GPUs have been called the rare Earth metals — even the gold — of artificial intelligence, because they’re foundational for today’s generative AI era.
Three technical reasons, and many stories, explain why that’s so. Each reason has multiple facets well worth exploring, but at a high level:
- GPUs employ parallel processing.
- GPU systems scale up to supercomputing heights.
- The GPU software stack for AI is broad and deep.
The net result is GPUs perform technical calculations faster and with greater energy efficiency than CPUs. That means they deliver leading performance for AI training and inference as well as gains across a wide array of applications that use accelerated computing.
In its recent report on AI, Stanford’s Human-Centered AI group provided some context. GPU performance “has increased roughly 7,000 times” since 2003 and price per performance is “5,600 times greater,” it reported.
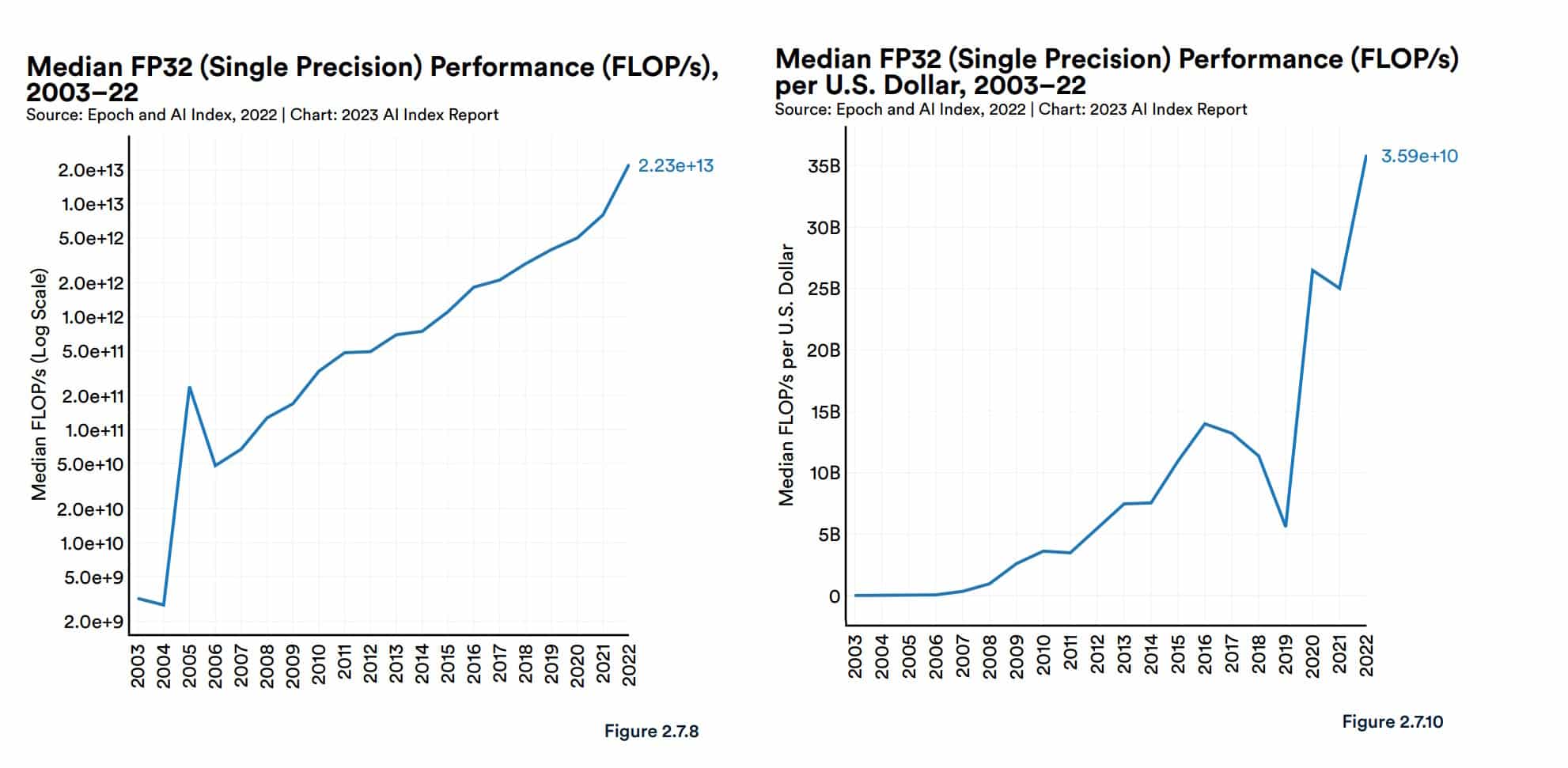
The report also cited analysis from Epoch, an independent research group that measures and forecasts AI advances.
“GPUs are the dominant computing platform for accelerating machine learning workloads, and most (if not all) of the biggest models over the last five years have been trained on GPUs … [they have] thereby centrally contributed to the recent progress in AI,” Epoch said on its site.
A 2020 study assessing AI technology for the U.S. government drew similar conclusions.
“We expect [leading-edge] AI chips are one to three orders of magnitude more cost-effective than leading-node CPUs when counting production and operating costs,” it said.
NVIDIA GPUs have increased performance on AI inference 1,000x in the last ten years, said Bill Dally, the company’s chief scientist in a keynote at Hot Chips, an annual gathering of semiconductor and systems engineers.
ChatGPT Spread the News
ChatGPT provided a powerful example of how GPUs are great for AI. The large language model (LLM), trained and run on thousands of NVIDIA GPUs, runs generative AI services used by more than 100 million people.
Since its 2018 launch, MLPerf, the industry-standard benchmark for AI, has provided numbers that detail the leading performance of NVIDIA GPUs on both AI training and inference.
For example, NVIDIA Grace Hopper Superchips swept the latest round of inference tests. NVIDIA TensorRT-LLM, inference software released since that test, delivers up to an 8x boost in performance and more than a 5x reduction in energy use and total cost of ownership. Indeed, NVIDIA GPUs have won every round of MLPerf training and inference tests since the benchmark was released in 2019.
In February, NVIDIA GPUs delivered leading results for inference, serving up thousands of inferences per second on the most demanding models in the STAC-ML Markets benchmark, a key technology performance gauge for the financial services industry.
A RedHat software engineering team put it succinctly in a blog: “GPUs have become the foundation of artificial intelligence.”
AI Under the Hood
A brief look under the hood shows why GPUs and AI make a powerful pairing.
An AI model, also called a neural network, is essentially a mathematical lasagna, made from layer upon layer of linear algebra equations. Each equation represents the likelihood that one piece of data is related to another.
For their part, GPUs pack thousands of cores, tiny calculators working in parallel to slice through the math that makes up an AI model. This, at a high level, is how AI computing works.
Highly Tuned Tensor Cores
Over time, NVIDIA’s engineers have tuned GPU cores to the evolving needs of AI models. The latest GPUs include Tensor Cores that are 60x more powerful than the first-generation designs for processing the matrix math neural networks use.
In addition, NVIDIA Hopper Tensor Core GPUs include a Transformer Engine that can automatically adjust to the optimal precision needed to process transformer models, the class of neural networks that spawned generative AI.
Along the way, each GPU generation has packed more memory and optimized techniques to store an entire AI model in a single GPU or set of GPUs.
Models Grow, Systems Expand
The complexity of AI models is expanding a whopping 10x a year.
The current state-of-the-art LLM, GPT4, packs more than a trillion parameters, a metric of its mathematical density. That’s up from less than 100 million parameters for a popular LLM in 2018.
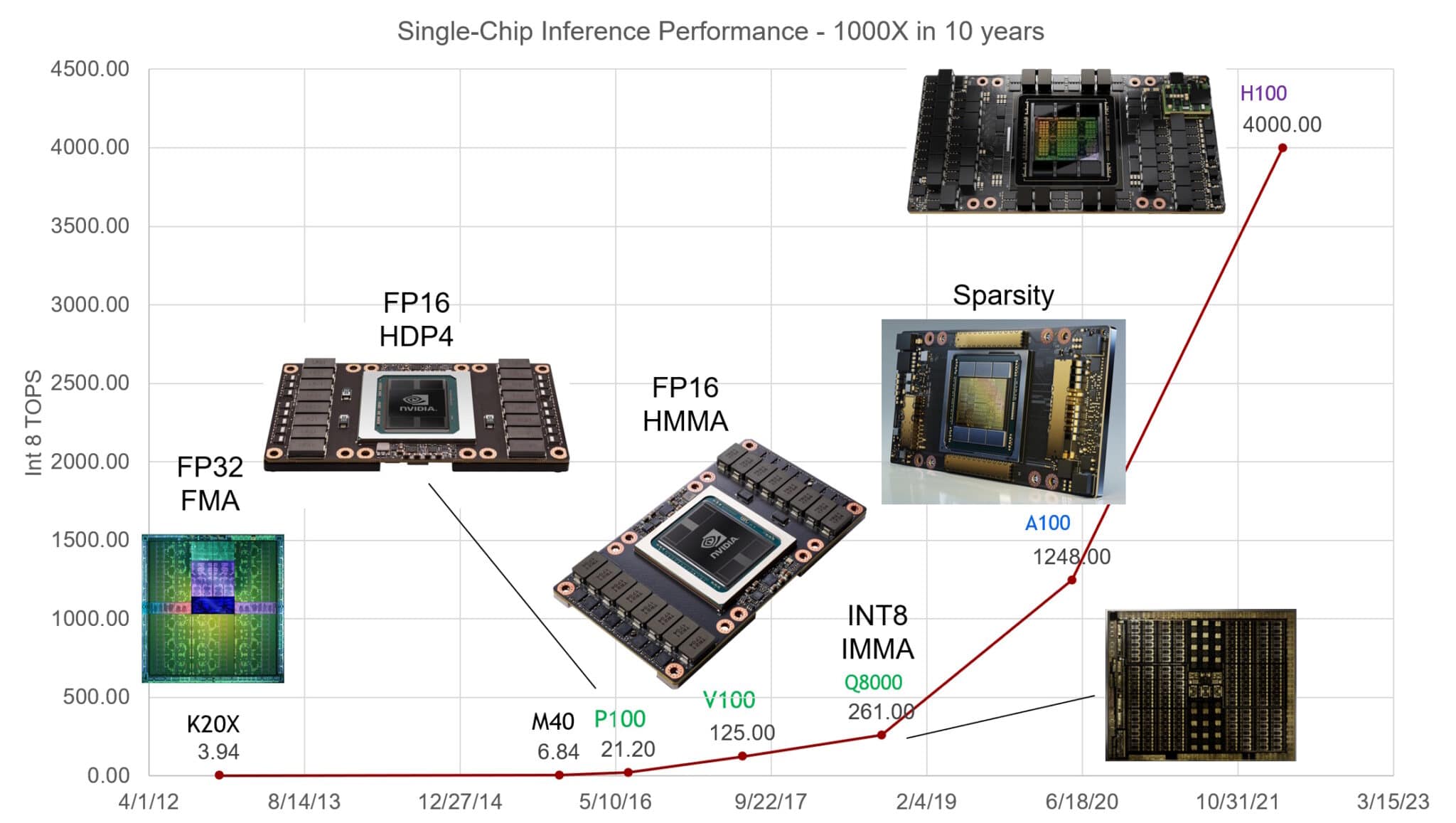
GPU systems have kept pace by ganging up on the challenge. They scale up to supercomputers, thanks to their fast NVLink interconnects and NVIDIA Quantum InfiniBand networks.
For example, the DGX GH200, a large-memory AI supercomputer, combines up to 256 NVIDIA GH200 Grace Hopper Superchips into a single data-center-sized GPU with 144 terabytes of shared memory.
Each GH200 superchip is a single server with 72 Arm Neoverse CPU cores and four petaflops of AI performance. A new four-way Grace Hopper systems configuration puts in a single compute node a whopping 288 Arm cores and 16 petaflops of AI performance with up to 2.3 terabytes of high-speed memory.
And NVIDIA H200 Tensor Core GPUs announced in November pack up to 288 gigabytes of the latest HBM3e memory technology.
Software Covers the Waterfront
An expanding ocean of GPU software has evolved since 2007 to enable every facet of AI, from deep-tech features to high-level applications.
The NVIDIA AI platform includes hundreds of software libraries and apps. The CUDA programming language and the cuDNN-X library for deep learning provide a base on top of which developers have created software like NVIDIA NeMo, a framework to let users build, customize and run inference on their own generative AI models.
Many of these elements are available as open-source software, the grab-and-go staple of software developers. More than a hundred of them are packaged into the NVIDIA AI Enterprise platform for companies that require full security and support. Increasingly, they’re also available from major cloud service providers as APIs and services on NVIDIA DGX Cloud.
SteerLM, one of the latest AI software updates for NVIDIA GPUs, lets users fine tune models during inference.
A 70x Speedup in 2008
Success stories date back to a 2008 paper from AI pioneer Andrew Ng, then a Stanford researcher. Using two NVIDIA GeForce GTX 280 GPUs, his three-person team achieved a 70x speedup over CPUs processing an AI model with 100 million parameters, finishing work that used to require several weeks in a single day.
“Modern graphics processors far surpass the computational capabilities of multicore CPUs, and have the potential to revolutionize the applicability of deep unsupervised learning methods,” they reported.

In a 2015 talk at NVIDIA GTC, Ng described how he continued using more GPUs to scale up his work, running larger models at Google Brain and Baidu. Later, he helped found Coursera, an online education platform where he taught hundreds of thousands of AI students.
Ng counts Geoff Hinton, one of the godfathers of modern AI, among the people he influenced. “I remember going to Geoff Hinton saying check out CUDA, I think it can help build bigger neural networks,” he said in the GTC talk.
The University of Toronto professor spread the word. “In 2009, I remember giving a talk at NIPS [now NeurIPS], where I told about 1,000 researchers they should all buy GPUs because GPUs are going to be the future of machine learning,” Hinton said in a press report.
Fast Forward With GPUs
AI’s gains are expected to ripple across the global economy.
A McKinsey report in June estimated that generative AI could add the equivalent of $2.6 trillion to $4.4 trillion annually across the 63 use cases it analyzed in industries like banking, healthcare and retail. So, it’s no surprise Stanford’s 2023 AI report said that a majority of business leaders expect to increase their investments in AI.
Today, more than 40,000 companies use NVIDIA GPUs for AI and accelerated computing, attracting a global community of 4 million developers. Together they’re advancing science, healthcare, finance and virtually every industry.
Among the latest achievements, NVIDIA described a whopping 700,000x speedup using AI to ease climate change by keeping carbon dioxide out of the atmosphere (see video below). It’s one of many ways NVIDIA is applying the performance of GPUs to AI and beyond.
Learn how GPUs put AI into production.
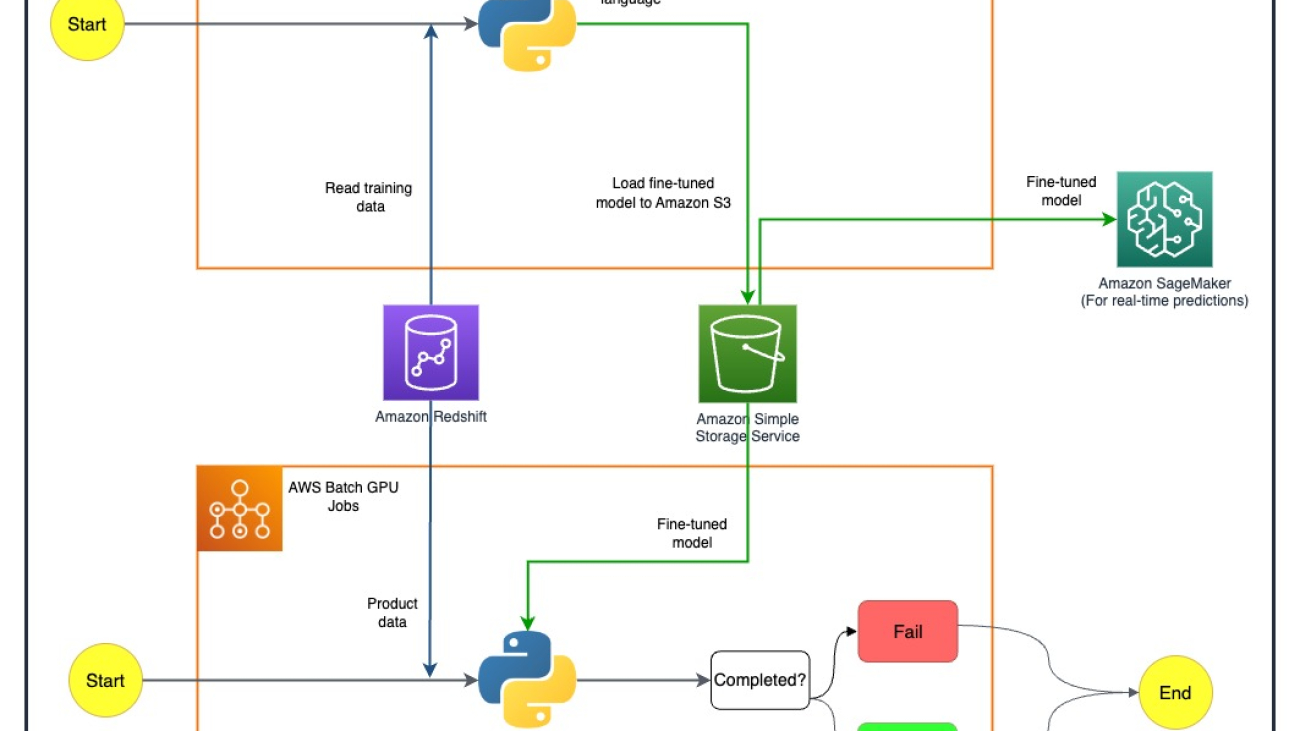

 Nafi Ahmet Turgut finished his master’s degree in Electrical & Electronics Engineering and worked as a graduate research scientist. His focus was building machine learning algorithms to simulate nervous network anomalies. He joined Getir in 2019 and currently works as a Senior Data Science & Analytics Manager. His team is responsible for designing, implementing, and maintaining end-to-end machine learning algorithms and data-driven solutions for Getir.
Nafi Ahmet Turgut finished his master’s degree in Electrical & Electronics Engineering and worked as a graduate research scientist. His focus was building machine learning algorithms to simulate nervous network anomalies. He joined Getir in 2019 and currently works as a Senior Data Science & Analytics Manager. His team is responsible for designing, implementing, and maintaining end-to-end machine learning algorithms and data-driven solutions for Getir. Hasan Burak Yel received his bachelor’s degree in Electrical & Electronics Engineering at Boğaziçi University. He worked at Turkcell, mainly focused on time series forecasting, data visualization, and network automation. He joined Getir in 2021 and currently works as a Data Science & Analytics Manager with the responsibility of Search, Recommendation, and Growth domains.
Hasan Burak Yel received his bachelor’s degree in Electrical & Electronics Engineering at Boğaziçi University. He worked at Turkcell, mainly focused on time series forecasting, data visualization, and network automation. He joined Getir in 2021 and currently works as a Data Science & Analytics Manager with the responsibility of Search, Recommendation, and Growth domains. Damla Şentürk received her bachelor’s degree of Computer Engineering at Galatasaray University. She continues her master’s degree of Computer Engineering in Boğaziçi University. She joined Getir in 2022, and has been working as a Data Scientist. She has worked on commercial, supply chain, and discovery-related projects.
Damla Şentürk received her bachelor’s degree of Computer Engineering at Galatasaray University. She continues her master’s degree of Computer Engineering in Boğaziçi University. She joined Getir in 2022, and has been working as a Data Scientist. She has worked on commercial, supply chain, and discovery-related projects. Esra Kayabalı is a Senior Solutions Architect at AWS, specialized in the analytics domain, including data warehousing, data lakes, big data analytics, batch and real-time data streaming, and data integration. She has 12 years of software development and architecture experience. She is passionate about learning and teaching cloud technologies.
Esra Kayabalı is a Senior Solutions Architect at AWS, specialized in the analytics domain, including data warehousing, data lakes, big data analytics, batch and real-time data streaming, and data integration. She has 12 years of software development and architecture experience. She is passionate about learning and teaching cloud technologies.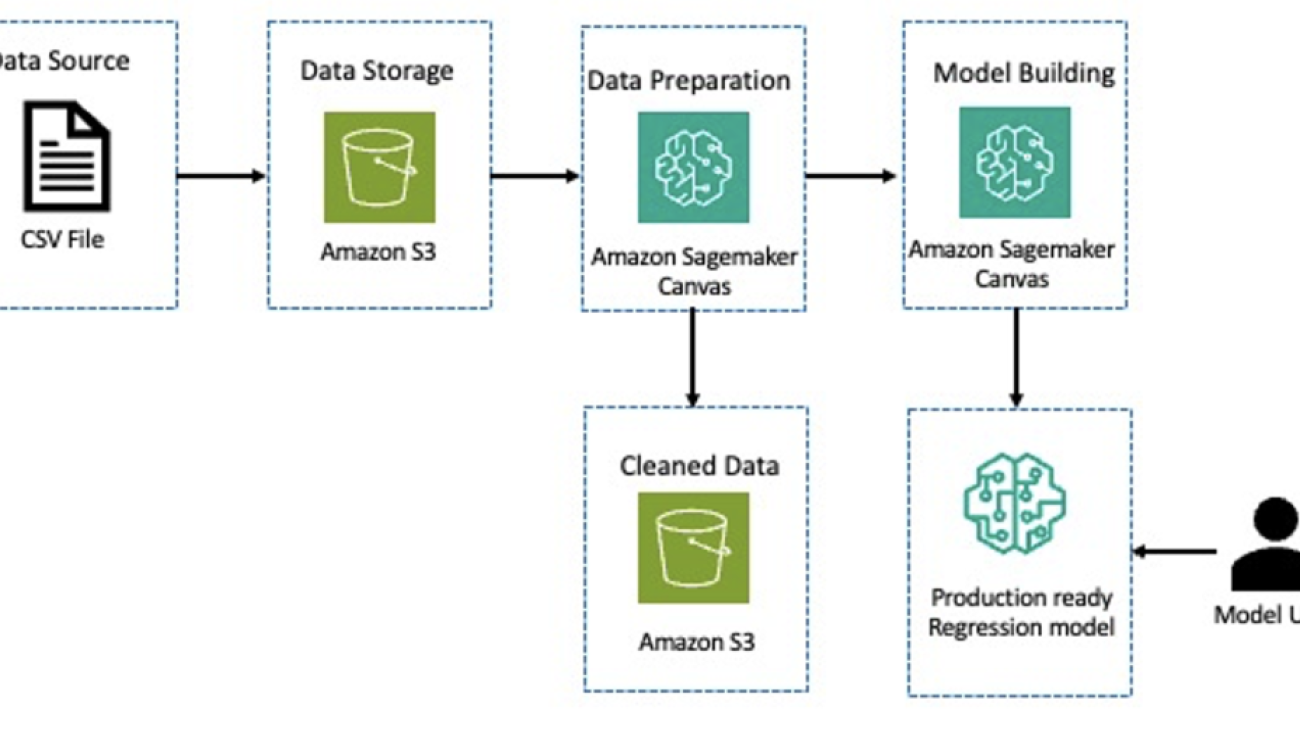
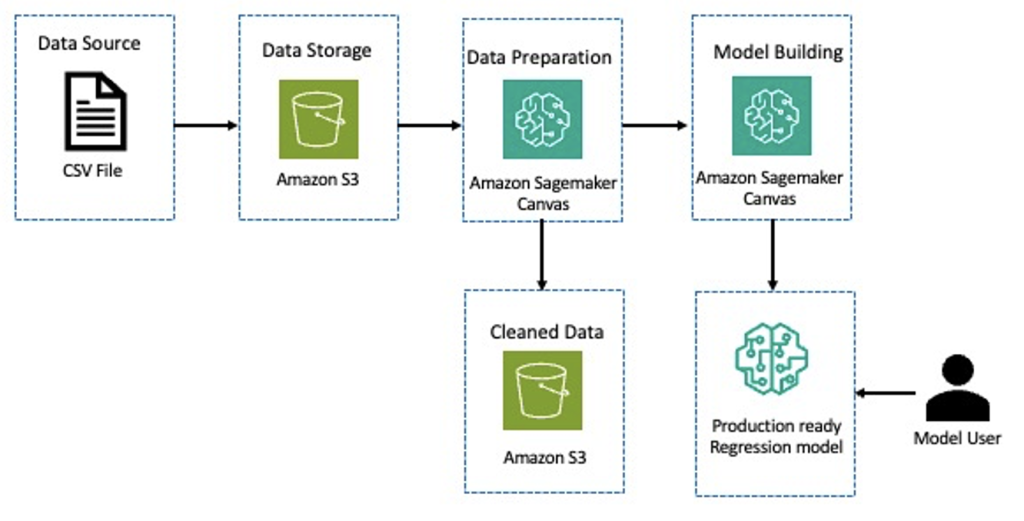














 Chida Sadayappan leads Deloitte’s Cloud AI/Machine Learning practice. He brings strong thought leadership experience to engagements and thrives in supporting executive stakeholders achieve performance improvement and modernization goals across industries using AI/ML. Chida is a serial tech entrepreneur and an avid community builder in the startup and developer ecosystems.
Chida Sadayappan leads Deloitte’s Cloud AI/Machine Learning practice. He brings strong thought leadership experience to engagements and thrives in supporting executive stakeholders achieve performance improvement and modernization goals across industries using AI/ML. Chida is a serial tech entrepreneur and an avid community builder in the startup and developer ecosystems. Kuldeep Singh, a Principal Global AI/ML leader at AWS with over 20 years in tech, skillfully combines his sales and entrepreneurship expertise with a deep understanding of AI, ML, and cybersecurity. He excels in forging strategic global partnerships, driving transformative solutions and strategies across various industries with a focus on generative AI and GSIs.
Kuldeep Singh, a Principal Global AI/ML leader at AWS with over 20 years in tech, skillfully combines his sales and entrepreneurship expertise with a deep understanding of AI, ML, and cybersecurity. He excels in forging strategic global partnerships, driving transformative solutions and strategies across various industries with a focus on generative AI and GSIs. Kasi Muthu is a senior partner solutions architect focusing on data and AI/ML at AWS based out of Houston, TX. He is passionate about helping partners and customers accelerate their cloud data journey. He is a trusted advisor in this field and has plenty of experience architecting and building scalable, resilient, and performant workloads in the cloud. Outside of work, he enjoys spending time with his family.
Kasi Muthu is a senior partner solutions architect focusing on data and AI/ML at AWS based out of Houston, TX. He is passionate about helping partners and customers accelerate their cloud data journey. He is a trusted advisor in this field and has plenty of experience architecting and building scalable, resilient, and performant workloads in the cloud. Outside of work, he enjoys spending time with his family.