 At the first Google.org Impact Summit, we’re announcing new AI tools nonprofits can use to create change.Read More
At the first Google.org Impact Summit, we’re announcing new AI tools nonprofits can use to create change.Read More

At the first Google.org Impact Summit, we’re announcing new AI tools nonprofits can use to create change.Read More

Edward Mehr works where AI meets the anvil. The company he cofounded, Machina Labs, blends the latest advancements in robotics and AI to form metal into countless shapes for use in defense, aerospace, and more. The company’s applications accelerate design and innovation, enabling rapid iteration and production in days instead of the months required by conventional processes. NVIDIA AI Podcast host Noah Kravitz speaks with Mehr, CEO of Machina Labs, on how the company uses AI to develop the first-ever robotic blacksmith. Its Robotic Craftsman platform integrates seven-axis robots that can shape, scan, trim and drill a wide range of materials — all capabilities made possible through AI.
1:12: What does Machina Labs do?
3:37: Mehr’s background
8:45: Machina Lab’s manufacturing platform, the Robotic Craftsman
10:39: Machina Lab’s history and how AI plays a role in its work
15:07: The versatility of the Robotic Craftsman
21:48: How the Robotic Craftsman was trained in simulations using AI-generated manufacturing data
28:10: From factory to household — Mehr’s insight on the future of robotic applications
How Two Stanford Students Are Building Robots for Handling Household Chores – Ep. 224
BEHAVIOR-1K is a robot that can perform 1,000 household chores, including picking up fallen objects or cooking. In this episode, Stanford Ph.D. students Chengshu Eric Li and Josiah David Wong discuss the breakthroughs and challenges they experienced while developing BEHAVIOR-1K.
Hittin’ the Sim: NVIDIA’s Matt Cragun on Conditioning Autonomous Vehicles in Simulation – Ep. 185
NVIDIA DRIVE Sim, built on Omniverse, provides a virtual proving ground for AV testing and validation. It’s a highly accurate simulation platform that can enable groundbreaking tools — including synthetic data and neural reconstruction — to build digital twins of driving environments. In this episode, Matt Cragun, senior product manager for AV simulation at NVIDIA, details the origins and inner workings of DRIVE Sim.
NVIDIA’s Liila Torabi Talks the New Era of Robotics Through Isaac Sim – Ep. 147
Robotics are not just limited to the assembly line. Liila Torabi, senior product manager for NVIDIA Isaac Sim, works on making the next generation of robotics possible. In this episode, she discusses the new era of robotics — one driven by making robots smarter through AI.
Art(ificial) Intelligence: Pindar Van Arman Builds Robots That Paint – Ep. 129
Pindar Van Arman is an American artist and roboticist, designing painting robots that explore the intersection of human and computational creativity. He’s built multiple artificially creative robots, the most famous of which being Cloud Painter, which was awarded first place at Robotart 2018. Tune in to hear how Van Arman deconstructs his own artistic process and teaches it to robots.
Get the AI Podcast through iTunes, Google Play, Amazon Music, Castbox, DoggCatcher, Overcast, PlayerFM, Pocket Casts, Podbay, PodBean, PodCruncher, PodKicker, Soundcloud, Spotify, Stitcher and TuneIn.
Make the AI Podcast better: Have a few minutes to spare? Fill out this listener survey.
Editor’s note: This post is part of the AI Decoded series, which demystifies AI by making the technology more accessible, and showcases new hardware, software, tools and accelerations for RTX PC users.
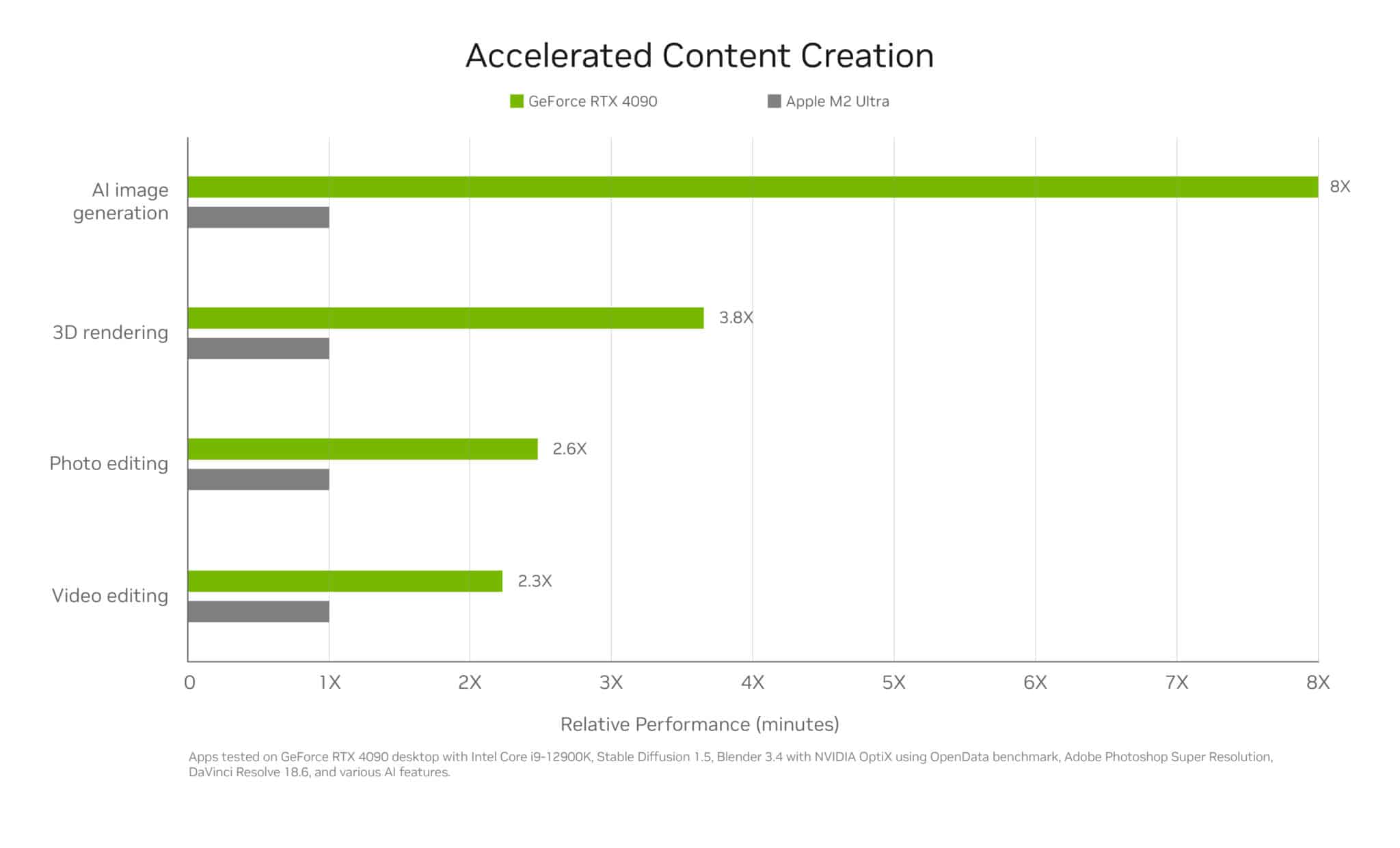
At the IFA Berlin consumer electronics and home appliances trade show this week, new RTX AI PCs will be announced, powered by RTX GPUs for advanced AI in gaming, content creation, development and academics and a neural processing unit (NPU) for offloading lightweight AI.
RTX GPUs, built with specialized AI hardware called Tensor Cores, provide the compute performance needed to run the latest and most demanding AI models. They now accelerate more than 600 AI-enabled games and applications, with more than 100 million GeForce RTX and NVIDIA RTX GPUs in users’ hands worldwide.

Since the launch of NVIDIA DLSS — the first widely deployed PC AI technology — more than five years ago, on-device AI has expanded beyond gaming to livestreaming, content creation, software development, productivity and STEM use cases.
AI boils down to massive matrix multiplication — in other words, incredibly complex math. CPUs can do math, but, as serial processors, they can only perform one operation per CPU core at a time. This makes them far too slow for practical use with AI.
GPUs, on the other hand, are parallel processors, performing multiple operations at once. With hundreds of Tensor Cores each and being optimized for AI, RTX GPUs can accelerate incredibly complex mathematical operations.
RTX-powered systems give users a powerful GPU accelerator for demanding AI workloads in gaming, content creation, software development and STEM subjects. Some also include an NPU, a lightweight accelerator for offloading select low-power workloads.
Local accelerators make AI capabilities always available (even without an internet connection), offer low latency for high responsiveness and increase privacy so that users don’t have to upload sensitive materials to an online database before they become usable by an AI model.
NVIDIA powers much of the world’s AI — from data center to the edge to an install base of over 100 million PCs worldwide.
The GeForce RTX and NVIDIA RTX GPUs found in laptops, desktops and workstations share the same architecture as cloud servers and provide up to 686 AI trillion operations operations per second (TOPS) across the GeForce RTX 40 Series Laptop GPU lineup.
 RTX GPUs unlock top-tier performance and power a wider range of AI and generative AI than systems with just an integrated system-on-a-chip (SoC).
RTX GPUs unlock top-tier performance and power a wider range of AI and generative AI than systems with just an integrated system-on-a-chip (SoC).
“Many projects, especially within Windows, are built for and expect to run on NVIDIA cards. In addition to the wide software support base, NVIDIA GPUs also have an advantage in terms of raw performance.” — Jon Allman, industry analyst at Puget Systems
Gamers can use DLSS for AI-enhanced performance and can look forward to NVIDIA ACE digital human technology for next-generation in-game experiences. Creators can use AI-accelerated video and photo editing tools, asset generators, AI denoisers and more. Everyday users can tap RTX Video Super Resolution and RTX Video HDR for improved video quality, and NVIDIA ChatRTX and NVIDIA Broadcast for productivity improvements. And developers can use RTX-powered coding and debugging tools, as well as the NVIDIA RTX AI Toolkit to build and deploy AI-enabled apps for RTX.
Large language models — like Google’s Gemma, Meta’s Llama and Microsoft’s Phi — all run faster on RTX AI PCs, as systems with GPUs load LLMs into VRAM. Add in NVIDIA TensorRT-LLM acceleration and RTX GPUs can run LLMs 10-100x faster than on CPUs.
New systems from ASUS and MSI are now shipping with up to GeForce RTX 4070 Laptop GPUs — delivering up to 321 AI TOPS of performance — and power-efficient SoCs with Windows 11 AI PC capabilities. Windows 11 AI PCs will receive a free update to Copilot+ PC experiences when available.

ASUS’ Zephyrus G16 comes with up to a GeForce RTX 4070 Laptop GPU to supercharge photo and video editing, image generation and coding, while game-enhancing features like DLSS create additional high-quality frames and improve image quality. The 321 TOPS of local AI processing power available from the GeForce RTX 4070 Laptop GPU enables multiple AI applications to run simultaneously, changing the way gamers, creators and engineers work and play.

The ASUS ProArt P16 is the first AI PC built for advanced AI workflows across creativity, gaming, productivity and more. Its GeForce RTX 4070 Laptop GPU provides creatives with RTX AI acceleration in top 2D, 3D, video editing and streaming apps. The ASUS ProArt P13 also comes with state-of-the-art graphics and an OLED touchscreen for ease of creation. Both laptops also come NVIDIA Studio-validated, enabling and accelerating your creativity.

The MSI Stealth A16 AI+ features the latest GeForce RTX 40 Series Laptop GPUs, delivering up to 321 AI TOPS with a GeForce RTX 4070 Laptop GPU. This fast and intelligent AI-powered PC is designed to excel in gaming, creation and productivity, offering access to next-level technology.
These laptops join hundreds of RTX AI PCs available today from top manufacturers, with support for the 600+ AI applications and games accelerated by RTX.
Generative AI is transforming graphics and interactive experiences of all kinds. Make sense of what’s new and what’s next by subscribing to the AI Decoded newsletter.
 Learn more about the upcoming Video Action Campaign upgrades to Demand Gen and how you can drive better performance with more powerful features.Read More
Learn more about the upcoming Video Action Campaign upgrades to Demand Gen and how you can drive better performance with more powerful features.Read More
 Our new Heat Resilience tool uses AI to help cities prioritize where to implement cooling strategies.Read More
Our new Heat Resilience tool uses AI to help cities prioritize where to implement cooling strategies.Read More
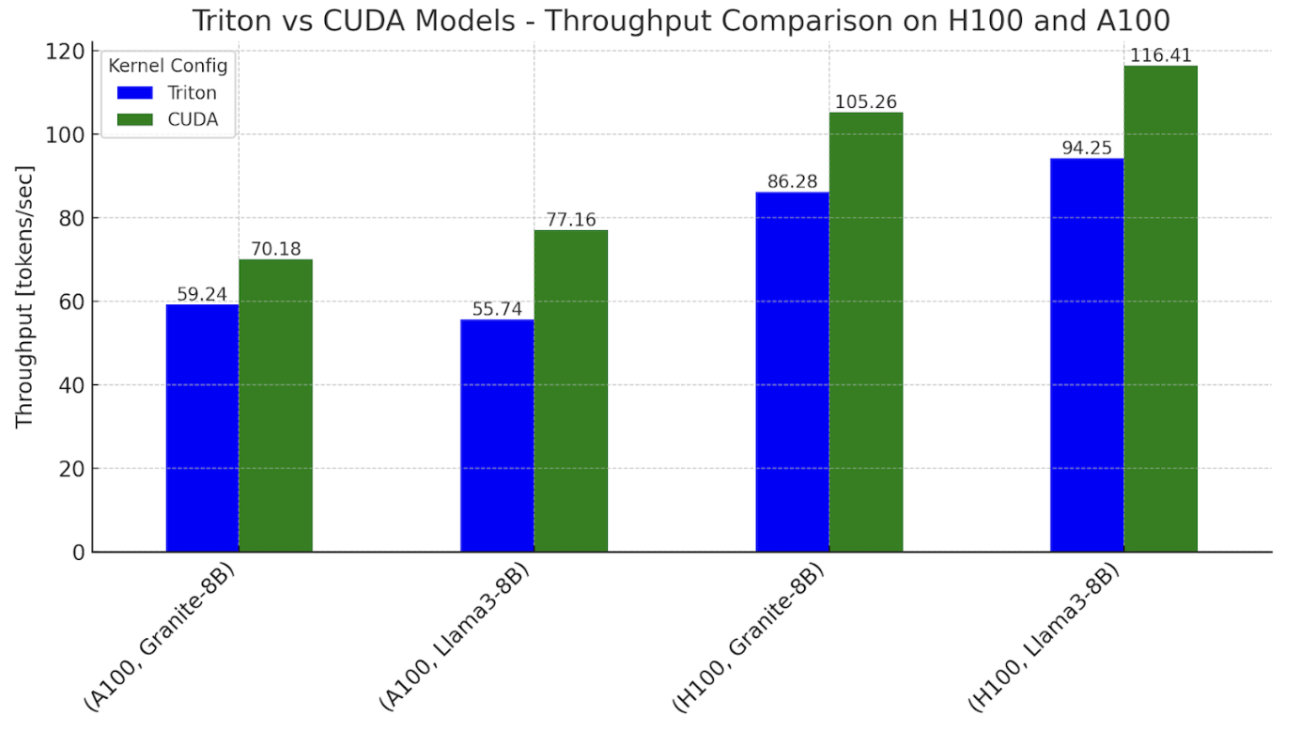
In this blog, we discuss the methods we used to achieve FP16 inference with popular LLM models such as Meta’s Llama3-8B and IBM’s Granite-8B Code, where 100% of the computation is performed using OpenAI’s Triton Language.
For single token generation times using our Triton kernel based models, we were able to approach 0.76-0.78x performance relative to the CUDA kernel dominant workflows for both Llama and Granite on Nvidia H100 GPUs, and 0.62-0.82x on Nvidia A100 GPUs.
Why explore using 100% Triton? Triton provides a path for enabling LLMs to run on different types of GPUs – NVIDIA, AMD, and in the future Intel and other GPU based accelerators. It also provides a higher layer of abstraction in Python for programming GPUs and has allowed us to write performant kernels faster than authoring them using vendor specific APIs. In the rest of this blog, we will share how we achieve CUDA-free compute, micro-benchmark individual kernels for comparison, and discuss how we can further improve future Triton kernels to close the gaps.
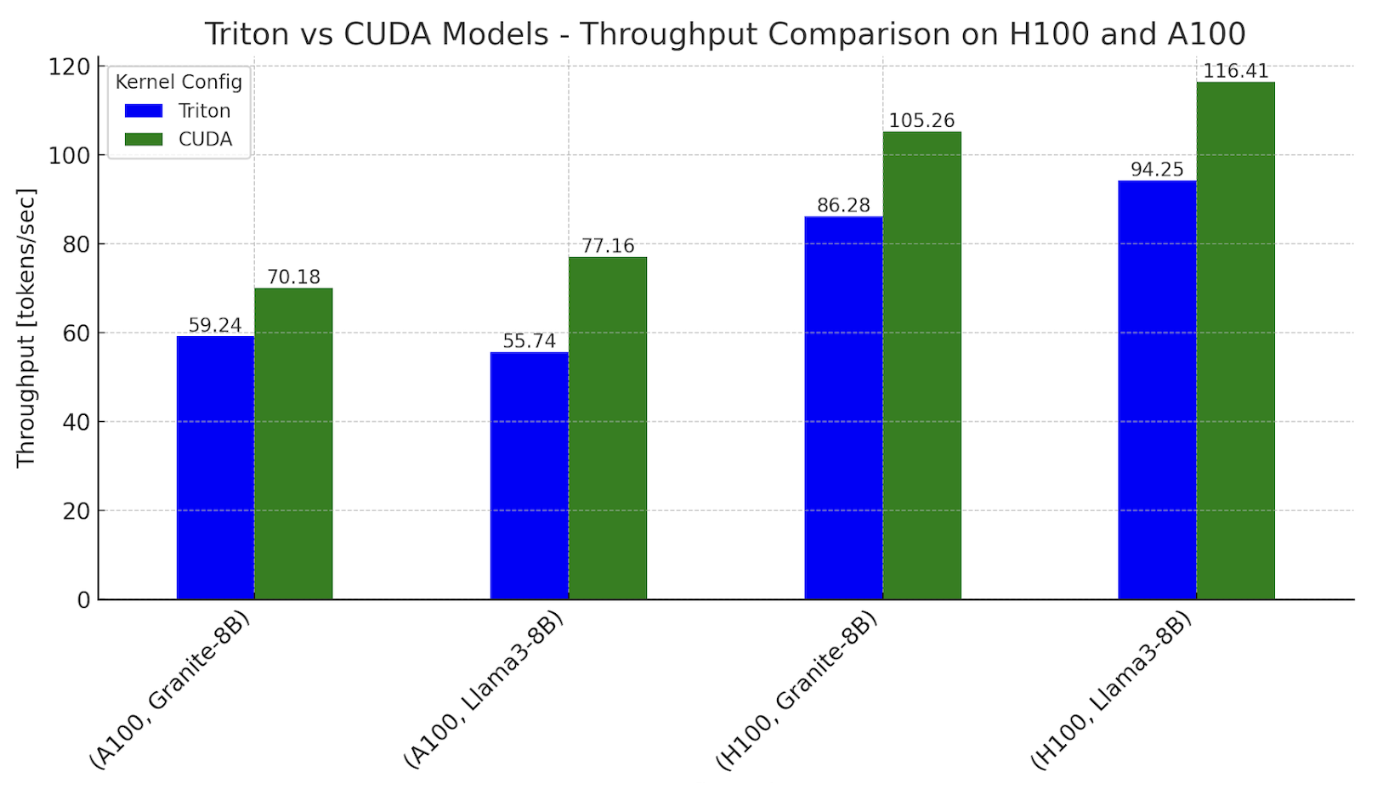
Figure 1. Inference throughput benchmarks with Triton and CUDA variants of Llama3-8B and Granite-8B, on NVIDIA H100 and A100
Settings: batch size = 2, input sequence length = 512, output sequence length = 256
2.0 Composition of a Transformer Block
We start with a breakdown of the computations that happen in Transformer-based models. The figure below shows the “kernels” of a typical Transformer block.
![]() Figure 2. Transformer Block by core kernels
Figure 2. Transformer Block by core kernels
The core operations for a Llama3 architecture are summarized in this list:
Each of these operations is computed on the GPU through the execution of one (or multiple) kernels. While the specifics of each of these kernels can vary across different transformer models, the core operations remain the same. For example, IBM’s Granite 8B Code model uses bias in the MLP layer, different from Llama3. Such changes do require modifications to the kernels. A typical model is a stack of these transformer blocks wired together with embedding layers.
3.0 Model Inference
Typical model architecture code is shared with a python model.py file that is launched by PyTorch. In the default PyTorch eager execution mode, these kernels are all executed with CUDA. To achieve 100% Triton for end-to-end Llama3-8B and Granite-8B inference we need to write and integrate handwritten Triton kernels as well as leverage torch.compile (to generate Triton ops). First, we replace smaller ops with compiler generated Triton kernels, and second, we replace more expensive and complex computations (e.g. matrix multiplication and flash attention) with handwritten Triton kernels.
Torch.compile generates Triton kernels automatically for RMSNorm, RoPE, SiLU and Element Wise Multiplication. Using tools like Nsight Systems we can observe these generated kernels; they appear as tiny dark green kernels in-between the matrix multiplications and attention.
 Figure 3. Trace of Llama3-8B with torch.compile, showing CUDA kernels being used for matrix multiplications and flash attention
Figure 3. Trace of Llama3-8B with torch.compile, showing CUDA kernels being used for matrix multiplications and flash attention
For the above trace, we note that the two major ops that make up 80% of the E2E latency in a Llama3-8B style model are matrix multiplication and attention kernels and both remain CUDA kernels. Thus to close the remaining gap, we replace both matmul and attention kernels with handwritten Triton kernels.
4.0 Triton SplitK GEMM Kernel
For the matrix multiplications in the linear layers, we wrote a custom FP16 Triton GEMM (General Matrix-Matrix Multiply) kernel that leverages a SplitK work decomposition. We have previously discussed this parallelization in other blogs as a way to accelerate the decoding portion of LLM inference.
5.0 GEMM Kernel Tuning
To achieve optimal performance we used the exhaustive search approach to tune our SplitK GEMM kernel. Granite-8B and Llama3-8B have linear layers with the following shapes:
| Linear Layer | Shape (in_features, out_features) |
|---|---|
| Fused QKV Projection | (4096, 6144) |
| Output Projection | (4096, 4096) |
| Fused Gate + Up Projection | (4096, 28672) |
| Down Projection | (14336, 4096) |
Figure 4. Granite-8B and Llama3-8B Linear Layer Weight Matrix Shapes
Each of these linear layers have different weight matrix shapes. Thus, for optimal performance the Triton kernel must be tuned for each of these shape profiles. After tuning for each linear layer we were able to achieve 1.20x E2E speedup on Llama3-8B and Granite-8B over the untuned Triton kernel.
6.0 Flash Attention Kernel
We evaluated a suite of existing Triton flash attention kernels with different configurations, namely:
We evaluated the text generation quality of each of these kernels, first, in eager mode and then (if we were able to torch.compile the kernel with standard methods) compile mode. For kernels 2-5, we noted the following:
| Kernel | Text Generation Quality | Torch.compile | Support for Arbitrary Sequence Length |
|---|---|---|---|
| AMD Flash | Coherent | Yes | Yes |
| OpenAI Flash | Incoherent | Did not evaluate. WIP to debug precision in eager mode first | No |
| Dao AI Lab Flash | Incoherent | Did not evaluate. WIP to debug precision in eager mode first | Yes |
| Xformers FlashDecoding | Hit a compilation error before we were able to evaluate text quality | WIP | No (This kernel is optimized for decoding) |
| PyTorch FlexAttention | Coherent | WIP | WIP |
Figure 5. Table of combinations we tried with different Flash Attention Kernels
The above table summarizes what we observed out-of-the box. With some effort we expect that kernels 2-5 can be modified to meet the above criteria. However, this also shows that having a kernel that works for benchmarking is often only the start of having it usable as an end to end production kernel.
We chose to use the AMD flash attention kernel in our subsequent tests as it can be compiled via torch.compile and produces legible output in both eager and compiled mode.
To satisfy torch.compile compatibility with the AMD flash attention kernel, we had to define it as a torch custom operator. This process is explained in detail here. The tutorial link discusses how to wrap a simple image crop operation. However, we note that wrapping a more complex flash attention kernel follows a similar process. The two step approach is as follows:


After defining the Triton flash kernel as a custom op, we were able to successfully compile it for our E2E runs.

Figure 6. Trace of Llama3-8B with torch.compile, after swapping in Triton matmul and Triton flash attention kernels
From Figure 5, we note that now, after integrating both the SplitK matrix multiplication kernel, the torch op wrapped flash attention kernel, and then running torch.compile, we are able to achieve a forward pass that uses 100% Triton computation kernels.
7.0 End-to-End Benchmarks
We performed end-to-end measurements on NVIDIA H100s and A100s (single GPU) with Granite-8B and Llama3-8B models. We performed our benchmarks with two different configurations.
The Triton kernel configuration uses:
The CUDA Kernel configuration uses:
We found the following throughput and inter-token latencies for both eager and torch compiled modes, with typical inference settings:
| GPU | Model | Kernel Config | Median Latency (Eager) [ms/tok] | Median Latency (Compiled) [ms/tok] |
|---|---|---|---|---|
| H100 | Granite-8B | Triton | 27.42 | 11.59 |
| CUDA | 18.84 | 9.50 | ||
| Llama3-8B | Triton | 20.36 | 10.61 | |
| CUDA | 16.59 | 8.59 | ||
| A100 | Granite-8B | Triton | 53.44 | 16.88 |
| CUDA | 37.13 | 14.25 | ||
| Llama3-8B | Triton | 44.44 | 17.94 | |
| CUDA | 32.45 | 12.96 |
Figure 7. Granite-8B and Llama3-8B Single Token Generation Latency on H100 and A100,
(batch size = 2, input sequence length = 512, output sequence length = 256)
To summarize, the Triton models can get up to 78% of the performance of the CUDA models on the H100 and up to 82% on the A100.
The performance gap can be explained by the kernel latencies we observe for matmul and flash attention, which are discussed in the next section.
8.0 Microbenchmarks
| Kernel | Triton [us] | CUDA [us] |
|---|---|---|
| QKV Projection Matmul | 25 | 21 |
| Flash Attention | 13 | 8 |
| Output Projection Matmul | 21 | 17 |
| Gate + Up Projection Matmul | 84 | 83 |
| Down Projection Matmul | 58 | 42 |
Figure 8. Triton and CUDA Kernel Latency Comparison (Llama3-8B on NVIDIA H100)
Input was an arbitrary prompt (bs=1, prompt = 44 seq length), decoding latency time
From the above, we note the following:
Triton matmul kernels are 1.2-1.4x slower than CUDA
AMDs Triton Flash Attention kernel is 1.6x slower than CUDA SDPA
These results highlight the need to further improve the performance of kernels that are core primitives like GEMM and Flash Attention. We leave this as future research, as recent works (e.g. FlashAttention-3, FlexAttention) provide ways to leverage the underlying hardware better as well as Triton pathways that we hope to be able to build on to produce greater speedups. To illustrate this, we compared FlexAttention with SDPA and AMD’s Triton Flash kernel.
We are working to verify E2E performance with FlexAttention. For now, initial microbenchmarks with Flex show promise for longer context lengths and decoding problem shapes, where the query vector is small:
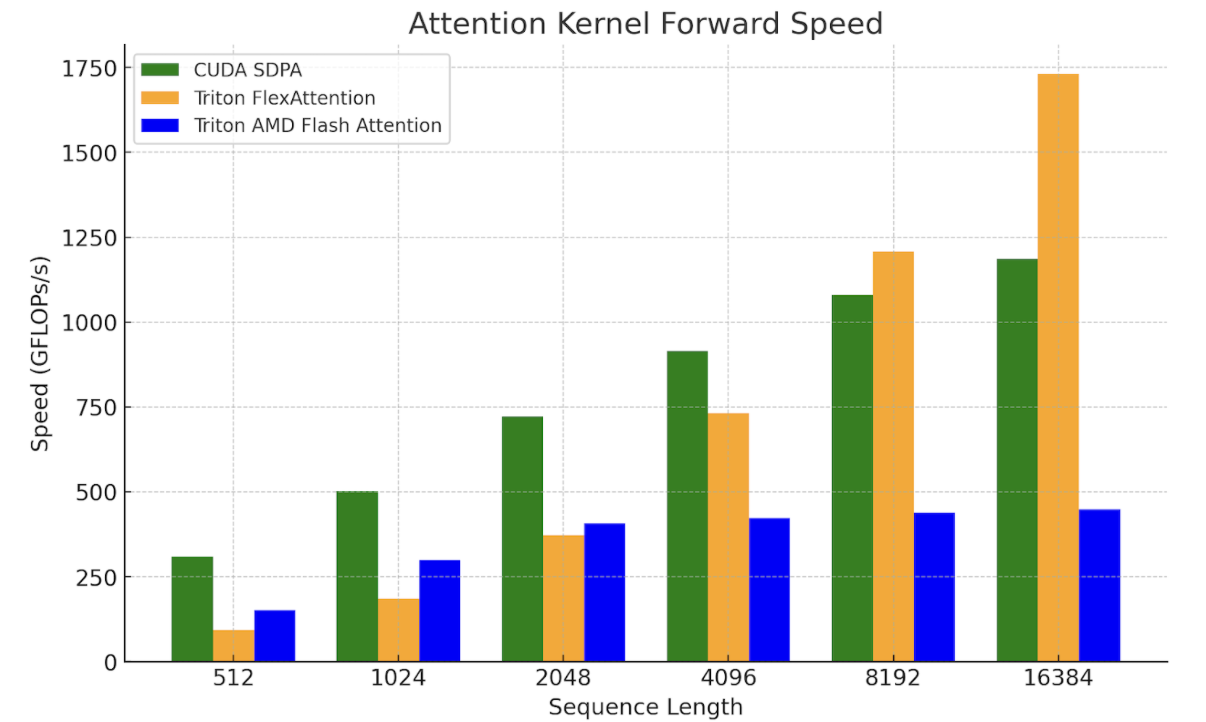
Figure 9. FlexAttention Kernel Benchmarks on NVIDIA H100 SXM5 80GB
(batch=1, num_heads=32, seq_len=seq_len, head_dim=128)
9.0 Future Work
For future work we plan to explore ways to further optimize our matmuls that leverage the hardware better, such as this blog we published on utilizing TMA for H100, as well as different work decompositions (persistent kernel techniques like StreamK etc.) to get greater speedups for our Triton-based approach. For flash attention, we plan to explore FlexAttention and FlashAttention-3 as the techniques used in these kernels can be leveraged to help further close the gap between Triton and CUDA.
We also note that our prior work has shown promising results for FP8 Triton GEMM kernel performance versus cuBLAS FP8 GEMM, thus in a future post we will explore E2E FP8 LLM inference.
Generating image descriptions is a common requirement for applications across many industries. One common use case is tagging images with descriptive metadata to improve discoverability within an organization’s content repositories. Ecommerce platforms also use automatically generated image descriptions to provide customers with additional product details. Descriptive image captions also improve accessibility for users with visual impairments.
With advances in generative artificial intelligence (AI) and multimodal models, producing image descriptions is now more straightforward. Amazon Bedrock provides access to the Anthropic’s Claude 3 family of models, which incorporates new computer vision capabilities enabling Anthropic’s Claude to comprehend and analyze images. This unlocks new possibilities for multimodal interaction. However, building an end-to-end application often requires substantial infrastructure and slows development.
The Generative AI CDK Constructs coupled with Amazon Bedrock offer a powerful combination to expedite application development. This integration provides reusable infrastructure patterns and APIs, enabling seamless access to cutting-edge foundation models (FMs) from Amazon and leading startups. Amazon Bedrock is a fully managed service that offers a choice of high-performing FMs from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. Generative AI CDK Constructs can accelerate application development by providing reusable infrastructure patterns, allowing you to focus your time and effort on the unique aspects of your application.
In this post, we delve into the process of building and deploying a sample application capable of generating multilingual descriptions for multiple images with a Streamlit UI, AWS Lambda powered with the Amazon Bedrock SDK, and AWS AppSync driven by the open source Generative AI CDK Constructs.
Multimodal AI systems are an advanced type of AI that can process and analyze data from multiple modalities at once, including text, images, audio, and video. Unlike traditional AI models trained on a single data type, multimodal AI integrates diverse data sources to develop a more comprehensive understanding of complex information.
Anthropic’s Claude 3 on Amazon Bedrock is a leading multimodal model with computer vision capabilities to analyze images and generate descriptive text outputs. Anthropic’s Claude 3 excels at interpreting complex visual assets like charts, graphs, diagrams, reports, and more. The model combines its computer vision with language processing to provide nuanced text summaries of key information extracted from images. This allows Anthropic’s Claude 3 to develop a deeper understanding of visual data than traditional single-modality AI.
In March 2024, Amazon Bedrock provided access to the Anthropic’s Claude 3 family. The three models in the family are Anthropic’s Claude 3 Haiku, the fastest and most compact model for near-instant responsiveness, Anthropic’s Claude 3 Sonnet, the ideal balanced model between skills and speed, and Anthropic’s Claude 3 Opus, the most intelligent offering for top-level performance on highly complex tasks. In June 2024, Amazon Bedrock announced support for Anthropic’s Claude 3.5 as well. The sample application in this post supports Claude 3.5 Sonnet and all the three Claude 3 models.
Generative AI CDK Constructs, an extension to the AWS Cloud Development Kit (AWS CDK), is an open source development framework for defining cloud infrastructure as code (IaC) and deploying it through AWS CloudFormation.
Constructs are the fundamental building blocks of AWS CDK applications. The AWS Construct Library categorizes constructs into three levels: Level 1 (the lowest-level construct with no abstraction), Level 2 (mapping directly to single AWS CloudFormation resources), and Level 3 (patterns with the highest level of abstraction).
The Generative AI CDK Constructs Library provides modular building blocks to seamlessly integrate AWS services and resources into solutions using generative AI capabilities. By using Amazon Bedrock to access FMs and combining with serverless AWS services such as Lambda and AWS AppSync, these AWS CDK constructs streamline the process of assembling cloud infrastructure for generative AI. You can rapidly configure and deploy solutions to generate content using intuitive abstractions. This approach boosts productivity and reduces time-to-market for delivering innovative applications powered by the latest advances in generative AI on the AWS Cloud.
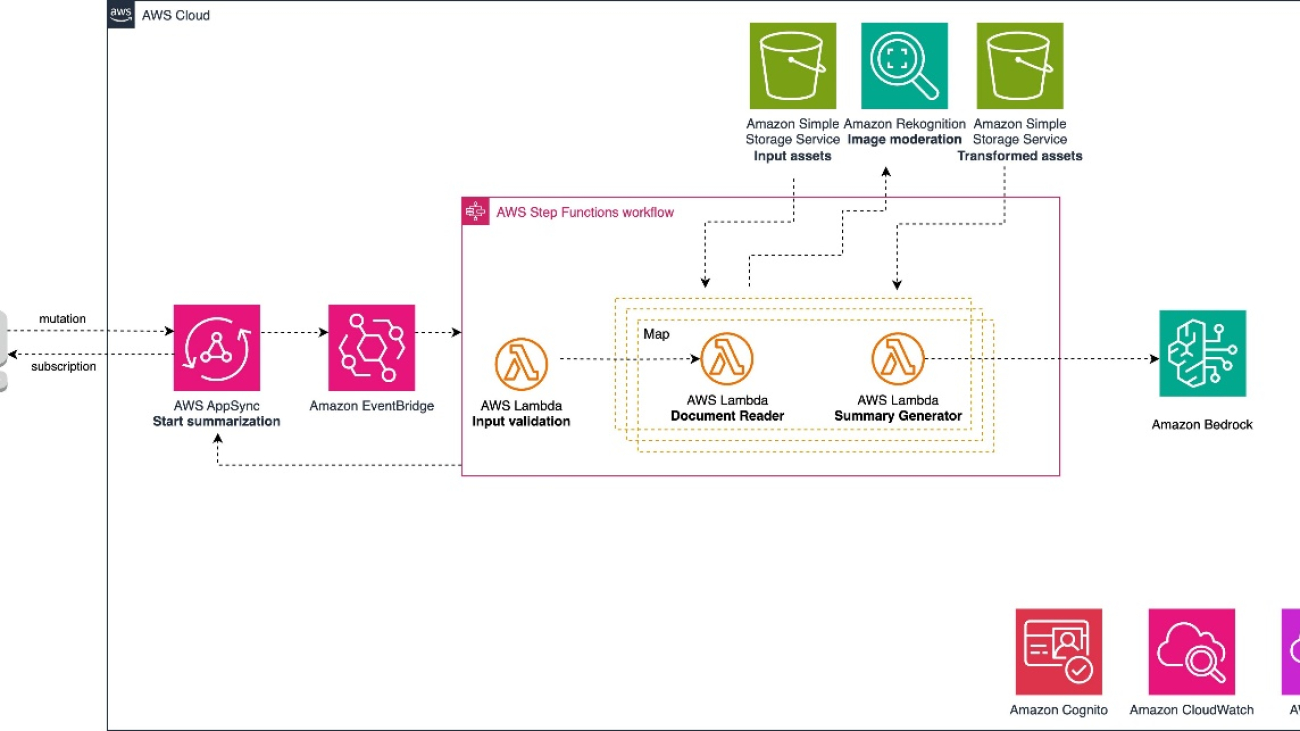
The sample application in this post uses the aws-summarization-appsync-stepfn construct from the Generative AI CDK Constructs Library. The aws-summarization-appsync-stepfn construct provides a serverless architecture that uses AWS AppSync, AWS Step Functions, and Amazon EventBridge to deliver an asynchronous image summarization service. This construct offers a scalable and event-driven solution for processing and generating descriptions for image assets.
AWS AppSync acts as the entry point, exposing a GraphQL API that enables clients to initiate image summarization and description requests. The API utilizes subscription mutations, allowing for asynchronous runs of the requests. This decoupling promotes best practices for event-driven, loosely coupled systems.
EventBridge serves as the event bus, facilitating the communication between AWS AppSync and Step Functions. When a client submits a request through the GraphQL API, an event is emitted to EventBridge, invoking a run of the Step Functions workflow.
Step Functions orchestrates the run of three Lambda functions, each responsible for a specific task in the image summarization process:
The Step Functions workflow orchestrator employs a Map state, enabling parallel runs of multiple image assets. This concurrent processing capability provides optimal resource utilization and minimizes latency, delivering a highly scalable and efficient image summarization solution.
User authentication and authorization are handled by Amazon Cognito, providing secure access management and identity services for the application’s users. This makes sure only authenticated and authorized users can access and interact with the image summarization service. The solution incorporates observability features through integration with Amazon CloudWatch and AWS X-Ray.
The UI for the application is implemented using the Streamlit open source framework, providing a modern and responsive experience for interacting with the image summarization service. You can access the source code for the project in the public GitHub repository.
The following diagram shows the architecture to deliver this use case.

The workflow to generate image descriptions includes the following steps:
The following figure illustrates the workflow of the Step Functions state machine.

To implement this solution, you should have the following prerequisites:
Complete the following steps to set up the solution:
If using SSH, use the following code:
image-description-stack.ts
The preceding command deploys the stack in your account. The deployment will take approximately 5 minutes to complete.
client_app:
/client_app directory, create a new file named .env with the following content. Replace the property values with the values retrieved from the stack outputs.
COGNITO_CLIENT_SECRET is a secret value that can be retrieved from the Amazon Cognito console. Navigate to the user pool created by the stack. Under App integration, navigate to App clients and analytics, and choose App client name. Under App client information, choose Show client secret and copy the value of the client secret.
client_app:
When the client application is up and running, it will open the browser 8501 port (http://localhost:8501/Home).
Make sure your virtual environment is free from SSL certificate issues. If any SSL certificate issues are present, reinstall the CA certificates and OpenSSL package using the following command:
To test the solution, we upload some sample images and generate descriptions in different applications. Complete the following steps:



The uploaded image and the generated description are shown in the center pane.

The image description is generated in French.
To avoid incurring unintended charges, delete the resources you created:
CDK destroyIn this post, we discussed how to integrate Amazon Bedrock with Generative AI CDK Constructs. This solution enables the rapid development and deployment of cloud infrastructure tailored for an image description application by using the power of generative AI, specifically Anthropic’s Claude 3. The Generative AI CDK Constructs abstract the intricate complexities of infrastructure, thereby accelerating development timelines.
The Generative AI CDK Constructs Library offers a comprehensive suite of constructs, empowering developers to augment and enhance generative AI capabilities within their applications, unlocking a myriad of possibilities for innovation. Try out the Generative AI CDK Constructs Library for your own use cases, and share your feedback and questions in the comments.
 Dinesh Sajwan is a Senior Solutions Architect with the Prototyping Acceleration team at Amazon Web Services. He helps customers to drive innovation and accelerate their adoption of cutting-edge technologies, enabling them to stay ahead of the curve in an ever-evolving technological landscape. Beyond his professional endeavors, Dinesh enjoys a quiet life with his wife and three children.
Dinesh Sajwan is a Senior Solutions Architect with the Prototyping Acceleration team at Amazon Web Services. He helps customers to drive innovation and accelerate their adoption of cutting-edge technologies, enabling them to stay ahead of the curve in an ever-evolving technological landscape. Beyond his professional endeavors, Dinesh enjoys a quiet life with his wife and three children.
 Justin Lewis leads the Emerging Technology Accelerator at AWS. Justin and his team help customers build with emerging technologies like generative AI by providing open source software examples to inspire their own innovation. He lives in the San Francisco Bay Area with his wife and son.
Justin Lewis leads the Emerging Technology Accelerator at AWS. Justin and his team help customers build with emerging technologies like generative AI by providing open source software examples to inspire their own innovation. He lives in the San Francisco Bay Area with his wife and son.
 Alain Krok is a Senior Solutions Architect with a passion for emerging technologies. His past experience includes designing and implementing IIoT solutions for the oil and gas industry and working on robotics projects. He enjoys pushing the limits and indulging in extreme sports when he is not designing software.
Alain Krok is a Senior Solutions Architect with a passion for emerging technologies. His past experience includes designing and implementing IIoT solutions for the oil and gas industry and working on robotics projects. He enjoys pushing the limits and indulging in extreme sports when he is not designing software.
 Michael Tran is a Sr. Solutions Architect with Prototyping Acceleration team at Amazon Web Services. He provides technical guidance and helps customers innovate by showing the art of the possible on AWS. He specializes in building prototypes in the AI/ML space. You can contact him @Mike_Trann on Twitter.
Michael Tran is a Sr. Solutions Architect with Prototyping Acceleration team at Amazon Web Services. He provides technical guidance and helps customers innovate by showing the art of the possible on AWS. He specializes in building prototypes in the AI/ML space. You can contact him @Mike_Trann on Twitter.
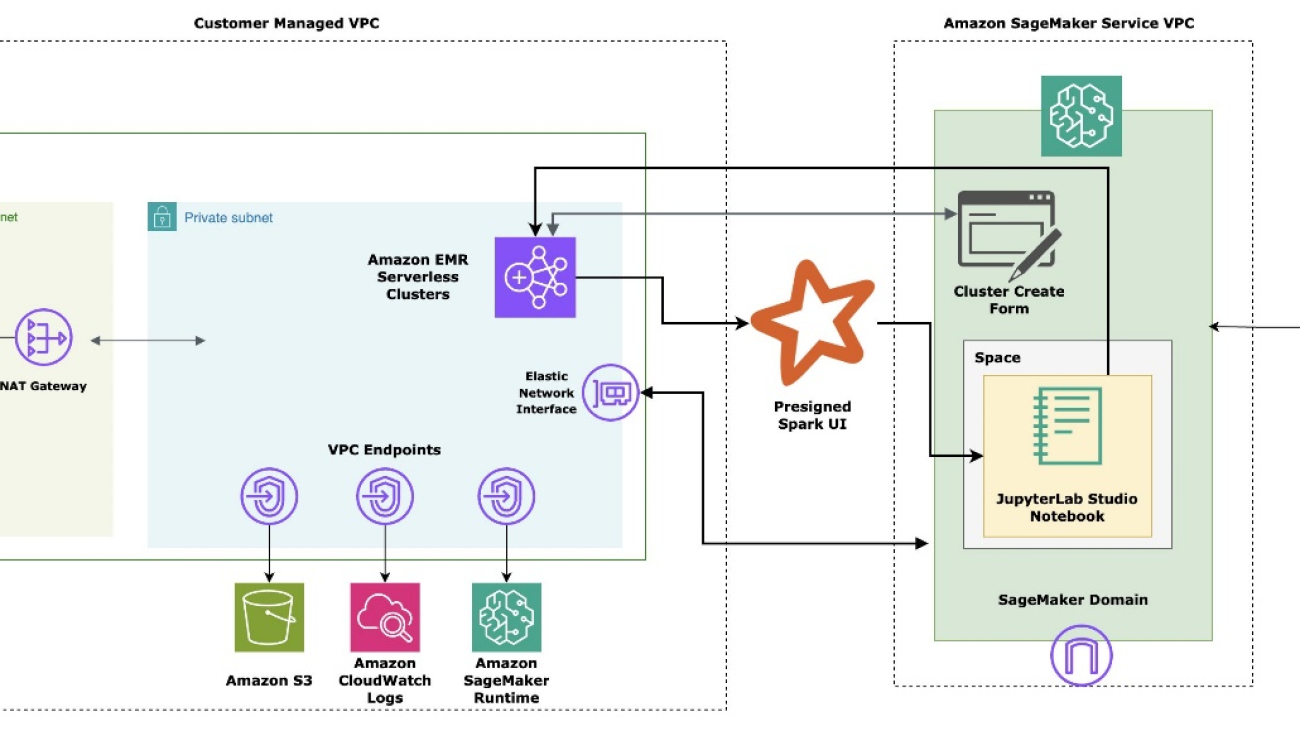
Harnessing the power of big data has become increasingly critical for businesses looking to gain a competitive edge. From deriving insights to powering generative artificial intelligence (AI)-driven applications, the ability to efficiently process and analyze large datasets is a vital capability. However, managing the complex infrastructure required for big data workloads has traditionally been a significant challenge, often requiring specialized expertise. That’s where the new Amazon EMR Serverless application integration in Amazon SageMaker Studio can help.
With the introduction of EMR Serverless support for Apache Livy endpoints, SageMaker Studio users can now seamlessly integrate their Jupyter notebooks running sparkmagic kernels with the powerful data processing capabilities of EMR Serverless. This allows SageMaker Studio users to perform petabyte-scale interactive data preparation, exploration, and machine learning (ML) directly within their familiar Studio notebooks, without the need to manage the underlying compute infrastructure. By using the Livy REST APIs, SageMaker Studio users can also extend their interactive analytics workflows beyond just notebook-based scenarios, enabling a more comprehensive and streamlined data science experience within the Amazon SageMaker ecosystem.
In this post, we demonstrate how to leverage the new EMR Serverless integration with SageMaker Studio to streamline your data processing and machine learning workflows.
The EMR Serverless application integration in SageMaker Studio offers several key benefits that can transform the way your organization approaches big data:
SageMaker Studio is a fully integrated development environment (IDE) for ML that enables data scientists and developers to build, train, debug, deploy, and monitor models within a single web-based interface. SageMaker Studio runs inside an AWS managed virtual private cloud (VPC), with network access for SageMaker Studio domains, in this setup configured as VPC-only. SageMaker Studio automatically creates an elastic network interface within your VPC’s private subnet, which connects to the required AWS services through VPC endpoints. This same interface is also used for provisioning EMR clusters. The following diagram illustrates this solution.

An ML platform administrator can manage permissioning for the EMR Serverless integration in SageMaker Studio. The administrator can configure the appropriate privileges by updating the runtime role with an inline policy, allowing SageMaker Studio users to interactively create, update, list, start, stop, and delete EMR Serverless clusters. SageMaker Studio users are presented with built-in forms within the SageMaker Studio UI that don’t require additional configuration to interact with both EMR Serverless and Amazon Elastic Compute Cloud (Amazon EC2) based clusters.

Apache Spark and its Python API, PySpark, empower users to process massive datasets effortlessly by using distributed computing across multiple nodes. These powerful frameworks simplify the complexities of parallel processing, enabling you to write code in a familiar syntax while the underlying engine manages data partitioning, task distribution, and fault tolerance. With scalability as a core strength, Spark and PySpark allow you to handle datasets of virtually any size, eliminating the constraints of a single machine.
Empowering knowledge retrieval and generation with scalable Retrieval Augmented Generation (RAG) architecture is increasingly important in today’s era of ever-growing information. Effectively using data to provide contextual and informative responses has become a crucial challenge. This is where RAG systems excel, combining the strengths of information retrieval and text generation to deliver comprehensive and accurate results. In this post, we explore how to build a scalable and efficient RAG system using the new EMR Serverless integration, Spark’s distributed processing, and an Amazon OpenSearch Service vector database powered by the LangChain orchestration framework. This solution enables you to process massive volumes of textual data, generate relevant embeddings, and store them in a powerful vector database for seamless retrieval and generation.
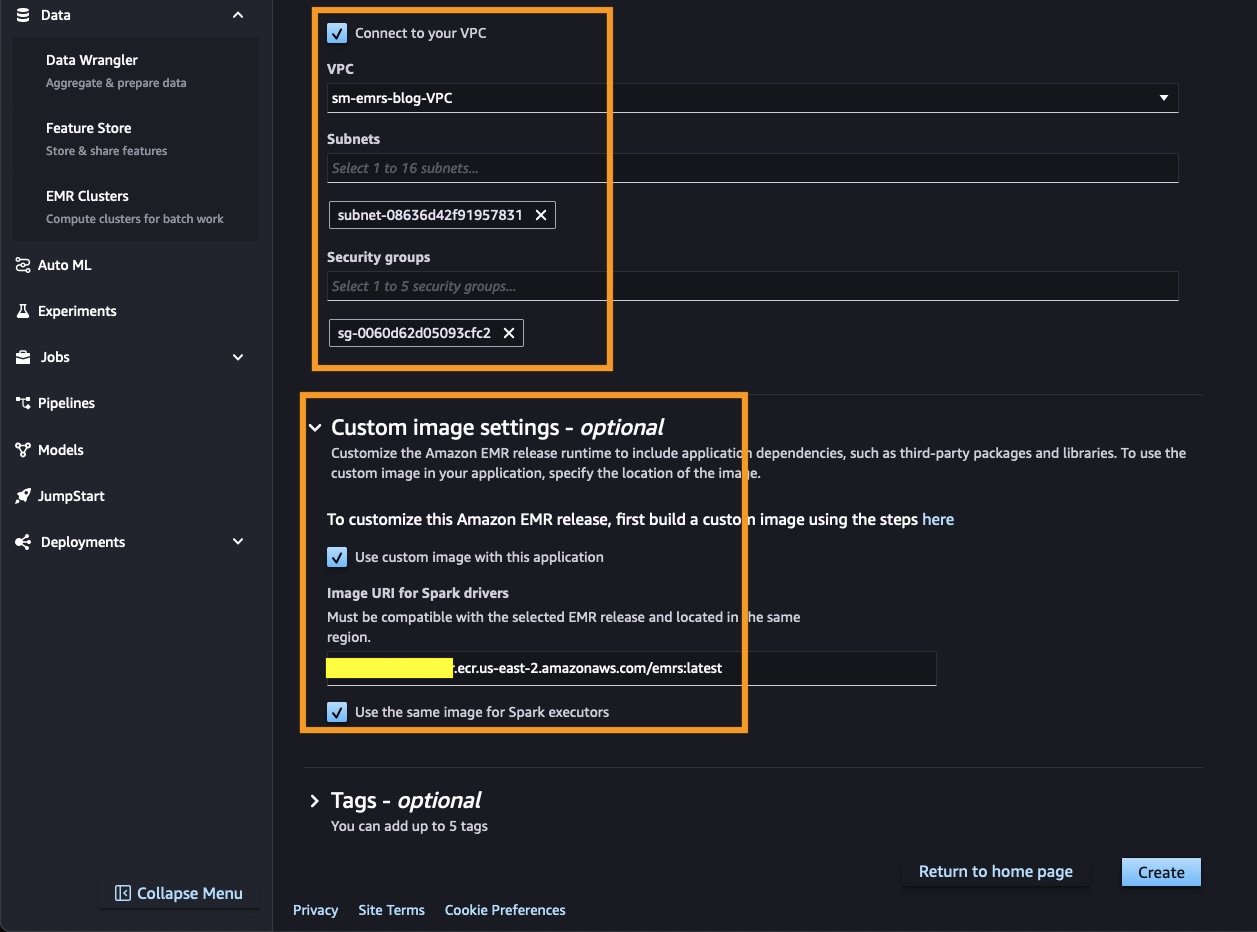
When integrating EMR Serverless in SageMaker Studio, you can use runtime roles. Runtime roles are AWS Identity and Access Management (IAM) roles that you can specify when submitting a job or query to an EMR Serverless application. These runtime roles provide the necessary permissions for your workloads to access AWS resources, such as Amazon Simple Storage Service (Amazon S3) buckets. When integrating EMR Serverless in SageMaker Studio, you can configure the IAM role to be used by SageMaker Studio. By using EMR runtime roles, you can make sure your workloads have the minimum set of permissions required to access the necessary resources, following the principle of least privilege. This enhances the overall security of your data processing pipelines and helps you maintain better control over the access to your AWS resources.
EMR Serverless clusters created within SageMaker Studio are automatically tagged with system default tags, specifically the domain-arn and user-profile-arn tags. These system-generated tags simplify cost allocation and attribution of Amazon EMR resources. See the following code:
To learn more about enterprise-level cost allocation for ML environments, refer to Set up enterprise-level cost allocation for ML environments and workloads using resource tagging in Amazon SageMaker.
Before you get started, complete the prerequisite steps in this section.
This post walks you through the integration between SageMaker Studio and EMR Serverless using an interactive SageMaker Studio notebook. We assume you already have a SageMaker Studio domain provisioned with a UserProfile and an ExecutionRole. If you don’t have a SageMaker Studio domain available, refer to Quick setup to Amazon SageMaker to provision one.
EMR Serverless allows you to specify IAM role permissions that an EMR Serverless job run can assume when calling other services on your behalf. This includes access to Amazon S3 for data sources and targets, as well as other AWS resources like Amazon Redshift clusters and Amazon DynamoDB tables. To learn more about creating a role, refer to Create a job runtime role.
The sample following IAM inline policy attached to a runtime role allows EMR Serverless to assume a runtime role that provides access to an S3 bucket and AWS Glue. You can modify the role to include any additional services that EMR Serverless needs to access at runtime. Additionally, make sure you scope down the resources in the runtime policies to adhere to the principle of least privilege.
Lastly, make sure your role has a trust relationship with EMR Serverless:

Optionally, you can create a runtime role and policy using infrastructure as code (IaC), such as with AWS CloudFormation or Terraform, or using the AWS Command Line Interface (AWS CLI).
This one-time task enables SageMaker Studio users to create, update, list, start, stop, and delete EMR Serverless clusters. We begin by creating an inline policy that grants the necessary permissions for these actions on EMR Serverless clusters, then attach the policy to the Studio domain or user profile role:
SageMaker Studio supports access to EMR Serverless clusters in two ways: in the same account as the SageMaker Studio domain or across accounts.
To interact with EMR Serverless clusters created in the same account as the SageMaker Studio domain, create a file named same-account-update-domain.json:
Then run an update-domain command to allow all users inside a domain to allow users to use the runtime role:
For EMR Serverless clusters created in a different account, create a file named cross-account-update-domain.json:
Then run an update-domain command to allow all users inside a domain to allow users to use the runtime role:
Optionally, this update can be applied more granularly at the user profile level instead of the domain level. Similar to domain update, to interact with EMR Serverless clusters created in the same account as the SageMaker Studio domain, create a file named same-account-update-user-profile.json:
Then run an update-user-profile command to allow this user profile use this run time role:
For EMR Serverless clusters created in a different account, create a file named cross-account-update-user-profile.json:
Then run an update-user-profile command to allow all users inside a domain to allow users to use the runtime role:
The recommended way to customize environments within EMR Serverless clusters is by using custom Docker images.
Make sure you have an Amazon ECR repository in the same AWS Region where you launch EMR Serverless applications. To create an ECR private repository, refer to Creating an Amazon ECR private repository to store images.
To grant users access to your ECR repository, add the following policies to the users and roles that create or update EMR Serverless applications using images from this repository:
Customizing cluster runtimes in advance is crucial for a seamless experience. As mentioned earlier, we use custom-built Docker images from an ECR repository to optimize our cluster environment, including the necessary packages and binaries. The simplest way to build these images is by using the SageMaker Studio built-in Docker functionality, as discussed in Accelerate ML workflows with Amazon SageMaker Studio Local Mode and Docker support. In this post, we build a Docker image that includes the Python 3.11 runtime and essential packages for a typical RAG workflow, such as langchain, sagemaker, opensearch-py, PyPDF2, and more.
Complete the following steps:

In this section, we demonstrate the integration of EMR Serverless into SageMaker Studio and how you can effortlessly interact with your clusters, whether they are in the same account or across different accounts. To access SageMaker Studio, complete the following steps:

The new Studio experience is a serverless web UI, which makes sure any updates occur seamlessly and asynchronously, without interrupting your development experience.
You can navigate to two different tabs: EMR Serverless Applications or EMR Clusters (on Amazon EC2). For this post, we focus on EMR Serverless.

To create a new EMR Serverless cluster, complete the following steps:

EMR Serverless clusters can automatically scale down to zero when not in use, eliminating costs associated with idling resources. This feature makes EMR Serverless clusters highly flexible and cost-effective. You can list, view, create, start, stop, and delete all your EMR Serverless clusters directly within SageMaker Studio.

You can also interactively attach an existing cluster to a notebook by choosing Attach to new notebook.

In this section, we use the SageMaker Studio cluster integration to parallelize data processing at a massive scale. A typical RAG framework consists of two main components:
In the following sections, we focus on the offline document embedding generation process and explore how to use PySpark on EMR Serverless using an interactive SageMaker Studio JupyterLab notebook to efficiently parallel process PDF documents.
For this use case, we use the Hugging Face All MiniLM L6 v2 embeddings model from Amazon SageMaker JumpStart. To quickly deploy this embedding model, complete the following steps:
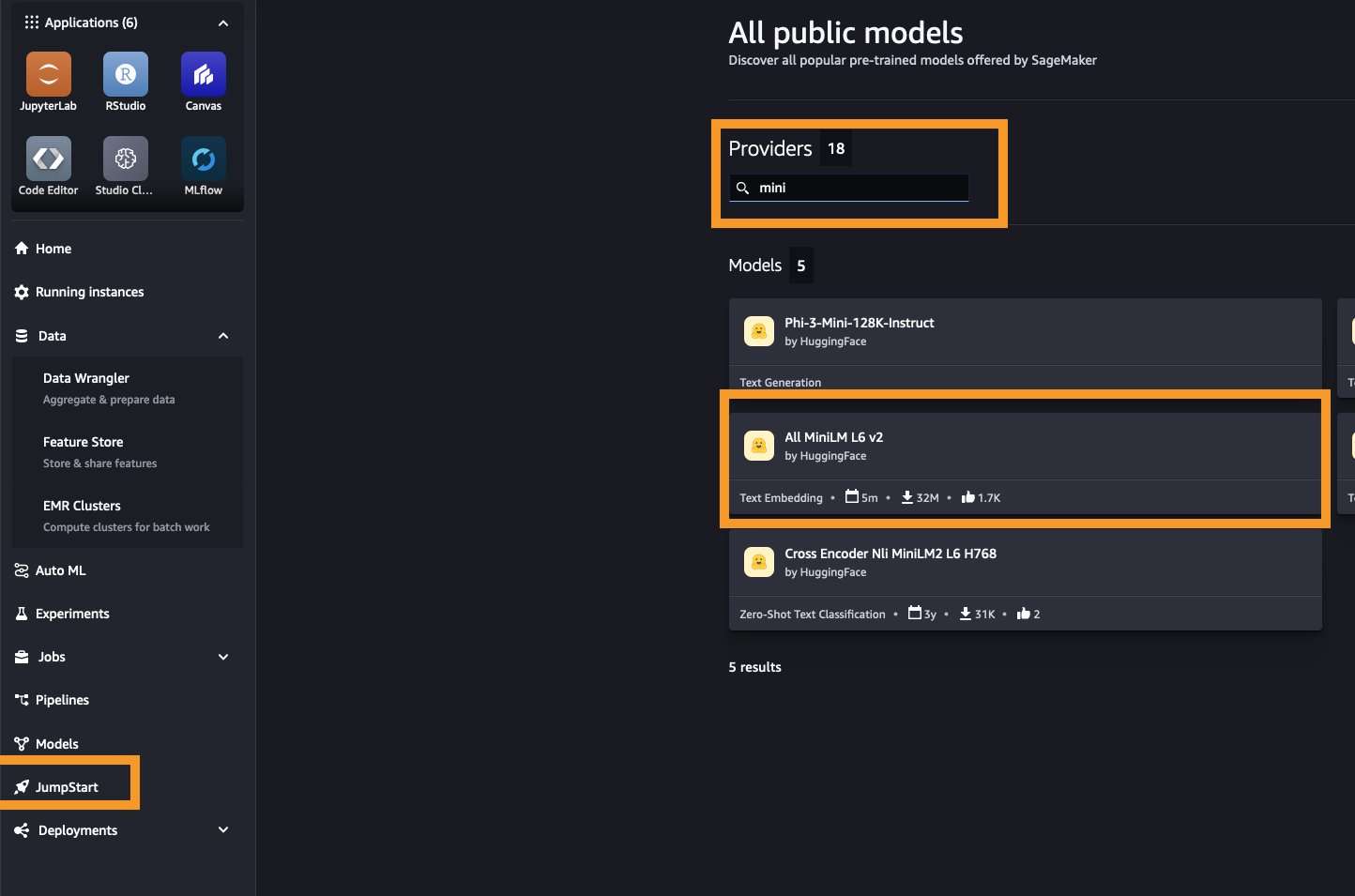
Your model will be ready within a few minutes. Alternatively, you can choose any other embedding models from SageMaker JumpStart by filtering Task type to Text embedding.
In this section, we use code from the following GitHub repo and interactively build a document processing engine using LangChain and PySpark. Complete the following steps:
You can change the instance type at any time by stopping and restarting the space.

use-cases/pyspark-langchain-rag-processor/Offline_RAG_Processor_on_SageMaker_Studio_using_EMR-Serverless.ipynb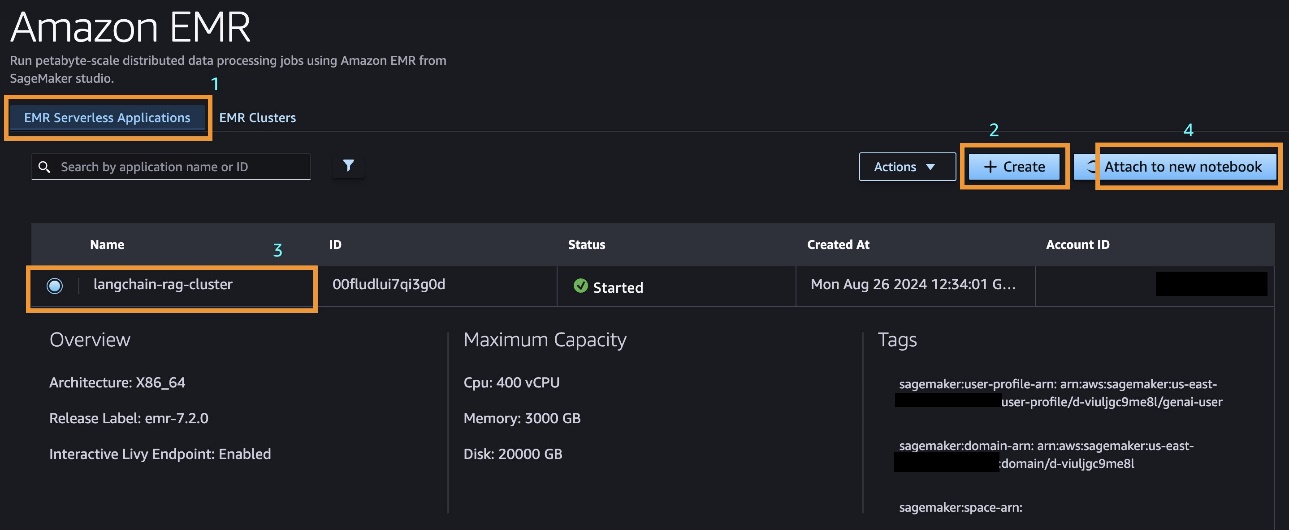
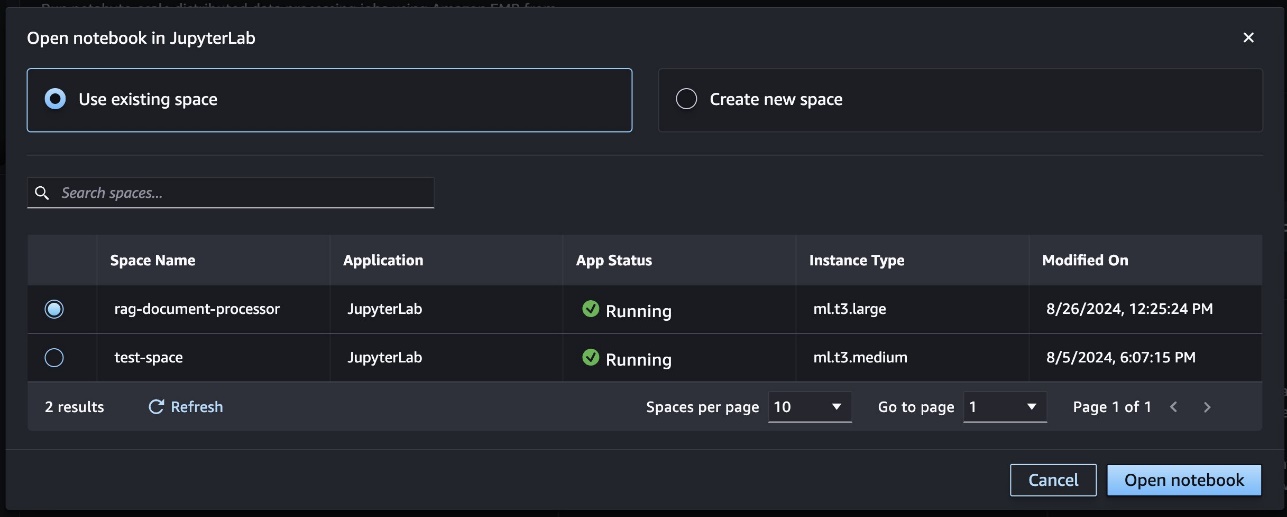
Alternatively, you can attach your cluster to any notebook within your JupyterLab space by choosing Cluster and selecting the EMR Serverless cluster you want to attach to the notebook.

Make sure you choose the SparkMagic PySpark kernel when interactively running PySpark workloads.

A successful cluster connection to a notebook should result in a useable Spark session and links to the Spark UI and driver logs.

When a notebook cell is run within a SparkMagic PySpark kernel, the operations are, by default, run inside a Spark cluster. However, if you decorate the cell with %%local, it allows the code to be run on the local compute where the JupyterLab notebook is hosted. We begin by reading a list of PDF documents from Amazon S3 directly into the cluster memory, as illustrated in the following diagram.

Next, you can visualize the size of each document to understand the volume of data you’re processing.

Every PDF document contains multiple pages to process, and this task can be run in parallel using Spark. Each document is split page by page, with each page referencing the global in-memory PDFs. We achieve parallelism at the page level by creating a list of pages and processing each one in parallel. The following diagram provides a visual representation of this process.

The extracted text from each page of multiple documents is converted into a LangChain-friendly Document class.
CustomDocument class, shown in the following code, is a custom implementation of the Document class that allows you to convert custom text blobs into a format recognized by LangChain. After conversion, the documents are split into chunks and prepared for embedding.
OpenSearchVectorSearch to create text embeddings. However, we use a custom EmbeddingsGenerator class that parallelizes (using PySpark) the embeddings generation process using a load-balanced SageMaker hosted embeddings model endpoint:
The custom EmbeddingsGenerator class can generate embeddings for approximately 2,500 pages (12,000 chunks) of documents in under 180 seconds using just two concurrent load-balanced SageMaker embedding model endpoints and 10 PySpark worker nodes. This process can be further accelerated by increasing the number of load-balanced embedding endpoints and worker nodes in the cluster.
The integration of EMR Serverless with SageMaker Studio represents a significant leap forward in simplifying and enhancing big data processing and ML workflows. By eliminating the complexities of infrastructure management, enabling seamless scalability, and optimizing costs, this powerful combination empowers organizations to use petabyte-scale data processing without the overhead typically associated with managing Spark clusters. The streamlined experience within SageMaker Studio enables data scientists and engineers to focus on what truly matters—driving insights and innovation from their data. Whether you’re processing massive datasets, building RAG systems, or exploring other advanced analytics, this integration opens up new possibilities for efficiency and scale, all within the familiar and user-friendly environment of SageMaker Studio.
As data continues to grow in volume and complexity, adopting tools like EMR Serverless and SageMaker Studio will be key to maintaining a competitive edge in the ever-evolving landscape of data-driven decision-making. We encourage you to try this feature today by setting up SageMaker Studio using the SageMaker quick setup guide. To learn more about the EMR Serverless integration with SageMaker Studio, refer to Prepare data using EMR Serverless. You can explore more generative AI samples and use cases in the GitHub repository.
 Raj Ramasubbu is a Senior Analytics Specialist Solutions Architect focused on big data and analytics and AI/ML with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS. Raj provided technical expertise and leadership in building data engineering, big data analytics, business intelligence, and data science solutions for over 18 years prior to joining AWS. He helped customers in various industry verticals like healthcare, medical devices, life science, retail, asset management, car insurance, residential REIT, agriculture, title insurance, supply chain, document management, and real estate.
Raj Ramasubbu is a Senior Analytics Specialist Solutions Architect focused on big data and analytics and AI/ML with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS. Raj provided technical expertise and leadership in building data engineering, big data analytics, business intelligence, and data science solutions for over 18 years prior to joining AWS. He helped customers in various industry verticals like healthcare, medical devices, life science, retail, asset management, car insurance, residential REIT, agriculture, title insurance, supply chain, document management, and real estate.
 Pranav Murthy is an AI/ML Specialist Solutions Architect at AWS. He focuses on helping customers build, train, deploy and migrate machine learning (ML) workloads to SageMaker. He previously worked in the semiconductor industry developing large computer vision (CV) and natural language processing (NLP) models to improve semiconductor processes using state of the art ML techniques. In his free time, he enjoys playing chess and traveling. You can find Pranav on LinkedIn.
Pranav Murthy is an AI/ML Specialist Solutions Architect at AWS. He focuses on helping customers build, train, deploy and migrate machine learning (ML) workloads to SageMaker. He previously worked in the semiconductor industry developing large computer vision (CV) and natural language processing (NLP) models to improve semiconductor processes using state of the art ML techniques. In his free time, he enjoys playing chess and traveling. You can find Pranav on LinkedIn.
 Naufal Mir is an Senior GenAI/ML Specialist Solutions Architect at AWS. He focuses on helping customers build, train, deploy and migrate machine learning (ML) workloads to SageMaker. He previously worked at financial services institutes developing and operating systems at scale. He enjoys ultra endurance running and cycling.
Naufal Mir is an Senior GenAI/ML Specialist Solutions Architect at AWS. He focuses on helping customers build, train, deploy and migrate machine learning (ML) workloads to SageMaker. He previously worked at financial services institutes developing and operating systems at scale. He enjoys ultra endurance running and cycling.
 Kunal Jha is a Senior Product Manager at AWS. He is focused on building Amazon SageMaker Studio as the best-in-class choice for end-to-end ML development. In his spare time, Kunal enjoys skiing and exploring the Pacific Northwest. You can find him on LinkedIn.
Kunal Jha is a Senior Product Manager at AWS. He is focused on building Amazon SageMaker Studio as the best-in-class choice for end-to-end ML development. In his spare time, Kunal enjoys skiing and exploring the Pacific Northwest. You can find him on LinkedIn.
 Ashwin Krishna is a Senior SDE working for SageMaker Studio at Amazon Web Services. He is focused on building interactive ML solutions for AWS enterprise customers to achieve their business needs. He is a big supporter of Arsenal football club and spends spare time playing and watching soccer.
Ashwin Krishna is a Senior SDE working for SageMaker Studio at Amazon Web Services. He is focused on building interactive ML solutions for AWS enterprise customers to achieve their business needs. He is a big supporter of Arsenal football club and spends spare time playing and watching soccer.
 Harini Narayanan is a software engineer at AWS, where she’s excited to build cutting-edge data preparation technology for machine learning at SageMaker Studio. With a keen interest in sustainability, interior design, and a love for all things green, Harini brings a thoughtful approach to innovation, blending technology with her diverse passions.
Harini Narayanan is a software engineer at AWS, where she’s excited to build cutting-edge data preparation technology for machine learning at SageMaker Studio. With a keen interest in sustainability, interior design, and a love for all things green, Harini brings a thoughtful approach to innovation, blending technology with her diverse passions.

 Here’s how Google’s AI products and features can help students, educators, parents and guardians have their best back to school season yet.Read More
Here’s how Google’s AI products and features can help students, educators, parents and guardians have their best back to school season yet.Read More