 A new partnership between Victoria’s Secret & Company and Google Cloud uses AI and generative AI to make online shopping more personalized and inclusive.Read More
A new partnership between Victoria’s Secret & Company and Google Cloud uses AI and generative AI to make online shopping more personalized and inclusive.Read More

A new partnership between Victoria’s Secret & Company and Google Cloud uses AI and generative AI to make online shopping more personalized and inclusive.Read More
This post is co-written with Jayadeep Pabbisetty, Sr. Specialist Data Engineering at Merck, and Prabakaran Mathaiyan, Sr. ML Engineer at Tiger Analytics.
The large machine learning (ML) model development lifecycle requires a scalable model release process similar to that of software development. Model developers often work together in developing ML models and require a robust MLOps platform to work in. A scalable MLOps platform needs to include a process for handling the workflow of ML model registry, approval, and promotion to the next environment level (development, test, UAT, or production).
A model developer typically starts to work in an individual ML development environment within Amazon SageMaker. When a model is trained and ready to be used, it needs to be approved after being registered in the Amazon SageMaker Model Registry. In this post, we discuss how the AWS AI/ML team collaborated with the Merck Human Health IT MLOps team to build a solution that uses an automated workflow for ML model approval and promotion with human intervention in the middle.
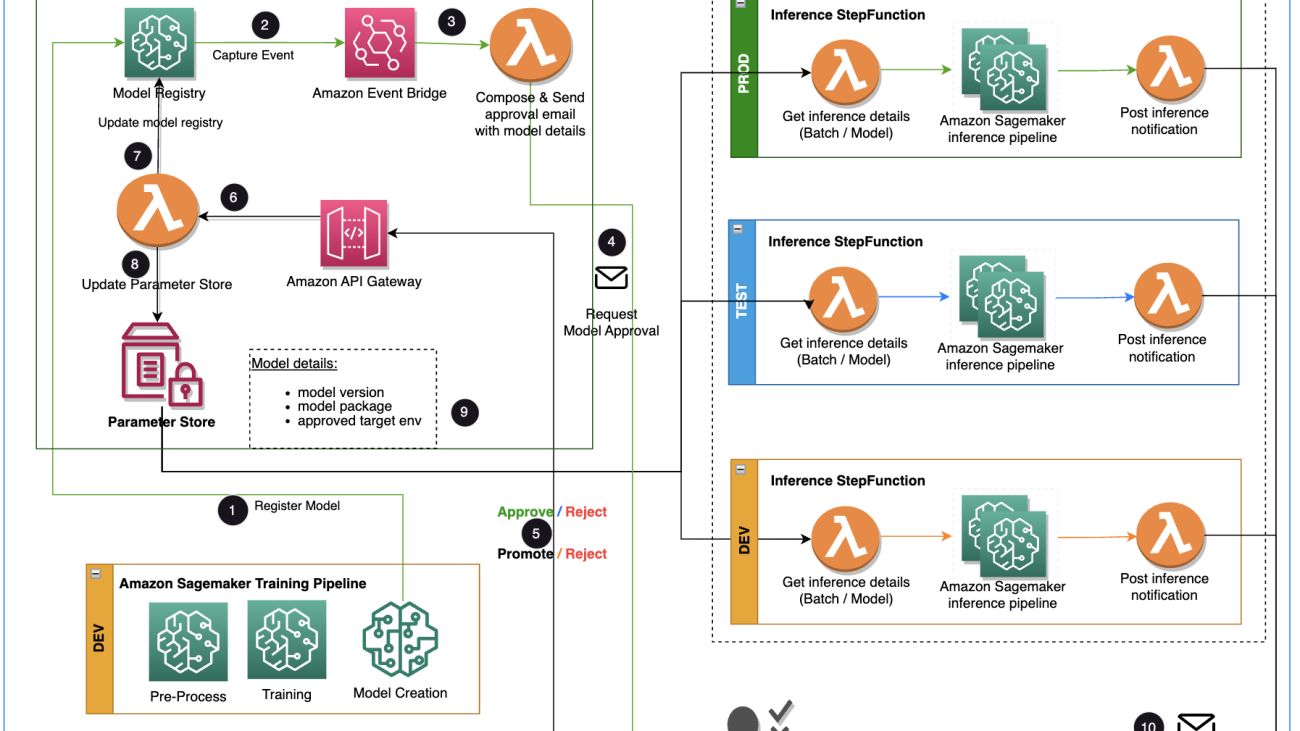
This post focuses on a workflow solution that the ML model development lifecycle can use between the training pipeline and inferencing pipeline. The solution provides a scalable workflow for MLOps in supporting the ML model approval and promotion process with human intervention. An ML model registered by a data scientist needs an approver to review and approve before it is used for an inference pipeline and in the next environment level (test, UAT, or production). The solution uses AWS Lambda, Amazon API Gateway, Amazon EventBridge, and SageMaker to automate the workflow with human approval intervention in the middle. The following architecture diagram shows the overall system design, the AWS services used, and the workflow for approving and promoting ML models with human intervention from development to production.

The workflow includes the following steps:
PendingManualApproval.Approved for the dev environment, but PendingManualApproval for test, UAT, and production).The workflow in this post assumes the environment for the training pipeline is set up in SageMaker, along with other resources. The input to the training pipeline is the features dataset. The feature generation details are not included in this post, but it focuses on the registry, approval, and promotion of ML models after they are trained. The model is registered in the model registry and is governed by a monitoring framework in Amazon SageMaker Model Monitor to detect for any drift and proceed to retraining in case of model drift.
The approval workflow starts with a model developed from a training pipeline. When data scientists develop a model, they register it to the SageMaker Model Registry with the model status of PendingManualApproval. EventBridge monitors SageMaker for the model registration event and triggers an event rule that invokes a Lambda function. The Lambda function dynamically constructs an email for an approval of the model with a link to an API Gateway endpoint to another Lambda function. When the approver follows the link to approve the model, API Gateway forwards the approval action to the Lambda function, which updates the SageMaker Model Registry and the model attributes in Parameter Store. The approver must be authenticated and part of the approver group managed by Active Directory. The initial approval marks the model as Approved for dev but PendingManualApproval for test, UAT, and production. The model attributes saved in Parameter Store include the model version, model package, and approved target environment.
When an inference pipeline needs to fetch a model, it checks Parameter Store for the latest model version approved for the target environment and gets the inference details. When the inference pipeline is complete, a post-inference notification email is sent to a stakeholder requesting an approval to promote the model to the next environment level. The email has the details about the model and metrics as well as an approval link to an API Gateway endpoint for a Lambda function that updates the model attributes.
The following is the sequence of events and implementation steps for the ML model approval/promotion workflow from model creation to production. The model is promoted from development to test, UAT, and production environments with an explicit human approval in each step.
We start with the training pipeline, which is ready for model development. The model version starts as 0 in SageMaker Model Registry.

 The Model Registry metadata has four custom fields for the environments:
The Model Registry metadata has four custom fields for the environments: dev, test, uat, and prod.











The complete history of the model versioning and approval is saved for review in Parameter Store.


The large ML model development lifecycle requires a scalable ML model approval process. In this post, we shared an implementation of an ML model registry, approval, and promotion workflow with human intervention using SageMaker Model Registry, EventBridge, API Gateway, and Lambda. If you are considering a scalable ML model development process for your MLOps platform, you can follow the steps in this post to implement a similar workflow.
 Tom Kim is a Senior Solution Architect at AWS, where he helps his customers achieve their business objectives by developing solutions on AWS. He has extensive experience in enterprise systems architecture and operations across several industries – particularly in Health Care and Life Science. Tom is always learning new technologies that lead to desired business outcome for customers – e.g. AI/ML, GenAI and Data Analytics. He also enjoys traveling to new places and playing new golf courses whenever he can find time.
Tom Kim is a Senior Solution Architect at AWS, where he helps his customers achieve their business objectives by developing solutions on AWS. He has extensive experience in enterprise systems architecture and operations across several industries – particularly in Health Care and Life Science. Tom is always learning new technologies that lead to desired business outcome for customers – e.g. AI/ML, GenAI and Data Analytics. He also enjoys traveling to new places and playing new golf courses whenever he can find time.
 Shamika Ariyawansa, serving as a Senior AI/ML Solutions Architect in the Healthcare and Life Sciences division at Amazon Web Services (AWS),specializes in Generative AI, with a focus on Large Language Model (LLM) training, inference optimizations, and MLOps (Machine Learning Operations). He guides customers in embedding advanced Generative AI into their projects, ensuring robust training processes, efficient inference mechanisms, and streamlined MLOps practices for effective and scalable AI solutions. Beyond his professional commitments, Shamika passionately pursues skiing and off-roading adventures.
Shamika Ariyawansa, serving as a Senior AI/ML Solutions Architect in the Healthcare and Life Sciences division at Amazon Web Services (AWS),specializes in Generative AI, with a focus on Large Language Model (LLM) training, inference optimizations, and MLOps (Machine Learning Operations). He guides customers in embedding advanced Generative AI into their projects, ensuring robust training processes, efficient inference mechanisms, and streamlined MLOps practices for effective and scalable AI solutions. Beyond his professional commitments, Shamika passionately pursues skiing and off-roading adventures.
 Jayadeep Pabbisetty is a Senior ML/Data Engineer at Merck, where he designs and develops ETL and MLOps solutions to unlock data science and analytics for the business. He is always enthusiastic about learning new technologies, exploring new avenues, and acquiring the skills necessary to evolve with the ever-changing IT industry. In his spare time, he follows his passion for sports and likes to travel and explore new places.
Jayadeep Pabbisetty is a Senior ML/Data Engineer at Merck, where he designs and develops ETL and MLOps solutions to unlock data science and analytics for the business. He is always enthusiastic about learning new technologies, exploring new avenues, and acquiring the skills necessary to evolve with the ever-changing IT industry. In his spare time, he follows his passion for sports and likes to travel and explore new places.
 Prabakaran Mathaiyan is a Senior Machine Learning Engineer at Tiger Analytics LLC, where he helps his customers to achieve their business objectives by providing solutions for the model building, training, validation, monitoring, CICD and improvement of machine learning solutions on AWS. Prabakaran is always learning new technologies that lead to desired business outcome for customers – e.g. AI/ML, GenAI, GPT and LLM. He also enjoys playing cricket whenever he can find time.
Prabakaran Mathaiyan is a Senior Machine Learning Engineer at Tiger Analytics LLC, where he helps his customers to achieve their business objectives by providing solutions for the model building, training, validation, monitoring, CICD and improvement of machine learning solutions on AWS. Prabakaran is always learning new technologies that lead to desired business outcome for customers – e.g. AI/ML, GenAI, GPT and LLM. He also enjoys playing cricket whenever he can find time.

Editor’s note: All papers referenced here represent collaborations throughout Microsoft and across academia and industry that include authors who contribute to Aether, the Microsoft internal advisory body for AI ethics and effects in engineering and research.

A surge of generative AI models in the past year has fueled much discussion about the impact of artificial intelligence on human history. Advances in AI have indeed challenged thinking across industries, from considering how people will function in creative roles to effects in education, medicine, manufacturing, and more. Whether exploring impressive new capabilities of large language models (LLMs) such as GPT-4 or examining the spectrum of machine learning techniques already embedded in our daily lives, researchers agree on the importance of transparency. For society to appropriately benefit from this powerful technology, people must be given the means for understanding model behavior.
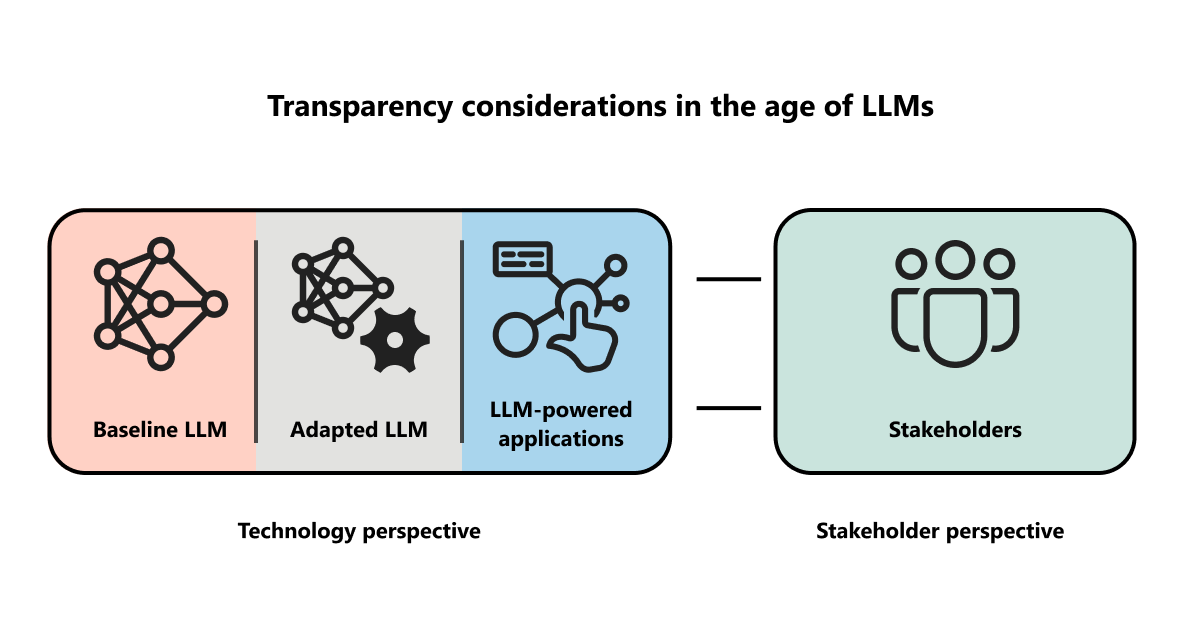
Transparency is a foundational principle of responsible, human-centered AI and is the bedrock of accountability. AI systems have a wide range of stakeholders: AI practitioners need transparency for evaluating data and model architecture so they can identify, measure, and mitigate potential failures; people using AI, expert and novice, must be able to understand the capabilities and limitations of AI systems; people affected by AI-assisted decision-making should have insights for redress when necessary; and indirect stakeholders, such as residents of cities using smart technologies, need clarity about how AI deployment may affect them.
Providing transparency when working with staggeringly complex and often proprietary models must take different forms to meet the needs of people who work with either the model or the user interface. This article profiles a selection of recent efforts for advancing transparency and responsible AI (RAI) by researchers and engineers affiliated with Aether, the Microsoft advisory body for AI ethics and effects in engineering and research. This work includes investigating LLM capabilities and exploring strategies for unlocking specialized-domain competencies of these powerful models while urging transparency approaches for both AI system developers and the people using these systems. Researchers are also working toward improving identification, measurement, and mitigation of AI harms while sharing practical guidance such as for red teaming LLM applications and for privacy-preserving computation. The goal of these efforts is to move from empirical findings to advancing the practice of responsible AI.

In this demo of GAM Coach, an example of an AI transparency approach, an interactive interface lets stakeholders in a loan allocation scenario understand how a model based its prediction and what factors they can change to meet their goals.
The sociotechnical nature of AI is readily apparent as product teams sprint to integrate the power and appeal of LLMs into conversational agents and productivity tools across domains. At the same time, recent accounts, such as a lawyer unwittingly submitting generative AI’s fictitious legal citations in a brief to the court (opens in new tab) or unsettling demonstrations of deepfakes, reveal the ample opportunity for misunderstanding these models’ capabilities and, worse yet, for deliberately misusing them.
Envisioning what could go wrong with an AI system that has not yet been deployed is the first step toward responsible AI. Addressing this challenge, researchers introduce AHA! (anticipating harms of AI), a human-AI collaboration for systematic impact assessment. This framework enables people to make judgments about the impact of potential deployment on stakeholders. It uses an LLM to generate vignettes, or fictional scenarios, that account for an ethical matrix of problematic AI behaviors or harms. Evaluation of this framework in a variety of decision-making contexts found it surfaced a broader range of potential harmful outcomes than either people or LLMs could singly envision.

AI practitioners can follow this planning guide to help them set up and manage red teaming for large language models (LLMs) and their applications. Based on firsthand experience of testing LLMs to identify potentially harmful outputs and plan for mitigation strategies, this guide provides tips for who should test, what to test, and how to test, plus pointers for recording the red-teaming data.
Responsible AI red teaming, or probing models and their applications to identify undesirable behaviors, is another method of harm identification. Microsoft has shared a practical guide for the RAI red teaming of LLMs and their applications, and automated tools for RAI red teaming are beginning to emerge. Although the vital task of impact assessment and testing for failures can be facilitated by LLMs helping with creative brainstorming, researchers emphasize that for AI to be human centered, such efforts should never be fully automated. To improve human-AI complementarity in red teaming, AdaTest++ builds on an existing tool that uses an LLM to generate test suggestions as it adapts to user feedback. The redesign offers greater human control for testing hypotheses, enabling editing and exploration of counterfactuals, and conducting in-depth testing across a broad diversity of topics.

In AI privacy, researchers demonstrate how prompt-tuning can be used to infer private information from an email system using a language model to provide autocompleted replies. In sharing their red-teaming technique, they encourage privacy-enhancing efforts for applications using language models and take the stance that transparency of publicly detailing a model’s vulnerability is an essential step toward adversarial robustness.
Identifying and exposing security vulnerabilities is a top concern, especially when these can seep into AI-generated code. The integration of LLMs for AI-assisted coding has reduced the entry barrier for novice programmers and increased productivity for veteran coders. But it is important to examine the reliability and safety of AI-assisted coding. Although static analysis tools can detect and remove insecure code suggestions caused by the adversarial manipulation of training data, researchers introduce two novel techniques for poisoning code-suggestion models that bypass static analysis mitigation: Covert inserts malicious code in docstrings and comments, while TrojanPuzzle tricks the transformer-based model into substituting tokens, giving the programmer harmless-looking but insecure code. Exposing these vulnerabilities, researchers call for new methods for training code-suggestion models and for processes to ensure code suggestions are secure before programmers ever see them.
We can’t begin to mitigate for the possibility of AI failures without first identifying and then measuring the potential harms of a model’s outputs, transparently examining who may or may not benefit or what could go wrong and to what extent.
A framework for automating the measurement of harms at speed and scale has two LLMs simulate product- or end-user interaction and evaluate outputs for potential harms, using resources created by relevant sociotechnical-domain experts. As researchers stress, the validity and reliability of such evaluation rely strictly on the quality of these resources—the templates and parameters for simulating interactions, the definition of harms, and their annotation guidelines. In other words, sociotechnical-domain expertise is indispensable.
Measurement validity—ensuring metrics align with measurement goals—is central to the practice of responsible AI. Model accuracy in and of itself is not an adequate metric for assessing sociotechnical systems: for example, in the context of productivity applications, capturing what is valuable to an individual using an AI system should also be taken into account. How do we identify metrics appropriate for context-dependent models that are deployed across domains to serve a variety of populations and purposes? Teams need methods to address measurement and mitigation for every deployment scenario.
Language models illustrate the maxim “context is everything.” When it comes to measuring and mitigating fairness-related harms that are context-dependent in AI-generated text, there’s generally not enough granularity in dataset labeling. Lumping harms under generalized labels like “toxic” or “hate speech” doesn’t capture the detail needed for measuring and mitigating harms specific to various populations. FairPrism is a new dataset for detecting gender- and sexuality-related harms that makes a case for greater granularity in human annotation and transparency in dataset documentation, including identifying groups of people that may be targeted. Researchers situate FairPrism as “a recipe” for creating better-detailed datasets for measuring and mitigating AI harms and demonstrate how the new dataset’s 5,000 examples of English text can probe for fairness-related harms to a specific group.

Similarly, researchers deepen the conversation around representational harms in automated image-tagging systems, voicing the need for improved transparency and specificity in taxonomies of harms for more precision in measurement and mitigation. Image tagging is generally intended for human consumption, as in alt text or online image search, differentiating it from object recognition. Image tagging can impute fairness-related harms of reifying social groups as well as stereotyping, demeaning, or erasure. Researchers identify these four specific representational harms and map them to computational measurement approaches in image tagging. They call out the benefits of increased granularity but note there is no silver bullet: efforts to mitigate by adding or removing particular tags to avoid harms may in fact introduce or exacerbate these representational harms.
Prioritizing what people value and designing for the optimal user experience (UX) is a goal of human-centered, responsible AI. Unfortunately, UX design has often been viewed as a secondary consideration in engineering organizations. But because AI is a sociotechnical discipline, where technical solutions must converge with societal perspectives and social science theory, AI not only brings UX expertise to the foreground but also positions designers as potential innovators, well situated to mitigate some harms and model failures with UX interventions. To realize this, UX designers need transparency—visibility into how models work—so they can form “designerly understanding of AI” to help them ideate effectively. A study of 23 UX designers completing a hands-on design task illustrates their need for better support, including model documentation that’s easier to understand and interactive tools to help them anticipate model failures, envision mitigations, and explore new uses of AI.
People with varying levels of AI experience or subject-matter expertise are suddenly harnessing commercially available generative AI copilots for productivity gains and decision-making support across domains. But generative AI can make mistakes, and the impact of these failures can differ greatly depending on the use case: for example, poor performance in a creative-writing task has a very different impact than an error in a health care recommendation. As the stakes rise, so does the call for mitigating these failures: people need tools and mechanisms that help them audit AI outputs. UX interventions are well suited for mitigating this type of harm. To begin, researchers propose a taxonomy of needs that co-auditing systems should address when helping people double-check generative AI model responses. Basic considerations should include how easy it is for individuals to detect an error, what their skill level is, and how costly or consequential an error may be in a given scenario. A prototype Excel add-in illustrates these considerations, helping the nonprogrammer inspect the accuracy of LLM-generated code.
There are productivity dividends to paying attention to people’s need and desire for transparency. A central problem people encounter with language models is crafting prompts that lead to useful output. Advancing a solution for this in LLM-based code generation, researchers demonstrate an interface that gives people visibility into how the model maps their natural language query to system action. This transparency approach helps people adapt their mental model of the code generator’s capabilities and modify their queries accordingly. Findings of the user study, which included participants with low expertise in coding, showed this transparency approach promoted user confidence and trust while facilitating explanation and debugging. Similarly, human-centered efforts such as modeling the timing of when a programmer finds it most valuable to receive a code suggestion emphasize the primacy of end users’ needs when addressing productivity.
This transparency approach provides nonexpert programmers with an interface that gives visibility into how a language model maps their natural language query to system action, helping them adapt their mental model and modify their prompts.
For experienced coders to be confident and benefit from AI-assisted code completion, they need to be able to easily spot and correct errors and security vulnerabilities. In the first empirical study of the effectiveness of token highlighting for communicating uncertainty of an AI prediction, researchers examine a UX technique that draws programmers’ attention in a way similar to a spell checker. Highlighting tokens that had the highest predicted likelihood of being edited resulted in programmers being able to complete tasks faster with better-targeted edits. Participants also desired more transparency in the form of explanations to help with diagnosing uncertainty and suggested interaction designs that would improve their efficiency and give them control.
Communicating the uncertainty of AI predictions in a way that is meaningful is a design challenge in every deployment context. How to provide transparency via explanations remains a conundrum—studies have shown that the mere presence of explanations can increase overreliance on AI. Designing UX that helps people meet their decision-making goals with confidence requires understanding their perceptions of how a given system works. But little is actually known about the processes decision-makers go through when debating whether to rely on an AI system’s output versus their own intuition. Conducting a think-aloud study for insights into the role of human intuition in reliance on AI predictions in AI-assisted decision making, researchers identified three types of intuition people use in deciding to override the system. While performing brief tasks of income prediction and biography classification with AI support, participants expressed “gut feel” about the decision outcome; how specific data characteristics, or features, may impact explanations; and the limitations of the AI system. Findings suggested what the authors call “intuition-driven pathways” to understanding the effect of different types of explanations on people’s decision to override AI. Results showed that example-based explanations, which were textual narratives, better aligned with people’s intuition and reasoning about a prediction than feature-based explanations, which conveyed information with bar charts and other visual tools. At the same time, participants echoed the familiar desire for help with understanding AI systems’ limitations. Suggestions included interface designs to better support transparency and user understanding—for example, interactive explanations that enable people to change attributes to explore the effect on the model’s prediction.
Accommodating varying levels of user expertise is a growing AI UX design challenge across domains and applications. For example, in business, people with limited knowledge of AI or statistics must increasingly engage AI visual-analytic systems to create reports and inform recommendations. While research seeks to address gaps in knowledge for improving user interaction with AI, some practical and evidence-driven tools are already available. A case study of business experts with varying levels of AI proficiency demonstrates the effectiveness of applying existing guidelines for human-AI interaction for transparency cues. Visual explanations improved participants’ ability to use a visual AI system to make recommendations. At the same time, researchers noted a high level of trust in outputs regardless of participants’ understanding of AI, illustrating the complexity of AI transparency for appropriate trust.
This research compilation highlights that transparency is fundamental to multiple components of responsible AI. It requires, among other things, the understanding and communication of datasets and their composition and of model behaviors, capabilities, and limitations. Transparency also touches every aspect of the responsible AI harm mitigation framework: identify, measure, mitigate. Furthermore, this research establishes a primary role for UX in mitigating harms as AI integrates into the apps people rely on every day in their personal and professional lives.
As authors of a research roadmap for transparency in the age of LLMs outline, these complex models’ massive datasets, nondeterministic outputs, adaptability, and rapid evolutionary pace present new challenges for deploying AI responsibly. There’s much work to be done to improve transparency for stakeholders of highly context-dependent AI systems—from improving how we publish the goals and results of evaluations when it comes to model reporting to providing appropriate explanations, communicating model uncertainty, and designing UX-based mitigations.
Prioritizing transparency in the design of our AI systems is to acknowledge the primacy of people, whom the technology is meant to serve. Transparency plays a critical role in respecting human agency and expertise in this new frontier of human-AI collaboration and, ultimately, can hold us accountable for the world we are shaping.

In his KDD 2023 keynote, Microsoft Chief Scientific Officer Eric Horvitz presents an overview of the power of LLM capabilities and the potential for enriching human-AI complementarity.
MICROSOFT RESEARCH PODCAST

In this episode, PhD students Jennifer Scurrell and Alejandro Cuevas talk to Senior Researcher Dr. Madeleine Daepp. They discuss the internship culture at Microsoft Research, from opportunities to connect with researchers to the teamwork they say helped make it possible for them to succeed, and the impact they hope to have with their work.
The post Advancing transparency: Updates on responsible AI research appeared first on Microsoft Research.

Welcome to Research Focus, a series of blog posts that highlights notable publications, events, code/datasets, new hires and other milestones from across the research community at Microsoft.

Long-term time series forecasting (LTSF), which aims to predict future values of a series given past values, is an important problem in the machine learning community. It’s useful in areas like weather modeling, traffic flow prediction, and financial forecasting.
The current state of the art on LTSF is attained in some cases by linear-centric models. However, real-world time series are usually nonstationary. For example, traffic patterns change on different days of the week. The inherent simplicity of linear-centric models makes them unable to capture these patterns. In a recent paper: Mixture-of-Linear-Experts for Long-term Time Series Forecasting, researchers from Microsoft and external colleagues propose Mixture-of-Linear-Experts (MoLE) to address this problem. Instead of training a single model, MoLE trains multiple linear-centric models (i.e., experts) and a router model that weighs and mixes their outputs. While the entire framework is trained end-to-end, each expert learns to specialize in a specific temporal pattern, and the router model learns to compose the experts adaptively. Experiments show that MoLE significantly reduces forecasting error of linear-centric models, and MoLE outperforms state-of-the-art transformer-based approaches in 68% of settings.
End-to-end (E2E) models are the dominant model structure in automatic speech recognition (ASR) and speech translation (ST). This has led to efforts to develop a unified E2E model for multilingual ASR and multilingual ST tasks. Streaming ASR and ST tasks have extensively utilized neural transducers in the past.
In a recent paper: A Weakly-Supervised Streaming Multilingual Speech Model with Truly Zero-Shot Capability, researchers from Microsoft present a streaming multilingual speech model – $SM^2$ – which employs a single neural transducer model for transcribing or translating multiple languages into target languages. $SM^2$ is trained using weakly supervised data created by converting speech recognition transcriptions with a machine translation model. Leveraging 351,000 hours of speech training data from 25 languages, $SM^2$ achieves impressive ST performance. Notably, no human-labeled ST data was employed during training. It was purely weakly supervised ST data generated by converting 351,000 hours of anonymized ASR data from 25 languages using text based machine translation service.
The researchers also demonstrate the truly zero-shot capability of $SM^2$ when expanding to new target languages, generating high-quality zero-shot ST translation for {source-speech, target-text} pairs that were not seen during training.
Microsoft Research Podcast

Peter Lee, head of Microsoft Research, and Ashley Llorens, AI scientist and engineer, discuss the future of AI research and the potential for GPT-4 as a medical copilot.
Deep generative models include large language models (LLMs) for text, plus models for other modalities, such as for vision and audio. In a recent paper: KBFormer: A Diffusion Model for Structured Entity Completion, researchers from Microsoft and external colleagues explore generative modeling of structured entities with heterogeneous properties, such as numerical, categorical, string, and composite. This includes entries in rich knowledge bases (KBs), items in product catalogs or scientific catalogs, and ontologies like the periodic table of elements and the various properties of isotopes.
Their approach handles such heterogeneous data through a mixed continuous-discrete diffusion process over the properties, using a flexible framework that can model entities with arbitrary hierarchical properties. Using this approach, the researchers obtain state-of-the-art performance on a majority of cases across 15 datasets. In addition, experiments with a device KB and a nuclear physics dataset demonstrate the model’s ability to learn representations useful for entity completion in diverse settings. This has many downstream use cases, including modeling numerical properties with high accuracy – critical for science applications, which also benefit from the model’s inherent probabilistic nature.
People are increasingly interacting with, and being affected by, the deployment of AI systems in the workplace. This is a pressing matter for system designers, policy-makers, and workers themselves, which researchers from Microsoft address in a recent paper: A Framework for Exploring the Consequences of AI-Mediated Enterprise Knowledge Access and Identifying Risks to Workers.
Organizations generate huge amounts of information that raise challenges associated with the maintenance, dissemination, and discovery of organizational knowledge. Recent developments in AI, notably large language models (LLMs), present a shift in what is possible in this domain. Recent advances could enable more extensive mining, knowledge synthesis, and natural language interaction in relation to knowledge.
The researchers propose the Consequence-Mechanism-Risk Framework to identify risks to workers associated with deploying AI-mediated enterprise knowledge access systems. The goal is to support those involved in the design and/or deployment of such systems to identify the risks they introduce, the specific system mechanisms that introduce those risks, and the actionable levers to reduce those risks.
Modern search engines are built on a stack of different components, including query understanding, retrieval, multi-stage ranking, and question answering, among others. These components are often optimized and deployed independently. In a recent paper: Large Search Model: Redefining Search Stack in the Era of LLMs, researchers from Microsoft introduce a novel conceptual framework called large search model, which redefines the conventional search stack by unifying search tasks with one large language model (LLM). All tasks are formulated as autoregressive text generation problems, allowing for the customization of tasks through the use of natural language prompts. This proposed framework capitalizes on the strong language understanding and reasoning capabilities of LLMs, offering the potential to enhance search result quality while simplifying the cumbersome search stack. To substantiate the feasibility of this framework, the researchers present a series of proof-of-concept experiments and discuss the potential challenges associated with implementing this approach within real-world search systems.
The post Research Focus: Week of January 8, 2024 appeared first on Microsoft Research.

NVIDIA continues to be among America’s very best places to work as judged by employees themselves, rising to second place on Glassdoor’s list of best employers for 2024.
This is the fourth consecutive year NVIDIA has been among the top five on the closely watched list, which is based on anonymous employee reviews about their job, company and work environment. Last year, NVIDIA ranked fifth.
Topping this year’s list is Bain & Co., with ServiceNow, MathWorks and Procore Technologies rounding out the top five.
Employees consistently share positive feedback about NVIDIA via Glassdoor’s anonymous reviews, which capture an authentic look at what it’s like to work at more than a million companies.
Some 98% of NVIDIANs approve of founder and CEO Jensen Huang’s leadership and 94% would recommend working at NVIDIA to a friend.
Here are some typical comments submitted by employees:
Learn more about NVIDIA life, culture and careers.
We demonstrate how to finetune a 7B parameter model on a typical consumer GPU (NVIDIA T4 16GB) with LoRA and tools from the PyTorch and Hugging Face ecosystem with complete reproducible Google Colab notebook.
Large Language Models (LLMs) have shown impressive capabilities in industrial applications. Often, developers seek to tailor these LLMs for specific use-cases and applications to fine-tune them for better performance. However, LLMs are large by design and require a large number of GPUs to be fine-tuned.
Let’s focus on a specific example by trying to fine-tune a Llama model on a free-tier Google Colab instance (1x NVIDIA T4 16GB). Llama-2 7B has 7 billion parameters, with a total of 28GB in case the model is loaded in full-precision. Given our GPU memory constraint (16GB), the model cannot even be loaded, much less trained on our GPU. This memory requirement can be divided by two with negligible performance degradation. You can read more about running models in half-precision and mixed precision for training here.
In the case of full fine-tuning with Adam optimizer using a half-precision model and mixed-precision mode, we need to allocate per parameter:
→ With a total of 16 bytes per trainable parameter, this makes a total of 112GB (excluding the intermediate hidden states). Given that the largest GPU available today can have up to 80GB GPU VRAM, it makes fine-tuning challenging and less accessible to everyone. To bridge this gap, Parameter Efficient Fine-Tuning (PEFT) methods are largely adopted today by the community.
PEFT methods aim at drastically reducing the number of trainable parameters of a model while keeping the same performance as full fine-tuning.
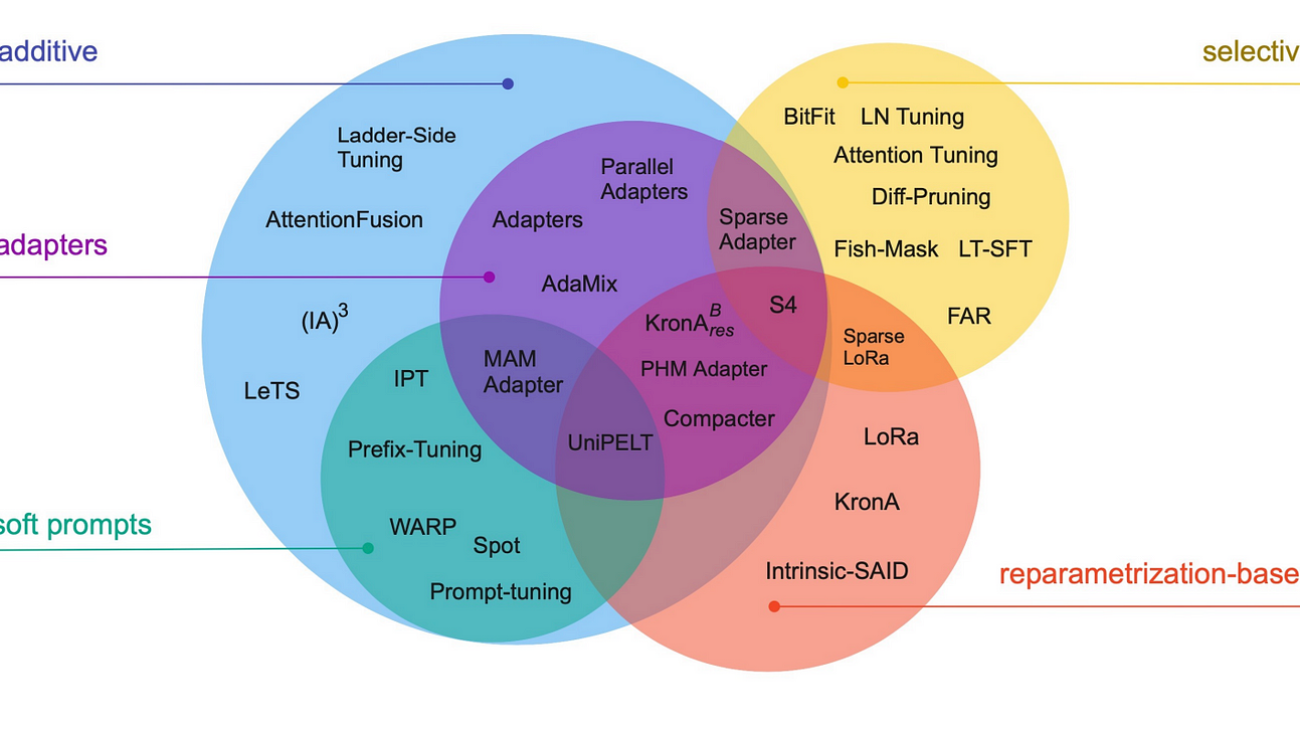
They can be differentiated by their conceptual framework: does the method fine-tune a subset of existing parameters, introduce new parameters, introduce trainable prompts, etc.? We recommend readers to have a look at the paper shared below that extensively compares existing PEFT methods.
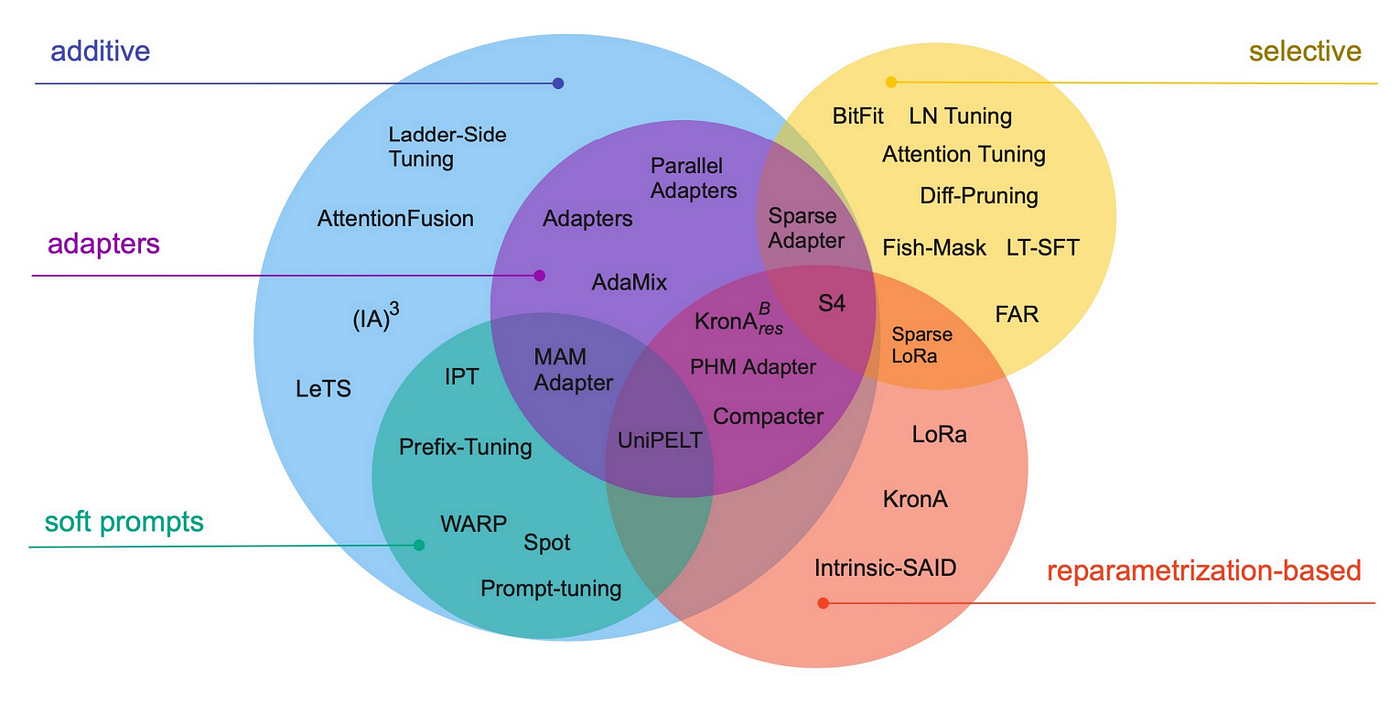
Image taken from the paper: Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning
For this blog post, we will focus on Low-Rank Adaption for Large Language Models (LoRA), as it is one of the most adopted PEFT methods by the community.
The LoRA method by Hu et al. from the Microsoft team came out in 2021, and works by attaching extra trainable parameters into a model(that we will denote by base model).
To make fine-tuning more efficient, LoRA decomposes a large weight matrix into two smaller, low-rank matrices (called update matrices). These new matrices can be trained to adapt to the new data while keeping the overall number of changes low. The original weight matrix remains frozen and doesn’t receive any further adjustments. To produce the final results, both the original and the adapted weights are combined.
This approach has several advantages:
In principle, LoRA can be applied to any subset of weight matrices in a neural network to reduce the number of trainable parameters. However, for simplicity and further parameter efficiency, in Transformer models LoRA is typically applied to attention blocks only. The resulting number of trainable parameters in a LoRA model depends on the size of the low-rank update matrices, which is determined mainly by the rank r and the shape of the original weight matrix.
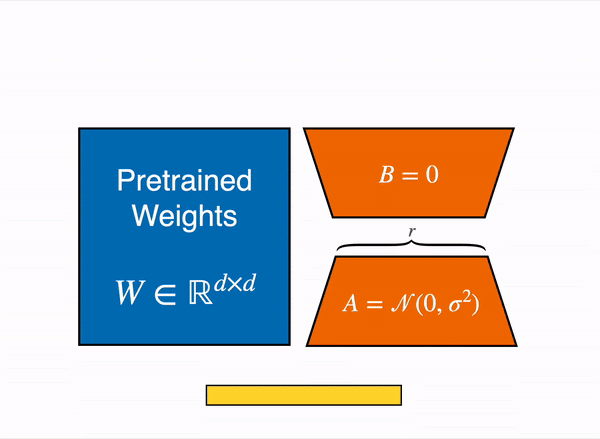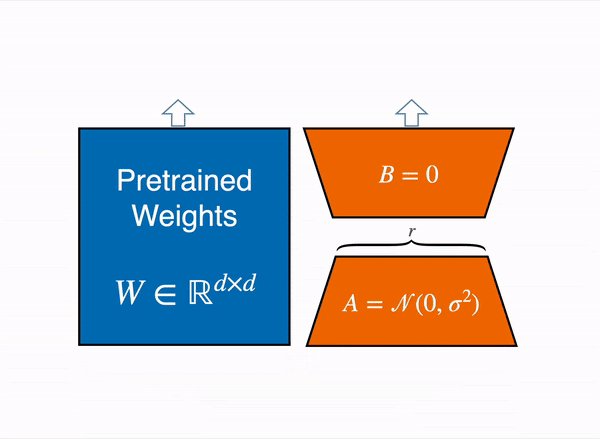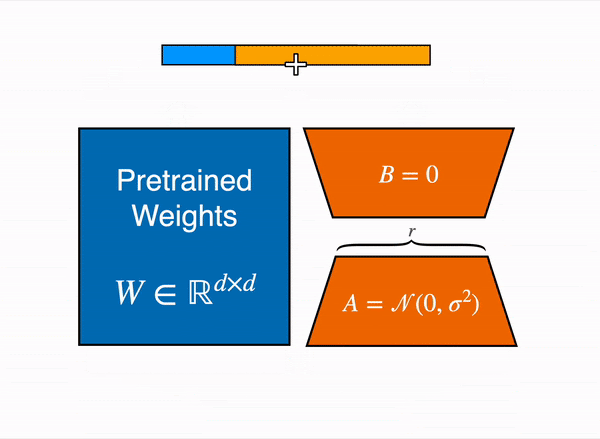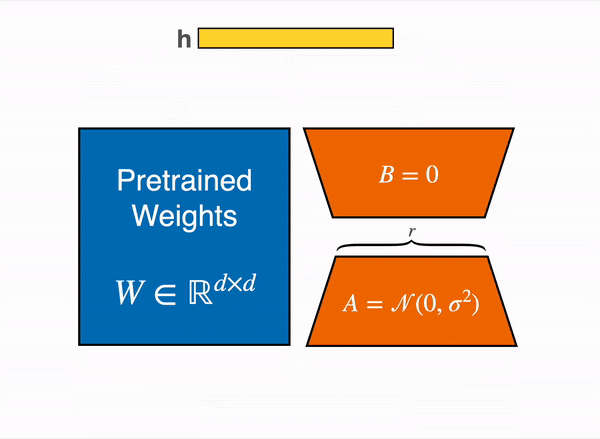
Animated diagram that show how LoRA works in practice – original content adapter from the figure 1 of LoRA original paper
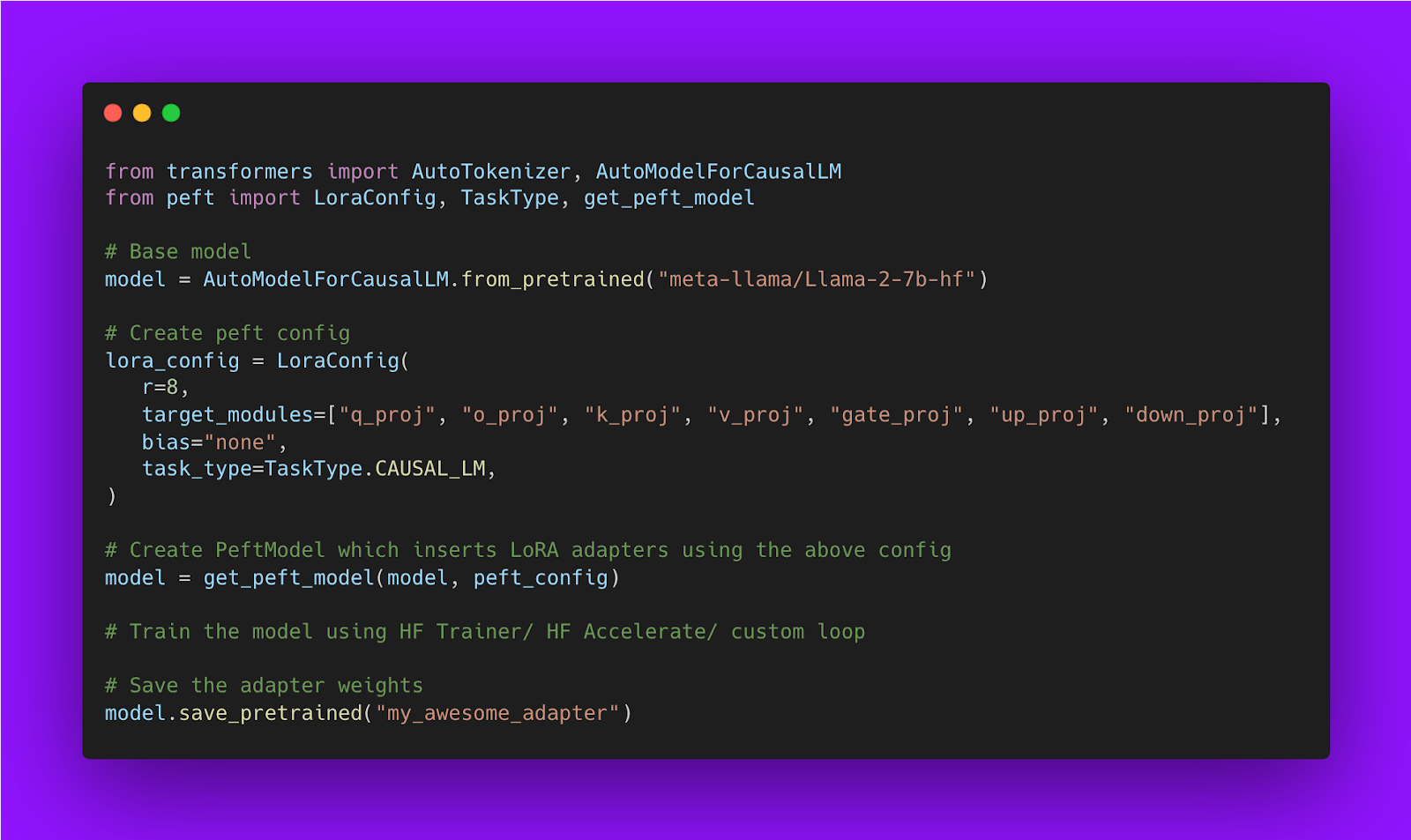
Below is a code snippet showing how to train LoRA model using Hugging Face PEFT library:
dtype: leveraging SOTA LLM quantization and loading the base model in 4-bit precisionAccording to the LoRA formulation, the base model can be compressed in any data type (‘dtype’) as long as the hidden states from the base model are in the same dtype as the output hidden states from the LoRA matrices.
Compressing and quantizing large language models has recently become an exciting topic as SOTA models become larger and more difficult to serve and use for end users. Many people in the community proposed various approaches for effectively compressing LLMs with minimal performance degradation.
This is where the bitsandbytes library comes in. Its purpose is to make cutting-edge research by Tim Dettmers, a leading academic expert on quantization and the use of deep learning hardware accelerators, accessible to the general public.
bitsandbytes towards the democratization of AIQuantization of LLMs has largely focused on quantization for inference, but the QLoRA (Quantized model weights + Low-Rank Adapters) paper showed the breakthrough utility of using backpropagation through frozen, quantized weights at large model scales.
With QLoRA we are matching 16-bit fine-tuning performance across all scales and models, while reducing fine-tuning memory footprint by more than 90%— thereby allowing fine-tuning of SOTA models on consumer-grade hardware.
In this approach, LoRA is pivotal both for purposes of fine-tuning and the correction of minimal, residual quantization errors. Due to the significantly reduced size of the quantized model it becomes possible to generously place low-rank adaptors at every network layer, which together still make up just 0.2% of the original model’s weight memory footprint. Through such usage of LoRA, we achieve performance that has been shown to be equivalent to 16-bit full model finetuning.
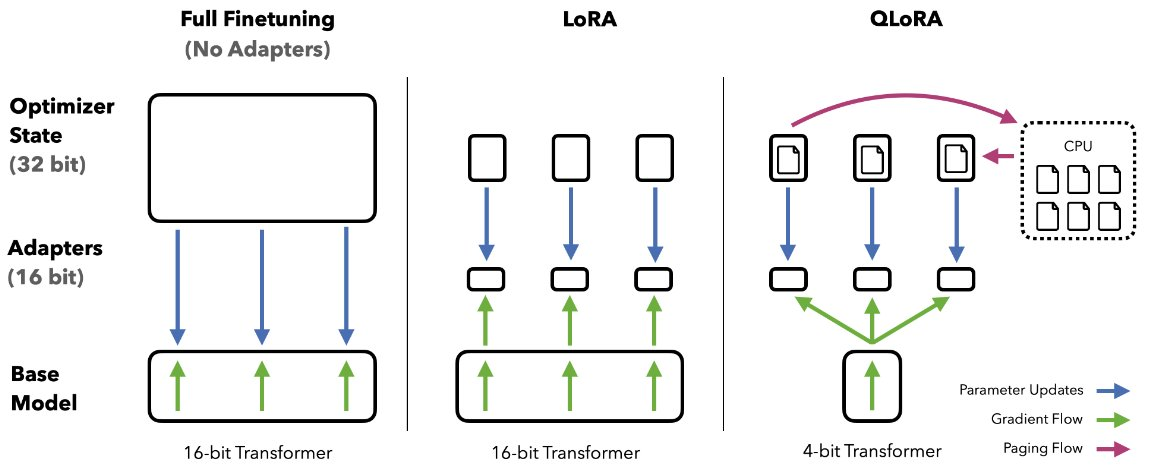
In addition to generous use of LoRA, to achieve high-fidelity fine-tuning of 4-bit models, QLoRA uses 3 further algorithmic tricks:
An interesting aspect is the dequantization of 4-bit weights in the GPU cache, with matrix multiplication performed as a 16-bit floating point operation. In other words, we use a low-precision storage data type (in our case 4-bit, but in principle interchangeable) and one normal precision computation data type. This is important because the latter defaults to 32-bit for hardware compatibility and numerical stability reasons, but should be set to the optimal BFloat16 for newer hardware supporting it to achieve the best performance.
To conclude, through combining these refinements to the quantization process and generous use of LoRA, we compress the model by over 90% and retain full model performance without the usual quantization degradation, while also retaining full fine-tuning capabilities with 16-bit LoRA adapters at every layer.
These SOTA quantization methods come packaged in the bitsandbytes library and are conveniently integrated with HuggingFace 🤗 Transformers. For instance, to use LLM.int8 and QLoRA algorithms, respectively, simply pass load_in_8bit and load_in_4bit to the from_pretrained method.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "facebook/opt-125m"
# For LLM.int8()
# model = AutoModelForCausalLM.from_pretrained(model_id, load_in_8bit=True)
# For QLoRA
model = AutoModelForCausalLM.from_pretrained(model_id, load_in_4bit=True)
You can read more about quantization features in this specific section of the documentation: https://huggingface.co/docs/transformers/main_classes/quantization
When using QLoRA with Adam optimizer using a 4-bit base model and mixed-precision mode, we need to allocate per parameter:
Giving a total of 14 bytes per trainable parameter times 0.0029 as we end up having only 0.29% trainable parameters with QLoRA, this makes the QLoRA training setup cost around 4.5GB to fit, but requires in practice ~7-10GB to include intermediate hidden states which are always in half-precision (7 GB for a sequence length of 512 and 10GB for a sequence length of 1024) in the Google Colab demo shared in the next section.
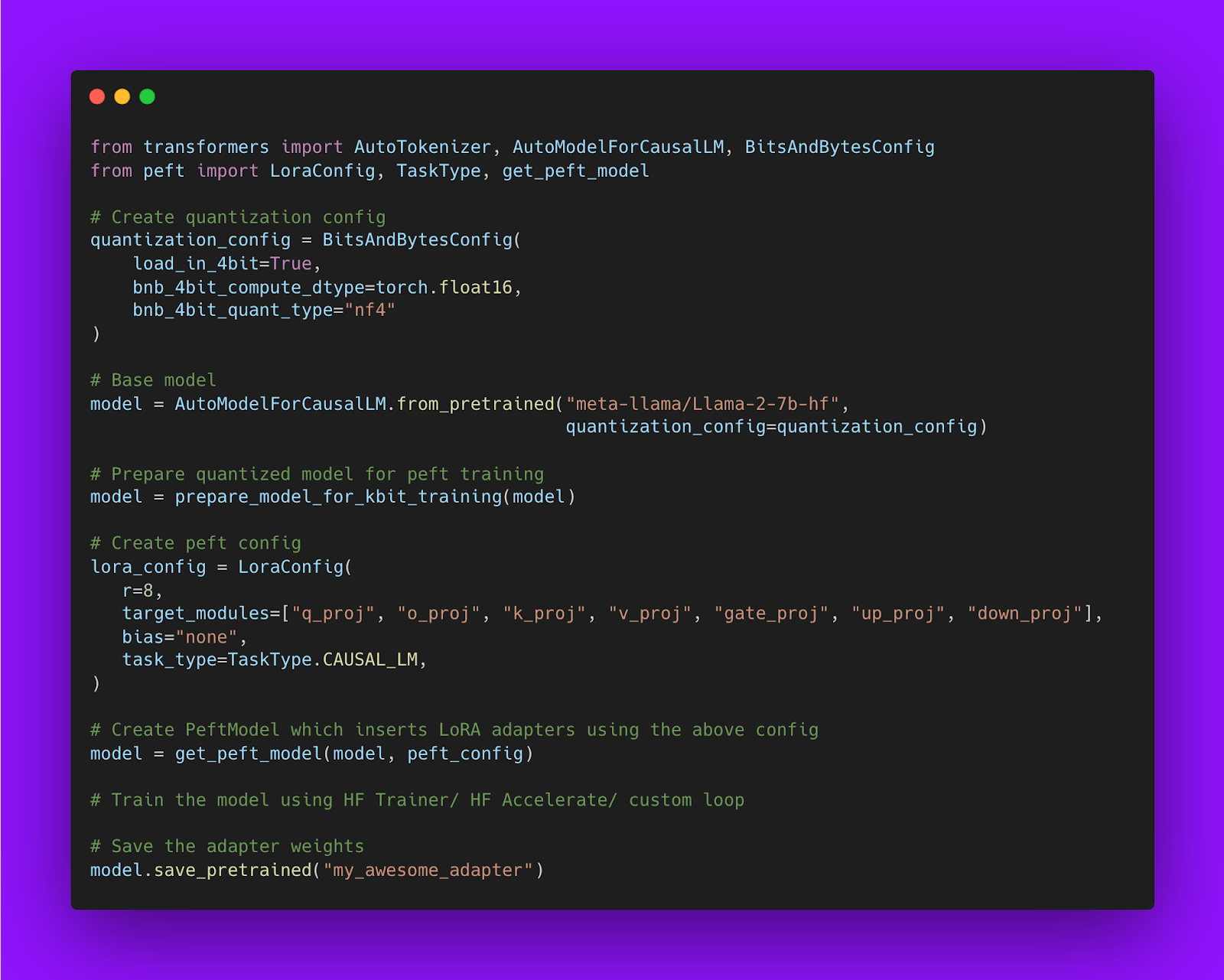
Below is the code snippet showing how to train QLoRA model using Hugging Face PEFT:
Models such as ChatGPT, GPT-4, and Claude are powerful language models that have been fine-tuned using a method called Reinforcement Learning from Human Feedback (RLHF) to be better aligned with how we expect them to behave and would like to use them. The finetuning goes through 3 steps:
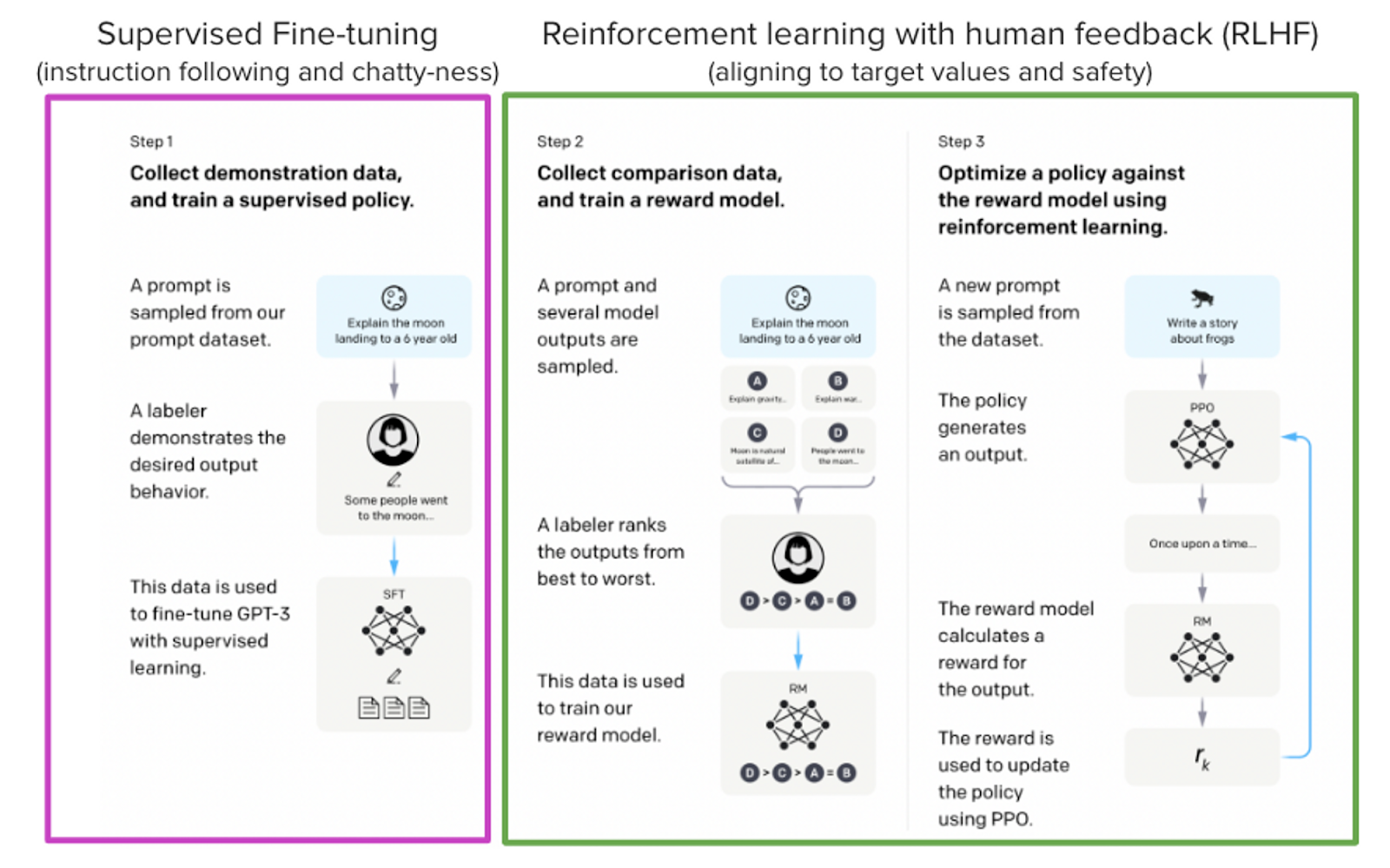
From InstructGPT paper: Ouyang, Long, et al. “Training language models to follow instructions with human feedback.” arXiv preprint arXiv:2203.02155 (2022).
Here, we will only focus on the supervised fine-tuning step. We train the model on the new dataset following a process similar to that of pretraining. The objective is to predict the next token (causal language modeling). Multiple techniques can be applied to make the training more efficient:
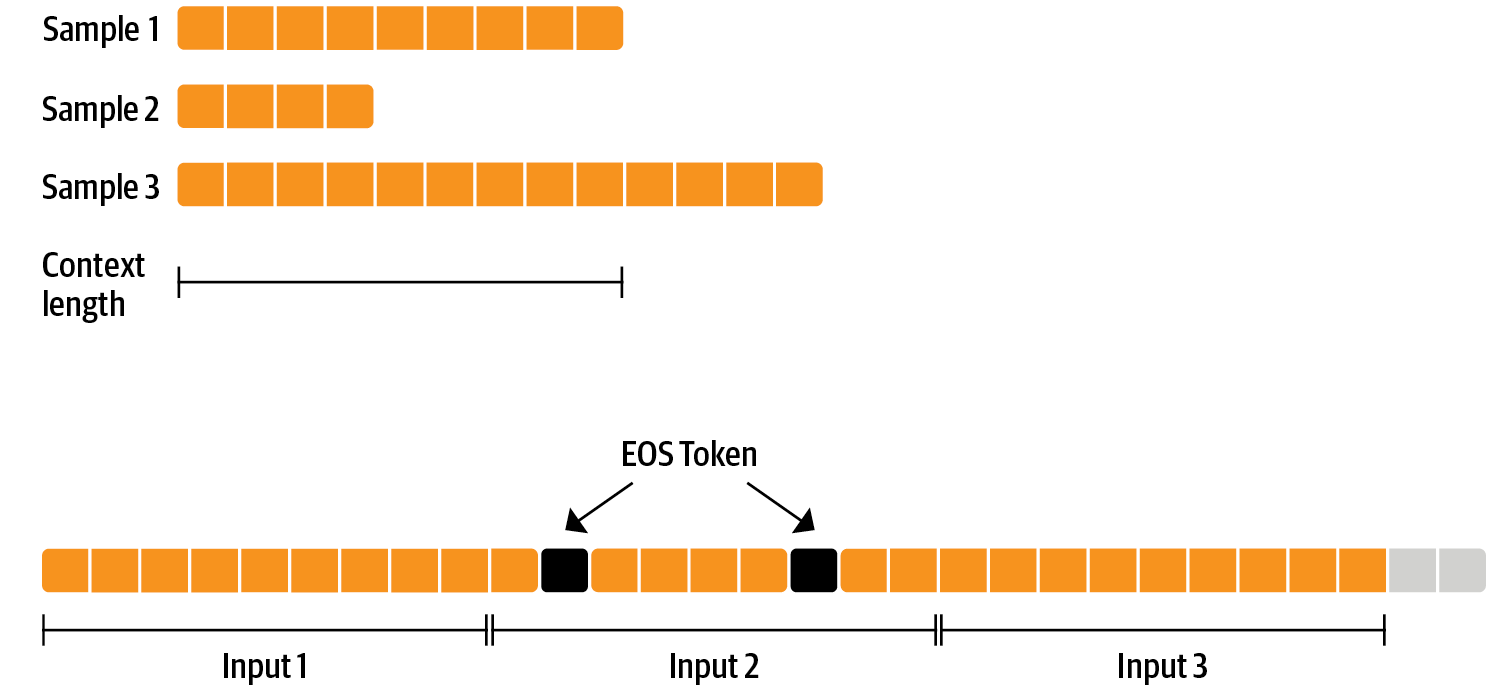
You can perform supervised fine-tuning with these techniques using SFTTrainer:
from trl import SFTTrainer
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=train_dataset,
dataset_text_field="text",
max_seq_length=1024,
packing=True,
)
Since SFTTrainer back-end is powered by 🤗accelerate, you can easily adapt the training to your hardware setup in one line of code!
For example, with you have 2 GPUs, you can perform Distributed Data Parallel training with using the following command:
accelerate launch --num_processes=2 training_llama_script.py
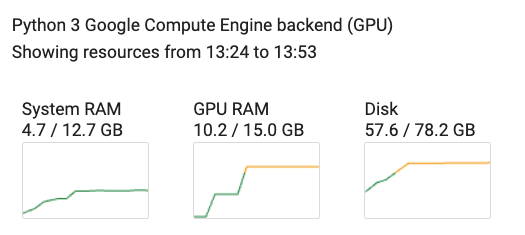
We made a complete reproducible Google Colab notebook that you can check through this link. We use all the components shared in the sections above and fine-tune a llama-7b model on UltraChat dataset using QLoRA. As it can be observed through the screenshot below, when using a sequence length of 1024 and a batch size od 4, the memory usage remains very low (around 10GB).
We’re launching a new ChatGPT plan for teams of all sizes, which provides a secure, collaborative workspace to get the most out of ChatGPT at work.OpenAI Blog
We’re launching the GPT Store to help you find useful and popular custom versions of ChatGPT.OpenAI Blog
With the rapid adoption of generative AI applications, there is a need for these applications to respond in time to reduce the perceived latency with higher throughput. Foundation models (FMs) are often pre-trained on vast corpora of data with parameters ranging in scale of millions to billions and beyond. Large language models (LLMs) are a type of FM that generate text as a response of the user inference. Inferencing these models with varying configurations of inference parameters may lead to inconsistent latencies. The inconsistency could be because of the varying number of response tokens you are expecting from the model or the type of accelerator the model is deployed on.
In either case, rather than waiting for the full response, you can adopt the approach of response streaming for your inferences, which sends back chunks of information as soon as they are generated. This creates an interactive experience by allowing you to see partial responses streamed in real time instead of a delayed full response.
With the official announcement that Amazon SageMaker real-time inference now supports response streaming, you can now continuously stream inference responses back to the client when using Amazon SageMaker real-time inference with response streaming. This solution will help you build interactive experiences for various generative AI applications such as chatbots, virtual assistants, and music generators. This post shows you how to realize faster response times in the form of Time to First Byte (TTFB) and reduce the overall perceived latency while inferencing Llama 2 models.
To implement the solution, we use SageMaker, a fully managed service to prepare data and build, train, and deploy machine learning (ML) models for any use case with fully managed infrastructure, tools, and workflows. For more information about the various deployment options SageMaker provides, refer to Amazon SageMaker Model Hosting FAQs. Let’s understand how we can address the latency issues using real-time inference with response streaming.
Because we want to address the aforementioned latencies associated with real-time inference with LLMs, let’s first understand how we can use the response streaming support for real-time inferencing for Llama 2. However, any LLM can take advantage of response streaming support with real-time inferencing.
Llama 2 is a collection of pre-trained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. Llama 2 models are autoregressive models with decoder only architecture. When provided with a prompt and inference parameters, Llama 2 models are capable of generating text responses. These models can be used for translation, summarization, question answering, and chat.
For this post, we deploy the Llama 2 Chat model meta-llama/Llama-2-13b-chat-hf on SageMaker for real-time inferencing with response streaming.
When it comes to deploying models on SageMaker endpoints, you can containerize the models using specialized AWS Deep Learning Container (DLC) images available for popular open source libraries. Llama 2 models are text generation models; you can use either the Hugging Face LLM inference containers on SageMaker powered by Hugging Face Text Generation Inference (TGI) or AWS DLCs for Large Model Inference (LMI).
In this post, we deploy the Llama 2 13B Chat model using DLCs on SageMaker Hosting for real-time inference powered by G5 instances. G5 instances are a high-performance GPU-based instances for graphics-intensive applications and ML inference. You can also use supported instance types p4d, p3, g5, and g4dn with appropriate changes as per the instance configuration.
To implement this solution, you should have the following:
Llama-2-13b-chat-hf, but you should be able to access other variants as well.In this section, we show you how to deploy the meta-llama/Llama-2-13b-chat-hf model to a SageMaker real-time endpoint with response streaming using Hugging Face TGI. The following table outlines the specifications for this deployment.
| Specification | Value |
| Container | Hugging Face TGI |
| Model Name | meta-llama/Llama-2-13b-chat-hf |
| ML Instance | ml.g5.12xlarge |
| Inference | Real-time with response streaming |
First, you retrieve the base image for the LLM to be deployed. You then build the model on the base image. Finally, you deploy the model to the ML instance for SageMaker Hosting for real-time inference.
Let’s observe how to achieve the deployment programmatically. For brevity, only the code that helps with the deployment steps is discussed in this section. The full source code for deployment is available in the notebook llama-2-hf-tgi/llama-2-13b-chat-hf/1-deploy-llama-2-13b-chat-hf-tgi-sagemaker.ipynb.
Retrieve the latest Hugging Face LLM DLC powered by TGI via pre-built SageMaker DLCs. You use this image to deploy the meta-llama/Llama-2-13b-chat-hf model on SageMaker. See the following code:
Define the environment for the model with the configuration parameters defined as follows:
Replace <YOUR_HUGGING_FACE_READ_ACCESS_TOKEN> for the config parameter HUGGING_FACE_HUB_TOKEN with the value of the token obtained from your Hugging Face profile as detailed in the prerequisites section of this post. In the configuration, you define the number of GPUs used per replica of a model as 4 for SM_NUM_GPUS. Then you can deploy the meta-llama/Llama-2-13b-chat-hf model on an ml.g5.12xlarge instance that comes with 4 GPUs.
Now you can build the instance of HuggingFaceModel with the aforementioned environment configuration:
Finally, deploy the model by providing arguments to the deploy method available on the model with various parameter values such as endpoint_name, initial_instance_count, and instance_type:
The Hugging Face TGI DLC comes with the ability to stream responses without any customizations or code changes to the model. You can use invoke_endpoint_with_response_stream if you are using Boto3 or InvokeEndpointWithResponseStream when programming with the SageMaker Python SDK.
The InvokeEndpointWithResponseStream API of SageMaker allows developers to stream responses back from SageMaker models, which can help improve customer satisfaction by reducing the perceived latency. This is especially important for applications built with generative AI models, where immediate processing is more important than waiting for the entire response.
For this example, we use Boto3 to infer the model and use the SageMaker API invoke_endpoint_with_response_stream as follows:
The argument CustomAttributes is set to the value accept_eula=false. The accept_eula parameter must be set to true to successfully obtain the response from the Llama 2 models. After the successful invocation using invoke_endpoint_with_response_stream, the method will return a response stream of bytes.
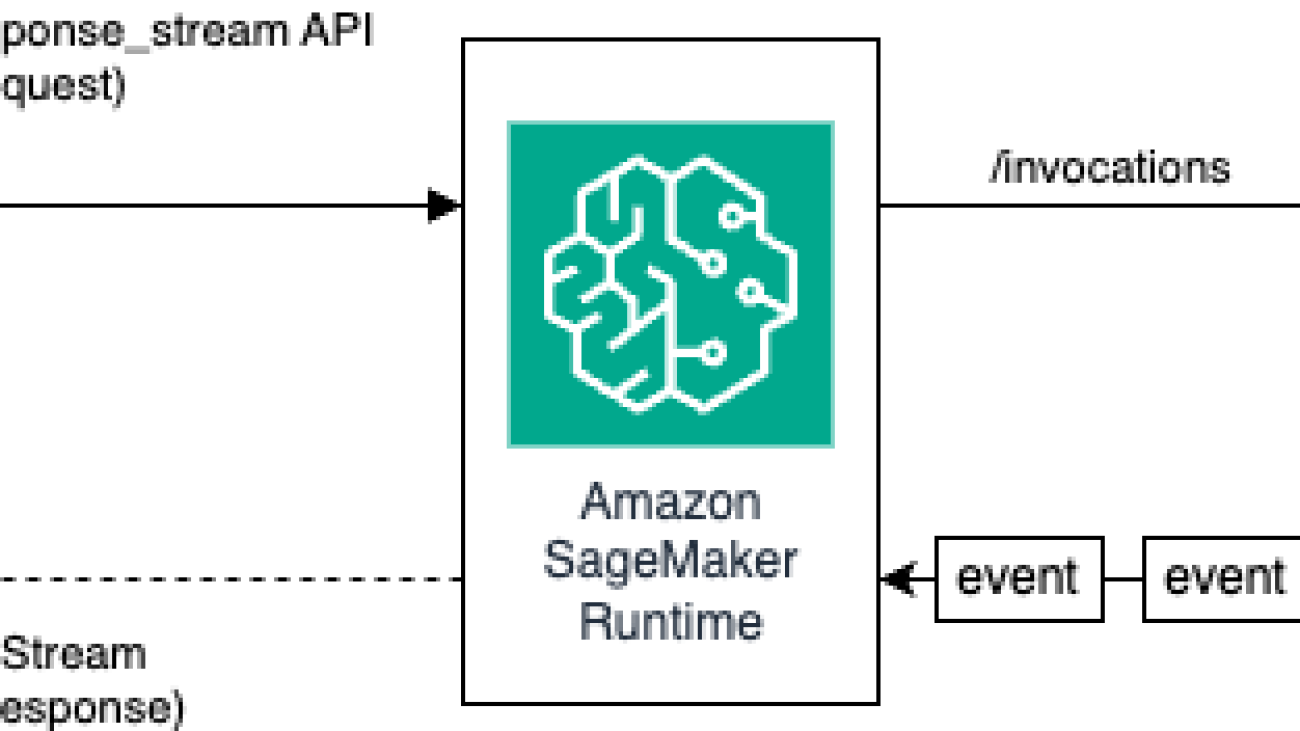
The following diagram illustrates this workflow.

You need an iterator that loops over the stream of bytes and parses them to readable text. The LineIterator implementation can be found at llama-2-hf-tgi/llama-2-13b-chat-hf/utils/LineIterator.py. Now you’re ready to prepare the prompt and instructions to use them as a payload while inferencing the model.
In this step, you prepare the prompt and instructions for your LLM. To prompt Llama 2, you should have the following prompt template:
You build the prompt template programmatically defined in the method build_llama2_prompt, which aligns with the aforementioned prompt template. You then define the instructions as per the use case. In this case, we’re instructing the model to generate an email for a marketing campaign as covered in the get_instructions method. The code for these methods is in the llama-2-hf-tgi/llama-2-13b-chat-hf/2-sagemaker-realtime-inference-llama-2-13b-chat-hf-tgi-streaming-response.ipynb notebook. Build the instruction combined with the task to be performed as detailed in user_ask_1 as follows:
We pass the instructions to build the prompt as per the prompt template generated by build_llama2_prompt.
We club the inference parameters along with prompt with the key stream with the value True to form a final payload. Send the payload to get_realtime_response_stream, which will be used to invoke an endpoint with response streaming:
The generated text from the LLM will be streamed to the output as shown in the following animation.

In this section, we demonstrate how to deploy the meta-llama/Llama-2-13b-chat-hf model to a SageMaker real-time endpoint with response streaming using LMI with DJL Serving. The following table outlines the specifications for this deployment.
| Specification | Value |
| Container | LMI container image with DJL Serving |
| Model Name | meta-llama/Llama-2-13b-chat-hf |
| ML Instance | ml.g5.12xlarge |
| Inference | Real-time with response streaming |
You first download the model and store it in Amazon Simple Storage Service (Amazon S3). You then specify the S3 URI indicating the S3 prefix of the model in the serving.properties file. Next, you retrieve the base image for the LLM to be deployed. You then build the model on the base image. Finally, you deploy the model to the ML instance for SageMaker Hosting for real-time inference.
Let’s observe how to achieve the aforementioned deployment steps programmatically. For brevity, only the code that helps with the deployment steps is detailed in this section. The full source code for this deployment is available in the notebook llama-2-lmi/llama-2-13b-chat/1-deploy-llama-2-13b-chat-lmi-response-streaming.ipynb.
With the aforementioned prerequisites, download the model on the SageMaker notebook instance and then upload it to the S3 bucket for further deployment:
Note that even though you don’t provide a valid access token, the model will download. But when you deploy such a model, the model serving won’t succeed. Therefore, it’s recommended to replace <YOUR_HUGGING_FACE_READ_ACCESS_TOKEN> for the argument token with the value of the token obtained from your Hugging Face profile as detailed in the prerequisites. For this post, we specify the official model’s name for Llama 2 as identified on Hugging Face with the value meta-llama/Llama-2-13b-chat-hf. The uncompressed model will be downloaded to local_model_path as a result of running the aforementioned code.
Upload the files to Amazon S3 and obtain the URI, which will be later used in serving.properties.
You will be packaging the meta-llama/Llama-2-13b-chat-hf model on the LMI container image with DJL Serving using the configuration specified via serving.properties. Then you deploy the model along with model artifacts packaged on the container image on the SageMaker ML instance ml.g5.12xlarge. You then use this ML instance for SageMaker Hosting for real-time inferencing.
Prepare your model artifacts by creating a serving.properties configuration file:
We use the following settings in this configuration file:
Python, DeepSpeed, FasterTransformer, and MPI. In this case, we set it to MPI. Model Parallelization and Inference (MPI) facilitates partitioning the model across all the available GPUs and therefore accelerates inference.djl_python.huggingface, djl_python.deepspeed, and djl_python.stable-diffusion. We use djl_python.huggingface for Hugging Face Accelerate.TRUE.auto, scheduler, and lmi-dist. We use lmi-dist for turning on continuous batching for Llama 2.{{model_id}} with the model ID of a pre-trained model hosted inside a model repository on Hugging Face or S3 path to the model artifacts.More configuration options can be found in Configurations and settings.
Because DJL Serving expects the model artifacts to be packaged and formatted in a .tar file, run the following code snippet to compress and upload the .tar file to Amazon S3:
Next, you use the DLCs available with SageMaker for LMI to deploy the model. Retrieve the SageMaker image URI for the djl-deepspeed container programmatically using the following code:
You can use the aforementioned image to deploy the meta-llama/Llama-2-13b-chat-hf model on SageMaker. Now you can proceed to create the model.
You can create the model whose container is built using the inference_image_uri and the model serving code located at the S3 URI indicated by s3_code_artifact:
Now you can create the model config with all the details for the endpoint configuration.
Use the following code to create a model config for the model identified by model_name:
The model config is defined for the ProductionVariants parameter InstanceType for the ML instance ml.g5.12xlarge. You also provide the ModelName using the same name that you used to create the model in the earlier step, thereby establishing a relation between the model and endpoint configuration.
Now that you have defined the model and model config, you can create the SageMaker endpoint.
Create the endpoint to deploy the model using the following code snippet:
You can view the progress of the deployment using the following code snippet:
After the deployment is successful, the endpoint status will be InService. Now that the endpoint is ready, let’s perform inference with response streaming.
As we covered in the earlier approach for Hugging Face TGI, you can use the same method get_realtime_response_stream to invoke response streaming from the SageMaker endpoint. The code for inferencing using the LMI approach is in the llama-2-lmi/llama-2-13b-chat/2-inference-llama-2-13b-chat-lmi-response-streaming.ipynb notebook. The LineIterator implementation is located in llama-2-lmi/utils/LineIterator.py. Note that the LineIterator for the Llama 2 Chat model deployed on the LMI container is different to the LineIterator referenced in Hugging Face TGI section. The LineIterator loops over the byte stream from Llama 2 Chat models inferenced with the LMI container with djl-deepspeed version 0.25.0. The following helper function will parse the response stream received from the inference request made via the invoke_endpoint_with_response_stream API:
The preceding method prints the stream of data read by the LineIterator in a human-readable format.
Let’s explore how to prepare the prompt and instructions to use them as a payload while inferencing the model.
Because you’re inferencing the same model in both Hugging Face TGI and LMI, the process of preparing the prompt and instructions is same. Therefore, you can use the methods get_instructions and build_llama2_prompt for inferencing.
The get_instructions method returns the instructions. Build the instructions combined with the task to be performed as detailed in user_ask_2 as follows:
Pass the instructions to build the prompt as per the prompt template generated by build_llama2_prompt:
We club the inference parameters along with the prompt to form a final payload. Then you send the payload to get_realtime_response_stream, which is used to invoke an endpoint with response streaming:
The generated text from the LLM will be streamed to the output as shown in the following animation.

To avoid incurring unnecessary charges, use the AWS Management Console to delete the endpoints and its associated resources that were created while running the approaches mentioned in the post. For both deployment approaches, perform the following cleanup routine:
Replace <SageMaker_Real-time_Endpoint_Name> for variable endpoint_name with the actual endpoint.
For the second approach, we stored the model and code artifacts on Amazon S3. You can clean up the S3 bucket using the following code:
In this post, we discussed how a varying number of response tokens or a different set of inference parameters can affect the latencies associated with LLMs. We showed how to address the problem with the help of response streaming. We then identified two approaches for deploying and inferencing Llama 2 Chat models using AWS DLCs—LMI and Hugging Face TGI.
You should now understand the importance of streaming response and how it can reduce perceived latency. Streaming response can improve the user experience, which otherwise would make you wait until the LLM builds the whole response. Additionally, deploying Llama 2 Chat models with response streaming improves the user experience and makes your customers happy.
You can refer to the official aws-samples amazon-sagemaker-llama2-response-streaming-recipes that covers deployment for other Llama 2 model variants.
 Pavan Kumar Rao Navule is a Solutions Architect at Amazon Web Services. He works with ISVs in India to help them innovate on AWS. He is a published author for the book “Getting Started with V Programming.” He pursued an Executive M.Tech in Data Science from the Indian Institute of Technology (IIT), Hyderabad. He also pursued an Executive MBA in IT specialization from the Indian School of Business Management and Administration, and holds a B.Tech in Electronics and Communication Engineering from the Vaagdevi Institute of Technology and Science. Pavan is an AWS Certified Solutions Architect Professional and holds other certifications such as AWS Certified Machine Learning Specialty, Microsoft Certified Professional (MCP), and Microsoft Certified Technology Specialist (MCTS). He is also an open-source enthusiast. In his free time, he loves to listen to the great magical voices of Sia and Rihanna.
Pavan Kumar Rao Navule is a Solutions Architect at Amazon Web Services. He works with ISVs in India to help them innovate on AWS. He is a published author for the book “Getting Started with V Programming.” He pursued an Executive M.Tech in Data Science from the Indian Institute of Technology (IIT), Hyderabad. He also pursued an Executive MBA in IT specialization from the Indian School of Business Management and Administration, and holds a B.Tech in Electronics and Communication Engineering from the Vaagdevi Institute of Technology and Science. Pavan is an AWS Certified Solutions Architect Professional and holds other certifications such as AWS Certified Machine Learning Specialty, Microsoft Certified Professional (MCP), and Microsoft Certified Technology Specialist (MCTS). He is also an open-source enthusiast. In his free time, he loves to listen to the great magical voices of Sia and Rihanna.
 Sudhanshu Hate is principal AI/ML specialist with AWS and works with clients to advise them on their MLOps and generative AI journey. In his previous role before Amazon, he conceptualized, created, and led teams to build ground-up open source-based AI and gamification platforms, and successfully commercialized it with over 100 clients. Sudhanshu to his credit a couple of patents, has written two books and several papers and blogs, and has presented his points of view in various technical forums. He has been a thought leader and speaker, and has been in the industry for nearly 25 years. He has worked with Fortune 1000 clients across the globe and most recently with digital native clients in India.
Sudhanshu Hate is principal AI/ML specialist with AWS and works with clients to advise them on their MLOps and generative AI journey. In his previous role before Amazon, he conceptualized, created, and led teams to build ground-up open source-based AI and gamification platforms, and successfully commercialized it with over 100 clients. Sudhanshu to his credit a couple of patents, has written two books and several papers and blogs, and has presented his points of view in various technical forums. He has been a thought leader and speaker, and has been in the industry for nearly 25 years. He has worked with Fortune 1000 clients across the globe and most recently with digital native clients in India.

Ninety-eight percent of retailers plan to invest in generative AI in the next 18 months, according to a new survey conducted by NVIDIA.
That makes retail one of the industries racing fastest to adopt generative AI to ramp up productivity, transform customer experiences and improve efficiency.
Early deployments in the retail industry include personalized shopping advisors and adaptive advertising, with retailers initially testing off-the-shelf models like GPT-4 from OpenAI.
But many are now realizing the value in developing custom models trained on their proprietary data to achieve brand-appropriate tone and personalized results in a scalable, cost-effective way.
Before building them, companies must first consider a variety of questions: whether to opt for an open-source, closed-source or enterprise model; how they plan to train and deploy the models; how to host them; and, most importantly, how to ensure future innovations and new products can be easily incorporated into them.
New offerings like NVIDIA AI Foundations, a curated collection of optimized, enterprise-grade foundation models from NVIDIA and leading open-source pretrained models, are giving retail companies the building blocks they need to construct their custom models. With NVIDIA NeMo, an end-to-end platform for large language model development, retailers can customize and deploy their models at scale using the latest state-of-the-art techniques.
Multimodal models are leading the new frontier in the generative AI landscape. They’re capable of processing, understanding and generating content and images from multiple sources such as text, image, video and 3D rendered assets.
This allows retailers to create eye-catching images or videos for a brand’s marketing and advertising campaign using only a few lines of text prompts. Or they can be used to deliver personalized shopping experiences with in-situ and try-on product image results. Yet another use case is in product description generation, where generative AI can intelligently generate detailed e-commerce product descriptions that include product attributes, using meta-tags to greatly improve SEO.
Many retailers are testing the generative AI waters first with internal deployments. For example, some are boosting the productivity of their engineering teams with AI-powered computer code generators that can write optimized lines of code for indicated outcomes. Others are using custom models to generate marketing copy and promotions for various audience segments, increasing click-to-conversion rates. Meanwhile, chatbots and translators are helping employees accomplish their day-to-day tasks.
To enhance customer experiences, retailers are deploying generative AI-powered shopping advisors that can offer personalized product recommendations in customer-tailored conversation styles and display images of products being recommended. It can even display those products if shoppers want to see the recommended product, for example, in their home by uploading a picture of a room. Another use case is a customer service multilingual chatbot capable of answering simple customer inquiries and routing complex ones to human agents for improved, more efficient service.
To learn more about how generative AI is shaping the future of retail, connect with the NVIDIA team at NRF: Retail’s Big Show, the world’s largest retail expo, taking place Jan. 14-16 at the Jacob K. Javits Convention Center in New York.
Attend the Big Ideas session on Jan. 14 at 2 p.m. ET to hear from Azita Martin, NVIDIA’s vice president of AI for retail, consumer packaged goods and quick-service restaurants, and others on how Target and Canadian Tire are using generative AI to deliver personalized shopping experiences and drive revenue and productivity.
Visit Dell’s booth on level three (4957) to meet with NVIDIA AI experts and experience NVIDIA’s generative AI demos.
Download the State of AI in Retail and CPG: 2024 Trends report for in-depth results and insights.