Digital assets are vital visual representations of products, services, culture, and brand identity for businesses in an increasingly digital world. Digital assets, together with recorded user behavior, can facilitate customer engagement by offering interactive and personalized experiences, allowing companies to connect with their target audience on a deeper level. Efficiently discovering and searching for specific content within digital assets is crucial for businesses to optimize workflows, streamline collaboration, and deliver relevant content to the right audience. According to a study, by 2021, videos already make up 81% of all consumer internet traffic. This observation comes as no surprise because video and audio are powerful mediums offering more immersive experiences and naturally engages target audiences on a higher emotional level.
As companies accumulate large volumes of digital assets, it becomes more challenging to organize and manage them effectively to maximize their value. Traditionally, companies attach metadata, such as keywords, titles, and descriptions, to these digital assets to facilitate search and retrieval of relevant content. But this requires a well-designed digital asset management system and additional efforts to store these assets in the first place. In reality, most of the digital assets lack informative metadata that enables efficient content search. Additionally, you often need to do an analysis of different segments of the whole file and discover the concepts that are covered there. This is time consuming and requires a lot of manual effort.
Generative AI, particularly in the realm of natural language processing and understanding (NLP and NLU), has revolutionized the way we comprehend and analyze text, enabling us to gain deeper insights efficiently and at scale. The advancements in large language models (LLMs) have led to richer representations of texts, which provides better search capabilities for digital assets. Retrieval Augmented Generation (RAG), built on top of LLMs and advanced prompt techniques, is a popular approach to provide more accurate answers based on information hidden in the enterprise digital asset store. By taking advantage of embedding models of LLMs, and powerful indexers and retrievers, RAG can comprehend and process spoken or written queries and quickly find the most relevant information in the knowledge base. Previous studies have shown how RAG can be applied to provide a Q&A solution connecting with an enterprise’s private domain knowledge. However, among all types of digital assets, video and audio assets are the most common and important.
The RAG-based video/audio question answering solution can potentially solve business problems of locating training and reference materials that are in the form of non-text content. With limited tags or metadata associated of these assets, the solution is trying to make users interact with the chatbot and get answers to their queries, which could be links to specific video training (“I need link to Amazon S3 data storage training”) links to documents (“I need link to learn about machine learning”), or questions that were covered in the videos (“Tell me how to create an S3 bucket”). The response from the chatbot will be able to directly answer the question and also include the links to the source videos with the specific timestamp of the contents that are most relevant to the user’s request.
In this post, we demonstrate how to use the power of RAG in building a Q&A solution for video and audio assets on Amazon SageMaker.
Solution overview
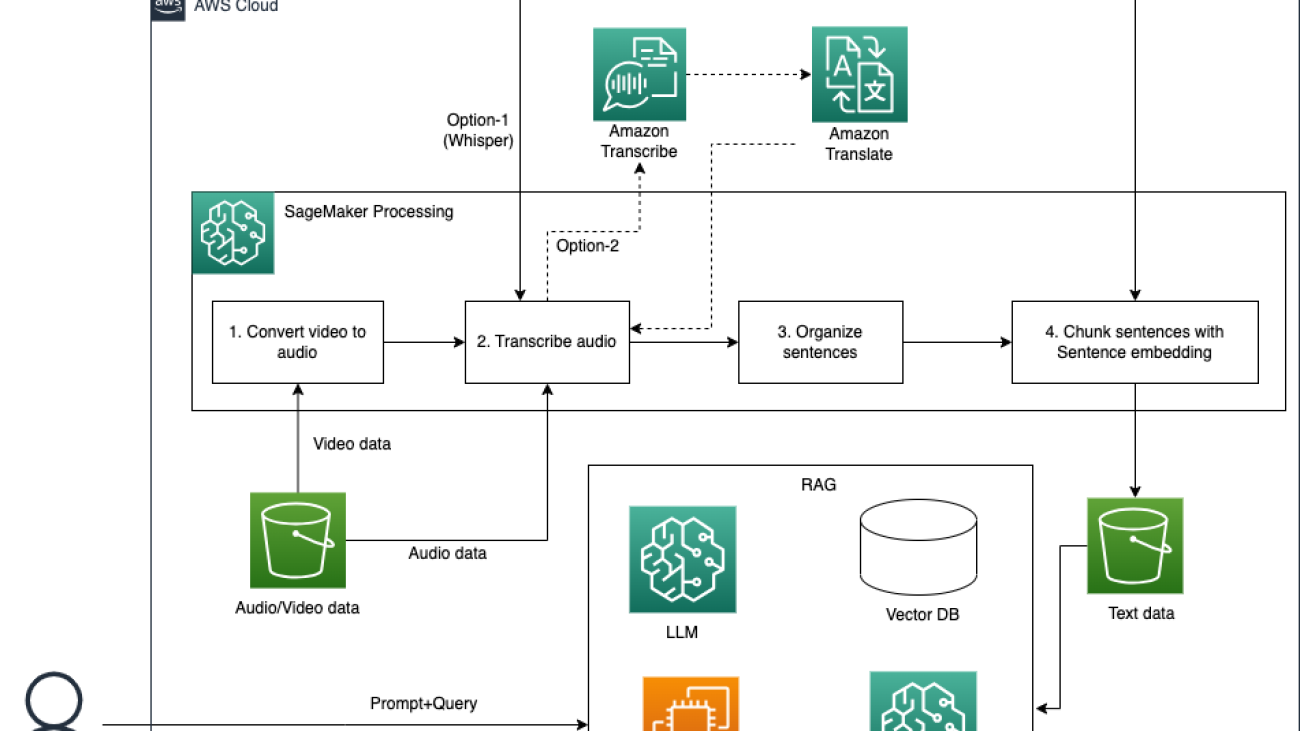
The following diagram illustrates the solution architecture.

The workflow mainly consists of the following stages:
- Convert video to text with a speech-to-text model and text alignment with videos and organization. We store the data in Amazon Simple Storage Service (Amazon S3).
- Enable intelligent video search using a RAG approach with LLMs and LangChain. Users can get answers generated by LLMs and relevant sources with timestamps.
- Build a multi-functional chatbot using LLMs with SageMaker, where the two aforementioned solutions are wrapped and deployed.
For a detailed implementation, refer to the GitHub repo.
Prerequisites
You need an AWS account with an AWS Identity and Access Management (IAM) role with permissions to manage resources created as part of the solution. For details, refer to create an AWS account.
If this is your first time working with Amazon SageMaker Studio, you first need to create a SageMaker domain. Additionally, you may need to request a service quota increase for the corresponding SageMaker processing and hosting instances. For preprocessing the video data, we use an ml.p3.2xlarge SageMaker processing instance. For hosting Falcon-40B, we use an ml.g5.12xlarge SageMaker hosting instance.
Convert video to text with a speech-to-text model and sentence embedding model
To be able to search through video or audio digital assets and provide contextual information from videos to LLMs, we need to convert all the media content to text and then follow the general approaches in NLP to process the text data. To make our solution more flexible to handle different scenarios, we provide the following options for this task:
- Amazon Transcribe and Amazon Translate – If each video and audio file only contains one language, we highly recommend that you choose Amazon Transcribe, which is an AWS managed service to transcribe audio and video files. If you need to translate them into the same language, Amazon Translate is another AWS managed service, which supports multilingual translation.
- Whisper – In real-world use cases, video data may include multiple languages, such as foreign language learning videos. Whisper is a multitasking speech recognition model that can perform multilingual speech recognition, speech translation, and language identification. You can use a Whisper model to detect and transcribe different languages on video data, and then translate all the different languages into one language. It’s important for most RAG solutions to run on the knowledge base with the same language. Even though OpenAI provides the Whisper API, for this post, we use the Whisper model from Hugging Face.
We run this task with an Amazon SageMaker Processing job on existing data. You can refer to data_preparation.ipynb for the details of how to run this task.
Convert video data to audio data
Because Amazon Transcribe can handle both video and audio data and the Whisper model can only accept audio data, to make both options work, we need to convert video data to audio data. In the following code, we use VideoFileClip from the library moviepy to run this job:
from moviepy.editor import VideoFileClip
video = VideoFileClip(video_path)
video.audio.write_audiofile(audio_path)Transcribe audio data
When the audio data is ready, we can choose from our two transcribing options. You can choose the optimal option based on your own use case with the criteria we mentioned earlier.
Option 1: Amazon Transcribe and Amazon Translate
The first option is to use Amazon AI services, such as Amazon Transcribe and Amazon Translate, to get the transcriptions of the video and audio datasets. You can refer to the following GitHub example when choosing this option.
Option 2: Whisper
A Whisper model can handle audio data up to 30 seconds in duration. To handle large audio data, we adopt transformers.pipeline to run inference with Whisper. When searching relevant video clips or generating contents with RAG, timestamps for the relevant clips are the important references. Therefore, we turn return_timestamps on to get outputs with timestamps. By setting the parameter language in generate_kwargs, all the different languages in one video file are transcribed and translated into the same language. stride_length_s is the length of stride on the left and right of each chunk. With this parameter, we can make the Whisper model see more context when doing inference on each chunk, which will lead to a more accurate result. See the following code:
from transformers import pipeline
import torch
target_language = "en"
whisper_model = "whisper-large-v2"
device = "cuda:0" if torch.cuda.is_available() else "cpu"
pipe = pipeline(
"automatic-speech-recognition",
model=f"openai/{whisper_model}",
device=device
)
generate_kwargs = {"task":"transcribe", "language":f"<|{target_language}|>"}
prediction = pipe(
file_path,
return_timestamps=True,
chunk_length_s=30,
stride_length_s=(5),
generate_kwargs=generate_kwargs
)The output of pipe is the dictionary format data with items of text and chunks. text contains the entire transcribed result, and chunks consists of chunks with the timestamp and corresponding transcribed result (see the following screenshot). We use data in chunks to do further processing.

As the preceding screenshot shows, lot of sentences have been cut off and split into different chunks. To make the chunks more meaningful, we need to combine sentences cut off and update timestamps in the next step.
Organize sentences
We use a very simple rule to combine sentences. When the chunk ends with a period (.), we don’t make any change; otherwise, we concatenate it with the next chunk. The following code snippet explains how we make this change:
prev_chunk = None
new_chunks = []
for chunk in chunks:
if prev_chunk:
chunk['text'] = prev_chunk['text'] + chunk['text']
chunk['timestamp'] = (prev_chunk['timestamp'][0], chunk['timestamp'][1])
if not chunk['text'].endswith('.'):
prev_chunk = chunk
else:
new_chunks.append(chunk)
prev_chunk = NoneCompared to the original chunks produced by the audio-to-text converts, we can get complete sentences that are cut off originally.

Chunk sentences
The text content in documents is normally organized by paragraph. Each paragraph focuses on the same topic. Chunking by paragraph may help embed texts into more meaningful vectors, which may improve retrieval accuracy.
Unlike the normal text content in documents, transcriptions from the transcription model are not paragraphed. Even though there are some stops in the audio files, sometimes it can’t be used to paragraph sentences. On the other hand, langchain provides the recursive chunking text splitter function RecursiveCharacterTextSplitter, which can keep all the semantically relevant content in the same chunk. Because we need to keep timestamps with chunks, we implement our own chunking process. Inspired by the post How to chunk text into paragraphs using python, we chunk sentences based on the similarity between the adjacent sentences with a sentence embedding approach. The basic idea is to take the sentences with the lowest similarity to adjacent sentences as the split points. We use all-MiniLM-L6-v2 for sentence embedding. You can refer the original post for the explanation of this approach. We have made some minor changes on the original source code; refer to our source code for the implementation. The core part for this process is as follows:
# Embed sentences
model_name = "all-minilm-l6-v2"
model = SentenceTransformer(model_name)
embeddings = model.encode(sentences_all)
# Create similarities matrix
similarities = cosine_similarity(embeddings)
# Let's apply our function. For long sentences i reccomend to use 10 or more sentences
minmimas = activate_similarities(similarities, p_size=p_size, order=order)
# Create empty string
split_points = [each for each in minmimas[0]]
text = ''
para_chunks = []
para_timestamp = []
start_timestamp = 0
for num, each in enumerate(sentences_all):
current_timestamp = timestamps_all[num]
if text == '' and (start_timestamp == current_timestamp[1]):
start_timestamp = current_timestamp[0]
if num in split_points:
para_chunks.append(text)
para_timestamp.append([start_timestamp, current_timestamp[1]])
text = f'{each}. '
start_timestamp = current_timestamp[1]
else:
text+=f'{each}. '
if len(text):
para_chunks.append(text)
para_timestamp.append([start_timestamp, timestamps_all[-1][1]])To evaluate the efficiency of chunking with sentence embedding, we conducted qualitative comparisons between different chunking mechanisms. The assumption underlying such comparisons is that if the chunked texts are more semantically different and separate, there will be less irrelevant contextual information being retrieved for the Q&A, so that the answer will be more accurate and precise. At the same time, because less contextual information is sent to LLMs, the cost of inference will also be less as charges increment with the size of tokens.
We visualized the first two components of a PCA by reducing high dimension into two dimensions. Compared to recursive chunking, we can see the distances between vectors representing different chunks with sentence embedding are more scattered, meaning the chunks are more semantically separate. This means when the vector of a query is close to the vector of one chunk, it may have less possibility to be close to other chunks. A retrieval task will have fewer opportunities to choose relevant information from multiple semantically similar chunks.

When the chunking process is complete, we attach timestamps to the file name of each chunk, save it as a single file, and then upload it to an S3 bucket.
Enable intelligent video search using a RAG-based approach with LangChain
There are typically four approaches to build a RAG solution for Q&A with LangChain:
- Using the
load_qa_chainfunctionality, which feeds all information to an LLM. This is not an ideal approach given the context window size and the volume of video and audio data. - Using the
RetrievalQAtool, which requires a text splitter, text embedding model, and vector store to process texts and retrieve relevant information. - Using
VectorstoreIndexCreator, which is a wrapper around all logic in the second approach. The text splitter, text embedding model, and vector store are configured together inside the function at one time. - Using the
ConversationalRetrievalChaintool, which further adds memory of chat history to the QA solution.
For this post, we use the second approach to explicitly customize and choose the best engineering practices. In the following sections, we describe each step in detail.
To search for the relevant content based on the user input queries, we use semantic search, which can better understand the intent behind and query and perform meaningful retrieval. We first use a pre-trained embedding model to embed all the transcribed text into a vector space. At search time, the query is also embedded into the same vector space and the closest embeddings from the source corpus are found. You can deploy the pre-trained embedding model as shown in Question answering using Retrieval Augmented Generation with foundation models in Amazon SageMaker JumpStart to create the embeddings for semantic search. In our post, we adopt similar ways to create an intelligent video search solution using a RAG-based approach with the open-source LangChain library. LangChain is an open-source framework for developing applications powered by language models. LangChain provides a generic interface for many different LLMs.
We first deploy an embedding model GPT-J 6B provided by Amazon SageMaker JumpStart and the language model Falcon-40B Instruct from Hugging Face to prepare for the solution. When the endpoints are ready, we follow similar steps described Question answering using Retrieval Augmented Generation with foundation models in Amazon SageMaker JumpStart to create the LLM model and embedding model for LangChain.
The following code snippet shows how to create the LLM model using the langchain.llms.sagemaker_endpoint.SagemakerEndpoint class and transform the request and response payload for the LLM in the ContentHandler:
from langchain.llms.sagemaker_endpoint import LLMContentHandler, SagemakerEndpoint
parameters = {
"max_new_tokens": 500,
}
class ContentHandler(LLMContentHandler):
content_type = "application/json"
accepts = "application/json"
def transform_input(self, prompt: str, model_kwargs={}) -> bytes:
self.len_prompt = len(prompt)
input_str = json.dumps({"inputs": prompt , "parameters": {**model_kwargs}})
return input_str.encode("utf-8")
def transform_output(self, output: bytes) -> str:
response_json = output.read()
res = json.loads(response_json)
print(res)
ans = res[0]['generated_text'][self.len_prompt:]
return ans
content_handler = ContentHandler()
sm_llm = SagemakerEndpoint(
endpoint_name=_MODEL_CONFIG_["huggingface-falcon-40b"]["endpoint_name"],
region_name=aws_region,
model_kwargs=parameters,
content_handler=content_handler,
) When we use a SageMaker JumpStart embedding model, we need to customize the LangChain SageMaker endpoint embedding class and transform the model request and response to integrate with LangChain. Load the processed video transcripts using the LangChain document loader and create an index.
We use the DirectoryLoader package in LangChain to load the text documents into the document loader:
loader = DirectoryLoader("./data/demo-video-sagemaker-doc/", glob="*/.txt")
documents = loader.load()Next, we use the embedding models to create the embeddings of the contents and store the embeddings in a FAISS vector store to create an index. We use this index to find relevant documents that are semantically similar to the input query. With the VectorstoreIndexCreator class, you can just write a few lines of code to achieve this task:
index_creator = VectorstoreIndexCreator(
vectorstore_cls=FAISS,
embedding=embeddings,
text_splitter=CharacterTextSplitter(chunk_size=500, chunk_overlap=0),
)
index = index_creator.from_loaders([loader])Now we can use the index to search for relevant context and pass it to the LLM model to generate an accurate response:
index.query(question=question, llm=sm_llm)Build a multi-functional chatbot with SageMaker
With the deployed LLM on SageMaker, we can build a multi-functional smart chatbot to show how these models can help your business build advanced AI-powered applications. In this example, the chatbot uses Streamlit to build the UI and the LangChain framework to chain together different components around LLMs. With the help of the text-to-text and speech-to-text LLMs deployed on SageMaker, this smart chatbot accepts inputs from text files and audio files so users can chat with the input files (accepts text and audio files) and further build applications on top of this. The following diagram shows the architecture of the chatbot.

When a user uploads a text file to the chatbot, the chatbot puts the content into the LangChain memory component and the user can chat with the uploaded document. This part is inspired by the following GitHub example that builds a document chatbot with SageMaker. We also add an option to allow users to upload audio files. Then the chatbot automatically invokes the speech-to-text model hosted on the SageMaker endpoint to extract the text content from the uploaded audio file and add the text content to the LangChain memory. Lastly, we allow the user to select the option to use the knowledge base when answering questions. This is the RAG capability shown in the preceding diagram. We have defined the SageMaker endpoints that are deployed in the notebooks provided in the previous sections. Note that you need to pass the actual endpoint names that are shown in your account when running the Streamlit app. You can find the endpoint names on the SageMaker console under Inference and Endpoints.
Falcon_endpoint_name = os.getenv("falcon_ep_name", default="falcon-40b-instruct-12xl")
whisper_endpoint_name = os.getenv('wp_ep_name', default="whisper-large-v2")
embedding_endpoint_name = os.getenv('embed_ep_name', default="huggingface-textembedding-gpt-j-6b")When the knowledge base option is not selected, we use the conversation chain, where we add the memory component using the ConversationBufferMemory provided by LangChain, so the bot can remember the current conversation history:
def load_chain():
memory = ConversationBufferMemory(return_messages=True)
chain = ConversationChain(llm=llm, memory=memory)
return chain
chatchain = load_chain()We use similar logic as shown in the earlier section for the RAG component and add the document retrieval function to the code. For demo purposes, we load the transcribed text stored in SageMaker Studio local storage as a document source. You can implement other RAG solutions using the vector databases based on your choice, such as Amazon OpenSearch Service, Amazon RDS, Amazon Kendra, and more.
When users use the knowledge base for the question, the following code snippet retrieves the relevant contents from the database and provides additional context for the LLM to answer the question. We used the specific method provided by FAISS, similarity_search_with_score, when searching for relevant documents. This is because it can also provide the metadata and similarity score of the retrieved source file. The returned distance score is L2 distance. Therefore, a lower score is better. This gives us more options to provide more context for the users, such as providing the exact timestamps of the source videos that are relevant to the input query. When the RAG option is selected by the user from the UI, the chatbot uses the load_qa_chain function provided by LangChain to provide the answers based on the input prompt.
docs = docsearch.similarity_search_with_score(user_input)
contexts = []
for doc, score in docs:
print(f"Content: {doc.page_content}, Metadata: {doc.metadata}, Score: {score}")
if score <= 0.9:
contexts.append(doc)
source.append(doc.metadata['source'].split('/')[-1])
print(f"n INPUT CONTEXT:{contexts}")
prompt_template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.:nn{context}nnQuestion: {question}nHelpful Answer:"""
PROMPT = PromptTemplate(template=prompt_template, input_variables=["context", "question"])
chain = load_qa_chain(llm=llm, prompt=PROMPT)
result = chain({"input_documents": contexts, "question": user_input},
return_only_outputs=True)["output_text"]
if len(source) != 0:
df = pd.DataFrame(source, columns=['knowledge source'])
st.data_editor(df)Run the chatbot app
Now we’re ready to run the Streamlit app. Open a terminal in SageMaker Studio and navigate to the cloned GitHub repository folder. You need to install the required Python packages that are specified in the requirements.txt file. Run pip install -r requirements.txt to prepare the Python dependencies.
Then run the following command to update the endpoint names in the environment variables based on the endpoints deployed in your account accordingly. When you run the chatbot.py file, it automatically updates the endpoint names based on the environment variables.
export falcon_ep_name=<the falcon endpoint name deployed in your account>
export wp_ep_name=<the whisper endpoint name deployed in your account>
export embed_ep_name=<the embedding endpoint name deployed in your account>
streamlit run app_chatbot/chatbot.py --server.port 6006 --server.maxUploadSize 6
To access the Streamlit UI, copy your SageMaker Studio URL and replace lab? with proxy/[PORT NUMBER]/. For this post, we specified the server port as 6006, so the URL should look like https://<domain ID>.studio.<region>.sagemaker.aws/jupyter/default/proxy/6006/.
Replace domain ID and region with the correct value in your account to access the UI.
Chat with your audio file
In the Conversation setup pane, choose Browse files to select local text or audio files to upload to the chatbot. If you select an audio file, it will automatically invoke the speech-to-text SageMaker endpoint to process the audio file and present the transcribed text to the console, as shown in the following screenshot. You can continue asking questions about the audio file and the chatbot will be able to remember the audio content and respond to your queries based on the audio content.

Use the knowledge base for the Q&A
When you want to answer questions that require specific domain knowledge or use the knowledge base, select Use knowledge base. This lets the chatbot retrieve relevant information from the knowledge base built earlier (the vector database) to add additional context to answer the question. For example, when we ask the question “what is the recommended way to first customize a foundation model?” to the chatbot without the knowledge base, the chatbot returns an answer similar to the following screenshot.

When we use the knowledge base to help answer this question, the chatbot returns a different response. In the demo video, we read the SageMaker document about how to customize a model in SageMaker Jumpstart.

The output also provides the original video file name with the retrieved timestamp of the corresponding text. Users can go back to the original video file and locate the specific clips in the original videos.

This example chatbot demonstrates how businesses can use various types of digital assets to enhance their knowledge base and provide multi-functional assistance to their employees to improve productivity and efficiency. You can build the knowledge database from documents, audio and video datasets, and even image datasets to consolidate all the resources together. With SageMaker serving as an advanced ML platform, you accelerate project ideation to production speed with the breadth and depth of the SageMaker services that cover the whole ML lifecycle.
Clean up
To save costs, delete all the resources you deployed as part of the post. You can follow the provided notebook’s cleanup section to programmatically delete the resources, or you can delete any SageMaker endpoints you may have created via the SageMaker console.
Conclusion
The advent of generative AI models powered by LLMs has revolutionized the way businesses acquire and apply insights from information. Within this context, digital assets, including video and audio content, play a pivotal role as visual representations of products, services, and brand identity. Efficiently searching and discovering specific content within these assets is vital for optimizing workflows, enhancing collaboration, and delivering tailored experiences to the intended audience. With the power of generative AI models on SageMaker, businesses can unlock the full potential of their video and audio resources. The integration of generative AI models empowers enterprises to build efficient and intelligent search solutions, enabling users to access relevant and contextual information from their digital assets, and thereby maximizing their value and fostering business success in the digital landscape.
For more information on working with generative AI on AWS, refer to Announcing New Tools for Building with Generative AI on AWS.
About the authors
 Gordon Wang is a Senior AI/ML Specialist TAM at AWS. He supports strategic customers with AI/ML best practices across many industries. He is passionate about computer vision, NLP, generative AI, and MLOps. In his spare time, he loves running and hiking.
Gordon Wang is a Senior AI/ML Specialist TAM at AWS. He supports strategic customers with AI/ML best practices across many industries. He is passionate about computer vision, NLP, generative AI, and MLOps. In his spare time, he loves running and hiking.
 Melanie Li is a Senior AI/ML Specialist TAM at AWS based in Sydney, Australia. She helps enterprise customers build solutions using state-of-the-art AI/ML tools on AWS and provides guidance on architecting and implementing ML solutions with best practices. In her spare time, she loves to explore nature and spend time with family and friends.
Melanie Li is a Senior AI/ML Specialist TAM at AWS based in Sydney, Australia. She helps enterprise customers build solutions using state-of-the-art AI/ML tools on AWS and provides guidance on architecting and implementing ML solutions with best practices. In her spare time, she loves to explore nature and spend time with family and friends.
 Guang Yang is a Senior Applied Scientist at the Amazon Generative AI Innovation Center, where he works with customers across various verticals and applies creative problem solving to generate value for customers with state-of-the-art generative AI solutions.
Guang Yang is a Senior Applied Scientist at the Amazon Generative AI Innovation Center, where he works with customers across various verticals and applies creative problem solving to generate value for customers with state-of-the-art generative AI solutions.
 Harjyot Malik is a Senior Program Manager at AWS based in Sydney, Australia. He works with the APJC Enterprise Support teams and helps them build and deliver strategies. He collaborates with business teams, delving into complex problems to unearth innovative solutions that in return drive efficiencies for the business. In his spare time, he loves to travel and explore new places.
Harjyot Malik is a Senior Program Manager at AWS based in Sydney, Australia. He works with the APJC Enterprise Support teams and helps them build and deliver strategies. He collaborates with business teams, delving into complex problems to unearth innovative solutions that in return drive efficiencies for the business. In his spare time, he loves to travel and explore new places.







 Rajakumar Sampathkumar is a Principal Technical Account Manager at AWS, providing customers guidance on business-technology alignment and supporting the reinvention of their cloud operation models and processes. He is passionate about cloud and machine learning. Raj is also a machine learning specialist and works with AWS customers to design, deploy, and manage their AWS workloads and architectures.
Rajakumar Sampathkumar is a Principal Technical Account Manager at AWS, providing customers guidance on business-technology alignment and supporting the reinvention of their cloud operation models and processes. He is passionate about cloud and machine learning. Raj is also a machine learning specialist and works with AWS customers to design, deploy, and manage their AWS workloads and architectures. Dr. Xin Huang is an Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. He has published many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Series A journal.
Dr. Xin Huang is an Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. He has published many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Series A journal. Evan Kravitz is a software engineer at Amazon Web Services, working on SageMaker JumpStart. He enjoys cooking and going on runs in New York City.
Evan Kravitz is a software engineer at Amazon Web Services, working on SageMaker JumpStart. He enjoys cooking and going on runs in New York City.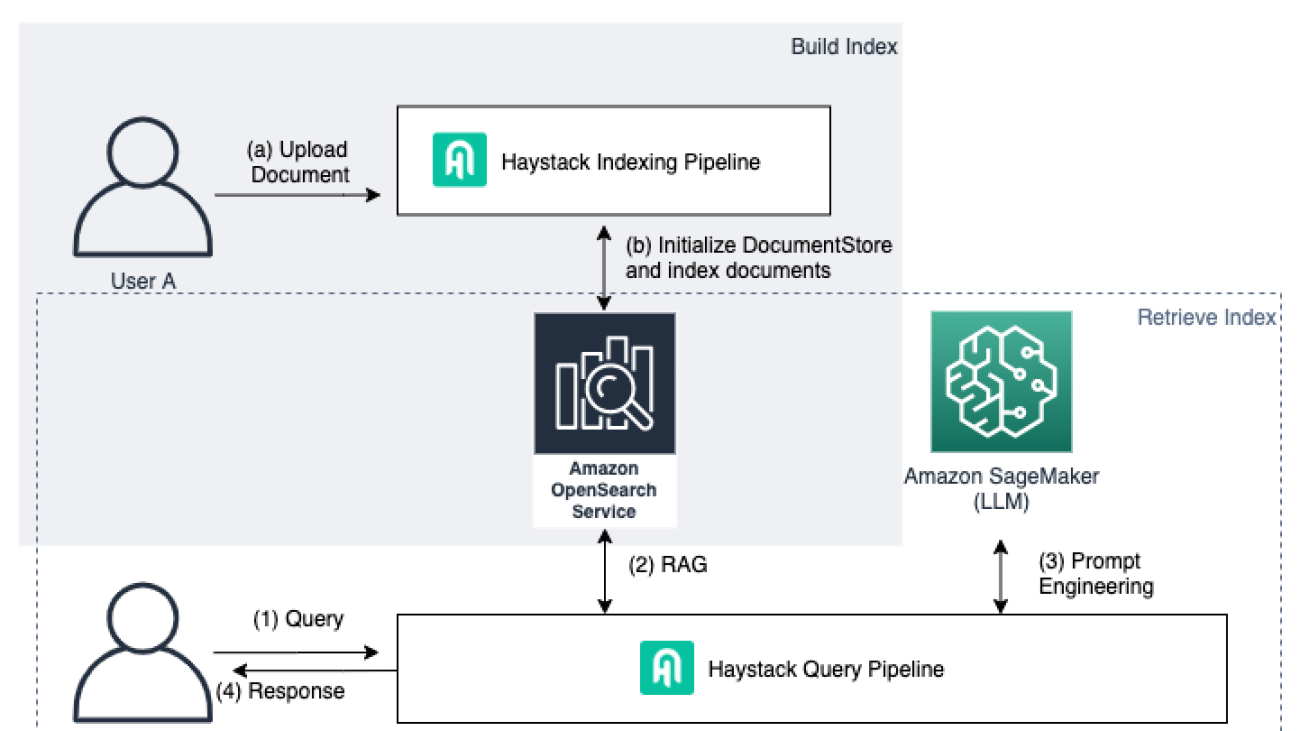




 Tuana Celik is the Lead Developer Advocate at deepset, where she focuses on the open-source community for Haystack. She leads the developer relations function and regularly speaks at events about NLP and creates learning materials for the community.
Tuana Celik is the Lead Developer Advocate at deepset, where she focuses on the open-source community for Haystack. She leads the developer relations function and regularly speaks at events about NLP and creates learning materials for the community. Roy Allela is a Senior AI/ML Specialist Solutions Architect at AWS based in Munich, Germany. Roy helps AWS customers—from small startups to large enterprises—train and deploy large language models efficiently on AWS. Roy is passionate about computational optimization problems and improving the performance of AI workloads.
Roy Allela is a Senior AI/ML Specialist Solutions Architect at AWS based in Munich, Germany. Roy helps AWS customers—from small startups to large enterprises—train and deploy large language models efficiently on AWS. Roy is passionate about computational optimization problems and improving the performance of AI workloads. Mia Chang is an ML Specialist Solutions Architect for Amazon Web Services. She works with customers in EMEA and shares best practices for running AI/ML workloads on the cloud with her background in applied mathematics, computer science, and AI/ML. She focuses on NLP-specific workloads, and shares her experience as a conference speaker and a book author. In her free time, she enjoys hiking, board games, and brewing coffee.
Mia Chang is an ML Specialist Solutions Architect for Amazon Web Services. She works with customers in EMEA and shares best practices for running AI/ML workloads on the cloud with her background in applied mathematics, computer science, and AI/ML. She focuses on NLP-specific workloads, and shares her experience as a conference speaker and a book author. In her free time, she enjoys hiking, board games, and brewing coffee. Inaam Syed is a Startup Solutions Architect at AWS, with a strong focus on assisting B2B and SaaS startups in scaling and achieving growth. He possesses a deep passion for serverless architectures and AI/ML. In his leisure time, Inaam enjoys quality moments with his family and indulges in his love for biking and badminton.
Inaam Syed is a Startup Solutions Architect at AWS, with a strong focus on assisting B2B and SaaS startups in scaling and achieving growth. He possesses a deep passion for serverless architectures and AI/ML. In his leisure time, Inaam enjoys quality moments with his family and indulges in his love for biking and badminton. David Tippett is the Senior Developer Advocate working on open-source OpenSearch at AWS. His work involves all areas of OpenSearch from search and relevance to observability and security analytics.
David Tippett is the Senior Developer Advocate working on open-source OpenSearch at AWS. His work involves all areas of OpenSearch from search and relevance to observability and security analytics.


 Sathya Balakrishnan is a Senior Consultant in the Professional Services team at AWS, specializing in data and ML solutions. He works with US federal financial clients. He is passionate about building pragmatic solutions to solve customers’ business problems. In his spare time, he enjoys watching movies and hiking with his family.
Sathya Balakrishnan is a Senior Consultant in the Professional Services team at AWS, specializing in data and ML solutions. He works with US federal financial clients. He is passionate about building pragmatic solutions to solve customers’ business problems. In his spare time, he enjoys watching movies and hiking with his family. Sid Padgaonkar is the Senior Product Manager for Amazon Translate, AWS’s natural language processing service. On weekends, you will find him playing squash and exploring the food scene in the Pacific Northwest.
Sid Padgaonkar is the Senior Product Manager for Amazon Translate, AWS’s natural language processing service. On weekends, you will find him playing squash and exploring the food scene in the Pacific Northwest.







 David Laredo is a Prototyping Architect at AWS Envision Engineering in LATAM, where he has helped develop multiple machine learning prototypes. Previously, he has worked as a Machine Learning Engineer and has been doing machine learning for over 5 years. His areas of interest are NLP, time series, and end-to-end ML.
David Laredo is a Prototyping Architect at AWS Envision Engineering in LATAM, where he has helped develop multiple machine learning prototypes. Previously, he has worked as a Machine Learning Engineer and has been doing machine learning for over 5 years. His areas of interest are NLP, time series, and end-to-end ML. Vikram Elango is an AI/ML Specialist Solutions Architect at Amazon Web Services, based in Virginia, US. Vikram helps financial and insurance industry customers with design and thought leadership to build and deploy machine learning applications at scale. He is currently focused on natural language processing, responsible AI, inference optimization, and scaling ML across the enterprise. In his spare time, he enjoys traveling, hiking, cooking, and camping with his family.
Vikram Elango is an AI/ML Specialist Solutions Architect at Amazon Web Services, based in Virginia, US. Vikram helps financial and insurance industry customers with design and thought leadership to build and deploy machine learning applications at scale. He is currently focused on natural language processing, responsible AI, inference optimization, and scaling ML across the enterprise. In his spare time, he enjoys traveling, hiking, cooking, and camping with his family. Dr. Vivek Madan is an Applied Scientist with the Amazon SageMaker JumpStart team. He got his PhD from University of Illinois at Urbana-Champaign and was a Post Doctoral Researcher at Georgia Tech. He is an active researcher in machine learning and algorithm design and has published papers in EMNLP, ICLR, COLT, FOCS, and SODA conferences.
Dr. Vivek Madan is an Applied Scientist with the Amazon SageMaker JumpStart team. He got his PhD from University of Illinois at Urbana-Champaign and was a Post Doctoral Researcher at Georgia Tech. He is an active researcher in machine learning and algorithm design and has published papers in EMNLP, ICLR, COLT, FOCS, and SODA conferences.