting and implementing ML solutions with best practices. In her spare time, she loves to explore nature and spend time with family and friends.
 Gordon Wang, is a Senior AI/ML Specialist TAM at AWS. He supports strategic customers with AI/ML best practices cross many industries. He is passionate about computer vision, NLP, Generative AI and MLOps. In his spare time, he loves running and hiking.
Gordon Wang, is a Senior AI/ML Specialist TAM at AWS. He supports strategic customers with AI/ML best practices cross many industries. He is passionate about computer vision, NLP, Generative AI and MLOps. In his spare time, he loves running and hiking.

Challenge Accepted: GeForce NOW Fires Up the Cloud With Ultimate Challenge and First Bethesda Games
Rise and shine, it’s time to quake up — the GeForce NOW Ultimate KovaaK’s challenge kicks off at the QuakeCon gaming festival today, giving gamers everywhere the chance to play to their ultimate potential with ultra-high 240 frames per second streaming. On top of bragging rights, top scorers can win some sweet prizes — including a 240Hz gaming monitor.
Bethesda’s award-winning titles Doom Eternal, Quake, Wolfenstein: The New Order, Wolfenstein II: The New Colossus and Wolfenstein: Youngblood heat up the cloud this week, leading 21 new games joining the GeForce NOW library.
Plus, Baldur’s Gate 3 has been a hit with members. Make sure to upgrade to Ultimate and Priority memberships today to skip the waiting lines over free members and get into gaming faster.
Ultimate Power, Ultimate Wins
Warning: The GeForce NOW Ultimate membership is so good that gamers can no longer blame their hardware for losses.
To celebrate the completion of the Ultimate upgrade, GeForce NOW is giving everyone a chance to experience the full power of an Ultimate membership and 240 fps cloud gaming with its Ultimate KovaaK’s challenge. See how streaming from a GeForce RTX 4080 gaming rig completely changes the game.
GeForce NOW has teamed with popular aim trainer KovaaK’s to create a custom demo on the GeForce NOW app for PC and macOS. Free and Priority members can stream the demo, then get a free one-day upgrade to 240 fps gaming with GeForce NOW Ultimate to instantly experience a major performance improvement. Members will receive an email once their free one-day upgrade is available, and should make sure their device settings are optimized for the challenge.
Gamers can replay the demo unlimited times on Ultimate during the one-day upgrade and aim for the top score against other GeForce NOW members on the challenge leaderboard. QuakeCon attendees and those playing from home can compete for prizes through Thursday, Sept. 21. Keep an eye out on Twitter and Facebook for more details.
Ultimate members who’ve already been enjoying ultra-high 240 fps cloud gaming can also join in on the fun — just try to show the newcomers a little mercy on the leaderboard.
The Cloud Just Got Hotter
After warming up with the Ultimate Challenge, bring the heat over to Bethesda’s highly acclaimed first-person shooter games.

Hell’s armies have invaded Earth once again in Doom Eternal, the latest entry in the legendary Doom franchise. Traverse various dimensions to stop the demonic invasion and save humanity. Raze enemies in the single-player campaign, or grab some buddies for “Battlemode” and face off against their demons as a fully armed, upgraded Doom Slayer in a best-of-five match. Each demon has unique abilities, while the Slayer can use its arsenal and power-ups to take the enemies down.

Grab the gaming classic Quake to step into the shoes of Ranger, a warrior armed with a powerful arsenal of weapons. Fight corrupted knights, deformed ogres and an army of twisted creatures. Brave it alone or with a squad of up to four players in an online co-op mode.

Take the fight over to the Wolfenstein franchise and battle against high-tech Nazi legions in a twisted version of history with Wolfenstein: The New Order, Wolfenstein II: The New Colossus and Wolfenstein: Youngblood joining the cloud. Experience popular character B.J. Blazkowicz’s story in New Order and The New Colossus, then play as his twin daughters in Youngblood. Members can also experience Wolfenstein: Youngblood with RTX ON for real-time cinematic lighting.
Those returning to the series or experiencing them for the first time can stream at up to 240 fps with a GeForce NOW Ultimate membership, which offers peak performance that’s helpful whether facing off against demons, war machines or other players around the world.
Bring on the New
The newest season of Apex Legends, the popular, free-to-play, battle-royale first-person shooter game, is now available to stream. Apex Legends: Resurrection brings a new look and deadly new abilities for offense-focused character Revenant. Plus, members can battle on new stages for Mixtape on Broken Moon. Or, gamers can put their skills to the test in a new Ranked season and terrorize foes from the Resurrection Battle Pass.
Members can look forward to the 21 new games joining this week:
- I Am Future (New release on Steam, Aug. 8)
- Atlas Fallen (New release on Steam, Aug. 10)
- Orwell: Keeping an Eye on You (Free game on Epic Games Store, Aug. 10)
- Sengoku Dynasty (New release on Steam, Aug. 10)
- Tales & Tactics (New release on Steam, Aug. 10)
- Aliens: Dark Descent (Epic Games Store)
- Doom Eternal (Steam)
- LEGO Brawls (Epic Games Store)
- Quake (Steam and Epic Games Store)
- Session Skate Sim (Epic Games Store)
- Smalland: Survive the Wilds (Epic Games Store)
- Superhot (Epic Games Store)
- Terra Invicta (Epic Games Store)
- Ultimate KovaaK’s Challenge
- Wall World (Steam)
- Wild West Dynasty (Epic Games Store)
- Wolfenstein: The New Order (Steam and Epic Games Store)
- Wolfenstein: Youngblood (Steam)
- Wolfenstein II: The New Colossus (Steam)
- WRECKFEST (Epic Games Store)
- Xenonauts 2 (Epic Games Store)
This week’s Game On giveaway with SteelSeries includes RuneScape and three-day Priority membership codes. Check the giveaway page for details on how to enter.
And we’ve got a question before the weekend starts. Let us know how you do with the Ultimate KovvaK’s challenge on Twitter or in the comments below.
Who’s up for a challenge?
—
NVIDIA GeForce NOW (@NVIDIAGFN) August 9, 2023


Strength in Numbers: NVIDIA and Generative Red Team Challenge Unleash Thousands to Vet Security at DEF CON
Thousands of hackers will tweak, twist and probe the latest generative AI platforms this week in Las Vegas as part of an effort to build more trustworthy and inclusive AI.
Collaborating with the hacker community to establish best practices for testing next-generation AI, NVIDIA is participating in a first-of-its-kind test of industry-leading LLM solutions, including NVIDIA NeMo and NeMo Guardrails.
The Generative Red Team Challenge, hosted by AI Village, SeedAI, and Humane Intelligence, will be among a series of workshops, training sessions and appearances by NVIDIA leaders at the Black Hat and DEF CON security conferences in Las Vegas.
The challenge — which gives hackers a number of vulnerabilities to exploit — promises to be the first of many opportunities to reality-check emerging AI technologies.
“AI empowers individuals to create and build previously impossible things,” said Austin Carson, founder of SeedAI and co-organizer of the Generative Red Team Challenge. “But without a large, diverse community to test and evaluate the technology, AI will just mirror its creators, leaving big portions of society behind.”
The collaboration with the hacker community comes amid a concerted push for AI safety making headlines across the world, with the Biden-Harris administration securing voluntary commitment from the leading AI companies working on cutting-edge generative models.
“AI Village draws the community concerned about the implications of AI systems – both malicious use and impact on society,” said Sven Cattell founder of AI Village and co-organizer of the Generative Red Team Challenge. “At DEFCON 29, we hosted the first Algorithmic Bias Bounty with Rumman Chowdhury’s former team at Twitter. This marked the first time a company had allowed public access to their model for scrutiny.”
This week’s challenge is a key step in the evolution of AI, thanks to the leading role played by the hacker community — with its ethos of skepticism, independence and transparency — in creating and field testing emerging security standards.
NVIDIA’s technologies are fundamental to AI, and NVIDIA was there at the beginning of the generative AI revolution. In 2016, NVIDIA founder and CEO Jensen Huang hand-delivered to OpenAI the first NVIDIA DGX AI supercomputer — the engine behind the large language model breakthrough powering ChatGPT.
NVIDIA DGX systems, originally used as an AI research instrument, are now running 24/7 at businesses across the world to refine data and process AI.
Management consultancy McKinsey estimates generative AI could add the equivalent of $2.6 trillion to $4.4 trillion annually to the global economy across 63 use cases.
This makes safety — and trust — an industry-wide concern.
That’s why NVIDIA employees are engaging with attendees at both last week’s Black Hat conference for security professionals and this week’s DEF CON gathering.
At Black Hat, NVIDIA hosted a two-day training session on using machine learning and a briefing on the risks of poisoning web-scale training datasets. It also participated in a panel discussion on the potential benefits of AI for security.
At DEF CON, NVIDIA is sponsoring a talk on the risks of breaking into baseboard management controllers. These specialized service processors monitor the physical state of a computer, network server or other hardware devices.
And through the Generative Red Team Challenge, part of the AI Village Prompt Detective workshop, thousands of DEF CON participants will be able to demonstrate prompt injection, attempt to elicit unethical behaviors and test other techniques to obtain inappropriate responses.
Models built by Anthropic, Cohere, Google, Hugging Face, Meta, NVIDIA, OpenAI and Stability, with participation from Microsoft, will be tested on an evaluation platform developed by Scale AI.
As a result, everyone gets smarter.
“We’re fostering the exchange of ideas and information while simultaneously addressing risks and opportunities,” said Rumman Chowdhury, a member of AI Village’s leadership team and co-founder of Humane Intelligence, the nonprofit designing the challenges. “The hacker community is exposed to different ideas, and community partners gain new skills that position them for the future.”
Released in April as open-source software, NeMo Guardrails can help developers guide generative AI applications to create impressive text responses that can stay on track — ensuring intelligent, LLM-powered applications are accurate, appropriate, on topic and secure.
To ensure transparency and the ability to put the technology to work across many environments, NeMo Guardrails — the product of several years of research — is open source, with much of the NeMo conversational AI framework already available as open-source code on GitHub, contributing to the developer community’s tremendous energy and work on AI safety.
Engaging with the DEF CON community builds on this, enabling NVIDIA to share what it has learned with NeMo Guardrails and to, in turn, learn from the community.
Organizers of the event — which include SeedAI, Humane Intelligence and AI Village — plan to analyze the data and publish their findings, including processes and learnings, to help other organizations conduct similar exercises.
Last week, organizers also issued a call for research proposals and received several proposals from leading researchers within the first 24 hours.
“Since this is the first instance of a live hacking event of a generative AI system at scale, we will be learning together,” Chowdhury said. “The ability to replicate this exercise and put AI testing into the hands of thousands is key to its success.”
The Generative Red Team Challenge will take place in the AI Village at DEF CON 31 from Aug. 10-13, at Caesar’s Forum in Las Vegas.
Intel Joins the PyTorch Foundation as a Premier Member
![]()
The PyTorch Foundation, a neutral home for the deep learning community to collaborate on the open source PyTorch framework and ecosystem, is announcing today that Intel has joined as a premier member.
“The PyTorch Foundation is thrilled to welcome Intel as a premier member, marking a significant milestone in our mission to empower the global AI community. Intel’s extensive expertise and commitment to advancing cutting-edge technologies align perfectly with our vision of fostering open-source innovation,” said PyTorch Foundation Executive Director Ibrahim Haddad. “Together, we will accelerate the development and democratization of PyTorch, and use the collaboration to shape a vibrant future of AI for all.”
Intel has developed and released several PyTorch-based tools and libraries to enable developers to accelerate their AI workflows, and is actively working on optimizing PyTorch to leverage Intel hardware capabilities.
“At Intel, we believe in the power of collaboration and open-source innovation to propel the ecosystem towards an AI Everywhere future. Joining the Governing Board of the PyTorch Foundation is a testament to Intel’s commitment to advancing and democratizing AI,” said Wei Li, Vice President and General Manager of Artificial Intelligence and Analytics (AIA) at Intel. “By harnessing the collective expertise and resources within the deep learning community, we aim to accelerate the development of PyTorch and continue to drive breakthroughs in AI research and applications.”
Intel fosters industry collaboration, co-engineering, and open source contributions to accelerate software innovation and develop new technologies that bring benefits to the open source community. By working together with other member companies and under the guidance of the PyTorch Foundation, Intel remains committed to actively contributing to and advocating for the community.
As a premier member, Intel is granted one seat to the PyTorch Foundation Governing Board. The Board sets policy through our bylaws, mission and vision statements, describing the overarching scope of foundation initiatives, technical vision, and direction.

We’re happy to welcome Wei Li, Vice President and General Manager of Artificial Intelligence and Analytics (AIA) at Intel, to our board. Dr. Wei Li is Vice President and General Manager of Artificial Intelligence and Analytics (AIA) at Intel, where he leads a world-wide team of engineering “magicians” who make AI Everywhere a reality by supercharging machine performance and developer productivity. Wei and his team have been instrumental in Intel’s recent multi-billion-dollar AI revenue growth by delivering 10-100X software acceleration, across deep learning, statistical machine learning and big data analytics, to complement Intel’s AI-optimized hardware portfolio.
To learn more about how you can be a part of the PyTorch Foundation, visit our website.
Read more about Intel’s commitment to the PyTorch Community here.
About Intel
Intel (Nasdaq: INTC) is an industry leader, creating world-changing technology that enables global progress and enriches lives. Inspired by Moore’s Law, we continuously work to advance the design and manufacturing of semiconductors to help address our customers’ greatest challenges. By embedding intelligence in the cloud, network, edge and every kind of computing device, we unleash the potential of data to transform business and society for the better. To learn more about Intel’s innovations, go to newsroom.intel.com and intel.com.
© Intel Corporation. Intel, the Intel logo and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
About PyTorch Foundation
The PyTorch Foundation is a neutral home for the deep learning community to collaborate on the open source PyTorch framework and ecosystem. The PyTorch Foundation is supported by its members and leading contributors to the PyTorch open source project. The Foundation leverages resources provided by members and contributors to enable community discussions and collaboration.
About The Linux Foundation
The Linux Foundation is the world’s leading home for collaboration on open source software, hardware, standards, and data. Linux Foundation projects are critical to the world’s infrastructure including Linux, Kubernetes, Node.js, ONAP, PyTorch, RISC-V, SPDX, OpenChain, and more. The Linux Foundation focuses on leveraging best practices and addressing the needs of contributors, users, and solution providers to create sustainable models for open collaboration. For more information, please visit us at linuxfoundation.org. The Linux Foundation has registered trademarks and uses trademarks. For a list of trademarks of The Linux Foundation, please see its trademark usage page. Linux is a registered trademark of Linus Torvalds.

Visual Effects Multiplier: Wylie Co. Goes All in on GPU Rendering for 24x Returns
Visual effects studios have long relied on render farms — vast numbers of servers — for computationally intensive, complex special effects, but that landscape is rapidly changing.
High silicon and energy costs at these server facilities, which can be restricted in performance gains by Moore’s law, cut into studio profits and increase production time.
To avoid those challenges, Wylie Co. — the visual effects studio behind Oscar-winning Dune, Marvel titles, HBO and Netflix work — is going all in on GPU rendering.
It’s estimated that rendering photoreal visual effects and stylized animations consumes nearly 10 billion CPU core hours a year. To render a single animated feature film, render farms can involve more than 50,000 CPU cores working for more than 300 million CPU core hours. These resources can create a substantial carbon effect and physical footprint.
While many studios already use GPUs for one leg of the rendering process, Wylie Co. is now using it for about everything, including final renders as well as for AI used in wire removals and many other aspects of compositing and visual effects workflows.
Move to GPUs Boosts Performance 24X
Render farms allow visual effects studios to offload large files of images, scenes or entire feature films, freeing up studio resources while these jobs may take hours or weeks to finish.
Many studios are moving to multi-GPU workstations that can handle some of the tasks that were previously sent to render farms. This enables studios to iterate faster as well as compress production time and costs.
Wylie Co. migrated to GPUs across a number of areas, realizing overall a 24x performance leap compared with CPUs1.
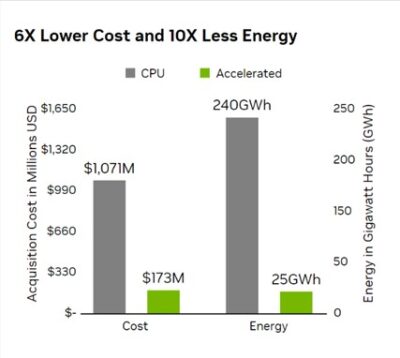
GPUs Deliver 10X Lower Energy Usage
While studios would like to reduce their costs from these compute-heavy rendering tasks, the reality is that the decreased energy and space costs also bring a lower carbon footprint benefit.
GPUs used in visual effects rendering pipelines can increase performance by as much as 46x2 while reducing energy consumption by 5x and capital expenses by 6x.
By switching to GPUs, the industry stands to save $900 million in acquisition costs worldwide and 215 gigawatt hours in energy consumed compared with using CPU-based render farms.
Learn about NVIDIA energy-efficiency solutions for digital rendering
1 25X performance for an NVIDIA Quadro RTXTM 8000 (4x GPUs per node) vs. Intel Xeon Gold 6126 processor (2x 12-core CPUs per node).
2 46X performance for NVIDIA RTX 6000 Ada generation (8x GPUs per node) vs. Intel Xeon Gold 6430 (2x 32-core CPUs per node). Performance and energy findings based on internal and industry benchmarks.

Advances in document understanding

The last few years have seen rapid progress in systems that can automatically process complex business documents and turn them into structured objects. A system that can automatically extract data from documents, e.g., receipts, insurance quotes, and financial statements, has the potential to dramatically improve the efficiency of business workflows by avoiding error-prone, manual work. Recent models, based on the Transformer architecture, have shown impressive gains in accuracy. Larger models, such as PaLM 2, are also being leveraged to further streamline these business workflows. However, the datasets used in academic literature fail to capture the challenges seen in real-world use cases. Consequently, academic benchmarks report strong model accuracy, but these same models do poorly when used for complex real-world applications.
In “VRDU: A Benchmark for Visually-rich Document Understanding”, presented at KDD 2023, we announce the release of the new Visually Rich Document Understanding (VRDU) dataset that aims to bridge this gap and help researchers better track progress on document understanding tasks. We list five requirements for a good document understanding benchmark, based on the kinds of real-world documents for which document understanding models are frequently used. Then, we describe how most datasets currently used by the research community fail to meet one or more of these requirements, while VRDU meets all of them. We are excited to announce the public release of the VRDU dataset and evaluation code under a Creative Commons license.
Benchmark requirements
First, we compared state-of-the-art model accuracy (e.g., with FormNet and LayoutLMv2) on real-world use cases to academic benchmarks (e.g., FUNSD, CORD, SROIE). We observed that state-of-the-art models did not match academic benchmark results and delivered much lower accuracy in the real world. Next, we compared typical datasets for which document understanding models are frequently used with academic benchmarks and identified five dataset requirements that allow a dataset to better capture the complexity of real-world applications:
- Rich Schema: In practice, we see a wide variety of rich schemas for structured extraction. Entities have different data types (numeric, strings, dates, etc.) that may be required, optional, or repeated in a single document or may even be nested. Extraction tasks over simple flat schemas like (header, question, answer) do not reflect typical problems encountered in practice.
- Layout-Rich Documents: The documents should have complex layout elements. Challenges in practical settings come from the fact that documents may contain tables, key-value pairs, switch between single-column and double-column layout, have varying font-sizes for different sections, include pictures with captions and even footnotes. Contrast this with datasets where most documents are organized in sentences, paragraphs, and chapters with section headers — the kinds of documents that are typically the focus of classic natural language processing literature on long inputs.
- Diverse Templates: A benchmark should include different structural layouts or templates. It is trivial for a high-capacity model to extract from a particular template by memorizing the structure. However, in practice, one needs to be able to generalize to new templates/layouts, an ability that the train-test split in a benchmark should measure.
- High-Quality OCR: Documents should have high-quality Optical Character Recognition (OCR) results. Our aim with this benchmark is to focus on the VRDU task itself and to exclude the variability brought on by the choice of OCR engine.
- Token-Level Annotation: Documents should contain ground-truth annotations that can be mapped back to corresponding input text, so that each token can be annotated as part of the corresponding entity. This is in contrast with simply providing the text of the value to be extracted for the entity. This is key to generating clean training data where we do not have to worry about incidental matches to the given value. For instance, in some receipts, the ‘total-before-tax’ field may have the same value as the ‘total’ field if the tax amount is zero. Having token level annotations prevents us from generating training data where both instances of the matching value are marked as ground-truth for the ‘total’ field, thus producing noisy examples.
 |
VRDU datasets and tasks
The VRDU dataset is a combination of two publicly available datasets, Registration Forms and Ad-Buy forms. These datasets provide examples that are representative of real-world use cases, and satisfy the five benchmark requirements described above.
The Ad-buy Forms dataset consists of 641 documents with political advertisement details. Each document is either an invoice or receipt signed by a TV station and a campaign group. The documents use tables, multi-columns, and key-value pairs to record the advertisement information, such as the product name, broadcast dates, total price, and release date and time.
The Registration Forms dataset consists of 1,915 documents with information about foreign agents registering with the US government. Each document records essential information about foreign agents involved in activities that require public disclosure. Contents include the name of the registrant, the address of related bureaus, the purpose of activities, and other details.
We gathered a random sample of documents from the public Federal Communications Commission (FCC) and Foreign Agents Registration Act (FARA) sites, and converted the images to text using Google Cloud’s OCR. We discarded a small number of documents that were several pages long and the processing did not complete in under two minutes. This also allowed us to avoid sending very long documents for manual annotation — a task that can take over an hour for a single document. Then, we defined the schema and corresponding labeling instructions for a team of annotators experienced with document-labeling tasks.
The annotators were also provided with a few sample labeled documents that we labeled ourselves. The task required annotators to examine each document, draw a bounding box around every occurrence of an entity from the schema for each document, and associate that bounding box with the target entity. After the first round of labeling, a pool of experts were assigned to review the results. The corrected results are included in the published VRDU dataset. Please see the paper for more details on the labeling protocol and the schema for each dataset.
 |
| Existing academic benchmarks (FUNSD, CORD, SROIE, Kleister-NDA, Kleister-Charity, DeepForm) fall-short on one or more of the five requirements we identified for a good document understanding benchmark. VRDU satisfies all of them. See our paper for background on each of these datasets and a discussion on how they fail to meet one or more of the requirements. |
We built four different model training sets with 10, 50, 100, and 200 samples respectively. Then, we evaluated the VRDU datasets using three tasks (described below): (1) Single Template Learning, (2) Mixed Template Learning, and (3) Unseen Template Learning. For each of these tasks, we included 300 documents in the testing set. We evaluate models using the F1 score on the testing set.
- Single Template Learning (STL): This is the simplest scenario where the training, testing, and validation sets only contain a single template. This simple task is designed to evaluate a model’s ability to deal with a fixed template. Naturally, we expect very high F1 scores (0.90+) for this task.
- Mixed Template Learning (MTL): This task is similar to the task that most related papers use: the training, testing, and validation sets all contain documents belonging to the same set of templates. We randomly sample documents from the datasets and construct the splits to make sure the distribution of each template is not changed during sampling.
- Unseen Template Learning (UTL): This is the most challenging setting, where we evaluate if the model can generalize to unseen templates. For example, in the Registration Forms dataset, we train the model with two of the three templates and test the model with the remaining one. The documents in the training, testing, and validation sets are drawn from disjoint sets of templates. To our knowledge, previous benchmarks and datasets do not explicitly provide such a task designed to evaluate the model’s ability to generalize to templates not seen during training.
The objective is to be able to evaluate models on their data efficiency. In our paper, we compared two recent models using the STL, MTL, and UTL tasks and made three observations. First, unlike with other benchmarks, VRDU is challenging and shows that models have plenty of room for improvements. Second, we show that few-shot performance for even state-of-the-art models is surprisingly low with even the best models resulting in less than an F1 score of 0.60. Third, we show that models struggle to deal with structured repeated fields and perform particularly poorly on them.
Conclusion
We release the new Visually Rich Document Understanding (VRDU) dataset that helps researchers better track progress on document understanding tasks. We describe why VRDU better reflects practical challenges in this domain. We also present experiments showing that VRDU tasks are challenging, and recent models have substantial headroom for improvements compared to the datasets typically used in the literature with F1 scores of 0.90+ being typical. We hope the release of the VRDU dataset and evaluation code helps research teams advance the state of the art in document understanding.
Acknowledgements
Many thanks to Zilong Wang, Yichao Zhou, Wei Wei, and Chen-Yu Lee, who co-authored the paper along with Sandeep Tata. Thanks to Marc Najork, Riham Mansour and numerous partners across Google Research and the Cloud AI team for providing valuable insights. Thanks to John Guilyard for creating the animations in this post.

Generative AI Revs Up New Age in Auto Industry, From Design and Engineering to Production and Sales
Generating content and code. Creating images and videos. Testing algorithms with synthetic data.
Generative AI is a force multiplier enabling leaps in productivity and creativity for nearly every industry, particularly transportation, where it’s streamlining workflows and driving new business.
Across the entire auto industry, companies are exploring generative AI to improve vehicle design, engineering, and manufacturing, as well as marketing and sales.
Beyond the automotive product lifecycle, generative AI is also enabling new breakthroughs in autonomous vehicle (AV) development. Such research areas include the use of neural radiance field (NeRF) technology to turn recorded sensor data into fully interactive 3D simulations. These digital twin environments, as well as synthetic data generation, can be used to develop, test and validate AVs at incredible scale.
Merge Ahead: Transformative Use Cases
Generative AI, large language models and recommender systems are the digital engines of the modern economy, NVIDIA founder and CEO Jensen Huang said.
Foundational models — like ChatGPT for text generation and Stable Diffusion for image generation — can support AI systems capable of multiple tasks. This unlocks many possibilities.
Much like when early iPhone app developers began using GPS, accelerometers and other sensors to create mobile applications, AI developers now can tap foundation models to build new experiences and capabilities.

Generative AI can help tie different data streams together, not just text to text, or text to image, but also with inputs and outputs like video or 3D. Using this powerful new computing model, a text prompt could return a physically accurate layout of an assembly plant.
Toyota, one of the world’s largest automakers, has developed a generative AI technique to ensure that early design sketches incorporate engineering parameters.
Meanwhile, Mercedes-Benz has demonstrated a ChatGPT-enabled voice assistant.
Other automotive industry players are also looking to generative AI to help accelerate design iterations and provide better results.
Designer and Artist Workflows Poised to Benefit
Currently, it takes designers and artists months of preparation and design reviews to progress from early concept ideation and sketching through to the development of full scale models. This is often hampered by incompatible tools, siloed data and serial workflows.
Artists often begin the design process by looking for “scrap,” or visual references, based on trends in automotive styling. They seek inspiration for design cues, pulling from image libraries based on keywords.
The process involves looking at vehicles across the industry, whether existing or historic. Then, with a great deal of human curation, some blend of popular designs and fresh inspirations based on a company’s stylings emerge. That forms the basis for artists’ 2D hand-drawn sketches that are then recreated as 3D models and clay prototypes.
These linear and time-consuming design concept processes are utilized for exterior parts like grilles, hoods and wheels, as well as interior aspects such as dashboards, seats, ergonomics and user interfaces.
To develop these 3D models, automotive styling teams work with engineers in tools like Autodesk Alias or Maya to develop “NURBS” models, short for non-uniform rational B-splines. The resulting mathematical representations of 3D geometry capture the shapes from 2D drafts. The end deliverable is a 3D representation that’s the result of bespoke styling, design and engineering work and can be used in computer-aided design applications to define surfaces.
The automotive industry now has an opportunity to use generative AI to instantly transform 2D sketches into NURBS models for leaps in productivity. These tools will not replace designers, but enable them to explore a wide range of options faster.
Generative AI Riding Shotgun on Concept and Styling
Design-oriented enterprises can use visual datasets and generative AI to assist their work across many fronts. This has already been achieved with coding tools such as GitHub Copilot — trained on billions of lines of code — and similarly promises to help compress lengthy design timelines.
In particular, when looking for “scrap” design elements, generative AI models can be trained on an automaker’s portfolio as well as vehicles industrywide, assisting this workflow. This can happen first by fine-tuning a small dataset of images with transfer learning, and then by tapping into NVIDIA TAO Toolkit. Or it might require a more robust dataset of some 100 million images, depending on the requirements of the generative AI model.
In this bring-your-own-model setup, design teams and developers could harness NVIDIA Picasso — a cloud-based foundry for building generative AI models for visual design — with Stable Diffusion.
In this case, designers and artists prompt the generative AI for design elements, such as “rugged,” “sophisticated” or “sleek.” It then generates examples from the external world of automakers as well as from a company’s internal catalogs of images, vastly accelerating this initial phase.
For vehicle interiors, large language models for text-to-image generation can enable designers to type in a description of a texture, like a floral pattern, and the generative AI will put it onto the surface of a seat, door panel or dashboard. If a designer wants to use a particular image to generate an interior design texture, generative AI can handle image-to-image texture creation.
Smart Factories Getting Generative AI Edge
Manufacturers developing smart factories are adopting Omniverse and generative AI application programming interfaces to connect design and engineering tools to build digital twins of their facilities. BMW Group is starting the global rollout of NVIDIA Omniverse to support its vision for a factory of the future.
When building manufacturing facilities, planning in simulation before launching into production helps to reduce costly change orders that can shut down factory lines.
Generative AI Benefits Marketing and Retail Sales
Generative AI is also making inroads in marketing and retail sales departments across many industries worldwide. These teams are expected to see a productivity lift from generative AI of more than $950 billion, according to a McKinsey report.
For instance, many are adopting ChatGPT to investigate, brainstorm and get feedback on writing topics to get a jump on marketing copy and advertising campaigns. Text-to-image generative AI is helping to support visual efforts in marketing and sales.
NVIDIA NeMo is a framework to build, customize and deploy generative AI models. It’s optimized to do inference for language and image applications and used in automated speech recognition, helping improve customer support with large language models. Automakers can develop next-generation customer service chatbots using its generative AI.
London advertising giant WPP and NVIDIA are working on a groundbreaking generative AI-enabled content engine to assist the $700 billion digital advertising industry.
Today ads are retrieved, but in the future when you engage information much of it will be generated — the computing model has changed, said Huang.
This innovative system is built with NVIDIA AI and Omniverse Cloud — a software platform for developing unified 3D workflows and OpenUSD applications — and offers automotive OEMs capabilities to help create highly personalized visual content faster and more efficiently.
In Omniverse, creative teams take advantage of OpenUSD to unify their complex 3D pipelines, seamlessly connecting design tools such as Adobe Substance 3D, Alias, and VRED to develop digital twins of client products. Accessing generative AI tools will enable content creation from trained datasets and built with NVIDIA Picasso, producing virtual sets. This will give WPP clients complete scenes to generate various ads, videos and 3D experiences.
DENZA, BYD’s joint venture with Mercedes-Benz, is relying on WPP to build and deploy the first of its kind car configurators with Omniverse Cloud.
Running on Generative AI: Faster, Better, Cheaper Everywhere
Generative AI’s contextual understanding, creative output and adaptive learning capacities mark a new era.
What began with the transformer model discovery has since unleashed incredible results, supported by massive models whose training has been made possible with leaps in performance from NVIDIA accelerated computing.
While it’s still early days, and therefore hard to quantify the full implications of this shift, automakers are embracing industry-specific “copilots” for design, engineering, manufacturing, marketing and sales to achieve better, more efficient and less expensive operations.
And they’re just getting started.
See how NVIDIA AI and Omniverse are revolutionizing the automotive industry from end to end.