This post is a follow-up to Generative AI and multi-modal agents in AWS: The key to unlocking new value in financial markets. This blog is part of the series, Generative AI and AI/ML in Capital Markets and Financial Services.
Financial analysts and research analysts in capital markets distill business insights from financial and non-financial data, such as public filings, earnings call recordings, market research publications, and economic reports, using a variety of tools for data mining. They face many challenges because of the increasing variety of tools and amount of data. They must synthesize massive amounts of data from multiple sources, qualitative and quantitative, to provide insights and recommendations. Analysts need to learn new tools and even some programming languages such as SQL (with different variations). To add to these challenges, they must think critically under time pressure and perform their tasks quickly to keep up with the pace of the market.
Investment research is the cornerstone of successful investing, and involves gathering and analyzing relevant information about potential investment opportunities. Through thorough research, analysts come up with a hypothesis, test the hypothesis with data, and understand the effect before portfolio managers make decisions on investments as well as mitigate risks associated with their investments. Artificial intelligence (AI)-powered assistants can boost the productivity of a financial analysts, research analysts, and quantitative trading in capital markets by automating many of the tasks, freeing them to focus on high-value creative work. AI-powered assistants can amplify an analyst’s productivity by searching for relevant information in the customer’s own database as well as online, conducting qualitative and quantitative analysis on structured and unstructured data, enabling analysts to work faster and with greater accuracy.
In this post, we introduce a solution using Agents for Amazon Bedrock and Knowledge Bases for Amazon Bedrock that can help financial analysts use various data sources of multifaceted financial data (text, audio, and databases) and various tools (detect phrases, portfolio optimization, sentiment analysis, and stock query) to gather financial insights. The interaction shows how AI-powered assistants recognize and plan based on user’s prompts, come up with steps to retrieve context from data stores, and pass through various tools and LLM to arrive at a response.
AI-powered assistants for investment research

So, what are AI-powered assistants? AI-powered assistants are advanced AI systems, powered by generative AI and large language models (LLMs), which use AI technologies to understand goals from natural language prompts, create plans and tasks, complete these tasks, and orchestrate the results from the tasks to reach the goal. Generative AI agents, which form the backbone of AI-powered assistants, can orchestrate interactions between foundation models, data sources, software applications, and users. As AI technology advances, the abilities of generative AI agents are expected to grow, providing more opportunities to gain a competitive advantage.
Leading this evolution is Amazon Bedrock, a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon using a single API, along with a broad set of capabilities to build and scale generative AI applications with security, privacy, and responsible AI.
You can now use Agents for Amazon Bedrock and Knowledge Bases for Amazon Bedrock to build specialized agents and AI-powered assistants that run actions based on natural language input prompts and your organization’s data. These managed agents act as intelligent orchestrators, coordinating interactions between foundation models, API integrations, user questions and instructions, and knowledge sources loaded with your proprietary data. At runtime, the agent intelligently handles and orchestrates the user inputs throughout a dynamic number of steps.
The following video demonstrates an AI-powered assistant in Agents for Amazon Bedrock in action.
Solution overview
A key component of an AI-powered assistant is Agents for Amazon Bedrock. An agent consists of the following components:
- Foundation model – The agent invokes an FM to interpret user input, generate subsequent prompts in its orchestration process, and generate responses.
- Instructions – Instructions telling the agent what it’s designed to do and how to do it.
- Action groups – Action groups are interfaces that an agent uses to interact with the different underlying components such as APIs and databases. An agent uses action groups to carry out actions, such as making an API call to another tool.
- Knowledge base – The knowledge base is a link to an existing knowledge base, consisting of customer’s documents (such as PDF files and text files) that allows the agent to query for extra context for the prompts.
Both the action groups and knowledge base are optional and not required for the agent itself.
In this post, an AI-powered assistant for investment research can use both structured and unstructured data for providing context to the LLM using a Retrieval Augmented Generation (RAG) architecture, as illustrated in the following diagram.

For the AI-powered assistant, the following the action groups are associated:
- Detect-phrases – Useful for when you need to detect key phrases in financial reports
- Portfolio-optimization – Useful for when you need to build an optimal allocation portfolio from a list of stock symbols using python functions
- Sentiment-analysis – Useful for when you need to analyze the sentiment of an excerpt from a financial report
- Stock-query – Useful for when you need to answer any question about historical stock prices
Depending on the prompts, the AI-powered assistant for investment research uses different types of structured and unstructured data. The agent can find insights from different modalities of financial data:
- Unstructured data – This includes annual 10K and quarterly 10Q earnings reports, which are converted into vectors using Amazon Titan Embeddings models and stored as vectors in an Amazon OpenSearch Serverless vector database, all orchestrated using a knowledge base
- Structured data – This includes tabular stock data, which is stored in Amazon Simple Storage Service (Amazon S3) and queried using Amazon Athena
- Other data modalities – This includes audio files of quarterly earnings calls, which are converted into unstructured data using Amazon Textract and Amazon Transcribe
When the AI-powered assistant receives a prompt from a business user, it follows a number of steps as part its orchestration:
- Break down the prompt into a number of steps using an LLM within Amazon Bedrock.
- Follow chain-of-thought reasoning and instructions, and complete the steps using appropriate action groups.
- As part of the process, depending on the prompt, search and identify relevant context for RAG.
- Pass the results with the prompt to an LLM within Amazon Bedrock.
- Generate the final response and respond to the user in English with relevant data.
The following diagram illustrates this workflow.

Technical architecture and key steps
The multi-modal agent orchestrates various steps based on natural language prompts from business users to generate insights. For unstructured data, the agent uses AWS Lambda functions with AI services such as Amazon Comprehend for natural language processing (NLP). For structured data, the agent uses the SQL Connector and SQLAlchemy to analyze the database through Athena. The agent also uses the selected LLM for computations and quantitative modeling, and the context session equips the agent with conversation history. The multi-modal agent is implemented using Agents for Amazon Bedrock and coordinates the different actions and knowledge bases based on prompts from business users through the AWS Management Console, although it can also be invoked through the AWS API.
The following diagram illustrates the technical architecture.

The key components of the technical architecture are as follows:
- Data storage and analytics – The quarterly financial earning recordings as audio files, financial annual reports as PDF files, and S&P stock data as CSV files are hosted on Amazon S3. Data exploration on stock data is done using Athena.
- Large language models – The LLMs available to be used by Agents for Amazon Bedrock are Anthropic Claude Instant v1, v2.0, and v2.1.
- Agents – We use Agents for Amazon Bedrock to build and configure autonomous agents. Agents orchestrate interactions between FMs, data sources, software applications, and user conversations. Depending on the user input, the agent decides the action or knowledge base to call to answer the question. We created the following purpose-built agent actions using Lambda and Agents for Amazon Bedrock for our scenario:
- Stocks querying – To query S&P stocks data using Athena and SQLAlchemy.
- Portfolio optimization – To build a portfolio based on the chosen stocks.
- Sentiment analysis – To identify and score sentiments on a topic using Amazon Comprehend.
- Detect phrases – To find key phrases in recent quarterly reports using Amazon Comprehend.
- Knowledge base – To search for financial earnings information stored in multi-page PDF files, we use a knowledge base (using an OpenSearch Serverless vector store).
To dive deeper into the solution and code for all the steps, see the GitHub repo.
Benefits and lessons learned in migrating from LangChain agents to Agents for Amazon Bedrock
Agents for Amazon Bedrock and LangChain agents both use an LLM to interpret user input and prompts in their orchestration processes. The LLM acts as a reasoning engine to determine next actions. Agents for Amazon Bedrock offers several benefits when implementing an agent-based solution.
Agents for Amazon Bedrock is serverless, meaning you can build agents without managing any infrastructure.
-
Conversation history and session management
By default, LangChain agents are stateless, meaning they don’t remember previous interactions or keep history of the conversation. It supports either a simple memory system that recalls the most recent conversations or complex memory structures that analyze historical messages to return the most relevant results. In our previous post, we deployed a persistent storage solution using Amazon DynamoDB.
Agents for Amazon Bedrock provides a short-term memory for conversations by default, allowing the user to interact with the agent continuously during the session.
Knowledge Bases for Amazon Bedrock provides an out-of-the-box RAG solution. It enables a faster time-to-market by abstracting the heavy lifting of building a pipeline and offers a persistent solution for keeping large data as vector embeddings in vector databases, thereby reducing latency to RAG systems.
A knowledge base simplifies the setup and implementation of RAG by automating several steps in this process:
- Preprocessing data – Split the documents into manageable chunks for efficient retrieval. The chunks are then converted to embeddings and written to a vector index while maintaining a mapping to the original document.
- Runtime processing – Embed user queries into vectors. Compare vector embeddings of user queries and document chunks to find semantically similar matches. Augment user prompts with context from matched chunks.
Knowledge Bases for Amazon Bedrock supports popular databases for vector storage, including the vector engine for OpenSearch Serverless, Pinecone, Redis Enterprise Cloud, Amazon Aurora (coming soon), and MongoDB (coming soon).
Most functions (tools) from our previous multi-modal agent can be migrated to Amazon Bedrock using action groups. Action groups define agent actions by providing an OpenAPI schema to define invocable APIs, as well as a Lambda function specifying input and output. Lambda natively supports Java, Go, PowerShell, Node.js, C#, Python, and Ruby code. LangChain’s supported languages do not include PowerShell and Node.js.
A key element to get optimal results in our LangChain agent was using a good and clear prompt. In our previous multi-modal agent, we used the following prompt:
You are a Minimization Solutionist with a set of tools at your disposal.
You would be presented with a problem. First understand the problem and devise a plan to solve the problem.
Please output the plan starting with the header 'Plan:' and then followed by a numbered list of steps.
Ensure the plan has the minimum amount of steps needed to solve the problem. Do not include unnecessary steps.
<instructions>
These are guidance on when to use a tool to solve a task, follow them strictly:
1. For the tool that specifically focuses on stock price data, use "Stock Query Tool".
2......
</instructions>nnAssistant:"""
The prompt provided detailed information to give the agent as much guidance as possible to respond to a question.
With Agents for Amazon Bedrock, we used simple instructions for the agent to obtain the same results. With a shorter prompt (“You are a financial analyst with a set of tools at your disposal”), we were able to answer the same questions with the same quality.
-
Editability of base prompts
Agents for Amazon Bedrock also exposes the four default base prompt templates that are used during the preprocessing, orchestration, knowledge base response generation, and postprocessing. You can optionally edit these base prompt templates to customize your agent’s behavior at each step of its sequence.
Each response from an Amazon Bedrock agent is accompanied by a trace that details the steps being orchestrated by the agent. The trace provides information about the inputs to the action groups that the agent invokes and the knowledge bases that it queries to respond to the user. In addition, the trace provides information about the outputs that the action groups and knowledge bases return.
You can securely connect LLMs to your company data sources using Agents for Amazon Bedrock. With a knowledge base, you can use agents to give LLMs in Amazon Bedrock access to additional data that helps the model generate more relevant, context-specific, and accurate responses without continually retraining the LLM.
Dive deeper into the solution
To dive deeper into the solution and the code shown in this post, see the GitHub repo. The repo contains instructions for the end-to-end solution, including setting up the agents, associated action groups, unstructured data (earnings reports PDF files, earnings call audio files), and structured data (stocks time series).
In the appendix at the end of this post, we share different questions asked by a financial analyst, the agent tools invoked, and the answer from the multi-modal agent.
Clean up
After you run the multi-modal agent, make sure to clean up any resources manually that won’t be used later:
- Delete your agent and the knowledge base associated to your agent.
- Delete the vector index containing the data embeddings.
- Delete the S3 buckets created by AWS CloudFormation and then delete the CloudFormation stack.
Conclusion
The solution presented in this post uses Agents for Amazon Bedrock and Knowledge Bases for Amazon Bedrock to assist financial analysts in navigating the complexities of multifaceted financial data. By seamlessly integrating various data sources, including text, audio, and databases, this AI-powered assistant can effectively plan and complete tasks based on user prompts—retrieving relevant information, processing it through various tools, and ultimately providing insightful conclusions. Agents for Amazon Bedrock and LangChain agents both use LLMs for interpreting user input and determining subsequent actions, but Agents for Amazon Bedrock offers several advantages, including serverless deployment, built-in stateful conversation history tracking, and out-of-the-box support for RAG with knowledge base integration. Additionally, Amazon Bedrock simplifies the agent development process by enabling migration of existing functions, requiring only basic prompts for optimal results, and providing traceability for agent actions and knowledge base queries. For further insights into generative AI, foundation models, and LLMs, Amazon Bedrock offers a wealth of use cases and resources. To learn more, see Generative AI and multi-modal agents in AWS: The key to unlocking new value in financial markets, which demonstrates how multi-modal agents use AWS services to efficiently gather financial insights from an organization’s text, speech, and tabular data sources for a financial analyst’s query using LangChain agents as alternative implementation.
Appendix
The following table contains example questions provided by a financial analyst to ask the AI-powered assistant for investment research based on structured and unstructured data.
| Question purpose |
Question asked by financial analyst to AI-powered assistant |
Action group or knowledge base invoked |
Intermediate steps from AI-powered assistant chain-of-thought reasoning |
Answer from AI-powered assistant |
| Prompt the agent to analyze the company’s financial health and performance. |
Analyze Amazon’s financial health based on the 10k report. Calculate important financial ratios. Please limit your answer to 5 sentences. |
Financial-Data-Explorer |
Step1: To analyze Amazon’s financial health and calculate important financial ratios based on their 10K report, I will need to search the knowledge base for relevant information from Amazon’s 10K filing. I can then extract key financial data like revenues, expenses, assets, liabilities, etc. and use that to calculate ratios like current ratio, debt-to-equity ratio, return on assets, etc. to assess their financial position and performance.
Step2: The search results provide some key financial data from Amazon’s recent 10K filing, including net sales, operating income, net income, and context around factors impacting their financials like foreign exchange rates and severance costs. To analyze their financial health and calculate ratios, I will need to extract additional data points like current assets, current liabilities, total assets, total liabilities, etc. from the 10K report.
Step3: With the additional balance sheet data from Amazon’s 10K report, I now have the key financial figures needed to calculate some important ratios to analyze their financial health:nnCurrent Ratio = Total Current Assets / Total Current Liabilitiesn= $146.8 billion / $155.4 billion = 0.94nnThis current ratio slightly below 1 indicates Amazon may have a bit of a liquidity crunch in the short-term to cover current obligations.nnDebt-to-Equity Ratio = Total Liabilities / Total Shareholders’ Equity n= ($155.4 billion + $161.2 billion) / ($462.7 billion – $316.6 billion)n= $316.6 billion / $146.1 billion = 2.17nnThe relatively high debt-to-equity ratio over 2 shows Amazon has a highly leveraged capital structure, though this may be expected given their large investments in infrastructure and growth initiatives.nnReturn on Assets = Net Income / Total Assetsn= $9.9 billion / ($146.8 billion + $315.9 billion) n= $9.9 billion / $462.7 billion = 2.1%nnThe low single-digit return on assets indicates Amazon is not very efficient at generating profits from its asset base currently, likely due to heavy investments and spending on growth.
|
The current ratio of 0.94 indicates Amazon may face some liquidity challenges in covering short-term obligations.[1]
The debt-to-equity ratio of 2.17 shows a highly leveraged capital structure, likely due to major investments in growth initiatives.[2]
The return on assets of 2.1% is relatively low, suggesting Amazon is not very efficient at generating profits from its asset base currently.[3]
|
| Prompt the agent to analyze the company’s financial performance from company’s earnings reports |
What were the main drivers of AWS’s revenue growth in the Q1 2023 quarter? Please limit your answers to 5 sentences. |
Financial-Data-Explorer |
To determine the main drivers of AWS’s revenue growth in Q1 2023, I will need to search the knowledge base for any information specifically related to AWS’s performance and growth factors during that quarter. |
The main drivers of AWS’s revenue growth of 16% in Q1 2023 were increased customer usage of AWS services, partially offset by pricing changes primarily driven by long-term customer contracts. Higher customer adoption and consumption of AWS offerings fueled the topline growth, though pricing concessions on long-term deals moderated the growth rate. |
| Prompt the agent to analyze the company’s management team and their plans for the future from company’s earnings reports |
What are Amazon’s top priorities for 2023? What are the biggest risks facing the company? Please limit your answers to 5 sentences. |
Financial-Data-Explorer |
To determine Amazon’s top priorities and biggest risks for 2023, I will search the knowledge base for any relevant information from their recent earnings reports, investor presentations, or other public statements outlining their strategic focus areas and potential risk factors. |
Amazon’s top priorities for 2023 include mitigating impacts from macroeconomic headwinds, managing foreign exchange volatility, and accurately forecasting customer demand amid economic uncertainty. Some of the biggest risks facing the company are inventory management challenges, rising payments processing costs and fraud risks, reliance on third-party payment providers, and a potential slowdown in enterprise AWS adoption due to customer cost optimization efforts. |
| Prompt the agent to perform sentiment analysis on the earnings call recordings |
What is the sentiment around inflation in Amazon’s earnings call? |
Sentiment Analysis Tool,
Financial-Data-Explorer
|
Step 1: To determine the sentiment around inflation expressed in Amazon’s earnings call, I will need to search the knowledge base for any relevant excerpts or commentary from the earnings call transcript related to inflation.
2: The search results provide some relevant excerpts from Amazon’s earnings guidance and commentary related to inflation and macroeconomic factors. To better assess the overall sentiment, I will use the Sentiment Analysis tool on these excerpts.
|
The sentiment around inflation in Amazon’s earnings call is decidedly negative. Amazon expresses concerns that ongoing inflationary pressures, rising costs, and recessionary fears are driving cautious consumer spending, shifts to lower-priced products, and challenges in forecasting demand. The company expects these macroeconomic factors to continue impacting operations, customer demand, and revenue growth rates across segments like AWS in the coming quarters. |
| Prompt the agent to build an optimal portfolio using the collected data |
What are the closing prices of stocks AAAA, WWW, DDD in year 2018? Can you build an optimized portfolio using these three stocks on how to allocate 10,000 USD? |
Stocks Querying Tool,
Portfolio Optimization Tool |
Step 1: To get the closing prices of the stocks AAAA, WWW, and DDD in 2018, I will use the Stock-Query tool
Step 2: The Stock-Query tool provided the closing prices for the requested stocks in 2018. To build an optimized portfolio allocation with $10,000 using these stocks, I will use the Portfolio-Optimization tool. |
Based on the closing prices of stocks AAAA, WWW, and DDD in 2018 provided by the <REDACTED> tool, and the optimized portfolio allocation from the <REDACTED> tool, here is how to allocate $10,000 across these three stocks: With $10,000: – Buy 48 shares of AAAA stock at $172.44 per share, investing $8,415 – Buy 1 share of WWW stock at $85.91 per share, investing $165.80 – Buy 14 shares of DDD stock at $9.82 per share, investing $1,419.20 This optimized portfolio allocation maximizes returns while minimizing risk based on the 2018 stock prices. |
About the Authors
 Omar Ashton is a Partner Solutions Architect in Colombia. With 17 years of experience in software design and development, IT solution architecture, technology strategy and leadership of development teams.
Omar Ashton is a Partner Solutions Architect in Colombia. With 17 years of experience in software design and development, IT solution architecture, technology strategy and leadership of development teams.
 Sovik Kumar Nath is an AI/ML and GenAI specialist senior solution architect with AWS working with financial services and capital markets customers. He has extensive experience designing end-to-end machine learning and business analytics solutions in finance, operations, marketing, healthcare, supply chain management, and IoT. Sovik has published articles and holds a patent in ML model monitoring. He has double masters degrees from the University of South Florida, University of Fribourg, Switzerland, and a bachelors degree from the Indian Institute of Technology, Kharagpur. Outside of work, Sovik enjoys traveling, taking ferry rides, and watching movies.
Sovik Kumar Nath is an AI/ML and GenAI specialist senior solution architect with AWS working with financial services and capital markets customers. He has extensive experience designing end-to-end machine learning and business analytics solutions in finance, operations, marketing, healthcare, supply chain management, and IoT. Sovik has published articles and holds a patent in ML model monitoring. He has double masters degrees from the University of South Florida, University of Fribourg, Switzerland, and a bachelors degree from the Indian Institute of Technology, Kharagpur. Outside of work, Sovik enjoys traveling, taking ferry rides, and watching movies.
 Jose Rojas is a Partner Solutions Architect at AWS. He helps Partners to increase productivity, efficiency and revenue by adopting and creating solutions on AWS. Before joining AWS, Jose worked at Cisco Meraki helping customers adopt cloud networking solutions. Outside work, he enjoys traveling with his family, swimming and cycling.
Jose Rojas is a Partner Solutions Architect at AWS. He helps Partners to increase productivity, efficiency and revenue by adopting and creating solutions on AWS. Before joining AWS, Jose worked at Cisco Meraki helping customers adopt cloud networking solutions. Outside work, he enjoys traveling with his family, swimming and cycling.
 Mohan Musti is a Principal Technical Account Manger based out of Dallas. Mohan helps customers architect and optimize applications on AWS. Mohan has Computer Science and Engineering from JNT University, India. In his spare time, he enjoys spending time with his family and camping.
Mohan Musti is a Principal Technical Account Manger based out of Dallas. Mohan helps customers architect and optimize applications on AWS. Mohan has Computer Science and Engineering from JNT University, India. In his spare time, he enjoys spending time with his family and camping.
 Jia (Vivian) Li is a Senior Solutions Architect in AWS, with specialization in AI/ML. She currently supports customers in financial industry. Prior to joining AWS in 2022, she had 7 years of experience supporting enterprise customers use AI/ML in the cloud to drive business results. Vivian has a BS from Peking University and a PhD from University of Southern California. In her spare time, she enjoys all the water activities, and hiking in the beautiful mountains in her home state, Colorado.
Jia (Vivian) Li is a Senior Solutions Architect in AWS, with specialization in AI/ML. She currently supports customers in financial industry. Prior to joining AWS in 2022, she had 7 years of experience supporting enterprise customers use AI/ML in the cloud to drive business results. Vivian has a BS from Peking University and a PhD from University of Southern California. In her spare time, she enjoys all the water activities, and hiking in the beautiful mountains in her home state, Colorado.
 Uchenna Egbe is an AI/ML and GenAI specialist Solutions Architect who enjoys building reusable AIML solutions. Uchenna has an MS from the University of Alaska Fairbanks. He spends his free time researching about herbs, teas, superfoods, and how to incorporate them into his daily diet.
Uchenna Egbe is an AI/ML and GenAI specialist Solutions Architect who enjoys building reusable AIML solutions. Uchenna has an MS from the University of Alaska Fairbanks. He spends his free time researching about herbs, teas, superfoods, and how to incorporate them into his daily diet.
Read More



 Vipul Parekh, is a senior customer solutions manager at AWS guiding our Capital Markets customers in accelerating their business transformation journey on Cloud. He is a GenAI ambassador and a member of AWS AI/ML technical field community. Prior to AWS, Vipul played various roles at the top investment banks, leading transformations spanning from front office to back-office, and regulatory compliance areas.
Vipul Parekh, is a senior customer solutions manager at AWS guiding our Capital Markets customers in accelerating their business transformation journey on Cloud. He is a GenAI ambassador and a member of AWS AI/ML technical field community. Prior to AWS, Vipul played various roles at the top investment banks, leading transformations spanning from front office to back-office, and regulatory compliance areas.  Raj Talasila, is a senior technical program manager at AWS. He comes to AWS with 30+ years of experience in the Financial Services, Media and Entertainment, and CPG.
Raj Talasila, is a senior technical program manager at AWS. He comes to AWS with 30+ years of experience in the Financial Services, Media and Entertainment, and CPG. Saby Sahoo, is a senior solutions architect at AWS. Saby has 20+ years of experience in the field of design and implementation of IT Solutions, Data Analytics, and AI/ML/GenAI.
Saby Sahoo, is a senior solutions architect at AWS. Saby has 20+ years of experience in the field of design and implementation of IT Solutions, Data Analytics, and AI/ML/GenAI. Sovik Kumar Nath is an AI/ML solution architect with AWS. He has extensive experience designing end-to-end machine learning and business analytics solutions in finance, operations, marketing, healthcare, supply chain management, and IoT. Sovik has published articles and holds a patent in ML model monitoring. He has double masters degrees from the University of South Florida, University of Fribourg, Switzerland, and a bachelors degree from the Indian Institute of Technology, Kharagpur. Outside of work, Sovik enjoys traveling, taking ferry rides, and watching movies.
Sovik Kumar Nath is an AI/ML solution architect with AWS. He has extensive experience designing end-to-end machine learning and business analytics solutions in finance, operations, marketing, healthcare, supply chain management, and IoT. Sovik has published articles and holds a patent in ML model monitoring. He has double masters degrees from the University of South Florida, University of Fribourg, Switzerland, and a bachelors degree from the Indian Institute of Technology, Kharagpur. Outside of work, Sovik enjoys traveling, taking ferry rides, and watching movies.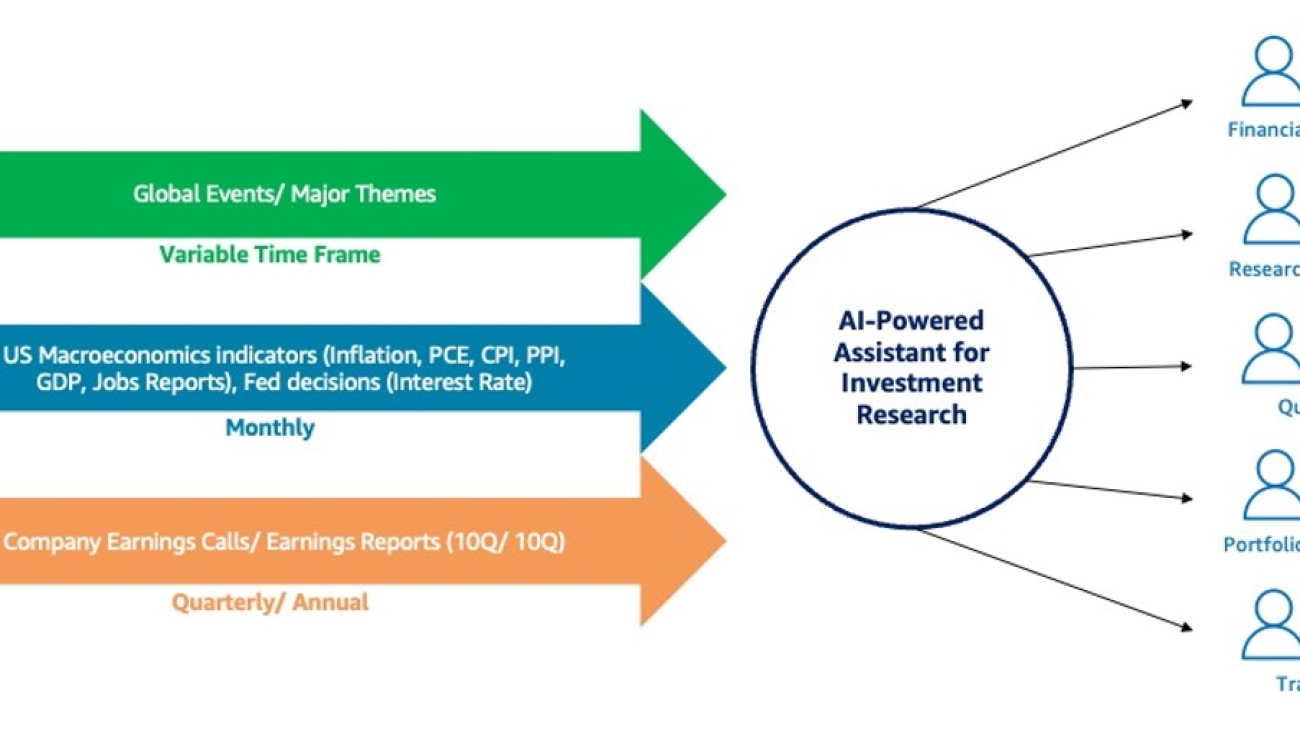





 Today we’re sharing 7 principles for responsible AI regulation, and endorsing 5 bills in Congress.
Today we’re sharing 7 principles for responsible AI regulation, and endorsing 5 bills in Congress.
 Joshua Broyde, PhD, is a Principal Solution Architect at AI21 Labs. He works with customers and AI21 partners across the generative AI value chain, including enabling generative AI at an enterprise level, using complex LLM workflows and chains for regulated and specialized environments, and using LLMs at scale.
Joshua Broyde, PhD, is a Principal Solution Architect at AI21 Labs. He works with customers and AI21 partners across the generative AI value chain, including enabling generative AI at an enterprise level, using complex LLM workflows and chains for regulated and specialized environments, and using LLMs at scale.




 Niithiyn Vijeaswaran is a Solutions Architect at AWS. His area of focus is generative AI and AWS AI Accelerators. He holds a Bachelor’s degree in Computer Science and Bioinformatics. Niithiyn works closely with the Generative AI GTM team to enable AWS customers on multiple fronts and accelerate their adoption of generative AI. He’s an avid fan of the Dallas Mavericks and enjoys collecting sneakers.
Niithiyn Vijeaswaran is a Solutions Architect at AWS. His area of focus is generative AI and AWS AI Accelerators. He holds a Bachelor’s degree in Computer Science and Bioinformatics. Niithiyn works closely with the Generative AI GTM team to enable AWS customers on multiple fronts and accelerate their adoption of generative AI. He’s an avid fan of the Dallas Mavericks and enjoys collecting sneakers. Emir Ayar is a Senior Tech Lead Solutions Architect with the AWS Prototyping team. He specializes in assisting customers with building ML and generative AI solutions, and implementing architectural best practices. He supports customers in experimenting with solution architectures to achieve their business objectives, emphasizing agile innovation and prototyping. He lives in Luxembourg and enjoys playing synthesizers.
Emir Ayar is a Senior Tech Lead Solutions Architect with the AWS Prototyping team. He specializes in assisting customers with building ML and generative AI solutions, and implementing architectural best practices. He supports customers in experimenting with solution architectures to achieve their business objectives, emphasizing agile innovation and prototyping. He lives in Luxembourg and enjoys playing synthesizers. Ziwen Ning is a software development engineer at AWS. He currently focuses on enhancing the AI/ML experience through the integration of AWS Neuron with containerized environments and Kubernetes. In his free time, he enjoys challenging himself with badminton, swimming and other various sports, and immersing himself in music.
Ziwen Ning is a software development engineer at AWS. He currently focuses on enhancing the AI/ML experience through the integration of AWS Neuron with containerized environments and Kubernetes. In his free time, he enjoys challenging himself with badminton, swimming and other various sports, and immersing himself in music. Rohit Talluri is a Generative AI GTM Specialist (Tech BD) at Amazon Web Services (AWS). He is partnering with top generative AI model builders, strategic customers, key AI/ML partners, and AWS Service Teams to enable the next generation of artificial intelligence, machine learning, and accelerated computing on AWS. He was previously an Enterprise Solutions Architect, and the Global Solutions Lead for AWS Mergers & Acquisitions Advisory.
Rohit Talluri is a Generative AI GTM Specialist (Tech BD) at Amazon Web Services (AWS). He is partnering with top generative AI model builders, strategic customers, key AI/ML partners, and AWS Service Teams to enable the next generation of artificial intelligence, machine learning, and accelerated computing on AWS. He was previously an Enterprise Solutions Architect, and the Global Solutions Lead for AWS Mergers & Acquisitions Advisory. Albert Opher is a Solutions Architect Intern at AWS. He is a rising senior at the University of Pennsylvania pursuing Dual Bachelor’s Degrees in Computer Information Science and Business Analytics in the Jerome Fisher Management and Technology Program. He has experience with multiple programming languages, AWS cloud services, AI/ML technologies, product and operations management, pre and early seed start-up ventures, and corporate finance.
Albert Opher is a Solutions Architect Intern at AWS. He is a rising senior at the University of Pennsylvania pursuing Dual Bachelor’s Degrees in Computer Information Science and Business Analytics in the Jerome Fisher Management and Technology Program. He has experience with multiple programming languages, AWS cloud services, AI/ML technologies, product and operations management, pre and early seed start-up ventures, and corporate finance. Geeta Gharpure is a senior software developer on the Annapurna ML engineering team. She is focused on running large scale AI/ML workloads on Kubernetes. She lives in Sunnyvale, CA and enjoys listening to audible in her free time
Geeta Gharpure is a senior software developer on the Annapurna ML engineering team. She is focused on running large scale AI/ML workloads on Kubernetes. She lives in Sunnyvale, CA and enjoys listening to audible in her free time