We propose using a Gaussian Mixture Model (GMM) as reverse transition operator (kernel) within the Denoising Diffusion Implicit Models (DDIM) framework, which is one of the most widely used approaches for accelerated sampling from pre-trained Denoising Diffusion Probabilistic Models (DDPM). Specifically we match the first and second order central moments of the DDPM forward marginals by constraining the parameters of the GMM. We see that moment matching is sufficient to obtain samples with equal or better quality than the original DDIM with Gaussian kernels. We provide experimental results…Apple Machine Learning Research
PLANNER: Generating Diversified Paragraph via Latent Language Diffusion Model
Autoregressive models for text sometimes generate repetitive and low-quality output because errors accumulate during the steps of generation. This issue is often attributed to exposure bias – the difference between how a model is trained and how it is used during inference. Denoising diffusion models provide an alternative approach in which a model can revisit and revise its output. However, they can be computationally expensive, and prior efforts on text have led to models that produce less fluent output compared to autoregressive models, especially for longer text and paragraphs. In this…Apple Machine Learning Research
Improving Vision-inspired Keyword Spotting Using a Streaming Conformer Encoder With Input-dependent Dynamic Depth
Using a vision-inspired keyword spotting framework, we propose an architecture with input-dependent dynamic depth capable of processing streaming audio. Specifically, we extend a Conformer encoder with trainable binary gates that allow to dynamically skip network modules according to the input audio. Our approach improves detection and localization accuracy on continuous speech using Librispeech’s 1,000 most frequent words while maintaining a small memory footprint. The inclusion of gates also allows the average amount of processing without affecting the overall performance to be reduced…Apple Machine Learning Research

New Class of Accelerated, Efficient AI Systems Mark the Next Era of Supercomputing
NVIDIA today unveiled at SC23 the next wave of technologies that will lift scientific and industrial research centers worldwide to new levels of performance and energy efficiency.
“NVIDIA hardware and software innovations are creating a new class of AI supercomputers,” said Ian Buck, vice president of the company’s high performance computing and hyperscale data center business, in a special address at the conference.
Some of the systems will pack memory-enhanced NVIDIA Hopper accelerators, others a new NVIDIA Grace Hopper systems architecture. All will use the expanded parallelism to run a full stack of accelerated software for generative AI, HPC and hybrid quantum computing.
Buck described the new NVIDIA HGX H200 as “the world’s leading AI computing platform.”

It packs up to 141GB of HBM3e, the first AI accelerator to use the ultrafast technology. Running models like GPT-3, NVIDIA H200 Tensor Core GPUs provide an 18x performance increase over prior-generation accelerators.
Among other generative AI benchmarks, they zip through 12,000 tokens per second on a Llama2-13B large language model (LLM).
Buck also revealed a server platform that links four NVIDIA GH200 Grace Hopper Superchips on an NVIDIA NVLink interconnect. The quad configuration puts in a single compute node a whopping 288 Arm Neoverse cores and 16 petaflops of AI performance with up to 2.3 terabytes of high-speed memory.

Demonstrating its efficiency, one GH200 Superchip using the NVIDIA TensorRT-LLM open-source library is 100x faster than a dual-socket x86 CPU system and nearly 2x more energy efficient than an X86 + H100 GPU server.
“Accelerated computing is sustainable computing,” Buck said. “By harnessing the power of accelerated computing and generative AI, together we can drive innovation across industries while reducing our impact on the environment.”
NVIDIA Powers 38 of 49 New TOP500 Systems
The latest TOP500 list of the world’s fastest supercomputers reflects the shift toward accelerated, energy-efficient supercomputing.
Thanks to new systems powered by NVIDIA H100 Tensor Core GPUs, NVIDIA now delivers more than 2.5 exaflops of HPC performance across these world-leading systems, up from 1.6 exaflops in the May rankings. NVIDIA’s contribution on the top 10 alone reaches nearly an exaflop of HPC and 72 exaflops of AI performance.
The new list contains the highest number of systems ever using NVIDIA technologies, 379 vs. 372 in May, including 38 of 49 new supercomputers on the list.
Microsoft Azure leads the newcomers with its Eagle system using H100 GPUs in NDv5 instances to hit No. 3 with 561 petaflops. Mare Nostrum5 in Barcelona ranked No. 8, and NVIDIA Eos — which recently set new AI training records on the MLPerf benchmarks — came in at No. 9.
Showing their energy efficiency, NVIDIA GPUs power 23 of the top 30 systems on the Green500. And they retained the No. 1 spot with the H100 GPU-based Henri system, which delivers 65.09 gigaflops per watt for the Flatiron Institute in New York.
Gen AI Explores COVID
Showing what’s possible, the Argonne National Laboratory used NVIDIA BioNeMo, a generative AI platform for biomolecular LLMs, to develop GenSLMs, a model that can generate gene sequences that closely resemble real-world variants of the coronavirus. Using NVIDIA GPUs and data from 1.5 million COVID genome sequences, it can also rapidly identify new virus variants.
The work won the Gordon Bell special prize last year and was trained on supercomputers, including Argonne’s Polaris system, the U.S. Department of Energy’s Perlmutter and NVIDIA’s Selene.
It’s “just the tip of the iceberg — the future is brimming with possibilities, as generative AI continues to redefine the landscape of scientific exploration,” said Kimberly Powell, vice president of healthcare at NVIDIA, in the special address.
Saving Time, Money and Energy
Using the latest technologies, accelerated workloads can see an order-of-magnitude reduction in system cost and energy used, Buck said.
For example, Siemens teamed with Mercedes to analyze aerodynamics and related acoustics for its new electric EQE vehicles. The simulations that took weeks on CPU clusters ran significantly faster using the latest NVIDIA H100 GPUs. In addition, Hopper GPUs let them reduce costs by 3x and reduce energy consumption by 4x (below).
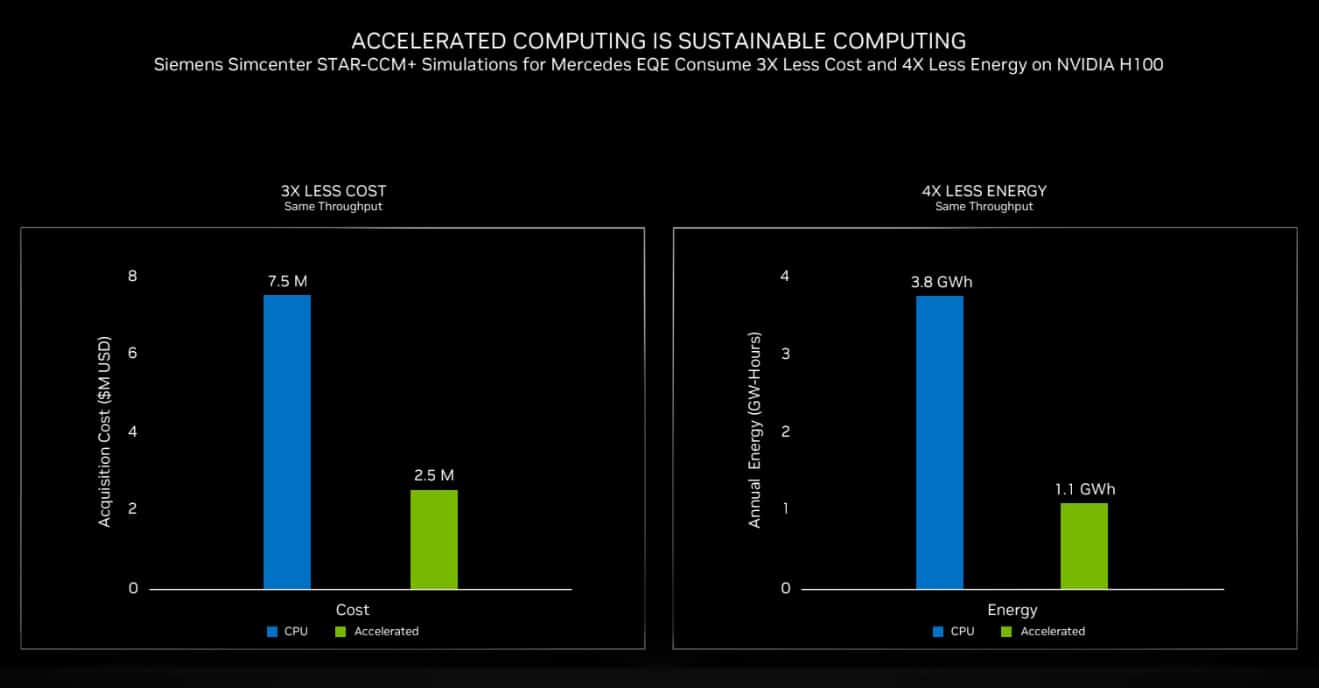
Switching on 200 Exaflops Beginning Next Year
Scientific and industrial advances will come from every corner of the globe where the latest systems are being deployed.
“We already see a combined 200 exaflops of AI on Grace Hopper supercomputers going to production 2024,” Buck said.
They include the massive JUPITER supercomputer at Germany’s Jülich center. It can deliver 93 exaflops of performance for AI training and 1 exaflop for HPC applications, while consuming only 18.2 megawatts of power.
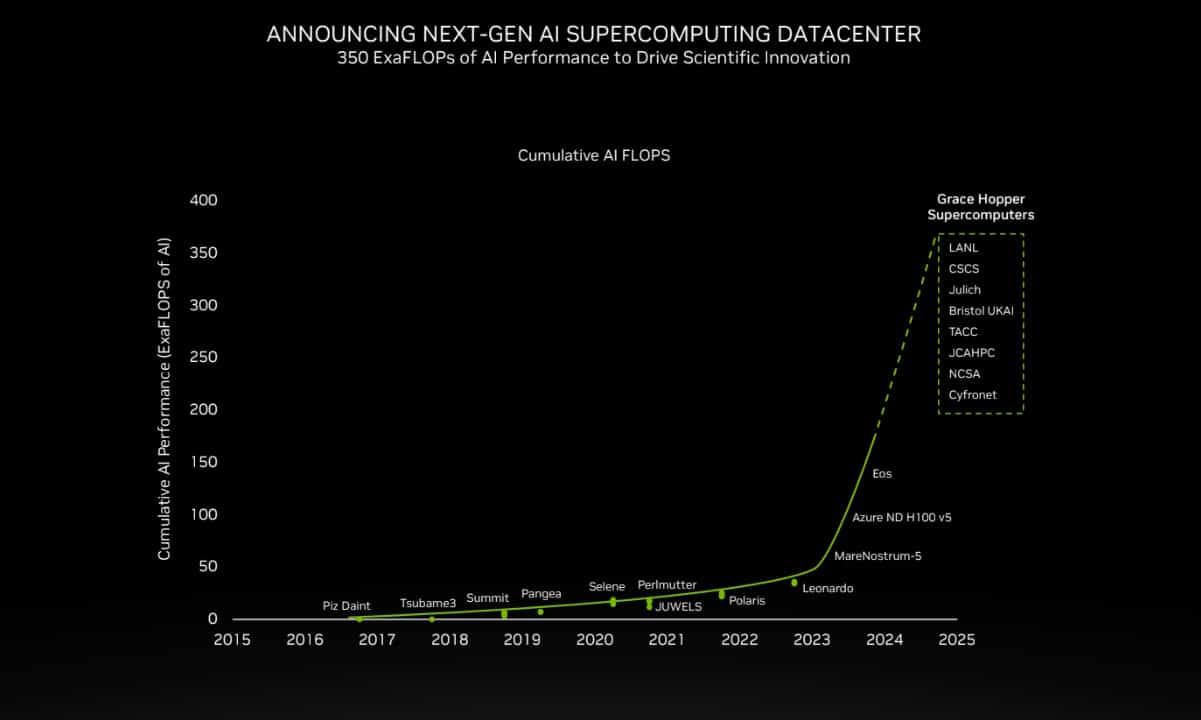
Based on Eviden’s BullSequana XH3000 liquid-cooled system, JUPITER will use the NVIDIA quad GH200 system architecture and NVIDIA Quantum-2 InfiniBand networking for climate and weather predictions, drug discovery, hybrid quantum computing and digital twins. JUPITER quad GH200 nodes will be configured with 864GB of high-speed memory.
It’s one of several new supercomputers using Grace Hopper that NVIDIA announced at SC23.
The HPE Cray EX2500 system from Hewlett Packard Enterprise will use the quad GH200 to power many AI supercomputers coming online next year.
For example, HPE uses the quad GH200 to power OFP-II, an advanced HPC system in Japan shared by the University of Tsukuba and the University of Tokyo, as well as the DeltaAI system, which will triple computing capacity for the U.S. National Center for Supercomputing Applications.
HPE is also building the Venado system for the Los Alamos National Laboratory, the first GH200 to be deployed in the U.S. In addition, HPE is building GH200 supercomputers in the Middle East, Switzerland and the U.K.
Grace Hopper in Texas and Beyond
At the Texas Advanced Computing Center (TACC), Dell Technologies is building the Vista supercomputer with NVIDIA Grace Hopper and Grace CPU Superchips.
More than 100 global enterprises and organizations, including NASA Ames Research Center and Total Energies, have already purchased Grace Hopper early-access systems, Buck said.
They join previously announced GH200 users such as SoftBank and the University of Bristol, as well as the massive Leonardo system with 14,000 NVIDIA A100 GPUs that delivers 10 exaflops of AI performance for Italy’s Cineca consortium.
The View From Supercomputing Centers
Leaders from supercomputing centers around the world shared their plans and work in progress with the latest systems.
“We’ve been collaborating with MeteoSwiss ECMWP as well as scientists from ETH EXCLAIM and NVIDIA’s Earth-2 project to create an infrastructure that will push the envelope in all dimensions of big data analytics and extreme scale computing,” said Thomas Schultess, director of the Swiss National Supercomputing Centre of work on the Alps supercomputer.
“There’s really impressive energy-efficiency gains across our stacks,” Dan Stanzione, executive director of TACC, said of Vista.
It’s “really the stepping stone to move users from the kinds of systems we’ve done in the past to looking at this new Grace Arm CPU and Hopper GPU tightly coupled combination and … we’re looking to scale out by probably a factor of 10 or 15 from what we are deploying with Vista when we deploy Horizon in a couple years,” he said.
Accelerating the Quantum Journey
Researchers are also using today’s accelerated systems to pioneer a path to tomorrow’s supercomputers.
In Germany, JUPITER “will revolutionize scientific research across climate, materials, drug discovery and quantum computing,” said Kristel Michelson, who leads Julich’s research group on quantum information processing.
“JUPITER’s architecture also allows for the seamless integration of quantum algorithms with parallel HPC algorithms, and this is mandatory for effective quantum HPC hybrid simulations,” she said.
CUDA Quantum Drives Progress
The special address also showed how NVIDIA CUDA Quantum — a platform for programming CPUs, GPUs and quantum computers also known as QPUs — is advancing research in quantum computing.
For example, researchers at BASF, the world’s largest chemical company, pioneered a new hybrid quantum-classical method for simulating chemicals that can shield humans against harmful metals. They join researchers at Brookhaven National Laboratory and HPE who are separately pushing the frontiers of science with CUDA Quantum.
NVIDIA also announced a collaboration with Classiq, a developer of quantum programming tools, to create a life sciences research center at the Tel Aviv Sourasky Medical Center, Israel’s largest teaching hospital. The center will use Classiq’s software and CUDA Quantum running on an NVIDIA DGX H100 system.
Separately, Quantum Machines will deploy the first NVIDIA DGX Quantum, a system using Grace Hopper Superchips, at the Israel National Quantum Center that aims to drive advances across scientific fields. The DGX system will be connected to a superconducting QPU by Quantware and a photonic QPU from ORCA Computing, both powered by CUDA Quantum.
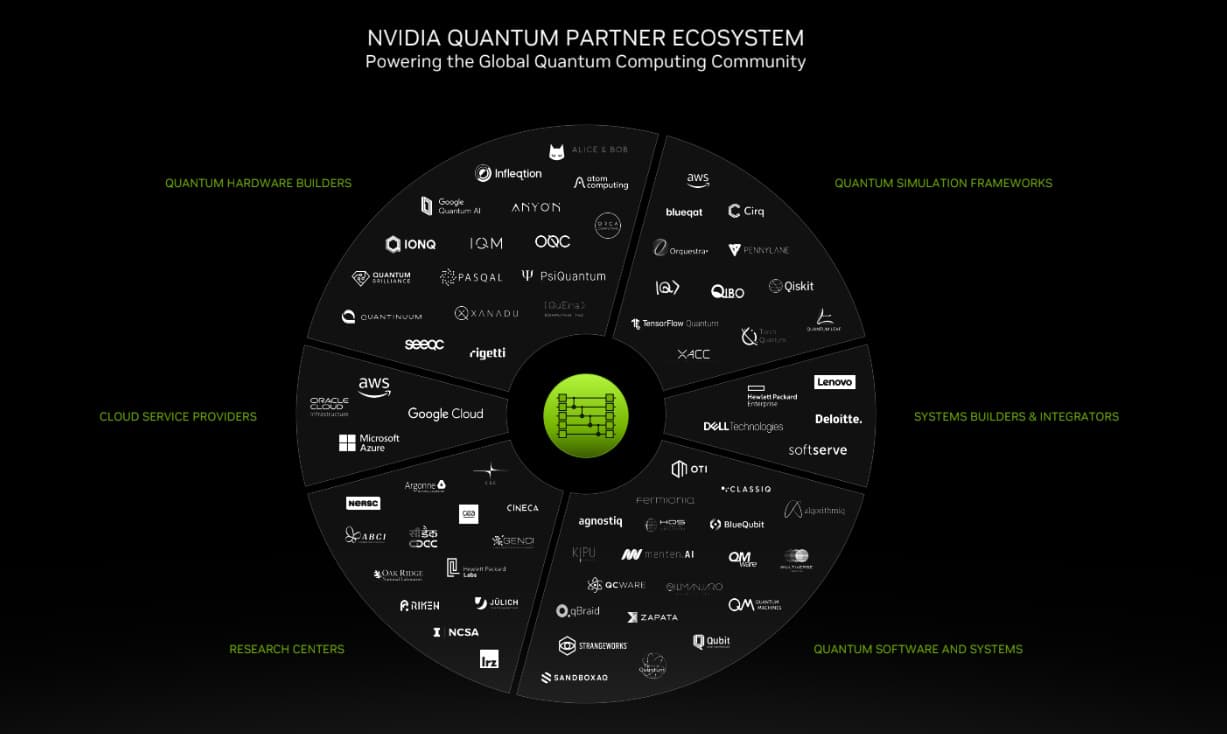
“In just two years, our NVIDIA quantum computing platform has amassed over 120 partners [above], a testament to its open, innovative platform,” Buck said.
Overall, the work across many fields of discovery reveals a new trend that combines accelerated computing at data center scale with NVIDIA’s full-stack innovation.
“Accelerated computing is paving the path for sustainable computing with advancements that provide not just amazing technology but a more sustainable and impactful future,” he concluded.
Watch NVIDIA’s SC23 special address below.
Implement real-time personalized recommendations using Amazon Personalize
At a basic level, Machine Learning (ML) technology learns from data to make predictions. Businesses use their data with an ML-powered personalization service to elevate their customer experience. This approach allows businesses to use data to derive actionable insights and help grow their revenue and brand loyalty.
Amazon Personalize accelerates your digital transformation with ML, making it easier to integrate personalized recommendations into existing websites, applications, email marketing systems, and more. Amazon Personalize enables developers to quickly implement a customized personalization engine, without requiring ML expertise. Amazon Personalize provisions the necessary infrastructure and manages the entire machine learning (ML) pipeline, including processing the data, identifying features, using the most appropriate algorithms, and training, optimizing, and hosting the models. You receive results through an API and pay only for what you use, with no minimum fees or upfront commitments.
The post Architecting near real-time personalized recommendations with Amazon Personalize shows how to architect near real-time personalized recommendations using Amazon Personalize and AWS purpose-built data services. In this post, we walk you through a reference implementation of a real-time personalized recommendation system using Amazon Personalize.
Solution overview
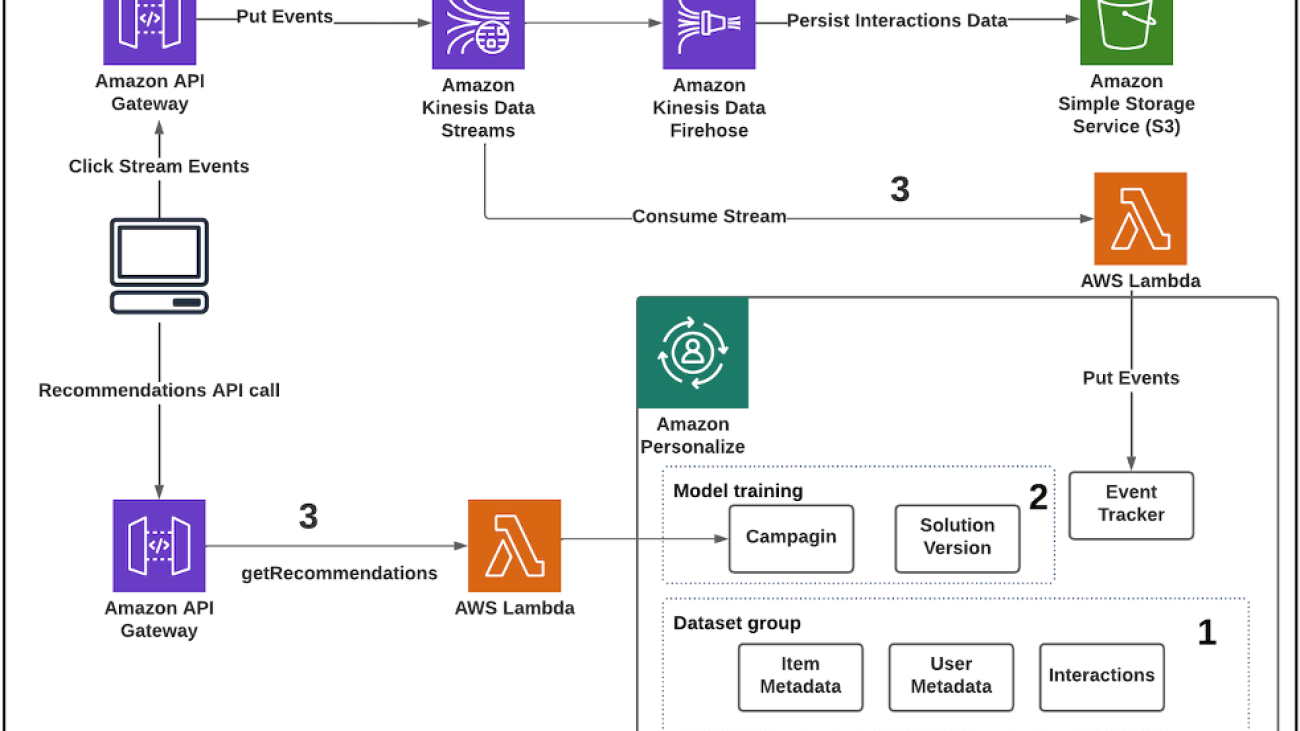
The real-time personalized recommendations solution is implemented using Amazon Personalize, Amazon Simple Storage Service (Amazon S3), Amazon Kinesis Data Streams, AWS Lambda, and Amazon API Gateway.
The architecture is implemented as follows:
- Data preparation – Start by creating a dataset group, schemas, and datasets representing your items, interactions, and user data.
- Train the model – After importing your data, select the recipe matching your use case, and then create a solution to train a model by creating a solution version. When your solution version is ready, you can create a campaign for your solution version.
- Get near real-time recommendations – When you have a campaign, you can integrate calls to the campaign in your application. This is where calls to the GetRecommendations or GetPersonalizedRanking APIs are made to request near real-time recommendations from Amazon Personalize.
For more information, refer to Architecting near real-time personalized recommendations with Amazon Personalize.
The following diagram illustrates the solution architecture.

Implementation
We demonstrate this implementation with a use case about making real-time movie recommendations to an end user based on their interactions with the movie database over time.
The solution is implemented using the following steps:
- Prerequisite (Data preparation)
- Setup your development environment
- Deploy the solution
- Create a solution version
- Create a campaign
- Create an event tracker
- Get recommendations
- Ingest real-time interactions
- Validate real-time recommendations
- Cleanup
Prerequisites
Before you get started, make sure you have the following prerequisites:
- Prepare your training data – Prepare and upload the data to an S3 bucket using the instructions. For this particular use case, you will be uploading interactions data and items data. An interaction is an event that you record and then import as training data. Amazon Personalize generates recommendations primarily based on the interactions data you import into an Interactions dataset. You can record multiple event types, such as click, watch, or like. Although the model created by Amazon Personalize can suggest based on a user’s past interactions, the quality of these suggestions can be enhanced when the model possesses data about the associations among users or items . If a user has engaged with movies categorized as Drama in the item dataset, Amazon Personalize will suggest movies (items) with the same genre.
- Setup your development environment – Install the AWS Command Line Interface (AWS CLI).
- Configure CLI with your Amazon account – Configure the AWS CLI with your AWS account information.
- Install and bootstrap AWS Cloud Development Kit (AWS CDK)
Deploy the solution
To deploy the solution, do the following:
Create a solution version
A solution refers to the combination of an Amazon Personalize recipe, customized parameters, and one or more solution versions (trained models). When you deploy the CDK project in the previous step, a solution with a User-Personalization recipe is created for you automatically. A solution version refers to a trained machine learning model. Create a solution version for the implementation.
Create a campaign
A campaign deploys a solution version (trained model) with a provisioned transaction capacity for generating real-time recommendations. Create a campaign for the implementation.
Create an event tracker
Amazon Personalize can make recommendations based on real-time event data only, historical event data only, or both. Record real-time events to build out your interactions data and allow Amazon Personalize to learn from your user’s most recent activity. This keeps your data fresh and improves the relevance of Amazon Personalize recommendations. Before you can record events, you must create an event tracker. An event tracker directs new event data to the Interactions dataset in your dataset group. Create and event tracker for the implementation.
Get recommendations
In this use case, the interaction dataset is composed of movie IDs. Consequently, the recommendations presented to the user will consist of movie IDs that align most closely with their personal preferences, determined from their historical interactions. You can use the getRecommendations API to retrieve personalized recommendations for a user by sending its associated userID, the number of results for recommendations that you need for the user as well as the campaign ARN. You can find the campaign ARN in the Amazon Personalize console menu.
For example, the following request will retrieve 5 recommendations for the user whose userId is 429:
The response from the request will be:
The items returned by the API call are the movies that Amazon Personalize recommends to the user based on their historical interactions.
The score values provided in this context represent floating-point numbers that range between zero and 1.0. These values correspond to the current campaign and the associated recipes for this use case. They are determined based on the collective scores assigned to all items present in your comprehensive dataset.
Ingest real-time interactions
In the previous example, recommendations were obtained for the user with an ID of 429 based on their historical interactions with the movie database. For real-time recommendations, the user interactions with the items must be ingested into Amazon Personalize in real-time. These interactions are ingested into the recommendation system through the Amazon Personalize Event Tracker. The type of interaction, also called EventType, is given by the column of the same name in the interaction data dataset (EVENT_TYPE). In this example, the events can be of type “watch” or “click”, but you can have your own types of events according to the needs of your application.
In this example, the exposed API that generates the events of the users with the items receives the “interactions” parameter that corresponds to the number of events (interactions) of a user (UserId) with a single element (itemId) right now. The trackingId parameter can be found in the Amazon Personalize console and in the response of the creation of Event Tracker request.
This example shows a putEvent request: Generate 1 interactions of click type, with an item id of ‘185’ for the user id ‘429’, using the current timestamp. Note that in production, the ‘sentAt’ should be set to the time of the user’s interaction. In the following example, we set this to the point in time in epoch time format when we wrote the API request for this post. The events are sent to Amazon Kinesis Data Streams through an API Gateway which is why you need to send the stream-name and PartitionKey parameters.
You will receive a confirmation response similar to the following:
Validate real-time recommendations
Because the interaction dataset has been updated, the recommendations will be automatically updated to consider the new interactions. To validate the recommendations updated in real-time, you can call the getRecommendations API again for the same user id 429, and the result should be different from the previous one. The following results show a new recommendation with an id of 594 and the recommendations with the id’s of 16, 596, 153and 261 changed their scores. These items brought in new movie genre (‘Animation|Children|Drama|Fantasy|Musical’) the top 5 recommendations.
Request:
Response:
The response shows that the recommendation provided by Amazon Personalize was updated in real-time.
Clean up
To avoid unnecessary charges, clean up the solution implementation by using Cleaning up resources.
Conclusion
In this post, we showed you how to implement a real-time personalized recommendations system using Amazon Personalize. The interactions with Amazon Personalize to ingest real-time interactions and get recommendations were executed through a command line tool called curl but these API calls can be integrated into a business application and derive the same outcome.
To choose a new recipe for your use case, refer to Real-time personalization. To measure the impact of the recommendations made by Amazon Personalize, refer to Measuring impact of recommendations.
About the Authors
 Cristian Marquez is a Senior Cloud Application Architect. He has vast experience designing, building, and delivering enterprise-level software, high load and distributed systems and cloud native applications. He has experience in backend and frontend programming languages, as well as system design and implementation of DevOps practices. He actively assists customers build and secure innovative cloud solutions, solving their business problems and achieving their business goals.
Cristian Marquez is a Senior Cloud Application Architect. He has vast experience designing, building, and delivering enterprise-level software, high load and distributed systems and cloud native applications. He has experience in backend and frontend programming languages, as well as system design and implementation of DevOps practices. He actively assists customers build and secure innovative cloud solutions, solving their business problems and achieving their business goals.
 Anand Komandooru is a Senior Cloud Architect at AWS. He joined AWS Professional Services organization in 2021 and helps customers build cloud-native applications on AWS cloud. He has over 20 years of experience building software and his favorite Amazon leadership principle is “Leaders are right a lot.“
Anand Komandooru is a Senior Cloud Architect at AWS. He joined AWS Professional Services organization in 2021 and helps customers build cloud-native applications on AWS cloud. He has over 20 years of experience building software and his favorite Amazon leadership principle is “Leaders are right a lot.“
Improve LLM responses in RAG use cases by interacting with the user
One of the most common applications of generative AI and large language models (LLMs) is answering questions based on a specific external knowledge corpus. Retrieval-Augmented Generation (RAG) is a popular technique for building question answering systems that use an external knowledge base. To learn more, refer to Build a powerful question answering bot with Amazon SageMaker, Amazon OpenSearch Service, Streamlit, and LangChain.
Traditional RAG systems often struggle to provide satisfactory answers when users ask vague or ambiguous questions without providing sufficient context. This leads to unhelpful responses like “I don’t know” or incorrect, made-up answers provided by an LLM. In this post, we demonstrate a solution to improve the quality of answers in such use cases over traditional RAG systems by introducing an interactive clarification component using LangChain.
The key idea is to enable the RAG system to engage in a conversational dialogue with the user when the initial question is unclear. By asking clarifying questions, prompting the user for more details, and incorporating the new contextual information, the RAG system can gather the necessary context to provide an accurate, helpful answer—even from an ambiguous initial user query.
Solution overview
To demonstrate our solution, we have set up an Amazon Kendra index (composed of the AWS online documentation for Amazon Kendra, Amazon Lex, and Amazon SageMaker), a LangChain agent with an Amazon Bedrock LLM, and a straightforward Streamlit user interface.
Prerequisites
To run this demo in your AWS account, complete the following prerequisites:
- Clone the GitHub repository and follow the steps explained in the README.
- Deploy an Amazon Kendra index in your AWS account. You can use the following AWS CloudFormation template to create a new index or use an already running index. Deploying a new index might add additional charges to your bill, therefore we recommend deleting it if you don’t longer need it. Note that the data within the index will be sent to the selected Amazon Bedrock foundation model (FM).
- The LangChain agent relies on FMs available in Amazon Bedrock, but this can be adapted to any other LLM that LangChain supports.
- To experiment with the sample front end shared with the code, you can use Amazon SageMaker Studio to run a local deployment of the Streamlit app. Note that running this demo will incur some additional costs.
Implement the solution
Traditional RAG agents are often designed as follows. The agent has access to a tool that is used to retrieve documents relevant to a user query. The retrieved documents are then inserted into the LLM prompt, so that the agent can provide an answer based on the retrieved document snippets.
In this post, we implement an agent that has access to KendraRetrievalTool and derives relevant documents from the Amazon Kendra index and provides the answer given the retrieved context:
Refer to the GitHub repo for the full implementation code. To learn more about traditional RAG use cases, refer to Question answering using Retrieval Augmented Generation with foundation models in Amazon SageMaker JumpStart.
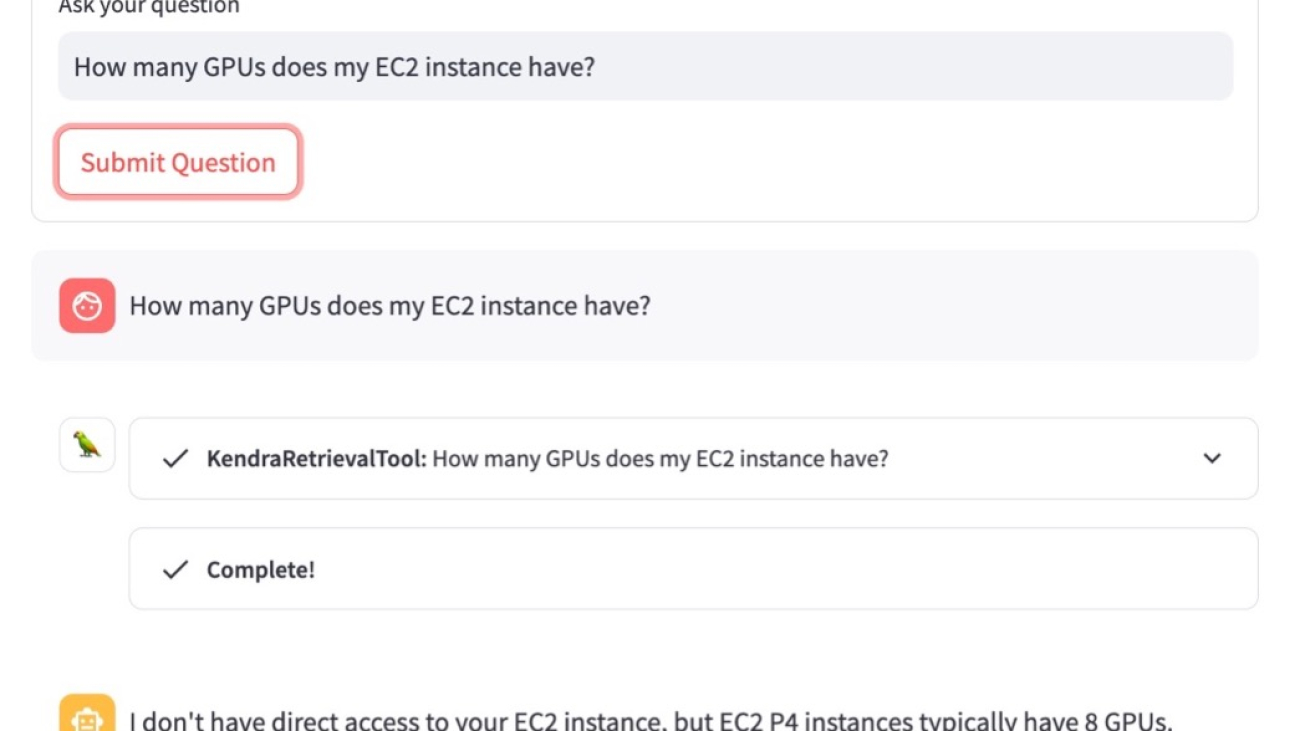
Consider the following example. A user asks “How many GPUs does my EC2 instance have?” As shown in the following screenshot, the agent is looking for the answer using KendraRetrievalTool. However, the agent realizes it doesn’t know which Amazon Elastic Compute Cloud (Amazon EC2) instance type the user is referencing and therefore provides no helpful answer to the user, leading to a poor customer experience.

To address this problem, we define an additional custom tool called AskHumanTool and provide it to the agent. The tool instructs an LLM to read the user question and ask a follow-up question to the user if KendraRetrievalTool is not able to return a good answer. This implies that the agent will now have two tools at its disposal:
This allows the agent to either refine the question or provide additional context that is needed to respond to the prompt. To guide the agent to use AskHumanTool for this purpose, we provide the following tool description to the LLM:
Use this tool if you don’t find an answer using the KendraRetrievalTool. Ask the human to clarify the question or provide the missing information. The input should be a question for the human.
As illustrated in the following screenshot, by using AskHumanTool, the agent is now identifying vague user questions and returning a follow-up question to the user asking to specify what EC2 instance type is being used.

After the user has specified the instance type, the agent is incorporating the additional answer into the context for the original question, before deriving the correct answer.

Note that the agent can now decide whether to use KendraRetrievalTool to retrieve the relevant documents or ask a clarifying question using AskHumanTool. The agent’s decision is based on whether it finds the document snippets inserted into the prompt sufficient to provide the final answer. This flexibility allows the RAG system to support different queries a user may submit, including both well-formulated and vague questions.
In our example, the full agent workflow is as follows:
- The user makes a request to the RAG app, asking “How many GPUs does my EC2 instance have?”
- The agent uses the LLM to decide what action to take: Find relevant information to answer the user’s request by calling the
KendraRetrievalTool. - The agent retrieves information from the Amazon Kendra index using the tool. The snippets from the retrieved documents are inserted into the agent prompt.
- The LLM (of the agent) derives that the retrieved documents from Amazon Kendra aren’t helpful or don’t contain enough context to provide an answer to the user’s request.
- The agent uses
AskHumanToolto formulate a follow-up question: “What is the specific EC2 instance type you are using? Knowing the instance type would help answer how many GPUs it has.” The user provides the answer “ml.g5.12xlarge,” and the agent callsKendraRetrievalToolagain, but this time adding the EC2 instance type into the search query. - After running through Steps 2–4 again, the agent derives a useful answer and sends it back to the user.
The following diagram illustrates this workflow.
The example described in this post illustrates how the addition of the custom AskHumanTool allows the agent to request clarifying details when needed. This can improve the reliability and accuracy of the responses, leading to a better customer experience in a growing number of RAG applications across different domains.
Clean up
To avoid incurring unnecessary costs, delete the Amazon Kendra index if you’re not using it anymore and shut down the SageMaker Studio instance if you used it to run the demo.
Conclusion
In this post, we showed how to enable a better customer experience for the users of a RAG system by adding a custom tool that enables the system to ask a user for a missing piece of information. This interactive conversational approach represents a promising direction for improving traditional RAG architectures. The ability to resolve vagueness through a dialogue can lead to delivering more satisfactory answers from a knowledge base.
Note that this approach is not limited to RAG use cases; you can use it in other generative AI use cases that depend on an agent at its core, where a custom AskHumanTool can be added.
For more information about using Amazon Kendra with generative AI, refer to Quickly build high-accuracy Generative AI applications on enterprise data using Amazon Kendra, LangChain, and large language models.
About the authors
 Antonia Wiebeler is a Data Scientist at the AWS Generative AI Innovation Center, where she enjoys building proofs of concept for customers. Her passion is exploring how generative AI can solve real-world problems and create value for customers. While she is not coding, she enjoys running and competing in triathlons.
Antonia Wiebeler is a Data Scientist at the AWS Generative AI Innovation Center, where she enjoys building proofs of concept for customers. Her passion is exploring how generative AI can solve real-world problems and create value for customers. While she is not coding, she enjoys running and competing in triathlons.
 Nikita Kozodoi is an Applied Scientist at the AWS Generative AI Innovation Center, where he develops ML solutions to solve customer problems across industries. In his role, he focuses on advancing generative AI to tackle real-world challenges. In his spare time, he loves playing beach volleyball and reading.
Nikita Kozodoi is an Applied Scientist at the AWS Generative AI Innovation Center, where he develops ML solutions to solve customer problems across industries. In his role, he focuses on advancing generative AI to tackle real-world challenges. In his spare time, he loves playing beach volleyball and reading.
Gen AI for the Genome: LLM Predicts Characteristics of COVID Variants
A widely acclaimed large language model for genomic data has demonstrated its ability to generate gene sequences that closely resemble real-world variants of SARS-CoV-2, the virus behind COVID-19.
Called GenSLMs, the model, which last year won the Gordon Bell special prize for high performance computing-based COVID-19 research, was trained on a dataset of nucleotide sequences — the building blocks of DNA and RNA. It was developed by researchers from Argonne National Laboratory, NVIDIA, the University of Chicago and a score of other academic and commercial collaborators.
When the researchers looked back at the nucleotide sequences generated by GenSLMs, they discovered that specific characteristics of the AI-generated sequences closely matched the real-world Eris and Pirola subvariants that have been prevalent this year — even though the AI was only trained on COVID-19 virus genomes from the first year of the pandemic.
“Our model’s generative process is extremely naive, lacking any specific information or constraints around what a new COVID variant should look like,” said Arvind Ramanathan, lead researcher on the project and a computational biologist at Argonne. “The AI’s ability to predict the kinds of gene mutations present in recent COVID strains — despite having only seen the Alpha and Beta variants during training — is a strong validation of its capabilities.”
In addition to generating its own sequences, GenSLMs can also classify and cluster different COVID genome sequences by distinguishing between variants. In a demo coming soon to NGC, NVIDIA’s hub for accelerated software, users can explore visualizations of GenSLMs’ analysis of the evolutionary patterns of various proteins within the COVID viral genome.
Reading Between the Lines, Uncovering Evolutionary Patterns
A key feature of GenSLMs is its ability to interpret long strings of nucleotides — represented with sequences of the letters A, T, G and C in DNA, or A, U, G and C in RNA — in the same way an LLM trained on English text would interpret a sentence. This capability enables the model to understand the relationship between different areas of the genome, which in coronaviruses consists of around 30,000 nucleotides.
In the demo, users will be able to choose from among eight different COVID variants to understand how the AI model tracks mutations across various proteins of the viral genome. The visualization depicts evolutionary couplings across the viral proteins — highlighting which snippets of the genome are likely to be seen in a given variant.
“Understanding how different parts of the genome are co-evolving gives us clues about how the virus may develop new vulnerabilities or new forms of resistance,” Ramanathan said. “Looking at the model’s understanding of which mutations are particularly strong in a variant may help scientists with downstream tasks like determining how a specific strain can evade the human immune system.”
GenSLMs was trained on more than 110 million prokaryotic genome sequences and fine-tuned with a global dataset of around 1.5 million COVID viral sequences using open-source data from the Bacterial and Viral Bioinformatics Resource Center. In the future, the model could be fine-tuned on the genomes of other viruses or bacteria, enabling new research applications.
To train the model, the researchers used NVIDIA A100 Tensor Core GPU-powered supercomputers, including Argonne’s Polaris system, the U.S. Department of Energy’s Perlmutter and NVIDIA’s Selene.
The GenSLMs research team’s Gordon Bell special prize was awarded at last year’s SC22 supercomputing conference. At this week’s SC23, in Denver, NVIDIA is sharing a new range of groundbreaking work in the field of accelerated computing. View the full schedule.
NVIDIA Research comprises hundreds of scientists and engineers worldwide, with teams focused on topics including AI, computer graphics, computer vision, self-driving cars and robotics. Learn more about NVIDIA Research and subscribe to NVIDIA healthcare news.
Main image courtesy of Argonne National Laboratory’s Bharat Kale.
This research was supported by the Exascale Computing Project (17-SC-20-SC), a collaborative effort of the U.S. DOE Office of Science and the National Nuclear Security Administration. Research was supported by the DOE through the National Virtual Biotechnology Laboratory, a consortium of DOE national laboratories focused on response to COVID-19, with funding from the Coronavirus CARES Act.

Researchers Poised for Advances With NVIDIA CUDA Quantum
Michael Kuehn and Davide Vodola are taking to new heights work that’s pioneering quantum computing for the world’s largest chemical company.
The BASF researchers are demonstrating how a quantum algorithm can see what no traditional simulation can — key attributes of NTA, a compound with applications that include removing toxic metals like iron from a city’s wastewater.
The quantum computing team at BASF simulated on GPUs how the equivalent of 24 qubits — the processing engines of a quantum computer — can tackle the challenge.
Many corporate R&D centers would consider that a major achievement, but they pressed on, and recently ran their first 60 qubit simulations on NVIDIA’s Eos H100 Supercomputer.
“It’s the largest simulation of a molecule using a quantum algorithm we’ve ever run,” said Kuehn.
Flexible, Friendly Software
BASF is running the simulation on NVIDIA CUDA Quantum, a platform for programming CPUs, GPUs and quantum computers, also known as QPUs.
Vodola described it as “very flexible and user friendly, letting us build up a complex quantum circuit simulation from relatively simple building blocks. Without CUDA Quantum, it would be impossible to run this simulation,” he said.
The work requires a lot of heavy lifting, too, so BASF turned to an NVIDIA DGX Cloud service that uses NVIDIA H100 Tensor Core GPUs.
“We need a lot of computing power, and the NVIDIA platform is significantly faster than CPU-based hardware for this kind of simulation,” said Kuehn.
BASF’s quantum computing initiative, which Kuehn helped launch, started in 2017. In addition to its work in chemistry, the team is developing use cases for quantum computing in machine learning as well as optimizations for logistics and scheduling.
An Expanding CUDA Quantum Community
Other research groups are also advancing science with CUDA Quantum.
At SUNY Stony Brook, researchers are pushing the boundaries of high-energy physics to simulate complex interactions of subatomic particles. Their work promises new discoveries in fundamental physics.
“CUDA Quantum enables us to do quantum simulations that would otherwise be impossible,” said Dmitri Kharzeev, a SUNY professor and scientist at Brookhaven National Lab.
In addition, a research team at Hewlett Packard Labs is using the Perlmutter supercomputer to explore magnetic phase transition in quantum chemistry in one of the largest simulations of its kind. The effort could reveal important and unknown details of physical processes too difficult to model with conventional techniques.
“As quantum computers progress toward useful applications, high-performance classical simulations will be key for prototyping novel quantum algorithms,” said Kirk Bresniker, a chief architect at Hewlett Packard Labs. “Simulating and learning from quantum data are promising avenues toward tapping quantum computing’s potential.”
A Quantum Center for Healthcare
These efforts come as support for CUDA Quantum expands worldwide.
Classiq — an Israeli startup that already has more than 400 universities using its novel approach to writing quantum programs — announced today a new research center at the Tel Aviv Sourasky Medical Center, Israel’s largest teaching hospital.
Created in collaboration with NVIDIA, it will train experts in life science to write quantum applications that could someday help doctors diagnose diseases or accelerate the discovery of new drugs.
Classiq created quantum design software that automates low-level tasks, so developers don’t need to know all the complex details of how a quantum computer works. It’s now being integrated with CUDA Quantum.
Terra Quantum, a quantum services company with headquarters in Germany and Switzerland, is developing hybrid quantum applications for life sciences, energy, chemistry and finance that will run on CUDA Quantum. And IQM in Finland is enabling its superconducting QPU to use CUDA Quantum.
Quantum Loves Grace Hopper
Several companies, including Oxford Quantum Circuits, will use NVIDIA Grace Hopper Superchips to power their hybrid quantum efforts. Based in Reading, England, Oxford Quantum is using Grace Hopper in a hybrid QPU/GPU system programmed by CUDA Quantum.
Quantum Machines announced that the Israeli National Quantum Center will be the first deployment of NVIDIA DGX Quantum, a system using Grace Hopper Superchips. Based in Tel Aviv, the center will tap DGX Quantum to power quantum computers from Quantware, ORCA Computing and more.
In addition, Grace Hopper is being put to work by qBraid, in Chicago, to build a quantum cloud service, and Fermioniq, in Amsterdam, to develop tensor-network algorithms.
The large quantity of shared memory and the memory bandwidth of Grace Hopper make these superchips an excellent fit for memory-hungry quantum simulations.
Get started programming hybrid quantum systems today with the latest release of CUDA Quantum from NGC, NVIDIA’s catalog of accelerated software, or GitHub.

NVIDIA Grace Hopper Superchip Powers 40+ AI Supercomputers Across Global Research Centers, System Makers, Cloud Providers
Dozens of new supercomputers for scientific computing will soon hop online, powered by NVIDIA’s breakthrough GH200 Grace Hopper Superchip for giant-scale AI and high performance computing.
The NVIDIA GH200 enables scientists and researchers to tackle the world’s most challenging problems by accelerating complex AI and HPC applications running terabytes of data.
At the SC23 supercomputing show, NVIDIA today announced that the superchip is coming to more systems worldwide, including from Dell Technologies, Eviden, Hewlett Packard Enterprise (HPE), Lenovo, QCT and Supermicro.
Bringing together the Arm-based NVIDIA Grace CPU and Hopper GPU architectures using NVIDIA NVLink-C2C interconnect technology, GH200 also serves as the engine behind scientific supercomputing centers across the globe.
Combined, these GH200-powered centers represent some 200 exaflops of AI performance to drive scientific innovation.
HPE Cray Supercomputers Integrate NVIDIA Grace Hopper
At the show in Denver, HPE announced it will offer HPE Cray EX2500 supercomputers with the NVIDIA Grace Hopper Superchip. The integrated solution will feature quad GH200 processors, scaling up to tens of thousands of Grace Hopper Superchip nodes to provide organizations with unmatched supercomputing agility and quicker AI training. This configuration will also be part of a supercomputing solution for generative AI that HPE introduced today.
“Organizations are rapidly adopting generative AI to accelerate business transformations and technological breakthroughs,” said Justin Hotard, executive vice president and general manager of HPC, AI and Labs at HPE. “Working with NVIDIA, we’re excited to deliver a full supercomputing solution for generative AI, powered by technologies like Grace Hopper, which will make it easy for customers to accelerate large-scale AI model training and tuning at new levels of efficiency.”
Next-Generation AI Supercomputing Centers
A vast array of the world’s supercomputing centers are powered by NVIDIA Grace Hopper systems. Several top centers announced at SC23 that they’re now integrating GH200 systems for their supercomputers.
Germany’s Jülich Supercomputing Centre will use GH200 superchips in JUPITER, set to become the first exascale supercomputer in Europe. The supercomputer will help tackle urgent scientific challenges, such as mitigating climate change, combating pandemics and bolstering sustainable energy production.
Japan’s Joint Center for Advanced High Performance Computing — established between the Center for Computational Sciences at the University of Tsukuba and the Information Technology Center at the University of Tokyo — promotes advanced computational sciences integrated with data analytics, AI and machine learning across academia and industry. Its next-generation supercomputer will be powered by NVIDIA Grace Hopper.
The Texas Advanced Computing Center, based in Austin, Texas, designs and operates some of the world’s most powerful computing resources. The center will power its Vista supercomputer with NVIDIA GH200 for low power and high-bandwidth memory to deliver more computation while enabling bigger models to run with greater efficiency.
The National Center for Supercomputing Applications at the University of Illinois Urbana-Champaign will tap NVIDIA Grace Hopper superchips to power DeltaAI, an advanced computing and data resource set to triple NCSA’s AI-focused computing capacity.
And, the University of Bristol recently received funding from the UK government to build Isambard-AI, set to be the country’s most powerful supercomputer, which will enable AI-driven breakthroughs in robotics, big data, climate research and drug discovery. The new system, being built by HPE, will be equipped with over 5,000 NVIDIA GH200 Grace Hopper Superchips, providing 21 exaflops of AI supercomputing power capable of making 21 quintillion AI calculations per second.
These systems join previously announced next-generation Grace Hopper systems from the Swiss National Supercomputing Centre, Los Alamos National Laboratory and SoftBank Corp.
GH200 Shipping Globally and Available in Early Access from CSPs
GH200 is available in early access from select cloud service providers such as Lambda and Vultr. Oracle Cloud Infrastructure today announced plans to offer GH200 instances, while CoreWeave detailed plans for early availability of its GH200 instances starting in Q1 2024.
Other system manufacturers such as ASRock Rack, ASUS, GIGABYTE and Ingrasys will begin shipping servers with the superchips by the end of the year.
NVIDIA Grace Hopper has been adopted in early access for supercomputing initiatives by more than 100 enterprises, organizations and government agencies across the globe, including the NASA Ames Research Center for aeronautics research and global energy company TotalEnergies.
In addition, the GH200 will soon become available through NVIDIA LaunchPad, which provides free access to enterprise NVIDIA hardware and software through an internet browser.
Learn more about Grace Hopper and other supercomputing breakthroughs by joining NVIDIA at SC23.

Taking legal action to protect users of AI and small businesses
 Today we’re taking action to protect users of Google’s Bard AI as well as against fraudsters who sought to weaponize copyright law for profitRead More
Today we’re taking action to protect users of Google’s Bard AI as well as against fraudsters who sought to weaponize copyright law for profitRead More