Mind–body interventions such as mindfulness-based stress reduction (MBSR) may improve well-being by increasing awareness and regulation of physiological and cognitive states. However, it is unclear how practice may alter long-term, baseline physiological processes, and whether these changes reflect improved well-being. Using respiration rate (RR), which can be sensitive to effects of meditation, and 3 aspects of self-reported well-being (psychological well-being [PWB], distress, and medical symptoms), we tested pre-registered hypotheses that: (1) Lower baseline RR (in a resting, non-meditative…Apple Machine Learning Research
Personalize your generative AI applications with Amazon SageMaker Feature Store
Large language models (LLMs) are revolutionizing fields like search engines, natural language processing (NLP), healthcare, robotics, and code generation. The applications also extend into retail, where they can enhance customer experiences through dynamic chatbots and AI assistants, and into digital marketing, where they can organize customer feedback and recommend products based on descriptions and purchase behaviors.
The personalization of LLM applications can be achieved by incorporating up-to-date user information, which typically involves integrating several components. One such component is a feature store, a tool that stores, shares, and manages features for machine learning (ML) models. Features are the inputs used during training and inference of ML models. For instance, in an application that recommends movies, features could include previous ratings, preference categories, and demographics. Amazon SageMaker Feature Store is a fully managed repository designed specifically for storing, sharing, and managing ML model features. Another essential component is an orchestration tool suitable for prompt engineering and managing different type of subtasks. Generative AI developers can use frameworks like LangChain, which offers modules for integrating with LLMs and orchestration tools for task management and prompt engineering.
Building on the concept of dynamically fetching up-to-date data to produce personalized content, the use of LLMs has garnered significant attention in recent research for recommender systems. The underlying principle of these approaches involves the construction of prompts that encapsulate the recommendation task, user profiles, item attributes, and user-item interactions. These task-specific prompts are then fed into the LLM, which is tasked with predicting the likelihood of interaction between a particular user and item. As stated in the paper Personalized Recommendation via Prompting Large Language Models, recommendation-driven and engagement-guided prompting components play a crucial role in enabling LLMs to focus on relevant context and align with user preferences.
In this post, we elucidate the simple yet powerful idea of combining user profiles and item attributes to generate personalized content recommendations using LLMs. As demonstrated throughout the post, these models hold immense potential in generating high-quality, context-aware input text, which leads to enhanced recommendations. To illustrate this, we guide you through the process of integrating a feature store (representing user profiles) with an LLM to generate these personalized recommendations.
Solution overview
Let’s imagine a scenario where a movie entertainment company promotes movies to different users via an email campaign. The promotion contains 25 well-known movies, and we want to select the top three recommendations for each user based on their interests and previous rating behaviors.
For example, given a user’s interest in different movie genres like action, romance, and sci-fi, we could have an AI system determine the top three recommended movies for that particular user. In addition, the system might generate personalized messages for each user in a tone tailored to their preferences. We include some examples of personalized messages later in this post.
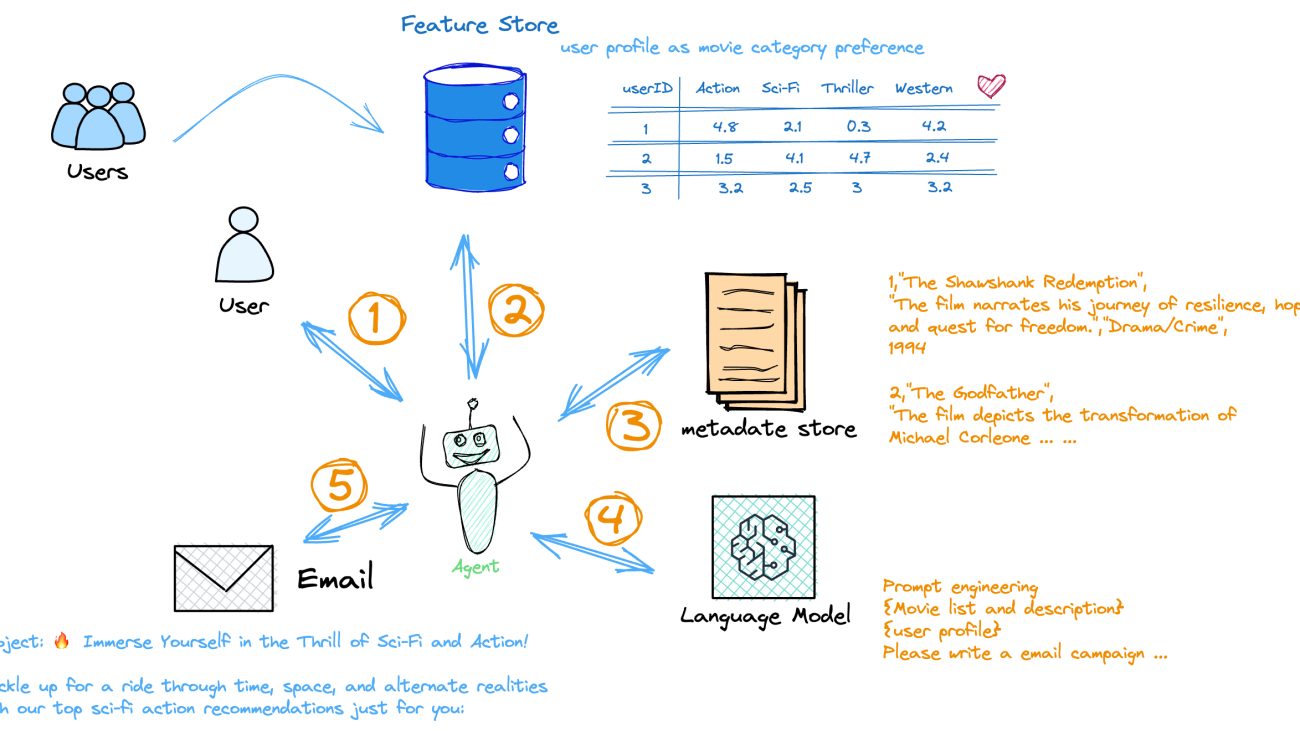
This AI application would include several components working together, as illustrated in the following diagram:
- A user profiling engine takes in a user’s previous behaviors and outputs a user profile reflecting their interests.
- A feature store maintains user profile data.
- A media metadata store keeps the promotion movie list up to date.
- A language model takes the current movie list and user profile data, and outputs the top three recommended movies for each user, written in their preferred tone.
- An orchestrating agent coordinates the different components.

In summary, intelligent agents could construct prompts using user- and item-related data and deliver customized natural language responses to users. This would represent a typical content-based recommendation system, which recommends items to users based on their profiles. The user’s profile is stored and maintained in the feature store and revolves around their preferences and tastes. It is commonly derived based on their previous behaviors, such as ratings.
The following diagram illustrates how it works.

The application follows these steps to provide responses to a user’s recommendation:
- The user profiling engine that takes a user’s historical movie rating as input, outputs user interest, and stores the feature in SageMaker Feature Store. This process can be updated in a scheduling manner.
- The agent takes the user ID as input, searches for the user interest, and completes the prompt template following the user’s interests.
- The agent takes the promotion item list (movie name, description, genre) from a media metadata store.
- The interests prompt template and promotion item list are fed into an LLM for email campaign messages.
- The agent sends the personalized email campaign to the end user.
The user profiling engine builds a profile for each user, capturing their preferences and interests. This profile can be represented as a vector with elements mapping to features like movie genres, with values indicating the user’s level of interest. The user profiles in the feature store allow the system to suggest personalized recommendations matching their interests. User profiling is a well-studied domain within recommendation systems. To simplify, you can build a regression algorithm using a user’s previous ratings across different categories to infer their overall preferences. This can be done with algorithms like XGBoost.
Code walkthrough
In this section, we provide examples of the code. The full code walkthrough is available in the GitHub repo.
After obtaining the user interests feature from the user profiling engine, we can store the results in the feature store. SageMaker Feature Store supports batch feature ingestion and online storage for real-time inference. For ingestion, data can be updated in an offline mode, whereas inference needs to happen in milliseconds. SageMaker Feature Store ensures that offline and online datasets remain in sync.
For data ingestion, we use the following code:
For real-time online storage, we could use the following code to extract the user profile based on the user ID:
Then we rank the top three interested movie categories to feed the downstream recommendation engine:
User ID: 42
Top3 Categories: [‘Animation’, ‘Thriller’, ‘Adventure’]
Our application employs two primary components. The first component retrieves data from a feature store, and the second component acquires a list of movie promotions from the metadata store. The coordination between these components is managed by Chains from LangChain, which represent a sequence of calls to components.
It’s worth mentioning that in complex scenarios, the application may need more than a fixed sequence of calls to LLMs or other tools. Agents, equipped with a suite of tools, use an LLM to determine the sequence of actions to be taken. Whereas Chains encode a hardcoded sequence of actions, agents use the reasoning power of a language model to dictate the order and nature of actions.
The connection between different data sources, including SageMaker Feature Store, is demonstrated in the following code. All the retrieved data is consolidated to construct an extensive prompt, serving as input for the LLM. We dive deep into the specifics of prompt design in the subsequent section. The following is a prompt template definition that interfaces with multiple data sources:
In addition, we use Amazon SageMaker to host our LLM model and expose it as the LangChain SageMaker endpoint. To deploy the LLM, we use Amazon SageMaker JumpStart (for more details, refer to Llama 2 foundation models from Meta are now available in Amazon SageMaker JumpStart). After the model is deployed, we can create the LLM module:
In the context of our application, the agent runs a sequence of steps, called an LLMChain. It integrates a prompt template, model, and guardrails to format the user input, pass it to the model, get a response, and then validate (and, if necessary, rectify) the model output.
In the next section, we walk through the prompt engineering for the LLM to output expected results.
LLM recommendation prompting and results
Following the high-level concept of engagement-guided prompting as described in the research study Personalized Recommendation via Prompting Large Language Models, the fundamental principle of our prompting strategy is to integrate user preferences in creating prompts. These prompts are designed to guide the LLM towards more effectively identifying attributes within the content description that align with user preferences. To elaborate further, our prompt comprises several components:
- Contextual relevance – The initial part of our prompt template incorporates media metadata such as item name (movie title), description (movie synopsis), and attribute (movie genre). By incorporating this information, the prompt provides the LLM with a broader context and a more comprehensive understanding of the content. This contextual information aids the LLM in better understanding the item through its description and attributes, thereby enhancing its utility in content recommendation scenarios.
- User preference alignment – By taking into account a user profile that signifies user preferences, potential recommendations are better positioned to identify content characteristics and features that resonate with target users. This alignment augments the utility of the item descriptions because it enhances the efficiency of recommending items that are relevant and in line with user preferences.
- Enhanced recommendation quality – The engagement-guided prompt uses user preferences to identify relevant promotional items. We can also use user preference to adjust the tone of the LLM for the final output. This can result in an accurate, informative, and personalized experience, thereby improving the overall performance of the content recommendation system.
The following code shows an example prompt template:
prompt_template = """Our company, "Classic Cinema" frequently promotes movies that we aim to recommend to our customers. This month, we have several popular movies on promotion.
As an AI agent, you are tasked to assist "Classic Cinema" in crafting an email campaign to recommend relevant movies to users. The recommendations should adhere to several guidelines, including contextual relevance, ensuring the recommendations are strictly from our promotional movie list. Additionally, the recommendations should align with user preferences, suggesting items that are relevant and in harmony with the user's preferred categories. You are to provide precisely three top recommended movies. Finally, please draft the email to reflect the tone of the user's preferred categories. The email should not exceed 100 words.
The recommended movies should be sourced from this contextual relevance movie list:{promotion_movie_list}.
The user has expressed interest in {user_preference}.
Please ensure the recommendations are relevant, and the tone of the email reflects the tastes of those interested in the {user_preference} movie category.
Ensure the letter appeals to those interested in the {user_preference} movie category, and keep the email campaign within a 100-word limit. """
The following is an example result with user preferences of sci-fi, adventure, and war genres:
Subject: Explore the Frontier of Classic Cinema with Our Sci-Fi, Adventure, and War Movies!
Dear [Name],
Are you ready to embark on a journey through time and space, experience heart-pumping action, and witness the bravery of heroes on the battlefield? Look no further! Classic Cinema proudly presents our carefully curated selection of movies, tailored specifically to your interests in Sci-Fi, Adventure, and War.First up, we have the iconic “Star Wars: Episode V – The Empire Strikes Back” (1980). This classic installment in the Star Wars saga follows Luke Skywalker’s journey to becoming a Jedi Master, while his friends face off against the evil Empire. With its groundbreaking special effects and memorable characters, this movie is a must-see for any fan of the genre.
Next, we recommend “Interstellar” (2014), a thought-provoking and visually stunning film that delves into the mysteries of time and space. As a group of explorers embark on a quest to save humanity, they encounter breathtaking landscapes and uncover the secrets of the universe.
Lastly, we have “Saving Private Ryan” (1998), a gripping and intense war drama that follows a group of soldiers on a dangerous mission to find and rescue a paratrooper whose brothers have been killed in action. This critically acclaimed film is a powerful tribute to the heroes of World War II.
Don’t miss out on these cinematic masterpieces! Watch them now and experience the thrill of adventure, the wonder of sci-fi, and the bravery of war heroes.
Happy viewing, and may the force be with you!Best regards,
Classic Cinema Team
The following is another example result with a user preference of documentary, musical, and drama:
Subject: Classic Cinema’s Recommendations for Documentary, Musical, and Drama Lovers
Dear [Name],
We hope this email finds you well and that you’re enjoying the variety of movies available on our platform. At Classic Cinema, we take pride in catering to the diverse tastes of our customers, and we’ve selected three exceptional movies that we believe will resonate with your interest in Documentary, Musical, and Drama.
First up, we have “The Shawshank Redemption” (1994), a powerful and uplifting drama that follows the journey of two prisoners as they find hope and redemption in a corrupt and unforgiving prison system. With its gripping storyline, outstanding performances, and timeless themes, this movie is a must-see for anyone who loves a well-crafted drama.
Next, we recommend “The Lord of the Rings: The Fellowship of the Ring” (2001), an epic adventure that combines breathtaking visuals, memorable characters, and a richly detailed world. This movie is a masterclass in storytelling, with a deep sense of history and culture that will transport you to Middle-earth and leave you wanting more.
Lastly, we suggest “The Pianist” (2002), a profound and moving documentary that tells the true story of Władysław Szpilman, a Polish Jewish pianist who struggled to survive the destruction of the Warsaw ghetto during World War II. This film is a powerful reminder of the human spirit’s capacity for resilience and hope, even in the face of unimaginable tragedy.
We hope these recommendations resonate with your interests and provide you with an enjoyable and enriching movie experience. Don’t miss out on these timeless classics – watch them now and discover the magic of Classic Cinema!
Best regards,
The Classic Cinema Team
We have carried out tests with both Llama 2 7B-Chat (see the following code sample) and Llama 70B for comparison. Both models performed well, yielding consistent conclusions. By using a prompt template filled with up-to-date data, we found it easier to test arbitrary LLMs, helping us choose the right balance between performance and cost. We have also made several shared observations that are worth noting.
Firstly, we can see that the recommendations provided genuinely align with user preferences. The movie recommendations are guided by various components within our application, most notably the user profile stored in the feature store.
Additionally, the tone of the emails corresponds to user preferences. Thanks to the advanced language understanding capabilities of LLM, we can customize the movie descriptions and email content, tailoring them to each individual user.
Furthermore, the final output format can be designed into the prompt. For example, in our case, the salutation “Dear [Name]” needs to be filled by the email service. It’s important to note that although we avoid exposing personally identifiable information (PII) within our generative AI application, there is the possibility to reintroduce this information during postprocessing, assuming the right level of permissions are granted.
Clean up
To avoid unnecessary costs, delete the resources you created as part of this solution, including the feature store and LLM inference endpoint deployed with SageMaker JumpStart.
Conclusion
The power of LLMs in generating personalized recommendations is immense and transformative, particularly when coupled with the right tools. By integrating SageMaker Feature Store and LangChain for prompt engineering, developers can construct and manage highly tailored user profiles. This results in high-quality, context-aware inputs that significantly enhance recommendation performance. In our illustrative scenario, we saw how this can be applied to tailor movie recommendations to individual user preferences, resulting in a highly personalized experience.
As the LLM landscape continues to evolve, we anticipate seeing more innovative applications that use these models to deliver even more engaging, personalized experiences. The possibilities are boundless, and we are excited to see what you will create with these tools. With resources such as SageMaker JumpStart and Amazon Bedrock now available to accelerate the development of generative AI applications, we strongly recommend exploring the construction of recommendation solutions using LLMs on AWS.
About the Authors
 Yanwei Cui, PhD, is a Senior Machine Learning Specialist Solutions Architect at AWS. He started machine learning research at IRISA (Research Institute of Computer Science and Random Systems), and has several years of experience building AI-powered industrial applications in computer vision, natural language processing, and online user behavior prediction. At AWS, he shares his domain expertise and helps customers unlock business potentials and drive actionable outcomes with machine learning at scale. Outside of work, he enjoys reading and traveling.
Yanwei Cui, PhD, is a Senior Machine Learning Specialist Solutions Architect at AWS. He started machine learning research at IRISA (Research Institute of Computer Science and Random Systems), and has several years of experience building AI-powered industrial applications in computer vision, natural language processing, and online user behavior prediction. At AWS, he shares his domain expertise and helps customers unlock business potentials and drive actionable outcomes with machine learning at scale. Outside of work, he enjoys reading and traveling.
 Gordon Wang is a Senior AI/ML Specialist TAM at AWS. He supports strategic customers with AI/ML best practices cross many industries. He is passionate about computer vision, NLP, generative AI, and MLOps. In his spare time, he loves running and hiking.
Gordon Wang is a Senior AI/ML Specialist TAM at AWS. He supports strategic customers with AI/ML best practices cross many industries. He is passionate about computer vision, NLP, generative AI, and MLOps. In his spare time, he loves running and hiking.
 Michelle Hong, PhD, works as Prototyping Solutions Architect at Amazon Web Services, where she helps customers build innovative applications using a variety of AWS components. She demonstrated her expertise in machine learning, particularly in natural language processing, to develop data-driven solutions that optimize business processes and improve customer experiences.
Michelle Hong, PhD, works as Prototyping Solutions Architect at Amazon Web Services, where she helps customers build innovative applications using a variety of AWS components. She demonstrated her expertise in machine learning, particularly in natural language processing, to develop data-driven solutions that optimize business processes and improve customer experiences.
 Bin Wang, PhD, is a Senior Analytic Specialist Solutions Architect at AWS, boasting over 12 years of experience in the ML industry, with a particular focus on advertising. He possesses expertise in natural language processing (NLP), recommender systems, diverse ML algorithms, and ML operations. He is deeply passionate about applying ML/DL and big data techniques to solve real-world problems. Outside of his professional life, he enjoys music, reading, and traveling.
Bin Wang, PhD, is a Senior Analytic Specialist Solutions Architect at AWS, boasting over 12 years of experience in the ML industry, with a particular focus on advertising. He possesses expertise in natural language processing (NLP), recommender systems, diverse ML algorithms, and ML operations. He is deeply passionate about applying ML/DL and big data techniques to solve real-world problems. Outside of his professional life, he enjoys music, reading, and traveling.
Teaching household robots where to find requested objects
Leveraging a large vision-language foundation model enables state-of-the-art performance in remote-object grounding.Read More

Build an image-to-text generative AI application using multimodality models on Amazon SageMaker
As we delve deeper into the digital era, the development of multimodality models has been critical in enhancing machine understanding. These models process and generate content across various data forms, like text and images. A key feature of these models is their image-to-text capabilities, which have shown remarkable proficiency in tasks such as image captioning and visual question answering.
By translating images into text, we unlock and harness the wealth of information contained in visual data. For instance, in ecommerce, image-to-text can automate product categorization based on images, enhancing search efficiency and accuracy. Similarly, it can assist in generating automatic photo descriptions, providing information that might not be included in product titles or descriptions, thereby improving user experience.
In this post, we provide an overview of popular multimodality models. We also demonstrate how to deploy these pre-trained models on Amazon SageMaker. Furthermore, we discuss the diverse applications of these models, focusing particularly on several real-world scenarios, such as zero-shot tag and attribution generation for ecommerce and automatic prompt generation from images.
Background of multimodality models
Machine learning (ML) models have achieved significant advancements in fields like natural language processing (NLP) and computer vision, where models can exhibit human-like performance in analyzing and generating content from a single source of data. More recently, there has been increasing attention in the development of multimodality models, which are capable of processing and generating content across different modalities. These models, such as the fusion of vision and language networks, have gained prominence due to their ability to integrate information from diverse sources and modalities, thereby enhancing their comprehension and expression capabilities.
In this section, we provide an overview of two popular multimodality models: CLIP (Contrastive Language-Image Pre-training) and BLIP (Bootstrapping Language-Image Pre-training).
CLIP model
CLIP is a multi-modal vision and language model, which can be used for image-text similarity and for zero-shot image classification. CLIP is trained on a dataset of 400 million image-text pairs collected from a variety of publicly available sources on the internet. The model architecture consists of an image encoder and a text encoder, as shown in the following diagram.

During training, an image and corresponding text snippet are fed through the encoders to get an image feature vector and text feature vector. The goal is to make the image and text features for a matched pair have a high cosine similarity, while features for mismatched pairs have low similarity. This is done through a contrastive loss. This contrastive pre-training results in encoders that map images and text to a common embedding space where semantics are aligned.
The encoders can then be used for zero-shot transfer learning for downstream tasks. At inference time, the image and text pre-trained encoder processes its respective input and transforms it into a high-dimensional vector representation, or an embedding. The embeddings of the image and text are then compared to determine their similarity, such as cosine similarity. The text prompt (image classes, categories, or tags) whose embedding is most similar (for example, has the smallest distance) to the image embedding is considered the most relevant, and the image is classified accordingly.
BLIP model
Another popular multimodality model is BLIP. It introduces a novel model architecture capable of adapting to diverse vision-language tasks and employs a unique dataset bootstrapping technique to learn from noisy web data. BLIP architecture includes an image encoder and text encoder: the image-grounded text encoder injects visual information into the transformer block of the text encoder, and the image-grounded text decoder incorporates visual information into the transformer decoder block. With this architecture, BLIP demonstrates outstanding performance across a spectrum of vision-language tasks that involve the fusion of visual and linguistic information, from image-based search and content generation to interactive visual dialog systems. In a previous post, we proposed a content moderation solution based on the BLIP model that addressed multiple challenges using computer vision unimodal ML approaches.
Use case 1: Zero-shot tag or attribute generation for an ecommerce platform
Ecommerce platforms serve as dynamic marketplaces teeming with ideas, products, and services. With millions of products listed, effective sorting and categorization poses a significant challenge. This is where the power of auto-tagging and attribute generation comes into its own. By harnessing advanced technologies like ML and NLP, these automated processes can revolutionize the operations of ecommerce platforms.
One of the key benefits of auto-tagging or attribute generation lies in its ability to enhance searchability. Products tagged accurately can be found by customers swiftly and efficiently. For instance, if a customer is searching for a “cotton crew neck t-shirt with a logo in front,” auto-tagging and attribute generation enable the search engine to pinpoint products that match not merely the broader “t-shirt” category, but also the specific attributes of “cotton” and “crew neck.” This precise matching can facilitate a more personalized shopping experience and boost customer satisfaction. Moreover, auto-generated tags or attributes can substantially improve product recommendation algorithms. With a deep understanding of product attributes, the system can suggest more relevant products to customers, thereby increasing the likelihood of purchases and enhancing customer satisfaction.
CLIP offers a promising solution for automating the process of tag or attribute generation. It takes a product image and a list of descriptions or tags as input, generating a vector representation, or embedding, for each tag. These embeddings exist in a high-dimensional space, with their relative distances and directions reflecting the semantic relationships between the inputs. CLIP is pre-trained on a large scale of image-text pairs to encapsulate these meaningful embeddings. If a tag or attribute accurately describes an image, their embeddings should be relatively close in this space. To generate corresponding tags or attributes, a list of potential tags can be inputted into the text part of the CLIP model, and the resulting embeddings stored. Ideally, this list should be exhaustive, covering all potential categories and attributes relevant to the products on the ecommerce platform. The following figure shows some examples.

To deploy the CLIP model on SageMaker, you can follow the notebook in the following GitHub repo. We use the SageMaker pre-built large model inference (LMI) containers to deploy the model. The LMI containers use DJL Serving to serve your model for inference. To learn more about hosting large models on SageMaker, refer to Deploy large models on Amazon SageMaker using DJLServing and DeepSpeed model parallel inference and Deploy large models at high performance using FasterTransformer on Amazon SageMaker.
In this example, we provide the files serving.properties, model.py, and requirements.txt to prepare the model artifacts and store them in a tarball file.
serving.propertiesis the configuration file that can be used to indicate to DJL Serving which model parallelization and inference optimization libraries you would like to use. Depending on your need, you can set the appropriate configuration. For more details on the configuration options and an exhaustive list, refer to Configurations and settings.model.pyis the script that handles any requests for serving.requirements.txtis the text file containing any additional pip wheels to install.
If you want to download the model from Hugging Face directly, you can set the option.model_id parameter in the serving.properties file as the model id of a pre-trained model hosted inside a model repository on huggingface.co. The container uses this model id to download the corresponding model during deployment time. If you set the model_id to an Amazon Simple Storage Service (Amazon S3) URL, the DJL will download the model artifacts from Amazon S3 and swap the model_id to the actual location of the model artifacts. In your script, you can point to this value to load the pre-trained model. In our example, we use the latter option, because the LMI container uses s5cmd to download data from Amazon S3, which significantly reduces the speed when loading models during deployment. See the following code:
In the model.py script, we load the model path using the model ID provided in the property file:
After the model artifacts are prepared and uploaded to Amazon S3, you can deploy the CLIP model to SageMaker hosting with a few lines of code:
When the endpoint is in service, you can invoke the endpoint with an input image and a list of labels as the input prompt to generate the label probabilities:
Use case 2: Automatic prompt generation from images
One innovative application using the multimodality models is to generate informative prompts from an image. In generative AI, a prompt refers to the input provided to a language model or other generative model to instruct it on what type of content or response is desired. The prompt is essentially a starting point or a set of instructions that guides the model’s generation process. It can take the form of a sentence, question, partial text, or any input that conveys the context or desired output to the model. The choice of a well-crafted prompt is pivotal in generating high-quality images with precision and relevance. Prompt engineering is the process of optimizing or crafting a textual input to achieve desired responses from a language model, often involving wording, format, or context adjustments.
Prompt engineering for image generation poses several challenges, including the following:
- Defining visual concepts accurately – Describing visual concepts in words can sometimes be imprecise or ambiguous, making it difficult to convey the exact image desired. Capturing intricate details or complex scenes through textual prompts might not be straightforward.
- Specifying desired styles effectively – Communicating specific stylistic preferences, such as mood, color palette, or artistic style, can be challenging through text alone. Translating abstract aesthetic concepts into concrete instructions for the model can be tricky.
- Balancing complexity to prevent overloading the model – Elaborate prompts could confuse the model or lead to overloading it with information, affecting the generated output. Striking the right balance between providing sufficient guidance and avoiding overwhelming complexity is essential.
Therefore, crafting effective prompts for image generation is time consuming, which requires iterative experimentation and refining to strike the right balance between precision and creativity, making it a resource-intensive task that heavily relies on human expertise.
The CLIP Interrogator is an automatic prompt engineering tool for images that combines CLIP and BLIP to optimize text prompts to match a given image. You can use the resulting prompts with text-to-image models like Stable Diffusion to create cool art. The prompts created by CLIP Interrogator offer a comprehensive description of the image, covering not only its fundamental elements but also the artistic style, the potential inspiration behind the image, the medium where the image could have been or might be used, and beyond. You can easily deploy the CLIP Interrogator solution on SageMaker to streamline the deployment process, and take advantage of the scalability, cost-efficiency, and robust security provided by the fully managed service. The following diagram shows the flow logic of this solution.

You can use the following notebook to deploy the CLIP Interrogator solution on SageMaker. Similarly, for CLIP model hosting, we use the SageMaker LMI container to host the solution on SageMaker using DJL Serving. In this example, we provided an additional input file with the model artifacts that specifies the models deployed to the SageMaker endpoint. You can choose different CLIP or BLIP models by passing the caption model name and the clip model name through the model_name.json file created with the following code:
The inference script model.py contains a handle function that DJL Serving will run your request by invoking this function. To prepare this entry point script, we adopted the code from the original clip_interrogator.py file and modified it to work with DJL Serving on SageMaker hosting. One update is the loading of the BLIP model. The BLIP and CLIP models are loaded via the load_caption_model() and load_clip_model() function during the initialization of the Interrogator object. To load the BLIP model, we first downloaded the model artifacts from Hugging Face and uploaded them to Amazon S3 as the target value of the model_id in the properties file. This is because the BLIP model can be a large file, such as the blip2-opt-2.7b model, which is more than 15 GB in size. Downloading the model from Hugging Face during model deployment will require more time for endpoint creation. Therefore, we point the model_id to the Amazon S3 location of the BLIP2 model and load the model from the model path specified in the properties file. Note that, during deployment, the model path will be swapped to the local container path where the model artifacts were downloaded to by DJL Serving from the Amazon S3 location. See the following code:
Because the CLIP model isn’t very big in size, we use open_clip to load the model directly from Hugging Face, which is the same as the original clip_interrogator implementation:
We use similar code to deploy the CLIP Interrogator solution to a SageMaker endpoint and invoke the endpoint with an input image to get the prompts that can be used to generate similar images.
Let’s take the following image as an example. Using the deployed CLIP Interrogator endpoint on SageMaker, it generates the following text description: croissant on a plate, pexels contest winner, aspect ratio 16:9, cgsocietywlop, 8 h, golden cracks, the artist has used bright, picture of a loft in morning, object features, stylized border, pastry, french emperor.

We can further combine the CLIP Interrogator solution with Stable Diffusion and prompt engineering techniques—a whole new dimension of creative possibilities emerges. This integration allows us to not only describe images with text, but also manipulate and generate diverse variations of the original images. Stable Diffusion ensures controlled image synthesis by iteratively refining the generated output, and strategic prompt engineering guides the generation process towards desired outcomes.
In the second part of the notebook, we detail the steps to use prompt engineering to restyle images with the Stable Diffusion model (Stable Diffusion XL 1.0). We use the Stability AI SDK to deploy this model from SageMaker JumpStart after subscribing to this model on the AWS marketplace. Because this is a newer and better version for image generation provided by Stability AI, we can get high-quality images based on the original input image. Additionally, if we prefix the preceding description and add an additional prompt mentioning a known artist and one of his works, we get amazing results with restyling. The following image uses the prompt: This scene is a Van Gogh painting with The Starry Night style, croissant on a plate, pexels contest winner, aspect ratio 16:9, cgsocietywlop, 8 h, golden cracks, the artist has used bright, picture of a loft in morning, object features, stylized border, pastry, french emperor.

The following image uses the prompt: This scene is a Hokusai painting with The Great Wave off Kanagawa style, croissant on a plate, pexels contest winner, aspect ratio 16:9, cgsocietywlop, 8 h, golden cracks, the artist has used bright, picture of a loft in morning, object features, stylized border, pastry, french emperor.

Conclusion
The emergence of multimodality models, like CLIP and BLIP, and their applications are rapidly transforming the landscape of image-to-text conversion. Bridging the gap between visual and semantic information, they are providing us with the tools to unlock the vast potential of visual data and harness it in ways that were previously unimaginable.
In this post, we illustrated different applications of the multimodality models. These range from enhancing the efficiency and accuracy of search in ecommerce platforms through automatic tagging and categorization to the generation of prompts for text-to-image models like Stable Diffusion. These applications open new horizons for creating unique and engaging content. We encourage you to learn more by exploring the various multimodality models on SageMaker and build a solution that is innovative to your business.
About the Authors
Yanwei Cui, PhD, is a Senior Machine Learning Specialist Solutions Architect at AWS. He started machine learning research at IRISA (Research Institute of Computer Science and Random Systems), and has several years of experience building AI-powered industrial applications in computer vision, natural language processing, and online user behavior prediction. At AWS, he shares his domain expertise and helps customers unlock business potentials and drive actionable outcomes with machine learning at scale. Outside of work, he enjoys reading and traveling.
 Raghu Ramesha is a Senior ML Solutions Architect with the Amazon SageMaker Service team. He focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.
Raghu Ramesha is a Senior ML Solutions Architect with the Amazon SageMaker Service team. He focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.
 Sam Edwards, is a Cloud Engineer (AI/ML) at AWS Sydney specialized in machine learning and Amazon SageMaker. He is passionate about helping customers solve issues related to machine learning workflows and creating new solutions for them. Outside of work, he enjoys playing racquet sports and traveling.
Sam Edwards, is a Cloud Engineer (AI/ML) at AWS Sydney specialized in machine learning and Amazon SageMaker. He is passionate about helping customers solve issues related to machine learning workflows and creating new solutions for them. Outside of work, he enjoys playing racquet sports and traveling.
 Melanie Li, PhD, is a Senior AI/ML Specialist TAM at AWS based in Sydney, Australia. She helps enterprise customers build solutions using state-of-the-art AI/ML tools on AWS and provides guidance on architecting and implementing ML solutions with best practices. In her spare time, she loves to explore nature and spend time with family and friends.
Melanie Li, PhD, is a Senior AI/ML Specialist TAM at AWS based in Sydney, Australia. She helps enterprise customers build solutions using state-of-the-art AI/ML tools on AWS and provides guidance on architecting and implementing ML solutions with best practices. In her spare time, she loves to explore nature and spend time with family and friends.
Gordon Wang is a Senior AI/ML Specialist TAM at AWS. He supports strategic customers with AI/ML best practices cross many industries. He is passionate about computer vision, NLP, generative AI, and MLOps. In his spare time, he loves running and hiking.
 Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.
Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.

Keeping an AI on Quakes: Researchers Unveil Deep Learning Model to Improve Forecasts
A research team is aiming to shake up the status quo for earthquake models.
Researchers from the Universities of California at Berkeley and Santa Cruz, and the Technical University of Munich recently released a paper describing a new model that delivers deep learning to earthquake forecasting.
Dubbed RECAST, the model can use larger datasets and offer greater flexibility than the current model standard, ETAS, which has improved only incrementally since its development in 1988, it argues.
The paper’s authors — Kelian Dascher-Cousineau, Oleksandr Shchur, Emily Brodsky and Stephan Günnemann — trained the model on NVIDIA GPU workstations.
“There’s a whole field of research that explores how to improve ETAS,” said Dacher-Cousineau, a postdoctoral researcher at UC Berkeley. “It’s an immensely useful model that has been used a lot, but it’s been frustratingly hard to improve on it.”
AI Drives Seismology Ahead
The promise of RECAST is that its model flexibility, self-learning capability and ability to scale will enable it to interpret larger datasets and make better predictions during earthquake sequences, he said.
Model advances with improved forecasts could help agencies such as the U.S. Geological Survey and its counterparts elsewhere offer better information to those who need to know. Firefighters and other first responders entering damaged buildings, for example, could benefit from more reliable forecasts on aftershocks.
“There’s a ton of room for improvement within the forecasting side of things. And for a variety of reasons, our community hasn’t really dove into the machine learning side of things, partly because of being conservative and partly because these are really impactful decisions,” said Dacher-Cousineau.
RECAST Model Moves the Needle
While past work on aftershock predictions has relied on statistical models, this doesn’t scale to handle the larger datasets becoming available from an explosion of newly enhanced data capabilities, according to the researchers.
The RECAST model architecture builds on developments in neural temporal point processes, which are probabilistic generative models for continuous time event sequences. In a nutshell, the model has an encoder-decoder neural network architecture used for predicting the timing of a next event based on a history of past events.
Dacher-Cousineau said that releasing and benchmarking the model in the paper demonstrates that it can quickly learn to do what ETAS can do, while it holds vast potential to do more.
“Our model is a generative model that, just like a natural language processing model, you can generate paragraphs and paragraphs of words, and you can sample it and make synthetic catalogs,” said Dacher-Cousineau. “Part of the paper is there to convince old-school seismologists that this is a model that’s doing the right thing — we’re not overfitting.”
Boosting Earthquake Data With Enhanced Catalogs
Earthquake catalogs, or records of earthquake data, for particular geographies can be small. That’s because to this day many come from seismic analysts who interpret scribbles of raw data that comes from seismometers. But this, too, is an area where AI researchers are building models to autonomously interpret these P waves and other signals in the data in real time.
Enhanced data is meanwhile helping to fill the void. With the labeled data in earthquake catalogs, machine learning engineers are revisiting these sources of raw data and building enhanced catalogs to get 10x to 100x the number of earthquakes for training data and categories.
“So it’s not necessarily that we put out more instruments to gather data but rather that we enhance the datasets,” said Dacher-Cousineau.
Applying Larger Datasets to Other Settings
With the larger datasets, the researchers are starting to see improvements from RECAST over the standard ETAS model.
To advance the state of the art in earthquake forecasting, Dascher-Cousineau is working with a team of undergraduates at UC Berkeley to train earthquake catalogs on multiple regions for better predictions.
“I have the natural language processing analogies in mind, where it seems very plausible that earthquake sequences in Japan are useful to inform earthquakes in California,” he said. “And you can see that going in the right direction.”
Learn about synthetic data generation with NVIDIA Omniverse Replicator

Efficient and hardware-friendly neural architecture search with SpaceEvo
This research paper was presented at the 2023 IEEE/CVF International Conference on Computer Vision (opens in new tab) (ICCV), a premier academic conference for computer vision.

In the field of deep learning, where breakthroughs like the models ResNet (opens in new tab) and BERT (opens in new tab) have achieved remarkable success, a key challenge remains: developing efficient deep neural network (DNN) models that both excel in performance and minimize latency across diverse devices. To address this, researchers have introduced hardware-aware neural architecture search (NAS) to automate efficient model design for various hardware configurations. This approach involves a predefined search space, search algorithm, accuracy estimation, and hardware-specific cost prediction models.
However, optimizing the search space itself has often been overlooked. Current efforts rely mainly on MobileNets-based search spaces designed to minimize latency on mobile CPUs. But manual designs may not always align with different hardware requirements, limiting their suitability for a diverse range of devices.
In the paper, “SpaceEvo: Hardware-Friendly Search Space Design for Efficient INT8 Inference (opens in new tab),” presented at ICCV 2023, (opens in new tab) we introduce SpaceEvo, a novel method that automatically creates specialized search spaces optimized for efficient INT8 inference on specific hardware platforms. What sets SpaceEvo apart is its ability to perform this design process automatically, creating a search space tailored for hardware-specific, quantization-friendly NAS.
Microsoft Research Podcast

Collaborators: Holoportation communication technology with Spencer Fowers and Kwame Darko
communication technology with Spencer Fowers and Kwame Darko
Spencer Fowers and Kwame Darko break down how the technology behind Holoportation and the telecommunication device being built around it brings patients and doctors together when being in the same room isn’t an easy option and discuss the potential impact of the work.
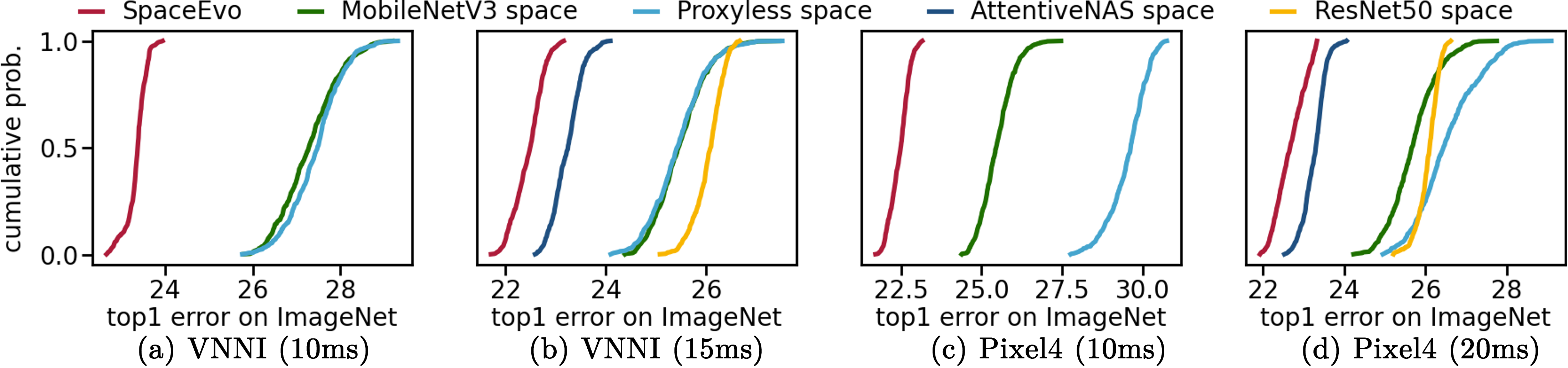
Notably, SpaceEvo’s lightweight design makes it ideal for practical applications, requiring only 25 GPU hours to create a hardware-specific solution and making it a cost-effective choice for hardware-aware NAS. This specialized search space, with hardware-preferred operators and configurations, enables the exploration of larger, more efficient models with low INT8 latency. Figure 1 demonstrates that our search space consistently outperforms existing alternatives in INT8 model quality. Conducting neural architecture searches within this hardware-friendly space yields models that set new INT8 accuracy benchmarks.
On-device quantization latency analysis
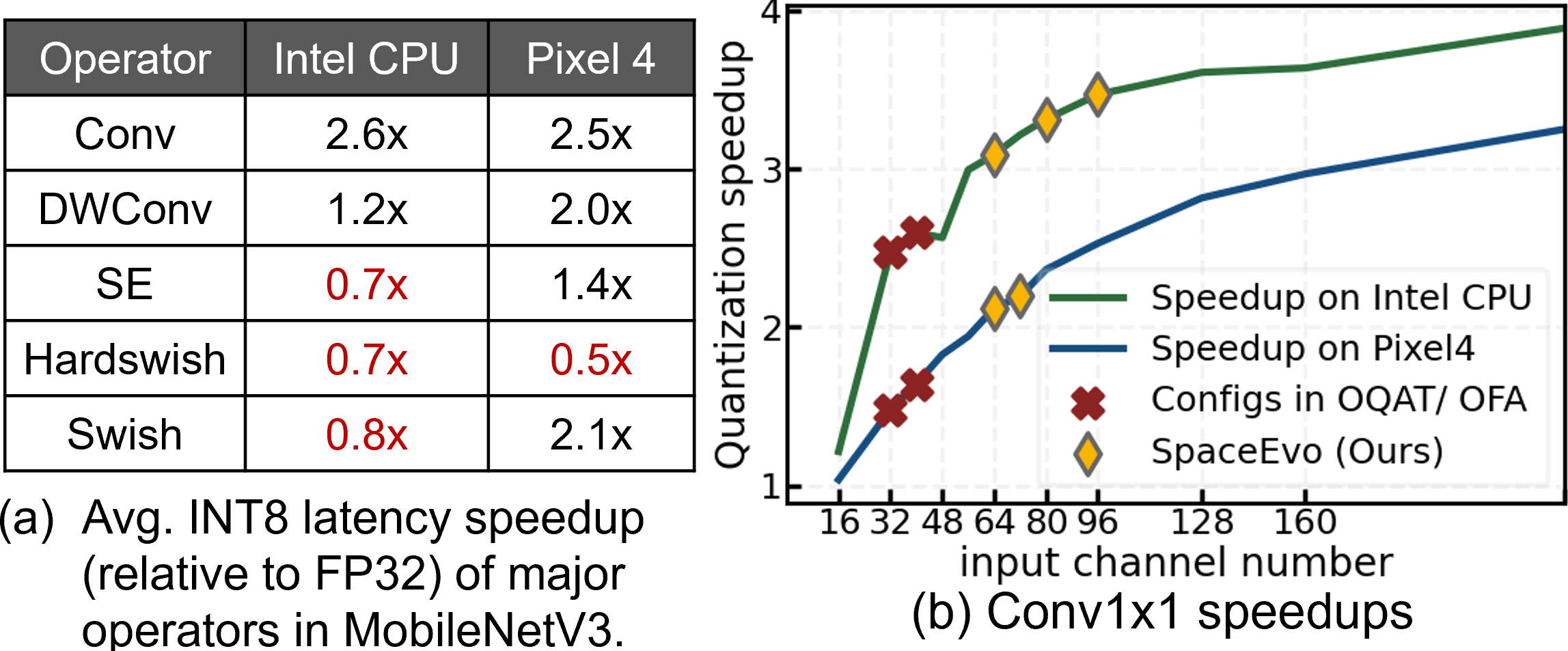
We began our investigation by trying to understand INT8 quantized latency factors and their implications for search space design. We conducted our study on two widely used devices: an Intel CPU with VNNI instructions and onnxruntime support, and a Pixel 4 phone CPU with TFLite 2.7.
Our study revealed two critical findings:
- Both the choice of operator type and configurations, like channel width, significantly affect INT8 latency, illustrated in Figure 2. For instance, operators like Squeeze-and-Excitation and Hardswish, while enhancing accuracy with minimal latency, can lead to slower INT8 inference on Intel CPUs. This slowdown primarily arises from the added costs of data transformation between INT32 and INT8, which outweigh the latency reduction achieved through INT8 computation.
- Quantization efficiency varies among different devices, and preferred operator types can be contradictory.
Finding diverse, efficient quantized models with SpaceEvo
Unlike traditional architecture search, which aims to find the best single model, our objective is to uncover a diverse population of billions of accurate and INT8 latency-friendly architectures within the search space.
Drawing inspiration from neural architecture search, we introduced an evolutionary search algorithm to explore this quantization-friendly model population in SpaceEvo. Our approach incorporated three key techniques:
- The introduction of the Q-T score as a metric to measure the quantization-friendliness of a candidate search space, based on the INT8 accuracy-latency of top-tier subnets.
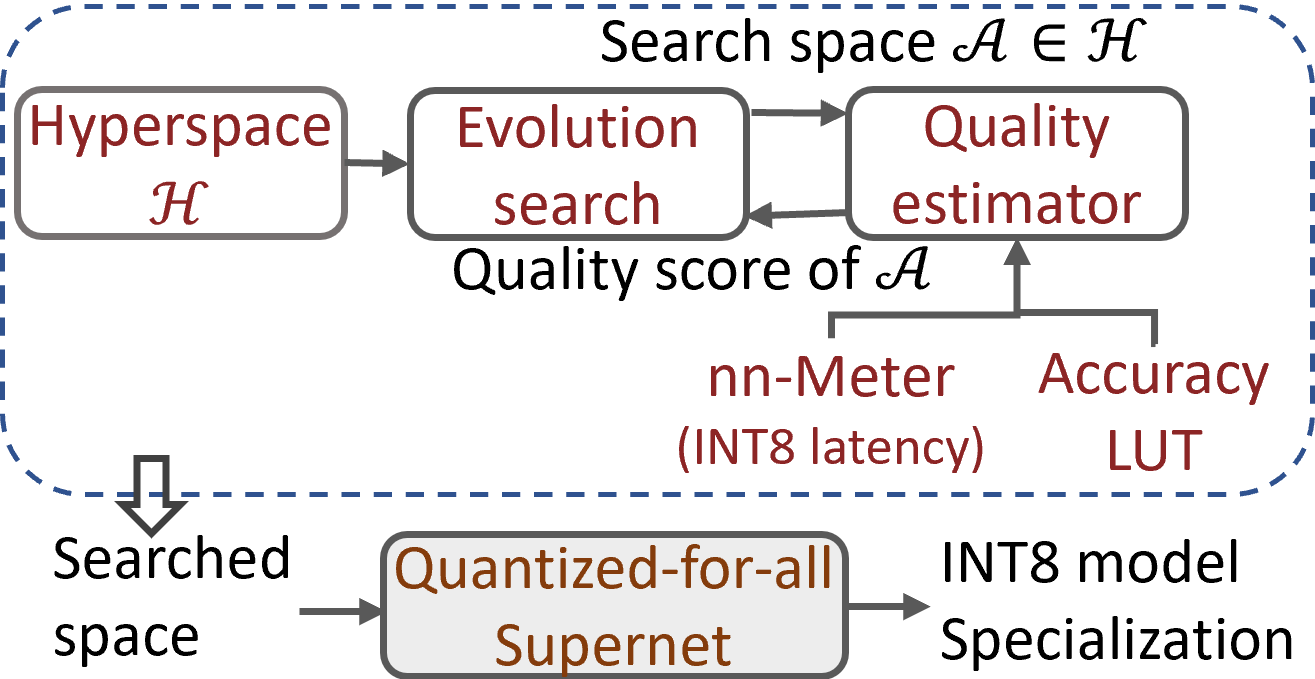
- Redesigned search algorithms that focus on exploring a collection of model populations (i.e., the search space) within the vast hyperspace, as illustrated in Figure 3. This is achieved through the “elastic stage,” which divides the search space into a sequence of elastic stages, allowing traditional evolution methods like aging evolution to explore effectively.
- A block-wise search space quantization scheme to reduce the training costs associated with exploring a search space that has a maximum Q-T score.
After discovering the search space, we employed a two-stage NAS process to train a quantized-for-all supernet over the search space. This ensured that all candidate models could achieve comparable quantized accuracy without individual fine-tuning or quantization. We utilized evolutionary search and nn-Meter (opens in new tab) for INT8 latency prediction to identify the best quantized models under various INT8 latency constraints. Figure 3 shows the overall design process.
Extensive experiments on two real-world edge devices and ImageNet demonstrated that our automatically designed search spaces significantly surpass manually designed search spaces. Table 1 showcases our discovered models, SEQnet, setting new benchmarks for INT8 quantized accuracy-latency tradeoffs.
| (a) Results on the Intel VNNI CPU with onnxruntime | |||||
| Model | Top-1 Acc % | Latency | Top-1 Acc % | FLOPs | |
| INT8 | INT8 | Speedup | FP32 | ||
| MobileNetV3Small | 66.3 | 4.4 ms | 1.1x | 67.4 | 56M |
| SEQnet@cpu-A0 | 74.7 | 4.4 ms | 2.0x | 74.8 | 163M |
| MobileNetV3Large | 74.5 | 10.3 ms | 1.5x | 75.2 | 219M |
| SEQnet@cpu-A1 | 77.4 | 8.8 ms | 2.4x | 77.5 | 358M |
| FBNetV3-A | 78.2 | 27.7 ms | 1.3x | 79.1 | 357M |
| SEQnet@cpu-A4 | 80.0 | 24.4 ms | 2.4x | 80.1 | 1267M |
| (b) Results on the Google Pixel 4 with TFLite | |||||
| MobileNetV3Small | 66.3 | 6.4 ms | 1.3x | 67.4 | 56M |
| SEQnet@pixel4-A0 | 73.6 | 5.9 ms | 2.1x | 73.7 | 107M |
| MobileNetV3Large | 74.5 | 15.7 ms | 1.5x | 75.2 | 219M |
| EfficientNet-B0 | 76.7 | 36.4 ms | 1.7x | 77.3 | 390M |
| SEQnet@pixel4-A1 | 77.6 | 14.7 ms | 2.2x | 77.7 | 274M |
Potential for sustainable and efficient computing
SpaceEvo is the first attempt to address the hardware-friendly search space optimization challenge in NAS, paving the way for designing effective low-latency DNN models for diverse real-world edge devices. Looking ahead, the implications of SpaceEvo reach far beyond its initial achievements. Its potential extends to applications for other crucial deployment metrics, such as energy and memory consumption, enhancing the sustainability of edge computing solutions.
We are exploring adapting these methods to support diverse model architectures like transformers, further expanding its role in evolving deep learning model design and efficient deployment.
The post Efficient and hardware-friendly neural architecture search with SpaceEvo appeared first on Microsoft Research.
How economic data informs a more equitable employee experience at Amazon
Wharton professor Jessie Handbury lends her expertise to Amazon’s PXTCS Team as an Amazon Visiting Academic.Read More
Improve prediction quality in custom classification models with Amazon Comprehend
Artificial intelligence (AI) and machine learning (ML) have seen widespread adoption across enterprise and government organizations. Processing unstructured data has become easier with the advancements in natural language processing (NLP) and user-friendly AI/ML services like Amazon Textract, Amazon Transcribe, and Amazon Comprehend. Organizations have started to use AI/ML services like Amazon Comprehend to build classification models with their unstructured data to get deep insights that they didn’t have before. Although you can use pre-trained models with minimal effort, without proper data curation and model tuning, you can’t realize the full benefits AI/ML models.
In this post, we explain how to build and optimize a custom classification model using Amazon Comprehend. We demonstrate this using an Amazon Comprehend custom classification to build a multi-label custom classification model, and provide guidelines on how to prepare the training dataset and tune the model to meet performance metrics such as accuracy, precision, recall, and F1 score. We use the Amazon Comprehend model training output artifacts like a confusion matrix to tune model performance and guide you on improving your training data.
Solution overview
This solution presents an approach to building an optimized custom classification model using Amazon Comprehend. We go through several steps, including data preparation, model creation, model performance metric analysis, and optimizing inference based on our analysis. We use an Amazon SageMaker notebook and the AWS Management Console to complete some of these steps.
We also go through best practices and optimization techniques during data preparation, model building, and model tuning.
Prerequisites
If you don’t have a SageMaker notebook instance, you can create one. For instructions, refer to Create an Amazon SageMaker Notebook Instance.
Prepare the data
For this analysis, we use the Toxic Comment Classification dataset from Kaggle. This dataset contains 6 labels with 158,571 data points. However, each label only has less than 10% of the total data as positive examples, with two of the labels having less than 1%.
We convert the existing Kaggle dataset to the Amazon Comprehend two-column CSV format with the labels split using a pipe (|) delimiter. Amazon Comprehend expects at least one label for each data point. In this dataset, we encounter several data points that don’t fall under any of the provided labels. We create a new label called clean and assign any of the data points that aren’t toxic to be positive with this label. Finally, we split the curated datasets into training and test datasets using an 80/20 ratio split per label.
We will be using the Data-Preparation notebook. The following steps use the Kaggle dataset and prepare the data for our model.
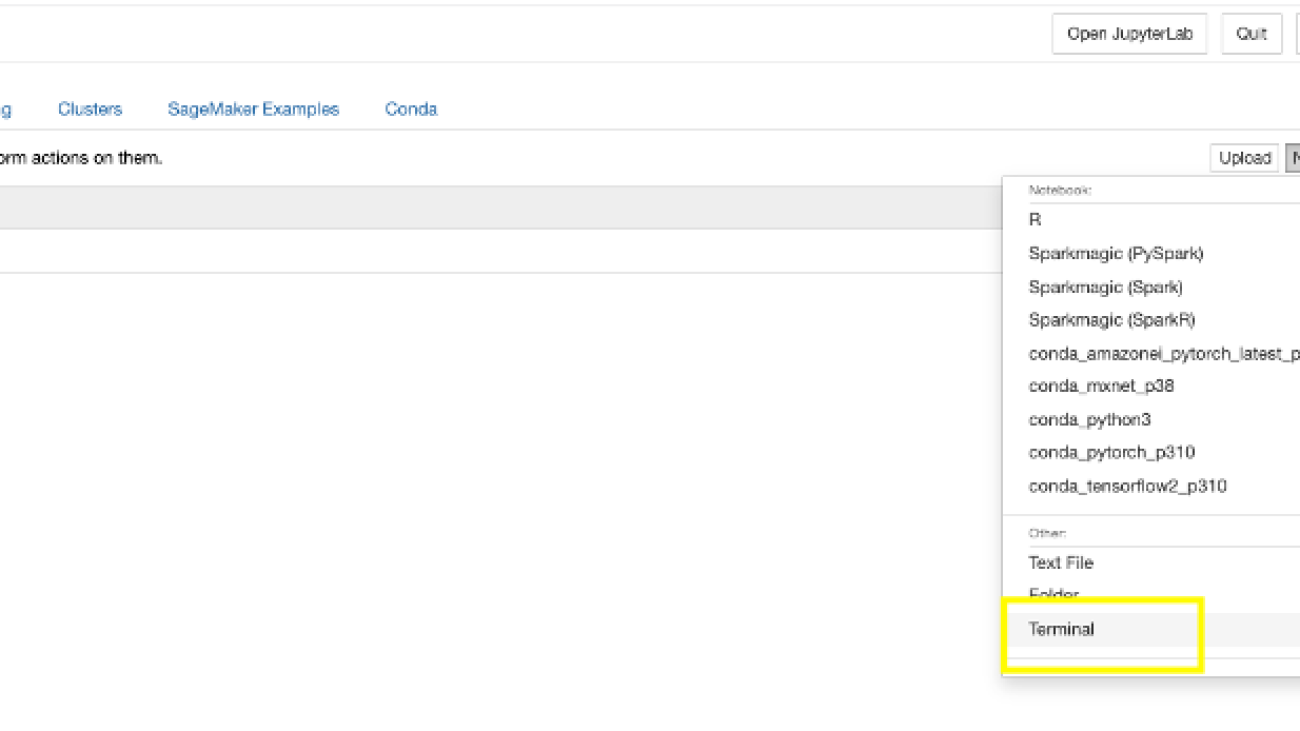
- On the SageMaker console, choose Notebook instances in the navigation pane.
- Select the notebook instance you have configured and choose Open Jupyter.
- On the New menu, choose Terminal.

- Run the following commands in the terminal to download the required artifacts for this post:
- Close the terminal window.
You should see three notebooks and train.csv files.
- Choose the notebook Data-Preparation.ipynb.
- Run all the steps in the notebook.
These steps prepare the raw Kaggle dataset to serve as curated training and test datasets. Curated datasets will be stored in the notebook and Amazon Simple Storage Service (Amazon S3).
Consider the following data preparation guidelines when dealing with large-scale multi-label datasets:
- Datasets must have a minimum of 10 samples per label.
- Amazon Comprehend accepts a maximum of 100 labels. This is a soft limit that can be increased.
- Ensure the dataset file is correctly formatted with the proper delimiter. Incorrect delimiters can introduce blank labels.
- All the data points must have labels.
- Training and test datasets should have balanced data distribution per label. Don’t use random distribution because it might introduce bias in the training and test datasets.
Build a custom classification model
We use the curated training and test datasets we created during the data preparation step to build our model. The following steps create an Amazon Comprehend multi-label custom classification model:
- On the Amazon Comprehend console, choose Custom classification in the navigation pane.
- Choose Create new model.
- For Model name, enter toxic-classification-model.
- For Version name, enter 1.
- For Annotation and data format, choose Using Multi-label mode.
- For Training dataset, enter the location of the curated training dataset on Amazon S3.
- Choose Customer provided test dataset and enter the location of the curated test data on Amazon S3.
- For Output data, enter the Amazon S3 location.
- For IAM role, select Create an IAM role, specify the name suffix as “comprehend-blog”.
- Choose Create to start the custom classification model training and model creation.
The following screenshot shows the custom classification model details on the Amazon Comprehend console.

Tune for model performance
The following screenshot shows the model performance metrics. It includes key metrics like precision, recall, F1 score, accuracy, and more.

After the model is trained and created, it will generate the output.tar.gz file, which contains the labels from the dataset as well as the confusion matrix for each of the labels. To further tune the model’s prediction performance, you have to understand your model with the prediction probabilities for each class. To do this, you need to create an analysis job to identify the scores Amazon Comprehend assigned to each of the data points.
Complete the following steps to create an analysis job:
- On the Amazon Comprehend console, choose Analysis jobs in the navigation pane.
- Choose Create job.
- For Name, enter
toxic_train_data_analysis_job. - For Analysis type, choose Custom classification.
- For Classification models and flywheels, specify
toxic-classification-model. - For Version, specify 1.
- For Input data S3 location, enter the location of the curated training data file.
- For Input format, choose One document per line.
- For Output data S3 location, enter the location.
- For Access Permissions, select Use an existing IAM Role and pick the role created previously.
- Choose Create job to start the analysis job.
- Select the Analysis jobs to view the job details. Please take a note of the job id under Job details. We will be using the job id in our next step.

Repeat the steps to the start analysis job for the curated test data. We use the prediction outputs from our analysis jobs to learn about our model’s prediction probabilities. Please make note of job ids of training and test analysis jobs.
We use the Model-Threshold-Analysis.ipynb notebook to test the outputs on all possible thresholds and score the output based on the prediction probability using the scikit-learn’s precision_recall_curve function. Additionally, we can compute the F1 score at each threshold.
We will need the Amazon Comprehend analysis job id’s as input for Model-Threshold-Analysis notebook. You can get the job ids from Amazon Comprehend console. Execute all the steps in Model-Threshold-Analysis notebook to observe the thresholds for all the classes.

Notice how precision goes up as the threshold goes up, while the inverse occurs with recall. To find the balance between the two, we use the F1 score where it has visible peaks in their curve. The peaks in the F1 score correspond to a particular threshold that can improve the model’s performance. Notice how most of the labels fall around the 0.5 mark for the threshold except for threat label, which has a threshold around 0.04.

We can then use this threshold for specific labels that are underperforming with just the default 0.5 threshold. By using the optimized thresholds, the results of the model on the test data improve for the label threat from 0.00 to 0.24. We are using the max F1 score at the threshold as a benchmark to determine positive vs. negative for that label instead of a common benchmark (a standard value like > 0.7) for all the labels.

Handling underrepresented classes
Another approach that’s effective for an imbalanced dataset is oversampling. By oversampling the underrepresented class, the model sees the underrepresented class more often and emphasizes the importance of those samples. We use the Oversampling-underrepresented.ipynb notebook to optimize the datasets.
For this dataset, we tested how the model’s performance on the evaluation dataset changes as we provide more samples. We use the oversampling technique to increase the occurrence of underrepresented classes to improve the performance.

In this particular case, we tested on 10, 25, 50, 100, 200, and 500 positive examples. Notice that although we are repeating data points, we are inherently improving the performance of the model by emphasizing the importance of the underrepresented class.
Cost
With Amazon Comprehend, you pay as you go based on the number of text characters processed. Refer to Amazon Comprehend Pricing for actual costs.
Clean up
When you’re finished experimenting with this solution, clean up your resources to delete all the resources deployed in this example. This helps you avoid continuing costs in your account.
Conclusion
In this post, we have provided best practices and guidance on data preparation, model tuning using prediction probabilities and techniques to handle underrepresented data classes. You can use these best practices and techniques to improve the performance metrics of your Amazon Comprehend custom classification model.
For more information about Amazon Comprehend, visit Amazon Comprehend developer resources to find video resources and blog posts, and refer to AWS Comprehend FAQs.
About the Authors
 Sathya Balakrishnan is a Sr. Customer Delivery Architect in the Professional Services team at AWS, specializing in data and ML solutions. He works with US federal financial clients. He is passionate about building pragmatic solutions to solve customers’ business problems. In his spare time, he enjoys watching movies and hiking with his family.
Sathya Balakrishnan is a Sr. Customer Delivery Architect in the Professional Services team at AWS, specializing in data and ML solutions. He works with US federal financial clients. He is passionate about building pragmatic solutions to solve customers’ business problems. In his spare time, he enjoys watching movies and hiking with his family.
 Prince Mallari is an NLP Data Scientist in the Professional Services team at AWS, specializing in applications of NLP for public sector customers. He is passionate about using ML as a tool to allow customers to be more productive. In his spare time, he enjoys playing video games and developing one with his friends.
Prince Mallari is an NLP Data Scientist in the Professional Services team at AWS, specializing in applications of NLP for public sector customers. He is passionate about using ML as a tool to allow customers to be more productive. In his spare time, he enjoys playing video games and developing one with his friends.
Fast and cost-effective LLaMA 2 fine-tuning with AWS Trainium
Large language models (LLMs) have captured the imagination and attention of developers, scientists, technologists, entrepreneurs, and executives across several industries. These models can be used for question answering, summarization, translation, and more in applications such as conversational agents for customer support, content creation for marketing, and coding assistants.
Recently, Meta released Llama 2 for both researchers and commercial entities, adding to the list of other LLMs, including MosaicML MPT and Falcon. In this post, we walk through how to fine-tune Llama 2 on AWS Trainium, a purpose-built accelerator for LLM training, to reduce training times and costs. We review the fine-tuning scripts provided by the AWS Neuron SDK (using NeMo Megatron-LM), the various configurations we used, and the throughput results we saw.
About the Llama 2 model
Similar to the previous Llama 1 model and other models like GPT, Llama 2 uses the Transformer’s decoder-only architecture. It comes in three sizes: 7 billion, 13 billion, and 70 billion parameters. Compared to Llama 1, Llama 2 doubles context length from 2,000 to 4,000, and uses grouped-query attention (only for 70B). Llama 2 pre-trained models are trained on 2 trillion tokens, and its fine-tuned models have been trained on over 1 million human annotations.
Distributed training of Llama 2
To accommodate Llama 2 with 2,000 and 4,000 sequence length, we implemented the script using NeMo Megatron for Trainium that supports data parallelism (DP), tensor parallelism (TP), and pipeline parallelism (PP). To be specific, with the new implementation of some features like untie word embedding, rotary embedding, RMSNorm, and Swiglu activation, we use the generic script of GPT Neuron Megatron-LM to support the Llama 2 training script.
Our high-level training procedure is as follows: for our training environment, we use a multi-instance cluster managed by the SLURM system for distributed training and scheduling under the NeMo framework.
First, download the Llama 2 model and training datasets and preprocess them using the Llama 2 tokenizer. For example, to use the RedPajama dataset, use the following command:
For detailed guidance of downloading models and the argument of the preprocessing script, refer to Download LlamaV2 dataset and tokenizer.
Next, compile the model:
After the model is compiled, launch the training job with the following script that is already optimized with the best configuration and hyperparameters for Llama 2 (included in the example code):
Lastly, we monitor TensorBoard to keep track of training progress:
For the complete example code and scripts we mentioned, refer to the Llama 7B tutorial and NeMo code in the Neuron SDK to walk through more detailed steps.
Fine-tuning experiments
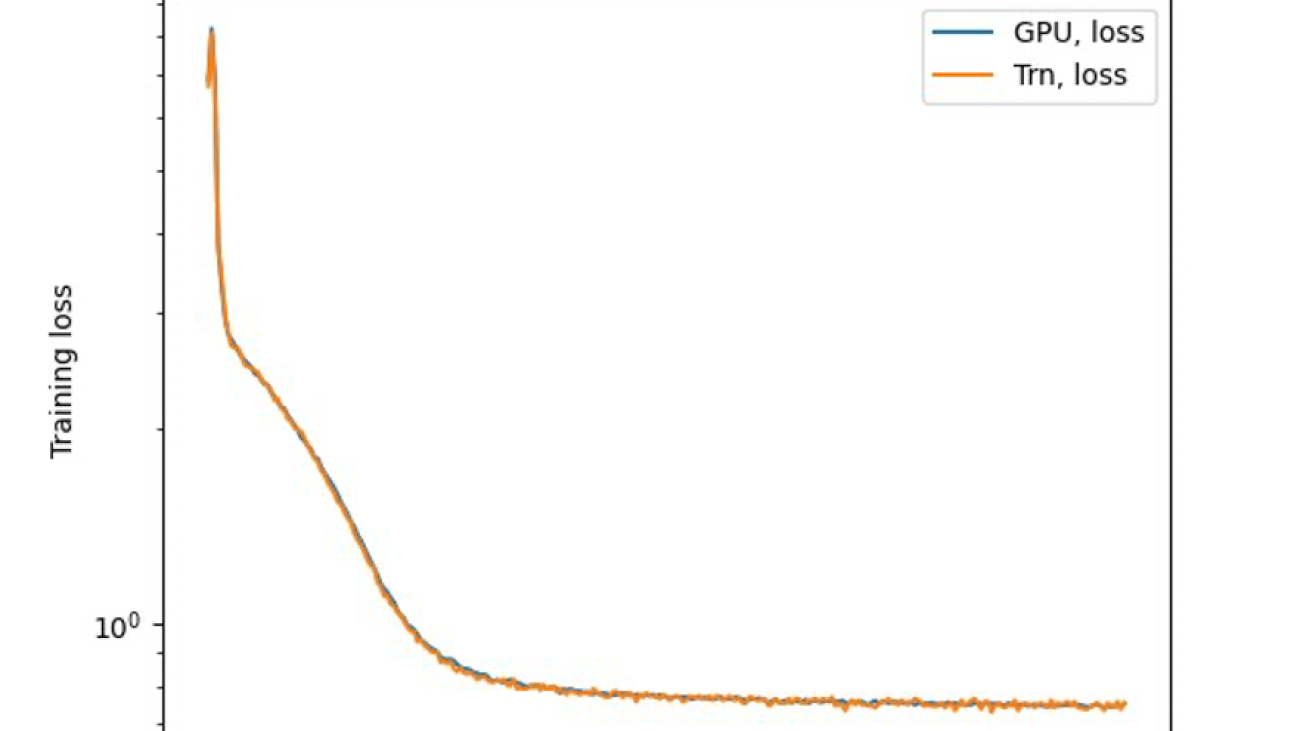
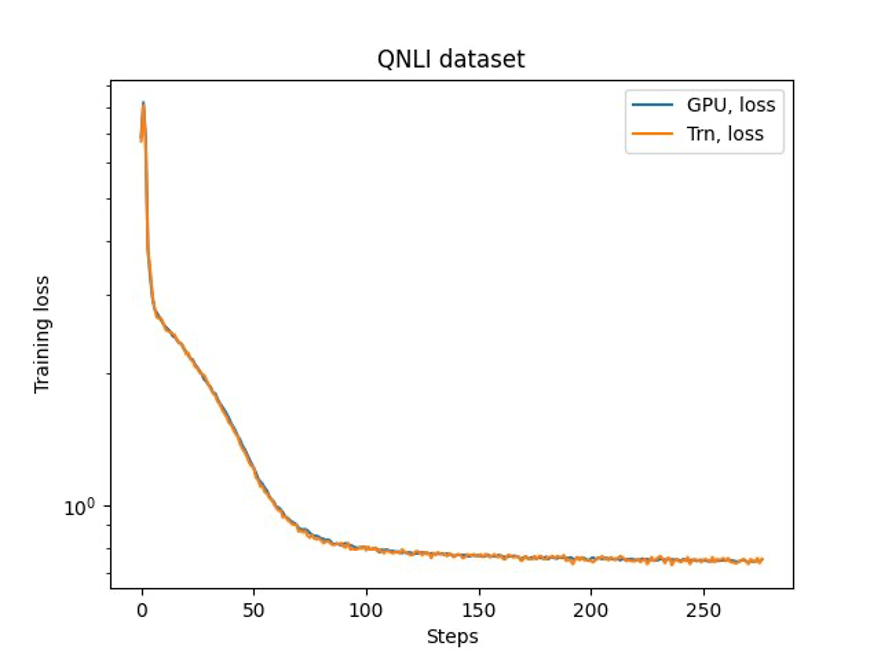
We fine-tuned the 7B model on the OSCAR (Open Super-large Crawled ALMAnaCH coRpus) and QNLI (Question-answering NLI) datasets in a Neuron 2.12 environment (PyTorch). For each 2,000 and 4,000 sequence length, we optimized some configurations, such as batchsize and gradient_accumulation, for training efficiency. As a fine-tuning strategy, we adopted full fine-tuning of all parameters (about 500 steps), which can be extended to pre-training with longer steps and larger datasets (for example, 1T RedPajama). Sequence parallelism can also be enabled to allow NeMo Megatron to successfully fine-tune models with a larger sequence length of 4,000. The following table shows the configuration and throughput results of the Llama 7B fine-tuning experiment. The throughput scales almost linearly as the number of instances increase up to 4.
| Distributed Library | Datasets | Sequence Length | Number of Instances | Tensor Parallel | Data Parallel | Pipeline Parellel | Global Batch size | Throughput (seq/s) |
| Neuron NeMo Megatron | OSCAR | 4096 | 1 | 8 | 4 | 1 | 256 | 3.7 |
| . | . | 4096 | 2 | 8 | 4 | 1 | 256 | 7.4 |
| . | . | 4096 | 4 | 8 | 4 | 1 | 256 | 14.6 |
| . | QNLI | 4096 | 4 | 8 | 4 | 1 | 256 | 14.1 |
The last step is to verify the accuracy with the base model. We implemented a reference script for GPU experiments and confirmed the training curves for GPU and Trainium matched as shown in the following figure. The figure illustrates loss curves over the number of training steps on the QNLI dataset. Mixed-precision was adopted for GPU (blue), and bf16 with default stochastic rounding for Trainium (orange).
Conclusion
In this post, we showed that Trainium delivers high performance and cost-effective fine-tuning of Llama 2. For more resources on using Trainium for distributed pre-training and fine-tuning your generative AI models using NeMo Megatron, refer to AWS Neuron Reference for NeMo Megatron.
About the Authors
 Hao Zhou is a Research Scientist with Amazon SageMaker. Before that, he worked on developing machine learning methods for fraud detection for Amazon Fraud Detector. He is passionate about applying machine learning, optimization, and generative AI techniques to various real-world problems. He holds a PhD in Electrical Engineering from Northwestern University.
Hao Zhou is a Research Scientist with Amazon SageMaker. Before that, he worked on developing machine learning methods for fraud detection for Amazon Fraud Detector. He is passionate about applying machine learning, optimization, and generative AI techniques to various real-world problems. He holds a PhD in Electrical Engineering from Northwestern University.
 Karthick Gopalswamy is an Applied Scientist with AWS. Before AWS, he worked as a scientist in Uber and Walmart Labs with a major focus on mixed integer optimization. At Uber, he focused on optimizing the public transit network with on-demand SaaS products and shared rides. At Walmart Labs, he worked on pricing and packing optimizations. Karthick has a PhD in Industrial and Systems Engineering with a minor in Operations Research from North Carolina State University. His research focuses on models and methodologies that combine operations research and machine learning.
Karthick Gopalswamy is an Applied Scientist with AWS. Before AWS, he worked as a scientist in Uber and Walmart Labs with a major focus on mixed integer optimization. At Uber, he focused on optimizing the public transit network with on-demand SaaS products and shared rides. At Walmart Labs, he worked on pricing and packing optimizations. Karthick has a PhD in Industrial and Systems Engineering with a minor in Operations Research from North Carolina State University. His research focuses on models and methodologies that combine operations research and machine learning.
 Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. He has published many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Series A.
Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. He has published many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Series A.
 Youngsuk Park is a Sr. Applied Scientist at AWS Annapurna Labs, working on developing and training foundation models on AI accelerators. Prior to that, Dr. Park worked on R&D for Amazon Forecast in AWS AI Labs as a lead scientist. His research lies in the interplay between machine learning, foundational models, optimization, and reinforcement learning. He has published over 20 peer-reviewed papers in top venues, including ICLR, ICML, AISTATS, and KDD, with the service of organizing workshop and presenting tutorials in the area of time series and LLM training. Before joining AWS, he obtained a PhD in Electrical Engineering from Stanford University.
Youngsuk Park is a Sr. Applied Scientist at AWS Annapurna Labs, working on developing and training foundation models on AI accelerators. Prior to that, Dr. Park worked on R&D for Amazon Forecast in AWS AI Labs as a lead scientist. His research lies in the interplay between machine learning, foundational models, optimization, and reinforcement learning. He has published over 20 peer-reviewed papers in top venues, including ICLR, ICML, AISTATS, and KDD, with the service of organizing workshop and presenting tutorials in the area of time series and LLM training. Before joining AWS, he obtained a PhD in Electrical Engineering from Stanford University.
 Yida Wang is a principal scientist in the AWS AI team of Amazon. His research interest is in systems, high-performance computing, and big data analytics. He currently works on deep learning systems, with a focus on compiling and optimizing deep learning models for efficient training and inference, especially large-scale foundation models. The mission is to bridge the high-level models from various frameworks and low-level hardware platforms including CPUs, GPUs, and AI accelerators, so that different models can run in high performance on different devices.
Yida Wang is a principal scientist in the AWS AI team of Amazon. His research interest is in systems, high-performance computing, and big data analytics. He currently works on deep learning systems, with a focus on compiling and optimizing deep learning models for efficient training and inference, especially large-scale foundation models. The mission is to bridge the high-level models from various frameworks and low-level hardware platforms including CPUs, GPUs, and AI accelerators, so that different models can run in high performance on different devices.
 Jun (Luke) Huan is a Principal Scientist at AWS AI Labs. Dr. Huan works on AI and Data Science. He has published more than 160 peer-reviewed papers in leading conferences and journals and has graduated 11 PhD students. He was a recipient of the NSF Faculty Early Career Development Award in 2009. Before joining AWS, he worked at Baidu Research as a distinguished scientist and the head of Baidu Big Data Laboratory. He founded StylingAI Inc., an AI start-up, and worked as the CEO and Chief Scientist in 2019–2021. Before joining the industry, he was the Charles E. and Mary Jane Spahr Professor in the EECS Department at the University of Kansas. From 2015–2018, he worked as a program director at the US NSF in charge of its big data program.
Jun (Luke) Huan is a Principal Scientist at AWS AI Labs. Dr. Huan works on AI and Data Science. He has published more than 160 peer-reviewed papers in leading conferences and journals and has graduated 11 PhD students. He was a recipient of the NSF Faculty Early Career Development Award in 2009. Before joining AWS, he worked at Baidu Research as a distinguished scientist and the head of Baidu Big Data Laboratory. He founded StylingAI Inc., an AI start-up, and worked as the CEO and Chief Scientist in 2019–2021. Before joining the industry, he was the Charles E. and Mary Jane Spahr Professor in the EECS Department at the University of Kansas. From 2015–2018, he worked as a program director at the US NSF in charge of its big data program.
 Shruti Koparkar is a Senior Product Marketing Manager at AWS. She helps customers explore, evaluate, and adopt Amazon EC2 accelerated computing infrastructure for their machine learning needs.
Shruti Koparkar is a Senior Product Marketing Manager at AWS. She helps customers explore, evaluate, and adopt Amazon EC2 accelerated computing infrastructure for their machine learning needs.
How Amazon DataZone helps customers find value in oceans of data
The service, which is now generally available, uses machine learning to make it faster and easier to catalogue, discover, share, and govern data.Read More