Solution method uses new infrastructure that reduces proof-checking overhead by more than 90%.Read More
Build a contextual text and image search engine for product recommendations using Amazon Bedrock and Amazon OpenSearch Serverless
The rise of contextual and semantic search has made ecommerce and retail businesses search straightforward for its consumers. Search engines and recommendation systems powered by generative AI can improve the product search experience exponentially by understanding natural language queries and returning more accurate results. This enhances the overall user experience, helping customers find exactly what they’re looking for.
Amazon OpenSearch Service now supports the cosine similarity metric for k-NN indexes. Cosine similarity measures the cosine of the angle between two vectors, where a smaller cosine angle denotes a higher similarity between the vectors. With cosine similarity, you can measure the orientation between two vectors, which makes it a good choice for some specific semantic search applications.
In this post, we show how to build a contextual text and image search engine for product recommendations using the Amazon Titan Multimodal Embeddings model, available in Amazon Bedrock, with Amazon OpenSearch Serverless.
A multimodal embeddings model is designed to learn joint representations of different modalities like text, images, and audio. By training on large-scale datasets containing images and their corresponding captions, a multimodal embeddings model learns to embed images and texts into a shared latent space. The following is a high-level overview of how it works conceptually:
- Separate encoders – These models have separate encoders for each modality—a text encoder for text (for example, BERT or RoBERTa), image encoder for images (for example, CNN for images), and audio encoders for audio (for example, models like Wav2Vec). Each encoder generates embeddings capturing semantic features of their respective modalities
- Modality fusion – The embeddings from the uni-modal encoders are combined using additional neural network layers. The goal is to learn interactions and correlations between the modalities. Common fusion approaches include concatenation, element-wise operations, pooling, and attention mechanisms.
- Shared representation space – The fusion layers help project the individual modalities into a shared representation space. By training on multimodal datasets, the model learns a common embedding space where embeddings from each modality that represent the same underlying semantic content are closer together.
- Downstream tasks – The joint multimodal embeddings generated can then be used for various downstream tasks like multimodal retrieval, classification, or translation. The model uses correlations across modalities to improve performance on these tasks compared to individual modal embeddings. The key advantage is the ability to understand interactions and semantics between modalities like text, images, and audio through joint modeling.
Solution overview
The solution provides an implementation for building a large language model (LLM) powered search engine prototype to retrieve and recommend products based on text or image queries. We detail the steps to use an Amazon Titan Multimodal Embeddings model to encode images and text into embeddings, ingest embeddings into an OpenSearch Service index, and query the index using the OpenSearch Service k-nearest neighbors (k-NN) functionality.
This solution includes the following components:
- Amazon Titan Multimodal Embeddings model – This foundation model (FM) generates embeddings of the product images used in this post. With Amazon Titan Multimodal Embeddings, you can generate embeddings for your content and store them in a vector database. When an end-user submits any combination of text and image as a search query, the model generates embeddings for the search query and matches them to the stored embeddings to provide relevant search and recommendations results to end-users. You can further customize the model to enhance its understanding of your unique content and provide more meaningful results using image-text pairs for fine-tuning. By default, the model generates vectors (embeddings) of 1,024 dimensions, and is accessed via Amazon Bedrock. You can also generate smaller dimensions to optimize for speed and performance
- Amazon OpenSearch Serverless – It is an on-demand serverless configuration for OpenSearch Service. We use Amazon OpenSearch Serverless as a vector database for storing embeddings generated by the Amazon Titan Multimodal Embeddings model. An index created in the Amazon OpenSearch Serverless collection serves as the vector store for our Retrieval Augmented Generation (RAG) solution.
- Amazon SageMaker Studio – It is an integrated development environment (IDE) for machine learning (ML). ML practitioners can perform all ML development steps—from preparing your data to building, training, and deploying ML models.
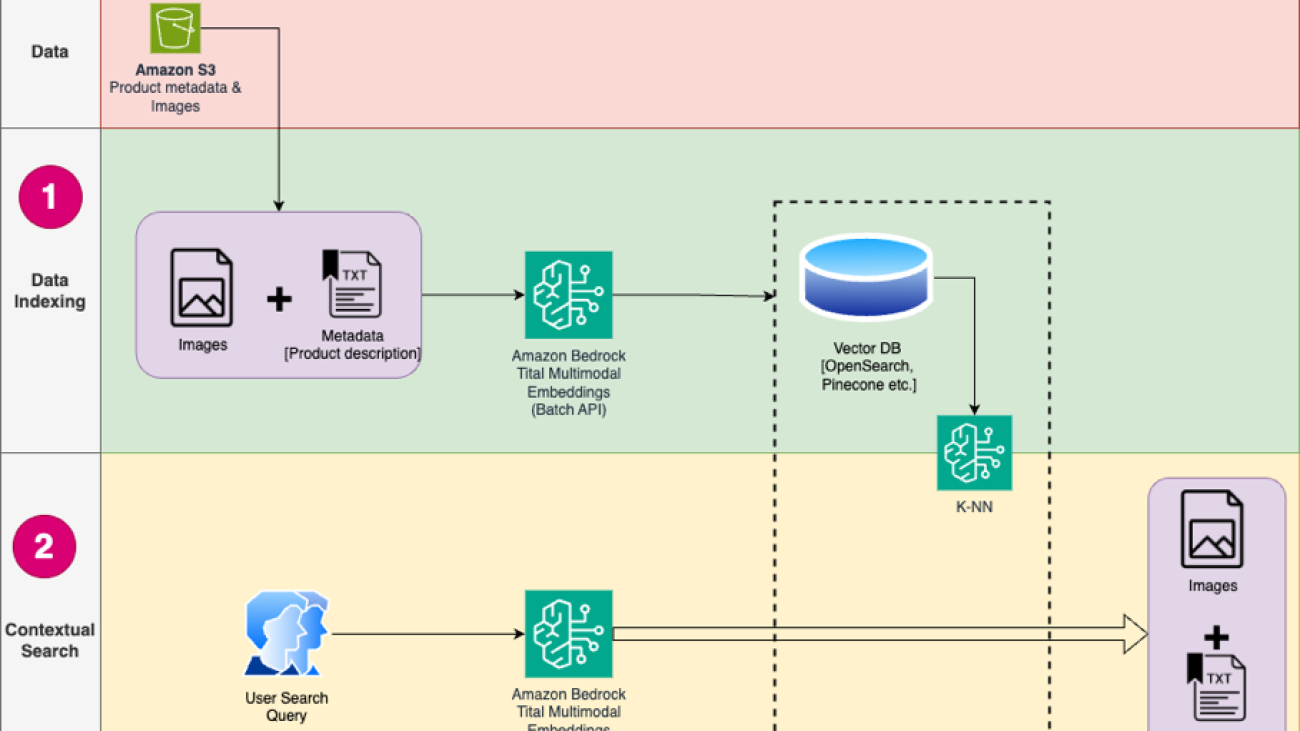
The solution design consists of two parts: data indexing and contextual search. During data indexing, you process the product images to generate embeddings for these images and then populate the vector data store. These steps are completed prior to the user interaction steps.
In the contextual search phase, a search query (text or image) from the user is converted into embeddings and a similarity search is run on the vector database to find the similar product images based on similarity search. You then display the top similar results. All the code for this post is available in the GitHub repo.
The following diagram illustrates the solution architecture.

The following are the solution workflow steps:
- Download the product description text and images from the public Amazon Simple Storage Service (Amazon S3) bucket.
- Review and prepare the dataset.
- Generate embeddings for the product images using the Amazon Titan Multimodal Embeddings model (amazon.titan-embed-image-v1). If you have a huge number of images and descriptions, you can optionally use the Batch inference for Amazon Bedrock.
- Store embeddings into the Amazon OpenSearch Serverless as the search engine.
- Finally, fetch the user query in natural language, convert it into embeddings using the Amazon Titan Multimodal Embeddings model, and perform a k-NN search to get the relevant search results.
We use SageMaker Studio (not shown in the diagram) as the IDE to develop the solution.
These steps are discussed in detail in the following sections. We also include screenshots and details of the output.
Prerequisites
To implement the solution provided in this post, you should have the following:
- An AWS account and familiarity with FMs, Amazon Bedrock, Amazon SageMaker, and OpenSearch Service.
- The Amazon Titan Multimodal Embeddings model enabled in Amazon Bedrock. You can confirm it’s enabled on the Model access page of the Amazon Bedrock console. If Amazon Titan Multimodal Embeddings is enabled, the access status will show as Access granted, as shown in the following screenshot.

If the model is not available, enable access to the model by choosing Manage model access, selecting Amazon Titan Multimodal Embeddings G1, and choosing Request model access. The model is enabled for use immediately.

- You also need a SageMaker Studio domain. If you don’t have a SageMaker Studio domain already configured, refer to Amazon SageMaker simplifies the Amazon SageMaker Studio setup for individual users for steps to create one.
Set up the solution
When the prerequisite steps are complete, you’re ready to set up the solution:
- In your AWS account, open the SageMaker console and choose Studio in the navigation pane.
- Choose your domain and user profile, then choose Open Studio.
Your domain and user profile name may be different.

- Choose System terminal under Utilities and files.
- Run the following command to clone the GitHub repo to the SageMaker Studio instance:
- Navigate to the
multimodal/Titan/titan-multimodal-embeddings/amazon-bedrock-multimodal-oss-searchengine-e2efolder. - Open the
titan_mm_embed_search_blog.ipynbnotebook.
Run the solution
Open the file titan_mm_embed_search_blog.ipynb and use the Data Science Python 3 kernel. On the Run menu, choose Run All Cells to run the code in this notebook.
This notebook performs the following steps:
- Install the packages and libraries required for this solution.
- Load the publicly available Amazon Berkeley Objects Dataset and metadata in a pandas data frame.
The dataset is a collection of 147,702 product listings with multilingual metadata and 398,212 unique catalogue images. For this post, you only use the item images and item names in US English. You use approximately 1,600 products.

- Generate embeddings for the item images using the Amazon Titan Multimodal Embeddings model using the
get_titan_multomodal_embedding()function. For the sake of abstraction, we have defined all important functions used in this notebook in theutils.pyfile.

Next, you create and set up an Amazon OpenSearch Serverless vector store (collection and index).
- Before you create the new vector search collection and index, you must first create three associated OpenSearch Service policies: the encryption security policy, network security policy, and data access policy.


- Finally, ingest the image embedding into the vector index.

Now you can perform a real-time multimodal search.
Run a contextual search
In this section, we show the results of contextual search based on a text or image query.
First, let’s perform an image search based on text input. In the following example, we use the text input “drinkware glass” and send it to the search engine to find similar items.

The following screenshot shows the results.

Now let’s look at the results based on a simple image. The input image gets converted into vector embeddings and, based on the similarity search, the model returns the result.
You can use any image, but for the following example, we use a random image from the dataset based on item ID (for example, item_id = “B07JCDQWM6”), and then send this image to the search engine to find similar items.

The following screenshot shows the results.

Clean up
To avoid incurring future charges, delete the resources used in this solution. You can do this by running the cleanup section of the notebook.

Conclusion
This post presented a walkthrough of using the Amazon Titan Multimodal Embeddings model in Amazon Bedrock to build powerful contextual search applications. In particular, we demonstrated an example of a product listing search application. We saw how the embeddings model enables efficient and accurate discovery of information from images and textual data, thereby enhancing the user experience while searching for the relevant items.
Amazon Titan Multimodal Embeddings helps you power more accurate and contextually relevant multimodal search, recommendation, and personalization experiences for end-users. For example, a stock photography company with hundreds of millions of images can use the model to power its search functionality, so users can search for images using a phrase, image, or a combination of image and text.
The Amazon Titan Multimodal Embeddings model in Amazon Bedrock is now available in the US East (N. Virginia) and US West (Oregon) AWS Regions. To learn more, refer to Amazon Titan Image Generator, Multimodal Embeddings, and Text models are now available in Amazon Bedrock, the Amazon Titan product page, and the Amazon Bedrock User Guide. To get started with Amazon Titan Multimodal Embeddings in Amazon Bedrock, visit the Amazon Bedrock console.
Start building with the Amazon Titan Multimodal Embeddings model in Amazon Bedrock today.
About the Authors
 Sandeep Singh is a Senior Generative AI Data Scientist at Amazon Web Services, helping businesses innovate with generative AI. He specializes in Generative AI, Artificial Intelligence, Machine Learning, and System Design. He is passionate about developing state-of-the-art AI/ML-powered solutions to solve complex business problems for diverse industries, optimizing efficiency and scalability.
Sandeep Singh is a Senior Generative AI Data Scientist at Amazon Web Services, helping businesses innovate with generative AI. He specializes in Generative AI, Artificial Intelligence, Machine Learning, and System Design. He is passionate about developing state-of-the-art AI/ML-powered solutions to solve complex business problems for diverse industries, optimizing efficiency and scalability.
 Mani Khanuja is a Tech Lead – Generative AI Specialists, author of the book Applied Machine Learning and High Performance Computing on AWS, and a member of the Board of Directors for Women in Manufacturing Education Foundation Board. She leads machine learning projects in various domains such as computer vision, natural language processing, and generative AI. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for long runs along the beach.
Mani Khanuja is a Tech Lead – Generative AI Specialists, author of the book Applied Machine Learning and High Performance Computing on AWS, and a member of the Board of Directors for Women in Manufacturing Education Foundation Board. She leads machine learning projects in various domains such as computer vision, natural language processing, and generative AI. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for long runs along the beach.
 Rupinder Grewal is a Senior AI/ML Specialist Solutions Architect with AWS. He currently focuses on serving of models and MLOps on Amazon SageMaker. Prior to this role, he worked as a Machine Learning Engineer building and hosting models. Outside of work, he enjoys playing tennis and biking on mountain trails.
Rupinder Grewal is a Senior AI/ML Specialist Solutions Architect with AWS. He currently focuses on serving of models and MLOps on Amazon SageMaker. Prior to this role, he worked as a Machine Learning Engineer building and hosting models. Outside of work, he enjoys playing tennis and biking on mountain trails.

A New Lens: Dotlumen CEO Cornel Amariei on Assistive Technology for the Visually Impaired
Dotlumen is illuminating a new technology to help people with visual impairments navigate the world.
In this episode of NVIDIA’s AI Podcast, recorded live at the NVIDIA GTC global AI conference, host Noah Kravitz spoke with the Romanian startup’s founder and CEO, Cornel Amariei, about developing its flagship Dotlumen Glasses.
Equipped with sensors and powered by AI, the glasses compute a safely walkable path for visually impaired individuals and offer haptic — or tactile — feedback on how to proceed via corresponding vibrations. Amariei further discusses the process and challenges of developing assistive technology and its potential for enhancing accessibility.
Dotlumen is a member of the NVIDIA Inception program for cutting-edge startups.
Stay tuned for more episodes recorded live from GTC.
Time Stamps
0:52: Background on the glasses
4:28: User experience of the glasses
7:29: How the glasses sense the physical world and compute a walkable path
18:07: The hardest part of the development process
22:20: Expected release and availability of the glasses
25:57: Dotlumen’s technical breakthrough moments
30:19: Other assistive technologies to look out for
You Might Also Like…
Personalized Health: Viome’s Guru Banavar Discusses Startup’s AI-Driven Approach – Ep. 216
Viome Chief Technology Officer Guru Banavar discusses how the startup’s innovations in AI and genomics advance personalized health and wellness.
Cardiac Clarity: Dr. Keith Channon Talks Revolutionizing Heart Health With AI – Ep. 212
Here’s some news to still beating hearts: AI is helping bring some clarity to cardiology. Caristo Diagnostics has developed an AI-powered solution for detecting coronary inflammation in cardiac CT scans.
Matice Founder Jessica Whited on Harnessing Regenerative Species for Medical Breakthroughs – Ep. 198
Scientists at Matice Biosciences are using AI to study the regeneration of tissues in animals known as super-regenerators, such as salamanders and planarians. The goal of the research is to develop new treatments that will help humans heal from injuries without scarring.
How GluxKind Created Ella, the AI-Powered Smart Stroller – Ep. 193
Imagine a stroller that can drive itself, help users up hills, brake on slopes and provide alerts of potential hazards. That’s what GlüxKind has done with Ella, an award-winning smart stroller that uses the NVIDIA Jetson edge AI and robotics platform to power its AI features.
Subscribe to the AI Podcast
Get the AI Podcast through iTunes, Google Podcasts, Google Play, Amazon Music, Castbox, DoggCatcher, Overcast, PlayerFM, Pocket Casts, Podbay, PodBean, PodCruncher, PodKicker, Soundcloud, Spotify, Stitcher and TuneIn.
Make the AI Podcast better: Have a few minutes to spare? Fill out this listener survey.

Coming Up ACEs: Decoding the AI Technology That’s Enhancing Games With Realistic Digital Humans
Editor’s note: This post is part of the AI Decoded series, which demystifies AI by making the technology more accessible, and which showcases new hardware, software, tools and accelerations for RTX PC users.
Digital characters are leveling up.
Non-playable characters often play a crucial role in video game storytelling, but since they’re usually designed with a fixed purpose, they can get repetitive and boring — especially in vast worlds where there are thousands.
Thanks in part to incredible advances in visual computing like ray tracing and DLSS, video games are more immersive and realistic than ever, making dry encounters with NPCs especially jarring.
Earlier this year, production microservices for the NVIDIA Avatar Cloud Engine launched, giving game developers and digital creators an ace up their sleeve when it comes to making lifelike NPCs. ACE microservices allow developers to integrate state-of-the-art generative AI models into digital avatars in games and applications. With ACE microservices, NPCs can dynamically interact and converse with players in-game and in real time.
Leading game developers, studios and startups are already incorporating ACE into their titles, bringing new levels of personality and engagement to NPCs and digital humans.
Bring Avatars to Life With NVIDIA ACE
The process of creating NPCs starts with providing them a backstory and purpose, which helps guide the narrative and ensures contextually relevant dialogue. Then, ACE subcomponents work together to build avatar interactivity and enhance responsiveness.
NPCs tap up to four AI models to hear, process, generate dialogue and respond.
The player’s voice first goes into NVIDIA Riva, a technology that builds fully customizable, real-time conversational AI pipelines and turns chatbots into engaging and expressive assistants using GPU-accelerated multilingual speech and translation microservices.
With ACE, Riva’s automatic speech recognition (ASR) feature processes what was said and uses AI to deliver a highly accurate transcription in real time. Explore a Riva-powered demo of speech-to-text in a dozen languages.
The transcription then goes into an LLM — such as Google’s Gemma, Meta’s Llama 2 or Mistral — and taps Riva’s neural machine translation to generate a natural language text response. Next, Riva’s Text-to-Speech functionality generates an audio response.
Finally, NVIDIA Audio2Face (A2F) generates facial expressions that can be synced to dialogue in many languages. With the microservice, digital avatars can display dynamic, realistic emotions streamed live or baked in during post-processing.
The AI network automatically animates face, eyes, mouth, tongue and head motions to match the selected emotional range and level of intensity. And A2F can automatically infer emotion directly from an audio clip.
Each step happens in real time to ensure fluid dialogue between the player and the character. And the tools are customizable, giving developers the flexibility to build the types of characters they need for immersive storytelling or worldbuilding.
Born to Roll
At GDC and GTC, developers and platform partners showcased demos leveraging NVIDIA ACE microservices — from interactive NPCs in gaming to powerful digital human nurses.
Ubisoft is exploring new types of interactive gameplay with dynamic NPCs. NEO NPCs, the product of its latest research and development project, are designed to interact in real time with players, their environment and other characters, opening up new possibilities for dynamic and emergent storytelling.
The capabilities of these NEO NPCs were showcased through demos, each focused on different aspects of NPC behaviors, including environmental and contextual awareness; real-time reactions and animations; and conversation memory, collaboration and strategic decision-making. Combined, the demos spotlighted the technology’s potential to push the boundaries of game design and immersion.
Using Inworld AI technology, Ubisoft’s narrative team created two NEO NPCs, Bloom and Iron, each with their own background story, knowledge base and unique conversational style. Inworld technology also provided the NEO NPCs with intrinsic knowledge of their surroundings, as well as interactive responses powered by Inworld’s LLM. NVIDIA A2F provided facial animations and lip syncing for the two NPCs real time.
Inworld and NVIDIA set GDC abuzz with a new technology demo called Covert Protocol, which showcased NVIDIA ACE technologies and the Inworld Engine. In the demo, players controlled a private detective who completed objectives based on the outcome of conversations with NPCs on the scene. Covert Protocol unlocked social simulation game mechanics with AI-powered digital characters that acted as bearers of crucial information, presented challenges and catalyzed key narrative developments. This enhanced level of AI-driven interactivity and player agency is set to open up new possibilities for emergent, player-specific gameplay.
Built on Unreal Engine 5, Covert Protocol uses the Inworld Engine and NVIDIA ACE, including NVIDIA Riva ASR and A2F, to augment Inworld’s speech and animation pipelines.
In the latest version of the NVIDIA Kairos tech demo built in collaboration with Convai, which was shown at CES, Riva ASR and A2F were used to significantly improve NPC interactivity. Convai’s new framework allowed the NPCs to converse among themselves and gave them awareness of objects, enabling them to pick up and deliver items to desired areas. Furthermore, NPCs gained the ability to lead players to objectives and traverse worlds.
Digital Characters in the Real World
The technology used to create NPCs is also being used to animate avatars and digital humans. Going beyond gaming, task-specific generative AI is moving into healthcare, customer service and more.
NVIDIA collaborated with Hippocratic AI at GTC to extend its healthcare agent solution, showcasing the potential of a generative AI healthcare agent avatar. More work underway to develop a super-low-latency inference platform to power real-time use cases.
“Our digital assistants provide helpful, timely and accurate information to patients worldwide,” said Munjal Shah, cofounder and CEO of Hippocratic AI. “NVIDIA ACE technologies bring them to life with cutting-edge visuals and realistic animations that help better connect to patients.”
Internal testing of Hippocratic’s initial AI healthcare agents is focused on chronic care management, wellness coaching, health risk assessments, social determinants of health surveys, pre-operative outreach and post-discharge follow-up.
UneeQ is an autonomous digital human platform focused on AI-powered avatars for customer service and interactive applications. UneeQ integrated the NVIDIA A2F microservice into its platform and combined it with its Synanim ML synthetic animation technology to create highly realistic avatars for enhanced customer experiences and engagement.
“UneeQ combines NVIDIA animation AI with our own Synanim ML synthetic animation technology to deliver real-time digital human interactions that are emotionally responsive and deliver dynamic experiences powered by conversational AI,” said Danny Tomsett, founder and CEO at UneeQ.
AI in Gaming
ACE is one of the many NVIDIA AI technologies that bring games to the next level.
- NVIDIA DLSS is a breakthrough graphics technology that uses AI to increase frame rates and improve image quality on GeForce RTX GPUs.
- NVIDIA RTX Remix enables modders to easily capture game assets, automatically enhance materials with generative AI tools and quickly create stunning RTX remasters with full ray tracing and DLSS.
- NVIDIA Freestyle, accessed through the new NVIDIA app beta, lets users personalize the visual aesthetics of more than 1,200 games through real-time post-processing filters, with features like RTX HDR, RTX Dynamic Vibrance and more.
- The NVIDIA Broadcast app transforms any room into a home studio, giving livestream AI-enhanced voice and video tools, including noise and echo removal, virtual background and AI green screen, auto-frame, video noise removal and eye contact.
Experience the latest and greatest in AI-powered experiences with NVIDIA RTX PCs and workstations, and make sense of what’s new, and what’s next, with AI Decoded.
Get weekly updates directly in your inbox by subscribing to the AI Decoded newsletter.

Our new report on AI’s opportunity for developing countries
 Today we’re releasing our “AI Sprinters” report, outlining ways for developing countries to take advantage of AI’s potential.Read More
Today we’re releasing our “AI Sprinters” report, outlining ways for developing countries to take advantage of AI’s potential.Read More

AWS and Mistral AI commit to democratizing generative AI with a strengthened collaboration
The generative artificial intelligence (AI) revolution is in full swing, and customers of all sizes and across industries are taking advantage of this transformative technology to reshape their businesses. From reimagining workflows to make them more intuitive and easier to enhancing decision-making processes through rapid information synthesis, generative AI promises to redefine how we interact with machines. It’s been amazing to see the number of companies launching innovative generative AI applications on AWS using Amazon Bedrock. Siemens is integrating Amazon Bedrock into its low-code development platform Mendix to allow thousands of companies across multiple industries to create and upgrade applications with the power of generative AI. Accenture and Anthropic are collaborating with AWS to help organizations—especially those in highly-regulated industries like healthcare, public sector, banking, and insurance—responsibly adopt and scale generative AI technology with Amazon Bedrock. This collaboration will help organizations like the District of Columbia Department of Health speed innovation, improve customer service, and improve productivity, while keeping data private and secure. Amazon Pharmacy is using generative AI to fill prescriptions with speed and accuracy, making customer service faster and more helpful, and making sure that the right quantities of medications are stocked for customers.
To power so many diverse applications, we recognized the need for model diversity and choice for generative AI early on. We know that different models excel in different areas, each with unique strengths tailored to specific use cases, leading us to provide customers with access to multiple state-of-the-art large language models (LLMs) and foundation models (FMs) through a unified service: Amazon Bedrock. By facilitating access to top models from Amazon, Anthropic, AI21 Labs, Cohere, Meta, Mistral AI, and Stability AI, we empower customers to experiment, evaluate, and ultimately select the model that delivers optimal performance for their needs.
Announcing Mistral Large on Amazon Bedrock
Today, we are excited to announce the next step on this journey with an expanded collaboration with Mistral AI. A French startup, Mistral AI has quickly established itself as a pioneering force in the generative AI landscape, known for its focus on portability, transparency, and its cost-effective design requiring fewer computational resources to run. We recently announced the availability of Mistral 7B and Mixtral 8x7B models on Amazon Bedrock, with weights that customers can inspect and modify. Today, Mistral AI is bringing its latest and most capable model, Mistral Large, to Amazon Bedrock, and is committed to making future models accessible to AWS customers. Mistral AI will also use AWS AI-optimized AWS Trainium and AWS Inferentia to build and deploy its future foundation models on Amazon Bedrock, benefitting from the price, performance, scale, and security of AWS. Along with this announcement, starting today, customers can use Amazon Bedrock in the AWS Europe (Paris) Region. At launch, customers will have access to some of the latest models from Amazon, Anthropic, Cohere, and Mistral AI, expanding their options to support various use cases from text understanding to complex reasoning.
Mistral Large boasts exceptional language understanding and generation capabilities, which is ideal for complex tasks that require reasoning capabilities or ones that are highly specialized, such as synthetic text generation, code generation, Retrieval Augmented Generation (RAG), or agents. For example, customers can build AI agents capable of engaging in articulate conversations, generating nuanced content, and tackling complex reasoning tasks. The model’s strengths also extend to coding, with proficiency in code generation, review, and comments across mainstream coding languages. And Mistral Large’s exceptional multilingual performance, spanning French, German, Spanish, and Italian, in addition to English, presents a compelling opportunity for customers. By offering a model with robust multilingual support, AWS can better serve customers with diverse language needs, fostering global accessibility and inclusivity for generative AI solutions.
By integrating Mistral Large into Amazon Bedrock, we can offer customers an even broader range of top-performing LLMs to choose from. No single model is optimized for every use case, and to unlock the value of generative AI, customers need access to a variety of models to discover what works best based for their business needs. We are committed to continuously introducing the best models, providing customers with access to the latest and most innovative generative AI capabilities.
“We are excited to announce our collaboration with AWS to accelerate the adoption of our frontier AI technology with organizations around the world. Our mission is to make frontier AI ubiquitous, and to achieve this mission, we want to collaborate with the world’s leading cloud provider to distribute our top-tier models. We have a long and deep relationship with AWS and through strengthening this relationship today, we will be able to provide tailor-made AI to builders around the world.”
– Arthur Mensch, CEO at Mistral AI.
Customers appreciate choice
Since we first announced Amazon Bedrock, we have been innovating at a rapid clip—adding more powerful features like agents and guardrails. And we’ve said all along that more exciting innovations, including new models will keep coming. With more model choice, customers tell us they can achieve remarkable results:
“The ease of accessing different models from one API is one of the strengths of Bedrock. The model choices available have been exciting. As new models become available, our AI team is able to quickly and easily evaluate models to know if they fit our needs. The security and privacy that Bedrock provides makes it a great choice to use for our AI needs.”
– Jamie Caramanica, SVP, Engineering at CS Disco.
“Our top priority today is to help organizations use generative AI to support employees and enhance bots through a range of applications, such as stronger topic, sentiment, and tone detection from customer conversations, language translation, content creation and variation, knowledge optimization, answer highlighting, and auto summarization. To make it easier for them to tap into the potential of generative AI, we’re enabling our users with access to a variety of large language models, such as Genesys-developed models and multiple third-party foundational models through Amazon Bedrock, including Anthropic’s Claude, AI21 Labs’s Jurrassic-2, and Amazon Titan. Together with AWS, we’re offering customers exponential power to create differentiated experiences built around the needs of their business, while helping them prepare for the future.”
– Glenn Nethercutt, CTO at Genesys.
As the generative AI revolution continues to unfold, AWS is poised to shape its future, empowering customers across industries to drive innovation, streamline processes, and redefine how we interact with machines. Together with outstanding partners like Mistral AI, and with Amazon Bedrock as the foundation, our customers can build more innovative generative AI applications.
Democratizing access to LLMs and FMs
Amazon Bedrock is democratizing access to cutting-edge LLMs and FMs and AWS is the only cloud provider to offer the most popular and advanced FMs to customers. The collaboration with Mistral AI represents a significant milestone in this journey, further expanding Amazon Bedrock’s diverse model offerings and reinforcing our commitment to empowering customers with unparalleled choice through Amazon Bedrock. By recognizing that no single model can optimally serve every use case, AWS has paved the way for customers to unlock the full potential of generative AI. Through Amazon Bedrock, organizations can experiment with and take advantage of the unique strengths of multiple top-performing models, tailoring their solutions to specific needs, industry domains, and workloads. This unprecedented choice, combined with the robust security, privacy, and scalability of AWS, enables customers to harness the power of generative AI responsibly and with confidence, no matter their industry or regulatory constraints.
Resources
About the author
 Swami Sivasubramanian is Vice President of Data and Machine Learning at AWS. In this role, Swami oversees all AWS Database, Analytics, and AI & Machine Learning services. His team’s mission is to help organizations put their data to work with a complete, end-to-end data solution to store, access, analyze, and visualize, and predict.
Swami Sivasubramanian is Vice President of Data and Machine Learning at AWS. In this role, Swami oversees all AWS Database, Analytics, and AI & Machine Learning services. His team’s mission is to help organizations put their data to work with a complete, end-to-end data solution to store, access, analyze, and visualize, and predict.
Generative AI roadshow in North America with AWS and Hugging Face
In 2023, AWS announced an expanded collaboration with Hugging Face to accelerate our customers’ generative artificial intelligence (AI) journey. Hugging Face, founded in 2016, is the premier AI platform with over 500,000 open source models and more than 100,000 datasets. Over the past year, we have partnered to make it effortless to train, fine-tune, and deploy Hugging Face models using Amazon SageMaker, AWS Trainium, and AWS Inferentia. Developers using Hugging Face can now optimize performance and lower cost to bring generative AI applications to production faster.
We are happy to announce a generative AI roadshow in North America where you can meet with Hugging Face and AWS experts, learn about the latest developments in generative AI, and get hands-on experience with fine-tuning and deploying foundation models. As part of this roadshow, Julien Simon, Chief Evangelist at Hugging Face, will travel to eight AWS headquarters across North America between April and June. You can meet with Julien and AWS experts to dive deep into your use cases and learn how AWS and Hugging Face can help.

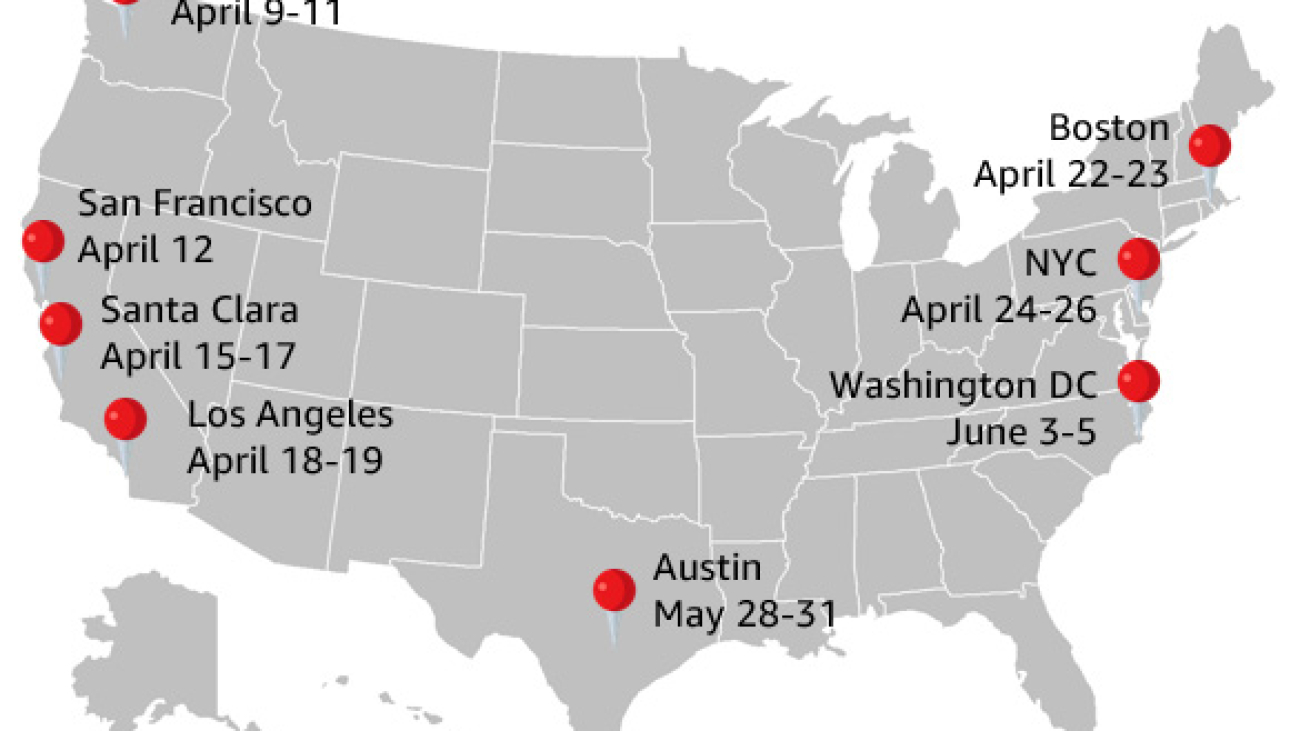
The following are the cities and dates for the 2024 roadshow:
- Seattle, WA: April 9–11
- San Francisco, CA: April 12
- Santa Clara, CA: April 15, April 17
- Los Angeles, CA: April 18–19
- Boston, MA: April 22–23
- New York City, NY: April 24–26
- Austin, TX: May 28–31
- Arlington, Washington DC: June 3–5
You can participate in the roadshow in two ways:
- Request a 1:1 meeting with Julien Simon and AWS experts. Reach out to your AWS Account Manager or submit your request.
- Register for an in-person, hands-on developer workshop in one of the following four cities, to learn how to deploy open source models from Hugging Face to build generative AI applications while reducing production costs with SageMaker and AWS Inferentia2:
- Register for Seattle
- Register for Santa Clara
- Register for NYC
- Register for Austin
For further inquiries, reach out to the AMER Hugging Face roadshow organizers.
We look forward to seeing you there. To learn more about the AWS collaboration with Hugging Face, visit the Amazon SageMaker resources and AWS Inferentia and Trainium space on the Hugging Face website.
About the authors
 Shruti Koparkar is a Senior Product Marketing Manager at AWS. She helps customers explore, evaluate, and adopt Amazon EC2 accelerated computing infrastructure for their machine learning needs.
Shruti Koparkar is a Senior Product Marketing Manager at AWS. She helps customers explore, evaluate, and adopt Amazon EC2 accelerated computing infrastructure for their machine learning needs.
 Hoko Hongo is a Senior GTM Specialist at AWS, supporting go-to-market and customer acceleration programs to further the customer’s generative AI journey.
Hoko Hongo is a Senior GTM Specialist at AWS, supporting go-to-market and customer acceleration programs to further the customer’s generative AI journey.

Gradient makes LLM benchmarking cost-effective and effortless with AWS Inferentia
This is a guest post co-written with Michael Feil at Gradient.
Evaluating the performance of large language models (LLMs) is an important step of the pre-training and fine-tuning process before deployment. The faster and more frequent you’re able to validate performance, the higher the chances you’ll be able to improve the performance of the model.
At Gradient, we work on custom LLM development, and just recently launched our AI Development Lab, offering enterprise organizations a personalized, end-to-end development service to build private, custom LLMs and artificial intelligence (AI) co-pilots. As part of this process, we regularly evaluate the performance of our models (tuned, trained, and open) against open and proprietary benchmarks. While working with the AWS team to train our models on AWS Trainium, we realized we were restricted to both VRAM and the availability of GPU instances when it came to the mainstream tool for LLM evaluation, lm-evaluation-harness. This open source framework lets you score different generative language models across various evaluation tasks and benchmarks. It is used by leaderboards such as Hugging Face for public benchmarking.
To overcome these challenges, we decided to build and open source our solution—integrating AWS Neuron, the library behind AWS Inferentia and Trainium, into lm-evaluation-harness. This integration made it possible to benchmark v-alpha-tross, an early version of our Albatross model, against other public models during the training process and after.
For context, this integration runs as a new model class within lm-evaluation-harness, abstracting the inference of tokens and log-likelihood estimation of sequences without affecting the actual evaluation task. The decision to move our internal testing pipeline to Amazon Elastic Compute Cloud (Amazon EC2) Inf2 instances (powered by AWS Inferentia2) enabled us to access up to 384 GB of shared accelerator memory, effortlessly fitting all of our current public architectures. By using AWS Spot Instances, we were able to take advantage of unused EC2 capacity in the AWS Cloud—enabling cost savings up to 90% discounted from on-demand prices. This minimized the time it took for testing and allowed us to test more frequently because we were able to test across multiple instances that were readily available and release the instances when we were finished.
In this post, we give a detailed breakdown of our tests, the challenges that we encountered, and an example of using the testing harness on AWS Inferentia.
Benchmarking on AWS Inferentia2
The goal of this project was to generate identical scores as shown in the Open LLM Leaderboard (for many CausalLM models available on Hugging Face), while retaining the flexibility to run it against private benchmarks. To see more examples of available models, see AWS Inferentia and Trainium on Hugging Face.
The code changes required to port over a model from Hugging Face transformers to the Hugging Face Optimum Neuron Python library were quite low. Because lm-evaluation-harness uses AutoModelForCausalLM, there is a drop in replacement using NeuronModelForCausalLM. Without a precompiled model, the model is automatically compiled in the moment, which could add 15–60 minutes onto a job. This gave us the flexibility to deploy testing for any AWS Inferentia2 instance and supported CausalLM model.
Results
Because of the way the benchmarks and models work, we didn’t expect the scores to match exactly across different runs. However, they should be very close based on the standard deviation, and we have consistently seen that, as shown in the following table. The initial benchmarks we ran on AWS Inferentia2 were all confirmed by the Hugging Face leaderboard.
In lm-evaluation-harness, there are two main streams used by different tests: generate_until and loglikelihood. The gsm8k test primarily uses generate_until to generate responses just like during inference. Loglikelihood is mainly used in benchmarking and testing, and examines the probability of different outputs being produced. Both work in Neuron, but the loglikelihood method in SDK 2.16 uses additional steps to determine the probabilities and can take extra time.
| Lm-evaluation-harness Results | ||
| Hardware Configuration | Original System | AWS Inferentia inf2.48xlarge |
| Time with batch_size=1 to evaluate mistralai/Mistral-7B-Instruct-v0.1 on gsm8k | 103 minutes | 32 minutes |
| Score on gsm8k (get-answer – exact_match with std) | 0.3813 – 0.3874 (± 0.0134) | 0.3806 – 0.3844 (± 0.0134) |
Get started with Neuron and lm-evaluation-harness
The code in this section can help you use lm-evaluation-harness and run it against supported models on Hugging Face. To see some available models, visit AWS Inferentia and Trainium on Hugging Face.
If you’re familiar with running models on AWS Inferentia2, you might notice that there is no num_cores setting passed in. Our code detects how many cores are available and automatically passes that number in as a parameter. This lets you run the test using the same code regardless of what instance size you are using. You might also notice that we are referencing the original model, not a Neuron compiled version. The harness automatically compiles the model for you as needed.
The following steps show you how to deploy the Gradient gradientai/v-alpha-tross model we tested. If you want to test with a smaller example on a smaller instance, you can use the mistralai/Mistral-7B-v0.1 model.
- The default quota for running On-Demand Inf instances is 0, so you should request an increase via Service Quotas. Add another request for all Inf Spot Instance requests so you can test with Spot Instances. You will need a quota of 192 vCPUs for this example using an inf2.48xlarge instance, or a quota of 4 vCPUs for a basic inf2.xlarge (if you are deploying the Mistral model). Quotas are AWS Region specific, so make sure you request in
us-east-1orus-west-2. - Decide on your instance based on your model. Because
v-alpha-trossis a 70B architecture, we decided use an inf2.48xlarge instance. Deploy an inf2.xlarge (for the 7B Mistral model). If you are testing a different model, you may need to adjust your instance depending on the size of your model. - Deploy the instance using the Hugging Face DLAMI version 20240123, so that all the necessary drivers are installed. (The price shown includes the instance cost and there is no additional software charge.)
- Adjust the drive size to 600 GB (100 GB for Mistral 7B).
- Clone and install
lm-evaluation-harnesson the instance. We specify a build so that we know any variance is due to model changes, not test or code changes.
- Run
lm_evalwith the hf-neuron model type and make sure you have a link to the path back to the model on Hugging Face:
If you run the preceding example with Mistral, you should receive the following output (on the smaller inf2.xlarge, it could take 250 minutes to run):
Clean up
When you are done, be sure to stop the EC2 instances via the Amazon EC2 console.
Conclusion
The Gradient and Neuron teams are excited to see a broader adoption of LLM evaluation with this release. Try it out yourself and run the most popular evaluation framework on AWS Inferentia2 instances. You can now benefit from the on-demand availability of AWS Inferentia2 when you’re using custom LLM development from Gradient. Get started hosting models on AWS Inferentia with these tutorials.
About the Authors
 Michael Feil is an AI engineer at Gradient and previously worked as a ML engineer at Rodhe & Schwarz and a researcher at Max-Plank Institute for Intelligent Systems and Bosch Rexroth. Michael is a leading contributor to various open source inference libraries for LLMs and open source projects such as StarCoder. Michael holds a bachelor’s degree in mechatronics and IT from KIT and a master’s degree in robotics from Technical University of Munich.
Michael Feil is an AI engineer at Gradient and previously worked as a ML engineer at Rodhe & Schwarz and a researcher at Max-Plank Institute for Intelligent Systems and Bosch Rexroth. Michael is a leading contributor to various open source inference libraries for LLMs and open source projects such as StarCoder. Michael holds a bachelor’s degree in mechatronics and IT from KIT and a master’s degree in robotics from Technical University of Munich.
 Jim Burtoft is a Senior Startup Solutions Architect at AWS and works directly with startups like Gradient. Jim is a CISSP, part of the AWS AI/ML Technical Field Community, a Neuron Ambassador, and works with the open source community to enable the use of Inferentia and Trainium. Jim holds a bachelor’s degree in mathematics from Carnegie Mellon University and a master’s degree in economics from the University of Virginia.
Jim Burtoft is a Senior Startup Solutions Architect at AWS and works directly with startups like Gradient. Jim is a CISSP, part of the AWS AI/ML Technical Field Community, a Neuron Ambassador, and works with the open source community to enable the use of Inferentia and Trainium. Jim holds a bachelor’s degree in mathematics from Carnegie Mellon University and a master’s degree in economics from the University of Virginia.

Enable single sign-on access of Amazon SageMaker Canvas using AWS IAM Identity Center: Part 2
Amazon SageMaker Canvas allows you to use machine learning (ML) to generate predictions without having to write any code. It does so by covering the end-to-end ML workflow: whether you’re looking for powerful data preparation and AutoML, managed endpoint deployment, simplified MLOps capabilities, or the ability to configure foundation models for generative AI, SageMaker Canvas can help you achieve your goals.
To enable agility for your users while ensuring secure environments, you can adopt single sign-on (SSO) using AWS IAM Identity Center, which is the recommended AWS service for managing user access to AWS resources. With IAM Identity Center, you can create or connect workforce users and centrally manage their access across all their AWS accounts and applications.
Part 1 of this series describes the necessary steps to configure SSO for SageMaker Canvas using IAM Identity Center for Amazon SageMaker Studio Classic.
In this post, we walk you through the necessary steps to configure SSO for SageMaker Canvas using IAM Identity Center for the updated Amazon SageMaker Studio. Your users can seamlessly access SageMaker Canvas with their credentials from IAM Identity Center without having to first go through the AWS Management Console. We also demonstrate how you can streamline user management with IAM Identity Center.
Solution overview
To configure SSO from IAM Identity Center, you need to complete the following steps:
- Enable IAM Identity Center using AWS Organizations
- Create a SageMaker Studio domain that uses IAM Identity Center for user authentication
- Create users or groups in IAM Identity Center
- Add users or groups to the SageMaker Studio domain
We will also show how to rename the SageMaker Studio application to clearly identify it as SageMaker Canvas, and how to access it using IAM Identity Center.
Enable IAM Identity Center
Follow these steps to connect SageMaker Canvas to IAM Identity Center:
- On the IAM Identity Center console, choose Enable.
- Choose Enable with AWS Organizations.

- Choose Edit to add an instance name.

- Enter a name for your instance (for this post, canvas-app).
- Choose Save changes.

Create the SageMaker Studio domain
In this section, we create SageMaker Studio domain and configure the authentication method as IAM Identity Center. Complete the following steps:
- On the SageMaker console, choose Domains.
- Choose Create domain.

- Choose Set up for organizations.
- Choose Set up.

- Enter a domain name of your choice (for this post,
canvas-domain). - Choose Next.

- Select AWS Identity Center.

- Choose Create a new role.
- Select the SageMaker Canvas permissions that you want to grant.
For more details about permissions, see Users and ML Activities.
- Specify one or more Amazon Simple Storage Service (Amazon S3) bucket.
- Choose Next.

- Select SageMaker Studio – New.

- Choose Next.

Next, you can provide VPC details for your network configuration.
- For this post, we select Public internet access.

- Choose your VPC, subnets, and security groups.
- Choose Next.

- Keep default storage configuration and choose Next.

- Choose Submit.

Wait for SageMaker domain status to change to InService.
Rename the SageMaker Studio application
Before we create a user, let’s rename the SageMaker Studio application name. This will allow users to quickly identify the SageMaker Canvas application when they log in through IAM Identity Center, where they may have access to multiple applications.
- On the IAM Identity Center console, choose Applications.
- Choose the SageMaker Studio application on the AWS managed tab.

- Choose Edit details on the Actions menu.

- For Display name, enter a name (for this post,
Canvas). - For Description, enter a description.
- Choose Save changes.

Create a user in IAM Identity Center
Now you can create users, and optionally, groups, that will be given access to SageMaker Canvas. For this post, we create a single user to demonstrate the process to provide access. However, groups are typically preferred for better user management, and to provision access in organizations.
A user group is a collection of users. Groups let you specify permissions for multiple users, which can make it more straightforward to manage the permissions for those users. For example, you could have a user group called business analysts and give that user group permission to SageMaker Canvas; all users in that group will have SageMaker Canvas access. If a new user joins your organization and needs access to SageMaker Canvas, you can add the user to the business analyst group. If a person changes jobs in your organization, instead of editing that user’s permissions, you can remove them from the old user groups and add them to the appropriate new user groups.
Complete the following steps to create a user in IAM Identity Center to test the SageMaker Canvas application access:
- On the IAM Identity Center console, choose Users in the navigation pane.
- Choose Add user.

- Provide required details such as the user name, email address, first name, and last name.

- Choose Next.

- Choose Add user.

You see a success message that the user has been added successfully.
Add users to the SageMaker Studio domain
You need to add this user to the SageMaker domain you created. If you’re using groups, then you add the group, not just a single user.
- On the SageMaker console, choose Domains in the navigation pane.
- Choose the domain you created.

- Choose Assign users and groups.

- On the Users tab, select the user you created.
- Choose Assign users and groups.

Access the SageMaker Canvas application from IAM Identity Center
The user will receive an email with a link to set up a password and instructions to connect to the AWS access portal. The link will be valid for up to 7 days.
When the user receives the email, they must complete the following steps to gain access to SageMaker Canvas:
- Choose Accept invitation from the email.

- Set a new password to access SageMaker Canvas in the specified account and domain.

After authentication has been performed, the user has three options to log in to SageMaker Canvas:
- Option 1 – Access from SageMaker Studio through the IAM Identity Center portal
- Option 2 – Access from SageMaker Canvas through the IAM Identity Center portal, bypassing SageMaker Studio
- Option 3 – Use the IAM Identity Center portal link in IAM Identity Center to access SageMaker Canvas
We go through each of these options in this section.
Option 1
In the first option, the user first accesses SageMaker Studio to access SageMaker Canvas. This option is appropriate for users that should be able to access all relevant applications from SageMaker Studio, including SageMaker Canvas.
- Navigate to the AWS access portal URL from your email.

- Log in with the credentials you set for the user.
You will see the application name you configured earlier.
- Choose the SageMaker Canvas application.

You’re redirected to SageMaker Studio.
- Choose Run Canvas.

- Choose Open Canvas.

You’re redirected to SageMaker Canvas.
Option 2
In this option, the user still goes through the IAM Identity Center portal, but bypasses SageMaker Studio to go directly into SageMaker Canvas. This option should be used when access SageMaker Studio is not needed, since the user’s SageMaker login will always take them directly to SageMaker Canvas.
- On the SageMaker console, choose Domains in the navigation pane.
- Note down the SageMaker domain ID.

- Open AWS CloudShell or any other CLI and run the following command, providing your domain ID. This command updates the default landing application for the SageMaker domain from SageMaker Studio to SageMaker Canvas:
You will see the following response if the command runs successfully.
- Navigate to the AWS access portal URL from your email.
- Log in with the credentials you set for the user.
- Choose the SageMaker Canvas application.

This time you’re redirected to SageMaker Canvas, bypassing SageMaker Studio.
Option 3
If the default landing application for the SageMaker domain has been updated from SageMaker Studio to SageMaker Canvas in Option 2, a user can also use the IAM Identity Center portal link to access SageMaker Canvas. To do so, choose the AWS access portal URL shown in the identity source on the IAM Identity Center console. You can use this URL as a browser bookmark, or integrated with your custom application for direct SageMaker Canvas access.
Clean up
To avoid incurring future session charges, log out of SageMaker Canvas.

Conclusion
In this post, we discussed how users can securely access SageMaker Canvas using SSO. To do this, we configured IAM Identity Center and linked it to the SageMaker domain where SageMaker Canvas is used. Users are now one click away from using SageMaker Canvas and solving new challenges with no-code ML. This approach supports the secure environment requirements of cloud engineering and security teams, while allowing for the agility and independence of development teams.
To learn more about SageMaker Canvas, check out Announcing Amazon SageMaker Canvas – a Visual, No Code Machine Learning Capability for Business Analysts. SageMaker Canvas also enables collaboration with data science teams. To learn more, see Build, Share, Deploy: how business analysts and data scientists achieve faster time-to-market using no-code ML and Amazon SageMaker Canvas. For IT administrators, we suggest checking out Setting up and managing Amazon SageMaker Canvas (for IT administrators).
About the Authors
 Dhiraj Thakur is a Solutions Architect with Amazon Web Services. He works with AWS customers and partners to provide guidance on enterprise cloud adoption, migration, and strategy. He is passionate about technology and enjoys building and experimenting in the analytics and AI/ML space.
Dhiraj Thakur is a Solutions Architect with Amazon Web Services. He works with AWS customers and partners to provide guidance on enterprise cloud adoption, migration, and strategy. He is passionate about technology and enjoys building and experimenting in the analytics and AI/ML space.
 Dan Sinnreich is a Senior Product Manager at AWS, helping democratize ML with low-code/no-code innovations. Previous to AWS, Dan built and commercialized SaaS platforms and time series risk models used by institutional investors to manage risk and optimize investment portfolios. Outside of work, he can be found playing hockey, scuba diving, and reading science fiction.
Dan Sinnreich is a Senior Product Manager at AWS, helping democratize ML with low-code/no-code innovations. Previous to AWS, Dan built and commercialized SaaS platforms and time series risk models used by institutional investors to manage risk and optimize investment portfolios. Outside of work, he can be found playing hockey, scuba diving, and reading science fiction.
Solar models from Upstage are now available in Amazon SageMaker JumpStart
This blog post is co-written with Hwalsuk Lee at Upstage.
Today, we’re excited to announce that the Solar foundation model developed by Upstage is now available for customers using Amazon SageMaker JumpStart. Solar is a large language model (LLM) 100% pre-trained with Amazon SageMaker that outperforms and uses its compact size and powerful track records to specialize in purpose-training, making it versatile across languages, domains, and tasks.
You can now use the Solar Mini Chat and Solar Mini Chat – Quant pretrained models within SageMaker JumpStart. SageMaker JumpStart is the machine learning (ML) hub of SageMaker that provides access to foundation models in addition to built-in algorithms to help you quickly get started with ML.
In this post, we walk through how to discover and deploy the Solar model via SageMaker JumpStart.
What’s the Solar model?
Solar is a compact and powerful model for English and Korean languages. It’s specifically fine-tuned for multi-turn chat purposes, demonstrating enhanced performance across a wide range of natural language processing tasks.
The Solar Mini Chat model is based on Solar 10.7B, with a 32-layer Llama 2 structure, and initialized with pre-trained weights from Mistral 7B compatible with the Llama 2 architecture. This fine-tuning equips it with the ability to handle extended conversations more effectively, making it particularly adept for interactive applications. It employs a scaling method called depth up-scaling (DUS), which is comprised of depth-wise scaling and continued pretraining. DUS allows for a much more straightforward and efficient enlargement of smaller models than other scaling methods such as mixture of experts (MoE).
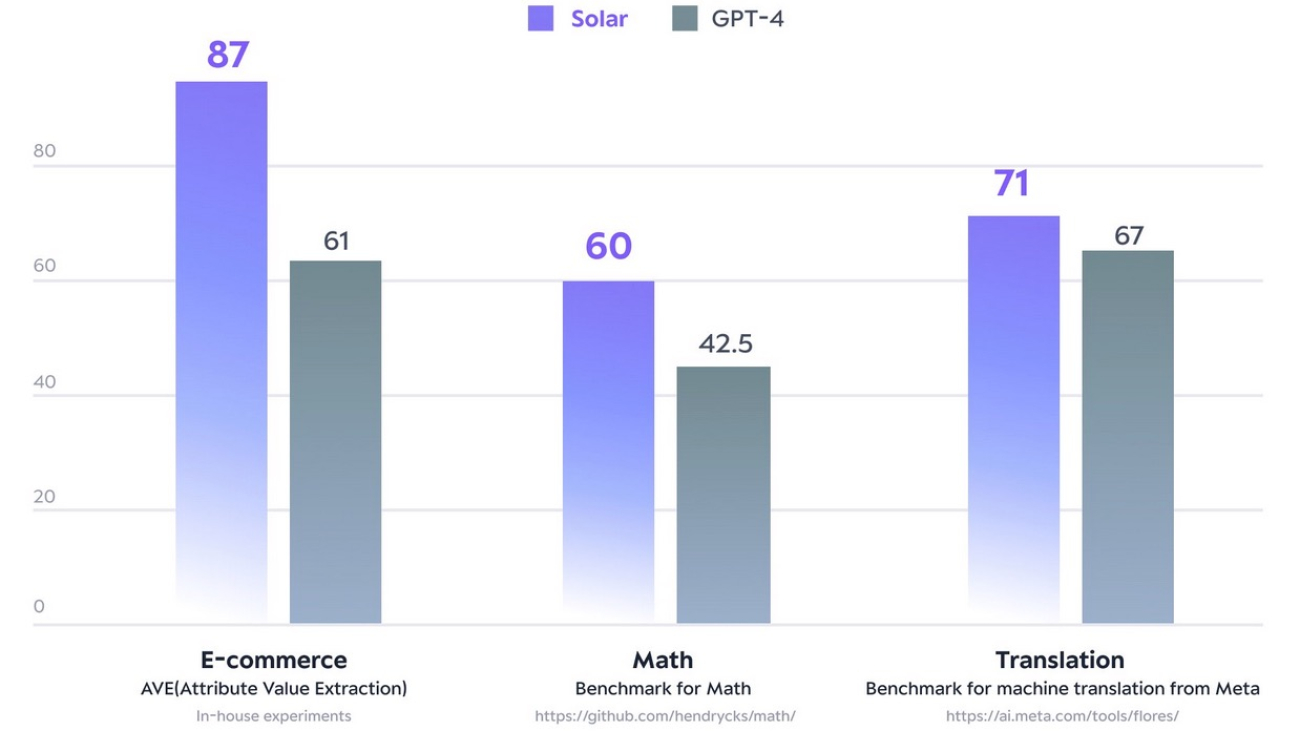
In December 2023, the Solar 10.7B model made waves by reaching the pinnacle of the Open LLM Leaderboard of Hugging Face. Using notably fewer parameters, Solar 10.7B delivers responses comparable to GPT-3.5, but is 2.5 times faster. Along with topping the Open LLM Leaderboard, Solar 10.7B outperforms GPT-4 with purpose-trained models on certain domains and tasks.
The following figure illustrates some of these metrics:

source: https://www.upstage.ai/solar-llm
With SageMaker JumpStart, you can deploy Solar 10.7B based pre-trained models: Solar Mini Chat and a quantized version of Solar Mini Chat, optimized for chat applications in English and Korean. The Solar Mini Chat model provides an advanced grasp of Korean language nuances, which significantly elevates user interactions in chat environments. It provides precise responses to user inputs, ensuring clearer communication and more efficient problem resolution in English and Korean chat applications.
Get started with Solar models in SageMaker JumpStart
To get started with Solar models, you can use SageMaker JumpStart, a fully managed ML hub service to deploy pre-built ML models into a production-ready hosted environment. You can access Solar models through SageMaker JumpStart in Amazon SageMaker Studio, a web-based integrated development environment (IDE) where you can access purpose-built tools to perform all ML development steps, from preparing data to building, training, and deploying your ML models.
On the SageMaker Studio console, choose JumpStart in the navigation pane. You can enter “solar” in the search bar to find Upstage’s solar models.

Let’s deploy the Solar Mini Chat – Quant model. Choose the model card to view details about the model such as the license, data used to train, and how to use the model. You will also find a Deploy option, which takes you to a landing page where you can test inference with an example payload.

This model requires an AWS Marketplace subscription. If you have already subscribed to this model, and have been approved to use the product, you can deploy the model directly.

If you have not subscribed to this model, choose Subscribe, go to AWS Marketplace, review the pricing terms and End User License Agreement (EULA), and choose Accept offer.

After you’re subscribed to the model, you can deploy your model to a SageMaker endpoint by selecting the deployment resources, such as instance type and initial instance count. Choose Deploy and wait an endpoint to be created for the model inference. You can select an ml.g5.2xlarge instance as a cheaper option for inference with the Solar model.

When your SageMaker endpoint is successfully created, you can test it through the various SageMaker application environments.
Run your code for Solar models in SageMaker Studio JupyterLab
SageMaker Studio supports various application development environments, including JupyterLab, a set of capabilities that augment the fully managed notebook offering. It includes kernels that start in seconds, a preconfigured runtime with popular data science, ML frameworks, and high-performance private block storage. For more information, see SageMaker JupyterLab.
Create a JupyterLab space within SageMaker Studio that manages the storage and compute resources needed to run the JupyterLab application.

You can find the code showing the deployment of Solar models on SageMaker JumpStart and an example of how to use the deployed model in the GitHub repo. You can now deploy the model using SageMaker JumpStart. The following code uses the default instance ml.g5.2xlarge for the Solar Mini Chat – Quant model inference endpoint.
Solar models support a request/response payload compatible to OpenAI’s Chat completion endpoint. You can test single-turn or multi-turn chat examples with Python.
# Get a SageMaker endpoint
sagemaker_runtime = boto3.client("sagemaker-runtime")
endpoint_name = sagemaker.utils.name_from_base(model_name)
# Multi-turn chat prompt example
input = {
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Can you provide a Python script to merge two sorted lists?"
},
{
"role": "assistant",
"content": """Sure, here is a Python script to merge two sorted lists:
```python
def merge_lists(list1, list2):
return sorted(list1 + list2)
```
"""
},
{
"role": "user",
"content": "Can you provide an example of how to use this function?"
}
]
}
# Get response from the model
response = sagemaker_runtime.invoke_endpoint(EndpointName=endpoint_name, ContentType='application/json', Body=json.dumps (input))
result = json.loads(response['Body'].read().decode())
print resultYou have successfully performed a real time inference with the Solar Mini Chat model.
Clean up
After you have tested the endpoint, delete the SageMaker inference endpoint and delete the model to avoid incurring charges.

You can also run the following code to delete the endpoint and mode in the notebook of SageMaker Studio JupyterLab:
# Delete the endpoint
model.sagemaker_session.delete_endpoint(endpoint_name)
model.sagemaker_session.delete_endpoint_config(endpoint_name)
# Delete the model
model.delete_model()For more information, see Delete Endpoints and Resources. Additionally, you can shut down the SageMaker Studio resources that are no longer required.
Conclusion
In this post, we showed you how to get started with Upstage’s Solar models in SageMaker Studio and deploy the model for inference. We also showed you how you can run your Python sample code on SageMaker Studio JupyterLab.
Because Solar models are already pre-trained, they can help lower training and infrastructure costs and enable customization for your generative AI applications.
Try it out on the SageMaker JumpStart console or SageMaker Studio console! You can also watch the following video, Try ‘Solar’ with Amazon SageMaker.
This guidance is for informational purposes only. You should still perform your own independent assessment, and take measures to ensure that you comply with your own specific quality control practices and standards, and the local rules, laws, regulations, licenses, and terms of use that apply to you, your content, and the third-party model referenced in this guidance. AWS has no control or authority over the third-party model referenced in this guidance, and does not make any representations or warranties that the third-party model is secure, virus-free, operational, or compatible with your production environment and standards. AWS does not make any representations, warranties, or guarantees that any information in this guidance will result in a particular outcome or result.
About the Authors
 Channy Yun is a Principal Developer Advocate at AWS, and is passionate about helping developers build modern applications on the latest AWS services. He is a pragmatic developer and blogger at heart, and he loves community-driven learning and sharing of technology.
Channy Yun is a Principal Developer Advocate at AWS, and is passionate about helping developers build modern applications on the latest AWS services. He is a pragmatic developer and blogger at heart, and he loves community-driven learning and sharing of technology.
 Hwalsuk Lee is Chief Technology Officer (CTO) at Upstage. He has worked for Samsung Techwin, NCSOFT, and Naver as an AI Researcher. He is pursuing his PhD in Computer and Electrical Engineering at the Korea Advanced Institute of Science and Technology (KAIST).
Hwalsuk Lee is Chief Technology Officer (CTO) at Upstage. He has worked for Samsung Techwin, NCSOFT, and Naver as an AI Researcher. He is pursuing his PhD in Computer and Electrical Engineering at the Korea Advanced Institute of Science and Technology (KAIST).
 Brandon Lee is a Senior Solutions Architect at AWS, and primarily helps large educational technology customers in the Public Sector. He has over 20 years of experience leading application development at global companies and large corporations.
Brandon Lee is a Senior Solutions Architect at AWS, and primarily helps large educational technology customers in the Public Sector. He has over 20 years of experience leading application development at global companies and large corporations.