 Learn how new Google AI on Android features can boost employee productivity, help developers to build smarter tools and improve business workflows.Read More
Learn how new Google AI on Android features can boost employee productivity, help developers to build smarter tools and improve business workflows.Read More

Learn how new Google AI on Android features can boost employee productivity, help developers to build smarter tools and improve business workflows.Read More

Editor’s note: This post is part of Into the Omniverse, a series focused on how artists, developers and enterprises can transform their workflows using the latest advances in OpenUSD and NVIDIA Omniverse.
Industrial digitalization is driving automotive innovation.
In response to the industry’s growing demand for seamless, connected driving experiences, SoftServe, a leading IT consulting and digital services provider, worked with Continental, a leading German automotive technology company, to develop Industrial Co-Pilot, a virtual agent powered by generative AI that enables engineers to streamline maintenance workflows.
SoftServe helps manufacturers like Continental to further optimize their operations by integrating the Universal Scene Description, or OpenUSD, framework into virtual factory solutions — such as Industrial Co-Pilot — developed on the NVIDIA Omniverse platform.
OpenUSD offers the flexibility and extensibility organizations need to harness the full potential of digital transformation, streamlining operations and driving efficiency. Omniverse is a platform of application programming interfaces, software development kits and services that enable developers to easily integrate OpenUSD and NVIDIA RTX rendering technologies into existing software tools and simulation workflows.
Realizing the Benefits of OpenUSD
SoftServe and Continental’s Industrial Co-Pilot brings together generative AI and immersive 3D visualization to help factory teams increase productivity during equipment and production line maintenance. With the copilot, engineers can oversee production lines and monitor the performance of individual stations or the shop floor.
They can also interact with the copilot to conduct root cause analysis and receive step-by-step work instructions and recommendations, leading to reduced documentation processes and improved maintenance procedures. It’s expected that these advancements will contribute to increased productivity and a10% reduction in maintenance effort and downtime.
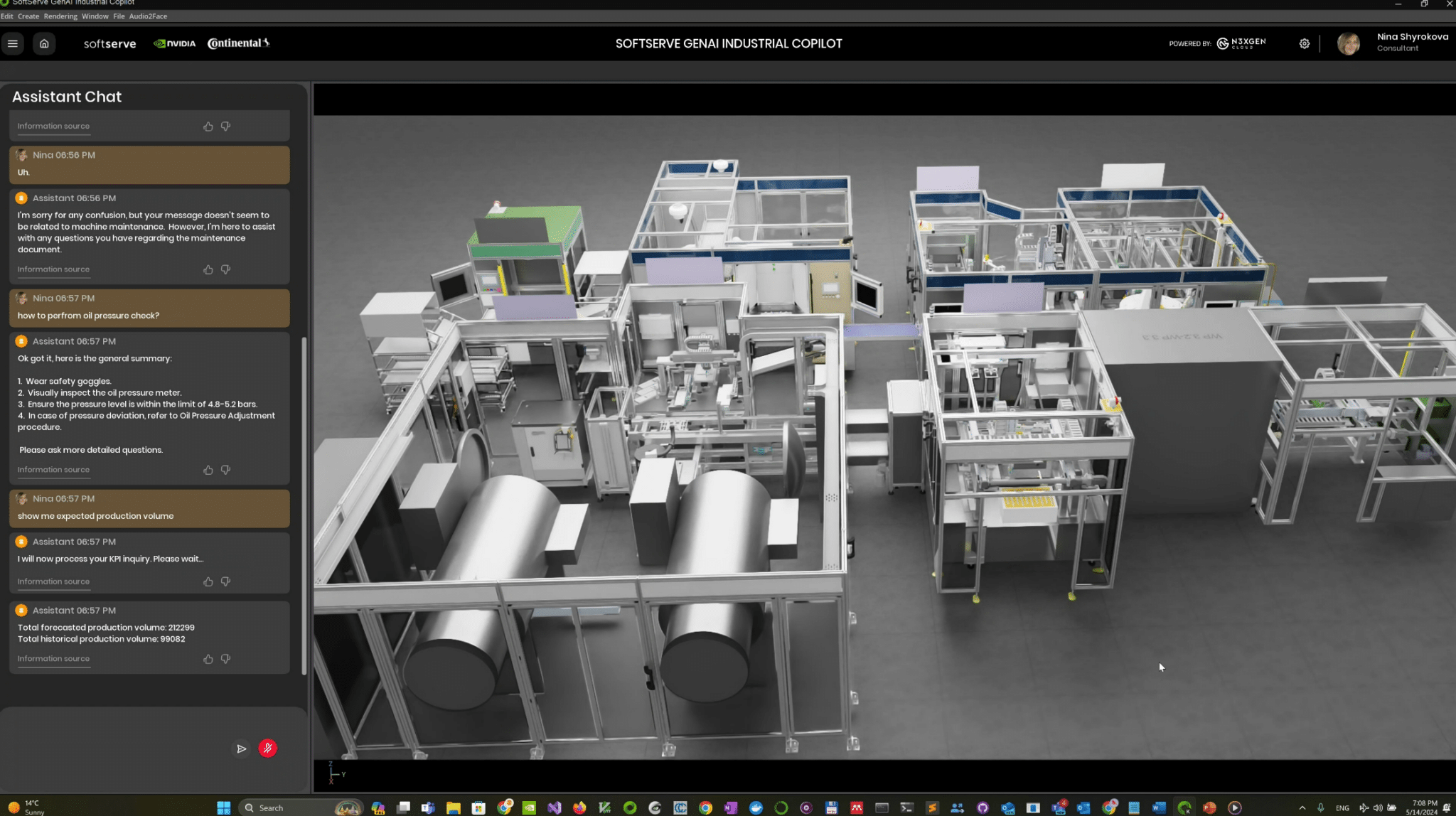
In a recent Omniverse community livestream, Benjamin Huber, who leads advanced automation and digitalization in the user experience business area at Continental, highlighted the significance of the company’s collaboration with SoftServe and its adoption of Omniverse.
The Omniverse platform equips Continental and SoftServe developers with the tools needed to build a new era of AI-enabled industrial applications and services. And by breaking down data silos and fostering multi-platform cooperation with OpenUSD, SoftServe and Continental developers enable engineers to work seamlessly across disciplines and systems, driving efficiency and innovation throughout their processes.
“Any engineer, no matter what tool they’re working with, can transform their data into OpenUSD and then interchange data from one discipline to another, and from one tool to another,” said Huber.
This sentiment was echoed by Vasyl Boliuk, senior lead and test automation engineer at SoftServe, who shared how OpenUSD and Omniverse — along with other NVIDIA technologies like NVIDIA Riva, NVIDIA NeMo and NVIDIA NIM microservices — enabled SoftServe and Continental teams to develop custom large language models and connect them to new 3D workflows.
“OpenUSD allows us to add any attribute or any piece of metadata we want to our applications,” he said.
Boliuk, Huber and other SoftServe and Continental representatives joined the livestream to share more about the potential unlocked from these OpenUSD-powered solutions. Watch the replay:
By embracing cutting-edge technologies and fostering collaboration, SoftServe and Continental are helping reshape automotive manufacturing.
Get Plugged Into the World of OpenUSD
Watch SoftServe and Continental’s on-demand NVIDIA GTC talks to learn more about their virtual factory solutions and experience developing on NVIDIA Omniverse with OpenUSD:
Learn about the latest technologies driving the next industrial revolution by watching NVIDIA founder and CEO Jensen Huang’s COMPUTEX keynote on Sunday, June 2, at 7 p.m. Taiwan time.
Check out a new video series about how OpenUSD can improve 3D workflows. For more resources on OpenUSD, explore the Alliance for OpenUSD forum and visit the AOUSD website.
Get started with NVIDIA Omniverse by downloading the standard license free, access OpenUSD resources and learn how Omniverse Enterprise can connect teams. Follow Omniverse on Instagram, Medium and X. For more, join the Omniverse community on the forums, Discord server, Twitch and YouTube channels.
Featured image courtesy of SoftServe.

Every week, GFN Thursday brings new games to the cloud, featuring some of the latest and greatest titles for members to play.
Leading the seven games joining GeForce NOW this week is the newest game in Ninja Theory’s Hellblade franchise, Senua’s Saga: Hellblade II. This day-and-date release expands the cloud gaming platform’s extensive library of over 1,900 games.
Members can also look forward to a new reward — a free in-game mount — for The Elder Scrolls Online starting Thursday, May 30. Get ready by opting into GeForce NOW’s Rewards program.

In Senua’s Saga: Hellblade II, the sequel to the award-winning Hellblade: Senua’s Sacrifice, Senua returns in a brutal journey of survival through the myth and torment of Viking Iceland.
Intent on saving those who’ve fallen victim to the horrors of tyranny, Senua battles the forces of darkness within and without. Sink deep into the next chapter of Senua’s story, a crafted experience told through cinematic immersion, beautifully realized visuals and encapsulating sound.
Priority and Ultimate members can fully immerse themselves in Senua’s story with epic cinematic gameplay at higher resolutions and frame rates over free members. Ultimate members can stream at up to 4K 120 frames per second with exclusive access to GeForce RTX 4080 SuperPODs in the cloud, even on underpowered devices.
Check out the full list of new games this week:
What are you planning to play this weekend? Let us know on X or in the comments below
what’s a life lesson you learned from a game?
—
NVIDIA GeForce NOW (@NVIDIAGFN) May 22, 2024


Behind every emerging technology is a great idea propelling it forward. In the new Microsoft Research Podcast series, Ideas, members of the research community at Microsoft discuss the beliefs that animate their research, the experiences and thinkers that inform it, and the positive human impact it targets.
In this episode, host Gretchen Huizinga talks with Distinguished Scientist and Lab Director Abigail Sellen. The idea that computers could be designed for people is commonplace today, but when Sellen was pursuing an advanced degree in psychology, it was a novel one that set her on course for a career in human-centric computing. Today, Sellen and the teams she oversees are studying how AI could—and should—be designed for people, focusing on helping to ensure new developments support people in growing the skills and qualities they value. Sellen explores those efforts through the AI, Cognition, and the Economy initiative—or AICE, for short—a collective of interdisciplinary scientists examining the short- and long-term effects of generative AI on human cognition, organizational structures, and the economy.
AI, Cognition, and the Economy (AICE)
Initiative page
Responsible AI Principles and Approach | Microsoft AI
The Rise of the AI Co-Pilot: Lessons for Design from Aviation and Beyond
Publication, 2023
The Myth of the Paperless Office
Book, 2003
GRETCHEN HUIZINGA: Hey, listeners. It’s host Gretchen Huizinga. Microsoft Research podcasts are known for bringing you stories about the latest in technology research and the scientists behind it. But if you want to dive even deeper, I encourage you to attend Microsoft Research Forum. Each episode is a series of talks and panels exploring recent advances in research, bold new ideas, and important discussions with the global research community in the era of general AI. The next episode is coming up on June 4, and you can register now at aka.ms/MyResearchForum (opens in new tab). Now, here’s today’s show.
[END OF SPOT] [TEASER] [MUSIC PLAYS UNDER DIALOGUE]ABIGAIL SELLEN: I’m not saying that we shouldn’t take concerns seriously about AI or be hugely optimistic about the opportunities, but rather, my view on this is that we can do research to get, kind of, line of sight into the future and what is going to happen with AI. And more than this, we should be using research to not just get line of sight but to steer the future, right. We can actually help to shape it. And especially being at Microsoft, we have a chance to do that.
[TEASER ENDS]GRETCHEN HUIZINGA: You’re listening to Ideas, a Microsoft Research Podcast that dives deep into the world of technology research and the profound questions behind the code. I’m Dr. Gretchen Huizinga. In this series, we’ll explore the technologies that are shaping our future and the big ideas that propel them forward.
My guest on this episode is Abigail Sellen, known by her friends and colleagues as Abi. A social scientist by training and an expert in human-computer interaction, Abi has a long list of accomplishments and honors, and she’s a fellow of many technical academies and societies. But today I’m talking to her in her role as distinguished scientist and lab director of Microsoft Research Cambridge, UK, where she oversees a diverse portfolio of research, some of which supports a new initiative centered around the big idea of AI, Cognition, and the Economy, also known as AICE. Abi Sellen. I’m so excited to talk to you today. Welcome to Ideas!
ABIGAIL SELLEN: Thanks! Me, too.
HUIZINGA: So before we get into an overview of the ideas behind AICE research, let’s talk about the big ideas behind you. Tell us your own research origin story, as it were, and if there was one, what big idea or animating “what if?” captured your imagination and inspired you to do what you’re doing today?
SELLEN: OK, well, you’re asking me to go back in the mists of time a little bit, but let me try. [LAUGHTER] So I would say, going … this goes back to my time when I started doing my PhD at UC San Diego. So I had just graduated as a psychologist from the University of Toronto, and I was going to go off and do a PhD in psychology with a guy called Don Norman. So back then, I really had very little interest in computers. And in fact, computers weren’t really a thing that normal people used. [LAUGHTER] They were things that you might, like, put punch cards into. Or, in fact, in my undergrad days, I actually programmed in hexadecimal, and it was horrible. But at UCSD, they were using computers everywhere, and it was, kind of, central to how everyone worked. And we even had email back then. So computers weren’t really for personal use, and it was clear that they were designed for engineers by engineers. And so they were horrible to use, people grappling with them, people were making mistakes. You could easily remove all your files just by doing rm*. So the big idea that was going around the lab at the time—and this was by a bunch of psychologists, not just Don, but other ones—was that we could design computers for people, for people to use, and take into account, you know, how people act and interact with things and what they want. And that was a radical idea at the time. And that was the start of this field called human-computer interaction, which is … you know, now we talk about designing computers for people and “user-friendly” and that’s a, kind of, like, normal thing, but back then …
HUIZINGA: Yeah …
SELLEN: … it was a radical idea. And so, to me, that changed everything for me to think about how we could design technology for people. And then, if I can, I’ll talk about one other thing that happened …
HUIZINGA: Yeah, please.
SELLEN: … during that time. So at that time, there was another gang of psychologists, people like Dave Rumelhart, Geoff Hinton, Jay McClelland, people like that, who were thinking about, how do we model human intelligence—learning, memory, cognition—using computers? And so these were psychologists thinking about, how do people represent ideas and knowledge, and how can we do that with computers?
HUIZINGA: Yeah …
SELLEN: And this was radical at the time because cognitive psychologists back then were thinking about … they did lots of, kind of, flow chart models of human cognition. And people like Dave Rumelhart did networks, neural networks, …
HUIZINGA: Ooh …
SELLEN: … and they were using what were then called spreading activation models of memory and things, which came from psychology. And that’s interesting because not only were they modeling human cognition in this, kind of, what they called parallel distributed processing, but they operationalized it. And that’s where Hinton and others came up with the back-propagation algorithm, and that was a huge leap forward in AI. So psychologists were actually directly responsible for the wave of AI we see today. A lot of computer scientists don’t know that. A lot of machine learning people don’t know that. But so, for me, long story short, that time in my life and doing my PhD at UC San Diego led to me understanding that social science, psychology in particular, and computing should be seen as things which mutually support one another and that can lead to huge breakthroughs in how we design computers and computer algorithms and how we do computing. So that, kind of, set the path for the rest of my career. And that was 40 years ago!
HUIZINGA: Did you have what we’ll call metacognition of that being an aha moment for you, and like, I’m going to embrace this, and this is my path forward? Or was it just, sort of, more iterative: these things interest you, you take the next step, these things interest you more, you take that step?
SELLEN: I think it was an aha moment at certain points. Like, for example, the day that Francis Crick walked into our seminar and started talking about biologically inspired models of computing, I thought, “Ooh, there’s something big going on here!”
HUIZINGA: Wow, yeah.
SELLEN: Because even then I knew that he was a big deal. So I knew there was something happening that was really, really interesting. I didn’t think so much about it from the point of view of, you know, I would have a career of helping to design human-centric computing, but more, wow, there’s a breakthrough in psychology and how we understand the human mind. And I didn’t realize at that time that that was going to lead to what’s happening in AI today.
HUIZINGA: Well, let’s talk about some of these people that were influential for you as a follow-up to the animating “big idea.” If I’m honest, Abi, my jaw dropped a little when I read your bio because it’s like a who’s who of human-centered computing and UX design. And now these people are famous. Maybe they weren’t so much at the time. But tell us about the influential people in your life, and how their ideas inspired you?
SELLEN: Yeah, sure, happy to. In fact, I’ll start with one person who is not a, sort of, HCI person, but my stepfather, John Senders, was this remarkable human being. He died three years ago at the age of 98. He worked almost to his dying day. Just an amazing man. He entered my life when I was about 13. He joined the family. And he went to Harvard. He trained with people like Skinner. He was taught by these, kind of, famous psychologists of the 20th century, and they were his friends and his colleagues, and he introduced me to a lot of them. You know, people like Danny Kahneman and, you know, Amos Tversky and Alan Baddeley, and all these people that, you know, I had learned about as an undergrad. But the main thing that John did for me was to open my eyes to how you could think about modeling humans as machines. And he really believed that. He was not only a psychologist, but he was an engineer. And he, sort of, kicked off or he was one of the founders of the field of human factors engineering. And that’s what human factors engineers do. They look at people, and they think, how can we mathematically model them? So, you know, we’d be sitting by a pool, and he’d say, “You can use information sampling to model the frequency with which somebody has to watch a baby as they go towards the pool. And it depends on their velocity and then their trajectory… !” [LAUGHTER] Or we go into a bank, and he’d say, “Abi, how would you use queuing theory to, you know, estimate the mean wait time?” Like, you know, so he got me thinking like that, and he recognized in me that I had this curiosity about the world and about people, but also, that I loved mathematics. So he was the first guy. Don Norman, I’ve already mentioned as my PhD supervisor, and I’ve said something about already how he, sort of, had this radical idea about designing computers for people. And I was fortunate to be there when the field of human-computer interaction was being born, and that was mainly down to him. And he’s just [an] incredible guy. He’s still going. He’s still working, consulting, and he wrote this famous book called The Psychology of Everyday Things, which now is, I think it’s been renamed The Design of Everyday Things, and he was really influential and been a huge supporter of mine. And then the third person I’ll mention is Bill Buxton. And …
HUIZINGA: Yeah …
SELLEN: Bill, Bill …
HUIZINGA: Bill, Bill, Bill! [LAUGHTER]
SELLEN: Yeah. I met Bill at, first, well, actually first at University of Toronto; when I was a grad student, I went up and told him his … the experiment he was describing was badly designed. And instead of, you know, brushing me off, he said, “Oh really, OK, I want to talk to you about that.” And then I met him at Apple later when I was an intern, and we just started working together. And he is, he’s just … amazing designer. Everything he does is based on, kind of, theory and deep thought. And he’s just so much fun. So I would say those three people have been big influences on me.
HUIZINGA: Yeah. What about Marilyn Tremaine? Was she a factor in what you did?
SELLEN: Yes, yeah, she was great. And Ron Baecker. So…
HUIZINGA: Yeah …
SELLEN: … after I did my PhD, I did a postdoc at Toronto in the Dynamic Graphics Project Lab. And they were building a media space, and they asked me to join them. And Marilyn and Ron and Bill were building this video telepresence media space, which was way ahead of its time.
HUIZINGA: Yeah.
SELLEN: So I worked with all three of them, and they were great fun.
HUIZINGA: Well, let’s talk about the research initiative AI, Cognition, and the Economy. For context, this is a global, interdisciplinary effort to explore the impact of generative AI on human cognition and thinking, work dynamics and practices, and labor markets and the economy. Now, we’ve already lined up some AICE researchers to come on the podcast and talk about specific projects, including pilot studies, workshops, and extended collaborations, but I’d like you to act as a, sort of, docent or tour guide for the initiative, writ large, and tell us why, particularly now, you think it’s important to bring this group of scientists together and what you hope to accomplish.
SELLEN: I think it’s important now because I think there are so many extreme views out there about how AI is going to impact people. A lot of hyperbole, right. So there’s a lot of fear about, you know, jobs going away, people being replaced, robots taking over the world. And there’s a lot of enthusiasm about how, you know, we’re all going to be more productive, have more free time, how it’s going to be the answer to all our problems. And so I think there are people at either end of that conversation. And I always … I love the Helen Fielding quote … I don’t know if you know Helen Fielding. She wrote…
HUIZINGA: Yeah, Bridget Jones’s Diary …
SELLEN: … Bridget Jones’s Diary. Yeah. [LAUGHTER] She says, “Nothing is either as bad or as good as it seems,” right. And I live by that because I think things are usually somewhere in the middle. So I’m not saying that we shouldn’t take concerns seriously about AI or be hugely optimistic about the opportunities, but rather, my view on this is that we can do research to get, kind of, line of sight into the future and what is going to happen with AI. And more than this, we should be using research to not just get line of sight but to steer the future, right. We can actually help to shape it. And especially being at Microsoft, we have a chance to do that. So what I mean here is that let’s begin by understanding first the capabilities of AI and get a good understanding of where it’s heading and the pace that it’s heading at because it’s changing so fast, right.
HUIZINGA: Mm-hmm …
SELLEN: And then let’s do some research looking at the impact, both in the short term and the long term, about its impact on tasks, on interaction, and, most importantly for me anyway, on people. Yeah, and then we can extrapolate out how this is going to impact jobs, skills, organizations, society at large, you know. So we get this, kind of, arc that we can trace, but we do it because we do research. We don’t just rely on the hyperbole and speculation, but we actually try and do it more systematically. And then I think the last piece here is that if we’re going to do this well and if we think about what AI’s impact can be, which we think is going to impact on a global scale, we need many different skills and disciplines. We need not just machine learning people and engineering and computer scientists at large, but we need designers, we need social scientists, we need even philosophers, and we need domain experts, right. So we need to bring all of these people together to do this properly.
HUIZINGA: Interesting. Well, let’s do break it down a little bit then. And I want to ask you a couple questions about each of the disciplines within the acronym A-I-C-E, or AICE. And I’ll start with AI and another author that we can refer to. Sci-fi author and futurist Arthur C. Clarke famously said that “any sufficiently advanced technology is indistinguishable from magic,” and for many people, AI systems seem to be magic. So in response to that, many in the industry have emphatically stated that AI is just a tool. But you’ve said things like AI is more a “collaborative copilot than a mere tool,” and recently, you said we might even think of it as a “very smart and intuitive butler.” So how do those ideas from the airline industry and Downton Abbey help us better understand and position AI and its role in our world?
SELLEN: Well, I’m going to use Wodehouse here in a minute as well, but um … so I think AI is different from many other tech developments in a number of important ways. One is, it has agency, right. So it can take initiative and do things on your behalf. It’s highly complex, and, you know, it’s getting more complex by the day. It changes. It’s dynamic. It’s probabilistic rather than deterministic, so it will give you different answers depending on when, you know, when you ask it and what you ask it. And it’s based on human-generated data. So it’s a vastly different kind of tool than HCI, as a field, has studied in the past. There are lots of downsides to that, right. One is it means it’s very hard to understand how it works under the hood, right …
HUIZINGA: Yeah …
SELLEN: … and understanding the output. It’s fraught with uncertainty because the output changes every time you use it. But then let’s think about the upsides, especially, large language models give us a way of conversationally interacting with AI like never before, right. So it really is a new interaction paradigm which has finally come of age. So I do think it’s going to get more personal over time and more anticipatory of our needs. And if we design it right, it can be like the perfect butler. So if you know P.G. Wodehouse, Jeeves and Wooster, you know, Jeeves knows that Bertie has had a rough night and has a hangover, so he’s there at the bedside with a tonic and a warm bath already ready for him. But he also knows what Wooster enjoys and what decisions should be left to him, and he knows when to get out of the way. He also knows when to be very discreet, right. So when I use that butler metaphor, I think about how it’s going to take time to get this right, but eventually, we may live in a world where AI helps us with good attention to privacy of getting that kind of partnership right between Jeeves and Wooster.
HUIZINGA: Right. Do you think that’s possible?
SELLEN: I don’t think we’ll ever get it exactly right, but if we have a conversational system where we can mutually shape the interaction, then even if Jeeves doesn’t get things right, Wooster can train him to do a better job.
HUIZINGA: Go back to the copilot analogy, which is a huge thing at Microsoft — in fact, they’ve got products named Copilot — and the idea of a copilot, which is, sort of, assuaging our fears that it would be the pilot …
SELLEN: Yeah …
HUIZINGA: … AI.
SELLEN: Yeah, yeah.
HUIZINGA: So how do we envision that in a way that … you say it’s more than a mere tool, but it’s more like a copilot?
SELLEN: Yeah, I actually like the copilot metaphor for what you’re alluding to, which is that the pilot is the one who has the final say, who has the, kind of, oversight of everything that’s happening and can step in. And also that the copilot is there in a supportive role, who kind of trains by dint of the fact that they work next to the pilot, and that they have, you know, specialist skills that can help.
HUIZINGA: Right …
SELLEN: So I really like that metaphor. I think there are other metaphors that we will explore in future and which will make sense for different contexts, but I think, as a metaphor for a lot of the things we’re developing today, it makes a lot of sense.
HUIZINGA: You know, it also feels like, in the conversation, words really matter in how people perceive what the tool is. So having these other frameworks to describe it and to implement it, I think, could be really helpful.
SELLEN: Yes, I agree.
[MUSIC BREAK]HUIZINGA: Well, let’s talk about intelligence for a second. One of the most interesting things about AI is it’s caused us to pay attention to other kinds of intelligence. As author Meghan O’Gieblyn puts it, “God, human, animal, machine … ” So why do you think, Abi, it’s important to understand the characteristics of each kind of intelligence, and how does that impact how we conceptualize, make, and use what we’re calling artificial intelligence?
SELLEN: Yeah, well, I actually prefer the term machine intelligence to artificial intelligence …
HUIZINGA: Me too! Thank you! [LAUGHTER]
SELLEN: Because the latter implies that there’s one kind of intelligence, and also, it does allude to the fact that that is human-like. You know, we’re trying to imitate the human. But if you think about animals, I think that’s really interesting. I mean, many of us have good relationships with our pets, right. And we know that they have a different kind of intelligence. And it’s different from ours, but that doesn’t mean we can’t understand it to some extent, right. And if you think about … animals are superhuman in many ways, right. They can do things we can’t. So whether it’s an ox pulling a plow or a dog who can sniff out drugs or ferrets who can, you know, thread electrical cables through pipes, they can do things. And bee colonies are fascinating to me, right. And they work as a, kind of, a crowd intelligence, or hive mind, right. [LAUGHTER] That’s where that comes from. And so in so many ways, animals are smarter than humans. But it doesn’t matter—like this “smarter than” thing also bugs me. It’s about being differently intelligent, right. And the reason I think that’s important when we think about machine intelligence is that machine intelligence is differently intelligent, as well. So the conversational interface allows us to explore the nature of that machine intelligence because we can speak to it in a kind of human-like way, but that doesn’t mean that it is intelligent in the same way a human is intelligent. And in fact, we don’t really want it to be, right.
HUIZINGA: Right …
SELLEN: Because we want it, we want it to be a partner with us, to do things that we can’t, you know, just like using the plow and the ox. That partnership works because the ox is stronger than we are. So I think machine intelligence is a much better word, and understanding it’s not human is a good thing. I do worry that, because it sounds like a human, it can seduce us into thinking it’s a human …
HUIZINGA: Yeah …
SELLEN: … and that can be problematic. You know, there are instances where people have been on, for example, dating sites and a bot is sounding like a human and people get fooled. So I think we don’t want to go down the path of fooling people. We want to be really careful about that.
HUIZINGA: Yeah, this idea of conflating different kinds of intelligences to our own … I think we can have a separate vision of animal intelligence, but machines are, like you say, kind of seductively built to be like us.
SELLEN: Yeah …
HUIZINGA: And so back to your comment about shaping how this technology moves forward and the psychology of it, how might we envision how we could shape, either through language or the way these machines operate, that we build in a “I’m not going to fool you” mechanism?
SELLEN: Well, I mean, there are things that we do at the, kind of, technical level in terms of guardrails and metaprompts, and we have guidelines around that. But there’s also the language that an AI character will use in terms of, you know, expressing thoughts and feelings and some suggestion of an inner life, which … these machines don’t have an inner life, right.
HUIZINGA: Right!
SELLEN: So … and one of the reasons we talk to people is we want to discover something about their inner life.
HUIZINGA: Yessss …
SELLEN: And so why would I talk to a machine to try and discover that? So I think there are things that we can do in terms of how we design these systems so that they’re not trying to deceive us. Unless we want them to deceive us. So if we want to be entertained or immersed, maybe that’s a good thing, right? That they deceive us. But we enter into that knowing that that’s what’s happening, and I think that’s the difference.
HUIZINGA: Well, let’s talk about the C in A-I-C-E, which is cognition. And we’ve just talked about other kinds of intelligence. Let’s broaden the conversation and talk about the impact of AI on humans themselves. Is there any evidence to indicate that machine intelligence actually has an impact on human intelligence, and if so, why is that an important data point?
SELLEN: Yeah, OK, great topic. This is one of my favorite topics. [LAUGHTER] So, well, let me just backtrack a little bit for a minute. A lot of the work that’s coming out today looking at the impact of AI on people is in terms of their productivity, in terms of how fast they can do something, how efficiently they can do a job, or the quality of the output of the tasks. And I do think that’s important to understand because, you know, as we deploy these new tools in peoples’ hands, we want to know what’s happening in terms of, you know, peoples’ productivity, workflow, and so on. But there’s far less of it on looking at the impact of using AI on people themselves and on how people think, on their cognitive processes, and how are these changing over time? Are they growing? Are they atrophying as they use them? And, relatedly, what’s happening to our skills? You know, over time, what’s going to be valued, and what’s going to drop away? And I think that’s important for all kinds of reasons. So if you think about generative AI, right, these are these AI systems that will write something for us or make a slide deck or a picture or a video. What they’re doing is they are taking the cognitive work of generation of an artifact or the effort of self-expression that most of us, in the old-fashioned world, will do, right—we write something, we make something—they’re doing that for us on our behalf. And so our job then is to think about how do we specify our intention to the machine, how do we talk to it to get it to do the things we want, and then how do we evaluate the output at the end? So it’s really radically shifting what we do, the work that we do, the cognitive and mental work that we do, when we engage with these tools. Now why is that a problem? Or should it be a problem? One concern is that many of us think and structure our thoughts through the process of making things, right. Through the process of writing or making something. So a big question for me is, if we’re removed from that process, how deeply will we learn or understand what we’re writing about? A second one is, you know, if we’re not deeply engaged in the process of generating these things, does that actually undermine our ability to evaluate the output when we do get presented with it?
HUIZINGA: Right …
SELLEN: Like, if it writes something for us and it’s full of problems and errors, if we stop writing for ourselves, are we going to be worse at, kind of, judging the output? Another one is, as we hand things over to more and more of these automated processes, will we start to blindly accept or over-rely on our AI assistants, right. And the aviation industry has known that for years …
HUIZINGA: Yeah …
SELLEN: … which is why they stick pilots in simulators. Because they rely on autopilot so much that they forget those key skills. And then another one is, kind of, longer term, which is like these new generations of people who are going to grow up with this technology, what are the fundamental skills that they’re going to need to not just to use the AI but to be kind of citizens of the world and also be able to judge the output of these AI systems? So the calculator, right, is a great example. When it was first introduced, there was a huge outcry around, you know, kids won’t be able to do math anymore! Or we don’t need to teach it anymore. Well, we do still teach it because when you use a calculator, you need to be able to see whether or not the output the machine is giving you is in the right ballpark, right.
HUIZINGA: Right …
SELLEN: You need to know the basics. And so what are the basics that kids are going to need to know? We just don’t have the answer to those questions. And then the last thing I’ll say on this, because I could go on for a long time, is we also know that there are changes in the brain when we use these new technologies. There are shifts in our cognitive skills, you know, things get better and things do deteriorate. So I think Susan Greenfield is famous for her work looking at what happens to the neural pathways in the age of the internet, for example. So she found that all the studies were pointing to the fact that reading online and on the internet meant that our visual-spatial skills were being boosted, but our capacity to do deep processing, mindful knowledge acquisition, critical thinking, reflection, were all decreasing over time. And I think any parent who has a teenager will know that focus of attention, flitting from one thing to another, multitasking, is, sort of, the order of the day. Well, not just for teenagers. I think all of us are suffering from this now. It’s much harder. I find it much harder to sit down and read something in a long, focused way …
HUIZINGA: Yeah …
SELLEN: … than I used to. So all of this long-winded answer is to say, we don’t understand what the impact of these new AI systems is going to be. We need to do research to understand it. And we need to do that research both looking at short-term impacts and long-term impacts. Not to say that this is all going to be bad, but we need to understand where it’s going so we can design around it.
HUIZINGA: You know, even as you asked each of those questions, Abi, I found myself answering it preemptively, “Yes. That’s going to happen. That’s going to happen.” [LAUGHS] And so even as you say all of this and you say we need research, do you already have some thinking about, you know, if research tells us the answer that we thought might be true already, do we have a plan in place or a thought process in place to address it?
SELLEN: Well, yes, and I think we’ve got some really exciting research going on in the company right now and in the AICE program, and I’m hoping your future guests will be able to talk more in-depth about these things. But we are looking at things like the impact of AI on writing, on comprehension, on mathematical abilities. But more than that. Not just understanding the impact on these skills and abilities, but how can we design systems better to help people think better, right?
HUIZINGA: Yeah …
SELLEN: To help them think more deeply, more creatively. I don’t think AI needs to necessarily de-skill us in the critical skills that we want and need. It can actually help us if we design them properly. And so that’s the other part of what we’re doing. It’s not just understanding the impact, but now saying, OK, now that we understand what’s going on, how do we design these systems better to help people deepen their skills, change the way that they think in ways that they want to change—in being more creative, thinking more deeply, you know, reading in different ways, understanding the world in different ways.
HUIZINGA: Right. Well, that is a brilliant segue into my next question. Because we’re on the last letter, E, in AICE: the economy. And that I think instills a lot of fear in people. To cite another author, since we’re on a citing authors roll, Clay Shirky, in his book Here Comes Everybody, writes about technical revolutions in general and the impact they have on existing economic paradigms. And he says, “Real revolutions don’t involve an orderly transition from point A to point B. Rather, they go from A, through a long period of chaos, and only then reach B. And in that chaotic period the old systems get broken long before the new ones become stable.” Let’s take Shirky’s idea and apply it to generative AI. If B equals the future of work, what’s getting broken in the period of transition from how things were to how things are going to be, what do we have to look forward to, and how do we progress toward B in a way that minimizes chaos?
SELLEN: Hmm … oh, those are big questions! [LAUGHS]
HUIZINGA: Too many questions! [LAUGHS]
SELLEN: Yeah, well, I mean, Shirky was right. Things take a long time to bed in, right. And much of what happens over time, I don’t think we can actually predict. You know, so who would have predicted echo chambers or the rise of deepfakes or, you know, the way social media could start revolutions in those early days of social media, right. So good and bad things happen, and a lot of it’s because it rolls out over time, it scales up, and then people get involved. And that’s the really unpredictable bit, is when people get involved en masse. I think we’re going to see the same thing with AI systems. They are going to take a long time to bed in, and its impact is going to be global, and it’s going to take a long time to unfold. So I think what we can do is, to some extent, we can see the glimmerings of what’s going to happen, right. So I think it’s the William Gibson quote is, you know, “The future’s already here; it’s just not evenly distributed,” or something like that, right. We can see some of the problems that are playing out, both in the hands of bad actors and things that will happen unintentionally. We can see those, and we can design for them, and we can do things about it because we are alert and we are looking to see what happens. And also, the good things, right. And all the good things that are playing out, …
HUIZINGA: Yeah …
SELLEN: … we can make the most of those. Other things we can do is, you know, at Microsoft, we have a set of responsible AI principles that we make sure all our products go through to make sure that we look into the future as much as we can, consider what the consequences might be, and then deploy things in very careful steps, evaluating as we go. And then, coming back to what I said earlier, doing deep research to try and get a better line of sight. So in terms of what’s going to happen with the future of work, I think, again, we need to steer it. Some of the things I talked about earlier in terms of making sure we build skills rather than undermine them, making sure we don’t over automate, making sure that we put agency in the hands of people. And always making sure that we design our AI experiences with human hope, aspirations, and needs in mind. If we do that, I think we’re on a good track, but we should always be vigilant, you know, to what’s evolving, what’s happening here.
HUIZINGA: Yeah …
SELLEN: I can’t really predict whether we’re headed for chaos or not. I don’t think we are, as long as we’re mindful.
HUIZINGA: Yeah. And it sounds like there’s a lot more involved outside of computer science, in terms of support systems and education and communication, to acclimatize people to a new kind of economy, which like you say, you can’t … I’m shocked that you can’t predict it, Abi. I was expecting that you could, but … [LAUGHTER]
SELLEN: Sorry.
HUIZINGA: Sorry! But yeah, I mean, do you see the ancillary industries, we’ll call them, in on this? And how can, you know, sort of, a lab in Cambridge, and labs around the world that are doing AI, how can they spread out to incorporate these other things to help the people who know nothing about what’s going on in your lab move forward here?
SELLEN: Well, I think, you know, there are lots of people that we need to talk to and to take account of. The word stakeholder … I hate that word stakeholder! I’m not sure why. [LAUGHTER] But anyway, stakeholders in this whole AI odyssey that we’re on … you know, public perceptions are one thing. I’m a member of a lot of societies where we do a lot of outreach and talks about AI and what’s going on, and I think that’s really, really important. And get people excited also about the possibilities of what could happen.
HUIZINGA: Yeah …
SELLEN: Because I think a lot of the media, a lot of the stories that get out there are very dystopian and scary, and it’s right that we are concerned and we are alert to possibilities, but I don’t think it does anybody any good to make people scared or anxious. And so I think there’s a lot we can do with the public. And there’s a lot we can do with, when I think about the future of work, different domains, you know, and talking to them about their needs and how they see AI fitting into their particular work processes.
HUIZINGA: So, Abi, we’re kind of [LAUGHS] dancing around these dystopian narratives, and whether they’re right or wrong, they have gained traction. So it’s about now that I ask all of my guests what could go wrong if you got everything right? So maybe you could present, in this area, some more hopeful, we’ll call them “-topias,” or preferred futures, if you will, around AI and how you and/or your lab and other people in the industry are preparing for them.
SELLEN: Well, again, I come back to the idea that the future is all around us to some extent, and we’re seeing really amazing breakthroughs, right, with AI. For example, scientific breakthroughs in terms of, you know, drug discovery, new materials to help tackle climate change, all kinds of things that are going to help us tackle some of the world’s biggest problems. Better understandings of the natural world, right, and how interventions can help us. New tools in the hands of low-literacy populations and support for, you know, different ways of working in different cultures. I think that’s another big area in which AI can help us. Personalization—personalized medicine, personalized tutoring systems, right. So we talked about education earlier. I think that AI could do a lot if we design it right to really help in education and help support people’s learning processes. So I think there’s a lot here, and there’s a lot of excitement—with good reason. Because we’re already seeing these things happening. And we should bear those things in mind when we start to get anxious about AI. And I personally am really, really excited about it. I’m excited about, you know, what the company I work for is doing in this area and other companies around the world. I think that it’s really going to help us in the long term, build new skills, see the world in new ways, you know, tackle some of these big problems.
HUIZINGA: I recently saw an ad—I’m not making this up—it was the quote-unquote “productivity app,” and it was simply a small wooden box filled with pieces of paper. And there was a young man who had a how-to video on how to use it on YouTube. [LAUGHS] He was clearly born into the digital age and found writing lists on paper to be a revolutionary idea. But I myself have toggled back and forth between what we’ll call the affordances of the digital world and the familiarity and comfort of the physical world. And you actually studied this and wrote about it in a book called The Myth of the Paperless Office. That was 20 years ago. Why did you do the work then, what’s changed in the ensuing years, and why in the age of AI do I love paper so much?
SELLEN: Yeah, so, that was quite a while ago now. It was a book that I cowrote with my husband. He’s a sociologist, so we, sort of, came together on that book, me as a psychologist and he as a sociologist. What we were responding to at the time was a lot of hype about the paperless office and the paperless future. At the time, I was working at EuroPARC, you know, which is the European sister lab of Xerox PARC. And so, obviously, they had big investment in this. And there were many people in that lab who really believed in the paperless office, and lots of great inventions came out of the fact that people were pursuing that vision. So that was a good side of that, but we also saw where things could go horribly wrong when you just took a paper-based system away and you just replaced it with a digital system.
HUIZINGA: Yeah …
SELLEN: I remember some of the disasters in air traffic control, for example, when they took the paper flight strips away and just made them all digital. And those are places where you don’t want to mess around with something that works.
HUIZINGA: Right.
SELLEN: You have to be really careful about how you introduce digital systems. Likewise, many people remember things that went wrong when hospitals tried to go paperless with health records being paperless. Now, those things are digital now, but we were talking about chaos earlier. There was a lot of chaos on the path. So what we’ve tried to say in that book to some extent is, let’s understand the work that paper is doing in these different work contexts and the affordances of paper. You know, what is it doing for people? Anything from, you know, I hand a document over to someone else; a physical document gives me the excuse to talk to that person …
HUIZINGA: Right…
SELLEN: … through to, you know, when I place a document on somebody’s desk, other people in the workplace can see that I’ve passed it on to someone else. Those kind of nuanced observations are useful because you then need to think, how’s the digital system going to replace that? Not in the same way, but it’s got to do the same job, right. So you need to talk to people, you need to understand the context of their work, and then you need to carefully plan out how you’re going to make the transition. So if we just try to inject AI into workflows or totally replace parts of workflows with AI without a really deep understanding of how that work is currently done, what the workers get from it, what is the value that the workers bring to that process, we could go through that chaos. And so it’s really important to get social scientists involved in this and good designers, and that’s where the, kind of, multidisciplinary thing really comes into its own. That’s where it’s really, really valuable.
HUIZINGA: Yeah … You know, it feels super important, that book, about a different thing, how it applies now and how you can take lessons from that arc to what you’re talking about with AI. I feel like people should go back and read that book.
SELLEN: I wouldn’t object! [LAUGHTER]
[MUSIC BREAK]HUIZINGA: Let’s talk about some research ideas that are on the horizon. Lots of research is basically just incremental building on what’s been done before, but there are always those moonshot ideas that seem outrageous at first. Now, you’re a scientist and an inventor yourself, and you’re also a lab director, so you’ve seen a lot of ideas over the years. [LAUGHS] You’ve probably had a lot of ideas. Have any of them been outrageous in your mind? And if so, what was the most outrageous, and how did it work out?
SELLEN: OK, well, I’m a little reluctant to say this one, but I always believed that the dream of AI was outrageous. [LAUGHTER] So, you know, going back to those early days when, you know, I was a psychologist in the ’80s and seeing those early expert systems that were being built back then and trying to codify and articulate expert knowledge into machines to make them artificially intelligent, it just seemed like they were on a road to nowhere. I didn’t really believe in the whole vision of AI for many, many years. I think that when deep learning, that whole revolution’s kicked off, I never saw where it was heading. So I am, to this day, amazed by what these systems can do and never believed that these things would be possible. And so I was a skeptic, and I am no longer a skeptic, [LAUGHTER] with a proviso of everything else I’ve said before, but I thought it was an outrageous idea that these systems would be capable of what they’re now capable of.
HUIZINGA: You know, that’s funny because, going back to what you said earlier about your stepdad walking you around and asking you how you’d codify a human into a machine … was that just outrageous to you, or is that just part of the exploratory mode that your stepdad, kind of, brought you into?
SELLEN: Well, so, back then I was quite young, and I was willing to believe him, and I, sort of, signed up to that. But later, especially when I met my husband, a sociologist, I realized that I didn’t agree with any of that at all. [LAUGHTER] So we had great, I’ll say, “energetic” discussions with my stepdad after that, which was fun.
HUIZINGA: I bet.
SELLEN: But yeah, but so, it was how I used to think and then I went through this long period of really rejecting all of that. And part of that was, you know, seeing these AI systems really struggle and fail. And now here we are today. So yeah.
HUIZINGA: Yeah, I just had Rafah Hosn on the podcast and when we were talking about this “outrageous ideas” question, she said, “Well, I don’t really see much that’s outrageous.” And I said, “Wait a minute! You’re living in outrageous! You are in AI Frontiers at Microsoft Research.” Maybe it’s just because it’s so outrageous that it’s become normal?
SELLEN: Yeah …
HUIZINGA: And yeah, well … Well, finally, Abi, your mentor and adviser, Don Norman … you referred to a book that he wrote, and I know it as The Design of Everyday Things, and in it he wrote this: “Design is really an act of communication, which means having a deep understanding of the person with whom the designer is communicating.” So as we close, I’d love it if you’d speak to this statement in the context of AI, Cognition, and the Economy. How might we see the design of AI systems as an act of communication with people, and how do we get to a place where an understanding of deeply human qualities plays a larger role in informing these ideas, and ultimately the products, that emerge from a lab like yours?
SELLEN: So this is absolutely critical to getting AI development and design right. It’s deeply understanding people and what they need, what their aspirations are, what human values are we designing for. You know, I would say that as a social scientist, but I also believe that most of the technologists and computer scientists and machine learning people that I interact with on a daily basis also believe that. And that’s one thing that I love about the lab that I’m a part of, is that it’s very interdisciplinary. We’re always putting the, kind of, human-centric spin on things. And, you know, Don was right. And that’s what he’s been all about through his career. We really need to understand, who are we designing this technology for? Ultimately, it’s for people; it’s for society; it’s for the, you know, it’s for the common good. And so that’s what we’re all about. Also, I’m really excited to say we are becoming, as an organization, much more globally distributed. Just recently taken on a lab in Nairobi. And the cultural differences and the differences in different countries casts a whole new light on how these technologies might be used. And so I think that it’s not just about understanding different people’s needs but different cultures and different parts of the world and how this is all going to play out on a global scale.
HUIZINGA: Yeah … So just to, kind of, put a cap on it, when I said the term “deeply human qualities,” what I’m thinking about is the way we collaborate and work as a team with other people, having empathy and compassion, being innovative and creative, and seeking well-being and prosperity. Those are qualities that I have a hard time superimposing onto or into a machine. Do you think that AI can help us?
SELLEN: Yeah, I think all of these things that you just named are things which, as you say, are deeply human, and they are the aspects of our relationship with technology that we want to not only protect and preserve but support and amplify. And I think there are many examples I’ve seen in development and coming out which have that in mind, which seek to augment those different aspects of human nature. And that’s exciting. And we always need to keep that in mind as we design these new technologies.
HUIZINGA: Yeah. Well, Abi Sellen, I’d love to stay and chat with you for another couple hours, but how fun to have you on the show. Thanks for joining us today on Ideas.
SELLEN: It’s been great. I really enjoyed it. Thank you.
[MUSIC]
The post Ideas: Designing AI for people with Abigail Sellen appeared first on Microsoft Research.
In the world of online retail, creating high-quality product descriptions for millions of products is a crucial, but time-consuming task. Using machine learning (ML) and natural language processing (NLP) to automate product description generation has the potential to save manual effort and transform the way ecommerce platforms operate. One of the main advantages of high-quality product descriptions is the improvement in searchability. Customers can more easily locate products that have correct descriptions, because it allows the search engine to identify products that match not just the general category but also the specific attributes mentioned in the product description. For example, a product that has a description that includes words such as “long sleeve” and “cotton neck” will be returned if a consumer is looking for a “long sleeve cotton shirt.” Furthermore, having factoid product descriptions can increase customer satisfaction by enabling a more personalized buying experience and improving the algorithms for recommending more relevant products to users, which raise the probability that users will make a purchase.
With the advancement of Generative AI, we can use vision-language models (VLMs) to predict product attributes directly from images. Pre-trained image captioning or visual question answering (VQA) models perform well on describing every-day images but can’t to capture the domain-specific nuances of ecommerce products needed to achieve satisfactory performance in all product categories. To solve this problem, this post shows you how to predict domain-specific product attributes from product images by fine-tuning a VLM on a fashion dataset using Amazon SageMaker, and then using Amazon Bedrock to generate product descriptions using the predicted attributes as input. So you can follow along, we’re sharing the code in a GitHub repository.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
You can use a managed service, such as Amazon Rekognition, to predict product attributes as explained in Automating product description generation with Amazon Bedrock. However, if you’re trying to extract specifics and detailed characteristics of your product or your domain (industry), fine-tuning a VLM on Amazon SageMaker is necessary.
Since 2021, there has been a rise in interest in vision-language models (VLMs), which led to the release of solutions such as Contrastive Language-Image Pre-training (CLIP) and Bootstrapping Language-Image Pre-training (BLIP). When it comes to tasks such as image captioning, text-guided image generation, and visual question-answering, VLMs have demonstrated state-of-the art performance.
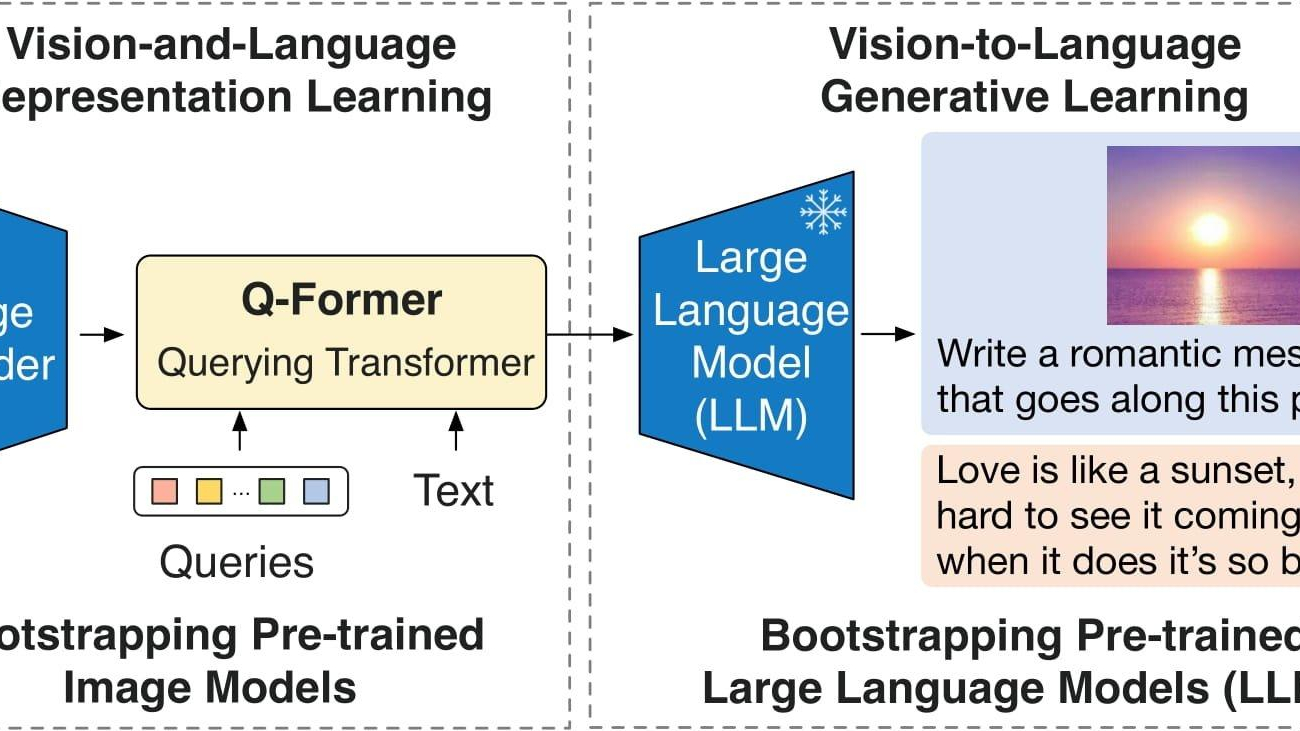
In this post, we use BLIP-2, which was introduced in BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models, as our VLM. BLIP-2 consists of three models: a CLIP-like image encoder, a Querying Transformer (Q-Former) and a large language model (LLM). We use a version of BLIP-2, that contains Flan-T5-XL as the LLM.
The following diagram illustrates the overview of BLIP-2:

Figure 1: BLIP-2 overview
The pre-trained version of the BLIP-2 model has been demonstrated in Build an image-to-text generative AI application using multimodality models on Amazon SageMaker and Build a generative AI-based content moderation solution on Amazon SageMaker JumpStart. In this post, we demonstrate how to fine-tune BLIP-2 for a domain-specific use case.
The following diagram illustrates the solution architecture.

Figure 2: High-level solution architecture
The high-level overview of the solution is:
In the following sections, we demonstrate how to:
An AWS account is needed with an AWS Identity and Access Management (IAM) role that has permissions to manage resources created as part of the solution. For details, see Creating an AWS account.
We use Amazon SageMaker Studio with the ml.t3.medium instance and the Data Science 3.0 image. However, you can also use an Amazon SageMaker notebook instance or any integrated development environment (IDE) of your choice.
Note: Be sure to set up your AWS Command Line Interface (AWS CLI) credentials correctly. For more information, see Configure the AWS CLI.
An ml.g5.2xlarge instance is used for SageMaker Training jobs, and an ml.g5.2xlarge instance is used for SageMaker endpoints. Ensure sufficient capacity for this instance in your AWS account by requesting a quota increase if required. Also check the pricing of the on-demand instances.
You need to clone this GitHub repository for replicating the solution demonstrated in this post. First, launch the notebook main.ipynb in SageMaker Studio by selecting the Image as Data Science and Kernel as Python 3. Install all the required libraries mentioned in the requirements.txt.
For this post, we use the Kaggle Fashion Images Dataset, which contain 44,000 products with multiple category labels, descriptions, and high resolution images. In this post we want to demonstrate how to fine-tune a model to learn attributes such as fabric, fit, collar, pattern, and sleeve length of a shirt using the image and a question as inputs.
Each product is identified by an ID such as 38642, and there is a map to all the products in styles.csv. From here, we can fetch the image for this product from images/38642.jpg and the complete metadata from styles/38642.json. To fine-tune our model, we need to convert our structured examples into a collection of question and answer pairs. Our final dataset has the following format after processing for each attribute:
Id | Question | Answer38642 | What is the fabric of the clothing in this picture? | Fabric: Cotton
To launch a SageMaker Training job, we need the HuggingFace Estimator. SageMaker starts and manages all of the necessary Amazon Elastic Compute Cloud (Amazon EC2) instances for us, supplies the appropriate Hugging Face container, uploads the specified scripts, and downloads data from our S3 bucket to the container to /opt/ml/input/data.
We fine-tune BLIP-2 using the Low-Rank Adaptation (LoRA) technique, which adds trainable rank decomposition matrices to every Transformer structure layer while keeping the pre-trained model weights in a static state. This technique can increase training throughput and reduce the amount of GPU RAM required by 3 times and the number of trainable parameters by 10,000 times. Despite using fewer trainable parameters, LoRA has been demonstrated to perform as well as or better than the full fine-tuning technique.
We prepared entrypoint_vqa_finetuning.py which implements fine-tuning of BLIP-2 with the LoRA technique using Hugging Face Transformers, Accelerate, and Parameter-Efficient Fine-Tuning (PEFT). The script also merges the LoRA weights into the model weights after training. As a result, you can deploy the model as a normal model without any additional code.
We can start our training job by running with the .fit() method and passing our Amazon S3 path for images and our input file.
We deploy the fine-tuned BLIP-2 model to the SageMaker real time endpoint using the HuggingFace Inference Container. You can also use the large model inference (LMI) container, which is described in more detail in Build a generative AI-based content moderation solution on Amazon SageMaker JumpStart, which deploys a pre-trained BLIP-2 model. Here, we reference our fine-tuned model in Amazon S3 instead of the pre-trained model available in the Hugging Face hub. We first create the model and deploy the endpoint.
When the endpoint status becomes in service, we can invoke the endpoint for the instructed vision-to-language generation task with an input image and a question as a prompt:
The output response looks like the following:
{"Sleeve Length": "Long Sleeves"}
To get started with Amazon Bedrock, request access to the foundational models (they are not enabled by default). You can follow the steps in the documentation to enable model access. In this post, we use Anthropic’s Claude in Amazon Bedrock to generate product descriptions. Specifically, we use the model anthropic.claude-3-sonnet-20240229-v1 because it provides good performance and speed.
After creating the boto3 client for Amazon Bedrock, we create a prompt string that specifies that we want to generate product descriptions using the product attributes.
You are an expert in writing product descriptions for shirts. Use the data below to create product description for a website. The product description should contain all given attributes.Provide some inspirational sentences, for example, how the fabric moves. Think about what a potential customer wants to know about the shirts. Here are the facts you need to create the product descriptions: [Here we insert the predicted attributes by the BLIP-2 model]
The prompt and model parameters, including maximum number of tokens used in the response and the temperature, are passed to the body. The JSON response must be parsed before the resulting text is printed in the final line.
The generated product description response looks like the following:
"Classic Striped Shirt Relax into comfortable casual style with this classic collared striped shirt. With a regular fit that is neither too slim nor too loose, this versatile top layers perfectly under sweaters or jackets."
We’ve shown you how the combination of VLMs on SageMaker and LLMs on Amazon Bedrock present a powerful solution for automating fashion product description generation. By fine-tuning the BLIP-2 model on a fashion dataset using Amazon SageMaker, you can predict domain-specific and nuanced product attributes directly from images. Then, using the capabilities of Amazon Bedrock, you can generate product descriptions from the predicted product attributes, enhancing the searchability and personalization of ecommerce platforms. As we continue to explore the potential of generative AI, LLMs and VLMs emerge as a promising avenue for revolutionizing content generation in the ever-evolving landscape of online retail. As a next step, you can try fine-tuning this model on your own dataset using the code provided in the GitHub repository to test and benchmark the results for your use cases.
 Antonia Wiebeler is a Data Scientist at the AWS Generative AI Innovation Center, where she enjoys building proofs of concept for customers. Her passion is exploring how generative AI can solve real-world problems and create value for customers. While she is not coding, she enjoys running and competing in triathlons.
Antonia Wiebeler is a Data Scientist at the AWS Generative AI Innovation Center, where she enjoys building proofs of concept for customers. Her passion is exploring how generative AI can solve real-world problems and create value for customers. While she is not coding, she enjoys running and competing in triathlons.
 Daniel Zagyva is a Data Scientist at AWS Professional Services. He specializes in developing scalable, production-grade machine learning solutions for AWS customers. His experience extends across different areas, including natural language processing, generative AI, and machine learning operations.
Daniel Zagyva is a Data Scientist at AWS Professional Services. He specializes in developing scalable, production-grade machine learning solutions for AWS customers. His experience extends across different areas, including natural language processing, generative AI, and machine learning operations.
 Lun Yeh is a Machine Learning Engineer at AWS Professional Services. She specializes in NLP, forecasting, MLOps, and generative AI and helps customers adopt machine learning in their businesses. She graduated from TU Delft with a degree in Data Science & Technology.
Lun Yeh is a Machine Learning Engineer at AWS Professional Services. She specializes in NLP, forecasting, MLOps, and generative AI and helps customers adopt machine learning in their businesses. She graduated from TU Delft with a degree in Data Science & Technology.
 Fotinos Kyriakides is an AI/ML Consultant at AWS Professional Services specializing in developing production-ready ML solutions and platforms for AWS customers. In his free time Fotinos enjoys running and exploring.
Fotinos Kyriakides is an AI/ML Consultant at AWS Professional Services specializing in developing production-ready ML solutions and platforms for AWS customers. In his free time Fotinos enjoys running and exploring.
Annotated data is an essential ingredient to train, evaluate, compare and productionalize machine learning models. It is therefore imperative that annotations are of high quality. For their creation, good quality management and thereby reliable quality estimates are needed. Then, if quality is insufficient during the annotation process, rectifying measures can be taken to improve it. For instance, project managers can use quality estimates to improve annotation guidelines, retrain annotators or catch as many errors as possible before release.
Quality estimation is often performed by having…Apple Machine Learning Research
Retrieval Augmented Generation (RAG) models have emerged as a promising approach to enhance the capabilities of language models by incorporating external knowledge from large text corpora. However, despite their impressive performance in various natural language processing tasks, RAG models still face several limitations that need to be addressed.
Naive RAG models face limitations such as missing content, reasoning mismatch, and challenges in handling multimodal data. Although they can retrieve relevant information, they may struggle to generate complete and coherent responses when required information is absent, leading to incomplete or inaccurate outputs. Additionally, even with relevant information retrieved, the models may have difficulty correctly interpreting and reasoning over the content, resulting in inconsistencies or logical errors. Furthermore, effectively understanding and reasoning over multimodal data remains a significant challenge for these primarily text-based models.
In this post, we present a new approach named multimodal RAG (mmRAG) to tackle those existing limitations in greater detail. The solution intends to address these limitations for practical generative artificial intelligence (AI) assistant use cases. Additionally, we examine potential solutions to enhance the capabilities of large language models (LLMs) and visual language models (VLMs) with advanced LangChain capabilities, enabling them to generate more comprehensive, coherent, and accurate outputs while effectively handling multimodal data. The solution uses Amazon Bedrock, a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies, providing a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
The mmRAG solution is based on a straightforward concept: to extract different data types separately, you generate text summarization using a VLM from different data types, embed text summaries along with raw data accordingly to a vector database, and store raw unstructured data in a document store. The query will prompt the LLM to retrieve relevant vectors from both the vector database and document store and generate meaningful and accurate answers.
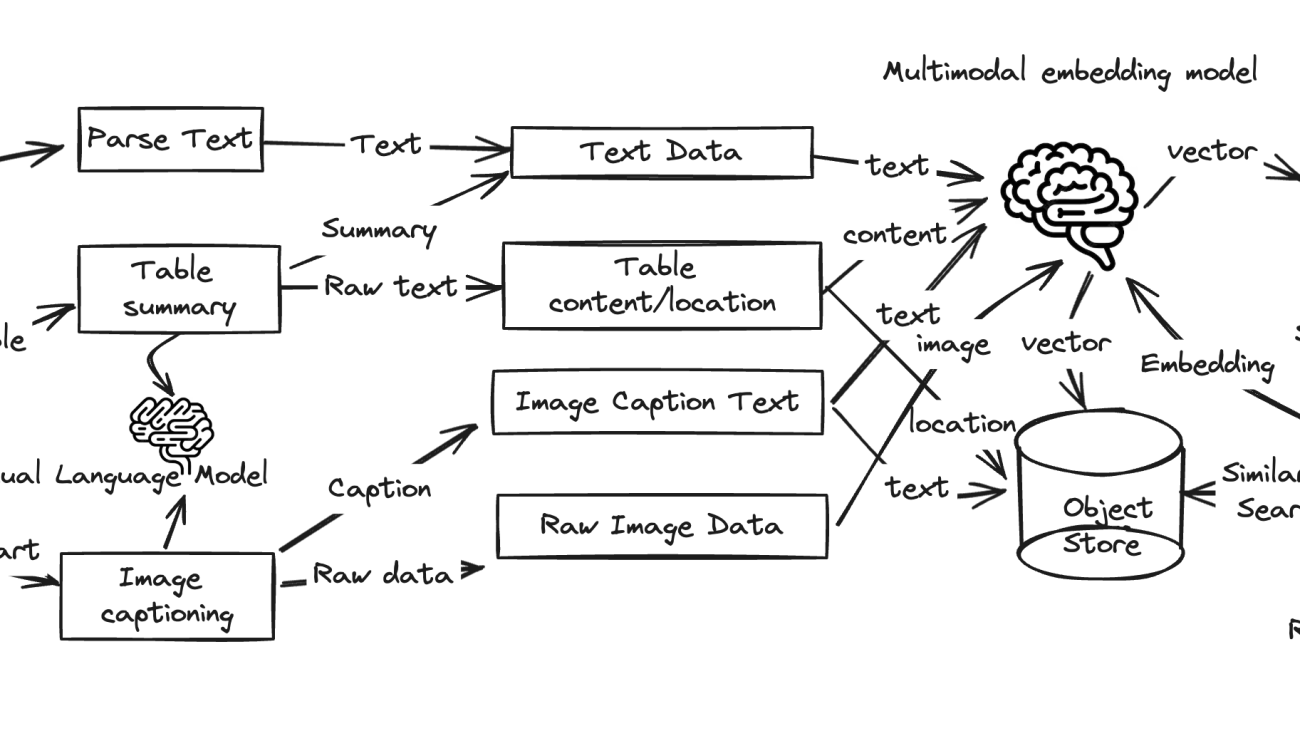
The following diagram illustrates the solution architecture.

The architecture diagram depicts the mmRAG architecture that integrates advanced reasoning and retrieval mechanisms. It combines text, table, and image (including chart) data into a unified vector representation, enabling cross-modal understanding and retrieval. The process begins with diverse data extractions from various sources such as URLs and PDF files by parsing and preprocessing text, table, and image data types separately, while table data is converted into raw text and image data into captions.
These parsed data streams are then fed into a multimodal embedding model, which encodes the various data types into uniform, high dimensional vectors. The resulting vectors, representing the semantic content regardless of original format, are indexed in a vector database for efficient approximate similarity searches. When a query is received, the reasoning and retrieval component performs similarity searches across this vector space to retrieve the most relevant information from the vast integrated knowledge base.
The retrieved multimodal representations are then used by the generation component to produce outputs such as text, images, or other modalities. The VLM component generates vector representations specifically for textual data, further enhancing the system’s language understanding capabilities. Overall, this architecture facilitates advanced cross-modal reasoning, retrieval, and generation by unifying different data modalities into a common semantic space.
Developers can access mmRAG source codes on the GitHub repo.
You start by configuring Amazon Bedrock to integrate with various components from the LangChain Community library. This allows you to work with the core FMs. You use the BedrockEmbeddings class to create two different embedding models: one for text (embedding_bedrock_text) and one for images (embeddings_bedrock_image). These embeddings represent textual and visual data in a numerical format, which is essential for various natural language processing (NLP) tasks.
Additionally, you use the LangChain Bedrock and BedrockChat classes to create a VLM model instance (llm_bedrock_claude3_haiku) from Anthropic Claude 3 Haiku and a chat instance based on a different model, Sonnet (chat_bedrock_claude3_sonnet). These instances are used for advanced query reasoning, argumentation, and retrieval tasks. See the following code snippet:
from langchain_community.embeddings import BedrockEmbeddings
from langchain_community.chat_models.bedrock import BedrockChat
embedding_bedrock_text = BedrockEmbeddings(client=boto3_bedrock, model_id="amazon.titan-embed-g1-text-02")
embeddings_bedrock_image = BedrockEmbeddings(client=boto3_bedrock, model_id="amazon.titan-embed-image-v1")
model_kwargs = {
"max_tokens": 2048,
"temperature": 0.0,
"top_k": 250,
"top_p": 1,
"stop_sequences": ["nnn"],
}
chat_bedrock_claude3_haiku = BedrockChat(
model_id="anthropic:claude-3-haiku-20240307-v1:0",
client=boto3_bedrock,
model_kwargs=model_kwargs,
)
chat_bedrock_claude3_sonnet = BedrockChat(
model_id="anthropic.claude-3-sonnet-20240229-v1:0",
client=boto3_bedrock,
model_kwargs=model_kwargs,
)In this section, we explore how to harness the power of Python to parse text, tables, and images from URLs and PDFs efficiently, using two powerful packages: Beautiful Soup and PyMuPDF. Beautiful Soup, a library designed for web scraping, makes it straightforward to sift through HTML and XML content, allowing you to extract the desired data from web pages. PyMuPDF offers an extensive set of functionalities for interacting with PDF files, enabling you to extract not just text but also tables and images with ease. See the following code:
from bs4 import BeautifulSoup as Soup
import fitz
def parse_tables_images_from_urls(url:str):
...
# Parse the HTML content using BeautifulSoup
soup = Soup(response.content, 'html.parser')
# Find all table elements
tables = soup.find_all('table')
# Find all image elements
images = soup.find_all('img')
...
def parse_images_tables_from_pdf(pdf_path:str):
...
pdf_file = fitz.open(pdf_path)
# Iterate through each page
for page_index in range(len(pdf_file)):
# Select the page
page = pdf_file[page_index]
# Search for tables on the page
tables = page.find_tables()
df = table.to_pandas()
# Search for images on the page
images = page.get_images()
image_info = pdf_file.extract_image(xref)
image_data = image_info["image"]
...The following code snippets demonstrate how to generate image captions using Anthropic Claude 3 by invoking the bedrock_get_img_description utility function. Additionally, they showcase how to embed image pixels along with image captioning using the Amazon Titan image embedding model amazon.titan_embeding_image_v1 by calling the get_text_embedding function.
image_caption = bedrock_get_img_description(model_id,
prompt='You are an expert at analyzing images in great detail. Your task is to carefully examine the provided
mage and generate a detailed, accurate textual description capturing all of the important elements and
context present in the image. Pay close attention to any numbers, data, or quantitative information visible,
and be sure to include those numerical values along with their semantic meaning in your description.
Thoroughly read and interpret the entire image before providing your detailed caption describing the
image content in text format. Strive for a truthful and precise representation of what is depicted',
image=image_byteio,
max_token=max_token,
temperature=temperature,
top_p=top_p,
top_k=top_k,
stop_sequences='Human:')
image_sum_vectors = get_text_embedding(image_base64=image_base64, text_description=image_caption, embd_model_id=embd_model_id) You can harness the capabilities of the newly released Anthropic Claude 3 Sonnet and Haiku on Amazon Bedrock, combined with the Amazon Titan image embedding model and LangChain. This powerful combination allows you to generate comprehensive text captions for tables and images, seamlessly integrating them into your content. Additionally, you can store vectors, objects, raw image file names, and source documents in an Amazon OpenSearch Serverless vector store and object store. Use the following code snippets to create image captions by invoking the utility function bedrock_get_img_description. Embed image pixels along with image captions using the Amazon Titan image embedding model amazon.titan_embeding_image_v1 by calling the get_text_embedding functions.
def get_text_embedding(image_base64=None, text_description=None, embd_model_id:str="amazon.titan-embed-image-v1"):
input_data = {}
if image_base64 is not None:
input_data["inputImage"] = image_base64
if text_description is not None:
input_data["inputText"] = text_description
if not input_data:
raise ValueError("At least one of image_base64 or text_description must be provided")
body = json.dumps(input_data)
response = boto3_bedrock.invoke_model(
body=body,
modelId=embd_model_id,
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response.get("body").read())
return response_body.get("embedding")
image_caption = bedrock_get_img_description(model_id,
prompt='You are an expert at analyzing images in great detail. Your task is to carefully examine the provided
mage and generate a detailed, accurate textual description capturing all of the important elements and
context present in the image. Pay close attention to any numbers, data, or quantitative information visible,
and be sure to include those numerical values along with their semantic meaning in your description.
Thoroughly read and interpret the entire image before providing your detailed caption describing the
image content in text format. Strive for a truthful and precise representation of what is depicted',
image=image_byteio,
max_token=max_token,
temperature=temperature,
top_p=top_p,
top_k=top_k,
stop_sequences='Human:')
image_sum_vectors = get_text_embedding(image_base64=image_base64, text_description=image_sum, embd_model_id=embd_model_id) You can consult the provided code examples for more information on how to embed multimodal and insert vector documents into the OpenSearch Serverless vector store. For more information about data access, refer to Data access control for Amazon OpenSearch Serverless.
# Form a data dictionary with image metatadata, raw image object store location and base64 encoded image data
document = {
"doc_source": image_url,
"image_filename": s3_image_path,
"embedding": image_base64
}
# Parse out only the iamge name from the full temp path
filename = f"jsons/{image_path.split('/')[-1].split('.')[0]}.json"
# Writing the data dict into JSON data
with open(filename, 'w') as file:
json.dump(document, file, indent=4)
#Load all json files from the temp directory
loader = DirectoryLoader("./jsons", glob='**/*.json', show_progress=False, loader_cls=TextLoader)
#loader = DirectoryLoader("./jsons", glob='**/*.json', show_progress=True, loader_cls=JSONLoader, loader_kwargs = {'jq_schema':'.content'})
new_documents = loader.load()
new_docs = text_splitter.split_documents(new_documents)
# Insert into AOSS
new_docsearch = OpenSearchVectorSearch.from_documents(
new_docs,
bedrock_embeddings,
opensearch_url=host,
http_auth=auth,
timeout = 100,
use_ssl = True,
verify_certs = True,
connection_class = RequestsHttpConnection,
index_name=new_index_name,
engine="faiss",
)Fusion in RAG presents an innovative search strategy designed to transcend the limitations of conventional search techniques, aligning more closely with the complex nature of human inquiries. This initiative elevates the search experience by integrating multi-faceted query generation and using Reciprocal Rank Fusion for an enhanced re-ranking of search outcomes. This approach offers a more nuanced and effective way to navigate the vast expanse of available information, catering to the intricate and varied demands of users’ searches.
The following diagram illustrates this workflow.

We use the Anthropic Claude 3 Sonnet and Haiku models, which possess the capability to process visual and language data, which enables them to handle the query decomposition (Haiku) and answer fusion (Sonnet) stages effectively. The following code snippet demonstrates how to create a retriever using OpenSearch Serverless:
from langchain.vectorstores import OpenSearchVectorSearch
retriever = OpenSearchVectorSearch(
opensearch_url = "{}.{}.aoss.amazonaws.com".format(<collection_id>, <my_region>),
index_name = <index_name>,
embedding_function = embd)The combination of decomposition and fusion intend to address the limitations of the chain-of-thought (CoT) method in language models. It involves breaking down complex problems into simpler, sequential sub-problems, where each sub-problem builds upon the solution of the previous one. This technique significantly enhances the problem-solving abilities of language models in areas such as symbolic manipulation, compositional generalization, and mathematical reasoning.
The RAG-decomposition approach, which uses the decomposition step (see the following code), underscores the potential of a technique called least-to-most prompting. This technique not only improves upon existing methods but also paves the way for more advanced, interactive learning frameworks for language models. The ultimate goal is to move towards a future where language models can learn from bidirectional conversations, enabling more effective reasoning and problem-solving capabilities.
# Decomposition
prompt_rag = hub.pull("rlm/rag-prompt")
template = """You are a helpful assistant that generates multiple sub-questions related to an input question. n
The goal is to break down the input into a set of sub-problems / sub-questions that can be answers in isolation. n
Generate multiple search queries semantically related to: {question} n
Output (5 queries):"""
prompt_decomposition = ChatPromptTemplate.from_template(template)
generate_queries_decomposition = ( prompt_decomposition | llm_bedrock | StrOutputParser() | (lambda x: x.split("n")))
questions = generate_queries_decomposition.invoke({"question":question})
def reciprocal_rank_fusion(results: list[list], k=60):
# Initialize a dictionary to hold fused scores for each unique document
fused_scores = {}
# Iterate through each list of ranked documents
for docs in results:
# Iterate through each document in the list, with its rank (position in the list)
for rank, doc in enumerate(docs):
# Convert the document to a string format to use as a key (assumes documents can be serialized to JSON)
doc_str = dumps(doc)
# If the document is not yet in the fused_scores dictionary, add it with an initial score of 0
if doc_str not in fused_scores:
fused_scores[doc_str] = 0
# Retrieve the current score of the document, if any
previous_score = fused_scores[doc_str]
# Update the score of the document using the RRF formula: 1 / (rank + k)
fused_scores[doc_str] += 1 / (rank + k)
# Sort the documents based on their fused scores in descending order to get the final reranked results
reranked_results = [
(loads(doc), score)
for doc, score in sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)
]
# Return the reranked results as a list of tuples, each containing the document and its fused score
return reranked_results
def retrieve_and_rag(question,prompt_rag,sub_question_generator_chain):
sub_questions = sub_question_generator_chain.invoke({"question":question})
# Initialize a list to hold RAG chain results
rag_results = []
for sub_question in sub_questions:
# Retrieve documents for each sub-question with reciprocal reranking
retrieved_docs = retrieval_chain_rag_fusion.invoke({"question": sub_question})
# Use retrieved documents and sub-question in RAG chain
answer = (prompt_rag
| chat_bedrock
| StrOutputParser()
| reciprocal_rank_fusion
).invoke({"context": retrieved_docs,"question": sub_question}
rag_results.append(answer)
return rag_results,sub_questions
def format_qa_pairs(questions, answers):
"""Format Q and A pairs"""
formatted_string = ""
for i, (question, answer) in enumerate(zip(questions, answers), start=1):
formatted_string += f"Question {i}: {question}nAnswer {i}: {answer}nn"
return formatted_string.strip()
context = format_qa_pairs(questions, answers)
# Prompt
template = """Here is a set of Q+A pairs:
{context}
Use these to synthesize an answer to the question: {question}
"""
prompt_fusion = ChatPromptTemplate.from_template(template)
final_rag_chain = (prompt_fusion | llm_bedrock| StrOutputParser())
# Decompsing and reciprocal reranking
retrieval_chain_rag_fusion = generate_queries_decomposition | retriever.map() | reciprocal_rank_fusion
# Wrap the retrieval and RAG process in a RunnableLambda for integration into a chain
answers, questions = retrieve_and_rag(question, prompt_rag, generate_queries_decomposition)
final_rag_chain.invoke({"context":context,"question":question})The RAG process is further enhanced by integrating a reciprocal re-ranker, which uses sophisticated NLP techniques. This makes sure the retrieved results are relevant and also semantically aligned with the user’s intended query. This multimodal retrieval approach seamlessly operates across vector databases and object stores, marking a significant advancement in the quest for more efficient, accurate, and contextually aware search mechanisms.
The mmRAG architecture enables the system to understand and process multimodal queries, retrieve relevant information from various sources, and generate multimodal answers by combining textual, tabular, and visual information in a unified manner. The following diagram highlights the data flows from queries to answers by using an advanced RAG and a multimodal retrieval engine powered by a multimodal embedding model (amazon.titan-embed-image-v1), an object store (Amazon S3), and a vector database (OpenSearch Serverless). For tables, the system retrieves relevant table locations and metadata, and computes the cosine similarity between the multimodal embedding and the vectors representing the table and its summary. Similarly, for images, the system retrieves relevant image locations and metadata, and computes the cosine similarity between the multimodal embedding and the vectors representing the image and its caption.

# Connect to the AOSS with given host and index name
docsearch = OpenSearchVectorSearch(
index_name=index_name, # TODO: use the same index-name used in the ingestion script
embedding_function=bedrock_embeddings,
opensearch_url=host, # TODO: e.g. use the AWS OpenSearch domain instantiated previously
http_auth=auth,
timeout = 100,
use_ssl = True,
verify_certs = True,
connection_class = RequestsHttpConnection,
engine="faiss",
)
# Query for images with text
query = "What is the math and reasoning score MMMU (val) for Anthropic Claude 3 Sonnet ?"
t2i_results = docsearch.similarity_search_with_score(query, k=3) # our search query # return 3 most relevant docs
# Or Query AOSS with image aka image-to-image
with open(obj_image_path, "rb") as image_file:
image_data = image_file.read()
image_base64 = base64.b64encode(image_data).decode('utf8')
image_vectors = get_image_embedding(image_base64=image_base64)
i2i_results = docsearch.similarity_search_with_score_by_vector(image_vectors, k=3) # our search query # return 3 most relevant docs
The following screenshot illustrates the improved accuracy and comprehensive understanding of the user’s query with multimodality capability. The mmRAG approach is capable of grasping the intent behind the query, extracting relevant information from the provided chart, and estimating the overall costs, including the estimated output token size. Furthermore, it can perform mathematical calculations to determine the cost difference. The output includes the source chart and a link to its original location.

Amazon Bedrock offers a comprehensive set of generative AI models for enhancing content comprehension across various modalities. By using the latest advancements in VLMs, such as Anthropic Claude 3 Sonnet and Haiku, as well as the Amazon Titan image embedding model, Amazon Bedrock enables you to expand your document understanding beyond text to include tables, charts, and images. The integration of OpenSearch Serverless provides enterprise-grade vector storage and approximate k-NN search capabilities, enabling efficient retrieval of relevant information. With advanced LangChain decomposition and fusion techniques, you can use multi-step querying across different LLMs to improve accuracy and gain deeper insights. This powerful combination of cutting-edge technologies allows you to unlock the full potential of multimodal content comprehension, enabling you to make informed decisions and drive innovation across various data sources.
The reliance on visual language models and image embedding models for comprehensive and accurate image captions has its limitations. Although these models excel at understanding visual and textual data, the multi-step query decomposition, reciprocal ranking, and fusion processes involved can lead to increased inference latency. This makes such solutions less suitable for real-time applications or scenarios that demand instantaneous responses. However, these solutions can be highly beneficial in use cases where higher accuracy and less time-sensitive responses are required, allowing for more detailed and accurate analysis of complex visual and textual data.
In this post, we discussed how you can use multimodal RAG to address limitations in multimodal generative AI assistants. We invite you to explore mmRAG and take advantage of the advanced features of Amazon Bedrock. These powerful tools can assist your business in gaining deeper insights, making well-informed decisions, and fostering innovation driven by more accurate data. Ongoing research efforts are focused on developing an agenic and graph-based pipeline to streamline the processes of parsing, injection, and retrieval. These approaches hold the promise of enhancing the reliability and reusability of the mmRAG system.
Authors would like to expression sincere gratitude to Nausheen Sayed, Karen Twelves, Li Zhang, Sophia Shramko, Mani Khanuja, Santhosh Kuriakose, and Theresa Perkins for their comprehensive reviews.
 Alfred Shen is a Senior AI/ML Specialist at AWS. He has been working in Silicon Valley, holding technical and managerial positions in diverse sectors including healthcare, finance, and high-tech. He is a dedicated applied AI/ML researcher, concentrating on CV, NLP, and multimodality. His work has been showcased in publications such as EMNLP, ICLR, and Public Health.
Alfred Shen is a Senior AI/ML Specialist at AWS. He has been working in Silicon Valley, holding technical and managerial positions in diverse sectors including healthcare, finance, and high-tech. He is a dedicated applied AI/ML researcher, concentrating on CV, NLP, and multimodality. His work has been showcased in publications such as EMNLP, ICLR, and Public Health.
 Changsha Ma is an generative AI Specialist at AWS. She is a technologist with a PhD in Computer Science, a master’s degree in Education Psychology, and years of experience in data science and independent consulting in AI/ML. She is passionate about researching methodological approaches for machine and human intelligence. Outside of work, she loves hiking, cooking, hunting food, mentoring college students for entrepreneurship, and spending time with friends and families.
Changsha Ma is an generative AI Specialist at AWS. She is a technologist with a PhD in Computer Science, a master’s degree in Education Psychology, and years of experience in data science and independent consulting in AI/ML. She is passionate about researching methodological approaches for machine and human intelligence. Outside of work, she loves hiking, cooking, hunting food, mentoring college students for entrepreneurship, and spending time with friends and families.
 Julianna Delua is a Principal Specialist for AI/ML and generative AI. She serves the financial services industry customers including those in Capital Markets, Fintech and Payments. Julianna enjoys helping businesses turn new ideas into solutions and transform the organizations with AI-powered solutions.
Julianna Delua is a Principal Specialist for AI/ML and generative AI. She serves the financial services industry customers including those in Capital Markets, Fintech and Payments. Julianna enjoys helping businesses turn new ideas into solutions and transform the organizations with AI-powered solutions.
This post is co-written with Aurélien Capdecomme and Bertrand d’Aure from 20 Minutes.
With 19 million monthly readers, 20 Minutes is a major player in the French media landscape. The media organization delivers useful, relevant, and accessible information to an audience that consists primarily of young and active urban readers. Every month, nearly 8.3 million 25–49-year-olds choose 20 Minutes to stay informed. Established in 2002, 20 Minutes consistently reaches more than a third (39 percent) of the French population each month through print, web, and mobile platforms.
As 20 Minutes’s technology team, we’re responsible for developing and operating the organization’s web and mobile offerings and driving innovative technology initiatives. For several years, we have been actively using machine learning and artificial intelligence (AI) to improve our digital publishing workflow and to deliver a relevant and personalized experience to our readers. With the advent of generative AI, and in particular large language models (LLMs), we have now adopted an AI by design strategy, evaluating the application of AI for every new technology product we develop.
One of our key goals is to provide our journalists with a best-in-class digital publishing experience. Our newsroom journalists work on news stories using Storm, our custom in-house digital editing experience. Storm serves as the front end for Nova, our serverless content management system (CMS). These applications are a focus point for our generative AI efforts.
In 2023, we identified several challenges where we see the potential for generative AI to have a positive impact. These include new tools for newsroom journalists, ways to increase audience engagement, and a new way to ensure advertisers can confidently assess the brand safety of our content. To implement these use cases, we rely on Amazon Bedrock.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon Web Services (AWS) through a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
This blog post outlines various use cases where we’re using generative AI to address digital publishing challenges. We dive into the technical aspects of our implementation and explain our decision to choose Amazon Bedrock as our foundation model provider.
Today’s fast-paced news environment presents both challenges and opportunities for digital publishers. At 20 Minutes, a key goal of our technology team is to develop new tools for our journalists that automate repetitive tasks, improve the quality of reporting, and allow us to reach a wider audience. Based on this goal, we have identified three challenges and corresponding use cases where generative AI can have a positive impact.
The first use case is to use automation to minimize the repetitive manual tasks that journalists perform as part of the digital publishing process. The core work of developing a news story revolves around researching, writing, and editing the article. However, when the article is complete, supporting information and metadata must be defined, such as an article summary, categories, tags, and related articles.
While these tasks can feel like a chore, they are critical to search engine optimization (SEO) and therefore the audience reach of the article. If we can automate some of these repetitive tasks, this use case has the potential to free up time for our newsroom to focus on core journalistic work while increasing the reach of our content.
The second use case is how we republish news agency dispatches at 20 Minutes. Like most news outlets, 20 Minutes subscribes to news agencies, such as the Agence France-Presse (AFP) and others, that publish a feed of news dispatches covering national and international news. 20 Minutes journalists select stories relevant to our audience and rewrite, edit, and expand on them to fit the editorial standards and unique tone our readership is used to. Rewriting these dispatches is also necessary for SEO, as search engines rank duplicate content low. Because this process follows a repeatable pattern, we decided to build an AI-based tool to simplify the republishing process and reduce the time spent on it.
The third and final use case we identified is to improve transparency around the brand safety of our published content. As a digital publisher, 20 Minutes is committed to providing a brand-safe environment for potential advertisers. Content can be classified as brand-safe or not brand-safe based on its appropriateness for advertising and monetization. Depending on the advertiser and brand, different types of content might be considered appropriate. For example, some advertisers might not want their brand to appear next to news content about sensitive topics such as military conflicts, while others might not want to appear next to content about drugs and alcohol.
Organizations such as the Interactive Advertising Bureau (IAB) and the Global Alliance for Responsible Media (GARM) have developed comprehensive guidelines and frameworks for classifying the brand safety of content. Based on these guidelines, data providers such as the IAB and others conduct automated brand safety assessments of digital publishers by regularly crawling websites such as 20minutes.fr and calculating a brand safety score.
However, this brand safety score is site-wide and doesn’t break down the brand safety of individual news articles. Given the reasoning capabilities of LLMs, we decided to develop an automated per-article brand safety assessment based on industry-standard guidelines to provide advertisers with a real-time, granular view of the brand safety of 20 Minutes content.
At 20 Minutes, we’ve been using AWS since 2017, and we aim to build on top of serverless services whenever possible.
The digital publishing frontend application Storm is a single-page application built using React and Material Design and deployed using Amazon Simple Storage Service (Amazon S3) and Amazon CloudFront. Our CMS backend Nova is implemented using Amazon API Gateway and several AWS Lambda functions. Amazon DynamoDB serves as the primary database for 20 Minutes articles. New articles and changes to existing articles are captured using DynamoDB Streams, which invokes processing logic in AWS Step Functions and feeds our search service based on Amazon OpenSearch.
We integrate Amazon Bedrock using AWS PrivateLink, which allows us to create a private connection between our Amazon Virtual Private Cloud (VPC) and Amazon Bedrock without traversing the public internet.
 When working on articles in Storm, journalists have access to several AI tools implemented using Amazon Bedrock. Storm is a block-based editor that allows journalists to combine multiple blocks of content, such as title, lede, text, image, social media quotes, and more, into a complete article. With Amazon Bedrock, journalists can use AI to generate an article summary suggestion block and place it directly into the article. We use a single-shot prompt with the full article text in context to generate the summary.
When working on articles in Storm, journalists have access to several AI tools implemented using Amazon Bedrock. Storm is a block-based editor that allows journalists to combine multiple blocks of content, such as title, lede, text, image, social media quotes, and more, into a complete article. With Amazon Bedrock, journalists can use AI to generate an article summary suggestion block and place it directly into the article. We use a single-shot prompt with the full article text in context to generate the summary.
Storm CMS also gives journalists suggestions for article metadata. This includes recommendations for appropriate categories, tags, and even in-text links. These references to other 20 Minutes content are critical to increasing audience engagement, as search engines rank content with relevant internal and external links higher.
To implement this, we use a combination of Amazon Comprehend and Amazon Bedrock to extract the most relevant terms from an article’s text and then perform a search against our internal taxonomic database in OpenSearch. Based on the results, Storm provides several suggestions of terms that should be linked to other articles or topics, which users can accept or reject.

News dispatches become available in Storm as soon as we receive them from our partners such as AFP. Journalists can browse the dispatches and select them for republication on 20minutes.fr. Every dispatch is manually reworked by our journalists before publication. To do so, journalists first invoke a rewrite of the article by an LLM using Amazon Bedrock. For this, we use a low-temperature single-shot prompt that instructs the LLM not to reinterpret the article during the rewrite, and to keep the word count and structure as similar as possible. The rewritten article is then manually edited by a journalist in Storm like any other article.
To implement our new brand safety feature, we process every new article published on 20minutes.fr. Currently, we use a single shot prompt that includes both the article text and the IAB brand safety guidelines in context to get a sentiment assessment from the LLM. We then parse the response, store the sentiment, and make it publicly available for each article to be accessed by ad servers.
When we started working on generative AI use cases at 20 Minutes, we were surprised at how quickly we were able to iterate on features and get them into production. Thanks to the unified Amazon Bedrock API, it’s easy to switch between models for experimentation and find the best model for each use case.
For the use cases described above, we use Anthropic’s Claude in Amazon Bedrock as our primary LLM because of its overall high quality and, in particular, its quality in recognizing French prompts and generating French completions. Because 20 Minutes content is almost exclusively French, these multilingual capabilities are key for us. We have found that careful prompt engineering is a key success factor and we closely adhere to Anthropic’s prompt engineering resources to maximize completion quality.
Even without relying on approaches like fine-tuning or retrieval-augmented generation (RAG) to date, we can implement use cases that deliver real value to our journalists. Based on data collected from our newsroom journalists, our AI tools save them an average of eight minutes per article. With around 160 pieces of content published every day, this is already a significant amount of time that can now be spent reporting the news to our readers, rather than performing repetitive manual tasks.
The success of these use cases depends not only on technical efforts, but also on close collaboration between our product, engineering, newsroom, marketing, and legal teams. Together, representatives from these roles make up our AI Committee, which establishes clear policies and frameworks to ensure the transparent and responsible use of AI at 20 Minutes. For example, every use of AI is discussed and approved by this committee, and all AI-generated content must undergo human validation before being published.
We believe that generative AI is still in its infancy when it comes to digital publishing, and we look forward to bringing more innovative use cases to our platform this year. We’re currently working on deploying fine-tuned LLMs using Amazon Bedrock to accurately match the tone and voice of our publication and further improve our brand safety analysis capabilities. We also plan to use Bedrock models to tag our existing image library and provide automated suggestions for article images.
Based on our evaluation of several generative AI model providers and our experience implementing the use cases described above, we selected Amazon Bedrock as our primary provider for all our foundation model needs. The key reasons that influenced this decision were:
In this blog post, we described how 20 Minutes is using generative AI on Amazon Bedrock to empower our journalists in the newsroom, reach a broader audience, and make brand safety transparent to our advertisers. With these use cases, we’re using generative AI to bring more value to our journalists today, and we’ve built a foundation for promising new AI use cases in the future.
To learn more about Amazon Bedrock, start with Amazon Bedrock Resources for documentation, blog posts, and more customer success stories.
 Aurélien Capdecomme is the Chief Technology Officer at 20 Minutes, where he leads the IT development and infrastructure teams. With over 20 years of experience in building efficient and cost-optimized architectures, he has a strong focus on serverless strategy, scalable applications and AI initiatives. He has implemented innovation and digital transformation strategies at 20 Minutes, overseeing the complete migration of digital services to the cloud.
Aurélien Capdecomme is the Chief Technology Officer at 20 Minutes, where he leads the IT development and infrastructure teams. With over 20 years of experience in building efficient and cost-optimized architectures, he has a strong focus on serverless strategy, scalable applications and AI initiatives. He has implemented innovation and digital transformation strategies at 20 Minutes, overseeing the complete migration of digital services to the cloud.
 Bertrand d’Aure is a software developer at 20 Minutes. An engineer by training, he designs and implements the backend of 20 Minutes applications, with a focus on the software used by journalists to create their stories. Among other things, he is responsible for adding generative AI features to the software to simplify the authoring process.
Bertrand d’Aure is a software developer at 20 Minutes. An engineer by training, he designs and implements the backend of 20 Minutes applications, with a focus on the software used by journalists to create their stories. Among other things, he is responsible for adding generative AI features to the software to simplify the authoring process.
 Dr. Pascal Vogel is a Solutions Architect at Amazon Web Services. He collaborates with enterprise customers across EMEA to build cloud-native solutions with a focus on serverless and generative AI. As a cloud enthusiast, Pascal loves learning new technologies and connecting with like-minded customers who want to make a difference in their cloud journey.
Dr. Pascal Vogel is a Solutions Architect at Amazon Web Services. He collaborates with enterprise customers across EMEA to build cloud-native solutions with a focus on serverless and generative AI. As a cloud enthusiast, Pascal loves learning new technologies and connecting with like-minded customers who want to make a difference in their cloud journey.

In the latest ranking of the world’s most energy-efficient supercomputers, known as the Green500, NVIDIA-powered systems swept the top three spots, and took seven of the top 10.
The strong showing demonstrates how accelerated computing represents the most energy-efficient method for high-performance computing.
The top three systems were all powered by the NVIDIA GH200 Grace Hopper Superchip, showcasing the widespread adoption and efficiency of NVIDIA’s Grace Hopper architecture.
Leading the pack was the JEDI system, at Germany’s Forschungszentrum Jülich, which achieved an impressive 72.73 GFlops per Watt.
More’s coming. The ability to do more work using less power is driving the construction of more Grace Hopper supercomputers around the world.
Such achievements underscore NVIDIA’s pivotal role in advancing the global agenda for sustainable high-performance computing over the past decade.
Accelerated computing has proven to be the cornerstone of energy efficiency, with the majority of systems on the Green500 list — including 40 of the top 50 — now featuring this advanced technology.
Pioneered by NVIDIA, accelerated computing uses GPUs that optimize throughput — getting a lot done at once — to perform complex computations faster than systems based on CPUs alone.
And the Grace Hopper architecture is proving to be a game-changer by enhancing computational speed and dramatically increasing energy efficiency across multiple platforms.
For example, the GH200 chip embedded within the Grace Hopper systems offers over 1,000x more energy efficiency on mixed precision and AI tasks than previous generations.
This capability is crucial for accelerating tasks that address complex scientific challenges, speeding up the work of researchers across various disciplines.
NVIDIA’s supercomputing technology excels in traditional benchmarks — and it’s set new standards in energy efficiency.
For instance, the Alps system, at the Swiss National Supercomputing Centre (CSCS), is equipped with NVIDIA Grace Hopper GH200. The CSCS submission optimized for the Green500, dubbed preAlps,It recorded 270 petaflops on the High-Performance Linpack benchmark, used for solving complex linear equations.
The Green500 rankings highlight platforms that provide highly efficient FP64 performance, which is crucial for accurate simulations used in scientific computing. This result underscores NVIDIA’s commitment to powering supercomputers for tasks across a full range of capabilities.
This metric demonstrates substantial system performance, leading to its high ranking on the TOP500 list of the world’s fastest supercomputers. The high position on the Green500 list indicates that this scalable performance does not come at the cost of energy efficiency.
Such performance shows how the Grace Hopper architecture introduces a new era in processing technology, merging tightly coupled CPU and GPU functionalities to enhance not only performance but also significantly improve energy efficiency.
This advancement is supported by the incorporation of an optimized high-efficiency link that moves data between the CPU and GPU.
NVIDIA’s upcoming Blackwell platform is set to build on this by offering the computational power of the Titan supercomputer launched 10 years ago — a $100 million system the size of a tennis court — yet be efficient enough to be powered by a wall socket just like a typical home appliance.
In short, over the past decade, NVIDIA innovations have enhanced the accessibility and sustainability of high-performance computing, making scientific breakthroughs faster, cheaper and greener.
As NVIDIA continues to push the boundaries of what’s possible in high-performance computing, it remains committed to enhancing the energy efficiency of global computing infrastructure.
The success of the Grace Hopper supercomputers in the Green500 rankings highlights NVIDIA’s leadership and its commitment to more sustainable global computing.
Explore how NVIDIA’s pioneering role in green computing is advancing scientific research, as well as shaping a more sustainable future worldwide.

In the rapidly evolving landscape of artificial intelligence (AI), the rise of generative AI models has ushered in a new era of personalized and intelligent experiences. Organizations are increasingly using the power of these language models to drive innovation and enhance their services, from natural language processing to content generation and beyond.
Using generative AI models in the enterprise environment, however, requires taming their intrinsic power and enhancing their skills to address specific customer needs. In cases where an out-of-the-box model is missing knowledge of domain- or organization-specific terminologies, a custom fine-tuned model, also called a domain-specific large language model (LLM), might be an option for performing standard tasks in that domain or micro-domain. BloombergGPT is an example of LLM that was trained from scratch to have a better understanding of highly specialized vocabulary found in the financial domain. In the same sense, domain specificity can be addressed through fine-tuning at a smaller scale. Customers are fine-tuning generative AI models based on domains including finance, sales, marketing, travel, IT, HR, finance, procurement, healthcare and life sciences, customer service, and many more. Additionally, independent software vendors (ISVs) are building secure, managed, multi-tenant, end-to-end generative AI platforms with models that are customized and personalized based on their customer’s datasets and domains. For example, Forethought introduced SupportGPT, a generative AI platform for customer support.
As the demands for personalized and specialized AI solutions grow, businesses often find themselves grappling with the challenge of efficiently managing and serving a multitude of fine-tuned models across diverse use cases and customer segments. With the need to serve a wide range of AI-powered use cases, from resume parsing and job skill matching, domain-specific to email generation and natural language understanding, these businesses are often left with the daunting task of managing hundreds of fine-tuned models, each tailored to specific customer needs or use cases. The complexities of this challenge are compounded by the inherent scalability and cost-effectiveness concerns that come with deploying and maintaining such a diverse model ecosystem. Traditional approaches to model serving can quickly become unwieldy and resource intensive, leading to increased infrastructure costs, operational overhead, and potential performance bottlenecks.
Fine-tuning enormous language models is prohibitively expensive in terms of the hardware required and the storage and switching cost for hosting independent instances for different tasks. LoRA (Low-Rank Adaptation) is an efficient adaptation strategy that neither introduces inference latency nor reduces input sequence length while retaining high model quality. Importantly, it allows for quick task switching when deployed as a service by sharing the vast majority of the model parameters.
In this post, we explore a solution that addresses these challenges head-on using LoRA serving with Amazon SageMaker. By using the new performance optimizations of LoRA techniques in SageMaker large model inference (LMI) containers along with inference components, we demonstrate how organizations can efficiently manage and serve their growing portfolio of fine-tuned models, while optimizing costs and providing seamless performance for their customers.
The latest SageMaker LMI container offers unmerged-LoRA inference, sped up with our LMI-Dist inference engine and OpenAI style chat schema. To learn more about LMI, refer to LMI Starting Guide, LMI handlers Inference API Schema, and Chat Completions API Schema.
There are two kinds of LoRA that can be put onto various engines:
The new LMI container offers out-of-box integration and abstraction with SageMaker for hosting multiple unmerged LoRA adapters with higher performance (low latency and high throughput) using the vLLM backend LMI-Dist backend that uses vLLM, which in-turn uses S-LORA and Punica. The LMI container offers two backends for serving LoRA adapters: the LMI-Dist backend (recommended) and the vLLM Backend. Both backends are based on the open source vLLM library for serving LoRA adapters, but the LMI-Dist backend provides additional optimized continuous (rolling) batching implementation. You are not required to configure these libraries separately; the LMI container provides the higher-level abstraction through the vLLM and LMI-Dist backends. We recommend you start with the LMI-Dist backend because it has additional performance optimizations related to continuous (rolling) batching.
S-LoRA stores all adapters in the main memory and fetches the adapters used by the currently running queries to the GPU memory. To efficiently use the GPU memory and reduce fragmentation, S-LoRA proposes unified paging. Unified paging uses a unified memory pool to manage dynamic adapter weights with different ranks and KV cache tensors with varying sequence lengths. Additionally, S-LoRA employs a novel tensor parallelism strategy and highly optimized custom CUDA kernels for heterogeneous batching of LoRA computation. Collectively, these features enable S-LoRA to serve thousands of LoRA adapters on a single GPU or across multiple GPUs with a small overhead.
Punica is designed to efficiently serve multiple LoRA models on a shared GPU cluster. It achieves this by following three design guidelines:
Punica uses a new CUDA kernel design called Segmented Gather Matrix-Vector Multiplication (SGMV) to batch GPU operations for concurrent runs of multiple LoRA models, significantly improving GPU efficiency in terms of memory and computation. Punica also implements a scheduler that routes requests to active GPUs and migrates requests for consolidation, optimizing GPU resource allocation. Overall, Punica achieves high throughput and low latency in serving multi-tenant LoRA models on a shared GPU cluster. For more information, read the Punica whitepaper.
The following figure shows the multi LoRA adapter serving stack of the LMI container on SageMaker.

As shown in the preceding figure, the LMI container provides the higher-level abstraction through the vLLM and LMI-Dist backends to serve LoRA adapters at scale on SageMaker. As a result, you’re not required to configure the underlying libraries (S-LORA, Punica, or vLLM) separately. However, there might be cases where you want to control some of the performance driving parameters depending on your use case and application performance requirements. The following are the common configuration options the LMI container provides to tune LoRA serving. For more details on configuration options specific to each backend, refer to vLLM Engine User Guide and LMI-Dist Engine User Guide.
Enterprises grappling with the complexities of managing generative AI models often encounter scenarios where a robust and flexible design pattern is crucial. One common use case involves a single base model with multiple LoRA adapters, each tailored to specific customer needs or use cases. This approach allows organizations to use a foundational language model while maintaining the agility to fine-tune and deploy customized versions for their diverse customer base.
An enterprise offering a resume parsing and job skill matching service may use a single high-performance base model, such as Mistral 7B. The Mistral 7B base model is particularly well-suited for job-related content generation tasks, such as creating personalized job descriptions and tailored email communications. Mistral’s strong performance in natural language generation and its ability to capture industry-specific terminology and writing styles make it a valuable asset for such an enterprise’s customers in the HR and recruitment space. By fine-tuning Mistral 7B with LoRA adapters, enterprises can make sure the generated content aligns with the unique branding, tone, and requirements of each customer, delivering a highly personalized experience.
On the other hand, the same enterprise may use the Llama 3 base model for more general natural language processing tasks, such as resume parsing, skills extraction, and candidate matching. Llama 3’s broad knowledge base and robust language understanding capabilities enable it to handle a wide range of documents and formats, making sure their services can effectively process and analyze candidate information, regardless of the source. By fine-tuning Llama 3 with LoRA adapters, such enterprises can tailor the model’s performance to specific customer requirements, such as regional dialects, industry-specific terminology, or unique data formats. By employing a multi-base model, multi-adapter design pattern, enterprises can take advantage of the unique strengths of each language model to deliver a comprehensive and highly personalized job profile to a candidate resume matching service. This approach allows enterprises to cater to the diverse needs of their customers, making sure each client receives tailored AI-powered solutions that enhance their recruitment and talent management processes.
Effectively implementing and managing these design patterns, where multiple base models are coupled with numerous LoRA adapters, is a key challenge that enterprises must address to unlock the full potential of their generative AI investments. A well-designed and scalable approach to model serving is crucial in delivering cost-effective, high-performance, and personalized experiences to customers.

The following sections outline the coding steps to deploy a base LLM, TheBloke/Llama-2-7B-Chat-fp16, with LoRA adapters on SageMaker. It involves preparing a compressed archive with the base model files and LoRA adapter files, uploading it to Amazon Simple Storage Service (Amazon S3), selecting and configuring the SageMaker LMI container to enable LoRA support, creating a SageMaker endpoint configuration and endpoint, defining an inference component for the model, and sending inference requests specifying different LoRA adapters like Spanish (“es”) and French (“fr”) in the request payload to use those fine-tuned language capabilities. For more information on deploying models using SageMaker inference components, see Amazon SageMaker adds new inference capabilities to help reduce foundation model deployment costs and latency.
To showcase multi-base models with their LoRA adapters, we add another base model, mistralai/Mistral-7B-v0.1, and its LoRA adapter to the same SageMaker endpoint, as shown in the following diagram.

You need to complete some prerequisites before you can run the notebook:
To prepare the LoRA adapters, create a adapters.tar.gz compressed archive containing the LoRA adapters directory. The adapters directory should contain subdirectories for each of the LoRA adapters, with each adapter subdirectory containing the adapter_model.bin file (the adapter weights) and the adapter_config.json file (the adapter configuration). We typically obtain these adapter files by using the PeftModel.save_pretrained() method from the Peft library. After you assemble the adapters directory with the adapter files, you compress it into a adapters.tar.gz archive and upload it to an S3 bucket for deployment or sharing. We include the LoRA adapters in the adapters directory as follows:
Download LoRA adapters, compress them, and upload the compressed file to Amazon S3:
SageMaker provides optimized containers for LMI that support different frameworks for model parallelism, allowing the deployment of LLMs across multiple GPUs. For this post, we employ the DeepSpeed container, which encompasses frameworks such as DeepSpeed and vLLM, among others. See the following code:
Create an endpoint configuration using the appropriate instance type. Set ContainerStartupHealthCheckTimeoutInSeconds to account for the time taken to download the LLM weights from Amazon S3 or the model hub, and the time taken to load the model on the GPUs:
Create a SageMaker endpoint based on the endpoint configuration defined in the previous step. You use this endpoint for hosting the inference component (model) inference and make invocations.
Now that you have created a SageMaker endpoint, let’s create our model as an inference component. The SageMaker inference component enables you to deploy one or more foundation models (FMs) on the same SageMaker endpoint and control how many accelerators and how much memory is reserved for each FM. See the following code:
With the endpoint and inference model ready, you can now send requests to the endpoint using the LoRA adapters you fine-tuned for Spanish and French languages. The specific LoRA adapter is specified in the request payload under the "adapters" field. We use "es" for the Spanish language adapter and "fr" for the French language adapter, as shown in the following code:
Let’s add another base model and its LoRA adapter to the same SageMaker endpoint for multi-base models with multiple fine-tuned LoRA adapters. The code is very similar to the previous code for creating the Llama base model and its LoRA adapter.
Configure the SageMaker LMI container to host the base model (mistralai/Mistral-7B-v0.1) and its LoRA adapter (mistral-lora-multi-adapter/adapters/fr):
Create a new SageMaker model and inference component for the base model (mistralai/Mistral-7B-v0.1) and its LoRA adapter (mistral-lora-multi-adapter/adapters/fr):
Invoke the same SageMaker endpoint for the newly created inference component for the base model (mistralai/Mistral-7B-v0.1) and its LoRA adapter (mistral-lora-multi-adapter/adapters/fr):
Delete the SageMaker inference components, models, endpoint configuration, and endpoint to avoid incurring unnecessary costs:
The ability to efficiently manage and serve a diverse portfolio of fine-tuned generative AI models is paramount if you want your organization to deliver personalized and intelligent experiences at scale in today’s rapidly evolving AI landscape. With the inference capabilities of SageMaker LMI coupled with the performance optimizations of LoRA techniques, you can overcome the challenges of multi-tenant fine-tuned LLM serving. This solution enables you to consolidate AI workloads, batch operations across multiple models, and optimize resource utilization for cost-effective, high-performance delivery of tailored AI solutions to your customers. As demand for specialized AI experiences continues to grow, we’ve shown how the scalable infrastructure and cutting-edge model serving techniques of SageMaker position AWS as a powerful platform for unlocking generative AI’s full potential. To start exploring the benefits of this solution for yourself, we encourage you to use the code example and resources we’ve provided in this post.
 Michael Nguyen is a Senior Startup Solutions Architect at AWS, specializing in leveraging AI/ML to drive innovation and develop business solutions on AWS. Michael holds 12 AWS certifications and has a BS/MS in Electrical/Computer Engineering and an MBA from Penn State University, Binghamton University, and the University of Delaware.
Michael Nguyen is a Senior Startup Solutions Architect at AWS, specializing in leveraging AI/ML to drive innovation and develop business solutions on AWS. Michael holds 12 AWS certifications and has a BS/MS in Electrical/Computer Engineering and an MBA from Penn State University, Binghamton University, and the University of Delaware.
 Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.
Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.
![]() Vivek Gangasani is a AI/ML Startup Solutions Architect for Generative AI startups at AWS. He helps emerging GenAI startups build innovative solutions using AWS services and accelerated compute. Currently, he is focused on developing strategies for fine-tuning and optimizing the inference performance of Large Language Models. In his free time, Vivek enjoys hiking, watching movies and trying different cuisines.
Vivek Gangasani is a AI/ML Startup Solutions Architect for Generative AI startups at AWS. He helps emerging GenAI startups build innovative solutions using AWS services and accelerated compute. Currently, he is focused on developing strategies for fine-tuning and optimizing the inference performance of Large Language Models. In his free time, Vivek enjoys hiking, watching movies and trying different cuisines.
 Qing Lan is a Software Development Engineer in AWS. He has been working on several challenging products in Amazon, including high performance ML inference solutions and high performance logging system. Qing’s team successfully launched the first Billion-parameter model in Amazon Advertising with very low latency required. Qing has in-depth knowledge on the infrastructure optimization and Deep Learning acceleration.
Qing Lan is a Software Development Engineer in AWS. He has been working on several challenging products in Amazon, including high performance ML inference solutions and high performance logging system. Qing’s team successfully launched the first Billion-parameter model in Amazon Advertising with very low latency required. Qing has in-depth knowledge on the infrastructure optimization and Deep Learning acceleration.