The telecommunications industry — the backbone of today’s interconnected world — is valued at a staggering $1.7 trillion globally, according to IDC.
It’s a massive operation, as telcos process hundreds of petabytes of data in their networks each day. That magnitude is only increasing, as the total amount of data transacted globally is forecast to grow to more than 180 zettabytes by 2025.
To meet this demand for data processing and analysis, telcos are turning to generative AI, which is improving efficiency and productivity across industries.
NVIDIA announced an AI foundry service — a collection of NVIDIA AI Foundation Models, NVIDIA NeMo framework and tools, and NVIDIA DGX Cloud AI supercomputing and services — that gives enterprises an end-to-end solution for creating and optimizing custom generative AI models.
Using the AI foundry service, Amdocs, a leading provider of software and services for communications and media providers, will optimize enterprise-grade large language models for the telco and media industries to efficiently deploy generative AI use cases across their businesses, from customer experiences to network operations and provisioning. The LLMs will run on NVIDIA accelerated computing as part of the Amdocs amAIz framework.
The collaboration builds on the previously announced Amdocs-Microsoft partnership, enabling service providers to adopt these applications in secure, trusted environments, including on premises and in the cloud.
Custom Models for Custom Results
While preliminary applications of generative AI used broad datasets, enterprises have become increasingly focused on developing custom models to perform specialized, industry-specific skills.
By training models on proprietary data, telcos can deliver tailored solutions that produce more accurate results for their use cases.
To simplify the development, tuning and deployment of such custom models, Amdocs is integrating the new NVIDIA AI foundry service.
Equipped with these new generative AI capabilities — including guardrail features — service providers can enhance performance, optimize resource utilization and flexibly scale to meet future needs.
Amdocs’ Global Telco Ecosystem Footprint
More than 350 of the world’s leading telecom and media companies across 90 countries take advantage of Amdocs services each day, including 27 of the world’s top 30 service providers, according to OMDIA.(1) Powering more than 1.7 billion daily digital journeys, Amdocs platforms impact more than 3 billion people around the world.
NVIDIA and Amdocs are exploring several generative AI use cases to simplify and improve operations by providing secure, cost-effective, and high-performance generative AI capabilities.
Initial use cases span customer care, including accelerating resolution of customer inquiries by drawing information from across company data.
And in network operations, the companies are exploring ways to generate solutions to address configuration, coverage or performance issues as they arise.
Automotive companies are transforming every phase of their product lifecycle — evolving their primarily physical, manual processes into software-driven, AI-enhanced digital systems.
To help them save costs and reduce lead times, NVIDIA is announcing two new simulation engines on Omniverse Cloud: the virtual factory simulation engine and the autonomous vehicle (AV) simulation engine.
Omniverse Cloud, a platform-as-a-service for developing and deploying applications for industrial digitalization, is hosted on Microsoft Azure. This one-stop shop enables automakers worldwide to unify digitalization across their core product and business processes. It allows enterprises to achieve faster production and more efficient operations, improving time to market and enhancing sustainability initiatives.
For design, engineering and manufacturing teams, digitalization streamlines their work, converting once primarily manual industrial processes into efficient systems for concept and styling; AV development, testing and validation; and factory planning.
Virtual Factory Simulation Engine
The Omniverse Cloud virtual factory simulation engine is a collection of customizable developer applications and services that enable factory planning teams to connect large-scale industrial datasets while collaborating, navigating and reviewing them in real time.
Design teams working with 3D data can assemble virtual factories and share their work with thousands of planners who can view, annotate and update the full-fidelity factory dataset from lightweight devices. By simulating virtual factories on Omniverse Cloud, automakers can increase throughput and production quality while saving years of effort and millions of dollars that would result from making changes once construction is underway.
On Omniverse Cloud, teams can create interoperability between existing software applications such as Autodesk Factory Planning, which supports the entire lifecycle for building, mechanical, electrical, and plumbing and factory lines, as well as Siemens’ NX, Process Simulate and Teamcenter Visualization software and the JT file format. They can share knowledge and data in real time in live, virtual factory reviews across 2D devices or in extended reality.
T-Systems, a leading IT solutions provider for Europe’s largest automotive manufacturers, is building and deploying a custom virtual factory application that its customers can deploy in Omniverse Cloud.
SoftServe, an elite member of the NVIDIA Service Delivery Partner program, is also developing custom factory simulation and visualization solutions on this Omniverse Cloud engine, covering factory design, production planning and control.
AV Simulation Engine
The AV simulation engine is a service that delivers physically based sensor simulation, enabling AV and robotics developers to run autonomous systems in a closed-loop virtual environment.
The next generation of AV architectures will be built on large, unified AI models that combine layers of the vehicle stack, including perception, planning and control. Such new architectures call for an integrated approach to development.
With previous architectures, developers could train and test these layers independently, as they were governed by different models. For example, simulation could be used to develop a vehicle’s planning and control system, which only needs basic information about objects in a scene — such as the speed and distance of surrounding vehicles — while perception networks could be trained and tested on recorded sensor data.
However, using simulation to develop an advanced unified AV architecture requires sensor data as the input. For a simulator to be effective, it must be able to simulate vehicle sensors, such as cameras, radars and lidars, with high fidelity.
To address this challenge, NVIDIA is bringing state-of-the-art sensor simulation pipelines used in DRIVE Sim and Isaac Sim to Omniverse Cloud on Microsoft Azure.
Omniverse Cloud sensor simulation provides AV and robotics workflows with high-fidelity, physically based simulation for cameras, radars, lidars and other types of sensors. It can be connected to existing simulation applications, whether developed in-house or provided by a third party, via Omniverse Cloud application programming interfaces for integration into workflows.
Fast Track to Digitalization
The factory simulation engine is now available to customers via an Omniverse Cloud enterprise private offer through the Azure Marketplace, which provides access to NVIDIA OVX systems and fully managed Omniverse software, reference applications and workflows. The sensor simulation engine is coming soon.
As NVIDIA continues to collaborate with Microsoft to build state-of-the-art AI infrastructure, Microsoft is introducing additional H100-based virtual machines to Microsoft Azure to accelerate demanding AI workloads.
At its Ignite conference in Seattle today, Microsoft announced its new NC H100 v5 VM series for Azure, the industry’s first cloud instances featuring NVIDIA H100 NVL GPUs.
This offering brings together a pair of PCIe-based H100 GPUs connected via NVIDIA NVLink, with nearly 4 petaflops of AI compute and 188GB of faster HBM3 memory. The NVIDIA H100 NVL GPU can deliver up to 12x higher performance on GPT-3 175B over the previous generation and is ideal for inference and mainstream training workloads.
Additionally, Microsoft announced plans to add the NVIDIA H200 Tensor Core GPU to its Azure fleet next year to support larger model inferencing with no increase in latency. This new offering is purpose-built to accelerate the largest AI workloads, including LLMs and generative AI models.
The H200 GPU brings dramatic increases both in memory capacity and bandwidth using the latest-generation HBM3e memory. Compared to the H100, this new GPU will offer 141GB of HBM3e memory (1.8x more) and 4.8 TB/s of peak memory bandwidth (a 1.4x increase).
Cloud Computing Gets Confidential
Further expanding availability of NVIDIA-accelerated generative AI computing for Azure customers, Microsoft announced another NVIDIA-powered instance: the NCC H100 v5.
These Azure confidential VMs with NVIDIA H100 Tensor Core GPUs allow customers to protect the confidentiality and integrity of their data and applications in use, in memory, while accessing the unsurpassed acceleration of H100 GPUs. These GPU-enhanced confidential VMs will be coming soon to private preview.
To learn more about the new confidential VMs with NVIDIA H100 Tensor Core GPUs, and sign up for the preview, read the blog.
Today’s landscape of free, open-source large language models (LLMs) is like an all-you-can-eat buffet for enterprises. This abundance can be overwhelming for developers building custom generative AI applications, as they need to navigate unique project and business requirements, including compatibility, security and the data used to train the models.
NVIDIA AI Foundation Models — a curated collection of enterprise-grade pretrained models — give developers a running start for bringing custom generative AI to their enterprise applications.
NVIDIA-Optimized Foundation Models Speed Up Innovation
NVIDIA AI Foundation Models can be experienced through a simple user interface or API, directly from a browser. Additionally, these models can be accessed from NVIDIA AI Foundation Endpoints to test model performance from within their enterprise applications.
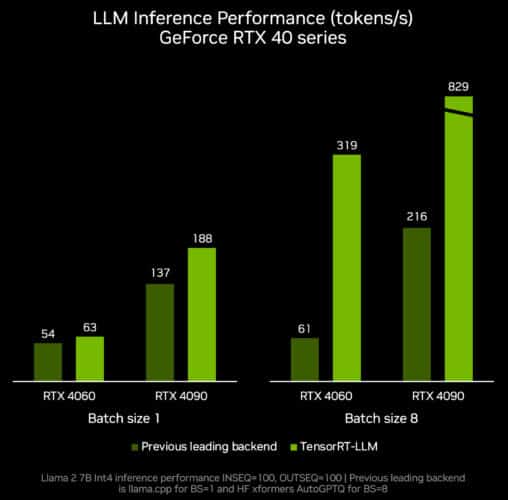
Available models include leading community models such as Llama 2, Stable Diffusion XL and Mistral, which are formatted to help developers streamline customization with proprietary data. Additionally, models have been optimized with NVIDIA TensorRT-LLM to deliver the highest throughput and lowest latency and to run at scale on any NVIDIA GPU-accelerated stack. For instance, the Llama 2 model optimized with TensorRT-LLM runs nearly 2x faster on NVIDIA H100.
The new NVIDIA family of Nemotron-3 8B foundation models supports the creation of today’s most advanced enterprise chat and Q&A applications for a broad range of industries, including healthcare, telecommunications and financial services.
The models are a starting point for customers building secure, production-ready generative AI applications, are trained on responsibly sourced datasets and operate at comparable performance to much larger models. This makes them ideal for enterprise deployments.
Multilingual capabilities are a key differentiator of the Nemotron-3 8B models. Out of the box, the models are proficient in over 50 languages, including English, German, Russian, Spanish, French, Japanese, Chinese, Korean, Italian and Dutch.
Fast-Track Customization to Deployment
Enterprises leveraging generative AI across business functions need an AI foundry to customize models for their unique applications. NVIDIA’s AI foundry features three elements — NVIDIA AI Foundation Models, NVIDIA NeMo framework and tools, and NVIDIA DGX Cloud AI supercomputing services. Together, these provide an end-to-end enterprise offering for creating custom generative AI models.
Importantly, enterprises own their customized models and can deploy them virtually anywhere on accelerated computing with enterprise-grade security, stability and support using NVIDIA AI Enterprise software.
To understand the latest advance in generative AI, imagine a courtroom.
Judges hear and decide cases based on their general understanding of the law. Sometimes a case — like a malpractice suit or a labor dispute — requires special expertise, so judges send court clerks to a law library, looking for precedents and specific cases they can cite.
Like a good judge, large language models (LLMs) can respond to a wide variety of human queries. But to deliver authoritative answers that cite sources, the model needs an assistant to do some research.
The court clerk of AI is a process called retrieval-augmented generation, or RAG for short.
The Story of the Name
Patrick Lewis, lead author of the 2020 paper that coined the term, apologized for the unflattering acronym that now describes a growing family of methods across hundreds of papers and dozens of commercial services he believes represent the future of generative AI.
Patrick Lewis
“We definitely would have put more thought into the name had we known our work would become so widespread,” Lewis said in an interview from Singapore, where he was sharing his ideas with a regional conference of database developers.
“We always planned to have a nicer sounding name, but when it came time to write the paper, no one had a better idea,” said Lewis, who now leads a RAG team at AI startup Cohere.
So, What Is Retrieval-Augmented Generation?
Retrieval-augmented generation is a technique for enhancing the accuracy and reliability of generative AI models with facts fetched from external sources.
In other words, it fills a gap in how LLMs work. Under the hood, LLMs are neural networks, typically measured by how many parameters they contain. An LLM’s parameters essentially represent the general patterns of how humans use words to form sentences.
That deep understanding, sometimes called parameterized knowledge, makes LLMs useful in responding to general prompts at light speed. However, it does not serve users who want a deeper dive into a current or more specific topic.
Combining Internal, External Resources
Lewis and colleagues developed retrieval-augmented generation to link generative AI services to external resources, especially ones rich in the latest technical details.
The paper, with coauthors from the former Facebook AI Research (now Meta AI), University College London and New York University, called RAG “a general-purpose fine-tuning recipe” because it can be used by nearly any LLM to connect with practically any external resource.
Building User Trust
Retrieval-augmented generation gives models sources they can cite, like footnotes in a research paper, so users can check any claims. That builds trust.
What’s more, the technique can help models clear up ambiguity in a user query. It also reduces the possibility a model will make a wrong guess, a phenomenon sometimes called hallucination.
Another great advantage of RAG is it’s relatively easy. A blog by Lewis and three of the paper’s coauthors said developers can implement the process with as few as five lines of code.
That makes the method faster and less expensive than retraining a model with additional datasets. And it lets users hot-swap new sources on the fly.
How People Are Using Retrieval-Augmented Generation
With retrieval-augmented generation, users can essentially have conversations with data repositories, opening up new kinds of experiences. This means the applications for RAG could be multiple times the number of available datasets.
For example, a generative AI model supplemented with a medical index could be a great assistant for a doctor or nurse. Financial analysts would benefit from an assistant linked to market data.
In fact, almost any business can turn its technical or policy manuals, videos or logs into resources called knowledge bases that can enhance LLMs. These sources can enable use cases such as customer or field support, employee training and developer productivity.
The broad potential is why companies including AWS, IBM, Glean, Google, Microsoft, NVIDIA, Oracle and Pinecone are adopting RAG.
Getting Started With Retrieval-Augmented Generation
The software components are all part of NVIDIA AI Enterprise, a software platform that accelerates development and deployment of production-ready AI with the security, support and stability businesses need.
Getting the best performance for RAG workflows requires massive amounts of memory and compute to move and process data. The NVIDIA GH200 Grace Hopper Superchip, with its 288GB of fast HBM3e memory and 8 petaflops of compute, is ideal — it can deliver a 150x speedup over using a CPU.
Once companies get familiar with RAG, they can combine a variety of off-the-shelf or custom LLMs with internal or external knowledge bases to create a wide range of assistants that help their employees and customers.
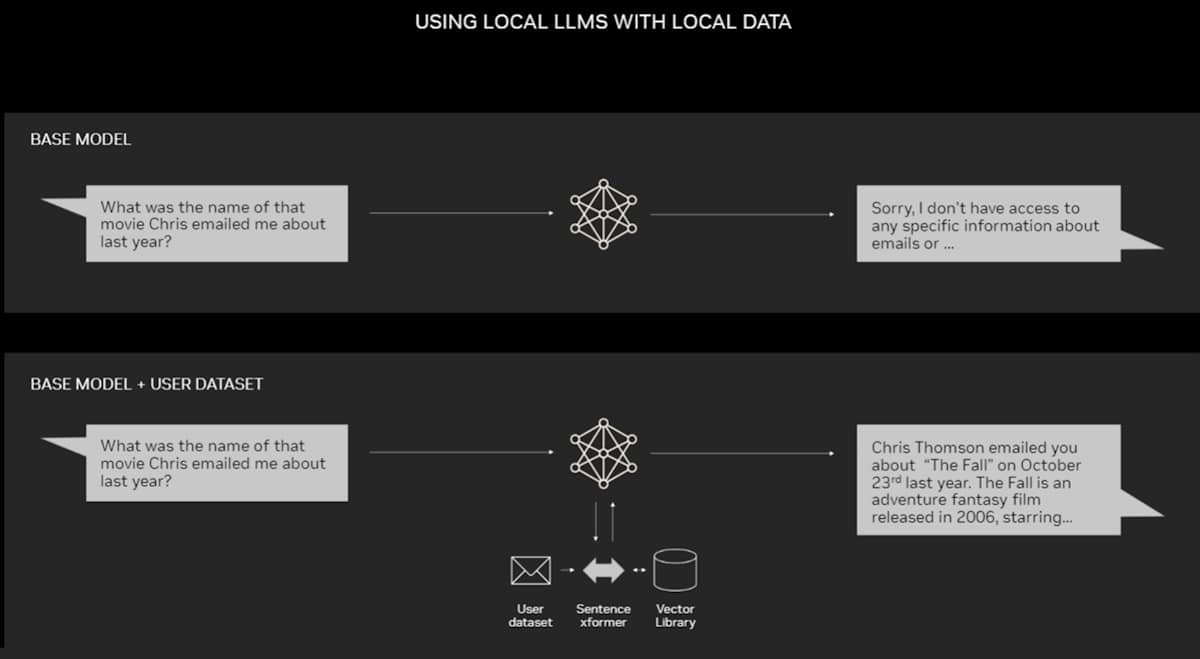
RAG doesn’t require a data center. LLMs are debuting on Windows PCs, thanks to NVIDIA software that enables all sorts of applications users can access even on their laptops.
An example application for RAG on a PC.
PCs equipped with NVIDIA RTX GPUs can now run some AI models locally. By using RAG on a PC, users can link to a private knowledge source – whether that be emails, notes or articles – to improve responses. The user can then feel confident that their data source, prompts and response all remain private and secure.
A recent blog provides an example of RAG accelerated by TensorRT-LLM for Windows to get better results fast.
The History of Retrieval-Augmented Generation
The roots of the technique go back at least to the early 1970s. That’s when researchers in information retrieval prototyped what they called question-answering systems, apps that use natural language processing (NLP) to access text, initially in narrow topics such as baseball.
The concepts behind this kind of text mining have remained fairly constant over the years. But the machine learning engines driving them have grown significantly, increasing their usefulness and popularity.
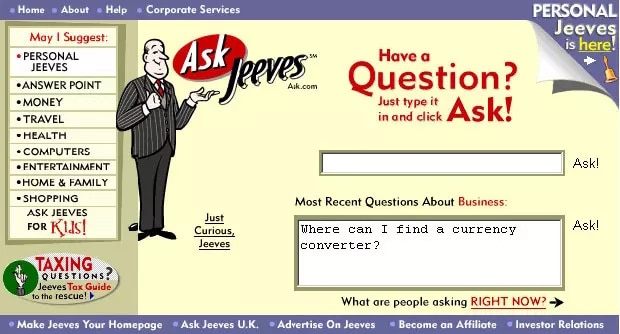
In the mid-1990s, the Ask Jeeves service, now Ask.com, popularized question answering with its mascot of a well-dressed valet. IBM’s Watson became a TV celebrity in 2011 when it handily beat two human champions on the Jeopardy! game show.
Today, LLMs are taking question-answering systems to a whole new level.
Insights From a London Lab
The seminal 2020 paper arrived as Lewis was pursuing a doctorate in NLP at University College London and working for Meta at a new London AI lab. The team was searching for ways to pack more knowledge into an LLM’s parameters and using a benchmark it developed to measure its progress.
Building on earlier methods and inspired by a paper from Google researchers, the group “had this compelling vision of a trained system that had a retrieval index in the middle of it, so it could learn and generate any text output you wanted,” Lewis recalled.
The IBM Watson question-answering system became a celebrity when it won big on the TV game show Jeopardy!
When Lewis plugged into the work in progress a promising retrieval system from another Meta team, the first results were unexpectedly impressive.
“I showed my supervisor and he said, ‘Whoa, take the win. This sort of thing doesn’t happen very often,’ because these workflows can be hard to set up correctly the first time,” he said.
Lewis also credits major contributions from team members Ethan Perez and Douwe Kiela, then of New York University and Facebook AI Research, respectively.
When complete, the work, which ran on a cluster of NVIDIA GPUs, showed how to make generative AI models more authoritative and trustworthy. It’s since been cited by hundreds of papers that amplified and extended the concepts in what continues to be an active area of research.
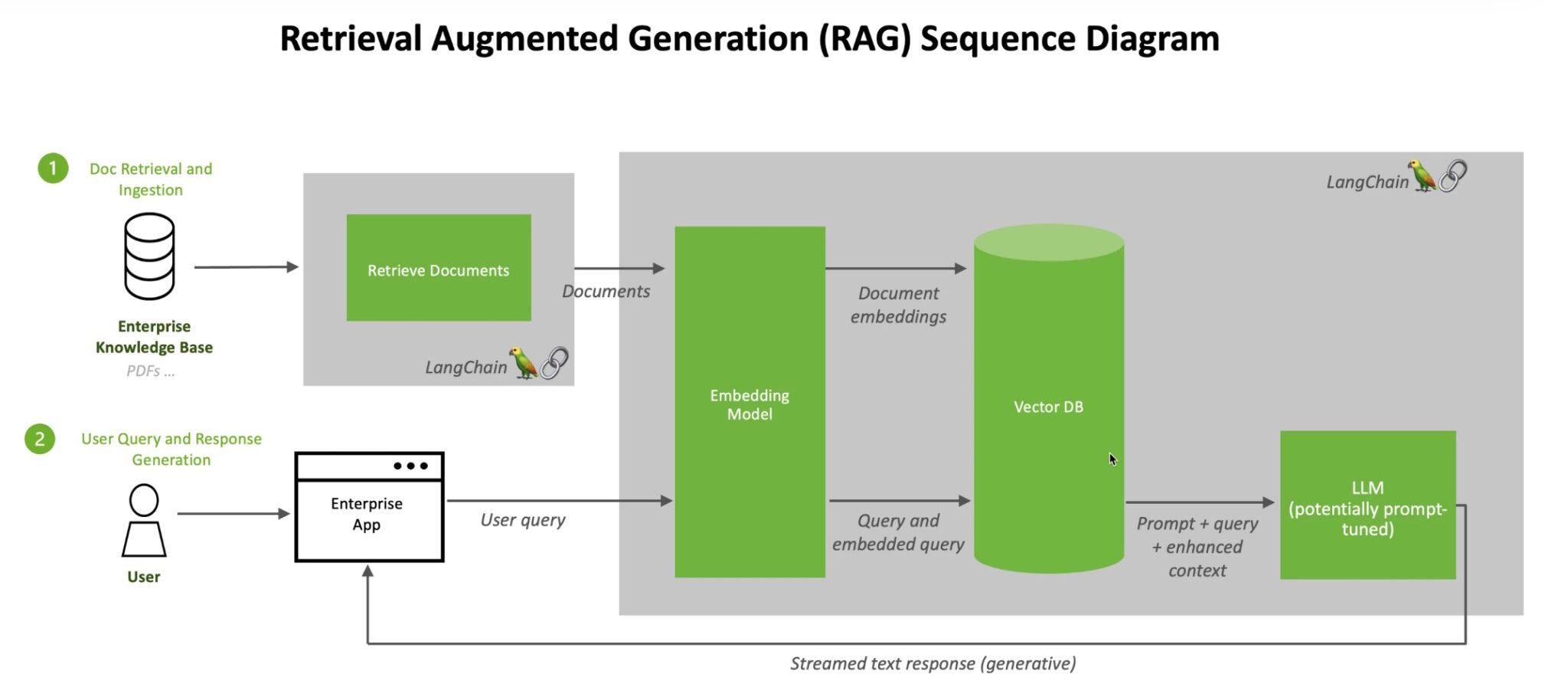
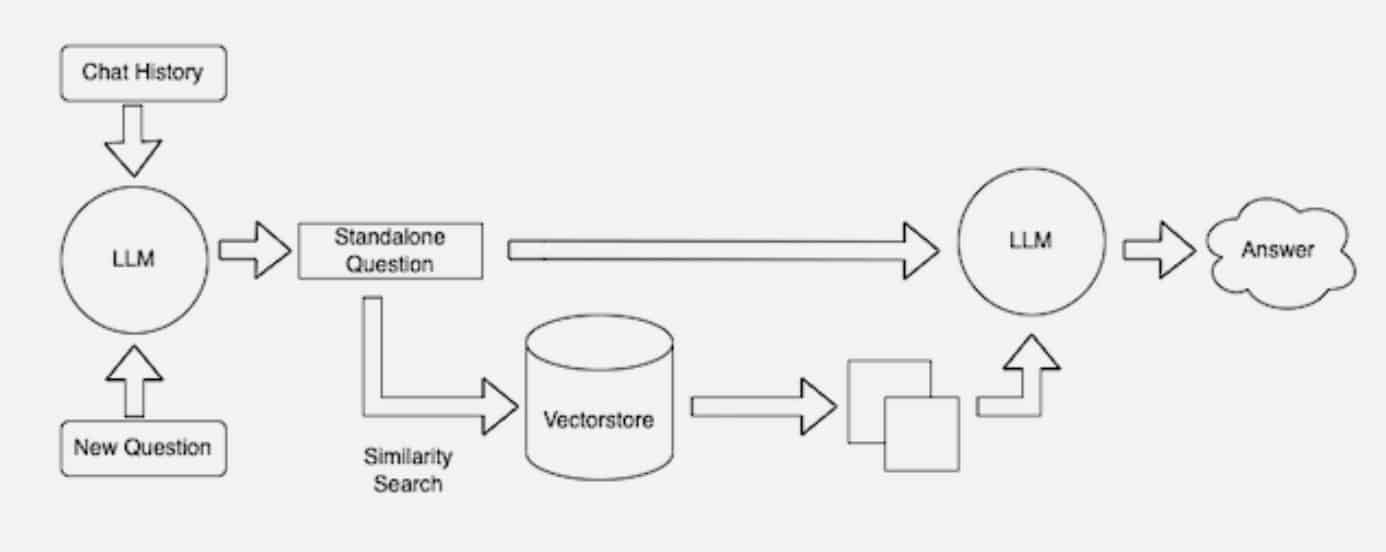
When users ask an LLM a question, the AI model sends the query to another model that converts it into a numeric format so machines can read it. The numeric version of the query is sometimes called an embedding or a vector.
Retrieval-augmented generation combines LLMs with embedding models and vector databases.
The embedding model then compares these numeric values to vectors in a machine-readable index of an available knowledge base. When it finds a match or multiple matches, it retrieves the related data, converts it to human-readable words and passes it back to the LLM.
Finally, the LLM combines the retrieved words and its own response to the query into a final answer it presents to the user, potentially citing sources the embedding model found.
Keeping Sources Current
In the background, the embedding model continuously creates and updates machine-readable indices, sometimes called vector databases, for new and updated knowledge bases as they become available.
Retrieval-augmented generation combines LLMs with embedding models and vector databases.
Many developers find LangChain, an open-source library, can be particularly useful in chaining together LLMs, embedding models and knowledge bases. NVIDIA uses LangChain in its reference architecture for retrieval-augmented generation.
Looking forward, the future of generative AI lies in creatively chaining all sorts of LLMs and knowledge bases together to create new kinds of assistants that deliver authoritative results users can verify.
Get a hands on using retrieval-augmented generation with an AI chatbot in this NVIDIA LaunchPad lab.
Artificial intelligence on Windows 11 PCs marks a pivotal moment in tech history, revolutionizing experiences for gamers, creators, streamers, office workers, students and even casual PC users.
It offers unprecedented opportunities to enhance productivity for users of the more than 100 million Windows PCs and workstations that are powered by RTX GPUs. And NVIDIA RTX technology is making it even easier for developers to create AI applications to change the way people use computers.
New optimizations, models and resources announced at Microsoft Ignite will help developers deliver new end-user experiences, quicker.
An upcoming update to TensorRT-LLM — open-source software that increases AI inference performance — will add support for new large language models and make demanding AI workloads more accessible on desktops and laptops with RTX GPUs starting at 8GB of VRAM.
TensorRT-LLM for Windows will soon be compatible with OpenAI’s popular Chat API through a new wrapper. This will enable hundreds of developer projects and applications to run locally on a PC with RTX, instead of in the cloud — so users can keep private and proprietary data on Windows 11 PCs.
Custom generative AI requires time and energy to maintain projects. The process can become incredibly complex and time-consuming, especially when trying to collaborate and deploy across multiple environments and platforms.
AI Workbench is a unified, easy-to-use toolkit that allows developers to quickly create, test and customize pretrained generative AI models and LLMs on a PC or workstation. It provides developers a single platform to organize their AI projects and tune models to specific use cases.
This enables seamless collaboration and deployment for developers to create cost-effective, scalable generative AI models quickly. Join the early access list to be among the first to gain access to this growing initiative and to receive future updates.
To support AI developers, NVIDIA and Microsoft will release are releasing DirectML enhancements to accelerate one two of the most popular foundational AI models,: Llama 2 and Stable Diffusion. Developers now have more options for cross-vendor deployment, in addition to setting a new standard for performance.
Portable AI
Last month, NVIDIA announced TensorRT-LLM for Windows, a library for accelerating LLM inference.
The next TensorRT-LLM release, v0.6.0 coming later this month, will bring improved inference performance — up to 5x faster — and enable support for additional popular LLMs, including the new Mistral 7B and Nemotron-3 8B. Versions of these LLMs will run on any GeForce RTX 30 Series and 40 Series GPU with 8GB of RAM or more, making fast, accurate, local LLM capabilities accessible even in some of the most portable Windows devices.
Up to 5X performance with the new TensorRT-LLM v0.6.0.
The new release of TensorRT-LLM will be available for install on the /NVIDIA/TensorRT-LLM GitHub repo. New optimized models will be available on ngc.nvidia.com.
Conversing With Confidence
Developers and enthusiasts worldwide use OpenAI’s Chat API for a wide range of applications — from summarizing web content and drafting documents and emails to analyzing and visualizing data and creating presentations.
One challenge with such cloud-based AIs is that they require users to upload their input data, making them impractical for private or proprietary data or for working with large datasets.
To address this challenge, NVIDIA is soon enabling TensorRT-LLM for Windows to offer a similar API interface to OpenAI’s widely popular ChatAPI, through a new wrapper, offering a similar workflow to developers whether they are designing models and applications to run locally on a PC with RTX or in the cloud. By changing just one or two lines of code, hundreds of AI-powered developer projects and applications can now benefit from fast, local AI. Users can keep their data on their PCs and not worry about uploading datasets to the cloud.
Perhaps the best part is that many of these projects and applications are open source, making it easy for developers to leverage and extend their capabilities to fuel the adoption of generative AI on Windows, powered by RTX.
The wrapper will work with any LLM that’s been optimized for TensorRT-LLM (for example, Llama 2, Mistral and NV LLM) and is being released as a reference project on GitHub, alongside other developer resources for working with LLMs on RTX.
Model Acceleration
Developers can now leverage cutting-edge AI models and deploy with a cross-vendor API. As part of an ongoing commitment to empower developers, NVIDIA and Microsoft have been working together to accelerate Llama on RTX via the DirectML API.
Building on the announcements for the fastest inference performance for these models announced last month, this new option for cross-vendor deployment makes it easier than ever to bring AI capabilities to PC.
Developers and enthusiasts can experience the latest optimizations by downloading the latest ONNX runtime and following the installation instructions from Microsoft, and installing the latest driver from NVIDIA, which will be available on Nov. 21.
These new optimizations, models and resources will accelerate the development and deployment of AI features and applications to the 100 million RTX PCs worldwide, joining the more than 400 partners shipping AI-powered apps and games already accelerated by RTX GPUs.
As models become even more accessible and developers bring more generative AI-powered functionality to RTX-powered Windows PCs, RTX GPUs will be critical for enabling users to take advantage of this powerful technology.
We give the first result for agnostically learning Single-Index Models (SIMs) with arbitrary monotone and Lipschitz activations. All prior work either held only in the realizable setting or required the activation to be known. Moreover, we only require the marginal to have bounded second moments, whereas all prior work required stronger distributional assumptions (such as anticoncentration or boundedness). Our algorithm is based on recent work by [GHK+23] on omniprediction using predictors satisfying calibrated multiaccuracy. Our analysis is simple and relies on the relationship between…Apple Machine Learning Research
Online communities are driving user engagement across industries like gaming, social media, ecommerce, dating, and e-learning. Members of these online communities trust platform owners to provide a safe and inclusive environment where they can freely consume content and contribute. Content moderators are often employed to review user-generated content and check that it’s safe and compliant with your terms of use. However, the ever-increasing scale, complexity, and variety of inappropriate content makes human moderation workflows unscalable and expensive. The result is poor, harmful, and non-inclusive communities that disengage users and negatively impact the community and business.
Along with user-generated content, machine-generated content has brought a fresh challenge to content moderation. It automatically creates highly realistic content that may be inappropriate or harmful at scale. The industry is facing the new challenge of automatically moderating content generated by AI to protect users from harmful material.
In this post, we introduce toxicity detection, a new feature from Amazon Comprehend that helps you automatically detect harmful content in user- or machine-generated text. This includes plain text, text extracted from images, and text transcribed from audio or video content.
Detect toxicity in text content with Amazon Comprehend
Amazon Comprehend is a natural-language processing (NLP) service that uses machine learning (ML) to uncover valuable insights and connections in text. It offers a range of ML models that can be either pre-trained or customized through API interfaces. Amazon Comprehend now provides a straightforward, NLP-based solution for toxic content detection in text.
The Amazon Comprehend Toxicity Detection API assigns an overall toxicity score to text content, ranging from 0–1, indicating the likelihood of it being toxic. It also categorizes text into the following seven categories and provides a confidence score for each:
HATE_SPEECH – Speech that criticizes, insults, denounces, or dehumanizes a person or a group on the basis of an identity, be it race, ethnicity, gender identity, religion, sexual orientation, ability, national origin, or another identity group.
GRAPHIC – Speech that uses visually descriptive, detailed, and unpleasantly vivid imagery. Such language is often made verbose so as to amplify an insult, or discomfort or harm to the recipient.
HARASSMENT_OR_ABUSE – Speech that imposes disruptive power dynamics between the speaker and hearer (regardless of intent), seeks to affect the psychological well-being of the recipient, or objectifies a person.
SEXUAL – Speech that indicates sexual interest, activity, or arousal by using direct or indirect references to body parts, physical traits, or sex.
VIOLENCE_OR_THREAT – Speech that includes threats that seek to inflict pain, injury, or hostility towards a person or group.
INSULT – Speech that includes demeaning, humiliating, mocking, insulting, or belittling language.
PROFANITY – Speech that contains words, phrases, or acronyms that are impolite, vulgar, or offensive.
You can access the Toxicity Detection API by calling it directly using the AWS Command Line Interface (AWS CLI) and AWS SDKs. Toxicity detection in Amazon Comprehend is currently supported in the English language.
Use cases
Text moderation plays a crucial role in managing user-generated content across diverse formats, including social media posts, online chat messages, forum discussions, website comments, and more. Moreover, platforms that accept video and audio content can use this feature to moderate transcribed audio content.
The emergence of generative AI and large language models (LLMs) represents the latest trend in the field of AI. Consequently, there is a growing need for responsive solutions to moderate content generated by LLMs. The Amazon Comprehend Toxicity Detection API is ideally suited for addressing this need.
Amazon Comprehend Toxicity Detection API request
You can send up to 10 text segments to the Toxicity Detection API, each with a size limit of 1 KB. Every text segment in the request is handled independently. In the following example, we generate a JSON file named toxicity_api_input.json containing the text content, including three sample text segments for moderation. Note that in the example, the profane words are masked as XXXX.
{
"TextSegments": [
{"Text": "and go through the door go through the door he's on the right"},
{"Text": "he's on the right XXXXX him"},
{"Text": "what the XXXX are you doing man that's why i didn't want to play"}
],
"LanguageCode": "en"
}
You can use the AWS CLI to invoke the Toxicity Detection API using the preceding JSON file containing the text content:
The Toxicity Detection API response JSON output will include the toxicity analysis result in the ResultList field. ResultList lists the text segment items, and the sequence represents the order in which the text sequences were received in the API request. Toxicity represents the overall confidence score of detection (between 0–1). Labels includes a list of toxicity labels with confidence scores, categorized by the type of toxicity.
The following code shows the JSON response from the Toxicity Detection API based on the request example in the previous section:
In the preceding JSON, the first text segment is considered safe with a low toxicity score. However, the second and third text segments received toxicity scores of 73% and 98%, respectively. For the second segment, Amazon Comprehend detects a high toxicity score for VIOLENCE_OR_THREAT; for the third segment, it detects PROFANITY with a high toxicity score.
Sample request using the Python SDK
The following code snippet demonstrates how to utilize the Python SDK to invoke the Toxicity Detection API. This code receives the same JSON response as the AWS CLI command demonstrated earlier.
import boto3 import base64
# Initialize a Comprehend boto3 client object
comprehend_client = session.client('comprehend')
# Call comprehend Detect Toxic Content API with text segments
response = comprehend_client.detect_toxic_content(
TextSegments=[
{"Text": "and go through the door go through the door he's on the right"},
{"Text": "he's on the right XXXXX him"},
{"Text": "what the XXXX are you doing man that's why i didn't want to play"}
],
LanguageCode='en'
)
Summary
In this post, we provided an overview of the new Amazon Comprehend Toxicity Detection API. We also described how you can parse the API response JSON. For more information, refer to Comprehend API document.
Amazon Comprehend toxicity detection is now generally available in four Regions: us-east-1, us-west-2, eu-west-1, and ap-southeast-2.
Lana Zhang is a Senior Solutions Architect at AWS WWSO AI Services team, specializing in AI and ML for Content Moderation, Computer Vision, Natural Language Processing and Generative AI. With her expertise, she is dedicated to promoting AWS AI/ML solutions and assisting customers in transforming their business solutions across diverse industries, including social media, gaming, e-commerce, media, advertising & marketing.
Ravisha SK is a Senior Product Manager, Technical at AWS with a focus on AI/ML. She has over 10 years of experience in data analytics and machine learning across different domains. In her spare time, she enjoys reading, experimenting in the kitchen and exploring new coffee shops.
Posted by Isaac Noble, Software Engineer, Google Research, and Anelia Angelova, Research Scientist, Google DeepMind
When building machine learning models for real-life applications, we need to consider inputs from multiple modalities in order to capture various aspects of the world around us. For example, audio, video, and text all provide varied and complementary information about a visual input. However, building multimodal models is challenging due to the heterogeneity of the modalities. Some of the modalities might be well synchronized in time (e.g., audio, video) but not aligned with text. Furthermore, the large volume of data in video and audio signals is much larger than that in text, so when combining them in multimodal models, video and audio often cannot be fully consumed and need to be disproportionately compressed. This problem is exacerbated for longer video inputs.
In “Mirasol3B: A Multimodal Autoregressive model for time-aligned and contextual modalities”, we introduce a multimodal autoregressive model (Mirasol3B) for learning across audio, video, and text modalities. The main idea is to decouple the multimodal modeling into separate focused autoregressive models, processing the inputs according to the characteristics of the modalities. Our model consists of an autoregressive component for the time-synchronized modalities (audio and video) and a separate autoregressive component for modalities that are not necessarily time-aligned but are still sequential, e.g., text inputs, such as a title or description. Additionally, the time-aligned modalities are partitioned in time where local features can be jointly learned. In this way, audio-video inputs are modeled in time and are allocated comparatively more parameters than prior works. With this approach, we can effortlessly handle much longer videos (e.g., 128-512 frames) compared to other multimodal models. At 3B parameters, Mirasol3B is compact compared to prior Flamingo (80B) and PaLI-X (55B) models. Finally, Mirasol3B outperforms the state-of-the-art approaches on video question answering (video QA), long video QA, and audio-video-text benchmarks.
The Mirasol3B architecture consists of an autoregressive model for the time-aligned modalities (audio and video), which are partitioned in chunks, and a separate autoregressive model for the unaligned context modalities (e.g., text). Joint feature learning is conducted by the Combiner, which learns compact but sufficiently informative features, allowing the processing of long video/audio inputs.
Coordinating time-aligned and contextual modalities
Video, audio and text are diverse modalities with distinct characteristics. For example, video is a spatio-temporal visual signal with 30–100 frames per second, but due to the large volume of data, typically only 32–64 frames per video are consumed by current models. Audio is a one-dimensional temporal signal obtained at much higher frequency than video (e.g., at 16 Hz), whereas text inputs that apply to the whole video, are typically 200–300 word-sequence and serve as a context to the audio-video inputs. To that end, we propose a model consisting of an autoregressive component that fuses and jointly learns the time-aligned signals, which occur at high frequencies and are roughly synchronized, and another autoregressive component for processing non-aligned signals. Learning between the components for the time-aligned and contextual modalities is coordinated via cross-attention mechanisms that allow the two to exchange information while learning in a sequence without having to synchronize them in time.
Time-aligned autoregressive modeling of video and audio
Long videos can convey rich information and activities happening in a sequence. However, present models approach video modeling by extracting all the information at once, without sufficient temporal information. To address this, we apply an autoregressive modeling strategy where we condition jointly learned video and audio representations for one time interval on feature representations from previous time intervals. This preserves temporal information.
The video is first partitioned into smaller video chunks. Each chunk itself can be 4–64 frames. The features corresponding to each chunk are then processed by a learning module, called the Combiner (described below), which generates a joint audio and video feature representation at the current step — this step extracts and compacts the most important information per chunk. Next, we process this joint feature representation with an autoregressive Transformer, which applies attention to the previous feature representation and generates the joint feature representation for the next step. Consequently, the model learns how to represent not only each individual chunk, but also how the chunks relate temporally.
We use an autoregressive modeling of the audio and video inputs, partitioning them in time and learning joint feature representations, which are then autoregressively learned in sequence.
Modeling long videos with a modality combiner
To combine the signals from the video and audio information in each video chunk, we propose a learning module called the Combiner. Video and audio signals are aligned by taking the audio inputs that correspond to a specific video timeframe. We then process video and audio inputs spatio-temporally, extracting information particularly relevant to changes in the inputs (for videos we use sparse video tubes, and for audio we apply the spectrogram representation, both of which are processed by a Vision Transformer). We concatenate and input these features to the Combiner, which is designed to learn a new feature representation capturing both these inputs. To address the challenge of the large volume of data in video and audio signals, another goal of the Combiner is to reduce the dimensionality of the joint video/audio inputs, which is done by selecting a smaller number of output features to be produced. The Combiner can be implemented simply as a causal Transformer, which processes the inputs in the direction of time, i.e., using only inputs of the prior steps or the current one. Alternatively, the Combiner can have a learnable memory, described below.
Combiner styles
A simple version of the Combiner adapts a Transformer architecture. More specifically, all audio and video features from the current chunk (and optionally prior chunks) are input to a Transformer and projected to a lower dimensionality, i.e., a smaller number of features are selected as the output “combined” features. While Transformers are not typically used in this context, we find it effective for reducing the dimensionality of the input features, by selecting the last m outputs of the Transformer, if m is the desired output dimension (shown below). Alternatively, the Combiner can have a memory component. For example, we use the Token Turing Machine (TTM), which supports a differentiable memory unit, accumulating and compressing features from all previous timesteps. Using a fixed memory allows the model to work with a more compact set of features at every step, rather than process all the features from previous steps, which reduces computation.
We use a simple Transformer-based Combiner (left) and a Memory Combiner (right), based on the Token Turing Machine (TTM), which uses memory to compress previous history of features.
Results
We evaluate our approach on several benchmarks, MSRVTT-QA, ActivityNet-QA and NeXT-QA, for the video QA task, where a text-based question about a video is issued and the model needs to answer. This evaluates the ability of the model to understand both the text-based question and video content, and to form an answer, focusing on only relevant information. Of these benchmarks, the latter two target long video inputs and feature more complex questions.
We also evaluate our approach in the more challenging open-ended text generation setting, wherein the model generates the answers in an unconstrained fashion as free form text, requiring an exact match to the ground truth answer. While this stricter evaluation counts synonyms as incorrect, it may better reflect a model’s ability to generalize.
Our results indicate improved performance over state-of-the-art approaches for most benchmarks, including all with open-ended generation evaluation — notable considering our model is only 3B parameters, considerably smaller than prior approaches, e.g., Flamingo 80B. We used only video and text inputs to be comparable to other work. Importantly, our model can process 512 frames without needing to increase the model parameters, which is crucial for handling longer videos. Finally with the TTM Combiner, we see both better or comparable performance while reducing compute by 18%.
Results on NeXT-QA benchmark, which features long videos for the video QA task.
Results on audio-video benchmarks
Results on the popular audio-video datasets VGG-Sound and EPIC-SOUNDS are shown below. Since these benchmarks are classification-only, we treat them as an open-ended text generative setting where our model produces the text of the desired class; e.g., for the class ID corresponding to the “playing drums” activity, we expect the model to generate the text “playing drums”. In some cases our approach outperforms the prior state of the art by large margins, even though our model outputs the results in the generative open-ended setting.
Results on the VGG-Sound (audio-video QA) dataset.
Results on the EPIC-SOUNDS (audio-video QA) dataset.
Benefits of autoregressive modeling
We conduct an ablation study comparing our approach to a set of baselines that use the same input information but with standard methods (i.e., without autoregression and the Combiner). We also compare the effects of pre-training. Because standard methods are ill-suited for processing longer video, this experiment is conducted for 32 frames and four chunks only, across all settings for fair comparison. We see that Mirasol3B’s improvements are still valid for relatively short videos.
Ablation experiments comparing the main components of our model. Using the Combiner, the autoregressive modeling, and pre-training all improve performance.
Conclusion
We present a multimodal autoregressive model that addresses the challenges associated with the heterogeneity of multimodal data by coordinating the learning between time-aligned and time-unaligned modalities. Time-aligned modalities are further processed autoregressively in time with a Combiner, controlling the sequence length and producing powerful representations. We demonstrate that a relatively small model can successfully represent long video and effectively combine with other modalities. We outperform the state-of-the-art approaches (including some much bigger models) on video- and audio-video question answering.
Acknowledgements
This research is co-authored by AJ Piergiovanni, Isaac Noble, Dahun Kim, Michael Ryoo, Victor Gomes, and Anelia Angelova. We thank Claire Cui, Tania Bedrax-Weiss, Abhijit Ogale, Yunhsuan Sung, Ching-Chung Chang, Marvin Ritter, Kristina Toutanova, Ming-Wei Chang, Ashish Thapliyal, Xiyang Luo, Weicheng Kuo, Aren Jansen, Bryan Seybold, Ibrahim Alabdulmohsin, Jialin Wu, Luke Friedman, Trevor Walker, Keerthana Gopalakrishnan, Jason Baldridge, Radu Soricut, Mojtaba Seyedhosseini, Alexander D’Amour, Oliver Wang, Paul Natsev, Tom Duerig, Younghui Wu, Slav Petrov, Zoubin Ghahramani for their help and support. We also thank Tom Small for preparing the animation.