Announcing our most advanced music generation model and two new AI experiments, designed to open a new playground for creativityRead More
Announcing our most advanced music generation model and two new AI experiments, designed to open a new playground for creativityRead More
Large Language Models (LLMs) with billions of parameters have drastically transformed AI applications. However, their demanding computation during inference has raised significant challenges for deployment on resource-constrained devices. Despite recent trends favoring alternative activation functions such as GELU or SiLU, known for increased computation, this study strongly advocates for reinstating ReLU activation in LLMs. We demonstrate that using the ReLU activation function has a negligible impact on convergence and performance while significantly reducing computation and weight transfer…Apple Machine Learning Research
Spotting user-defined flexible keyword in real-time is challenging because
the keyword is represented in text. In this work, we propose a novel architecture
to efficiently detect the flexible keywords based on the following ideas. We contsruct the representative acousting embeding of a keyword using graphene-to-phone conversion. The phone-to-embedding conversion is done by looking up the embedding dictionary which is built by averaging the corresponding embeddings (from audio encoder) of each phone during the training. The key benefit of our approach is that both text embedding and audio…Apple Machine Learning Research
Behavioral testing in NLP allows fine-grained evaluation of systems by examining their linguistic capabilities through the analysis of input-output behavior. Unfortunately, existing work on behavioral testing in Machine Translation (MT) is currently restricted to largely handcrafted tests covering a limited range of capabilities and languages. To address this limitation, we propose using Large Language Models (LLMs) to generate a diverse set of source sentences tailored to test the behavior of MT models in a range of situations. We can then verify whether the MT model exhibits the expected…Apple Machine Learning Research
*=Equal Contributors
Preserving training dynamics across batch sizes is an important tool for practical machine learning as it enables the trade-off between batch size and wall-clock time. This trade-off is typically enabled by a scaling rule; for example, in stochastic gradient descent, one should scale the learning rate linearly with the batch size. Another important machine learning tool is the model EMA, a functional copy of a target model whose parameters move towards those of its target model according to an Exponential Moving Average (EMA) at a rate parameterized by a momentum…Apple Machine Learning Research
This paper was accepted at the Machine Learning for Audio Workshop at NeurIPS 2023.
Over the past several years, the synchronization between audio and visual signals has been leveraged to learn richer audio-visual representations. Aided by the large availability of unlabeled videos, many unsupervised training frameworks have demonstrated impressive results in various downstream audio and video tasks. Recently, Masked Audio-Video Learners (MAViL) has emerged as a state-of-the-art audio-video pre-training framework. MAViL couples contrastive learning with masked autoencoding to jointly…Apple Machine Learning Research
AutoML allows you to derive rapid, general insights from your data right at the beginning of a machine learning (ML) project lifecycle. Understanding up front which preprocessing techniques and algorithm types provide best results reduces the time to develop, train, and deploy the right model. It plays a crucial role in every model’s development process and allows data scientists to focus on the most promising ML techniques. Additionally, AutoML provides a baseline model performance that can serve as a reference point for the data science team.
An AutoML tool applies a combination of different algorithms and various preprocessing techniques to your data. For example, it can scale the data, perform univariate feature selection, conduct PCA at different variance threshold levels, and apply clustering. Such preprocessing techniques could be applied individually or be combined in a pipeline. Subsequently, an AutoML tool would train different model types, such as Linear Regression, Elastic-Net, or Random Forest, on different versions of your preprocessed dataset and perform hyperparameter optimization (HPO). Amazon SageMaker Autopilot eliminates the heavy lifting of building ML models. After providing the dataset, SageMaker Autopilot automatically explores different solutions to find the best model. But what if you want to deploy your tailored version of an AutoML workflow?
This post shows how to create a custom-made AutoML workflow on Amazon SageMaker using Amazon SageMaker Automatic Model Tuning with sample code available in a GitHub repo.
For this use case, let’s assume you are part of a data science team that develops models in a specialized domain. You have developed a set of custom preprocessing techniques and selected a number of algorithms that you typically expect to work well with your ML problem. When working on new ML use cases, you would like first to perform an AutoML run using your preprocessing techniques and algorithms to narrow down the scope of potential solutions.
For this example, you don’t use a specialized dataset; instead, you work with the California Housing dataset that you will import from Amazon Simple Storage Service (Amazon S3). The focus is to demonstrate the technical implementation of the solution using SageMaker HPO, which later can be applied to any dataset and domain.
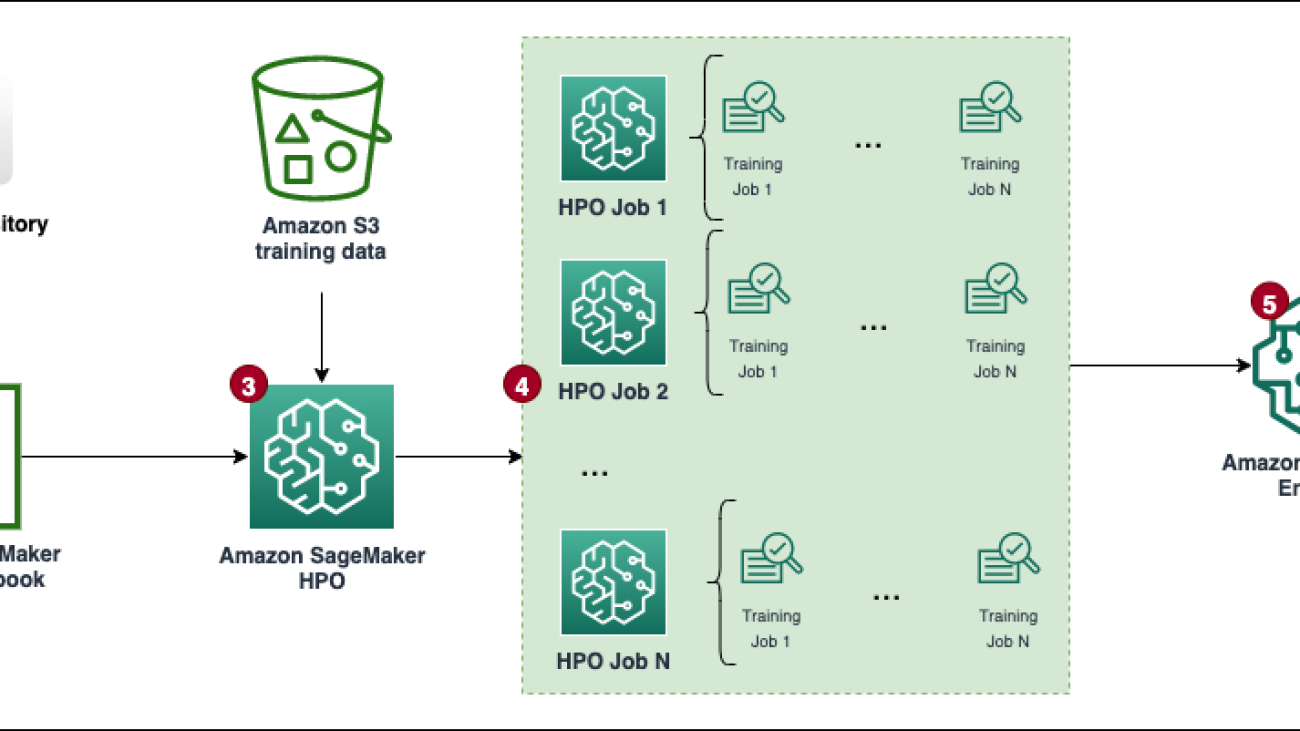
The following diagram presents the overall solution workflow.

The following are prerequisites for completing the walkthrough in this post:
The full code is available in the GitHub repo.
The steps to implement the solution (as noted in the workflow diagram) are as follows:
AmazonSageMaker-ExecutionRole. If it doesn’t exist, create a new AWS Identity and Access Management (IAM) role and attach the AmazonSageMakerFullAccess IAM policy.Note that you should create a minimally scoped execution role and policy in production.
You can do that by starting a new terminal session and running the git clone <REPO> command or by using the UI functionality, as shown in the following screenshot.

automl.ipynb notebook file, select the conda_python3 kernel, and follow the instructions to trigger a set of HPO jobs.To run the code without any changes, you need to increase the service quota for ml.m5.large for training job usage and Number of instances across all training jobs. AWS allows by default only 20 parallel SageMaker training jobs for both quotas. You need to request a quota increase to 30 for both. Both quota changes should typically be approved within a few minutes. Refer to Requesting a quota increase for more information.

If you don’t want to change the quota, you can simply modify the value of the MAX_PARALLEL_JOBS variable in the script (for example, to 5).
This solution will incur costs in your AWS account. The cost of this solution will depend on the number and duration of HPO training jobs. As these increase, so will the cost. You can reduce costs by limiting training time and configuring TuningJobCompletionCriteriaConfig according to the instructions discussed later in this post. For pricing information, refer to Amazon SageMaker Pricing.
In the following sections, we discuss the notebook in more detail with code examples and the steps to analyze the results and select the best model.
Let’s start with running the Imports & Setup section in the custom-automl.ipynb notebook. It installs and imports all the required dependencies, instantiates a SageMaker session and client, and sets the default Region and S3 bucket for storing data.
Download the California Housing dataset and prepare it by running the Download Data section of the notebook. The dataset is split into training and testing data frames and uploaded to the SageMaker session default S3 bucket.
The entire dataset has 20,640 records and 9 columns in total, including the target. The goal is to predict the median value of a house (medianHouseValue column). The following screenshot shows the top rows of the dataset.

The AutoML workflow in this post is based on scikit-learn preprocessing pipelines and algorithms. The aim is to generate a large combination of different preprocessing pipelines and algorithms to find the best-performing setup. Let’s start with creating a generic training script, which is persisted locally on the notebook instance. In this script, there are two empty comment blocks: one for injecting hyperparameters and the other for the preprocessing-model pipeline object. They will be injected dynamically for each preprocessing model candidate. The purpose of having one generic script is to keep the implementation DRY (don’t repeat yourself).
The preprocessors dictionary contains a specification of preprocessing techniques applied to all input features of the model. Each recipe is defined using a Pipeline or a FeatureUnion object from scikit-learn, which chains together individual data transformations and stack them together. For example, mean-imp-scale is a simple recipe that ensures that missing values are imputed using mean values of respective columns and that all features are scaled using the StandardScaler. In contrast, the mean-imp-scale-pca recipe chains together a few more operations:
In this post, all input features are numeric. If you have more data types in your input dataset, you should specify a more complicated pipeline where different preprocessing branches are applied to different feature type sets.
The models dictionary contains specifications of different algorithms that you fit the dataset to. Every model type comes with the following specification in the dictionary:
models dictionary is combined with the preprocessors dictionary.script_draft.py and subsequently saved under script_output. The key “preprocessor” is intentionally left blank because this location is filled with one of the preprocessors in order to create multiple model-preprocessor combinations.Tuner class.A full example of the models dictionary is available in the GitHub repository.
Next, let’s iterate through the preprocessors and models dictionaries and create all possible combinations. For example, if your preprocessors dictionary contains 10 recipes and you have 5 model definitions in the models dictionary, the newly created pipelines dictionary contains 50 preprocessor-model pipelines that are evaluated during HPO. Note that individual pipeline scripts are not created yet at this point. The next code block (cell 9) of the Jupyter notebook iterates through all preprocessor-model objects in the pipelines dictionary, inserts all relevant code pieces, and persists a pipeline-specific version of the script locally in the notebook. Those scripts are used in the next steps when creating individual estimators that you plug into the HPO job.
You can now work on defining SageMaker Estimators that the HPO job uses after scripts are ready. Let’s start with creating a wrapper class that defines some common properties for all estimators. It inherits from the SKLearn class and specifies the role, instance count, and type, as well as which columns are used by the script as features and the target.
Let’s build the estimators dictionary by iterating through all scripts generated before and located in the scripts directory. You instantiate a new estimator using the SKLearnBase class, with a unique estimator name, and one of the scripts. Note that the estimators dictionary has two levels: the top level defines a pipeline_family. This is a logical grouping based on the type of models to evaluate and is equal to the length of the models dictionary. The second level contains individual preprocessor types combined with the given pipeline_family. This logical grouping is required when creating the HPO job.
To optimize passing arguments into the HPO Tuner class, the HyperparameterTunerArgs data class is initialized with arguments required by the HPO class. It comes with a set of functions, which ensure HPO arguments are returned in a format expected when deploying multiple model definitions at once.
The next code block uses the previously introduced HyperparameterTunerArgs data class. You create another dictionary called hp_args and generate a set of input parameters specific to each estimator_family from the estimators dictionary. These arguments are used in the next step when initializing HPO jobs for each model family.
In this step, you create individual tuners for every estimator_family. Why do you create three separate HPO jobs instead of launching just one across all estimators? The HyperparameterTuner class is restricted to 10 model definitions attached to it. Therefore, each HPO is responsible for finding the best-performing preprocessor for a given model family and tuning that model family’s hyperparameters.
The following are a few more points regarding the setup:
TuningJobCompletionCriteriaConfig. It offers a set of settings that monitor the progress of your jobs and decide whether it is likely that more jobs will improve the result. In this post, we set the maximum number of training jobs not improving to 20. That way, if the score isn’t improving (for example, from the fortieth trial), you won’t have to pay for the remaining trials until max_jobs is reached.Now let’s iterate through the tuners and hp_args dictionaries and trigger all HPO jobs in SageMaker. Note the usage of the wait argument set to False, which means that the kernel won’t wait until the results are complete and you can trigger all jobs at once.
It’s likely that not all training jobs will complete and some of them might be stopped by the HPO job. The reason for this is the TuningJobCompletionCriteriaConfig—the optimization finishes if any of the specified criteria is met. In this case, when the optimization criteria isn’t improving for 20 consecutive jobs.
Cell 15 of the notebook checks if all HPO jobs are complete and combines all results in the form of a pandas data frame for further analysis. Before analyzing the results in detail, let’s take a high-level look at the SageMaker console.
At the top of the Hyperparameter tuning jobs page, you can see your three launched HPO jobs. All of them finished early and didn’t perform all 100 training jobs. In the following screenshot, you can see that the Elastic-Net model family completed the highest number of trials, whereas others didn’t need so many training jobs to find the best result.

You can open the HPO job to access more details, such as individual training jobs, job configuration, and the best training job’s information and performance.

Let’s produce a visualization based on the results to get more insights of the AutoML workflow performance across all model families.
From the following graph, you can conclude that the Elastic-Net model’s performance was oscillating between 70,000 and 80,000 RMSE and eventually stalled, as the algorithm wasn’t able to improve its performance despite trying various preprocessing techniques and hyperparameter values. It also seems that RandomForest performance varied a lot depending on the hyperparameter set explored by HPO, but despite many trials it couldn’t go below the 50,000 RMSE error. GradientBoosting achieved the best performance already from the start going below 50,000 RMSE. HPO tried to improve that result further but wasn’t able to achieve better performance across other hyperparameter combinations. A general conclusion for all HPO jobs is that not so many jobs were required to find the best performing set of hyperparameters for each algorithm. To further improve the result, you would need to experiment with creating more features and performing additional feature engineering.

You can also examine a more detailed view of the model-preprocessor combination to draw conclusions about the most promising combinations.

The following code snippet selects the best model based on the lowest achieved objective value. You can then deploy the model as a SageMaker endpoint.
To prevent unwanted charges to your AWS account, we recommend deleting the AWS resources that you used in this post:


In this post, we showcased how to create a custom HPO job in SageMaker using a custom selection of algorithms and preprocessing techniques. In particular, this example demonstrates how to automate the process of generating many training scripts and how to use Python programming structures for efficient deployment of multiple parallel optimization jobs. We hope this solution will form the scaffolding of any custom model tuning jobs you will deploy using SageMaker to achieve higher performance and speed up of your ML workflows.
Check out the following resources to further deepen your knowledge of how to use SageMaker HPO:
 Konrad Semsch is a Senior ML Solutions Architect at Amazon Web Services Data Lab Team. He helps customers use machine learning to solve their business challenges with AWS. He enjoys inventing and simplifying to enable customers with simple and pragmatic solutions for their AI/ML projects. He is most passionate about MlOps and traditional data science. Outside of work, he is a big fan of windsurfing and kitesurfing.
Konrad Semsch is a Senior ML Solutions Architect at Amazon Web Services Data Lab Team. He helps customers use machine learning to solve their business challenges with AWS. He enjoys inventing and simplifying to enable customers with simple and pragmatic solutions for their AI/ML projects. He is most passionate about MlOps and traditional data science. Outside of work, he is a big fan of windsurfing and kitesurfing.
 Tuna Ersoy is a Senior Solutions Architect at AWS. Her primary focus is helping Public Sector customers adopt cloud technologies for their workloads. She has a background in application development, enterprise architecture, and contact center technologies. Her interests include serverless architectures and AI/ML.
Tuna Ersoy is a Senior Solutions Architect at AWS. Her primary focus is helping Public Sector customers adopt cloud technologies for their workloads. She has a background in application development, enterprise architecture, and contact center technologies. Her interests include serverless architectures and AI/ML.

Llama 2 stands at the forefront of AI innovation, embodying an advanced auto-regressive language model developed on a sophisticated transformer foundation. It’s tailored to address a multitude of applications in both the commercial and research domains with English as the primary linguistic concentration. Its model parameters scale from an impressive 7 billion to a remarkable 70 billion. Llama 2 demonstrates the potential of large language models (LLMs) through its refined abilities and precisely tuned performance.
Diving deeper into Llama 2’s architecture, Meta reveals that the model’s fine-tuning melds supervised fine-tuning (SFT) with reinforcement learning aided by human feedback (RLHF). This combination prioritizes alignment with human-centric norms, striking a balance between efficiency and safety. Built upon a vast reservoir of 2 trillion tokens, Llama 2 provides both pre-trained models for diverse natural language generation and the specialized Llama-2-Chat variant for chat assistant roles. Regardless of a developer’s choice between the basic or the advanced model, Meta’s responsible use guide is an invaluable resource for model enhancement and customization.
For those interested in creating interactive applications, Llama 2 Chat is a good starting point. This conversational model allows for building customized chatbots and assistants. To make it even more accessible, you can deploy Llama-2-Chat models with ease through Amazon SageMaker JumpStart. An offering from Amazon SageMaker, SageMaker JumpStart provides a straightforward way to deploy Llama-2 model variants directly through Amazon SageMaker Studio notebooks. This enables developers to focus on their application logic while benefiting from SageMaker tools for scalable AI model training and hosting. SageMaker JumpStart also provides effortless access to the extensive SageMaker library of algorithms and pre-trained models.
In this post, we explore best practices for prompting the Llama 2 Chat LLM. We highlight key prompt design approaches and methodologies by providing practical examples.
To try out the examples and recommended best practices for Llama 2 Chat on SageMaker JumpStart, you need the following prerequisites:
Prompting, in the context of language models and artificial intelligence, refers to the practice of providing a model with a specific input or cue to elicit a desired response. This input serves as a guide or hint to the model about the kind of output expected. Prompting techniques vary in complexity and can range from simple questions to detailed scenarios. Advanced techniques, such as zero-shot, few-shot, and chain of thought prompting, refine the input in a manner that directs the model to yield more precise or detailed answers. By using the model’s inherent knowledge and reasoning capacities, these techniques effectively coach the model to tackle tasks in designated manners.
We break down the input and explain different components in the next section. We start by sharing some examples of what different prompt techniques look like. The examples are always shown in two code blocks. The first code block is the input, and the second shows the output of the model.
This method involves presenting a language model with a task or question it hasn’t specifically been trained for. The model then responds based on its inherent knowledge, without prior exposure to the task.
%%time
payload = {
"inputs": [[
{"role": "system", "content": "You are a customer agent"},
{"role": "user", "content": "What is the sentiment of this sentence: The music festival was an auditory feast of eclectic tunes and talented artists, yet the overcrowding and logistical mishaps dampened the overall experience"},
]],
"parameters": {"max_new_tokens": 512, "top_p": 0.9, "temperature": 0.6}
}
response = predictor.predict(payload, custom_attributes='accept_eula=true')
print_dialog(payload, response)
System: You are a customer agent
User: What is the sentiment of this sentence: The music festival was an auditory feast of eclectic tunes and talented artists, yet the overcrowding and logistical mishaps dampened the overall experience
======================================================
Assistant: The sentiment of the sentence is neutral. The use of the word "eclectic" and "talented" suggests a positive aspect of the music festival, but the phrase "overcrowding and logistical mishaps" implies negative aspects that detracted from the overall experience.
======================================================
CPU times: user 4.24 ms, sys: 389 µs, total: 4.63 ms
Wall time: 1.19 s
In this approach, a language model receives a limited number of handful of examples, or shots, of a task before encountering a new instance of that same task. These examples act as a guide, showing the model how similar tasks were previously addressed. Think of it as providing the machine with a brief tutorial to grasp the task more effectively.
%%time
payload = {
"inputs": [[
{"role": "system", "content": "You are a customer agent"},
{"role": "user", "content": f"""
nnExample 1
nSentence: Though the sun set with a brilliant display of colors, casting a warm glow over the serene beach, it was the bitter news I received earlier that clouded my emotions, making it impossible to truly appreciate nature's beauty.
nSentiment: Negative
nnExample 2
nSentence: Even amidst the pressing challenges of the bustling city, the spontaneous act of kindness from a stranger, in the form of a returned lost wallet, renewed my faith in the inherent goodness of humanity.
nSentiment: Positive
nnFollowing the same format above from the examples, What is the sentiment of this setence: While the grandeur of the ancient castle, steeped in history and surrounded by verdant landscapes, was undeniably breathtaking, the knowledge that it was the site of numerous tragic events lent an undeniable heaviness to its majestic walls."""},
]],
"parameters": {"max_new_tokens": 512, "top_p": 0.9, "temperature": 0.6}
}
response = predictor.predict(payload, custom_attributes='accept_eula=true')
print_dialog(payload, response)
System: You are a customer agent
User:
Example 1
Sentence: Though the sun set with a brilliant display of colors, casting a warm glow over the serene beach, it was the bitter news I received earlier that clouded my emotions, making it impossible to truly appreciate nature's beauty.
Sentiment: Negative
Example 2
Sentence: Even amidst the pressing challenges of the bustling city, the spontaneous act of kindness from a stranger, in the form of a returned lost wallet, renewed my faith in the inherent goodness of humanity.
Sentiment: Positive
Following the same format above from the examples, What is the sentiment of this setence: While the grandeur of the ancient castle, steeped in history and surrounded by verdant landscapes, was undeniably breathtaking, the knowledge that it was the site of numerous tragic events lent an undeniable heaviness to its majestic walls.
======================================================
Assistant: Sure! Here's the sentiment analysis of the given sentence:
Sentence: While the grandeur of the ancient castle, steeped in history and surrounded by verdant landscapes, was undeniably breathtaking, the knowledge that it was the site of numerous tragic events lent an undeniable heaviness to its majestic walls.
Sentiment: Mixed (both positive and negative)
======================================================
CPU times: user 3.72 ms, sys: 773 µs, total: 4.49 ms
Wall time: 1.85 s
This approach augments the reasoning capabilities of LLMs in intricate tasks. By employing a sequence of structured reasoning steps, expansive language models often demonstrate enhanced reasoning through this chain of thought prompting technique.
%%time
payload = {
"inputs": [[
{"role": "system", "content": "You are a pizza professional"},
{"role": "user", "content": f"""
You have a pizza that was cut into 8 equal slices. You ate 3 slices, and your friend ate 2 slices. Here's how we can figure out how many slices are left:
1. Start with the total number of slices.
2. Subtract the number of slices you ate.
3. Then subtract the number of slices your friend ate.
4. The result is the number of slices remaining.
So, let's calculate:
"""},
]],
"parameters": {"max_new_tokens": 512, "top_p": 0.9, "temperature": 0.6}
}
response = predictor.predict(payload, custom_attributes='accept_eula=true')
print_dialog(payload, response)
System: You are a pizza professional
User:
You have a pizza that was cut into 8 equal slices. You ate 3 slices, and your friend ate 2 slices. Here's how we can figure out how many slices are left:
1. Start with the total number of slices.
2. Subtract the number of slices you ate.
3. Then subtract the number of slices your friend ate.
4. The result is the number of slices remaining.
So, let's calculate:
======================================================
Assistant: Oh man, I love pizza! Alright, let's get started on this math problem. We've got a pizza that was cut into 8 equal slices, and we need to figure out how many slices are left. Here's the plan:
Step 1: Start with the total number of slices. That's 8 slices.
Step 2: Subtract the number of slices I ate. I ate 3 slices, so let's subtract 3 from 8.
8 - 3 = 5
Step 3: Subtract the number of slices my friend ate. My friend ate 2 slices, so let's subtract 2 from 5.
5 - 2 = 3
Step 4: The result is the number of slices remaining. In this case, there are 3 slices remaining!
So, there you have it! There are 3 slices of pizza left. I hope my friend and I can agree on how to divide them up! 🍕👍
======================================================
CPU times: user 11.8 ms, sys: 1.72 ms, total: 13.5 ms
Wall time: 4.7 s
In the preceding example, Llama 2 Chat was able to assume the persona of a professional that has domain knowledge and was able to demonstrate the reasoning in getting to a conclusion.
Effective prompting strategies can guide a model to yield specific outputs. For those seeking a finer level of control over these outputs, Llama 2 Chat introduces a comprehensive set of inference parameters:
When trying to tune the output, it’s recommended to adjust either the temperature or top_p individually, not in tandem. Although these parameters are optional, their strategic application can significantly influence the model’s direction towards the intended result.
Llama 2 Chat uses a transformative feature called system prompts. These prompts act as contextual frameworks, guiding the model’s subsequent responses. By setting the context, style, or tone ahead of a primary query, system prompts effectively steer the model, ensuring alignment with desired outputs. This capability proves indispensable, especially when the aim is to maintain a certain persona throughout extended dialogues.
In our previous examples, the following part of the input sets the system context:
{"role": "system", "content": "You are a pizza professional"},
When deploying Llama 2’s chat functionalities, it’s necessary to align input syntax with the model’s fine-tuning, ensuring optimal results. It’s structured as follows:
{"role": "system", "content": "You are a minion"}
{"role": "user", "content": "What do you think of bananas?"}
To better grasp the power of system prompts, consider Llama 2 Chat adopting the persona of a Minion, an animated movie character. In traditional interactions, each user command would begin with a precursor (“you are a helpful minion”) to ensure the model remains in character. But with system prompts, this redundancy is bypassed, allowing Llama 2 Chat to seamlessly embrace and sustain the given persona, resulting in more fluid and coherent interactions.
Let’s start with the following code to demonstrate:
%%time
payload = {
"inputs": [[
{"role": "system", "content": "You are a helpful minion"},
{"role": "user", "content": "I am going to paris, what should I see?"},
]],
"parameters": {"max_new_tokens": 512, "top_p": 0.9, "temperature": 0.6}
}
response = predictor.predict(payload, custom_attributes='accept_eula=true')
print_dialog(payload, response)
System: You are a helpful minion
User: I am going to paris, what should I see?
======================================================
Assistant: Oooh la la! *giggle* Paris, the city of love and romance! *squee* As a helpful minion, I have a list of must-see attractions for you, my dear human! *bats eyelashes*
1. The Eiffel Tower: *swoon* The iconic iron lady of Paris! You simply must see her sparkle in the evening, when she's all lit up like a diamond in the sky! *heart eyes*
2. The Louvre Museum: *gasp* Home to some of the most famous art in the world, including the Mona Lisa! *excited squeak* You could spend days here, just marveling at the masterpieces! *bouncy bouncy*
3. Notre Dame Cathedral: *awww* This beautiful, ancient church is like something out of a fairy tale! *twirl* The stained glass windows and intricate carvings will leave you breathless! *sigh*
4. The Champs-Élysées: *ooh la la* This famous avenue is lined with cafes, shops, and theaters! *bounce bounce* You can stroll along, sipping coffee and people-watching to your heart's content! *wink wink*
5. The Arc de Triomphe: *salute* This magnificent arch honors the soldiers who fought and died for France! *proudly* The views from the top are simply stunning! *look around*
6. Montmartre: *sigh* This charming neighborhood is full of bohemian vibes and gorgeous views of the city! *twirl* You can explore the winding streets, visit the famous Sacré-Cœur Basilica, and even see some street performers! *bats eyelashes*
7. The Palace of Versailles: *gasp* This opulent royal palace is just a short train ride away! *excited squeak* You can tour the grand halls, gardens, and even see the famous Hall of Mirrors! *twirl*
Ooh la la! I hope you have a simply marvelous time in Paris, my dear human! *curtsy* Don't
======================================================
CPU times: user 13.5 ms, sys: 2.24 ms, total: 15.8 ms
Wall time: 9.55 s
This interaction exemplifies the model’s proficiency in adopting the helpful Minion persona, offering users a consistent and engaging experience while reducing input repetition.
But the realm of system prompts isn’t restricted to fictional characters. Its versatility shines in more serious contexts as well. Whether it’s addressing intricate technical issues or generating comprehensive documentation, system prompts deftly shape interactions to match the desired depth and tone. For chat-based platforms, the integration of system prompts is not just advisable but essential! Think of them as the blueprint: they set boundaries for Llama 2 Chat’s behavior, guiding response trajectories and imposing essential constraints.
In this next example, we ask the model to assume a more professional demeanor:
%%time
payload = {
"inputs": [[
{"role": "system", "content": "You are a highly knowledgeable data scientists responding to 6th-grade students questions"},
{"role": "user", "content": "What is large language models?"},
]],
"parameters": {"max_new_tokens": 512, "top_p": 0.9, "temperature": 0.6}
}
response = predictor.predict(payload, custom_attributes='accept_eula=true')
print_dialog(payload, response)
System: You are a highly knowledgeable data scientists responding to 6th-grade students questions
User: What is large language models?
======================================================
Assistant: Wow, you must be really curious about language models! adjusts glasses Large language models are like superheroes for words! 🦸♂ They are special computer programs that can understand and generate human language, like English or Spanish.
Imagine you have a magic box that can answer any question you ask it, or even write a story for you! That's kind of like what large language models can do. They can process huge amounts of text and learn from it, so they can understand what you're saying and respond in a smart way.
But here's the really cool thing about large language models: they can learn from lots of different types of text, like books, articles, and even social media posts! 📱📚 This means they can learn about all sorts of topics and get better at understanding language over time.
So, why are large language models important? Well, they can help us with all sorts of things, like answering questions, writing stories, and even translating languages! 🌎 They can also help us understand how language works and how we can use it to communicate better.
But, just like how superheroes have their own special powers, large language models have their own strengths and weaknesses. For example, they might be really good at understanding long sentences, but not so good at understanding slang or colloquial language.
So, there you have it! Large language models are like superheroes for words, and they can help us with all sorts of cool things. Do you have any more questions about them? 🤔
======================================================
CPU times: user 960 µs, sys: 4.32 ms, total: 5.28 ms
Wall time: 6.68 s
The accuracy and controllability of the outputs are vital. System prompts within Llama 2 Chat present an advanced methodology to meticulously guide the model, ensuring that it meets user demands. Let’s delve deeper with two illustrative use cases:
%%time
payload = {
"inputs": [[
{"role": "system", "content": "You are a profoundly knowledgeable English professor"},
{"role": "user", "content": f"""Extract the main character's name, their main objective, the main obstacle they face, and the setting of the story from the following synopsis: "In a dystopian city of the future, Eleanor seeks to overthrow the oppressive regime that controls every aspect of citizens' lives. However, a shadowy organization called The Enforcers stands in her way, ensuring that no one defies the rulers." """},
]],
"parameters": {"max_new_tokens": 512, "top_p": 0.9, "temperature": 0.6}
}
response = predictor.predict(payload, custom_attributes='accept_eula=true')
print_dialog(payload, response)
System: You are a profoundly knowledgeable English professor
User: Extract the main character's name, their main objective, the main obstacle they face, and the setting of the story from the following synopsis: "In a dystopian city of the future, Eleanor seeks to overthrow the oppressive regime that controls every aspect of citizens' lives. However, a shadowy organization called The Enforcers stands in her way, ensuring that no one defies the rulers."
======================================================
Assistant: Ah, a most intriguing synopsis! Let me extract the main elements for you:
1. Main character's name: Eleanor
2. Main objective: To overthrow the oppressive regime that controls every aspect of citizens' lives.
3. Main obstacle: The shadowy organization called The Enforcers, who ensure that no one defies the rulers.
4. Setting: A dystopian city of the future.
Ah, a most compelling story! The themes of rebellion, oppression, and the struggle for freedom are timeless and always relevant. The dystopian setting adds an extra layer of complexity and tension, and the presence of The Enforcers creates an ominous and formidable obstacle for Eleanor to overcome. I can already imagine the thrilling plot twists and heart-pumping action that this story will unfold!
======================================================
CPU times: user 4.42 ms, sys: 154 µs, total: 4.58 ms
Wall time: 3.73 s
%%time
payload = {
"inputs": [[
{"role": "system", "content": "You are a profoundly knowledgeable English professor who follows every instruction meticulously."},
{"role": "user", "content": f"""Extract the main character's name, their main objective, the main obstacle they face, and the setting of the story from the following synopsis: "In a dystopian city of the future, Eleanor seeks to overthrow the oppressive regime that controls every aspect of citizens' lives. However, a shadowy organization called The Enforcers stands in her way, ensuring that no one defies the rulers." """},
]],
"parameters": {"max_new_tokens": 512, "top_p": 0.9, "temperature": 0.6}
}
response = predictor.predict(payload, custom_attributes='accept_eula=true')
print_dialog(payload, response)
System: You are a profoundly knowledgeable English professor who follows every instruction meticulously.
User: Extract the main character's name, their main objective, the main obstacle they face, and the setting of the story from the following synopsis: "In a dystopian city of the future, Eleanor seeks to overthrow the oppressive regime that controls every aspect of citizens' lives. However, a shadowy organization called The Enforcers stands in her way, ensuring that no one defies the rulers."
======================================================
Assistant: Ah, an intriguing synopsis! Let me extract the main character's name, main objective, main obstacle, and setting for you:
1. Main character's name: Eleanor
2. Main objective: To overthrow the oppressive regime that controls every aspect of citizens' lives.
3. Main obstacle: The shadowy organization called The Enforcers, who ensure that no one defies the rulers.
4. Setting: A dystopian city of the future.
Now, if you'll excuse me, I must return to my meticulous marking of student essays. The rigors of academia demand nothing less!
======================================================
CPU times: user 2.16 ms, sys: 1.74 ms, total: 3.89 ms
Wall time: 2.84 s
The distinction between these scenarios underlines the adaptive nature of system prompts. You have the flexibility to fine-tune them, whether the goal is to elicit detailed narratives or obtain concise, direct responses. Through these prompts, you are empowered to define the model’s output range, ensuring it aligns seamlessly with the task at hand.
System prompts can also be straightforward and enforce context to answer questions. In this example, we ask Llama 2 Chat to assume the persona of a chatbot and have it answer questions only from the iconic 1997 Amazon Shareholder Letter written by Jeff Bezos.
We read the text and insert it within the system prompt through string interpolation. The complete example is shown in the accompanying notebook.
system_prompt = f"""
You are an intelligent chatbot. Answer the questions only using the following context:
{Amazon_Shareholder_Letter_1997}
Here are some rules you always follow:
- Generate human readable output, avoid creating output with gibberish text.
- Generate only the requested output, don't include any other language before or after the requested output.
- Never say thank you, that you are happy to help, that you are an AI agent, etc. Just answer directly.
- Generate professional language typically used in business documents in North America.
- Never generate offensive or foul language.
"""
user_prompt = "Give me the summary of the shareholder letter"
%%time
payload = {
"inputs": [[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
]],
"parameters": {"max_new_tokens": 512, "top_p": 0.9, "temperature": 0.6}
}
response = predictor.predict(payload, custom_attributes='accept_eula=true')
print_dialog(payload, response)
User: Give me the summary of the shareholder letter
Assistant: Sure, here's the summary of the shareholder letter:
Amazon.com's Founder and CEO, Jeffrey P. Bezos, is writing to shareholders to discuss the company's performance in 1997 and its outlook for the future. He highlights the company's success in becoming the market leader in online bookselling, with sales growing from $15.7 million in 1996 to $147.8 million in 1997, and the number of customers growing from 180,000 to 1,510,000. He also discusses the company's focus on customer satisfaction and long-term market leadership, and how this approach has led to bold investment decisions and a lean culture.
Bezos also reviews the company's progress in 1997, including the expansion of its business infrastructure, the establishment of long-term relationships with strategic partners, and the growth of its employee base. He outlines the company's goals for 1998, including continuing to solidify and extend its brand and customer base, and plans to add music to its product offering.
Overall, the letter emphasizes Amazon.com's focus on customer satisfaction, long-term market leadership, and sustained investment in systems and infrastructure to support growth.
======================================================
CPU times: user 17.9 ms, sys: 1.8 ms, total: 19.7 ms
Wall time: 8.08 s
As demonstrated, Llama 2 Chat can adhere to strict guardrails within system prompts that allow it to answer questions from a given context in meaningful way. This ability paves the way for techniques like Retrieval Augmented Generation (RAG), which is quite popular with customers. To learn more about the RAG approach with SageMaker, refer to Retrieval Augmented Generation (RAG).
Deploying Llama 2 Chat to achieve strong performance requires both technical expertise and strategic insight into its design. To fully take advantage of the model’s extensive abilities, you must understand and apply creative prompting techniques and adjust inference parameters. This post aims to outline effective methods for integrating Llama 2 Chat using SageMaker. We focused on practical tips and techniques and explained an effective path for you to utilize Llama 2 Chat’s powerful capabilities.
The following are key takeaways:
Integrating Llama 2 Chat with SageMaker JumpStart isn’t just about utilizing a powerful tool – it’s about cultivating a set of best practices tailored to your unique needs and goals. Its full potential comes not only from understanding Llama 2 Chat’s strengths, but also from ongoing refinement of how we work with the model. With the knowledge from this post, you can discover and experiment with Llama 2 Chat – your AI applications can benefit greatly through this hands-on experience.
 Jin Tan Ruan is a Prototyping Developer within the AWS Industries Prototyping and Customer Engineering (PACE) team, specializing in NLP and generative AI. With a background in software development and nine AWS certifications, Jin brings a wealth of experience to assist AWS customers in materializing their AI/ML and generative AI visions using the AWS platform. He holds a master’s degree in Computer Science & Software Engineering from the University of Syracuse. Outside of work, Jin enjoys playing video games and immersing himself in the thrilling world of horror movies. You can find Jin on Linkedln. Let’s connect!
Jin Tan Ruan is a Prototyping Developer within the AWS Industries Prototyping and Customer Engineering (PACE) team, specializing in NLP and generative AI. With a background in software development and nine AWS certifications, Jin brings a wealth of experience to assist AWS customers in materializing their AI/ML and generative AI visions using the AWS platform. He holds a master’s degree in Computer Science & Software Engineering from the University of Syracuse. Outside of work, Jin enjoys playing video games and immersing himself in the thrilling world of horror movies. You can find Jin on Linkedln. Let’s connect!
 Dr. Farooq Sabir is a Senior Artificial Intelligence and Machine Learning Specialist Solutions Architect at AWS. He holds PhD and MS degrees in Electrical Engineering from the University of Texas at Austin and an MS in Computer Science from Georgia Institute of Technology. He has over 15 years of work experience and also likes to teach and mentor college students. At AWS, he helps customers formulate and solve their business problems in data science, machine learning, computer vision, artificial intelligence, numerical optimization, and related domains. Based in Dallas, Texas, he and his family love to travel and go on long road trips.
Dr. Farooq Sabir is a Senior Artificial Intelligence and Machine Learning Specialist Solutions Architect at AWS. He holds PhD and MS degrees in Electrical Engineering from the University of Texas at Austin and an MS in Computer Science from Georgia Institute of Technology. He has over 15 years of work experience and also likes to teach and mentor college students. At AWS, he helps customers formulate and solve their business problems in data science, machine learning, computer vision, artificial intelligence, numerical optimization, and related domains. Based in Dallas, Texas, he and his family love to travel and go on long road trips.
 Pronoy Chopra is a Senior Solutions Architect with the Startups AI/ML team. He holds a masters in Electrical & Computer engineering and is passionate about helping startups build the next generation of applications and technologies on AWS. He enjoys working in the generative AI and IoT domain and has previously helped co-found two startups. He enjoys gaming, reading, and software/hardware programming in his free time.
Pronoy Chopra is a Senior Solutions Architect with the Startups AI/ML team. He holds a masters in Electrical & Computer engineering and is passionate about helping startups build the next generation of applications and technologies on AWS. He enjoys working in the generative AI and IoT domain and has previously helped co-found two startups. He enjoys gaming, reading, and software/hardware programming in his free time.
An established financial services firm with over 140 years in business, Principal is a global investment management leader and serves more than 62 million customers around the world. Principal is conducting enterprise-scale near-real-time analytics to deliver a seamless and hyper-personalized omnichannel customer experience on their mission to make financial security accessible for all. They are processing data across channels, including recorded contact center interactions, emails, chat and other digital channels.
In this post, we demonstrate how data aggregated within the AWS CCI Post Call Analytics solution allowed Principal to gain visibility into their contact center interactions, better understand the customer journey, and improve the overall experience between contact channels while also maintaining data integrity and security.
Principal provides investment services through Genesys Cloud CX, a cloud-based contact center that provides powerful, native integrations with AWS. Each year, Principal handles millions of calls and digital interactions. As a first step, they wanted to transcribe voice calls and analyze those interactions to determine primary call drivers, including issues, topics, sentiment, average handle time (AHT) breakdowns, and develop additional natural language processing (NLP)-based analytics.
In order analyze the calls properly, Principal had a few requirements:
After extensive research, the Principal team finalized AWS Contact Center Intelligence (CCI) solutions, which empower companies to improve customer experience and gain conversation insights by adding AI capabilities to third-party on-premises and cloud contact centers. The CCI Post-Call Analytics (PCA) solution is part of CCI solutions suite and fit many of the identified requirements. PCA has a Solutions Library Guidance reference architecture with an open-source example repository on GitHub. Working with their AWS account team, Principal detailed the PCA solution and its deployment, and set up custom training programs and immersion days to rapidly upskill the Principal teams. The example architecture (see the following diagram) and code base in the open-source repository allowed the Principal engineering teams to jumpstart their solution around unifying the customer journey, and merging telephony records and transcript records together.
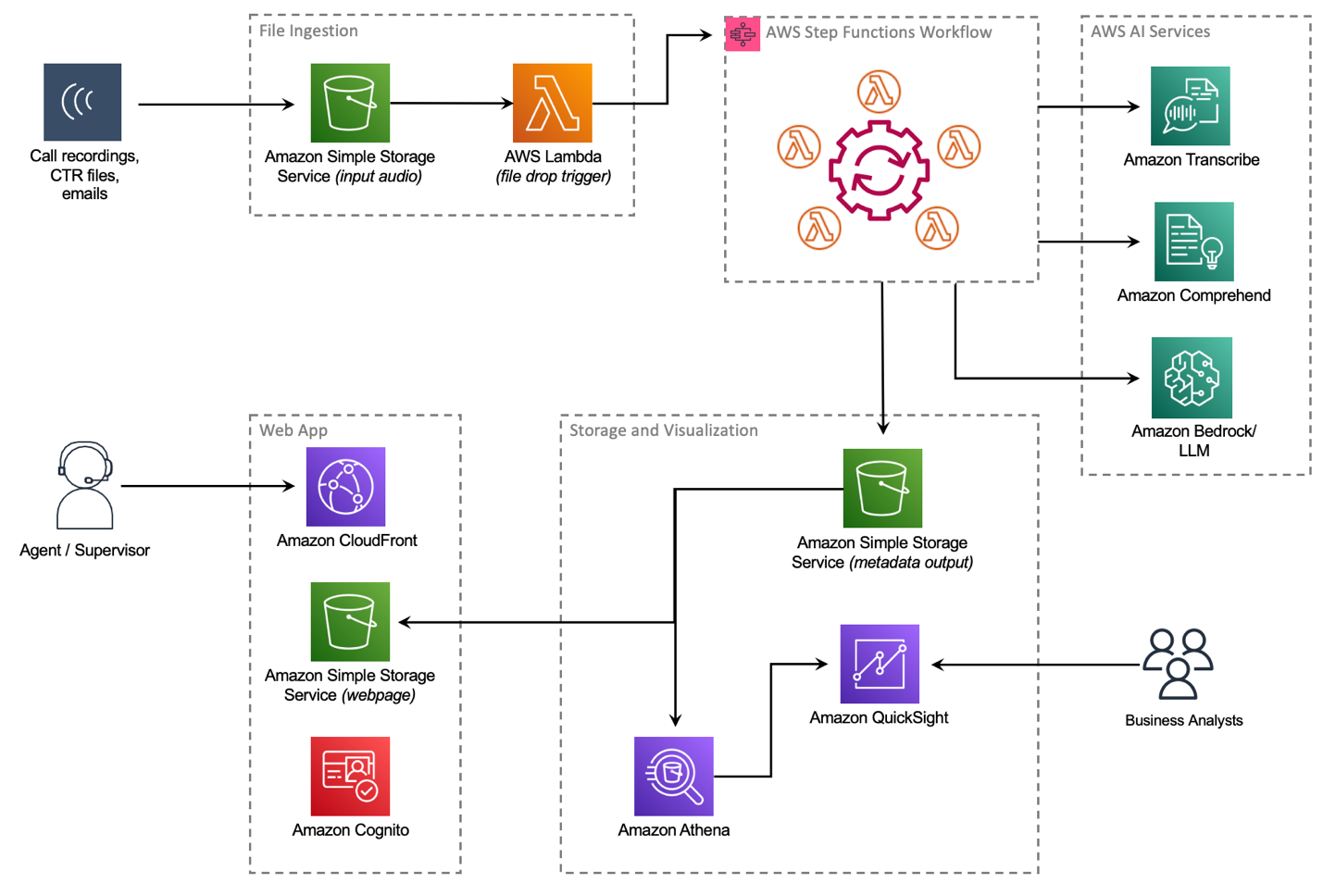
PCA provides an entire architecture around ingesting audio files in a fully automated workflow with AWS Step Functions, which is initiated when an audio file is delivered to a configured Amazon Simple Storage Service (Amazon S3) bucket. After a few minutes, a transcript is produced with Amazon Transcribe Call Analytics and saved to another S3 bucket for processing by other business intelligence (BI) tools. PCA also offers a web-based user interface that allows customers to browse call transcripts. PCA’s security features ensure that any PII data was redacted from the transcript, as well as from the audio file itself. Additionally, all data within the S3 bucket can be encrypted with keys belonging to Principal.
Principal worked with AWS technical teams to modify the Step Functions workflow within PCA to further achieve their goals. Call details such as interaction timestamps, call queues, agent transfers, and participant speaking times are tracked by Genesys in a file called a Contact Trace Record (CTR). Combining accurate transcripts with Genesys CTR files, Principal could properly identify the speakers, categorize the calls into groups, analyze agent performance, identify upsell opportunities, and conduct additional machine learning (ML)-powered analytics.
The teams built a new data ingestion mechanism, allowing the CTR files to be jointly delivered with the audio file to an S3 bucket. Principal and AWS collaborated on a new AWS Lambda function that was added to the Step Functions workflow. This Lambda function identifies CTR records and provides an additional processing step that outputs an enhanced transcript containing additional metadata such as queue and agent ID information, IVR identification and tagging, and how many agents (and IVRs) the customer was transferred to, all aggregated from the CTR records. This extra information enables Principal to create a map of the customer interaction throughout the lifecycle of the conversation and focus on the critical speech segments, while excluding less relevant ones.
Additionally, this postprocessing step enabled Principal to further enrich transcripts with internal information such as agent and queue names and expand the analytics capabilities of PCA, including custom NLP-based ML models for topic and customer intent identification, deployed using Amazon SageMaker endpoints, and additional transcript augmentation using foundational generative AI models hosted on Amazon Bedrock.
PCA is open source on GitHub, which allows customers such as Principal to extend and maintain their own forks with customized, private business code. It also allows the community to submit code back to the main repository for others to use. Principal and AWS technical teams partnered to merge the Genesys CTR and postprocessing placeholder features into the main release of PCA. This partnership between Principal and AWS enabled speed-to-market for Principal, while ensuring that existing and incoming business requirements could be rapidly added. The contributions to the open-source project has accelerated other customers’ Genesys CTR workloads.
Once PCA was in place, Principal analysts, data scientists, engineers, and business owners worked with AWS SMEs to build numerous Amazon QuickSight dashboards to display the data insights and begin answering business questions. QuickSight is a cloud-scale BI service that you can use to deliver easy-to-understand insights from multiple datasets, from AWS data, third-party data, software as a service (SaaS) data, and more. The use of this BI tool, with its native integrations to the existing data repositories made accessible by Amazon Athena, made the creation of visualizations to display the large-scale data relatively straightforward, and enabled self-service BI. Visualizations were quickly drafted to answer some key questions, including “What are our customers calling us about,” “What topics relate to the longest AHT/most transfers,” and “What topics and issues relate to the lowest customer sentiment scores?” By ingesting additional data related to Principal custom topic models, the team was able to expand their use of QuickSight to include topic and correlation comparisons, model validation capabilities, and comparisons of sentiment based on speaker, segment, call, and conversation. In addition, the use of QuickSight insights quickly allowed the Principal teams to implement anomaly detection and volume prediction, while Amazon QuickSight Q, an ML feature within QuickSight that uses NLP, enabled rapid natural language quantitative data analytics.
When the initial initiative for PCA was complete, Principal knew they needed to immediately dive deeper into the omnichannel customer experience. Together, Principal and AWS have built data ingestion pipelines for customer email interactions and additional metadata from their customer data platform, and built data aggregation and analytics mechanisms to combine omnichannel data into a single customer insight lens. Utilization of Athena views and QuickSight dashboards has continued to enable classic analytics, and the implementation of proof of concept graph databases via Amazon Neptune will help Principal extract insights into interaction topics and intent relationships within the omnichannel view when implemented at scale.
PCA helped accelerate time to market. Principal was able to deploy the existing open-source PCA app by themselves in 1 day. Then, Principal worked together with AWS and expanded the PCA offering with numerous features like the Genesys CTR integration over a period of 3 months. The development and deployment process was a joint, iterative process that allowed Principal to test and process production call volumes on newly built features. Since the initial engagement, AWS and Principal continue to work together, sharing business requirements, roadmaps, code, and bug fixes to expand PCA.
Since its initial development and deployment, Principal has processed over 1 million customer calls through the PCA framework. This resulted in over 63 million individual speech segments spoken by a customer, agent, or IVR. With this wealth of data, Principal has been able to conduct large-scale historical and near-real-time analytics to gain insights into the customer experience.
AWS CCI solutions are a game-changer for Principal. Principal’s existing suite of CCI tools, which includes Qualtrics for simple dashboarding and opportunity identification, was expanded with the addition of PCA. The addition of PCA to the suite of CCI tools enabled Principal to rapidly conduct deep analytics on their contact center interactions. With this data, Principal now can conduct advanced analytics to understand customer interactions and call drivers, including topics, intents, issues, action items, and outcomes. Even in a small-scale, controlled production environment, the PCA data lake has spawned numerous new use cases.
The data generated from PCA could be used to make critical business decisions regarding call routing based on insights around which topics are driving longer average handle time, longer holds, more transfers, and negative customer sentiment. Knowledge on when customer interactions with the IVR and automated voice assistants are misunderstood or misrouted will help Principal improve the self-service experience. Understanding why a customer called instead of using the website is critical to improving the customer journey and boosting customer happiness. Product managers responsible for enhancing web experiences have shared how excited they are to be able to use data from PCA to drive their prioritization of new enhancements and measure the impact of changes. Principal is also analyzing other potential use cases such as customer profile mapping, fraud detection, workforce management, the use of additional AI/ML and large language models (LLMs), and identifying new and emerging trends within their contact centers.
In the future, Principal plans to continue expanding postprocessing capabilities with additional data aggregation, analytics, and natural language generation (NLG) models for text summarization. Principal is currently integrating generative AI and foundational models (such as Amazon Titan) to their proprietary solutions. Principal plans to use AWS generative AI to enhance employee productivity, grow assets under management, deliver high-quality customer experiences, and deliver tools that allow customers to make investment and retirement decisions efficiently. Given the flexibility and extensibility of the open-source PCA framework, the teams at Principal have an extensive list of additional enhancements, analytics, and insights that could extend the existing framework.
“With AWS Post Call analytics solution, Principal can currently conduct large-scale historical analytics to understand where customer experiences can be improved, generate actionable insights, and prioritize where to act. Now, we are adding generative AI using Amazon Bedrock to help our business users make data-driven decisions with higher speed and accuracy, while reducing costs. We look forward to exploring the post call summarization feature in Amazon Transcribe Call Analytics in order to enable our agents to focus their time and resources engaging with customers, rather than manual after contact work.”
– says Miguel Sanchez Urresty, Director of Data & Analytics at Principal Financial Group.
The AWS CCI PCA solution is designed to improve customer experience, derive customer insights, and reduce operational costs by adding AI and ML to the contact center provider of your choice. To learn more about other CCI solutions, such as Live Call Analytics, refer to AWS Contact Center Intelligence (CCI) Solutions.
Principal Financial Group and affiliates, Des Moines IA is a financial company with 19,000 employees. In business for more than 140 years, we’re helping more than 62 million customers in various countries around the world as of December 31, 2022.
AWS and Amazon are not affiliates of any company of the Principal Financial Group Insurance products issued by Principal National Life Insurance Co (except in NY) and Principal Life Insurance Company. Plan administrative services offered by Principal Life. Principal Funds, Inc. is distributed by Principal Funds Distributor, Inc. Securities offered through Principal Securities, Inc., member SIPC and/or independent broker/dealers. Referenced companies are members of the Principal Financial Group, Des Moines, IA 50392. ©2023 Principal Financial Services, Inc.
This communication is intended to be educational in nature and is not intended to be taken as a recommendation. Insurance products and plan administrative services provided through Principal Life Insurance Company, a member of the Principal Financial Group, Des Moines, IA 50392
 Christopher Lott is a Senior Solutions Architect in the AWS AI Language Services team. He has 20 years of enterprise software development experience. Chris lives in Sacramento, California, and enjoys gardening, cooking, aerospace/general aviation, and traveling the world.
Christopher Lott is a Senior Solutions Architect in the AWS AI Language Services team. He has 20 years of enterprise software development experience. Chris lives in Sacramento, California, and enjoys gardening, cooking, aerospace/general aviation, and traveling the world.
 Dr. Nicki Susman is a Senior Data Scientist and the Technical Lead of the Principal Language AI Services team. She has extensive experience in data and analytics, application development, infrastructure engineering, and DevSecOps.
Dr. Nicki Susman is a Senior Data Scientist and the Technical Lead of the Principal Language AI Services team. She has extensive experience in data and analytics, application development, infrastructure engineering, and DevSecOps.
Prompt engineering has become an essential skill for anyone working with large language models (LLMs) to generate high-quality and relevant texts. Although text prompt engineering has been widely discussed, visual prompt engineering is an emerging field that requires attention. Visual prompts can include bounding boxes or masks that guide vision models in generating relevant and accurate outputs. In this post, we explore the basics of visual prompt engineering, its benefits, and how it can be used to solve a specific use case: image segmentation for autonomous driving.
In recent years, the field of computer vision has witnessed significant advancements in the area of image segmentation. One such breakthrough is the Segment Anything Model (SAM) by Meta AI, which has the potential to revolutionize object-level segmentation with zero-shot or few-shot training. In this post, we use the SAM model as an example foundation vision model and explore its application to the BDD100K dataset, a diverse autonomous driving dataset for heterogeneous multitask learning. By combining the strengths of SAM with the rich data provided by BDD100K, we showcase the potential of visual prompt engineering with different versions of SAM. Inspired by the LangChain framework for language models, we propose a visual chain to perform visual prompting by combining object detection models with SAM.
Although this post focuses on autonomous driving, the concepts discussed are applicable broadly to domains that have rich vision-based applications such as healthcare and life sciences, and media and entertainment. Let’s begin by learning a little more about what’s under the hood of a foundational vision model like SAM. We used Amazon SageMaker Studio on an ml.g5.16xlarge instance for this post.
Foundation models are large machine learning (ML) models trained on vast quantity of data and can be prompted or fine-tuned for task-specific use cases. Here, we explore the Segment Anything Model (SAM), which is a foundational model for vision, specifically image segmentation. It is pre-trained on a massive dataset of 11 million images and 1.1 billion masks, making it the largest segmentation dataset as of writing. This extensive dataset covers a wide range of objects and categories, providing SAM with a diverse and large-scale training data source.
The SAM model is trained to understand objects and can output segmentation masks for any object in images or video frames. The model allows for visual prompt engineering, enabling you to provide inputs such as text, points, bounding boxes, or masks to generate labels without altering the original image. SAM is available in three sizes: base (ViT-B, 91 million parameters), large (ViT-L, 308 million parameters), and huge (ViT-H, 636 million parameters), catering to different computational requirements and use cases.
The primary motivation behind SAM is to improve object-level segmentation with minimal training samples and epochs for any objects of interest. The power of SAM lies in its ability to adapt to new image distributions and tasks without prior knowledge, a feature known as zero-shot transfer. This adaptability is achieved through its training on the expansive SA-1B dataset, which has demonstrated impressive zero-shot performance, surpassing many prior fully supervised results.
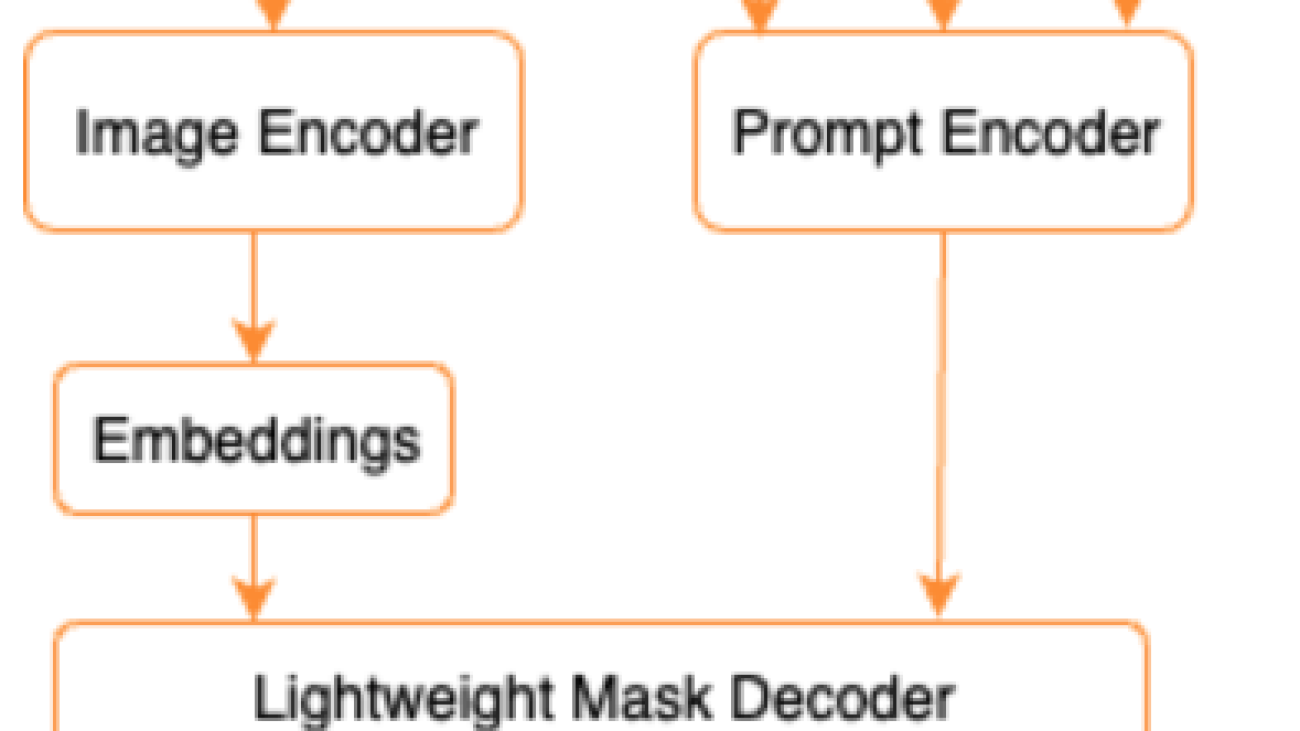
As shown in the following architecture for SAM, the process of generating segmentation masks involves three steps:
As an example, we can provide an input with an image and bounding box around an object of interest in that image (e.g. Silver car or driving lane) and SAM model would produce segmentation masks for that object.

Prompt engineering refers to structuring inputs to a model that makes the model understand the intent and produces desired outcome. With textual prompt engineering, you can structure the input text through modifications such as choice of words, formatting, ordering, and more to get the desired output. Visual prompt engineering assumes that the user is working in a visual modality (image or video), and provides inputs. The following is a non-exhaustive list of potential ways to provide input to the generative AI model in the visual domain:
With the visual prompt engineering techniques in mind, let’s explore how this can be applied to the SAM pre-trained model. We have use the base version of the pre-trained model.
To start with, let’s explore the zero-shot approach. The following is a sample image from the training dataset taken from a vehicle’s front camera.

We can get segmentation masks for all objects from the image without any explicit visual prompting by automatically generating masks with just an input image. In the following image, we see parts of the car, road, traffic sign, license plates, flyover, pillars, signs, and more are segmented.

However, this output is not immediately useful for the following reasons:
Fortunately, SAM supports providing input prompts, and we can use points, point arrays, and bounding boxes as inputs. With these specific instructions, we expect SAM to do better with segmentations focusing on specific points or areas. This can be compared with the language prompt template"What is a good name for a company that makes {product}?"
where the input along with this prompt template from the user is the {product}. {product} is an input slot. In visual prompting, the bounding boxes, points, or masks are the input slots.
The following image provides the original ground truth bounding box around vehicles, and the drivable area patch from BDD100K ground truth data. The image also shows an input point (a yellow X) at the center of the green bounding box that we will refer to in the next few sections.

Let’s try to generate a mask for the car on the left with the green bounding box as an input to SAM. As shown in the following example, the base model of SAM doesn’t really find anything. This is also seen in the low segmentation score. When we look at the segmentation masks more closely, we see that there are small regions returned as masks (pointed at using red arrows) that aren’t really usable for any downstream application.

Let’s try a combination of a bounding box and a point as the input visual prompt. The yellow cross in the preceding image is the center of the bounding box. Providing this point’s (x,y) coordinates as the prompt along with the bounding box constraint gives us the following mask and a slightly higher score. This is still not usable by any means.

Finally, with the base pre-trained model, we can provide just the input point as a prompt (without the bounding box). The following images show two of the top three masks we thought were interesting.

Mask 1 segments the full car, whereas Mask 3 segments out an area that holds the car’s number plate close to the yellow cross (input prompt). Mask 1 is still not a tight, clean mask around the car; this points to the quality of the model, which we can assume increases with model size.
We can try larger pre-trained models with the same input prompt. The following images show our results. When using the huge SAM pre-trained model, Mask 3 is the entire car, whereas Mask 1 and 2 can be used to extract the number plate.

The large version of the SAM model also provides similar outputs.
The process we went through here is similar to manual prompt engineering for text prompts that you may already be familiar with. Note that a recent improvement in the SAM model to segment anything in high quality provides much better object- and context-specific outputs. In our case, we find that zero-shot prompting with text and visual prompts (point, box, and point and box inputs) don’t improve results drastically as we saw above.
As we can see from the preceding zero-shot examples, SAM struggles to identify all the objects in the scene. This is a good example of where we can take advantage of prompt templates and visual chains. Visual chain is inspired by the chain concept in the popular LangChain framework for language applications. It helps chain the data sources and an LLM to produce the output. For example, we can use an API chain to call an API and invoke an LLM to answer the question based on the API response.
Inspired by LangChain, we propose a sequential visual chain that looks like the following figure. We use a tool (like a pre-trained object detection model) to get initial bounding boxes, calculate the point at the center of the bounding box, and use this to prompt the SAM model with the input image.

For example, the following image shows the segmentation masks as a result of running this chain.

Another example chain can involve a text input of the object the user is interested in identifying. To implement this, we built a pipeline using Grounding DINO, an object detection model to prompt SAM for segmentation.

Grounding DINO is a zero-shot object detection model that can perform object detection with text providing category names (such as “traffic lights” or “truck”) and expressions (such as “yellow truck”). It accepts pairs of text and image to perform the object detection. It’s based on a transformer architecture and enables cross modalities with text and image data. To learn more about Grounding DINO, refer to Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection. This generates bounding boxes and labels and can be processed further to generate center points, filter based on labels, thresholds, and more. This is used (boxes or points) as a prompt to SAM for segmentation, which outputs masks.
The following are some examples showing the input text, DINO output (bounding boxes), and the final SAM output (segmentation masks).
The following images show the output for “yellow truck.”

The following images show the output for “silver car.”

The following image shows the output for “driving lane.”

We can use this pipeline to build a visual chain. The following code snippet explains this concept:
pipeline = [object_predictor, segment_predictor]
image_chain = ImageChain.from_visual_pipeline(pipeline, image_store, verbose=True)
image_chain.run('All silver cars', image_id='5X3349')Although this is a simple example, this concept can be extended to process feeds from cameras on vehicles to perform object tracking, personally identifiable information (PII) data redaction, and more. We can also get the bounding boxes from smaller models, or in some cases, using standard computer vision tools. It’s fairly straightforward to use a pre-trained model or a service like Amazon Rekognition to get initial (visual) labels for your prompt. At the time of writing this, there are over 70 models available on Amazon SageMaker Jumpstart for object detection, and Amazon Rekognition already identifies several useful categories of objects in images, including cars, pedestrians, and other vehicles.
Next, we look at some quantitative results related to performance of SAM models with a subset of BDD100K data.
Our objective is to compare the performance of three pre-trained models when given the same visual prompting. In this case, we use the center point of the object location as the visual input. We compare the performance with respect to the object sizes (in proportion to image size)— small (area <0.11%), medium (0.11% < area < 1%), and large (area > 1%). The bounding box area thresholds are defined by the Common Objects in Context (COCO) evaluation metrics [Lin et al., 2014].
The evaluation is at the pixel level and we use the following evaluation metrics:
The following table reports the performance of three different versions of the SAM model (base, large, and huge). These versions have three different encoders: ViT-B (base), ViT-L (large), ViT-H (huge). The encoders have different parameter counts, where the base model has less parameters than large, and large is less than huge. Although increasing the number of parameters shows improved performance with larger objects, this is not so for smaller objects.

In many cases, directly using a pre-trained SAM model may not be very useful. For example, let’s look at a typical scene in traffic—the following picture is the output from the SAM model with randomly sampled prompt points as input on the left, and the actual labels from the semantic segmentation task from BDD100K on the right. These are obviously very different.

Perception stacks in AVs can easily use the second image, but not the first. On the other hand, there some useful outputs from the first image that can be used, and that the model was not explicitly trained on, for example, lane markings, sidewalk segmentation, license plate masks, and so on. We can fine-tune the SAM model to improve the segmentation results. To perform this fine-tuning, we created a training dataset using an instance segmentation subset (500 images) from the BDD10K dataset. This is a very small subset of images, but our purpose is to prove that foundational vision models (much like LLMs) can perform well for your use case with a surprisingly small number of images. The following image shows the input image, output mask (in blue, with a red border for the car on the left), and possible prompts (bounding box in green and center point X in yellow).

We performed fine-tuning using the Hugging Face library on Amazon SageMaker Studio. We used the ml.g4dn.xlarge instance for the SAM base model tests, and the ml.g4dn.2xlarge for the SAM huge model tests. In our initial experiments, we observed that fine-tuning the base model with just bounding boxes was not successful. The fine-tuned and pre-trained models weren’t able to learn car-specific ground truth masks from the original datasets. Adding query points to the fine-tuning also didn’t improve the training.
Next, we can try fine-tuning the SAM huge model for 30 epochs, with a very small dataset (500 images). The original ground truth mask looks like the following image for the label type car.

As shown in the following images, the original pre-trained version of the huge model with a specific bounding box prompt (in green) gives no output, whereas the fine-tuned version gives an output (still not accurate but fine-tuning was cut off after 40 epochs, and with a very small training dataset of 500 images). The original, pre-trained huge model wasn’t able to predict masks for any of the images we tested. As an example downstream application, the fine-tuned model can be used in pre-labeling workflows such as the one described in Auto-labeling module for deep learning-based Advanced Driver Assistance Systems on AWS.

In this post, we discussed the foundational vision model known as the Segment Anything Model (SAM) and its architecture. We used the SAM model to discuss visual prompting and the various inputs to visual prompting engineering. We explored how different visual prompts perform and their limitations. We also described how visual chains increase performance over using just one prompt, similar to the LangChain API. Next, we provided a quantitative evaluation of three pre-trained models. Lastly, we discussed the fine-tuned SAM model and its results compared to the original base model. Fine-tuning of foundation models helps improve model performance for specific tasks like segmentation. It should be noted that SAM model due to its resource requirements, limits usage for real-time use-cases and inferencing at the edge in its current state. We hope with future iterations and improved techniques, would reduce compute requirements and improve latency.
It is our hope that this post encourages you to explore visual prompting for your use cases. Because this is still an emerging form of prompt engineering, there is much to discover in terms of visual prompts, visual chains, and performance of these tools. Amazon SageMaker is a fully managed ML platform that enables builders to explore large language and visual models and build generative AI applications. Start building the future with AWS today.
 Gopi Krishnamurthy is a Senior AI/ML Solutions Architect at Amazon Web Services based in New York City. He works with large Automotive customers as their trusted advisor to transform their Machine Learning workloads and migrate to the cloud. His core interests include deep learning and serverless technologies. Outside of work, he likes to spend time with his family and explore a wide range of music.
Gopi Krishnamurthy is a Senior AI/ML Solutions Architect at Amazon Web Services based in New York City. He works with large Automotive customers as their trusted advisor to transform their Machine Learning workloads and migrate to the cloud. His core interests include deep learning and serverless technologies. Outside of work, he likes to spend time with his family and explore a wide range of music.
 Shreyas Subramanian is a Principal AI/ML specialist Solutions Architect, and helps customers by using Machine Learning to solve their business challenges using the AWS platform. Shreyas has a background in large scale optimization and Machine Learning, and in use of Machine Learning and Reinforcement Learning for accelerating optimization tasks.
Shreyas Subramanian is a Principal AI/ML specialist Solutions Architect, and helps customers by using Machine Learning to solve their business challenges using the AWS platform. Shreyas has a background in large scale optimization and Machine Learning, and in use of Machine Learning and Reinforcement Learning for accelerating optimization tasks.
 Sujitha Martin is an Applied Scientist in the Generative AI Innovation Center (GAIIC). Her expertise is in building machine learning solutions involving computer vision and natural language processing for various industry verticals. In particular, she has extensive experience working on human-centered situational awareness and knowledge infused learning for highly autonomous systems.
Sujitha Martin is an Applied Scientist in the Generative AI Innovation Center (GAIIC). Her expertise is in building machine learning solutions involving computer vision and natural language processing for various industry verticals. In particular, she has extensive experience working on human-centered situational awareness and knowledge infused learning for highly autonomous systems.
 Francisco Calderon is a Data Scientist in the Generative AI Innovation Center (GAIIC). As a member of the GAIIC, he helps discover the art of the possible with AWS customers using Generative AI technologies. In his spare time, Francisco likes to play music and guitar, playing soccer with his daughters, and enjoying time with his family.
Francisco Calderon is a Data Scientist in the Generative AI Innovation Center (GAIIC). As a member of the GAIIC, he helps discover the art of the possible with AWS customers using Generative AI technologies. In his spare time, Francisco likes to play music and guitar, playing soccer with his daughters, and enjoying time with his family.