This paper was accepted at the EMNLP Workshop on Computational Approaches to Linguistic Code-Switching (CALCS).
Code-switching (CS), i.e. mixing different languages in a single sentence, is a common phenomenon in communication and can be challenging in many Natural Language Processing (NLP) settings. Previous studies on CS speech have shown promising results for end-to-end speech translation (ST), but have been limited to offline scenarios and to translation to one of the languages present in the source (monolingual transcription).
In this paper, we focus on two essential yet unexplored areas…Apple Machine Learning Research

Audioplethysmography for cardiac monitoring with hearable devices

The market for true wireless stereo (TWS) active noise canceling (ANC) hearables (headphones and earbuds) has been soaring in recent years, and the global shipment volume will nearly double that of smart wristbands and watches in 2023. The on-head time for hearables has extended significantly due to the recent advances in ANC, transparency mode, and artificial intelligence. Users frequently wear hearables not just for music listening, but also for exercising, focusing, or simply mood adjustment. However, hearable health is still mostly uncharted territory for the consumer market.
In “APG: Audioplethysmography for Cardiac Monitoring in Hearables,” presented at MobiCom 2023, we introduce a novel active in-ear health sensing modality. Audioplethysmography (APG) enables ANC hearables to monitor a user’s physiological signals, such as heart rate and heart rate variability, without adding extra sensors or compromising battery life. APG exhibits high resilience to motion artifacts, adheres to safety regulations with an 80 dB margin below the limit, remains unaffected by seal conditions, and is inclusive of all skin tones.
 |
| APG sends a low intensity ultrasound transmitting wave (TX wave) using an ANC headphone’s speakers and collects the receiving wave (RX wave) via the on-board feedback microphones. The APG signal is a pulse-like waveform that synchronizes with heartbeat and reveals rich cardiac information, such as dicrotic notches. |
Health sensing in the ear canal
The auditory canal receives its blood supply from the arteria auricularis profunda, also known as the deep ear artery. This artery forms an intricate network of smaller vessels that extensively permeate the auditory canal. Slight variations in blood vessel shape caused by the heartbeat (and blood pressure) can lead to subtle changes in the volume and pressure of the ear canals, making the ear canal an ideal location for health sensing.
Recent research has explored using hearables for health sensing by packaging together a plethora of sensors — e.g., photoplethysmograms (PPG) and electrocardiograms (ECG) — with a microcontroller to enable health applications, such as sleep monitoring, heart rate and blood pressure tracking. However, this sensor mounting paradigm inevitably adds cost, weight, power consumption, acoustic design complexity, and form factor challenges to hearables, constituting a strong barrier to its wide adoption.
Existing ANC hearables deploy feedback and feedforward microphones to navigate the ANC function. These microphones create new opportunities for various sensing applications as they can detect or record many bio-signals inside and outside the ear canal. For example, feedback microphones can be used to listen to heartbeats and feedforward microphones can hear respirations. Academic research on this passive sensing paradigm has prompted many mobile applications, including heart rate monitoring, ear disease diagnosis, respiration monitoring, and body activity recognition. However, microphones in consumer-grade ANC headphones come with built-in high-pass filters to prevent saturation from body motions or strong wind noise. The signal quality of passive listening in the ear canal also heavily relies on the earbud seal conditions. As such, it is challenging to embed health features that rely on the passive listening of low frequency signals (≤ 50 Hz) on commercial ANC headphones.
Measuring tiny physiological signals
APG bypasses the aforementioned ANC headphone hardware constraints by sending a low intensity ultrasound probing signal through an ANC headphone’s speakers. This signal triggers echoes, which are received via on-board feedback microphones. We observe that the tiny ear canal skin displacement and heartbeat vibrations modulate these ultrasound echoes.
We build a cylindrical resonance model to understand APG’s underlying physics. This phenomenon happens at an extremely small scale, which makes the raw pulse signal invisible in the raw received ultrasound. We adopt coherent detection to retrieve this micro physiological modulation under the noise floor (we term this retrieved signal as mixed-down signal, see the paper for more details). The final APG waveform looks strikingly similar to a PPG waveform, but provides an improved view of cardiac activities with more pronounced dicrotic notches (i.e., pressure waveforms that provide rich insights about the central artery system, such as blood pressure).
 |
| A cylindrical model with cardiac activities ℎ(𝑡) that modulates both the phase and amplitude of the mixed-down signal. Based on the simulation from our analytical model, the amplitude 𝑅(𝑡) and phase Φ(𝑡) of the mixed-down APG signals both reflect the cardiac activities ℎ(𝑡). |
APG sensing in practice
During our initial experiments, we observed that APG works robustly with bad earbuds seals and with music playing. However, we noticed the APG signal can sometimes be very noisy and could be heavily disturbed by body motion. At that point, we determined that in order to make APG useful, we had to make it more robust to compete with more than 80 years of PPG development.
While PPGs are widely used and highly advanced, they do have some limitations. For example, PPGs sensors typically use two to four diodes to send and receive light frequencies for sensing. However, due to the ultra high-frequency nature (hundreds of Terahertz) of the light, it’s difficult for a single diode to send multiple colors with different frequencies. On the other hand, we can easily design a low-cost and low-power system that generates and receives more than ten audio tones (frequencies). We leverage channel diversity, a physical phenomenon that describes how wireless signals (e.g., light and audio) at different frequencies have different characters (e.g., different attenuation and reflection coefficients) when the signal propagates in a medium, to enable a higher quality APG signal and motion resilience.
Next, we experimentally demonstrate the effectiveness of using multiple frequencies in the APG signaling. We transmit three probing signals concurrently with their frequencies spanning evenly from 30 KHz to 32 KHz. A participant was asked to shake their head four times during the experiment to introduce interference. The figure below shows that different frequencies can be transmitted simultaneously to gather various information with coherent detection, a unique advantage to APG.
The 30 kHz phase shows the four head movements and the magnitude (amplitude) of 31 kHz shows the pulse wave signal. This observation shows that some ultrasound frequencies might be sensitive to cardiac activities while others might be sensitive to motion. Therefore, we can use the multi-tone APG as a calibration signal to find the best frequency that measures heart rate, and use only the best frequency to get high-quality pulse waveform.
 |
| The mixed-down amplitude (upper row) and phase (bottom row) for a customized multi-tone APG signal that spans from 30 kHz to 32 kHz. With channel diversity, the cardiac activities are captured in some frequencies (e.g., magnitude of 31 kHz) and head movements are captured in other frequencies (e.g., magnitude of 30 kHz, 30 kHz, and phase of 31 kHz). |
After choosing the best frequency to measure heart rate, the APG pulse waveform becomes more visible with pronounced dicrotic notches , and enables accurate heart rate variability measurement.
 |
| The final APG signal used in the measurement phase (left) and chest ECG signal (right). |
Multi-tone translates to multiple simultaneous observations, which enable the development of array signal processing techniques. We demonstrate the spectrogram of a running session APG experiment before and after applying blind source separation (see the paper for more details). We also show the ground truth heart rate measurement in the same running experiment using a Polar ECG chest strap. In the raw APG, we see the running cadence (around 3.3 Hz) as well as two dim lines (around 2 Hz and 4 Hz) that indicate the user’s heart rate frequency and its harmonics. The heart rate frequencies are significantly enhanced in signal to noise ratio (SNR) after the blind source separation, which align with the ground truth heart rate frequencies. We also show the calculated heart rate and running cadence from APG and ECG. We can see that APG tracks the growth of heart rate during the running session accurately.
 |
| APG tracks the heart rate accurately during the running session and also measures the running cadence. |
Field study and closing thoughts
We conducted two rounds of user experience (UX) studies with 153 participants. Our results demonstrate that APG achieves consistently accurate heart rate (3.21% median error across participants in all activity scenarios) and heart rate variability (2.70% median error in inter-beat interval) measurements. Unlike PPG, which exhibits variable performance across skin tones, our study shows that APG is resilient to variation in: skin tone, sub-optimal seal conditions, and ear canal size. More detailed evaluations can be found in the paper.
APG transforms any TWS ANC headphones into smart sensing headphones with a simple software upgrade, and works robustly across various user activities. The sensing carrier signal is completely inaudible and not impacted by music playing. More importantly, APG represents new knowledge in biomedical and mobile research and unlocks new possibilities for low-cost health sensing.
Acknowledgements
APG is the result of collaboration across Google Health, product, UX and legal teams. We would like to thank David Pearl, Jesper Ramsgaard, Cody Wortham, Octavio Ponce, Patrick Amihood, Sam Sheng, Michael Pate, Leonardo Kusumo, Simon Tong, Tim Gladwin, Russ Mirov, Kason Walker, Govind Kannan, Jayvon Timmons, Dennis Rauschmayer, Chiong Lai, Shwetak Patel, Jake Garrison, Anran Wang, Shiva Rajagopal, Shelten Yuen, Seobin Jung, Yun Liu, John Hernandez, Issac Galatzer-Levy, Isaiah Fischer-Brown, Jamie Rogers, Pramod Rudrapatna, Andrew Barakat, Jason Guss, Ethan Grabau, Pol Peiffer, Bill Park, Helen O’Connor, Mia Cheng, Keiichiro Yumiba, Felix Bors, Priyanka Jantre, Luzhou Xu, Jian Wang, Jaime Lien, Gerry Pallipuram, Nicholas Gillian, Michal Matuszak, Jakub Wojciechowski, Bryan Allen, Jane Hilario, and Phil Carmack for their invaluable insights and support. Thanks to external collaborators Longfei Shangguan and Rich Howard, Rutgers University and University of Pittsburgh.
Elevate your marketing solutions with Amazon Personalize and generative AI
Generative artificial intelligence is transforming how enterprises do business. Organizations are using AI to improve data-driven decisions, enhance omnichannel experiences, and drive next-generation product development. Enterprises are using generative AI specifically to power their marketing efforts through emails, push notifications, and other outbound communication channels. Gartner predicts that “by 2025, 30% of outbound marketing messages from large organizations will be synthetically generated.” However, generative AI alone isn’t enough to deliver engaging customer communication. Research shows that the most impactful communication is personalized—showing the right message to the right user at the right time. According to McKinsey, “71% of consumers expect companies to deliver personalized interactions.” Customers can use Amazon Personalize and generative AI to curate concise, personalized content for marketing campaigns, increase ad engagement, and enhance conversational chatbots.
Developers can use Amazon Personalize to build applications powered by the same type of machine learning (ML) technology used by Amazon.com for real-time personalized recommendations. With Amazon Personalize, developers can improve user engagement through personalized product and content recommendations with no ML expertise required. Using recipes (algorithms prepared to support specific uses cases) provided by Amazon Personalize, customers can deliver a wide array of personalization, including specific product or content recommendations, personalized ranking, and user segmentation. Additionally, as a fully managed artificial intelligence service, Amazon Personalize accelerates customers’ digital transformations with ML, making it easier to integrate personalized recommendations into existing websites, applications, email marketing systems, and so on.
In this post, we illustrate how you can elevate your marketing campaigns using Amazon Personalize and generative AI with Amazon Bedrock. Together, Amazon Personalize and generative AI help you tailor your marketing to individual consumer preferences.
How exactly do Amazon Personalize and Amazon Bedrock work together to achieve this? Imagine as a marketer that you want to send tailored emails to users recommending movies they would enjoy based on their interactions across your platform. Or perhaps you want to send targeted emails to a segment of users promoting a new shoe they might be interested in. The following use cases use generative AI to enhance two common marketing emails.
Use Case 1: Use generative AI to deliver targeted one-to-one personalized emails
With Amazon Personalize and Amazon Bedrock, you can generate personalized recommendations and create outbound messages with a personal touch tailored to each of your users.
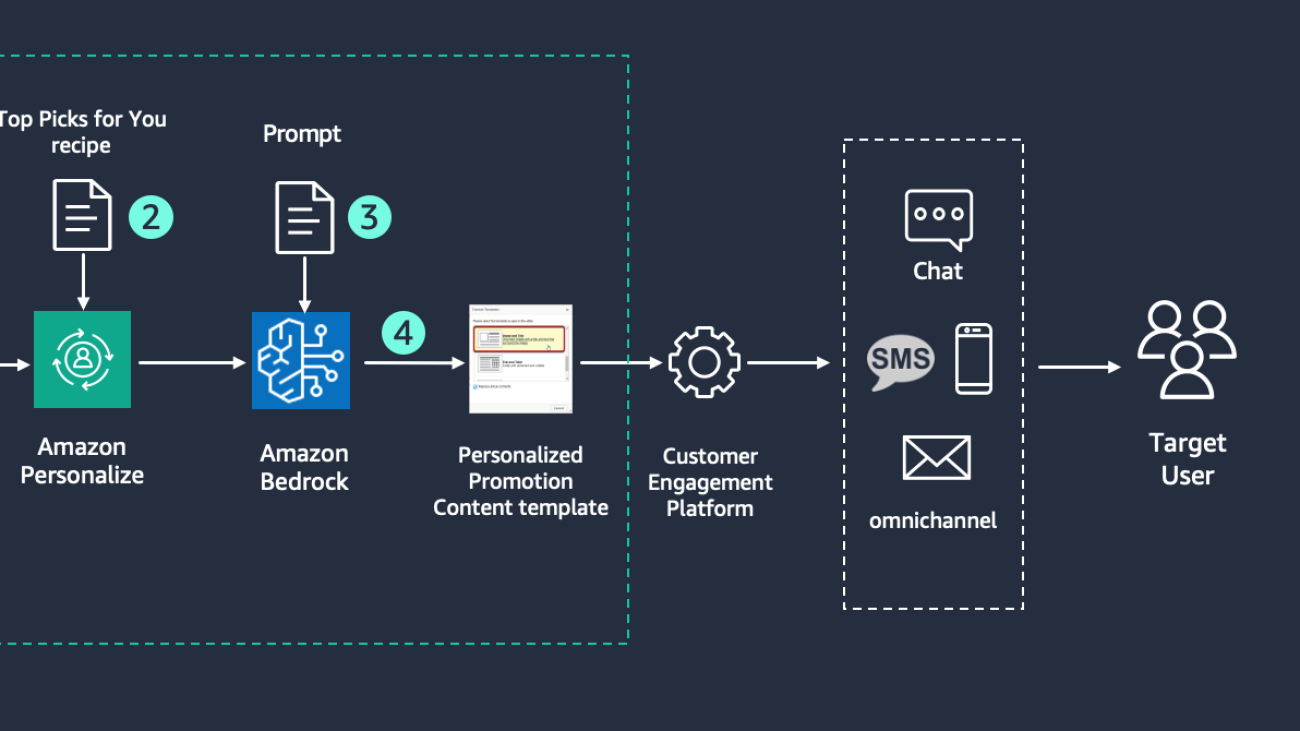
The following diagram illustrates the architecture and workflow for delivering targeted personalized emails powered by generative AI.

First, import your dataset of users’ interactions into Amazon Personalize for training. Amazon Personalize automatically trains a model using the Top Picks for You recipe. As an output, Amazon Personalize provides recommendations that align with the users’ preferences.
You can use the following code to identify recommended items for users:
For more information, see the Amazon Personalize API reference.
The provided output of recommendations is ingested by Amazon Bedrock using a prompt, which includes your user preferences, demographics, and Amazon Personalize recommended items.
For example, a marketer who wants to create a personalized email that is charming and fun for a user might use the following prompt:
Create a personalized email which is charming and fun so that the user is engaged. The user has recently watched family-friendly films. These are the recommended items – The Little Mermaid, Encanto, Spider-Man: Into the Spider-Verse.
By invoking one of the foundation models (FM) provided in Amazon Bedrock, such as Claude 2, with the prompt and sample code that follows, you can create a personalized email for a user:
For more information, see the Amazon Bedrock API reference.
Amazon Bedrock returns a personalized email for the user:
Subject: Fall in love with this recommended selection for movie night!
Dear <user name>,
Desiring the cozy feel of fall? No problem! Check our top three recommendations for movies that will have you cozy on the couch with your loved ones:
1. The Little Mermaid: This classic Disney movie is all about a mermaid princess named Ariel, who dreams of the human world. Because of her fascination, she makes a deal with the sea witch Ursula and learns a major lesson.
2. Encanto: This Disney movie is about the Madrigals, a Colombian family who lives in a magical house. Each member of the family has a unique gift, except for young Maribel who must help save her family.
3. Spider-Man: Into the Spider-Verse: This animated superhero movie is a must-see action movie. Spider-man, a Brooklyn teen named Miles Morales, teams up with other spider-powered people to save the multiverse.
With lovable characters, catchy tunes, and moving stories, you really can’t go wrong with any of these three. Grab the popcorn because you’re in for a treat!
Use case 2: Use generative AI to elevate one-to-many marketing campaigns
When it comes to one-to-many email marketing, generic content can result in low engagement (that is, low open rates and unsubscribes). One way companies circumvent this outcome is to manually craft variations of outbound messages with compelling subjects. This can lead to inefficient use of time. By integrating Amazon Personalize and Amazon Bedrock into your workflow, you can quickly identify the interested segment of users and create variations of email content with greater relevance and engagement.
The following diagram illustrates the architecture and workflow for elevating marketing campaigns powered by generative AI.

To compose one-to-many emails, first import your dataset of users’ interactions into Amazon Personalize for training. Amazon Personalize trains the model using the user segmentation recipe. With the user segmentation recipe, Amazon Personalize automatically identifies the individual users that demonstrate a propensity for the chosen items as the target audience.
To identify the target audience and retrieve metadata for an item you can use the following sample code:
For more information, see the Amazon Personalize API reference.
Amazon Personalize delivers a list of recommended users to target for each item to batch_output_path. You can then invoke the user segment into Amazon Bedrock using one of the FMs along with your prompt.
For this use case, you might want to market a newly released sneaker through email. An example prompt might include the following:
For the user segment “sneaker heads”, create a catchy email that promotes the latest sneaker “Ultra Fame II”. Provide users with discount code FAME10 to save 10%.
Similar to the first use case, you’ll use the following code in Amazon Bedrock:
For more information, see the Amazon Bedrock API reference.
Amazon Bedrock returns a personalized email based on the items chosen for each user as shown:
Subject: <<name>>, your ticket to the Hall of Fame awaits
Hey <<name>>,
The wait is over. Check out the new Ultra Fame II! It’s the most innovative and comfortable Ultra Fame shoe yet. Its new design will have you turning heads with every step. Plus, you’ll get a mix of comfort, support, and style that’s just enough to get you into the Hall of Fame.
Don’t wait until it’s too late. Use the code FAME10 to save 10% on your next pair.
To test and determine the email that leads to the highest engagement, you can use Amazon Bedrock to generate a variation of catchy subject lines and content in a fraction of the time it would take to manually produce test content.
Conclusion
By integrating Amazon Personalize and Amazon Bedrock, you are enabled to deliver personalized promotional content to the right audience.
Generative AI powered by FMs is changing how businesses build hyper-personalized experiences for consumers. AWS AI services, such as Amazon Personalize and Amazon Bedrock, can help recommend and deliver products, content, and compelling marketing messages personalized to your users. For more information on working with generative AI on AWS, see to Announcing New Tools for Building with Generative AI on AWS.
About the Authors
 Ba’Carri Johnson is a Sr. Technical Product Manager working with AWS AI/ML on the Amazon Personalize team. With a background in computer science and strategy, she is passionate about product innovation. In her spare time, she enjoys traveling and exploring the great outdoors.
Ba’Carri Johnson is a Sr. Technical Product Manager working with AWS AI/ML on the Amazon Personalize team. With a background in computer science and strategy, she is passionate about product innovation. In her spare time, she enjoys traveling and exploring the great outdoors.
 Ragini Prasad is a Software Development Manager with the Amazon Personalize team focused on building AI-powered recommender systems at scale. In her spare time, she enjoys art and travel.
Ragini Prasad is a Software Development Manager with the Amazon Personalize team focused on building AI-powered recommender systems at scale. In her spare time, she enjoys art and travel.
 Jingwen Hu is a Sr. Technical Product Manager working with AWS AI/ML on the Amazon Personalize team. In her spare time, she enjoys traveling and exploring local food.
Jingwen Hu is a Sr. Technical Product Manager working with AWS AI/ML on the Amazon Personalize team. In her spare time, she enjoys traveling and exploring local food.
 Anna Grüebler is a Specialist Solutions Architect at AWS focusing on artificial intelligence. She has more than 10 years of experience helping customers develop and deploy machine learning applications. Her passion is taking new technologies and putting them in the hands of everyone and solving difficult problems by taking advantage of using AI in the cloud.
Anna Grüebler is a Specialist Solutions Architect at AWS focusing on artificial intelligence. She has more than 10 years of experience helping customers develop and deploy machine learning applications. Her passion is taking new technologies and putting them in the hands of everyone and solving difficult problems by taking advantage of using AI in the cloud.
 Tim Wu Kunpeng is a Sr. AI Specialist Solutions Architect with extensive experience in end-to-end personalization solutions. He is a recognized industry expert in e-commerce and media and entertainment, with expertise in generative AI, data engineering, deep learning, recommendation systems, responsible AI, and public speaking.
Tim Wu Kunpeng is a Sr. AI Specialist Solutions Architect with extensive experience in end-to-end personalization solutions. He is a recognized industry expert in e-commerce and media and entertainment, with expertise in generative AI, data engineering, deep learning, recommendation systems, responsible AI, and public speaking.

Data Formulator: A concept-driven, AI-powered approach to data visualization
This research paper was presented at the IEEE Visualization Conference (opens in new tab) (VIS 2023), the premier forum for advances in visualization and visual analytics.

Effective data visualization plays a crucial role in data analysis. It enables data analysts and others to explore complex datasets, comprehend patterns, and convey meaningful insights to various stakeholders. Today, there are numerous tools for creating visual representations of data. However, these tools only work with tidy data, meaning that data points must be organized according to the specific categories required by the tool’s visualization format. This poses significant challenges for data analysts, requiring the use of additional tools to transform raw data into a compatible format before it is entered into one of these visualization tools.
For instance, consider a dataset displaying 2020 temperatures in Seattle and Atlanta. If an analyst aims to create a scatter plot comparing the temperatures of these two US cities on the x/y-axes, data transformation is essential. The visualization tool mandates separate columns for Seattle and Atlanta temperatures to map to the scatter plot’s axes. Consequently, the analyst must pivot the input table to generate these columns. Moreover, if the analyst intends to compare which city experiences warmer days or create a smoothed line chart illustrating Seattle’s 7-day moving average temperature, further computations on the transformed data are necessary. Fields like “Warmer” and “Seattle 7-day Moving Avg” need to be calculated to facilitate the visualization, as depicted in Figure 1. This intricate process highlights the complexity and expertise currently needed to prepare raw data for effective visualization.
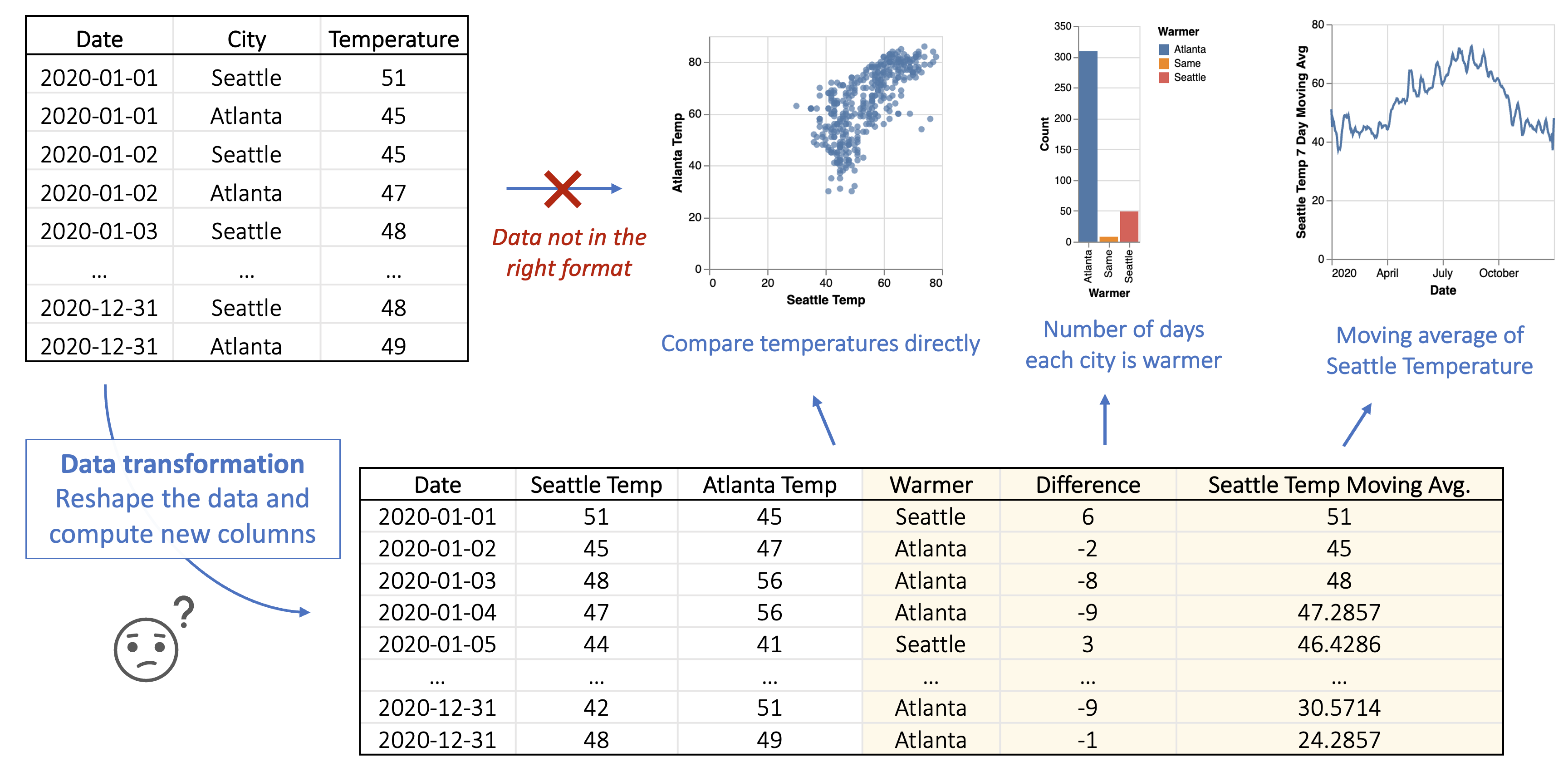
This hurdle is particularly daunting because it necessitates a certain level of programming expertise or familiarity with additional data processing tools. It highlights the complexities of data visualization and underscores the need for an easier and more seamless process for data analysts, enabling them to create impactful visualizations regardless of their technical background.
Against the backdrop of rapid advancements in learning language models (LLMs) and programming-by-example techniques, researchers have made significant strides in breaking down these barriers. In this context, we share our paper, “Data Formulator: AI-powered Concept-driven Visualization Authoring (opens in new tab),” presented at VIS 2023 (opens in new tab) and winner of the Best Paper Honorable Mention (opens in new tab) award. Data Formulator is an AI-powered visualization authoring tool developed through a collaboration between researchers studying AI and those studying human-computer interaction (HCI). The result is a new visualization paradigm that separates high-level visualization intents from low-level data transformation steps. The process begins with data analysts articulating their visualization ideas as data concepts. These concepts refer to specific data categories, or fields, that analysts want to visualize, even though they are not present in the raw input data. This way, they effectively convey their visualization intent with the AI agent, which, in turn, assists them in implementing their visualization.
Defining data concepts and creating visualizations
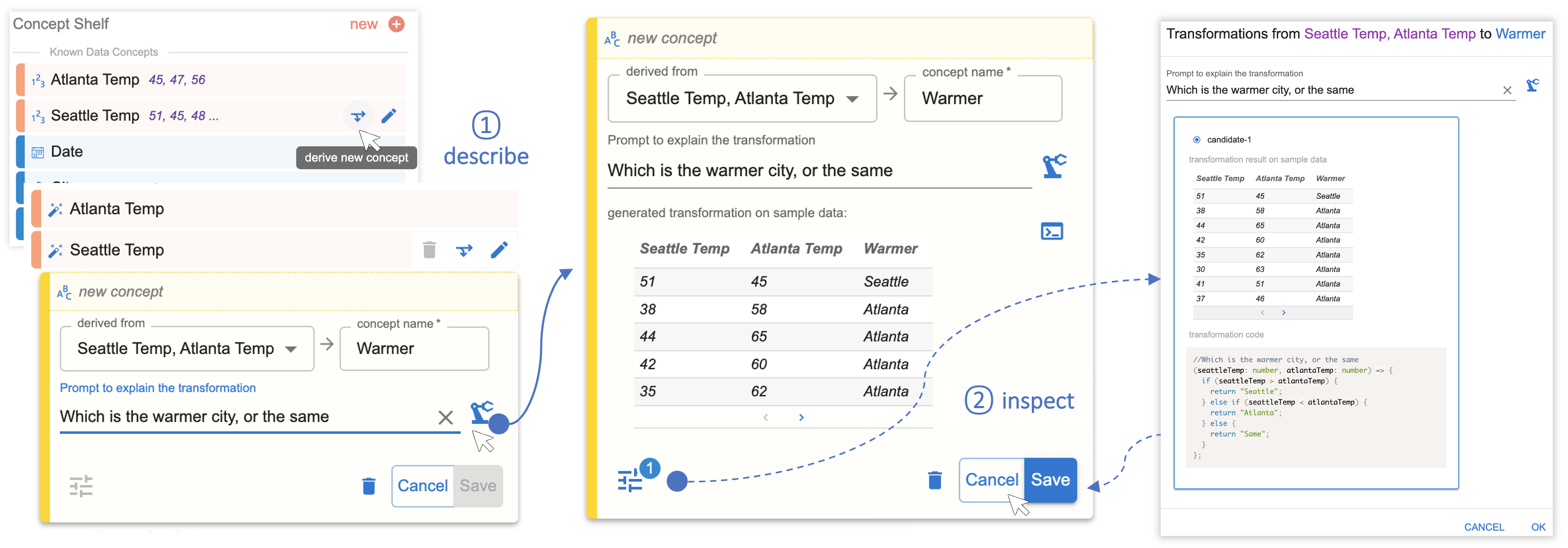
The way Data Formula operates is straightforward. The analyst defines the specific data concepts they plan to visualize, either through natural language queries or by providing categories, or example entries for the concept. Once these concepts are defined, they are linked to appropriate visual representation, as illustrated in Figure 2.
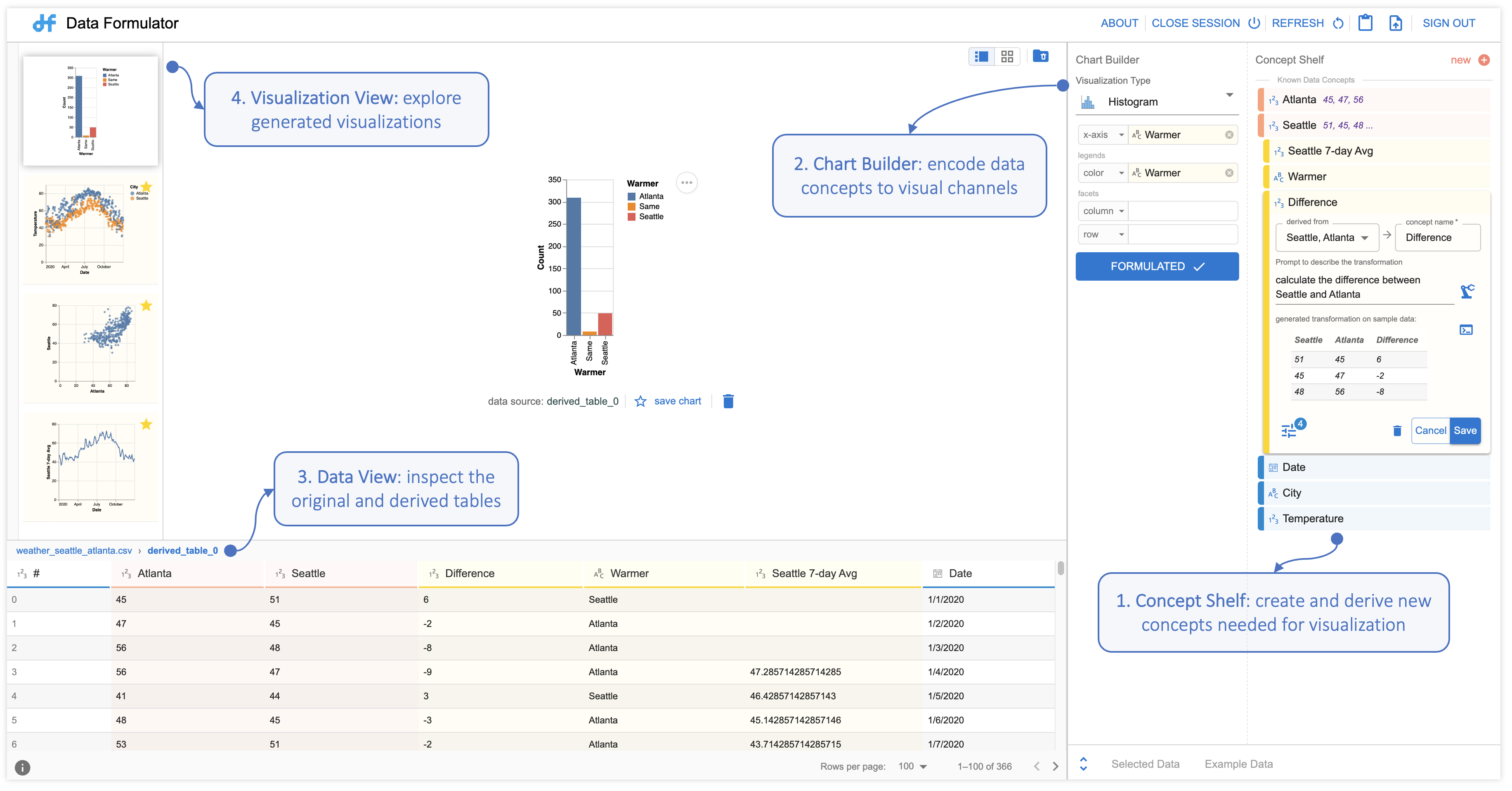
If the analyst defines concepts through examples, Data Formulator engages a program synthesizer, which generates a specialized data reshaping program, transforming the provided data to bring out the required data fields. Conversely, when an analyst introduces a new concept using natural language queries, Data Formulator calls on LLMs to generate code, which facilitates the creation of a new data category based on the provided description. In both cases, Data Formulator compiles the transformed data into a structured table and creates corresponding visualizations.
We recognize that analyst specifications can be ambiguous, so we designed Data Formulator to generate multiple visualization options to help them identify what they want. The tool also provides analysts with the AI-generated transformation program and the transformed data for inspection. This transparency helps analysts refine their intent for future iterations.
In continuing our Seattle/Atlanta temperatures example, the following two figures show how analysts can use Data Formulator to create visualizations without reformatting raw data using an external tool. Instead, the analyst provides example entries in the form of temperature values to create new the data concepts “Seattle Temp” and “Atlanta Temp,” shown in Figure 3. The analyst uses these natural language queries to create the new concept “Warmer” and instructs Data Formulator to format the data so that it can be visualized, shown in Figure 4.
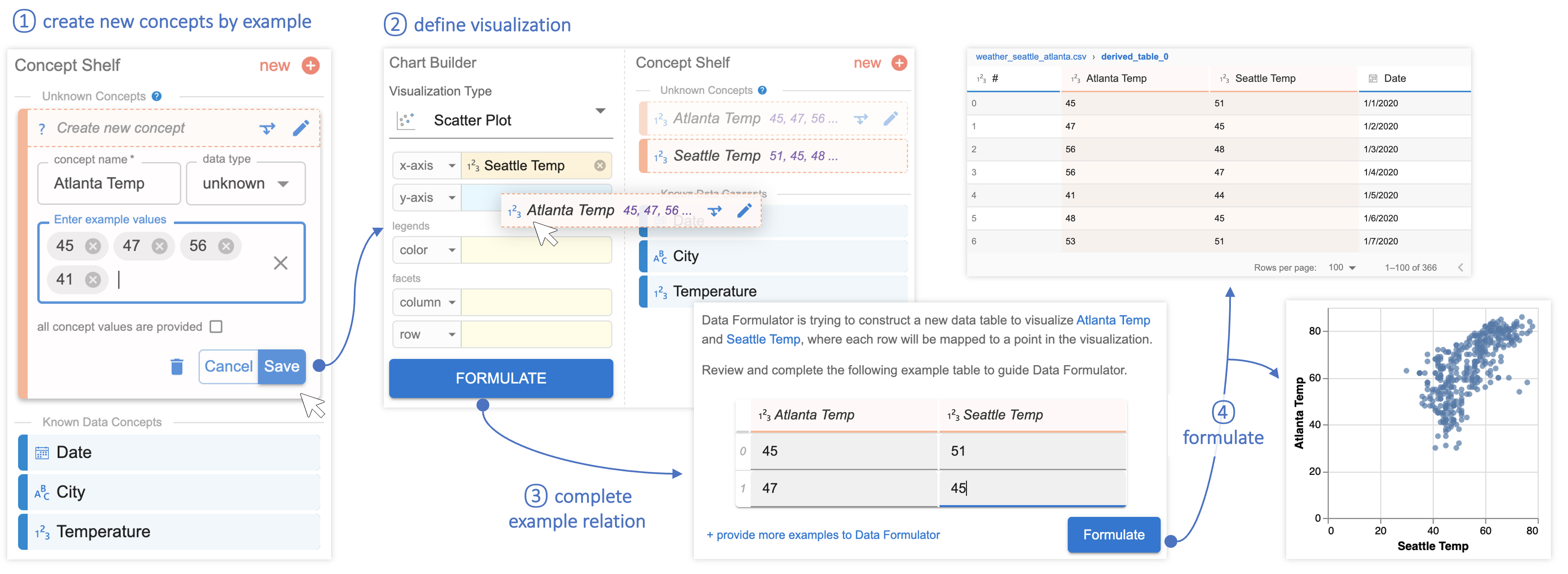
Looking ahead: Analyst-AI collaboration in data analysis
AI-powered data analysis tools have the potential to significantly streamline the entire data analysis process by consolidating various tasks into a single tool. Beyond just visualization, this concept-driven technique can be applied to data cleaning, data integration, visual data exploration, and visual storytelling. Our vision is for an AI system to take high-level instruction from the user and automatically recommend the necessary steps across the entire data analysis pipeline, enabling collaboration between the user and the AI agent to achieve their data visualization goals.
Inevitably, data analysts will need to tackle more complex tasks beyond the scope mentioned here. For this reason, it’s crucial to consider how to design AI-powered tools that effectively convey results to the analyst that are uncertain, ambiguous, or incorrect. This ensures that the analyst can trust the tool and collaborate effectively with AI to accomplish their objectives.
The post Data Formulator: A concept-driven, AI-powered approach to data visualization appeared first on Microsoft Research.
Better foundation models for video representation
Motion vectors — which are common in popular video formats — can be used to efficiently track regions of interest across multiple frames of video to generate motion-aware masks that improve video representation learning.Read More
Identifying Controversial Pairs in Item-to-Item Recommendations
*= Equal Contributors
Recommendation systems in large-scale online marketplaces are essential to aiding users in discovering new content. However, state-of-the-art systems for item-to-item recommendation tasks are often based on a shallow level of contextual relevance, which can make the system insufficient for tasks where item relationships are more nuanced. Contextually relevant item pairs can sometimes have problematic relationships that are confusing or even controversial to end users, and they could degrade user experiences and brand perception when recommended to users. For example, the…Apple Machine Learning Research
Modality Dropout for Multimodal Device Directed Speech Detection using Verbal and Non-Verbal Features
Device-directed speech detection (DDSD) is the binary classification task of distinguishing between queries directed at a voice assistant versus side conversation or background speech. State-of-the-art DDSD systems use verbal cues (for example, acoustic, text and/or automatic speech recognition system (ASR) features) to classify speech as device-directed or otherwise, and often have to contend with one or more of these modalities being unavailable when deployed in real-world settings. In this paper, we investigate fusion schemes for DDSD systems that can be made more robust to missing…Apple Machine Learning Research

Supporting benchmarks for AI safety with MLCommons

Standard benchmarks are agreed upon ways of measuring important product qualities, and they exist in many fields. Some standard benchmarks measure safety: for example, when a car manufacturer touts a “five-star overall safety rating,” they’re citing a benchmark. Standard benchmarks already exist in machine learning (ML) and AI technologies: for instance, the MLCommons Association operates the MLPerf benchmarks that measure the speed of cutting edge AI hardware such as Google’s TPUs. However, though there has been significant work done on AI safety, there are as yet no similar standard benchmarks for AI safety.
We are excited to support a new effort by the non-profit MLCommons Association to develop standard AI safety benchmarks. Developing benchmarks that are effective and trusted is going to require advancing AI safety testing technology and incorporating a broad range of perspectives. The MLCommons effort aims to bring together expert researchers across academia and industry to develop standard benchmarks for measuring the safety of AI systems into scores that everyone can understand. We encourage the whole community, from AI researchers to policy experts, to join us in contributing to the effort.
Why AI safety benchmarks?
Like most advanced technologies, AI has the potential for tremendous benefits but could also lead to negative outcomes without appropriate care. For example, AI technology can boost human productivity in a wide range of activities (e.g., improve health diagnostics and research into diseases, analyze energy usage, and more). However, without sufficient precautions, AI could also be used to support harmful or malicious activities and respond in biased or offensive ways.
By providing standard measures of safety across categories such as harmful use, out-of-scope responses, AI-control risks, etc., standard AI safety benchmarks could help society reap the benefits of AI while ensuring that sufficient precautions are being taken to mitigate these risks. Initially, nascent safety benchmarks could help drive AI safety research and inform responsible AI development. With time and maturity, they could help inform users and purchasers of AI systems. Eventually, they could be a valuable tool for policy makers.
In computer hardware, benchmarks (e.g., SPEC, TPC) have shown an amazing ability to align research, engineering, and even marketing across an entire industry in pursuit of progress, and we believe standard AI safety benchmarks could help do the same in this vital area.
What are standard AI safety benchmarks?
Academic and corporate research efforts have experimented with a range of AI safety tests (e.g., RealToxicityPrompts, Stanford HELM fairness, bias, toxicity measurements, and Google’s guardrails for generative AI). However, most of these tests focus on providing a prompt to an AI system and algorithmically scoring the output, which is a useful start but limited to the scope of the test prompts. Further, they usually use open datasets for the prompts and responses, which may already have been (often inadvertently) incorporated into training data.
MLCommons proposes a multi-stakeholder process for selecting tests and grouping them into subsets to measure safety for particular AI use-cases, and translating the highly technical results of those tests into scores that everyone can understand. MLCommons is proposing to create a platform that brings these existing tests together in one place and encourages the creation of more rigorous tests that move the state of the art forward. Users will be able to access these tests both through online testing where they can generate and review scores and offline testing with an engine for private testing.
AI safety benchmarks should be a collective effort
Responsible AI developers use a diverse range of safety measures, including automatic testing, manual testing, red teaming (in which human testers attempt to produce adversarial outcomes), software-imposed restrictions, data and model best-practices, and auditing. However, determining that sufficient precautions have been taken can be challenging, especially as the community of companies providing AI systems grows and diversifies. Standard AI benchmarks could provide a powerful tool for helping the community grow responsibly, both by helping vendors and users measure AI safety and by encouraging an ecosystem of resources and specialist providers focused on improving AI safety.
At the same time, development of mature AI safety benchmarks that are both effective and trusted is not possible without the involvement of the community. This effort will need researchers and engineers to come together and provide innovative yet practical improvements to safety testing technology that make testing both more rigorous and more efficient. Similarly, companies will need to come together and provide test data, engineering support, and financial support. Some aspects of AI safety can be subjective, and building trusted benchmarks supported by a broad consensus will require incorporating multiple perspectives, including those of public advocates, policy makers, academics, engineers, data workers, business leaders, and entrepreneurs.
Google’s support for MLCommons
Grounded in our AI Principles that were announced in 2018, Google is committed to specific practices for the safe, secure, and trustworthy development and use of AI (see our 2019, 2020, 2021, 2022 updates). We’ve also made significant progress on key commitments, which will help ensure AI is developed boldly and responsibly, for the benefit of everyone.
Google is supporting the MLCommons Association’s efforts to develop AI safety benchmarks in a number of ways.
- Testing platform: We are joining with other companies in providing funding to support the development of a testing platform.
- Technical expertise and resources: We are providing technical expertise and resources, such as the Monk Skin Tone Examples Dataset, to help ensure that the benchmarks are well-designed and effective.
- Datasets: We are contributing an internal dataset for multilingual representational bias, as well as already externalized tests for stereotyping harms, such as SeeGULL and SPICE. Moreover, we are sharing our datasets that focus on collecting human annotations responsibly and inclusively, like DICES and SRP.
Future direction
We believe that these benchmarks will be very useful for advancing research in AI safety and ensuring that AI systems are developed and deployed in a responsible manner. AI safety is a collective-action problem. Groups like the Frontier Model Forum and Partnership on AI are also leading important standardization initiatives. We’re pleased to have been part of these groups and MLCommons since their beginning. We look forward to additional collective efforts to promote the responsible development of new generative AI tools.
Acknowledgements
Many thanks to the Google team that contributed to this work: Peter Mattson, Lora Aroyo, Chris Welty, Kathy Meier-Hellstern, Parker Barnes, Tulsee Doshi, Manvinder Singh, Brian Goldman, Nitesh Goyal, Alice Friend, Nicole Delange, Kerry Barker, Madeleine Elish, Shruti Sheth, Dawn Bloxwich, William Isaac, Christina Butterfield.
Intelligently search Drupal content using Amazon Kendra
Amazon Kendra is an intelligent search service powered by machine learning (ML). Amazon Kendra helps you easily aggregate content from a variety of content repositories into a centralized index that lets you quickly search all your enterprise data and find the most accurate answer. Drupal is a content management software. It’s used to make many of the websites and applications we use every day. Drupal has a great feature set, like straightforward content authoring, reliable performance, and security. Many organizations use Drupal to store their content. One of the key requirements for many customers using Drupal is the ability to easily and securely find accurate information across all the documents in the data source.
With the Amazon Kendra Drupal connector, you can index Drupal content, filter the types of custom content you want to index, and easily search through Drupal content using Amazon Kendra intelligent search.
This post shows you how to use the Amazon Kendra Drupal connector to configure the connector as a data source for your Amazon Kendra index and search your Drupal documents. Based on the configuration of the Drupal connector, you can synchronize the connector to crawl and index different types of Drupal content such as blogs and wikis. The connector also ingests the access control list (ACL) information for each file. The ACL information is used for user context filtering, where search results for a query are filtered by what a user has authorized access to.
Prerequisites
To try out the Amazon Kendra connector for Drupal using this post as a reference, you need the following:
- An AWS account with privileges to create AWS Identity and Access Management (IAM) roles and policies. For more information, see Overview of access management: Permissions and policies and IAM roles for Drupal data sources.
- Basic knowledge of AWS and working knowledge of Drupal administration.
- Drupal set up with a user with the
Administratorrole. We will store the administrator user name and password in AWS Secrets Manager.

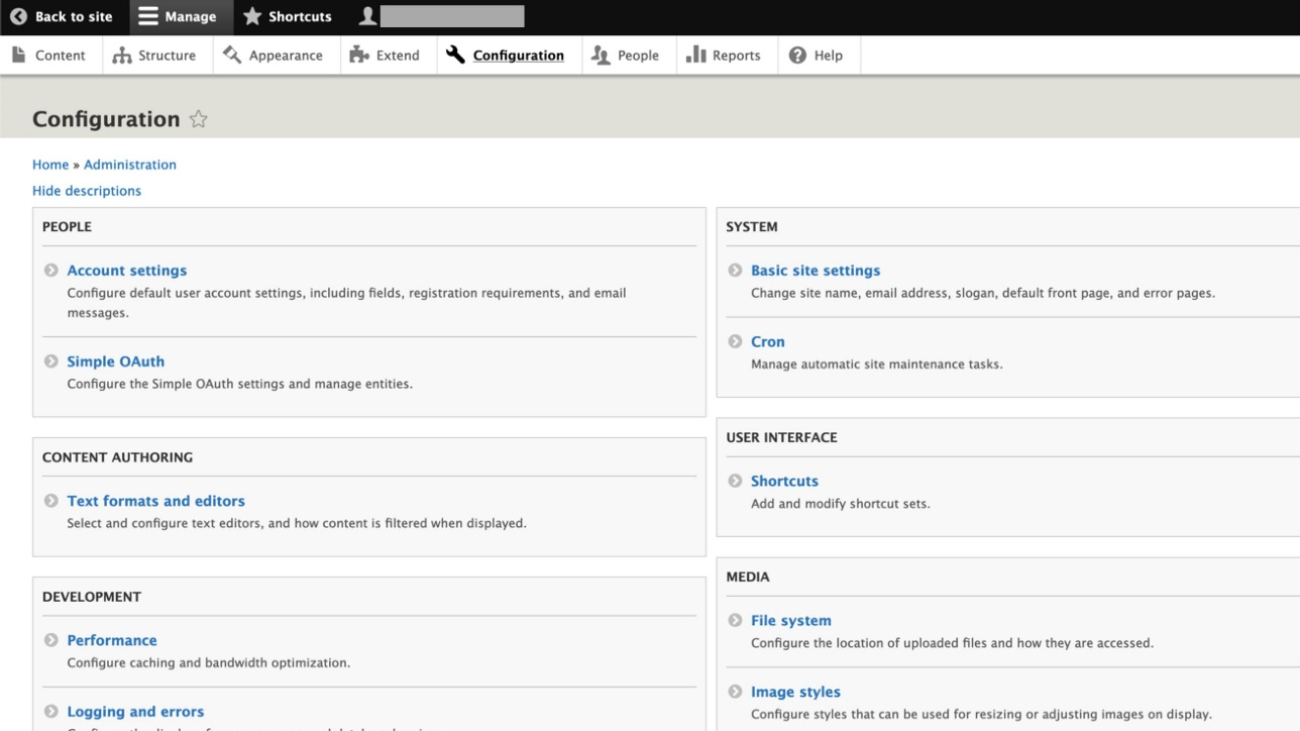
Configure the data source using the Amazon Kendra connector for Drupal
To add a data source to your Amazon Kendra index using the Drupal connector, you can use an existing index or create a new index. Then complete the following steps. For more information on this topic, refer to the Amazon Kendra Developer Guide.
- On the Amazon Kendra console, open your index and choose Data sources in the navigation pane.
- Choose Add data source.
- Under Drupal, choose Add connector.

- In the Specify data source details section, enter a name and description and choose Next.

- On the Define access and security section, for Drupal Host URL, enter the Drupal site URL.
- To configure the SSL certificates, you can create a self-signed certificate for this setup using the
openssl x509 -in mydrupalsite.pem -out drupal.crtcommand and store the certificate in an Amazon Simple Storage Service (Amazon S3) bucket. For more details on generating a private key and the certificate, refer to Generating Certificates. - Choose Browse S3 and choose the S3 bucket with the SSL certificate.

- Under Authentication, you have two options:
- Use Secrets Manager to create new Drupal authentication credentials. You need a Drupal admin user name and password (additionally, a client ID and client secret for OAuth 2.0 authentication).
- Use an existing Secrets Manager secret that has the Drupal authentication credentials you want the connector to access (additionally, a client ID and client secret for OAuth 2.0 authentication).
- Choose Save and add secret.

- For IAM role, choose Create a new role or choose an existing IAM role configured with appropriate IAM policies to access the Secrets Manager secret, Amazon Kendra index, and data source.
Refer to IAM roles for data sources for the required permissions for the IAM role.
- Choose Next.

- In the Configure sync settings section, select Articles, Basic pages, Basic blocks, Custom content types, and Custom Blocks along with options to crawl comments and attachments as needed.
- Optionally, enter the include/exclude patterns for the entity titles.
- Provide information about your sync scope (full or delta only) and specify the run schedule.
- Choose Next.


- In the Set field mappings section, add custom Drupal fields you want to sync and their respective Amazon Kendra field mappings. The required fields are pre-mapped by Amazon Kendra.

- Choose Next.
- Review the configuration settings and save the data source.
- Choose Sync now on the created data source to start data synchronization with the Amazon Kendra Index.

The time required to crawl and sync the contents into Amazon Kendra varies based on the volume of content and the throughput.

You can now search the indexed Drupal content using the search console or a search application. Optionally, you can search with ACL with the following additional steps.
- Go to the index page that you created and on the User access control tab, choose Edit settings.

- Under Access control settings, select Yes, keep the default values for Username and Groups, choose JSON for Token type, and keep the user-group expansion as None.
- On the next page, retain the default values (or change them based on your capacity requirements) and choose Update.

Perform intelligent search with Amazon Kendra
Before you try searching on the Amazon Kendra console or using the API, make sure that the data source sync is complete. To check, view the data sources and verify if the last sync was successful.

- To start your search, on the Amazon Kendra console, choose Search indexed content in the navigation pane.
You’re redirected to the Amazon Kendra search console. Now you can search information from the Drupal documents you indexed using Amazon Kendra.
- For this post, we search for a document stored in the Drupal data source.

- Expand Test query with an access token and choose Apply token.
- For Username, enter the email address associated with your Drupal account.
- Choose Apply.

Now the user can only see the content they have access based on the user name or groups specified. In our example, the Drupal user with the test@amazon.com email doesn’t have access to any documents on Drupal, so none are displayed.

Limitations
Note the following limitations when using this solution:
- The content types (such as article, or basic page) that aren’t associated with any view cannot be crawled.
- If an administrator doesn’t have access to a block, then you can’t crawl the data from the block.
- The document body for article, basic page, basic block, user-defined content type, and user-defined block type is displayed in HTML format. If the HTML content is not well-formed, then the HTML related tags will appear in the document body and therefore can be seen on the Amazon Kendra search results. This is the same with comments of article, basic page, basic block, user-defined content type, user-defined block type.
- The content type or block type without description or body will not be injected into the Amazon Kendra index because there is a validation on the Amazon Kendra SDK side. However, Drupal allows you to create the content type without description or body. Only the comments and attachments of the respective content types or block types (if they exist) will be injected into the Amazon Kendra index.
Clean up
To avoid incurring future costs, clean up the resources you created as part of this solution. If you created a new Amazon Kendra index while testing this solution, delete it. If you only added a new data source using the Amazon Kendra connector for Drupal, delete that data source. Delete any IAM users created.
Conclusion
With the Amazon Kendra Drupal connector, your organization can search contents stored in a Drupal site securely using intelligent search powered by Amazon Kendra. In this post, we introduced you to the integration, but there are many additional features that we didn’t cover, such as the following:
- You can map additional fields to Amazon Kendra index attributes and enable them for faceting, search, and display in the search results
- You can integrate the Drupal data source with the Custom Document Enrichment (CDE) capability in Amazon Kendra to perform additional attribute mapping logic and even custom content transformation during ingestion
To learn more about the possibilities with Drupal, refer to the Amazon Kendra Developer Guide.
For more information on other Amazon Kendra built-in connectors for popular data sources, refer to the Amazon Kendra Connectors page.
About the authors
 Channa Basavaraja is a Senior Solutions Architect at AWS with over 2 decades of experience building distributed business solutions. His areas of depth span Machine Learning, app/mobile dev, event-driven architecture, and IoT/edge computing.
Channa Basavaraja is a Senior Solutions Architect at AWS with over 2 decades of experience building distributed business solutions. His areas of depth span Machine Learning, app/mobile dev, event-driven architecture, and IoT/edge computing.
 Yuanhua Wang is a software engineer at AWS with more than 15 years of experience in the technology industry. His interests are software architecture and build tools on cloud computing.
Yuanhua Wang is a software engineer at AWS with more than 15 years of experience in the technology industry. His interests are software architecture and build tools on cloud computing.

Intuitivo achieves higher throughput while saving on AI/ML costs using AWS Inferentia and PyTorch
This is a guest post by Jose Benitez, Founder and Director of AI and Mattias Ponchon, Head of Infrastructure at Intuitivo.
Intuitivo, a pioneer in retail innovation, is revolutionizing shopping with its cloud-based AI and machine learning (AI/ML) transactional processing system. This groundbreaking technology enables us to operate millions of autonomous points of purchase (A-POPs) concurrently, transforming the way customers shop. Our solution outpaces traditional vending machines and alternatives, offering an economical edge with its ten times cheaper cost, easy setup, and maintenance-free operation. Our innovative new A-POPs (or vending machines) deliver enhanced customer experiences at ten times lower cost because of the performance and cost advantages AWS Inferentia delivers. Inferentia has enabled us to run our You Only Look Once (YOLO) computer vision models five times faster than our previous solution and supports seamless, real-time shopping experiences for our customers. Additionally, Inferentia has also helped us reduce costs by 95 percent compared to our previous solution. In this post, we cover our use case, challenges, and a brief overview of our solution using Inferentia.
The changing retail landscape and need for A-POP
The retail landscape is evolving rapidly, and consumers expect the same easy-to-use and frictionless experiences they are used to when shopping digitally. To effectively bridge the gap between the digital and physical world, and to meet the changing needs and expectations of customers, a transformative approach is required. At Intuitivo, we believe that the future of retail lies in creating highly personalized, AI-powered, and computer vision-driven autonomous points of purchase (A-POP). This technological innovation brings products within arm’s reach of customers. Not only does it put customers’ favorite items at their fingertips, but it also offers them a seamless shopping experience, devoid of long lines or complex transaction processing systems. We’re excited to lead this exciting new era in retail.
With our cutting-edge technology, retailers can quickly and efficiently deploy thousands of A-POPs. Scaling has always been a daunting challenge for retailers, mainly due to the logistic and maintenance complexities associated with expanding traditional vending machines or other solutions. However, our camera-based solution, which eliminates the need for weight sensors, RFID, or other high-cost sensors, requires no maintenance and is significantly cheaper. This enables retailers to efficiently establish thousands of A-POPs, providing customers with an unmatched shopping experience while offering retailers a cost-effective and scalable solution.

Using cloud inference for real-time product identification
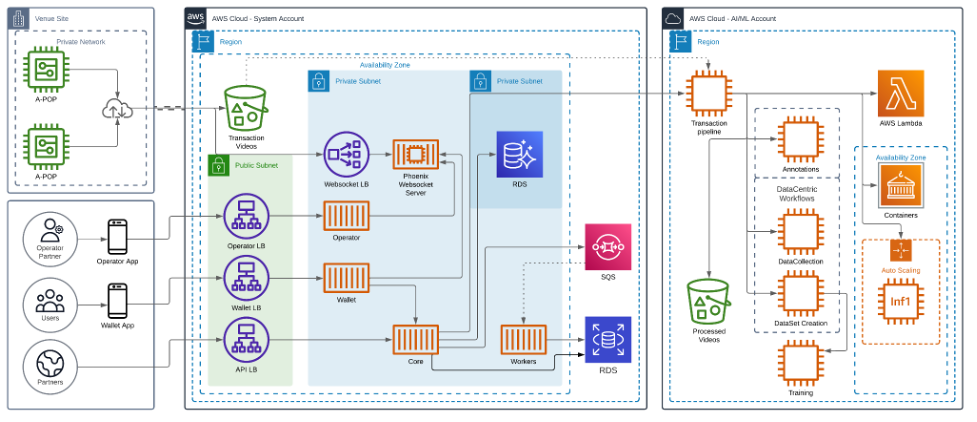
While designing a camera-based product recognition and payment system, we ran into a decision of whether this should be done on the edge or the cloud. After considering several architectures, we designed a system that uploads videos of the transactions to the cloud for processing.
Our end users start a transaction by scanning the A-POP’s QR code, which triggers the A-POP to unlock and then customers grab what they want and go. Preprocessed videos of these transactions are uploaded to the cloud. Our AI-powered transaction pipeline automatically processes these videos and charges the customer’s account accordingly.
The following diagram shows the architecture of our solution.
Unlocking high-performance and cost-effective inference using AWS Inferentia
As retailers look to scale operations, cost of A-POPs becomes a consideration. At the same time, providing a seamless real-time shopping experience for end-users is paramount. Our AI/ML research team focuses on identifying the best computer vision (CV) models for our system. We were now presented with the challenge of how to simultaneously optimize the AI/ML operations for performance and cost.
We deploy our models on Amazon EC2 Inf1 instances powered by Inferentia, Amazon’s first ML silicon designed to accelerate deep learning inference workloads. Inferentia has been shown to reduce inference costs significantly. We used the AWS Neuron SDK—a set of software tools used with Inferentia—to compile and optimize our models for deployment on EC2 Inf1 instances.
The code snippet that follows shows how to compile a YOLO model with Neuron. The code works seamlessly with PyTorch and functions such as torch.jit.trace()and neuron.trace()record the model’s operations on an example input during the forward pass to build a static IR graph.
We migrated our compute-heavy models to Inf1. By using AWS Inferentia, we achieved the throughput and performance to match our business needs. Adopting Inferentia-based Inf1 instances in the MLOps lifecycle was a key to achieving remarkable results:
- Performance improvement: Our large computer vision models now run five times faster, achieving over 120 frames per second (FPS), allowing for seamless, real-time shopping experiences for our customers. Furthermore, the ability to process at this frame rate not only enhances transaction speed, but also enables us to feed more information into our models. This increase in data input significantly improves the accuracy of product detection within our models, further boosting the overall efficacy of our shopping systems.
- Cost savings: We slashed inference costs. This significantly enhanced the architecture design supporting our A-POPs.
Data parallel inference was easy with AWS Neuron SDK
To improve performance of our inference workloads and extract maximum performance from Inferentia, we wanted to use all available NeuronCores in the Inferentia accelerator. Achieving this performance was easy with the built-in tools and APIs from the Neuron SDK. We used the torch.neuron.DataParallel() API. We’re currently using inf1.2xlarge which has one Inferentia accelerator with four Neuron accelerators. So we’re using torch.neuron.DataParallel() to fully use the Inferentia hardware and use all available NeuronCores. This Python function implements data parallelism at the module level on models created by the PyTorch Neuron API. Data parallelism is a form of parallelization across multiple devices or cores (NeuronCores for Inferentia), referred to as nodes. Each node contains the same model and parameters, but data is distributed across the different nodes. By distributing the data across multiple nodes, data parallelism reduces the total processing time of large batch size inputs compared to sequential processing. Data parallelism works best for models in latency-sensitive applications that have large batch size requirements.
Looking ahead: Accelerating retail transformation with foundation models and scalable deployment
As we venture into the future, the impact of foundation models on the retail industry cannot be overstated. Foundation models can make a significant difference in product labeling. The ability to quickly and accurately identify and categorize different products is crucial in a fast-paced retail environment. With modern transformer-based models, we can deploy a greater diversity of models to serve more of our AI/ML needs with higher accuracy, improving the experience for users and without having to waste time and money training models from scratch. By harnessing the power of foundation models, we can accelerate the process of labeling, enabling retailers to scale their A-POP solutions more rapidly and efficiently.
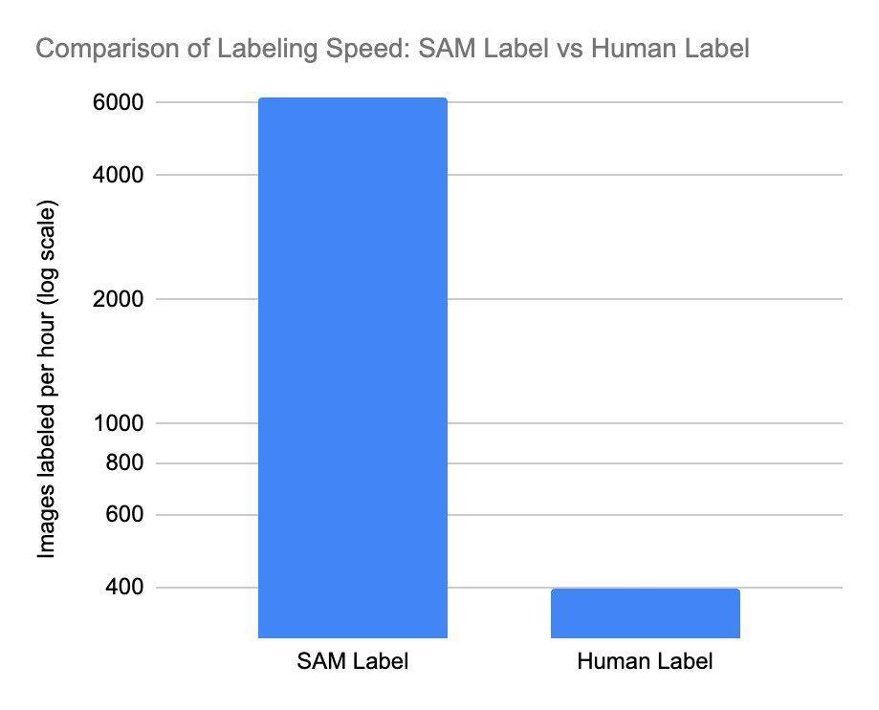
We have begun implementing Segment Anything Model (SAM), a vision transformer foundation model that can segment any object in any image (we will discuss this further in another blog post). SAM allows us to accelerate our labeling process with unparalleled speed. SAM is very efficient, able to process approximately 62 times more images than a human can manually create bounding boxes for in the same timeframe. SAM’s output is used to train a model that detects segmentation masks in transactions, opening up a window of opportunity for processing millions of images exponentially faster. This significantly reduces training time and cost for product planogram models.
Our product and AI/ML research teams are excited to be at the forefront of this transformation. The ongoing partnership with AWS and our use of Inferentia in our infrastructure will ensure that we can deploy these foundation models cost effectively. As early adopters, we’re working with the new AWS Inferentia 2-based instances. Inf2 instances are built for today’s generative AI and large language model (LLM) inference acceleration, delivering higher performance and lower costs. Inf2 will enable us to empower retailers to harness the benefits of AI-driven technologies without breaking the bank, ultimately making the retail landscape more innovative, efficient, and customer-centric.
As we continue to migrate more models to Inferentia and Inferentia2, including transformers-based foundational models, we are confident that our alliance with AWS will enable us to grow and innovate alongside our trusted cloud provider. Together, we will reshape the future of retail, making it smarter, faster, and more attuned to the ever-evolving needs of consumers.
Conclusion
In this technical traverse, we’ve highlighted our transformational journey using AWS Inferentia for its innovative AI/ML transactional processing system. This partnership has led to a five times increase in processing speed and a stunning 95 percent reduction in inference costs compared to our previous solution. It has changed the current approach of the retail industry by facilitating a real-time and seamless shopping experience.
If you’re interested in learning more about how Inferentia can help you save costs while optimizing performance for your inference applications, visit the Amazon EC2 Inf1 instances and Amazon EC2 Inf2 instances product pages. AWS provides various sample codes and getting started resources for Neuron SDK that you can find on the Neuron samples repository.
About the Authors
Matias Ponchon is the Head of Infrastructure at Intuitivo. He specializes in architecting secure and robust applications. With extensive experience in FinTech and Blockchain companies, coupled with his strategic mindset, helps him to design innovative solutions. He has a deep commitment to excellence, that’s why he consistently delivers resilient solutions that push the boundaries of what’s possible.
Jose Benitez is the Founder and Director of AI at Intuitivo, specializing in the development and implementation of computer vision applications. He leads a talented Machine Learning team, nurturing an environment of innovation, creativity, and cutting-edge technology. In 2022, Jose was recognized as an ‘Innovator Under 35’ by MIT Technology Review, a testament to his groundbreaking contributions to the field. This dedication extends beyond accolades and into every project he undertakes, showcasing a relentless commitment to excellence and innovation.
Diwakar Bansal is an AWS Senior Specialist focused on business development and go-to-market for Gen AI and Machine Learning accelerated computing services. Previously, Diwakar has led product definition, global business development, and marketing of technology products for IoT, Edge Computing, and Autonomous Driving focusing on bringing AI and Machine Learning to these domains.