“Best-fit packing” adapts bin-packing to avoid unnecessary truncation of training documents, improving LLM performance across a wide range of tasks and reducing hallucination.Read More
NVIDIA’s AI Masters Sweep KDD Cup 2024 Data Science Competition
Team NVIDIA has triumphed at the Amazon KDD Cup 2024, securing first place Friday across all five competition tracks.
The team — consisting of NVIDIANs Ahmet Erdem, Benedikt Schifferer, Chris Deotte, Gilberto Titericz, Ivan Sorokin and Simon Jegou — demonstrated its prowess in generative AI, winning in categories that included text generation, multiple-choice questions, name entity recognition, ranking, and retrieval.
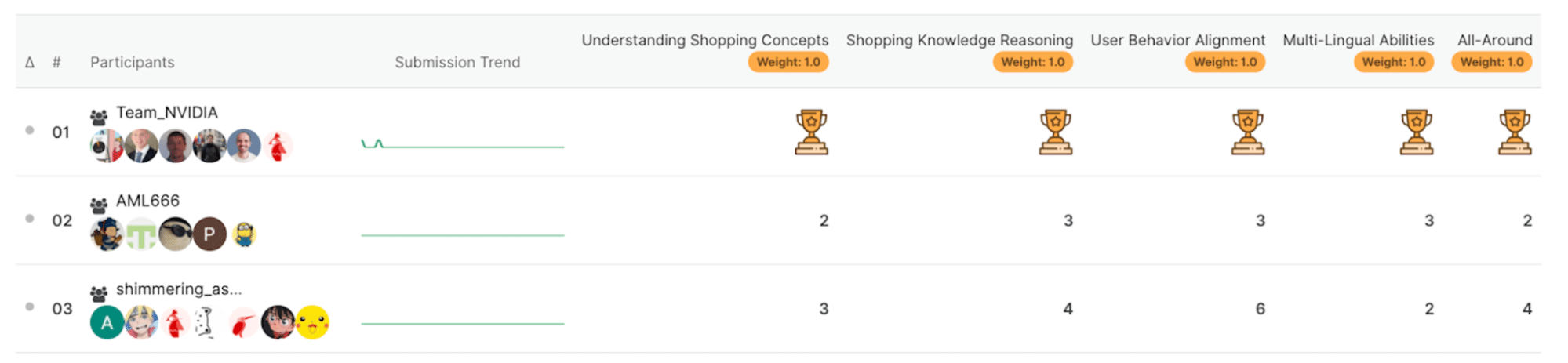
The competition, themed “Multi-Task Online Shopping Challenge for LLMs,” asked participants to solve various challenges using limited datasets.
“The new trend in LLM competitions is that they don’t give you training data,” said Deotte, a senior data scientist at NVIDIA. “They give you 96 example questions — not enough to train a model — so we came up with 500,000 questions on our own.”
Deotte explained that the NVIDIA team generated a variety of questions by writing some themselves, using a large language model to create others, and transforming existing e-commerce datasets.
“Once we had our questions, it was straightforward to use existing frameworks to fine-tune a language model,” he said.
The competition organizers hid the test questions to ensure participants couldn’t exploit previously known answers. This approach encourages models that generalize well to any question about e-commerce, proving the model’s capability to handle real-world scenarios effectively.
Despite these constraints, Team NVIDIA’s innovative approach outperformed all competitors by using Qwen2-72B, a just-released LLM with 72 billion parameters, fine-tuned on eight NVIDIA A100 Tensor Core GPUs, and employing QLoRA, a technique for fine-tuning models with datasets.
About the KDD Cup 2024
The KDD Cup, organized by the Association for Computing Machinery’s Special Interest Group on Knowledge Discovery and Data Mining, or ACM SIGKDD, is a prestigious annual competition that promotes research and development in the field.
This year’s challenge, hosted by Amazon, focused on mimicking the complexities of online shopping with the goal of making it a more intuitive and satisfying experience using large language models. Organizers utilized the test dataset ShopBench — a benchmark that replicates the massive challenge for online shopping with 57 tasks and about 20,000 questions derived from real-world Amazon shopping data — to evaluate participants’ models.
The ShopBench benchmark focused on four key shopping skills, along with a fifth “all-in-one” challenge:
- Shopping Concept Understanding: Decoding complex shopping concepts and terminologies.
- Shopping Knowledge Reasoning: Making informed decisions with shopping knowledge.
- User Behavior Alignment: Understanding dynamic customer behavior.
- Multilingual Abilities: Shopping across languages.
- All-Around: Solving all tasks from the previous tracks in a unified solution.
NVIDIA’s Winning Solution
NVIDIA’s winning solution involved creating a single model for each track.
The team fine-tuned the just-released Qwen2-72B model using eight NVIDIA A100 Tensor Core GPUs for approximately 24 hours. The GPUs provided fast and efficient processing, significantly reducing the time required for fine-tuning.

First, the team generated training datasets based on the provided examples and synthesized additional data using Llama 3 70B hosted on build.nvidia.com.
Next, they employed QLoRA (Quantized Low-Rank Adaptation), a training process using the data created in step one. QLoRA modifies a smaller subset of the model’s weights, allowing efficient training and fine-tuning.
The model was then quantized — making it smaller and able to run on a system with a smaller hard drive and less memory — with AWQ 4-bit and used the vLLM inference library to predict the test datasets on four NVIDIA T4 Tensor Core GPUs within the time constraints.
This approach secured the top spot in each individual track and the overall first place in the competition—a clean sweep for NVIDIA for the second year in a row.
The team plans to submit a detailed paper on its solution next month and plans to present its findings at KDD 2024 in Barcelona.

Microsoft at ICML 2024: Innovations in machine learning

In an era increasingly steered by data, machine learning is a pivotal force, transforming vast amounts of information into actionable intelligence with unprecedented speed and accuracy. For example, recent advances in machine learning have led to breakthroughs in precision health, helping doctors make more informed decisions about patient care. Similarly, in climate science, machine learning is improving scientists’ ability to predict and mitigate the impact of extreme weather events. These innovations illustrate that machine learning not only streamlines workflows, it also equips people with the tools to tackle some of today’s most pressing challenges with efficiency and innovation.
As the field continues to evolve, the International Conference on Machine Learning (ICML 2024) serves as a premier forum that showcases the latest breakthroughs and innovations, bringing together researchers, academics, and industry professionals from across the globe. Microsoft is proud to support ICML 2024 as a returning sponsor and is pleased to share that 68 papers by Microsoft researchers and their collaborators have been accepted this year, including four chosen for oral presentations.
This post highlights these presentations, each exploring machine learning’s potential to refine decision-making processes, improve automation, and model complex behaviors. A good example is NaturalSpeech 3, which introduces a new approach to speech synthesis that could transform how machines communicate. Together, these advances not only demonstrate the versatility and depth of machine learning applications, but also underscore an ongoing commitment to solving practical and theoretical challenges. Continue reading to discover more about this research and explore some of Microsoft’s contributions to ICML 2024.
Oral sessions
CompeteAI: Understanding the Competition Dynamics in Large Language Model-based Agents
Qinlin Zhao, Jindong Wang, Yixuan Zhang, Yiqiao Jin, Kaijie Zhu, Hao Chen, Xing Xie
This study aims to explore the possibilities of using LLM agents to help accelerate social science research. To that end, the authors propose a framework for studying agent competition by implementing a competitive environment, using GPT-4 to simulate a virtual town featuring restaurant and customer agents. Restaurant agents compete to attract customers, driving them to develop new operating strategies. Findings highlight phenomena such as social learning and the effect of accumulated advantage, aligning with existing sociological and economic theories. Further investigation into agent competition could enable a better understanding of society.
NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models
Zeqian Ju, Yuancheng Wang, Kai Shen, Xu Tan, Detai Xin, Dongchao Yang, Yanqing Liu, Yichong Leng, Kaitao Song, Siliang Tang, Zhizheng Wu, Tao Qin, Xiang-Yang Li, Wei Ye, Shikun Zhang, Jiang Bian, Lei He, Jinyu Li, Sheng Zhao
This work introduces NaturalSpeech 3, a text-to-speech (TTS) system using novel factorized diffusion models for zero-shot speech generation. First, the research team developed a neural codec with factorized vector quantization (FVQ) to separate speech waveforms into content, prosody, timbre, and acoustic details. Second, the factorized diffusion model generates attributes in each subspace based on corresponding prompts. This divide-and-conquer approach allows NaturalSpeech 3 to model intricate speech effectively and efficiently. Experimental results show that NaturalSpeech 3 surpasses state-of-the-art TTS systems in quality, similarity, prosody, and intelligibility.
Position: Rethinking Post-Hoc Search-Based Neural Approaches for Solving Large-Scale Traveling Salesman Problems
Yifan Xia, Xianliang Yang, Zichuan Liu, Zhihao Liu, Lei Song, Jiang Bian
Recent advances in solving complex routing problems, like the traveling salesman problem (TSP), use a novel approach where machine learning (ML) models generate heatmaps to guide Monte Carlo tree search (MCTS) algorithms. These heatmaps indicate the likelihood of each route being part of the optimal solution. However, the authors’ analysis questions the effectiveness of ML-generated heatmaps. They found that a simple method often outperforms complex ML approaches. Additionally, the heatmap-guided MCTS is less effective than the traditional LKH-3 heuristic. The authors recommend that future research focus on better heatmap methods and more versatile ML approaches for combinatorial problems.
PRISE: LLM-Style Sequence Compression for Learning Temporal Action Abstractions in Control
Ruijie Zheng, Ching-An Cheng, Hal Daumé III, Furong Huang, Andrey Kolobov
Temporal action abstractions promise more effective AI decision-making and data-efficient training of large robotic models. This work draws a novel analogy between temporal action abstraction and text tokenization—a seemingly unrelated sequential data compression mechanism in LLMs typically implemented using byte pair encoding (BPE). Based on this, the authors propose Primitive Sequence Encoding (PRISE), an approach that combines action quantization with BPE for skill learning for continuous control. Results show that high-level skills learned by PRISE from robotic manipulation demonstrations greatly improve behavior cloning performance in downstream tasks.
Discover more about our work and contributions to ICML 2024, including our full list of publications and sessions, on our conference webpage.
Spotlight: AI-POWERED EXPERIENCE

Microsoft research copilot experience
Discover more about research at Microsoft through our AI-powered experience
The post Microsoft at ICML 2024: Innovations in machine learning appeared first on Microsoft Research.

Sustainable Strides: How AI and Accelerated Computing Are Driving Energy Efficiency
AI and accelerated computing — twin engines NVIDIA continuously improves — are delivering energy efficiency for many industries.
It’s progress the wider community is starting to acknowledge.
“Even if the predictions that data centers will soon account for 4% of global energy consumption become a reality, AI is having a major impact on reducing the remaining 96% of energy consumption,” said a report from Lisbon Council Research, a nonprofit formed in 2003 that studies economic and social issues.
The article from the Brussels-based research group is among a handful of big-picture AI policy studies starting to emerge. It uses Italy’s Leonardo supercomputer, accelerated with nearly 14,000 NVIDIA GPUs, as an example of a system advancing work in fields from automobile design and drug discovery to weather forecasting.
Why Accelerated Computing Is Sustainable Computing
Accelerated computing uses the parallel processing of NVIDIA GPUs to do more work in less time. As a result, it consumes less energy than general-purpose servers that employ CPUs built to handle one task at a time.
That’s why accelerated computing is sustainable computing.

The gains are even greater when accelerated systems apply AI, an inherently parallel form of computing that’s the most transformative technology of our time.
“When it comes to frontier applications like machine learning or deep learning, the performance of GPUs is an order of magnitude better than that of CPUs,” the report said.
User Experiences With Accelerated AI
Users worldwide are documenting energy-efficiency gains with AI and accelerated computing.
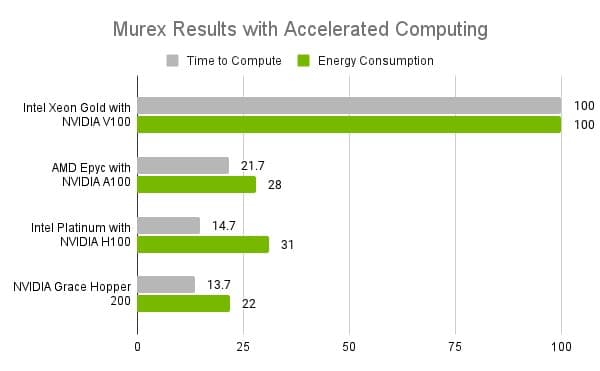
In financial services, Murex — a Paris-based company with a trading and risk-management platform used daily by more than 60,000 people — tested the NVIDIA Grace Hopper Superchip. On its workloads, the CPU-GPU combo delivered a 4x reduction in energy consumption and a 7x reduction in time to completion compared with CPU-only systems (see chart below).
“On risk calculations, Grace is not only the fastest processor, but also far more power-efficient, making green IT a reality in the trading world,” said Pierre Spatz, head of quantitative research at Murex.
In manufacturing, Taiwan-based Wistron built a digital copy of a room where NVIDIA DGX systems undergo thermal stress tests to improve operations at the site. It used NVIDIA Omniverse, a platform for industrial digitization, with a surrogate model, a version of AI that emulates simulations.
The digital twin, linked to thousands of networked sensors, enabled Wistron to increase the facility’s overall energy efficiency by up to 10%. That amounts to reducing electricity consumption by 120,000 kWh per year and carbon emissions by a whopping 60,000 kilograms.
Up to 80% Fewer Carbon Emissions
The RAPIDS Accelerator for Apache Spark can reduce the carbon footprint for data analytics, a widely used form of machine learning, by as much as 80% while delivering 5x average speedups and 4x reductions in computing costs, according to a recent benchmark.
Thousands of companies — about 80% of the Fortune 500 — use Apache Spark to analyze their growing mountains of data. Companies using NVIDIA’s Spark accelerator include Adobe, AT&T and the U.S. Internal Revenue Service.
In healthcare, Insilico Medicine discovered and put into phase 2 clinical trials a drug candidate for a relatively rare respiratory disease, thanks to its NVIDIA-powered AI platform.
Using traditional methods, the work would have cost more than $400 million and taken up to six years. But with generative AI, Insilico hit the milestone for one-tenth of the cost in one-third of the time.
“This is a significant milestone not only for us, but for everyone in the field of AI-accelerated drug discovery,” said Alex Zhavoronkov, CEO of Insilico Medicine.
This is just a sampler of results that users of accelerated computing and AI are pursuing at companies such as Amgen, BMW, Foxconn, PayPal and many more.
Speeding Science With Accelerated AI
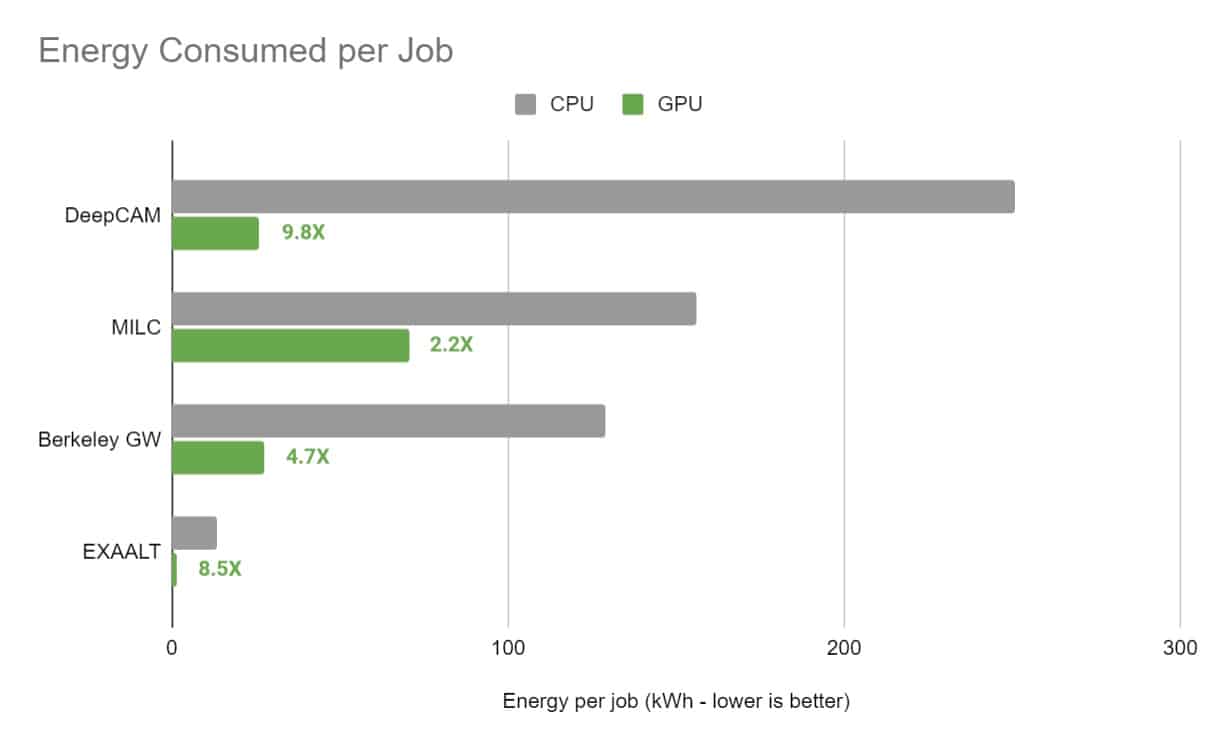
In basic research, the National Energy Research Scientific Computing Center (NERSC), the U.S. Department of Energy’s lead facility for open science, measured results on a server with four NVIDIA A100 Tensor Core GPUs compared with dual-socket x86 CPU servers across four of its key high-performance computing and AI applications.
Researchers found that the apps, when accelerated with the NVIDIA A100 GPUs, saw energy efficiency rise 5x on average (see below). One application, for weather forecasting, logged gains of nearly 10x.
Scientists and researchers worldwide depend on AI and accelerated computing to achieve high performance and efficiency.
In a recent ranking of the world’s most energy-efficient supercomputers, known as the Green500, NVIDIA-powered systems swept the top six spots, and 40 of the top 50.
Underestimated Energy Savings
The many gains across industries and science are sometimes overlooked in forecasts that extrapolate only the energy consumption of training the largest AI models. That misses the benefits from most of an AI model’s life when it’s consuming relatively little energy, delivering the kinds of efficiencies users described above.
In an analysis citing dozens of sources, a recent study debunked as misleading and inflated projections based on training models.
“Just as the early predictions about the energy footprints of e-commerce and video streaming ultimately proved to be exaggerated, so too will those estimates about AI likely be wrong,” said the report from the Information Technology and Innovation Foundation (ITIF), a Washington-based think tank.
The report notes as much as 90% of the cost — and all the efficiency gains — of running an AI model are in deploying it in applications after it’s trained.
“Given the enormous opportunities to use AI to benefit the economy and society — including transitioning to a low-carbon future — it is imperative that policymakers and the media do a better job of vetting the claims they entertain about AI’s environmental impact,” said the report’s author, who described his findings in a recent podcast.
Others Cite AI’s Energy Benefits
Policy analysts from the R Street Institute, also in Washington, D.C., agreed.
“Rather than a pause, policymakers need to help realize the potential for gains from AI,” the group wrote in a 1,200-word article.
“Accelerated computing and the rise of AI hold great promise for the future, with significant societal benefits in terms of economic growth and social welfare,” it said, citing demonstrated benefits of AI in drug discovery, banking, stock trading and insurance.
AI can make the electric grid, manufacturing and transportation sectors more efficient, it added.
AI Supports Sustainability Efforts
The reports also cited the potential of accelerated AI to fight climate change and promote sustainability.
“AI can enhance the accuracy of weather modeling to improve public safety as well as generate more accurate predictions of crop yields. The power of AI can also contribute to … developing more precise climate models,” R Street said.
The Lisbon report added that AI plays “a crucial role in the innovation needed to address climate change” for work such as discovering more efficient battery materials.
How AI Can Help the Environment
ITIF called on governments to adopt AI as a tool in efforts to decarbonize their operations.
Public and private organizations are already applying NVIDIA AI to protect coral reefs, improve tracking of wildfires and extreme weather, and enhance sustainable agriculture.
For its part, NVIDIA is working with hundreds of startups employing AI to address climate issues. NVIDIA also announced plans for Earth-2, expected to be the world’s most powerful AI supercomputer dedicated to climate science.
Enhancing Energy Efficiency Across the Stack
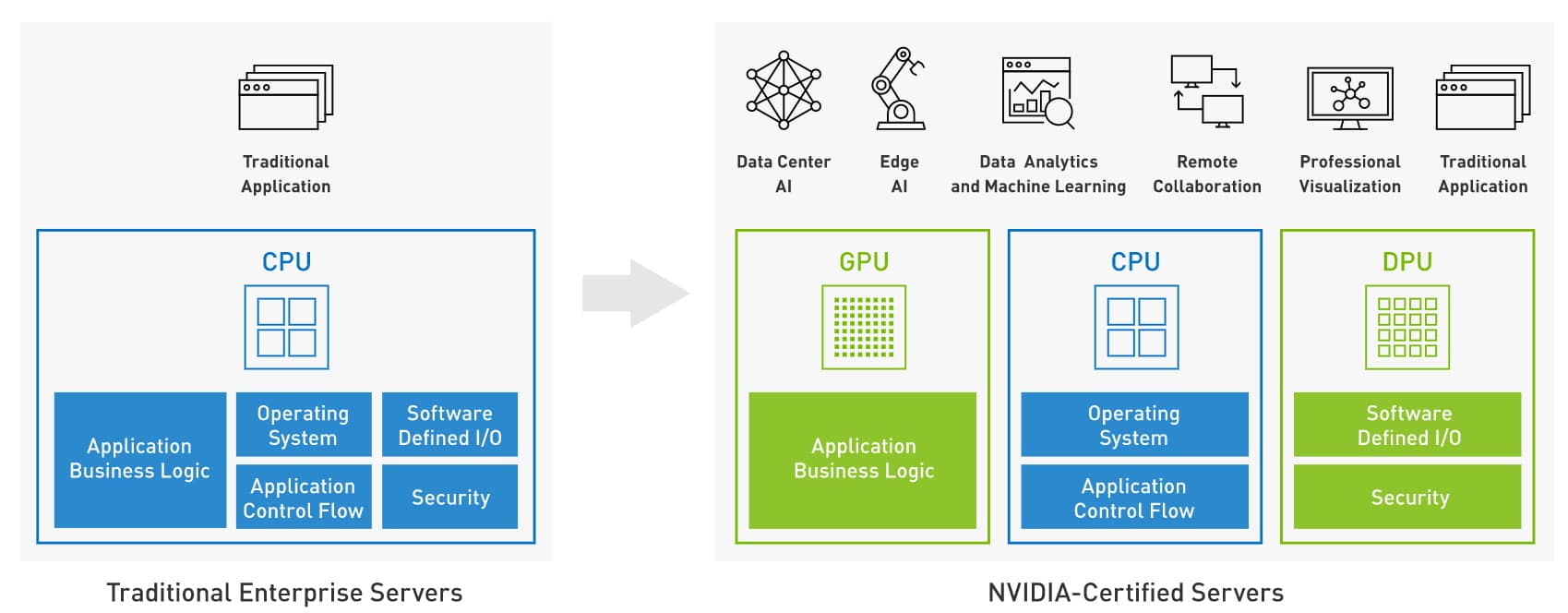
Since its founding in 1993, NVIDIA has worked on energy efficiency across all its products — GPUs, CPUs, DPUs, networks, systems and software, as well as platforms such as Omniverse.
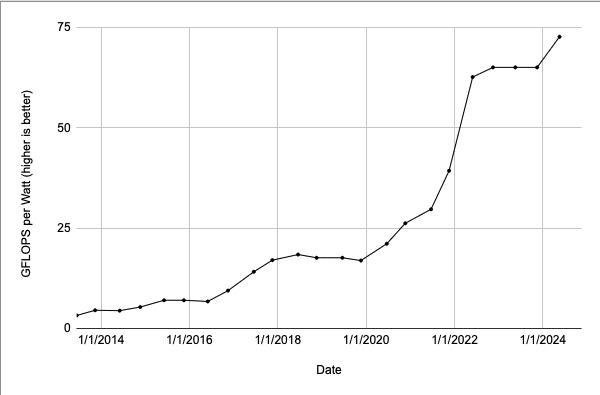
In AI, the brunt of an AI model’s life is in inference, delivering insights that help users achieve new efficiencies. The NVIDIA GB200 Grace Blackwell Superchip has demonstrated 25x energy efficiency over the prior NVIDIA Hopper GPU generation in AI inference.
Over the last eight years, NVIDIA GPUs have advanced a whopping 45,000x in their energy efficiency running large language models (see chart below).
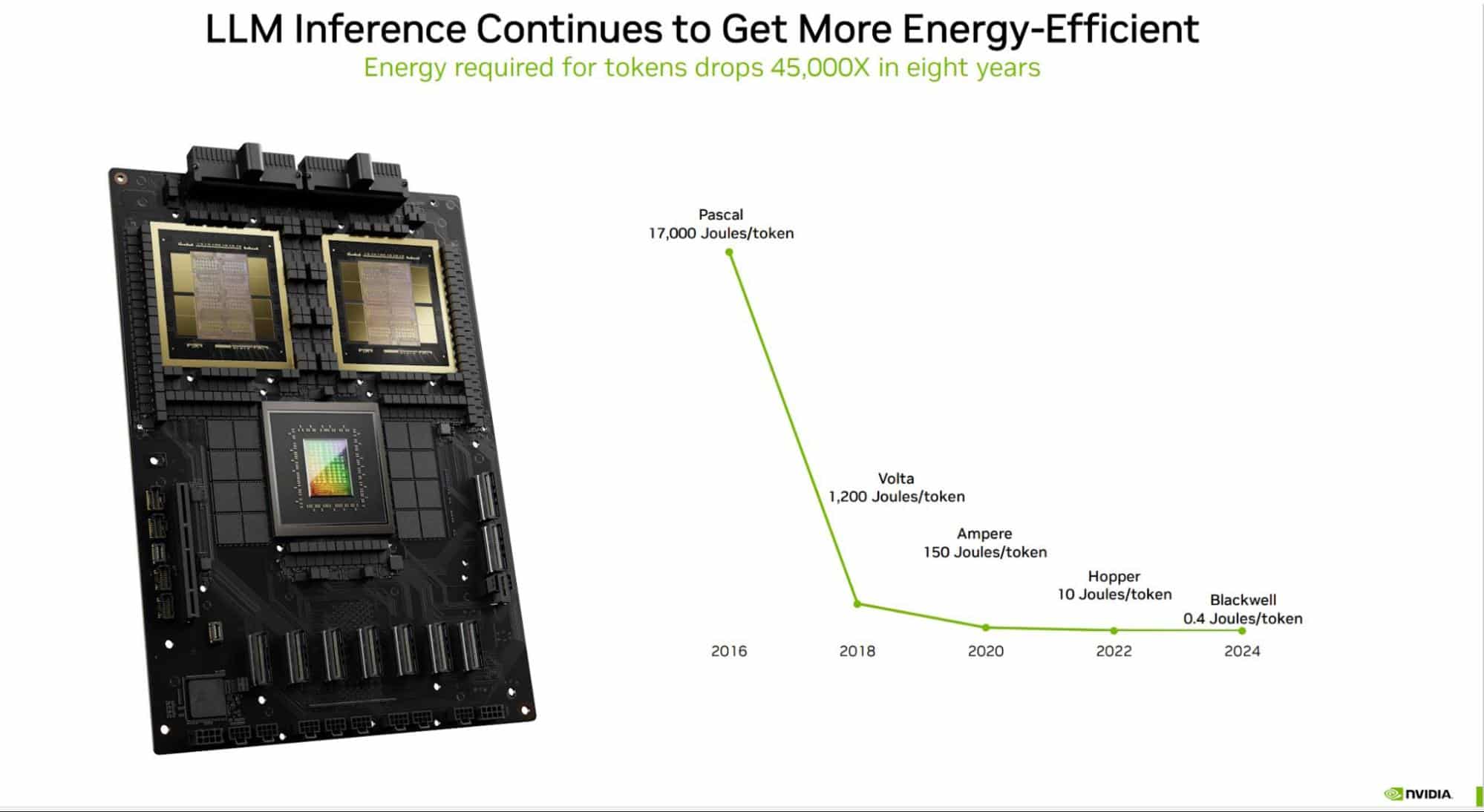
Recent innovations in software include TensorRT-LLM. It can help GPUs reduce 3x the energy consumption of LLM inference.
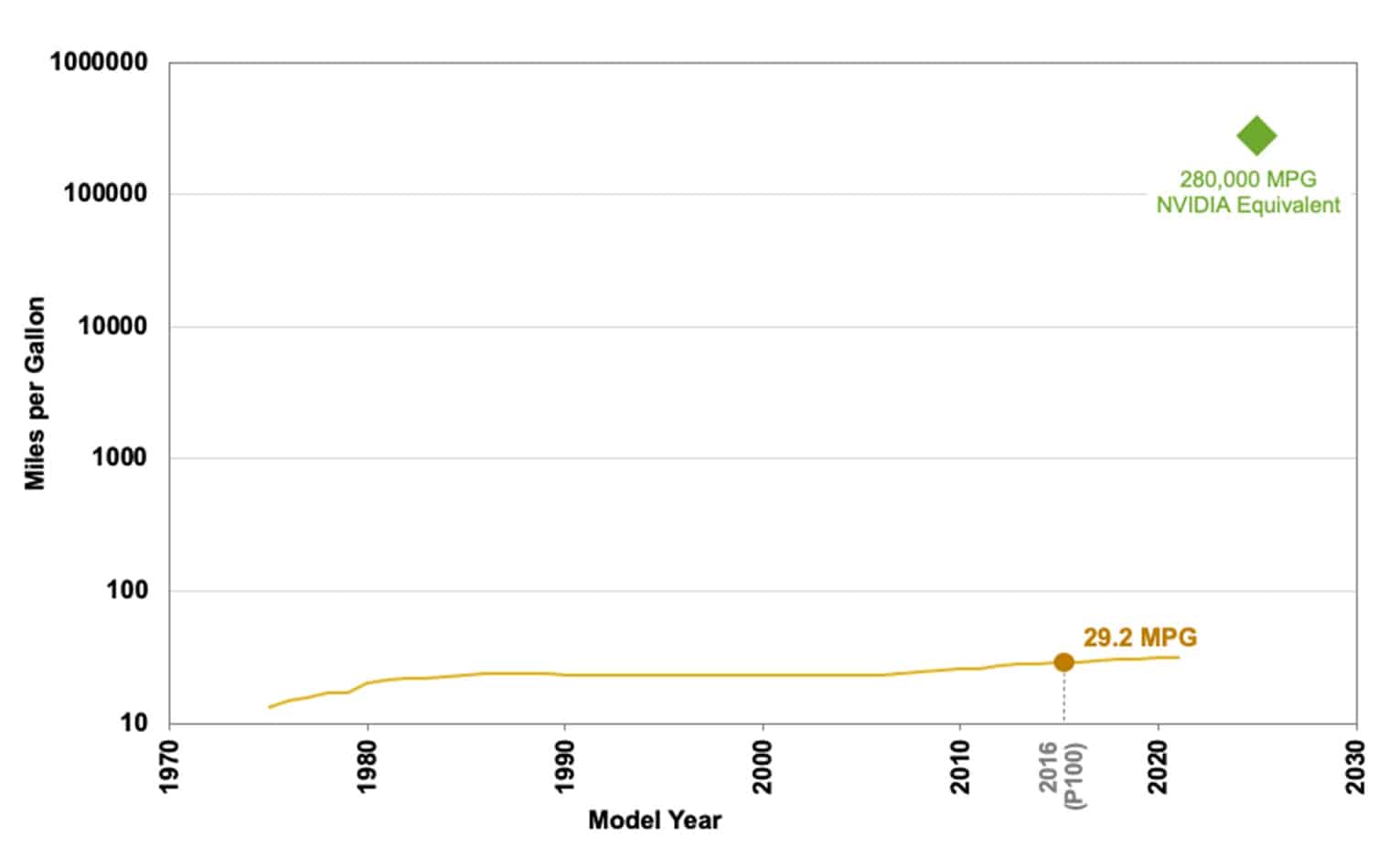
Here’s an eye-popping stat: If the efficiency of cars improved as much as NVIDIA has advanced the efficiency of AI on its accelerated computing platform, cars would get 280,000 miles per gallon. That means you could drive to the moon on less than a gallon of gas.
The analysis applies to the fuel efficiency of cars NVIDIA’s whopping 10,000x efficiency gain in AI training and inference from 2016 to 2025 (see chart below).
Driving Data Center Efficiency
NVIDIA delivers many optimizations through system-level innovations. For example, NVIDIA BlueField-3 DPUs can reduce power consumption up to 30% by offloading essential data center networking and infrastructure functions from less efficient CPUs.

Last year, NVIDIA received a $5 million grant from the U.S. Department of Energy — the largest of 15 grants from a pool of more than 100 applications — to design a new liquid-cooling technology for data centers. It will run 20% more efficiently than today’s air-cooled approaches and has a smaller carbon footprint.
These are just some of the ways NVIDIA contributes to the energy efficiency of data centers.

Data centers are among the most efficient users of energy and one of the largest consumers of renewable energy.
The ITIF report notes that between 2010 and 2018, global data centers experienced a 550% increase in compute instances and a 2,400% increase in storage capacity, but only a 6% increase in energy use, thanks to improvements across hardware and software.
NVIDIA continues to drive energy efficiency for accelerated AI, helping users in science, government and industry accelerate their journeys toward sustainable computing.
Try NVIDIA’s energy-efficiency calculator to find ways to improve energy efficiency. And check out NVIDIA’s sustainable computing site and corporate sustainability report for more information.
Deep Dive on the Hopper TMA Unit for FP8 GEMMs
Abstract
The Hopper (H100) GPU architecture, billed as the “first truly asynchronous GPU”, includes a new, fully asynchronous hardware copy engine for bulk data movement between global and shared memory called Tensor Memory Accelerator (TMA). While CUTLASS has built-in support for TMA via its asynchronous pipeline paradigm, Triton exposes TMA support via an experimental API.
In this post, we provide a deeper dive into the details of how TMA works, for developers to understand the new async copy engine. We also show the importance of leveraging TMA for H100 kernels by building a TMA enabled FP8 GEMM kernel in Triton, which delivers from 1.4-2.2x performance gains over cuBLAS FP16 for small-to-medium problem sizes. Finally, we showcase key implementation differences between Triton and CUTLASS that may account for reports of performance regressions with TMA in Triton. We open source our implementation for reproducibility and review at https://github.com/pytorch-labs/applied-ai/tree/main/kernels
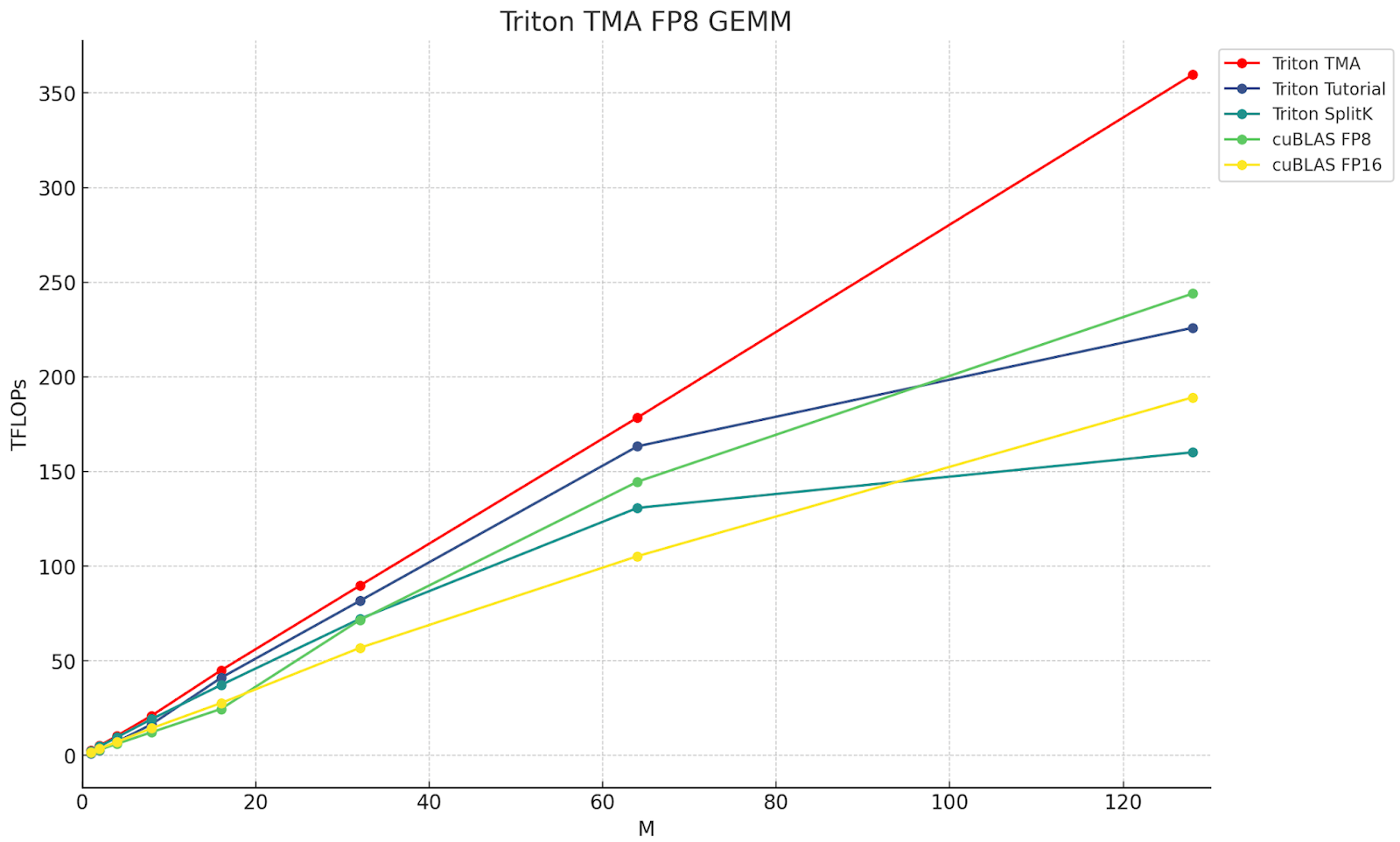
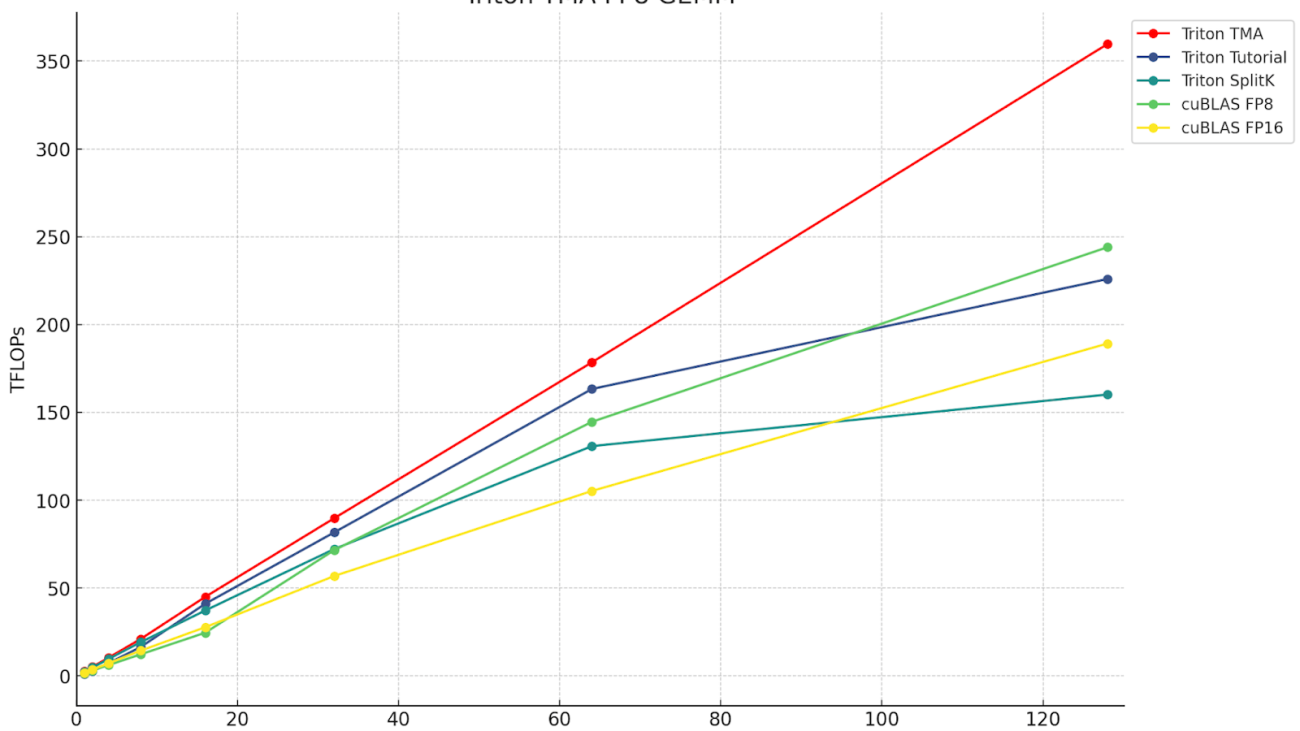
Figure 1. The throughput in TFLOPs of various Triton and cuBLAS FP8 and FP16 kernels, for M=M, N=4096, K=4096. The red line is the Triton TMA, which showcases the advantages of leveraging TMA.
TMA Background
TMA is an H100 hardware addition that allows applications to asynchronously and bi-directionally transfer 1D-5D tensors between GPU global and shared memory. In addition, TMA can also transfer the same data to not just the calling SM’s shared memory, but to other SM’s shared memory if they are part of the same Thread Block Cluster. This is termed ‘multicast’.
TMA is very lightweight as only a single thread is needed to kick off a TMA transfer. By moving data directly from GMEM (global) to SMEM (shared), this avoids earlier GPU requirements of using registers for moving data between different memory spaces.
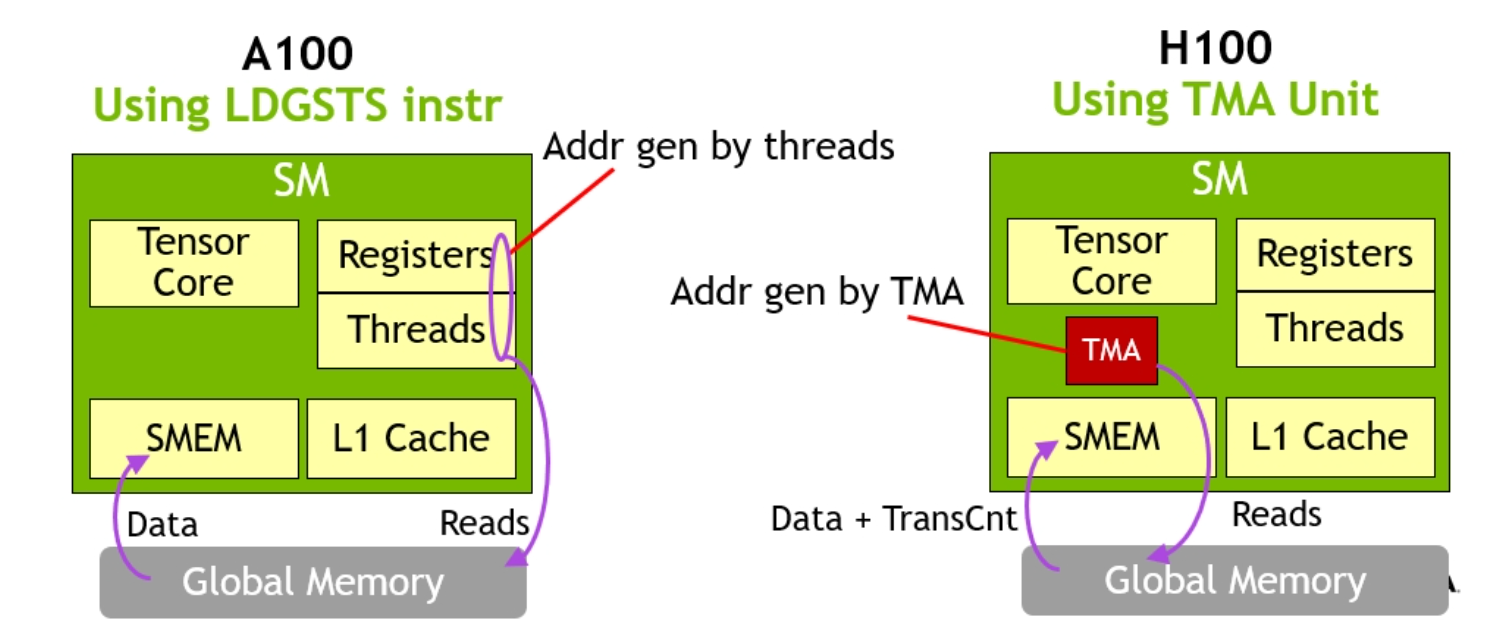
Figure 2. A100-style data movement vs H100 with TMA. TMA hardware eliminates the need for a large amount of threads and registers participating in bulk data transfers. (Image credit Nvidia)
A single thread can issue large data movement instructions, allowing the majority of a given thread block to continue working on other instructions while data is in-flight. Combined with asynchronous pipelining, this allows memory transfers to be easily hidden and ensure the majority of any given thread block cluster can focus on computational task.
This lightweight invocation for data movement enables the creation of warp-group specialized kernels, where warp-groups take on different roles, namely producers and consumers. Producers elect a leader thread that fires off TMA requests, which are then asynchronously coordinated with the consumer (MMA) warp-groups via an arrival barrier. Consumers then process the data using warp-group MMA, and signal back to the producers when they have finished reading from the SMEM buffer and the cycle repeats.
Further, within threadblock clusters, producers can lower their max register requirements since they are only issuing TMA calls, and effectively transfer additional registers to MMA consumers, which helps to alleviate register pressure for consumers.
In addition, TMA handles the address computation for the shared memory destination where the data requested should be placed. This is why calling threads (producers) can be so lightweight.
To ensure maximum read access speed, TMA can lay out the arriving data based on swizzling instructions, to ensure the arriving data can be read as fast as possible by consumers, as the swizzling pattern helps avoid shared memory bank conflicts.
Finally for TMA instructions that are outgoing, or moving data from SMEM to GMEM, TMA can also include reduction operations (add/min/max) and bitwise (and/or) operations.
TMA usage in Triton
Pre-Hopper Load:
offs_m = pid_m*block_m + tl.arange(0, block_m)
offs_n = pid_n*block_n + tl.arange(0, block_n)
offs_k = tl.arange(0, block_k)
a_ptrs = a_ptr + (offs_am[:, None]*stride_am + offs_k[None, :]*stride_ak)
b_ptrs = b_ptr + (offs_k[:, None]*stride_bk + offs_bn[None, :]*stride_bn)
a = tl.load(a_ptrs)
b = tl.load(b_ptrs)
Figure 3. Traditional style bulk load from global to shared memory in Triton
In the above Triton example showing a pre-Hopper load, we see how the data for tensors a and b are loaded by each thread block computing global offsets (a_ptrs, b_ptrs) from their relevant program_id (pid_m, pid_n, k) and then making a request to move blocks of memory into shared memory for a and b.
Now let’s examine how to perform a load using TMA in Triton.
The TMA instruction requires a special data structure called a tensor map, in contrast to the above where we directly pass pointers to global memory. To build the tensor map, we first create a TMA descriptor on the CPU. The descriptor handles the creation of the tensor map by using the cuTensorMapEncode API. The tensor map holds metadata such as the global and shared memory layout of the tensor and serves as a compressed representation of the structure of the multi-dimensional tensor stored in global memory.
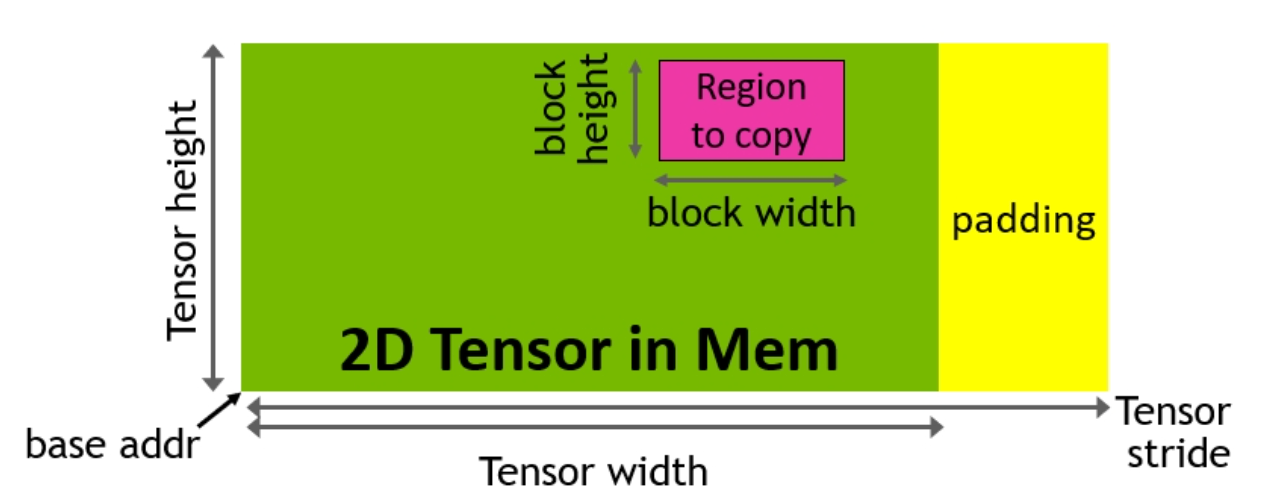
Figure 4. TMA address generation via a copy descriptor (Image credit: Nvidia)
The TMA descriptor holds the tensor’s key properties:
- Base Pointer
- Shape and Block Size
- Datatype
The TMA descriptor is created on the host before the kernel, and then moved to device by passing the descriptor to a torch tensor. Thus, in Triton, the GEMM kernel receives a global pointer to the tensor map.
Triton Host Code
desc_a = np.empty(TMA_SIZE, dtype=np.int8)
desc_b = np.empty(TMA_SIZE, dtype=np.int8)
desc_c = np.empty(TMA_SIZE, dtype=np.int8)
triton.runtime.driver.active.utils.fill_2d_tma_descriptor(a.data_ptr(), m, k, block_m, block_k, a.element_size(), desc_a)
triton.runtime.driver.active.utils.fill_2d_tma_descriptor(b.data_ptr(), n, k, block_n, block_k, b.element_size(), desc_b)
triton.runtime.driver.active.utils.fill_2d_tma_descriptor(c.data_ptr(), m, n, block_m, block_n, c.element_size(), desc_c)
desc_a = torch.tensor(desc_a, device='cuda')
desc_b = torch.tensor(desc_b, device='cuda')
desc_c = torch.tensor(desc_c, device='cuda')
This is the code that is used to set up the descriptors in the kernel invoke function.
Triton Device Code
Offsets/Pointer Arithmetic:
offs_am = pid_m * block_m
offs_bn = pid_n * block_n
offs_k = 0
Load:
a = tl._experimental_descriptor_load(a_desc_ptr, [offs_am, offs_k], [block_m, block_k], tl.float8e4nv)
b = tl._experimental_descriptor_load(b_desc_ptr, [offs_bn, offs_k], [block_n, block_k], tl.float8e4nv)
Store:
tl._experimental_descriptor_store(c_desc_ptr, accumulator, [offs_am, offs_bn])
We no longer need to calculate a pointer array for both load and store functions in the kernel. Instead, we pass a single descriptor pointer, the offsets, block size and the input datatype. This simplifies address calculation and reduces register pressure, as we no longer have to do complex pointer arithmetic in software and dedicate CUDA cores for address computation.
TMA Performance Analysis
Below, we discuss the PTX instructions for different load mechanisms on Hopper.
PTX for Loading Tile (cp.async) – H100 no TMA
add.s32 %r27, %r100, %r8;
add.s32 %r29, %r100, %r9;
selp.b32 %r30, %r102, 0, %p18;
@%p1 cp.async.cg.shared.global [ %r27 + 0 ], [ %rd20 + 0 ], 0x10, %r30;
@%p1 cp.async.cg.shared.global [ %r29 + 0 ], [ %rd21 + 0 ], 0x10, %r30;
cp.async.commit_group ;
Here, we observe the older cp.async instruction responsible for global memory copies. From the traces below we can see that both loads bypass the L1 cache. A major difference in the newer TMA load is that before tiles from A and B were ready to be consumed by the Tensor Core we would need to execute an ldmatrix instruction that operated on data contained in register files. On Hopper, the data can now be directly reused from shared memory.
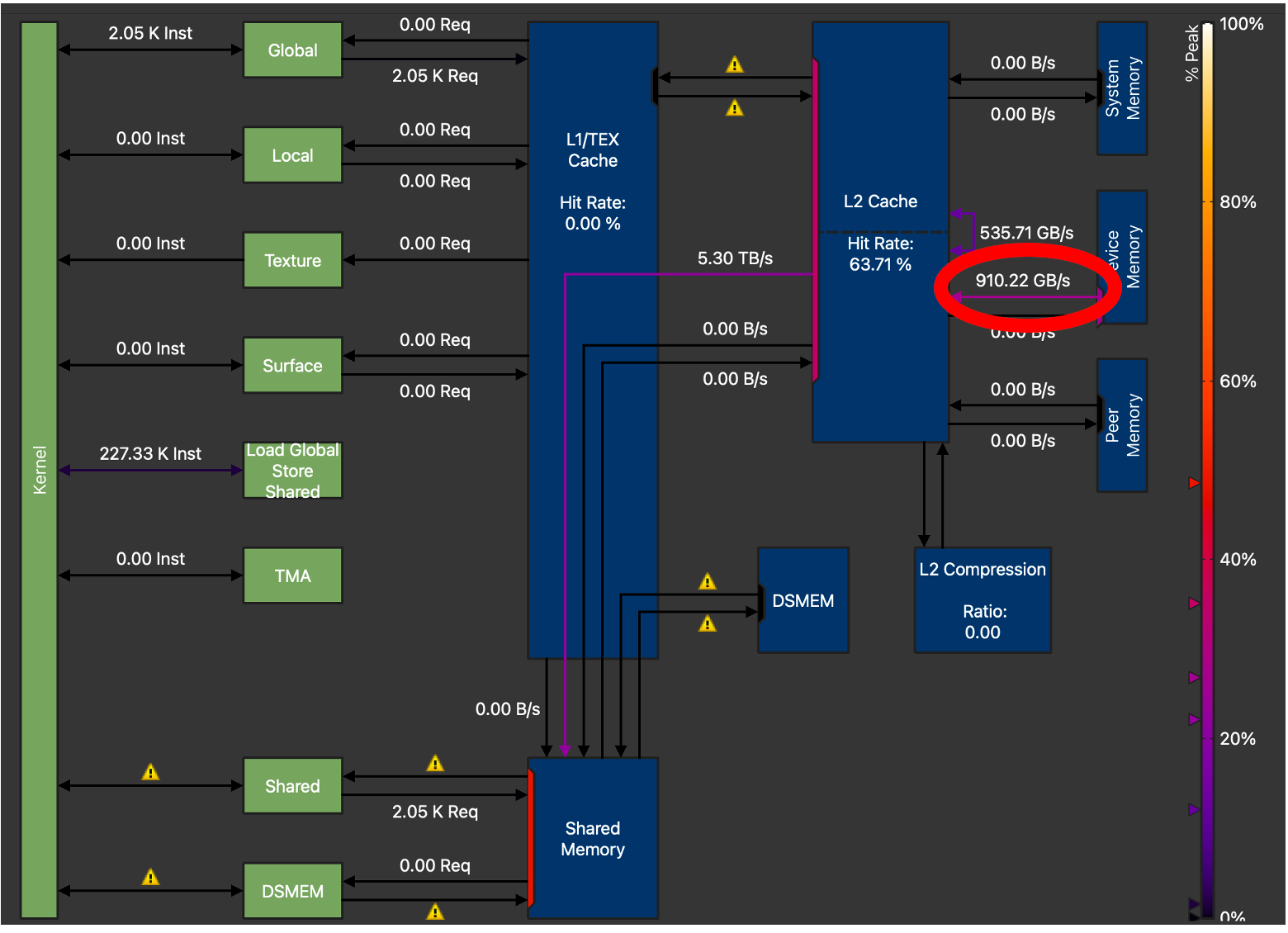
Figure 5. H100 Memory Chart showing GMEM Throughput = 910.22 GB/s (Triton GEMM without TMA) for M=128, N=4096, K=4096
By leveraging TMA through the Triton API changes we mentioned above, we can investigate the PTX that Triton generates for a single 2D tile load with TMA.
PTX for Loading Tile (cp.async.bulk.tensor) – H100 using TMA
bar.sync 0;
shr.u32 %r5, %r4, 5;
shfl.sync.idx.b32 %r66, %r5, 0, 31, -1;
elect.sync _|%p7, 0xffffffff;
add.s32 %r24, %r65, %r67;
shl.b32 %r25, %r66, 7;
@%p8
cp.async.bulk.tensor.2d.shared::cluster.global.mbarrier::complete_tx::bytes [%r24], [%rd26, {%r25,%r152}], [%r19];
The cp.async.bulk.tensor.2d.shared TMA instruction is passed the destination address in shared memory, a pointer to the tensor map, the tensor map coordinates and a pointer to the mbarrier object, respectively.
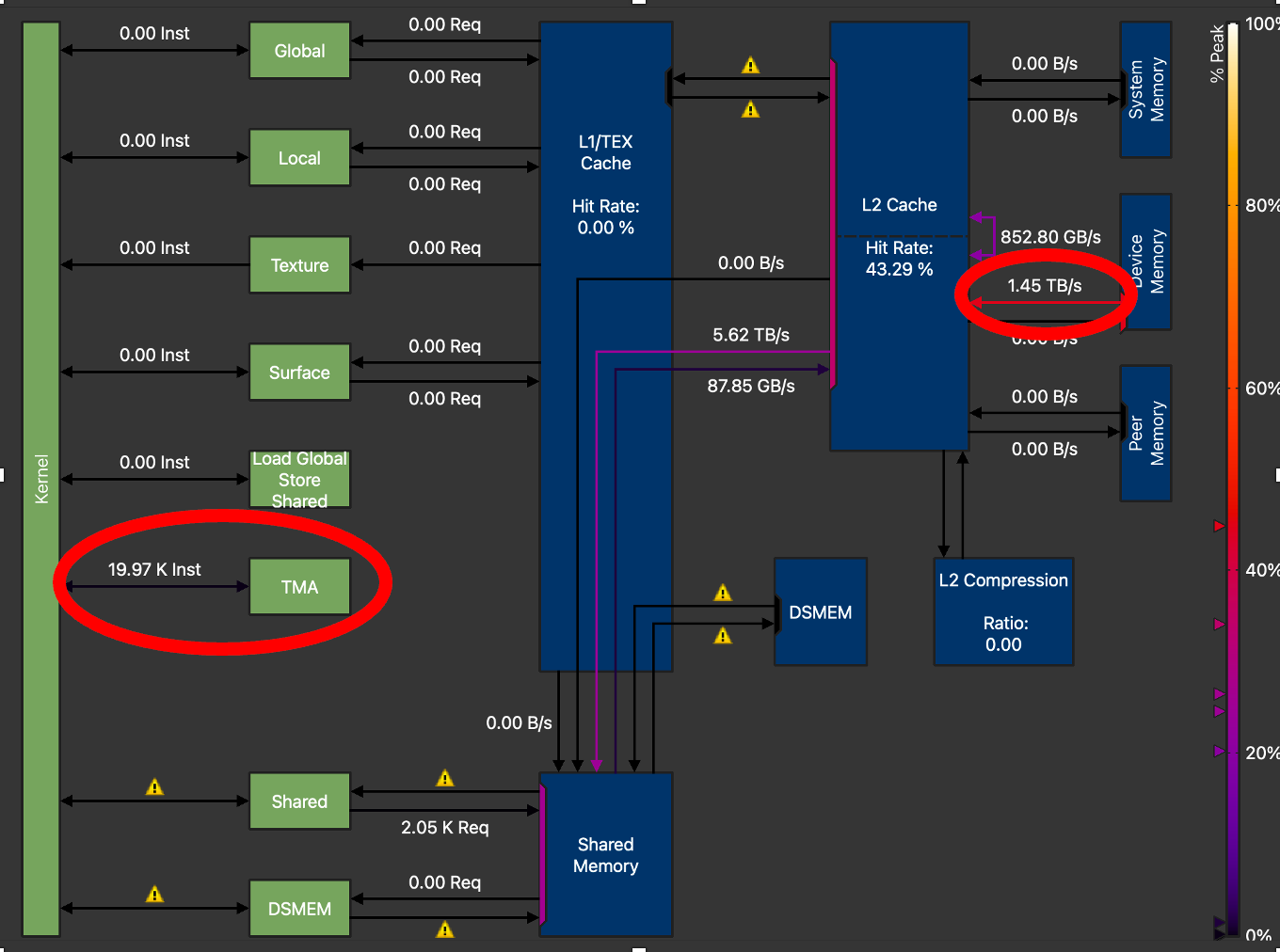
Figure 6. H100 Memory Chart GMEM Throughput =1.45 TB/s (Triton GEMM with TMA) for M=128, N=4096, K=4096
For optimal performance we tuned the TMA GEMM kernel extensively. Amongst other parameters such as tile sizes, number of warps and number of pipeline stages, the biggest increase in memory throughput was observed when we increased the TMA_SIZE (descriptor size) from 128 to 512. From the above NCU profiles, we can see that the final tuned kernel has increased global memory transfer throughput from 910 GB/s to 1.45 TB/s, a 59% increase in GMEM throughput, over the non-TMA Triton GEMM kernel.
Comparison of CUTLASS and Triton FP8 GEMM and TMA Implementation – Kernel Architecture
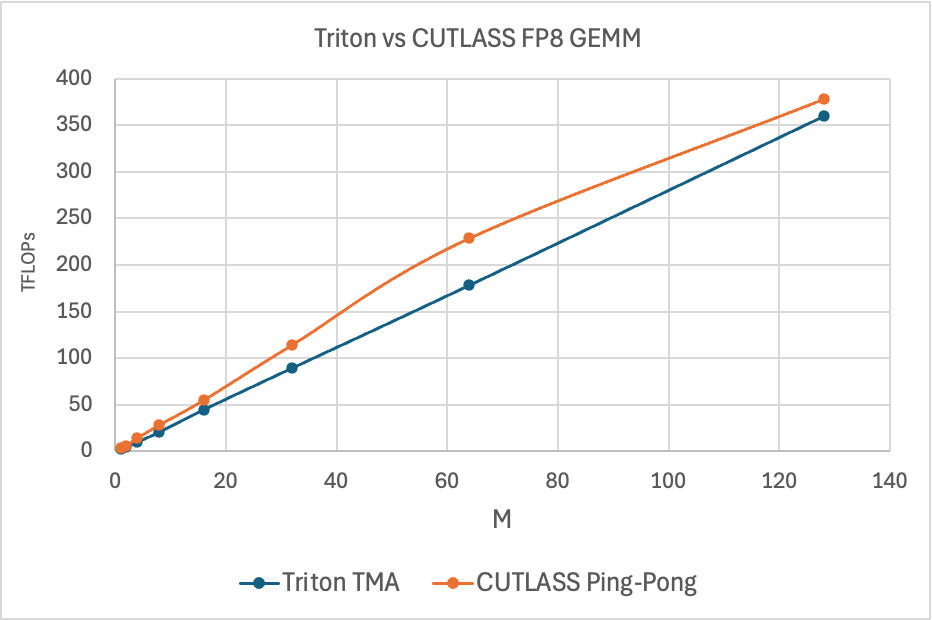
Figure 7. Triton vs CUTLASS Ping-Pong FP8 GEMM TFLOPs, M=M, N=4096, K=4096
The above chart shows the performance of a CUTLASS Ping-Pong GEMM kernel against Triton. The Ping-Pong kernel leverages TMA differently than Triton. It makes use of all of its HW and SW software capabilities, while Triton currently does not. Specifically, CUTLASS supports the below TMA features that help explain the performance gaps in pure GEMM performance:.
-
TMA Multicast
- Enables copy of data from GMEM to multiple SMs
-
Warp Specialization
- Enables warp groups within a threadblock to take on different roles
-
Tensor Map (TMA Descriptor) Prefetch
- Enables prefetching the Tensor Map object from GMEM, which allows pipelining of TMA loads
To put the performance numbers in perspective, below we show a ‘speed-up’ chart highlighting the latency differences on a percentage basis:
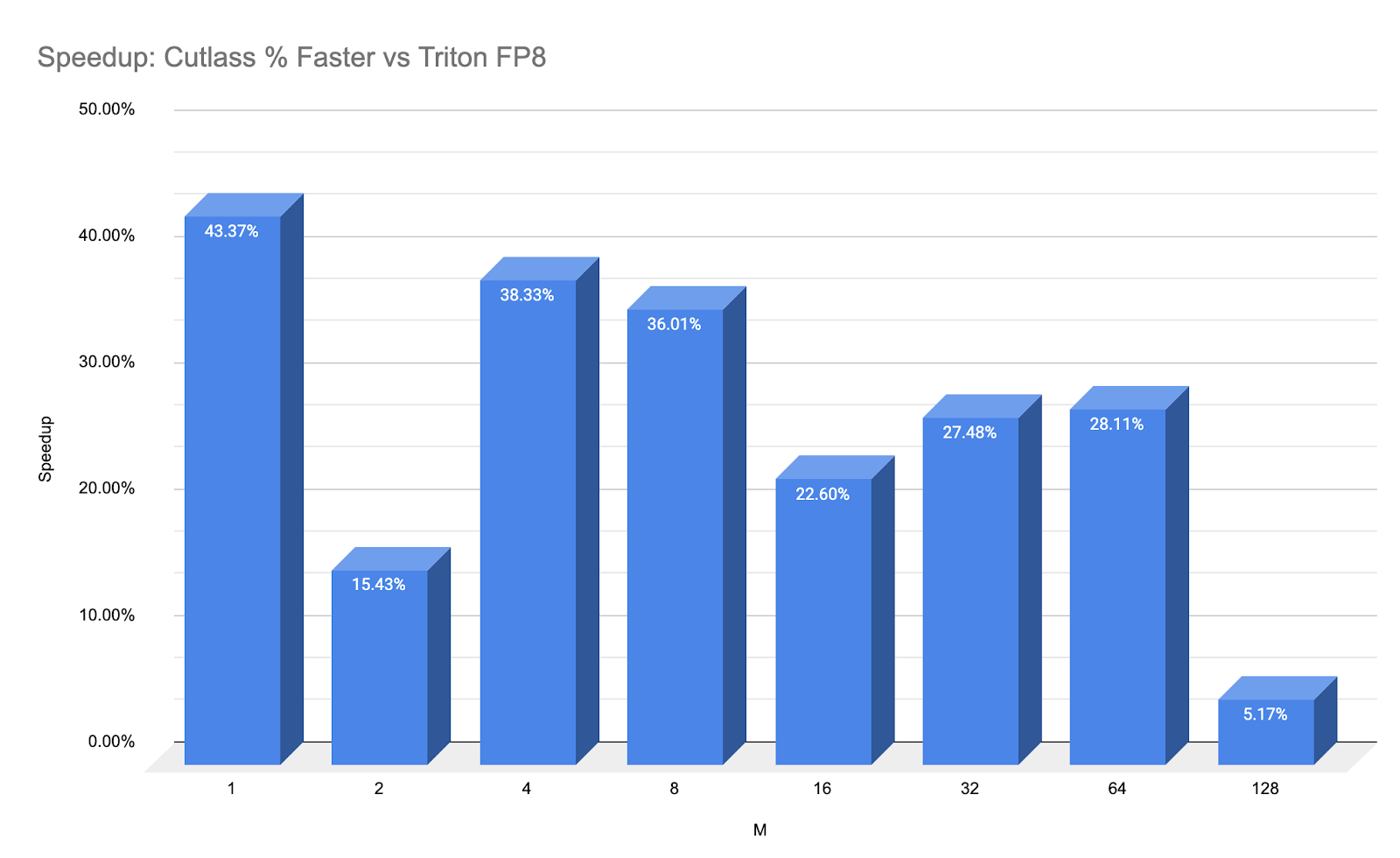
Figure 8: % Speedup of CUTLASS Ping-Pong vs Triton FP8 with TMA.
This speedup is purely kernel throughput, not including E2E launch overhead which we will discuss below.
TMA Descriptor movement – a key difference between Triton and CUTLASS with E2E performance implications
As noted previously, creation of a 2D+ dimensional TMA descriptor takes place on the host and is then transferred to the device. However, this transfer process takes place very differently depending on the implementation.
Here we showcase the differences between how Triton transfers TMA descriptors compared with CUTLASS.
Recall, TMA transfers require a special data structure, a tensor map to be created on CPU through the cuTensorMap API, which for an FP8 GEMM Kernel means creating three descriptors, one for each A, B and C. We see below that for both the Triton and CUTLASS Kernels the same CPU procedures are invoked.
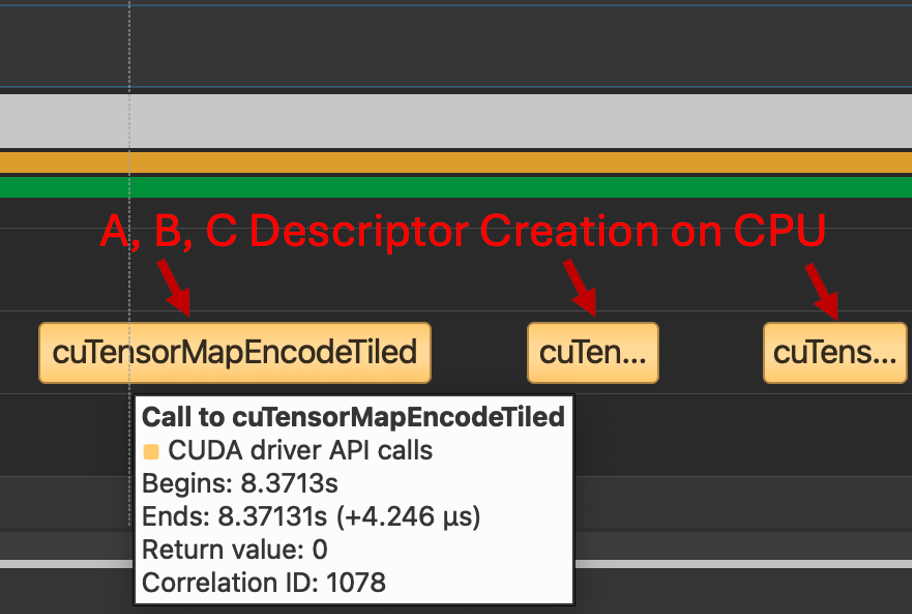
Figure 7. Calls to cuTensorMapEncodeTiled (Both Triton and CUTLASS use this path)
However, for Triton, each descriptor is transferred in its own distinct copy kernel, which adds a significant amount of overhead and serves as a barrier to use this kernel in an end-to-end use inference scenario.

Figure 8. Three H2D Copy Kernels are launched before the kernel execution, for A, B and C
These copies are not observed in the CUTLASS implementation, due to the way that TMA descriptors are passed to the kernel. We can see from the PTX below that with Cutlass, tensor maps are passed-by-value to the kernel.
.entry _ZN7cutlass13device_kernelIN49_GLOBAL__N__8bf0e19b_16_scaled_mm_c3x_cu_2bec3df915cutlass_3x_gemmIaNS_6half_tENS1_14ScaledEpilogueEN4cute5tupleIJNS5_1CILi64EEENS7_ILi128EEES9_EEENS6_IJNS7_ILi2EEENS7_ILi1EEESC_EEENS_4gemm32KernelTmaWarpSpecializedPingpongENS_8epilogue18TmaWarpSpecializedEE10GemmKernelEEEvNT_6ParamsE(
.param .align 64 .b8 _ZN7cutlass13device_kernelIN49_GLOBAL__N__8bf0e19b_16_scaled_mm_c3x_cu_2bec3df915cutlass_3x_gemmIaNS_6half_tENS1_14ScaledEpilogueEN4cute5tupleIJNS5_1CILi64EEENS7_ILi128EEES9_EEENS6_IJNS7_ILi2EEENS7_ILi1EEESC_EEENS_4gemm32KernelTmaWarpSpecializedPingpongENS_8epilogue18TmaWarpSpecializedEE10GemmKernelEEEvNT_6ParamsE_param_0[1024]
mov.b64 %rd110, _ZN7cutlass13device_kernelIN49_GLOBAL__N__8bf0e19b_16_scaled_mm_c3x_cu_2bec3df915cutlass_3x_gemmIaNS_10bfloat16_tENS1_14ScaledEpilogueEN4cute5tupleIJNS5_1CILi64EEES8_NS7_ILi256EEEEEENS6_IJNS7_ILi1EEESB_SB_EEENS_4gemm24KernelTmaWarpSpecializedENS_8epilogue18TmaWarpSpecializedEE10GemmKernelEEEvNT_6ParamsE_param_0;
add.s64 %rd70, %rd110, 704;
cvta.param.u64 %rd69, %rd70;
cp.async.bulk.tensor.2d.global.shared::cta.bulk_group [%rd69, {%r284, %r283}], [%r1880];
Figure 9. CUTLASS kernel PTX showing pass-by-value
By directly passing the TMA Descriptor as opposed to passing a global memory pointer, the CUTLASS kernel avoids the three extra H2D copy kernels and instead these copies are included in the single device kernel launch for the GEMM.
Because of the difference in how descriptors are moved to the device, the kernel latencies including the time to prepare the tensors to be consumed by the TMA is drastically different. For M=1-128, N=4096, K=4096 the CUTLASS pingpong kernel has an average latency of 10us Triton TMA kernels complete in an average of 4ms. This is a factor of ~3330x slower and appears to be directly linked to the 3 independent kernel launches for TMA descriptor transfer by Triton.
Cuda graphs may be one way to reduce this, but given the overhead created by the H2D copies the current Triton implementation when measured end to end is not competitive. A rework of how the Triton compiler manages TMA descriptors would likely resolve this gap. We thus focused on comparing the actual compute kernel throughput and not E2E in our data above.
Results Summary
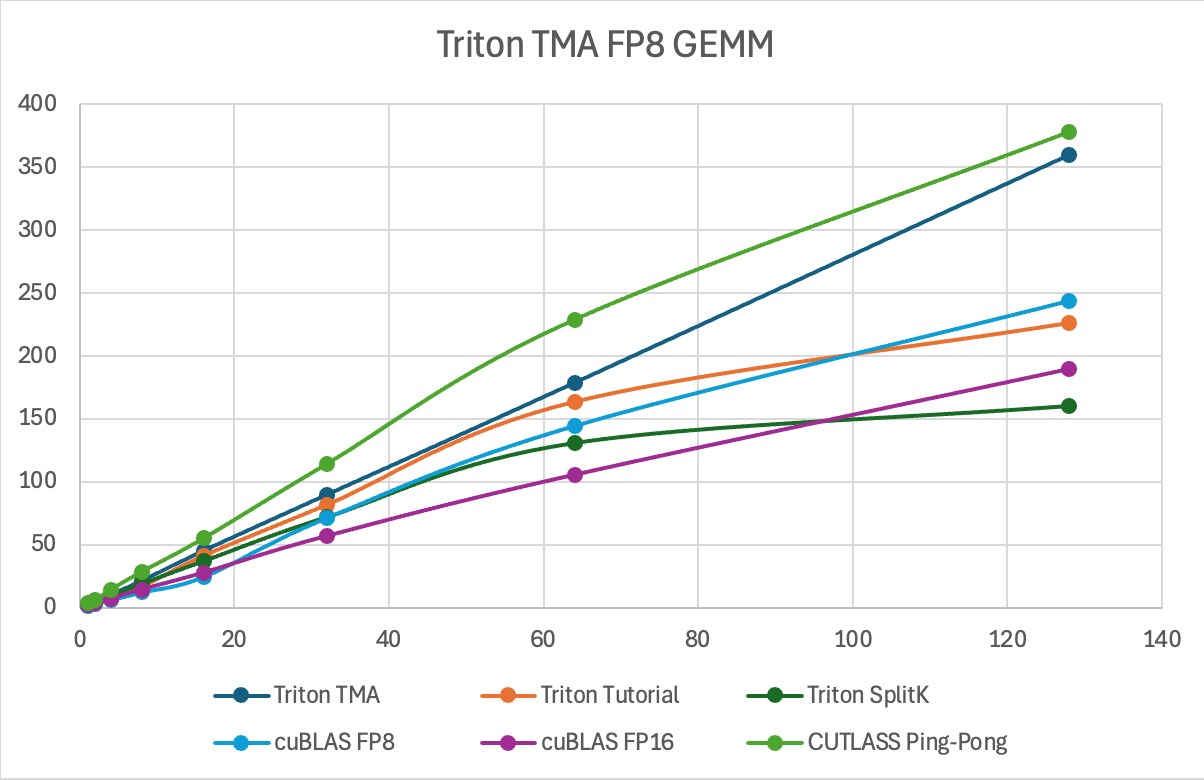
Figure 10. Triton FP8 TMA GEMM TFLOPs Comparison
| M | Triton TMA | Triton Tutorial | Triton SplitK | cuBLAS FP8 | cuBLAS FP16 | CUTLASS Ping-Pong FP8 |
| 1 | 2.5 | 1 | 2.4 | 1.5 | 1.8 | 3.57 |
| 2 | 5.1 | 2.5 | 4.8 | 3.1 | 3.6 | 5.9 |
| 4 | 10.3 | 7.21 | 9.6 | 6.1 | 7.2 | 14.3 |
| 8 | 21.0 | 16.5 | 19.2 | 12.3 | 14.4 | 28.6 |
| 16 | 44.5 | 41.0 | 37.2 | 24.5 | 27.7 | 55.1 |
| 32 | 89.7 | 81.2 | 72.2 | 71.6 | 56.8 | 114.4 |
| 64 | 178.5 | 163.7 | 130.8 | 144.6 | 105.3 | 228.7 |
| 128 | 359.7 | 225.9 | 160.1 | 244.0 | 189.2 | 377.7 |
Figure 11. Triton FP8 TMA GEMM TFLOPs Comparison Table
The above chart and table summarize the gain we’ve been able to achieve on a single NVIDIA H100 for FP8 GEMM, by leveraging the TMA Hardware Unit, over non-TMA Triton kernels and high performance CUDA (cuBLAS) kernels. The key point to note is this kernel’s superior scaling (with the batch size) properties over the competition. The problem sizes we benchmarked on are representative of the matrix shapes found in small-to-medium batch size LLM inference. Thus, TMA GEMM kernel performance in the mid-M regime (M=32 to M=128) will be critical for those interested in leveraging this kernel for FP8 LLM deployment use cases, as the FP8 compressed data type can allow larger matrices to fit in GPUs memory.
To summarize our analysis, the TMA implementation in Triton and CUTLASS differ in terms of full featureset support (multicast, prefetch etc.) and how the TMA Descriptor is passed to the GPU kernel. If this descriptor is passed in a manner that more closely matches the CUTLASS kernel (pass-by-value), the extraneous H2D copies could be avoided and thus the E2E performance would be greatly improved.
Future Work
For future research, we plan to improve upon these results, by working with the community to incorporate the CUTLASS architecture of TMA loads into Triton as well as investigating the Cooperative Kernel for FP8 GEMM, a modified strategy to the Ping-Pong Kernel.
In addition, once features like thread block clusters and TMA atomic operations are enabled in Triton, we may be able to get further speedups by leveraging the SplitK strategy in the TMA GEMM Kernel, as atomic operations on Hopper can be performed in Distributed Shared Memory (DSMEM) as opposed to L2 Cache. We also note the similarities of NVIDIA Hopper GPUs with other AI hardware accelerators like Google’s TPU and IBM’s AIU which are dataflow architectures. On Hopper, data can now “flow” from GMEM to a network of connected SMs due to the additions of TMA, which we discussed extensively in this blog, and DSMEM, which we plan to cover in a future post.
Are We Ready for Multi-Image Reasoning? Launching VHs: The Visual Haystacks Benchmark!
Humans excel at processing vast arrays of visual information, a skill that is crucial for achieving artificial general intelligence (AGI). Over the decades, AI researchers have developed Visual Question Answering (VQA) systems to interpret scenes within single images and answer related questions. While recent advancements in foundation models have significantly closed the gap between human and machine visual processing, conventional VQA has been restricted to reason about only single images at a time rather than whole collections of visual data.
This limitation poses challenges in more complex scenarios. Take, for example, the challenges of discerning patterns in collections of medical images, monitoring deforestation through satellite imagery, mapping urban changes using autonomous navigation data, analyzing thematic elements across large art collections, or understanding consumer behavior from retail surveillance footage. Each of these scenarios entails not only visual processing across hundreds or thousands of images but also necessitates cross-image processing of these findings. To address this gap, this project focuses on the “Multi-Image Question Answering” (MIQA) task, which exceeds the reach of traditional VQA systems.

Visual Haystacks: the first “visual-centric” Needle-In-A-Haystack (NIAH) benchmark designed to rigorously evaluate Large Multimodal Models (LMMs) in processing long-context visual information.

Byte-Sized Courses: NVIDIA Offers Self-Paced Career Development in AI and Data Science
AI has seen unprecedented growth — spurring the need for new training and education resources for students and industry professionals.
NVIDIA’s latest on-demand webinar, Essential Training and Tips to Accelerate Your Career in AI, featured a panel discussion with industry experts on fostering career growth and learning in AI and other advanced technologies.
Over 1,800 attendees gained insights on how to kick-start their careers and use NVIDIA’s technologies and resources to accelerate their professional development.
Opportunities in AI
AI’s impact is touching nearly every industry, presenting new career opportunities for professionals of all backgrounds.
Lauren Silveira, a university recruiting program manager at NVIDIA, challenged attendees to take their unique education and experience and apply it in the AI field.
“You don’t have to work directly in AI to impact the industry,” said Silveira. “I knew I wouldn’t be a doctor or engineer — that wasn’t in my career path — but I could create opportunities for those that wanted to pursue those dreams.”
Kevin McFall, a principal instructor for the NVIDIA Deep Learning Institute, offered some advice for those looking to navigate a career in AI and advanced technologies but finding themselves overwhelmed or unsure of where to start.
“Don’t try to do it all by yourself,” he said. “Don’t get focused on building everything from scratch — the best skill that you can have is being able to take pieces of code or inspiration from different resources and plug them together to make a whole.”
A main takeaway from the panelists was that students and industry professionals can significantly enhance their capabilities by leveraging tools and resources in addition to their networks.
Every individual can access a variety of free software development kits, community resources and specialized courses in areas like robotics, CUDA and OpenUSD through the NVIDIA Developer Program. Additionally, they can kick off projects with the CUDA code sample library and explore specialized guides such as “A Simple Guide to Deploying Generative AI With NVIDIA NIM”.
Spinning a Network
Staying up to date on the rapidly expanding technology industry involves more than just keeping up with the latest education and certifications.
Sabrina Koumoin, a senior software engineer at NVIDIA, spoke on the importance of networking. She believes people can find like-minded peers and mentors to gain inspiration from by sharing their personal learning journeys or projects on social platforms like LinkedIn.
A self-taught coder, Koumoin also advocates for active engagement and education accessibility. Outside of work, she hosted multiple coding bootcamps for people looking to break into tech.
“It’s a way to show that learning technical skills can be engaging, not intimidating,” she said.
David Ajoku, founder and CEO at Demystifyd and Aware.ai, also emphasized the importance of using LinkedIn to build connections, demonstrate key accomplishments and show passion.
He outlined a three-step strategy to enhance your LinkedIn presence, designed to help you stand out, gain deeper insights into your preferred companies and boldly share your aspirations and interests:
- Think about a company you’d like to work for and what draws you to it.
- Research thoroughly, focusing on its main activities, mission and goals.
- Be bold — create a series of posts informing your network about your career journey and what advancements interest you in the chosen company.
One attendee asked about how AI might evolve over the next decade and what skills professionals should focus on to stay relevant. Louis Stewart, head of strategic initiatives at NVIDIA, replied that crafting a personal narrative and growth journey is just as important as ensuring certifications and skills are up to date.
“Be intentional and purposeful — have an end in mind,” he said. “That’s how you connect with future potential companies and people — it’s a skill you have to develop to stay ahead.”
Deep Dive Into Learning
NVIDIA offers a variety of programs and resources to equip the next generation of AI professionals with the skills and training needed to excel in a career in AI.
NVIDIA’s AI Learning Essentials is designed to give individuals the knowledge, skills and certifications they need to be prepared for the workforce and the fast moving field of AI. It includes free access to self-paced introductory courses and webinars on topics such as generative AI, retrieval-augmented generation (RAG) and CUDA.
The NVIDIA Deep Learning Institute (DLI) provides a diverse range of resources, including learning materials, self-paced and live trainings, and educator programs spanning AI, accelerated computing and data science, graphics simulation and more. They also offer technical workshops for students currently enrolled in universities.
DLI provides comprehensive training for generative AI, RAG, NVIDIA NIM inference microservices and large language models. Offerings also include certifications for generative AI LLMs and generative AI multimodal that help learners showcase their expertise and stand out from the crowd.
Get started with AI Learning Essentials, the NVIDIA Deep Learning Institute and on-demand resources.

Magnetic Marvels: NVIDIA’s Supercomputers Spin a Quantum Tale
Research published earlier this month in the science journal Nature used NVIDIA-powered supercomputers to validate a pathway toward the commercialization of quantum computing.
The research, led by Nobel laureate Giorgio Parisi, focuses on quantum annealing, a method that may one day tackle complex optimization problems that are extraordinarily challenging to conventional computers.
To conduct their research, the team utilized 2 million GPU computing hours at the Leonardo facility (Cineca, in Bologna, Italy), nearly 160,000 GPU computing hours on the Meluxina-GPU cluster, in Luxembourg, and 10,000 GPU hours from the Spanish Supercomputing Network. Additionally, they accessed the Dariah cluster, in Lecce, Italy.
They used these state-of-the-art resources to simulate the behavior of a certain kind of quantum computing system known as a quantum annealer.
Quantum computers fundamentally rethink how information is computed to enable entirely new solutions.
Unlike classical computers, which process information in binary — 0s and 1s — quantum computers use quantum bits or qubits that can allow information to be processed in entirely new ways.
Quantum annealers are a special type of quantum computer that, though not universally useful, may have advantages for solving certain types of optimization problems.
The paper, “The Quantum Transition of the Two-Dimensional Ising Spin Glass,” represents a significant step in understanding the phase transition — a change in the properties of a quantum system — of Ising spin glass, a disordered magnetic material in a two-dimensional plane, a critical problem in computational physics.
The paper addresses the problem of how the properties of magnetic particles arranged in a two-dimensional plane can abruptly change their behavior.
The study also shows how GPU-powered systems play a key role in developing approaches to quantum computing.
GPU-accelerated simulations allow researchers to understand the complex systems’ behavior in developing quantum computers, illuminating the most promising paths forward.
Quantum annealers, like the systems developed by the pioneering quantum computing company D-Wave, operate by methodically decreasing a magnetic field that is applied to a set of magnetically susceptible particles.
When strong enough, the applied field will act to align the magnetic orientation of the particles — similar to how iron filings will uniformly stand to attention near a bar magnet.
If the strength of the field is varied slowly enough, the magnetic particles will arrange themselves to minimize the energy of the final arrangement.
Finding this stable, minimum-energy state is crucial in a particularly complex and disordered magnetic system known as a spin glass since quantum annealers can encode certain kinds of problems into the spin glass’s minimum-energy configuration.
Finding the stable arrangement of the spin glass then solves the problem.
Understanding these systems helps scientists develop better algorithms for solving difficult problems by mimicking how nature deals with complexity and disorder.
That’s crucial for advancing quantum annealing and its applications in solving extremely difficult computational problems that currently have no known efficient solution — problems that are pervasive in fields ranging from logistics to cryptography.
Unlike gate-model quantum computers, which operate by applying a sequence of quantum gates, quantum annealers allow a quantum system to evolve freely in time.
This is not a universal computer — a device capable of performing any computation given sufficient time and resources — but may have advantages for solving particular sets of optimization problems in application areas such as vehicle routing, portfolio optimization and protein folding.
Through extensive simulations performed on NVIDIA GPUs, the researchers learned how key parameters of the spin glasses making up quantum annealers change during their operation, allowing a better understanding of how to use these systems to achieve a quantum speedup on important problems.
Much of the work for this groundbreaking paper was first presented at NVIDIA’s GTC 2024 technology conference. Read the full paper and learn more about NVIDIA’s work in quantum computing.
AWS VP of AI and data on computer vision research at Amazon
In his keynote address at CVPR, Swami Sivasubramanian considers the many ways that Amazon incorporates computer vision technology into its products and makes it directly available to Amazon Web Services’ customers.Read More

Google DeepMind at ICML 2024
Exploring AGI, the challenges of scaling and the future of multimodal generative AIRead More