Today, we are excited to announce the Mixtral-8x22B large language model (LLM), developed by Mistral AI, is available for customers through Amazon SageMaker JumpStart to deploy with one click for running inference. You can try out this model with SageMaker JumpStart, a machine learning (ML) hub that provides access to algorithms and models so you can quickly get started with ML. In this post, we walk through how to discover and deploy the Mixtral-8x22B model.
What is Mixtral 8x22B
Mixtral 8x22B is Mistral AI’s latest open-weights model and sets a new standard for performance and efficiency of available foundation models, as measured by Mistral AI across standard industry benchmarks. It is a sparse Mixture-of-Experts (SMoE) model that uses only 39 billion active parameters out of 141 billion, offering cost-efficiency for its size. Continuing with Mistral AI’s belief in the power of publicly available models and broad distribution to promote innovation and collaboration, Mixtral 8x22B is released under Apache 2.0, making the model available for exploring, testing, and deploying. Mixtral 8x22B is an attractive option for customers selecting between publicly available models and prioritizing quality, and for those wanting a higher quality from mid-sized models, such as Mixtral 8x7B and GPT 3.5 Turbo, while maintaining high throughput.
Mixtral 8x22B provides the following strengths:
- Multilingual native capabilities in English, French, Italian, German, and Spanish languages
- Strong mathematics and coding capabilities
- Capable of function calling that enables application development and tech stack modernization at scale
- 64,000-token context window that allows precise information recall from large documents
About Mistral AI
Mistral AI is a Paris-based company founded by seasoned researchers from Meta and Google DeepMind. During his time at DeepMind, Arthur Mensch (Mistral CEO) was a lead contributor on key LLM projects such as Flamingo and Chinchilla, while Guillaume Lample (Mistral Chief Scientist) and Timothée Lacroix (Mistral CTO) led the development of LLaMa LLMs during their time at Meta. The trio are part of a new breed of founders who combine deep technical expertise and operating experience working on state-of-the-art ML technology at the largest research labs. Mistral AI has championed small foundational models with superior performance and commitment to model development. They continue to push the frontier of artificial intelligence (AI) and make it accessible to everyone with models that offer unmatched cost-efficiency for their respective sizes, delivering an attractive performance-to-cost ratio. Mixtral 8x22B is a natural continuation of Mistral AI’s family of publicly available models that include Mistral 7B and Mixtral 8x7B, also available on SageMaker JumpStart. More recently, Mistral launched commercial enterprise-grade models, with Mistral Large delivering top-tier performance and outperforming other popular models with native proficiency across multiple languages.
What is SageMaker JumpStart
With SageMaker JumpStart, ML practitioners can choose from a growing list of best-performing foundation models. ML practitioners can deploy foundation models to dedicated Amazon SageMaker instances within a network isolated environment, and customize models using SageMaker for model training and deployment. You can now discover and deploy Mixtral-8x22B with a few clicks in Amazon SageMaker Studio or programmatically through the SageMaker Python SDK, enabling you to derive model performance and MLOps controls with SageMaker features such as Amazon SageMaker Pipelines, Amazon SageMaker Debugger, or container logs. The model is deployed in an AWS secure environment and under your VPC controls, providing data encryption at rest and in-transit.
SageMaker also adheres to standard security frameworks such as ISO27001 and SOC1/2/3 in addition to complying with various regulatory requirements. Compliance frameworks like General Data Protection Regulation (GDPR) and California Consumer Privacy Act (CCPA), Health Insurance Portability and Accountability Act (HIPAA), and Payment Card Industry Data Security Standard (PCI DSS) are supported to make sure data handling, storing, and process meet stringent security standards.
SageMaker JumpStart availability is dependent on the model; Mixtral-8x22B v0.1 is currently supported in the US East (N. Virginia) and US West (Oregon) AWS Regions.
Discover models
You can access Mixtral-8x22B foundation models through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK. In this section, we go over how to discover the models in SageMaker Studio.
SageMaker Studio is an integrated development environment (IDE) that provides a single web-based visual interface where you can access purpose-built tools to perform all ML development steps, from preparing data to building, training, and deploying your ML models. For more details on how to get started and set up SageMaker Studio, refer to Amazon SageMaker Studio.
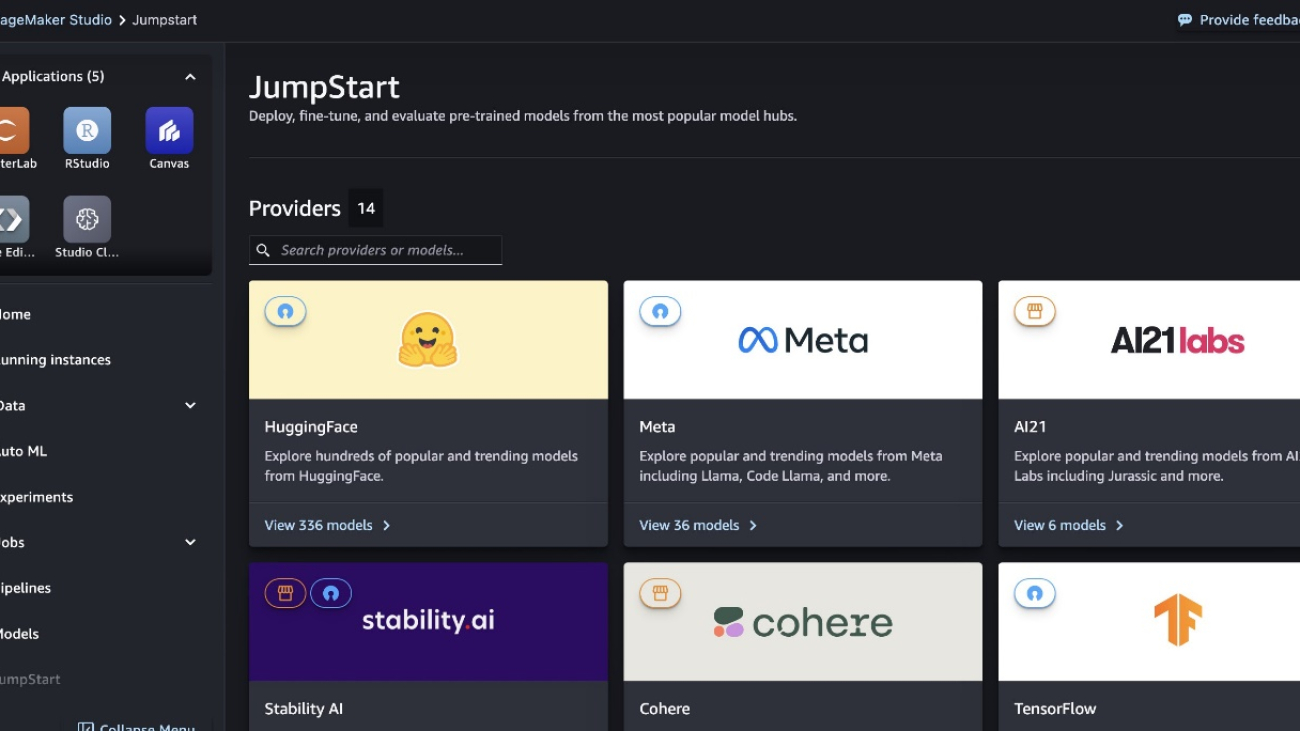
In SageMaker Studio, you can access SageMaker JumpStart by choosing JumpStart in the navigation pane.

From the SageMaker JumpStart landing page, you can search for “Mixtral” in the search box. You will see search results showing Mixtral 8x22B Instruct, various Mixtral 8x7B models, and Dolphin 2.5 and 2.7 models.

You can choose the model card to view details about the model such as license, data used to train, and how to use. You will also find the Deploy button, which you can use to deploy the model and create an endpoint.
SageMaker has seamless logging, monitoring, and auditing enabled for deployed models with native integrations with services like AWS CloudTrail for logging and monitoring to provide insights into API calls and Amazon CloudWatch to collect metrics, logs, and event data to provide information into the model’s resource utilization.

Deploy a model
Deployment starts when you choose Deploy. After deployment finishes, an endpoint has been created. You can test the endpoint by passing a sample inference request payload or selecting your testing option using the SDK. When you select the option to use the SDK, you will see example code that you can use in your preferred notebook editor in SageMaker Studio. This will require an AWS Identity and Access Management (IAM) role and policy attached to it to restrict model access. Additionally, if you choose to deploy the model endpoint within SageMaker Studio, you will be prompted to choose an instance type, initial instance count, and maximum instance count. The ml.p4d.24xlarge and ml.p4de.24xlarge instance types are the only instance types currently supported for Mixtral 8x22B Instruct v0.1.
To deploy using the SDK, we start by selecting the Mixtral-8x22b model, specified by the model_id with value huggingface-llm-mistralai-mixtral-8x22B-instruct-v0-1. You can deploy any of the selected models on SageMaker with the following code. Similarly, you can deploy Mixtral-8x22B instruct using its own model ID.
from sagemaker.jumpstart.model import JumpStartModel model = JumpStartModel(model_id=""huggingface-llm-mistralai-mixtral-8x22B-instruct-v0-1") predictor = model.deploy()
This deploys the model on SageMaker with default configurations, including the default instance type and default VPC configurations. You can change these configurations by specifying non-default values in JumpStartModel.
After it’s deployed, you can run inference against the deployed endpoint through the SageMaker predictor:
payload = {"inputs": "Hello!"}
predictor.predict(payload)
Example prompts
You can interact with a Mixtral-8x22B model like any standard text generation model, where the model processes an input sequence and outputs predicted next words in the sequence. In this section, we provide example prompts.
Mixtral-8x22b Instruct
The instruction-tuned version of Mixtral-8x22B accepts formatted instructions where conversation roles must start with a user prompt and alternate between user instruction and assistant (model answer). The instruction format must be strictly respected, otherwise the model will generate sub-optimal outputs. The template used to build a prompt for the Instruct model is defined as follows:
<s> [INST] Instruction [/INST] Model answer</s> [INST] Follow-up instruction [/INST]]
<s> and </s> are special tokens for beginning of string (BOS) and end of string (EOS), whereas [INST] and [/INST] are regular strings.
The following code shows how you can format the prompt in instruction format:
from typing import Dict, List
def format_instructions(instructions: List[Dict[str, str]]) -> List[str]:
"""Format instructions where conversation roles must alternate user/assistant/user/assistant/..."""
prompt: List[str] = []
for user, answer in zip(instructions[::2], instructions[1::2]):
prompt.extend(["<s>", "[INST] ", (user["content"]).strip(), " [/INST] ", (answer["content"]).strip(), "</s>"])
prompt.extend(["<s>", "[INST] ", (instructions[-1]["content"]).strip(), " [/INST] ","</s>"])
return "".join(prompt)
def print_instructions(prompt: str, response: str) -> None:
bold, unbold = '33[1m', '33[0m'
print(f"{bold}> Input{unbold}n{prompt}nn{bold}> Output{unbold}n{response[0]['generated_text']}n")
Summarization prompt
You can use the following code to get a response for a summarization:
instructions = [{"role": "user", "content": """Summarize the following information. Format your response in short paragraph.
Article:
Contextual compression - To address the issue of context overflow discussed earlier, you can use contextual compression to compress and filter the retrieved documents in alignment with the query’s context, so only pertinent information is kept and processed. This is achieved through a combination of a base retriever for initial document fetching and a document compressor for refining these documents by paring down their content or excluding them entirely based on relevance, as illustrated in the following diagram. This streamlined approach, facilitated by the contextual compression retriever, greatly enhances RAG application efficiency by providing a method to extract and utilize only what’s essential from a mass of information. It tackles the issue of information overload and irrelevant data processing head-on, leading to improved response quality, more cost-effective LLM operations, and a smoother overall retrieval process. Essentially, it’s a filter that tailors the information to the query at hand, making it a much-needed tool for developers aiming to optimize their RAG applications for better performance and user satisfaction.
"""}]
prompt = format_instructions(instructions)
payload = {
"inputs": prompt,
"parameters": {"max_new_tokens": 1500}
}
response=predictor.predict(payload)
print_instructions(prompt, response)
The following is an example of the expected output:
> > Input
<s>[INST] Summarize the following information. Format your response in short paragraph.
Article:
Contextual compression - To address the issue of context overflow discussed earlier, you can use contextual compression to compress and filter the retrieved documents in alignment with the query’s context, so only pertinent information is kept and processed. This is achieved through a combination of a base retriever for initial document fetching and a document compressor for refining these documents by paring down their content or excluding them entirely based on relevance, as illustrated in the following diagram. This streamlined approach, facilitated by the contextual compression retriever, greatly enhances RAG application efficiency by providing a method to extract and utilize only what’s essential from a mass of information. It tackles the issue of information overload and irrelevant data processing head-on, leading to improved response quality, more cost-effective LLM operations, and a smoother overall retrieval process. Essentially, it’s a filter that tailors the information to the query at hand, making it a much-needed tool for developers aiming to optimize their RAG applications for better performance and user satisfaction. [/INST] </s>
> Output
<s>[INST] Summarize the following information. Format your response in short paragraph.
Article:
Contextual compression - To address the issue of context overflow discussed earlier, you can use contextual compression to compress and filter the retrieved documents in alignment with the query’s context, so only pertinent information is kept and processed. This is achieved through a combination of a base retriever for initial document fetching and a document compressor for refining these documents by paring down their content or excluding them entirely based on relevance, as illustrated in the following diagram. This streamlined approach, facilitated by the contextual compression retriever, greatly enhances RAG application efficiency by providing a method to extract and utilize only what’s essential from a mass of information. It tackles the issue of information overload and irrelevant data processing head-on, leading to improved response quality, more cost-effective LLM operations, and a smoother overall retrieval process. Essentially, it’s a filter that tailors the information to the query at hand, making it a much-needed tool for developers aiming to optimize their RAG applications for better performance and user satisfaction. [/INST] </s>Contextual compression is a technique used to manage the issue of context overflow in information retrieval. This method involves compressing and filtering the retrieved documents to align with the query's context, ensuring that only relevant information is processed. This is achieved through a two-step process: a base retriever fetches the initial set of documents, and a document compressor refines these documents by either reducing their content or excluding them entirely based on relevance.
The contextual compression retriever significantly improves the efficiency of Retrieval-Augmented Generation (RAG) applications by extracting and utilizing only the essential information from a large pool of data. This approach addresses the problem of information overload and irrelevant data processing, leading to improved response quality, cost-effective operations, and a smoother retrieval process. In essence, contextual compression acts as a filter that tailors the information to the specific query, making it an indispensable tool for developers aiming to optimize their RAG applications for better performance and user satisfaction.
Multilingual translation prompt
You can use the following code to get a response for a multilingual translation:
Prompt
instructions = [{"role": "user", "content": """
<You are a multilingual assistant. Translate the following sentences in the order in which they are presented into French, German, and Spanish. Make sure to label each section as French, German, and Spanish. [/INST]
1. Customer: "I recently ordered a set of wireless headphones, but I received a different model. What steps should I take to receive the correct product I ordered?"
2. Customer: "I purchased a customizable laptop last month and opted for specific upgrades. However, the laptop's performance isn't as expected. Can I have a technician look into it, or should I consider returning it?"
3. Customer: "My order for a designer handbag was supposed to include a matching wallet as part of a promotional deal, but the wallet was not in the package. How can this issue be resolved?"
4. Customer: "I see that the tracking information for my order of ceramic cookware shows it was delivered, but I haven't received it. Could you assist in determining where my package might be?"
5. Customer: "I'm trying to buy an antique mirror from your vintage collection, but the website keeps giving me an error when I try to check out. Is there another way to complete my purchase?"
"""}]
prompt = format_instructions(instructions)
payload = {
"inputs": prompt,
"parameters": {"max_new_tokens": 2000, "do_sample": True}
}
response=predictor.predict(payload)
print_instructions(prompt, response)
The following is an example of the expected output:
> Input
<s>[INST] <You are a multilingual assistant. Translate the following sentences in the order in which they are presented into French, German, and Spanish. Make sure to label each section as French, German, and Spanish. [/INST]
1. Customer: "I recently ordered a set of wireless headphones, but I received a different model. What steps should I take to receive the correct product I ordered?"
2. Customer: "I purchased a customizable laptop last month and opted for specific upgrades. However, the laptop's performance isn't as expected. Can I have a technician look into it, or should I consider returning it?"
3. Customer: "My order for a designer handbag was supposed to include a matching wallet as part of a promotional deal, but the wallet was not in the package. How can this issue be resolved?"
4. Customer: "I see that the tracking information for my order of ceramic cookware shows it was delivered, but I haven't received it. Could you assist in determining where my package might be?"
5. Customer: "I'm trying to buy an antique mirror from your vintage collection, but the website keeps giving me an error when I try to check out. Is there another way to complete my purchase?" [/INST] </s>
> Output
<s>[INST] <You are a multilingual assistant. Translate the following sentences in the order in which they are presented into French, German, and Spanish. Make sure to label each section as French, German, and Spanish. [/INST]
1. Customer: "I recently ordered a set of wireless headphones, but I received a different model. What steps should I take to receive the correct product I ordered?"
2. Customer: "I purchased a customizable laptop last month and opted for specific upgrades. However, the laptop's performance isn't as expected. Can I have a technician look into it, or should I consider returning it?"
3. Customer: "My order for a designer handbag was supposed to include a matching wallet as part of a promotional deal, but the wallet was not in the package. How can this issue be resolved?"
4. Customer: "I see that the tracking information for my order of ceramic cookware shows it was delivered, but I haven't received it. Could you assist in determining where my package might be?"
5. Customer: "I'm trying to buy an antique mirror from your vintage collection, but the website keeps giving me an error when I try to check out. Is there another way to complete my purchase?" [/INST] </s>
French:
1. Client : "J'ai récemment commandé un casque audio sans fil, mais j'ai reçu un modèle différent. Quelles sont les étapes à suivre pour recevoir le produit correct que j'ai commandé ?"
2. Client : "J'ai acheté un ordinateur portable personnalisable le mois dernier et j'ai opté pour des mises à niveau spécifiques. Cependant, les performances de l'ordinateur portable ne sont pas à la hauteur de mes attentes. Puis-je avoir un technicien qui vérifie cela, ou devrais-je envisager de le retourner ?"
3. Client : "Ma commande pour un sac à main de designer devait inclure un portefeuille assorti dans le cadre d'une offre promotionnelle, mais le portefeuille ne se trouvait pas dans le paquet. Comment puis-je résoudre ce problème ?"
4. Client : "Je vois que les informations de suivi de ma commande de batterie de cuisine en céramique indiquent qu'elle a été livrée, mais je ne l'ai pas reçue. Pourriez-vous m'aider à déterminer où se trouve mon colis ?"
5. Client : "J'essaie d'acheter un miroir antique de votre collection vintage, mais le site continue de me donner une erreur lorsque j'essaie de passer à la caisse. Existe-t-il un autre moyen de finaliser mon achat ?"
German:
1. Kunde: "Ich habe kürzlich ein Set kabelloser Kopfhörer bestellt, aber ich habe ein anderes Modell erhalten. Welche Schritte sollte ich unternehmen, um das richtige Produkt zu erhalten, das ich bestellt habe?"
2. Kunde: "Ich habe letzten Monat einen anpassbaren Laptop gekauft und habe mich für spezifische Upgrades entschieden. Allerdings entspricht die Leistung des Laptops nicht meinen Erwartungen. Kann ich einen Techniker hinzuziehen lassen oder sollte ich eine Rückgabe in Erwägung ziehen?"
3. Kunde: "Meine Bestellung für eine Designer-Handtasche sollte inklusive eines passenden Portemonnaies als Teil einer Werbeaktion sein, aber das Portemonnaie war nicht im Paket. Wie kann dieses Problem gelöst werden?"
4. Kunde: "Ich sehe, dass die Sendungsverfolgungsinformationen für meine Bestellung von Keramik-Kochgeschirr anzeigen, dass es geliefert wurde, aber ich habe es nicht erhalten. Könnten Sie mir dabei helfen, festzustellen, wo sich mein Paket befindet?"
5. Kunde: "Ich versuche ein Antikspiegel aus Ihrer Vintage-Kollektion zu kaufen, aber die Website gibt mir jedes Mal einen Fehler, wenn ich versuche, den Bestellvorgang abzuschließen. Gibt es einen anderen Weg, meinen Kauf abzuschließen?"
Spanish:
1. Cliente: "Recientemente ordené un conjunto de audífonos inalámbricos, pero recibí un modelo diferente. ¿Cuáles son los pasos que debo seguir para recibir el producto correcto que ordené?"
2. Cliente: "Compré una computadora personalizable el mes pasado y opté por actualizaciones específicas. Sin embargo, el rendimiento de la computadora no está a la altura de mis expectativas. ¿Puedo tener un técnico que revise esto, o debería considerar devolverla?"
3. Cliente: "Mi pedido de un bolso de diseñador debería haber incluido una billetera a juego como parte de una oferta promocional, pero la billetera no estaba en el paquete. ¿Cómo puedo resolver este problema?"
4. Cliente: "Veo que la información de seguimiento de mi pedido de utensilios de cocina de cerámica indica que ha sido entregado, pero aún no lo he recibido. ¿Podría ayudarme a determinar dónde se encuentra mi paquete?"
5. Cliente: "Estoy tratando de comprar un espejo antiguo de su colección de vintage, pero el sitio sigue dándome un error cada vez que trato de realizar el pago. ¿Hay otra forma de completar mi compra?"
Code generation
You can use the following code to get a response for code generation:
instructions = [{"role": "user", "content": "Write a program on Dijstra's algorithm using a priority queue in python:"}]
prompt = format_instructions(instructions)
payload = {
"inputs": prompt,
"parameters": {"max_new_tokens": 1000}
}
response=predictor.predict(payload)
print_instructions(prompt, response)
You get the following output:
> Input
<s>[INST] Write a program on Dijstra's algorithm using a priority queue in python: [/INST] </s>
> Output
<s>[INST] Write a program on Dijstra's algorithm using a priority queue in python: [/INST] </s>Here is a Python implementation of Dijkstra's algorithm using a priority queue (heapq module):
```python
import heapq
def dijkstra(graph, start):
# Initialize the priority queue with the starting vertex and its distance (0)
priority_queue = [(0, start)]
# Initialize the distances dictionary with infinite distances for all vertices except the starting vertex
distances = {vertex: float('inf') for vertex in graph}
distances[start] = 0
# Initialize the previous dictionary to keep track of the shortest path
previous = {vertex: None for vertex in graph}
while priority_queue:
# Get the vertex with the smallest distance from the priority queue
current_distance, current_vertex = heapq.heappop(priority_queue)
# If the current distance is greater than the stored distance, skip this vertex
if current_distance > distances[current_vertex]:
continue
# Update the distances of the adjacent vertices
for neighbor, weight in graph[current_vertex].items():
distance = current_distance + weight
# If the new distance is smaller than the stored distance, update the distance and previous vertex
if distance < distances[neighbor]:
distances[neighbor] = distance
previous[neighbor] = current_vertex
# Add the neighbor to the priority queue
heapq.heappush(priority_queue, (distance, neighbor))
return distances, previous
# Example usage:
graph = {
'A': {'B': 1, 'C': 4},
'B': {'A': 1, 'C': 2, 'D': 5},
'C': {'A': 4, 'B': 2, 'D': 1},
'D': {'B': 5, 'C': 1}
}
distances, previous = dijkstra(graph, 'A')
print(distances) # {'A': 0, 'B': 1, 'C': 3, 'D': 4}
```
In this implementation, the `graph` parameter is a dictionary where the keys are the vertices and the values are dictionaries that map adjacent vertices to their weights. The `start` parameter is the starting vertex for the algorithm. The function returns two dictionaries: `distances` and `previous`. The `distances` dictionary maps each vertex to its shortest distance from the starting vertex, and the `previous` dictionary maps each vertex to its previous vertex in the shortest path.
Reasoning and math
You can use the following code to get a response for reasoning and math:
instructions = [{"role": "user", "content": """Sarah went to a car shop to buy a car from Fred for $20,000 in 2024. She plans to sell the car but it depreciates by 2% each year after she has bought it. She went to a dealer in which that dealer told her that the car has only depreciated by 1.4% each year. After 7 years of using the car, Sarah decides to sell it directly to another person.
How much did Sarah sell the car for and what year is it? Explain the steps before answering. It's ok to make some assumptions as you come to your answer.
"""}]
prompt = format_instructions(instructions)
payload = {
"inputs": prompt,
"parameters": {"max_new_tokens": 2000, "do_sample": True}
}
response=predictor.predict(payload)
print_instructions(prompt, response)
You get the following output:
<s>[INST] Sarah went to a car shop to buy a car from Fred for $20,000 in 2024. She plans to sell the car but it depreciates by 2% each year after she has bought it. She went to a dealer in which that dealer told her that the car has only depreciated by 1.4% each year. After 7 years of using the car, Sarah decides to sell it directly to another person.
How much did Sarah sell the car for and what year is it? Explain the steps before answering. It's ok to make some assumptions as you come to your answer. [/INST] </s>To solve this problem, we need to calculate the value of the car after 7 years, assuming two different annual depreciation rates: 2% and 1.4%.
First, let's calculate the value of the car after 7 years assuming a 2% annual depreciation rate:
Year 1: $20,000 - ($20,000 * 2%) = $19,600
Year 2: $19,600 - ($19,600 * 2%) = $19,208
Year 3: $19,208 - ($19,208 * 2%) = $18,821.60
Year 4: $18,821.60 - ($18,821.60 * 2%) = $18,442.22
Year 5: $18,442.22 - ($18,442.22 * 2%) = $18,071.62
Year 6: $18,071.62 - ($18,071.62 * 2%) = $17,709.76
Year 7: $17,709.76 - ($17,709.76 * 2%) = $17,356.58
So, assuming a 2% annual depreciation rate, the value of the car after 7 years would be approximately $17,356.58.
Next, let's calculate the value of the car after 7 years assuming a 1.4% annual depreciation rate:
Year 1: $20,000 - ($20,000 * 1.4%) = $19,728
Year 2: $19,728 - ($19,728 * 1.4%) = $19,463.23
Year 3: $19,463.23 - ($19,463.23 * 1.4%) = $19,205.80
Year 4: $19,205.80 - ($19,205.80 * 1.4%) = $18,955.66
Year 5: $18,955.66 - ($18,955.66 * 1.4%) = $18,712.73
Year 6: $18,712.73 - ($18,712.73 * 1.4%) = $18,476.95
Year 7: $18,476.95 - ($18,476.95 * 1.4%) = $18,248.33
So, assuming a 1.4% annual depreciation rate, the value of the car after 7 years would be approximately $18,248.33.
Now, since Sarah sells the car directly to another person, we can assume that she sold it for the higher of the two values. Therefore, she sold the car for $18,248.33.
As for the year in which she sold the car, since we know that Sarah purchased the car in 2024 and used it for 7 years, we can calculate the year as follows:
2024 + 7 = 2031
Therefore, Sarah sold the car in the year 2031.
So, Sarah sold the car for $18,248.33 in the year 2031.
Clean up
After you’re done running the notebook, delete all resources that you created in the process so your billing is stopped. Use the following code:
predictor.delete_model()
predictor.delete_endpoint()
Conclusion
In this post, we showed you how to get started with Mixtral-8x22B in SageMaker Studio and deploy the model for inference. Because foundation models are pre-trained, they can help lower training and infrastructure costs and enable customization for your use case. Visit SageMaker JumpStart in SageMaker Studio now to get started.
Now that you are aware of Mistral AI and their Mixtral 8x22B models, we encourage you to deploy an endpoint on SageMaker to perform inference testing and try out responses for yourself. Refer to the following resources for more information:
About the Authors
 Marco Punio is a Solutions Architect focused on generative AI strategy, applied AI solutions, and conducting research to help customers hyper-scale on AWS. He is a qualified technologist with a passion for machine learning, artificial intelligence, and mergers and acquisitions. Marco is based in Seattle, WA, and enjoys writing, reading, exercising, and building applications in his free time.
Marco Punio is a Solutions Architect focused on generative AI strategy, applied AI solutions, and conducting research to help customers hyper-scale on AWS. He is a qualified technologist with a passion for machine learning, artificial intelligence, and mergers and acquisitions. Marco is based in Seattle, WA, and enjoys writing, reading, exercising, and building applications in his free time.
 Preston Tuggle is a Sr. Specialist Solutions Architect working on generative AI.
Preston Tuggle is a Sr. Specialist Solutions Architect working on generative AI.
 June Won is a product manager with Amazon SageMaker JumpStart. He focuses on making foundation models easily discoverable and usable to help customers build generative AI applications. His experience at Amazon also includes mobile shopping application and last mile delivery.
June Won is a product manager with Amazon SageMaker JumpStart. He focuses on making foundation models easily discoverable and usable to help customers build generative AI applications. His experience at Amazon also includes mobile shopping application and last mile delivery.
 Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
 Shane Rai is a Principal GenAI Specialist with the AWS World Wide Specialist Organization (WWSO). He works with customers across industries to solve their most pressing and innovative business needs using AWS’s breadth of cloud-based AI/ML services including model offerings from top tier foundation model providers.
Shane Rai is a Principal GenAI Specialist with the AWS World Wide Specialist Organization (WWSO). He works with customers across industries to solve their most pressing and innovative business needs using AWS’s breadth of cloud-based AI/ML services including model offerings from top tier foundation model providers.
 Hemant Singh is an Applied Scientist with experience in Amazon SageMaker JumpStart. He got his master’s from Courant Institute of Mathematical Sciences and B.Tech from IIT Delhi. He has experience in working on a diverse range of machine learning problems within the domain of natural language processing, computer vision, and time series analysis.
Hemant Singh is an Applied Scientist with experience in Amazon SageMaker JumpStart. He got his master’s from Courant Institute of Mathematical Sciences and B.Tech from IIT Delhi. He has experience in working on a diverse range of machine learning problems within the domain of natural language processing, computer vision, and time series analysis.
Read More













 Veda Raman is a Senior Specialist Solutions Architect for Generative AI and machine learning based at AWS. Veda works with customers to help them architect efficient, secure and scalable machine learning applications. Veda specializes in generative AI services like Amazon Bedrock and Amazon Sagemaker.
Veda Raman is a Senior Specialist Solutions Architect for Generative AI and machine learning based at AWS. Veda works with customers to help them architect efficient, secure and scalable machine learning applications. Veda specializes in generative AI services like Amazon Bedrock and Amazon Sagemaker. Uma Ramadoss is a Principal Solutions Architect at Amazon Web Services, focused on the Serverless and Integration Services. She is responsible for helping customers design and operate event-driven cloud-native applications using services like Lambda, API Gateway, EventBridge, Step Functions, and SQS. Uma has a hands on experience leading enterprise-scale serverless delivery projects and possesses strong working knowledge of event-driven, micro service and cloud architecture.
Uma Ramadoss is a Principal Solutions Architect at Amazon Web Services, focused on the Serverless and Integration Services. She is responsible for helping customers design and operate event-driven cloud-native applications using services like Lambda, API Gateway, EventBridge, Step Functions, and SQS. Uma has a hands on experience leading enterprise-scale serverless delivery projects and possesses strong working knowledge of event-driven, micro service and cloud architecture.