This is a guest post by Mark McQuade, Malikeh Ehghaghi, and Shamane Siri from Arcee.
In recent years, large language models (LLMs) have gained attention for their effectiveness, leading various industries to adapt general LLMs to their data for improved results, making efficient training and hardware availability crucial. At Arcee, we focus primarily on enhancing the domain adaptation of LLMs in a client-centric manner. Arcee’s innovative continual pre-training (CPT) and model merging techniques have brought a significant leap forward in the efficient training of LLMs, with particularly strong evaluations in the medical, legal, and financial verticals. Close collaboration with AWS Trainium has also played a major role in making the Arcee platform extremely performant, not only accelerating model training but also reducing overall costs and enforcing compliance and data integrity in the secure AWS environment. In this post, we show you how efficient we make our continual pre-training by using Trainium chips.
Understanding continual pre-training
Arcee recognizes the critical importance of continual CPT [1] in tailoring models to specific domains, as evidenced by previous studies such as PMC-LLaMA [2] and ChipNeMo [3]. These projects showcase the power of domain adaptation pre-training in enhancing model performance across diverse fields, from medical applications to industrial chip design. Inspired by these endeavors, our approach to CPT involves extending the training of base models like Llama 2 using domain-specific datasets, allowing us to fine-tune models to the nuances of specialized fields. To further amplify the efficiency of our CPT process, we collaborated with the Trainium team, using their cutting-edge technology to enhance a Llama 2 [4] model using a PubMed dataset [2] comprising 88 billion tokens. This collaboration represents a significant milestone in our quest for innovation, and through this post, we’re excited to share the transformative insights we’ve gained. Join us as we unveil the future of domain-specific model adaptation and the potential of CPT with Trainium in optimizing model performance for real-world applications.
Dataset collection
We followed the methodology outlined in the PMC-Llama paper [6] to assemble our dataset, which includes PubMed papers sourced from the Semantic Scholar API and various medical texts cited within the paper, culminating in a comprehensive collection of 88 billion tokens. For further details on the dataset, the original paper offers in-depth information.
To prepare this dataset for training, we used the Llama 2 tokenizer within an AWS Glue pipeline for efficient processing. We then organized the data so that each row contained 4,096 tokens, adhering to recommendations from the Neuron Distributed tutorials.
Why Trainium?
Continual pre-training techniques like the ones described in this post require access to high-performance compute instances, which has become more difficult to get as more developers are using generative artificial intelligence (AI) and LLMs for their applications. Traditionally, these workloads have been deployed to GPUs; however, in recent years, the cost and availability of GPUs has stifled model building innovations. With the introduction of Trainium, we are able to unlock new techniques that enable us to continue model innovations that will allow us to build models more efficiently and most importantly, at lower costs. Trainium is the second-generation machine learning (ML) accelerator that AWS purpose built to help developers access high-performance model training accelerators to help lower training costs by up to 50% over comparable Amazon Elastic Compute Cloud (Amazon EC2) instances. With Trainium available in AWS Regions worldwide, developers don’t have to take expensive, long-term compute reservations just to get access to clusters of GPUs to build their models. Trainium instances offer developers the performance they need with the elasticity they want to optimize both for training efficiency and lowering model building costs.
Setting up the Trainium cluster
We used AWS ParallelCluster to build a High Performance Computing (HPC) compute environment that uses Trn1 compute nodes to run our distributed ML training job (see the GitHub tutorial). You can also use developer flows like Amazon SageMaker, Amazon Elastic Kubernetes Service (Amazon EKS), Ray, or others (to learn more, see Developer Flows). After the nodes were launched, we ran a training task to confirm that the nodes were working, and used slurm commands to check the job status. In this part, we used the AWS pcluster command to run a .yaml file to generate the cluster. Our cluster consisted of 16 nodes, each equipped with a trn1n.32xlarge instance featuring 32 GB of VRAM.
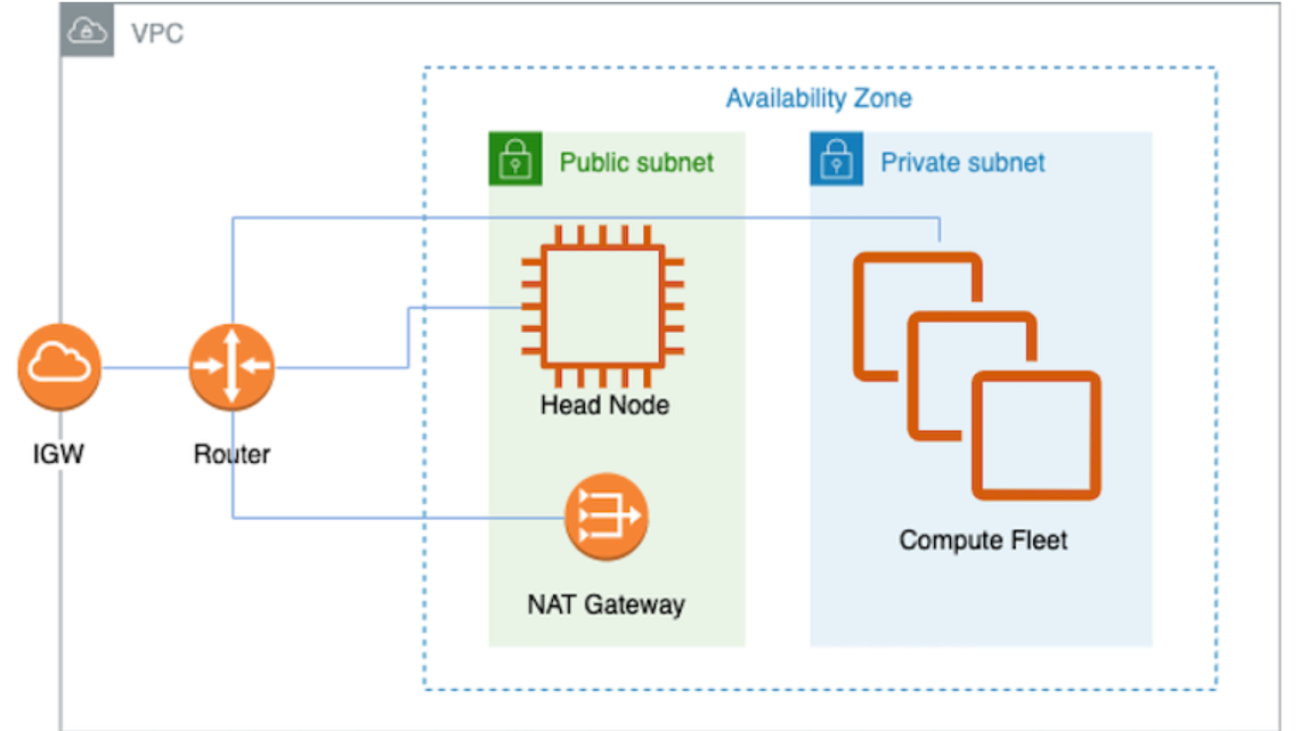
We set up our ParallelCluster infrastructure as shown in the following diagram (source).

As shown in the preceding figure, inside a VPC, there are two subnets, a public one and a private one. The head node resides in the public subnet, and the compute fleet (in this case, Trn1 instances) is in the private subnet. A NAT gateway is also needed in order for nodes in the private subnet to connect to clients outside the VPC. In the following section, we describe how to set up the necessary infrastructure for Trn1 ParallelCluster.
Set up the environment
To set up your environment, complete the following steps:
- Install the VPC and necessary components for
ParallelCluster. For instructions, see VPC setup for ParallelCluster with Trn1. - Create and launch
ParallelClusterin the VPC. For instructions, see Create ParallelCluster.
Now you can launch a training job to submit a model training script as a slurm job.
Deploy to Trainium
Trainium-based EC2 Trn1 instances use the AWS Neuron SDK and support common ML frameworks like PyTorch and TensorFlow. Neuron allows for effortless distributed training and has integrations with Megatron Nemo and Neuron Distributed.
When engaging with Trainium, it’s crucial to understand several key parameters:
- Tensor parallel size – This determines the level of tensor parallelization, particularly in self-attention computations within transformers, and is crucial for optimizing memory usage (not computational time efficiency) during model loading
- NeuronCores – Each Trainium device has two NeuronCores, and an eight-node setup equates to a substantial 256 cores
- Mini batch – This reflects the number of examples processed in each batch as determined by the data loader
- World size – This is the total count of nodes involved in the training operation
A deep understanding of these parameters is vital for anyone looking to harness the power of Trainium devices effectively.
Train the model
For this post, we train a Llama 2 7B model with tensor parallelism. For a streamlined and effective training process, we adhered to the following steps:
- Download the Llama 2 full checkpoints (model weights and tokenizer) from Hugging Face.
- Convert these checkpoints to a format compatible with the Neuron Distributed setup, so they can be efficiently utilized in our training infrastructure.
- Determine the number of steps required per epoch, incorporating the effective batch size and dataset size to tailor the training process to our specific needs.

- Launch the training job, carefully monitoring its progress and performance.
- Periodically save training checkpoints. Initially, this process may be slow due to its synchronous nature, but improvements are anticipated as the NeuronX team works on enhancements.
- Finally, convert the saved checkpoints back to a standard format for subsequent use, employing scripts for seamless conversion.
For more details, you can find the full implementation of the training steps in the following GitHub repository.
Clean up
Don’t forget to tear down any resources you set up in this post.
Results
Our study focused on evaluating the quality of the CPT-enhanced checkpoints. We monitored the perplexity of a held-out PubMed dataset [6] across various checkpoints obtained during training, which provided valuable insights into the model’s performance improvements over time.
Through this journey, we’ve advanced our model’s capabilities, and hope to contribute to the broader community’s understanding of effective model adaptation strategies.
The following figure shows the perplexity of the baseline Llama 2 7B checkpoint vs. its CPT-enhanced checkpoint on the PMC test dataset. Based on these findings, continual pre-training on domain-specific raw data, specifically PubMed papers in our study, resulted in an enhancement of the Llama 2 7B checkpoint, leading to improved perplexity of the model on the PMC test set.

The following figure shows the perplexity of the CPT-enhanced checkpoints of the Llama 2 7B model across varying numbers of trained tokens. The increasing number of trained tokens correlated with enhanced model performance, as measured by the perplexity metric.

The following figure shows the perplexity comparison between the baseline Llama 2 7B model and its CPT-enhanced checkpoints, with and without data mixing. This underscores the significance of data mixing, where we have added 1% of general tokens to the domain-specific dataset, wherein utilizing a CPT-enhanced checkpoint with data mixing exhibited better performance compared to both the baseline Llama 2 7B model and the CPT-enhanced checkpoint solely trained on PubMed data.

Conclusion
Arcee’s innovative approach to CPT and model merging, as demonstrated through our collaboration with Trainium, signifies a transformative advancement in the training of LLMs, particularly in specialized domains such as medical research. By using the extensive capabilities of Trainium, we have not only accelerated the model training process, but also significantly reduced costs, with an emphasis on security and compliance that provides data integrity within a secure AWS environment.
The results from our training experiments, as seen in the improved perplexity scores of domain-specific models, underscore the effectiveness of our method in enhancing the performance and applicability of LLMs across various fields. This is particularly evident from the direct comparisons of time-to-train metrics between Trainium and traditional GPU setups, where Trainium’s efficiency and cost-effectiveness shine.
Furthermore, our case study using PubMed data for domain-specific training highlights the potential of Arcee’s CPT strategies to fine-tune models to the nuances of highly specialized datasets, thereby creating more accurate and reliable tools for professionals in those fields.
As we continue to push the boundaries of what’s possible in LLM training, we encourage researchers, developers, and enterprises to take advantage of the scalability, efficiency, and enhanced security features of Trainium and Arcee’s methodologies. These technologies not only facilitate more effective model training, but also open up new avenues for innovation and practical application in AI-driven industries.
The integration of Trainium’s advanced ML capabilities with Arcee’s pioneering strategies in model training and adaptation is poised to revolutionize the landscape of LLM development, making it more accessible, economical, and tailored to meet the evolving demands of diverse industries.
To learn more about Arcee.ai, visit Arcee.ai or reach out to our team.
Additional resources
- Arcee’s whitepaper: Case Study on How Arcee is Innovating Domain Adaptation, through Continual Pre-Training and Model Merging
- Arcee’s paper on Arxiv on model merging: Arcee’s MergeKit: A Toolkit for Merging Large Language Models
- Arcee’s Mergekit repository on GitHub
References
- Gupta, Kshitij, et al. “Continual Pre-Training of Large Language Models: How to (re) warm your model?.” arXiv preprint arXiv:2308.04014 (2023).
- Wu, Chaoyi, et al. “Pmc-LLaMA: Towards building open-source language models for medicine.” arXiv preprint arXiv:2305.10415 6 (2023).
- Liu, Mingjie, et al. “Chipnemo: Domain-adapted llms for chip design.” arXiv preprint arXiv:2311.00176 (2023).
- Touvron, Hugo, et al. “Llama 2: Open foundation and fine-tuned chat models.” arXiv preprint arXiv:2307.09288 (2023).
- https://aws.amazon.com/ec2/instance-types/trn1/
- Wu, C., Zhang, X., Zhang, Y., Wang, Y., & Xie, W. (2023). Pmc-llama: Further fine tuning llama on medical papers. arXiv preprint arXiv:2304.14454.
About the Authors
 Mark McQuade is the CEO/Co-Founder at Arcee. Mark co-founded Arcee with a vision to empower enterprises with industry-specific AI solutions. This idea emerged from his time at Hugging Face, where he helped spearhead the Monetization team, collaborating with high-profile enterprises. This frontline experience exposed him to critical industry pain points: the reluctance to rely on closed source APIs and the challenges of training open source models without compromising data security.
Mark McQuade is the CEO/Co-Founder at Arcee. Mark co-founded Arcee with a vision to empower enterprises with industry-specific AI solutions. This idea emerged from his time at Hugging Face, where he helped spearhead the Monetization team, collaborating with high-profile enterprises. This frontline experience exposed him to critical industry pain points: the reluctance to rely on closed source APIs and the challenges of training open source models without compromising data security.
 Shamane Siri Ph.D. is the Head of Applied NLP Research at Arcee. Before joining Arcee, Shamane worked in both industry and academia, developing recommendation systems using language models to address the cold start problem, and focusing on information retrieval, multi-modal emotion recognition, and summarization. Shamane has also collaborated with the Hugging Face Transformers crew and Meta Reality Labs on cutting-edge projects. He holds a PhD from the University of Auckland, where he specialized in domain adaptation of foundational language models.
Shamane Siri Ph.D. is the Head of Applied NLP Research at Arcee. Before joining Arcee, Shamane worked in both industry and academia, developing recommendation systems using language models to address the cold start problem, and focusing on information retrieval, multi-modal emotion recognition, and summarization. Shamane has also collaborated with the Hugging Face Transformers crew and Meta Reality Labs on cutting-edge projects. He holds a PhD from the University of Auckland, where he specialized in domain adaptation of foundational language models.
 Malikeh Ehghaghi is an Applied NLP Research Engineer at Arcee. Malikeh’s research interests are NLP, domain-adaptation of LLMs, ML for healthcare, and responsible AI. She earned an MScAC degree in Computer Science from the University of Toronto. She previously collaborated with Lavita AI as a Machine Learning Consultant, developing healthcare chatbots in partnership with Dartmouth Center for Precision Health and Artificial Intelligence. She also worked as a Machine Learning Research Scientist at Cambridge Cognition Inc. and Winterlight Labs, with a focus on monitoring and detection of mental health disorders through speech and language. Malikeh has authored several publications presented at top-tier conferences such as ACL, COLING, AAAI, NAACL, IEEE-BHI, and MICCAI.
Malikeh Ehghaghi is an Applied NLP Research Engineer at Arcee. Malikeh’s research interests are NLP, domain-adaptation of LLMs, ML for healthcare, and responsible AI. She earned an MScAC degree in Computer Science from the University of Toronto. She previously collaborated with Lavita AI as a Machine Learning Consultant, developing healthcare chatbots in partnership with Dartmouth Center for Precision Health and Artificial Intelligence. She also worked as a Machine Learning Research Scientist at Cambridge Cognition Inc. and Winterlight Labs, with a focus on monitoring and detection of mental health disorders through speech and language. Malikeh has authored several publications presented at top-tier conferences such as ACL, COLING, AAAI, NAACL, IEEE-BHI, and MICCAI.

 For National Small Business Week, we’re spotlighting Prados Beauty founder and CEO Cece Meadows.
For National Small Business Week, we’re spotlighting Prados Beauty founder and CEO Cece Meadows.





 Shikhar Kwatra is an AI/ML Specialist Solutions Architect at Amazon Web Services, working with a leading Global System Integrator. He has earned the title of one of the Youngest Indian Master Inventors with over 400 patents in the AI/ML and IoT domains. He has over 8 years of industry experience from startups to large-scale enterprises, from IoT Research Engineer, Data Scientist, to Data & AI Architect. Shikhar aids in architecting, building, and maintaining cost-efficient, scalable cloud environments for organizations and supports GSI partners in building strategic industry
Shikhar Kwatra is an AI/ML Specialist Solutions Architect at Amazon Web Services, working with a leading Global System Integrator. He has earned the title of one of the Youngest Indian Master Inventors with over 400 patents in the AI/ML and IoT domains. He has over 8 years of industry experience from startups to large-scale enterprises, from IoT Research Engineer, Data Scientist, to Data & AI Architect. Shikhar aids in architecting, building, and maintaining cost-efficient, scalable cloud environments for organizations and supports GSI partners in building strategic industry Niithiyn Vijeaswaran is a Solutions Architect at AWS. His area of focus is generative AI and AWS AI Accelerators. He holds a Bachelor’s degree in Computer Science and Bioinformatics. Niithiyn works closely with the Generative AI GTM team to enable AWS customers on multiple fronts and accelerate their adoption of generative AI. He’s an avid fan of the Dallas Mavericks and enjoys collecting sneakers.
Niithiyn Vijeaswaran is a Solutions Architect at AWS. His area of focus is generative AI and AWS AI Accelerators. He holds a Bachelor’s degree in Computer Science and Bioinformatics. Niithiyn works closely with the Generative AI GTM team to enable AWS customers on multiple fronts and accelerate their adoption of generative AI. He’s an avid fan of the Dallas Mavericks and enjoys collecting sneakers. Sebastian Bustillo is a Solutions Architect at AWS. He focuses on AI/ML technologies with a profound passion for generative AI and compute accelerators. At AWS, he helps customers unlock business value through generative AI. When he’s not at work, he enjoys brewing a perfect cup of specialty coffee and exploring the world with his wife.
Sebastian Bustillo is a Solutions Architect at AWS. He focuses on AI/ML technologies with a profound passion for generative AI and compute accelerators. At AWS, he helps customers unlock business value through generative AI. When he’s not at work, he enjoys brewing a perfect cup of specialty coffee and exploring the world with his wife. Armando Diaz is a Solutions Architect at AWS. He focuses on generative AI, AI/ML, and data analytics. At AWS, Armando helps customers integrating cutting-edge generative AI capabilities into their systems, fostering innovation and competitive advantage. When he’s not at work, he enjoys spending time with his wife and family, hiking, and traveling the world.
Armando Diaz is a Solutions Architect at AWS. He focuses on generative AI, AI/ML, and data analytics. At AWS, Armando helps customers integrating cutting-edge generative AI capabilities into their systems, fostering innovation and competitive advantage. When he’s not at work, he enjoys spending time with his wife and family, hiking, and traveling the world.







 Suman Debnath is a Principal Developer Advocate for Machine Learning at Amazon Web Services. He frequently speaks at AI/ML conferences, events, and meetups around the world. He is passionate about large-scale distributed systems and is an avid fan of Python.
Suman Debnath is a Principal Developer Advocate for Machine Learning at Amazon Web Services. He frequently speaks at AI/ML conferences, events, and meetups around the world. He is passionate about large-scale distributed systems and is an avid fan of Python. Sebastian Munera is a Software Engineer in the Amazon Bedrock Knowledge Bases team at AWS where he focuses on building customer solutions that leverage Generative AI and RAG applications. He has previously worked on building Generative AI-based solutions for customers to streamline their processes and Low code/No code applications. In his spare time he enjoys running, lifting and tinkering with technology.
Sebastian Munera is a Software Engineer in the Amazon Bedrock Knowledge Bases team at AWS where he focuses on building customer solutions that leverage Generative AI and RAG applications. He has previously worked on building Generative AI-based solutions for customers to streamline their processes and Low code/No code applications. In his spare time he enjoys running, lifting and tinkering with technology.
 Over the past 18 months, AI has augmented and inspired the work of many creative professionals. At the same time, many are concerned about the effects of this technology…
Over the past 18 months, AI has augmented and inspired the work of many creative professionals. At the same time, many are concerned about the effects of this technology…







 Sanjay Tiwary is a Specialist Solutions Architect AI/ML who spends his time working with strategic customers to define business requirements, provide L300 sessions around specific use cases, and design AI/ML applications and services that are scalable, reliable, and performant. He has helped launch and scale the AI/ML powered Amazon SageMaker service and has implemented several proofs of concept using Amazon AI services. He has also developed the advanced analytics platform as a part of the digital transformation journey.
Sanjay Tiwary is a Specialist Solutions Architect AI/ML who spends his time working with strategic customers to define business requirements, provide L300 sessions around specific use cases, and design AI/ML applications and services that are scalable, reliable, and performant. He has helped launch and scale the AI/ML powered Amazon SageMaker service and has implemented several proofs of concept using Amazon AI services. He has also developed the advanced analytics platform as a part of the digital transformation journey. Kiran Challapalli is a deep tech business developer with the AWS public sector. He has more than 8 years of experience in AI/ML and 23 years of overall software development and sales experience. Kiran helps public sector businesses across India explore and co-create cloud-based solutions that use AI, ML, and generative AI—including large language models—technologies.
Kiran Challapalli is a deep tech business developer with the AWS public sector. He has more than 8 years of experience in AI/ML and 23 years of overall software development and sales experience. Kiran helps public sector businesses across India explore and co-create cloud-based solutions that use AI, ML, and generative AI—including large language models—technologies.