The rapid advancements in artificial intelligence and machine learning (AI/ML) have made these technologies a transformative force across industries. According to a McKinsey study, across the financial services industry (FSI), generative AI is projected to deliver over $400 billion (5%) of industry revenue in productivity benefits. As maintained by Gartner, more than 80% of enterprises will have AI deployed by 2026. At Amazon, we believe innovation (rethink and reinvent) drives improved customer experiences and efficient processes, leading to increased productivity. Generative AI is a catalyst for business transformation, making it imperative for FSI organizations to determine where generative AI’s current capabilities could deliver the biggest value for FSI customers.
Organizations across industries face numerous challenges implementing generative AI across their organization, such as lack of clear business case, scaling beyond proof of concept, lack of governance, and availability of the right talent. An effective approach that addresses a wide range of observed issues is the establishment of an AI/ML center of excellence (CoE). An AI/ML CoE is a dedicated unit, either centralized or federated, that coordinates and oversees all AI/ML initiatives within an organization, bridging business strategy to value delivery. As observed by Harvard Business Review, an AI/ML CoE is already established in 37% of large companies in the US. For organizations to be successful in their generative AI journey, there is growing importance for coordinated collaboration across lines of businesses and technical teams.
This post, along with the Cloud Adoption Framework for AI/ML and Well-Architected Machine Learning Lens, serves as a guide for implementing an effective AI/ML CoE with the objective to capture generative AI’s possibilities. This includes guiding practitioners to define the CoE mission, forming a leadership team, integrating ethical guidelines, qualification and prioritization of use cases, upskilling of teams, implementing governance, creating infrastructure, embedding security, and enabling operational excellence.
What is an AI/ML CoE?
The AI/ML CoE is responsible for partnering with lines of business and end-users in identifying AI/ML use cases aligned to business and product strategy, recognizing common reusable patterns from different business units (BUs), implementing a company-wide AI/ML vision, and deploying an AI/ML platform and workloads on the most appropriate combination of computing hardware and software. The CoE team synergizes business acumen with profound technical AI/ML proficiency to develop and implement interoperable, scalable solutions throughout the organization. They establish and enforce best practices encompassing design, development, processes, and governance operations, thereby mitigating risks and making sure robust business, technical, and governance frameworks are consistently upheld. For ease of consumption, standardization, scalability, and value delivery, the outputs of an AI/ML CoE can be of two types: guidance such as published guidance, best practices, lessons learned, and tutorials, and capabilities such as people skills, tools, technical solutions, and reusable templates.
The following are benefits of establishing an AI/ML CoE:
- Faster time to market through a clear path to production
- Maximized return on investments through delivering on the promise of generative AI business outcomes
- Optimized risk management
- Structured upskilling of teams
- Sustainable scaling with standardized workflows and tooling
- Better support and prioritization of innovation initiatives
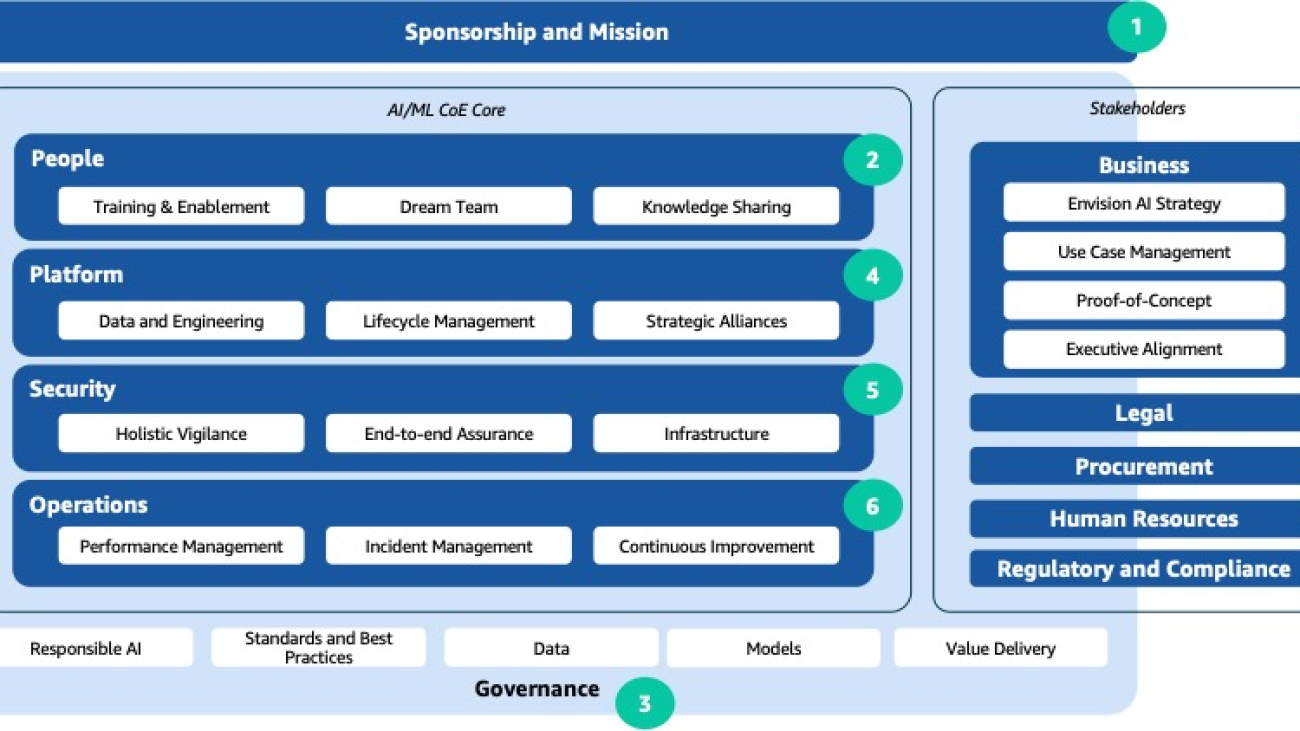
The following figure illustrates the key components for establishing an effective AI/ML CoE.

In the following sections, we discuss each numbered component in detail.
1. Sponsorship and mission
The foundational step in setting up an AI/ML CoE is securing sponsorship from senior leadership, establishing leadership, defining its mission and objectives, and aligning empowered leadership.
Establish sponsorship
Establish clear leadership roles and structure to provide decision-making processes, accountability, and adherence to ethical and legal standards:
- Executive sponsorship – Secure support from senior leadership to champion AI/ML initiatives
- Steering committee – Form a committee of key stakeholders to oversee the AI/ML CoE’s activities and strategic direction
- Ethics board – Create a board to address ethical and responsible AI considerations in AI/ML development and deployment
Define the mission
Making the mission customer- or product-focused and aligned with the organization’s overall strategic goals helps outline the AI/ML CoE’s role in achieving them. This mission, usually set by the executive sponsor in alignment with the heads of business units, serves as a guiding principle for all CoE activities, and contains the following:
- Mission statement – Clearly articulate the purpose of the CoE in advancing customer and product outcomes applying AI/ML technologies
- Strategic objectives – Outline tangible and measurable AI/ML goals that align with the organization’s overall strategic goals
- Value proposition – Quantify the expected business value Key Performance Indicators (KPIs) such as cost savings, revenue gains, user satisfaction, time savings, and time-to-market
2. People
According to a Gartner report, 53% of business, functional, and technical teams rate their technical acumen on generative AI as “Intermediate” and 64% of senior leadership rate their skill as “Novice.” By developing customized solutions tailored to the specific and evolving needs of the business, you can foster a culture of continuous growth and learning and cultivate a deep understanding of AI and ML technologies, including generative AI skill development and enablement.
Training and enablement
To help educate employees on AI/ML concepts, tools, and techniques, the AI/ML CoE can develop training programs, workshops, certification programs, and hackathons. These programs can be tailored to different levels of expertise and designed to help employees understand how to use AI/ML to solve business problems. Additionally, the CoE could provide a mentoring platform to employees who are interested in further enhancing their AI/ML skills, develop certification programs to recognize employees who have achieved a certain level of proficiency in AI/ML, and provide ongoing training to keep the team updated with the latest technologies and methodologies.
Dream team
Cross-functional engagement is essential to achieve well-rounded AI/ML solutions. Having a multidisciplinary AI/ML CoE that combines industry, business, technical, compliance, and operational expertise helps drive innovation. It harnesses the 360 view potential of AI in achieving a company’s strategic business goals. Such a diverse team with AI/ML expertise may include roles such as:
- Product strategists – Make sure all products, features, and experiments are cohesive to the overall transformation strategy
- AI researchers – Employ experts in the field to drive innovation and explore cutting-edge techniques such as generative AI
- Data scientists and ML engineers – Develop capabilities for data preprocessing, model training, and validation
- Domain experts – Collaborate with professionals from business units who understand the specific applications and business need
- Operations – Develop KPIs, demonstrate value delivery, and manage machine learning operations (MLOPs) pipelines
- Project managers – Appoint project managers to implement projects efficiently
Knowledge sharing
By fostering collaboration within the CoE, internal stakeholders, business unit teams, and external stakeholders, you can enable knowledge sharing and cross-disciplinary teamwork. Encourage knowledge sharing, establish a knowledge repository, and facilitate cross-functional projects to maximize the impact of AI/ML initiatives. Some example key actions to foster knowledge sharing are:
- Cross-functional collaborations – Promote teamwork between experts in generative AI and business unit domain-specific professionals to innovate on cross-functional use cases
- Strategic partnerships – Investigate partnerships with research institutions, universities, and industry leaders specializing in generative AI to take advantage of their collective expertise and insights
3. Governance
Establish governance that enables the organization to scale value delivery from AI/ML initiatives while managing risk, compliance, and security. Additionally, pay special attention to the changing nature of the risk and cost that is associated with the development as well as the scaling of AI.
Responsible AI
Organizations can navigate potential ethical dilemmas associated with generative AI by incorporating considerations such as fairness, explainability, privacy and security, robustness, governance, and transparency. To provide ethical integrity, an AI/ML CoE helps integrate robust guidelines and safeguards across the AI/ML lifecycle in collaboration with stakeholders. By taking a proactive approach, the CoE provides ethical compliance but also builds trust, enhances accountability, and mitigates potential risks such as veracity, toxicity, data misuse, and intellectual property concerns.
Standards and best practices
Continuing its stride towards excellence, the CoE helps define common standards, industry-leading practices, and guidelines. These encompass a holistic approach, covering data governance, model development, ethical deployment, and ongoing monitoring, reinforcing the organization’s commitment to responsible and ethical AI/ML practices. Examples of such standards include:
- Development framework – Establishing standardized frameworks for AI development, deployment, and governance provides consistency across projects, making it easier to adopt and share best practices.
- Repositories – Centralized code and model repositories facilitate the sharing of best practices and industry standard solutions in coding standards, enabling teams to adhere to consistent coding conventions for better collaboration, reusability, and maintainability.
- Centralized knowledge hub – A central repository housing datasets and research discoveries to serve as a comprehensive knowledge center.
- Platform – A central platform such as Amazon SageMaker for creation, training, and deployment. It helps manage and scale central policies and standards.
- Benchmarking and metrics – Defining standardized metrics and benchmarking to measure and compare the performance of AI models, and the business value derived.
Data governance
Data governance is a crucial function of an AI/ML CoE, such as making sure data is collected, used, and shared in a responsible and trustworthy manner. Data governance is essential for AI applications, because these applications often use large amounts of data. The quality and integrity of this data are critical to the accuracy and fairness of AI-powered decisions. The AI/ML CoE helps define best practices and guidelines for data preprocessing, model development, training, validation, and deployment. The CoE should make sure that data is accurate, complete, and up-to-date; the data is protected from unauthorized access, use, or disclosure; and data governance policies demonstrate the adherence to regulatory and internal compliance.
Model oversight
Model governance is a framework that determines how a company implements policies, controls access to models, and tracks their activity. The CoE helps make sure that models are developed and deployed in a safe, trustworthy, and ethical fashion. Additionally, it can confirm that model governance policies demonstrate the organization’s commitment to transparency, fostering trust with customers, partners, and regulators. It can also provide safeguards customized to your application requirements and make sure responsible AI policies are implemented using services such as Guardrails for Amazon Bedrock.
Value delivery
Manage the AI/ML initiative return on investment, platform and services expenses, efficient and effective use of resources, and ongoing optimization. This requires monitoring and analyzing use case-based value KPIs and expenditures related to data storage, model training, and inference. This includes assessing the performance of various AI models and algorithms to identify cost-effective, resource-optimal solutions such as using AWS Inferentia for inference and AWS Trainium for training. Setting KPIs and metrics is pivotal to gauge effectiveness. Some example KPIs are:
- Return on investment (ROI) – Evaluating financial returns against investments justifies resource allocation for AI projects
- Business impact – Measuring tangible business outcomes like revenue uplift or enhanced customer experiences validates AI’s value
- Project delivery time – Tracking time from project initiation to completion showcases operational efficiency and responsiveness
4. Platform
The AI/ML CoE, in collaboration with the business and technology teams, can help build an enterprise-grade and scalable AI platform, enabling organizations to operate AI-enabled services and products across business units. It can also help develop custom AI solutions and help practitioners adapt to change in AI/ML development.
Data and engineering architecture
The AI/ML CoE helps set up the right data flows and engineering infrastructure, in collaboration with the technology teams, to accelerate the adoption and scaling of AI-based solutions:
- High-performance computing resources – Powerful GPUs such as Amazon Elastic Compute Cloud (Amazon EC2) instances, powered by the latest NVIDIA H100 Tensor Core GPUs, are essential for training complex models.
- Data storage and management – Implement robust data storage, processing, and management systems such as AWS Glue and Amazon OpenSearch Service.
- Platform – Using cloud platforms can provide flexibility and scalability for AI/ML projects for tasks such as SageMaker, which can help provide end-to-end ML capability across generative AI experimentation, data prep, model training, deployment, and monitoring. This further helps accelerate generative AI workloads from experimentation to production. Amazon Bedrock is an easier way to build and scale generative AI applications with foundation models (FMs). As a fully managed service, it offers a choice of high-performing FMs from leading AI companies including AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon.
- Development tools and frameworks – Use industry-standard AI/ML frameworks and tools such as Amazon CodeWhisperer, Apache MXNet, PyTorch, and TensorFlow.
- Version control and collaboration tools – Git repositories, project management tools, and collaboration platforms can facilitate teamwork, such as AWS CodePipeline and Amazon CodeGuru.
- Generative AI frameworks – Utilize state-of-the-art foundation models, tools, agents, knowledge bases, and guardrails available on Amazon Bedrock.
- Experimentation platforms – Deploy platforms for experimentation and model development, allowing for reproducibility and collaboration, such as Amazon SageMaker JumpStart.
- Documentation – Emphasize the documentation of processes, workflows, and best practices within the platform to facilitate knowledge sharing among practitioners and teams.
Lifecycle management
Within the AI/ML CoE, the emphasis on scalability, availability, reliability, performance, and resilience is fundamental to the success and adaptability of AI/ML initiatives. Implementation and operationalization of a lifecycle management system such as MLOps can help automate deployment and monitoring, resulting in improved reliability, time to market, and observability. Using tools like Amazon SageMaker Pipelines for workflow management, Amazon SageMaker Experiments for managing experiments, and Amazon Elastic Kubernetes Service (Amazon EKS) for container orchestration enables adaptable deployment and management of AI/ML applications, fostering scalability and portability across various environments. Similarly, employing serverless architectures such as AWS Lambda empowers automatic scaling based on demand, reducing operational complexity while offering flexibility in resource allocation.
Strategic alliances in AI services
The decision to buy or build solutions involves trade-offs. Buying offers speed and convenience by using pre-built tools, but may lack customization. On the other hand, building provides tailored solutions but demands time and resources. The balance hinges on the project scope, timeline, and long-term needs, achieving optimal alignment with organizational goals and technical requirements. The decision, ideally, can be based on a thorough assessment of the specific problem to be solved, the organization’s internal capabilities, and the area of the business targeted for growth. For example, if the business system helps establish uniqueness and then builds to differentiate in the market, or if the business system supports a standard commoditized business process, then buys to save.
By partnering with third-party AI service providers, such as AWS Generative AI Competency Partners, the CoE can use their expertise and experience to accelerate the adoption and scaling of AI-based solutions. These partnerships can help the CoE stay up to date with the latest AI/ML research and trends, and can provide access to cutting-edge AI/ML tools and technologies. Additionally, third-party AI service providers can help the CoE identify new use cases for AI/ML and can provide guidance on how to implement AI/ML solutions effectively.
5. Security
Emphasize, assess, and implement security and privacy controls across the organization’s data, AI/ML, and generative AI workloads. Integrate security measures across all aspects of AI/ML to identify, classify, remediate, and mitigate vulnerabilities and threats.
Holistic vigilance
Based on how your organization is using generative AI solutions, scope the security efforts, design resiliency of the workloads, and apply relevant security controls. This includes employing encryption techniques, multifactor authentication, threat detection, and regular security audits to make sure data and systems remain protected against unauthorized access and breaches. Regular vulnerability assessments and threat modeling are crucial to address emerging threats. Strategies such as model encryption, using secure environments, and continuous monitoring for anomalies can help protect against adversarial attacks and malicious misuse. To monitor the model for threats detection, you can use tools like Amazon GuardDuty. With Amazon Bedrock, you have full control over the data you use to customize the foundation models for your generative AI applications. Data is encrypted in transit and at rest. User inputs and model outputs are not shared with any model providers; keeping your data and applications secure and private.
End-to-end assurance
Enforcing the security of the three critical components of any AI system (inputs, model, and outputs) is critical. Establishing clearly defined roles, security policies, standards, and guidelines across the lifecycle can help manage the integrity and confidentiality of the system. This includes implementation of industry best practice measures and industry frameworks, such as NIST, OWASP-LLM, OWASP-ML, MITRE Atlas. Furthermore, evaluate and implement requirements such as Canada’s Personal Information Protection and Electronic Documents Act (PIPEDA) and European Union’s General Data Protection Regulation (GDPR). You can use tools such as Amazon Macie to discover and protect your sensitive data.
Infrastructure (data and systems)
Given the sensitivity of the data involved, exploring and implementing access and privacy-preserving techniques is vital. This involves techniques such as least privilege access, data lineage, keeping only relevant data for use case, and identifying and classifying sensitive data to enable collaboration without compromising individual data privacy. It’s essential to embed these techniques within the AI/ML development lifecycle workflows, maintain a secure data and modeling environment, and stay in compliance with privacy regulations and protect sensitive information. By integrating security-focused measures into the AI/ML CoE’s strategies, the organization can better mitigate risks associated with data breaches, unauthorized access, and adversarial attacks, thereby providing integrity, confidentiality, and availability for its AI assets and sensitive information.
6. Operations
The AI/ML CoE needs to focus on optimizing the efficiency and growth potential of implementing generative AI within the organization’s framework. In this section, we discuss several key aspects aimed at driving successful integration while upholding workload performance.
Performance management
Setting KPIs and metrics is pivotal to gauge effectiveness. Regular assessment of these metrics allows you to track progress, identify trends, and foster a culture of continual improvement within the CoE. Reporting on these insights provides alignment with organizational objectives and informs decision-making processes for enhanced AI/ML practices. Solutions such as Bedrock integration with Amazon CloudWatch, helps track and manage usage metrics, and build customized dashboards for auditing.
An example KPI is model accuracy: assessing models against benchmarks provides reliable and trustworthy AI-generated outcomes.
Incident management
AI/ML solutions need ongoing control and observation to manage any anomalous activities. This requires establishing processes and systems across the AI/ML platform, ideally automated. A standardized incident response strategy needs to be developed and implemented in alignment with the chosen monitoring solution. This includes elements such as formalized roles and responsibilities, data sources and metrics to be monitored, systems for monitoring, and response actions such as mitigation, escalation, and root cause analysis.
Continuous improvement
Define rigorous processes for generative AI model development, testing, and deployment. Streamline the development of generative AI models by defining and refining robust processes. Regularly evaluate the AI/ML platform performance and enhance generative AI capabilities. This involves incorporating feedback loops from stakeholders and end-users and dedicating resources to exploratory research and innovation in generative AI. These practices drive continual improvement and keep the CoE at the forefront of AI innovation. Furthermore, implement generative AI initiatives seamlessly by adopting agile methodologies, maintaining comprehensive documentation, conducting regular benchmarking, and implementing industry best practices.
7. Business
The AI/ML CoE helps drive business transformation by continuously identifying priority pain points and opportunities across business units. Aligning business challenges and opportunities to customized AI/ML capabilities, the CoE drives rapid development and deployment of high-value solutions. This alignment to real business needs enables step-change value creation through new products, revenue streams, productivity, optimized operations, and customer satisfaction.
Envision an AI strategy
With the objective to drive business outcomes, establish a compelling multi-year vision and strategy on how the adoption of AI/ML and generative AI techniques can transform major facets of the business. This includes quantifying the tangible value at stake from AI/ML in terms of revenues, cost savings, customer satisfaction, productivity, and other vital performance indicators over a defined strategic planning timeline, such as 3–5 years. Additionally, the CoE must secure buy-in from executives across business units by making the case for how embracing AI/ML will create competitive advantages and unlock step-change improvements in key processes or offerings.
Use case management
To identify, qualify, and prioritize the most promising AI/ML use cases, the CoE facilitates an ongoing discovery dialogue with all business units to surface their highest-priority challenges and opportunities. Each complex business issue or opportunity must be articulated by the CoE, in collaboration with business unit leaders, as a well-defined problem and opportunity statement that lends itself to an AI/ML-powered solution. These opportunities establish clear success metrics tied to business KPIs and outline the potential value impact vs. implementation complexity. A prioritized pipeline of high-potential AI/ML use cases can then be created, ranking opportunities based on expected business benefit and feasibility.
Proof of concept
Before undertaking full production development, prototype proposed solutions for high-value use cases through controlled proof of concept (PoC) projects focused on demonstrating initial viability. Rapid feedback loops during these PoC phases allow for iteration and refinement of approaches at a small scale prior to wider deployment. The CoE establishes clear success criteria for PoCs, in alignment with business unit leaders, that map to business metrics and KPIs for ultimate solution impact. Furthermore, the CoE can engage to share expertise, reusable assets, best practices, and standards.
Executive alignment
To provide full transparency, the business unit executive stakeholders must be aligned with AI/ML initiatives, and have regular reporting with them. This way, any challenges that need to be escalated can be quickly resolved with executives who are familiar with the initiatives.
8. Legal
The legal landscape of AI/ML and generative AI is complex and evolving, presenting a myriad of challenges and implications for organizations. Issues such as data privacy, intellectual property, liability, and bias require careful consideration within the AI/ML CoE. As regulations struggle to keep pace with technological advancements, the CoE must partner with the organization’s legal team to navigate this dynamic terrain to enforce compliance and responsible development and deployment of these technologies. The evolving landscape demands that the CoE, working in collaboration with the legal team, develops comprehensive AI/ML governance policies covering the entire AI/ML lifecycle. This process involves business stakeholders in decision-making processes and regular audits and reviews of AI/ML systems to validate compliance with governance policies.
9. Procurement
The AI/ML CoE needs to work with partners, both Independent Software Vendors (ISV) and System Integrators (SI) to help with the buy and build strategies. They need to partner with the procurement team to develop a selection, onboarding, management, and exit framework. This includes acquiring technologies, algorithms, and datasets (sourcing reliable datasets is crucial for training ML models, and acquiring cutting-edge algorithms and generative AI tools enhances innovation). This will help accelerated development of capabilities needed for business. Procurement strategies must prioritize ethical considerations, data security, and ongoing vendor support to provide sustainable, scalable, and responsible AI integration.
10. Human Resources
Partner with Human Resources (HR) on AI/ML talent management and pipeline. This involves cultivating talent to understand, develop, and implement these technologies. HR can help bridge the technical and non-technical divide, fostering interdisciplinary collaboration, building a path for onboarding new talent, training them, and growing them on both professional and skills. They can also address ethical concerns through compliance training, upskill employees on the latest emerging technologies, and manage the impact of job roles that are critical for continued success.
11. Regulatory and compliance
The regulatory landscape for AI/ML is rapidly evolving, with governments worldwide racing to establish governance regimes for the increasing adoption of AI applications. The AI/ML CoE needs a focused approach to stay updated, derive actions, and implement regulatory legislations such as Brazil’s General Personal Data Protection Law (LGPD), Canada’s Personal Information Protection and Electronic Documents Act (PIPEDA), and the European Union’s General Data Protection Regulation (GDPR), and frameworks such as ISO 31700, ISO 29100, ISO 27701, Federal Information Processing Standards (FIPS), and NIST Privacy Framework. In the US, regulatory actions include mitigating risks posed by the increased adoption of AI, protecting workers affected by generative AI, and providing stronger consumer protections. The EU AI Act includes new assessment and compliance requirements.
As AI regulations continue to take shape, organizations are advised to establish responsible AI as a C-level priority, set and enforce clear governance policies and processes around AI/ML, and involve diverse stakeholders in decision-making processes. The evolving regulations emphasize the need for comprehensive AI governance policies that cover the entire AI/ML lifecycle, and regular audits and reviews of AI systems to address biases, transparency, and explainability in algorithms. Adherence to standards fosters trust, mitigates risks, and promotes responsible deployment of these advanced technologies.
Conclusion
The journey to establishing a successful AI/ML center of excellence is a multifaceted endeavor that requires dedication and strategic planning, while operating with agility and collaborative spirit. As the landscape of artificial intelligence and machine learning continues to evolve at a rapid pace, the creation of an AI/ML CoE represents a necessary step towards harnessing these technologies for transformative impact. By focusing on the key considerations, from defining a clear mission to fostering innovation and enforcing ethical governance, organizations can lay a solid foundation for AI/ML initiatives that drive value. Moreover, an AI/ML CoE is not just a hub for technological innovation; it’s a beacon for cultural change within the organization, promoting a mindset of continuous learning, ethical responsibility, and cross-functional collaboration.
Stay tuned as we continue to explore the AI/ML CoE topics in our upcoming posts in this series. If you need help establishing an AI/ML Center of Excellence, please reach out to a specialist.
About the Authors
 Ankush Chauhan is a Sr. Manager, Customer Solutions at AWS based in New York, US. He supports Capital Markets customers optimize their cloud journey, scale adoption, and realize the transformative value of building and inventing in the cloud. In addition, he is focused on enabling customers on their AI/ML journeys including generative AI. Beyond work, you can find Ankush running, hiking, or watching soccer.
Ankush Chauhan is a Sr. Manager, Customer Solutions at AWS based in New York, US. He supports Capital Markets customers optimize their cloud journey, scale adoption, and realize the transformative value of building and inventing in the cloud. In addition, he is focused on enabling customers on their AI/ML journeys including generative AI. Beyond work, you can find Ankush running, hiking, or watching soccer.
 Ava Kong is a Generative AI Strategist at the AWS Generative AI Innovation Center, specializing in the financial services sector. Based in New York, Ava has worked closely with a variety of financial institutions on a variety of use cases, combining the latest in generative AI technology with strategic insights to enhance operational efficiency, drive business outcomes, and demonstrate the broad and impactful application of AI technologies.
Ava Kong is a Generative AI Strategist at the AWS Generative AI Innovation Center, specializing in the financial services sector. Based in New York, Ava has worked closely with a variety of financial institutions on a variety of use cases, combining the latest in generative AI technology with strategic insights to enhance operational efficiency, drive business outcomes, and demonstrate the broad and impactful application of AI technologies.
 Vikram Elango is a Sr. AI/ML Specialist Solutions Architect at AWS, based in Virginia, US. He is currently focused on generative AI, LLMs, prompt engineering, large model inference optimization, and scaling ML across enterprises. Vikram helps financial and insurance industry customers with design and thought leadership to build and deploy machine learning applications at scale. In his spare time, he enjoys traveling, hiking, cooking, and camping with his family.
Vikram Elango is a Sr. AI/ML Specialist Solutions Architect at AWS, based in Virginia, US. He is currently focused on generative AI, LLMs, prompt engineering, large model inference optimization, and scaling ML across enterprises. Vikram helps financial and insurance industry customers with design and thought leadership to build and deploy machine learning applications at scale. In his spare time, he enjoys traveling, hiking, cooking, and camping with his family.
 Rifat Jafreen is a Generative AI Strategist in the AWS Generative AI Innovation center where her focus is to help customers realize business value and operational efficiency by using generative AI. She has worked in industries across telecom, finance, healthcare and energy; and onboarded machine learning workloads for numerous customers. Rifat is also very involved in MLOps, FMOps and Responsible AI.
Rifat Jafreen is a Generative AI Strategist in the AWS Generative AI Innovation center where her focus is to help customers realize business value and operational efficiency by using generative AI. She has worked in industries across telecom, finance, healthcare and energy; and onboarded machine learning workloads for numerous customers. Rifat is also very involved in MLOps, FMOps and Responsible AI.
Authors would like to extend special thanks to Arslan Hussain, David Ping, Jarred Graber, and Raghvender Arni, for their support, expertise, and guidance.



 NVIDIA GeForce NOW (@NVIDIAGFN)
NVIDIA GeForce NOW (@NVIDIAGFN) 

 Hemant Singh is an Applied Scientist with experience in Amazon SageMaker JumpStart. He got his master’s from Courant Institute of Mathematical Sciences and B.Tech from IIT Delhi. He has experience in working on a diverse range of machine learning problems within the domain of natural language processing, computer vision, and time series analysis.
Hemant Singh is an Applied Scientist with experience in Amazon SageMaker JumpStart. He got his master’s from Courant Institute of Mathematical Sciences and B.Tech from IIT Delhi. He has experience in working on a diverse range of machine learning problems within the domain of natural language processing, computer vision, and time series analysis. Rachna Chadha is a Principal Solutions Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that the ethical and responsible use of AI can improve society in the future and bring economic and social prosperity. In her spare time, Rachna likes spending time with her family, hiking, and listening to music.
Rachna Chadha is a Principal Solutions Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that the ethical and responsible use of AI can improve society in the future and bring economic and social prosperity. In her spare time, Rachna likes spending time with her family, hiking, and listening to music. Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.






 Chamika Ramanayake is the Head of AI Platforms at Dialog Axiata PLC, Sri Lanka’s leading telecommunications company. He leverages his 7 years of experience in the telecommunication industry when leading his team to design and set the foundation to operationalize the end-to-end AI/ML system life cycle in the AWS cloud environment. He holds an MBA from PIM, University of Sri Jayawardenepura, and a B.Sc. Eng (Hons) in Electronics and Telecommunication Engineering from the University of Moratuwa.
Chamika Ramanayake is the Head of AI Platforms at Dialog Axiata PLC, Sri Lanka’s leading telecommunications company. He leverages his 7 years of experience in the telecommunication industry when leading his team to design and set the foundation to operationalize the end-to-end AI/ML system life cycle in the AWS cloud environment. He holds an MBA from PIM, University of Sri Jayawardenepura, and a B.Sc. Eng (Hons) in Electronics and Telecommunication Engineering from the University of Moratuwa.












 Siamak Nariman is a Senior Product Manager at AWS. He is focused on AI/ML technology, digital transformation, and enabling automation to improve overall organizational efficiency and productivity. He has over 7 years of automation experience deploying various technologies. In his spare time, Siamak enjoys exploring the outdoors, long-distance running, and playing sports.
Siamak Nariman is a Senior Product Manager at AWS. He is focused on AI/ML technology, digital transformation, and enabling automation to improve overall organizational efficiency and productivity. He has over 7 years of automation experience deploying various technologies. In his spare time, Siamak enjoys exploring the outdoors, long-distance running, and playing sports. Kareem Syed-Mohammed is a Product Manager at AWS. He is focused on ML Observability and ML Governance. Prior to this, at Amazon QuickSight, he led embedded analytics, and developer experience. In addition to QuickSight, he has been with AWS Marketplace and Amazon retail as a Product Manager. Kareem started his career as a developer for call center technologies, Local Expert and Ads for Expedia, and management consultant at McKinsey.
Kareem Syed-Mohammed is a Product Manager at AWS. He is focused on ML Observability and ML Governance. Prior to this, at Amazon QuickSight, he led embedded analytics, and developer experience. In addition to QuickSight, he has been with AWS Marketplace and Amazon retail as a Product Manager. Kareem started his career as a developer for call center technologies, Local Expert and Ads for Expedia, and management consultant at McKinsey. Dr. Sokratis Kartakis is a Principal Machine Learning and Operations Specialist Solutions Architect at AWS. Sokratis focuses on enabling enterprise customers to industrialize their Machine Learning (ML) and generative AI solutions by exploiting AWS services and shaping their operating model, i.e. MLOps/FMOps/LLMOps foundations, and transformation roadmap leveraging best development practices. He has spent 15+ years on inventing, designing, leading, and implementing innovative end-to-end production-level ML and AI solutions in the domains of energy, retail, health, finance, motorsports etc.
Dr. Sokratis Kartakis is a Principal Machine Learning and Operations Specialist Solutions Architect at AWS. Sokratis focuses on enabling enterprise customers to industrialize their Machine Learning (ML) and generative AI solutions by exploiting AWS services and shaping their operating model, i.e. MLOps/FMOps/LLMOps foundations, and transformation roadmap leveraging best development practices. He has spent 15+ years on inventing, designing, leading, and implementing innovative end-to-end production-level ML and AI solutions in the domains of energy, retail, health, finance, motorsports etc. Ram Vittal is a Principal ML Solutions Architect at AWS. He has over 3 decades of experience architecting and building distributed, hybrid, and cloud applications. He is passionate about building secure and scalable AI/ML and big data solutions to help enterprise customers with their cloud adoption and optimization journey to improve their business outcomes. In his spare time, he rides his motorcycle and walks with his 3-year-old Sheepadoodle.
Ram Vittal is a Principal ML Solutions Architect at AWS. He has over 3 decades of experience architecting and building distributed, hybrid, and cloud applications. He is passionate about building secure and scalable AI/ML and big data solutions to help enterprise customers with their cloud adoption and optimization journey to improve their business outcomes. In his spare time, he rides his motorcycle and walks with his 3-year-old Sheepadoodle.



 Our new AI model AlphaFold 3 can predict the structure and interactions of all life’s molecules with unprecedented accuracy.
Our new AI model AlphaFold 3 can predict the structure and interactions of all life’s molecules with unprecedented accuracy.
